
Implicit Stance Detection with Hashtag Semantic Enrichment

Abstract
:1. Introduction
- We propose a LKESD framework for stance detection that can learn the semantic information of hashtags from both LLMs and corpora, thereby enhancing its applicability in real-world social media scenarios.
- We investigate stance detection from a novel perspective by exploring the semantic expressions of hashtags. We propose a novel KFN to achieve dynamic fusion of different semantic representation features.
- To validate the effectiveness of the LKESD model for stance detection on social media, we perform comprehensive experiments on widely used benchmarks. The experimental results demonstrate the effectiveness of the proposed method.
2. Related Work
2.1. Stance Detection
2.2. Incorporating Background Knowledge
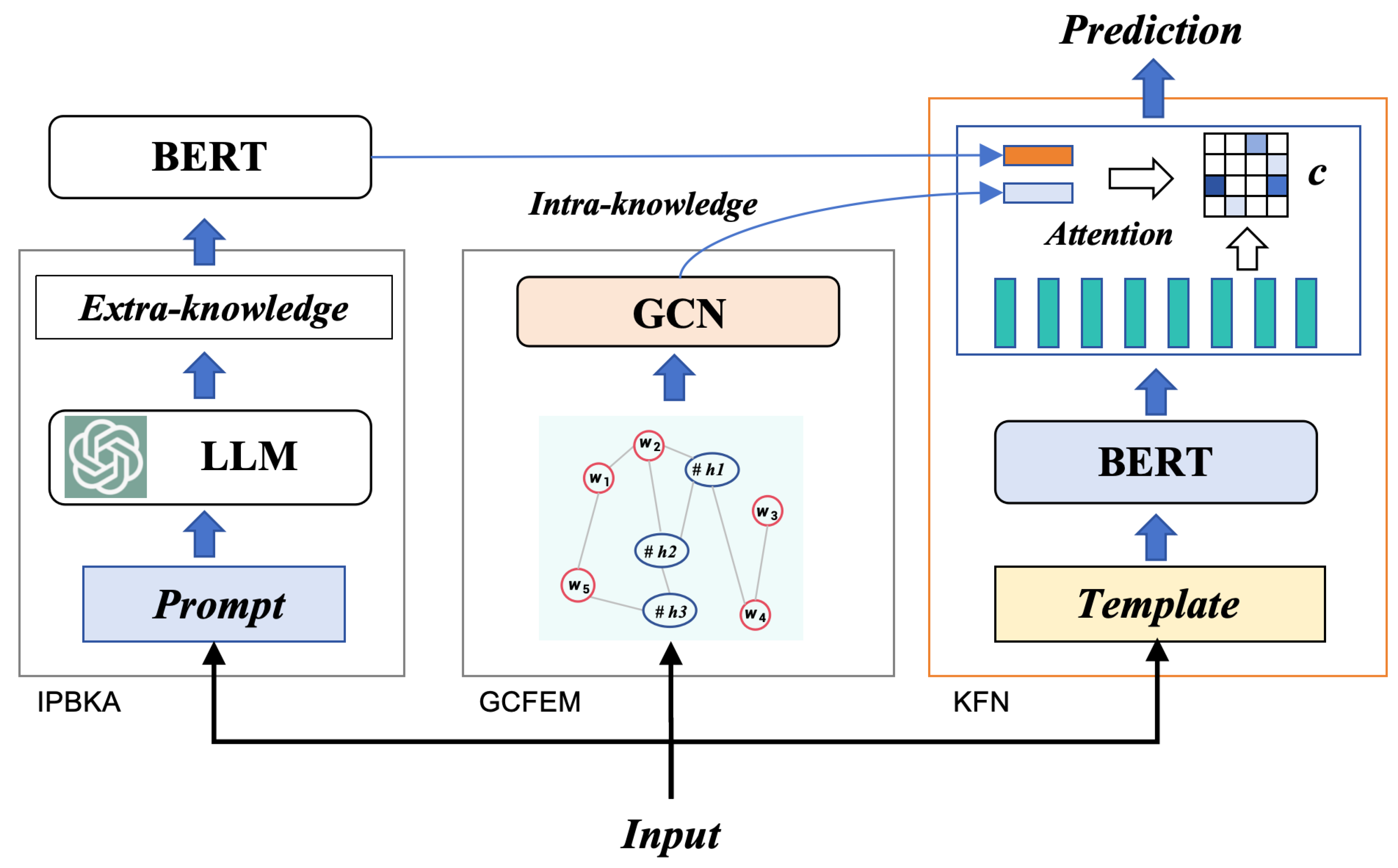
3. LKESD Framework
3.1. Problem Definition
3.2. Framework Overview
3.3. IPBKA

3.4. GCFEM
3.5. Knowledge Fusion Network

4. Experiments
4.1. Experimental Data
- ISD. The ISD dataset [12] is proposed for the stance detection task on social media, which presents a challenge as it consists of texts lacking explicit sentiment words. Therefore, understanding the relationship between the text and contextual knowledge, including the target and hashtag knowledge, is crucial for predicting stance polarity. ISD includes two targets: Trump (DT) and Biden (JB).
- SEM16. The original SEM16 dataset includes 4870 texts and annotated with one of three stance labels: “favor”, ”against”, or “neutral”. To validate the efficacy of our hashtag fusion approach, we reorganized the original dataset. Hashtags containing only crawled user data were removed, and the remaining data were consolidated into a single dataset (SEM16-h). SEM16-h contains the same four targets as in previous work [21].
- COVID-19. The COVID-19 dataset contains 6133 tweets, each reflecting user positions on four specific targets associated with COVID-19 health mandates. Similar to SEM16, we process the dataset, and the remaining data are consolidated into a single task (COV-h). COV-h contains the same four targets as [34].
4.2. Compared Baseline Methods
- BiLSTM [20] adopts a bidirectional LSTM framework to encode the text and target separately, enabling the extraction of independent semantic features.
- BiCond [20] employs a bidirectional LSTM framework to simultaneously encode the text and target, thereby capturing their shared semantic features.
- CrossNet [35] builds upon the BiCond architecture by integrating a self-attention mechanism, which selectively highlights salient textual features.
- AoA [36] employs a dual-LSTM architecture, wherein two separate LSTM networks are dedicated to modeling the target and context, respectively, and an interactive attention mechanism is integrated to facilitate the examination of their relationships.
- TPDG [37] proposes a target-adaptive convolutional graph framework, which boosts stance detection accuracy by leveraging shared features from similar targets and capitalizing on their inherent relationships.
- BERT [8] leverages a pre-trained BERT architecture for stance detection, reformulating the input format to “[CLS] + text + [SEP] + target + [SEP]” to optimize the model’s training and fine-tuning procedures.
- PT-HCL [6] exploits contrastive learning to enhance the detection of subtle stance variations.
- MPT [38] introduces a knowledge-infused prompt-tuning method for stance detection, which exploits a verbalizer carefully crafted by human experts to enhance the detection of subtle stance variations.
- KPT [39] leverages external lexicals to initialize the verbalizer component, which is embedded within the prompt framework, to facilitate the integration of domain-specific knowledge.
- KEprompt [12] employs a topic model to acquire hashtag representations and then performs prompt-tuning methods for stance detection.
- SEKT [22] presents a GCN framework that incorporates semantic knowledge to enhance stance detection capabilities.
- TarBK [29] integrates the target-related wiki knowledge from Wikipedia for stance detection.
- Ts-CoT [40] first proposes CoT methods with LLMs for stance detection.
- KASD [32] proposes to augment the hashtag by utilizing LLMs.
4.3. Implementation Details and Evaluation Metrics
4.4. Overall Performance
4.4.1. In-Target Setup
4.4.2. Cross-Target Setup
4.4.3. Zero-Shot Stance Detection
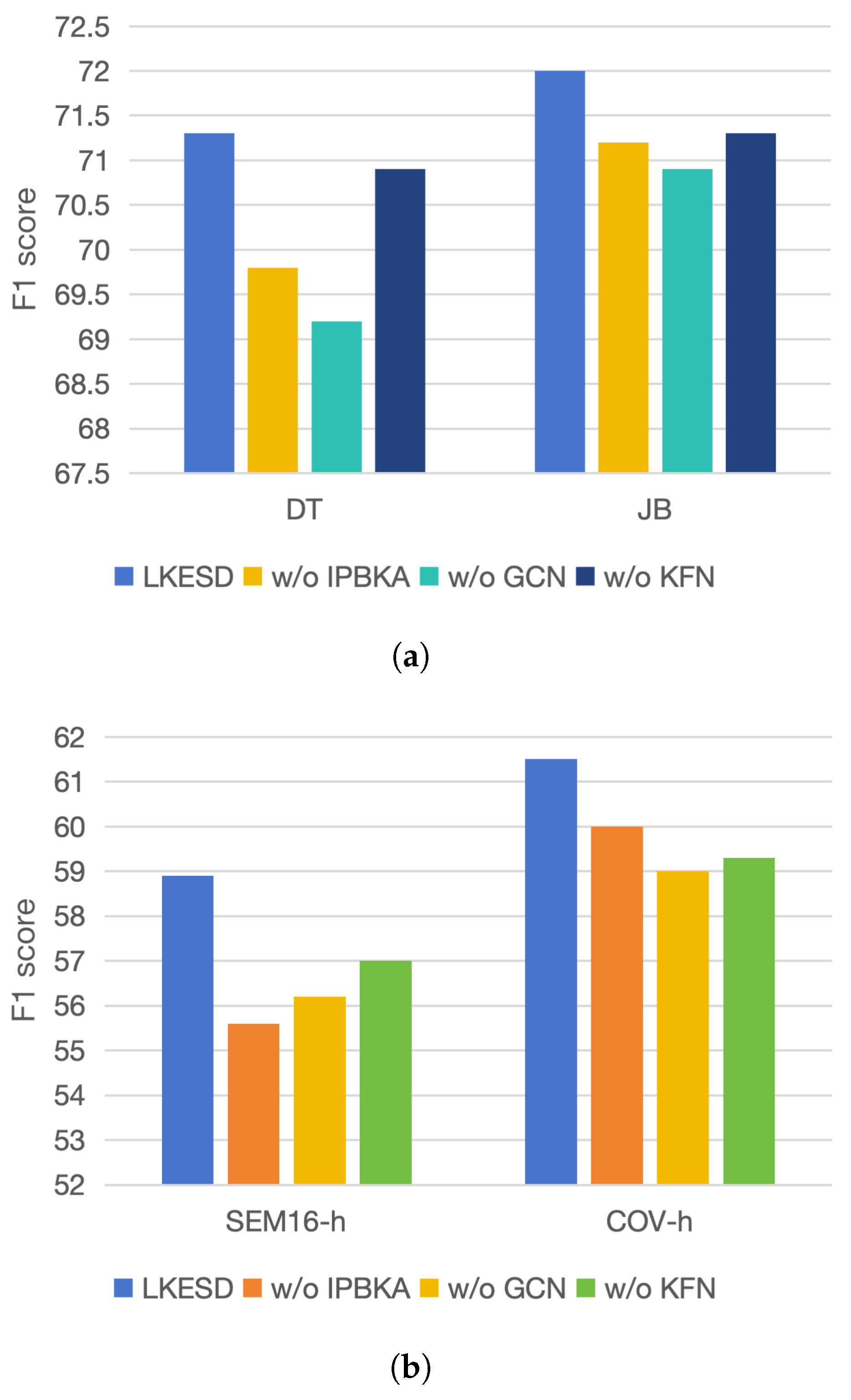
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Küçük, D.; Can, F. Stance detection: A survey. ACM Comput. Surv. CSUR 2020, 53, 1–37. [Google Scholar] [CrossRef]
- Yang, M.; Zhao, W.; Chen, L.; Qu, Q.; Zhao, Z.; Shen, Y. Investigating the transferring capability of capsule networks for text classification. Neural Netw. 2019, 118, 247–261. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Tiwari, P.; Song, D.; Mao, X.; Wang, P.; Li, X.; Pandey, H.M. Learning interaction dynamics with an interactive LSTM for conversational sentiment analysis. Neural Netw. 2021, 133, 40–56. [Google Scholar] [CrossRef] [PubMed]
- Du, J.; Xu, R.; He, Y.; Gui, L. Stance classification with target-specific neural attention networks. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Sun, Q.; Wang, Z.; Zhu, Q.; Zhou, G. Stance detection with hierarchical attention network. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NW, USA, 21–25 August 2018; pp. 2399–2409. [Google Scholar]
- Liang, B.; Chen, Z.; Gui, L.; He, Y.; Yang, M.; Xu, R. Zero-Shot Stance Detection via Contrastive Learning. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 2738–2747. [Google Scholar]
- Liu, R.; Lin, Z.; Tan, Y.; Wang, W. Enhancing zero-shot and few-shot stance detection with commonsense knowledge graph. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 3152–3157. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Mohammad, S.; Kiritchenko, S.; Sobhani, P.; Zhu, X.; Cherry, C. SemEval-2016 Task 6: Detecting Stance in Tweets. In Proceedings of the 10th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT, San Diego, CA, USA, 16–17 June 2016; pp. 31–41. [Google Scholar]
- Li, Y.; Sosea, T.; Sawant, A.; Nair, A.J.; Inkpen, D.; Caragea, C. P-Stance: A Large Dataset for Stance Detection in Political Domain. In Proceedings of the Findings of the Association for Computational Linguistics: ACL/IJCNLP, Online, 1–6 August 2021. [Google Scholar]
- Huang, H.; Zhang, B.; Li, Y.; Zhang, B.; Sun, Y.; Luo, C.; Peng, C. Knowledge-enhanced prompt-tuning for stance detection. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 22, 1–20. [Google Scholar] [CrossRef]
- Darwish, K.; Stefanov, P.; Aupetit, M.; Nakov, P. Unsupervised user stance detection on Twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Atlanta, GA, USA, 8 June 2020; Volume 14, pp. 141–152. [Google Scholar]
- Jain, R.; Jain, D.K.; Dharana; Sharma, N. Fake News Classification: A Quantitative Research Description. ACM Trans. Asian Low Resour. Lang. Inf. Process. 2022, 21, 1–17. [Google Scholar] [CrossRef]
- Rani, S.; Kumar, P. Aspect-based Sentiment Analysis using Dependency Parsing. ACM Trans. Asian Low Resour. Lang. Inf. Process. 2022, 21, 1–19. [Google Scholar] [CrossRef]
- Dey, K.; Shrivastava, R.; Kaushik, S. Topical Stance Detection for Twitter: A Two-Phase LSTM Model Using Attention. In Proceedings of the European Conference on Information Retrieval, Grenoble, France, 26–29 March 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 529–536. [Google Scholar]
- Li, C.; Peng, H.; Li, J.; Sun, L.; Lyu, L.; Wang, L.; Yu, P.S.; He, L. Joint Stance and Rumor Detection in Hierarchical Heterogeneous Graph. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 2530–2542. [Google Scholar] [CrossRef] [PubMed]
- Cignarella, A.T.; Bosco, C.; Rosso, P. Do Dependency Relations Help in the Task of Stance Detection? In Proceedings of the Third Workshop on Insights from Negative Results in NLP, Insights@ACL 2022, Dublin, Ireland, 26 May 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 10–17. [Google Scholar]
- Conforti, C.; Berndt, J.; Pilehvar, M.T.; Giannitsarou, C.; Toxvaerd, F.; Collier, N. Synthetic Examples Improve Cross-Target Generalization: A Study on Stance Detection on a Twitter corpus. In Proceedings of the Eleventh Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, WASSA@EACL 2021, Online, 19 April 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 181–187. [Google Scholar]
- Augenstein, I.; Rocktaeschel, T.; Vlachos, A.; Bontcheva, K. Stance Detection with Bidirectional Conditional Encoding. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Wei, P.; Mao, W. Modeling Transferable Topics for Cross-Target Stance Detection. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; ACM: New York, NY, USA, 2019; pp. 1173–1176. [Google Scholar]
- Zhang, B.; Yang, M.; Li, X.; Ye, Y.; Xu, X.; Dai, K. Enhancing cross-target stance detection with transferable semantic-emotion knowledge. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3188–3197. [Google Scholar]
- Cambria, E.; Poria, S.; Hazarika, D.; Kwok, K. SenticNet 5: Discovering conceptual primitives for sentiment analysis by means of context embeddings. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Allaway, E.; McKeown, K.R. Zero-Shot Stance Detection: A Dataset and Model using Generalized Topic Representations. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 8913–8931. [Google Scholar]
- Allaway, E.; Srikanth, M.; McKeown, K.R. Adversarial Learning for Zero-Shot Stance Detection on Social Media. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, 6–11 June 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 4756–4767. [Google Scholar]
- Nguyen, D.Q.; Vu, T.; Nguyen, A.T. BERTweet: A pre-trained language model for English Tweets. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, EMNLP 2020—Demos, Online, 16–20 November 2020; Liu, Q., Schlangen, D., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 9–14. [Google Scholar] [CrossRef]
- Müller, M.; Salathé, M.; Kummervold, P.E. COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter. arXiv 2020, arXiv:2005.07503. [Google Scholar] [CrossRef] [PubMed]
- Hanawa, K.; Sasaki, A.; Okazaki, N.; Inui, K. Stance Detection Attending External Knowledge from Wikipedia. J. Inf. Process. 2019, 27, 499–506. [Google Scholar] [CrossRef]
- Zhu, Q.; Liang, B.; Sun, J.; Du, J.; Zhou, L.; Xu, R. Enhancing Zero-Shot Stance Detection via Targeted Background Knowledge. In Proceedings of the SIGIR ’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; Amigó, E., Castells, P., Gonzalo, J., Carterette, B., Culpepper, J.S., Kazai, G., Eds.; ACM: New York, NY, USA, 2022; pp. 2070–2075. [Google Scholar] [CrossRef]
- Ghosh, S.; Singhania, P.; Singh, S.; Rudra, K.; Ghosh, S. Stance Detection in Web and Social Media: A Comparative Study. In Proceedings of the Experimental IR Meets Multilinguality, Multimodality, and Interaction—10th International Conference of the CLEF Association, CLEF 2019, Lugano, Switzerland, 9–12 September 2019; Springer: Berlin/Heidelberg, Germany, 2019. Lecture Notes in Computer Science. Volume 11696, pp. 75–87. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, A.; Li, M.; Smola, A. Automatic chain of thought prompting in large language models. arXiv 2022, arXiv:2210.03493. [Google Scholar]
- Li, A.; Liang, B.; Zhao, J.; Zhang, B.; Yang, M.; Xu, R. Stance detection on social media with background knowledge. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 15703–15717. [Google Scholar]
- Ding, D.; Chen, R.; Jing, L.; Zhang, B.; Huang, X.; Dong, L.; Zhao, X.; Song, G. Cross-target Stance Detection by Exploiting Target Analytical Perspectives. arXiv 2024, arXiv:2401.01761. [Google Scholar]
- Glandt, K.; Khanal, S.; Li, Y.; Caragea, D.; Caragea, C. Stance Detection in COVID-19 Tweets. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, Virtual Event, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; Volume 1: Long Papers, pp. 1596–1611. [Google Scholar] [CrossRef]
- Xu, C.; Paris, C.; Nepal, S.; Sparks, R. Cross-Target Stance Classification with Self-Attention Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 2: Short Papers, pp. 778–783. [Google Scholar]
- Huang, B.; Ou, Y.; Carley, K.M. Aspect level sentiment classification with attention-over-attention neural networks. In Proceedings of the International Conference on Social Computing, Behavioral-Cultural Modeling and Prediction and Behavior Representation in Modeling and Simulation, Washington DC, USA, 10–13 July 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 197–206. [Google Scholar]
- Liang, B.; Fu, Y.; Gui, L.; Yang, M.; Du, J.; He, Y.; Xu, R. Target-adaptive Graph for Cross-target Stance Detection. In Proceedings of the WWW ’21: The Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 3453–3464. [Google Scholar]
- Hu, S.; Ding, N.; Wang, H.; Liu, Z.; Li, J.; Sun, M. Knowledgeable prompt-tuning: Incorporating knowledge into prompt verbalizer for text classification. arXiv 2021, arXiv:2108.02035. [Google Scholar]
- Shin, T.; Razeghi, Y.; IV, R.L.L.; Wallace, E.; Singh, S. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 4222–4235. [Google Scholar]
- Zhang, B.; Fu, X.; Ding, D.; Huang, H.; Li, Y.; Jing, L. Investigating Chain-of-thought with ChatGPT for Stance Detection on Social Media. arXiv 2023, arXiv:2304.03087. [Google Scholar]
- Liang, B.; Zhu, Q.; Li, X.; Yang, M.; Gui, L.; He, Y.; Xu, R. Jointcl: A joint contrastive learning framework for zero-shot stance detection. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; Volume 1: Long Papers, pp. 81–91. [Google Scholar]

{kind=link}
{kind=link}
| Method | Year | Brief Description |
|---|---|---|
| Dey et al. [16] | 2018 | Attention-based stance polarity detection using target-relevant information. |
| Du et al. [4] | 2017 | Attention mechanisms for determining stance polarity. |
| Sun et al. [5] | 2018 | Employing attention methods for stance classification. |
| Li et al. [17] | 2022 | GCN for modeling relations between target and text. |
| Cignarella et al. [18] | 2022 | GCN-based analysis of text-target connections. |
| Conforti et al. [19] | 2021 | GCN utilization for nuanced stance analysis. |
| Augenstein et al. [20] | 2016 | Word-level transfer leveraging word commonality. |
| Wei et al. [21] | 2019 | Concept-level transfer using shared concepts. |
| Zhang et al. [22] | 2020 | Enhancing cross-target understanding with concepts. |
| Cambria et al. [23] | 2018 | Concept-based transfer for stance detection. |
| Allaway et al. [24] | 2020 | Human-annotated dataset for zero-shot stance detection. |
| Allaway et al. [25] | 2021 | Adversarial learning for target-invariant features. |
| Liu et al. [7] | 2021 | Graph-based model integrating semantic knowledge. |
| Liang et al. [6] | 2022 | Identifying transferable features for zero-shot learning. |
| Zhang et al. [22] | 2020 | Extracting semantic and emotional word-level knowledge from lexicons. |
| Nguyen et al. [26] | 2020 | Pre-training on a corpus specific to the target domain (BERTweet). |
| Mueller et al. [27] | 2020 | Pre-training on COVID-19 related tweets (COVID-Twitter-BERT). |
| Hanawa et al. [28] | 2019 | Extracting relevant concepts and events from Wikipedia articles. |
| Zhu et al. [29] | 2022 | Keyword-based filtering for knowledge retrieval. |
| Ghosh et al. [30] | 2019 | Splitting hashtags into individual words and using substitute vocabulary. |
| Zhang et al. [31] | 2022 | Using an unsupervised topic model for semantic representation of hashtags. |
| Li et al. [32] | 2023 | Incorporating LLM to generate explanations of hashtags. |
| Dataset | Target | Favor | Against | Neutral |
|---|---|---|---|---|
| SEM16 | SEM16-h | 598 | 1620 | 648 |
| COVID19 | COV-h | 1990 | 1928 | 2215 |
| ISD | DT | 875 | 1096 | 1134 |
| JB | 1046 | 525 | 912 |
| Methods | DT | JB | SEM16-h | COV-h | |
|---|---|---|---|---|---|
| glove | Bilstm | 28.6 | 35.0 | 35.6 | 38.8 |
| Bicond | 55.2 | 50.5 | 37.2 | 39.1 | |
| MemNet | 53.5 | 52.2 | 37.9 | 40.3 | |
| AoA | 55.9 | 57.6 | 38.1 | 40.9 | |
| TPDG | 64.2 | 60.0 | 45.4 | 47.7 | |
| BERT | BERT-FT | 69.1 | 65.6 | 45.7 | 50.2 |
| MPT | 69.0 | 65.9 | 46.8 | 52.2 | |
| KPT | 69.4 | 66.4 | 49.2 | 54.6 | |
| KEPrompt | 70.5 | 67.4 | 50.3 | 56.9 | |
| TarBK | 69.5 | 66.6 | 50.1 | 54.1 | |
| Ts-CoT | 69.4 | 69.1 | 53.9 | 57.4 | |
| KASD | 70.2 | 68.4 | 55.1 | 59.3 | |
| LKESD | 71.3† | 72.0† | 58.9† | 61.5† |
| Methods | JB→DT | DT→JB | COV-h→SEM16-h | SEM16-h→COV-h | |
|---|---|---|---|---|---|
| glove | BiCond | 47.9 | 43.6 | 30.2 | 33.8 |
| CrossNet | 48.0 | 44.2 | 36.5 | 34.8 | |
| SEKT | 51.2 | 52.3 | 39.1 | 38.7 | |
| BERT | BERT-FT | 55.7 | 57.3 | 40.2 | 41.5 |
| MPT | 58.9 | 60.1 | 44.4 | 48.1 | |
| KEprompt | 60.4 | 64.2 | 45.3 | 50.3 | |
| KASD | 62.6 | 65.3 | 51.2 | 53.1 | |
| LKESD | 64.3 | 67.0 | 50.8 | 55.2 |
| Methods | →DT | →JB | →SEM16-h | →COV-h | |
|---|---|---|---|---|---|
| glove | BiCond | 44.5 | 41.7 | 31.2 | 31.7 |
| SEKT | 46.8 | 49.1 | 34.0 | 33.4 | |
| BERT | BERT-FT | 54.7 | 58.0 | 35.9 | 38.1 |
| MPT | 59.2 | 58.9 | 36.5 | 40.3 | |
| KEprompt | 59.3 | 58.7 | 40.2 | 42.6 | |
| PT-HCL | 60.1 | 59.6 | 41.7 | 43.3 | |
| KASD | 61.9 | 63.3 | 46.3 | 48.2 | |
| LKESD | 62.0 | 64.2 | 46.9 | 50.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, L.; Su, Z.; Fu, X.; Zhang, B.; Dai, G. Implicit Stance Detection with Hashtag Semantic Enrichment. Mathematics 2024, 12, 1663. https://doi.org/10.3390/math12111663
Dong L, Su Z, Fu X, Zhang B, Dai G. Implicit Stance Detection with Hashtag Semantic Enrichment. Mathematics. 2024; 12(11):1663. https://doi.org/10.3390/math12111663
Chicago/Turabian StyleDong, Li, Zinao Su, Xianghua Fu, Bowen Zhang, and Genan Dai. 2024. "Implicit Stance Detection with Hashtag Semantic Enrichment" Mathematics 12, no. 11: 1663. https://doi.org/10.3390/math12111663