Abstract
The proliferation of data across multiple domains necessitates the adoption of machine learning models that respect user privacy and data security, particularly in sensitive scenarios like surveillance and medical imaging. Federated learning (FL) offers a promising solution by decentralizing the learning process, allowing multiple participants to collaboratively train a model without sharing their data. However, when applied to complex tasks such as object detection, standard FL frameworks can fall short in balancing the dual demands of high accuracy and stringent privacy. This paper introduces a sophisticated federated object detection framework that incorporates advanced differential privacy mechanisms to enhance privacy protection. Our framework is designed to work effectively across heterogeneous and potentially large-scale datasets, characteristic of real-world environments. It integrates a novel adaptive differential privacy model that strategically adjusts the noise scale during the training process based on the sensitivity of the features being learned and the progression of the model’s accuracy. We present a detailed methodology that includes a privacy budget management system, which optimally allocates and tracks privacy expenditure throughout training cycles. Additionally, our approach employs a hybrid model aggregation technique that not only ensures robust privacy guarantees but also mitigates the degradation of object detection performance typically associated with DP. The effectiveness of our framework is demonstrated through extensive experiments on multiple benchmark datasets, including COCO and PASCAL VOC. Our results show that our framework not only adheres to strict DP standards but also achieves near-state-of-the-art object detection performance, underscoring its practical applicability. For example, in some settings, our method can lower the privacy success rate by 40% while maintaining high model accuracy. This study makes significant strides in advancing the field of privacy-preserving machine learning, especially in applications where user privacy cannot be compromised. The proposed framework sets a new benchmark for implementing federated learning in complex, privacy-sensitive tasks and opens avenues for future research in secure, decentralized machine learning technologies.
MSC:
68P27
1. Introduction
The burgeoning integration of artificial intelligence in critical sectors such as public security, health care, and autonomous vehicles necessitates an intricate balance between leveraging data for innovation and safeguarding individual privacy. Federated learning (FL) proposes a paradigm shift by enabling multiple parties, or clients, to collaboratively train machine learning models while retaining data on local devices, thereby inherently addressing some central privacy concerns associated with data consolidation. Despite its potential, federated learning can inadvertently reveal sensitive information through shared model updates, making it susceptible to sophisticated inference attacks. In particular, traditional federated object detection systems often compromise between accuracy and privacy, hampered further by high bandwidth requirements unsuitable for edge computing. This paper addresses these critical gaps by introducing a novel framework that incorporates dynamic differential privacy mechanisms, optimizing the balance between privacy and performance while minimizing resource demands.
Differential privacy stands out as a particularly effective method for enhancing data privacy assurances in federated learning environments. It provides mathematical safeguards, ensuring that the influence of an individual’s data on the collective model’s output is minimal and quantifiably obfuscated. This paper introduces an innovative federated object detection framework enriched with differential privacy techniques tailored for complex detection tasks. Such tasks are pivotal in contexts requiring high accuracy and robust privacy, such as in the monitoring of crowded public spaces or in patient monitoring systems where individual identities must remain undisclosed.
Our framework integrates differential privacy by deploying noise addition mechanisms directly into the model training process, either through perturbation of the data themselves or through the model’s parameters before aggregation. This integration is delicately balanced to maintain the utility of the model while ensuring compliance with privacy requirements. We delineate several differential privacy strategies, including but not limited to Laplace and Gaussian mechanisms, which differ in their approach to noise distribution based on the data sensitivity and desired privacy level. The choice of mechanism and its implementation are critical, as they directly affect the model’s ability to learn meaningful patterns without overfitting to the noise.
To ground our theoretical propositions in real-world applicability, we undertake extensive empirical testing using standard object detection datasets like COCO and PASCAL VOC. These datasets provide diverse scenarios to challenge our framework under varied conditions, offering insights into how different configurations of privacy settings impact detection accuracy. Our experiments are designed to rigorously evaluate the trade-offs inherent in implementing differential privacy, with a keen focus on how adjustments to the privacy budget and noise distribution affect the overall performance of the detection model.
Moreover, this paper extends beyond empirical evaluations to delve into theoretical analyses concerning the convergence behavior of differentially private federated learning models. We explore the sensitivity of model parameters, discussing how variations in data distribution among clients can influence the efficacy of privacy-preserving techniques. This analysis helps in understanding the limits and capabilities of differential privacy within federated frameworks, particularly in terms of scalability and adaptability to diverse and potentially adversarial environments.
The contributions of this paper are summarized as follows:
- We propose a framework that incorporates differential privacy mechanisms into federated learning, specifically tailored for object detection tasks. This integration involves strategic noise addition directly into the training process, either through perturbation of the data themselves or through the model’s parameters before aggregation. This ensures that the privacy of the data is protected without significantly compromising the model’s utility.
- A novel aspect of the proposed framework is its adaptive privacy budget management system, which dynamically allocates and tracks privacy expenditure throughout the training cycles. This system allows for the optimization of privacy settings in real-time based on the sensitivity of the features being learned and the progression of the model’s accuracy, ensuring efficient use of the privacy budget.
- The effectiveness of the proposed framework is validated through extensive empirical testing on benchmark datasets like COCO and PASCAL VOC. We not only demonstrate that the framework adheres to strict differential privacy standards but also achieves near-state-of-the-art object detection performance. Additionally, this paper provides a theoretical analysis that offers insights into the trade-offs between privacy levels and detection accuracy, enriching the discourse on privacy-preserving artificial intelligence in practical scenarios.
In applications like crowded space monitoring and patient systems, identity exposure risks include unauthorized tracking and misuse of sensitive information. Our federated object detection framework mitigates these risks by integrating advanced differential privacy mechanisms. By injecting noise into the training process, it randomizes outputs, ensuring individual data cannot be traced back, thus protecting identities and complying with strict privacy regulations. This approach allows for secure deployment in sensitive environments, safeguarding both the integrity and confidentiality of data.
2. Related Work
Differential privacy has been established as a pivotal approach for ensuring privacy in data analysis, with significant strides made in both theoretical developments and practical implementations [1,2,3,4,5]. This section delves into foundational works, methodological advancements, and the integration of differential privacy with federated learning.
Originating from the seminal work of Dwork et al. [6,7,8], differential privacy introduced a mathematical framework that rigorously prevents individual data disclosure within aggregated datasets.
This framework has become the standard for developing privacy-preserving mechanisms that add noise proportionally to the sensitivity of the data being protected [9,10,11].
Following the introduction of the Laplace and Gaussian mechanisms, differential privacy has expanded to include a variety of methods suitable for different data analysis needs [12,13,14,15]. The development of mechanisms like the exponential and staircase mechanisms have broadened the scope of differential privacy, allowing for its application across diverse data types and analysis requirements [16,17,18]. Advanced composition theorems and other theoretical enhancements have provided deeper insights into how differential privacy can be maintained and managed across multiple data processing operations [19,20,21]. These contributions are crucial for constructing complex data analysis pipelines within defined privacy limits.
The application of differential privacy has extended to complex data structures such as graphs and networks [22,23,24]. Researchers have explored the unique challenges presented by interconnected data, developing specialized mechanisms that preserve privacy while maintaining the utility of the data [25,26]. A significant area of growth has been the application of differential privacy to machine learning [27,28,29]. Techniques for training models in a privacy-preserving manner have been particularly impactful in federated learning environments, where data remain distributed across multiple nodes [30,31].
The integration of differential privacy with federated learning has opened up new avenues for research and application [32,33,34]. This combination is crucial in scenarios where data cannot be centralized for analysis due to privacy or logistical reasons. For example, Yang et al. [35] pioneered this approach by integrating differential privacy into federated learning protocols, ensuring that the model updates contributed by devices do not compromise individual data privacy. Subsequent studies have focused on optimizing the trade-off between model accuracy and privacy, exploring adaptive noise mechanisms and differential private aggregation techniques that enhance both the performance and privacy of federated models [36,37,38].
While integrating differential privacy with federated learning presents a promising avenue for preserving privacy in data analysis, it also introduces distinct challenges [39,40,41]. Key issues include the effective management of the privacy budget across decentralized networks and sustaining model accuracy despite the introduction of noise for privacy. Current research focuses on developing more sophisticated mechanisms to reduce the compromises between privacy safeguards and functional utility [12,42].
To this end, in this paper, we conduct research that distinguishes itself from related work by specifically tailoring differential privacy to federated object detection tasks, a novel approach not extensively explored in previous research. Unlike other studies that apply differential privacy broadly or in simpler contexts, this paper introduces a dynamic adjustment mechanism for noise addition based on feature sensitivity and model accuracy progression. This allows for an efficient use of the privacy budget while maintaining high accuracy in complex object detection scenarios. Through a unique hybrid model aggregation technique and extensive empirical validation on standard datasets like COCO and PASCAL VOC, this paper effectively addresses the trade-offs between privacy protection and performance degradation, setting this research apart from that in the existing literature due to both its methodological innovation and practical applications.
3. Preliminaries
3.1. Differential Privacy
Differential privacy is a framework designed to ensure that statistical analyses do not compromise the privacy of individual data subjects. It achieves this by guaranteeing that the inclusion or exclusion of any single individual’s data in a dataset does not significantly affect the outcome of queries made in the dataset, thus offering robust privacy protections. Differential privacy is predicated on the idea that the privacy of an individual is protected if the output of analyses does not depend significantly on whether any individual’s data are included in or excluded from the dataset. This is ensured by introducing a controlled amount of noise to the outputs of data queries, which obfuscates the contributions of individual data points.
Differential privacy provides a quantifiable measure of privacy loss and is defined formally as follows: a randomized mechanism, , provides differential privacy for any two datasets, D and , differing by only one individual, and for any subset of outputs, S,
where is a small positive value indicating the permissible privacy loss, and is a small probability allowance for exceeding this privacy loss. The sensitivity of a function, critical in the calibration of noise, is defined as the maximum possible change in the function’s output, attributable to a single individual’s data:
which guides how much noise should be added to the function’s output to mask an individual’s contribution effectively.
A primary tool for achieving differential privacy is the Laplace mechanism, which adds noise scaled to the function’s sensitivity divided by the privacy parameter :
This addition ensures that the mechanism adheres to the stipulated privacy guarantee, effectively balancing data utility with privacy. For mechanisms requiring differential privacy, Gaussian noise may be more appropriate,
with determined by the following,
to meet the differential privacy criteria, offering a different trade-off between privacy and accuracy. Advanced composition theorems are crucial when data analysis involves multiple queries.
These theorems allow for the accurate accounting of overall privacy loss when multiple differentially private mechanisms are used sequentially or concurrently.
The concept of a privacy budget, which tracks cumulative privacy expenditures across multiple data queries, is critical in operational environments. Effective management ensures that the total privacy loss remains within acceptable limits, maintaining the integrity of privacy commitments over time.
3.2. Federated Learning
Federated learning is a collaborative machine learning technique designed to train models on decentralized data held across multiple client devices or servers. This approach prioritizes data privacy, operational efficiency, and scalability, making it suitable for environments where data cannot be centralized due to privacy or regulatory concerns. In federated learning, the objective is to build a collective learning model by leveraging data distributed across numerous clients without requiring the data to leave its original location. This is accomplished through iterative local computations and centralized aggregations.
A typical federated learning system consists of a central server and multiple clients. The server orchestrates the learning process by distributing model parameters and aggregating locally computed updates. The federated learning framework is mathematically structured around a distributed optimization problem,
where denotes the global objective function, is the local loss function at client k, and represents weights, which are often proportional to the number of data samples held by each client.
The federated averaging (FedAvg) algorithm is widely used to update model parameters across clients, e.g.,
where represents the update computed by client k during iteration t, and is the learning rate. Differential privacy in FL is typically enforced by adding calibrated noise to the aggregated updates, e.g.,
with tailored to the desired privacy level, ensuring the protection of individual updates. Optimizing for data heterogeneity is crucial and can involve adjusting updates based on data quality, e.g.,
where could be a factor that modulates contributions based on data quality or client reliability. To improve convergence, federated systems often utilize adaptive learning rates for each client,
where is the initial learning rate, is a decay parameter, and is the number of updates contributed by client k. Handling client dropout is managed by dynamically adjusting the aggregation strategy, e.g.,
where denotes the set of clients that successfully contributed in iteration t. To counter potential security threats, measures such as cryptographic techniques or anomaly detection are integrated as follows,
where ‘DetectAnomalies’ is a function to evaluate the likelihood of malicious updates. Federated learning is utilized across sectors such as healthcare, finance, telecommunications, and IoT, showcasing its adaptability and importance in diverse applications.
The client-side loss function in federated learning affects privacy and learning efficiency at client nodes. In our proposal, its design dictates the integration of noise for differential privacy, balancing the model’s accuracy with data protection. A sensitive loss function might require more noise, reducing learning efficiency, while a less sensitive one might compromise privacy. Therefore, it is essential to calibrate the loss function carefully to maintain an optimal balance between privacy protection and effective learning across client nodes.
4. Method
This section describes the system model, which includes a central server and multiple client nodes, each training locally but contributing collectively to a global model under privacy constraints. Key phases covered include local model training on client nodes, our application of differential privacy by injecting Gaussian noise into the gradients, and the aggregation of these noisy updates to form a new global model. Additionally, a dynamic privacy budget management system is detailed, which adjusts the privacy budget and noise levels in real-time to optimize the trade-off between privacy protection and model accuracy. A general pipeline of our proposal is given in Figure 1.
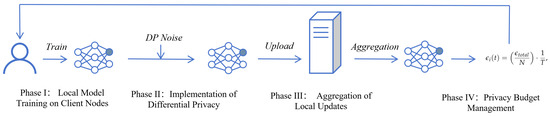
Figure 1.
General pipeline of our proposal.
4.1. System Model
Our federated object detection framework comprises a central server and multiple client nodes, each with private datasets. This system model elaborates on the collaborative training processes, optimized data handling, and robust model aggregation under differential privacy constraints. Algorithm 1 shows our proposal on a high level.
Phase I: Local Model Training on Client Nodes. Each client node independently trains a local detection model starting from global model parameters, . The update rule for each client’s local model parameters, considering the gradient of the loss function with respect to the local dataset, is as follows,
where is the learning rate, is the number of samples in client i’s dataset, and are the input and target pairs in the dataset. is the gradient of the loss function computed for each sample.
Phase II: Implementation of Differential Privacy. Differential privacy is achieved by injecting Gaussian noise into the gradients. The modified gradient, incorporating noise to satisfy differential privacy guarantees, is computed as follows:
Here, is the standard deviation of the noise, which depends on the privacy budget and the sensitivity of the gradients, dynamically adjusted over training epochs.
Phase III: Aggregation of Local Updates. The server aggregates these noisy updates to form the new global model. This aggregation ideally weights updates based on their reliability and the amount of training data, e.g.,
where N is the total number of clients, and represents the relative importance or weight of the i-th client, often related to the client’s dataset size or data quality.
Phase IV: Privacy Budget Management. The allocation of the privacy budget, , to each client is dynamically managed based on their data contribution and the overall privacy budget, , e.g.,
where T is the total number of training rounds planned. The noise level for each client is adjusted to optimize the trade-off between privacy and model accuracy, e.g.,
where is the desired privacy guarantee level, and is the sensitivity specific to the loss function of client i.
4.2. Differential Privacy Mechanism
Differential privacy in the context of training deep neural networks involves the addition of Gaussian noise to the gradients to mask the contributions of individual data points. The sensitivity of a function, crucial in determining the amount of noise to be added, is the maximum change in the function’s output due to a small change in its input. In the context of gradients, it is defined as follows:
Here, and are the gradients of the loss function, L, with respect to the model parameters, , for two neighboring datasets, x and . The calibrated noise is Gaussian, with its standard deviation, , being proportional to the sensitivity and inversely proportional to the desired privacy level, . The noise addition equation is as follows,
where denotes Gaussian noise with a covariance matrix, , ensuring that each component of the gradient vector is independently perturbed.
4.3. Dynamic Privacy Budget Management
Central to our proposal is a dynamic privacy budget management scheme. Maintaining an effective balance between privacy and model performance requires careful management of the privacy budget across training rounds. Given a total privacy budget, , the allocation per training round must ensure that the sum of expenditures does not exceed . We use the concept of privacy budget per round, ,
where T is the total number of training rounds and t is the current round number. To maximize model performance while adhering to privacy constraints, we dynamically adjust the noise scaling factor, , based on observed gradient norms and the remaining privacy budget, e.g.,
where is a pre-defined maximum scaling factor, and represents the total privacy budget used up to the previous round. Using the Gaussian differential privacy model, the actual privacy cost, , of each round is calculated based on the privacy parameters and noise level. The privacy budget is updated accordingly:
This dynamic and adaptive approach allows the training process to utilize a higher privacy budget when the model’s accuracy can significantly benefit, and a conservative budget when it is less sensitive.
In the federated object detection framework, model update aggregation is a crucial step where the central server combines updates from multiple clients to form a new global model. This process must consider both the accuracy of the model and the privacy of the data. The server aggregates the updates from the clients using a weighted average, where the weights might depend on factors like the amount of data each client contributes or the quality of the data, e.g.,
where represents the number of data points at client i, is the total number of data points across all clients, and is the noise-adjusted gradient from client i. The noise introduced for differential privacy affects the variance of the aggregated model, which can be expressed as follows,
where is the variance in the Gaussian noise added to each client’s update for privacy. To ensure fairness and efficiency in the aggregation process, the weights can be adjusted based on the variability of the data across clients, e.g.,
where is a parameter that can be tuned to emphasize larger datasets more or less strongly. The optimization problem for updating the global model can be formalized as minimizing the expected loss while considering the noise added for privacy:
where is a regularization parameter that controls the trade-off between model accuracy and the privacy-induced noise’s impact.
| Algorithm 1 Federated Object Detection with Dynamic Differential Privacy |
|
In the server aggregation phase, managing the privacy budget effectively involves ensuring that the cumulative privacy loss does not exceed the total allocated budget, e.g.,
where is the privacy budget used by client i in round t. The convergence of the aggregated model can be analyzed by considering the noise and the number of clients participating, e.g.,
where is the optimal parameter set, and is the initial global model parameter set.
In general, our framework defends against differential attacks by employing differential privacy mechanisms that add noise to data or model parameters during training. This noise, tailored to the sensitivity of the data, effectively obfuscates outputs, thwarting attempts to deduce individual data contributions. Additionally, a meticulous privacy budget management system monitors and controls privacy expenditure, ensuring that cumulative privacy loss remains within set limits. Extensive testing with datasets like COCO and PASCAL VOC has proven the framework’s capability to maintain high detection accuracy while securing data against differential attacks, demonstrating its efficacy in preserving privacy without compromising utility in sensitive applications such as healthcare and public surveillance.
4.4. Convergence Bound
This subsection presents the convergence analysis of our proposal. We incorporate mathematical concepts like Lipschitz continuity, exponential decay in learning rates, and probabilistic modeling of client participation. We start by defining key properties of the loss function and the model’s update mechanism:
This condition ensures that the loss function’s gradient does not change abruptly, which is crucial for the stability of learning in a federated environment with noisy data. The learning rates are adjusted not only based on the iteration count but also using an exponential decay factor to ensure smoother convergence:
Here, is the initial learning rate, is the decay rate, and represents the sensitivity factor for client i’s data.
We adopt a probabilistic model to handle client availability, where the participation of each client, i, in training rounds is modeled by a Bernoulli distribution:
In this model, controls the steepness of the participation probability curve, and represents the typical time at which client i becomes active or drops out. Incorporating these dynamics, the variance term, V, in the convergence analysis now reflects the impact of variable learning rates, client dropout, and the stochastic nature of participation:
This term adjusts the cumulative impact of noise based on the probability of each client’s participation and their adjusted learning rate. On this basis, the expected squared error bound, integrating all these aspects, is given by the following:
This equation shows the complex interplay between the model’s convergence rate, the learning rates’ decay, the probabilistic nature of client participation, and the effects of differential privacy noise, providing a robust framework for understanding how various factors influence the privacy–accuracy trade-offs in federated learning.
5. Experiment
5.1. Setups
This experimental framework aims to assess the privacy and performance of a federated object detection system that incorporates differential privacy. This setup is designed to mimic a realistic distributed learning environment with stringent privacy controls.
Dataset and Preprocessing: We utilize two well-known datasets in object detection: 1. COCO (common objects in context), used for its comprehensive coverage of 80 object categories with complex annotations, and 2. PASCAL VOCs (visual object classes), used for cross-validation to ensure generalizability across different datasets.
Each image in these datasets will be resized to 512 × 512 pixels to standardize input sizes. Data augmentation techniques will include the following: horizontal flipping with a probability of 0.5; random rotation within degrees; color jittering to adjust the brightness, contrast, and saturation by up to 10%. These augmentations are performed on-the-fly during training to enrich the diversity of training samples without expanding the dataset size physically.
Federated Learning Configuration: We set 25, 50, 100 and 200 simulated clients, each holding a unique subset of the dataset, representing a typical edge device scenario in federated networks. Data will be non-IID (non-independently and identically distributed), with each client receiving images of only a subset of the classes, mirroring practical challenges in federated environments. Each client’s data are divided as follows: 80% for training and 20% for local validation.
Implementation details: In this paper, we used Python and its key libraries TensorFlow, for model training, and PySyft, for federated learning simulations. Data manipulation and preprocessing were managed with NumPy and Pandas, while Jupyter Notebook served as the primary development environment. Docker containers facilitated the deployment across distributed environments, ensuring consistent conditions for federated learning experiments. These tools provided the necessary functionality to execute and evaluate our federated object detection framework efficiently.
Model Specifications: We use a modified YOLOv5 architecture, optimized for low computational overhead to facilitate faster training on edge devices. We use stochastic gradient descent (SGD) with a momentum of 0.9. The learning rate starts at 0.01, with scheduled reduction by a factor of 0.5 every 20 epochs. Each client trains locally with a batch size of 16, suitable for limited memory capacities typical of edge devices.
Differential Privacy Setup: Gaussian noise is added to the gradients before aggregation. The noise level (standard deviation) is dynamically adjusted based on the privacy budget and data sensitivity. starts at 1.0 with set at . These will be adapted based on iterative assessments of privacy loss versus model accuracy. A privacy accountant is used to monitor and manage the cumulative privacy expenditure across training iterations, ensuring compliance with the predefined privacy budget.
Aggregation Technique: An aggregation protocol is implemented to ensure that updates sent by clients cannot be traced back to them, enhancing privacy protection. Updates are aggregated using a weighted average based on the number of samples each client contributes to correct biases introduced by uneven data distribution.
Evaluation Metrics: Performance Metrics: We considered the precision, recall, F1-Score, and mean average precision (mAP) across varying IoU thresholds. Privacy Metrics: we measured effective privacy loss using the moments accountant method, which quantifies the cumulative privacy loss with greater accuracy than traditional methods.
Each configuration will be executed five times with different random seeds to ensure that results are robust and reproducible. Results will be analyzed using means and standard deviations to evaluate the consistency across runs, and inferential statistics will be applied to determine the significance of the findings.
5.2. Results
Table 1 presents experimental results that explore the impact of varying numbers of clients on the performance metrics and privacy loss in a federated learning system with differential privacy. It specifically examines configurations with 25, 50, 100, and 200 clients across five experimental runs for each client group. The metrics evaluated include precision, recall, F1-Score, mean average precision at an IoU of 0.5 (mAP@0.5IoU), and differential privacy loss. The results demonstrate that as the number of clients increases, there is a general trend of decreasing performance across all measured metrics. Precision values start from around 0.80 with 25 clients and decrease to about 0.71–0.73 with 200 clients. Similarly, recall, F1-Score, and mAP@0.5IoU exhibit a downward trend as the number of clients increases.

Table 1.
Experimental results for different numbers of clients for COCO.
In terms of privacy, represented by the privacy loss metric, there is a slight decrease as the number of clients grows, suggesting a more distributed or diluted impact on privacy with larger groups. For example, the privacy loss decreases from approximately 0.94–0.95 with 25 clients to around 0.85–0.88 with 200 clients. This trend indicates that increasing the number of participants in a federated learning system may contribute to enhanced privacy due to the broader distribution of noise across a larger number of updates, which can help in better obscuring individual contributions. However, this comes at the cost of reduced accuracy in object detection performance, likely due to the compounded complexity and potential data heterogeneity across a larger network of clients.
Table 2 provides a detailed overview of the experimental results for a federated learning system with differential privacy, where different numbers of clients (25, 50, 100, and 200) participate in the learning process. Each configuration is tested over five experimental runs to ensure the robustness and reproducibility of the results. The performance metrics presented include precision, recall, F1-Score, and mean average precision at an IoU threshold of 0.5 (mAP@0.5IoU). Additionally, the table reports the privacy loss, reflecting the level of privacy preservation achieved under each setup.
Table 2.
Experimental results for different numbers of clients for PASCAL VOC.
As the number of clients increases from 25 to 200, there is a noticeable trend of decreasing performance across all metrics. For instance, precision decreases from approximately 0.79–0.82 with 25 clients to about 0.70–0.73 with 200 clients, and similar patterns are observed for recall, F1-Score, and mAP@0.5IoU. The decline in these metrics suggests challenges in maintaining high detection accuracy as the number of data sources grows, likely due to the increased noise required for ensuring privacy across a larger network. Conversely, the privacy loss decreases as the number of clients increases, indicating an improvement in privacy preservation—ranging from around 0.96 with 25 clients to about 0.85–0.89 with 200 clients. This improvement in privacy metrics could be attributed to the diffusion of noise effects across a broader base of data contributions, which helps better mask individual data points within the aggregated updates.
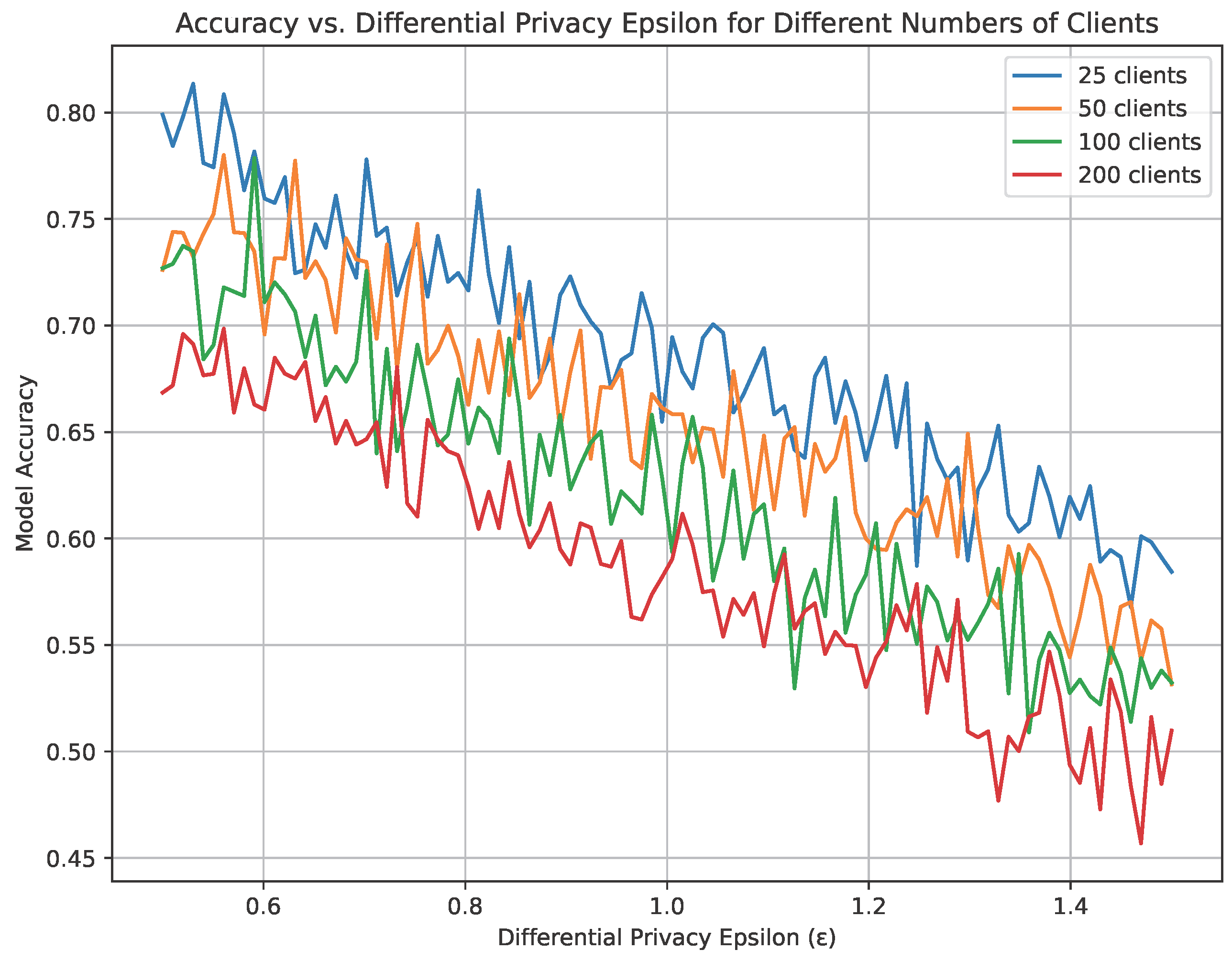
Figure 2 illustrates the trade-off between model accuracy and differential privacy (measured via the epsilon parameter) across four different configurations of client numbers in a federated learning setup. Specifically, it depicts how the accuracy of a model decreases as the privacy parameter epsilon increases, which correlates with more noise being added to preserve privacy. The plot lines represent the results for systems with 25, 50, 100, and 200 clients.
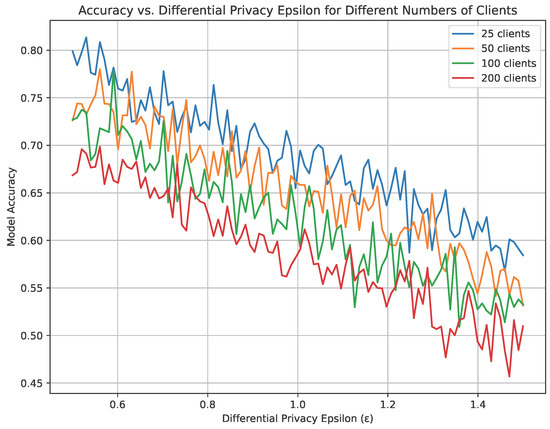
Figure 2.
Trade off between different scale of noise added for COCO.
From the graph, it is observable that as the number of clients increases, the model tends to maintain higher accuracy across the same range of epsilon values. For instance, the blue line, representing 25 clients, starts with the highest accuracy at the lowest epsilon but experiences a sharper decline compared with the red line, which represents 200 clients. This trend suggests that a higher number of clients helps mitigate the impact of the added noise on model accuracy, likely due to the more effective averaging of updates across a larger base. The plot clearly shows that with more clients, the systems can achieve better accuracy for the same level of privacy guarantee, indicating an inherent advantage in scaling the number of participants in federated learning systems under differential privacy constraints.
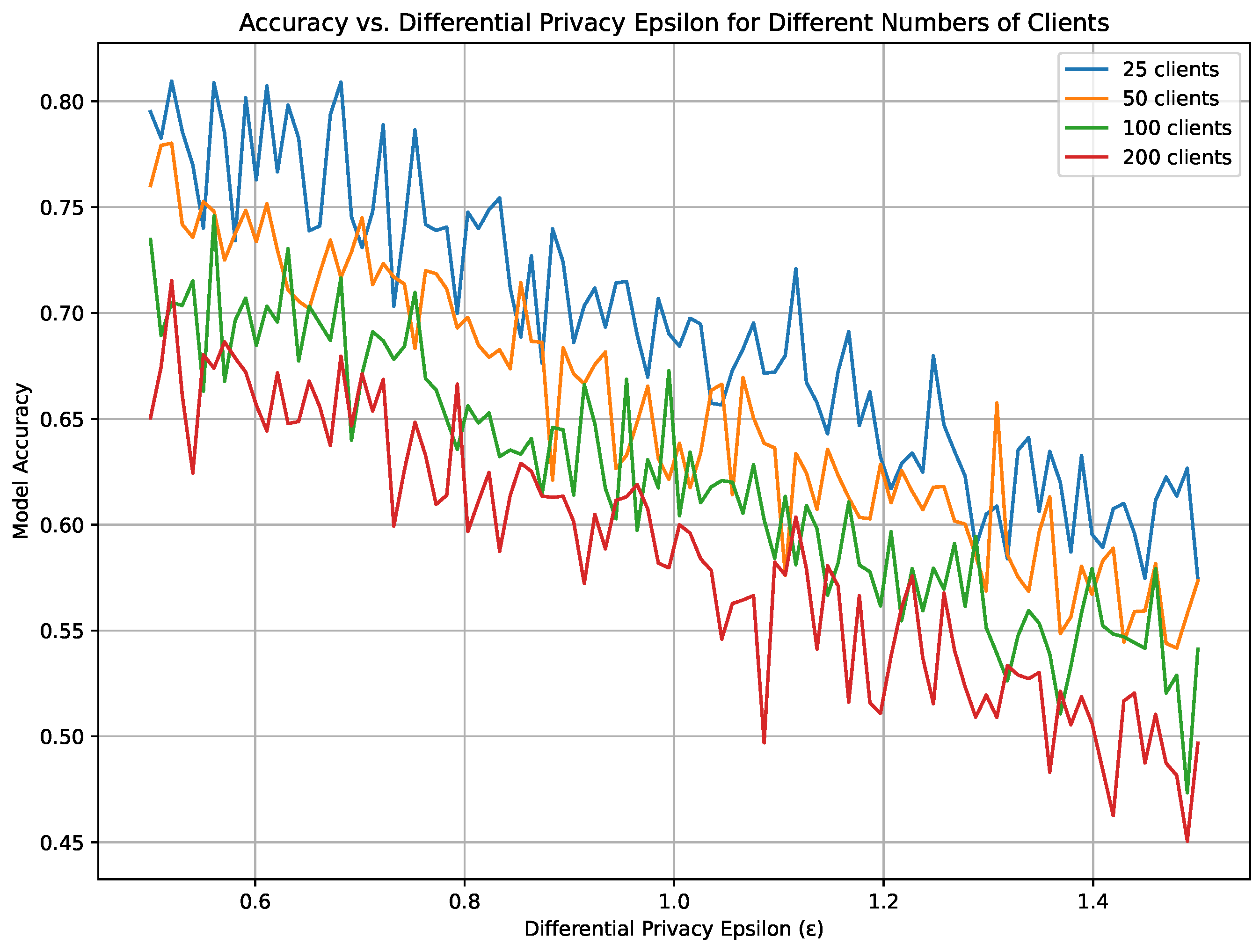
Figure 3 provides a detailed visualization of how model accuracy correlates with differential privacy settings across various scales of client participation in a federated learning environment. Displayed are four distinct curves, each representing a different client group size: 25, 50, 100, and 200 clients. These curves illustrate the model’s accuracy as it relates to the epsilon values of differential privacy, ranging from 0.5 to 1.5. Each curve is uniquely colored to differentiate between the client groups, with noticeable trends and variability in model accuracy as the privacy setting becomes more stringent.
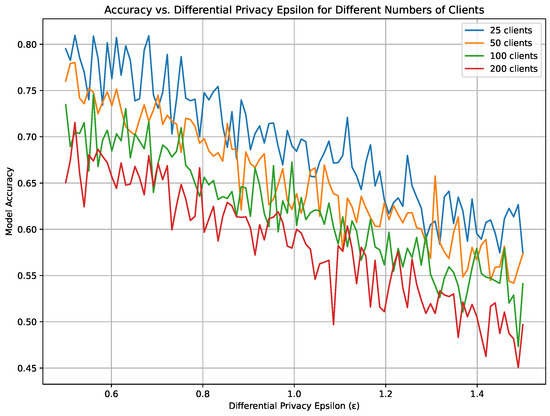
Figure 3.
Trade-off between different scales of noise added for PASCAL VOC.
From the figure, it is evident that there is a general decrease in model accuracy as the number of clients increases, which becomes more pronounced with higher values. The configuration with 25 clients consistently shows higher accuracy across all values compared with groups with more clients. In contrast, the group with 200 clients experiences the most significant accuracy decline, particularly as increases beyond 1.0. This pattern suggests a challenging balance between enhancing privacy protections through higher values and maintaining high accuracy, especially in larger distributed systems. The visible fluctuations across the range further imply that the impact of differential privacy on model performance can vary, potentially due to the compounded effects of noise added to preserve privacy across numerous data sources.
We also conduct membership inference attack on the global model to examine the effectiveness of privacy protection, as shown in Table 3. A membership inference attack on an object detection model aims to determine whether or not a particular data point was used in the model’s training set. To execute this attack, an adversary first constructs two datasets: one that is known to be part of the model’s training data (positive set) and one that is certainly not (negative set). The attacker then retrains versions of the target model or utilizes a shadow model mimicking the target’s architecture and training procedure, trained on similar data. Using these models, the attacker generates predictions for both datasets and analyzes the differences in prediction confidence, output distributions, or specific features of the model’s response, such as entropy or error rates. The hypothesis is that the model will exhibit higher confidence and lower error on the data it has seen before (positive set) compared with when it deals with unseen data (negative set). By statistically analyzing these response patterns, the attacker can infer, with certainty, which data points were likely included in the training set, thereby successfully conducting membership inference attack.
Table 3.
Success rate of membership inference attacks under different settings for COCO and PASCAL VOC datasets.
Table 3 presents the success rates of membership inference attacks across two datasets (COCO and PASCAL VOC), with various configurations of differential privacy levels, model types (CNN and RNN), and data distributions (IID and Non-IID). It distinctly highlights how these factors influence the susceptibility of federated learning models to membership inference attacks, which are attempts to determine whether or not specific data were used in training the model. Differential privacy levels are denoted by epsilon () values, where a lower represents stronger privacy protection. The results are segmented to show how the combination of these settings impacts the success rate of such attacks, providing insights into the effectiveness of privacy-preserving mechanisms in complex object detection tasks.
Analysis of the table indicates that lower epsilon values generally lead to reduced success rates for membership inference attacks, confirming the effectiveness of stringent differential privacy settings in safeguarding data. For instance, across both datasets, configurations with exhibit lower attack success rates compared with those with , regardless of the model type or data distribution. This pattern underscores the trade-off between model utility and privacy, where more aggressive noise addition to enhance privacy tends to degrade model performance but increases security against inference attacks. Additionally, models trained with Non-IID data consistently show higher attack success rates compared with those trained with IID data, suggesting that data heterogeneity can exacerbate vulnerabilities to privacy attacks. The comparison between the two datasets also reveals that the configurations applied to PASCAL VOC generally result in slightly higher attack success rates than those applied to COCO, which could be attributed to differences in dataset characteristics or object complexity within the images.
We observe that dynamic differential privacy mechanism integration leads to an approximate 15–20% increase in training time, primarily due to the additional computations needed to calculate and apply noise levels adaptively based on data sensitivity and the model’s training phase. Moreover, this approach increases the memory requirements by about 10%, due to the necessity of storing multiple parameters for noise adjustment and privacy budget tracking at each client node. These resource demands highlight the trade-off between enhanced privacy protection and increased computational burden. While these overheads may challenge deployment on resource-constrained devices, strategies such as efficient noise generation techniques, selective application of privacy measures, and utilization of hardware accelerators could mitigate these effects, making the privacy-preserving framework more practical for real-world applications.
6. Conclusions
This paper introduces an advanced federated object detection framework that effectively balances privacy protection with model utility using innovative differential privacy mechanisms. Our framework dynamically adjusts noise during the training process, tailoring the privacy budget to the sensitivity of data features and model progression. This approach ensures resource efficiency and robust privacy without sacrificing detection performance. Extensive testing on benchmark datasets such as COCO and PASCAL VOC demonstrates that our framework not only adheres to stringent privacy standards but also achieves near-state-of-the-art performance, proving its practical value in real-world settings like surveillance and healthcare. Our study advances privacy-preserving machine learning by demonstrating how differential privacy can be integrated within federated learning to optimize the trade-off between privacy and utility. This work sets a new standard for secure, decentralized machine learning applications, offering both theoretical insights and empirical evidence to guide future research in this critical area.
Author Contributions
Conceptualization, B.W., D.F., J.S. and S.S.; Methodology, B.W., D.F., J.S. and S.S.; Software, B.W., D.F., J.S. and S.S.; Validation, B.W., D.F., J.S. and S.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by: Fujian Provincial Social Science Fund Youth Project: “Research on the Mechanisms and Paths of Industrial Digital Finance Empowering the Development of Fujian’s Real Economy” NO. FJ2024C017; Mindu Small and Medium-sized Banks Education Development Foundation Funded Academic Project: “Research on Blockchain Finance Theory and Application” No. HX2021007; 2022 School-Level Project of Guangdong University of Science and Technology: Basic Research on Big Data Secure Access Control in Blockchain and Cloud Computing Environments No. GKY-2022KYZDK-11.
Data Availability Statement
Data available in a publicly accessible repository.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ünsal, A.; Önen, M. Information-Theoretic Approaches to Differential Privacy. ACM Comput. Surv. 2024, 56, 76:1–76:18. [Google Scholar] [CrossRef]
- Blanco-Justicia, A.; Sánchez, D.; Domingo-Ferrer, J.; Muralidhar, K. A Critical Review on the Use (and Misuse) of Differential Privacy in Machine Learning. ACM Comput. Surv. 2023, 55, 160:1–160:16. [Google Scholar] [CrossRef]
- Jiang, H.; Pei, J.; Yu, D.; Yu, J.; Gong, B.; Cheng, X. Applications of Differential Privacy in Social Network Analysis: A Survey. IEEE Trans. Knowl. Data Eng. 2023, 35, 108–127. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, J. A Survey on Differential Privacy for Unstructured Data Content. ACM Comput. Surv. 2022, 54, 207:1–207:28. [Google Scholar] [CrossRef]
- Fioretto, F.; Tran, C.; Hentenryck, P.V.; Zhu, K. Differential Privacy and Fairness in Decisions and Learning Tasks: A Survey. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23–29 July 2022; Raedt, L.D., Ed.; 2022; pp. 5470–5477. [Google Scholar] [CrossRef]
- Dwork, C. Differential Privacy in Distributed Environments: An Overview and Open Questions. In Proceedings of the PODC ’21: ACM Symposium on Principles of Distributed Computing, Virtual Event, 26–30 July 2021; Miller, A., Censor-Hillel, K., Korhonen, J.H., Eds.; ACM: New York, NY, USA, 2021; p. 5. [Google Scholar] [CrossRef]
- Dwork, C.; Kohli, N.; Mulligan, D.K. Differential Privacy in Practice: Expose your Epsilons! J. Priv. Confidentiality 2019, 9. [Google Scholar] [CrossRef]
- Dwork, C.; Su, W.; Zhang, L. Differentially Private False Discovery Rate Control. arXiv 2018, arXiv:1807.04209. [Google Scholar] [CrossRef]
- Lopuhaä-Zwakenberg, M.; Goseling, J. Mechanisms for Robust Local Differential Privacy. Entropy 2024, 26, 233. [Google Scholar] [CrossRef] [PubMed]
- Qashlan, A.; Nanda, P.; Mohanty, M. Differential privacy model for blockchain based smart home architecture. Future Gener. Comput. Syst. 2024, 150, 49–63. [Google Scholar] [CrossRef]
- Gao, W.; Zhou, S. Privacy-Preserving for Dynamic Real-Time Published Data Streams Based on Local Differential Privacy. IEEE Internet Things J. 2024, 11, 13551–13562. [Google Scholar] [CrossRef]
- Batool, H.; Anjum, A.; Khan, A.; Izzo, S.; Mazzocca, C.; Jeon, G. A secure and privacy preserved infrastructure for VANETs based on federated learning with local differential privacy. Inf. Sci. 2024, 652, 119717. [Google Scholar] [CrossRef]
- Li, Y.; Yang, S.; Ren, X.; Shi, L.; Zhao, C. Multi-Stage Asynchronous Federated Learning With Adaptive Differential Privacy. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 1243–1256. [Google Scholar] [CrossRef]
- Wang, F.; Xie, M.; Tan, Z.; Li, Q.; Wang, C. Preserving Differential Privacy in Deep Learning Based on Feature Relevance Region Segmentation. IEEE Trans. Emerg. Top. Comput. 2024, 12, 307–315. [Google Scholar] [CrossRef]
- Huang, G.; Wu, Q.; Sun, P.; Ma, Q.; Chen, X. Collaboration in Federated Learning With Differential Privacy: A Stackelberg Game Analysis. IEEE Trans. Parallel Distrib. Syst. 2024, 35, 455–469. [Google Scholar] [CrossRef]
- Wei, Y.; Yuan, H.; Fu, X.; Sun, Q.; Peng, H.; Li, X.; Hu, C. Poincaré Differential Privacy for Hierarchy-Aware Graph Embedding. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, Vancouver, BC, Canada, 20–27 February 2024; Wooldridge, M.J., Dy, J.G., Natarajan, S., Eds.; AAAI Press: Washington, DC, USA, 2024; pp. 9160–9168. [Google Scholar] [CrossRef]
- Chen, W.; Cormode, G.; Bharadwaj, A.; Romov, P.; Özgür, A. Federated Experiment Design under Distributed Differential Privacy. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Palau de Congressos, Valencia, Spain, 2–4 May 2024; Dasgupta, S., Mandt, S., Li, Y., Eds.; PMLR: London, UK, 2024. Proceedings of Machine Learning Research. Volume 238, pp. 2458–2466. [Google Scholar]
- Torkamani, S.; Ebrahimi, J.B.; Sadeghi, P.; D’Oliveira, R.G.L.; Médard, M. Optimal Binary Differential Privacy via Graphs. IEEE J. Sel. Areas Inf. Theory 2024, 5, 162–174. [Google Scholar] [CrossRef]
- Zhang, M.; Wei, E.; Berry, R.; Huang, J. Age-Dependent Differential Privacy. IEEE Trans. Inf. Theory 2024, 70, 1300–1319. [Google Scholar] [CrossRef]
- Yang, C.; Qi, J.; Zhou, A. Wasserstein Differential Privacy. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, Vancouver, BC, Canada, 20–27 February 2024; Wooldridge, M.J., Dy, J.G., Natarajan, S., Eds.; AAAI Press: Washington, DC, USA, 2024; pp. 16299–16307. [Google Scholar] [CrossRef]
- Romijnders, R.; Louizos, C.; Asano, Y.M.; Welling, M. Protect Your Score: Contact-Tracing with Differential Privacy Guarantees. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, Vancouver, BC, Canada, 20–27 February 2024; Wooldridge, M.J., Dy, J.G., Natarajan, S., Eds.; AAAI Press: Washington, DC, USA, 2024; pp. 14829–14837. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Q.; Zhao, L.; Wang, C. Differential privacy in deep learning: Privacy and beyond. Future Gener. Comput. Syst. 2023, 148, 408–424. [Google Scholar] [CrossRef]
- Shen, Z.; Zhong, T.; Sun, H.; Qi, B. RRN: A differential private approach to preserve privacy in image classification. IET Image Process. 2023, 17, 2192–2203. [Google Scholar] [CrossRef]
- Gong, W.; Cao, L.; Zhu, Y.; Zuo, F.; He, X.; Zhou, H. Federated Inverse Reinforcement Learning for Smart ICUs With Differential Privacy. IEEE Internet Things J. 2023, 10, 19117–19124. [Google Scholar] [CrossRef]
- Chen, L.; Ding, X.; Zhou, P.; Jin, H. Distributed dynamic online learning with differential privacy via path-length measurement. Inf. Sci. 2023, 630, 135–157. [Google Scholar] [CrossRef]
- Fernandes, N.; McIver, A.; Palamidessi, C.; Ding, M. Universal optimality and robust utility bounds for metric differential privacy. J. Comput. Secur. 2023, 31, 539–580. [Google Scholar] [CrossRef]
- Wang, D.; Hu, L.; Zhang, H.; Gaboardi, M.; Xu, J. Generalized Linear Models in Non-interactive Local Differential Privacy with Public Data. J. Mach. Learn. Res. 2023, 24, 132:1–132:57. [Google Scholar]
- Hong, D.; Jung, W.; Shim, K. Collecting Geospatial Data Under Local Differential Privacy With Improving Frequency Estimation. IEEE Trans. Knowl. Data Eng. 2023, 35, 6739–6751. [Google Scholar] [CrossRef]
- Zhou, H.; Yang, G.; Xiang, Y.; Bai, Y.; Wang, W. A Lightweight Matrix Factorization for Recommendation With Local Differential Privacy in Big Data. IEEE Trans. Big Data 2023, 9, 160–173. [Google Scholar] [CrossRef]
- Lin, X.; Wu, J.; Li, J.; Sang, C.; Hu, S.; Deen, M.J. Heterogeneous Differential-Private Federated Learning: Trading Privacy for Utility Truthfully. IEEE Trans. Dependable Secur. Comput. 2023, 20, 5113–5129. [Google Scholar] [CrossRef]
- Chen, L.; Yue, D.; Ding, X.; Wang, Z.; Choo, K.R.; Jin, H. Differentially Private Deep Learning With Dynamic Privacy Budget Allocation and Adaptive Optimization. IEEE Trans. Inf. Forensics Secur. 2023, 18, 4422–4435. [Google Scholar] [CrossRef]
- Ling, J.; Zheng, J.; Chen, J. Efficient federated learning privacy preservation method with heterogeneous differential privacy. Comput. Secur. 2024, 139, 103715. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, C.; Li, S. Differential private knowledge trading in vehicular federated learning using contract theory. Knowl. Based Syst. 2024, 285, 111356. [Google Scholar] [CrossRef]
- Jiang, Z.; Wang, W.; Chen, R. Dordis: Efficient Federated Learning with Dropout-Resilient Differential Privacy. In Proceedings of the Nineteenth European Conference on Computer Systems, EuroSys 2024, Athens, Greece, 22–25 April 2024; ACM: New York, NY, USA, 2024; pp. 472–488. [Google Scholar] [CrossRef]
- Yang, Y.; Hui, B.; Yuan, H.; Gong, N.Z.; Cao, Y. PrivateFL: Accurate, Differentially Private Federated Learning via Personalized Data Transformation. In Proceedings of the 32nd USENIX Security Symposium, USENIX Security 2023, Anaheim, CA, USA, 9–11 August 2023; Calandrino, J.A., Troncoso, C., Eds.; USENIX Association: Berkeley, CA, USA, 2023; pp. 1595–1612. [Google Scholar]
- Wang, B.; Chen, Y.; Jiang, H.; Zhao, Z. PPeFL: Privacy-Preserving Edge Federated Learning With Local Differential Privacy. IEEE Internet Things J. 2023, 10, 15488–15500. [Google Scholar] [CrossRef]
- Zhou, J.; Wu, N.; Wang, Y.; Gu, S.; Cao, Z.; Dong, X.; Choo, K.R. A Differentially Private Federated Learning Model Against Poisoning Attacks in Edge Computing. IEEE Trans. Dependable Secur. Comput. 2023, 20, 1941–1958. [Google Scholar] [CrossRef]
- Song, W.; Chen, H.; Qiu, Z.; Luo, L. A Federated Learning Scheme Based on Lightweight Differential Privacy. In Proceedings of the IEEE International Conference on Big Data, BigData 2023, Sorrento, Italy, 15–18 December 2023; He, J., Palpanas, T., Hu, X., Cuzzocrea, A., Dou, D., Slezak, D., Wang, W., Gruca, A., Lin, J.C., Agrawal, R., Eds.; IEEE: Piscataway, NJ, USA, 2023; pp. 2356–2361. [Google Scholar] [CrossRef]
- Huang, R.; Zhang, H.; Melis, L.; Shen, M.; Hejazinia, M.; Yang, J. Federated Linear Contextual Bandits with User-level Differential Privacy. In Proceedings of the International Conference on Machine Learning, ICML 2023, Honolulu, HI, USA, 23–29 July 2023; Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J., Eds.; PMLR: London, UK, 2023. Proceedings of Machine Learning Research. Volume 202, pp. 14060–14095. [Google Scholar]
- Li, Z.; Wang, T.; Li, N. Differentially Private Vertical Federated Clustering. Proc. VLDB Endow. 2023, 16, 1277–1290. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, X.; Ma, J.; Jin, Q. LDP-Fed+: A robust and privacy-preserving federated learning based classification framework enabled by local differential privacy. Concurr. Comput. Pract. Exp. 2023, 35, e7429. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, T.; Chen, C.; Wang, Y. Federated Submodular Maximization With Differential Privacy. IEEE Internet Things J. 2024, 11, 1827–1839. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).