Teaching–Learning-Based Optimization Algorithm with Stochastic Crossover Self-Learning and Blended Learning Model and Its Application


Abstract
1. Introduction
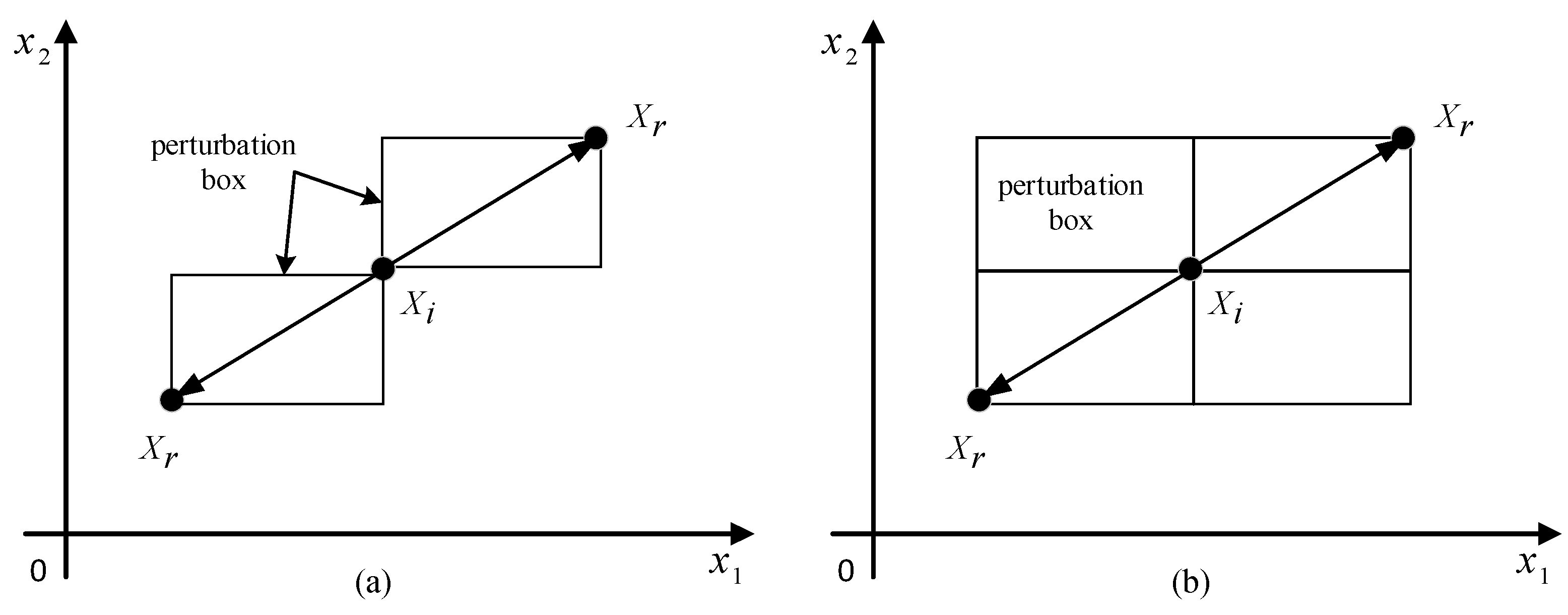
- The perturbation conditions in the “teaching” and “learning” stages of the original TLBO algorithm are interpreted geometrically, then improved on this basis.
- A random crossover self-study phase is established and the structure of TLBO is modified into three stages: pre-course, classroom learning, and post-course consolidation.
- This paper validates the BLTLBO algorithm by conducting a comparison with other algorithms on 18 multimodal functions of CEC2008 and CEC2014.
- This paper applies BLTLBO to a high-dimensional portfolio optimization problem to test its practicality.
2. Original TLBO
2.1. Initialization
2.2. ”Teaching” Phase
2.3. “Learning” Phase
3. Geometric Analysis of TLBO
3.1. Analysis of the “Teaching” Phase
3.2. Analysis of the “Learning” Phase
3.3. Confirmatory Experiment
4. TLBO Based on Blended Learning Model
4.1. Pre-Course Random Crossover Self-Study Phase
4.2. Classroom Blended Learning
4.2.1. Adjustment of Class Average Status
4.2.2. Blended Classroom Instruction
4.3. Post-Course Consolidation Phases
4.4. Flow of BLTLBO Algorithm
4.5. Time Complexity Analysis of BLTLBO
5. Simulation Experiments
5.1. Experimental Environment and Parameter Settings
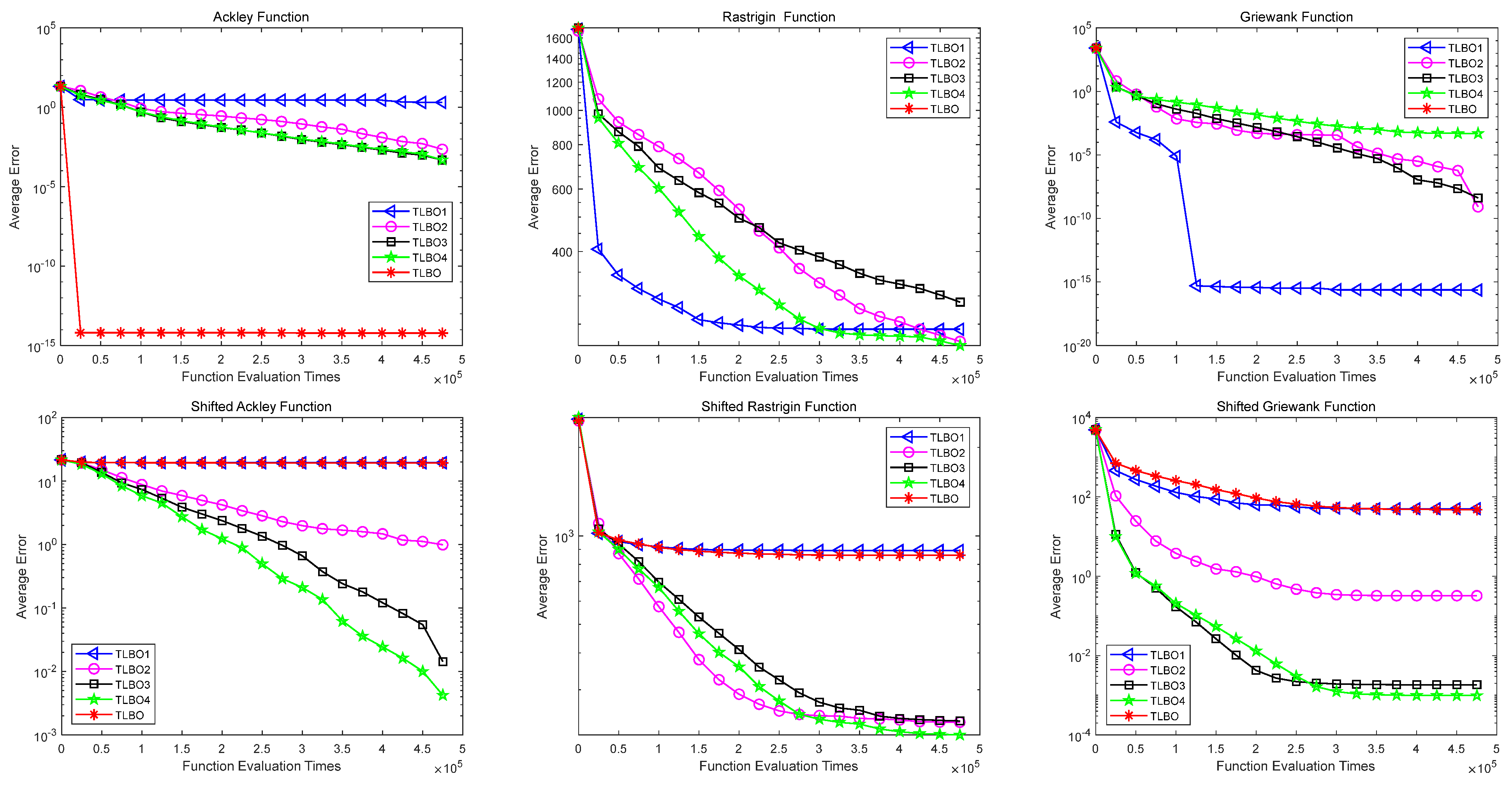
5.2. Simulation Results and Analysis
5.2.1. Simulation of Complex Multimodal Problems
5.2.2. Scalable Multimodal Problem Simulation
5.2.3. Impact Analysis of the Three Improvement Phases
5.2.4. Population Diversity Analysis of BLTLBO Algorithm
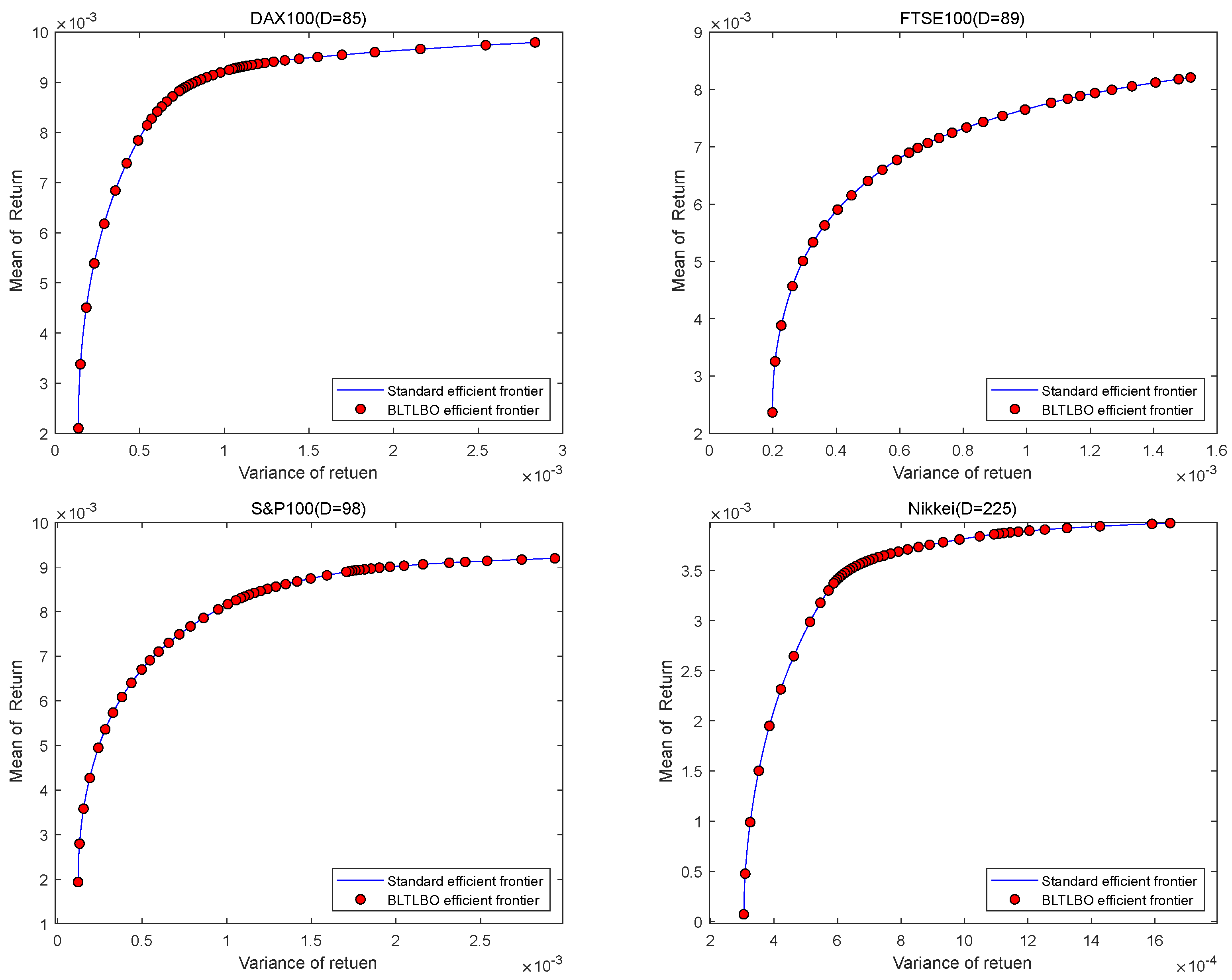
6. Application of BLTLBO in Portfolio Optimization
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rao, R.V.; Savsani, V.J.; Vakharia, D.P. Teaching–learning-based optimization: A novel method for constrained mechanical design optimization problems. Comput.-Aided Des. 2011, 43, 303–315. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, B.; Li, H. A Surrogate-Assisted Teaching-Learning-Based Optimization for Parameter Identification of The Battery Model. IEEE Trans. Ind. Inform. 2021, 17, 5909–5918. [Google Scholar] [CrossRef]
- Yang, Z.; Li, K.; Guo, Y.; Ma, H.; Zheng, M. Compact Real-valued Teaching-Learning Based Optimization with the Applications to Neural Network Training. Knowl.-Based Syst. 2018, 159, 51–62. [Google Scholar] [CrossRef]
- Chen, D.; Zou, F.; Li, Z.; Wang, J.; Li, S. An improved teaching–learning-based optimization algorithm for solving global optimization problems. Inf. Sci. 2015, 297, 171–190. [Google Scholar] [CrossRef]
- Taheri, A.; Rahimizadeh, K.; Rao, R.V. An efficient Balanced Teaching-Learning-Based Optimization Algorithm with Individual Restarting Strategy for Solving Global Optimization Problems. Inf. Sci. 2021, 6, 68–104. [Google Scholar] [CrossRef]
- Dong, H.; Xu, Y.; Cao, D.; Zhang, W.; Yang, Z.; Li, X. An improved teaching-learning-based optimization algorithm with a modified learner phase and a new mutation-restarting phase. Knowl.-Based Syst. 2022, 10, 109989. [Google Scholar] [CrossRef]
- Sun, M.; Cai, Z.; Zhang, H. A teaching-learning-based optimization with feedback for L-R fuzzy flexible assembly job shop scheduling problem with batch splitting. Expert Syst. Appl. 2023, 224, 120043. [Google Scholar] [CrossRef]
- Zeng, Z.; Dong, H.; Xu, Y.; Zhang, W.; Yu, H.; Li, X. Teaching-learning-based optimization algorithm with dynamic neighborhood and crossover search mechanism for numerical optimization. Appl. Soft Comput. 2024, 154, 111332. [Google Scholar] [CrossRef]
- Xing, A.; Chen, Y.; Suo, J.; Zhang, J. Improving teaching-learning-based optimization algorithm with golden-sine and multi-population for global optimization. Math. Comput. Simul. 2024, 221, 94–134. [Google Scholar] [CrossRef]
- Bi, X.; Wang, J. Teaching–learning-based optimization algorithm with hybrid learning strategy. J. Zhejiang Univ. Eng. Sci. 2017, 51, 1024–1031. [Google Scholar]
- Wu, D.; Wang, S.; Liu, Q.; Abualigah, L.; Jia, H. An Improved Teaching-Learning-Based Optimization Algorithm with Reinforcement Learning Strategy for Solving Optimization Problems. Comput. Intell. Neurosci. 2022, 2022, 1535957. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Zhang, W. A teaching-learning-based optimization algorithm with reinforcement learning to address wind farm layout optimization problem. Appl. Soft Comput. 2024, 151, 111135. [Google Scholar] [CrossRef]
- Shukla, A.K.; Singh, P.; Vardhan, M. An adaptive inertia weight teaching-learning-based optimization algorithm and its applications. Appl. Math. Model. 2020, 77, 309–326. [Google Scholar] [CrossRef]
- Eirgash, M.A.; Toğan, V.; Dede, T.; Başağa, H.B. Modified dynamic opposite learning assisted TLBO in solving Time-Cost optimization in generalized construction projects. Structures 2023, 53, 806–821. [Google Scholar] [CrossRef]
- Ram, S.D.K.; Srivastava, S.; Mishra, K.K. Redefining teaching-and-learning-process in TLBO and its application in the cloud. Appl. Soft Comput. 2023, 135, 110017. [Google Scholar]
- Chen, Z.; Liu, Y.; Yang, Z.; Fu, X.; Tan, J.; Yang, X. An enhanced teaching-learning-based optimization algorithm with self-adaptive and earning operators and its search bias towards origin. Swarm Evol. Comput. 2021, 60, 100766. [Google Scholar] [CrossRef]
- Tang, H.; Fang, B.; Liu, R.; Li, Y.; Guo, S. A hybrid teaching and learning-based optimization algorithm for distributed sand casting job-shop scheduling problem. Appl. Soft Comput. 2022, 120, 108694. [Google Scholar] [CrossRef]
- Li, S.; Gong, W.; Wang, L.; Yan, X.; Hu, C. A hybrid adaptive teaching–learning-based optimization and differential evolution for parameter identification of photovoltaic models. Energy Convers. Manag. 2020, 225, 113474. [Google Scholar] [CrossRef]
- Tanmay, K.; Harish, G. LSMA-TLBO: A hybrid SMA-TLBO algorithm with lévy flight based mutation for numerical optimization and engineering design problems. Adv. Eng. Softw. 2022, 172, 103185. [Google Scholar]
- Pickard, J.K.; Carretero, J.A.; Bhavsar, V.C. On the convergence and origin bias of the Teaching-Learning-Based-Optimization algorithm. Appl. Soft Comput. 2016, 46, 115–127. [Google Scholar] [CrossRef]
- Yang, Z.; Tang, K.; Yao, X. Large-scale evolutionary optimization using cooperative coevolution. Inf. Sci. 2008, 178, 2985–2999. [Google Scholar] [CrossRef]
- Cheng, R.; Jin, Y. A Competitive Swarm Optimizer for Large Scale Optimization. IEEE Trans. Cybern. 2015, 45, 191–204. [Google Scholar] [CrossRef] [PubMed]
- Chang, T.J.; Meade, N.; Beasley, J.E.; Sharaiha, Y.M. Heuristics for cardinality constrained portfolio optimization. Comput. Oper. Res. 2000, 27, 1271–1302. [Google Scholar] [CrossRef]
- Cura, T. A rapidly converging artificial bee colony algorithm for portfolio optimization. Knowl.-Based Syst. 2021, 233, 107505. [Google Scholar] [CrossRef]
- Tuo, S. A Modified Harmony Search Algorithm for Portfolio Optimization Problems. Econ. Comput. Econ. Cybern. Stud. Res. 2016, 52, 3111–3326. [Google Scholar]
- Tuo, S.; He, H. Solving complex cardinality-constrained mean-variance portfolio optimization problems using hybrid HS and TLBO algorithm. Econ. Comput. Econ. Cybern. Stud. Res. 2018, 52, 231–248. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | Statistical Indicator | TLBO | TLBO1 | TLBO2 | TLBO3 | TLBO4 |
|---|---|---|---|---|---|---|
| Ackley | Mean | 6.04 × 10−15 | 2.05 | 2.29 × 10−3 | 4.78 × 10−4 | 4.84 × 10−4 |
| Std | 1.81 × 10−15 | 2.99 | 1.02 × 10−2 | 6.20 × 10−4 | 5.44 × 10−4 | |
| Time (s) | 1.91 | 2.87 | 2.50 | 3.00 | 2.86 | |
| Rastrigin | Mean | 0 | 2.42 × 102 | 2.24 × 102 | 2.88 × 102 | 2.18 × 102 |
| Std | 0 | 9.29 × 101 | 5.23 × 101 | 1.96 × 102 | 1.35 × 102 | |
| Time (s) | 2.30 | 3.40 | 3.55 | 3.60 | 3.80 | |
| Griewank | Mean | 0 | 2.33 × 10−16 | 8.32 × 10−10 | 4.20 × 10−9 | 4.94 × 10−4 |
| Std | 0 | 3.38 × 10−16 | 3.72 × 10−9 | 1.88 × 10−8 | 2.20 × 10−3 | |
| Time (s) | 2.19 | 2.62 | 3.09 | 3.32 | 3.39 | |
| Shifted Ackley | Mean | 1.92 × 101 | 1.93 × 101 | 9.87 × 10−1 | 1.43 × 10−2 | 4.22 × 10−3 |
| Std | 2.09 × 10−1 | 3.36 × 10−1 | 1.49 | 4.44 × 10−2 | 7.90 × 10−3 | |
| Time (s) | 6.59 | 6.50 | 6.29 | 6.20 | 6.01 | |
| Shifted Rastrigin | Mean | 8.60 × 102 | 8.93 × 102 | 2.32 × 102 | 2.35 × 102 | 2.10 × 102 |
| Std | 5.39 × 101 | 1.06 × 102 | 4.48 × 101 | 6.73 × 101 | 4.24 × 101 | |
| Time (s) | 6.35 | 6.22 | 6.16 | 6.35 | 6.12 | |
| Shifted Griewank | Mean | 4.79 × 101 | 5.00 × 101 | 3.22 × 10−1 | 1.85 × 10−3 | 9.86 × 10−4 |
| Std | 5.95 × 101 | 3.97 × 101 | 9.44 × 10−1 | 4.98 × 10−3 | 3.14 × 10−3 | |
| Time (s) | 7.31 | 7.07 | 7.04 | 6.83 | 6.77 |
| Function Name | Characteristic | |
|---|---|---|
| F1 | Shifted and Rotated Rosenbrock’s Function | Shifted, rotated, non-separable |
| F2 | Shifted and Rotated Ackley’s Function | Shifted, rotated, non-separable |
| F3 | Shifted and Rotated Weierstrass Function | Shifted, rotated, non-separable |
| F4 | Shifted and Rotated Griewank’s Function | Shifted, rotated, non-separable |
| F5 | Shifted Rastrigin’s Function | Shifted, separable |
| F6 | Shifted and Rotated Rastrigin’s Function | Shifted, rotated, separable |
| F7 | Shifted Schwefel’s Function | Shifted, separable |
| F8 | Shifted and Rotated Schwefel’s Function | Shifted, rotated, non-separable |
| F9 | Shifted and Rotated Katsuura Function | Shifted, rotated, non-separable |
| F10 | Shifted and Rotated HappyCat Function | Shifted, rotated, non-separable |
| F11 | Shifted and Rotated HGBat Function | Shifted, rotated, non-separable |
| F12 | Shifted and Rotated Expanded Griewank’s plus Rosenbrock’s Function | Shifted, rotated, non-separable |
| F13 | Shifted and Rotated Expanded Scaffer’s F6 Function | Shifted, rotated, non-separable |
| F14 | Shifted Rosenbrock’s Function | Shifted, non-separable, expandable |
| F15 | Rastrigin-shifted’s Function | Shifted, separable, expandable |
| F16 | Shifted Griewank’s Function | Shifted, non-separable, expandable |
| F17 | Shifted Ackley’s Function | Shifted, separable, expandable |
| F18 | FastFractal “DoubleDip” Function | Non-separable, expandable |
| Function | Statistical Indicator | BTLBO | SHSLTLBO | ITLBO | DSTLBO | RLTLBO | ATLDE | GMTLBO | BLTLBO |
|---|---|---|---|---|---|---|---|---|---|
| F1 | Mean | 2.32 × 102 | 2.77 × 102 | 1.25 × 104 | 2.19 × 102 | 4.72 × 102 | 4.72 × 102 | 4.72 × 102 | 1.85 × 102 |
| Std | 4.75 × 101 | 4.65 × 101 | 2.55 × 103 | 3.51 × 101 | 6.56 × 101 | 4.78 × 101 | 8.36 × 101 | 4.10 × 101 | |
| Times (s) | 41.28 | 14.03 | 11.61 | 18.03 | 32.59 | 73.30 | 13.63 | 20.80 | |
| F2 | Mean | 2.02 × 101 | 2.13 × 101 | 2.12 × 101 | 2.01 × 101 | 2.13 × 101 | 2.13 × 101 | 2.13 × 101 | 2.00 × 101 |
| Std | 1.71 × 10−1 | 2.83 × 10−2 | 4.30 × 10−2 | 7.56 × 10−2 | 1.58 × 10−2 | 2.35 × 10−2 | 2.47 × 10−2 | 4.28 × 10−6 | |
| Times (s) | 46.50 | 20.86 | 13.73 | 19.53 | 36.95 | 75.49 | 15.34 | 20.75 | |
| F3 | Mean | 8.79 × 101 | 8.78 × 101 | 1.34 × 102 | 1.06 × 102 | 1.20 × 102 | 1.20 × 102 | 1.20 × 102 | 1.23 × 101 |
| Std | 6.42 | 4.05 | 5.33 | 6.73 | 4.13 | 6.54 | 4.53 | 4.22 | |
| Times (s) | 220.60 | 187.35 | 183.97 | 197.65 | 462.64 | 240.25 | 184.71 | 188.78 | |
| F4 | Mean | 7.12 × 10−2 | 2.46 × 10−2 | 9.22 × 102 | 3.30 × 10−1 | 1.61 | 1.61 | 1.61 | 0 |
| Std | 1.36 × 10−1 | 4.55 × 10−2 | 1.39 × 102 | 1.10 | 1.82 | 5.77 × 10−2 | 2.13 × 10−1 | 0 | |
| Times (s) | 42.18 | 16.26 | 14.71 | 19.67 | 37.84 | 75.19 | 15.96 | 20.55 | |
| F5 | Mean | 2.01 × 102 | 3.75 × 102 | 8.85 × 102 | 4.69 × 102 | 5.68 × 102 | 5.68 × 102 | 5.68 × 102 | 0 |
| Std | 2.77 × 101 | 4.21 × 101 | 1.39 × 102 | 3.24 × 101 | 2.67 × 101 | 3.11 × 101 | 2.73 × 101 | 0 | |
| Times (s) | 33.05 | 8.76 | 6.07 | 11.06 | 15.83 | 72.64 | 7.24 | 11.79 | |
| F6 | Mean | 3.57 × 102 | 3.80 × 102 | 1.28 × 103 | 5.19 × 102 | 7.92 × 102 | 7.92 × 102 | 7.92 × 102 | 1.38 × 102 |
| Std | 8.47 × 101 | 3.18 × 101 | 1.74 × 102 | 4.45 × 101 | 4.60 × 101 | 4.99 × 101 | 5.79 × 101 | 2.22 × 101 | |
| Times (s) | 41.13 | 16.21 | 14.16 | 19.28 | 36.20 | 79.18 | 15.13 | 20.48 | |
| F7 | Mean | 7.66 × 102 | 1.01 × 104 | 2.47 × 104 | 1.18 × 104 | 1.43 × 104 | 1.43 × 104 | 1.43 × 104 | 2.95 × 10−1 |
| Std | 3.49 × 102 | 2.19 × 103 | 1.21 × 103 | 1.23 × 103 | 1.06 × 103 | 9.83 × 102 | 1.76 × 103 | 1.81 × 10−1 | |
| Times (s) | 41.12 | 15.84 | 12.36 | 17.99 | 32.57 | 78.31 | 14.82 | 18.71 | |
| F8 | Mean | 1.09 × 104 | 3.01 × 104 | 2.46 × 104 | 1.42 × 104 | 1.47 × 104 | 1.47 × 104 | 1.47 × 104 | 1.26 × 104 |
| Std | 1.33 × 103 | 4.50 × 102 | 1.12 × 103 | 1.08 × 103 | 1.48 × 103 | 1.09 × 103 | 1.65 × 103 | 1.21 × 103 | |
| Times (s) | 48.95 | 28.49 | 20.13 | 26.51 | 52.80 | 84.28 | 21.79 | 28.12 | |
| F9 | Mean | 5.09 × 10−1 | 4.02 | 1.94 | 1.83 | 3.89 | 3.89 | 3.89 | 3.55 × 10−1 |
| Std | 1.64 × 10−1 | 1.82 × 10−1 | 3.80 × 10−1 | 4.26 × 10−1 | 3.29 × 10−1 | 1.40 | 4.53 × 10−1 | 7.24 × 10−2 | |
| Times (s) | 79.45 | 53.51 | 46.10 | 52.87 | 118.50 | 111.27 | 49.69 | 54.23 | |
| F10 | Mean | 4.49 × 10−1 | 5.95 × 10−1 | 4.85 | 5.88 × 10−1 | 6.76 × 10−1 | 6.76 × 10−1 | 6.76 × 10−1 | 4.28 × 10−1 |
| Std | 6.22 × 10−2 | 5.77 × 10−2 | 3.82 × 10−1 | 6.77 × 10−2 | 8.66 × 10−2 | 5.66 × 10−2 | 8.40 × 10−2 | 4.79 × 10−2 | |
| Times (s) | 38.27 | 18.05 | 12.19 | 18.01 | 32.60 | 76.59 | 14.17 | 19.03 | |
| F11 | Mean | 2.98 × 10−1 | 3.31 × 10−1 | 2.62 × 102 | 3.46 × 10−1 | 3.17 × 10−1 | 3.17 × 10−1 | 3.17 × 10−1 | 2.96 × 10−1 |
| Std | 2.16 × 10−2 | 3.03 × 10−2 | 3.03 × 101 | 1.14 × 10−1 | 4.88 × 10−2 | 3.13 × 10−2 | 1.48 × 10−1 | 2.87 × 10−2 | |
| Times (s) | 39.58 | 19.11 | 12.50 | 18.34 | 33.55 | 78.65 | 14.30 | 19.54 | |
| F12 | Mean | 3.21 × 101 | 1.46 × 102 | 1.07 × 106 | 5.19 × 102 | 4.22 × 103 | 4.22 × 103 | 4.22 × 103 | 1.68 × 101 |
| Std | 6.11 | 4.48 × 101 | 3.44 × 105 | 3.20 × 102 | 1.83 × 103 | 3.12 × 101 | 1.53 × 103 | 2.60 | |
| Times (s) | 42.96 | 16.70 | 14.67 | 19.91 | 37.73 | 79.83 | 15.84 | 20.81 | |
| F13 | Mean | 3.95 × 101 | 4.63 × 101 | 4.31 × 101 | 4.22 × 101 | 4.49 × 101 | 4.49 × 101 | 4.49 × 101 | 3.91 × 101 |
| Std | 1.13 | 3.46 × 10−1 | 5.31 × 10−1 | 1.01 | 4.74 × 10−1 | 2.69 | 1.05 | 1.11 | |
| Times (s) | 44.03 | 21.17 | 14.22 | 20.57 | 39.17 | 78.56 | 16.32 | 21.96 |
| Algorithms | BTLBO | SHSLTLBO | ITLBO | DSTLBO | RLTLBO | ATLDE | GMTLBO | BLTLBO |
|---|---|---|---|---|---|---|---|---|
| ranking | 2.23 | 4.77 | 7.00 | 3.62 | 5.77 | 5.77 | 5.77 | 1.08 |
| BTLBO | SHSLTLBO | ITLBO | DSTLBO | RLTLBO | ATLD × 10 | GMTLBO | |
|---|---|---|---|---|---|---|---|
| F1 | 3.44 × 10−3 | 3.20 × 10−6 | 6.58 × 10−8 | 1.09 × 10−2 | 6.59 × 10−8 | 4.09 × 10−2 | 1.61 × 10−7 |
| F2 | 9.08 × 10−7 | 7.43 × 10−10 | 4.18 × 10−9 | 2.01 × 10−3 | 4.68 × 10−10 | 7.43 × 10−10 | 1.10 × 10−9 |
| F3 | 6.78 × 10−8 | 6.78 × 10−8 | 6.43 × 10−8 | 6.74 × 10−8 | 6.58 × 10−8 | 6.79 × 10−8 | 6.70 × 10−8 |
| F4 | 6.33 × 10−8 | 6.33 × 10−8 | 6.33 × 10−8 | 6.33 × 10−8 | 6.30 × 10−8 | 6.33 × 10−8 | 6.33 × 10−8 |
| F5 | 5.47 × 10−8 | 5.46 × 10−8 | 5.48 × 10−8 | 5.47 × 10−8 | 5.47 × 10−8 | 5.48 × 10−8 | 5.47 × 10−8 |
| F6 | 6.78 × 10−8 | 6.79 × 10−8 | 6.75 × 10−8 | 6.79 × 10−8 | 6.79 × 10−8 | 6.80 × 10−8 | 6.79 × 10−8 |
| F7 | 6.63 × 10−8 | 6.68 × 10−8 | 6.68 × 10−8 | 6.65 × 10−8 | 6.64 × 10−8 | 6.70 × 10−8 | 6.68 × 10−8 |
| F8 | 3.72 × 10−4 | 6.62 × 10−8 | 6.75 × 10−8 | 1.98 × 10−4 | 1.90 × 10−5 | 5.11 × 10−2 | 3.90 × 10−5 |
| F9 | 1.63 × 10−3 | 6.80 × 10−8 | 6.80 × 10−8 | 6.80 × 10−8 | 6.80 × 10−8 | 7.20 × 10−2 | 6.80 × 10−8 |
| F10 | 2.50 × 10−1 | 6.78 × 10−8 | 6.77 × 10−8 | 1.32 × 10−7 | 6.78 × 10−8 | 5.19 × 10−7 | 6.77 × 10−8 |
| F11 | 9.46 × 10−1 | 9.21 × 10−4 | 6.80 × 10−8 | 1.79 × 10−2 | 2.18 × 10−1 | 2.56 × 10−2 | 5.63 × 10−4 |
| F12 | 6.74 × 10−8 | 6.73 × 10−8 | 6.73 × 10−8 | 6.74 × 10−8 | 6.75 × 10−8 | 6.75 × 10−8 | 6.75 × 10−8 |
| F13 | 1.55 × 10−1 | 6.56 × 10−8 | 6.63 × 10−8 | 1.05 × 10−7 | 6.64 × 10−8 | 1.29 × 10−5 | 6.63 × 10−8 |
| + | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| − | 9 | 13 | 13 | 13 | 12 | 11 | 13 |
| = | 3 | 0 | 0 | 0 | 1 | 2 | 0 |
| Function | Algorithm | D = 100 | D = 200 | D = 500 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Std | Times (s) | Mean | Std | Times (s) | Mean | Std | Times (s) | ||
| F14 | BTLBO | 2.21 × 102 | 1.10 × 102 | 22.06 | 9.40 × 102 | 6.44 × 102 | 45.22 | 2.01 × 105 | 4.28 × 105 | 138.28 |
| CSO | 7.43 × 102 | 1.01 × 103 | 1.83 | 3.72 × 102 | 2.55 × 102 | 10.04 | 1.04 × 103 | 3.11 × 102 | 56.30 | |
| DECCG | 4.34 × 102 | 1.56 × 102 | 1.61 | 8.89 × 102 | 2.01 × 102 | 9.67 | 2.17 × 103 | 1.70 × 103 | 22.71 | |
| SHSLTLBO | 9.19 × 102 | 6.21 × 102 | 8.51 | 6.82 × 106 | 9.37 × 106 | 17.45 | 2.80 × 109 | 1.45 × 109 | 70.67 | |
| ITLBO | 2.86 × 1010 | 5.79 × 109 | 7.10 | 2.01 × 1011 | 2.88 × 1010 | 18.55 | 1.00 × 1012 | 5.18 × 1010 | 55.43 | |
| DSTLBO | 2.48 × 102 | 3.35 × 102 | 11.61 | 6.16 × 103 | 1.30 × 104 | 14.70 | 2.77 × 108 | 3.71 × 108 | 89.60 | |
| RLTLBO | 1.32 × 108 | 4.30 × 108 | 18.13 | 7.63 × 108 | 5.90 × 108 | 31.75 | 7.22 × 109 | 3.13 × 109 | 143.64 | |
| ATLDE | 1.32 × 108 | 6.81 × 107 | 33.87 | 7.63 × 108 | 7.64 × 108 | 79.48 | 7.22 × 109 | 2.25 × 109 | 774.00 | |
| GMTLBO | 1.32 × 108 | 4.01 × 102 | 7.75 | 7.63 × 108 | 2.16 × 103 | 19.15 | 7.22 × 109 | 7.04 × 108 | 65.98 | |
| BLTLBO | 1.78 × 102 | 6.39 × 101 | 11.14 | 4.72 × 102 | 7.75 × 101 | 27.79 | 3.24 × 103 | 4.09 × 102 | 138.27 | |
| F15 | BTLBO | 2.82 × 102 | 3.75 × 101 | 20.62 | 1.23 × 103 | 1.49 × 102 | 41.42 | 4.01 × 103 | 7.16 × 101 | 140.55 |
| CSO | 4.86 × 101 | 6.79 | 1.57 | 1.54 × 102 | 2.09 × 101 | 11.09 | 6.72 × 102 | 4.55 × 101 | 56.34 | |
| DECCG | 2.48 × 102 | 1.84 × 101 | 1.49 | 3.10 × 102 | 1.17 × 101 | 7.59 | 3.70 × 102 | 1.73 × 101 | 23.46 | |
| SHSLTLBO | 5.11 × 102 | 4.76 × 101 | 6.50 | 1.29 × 103 | 7.10 × 101 | 19.46 | 3.88 × 103 | 1.26 × 102 | 81.38 | |
| ITLBO | 1.08 × 103 | 1.59 × 102 | 6.12 | 3.27 × 103 | 6.71 × 101 | 20.53 | 9.11 × 103 | 2.52 × 102 | 60.22 | |
| DSTLBO | 6.86 × 102 | 5.34 × 101 | 8.32 | 1.52 × 103 | 5.10 × 101 | 16.91 | 4.04 × 103 | 8.04 × 101 | 96.72 | |
| RLTLBO | 8.51 × 102 | 5.35 × 101 | 14.82 | 1.71 × 103 | 4.35 × 101 | 23.67 | 4.29 × 103 | 7.01 × 101 | 172.50 | |
| ATLDE | 8.51 × 102 | 6.40 × 101 | 32.94 | 1.71 × 103 | 6.73 × 101 | 81.39 | 4.29 × 103 | 1.48 × 102 | 772.48 | |
| GMTLBO | 8.51 × 102 | 5.45 × 101 | 6.41 | 1.71 × 103 | 7.09 × 101 | 12.62 | 4.29 × 103 | 6.58 × 101 | 68.92 | |
| BLTLBO | 0 | 0 | 6.95 | 0 | 0 | 27.37 | 1.17 × 102 | 9.83 | 132.97 | |
| F16 | BTLBO | 3.24 × 10−2 | 5.19 × 10−2 | 22.02 | 1.10 | 2.10 | 49.10 | 1.14 | 1.73 | 171.90 |
| CSO | 0.00 | 0.00 | 1.93 | 0.00 | 0.00 | 12.03 | 3.94 × 10−3 | 6.79 × 10−3 | 65.09 | |
| DECCG | 1.11 × 10−3 | 4.95 × 10−3 | 2.00 | 4.19 × 10−3 | 7.61 × 10−3 | 12.88 | 2.46 × 10−3 | 5.68 × 10−3 | 39.02 | |
| SHSLTLBO | 3.14 × 10−1 | 4.29 × 10−1 | 8.30 | 5.75 | 5.86 | 22.93 | 1.65 × 102 | 3.46 × 101 | 111.80 | |
| ITLBO | 8.80 × 102 | 9.56 × 101 | 7.46 | 3.25 × 103 | 2.63 × 102 | 24.35 | 1.22 × 104 | 4.07 × 102 | 106.12 | |
| DSTLBO | 1.65 | 4.93 | 10.12 | 3.81 × 10−1 | 3.63 × 10−1 | 18.13 | 6.59 | 1.09 × 101 | 124.97 | |
| RLTLBO | 1.34 × 101 | 1.89 × 101 | 18.85 | 5.84 × 101 | 4.17 × 101 | 29.87 | 3.68 × 102 | 1.53 × 102 | 244.16 | |
| ATLDE | 1.34 × 101 | 3.92 × 10−1 | 34.20 | 5.84 × 101 | 1.52 | 82.90 | 3.68 × 102 | 2.80 × 101 | 802.68 | |
| GMTLBO | 1.34 × 101 | 8.47 × 10−1 | 7.70 | 5.84 × 101 | 5.87 × 10−1 | 13.40 | 3.68 × 102 | 8.15 × 101 | 107.63 | |
| BLTLBO | 0 | 0 | 8.11 | 0 | 0 | 30.26 | 3.28 × 10−3 | 7.33 × 10−3 | 171.65 | |
| F17 | BTLBO | 2.25 | 2.55 × 10−1 | 21.36 | 8.86 | 8.43 × 10−1 | 45.47 | 1.88 × 101 | 1.11 × 10−1 | 141.07 |
| CSO | 0 | 0 | 1.63 | 0.00 | 0.00 | 9.98 | 9.78 × 10−1 | 3.92 × 10−1 | 54.82 | |
| DECCG | 4.00 × 10−4 | 1.98 × 10−4 | 1.56 | 9.56 × 10−2 | 3.02 × 10−1 | 9.62 | 2.16 × 10−7 | 6.79 × 10−7 | 28.36 | |
| SHSLTLBO | 1.16 × 101 | 1.42 | 7.28 | 1.64 × 101 | 5.62 × 10−1 | 18.93 | 1.90 × 101 | 1.20 × 10−1 | 82.26 | |
| ITLBO | 2.00 × 101 | 2.29 × 10−1 | 6.76 | 2.09 × 101 | 5.93 × 10−2 | 21.14 | 2.12 × 101 | 3.71 × 10−2 | 62.18 | |
| DSTLBO | 1.69 × 101 | 8.75 × 10−1 | 9.75 | 1.88 × 101 | 2.17 × 10−1 | 15.09 | 1.92 × 101 | 2.72 × 10−2 | 96.71 | |
| RLTLBO | 1.89 × 101 | 5.82 × 10−1 | 16.01 | 1.94 × 101 | 2.70 × 10−1 | 24.86 | 1.94 × 101 | 8.38 × 10−2 | 184.21 | |
| ATLDE | 1.89 × 101 | 1.99 | 33.61 | 1.94 × 101 | 3.88 × 10−1 | 82.45 | 1.94 × 101 | 8.42 × 10−2 | 792.81 | |
| GMTLBO | 1.89 × 101 | 1.45 × 10−1 | 6.57 | 1.94 × 101 | 4.17 × 10−2 | 10.94 | 1.94 × 101 | 1.47 × 10−1 | 76.02 | |
| BLTLBO | 0 | 0 | 8.28 | 0 | 0 | 25.18 | 1.67 | 1.05 × 10−1 | 134.67 | |
| F18 | BTLBO | −1.43 × 103 | 2.06 × 101 | 44.73 | −2.71 × 103 | 3.59 × 101 | 129.15 | −6.21 × 103 | 1.64 × 102 | 502.70 |
| CSO | −1.48 × 103 | 2.55 × 101 | 9.20 | −2.88 × 103 | 1.51 × 101 | 84.66 | −6.96 × 103 | 1.12 × 101 | 419.17 | |
| DECCG | −1.20 × 103 | 1.02 × 101 | 9.16 | −2.12 × 103 | 9.30 × 101 | 82.05 | −5.52 × 103 | 3.81 × 101 | 388.11 | |
| SHSLTLBO | −9.51 × 102 | 8.20 × 101 | 32.16 | −1.88 × 103 | 1.91 × 102 | 104.06 | −4.93 × 103 | 4.48 × 101 | 442.04 | |
| ITLBO | −1.00 × 103 | 3.29 × 101 | 23.85 | −1.76 × 103 | 4.58 × 101 | 93.57 | −3.81 × 103 | 6.04 × 101 | 360.80 | |
| DSTLBO | −1.21 × 103 | 4.55 × 101 | 28.18 | −2.21 × 103 | 8.29 × 101 | 65.23 | −5.00 × 103 | 1.41 × 102 | 434.37 | |
| RLTLBO | −1.11 × 103 | 7.41 × 101 | 62.96 | −2.02 × 103 | 1.33 × 102 | 129.53 | −5.10 × 103 | 3.72 × 102 | 947.70 | |
| ATLDE | −1.11 × 103 | 2.38 × 101 | 52.81 | −2.02 × 103 | 2.87 × 101 | 124.31 | −5.10 × 103 | 8.36 × 101 | 1052.60 | |
| GMTLBO | −1.11 × 103 | 4.83 × 101 | 25.26 | −2.02 × 103 | 1.02 × 102 | 63.40 | −5.10 × 103 | 3.79 × 102 | 387.87 | |
| BLTLBO | −1.55 × 103 | 2.88 | 25.56 | −3.02 × 103 | 6.87 | 93.81 | −7.26 × 103 | 1.89 × 101 | 456.15 | |
| Algorithms | BTLBO | CSO | DECCG | SHSLTLBO | ITLBO | DSTLBO | RLTLBO | ATLDE | GMTLBO | BLTLBO | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ranking | D = 100 | 3.4 | 2.4 | 3.6 | 6.2 | 9.8 | 5.0 | 7.8 | 7.8 | 7.8 | 1.2 |
| D = 200 | 4 | 1.6 | 3.4 | 6.2 | 10 | 5 | 7.8 | 7.8 | 7.8 | 1.4 | |
| D = 500 | 4 | 2.2 | 2 | 6 | 10 | 6 | 7.6 | 7.6 | 7.6 | 2 | |
| Dimension | Function | BTLBO | CSO | DECCG | SHSLTLBO | ITLBO | DSTLBO | RLTLBO | ATLDE | GMTLBO |
|---|---|---|---|---|---|---|---|---|---|---|
| D = 100 | F14 | 1.59 × 10−1 | 2.23 × 10−1 | 2.75 × 10−7 | 6.80 × 10−8 | 6.80 × 10−8 | 6.95 × 10−1 | 6.80 × 10−8 | 4.22 × 10−7 | 6.79 × 10−8 |
| F15 | 6.71 × 10−8 | 6.67 × 10−8 | 6.72 × 10−8 | 6.72 × 10−8 | 6.73 × 10−8 | 6.74 × 10−8 | 6.72 × 10−8 | 6.73 × 10−8 | 6.70 × 10−8 | |
| F16 | 6.67 × 10−5 | NaN | 8.01 × 10−9 | 7.99 × 10−9 | 7.99 × 10−9 | 8.01 × 10−9 | 7.99 × 10−9 | 1.05 × 10−7 | 7.99 × 10−9 | |
| F17 | 8.01 × 10−9 | NaN | 8.01 × 10−9 | 8.01 × 10−9 | 8.01 × 10−9 | 8.01 × 10−9 | 8.01 × 10−9 | 8.01 × 10−9 | 8.01 × 10−9 | |
| F18 | 3.48 × 10−8 | 3.33 × 10−8 | 2.60 × 10−8 | 3.66 × 10−8 | 3.58 × 10−8 | 3.53 × 10−8 | 3.60 × 10−8 | 3.46 × 10−8 | 3.63 × 10−8 | |
| D = 200 | F14 | 2.11 × 10−2 | 4.57 × 10−3 | 3.28 × 10−4 | 1.82 × 10−4 | 1.81 × 10−4 | 1.82 × 10−4 | 1.82 × 10−4 | 1.82 × 10−4 | 1.81 × 10−4 |
| F15 | 1.83 × 10−4 | 1.83 × 10−4 | 1.82 × 10−4 | 1.83 × 10−4 | 1.82 × 10−4 | 1.79 × 10−4 | 1.82 × 10−4 | 1.81 × 10−4 | 1.81 × 10−4 | |
| F16 | 6.39 × 10−5 | NaN | 6.39 × 10−5 | 6.39 × 10−5 | 6.39 × 10−5 | 6.39 × 10−5 | 6.39 × 10−5 | 6.39 × 10−5 | 6.39 × 10−5 | |
| F17 | 6.39 × 10−5 | NaN | 6.39 × 10−5 | 6.16 × 10−5 | 4.73 × 10−5 | 5.47 × 10−5 | 6.25 × 10−5 | 5.94 × 10−5 | 3.32 × 10−5 | |
| F18 | 1.45 × 10−4 | 1.39 × 10−4 | 1.43 × 10−4 | 1.44 × 10−4 | 1.45 × 10−4 | 1.44 × 10−4 | 1.45 × 10−4 | 1.41 × 10−4 | 1.45 × 10−4 | |
| D = 500 | F14 | 1.83 × 10−4 | 1.83 × 10−4 | 2.83 × 10−3 | 1.83 × 10−4 | 1.78 × 10−4 | 1.83 × 10−4 | 1.83 × 10−4 | 1.83 × 10−4 | 1.83 × 10−4 |
| F15 | 1.79 × 10−4 | 1.83 × 10−4 | 1.82 × 10−4 | 1.82 × 10−4 | 1.83 × 10−4 | 1.78 × 10−4 | 1.80 × 10−4 | 1.83 × 10−4 | 1.77 × 10−4 | |
| F16 | 5.83 × 10−4 | 6.95 × 10−2 | 1.11 × 10−2 | 1.83 × 10−4 | 1.79 × 10−4 | 1.83 × 10−4 | 1.83 × 10−4 | 2.46 × 10−4 | 1.83 × 10−4 | |
| F17 | 1.59 × 10−4 | 1.82 × 10−4 | 1.82 × 10−4 | 1.71 × 10−4 | 1.29 × 10−4 | 6.39 × 10−5 | 1.31 × 10−4 | 1.58 × 10−4 | 1.59 × 10−4 | |
| F18 | 1.55 × 10−4 | 1.49 × 10−4 | 1.43 × 10−4 | 1.44 × 10−4 | 1.42 × 10−4 | 1.41 × 10−4 | 1.44 × 10−4 | 1.41 × 10−4 | 1.46 × 10−4 | |
| + | 0 | 1 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | |
| − | 14 | 8 | 13 | 15 | 15 | 15 | 15 | 15 | 15 | |
| = | 1 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Testing Data | Evaluation Indicators | GA | PSO | HSDS | HS-TLBO | BLTLBO |
|---|---|---|---|---|---|---|
| DAX100 (D = 85) | MED | 1.20 × 10−3 | 1.40 × 10−3 | 3.39 × 10−6 | 1.80 × 10−6 | 1.40 × 10−6 |
| VRE | 3.10 × 10−1 | 3.90 × 10−1 | 2.01 × 10−1 | 9.60 × 10−2 | 7.85 × 10−2 | |
| MRE | 1.20 × 10−1 | 1.30 × 10−1 | 2.17 × 10−2 | 9.96 × 10−3 | 1.03 × 10−2 | |
| FTSE100 (D = 89) | MED | 3.00 × 10−4 | 3.30 × 10−4 | 3.64 × 10−6 | 4.75 × 10−7 | 4.94 × 10−7 |
| VRE | 5.00 × 10−1 | 5.40 × 10−1 | 2.57 × 10−1 | 2.37 × 10−2 | 2.27 × 10−2 | |
| MRE | 5.70 × 10−2 | 6.40 × 10−2 | 3.19 × 10−2 | 5.86 × 10−3 | 7.00 × 10−3 | |
| S&P100 (D = 98) | MED | 6.20 × 10−4 | 7.90 × 10−4 | 3.86 × 10−6 | 1.56 × 10−6 | 1.55 × 10−6 |
| VRE | 6.10 × 10−1 | 6.90 × 10−1 | 2.88 × 10−1 | 7.28 × 10−2 | 7.13 × 10−2 | |
| MRE | 2.10 × 10−1 | 2.50 × 10−1 | 2.68 × 10−2 | 1.05 × 10−2 | 1.10 × 10−2 | |
| Nikkei (D = 225) | MED | 1.50 × 10−3 | 2.90 × 10−4 | 1.01 × 10−5 | 8.33 × 10−7 | 7.10 × 10−7 |
| VRE | 2.10 × 10−1 | 4.30 × 10−1 | 1.84 × 10−1 | 6.36 × 10−2 | 5.24 × 10−2 | |
| MRE | 9.30 × 10−1 | 1.40 × 10−1 | 5.90 × 10−2 | 1.34 × 10−2 | 1.30 × 10−2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Li, Y.; Yong, L. Teaching–Learning-Based Optimization Algorithm with Stochastic Crossover Self-Learning and Blended Learning Model and Its Application. Mathematics 2024, 12, 1596. https://doi.org/10.3390/math12101596
Ma Y, Li Y, Yong L. Teaching–Learning-Based Optimization Algorithm with Stochastic Crossover Self-Learning and Blended Learning Model and Its Application. Mathematics. 2024; 12(10):1596. https://doi.org/10.3390/math12101596
Chicago/Turabian StyleMa, Yindi, Yanhai Li, and Longquan Yong. 2024. "Teaching–Learning-Based Optimization Algorithm with Stochastic Crossover Self-Learning and Blended Learning Model and Its Application" Mathematics 12, no. 10: 1596. https://doi.org/10.3390/math12101596
APA StyleMa, Y., Li, Y., & Yong, L. (2024). Teaching–Learning-Based Optimization Algorithm with Stochastic Crossover Self-Learning and Blended Learning Model and Its Application. Mathematics, 12(10), 1596. https://doi.org/10.3390/math12101596