
Testing Multivariate Normality Based on Beta-Representative Points


Abstract
:1. Introduction
2. The MVN Test Based on Beta-Representative Points
2.1. The Beta M Distance
- 1.
- The adjusted M distance has an exact beta distribution up to a constant:
- 2.
- are asymptotically independent.
2.2. The RP Chi-Square Test with a Large Sample Size
2.3. The RP Chi-Square Test with High Dimension and a Small Sample Size
- 1.
- The adjusted M distance has an exact beta distribution up to a constant:
- 2.
- are asymptotically independent.
3. A Monte Carlo Study and an Illustrative Example
3.1. Comparison between the Empirical Type I Error Rates
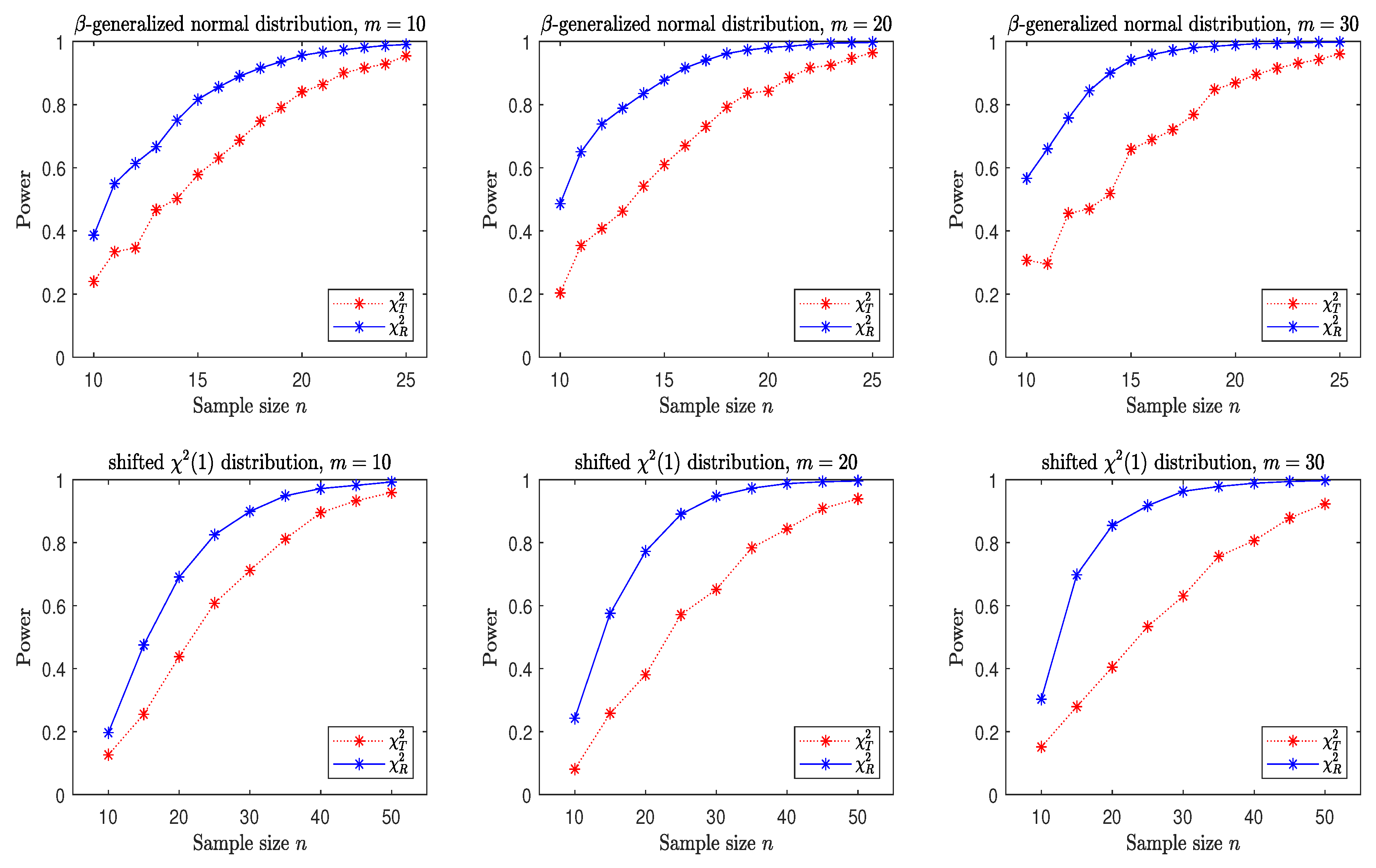
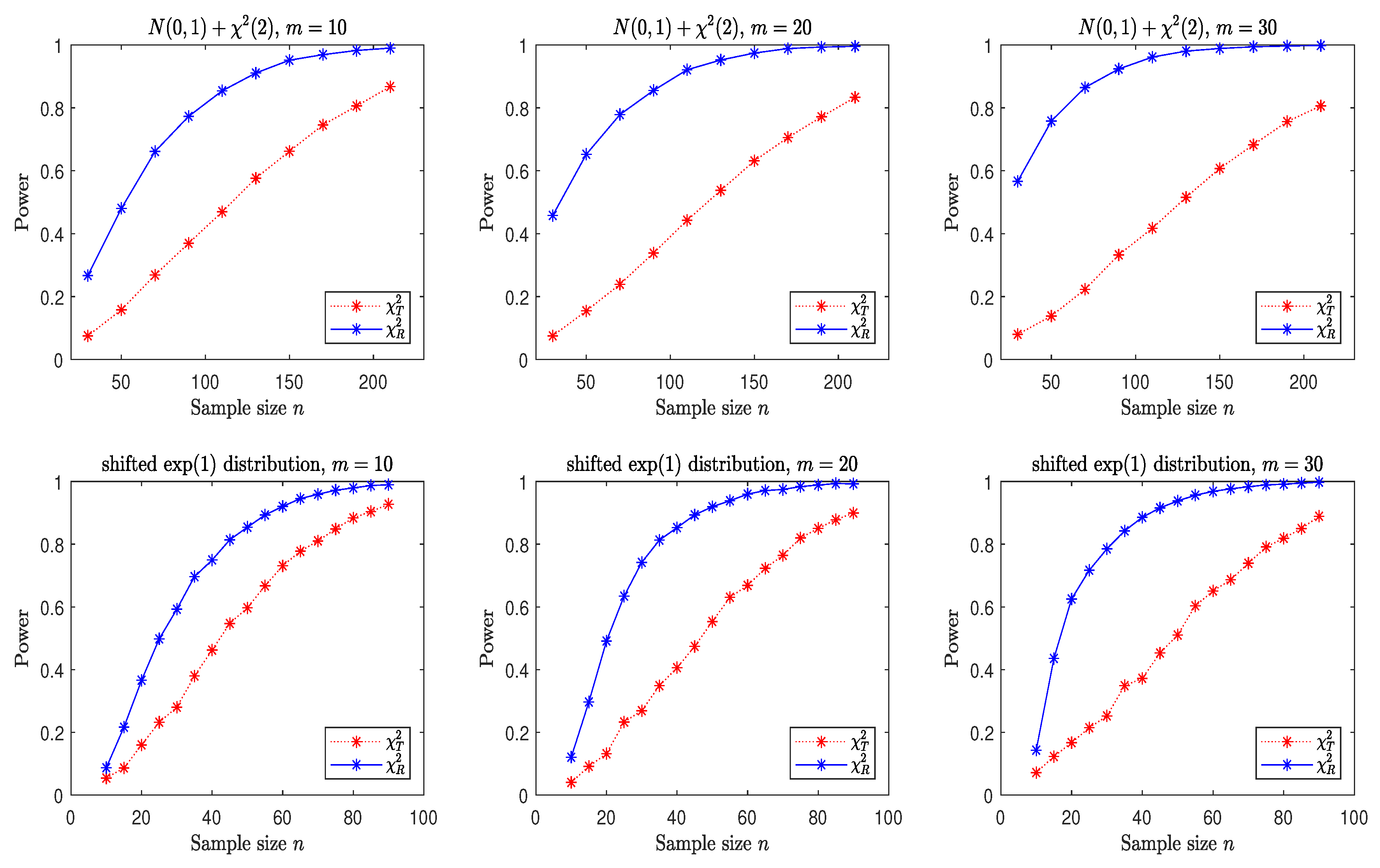
3.2. A Simple Power Comparison
- The multivariate t-distribution has a density function of the formwhich is symmetric about the origin , where “ ” stands for the Euclidean norm of a vector. Let .
- The multivariate Cauchy distribution has a density function of the form:which is symmetric about the origin, where is a normalizing constant depending on the dimension d.
- The -generalized normal distribution with has a density function of the form (by Goodman and Kotz [18]):which is symmetric about the origin, where is a parameter. Let and in the simulation and denote it by -g-normal.
- The shifted i.i.d. has i.i.d. marginals, where each marginal has the same distribution as that of the random variable , where , the univariate chi-square distribution with 1 degree of freedom and . This is a skewed distribution.
- The distribution consists of i.i.d. normal marginals and i.i.d. marginals. This is a skewed distribution.
- The shifted i.i.d. has i.i.d. marginals, where each marginal has the same distribution as that of the random variable , where , the univariate exponential distribution. This is a skewed distribution.
3.3. An Illustrative Example
| height from the waist up | arm length |
| bust | neck |
| shoulder length | width of the front part of chest |
| width of the back part of chest | height |
| height without head and neck | height from the waist down |
| waist circumference | buttocks |
4. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ebner, B.; Henze, N. Tests for multivariate normality—A critical review with emphasis on weighted L2-statistics. Test 2020, 29, 845–892. [Google Scholar] [CrossRef]
- Henze, N. Invariant tests for multivariate normality: A critical review. Stat. Pap. 2002, 43, 467–506. [Google Scholar] [CrossRef]
- Horswell, R.L.; Looney, S.W. A comparison of tests for multivariate normality that are based on measures of multivariate skewness and kurtosis. J. Statist. Comput. Simul. 1992, 42, 21–38. [Google Scholar] [CrossRef]
- Remeu, J.L.; Ozturk, A. A comparative study of goodness-of-fit tests for multivariate normality. J. Multivar. Anal. 1993, 46, 309–334. [Google Scholar] [CrossRef]
- Mecklin, C.J.; Mundfrom, D.J. An appraisal and bibliography of tests for multivariate normality. Int. Stat. Rev. 2004, 72, 123–138. [Google Scholar] [CrossRef]
- Fang, K.T.; He, S.D. The Problem of Selecting a Given Number of Representative Points in a Normal Population and a Generalized Mills Ratio; Stanford Technical Report; Stanford Statistics Department: Stanford, CA, USA, 1982; No. 327. [Google Scholar]
- Flury, B.A. Principal points. Biometrika 1990, 77, 33–41. [Google Scholar] [CrossRef]
- Liang, J.; He, P.; Yang, J. Testing multivariate normality based on t-representative points. Axioms 2022, 11, 587. [Google Scholar] [CrossRef]
- Wang, S.; Liang, J.; Zhou, M.; Ye, H. Testing multivariate normality based on F-representative points. Mathematics 2022, 10, 4300. [Google Scholar] [CrossRef]
- Mardia, K.V. Measures of multivariate skewness and kurtosis with applications. Biometrika 1970, 57, 519–530. [Google Scholar] [CrossRef]
- Mardia, K.V. Tests of univariate and multivariate normality. In Handbook of Statistics; Krishnaiah, P.R., Ed.; North-Holland Publishing Company: Amsterdam, The Netherlands, 1980; pp. 279–320. [Google Scholar]
- Small, N.J.H. Plotting squared radii. Biometrika 1978, 65, 657–658. [Google Scholar] [CrossRef]
- Ahn, S.K. F-probability plot and its application to multivariate normality. Commun. Stat. Theory Methods 1992, 21, 997–1023. [Google Scholar] [CrossRef]
- Wilks, S.S. Mathematical Statistics; Wiley: New York, NY, USA, 1962. [Google Scholar]
- Liang, J.; Li, R.; Fang, H.; Fang, K.T. Testing multinormality based on low-dimensional projection. J. Stat. Plan. Inference 2000, 86, 129–141. [Google Scholar] [CrossRef]
- Voinov, V.; Pya, N.; Alloyarova, R. A comparative study of some modified chi-squared tests. Commun. Stat. Simul. Comput. 2009, 38, 355–367. [Google Scholar] [CrossRef]
- Fang, K.T.; Kotz, S.; Ng, K.W. Symmetric Multivariate and Related Distributions; Chapman and Hall: London, UK; New York, NY, USA, 1990. [Google Scholar]
- Goodman, I.R.; Kotz, S. Multivariate q-generalized normal distribution. J. Multivar. Stat. Anal. 1990, 3, 204–219. [Google Scholar] [CrossRef]
- Fang, K.T.; Wang, Y. Number-Theoretic Methods in Statistics; Chapman and Hall: London, UK, 1994. [Google Scholar]
- Fang, K.T.; Yuan, K.; Bentler, P.M. Applications of sets of points uniformly distributed on a sphere to testing multinormality and robust estimation. In Probability and Statistics; Jiang, Z.P., Yan, S.J., Cheng, P., Wu, R., Eds.; World Scientific: Singapore, 1992; pp. 56–73. [Google Scholar]
- Graf, S.; Luschgy, H. Foundations of Quantization for Probability Distributions; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Quesenberry, C.P.; Miller, F.L., Jr. Power studies of some tests for uniformity. J. Stat. Comput. Simul. 1977, 5, 169–191. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Size n | RP m | ||||||
|---|---|---|---|---|---|---|---|
| 0.0357 | 0.0319 | 0.0323 | 0.0322 | 0.0318 | |||
| 0.0298 | 0.0319 | 0.0309 | 0.0310 | 0.0307 | |||
| 0.0734 | 0.0521 | 0.0469 | 0.0470 | 0.0420 | |||
| 0.0371 | 0.0335 | 0.0351 | 0.0324 | 0.0339 | |||
| 0.0612 | 0.0633 | 0.0694 | 0.0608 | 0.0546 | |||
| 0.0322 | 0.0344 | 0.0338 | 0.0375 | 0.0336 | |||
| 0.0330 | 0.0329 | 0.0325 | 0.0336 | 0.0366 | |||
| 0.0291 | 0.0296 | 0.0346 | 0.0312 | 0.0323 | |||
| 0.0506 | 0.0448 | 0.0426 | 0.0416 | 0.0404 | |||
| 0.0343 | 0.0337 | 0.0326 | 0.0340 | 0.0351 | |||
| 0.0623 | 0.0690 | 0.0542 | 0.0515 | 0.0525 | |||
| 0.0400 | 0.0400 | 0.0395 | 0.0389 | 0.0350 | |||
| 0.0314 | 0.0342 | 0.0327 | 0.0317 | 0.0293 | |||
| 0.0312 | 0.0296 | 0.0305 | 0.0323 | 0.0320 | |||
| 0.0414 | 0.0444 | 0.0401 | 0.0384 | 0.0407 | |||
| 0.0349 | 0.0345 | 0.0337 | 0.0359 | 0.0332 | |||
| 0.0695 | 0.0548 | 0.0504 | 0.0470 | 0.0492 | |||
| 0.0390 | 0.0394 | 0.0362 | 0.0382 | 0.0394 | |||
| 0.0329 | 0.0277 | 0.0316 | 0.0321 | 0.0343 | |||
| 0.0325 | 0.0314 | 0.0333 | 0.0314 | 0.0302 | |||
| 0.0418 | 0.0416 | 0.0367 | 0.0355 | 0.0371 | |||
| 0.0360 | 0.0355 | 0.0357 | 0.0352 | 0.0364 | |||
| 0.0529 | 0.0465 | 0.0455 | 0.0452 | 0.0459 | |||
| 0.0372 | 0.0354 | 0.0389 | 0.0375 | 0.0381 |
| RP | |||||||
| 0.0544 | 0.0538 | 0.0472 | 0.0594 | 0.0412 | 0.0438 | ||
| 0.0294 | 0.0346 | 0.0250 | 0.0310 | 0.0350 | 0.0326 | ||
| 0.0550 | 0.0706 | 0.0508 | 0.0702 | 0.0536 | 0.0566 | ||
| 0.0328 | 0.0370 | 0.0326 | 0.0380 | 0.0364 | 0.0372 | ||
| 0.0742 | 0.0784 | 0.0706 | 0.0886 | 0.0610 | 0.0666 | ||
| 0.0362 | 0.0398 | 0.0370 | 0.0380 | 0.0388 | 0.0430 | ||
| Subsets | ||||
|---|---|---|---|---|
| 0.8498 | 0.8853 | 0.8027 | ||
| 0.8677 | 0.8487 | 0.5286 | ||
| 0.9158 | 0.9016 | 0.8184 | ||
| 0.9558 | 0.7352 | 0.8518 | ||
| 0.8034 | 0.8133 | 0.7007 | ||
| 0.9241 | 0.5493 | 0.4342 | ||
| 0.5003 | 0.6428 | 0.8635 | ||
| 0.4012 | 0.5493 | 0.8518 | ||
| 0.4355 | 0.1499 | 0.3865 | ||
| 0.4944 | 0.8678 | 0.6886 | ||
| 0.6714 | 0.9141 | 0.7850 | ||
| 0.6371 | 0.7352 | 0.8733 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, Y.; Liang, J.; Xu, L.; Kang, J. Testing Multivariate Normality Based on Beta-Representative Points. Mathematics 2024, 12, 1711. https://doi.org/10.3390/math12111711
Cao Y, Liang J, Xu L, Kang J. Testing Multivariate Normality Based on Beta-Representative Points. Mathematics. 2024; 12(11):1711. https://doi.org/10.3390/math12111711
Chicago/Turabian StyleCao, Yiwen, Jiajuan Liang, Longhao Xu, and Jiangrui Kang. 2024. "Testing Multivariate Normality Based on Beta-Representative Points" Mathematics 12, no. 11: 1711. https://doi.org/10.3390/math12111711