Abstract
Ship detection and identification play pivotal roles in ensuring navigation safety and facilitating efficient maritime traffic management. Aiming at ship detection in complex environments, which often faces problems such as the dense occlusion of ship targets, low detection accuracy, and variable environmental conditions, in this paper, we propose a ship detection algorithm CSD-YOLO (Context guided block module, Slim-neck, Deformable large kernel attention-You Only Look Once) based on the deformable large kernel attention (D-LKA) mechanism, which was improved based on YOLOv8 to enhance its performance. This approach integrates several innovations to bolster its performance. Initially, the utilization of the Context Guided Block module (CG block) enhanced the c2f module of the backbone network, thereby augmenting the feature extraction capabilities and enabling a more precise capture of the key image information. Subsequently, the introduction of a novel neck architecture and the incorporation of the slim-neck module facilitated more effective feature fusion, thereby enhancing both the accuracy and efficiency of detection. Furthermore, the algorithm incorporates a D-LKA mechanism to dynamically adjust the convolution kernel shape and size, thereby enhancing the model’s adaptability to varying ship target shapes and sizes. To address data scarcity in complex marine environments, the experiments utilized a fused dataset comprising the SeaShips dataset and a proprietary dataset. The experimental results demonstrate that the CSD-YOLO algorithm outperformed the YOLOv8n algorithm across all model evaluation metrics. Specifically, the precision rate (precision) was 91.5%, the recall rate (recall) was 89.5%, and the mean accuracy (mAP) was 91.5%. Compared to the benchmark algorithm, the Recall was improved by 0.7% and the mAP was improved by 0.4%. These results indicate that the CSD-YOLO algorithm can effectively meet the requirements for ship target recognition and tracking in complex marine environments.
MSC:
68U10
1. Introduction
Waterway transportation plays a crucial role in comprehensive transportation, with a variety of ship types and numbers showing diversification and growth. As this growth continues, waterway transportation also demands a higher accuracy and efficiency in ship inspection. Real-time ship inspection technology based on deep learning has demonstrated significant potential in practical settings. The utilization of this technology is essential for improving the safety of ship navigation and the effective management of ports.
Driven by the rapid advancement of computer technology, deep learning has made substantial strides in target detection. Target detection networks primarily fall into two major categories, as shown in Table 1. The first category comprises two-stage target detection networks, exemplified by architectures such as R-CNN (Region-based Convolutional Network) [1], Faster-RCNN (Faster Region-based Convolutional Network) [2], and Mask-RCNN (Mask Region-based Convolutional Network) [3]. These models adopt a staged approach to target detection, initially generating potential regions of interest through predefined anchor frames, followed by pinpointing the features of these regions using classification and regression networks. Drawing inspiration from these algorithms, Qi et al. [4] introduced a ship detection algorithm based on an enhanced Faster R-CNN, which improved the ship feature information extraction by reducing the image size, thereby enhancing the model speed and performance in ship detection. Yu et al. [5] proposed a novel algorithm based on an enhanced Faster-RCNN, integrating multiple scale region suggestion, ROI pooling, visual attention mechanisms, and rotating region regression suppression to acquire multi-scale information. Leveraging Res2Net for rich multi-scale information, Chai et al. [6] proposed an improved R-CNN algorithm, demonstrating enhanced accuracy and recall. Lin et al. [7] introduced an enhanced Faster R-CNN network, further enhancing the detection performance through the utilization of squeezing and excitation mechanisms. Subsequently, addressing dense distribution and diverse size constraints, Gou et al. [8] presented an R-Libra CNN method that effectively integrated high-level semantic information with lower-level features. Park et al. [9] proposed a Mask-RCNN-based AI model for warship detection, leveraging MobileNetV2 to achieve model lightweighting. Another class of target detection networks includes SSD (Single Shot MultiBox Detector) [10] and YOLO [11]. These models follow an end-to-end detection approach, combining target localization and classification in a single stage. This design significantly reduces the time needed for target detection and enhances efficiency. Ye et al. [12] introduced an improved attention mechanism in the YOLOv4 algorithm to decrease the missed detections of overlapping vessels while maintaining efficiency. Wang et al. [13] proposed an enhanced YOLOv5 algorithm that decreased overlapping vessels by integrating a sensory field enhancement module and a spatial pyramid fast pooling module, along with adding an attention mechanism to boost the detection speed. Ting et al. [14] addressed the issue of incomplete feature capture in the original YOLOv5 algorithm by merging the feature extraction process with the GhostbottleNet algorithm to account for the uneven distribution of ship image features in lateral and vertical directions. Cen et al. [15] improved the detection speed of overlapping ships by combining the convolutional attention mechanism and residual connection in YOLOv7, enabling the accurate localization of ships in challenging environments with darkness and noise. Xing et al. [16] achieved real-time detection and tracking of ship targets by incorporating FasterNet and GSConv convolution in the YOLOv8 algorithm. Zhu et al. [17] accomplished the real-time detection and tracking of ship targets by optimizing the attention mechanism and adding detection heads to enhance the accuracy in detecting small targets at sea, while Cheng et al. [18] enhanced the accuracy without increasing the network width and depth by incorporating full-dimensional convolution into the YOLOv5 backbone network.

Table 1.
Comparison table of existing target detection algorithms.
Ship detection models currently face challenges such as a large number of parameters, high hardware requirements, low accuracy, and poor real-time performance. The focus of attention is on ensuring detection accuracy while reducing model complexity. Moreover, the complexity and variability of the marine environment present a challenge to ship detection performance. To tackle these issues, this paper introduces the CSD-YOLO ship detection algorithm, which is based on the deformable large kernel attention mechanism. This algorithm enhances the network structure of YOLOv8n, aiming to optimize the model structure, reduce parameters, improve computational efficiency, and accurately identify ship targets in complex environments. Specifically, it performs well under adverse conditions like fog, rain, and darkness. Overall, the proposed algorithm demonstrates excellent performance. The key advancements of this research can be outlined as follows:
- (1)
- Enhancement of the feature extraction capabilities of the backbone network’s c2f module was achieved through the implementation of the CG block module. This advancement enables the model to more accurately capture the crucial information in images.
- (2)
- To enhance feature fusion and improve the accuracy and efficiency of ship target detection, the neck part was redesigned to incorporate the slim-neck module.
- (3)
- The D-LKA mechanism, which combines large convolution kernels with deformable convolution, was adopted. It significantly enhanced the model’s adaptability to target shapes and sizes by dynamically adapting the shape and scale of the convolution kernel.
- (4)
- This study presents a fusion dataset for ship target detection by combining the SeaShips dataset with a self-made dataset. The dataset comprised 8000 visible ship images accurately labeled in a diverse marine setting.
2. Methods
2.1. Algorithm Overview
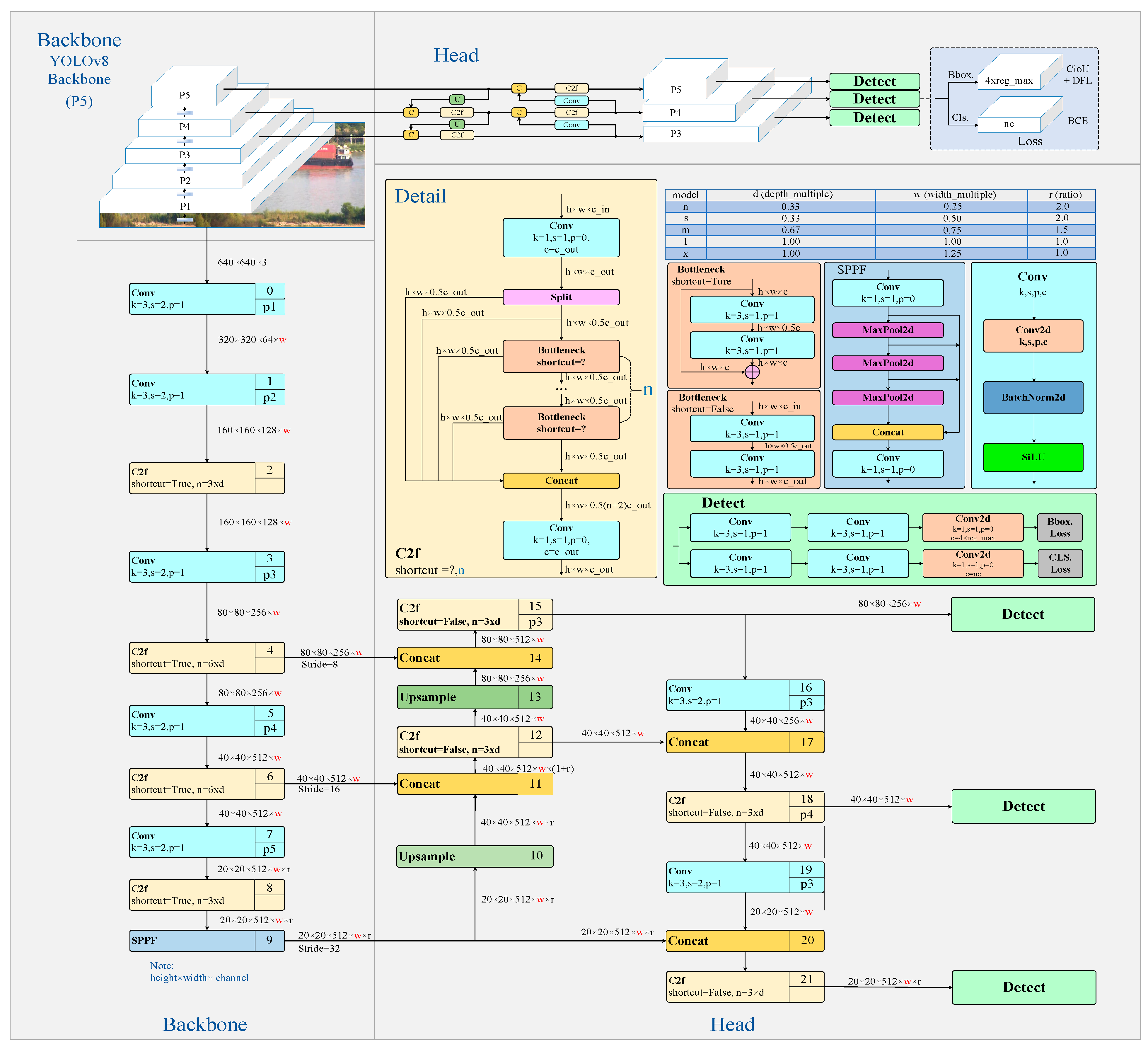
YOLOv8 is a state-of-the-art target object detection algorithm that has demonstrated excellent performance in pedestrian detection [19], ship recognition [20], and vehicle detection [21]. The YOLOv8 model consists of four main parts: the input end, trunk, neck, and head, as illustrated in Figure 1. In the backbone network, it retains the CSPDarkNet (Cross Stage Partial DarkNet) structure of YOLOv5, but innovates the C3 module into a c2f module [21]. The c2f module draws on the ELAN (Efficient and Light-weight Attention Network) design of YOLOv7, optimizing the convergence speed and effectiveness while achieving lightweight performance by increasing parallel gradient flow branches. It utilizes a PANnet (path aggregation network) structure in the neck network design, which effectively transmits shallow positioning information to deeper layers, improving the multi-scale positioning performance. In contrast to the coupling head and anchor-based strategy of YOLOv5, YOLOv8 utilizes a decoupling head and anchor-free approach. This involves discarding the objectness branch and focusing solely on the decoupled classification and regression branches. As a result, YOLOv8 achieves a faster convergence speed and improved detection effectiveness.
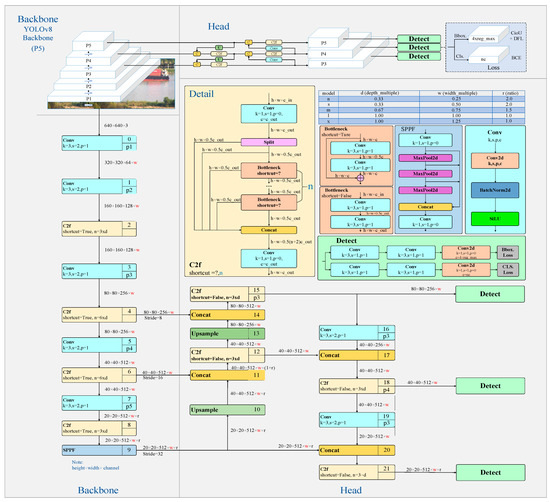
Figure 1.
YOLOv8 network structure diagram.
For classification and regression branching, YOLOv5 uses BCE loss (binary cross entropy loss) [22] and CIOU loss (complete intersection over union loss) [23], respectively, and YOLOv8 uses VFL loss (varifocal loss) and DFL loss (distribution local loss) + CIOU loss. VFL loss is designed based on BCE loss, introducing asymmetric weighting operations for positive and negative samples, as shown in Equations (1) and (2).
where represents the predicted value; represents the labeled value; represents the sample number.
In the model, “” represents the target score. For positive samples, it represents the IoU score between the generated bounding box and the ground truth (gt_IoU), while for negative samples, “” equals 0. “” can control the weight of each sample’s contribution to the loss, thereby reducing the influence of negative samples. “” serves as an adjustable proportional parameter to balance the loss between positive and negative samples.
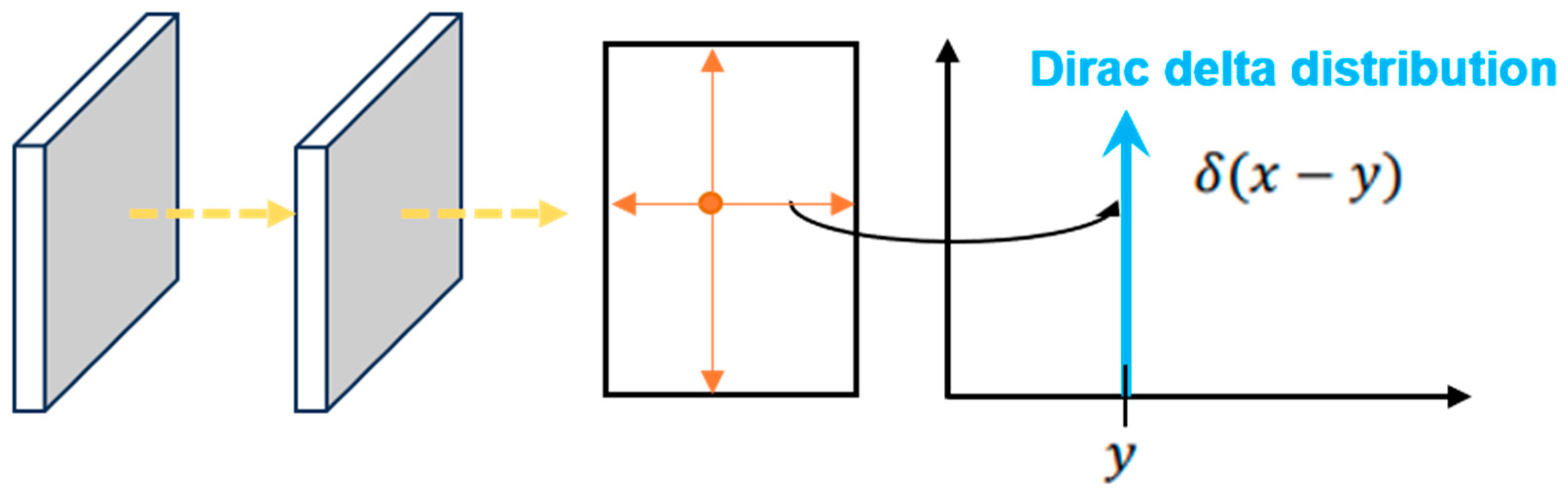
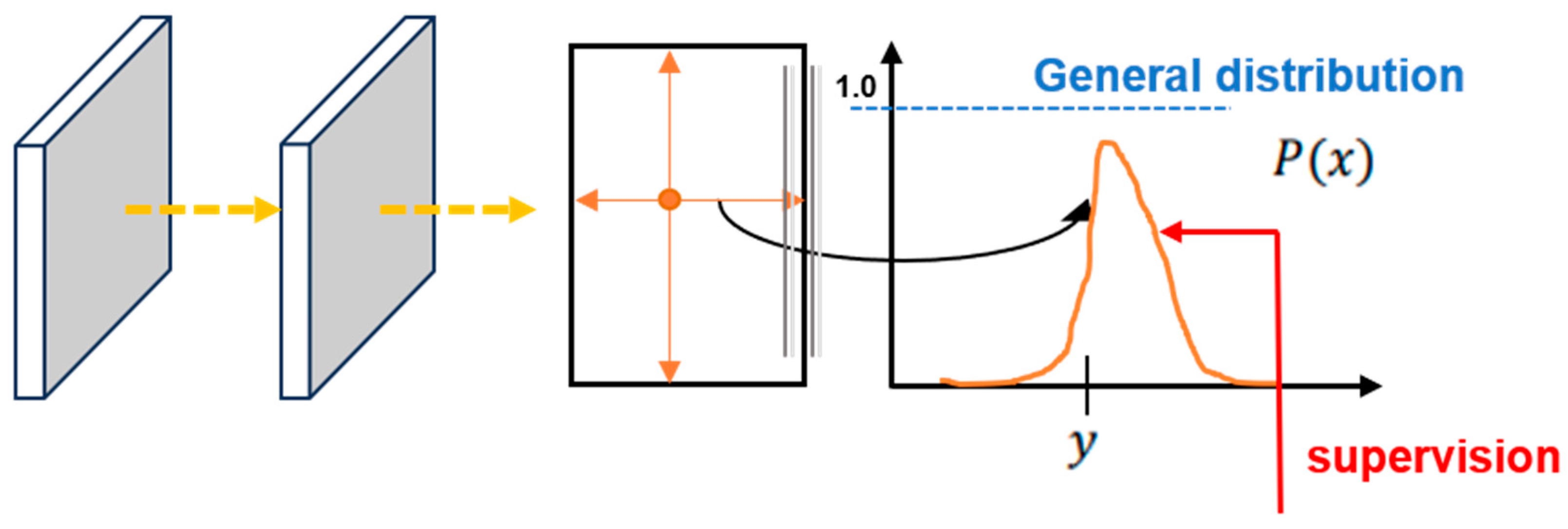
DFL loss was mainly proposed to address the inflexibility of generated bounding box representations [24]. Traditional object detection struggles to accurately define the true bounding boxes of target objects in complex scenes due to boundary ambiguity and uncertainty caused by factors such as subjective labeling, occlusion, and blurriness. Traditional regression methods approximate the predicted value to a discrete and certain value: the label position y, as shown in Figure 2. For complex scenes, the regression distribution range is more realistic compared to approximating discrete values. As shown in Figure 3, based on a similar concept, DFL loss models the box position as a general distribution, enabling the network to quickly focus on the vicinity of the label position y and improve the detection accuracy.
where y represents the labeled position of the detected object, while and represent the left and right positional coordinates of the predicted bounding box ( ≤ ≤ ), respectively.
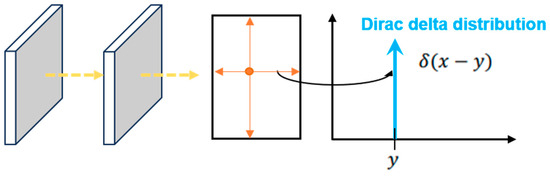
Figure 2.
Schematic diagram of the traditional regression method.
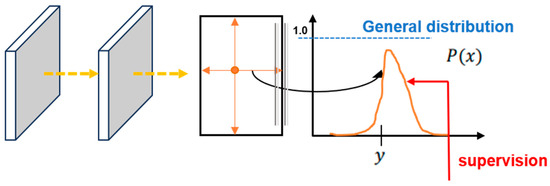
Figure 3.
Schematic of the range of the regression distribution.
The CIOU loss function can be calculated using the following formula:
The parameter is utilized for trade-off, while the parameter is used to assess the aspect ratio consistency. The variables and denote the centers of the prediction box and the marked box, respectively. represents the Euclidean distance between the two center points, and represents the length of the diagonal of the minimum outer rectangle that encompasses both the prediction box and the marked box.
In this article, we selected the YOLOv8 algorithm as the research foundation for several reasons. First of all, YOLOv8 has shown remarkable performance in target detection due to its sophisticated deep learning architecture and optimization techniques. It is capable of achieving rapid detection speeds without compromising accuracy, making it well-suited for real-time target detection applications. Second, YOLOv8 has outstanding generalization abilities, adapting to object detection tasks in different scenes and backgrounds. Regardless of the size, shape, or occlusion level of the target, YOLOv8 can achieve effective detection, making it widely applicable in various practical scenarios. Finally, YOLOv8 provides a simple and easy-to-use interface and tools, facilitating developers to integrate it into various application scenarios. Simultaneously, it supports cross-platform deployment including PCs, mobile devices, and embedded systems, further broadening the deployment possibilities of YOLOv8 in practical applications.
2.2. Improved YOLOv8n
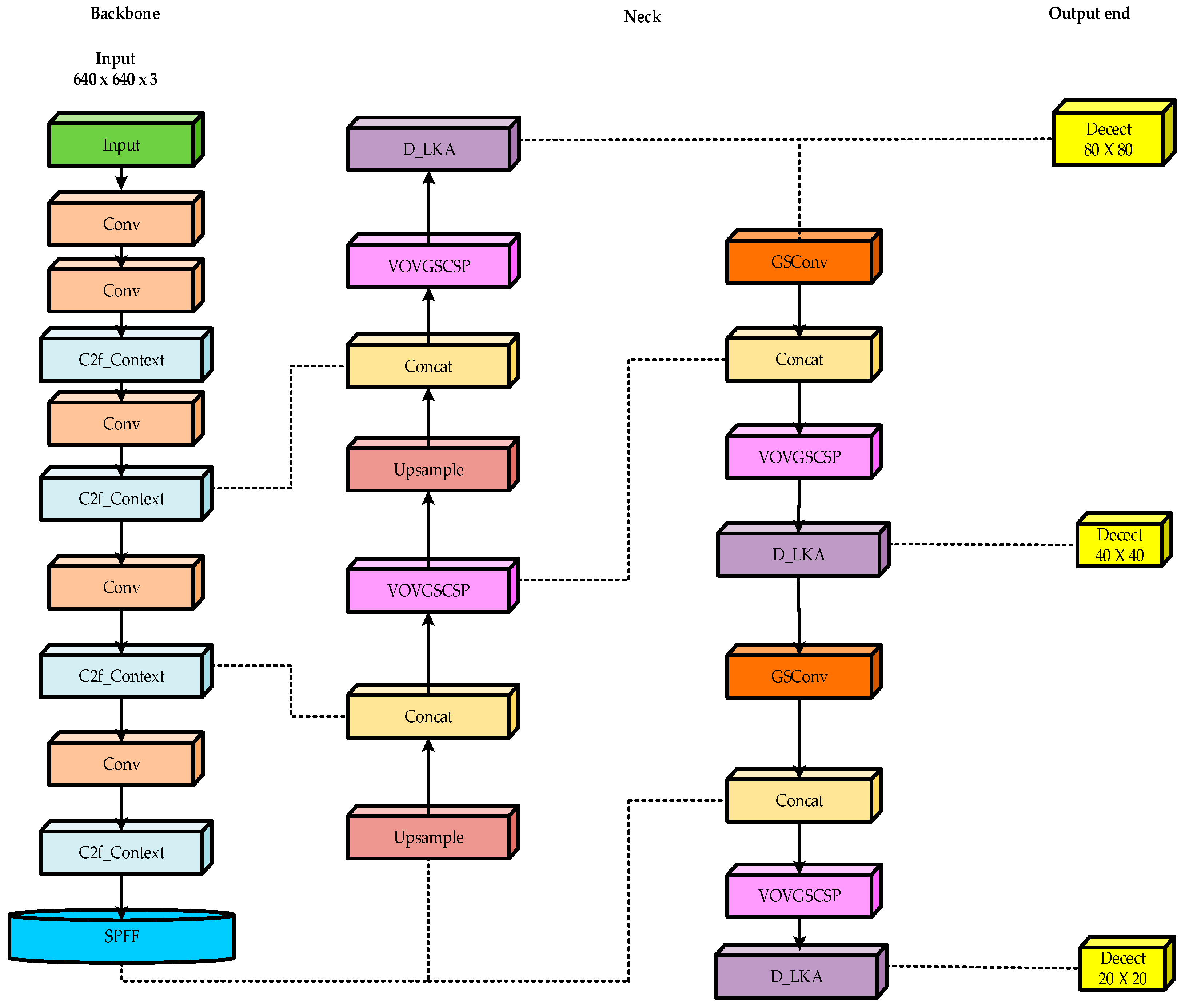
In the field of ship target recognition, the YOLOv8 algorithm faces challenges in maintaining detection accuracy and efficiency in complex environments. This study chose YOLOv8n as the reference model and proposed enhancements. The network structure diagram of the CSD-YOLO algorithm is illustrated in Figure 4. To begin with, the CG block module was integrated to enhance the c2f module of the backbone network, thereby improving the model’s feature extraction capability to accurately capture the crucial information in images. Second, the introduction of the slim-neck module optimized the neck section, achieving more efficient feature fusion and improving the accuracy and efficiency of ship target detection. Finally, in the neck network, the D-LKA mechanism was introduced. This mechanism combines the broad receptive field of large convolutional kernels with the flexible adaptability of deformable convolution. It not only efficiently processes complex visual information but also significantly enhances the model’s adaptability to target shapes and sizes, thereby improving the detection performance for small target objects in complex environments.
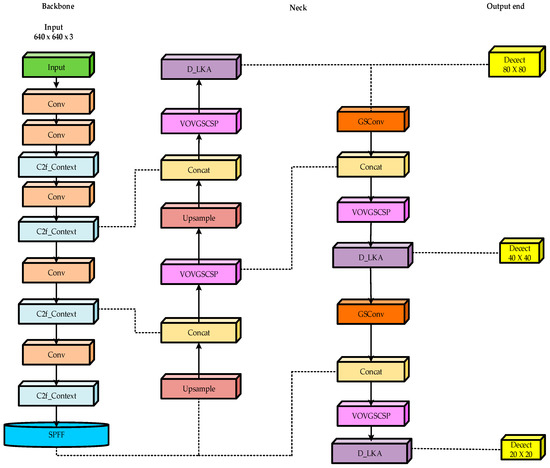
Figure 4.
CSD-YOLO algorithm network structure diagram.
2.3. Context Guided Block Module
The CG block is a lightweight module designed to capture local features, surrounding contexts, and global contexts. By effectively fusing this information, it significantly improves the accuracy of semantic segmentation. This module consists of several key components:
- (1)
- Local feature extractor : This learns local features from the input data through standard convolutional layers. These features become important information within the module and are subsequently combined with surrounding contextual features to build a comprehensive understanding of various regions of the image, thereby enhancing the network’s ability to grasp the image content.
- (2)
- Surrounding context extractor : This utilizes dilated convolution to expand the receptive field and enhance the processing capability of multi-scale information. This feature is particularly important when handling high-resolution images and semantic segmentation tasks in complex scenes.
- (3)
- Joint feature extractor : Through concatenation layers, batch normalization (BN), and parametric ReLU (PReLU) operations, it effectively fuses local features and surrounding contextual features to form joint features. These features not only retain the details of the input data, but also incorporate information from a wider area, enabling the network to comprehensively consider local and contextual information, thereby significantly improving the accuracy of semantic segmentation.
- (4)
- Global context extractor : This integrates global contexts through a global average pooling layer and subsequently utilizes a multilayer perceptron to deeply extract global features. Furthermore, a scaling layer is employed to weight the joint features, strengthening beneficial features and weakening redundant information. This mechanism effectively captures and utilizes global information from the input image, greatly enhancing the learning efficiency of the joint feature extractor.
The components collaborate to enhance the network’s capability in understanding multi-scale features within intricate scenes, thereby improving the accuracy of the backbone network in tasks like semantic segmentation and target detection. By integrating local and global contexts, the module achieves pixel-level classification accuracy, which is essential for image analysis. Figure 5 displays the structure diagram of the CG block module.
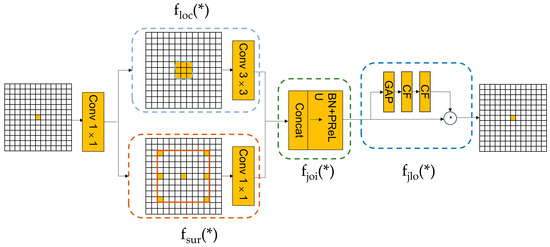
Figure 5.
Context guided block module structure.
2.4. Slim-Neck Construction
In the design of the YOLOv8n algorithm, standard convolution and the C2f module are widely used to improve prediction accuracy. However, this increase in accuracy is often accompanied by a decrease in computational speed and an increase in model parameters. This paper introduces the slim-neck structure to integrate feature information from the feature maps of different scales in the backbone network, reducing the model complexity without compromising accuracy. As a result, YOLOv8n achieves a more balanced performance in terms of efficiency and accuracy.
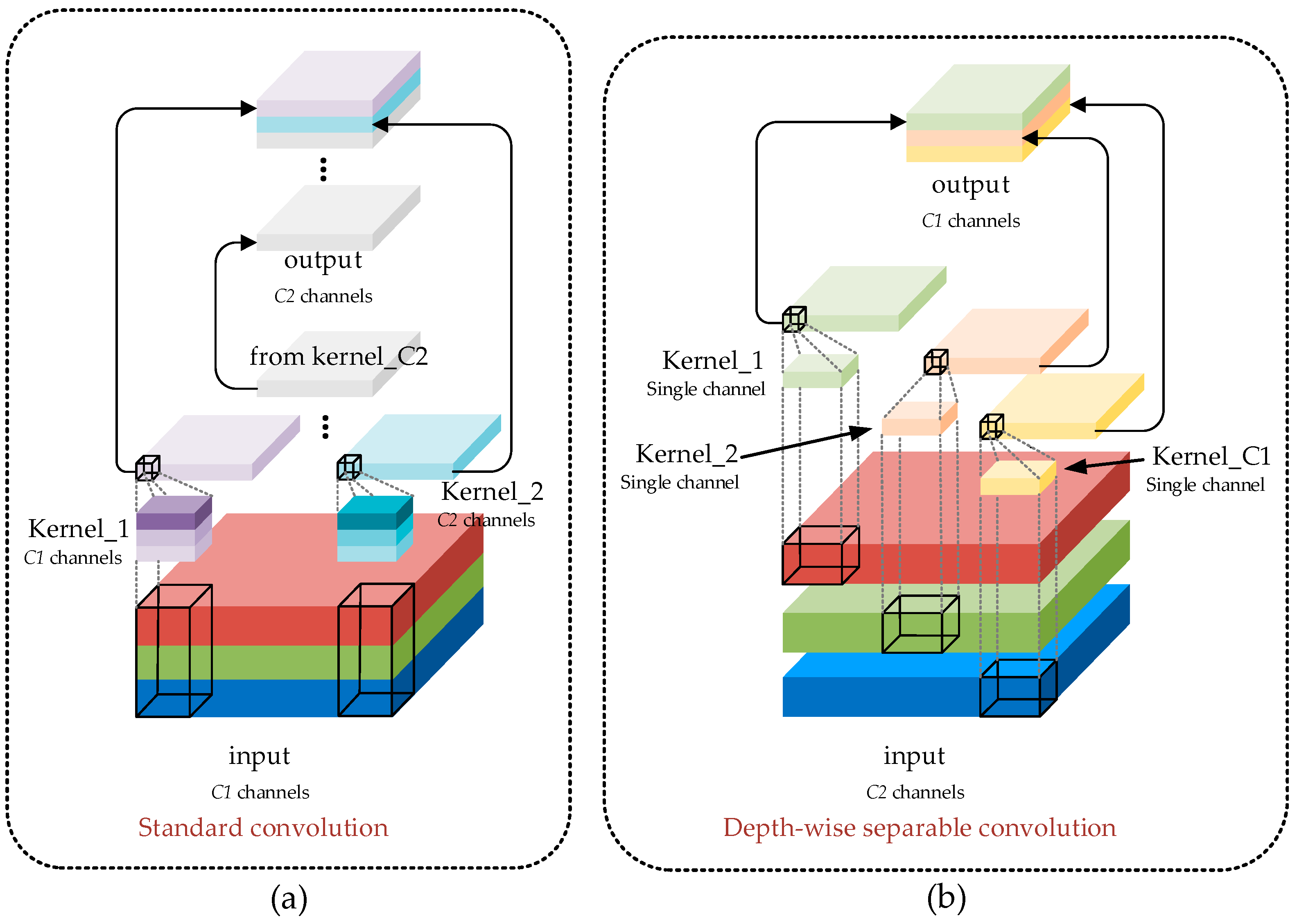
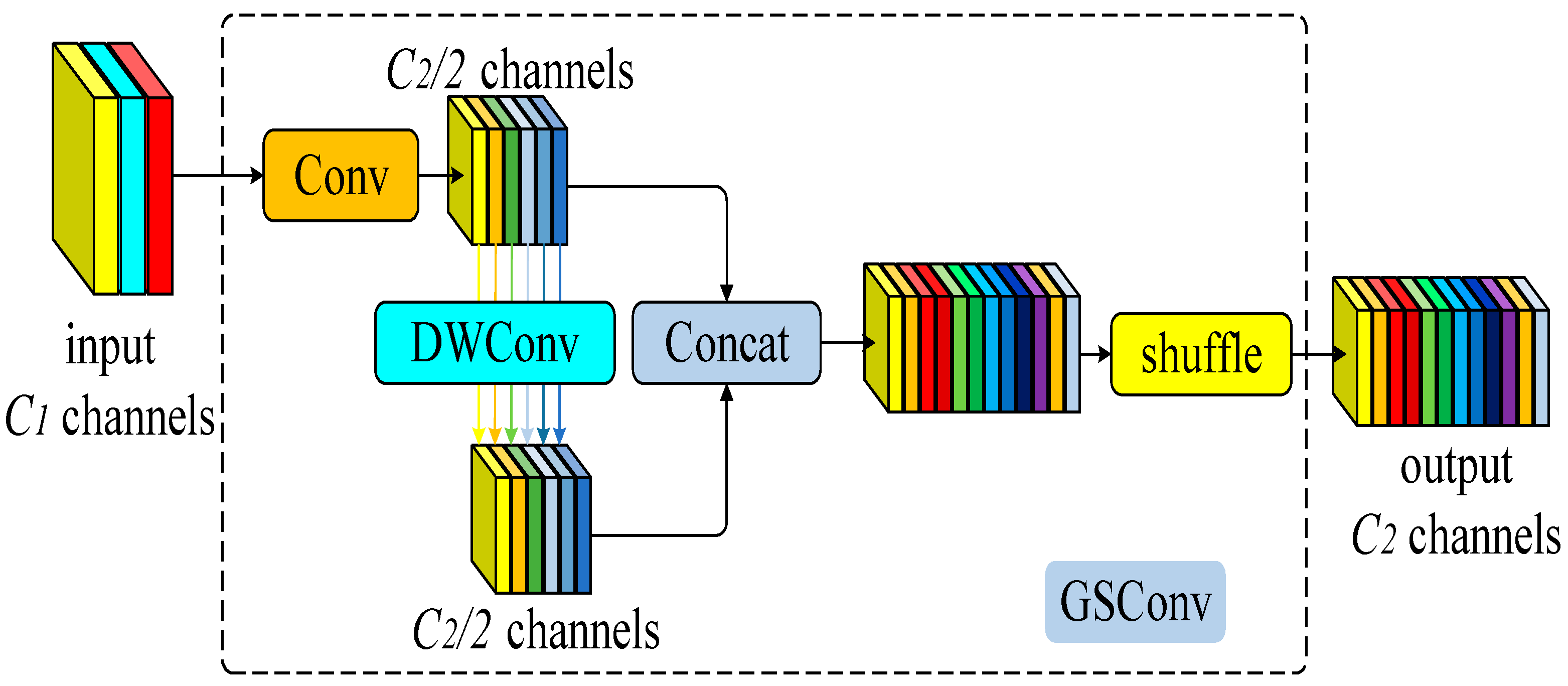
The slim-neck is a unique structure that optimizes the neck area, combining group-wise spatial convolution (GSConv) and modular elements. The GSConv module integrates spatial convolution (SC), depthwise separable convolution (DSC), and shuffle operations [25]. The parameter quantity and computational complexity of the convolutional layer can be expressed using Formulas (9) and (10).
where represents the number of input channels, represents the number of output channels, and represent the height and width of the convolution kernel, respectively, and and represent the height and width of the output feature map, respectively.
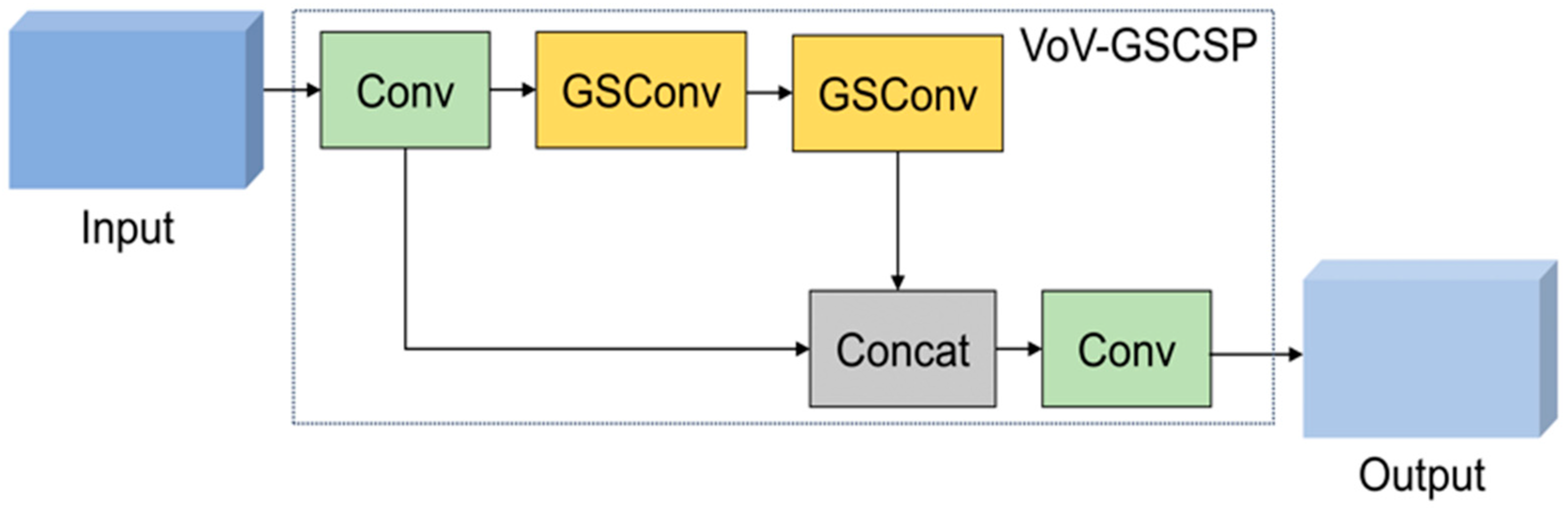
Compared with standard convolution, GSConv reduces its computational cost by approximately 30% to 40% while maintaining competitive performance. To enhance the model’s performance further, we replaced the standard convolution in the neck layer with GSConv and introduced a vision over vision-group-wise spatial convolution and shuffle pooling (VoV-GSCSP) module based on GSConv. This module can further improve the network’s lightweight and efficiency while ensuring accuracy. The calculation process of the SC and DSC is illustrated in Figure 6, and the calculation formulas are presented in Equations (11) and (12). The detailed structure of the GSConv and VoV-GSCSP modules is elaborated in Figure 7 and Figure 8.
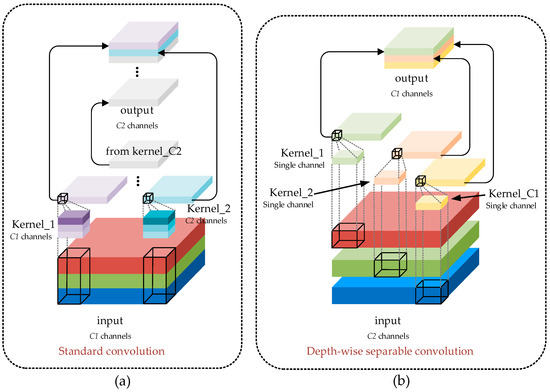
Figure 6.
(a) SC calculation process. (b) DSC calculation process.
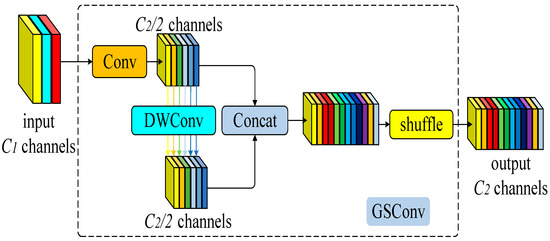
Figure 7.
GSConv module structure diagram.
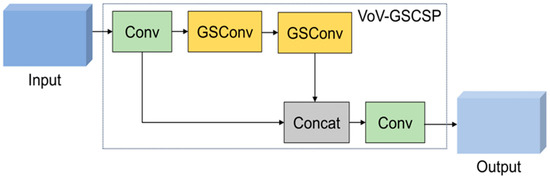
Figure 8.
VoV-GSCSP module structure diagram.
Among these parameters, represents the width of the output feature map, represents the height of the output feature map, denotes the size of the convolution kernel, indicates the number of channels of each convolution kernel and the input feature map, and represents the number of channels of the output feature map.
2.5. Deformable Large Kernel Attention Mechanism
The core idea of D-LKA lies in combining large convolution kernels with the attention mechanism of deformable convolution. By introducing large convolution kernels, it simulates the extensive receptive field achieved by the self-attention mechanism, while cleverly avoiding the high computational costs associated with traditional self-attention mechanisms. This design not only enhances the model’s ability to capture spatial information, but also ensures computational efficiency, allowing D-LKA to achieve higher efficiency while maintaining performance. The D-LKA module can be represented by Formulas (13) and (14).
The input feature is denoted as and . The attention component represents the attention map, where each value indicates the relative importance of the corresponding feature.
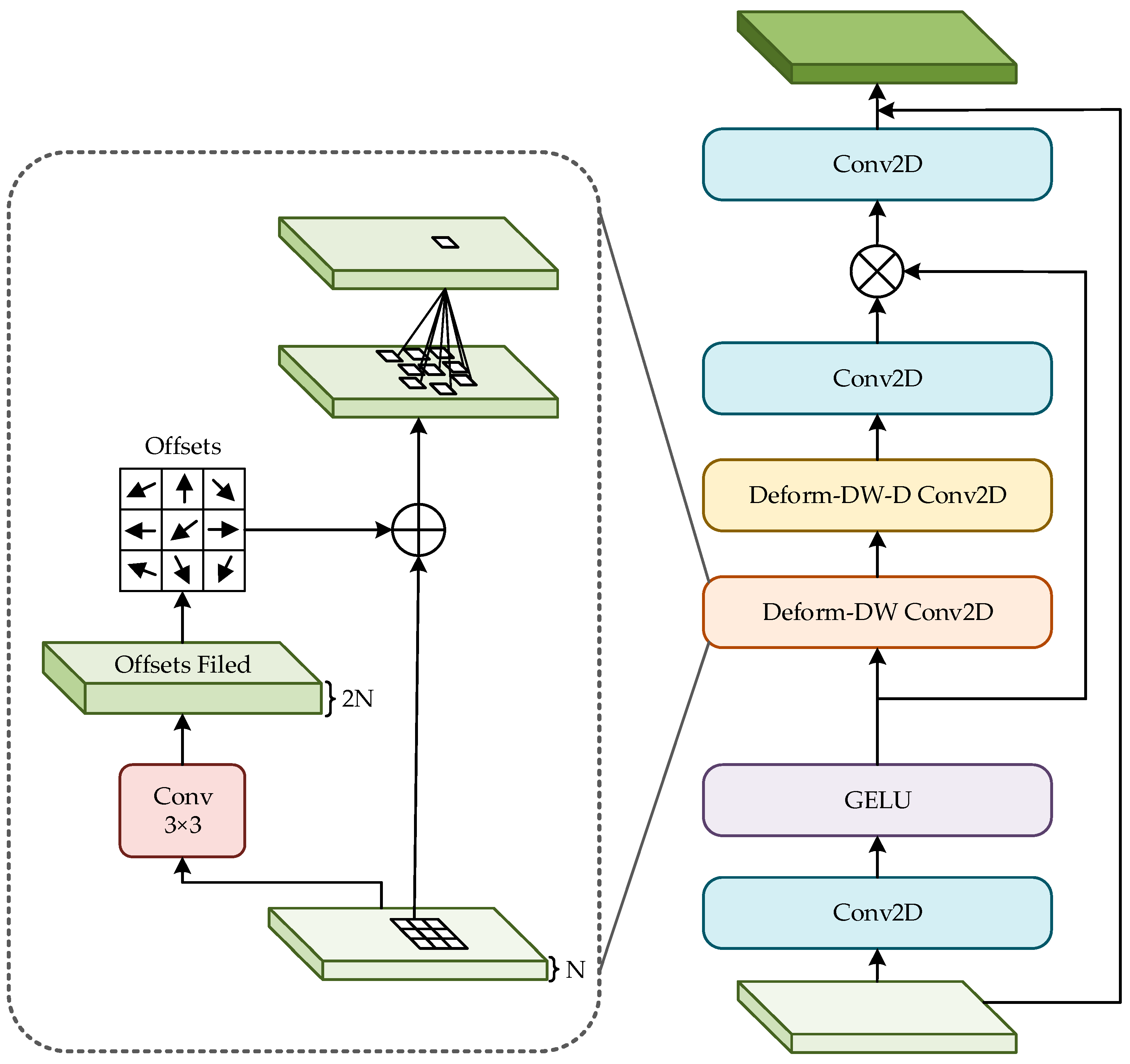
D-LKA mainly consists of the following three major components. First, large convolution kernels are used to capture extensive contextual information in images, simulating the large receptive field of the self-attention mechanism. Second, deformable convolution technology is combined to enable the model’s sampling grid to flexibly adjust based on image features, adapting to diverse data patterns. Finally, the 2D and 3D versions of D-LKA demonstrate excellent performance at different data depths. Additionally, D-LKA flexibly adjusts the sampling grid through deformable convolution, allowing the model to better adapt to different data patterns. This can effectively solve the difficulty of detecting small and multiple targets in complex backgrounds or under different lighting conditions. The architecture diagram of D-LKA is shown in Figure 9.
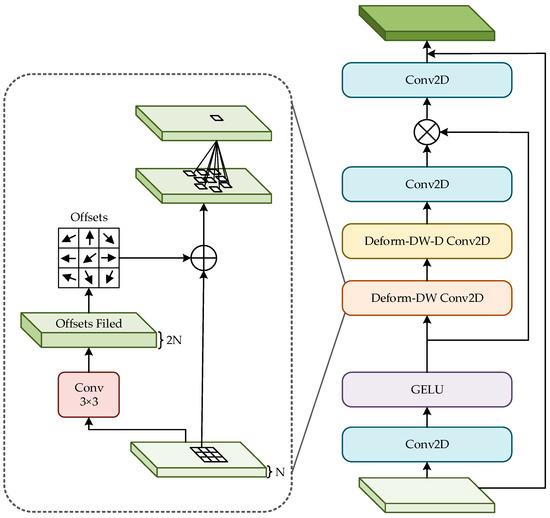
Figure 9.
Deformable-LKA architecture diagram.
3. Experiments
3.1. Experimental Environment
The experimental environment in this study was run on Windows 10 Professional Edition, utilizing an Intel Core i7-10750K CPU @ 2.60 GHz. Python was the chosen compilation language, with PyTorch used as the deep learning framework and YOLOv8n as the benchmark model. Table 2 presents the detailed configuration of the basic parameters in the algorithm.
Table 2.
Configuration parameters of the experimental platform.
3.2. Training Parameter Settings
The CSD-YOLO network was trained using carefully selected training parameters, as detailed in Table 3 following the experimental methodology.
Table 3.
Detailed parameter list for model training.
3.3. Datasets
The experimental dataset in this paper was comprised of two parts: one was a self-made dataset containing 1194 ship images, and the other was the publicly available SeaShips dataset [26], which contains 7000 ship images, as shown in Figure 10. To enhance data diversity and experimental accuracy, this paper combined these two datasets to form a mixed dataset. This mixed dataset covered nine common types of ships and island targets at sea including container ships, ore carriers, passenger ships, bulk carriers, fishing boats, cruise ships, general cargo ships, islands, and other ships.

Figure 10.
Partial image of the training set.
To ensure the rigor of the experiment, this paper randomly split the 8194 images in the mixed dataset into training, validation, and test sets in a 6:3:1 ratio. This splitting method ensured that each set had sufficient data volume while maintaining the randomness and representativeness of the data.
The mixed dataset used in the experiment included a rich variety of ship types and diverse navigation states covering various weather conditions and shooting environments (Table 4). This enabled a more accurate simulation of the actual situation of the camera’s environmental perception and image acquisition during the intelligent navigation of ships. This dataset not only provides a wide range of authentic data samples for this paper, but also lays a solid foundation for subsequent model training and evaluation, which is beneficial for improving the robustness and accuracy of an intelligent navigation system for ships.
Table 4.
Distribution of the number of datasets.
3.4. Indicators for Model Evaluation
In order to objectively assess the effectiveness of the CSD-YOLO ship recognition network model in this paper, reasonable evaluation indices were developed. Five types of metrics were used to evaluate the performance of the algorithm: precision (P) [27], recall (R) [28], average precision map@.5 [29] and map@.5:.95 [30], and frames per second (FPS) [31]. The specific formula for each metric is as follows:
represents the number of correctly predicted positive samples, represents the number of incorrectly predicted positive samples, and represents the proportion of correctly predicted positive samples among all of the detected positive samples.
represents the number of falsely predicted negative samples and represents the proportion of all correctly predicted positive samples out of all the samples detected.
represents a comprehensive evaluation metric for multiple detection results of each category of targets. The value of is the area under the precision–recall (P–R) curve, which means that for each recall value, the corresponding precision value is calculated, and finally, the average value is taken as the value for that category.
represents the average precision of the ith target category detection, and represents the mean average precision for multiple categories, which is the average of for all categories. refers to the value when the IoU threshold is 0.5. The is calculated for each IoU threshold from 0.5 to 0.95 with an increment of 0.05, and the average is taken to obtain .
stands for frames per second, indicating the number of image frames that can be detected per second. It refers to the number of images that the model can process per second, which is a measure of the model’s inference speed.
4. Results and Discussion
4.1. Ablation Experiment
4.1.1. Context Guided Block Module
Table 5 displays a comparison of the recognition outcomes between C2f integrated with the context guided block module and the original C2f model. The findings indicate that the overall performance index of C2f with the context guided block module was 0.002 points higher than the original Yolov8n model’s mAP@0.5.
Table 5.
Comparison of detection results for different c2f structures.
To better illustrate the impact of the CG block module on c2f enhancement and optimization, this study showcases the changes in the feature heat map with and without the introduction of the CG block module. In the first row in Figure 11, it is evident that the inclusion of the CG block module resulted in the extracted features being predominantly focused around the ship, whereas the baseline c2f structure still showed significant attention toward the sea surface and coast. The second row demonstrates that the CG block module enhanced the model’s ability to detect small target objects, with a more pronounced focus on the ship compared to the baseline c2f structure. Moreover, the integrated CG block module structure effectively suppressed the background features that were not part of the main object, as depicted in the last row of Figure 11. In conclusion, integrating the CG block module into the C2f structure enhanced the model’s feature extraction capability.
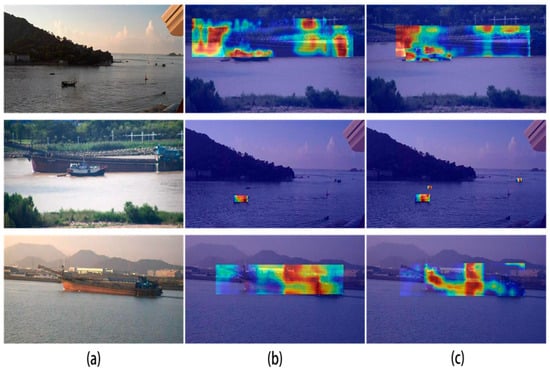
Figure 11.
Heatmap of the c2f-CG block structure showing the (a) original image, (b) YOLOv8-c2f, and (c) YOLOv8-c2f-CG block.
4.1.2. Slim-Neck Construction
Table 6 displays the evaluation metrics for whether or not the slim-neck structure is introduced. The results indicate that the introduction of the slim-neck structure effectively improved the overall performance of the model. Specifically, there was an increase of 0.004 in mAP@0.5 and an increase of 0.007 in mAP@0.5:0.95.
Table 6.
Comparison of detection results with and without the introduction of the slim-neck structure.
Figure 12 shows randomly selected image heatmaps. The design of the slim-neck structure takes full advantage of the benefits of depthwise separable convolution (DSC) while minimizing its drawbacks. Through the introduction of methods like GSConv, slim-neck can enhance detection performance while maintaining model accuracy, particularly excelling in detecting small targets and achieving a higher average precision. The results indicate that compared to the original structure, the slim-neck structure pays more attention to the tested objects. Additionally, by comparing the brightness of small targets, it can be observed that the introduction of the slim-neck structure enabled the better detection of small targets.

Figure 12.
Whether or not to introduce the slim-neck structure heat map display.
4.1.3. Deformable-LKA Attention Mechanism
Table 7 displays the impact of adopting the deformable-LKA attention mechanism on detection accuracy. The results indicate that compared to the original benchmark model without the D-LKA attention mechanism, the D-LKA attention mechanism significantly improved the detection accuracy of the existing model.
Table 7.
Impact of whether or not to use the deformable-LKA attention mechanism on the detection results.
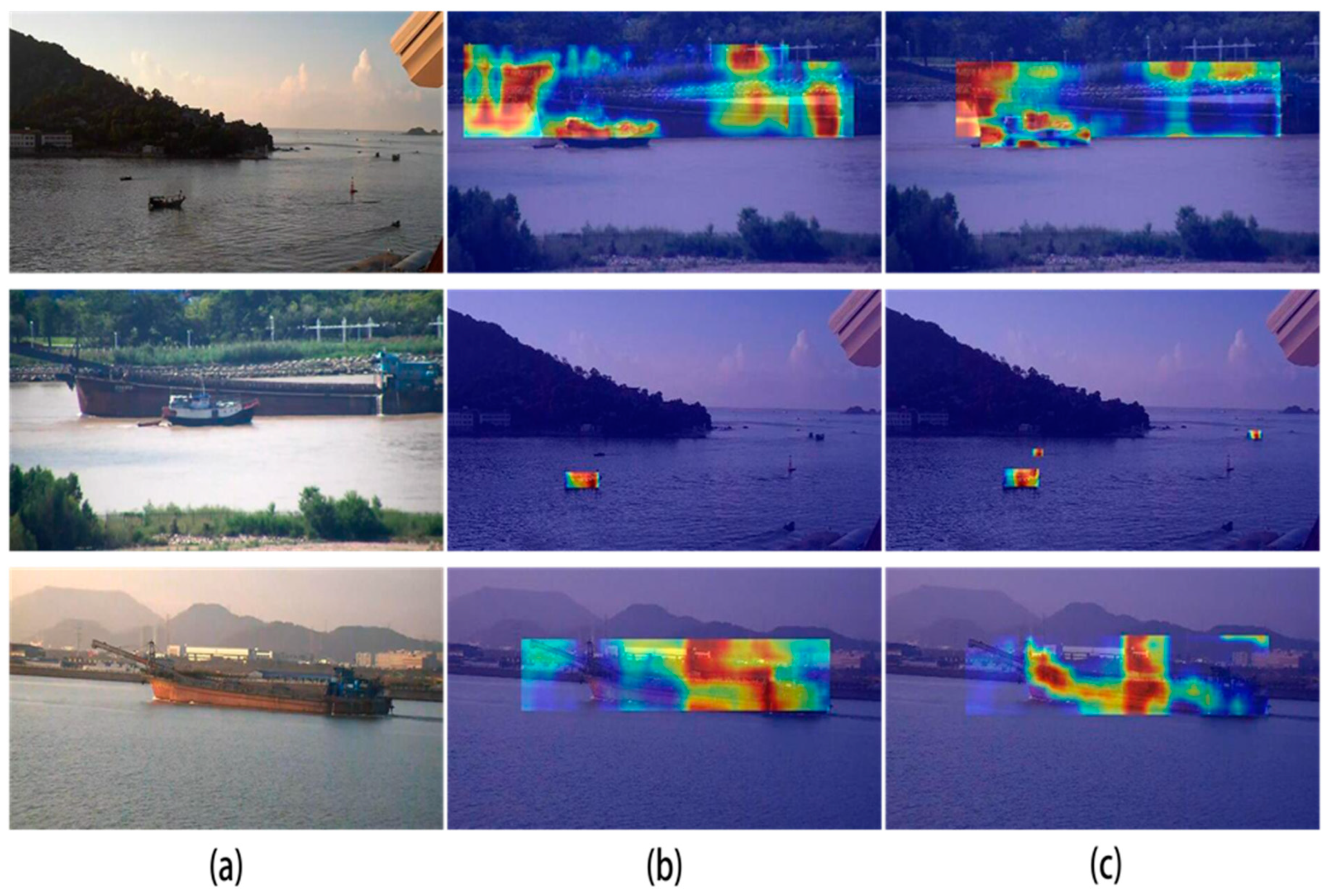
As shown in the heatmaps in Figure 13, the model adopting the deformable-LKA attention mechanism was highly focused on the detected objects. However, the original model tended to focus more on features in the background and peripheral areas. The results indicate that the adopted deformable-LKA attention mechanism can effectively improve the accuracy of detecting different ship targets and can adapt well to changes in complex environments.

Figure 13.
Heatmap with and without the D-LKA attention mechanism showing the (a) original image, (b) YOLOv8n, and (c) YOLOv8n-D-LKA.
4.2. Analysis of Test Results
To more intuitively reflect the performance differences between the improved algorithm and the baseline algorithm, this paper compared the main ship target detection effects and the ship detection results. As shown in Table 8 and Table 9, the CSD-YOLO algorithm outperformed the original algorithm in terms of detection accuracy for most major types of ship targets, indicating that the improved algorithm has enhanced performance and accuracy.
Table 8.
YOLOv8n algorithm detection of ship type performance results.
Table 9.
CSD-YOLO algorithm detection of ship type performance results.
As shown in Figure 14, this paper selected detection results from four different environments for comparison, from top to bottom: foggy environment, nighttime environment, multi-target environment, and small target environment. From the comparison chart, it can be seen that the CSD-YOLO algorithm outperformed the baseline algorithm in detection accuracy and efficiency in various environments.

Figure 14.
Comparison chart of the detection results. (a) Original image, (b) YOLOv8n, and the (c) CSD-YOLO algorithm.
4.3. Discussion
In order to further validate the efficacy of the proposed algorithm in this study, the CSD-YOLO algorithm was experimentally compared and analyzed with established algorithms like Faster R-CNN, SSD, YOLOv3, YOLOv4, YOLOv5, YOLOv7, YOLOv8n, etc. All of the experimental parameters remained consistent across the comparison, with 60% of fusion datasets comprising 4916 images used in the experiments and 200 training rounds conducted. The results of these comparison experiments are detailed in Table 10.
Table 10.
Experimental results comparing different algorithms.
Based on the experimental results presented in Table 10, the algorithms proposed in this study exhibited superior performance compared to the widely used algorithms in ship target detection. Notably, the Faster R-CNN and SSD algorithms are limited in their adaptability to multi-scale ship targets due to fixed anchor frame parameters, resulting in relatively low detection accuracy [32,33]. Although the YOLOv5 and YOLOv7 algorithms demonstrated faster detection speeds (47 and 54 FPS, respectively), their detection accuracies remained relatively low at 89.6% and 90.8%, respectively. In contrast, the CSD-YOLO algorithm achieved the highest detection accuracy while retaining real-time performance. The CSD-YOLO algorithm distinguishes itself from similar algorithms in several key ways. First, it introduces the slim-neck module to innovatively design the neck structure, significantly enhancing the feature fusion efficiency and improving the detection accuracy and speed. Second, it optimizes the c2f module of the backbone network by integrating the context guided block module, thereby markedly enhancing the model’s feature extraction capability and enabling a more accurate capture of essential information from the image. Finally, the introduction of the D-LKA mechanism dynamically adjusts the shape and size of the convolution kernel to better adapt to image features, consequently improving the model’s adaptability to target shape and size. By elucidating these advancements, the study underscores the significant contributions of the CSD-YOLO algorithm to the field of ship target detection, marking a notable stride in the advancement of detection accuracy and real-time performance.
The CSD-YOLO algorithm shares numerous similarities and differences with existing algorithms.
- (1)
- Both the CSD-YOLO algorithm and the existing algorithms use a deep learning-based framework.
- (2)
- The CSD-YOLO algorithm uses a similar dataset to all existing algorithms: the SeaShips dataset.
- (3)
- The CSD-YOLO algorithm achieved a similar performance to the existing algorithms in terms of ship recall (e.g., YOLOv5 has a recall of 89.5, and the CSD-YOLO algorithm has a recall of 89.5).
- (4)
- Model architecture: Compared with the benchmark YOLOv8n algorithm architecture, the CSD-YOLO algorithm introduces the deformable large kernel attention mechanism, which significantly improved the ship detection performance, as can be seen from the data in Table 7.
- (5)
- Multi-scale fusion of features: Unlike traditional methods that use only single-scale features, the CSD-YOLO algorithm applies the slim-neck module to the neck part to achieve more efficient scale fusion to enhance the model’s ability to characterize ships.
- (6)
- Speed and efficiency: As can be seen from the data in Table 10, compared to the benchmark algorithm, the CSD-YOLO algorithm significantly improved the accuracy of ship detection while maintaining the existing detection speed.
Overfitting is a problem to be aware of in deep learning and may lead to poor generalization of the model. In the preparation stage of the above experiments, many regularization methods were adopted in this paper. From the experimental results, it can be seen that the training and testing errors of the CSD-YOLO algorithm decreased synchronously with the increase in the number of training rounds, so the model did not suffer from the overfitting problem during the training process.
5. Conclusions
In response to the challenges faced in ship detection under complex marine environments, this study proposed a novel ship detection algorithm, termed CSD-YOLO, which addresses the limitations of maintaining detection accuracy and efficiency. The benchmark model utilized in this study was YOLOv8n. By innovatively redesigning the neck structure and incorporating the CG block module, the D-LKA mechanism was introduced and seamlessly integrated into the YOLOv8n algorithm. Experimental validation demonstrated that the CSD-YOLO algorithm significantly enhanced the performance of ship detection in complex navigational environments while maintaining real-time detection speeds. Specifically, the precision of the algorithm reached 91.5%, the recall achieved 89.5%, and the mAP attained 91.5%. Compared to the baseline algorithm, CSD-YOLO showed improvements in the recall rate (by 0.7%) and average precision (by 0.4%). These results provide robust technical support for the real-time tracking and identification of ships in challenging marine conditions.
In the future, we anticipate the enhancement of datasets representing various environmental scenarios at sea, thereby enriching the research presented in this paper. This will lay the groundwork for the development of a comprehensive target detection embedded system. The ultimate goal is to provide more reliable technical support for achieving intelligence, safety, and visualization in the maritime field. This advancement will contribute significantly to the realization of advanced capabilities in maritime applications.
Author Contributions
Conceptualization, T.W., H.Z., and D.J.; Methodology, T.W.; Software, T.W. and H.Z.; Validation, T.W. and H.Z.; Formal analysis, T.W.; Investigation, H.Z.; Resources, D.J.; Data curation, T.W.; Writing—original draft preparation, T.W. and H.Z.; Writing—review and editing, T.W. and D.J.; Visualization, H.Z.; Supervision, T.W. and D.J; Project administration, T.W. and D.J. All authors have read and agreed to the published version of the manuscript.
Funding
The research of this thesis was supported by the Ministry of Education, Industry-University Cooperation Collaborative Education Project (NO. 202102104008); Xiamen Municipal Natural Science Foundation Upper-level Project (NO. 3502Z202373038); Chongqing Municipal Postgraduate Student Supervisory Team Construction Project (NO. JDDSTD2022009).
Data Availability Statement
Data included in the article.
Conflicts of Interest
The authors declare no conflicts of interest.
Correction Statement
This article has been republished with a minor correction to correct typographical errors in Table 4. This change does not affect the scientific content of the article.
References
- Jiang, M.; Gu, L.; Li, X.; Gao, F.; Jiang, T. Ship Contour Extraction from SAR Images Based on Faster R-CNN and Chan–Vese Model. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Cai, J.; Du, S.; Lu, C.; Xiao, B.; Wu, M. Obstacle Detection of Unmanned Surface Vessel based on Faster RCNN. In Proceedings of the 2023 IEEE 6th International Conference on Industrial Cyber-Physical Systems (ICPS), Wuhan, China, 8–11 May 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Yang, J.-R.; Hao, L.-Y.; Liu, Y.; Zhang, Y. SLT-Net: Enhanced Mask RCNN network for ship long-tailed detection. In Proceedings of the 2023 IEEE 2nd Industrial Electronics Society Annual On-Line Conference (ONCON), Online, 8–10 December 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Qi, L.; Li, B.; Chen, L.; Wang, W.; Dong, L.; Jia, X.; Huang, J.; Ge, C.; Xue, G.; Wang, D. Ship Target Detection Algorithm Based on Improved Faster R-CNN. Electronics 2019, 8, 959. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Z.; Zhang, F.; Xie, J.; Xu, Z. Target scale information detection based on improved Faster R-CNN. In Proceedings of the Third International Seminar on Artificial Intelligence, Networking, and Information Technology (AINIT 2022), Shanghai, China, 23–25 September 2022. Proc. SPIE 12587, 125870V. [Google Scholar] [CrossRef]
- Chai, B.; Nie, X.; Zhou, Q.; Zhou, X. Enhanced Cascade R-CNN for Multi-scale Object Detection in Dense Scenes from SAR Images. IEEE Sens. J. 2024. early access. [Google Scholar] [CrossRef]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and excitation rank faster R-CNN for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 751–755. [Google Scholar] [CrossRef]
- Guo, H.; Yang, X.; Wang, N.; Song, B.; Gao, X. A rotational libra R-CNN method for ship detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5772–5781. [Google Scholar] [CrossRef]
- Park, J.; Moon, H. Lightweight Mask RCNN for Warship Detection and Segmentation. IEEE Access 2022, 10, 24936–24944. [Google Scholar] [CrossRef]
- Wen, G.; Cao, P.; Wang, H.; Chen, H.; Liu, X.; Xu, J.; Zaiane, O. MS-SSD: Multi-scale single shot detector for ship detection in remote sensing images. Appl. Intell. 2023, 53, 1586–1604. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ye, Y.; Zhen, R.; Shao, Z.; Pan, J.; Lin, Y. A novel intelligent ship detection method mased on attention mechanism feature enhancement. J. Mar. Sci. Eng. 2023, 11, 625. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Y.; Lin, Y.; Yan, S.; Xu, Y.; Sun, B. Ship Detection Algorithm Based on YOLOv5 Network Improved with Lightweight Convolution and Attention Mechanism. Algorithms 2023, 16, 534. [Google Scholar] [CrossRef]
- Ting, L.; Baijun, Z.; Yongsheng, Z.; Shun, Y. Ship Detection Algorithm based on Improved YOLO V5. In Proceedings of the 2021 6th International Conference on Automation, Control and Robotics Engineering (CACRE), Dalian, China, 15–17 July 2021; pp. 483–487. [Google Scholar] [CrossRef]
- Cen, J.; Feng, H.; Liu, X.; Hu, Y.; Li, H.; Li, H.; Huang, W. An Improved Ship Classification Method Based on YOLOv7 Model with Attention Mechanism. Wirel. Commun. Mob. Comput. 2023, 2023, 7196323. [Google Scholar] [CrossRef]
- Xing, B.; Wang, W.; Qian, J.; Pan, C.; Le, Q. A Lightweight Model for Real-Time Monitoring of Ships. Electronics 2023, 12, 3804. [Google Scholar] [CrossRef]
- Zhu, C.; Liu, W.; Liu, Y. Ship target detection method based on improved YOLOv8. In Proceedings of the International Conference on Computer Graphics, Artificial Intelligence, and Data Processing (ICCAID 2023), Qingdao, China, 1–3 December 2023. Proc. SPIE 13105, 131051E. [Google Scholar] [CrossRef]
- Cheng, S.; Zhu, Y.; Wu, S. Deep learning based efficient ship detection from drone-captured images for maritime surveillance. Ocean. Eng. 2023, 285, 115440. [Google Scholar] [CrossRef]
- Liu, Q.; Ye, H.; Wang, S.; Xu, Z. YOLOv8-CB: Dense Pedestrian Detection Algorithm Based on In-Vehicle Camera. Electronics 2024, 13, 236. [Google Scholar] [CrossRef]
- Chen, W.-Z.; Hao, L.-Y.; Liu, H.; Zhang, Y. Real-Time Ship Detection Algorithm Based on Improved YOLOv8 Network. In Proceedings of the 2023 IEEE 2nd Industrial Electronics Society Annual On-Line Conference (ONCON), Online, 8–10 December 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, H.; Liu, C.; Cai, Y.; Chen, L.; Li, Y. YOLOv8-QSD: An Improved Small Object Detection Algorithm for Autonomous Vehicles Based on YOLOv8. IEEE Trans. Instrum. Meas. 2024, 73, 1–16. [Google Scholar] [CrossRef]
- Wu, T.; Gao, G.; Huang, J.; Wei, X.; Wei, X.; Liu, C.H. Adaptive Spatial-BCE Loss for Weakly Supervised Semantic Segmentation. In Computer Vision—ECCV 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; ECCV 2022; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; Volume 13689. [Google Scholar] [CrossRef]
- Du, S.; Zhang, B.; Zhang, P.; Xiang, P. An Improved Bounding Box Regression Loss Function Based on CIOU Loss for Multiscale Object Detection. In Proceedings of the 2021 IEEE 2nd International Conference on Pattern Recognition and Machine Learning (PRML), Chengdu, China, 16–18 July 2021; pp. 92–98. [Google Scholar] [CrossRef]
- Zhao, S.; Tao, R.; Jia, F. DML-YOLOv8-SAR Image Object Detection Algorithm (Version 1). Res. Sq. 2024, preprint. [Google Scholar] [CrossRef]
- Jiang, T.; Chen, S. A Lightweight Forest Pest Image Recognition Model Based on Improved YOLOv8. Appl. Sci. 2024, 14, 1941. [Google Scholar] [CrossRef]
- Su, L.; Chen, Y.; Song, H.; Li, W. A survey of maritime vision datasets. Multimed Tools Appl. 2023, 82, 28873–28893. [Google Scholar] [CrossRef]
- Tang, X.; Zhang, J.; Xia, Y.; Xiao, H. DBW-YOLO: A High-Precision SAR Ship Detection Method for Complex Environments. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 7029–7039. [Google Scholar] [CrossRef]
- Zhu, H.Y.; Huang, H.C.; Rong, Y.; Wang, C. DB-YOLO: A Duplicate Bilateral YOLO Network for Multi-Scale Ship Detection in SAR Images. Sensors 2021, 21, 8146. [Google Scholar] [CrossRef]
- Liu, W.; Chen, Y. IL-YOLOv5: A Ship Detection Method Based on Incremental Learning. In Advanced Intelligent Computing Technology and Applications; Huang, D.S., Premaratne, P., Jin, B., Qu, B., Jo, K.H., Hussain, A., Eds.; ICIC 2023; Lecture Notes in Computer Science; Springer: Singapore, 2023; Volume 14087. [Google Scholar] [CrossRef]
- Wang, N.; Wang, Y.; Feng, Y.; Wei, Y. MDD-ShipNet: Math-Data Integrated Defogging for Fog-Occlusion Ship Detection. IEEE Trans. Intell. Transp. Syst. 2024. early access. [Google Scholar] [CrossRef]
- Ju, M.; Luo, J.; Zhang, P.; He, M.; Luo, H. A Simple and Efficient Network for Small Target Detection. IEEE Access 2019, 7, 85771–85781. [Google Scholar] [CrossRef]
- Li, X.; Fu, C.; Li, X.; Wang, Z. Improved Faster R-CNN for Multi-Scale Object Detection. J. Comput.-Aided Des. Comput. Graph. 2019, 31, 1095–1101. [Google Scholar] [CrossRef]
- Sun, J.; Xu, Z.; Liang, S. NSD-SSD: A Novel Real-Time Ship Detector Based on Convolutional Neural Network in Surveillance Video. Comput. Intell. Neurosci. 2021, 2021, 7018035. [Google Scholar] [CrossRef] [PubMed]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).