
Building an Analog Circuit Synapse for Deep Learning Neuromorphic Processing

 , ,
, ,  , and
, and 
Abstract
1. Introduction
2. Preliminaries
2.1. Spiking Neural Networks
2.2. RSTDP Learning Rule
3. Materials and Methods
3.1. Memristor Device

- Defining TE and BE and the tip of the filament (i.e., g) as electric nodes in Verilog-A. As each node in an electrical circuit possesses properties (voltage, currents, Magnetic Flow, and charge), the compiler knows how to compute the current from the tip of the filament to , by using .
- Providing alternative function implementations for exp() and sinh(), to limit the maximum slope, these can reach between the past and the next time step. Several simulator engines use dynamic time step selection for faster simulation periods and convergence issues. Of course, this limits the minimum time step a simulator can use, but avoids convergence issues or extended execution periods.
- Avoiding the usage of if–then–else statements to set the boundaries for the thickness of the filament. Instead, use a smooth, differentiable version of the unit step function.
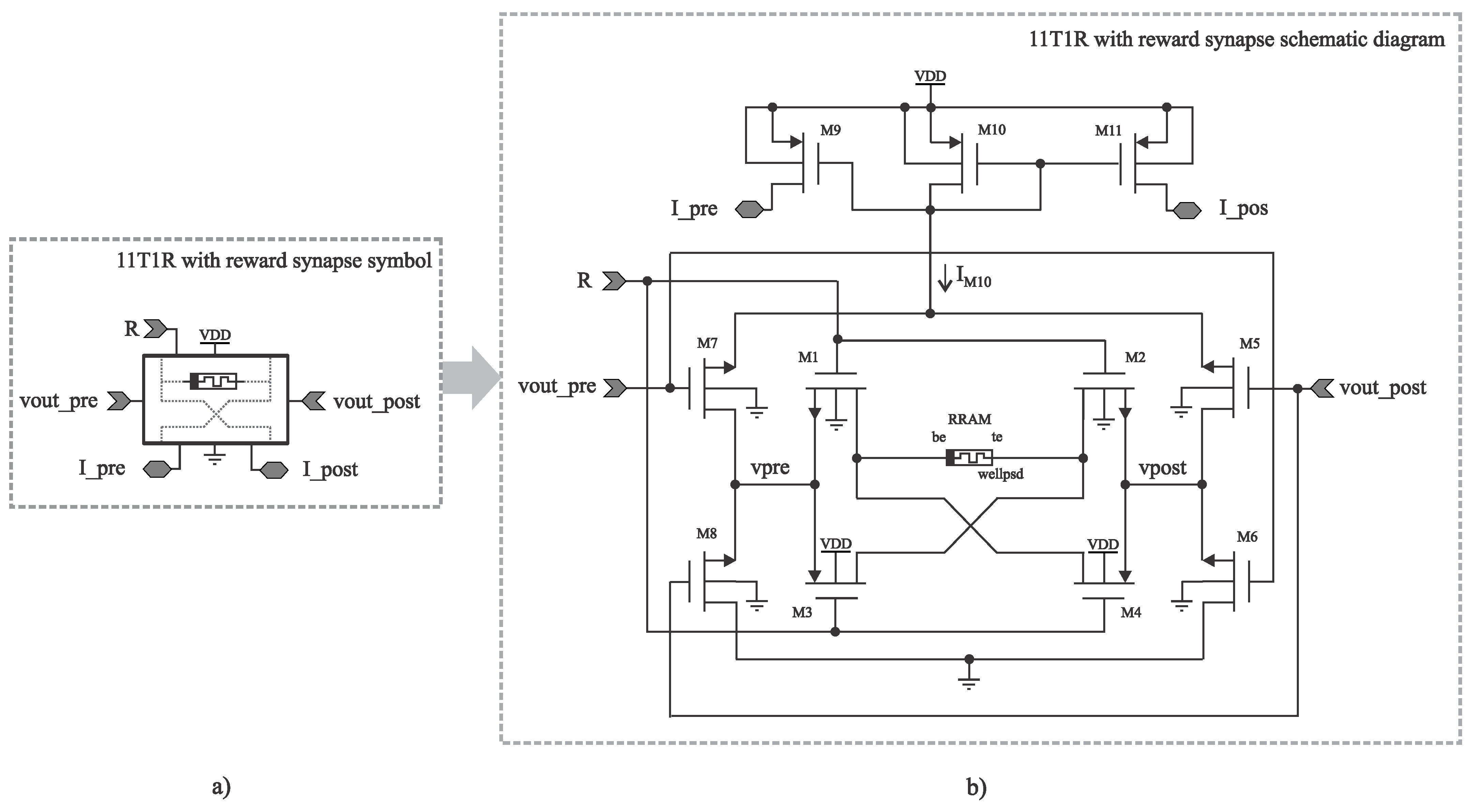
3.2. RSTDP Circuit Implementation
3.3. Adding Spike Reconformation and Current Decoupling to the Synapse
- V, when a presynaptic spike arrives and the reward signal is on. This routes the current from the BE to the TE in the memristor, yielding LTD;
- V. Due to the reward signal being negative, the same spike train that should produce LTD now produces LTP, as the current flows from the TE to the BE;
- V. For postsynaptic spikes with the reward signal on, the current flows from the TE to the BE, producing LTP;
- V. For postsynaptic spikes with the reward signal off, the current flows from the BE to the TE, producing LTD.
3.4. Neuron Circuit
- An external input current excitation arrives through (PMOS), enabled at the start. is set as a diode.
- charges for each incoming spike, increasing the voltage at node .
- A leaky current is flowing though at all times. If no further incoming electrical impulses are received, the neuron will lose all of its electrical charge. defines .
- When V, V, which is the threshold voltage for the NMOS device, enabling the charge to flow through and .
- also turns on, enabling current to flow and making the voltage at drop. At the same time, , turning off transistor , disabling the current integration for the neuron.
- As drops, rises, as works as an inverter. controls the current of the transistor , and conforming to the width of the spike. The node provides the final output spike, which can be fed to subsequent synapses.
- acts as a controlled diode, blocking any current from when the neuron is spiking.
4. Results
5. Discussion
5.1. Regarding the Synapse Circuitry
5.2. Future Work Towards Tailor-Made Neuromorphic Computing
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADC | analog-to-digital converter |
| BE | bottom electrode |
| BEOL | Back End Of the Line (manufacturing) |
| CMOS | Complementary Metal–Oxide Semiconductor |
| CPU | Central Processing Unit |
| DAC | digital-to-analog converter |
| DDPG | Deep Deterministic Policy Gradient |
| FPGA | Field Programmable Gate Array |
| GAN | Generative Adversarial Network |
| GDS | Graphic Database System |
| GPU | Graphic Processing Unit |
| HRS | high resistance state |
| IBM | International Business Machines |
| LIF | leaky integrate and fire |
| LRS | low resistance state |
| LTD | long-term depreciation |
| LTP | long-term potentiation |
| MIM | metal–insulator–metal |
| NMOS | Negative Metal–Oxide Semiconductor |
| PCELL | Parametric Cell |
| PMOS | Positive Metal–Oxide Semiconductor |
| RL | reinforcement learning |
| RRAM | Resistive Random Access Memory |
| RSTDP | Reward-Modulated spike-time-dependent plasticity |
| SNN | Spiking Neural Network |
| SPICE | Simulation Program with Integrated Circuit Emphasis |
| STDP | spike time-dependent plasticity |
| TAB | Trainable Analog Block |
| TCL | Tool Command Language |
| TD3 | Twin-Delayed Deep Deterministic Policy Gradient |
| TE | top electrode |
| VTEAM | Voltage Threshold Adaptive Memristor |
References
- Xu, R.; Wu, Y.; Qin, X.; Zhao, P. Population-coded Spiking Neural Network with Reinforcement Learning for Mapless Navigation. In Proceedings of the 2022 International Conference on Cyber-Physical Social Intelligence (ICCSI), Nanjing, China, 18–21 November 2022; pp. 518–523. [Google Scholar] [CrossRef]
- Kim, M.; Han, D.K.; Park, J.H.; Kim, J.S. Motion Planning of Robot Manipulators for a Smoother Path Using a Twin Delayed Deep Deterministic Policy Gradient with Hindsight Experience Replay. Appl. Sci. 2020, 10, 575. [Google Scholar] [CrossRef]
- Lee, M.H.; Moon, J. Deep reinforcement learning-based model-free path planning and collision avoidance for UAVs: A soft actor–critic with hindsight experience replay approach. ICT Express 2023, 9, 403–408. [Google Scholar] [CrossRef]
- Naya, K.; Kutsuzawa, K.; Owaki, D.; Hayashibe, M. Spiking Neural Network Discovers Energy-Efficient Hexapod Motion in Deep Reinforcement Learning. IEEE Access 2021, 9, 150345–150354. [Google Scholar] [CrossRef]
- Akl, M.; Sandamirskaya, Y.; Walter, F.; Knoll, A. Porting Deep Spiking Q-Networks to Neuromorphic Chip Loihi. In Proceedings of the International Conference on Neuromorphic Systems 2021, New York, NY, USA, 27–29 July 2021. ICONS 2021. [Google Scholar] [CrossRef]
- Matos, J.B.P.; de Lima Filho, E.B.; Bessa, I.; Manino, E.; Song, X.; Cordeiro, L.C. Counterexample Guided Neural Network Quantization Refinement. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2024, 43, 1121–1134. [Google Scholar] [CrossRef]
- Tang, G.; Kumar, N.; Yoo, R.; Michmizos, K. Deep Reinforcement Learning with Population-Coded Spiking Neural Network for Continuous Control. In Proceedings of the 2020 Conference on Robot Learning, Virtual, 16–18 November 2020; Proceedings of Machine Learning Research. Kober, J., Ramos, F., Tomlin, C., Eds.; PMLR: New York, NY, USA, 2021; Volume 155, pp. 2016–2029. [Google Scholar]
- DeWolf, T.; Patel, K.; Jaworski, P.; Leontie, R.; Hays, J.; Eliasmith, C. Neuromorphic control of a simulated 7-DOF arm using Loihi. Neuromorphic Comput. Eng. 2023, 3, 014007. [Google Scholar] [CrossRef]
- Gewaltig, M.O.; Diesmann, M. NEST (NEural Simulation Tool). Scholarpedia 2007, 2, 1430. [Google Scholar] [CrossRef]
- Eshraghian, J.K.; Ward, M.; Neftci, E.; Wang, X.; Lenz, G.; Dwivedi, G.; Bennamoun, M.; Jeong, D.S.; Lu, W.D. Training spiking neural networks using lessons from deep learning. Proc. IEEE 2023, 111, 1016–1054. [Google Scholar] [CrossRef]
- Bekolay, T.; Bergstra, J.; Hunsberger, E.; DeWolf, T.; Stewart, T.; Rasmussen, D.; Choo, X.; Voelker, A.; Eliasmith, C. Nengo: A Python tool for building large-scale functional brain models. Front. Neuroinform. 2014, 7, 48. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.Q.; Ghani, A.; Khurram, M. Population coding for neuromorphic hardware. Neurocomputing 2017, 239, 153–164. [Google Scholar] [CrossRef]
- Thakur, C.S.; Hamilton, T.J.; Wang, R.; Tapson, J.; van Schaik, A. A neuromorphic hardware framework based on population coding. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Hazan, A.; Tsur, E.E. Neuromorphic Spike Timing Dependent Plasticity with adaptive OZ Spiking Neurons. In Proceedings of the 2021 IEEE Biomedical Circuits and Systems Conference (BioCAS), Berlin, Germany, 7–9 October 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Yang, Z.; Han, Z.; Huang, Y.; Ye, T.T. 55nm CMOS Analog Circuit Implementation of LIF and STDP Functions for Low-Power SNNs. In Proceedings of the 2021 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), Boston, MA, USA, 26–28 July 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Shi, C.; Lu, J.; Wang, Y.; Li, P.; Tian, M. Exploiting Memristors for Neuromorphic Reinforcement Learning. In Proceedings of the 2021 IEEE 3rd International Conference on Artificial Intelligence Circuits and Systems (AICAS), Washington, DC, USA, 6–9 June 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Tian, M.; Lu, J.; Gao, H.; Wang, H.; Yu, J.; Shi, C. A Lightweight Spiking GAN Model for Memristor-centric Silicon Circuit with On-chip Reinforcement Adversarial Learning. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 27 May–1 June 2022; pp. 3388–3392. [Google Scholar] [CrossRef]
- Schöfmann, C.M.; Fasli, M.; Barros, M.T. Investigating Biologically Plausible Neural Networks for Reservoir Computing Solutions. IEEE Access 2024, 12, 50698–50709. [Google Scholar] [CrossRef]
- Juárez-Lora, A.; García-Sebastián, L.M.; Ponce-Ponce, V.H.; Rubio-Espino, E.; Molina-Lozano, H.; Sossa, H. Implementation of Kalman Filtering with Spiking Neural Networks. Sensors 2022, 22, 8845. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Sun, J.; Sun, Y.; Wang, C.; Hong, Q.; Du, S.; Zhang, J. Design of Artificial Neurons of Memristive Neuromorphic Networks Based on Biological Neural Dynamics and Structures. IEEE Trans. Circuits Syst. Regul. Pap. 2024, 71, 2320–2333. [Google Scholar] [CrossRef]
- Akl, M.; Ergene, D.; Walter, F.; Knoll, A. Toward robust and scalable deep spiking reinforcement learning. Front. Neurorobot. 2023, 16, 1075647. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, E.; Zheng, X.; Nelson, M.; Le, B.; Wong, H.S.; Mitra, S.; Wong, S.; Giordano, M.; Hodson, B.; Levy, A.; et al. High-Density Multiple Bits-per-Cell 1T4R RRAM Array with Gradual SET/RESET and its Effectiveness for Deep Learning. In Proceedings of the 2019 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 7–11 December 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Wang, T.; Roychowdhury, J. Well-Posed Models of Memristive Devices. arXiv 2016, arXiv:1605.04897. [Google Scholar]
- Jiang, Z.; Yu, S.; Wu, Y.; Engel, J.H.; Guan, X.; Wong, H.S.P. Verilog-A compact model for oxide-based resistive random access memory (RRAM). In Proceedings of the 2014 International Conference on Simulation of Semiconductor Processes and Devices (SISPAD), Yokohama, Japan, 9–11 September 2014; pp. 41–44. [Google Scholar] [CrossRef]
- Alshaya, A.; Han, Q.; Papavassiliou, C. RRAM, Device, Model and Memory. In Proceedings of the 2022 International Conference on Microelectronics (ICM), Casablanca, Morocco, 4–7 December 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Alshaya, A.; Malik, A.; Mifsud, A.; Papavassiliou, C. Comparison of 1T1R and 1C1R ReRAM Arrays. J. Phys. Conf. Ser. 2023, 2613, 012010. [Google Scholar] [CrossRef]
- Alshaya, A.; Han, Q.; Papavassiliou, C. Passive Selectorless Memristive Structure with One Capacitor-One Memristor. In Proceedings of the 2022 International Conference on Microelectronics (ICM), Casablanca, Morocco, 4–7 December 2022; pp. 121–124. [Google Scholar] [CrossRef]
- Skywater. User Guide 2014; SkyWater SKY130PDK 0.0.0-22-g72df095 Documentation. Available online: https://sky130-fd-pr-reram.readthedocs.io/en/latest/user_guide.html (accessed on 25 April 2024).
- Xyce(™) Parallel Electronic Simulator. [Computer Software]. 2013. Available online: https://helpx.adobe.com/acrobat/using/allow-or-block-links-internet.html (accessed on 25 April 2024).
- Juarez-Lora, A. GitHub—AlejandroJuarezLora. SNN-IPN, MICROSE-IPN. 2024. Available online: https://github.com/AlejandroJuarezLora/SNN_IPN (accessed on 25 April 2024).
- Kuthe, P.; Muller, M.; Schroter, M. VerilogAE: An Open Source Verilog-A Compiler for Compact Model Parameter Extraction. IEEE J. Electron Devices Soc. 2020, 8, 1416–1423. [Google Scholar] [CrossRef]
- Vogt, H. Ngspice, the Open Source Spice Circuit Simulator-Intro— ngspice.sourceforge.io. 2024. Available online: https://ngspice.sourceforge.io/index.html (accessed on 25 April 2024).
- Stoliar, P.; Akita, I.; Schneegans, O.; Hioki, M.; Rozenberg, M.J. A spiking neuron implemented in VLSI. J. Phys. Commun. 2022, 6, 021001. [Google Scholar] [CrossRef]
- Kvatinsky, S.; Ramadan, M.; Friedman, E.G.; Kolodny, A. VTEAM: A General Model for Voltage-Controlled Memristors. IEEE Trans. Circuits Syst. II Express Briefs 2015, 62, 786–790. [Google Scholar] [CrossRef]
- Ousterhout, J.; Hamachi, G.; Mayo, R.; Scott, W.; Taylor, G. Magic: A VLSI Layout System. In Proceedings of the 21st Design Automation Conference Proceedings, Albuquerque, NM, USA, 25–27 June 1984; pp. 152–159. Available online: https://ieeexplore.ieee.org/document/1585789 (accessed on 25 April 2024).
- Hazan, A.; Tsur, E.E. Neuromorphic Analog Implementation of Reservoir Computing for Machine Learning. In Proceedings of the 2022 29th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Glasgow, UK, 24–26 October 2022; pp. 1–4. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 4T1M Structure | 11T1M | Neuron | Test Bench |
|---|---|---|---|
| STDP Synapses | E. Tsur [14] | T. Tao [15] | 1M4T [17] | This Work |
|---|---|---|---|---|
| Number of transistors | 10 | 21 | 4 | 11 |
| PDK implementation | - | SMIC 55 nm | - | Skywater 130 nm |
| Die Area | - | 45 m × 35 m | - | 15 m × 14.3 m |
| Uses capacitors | 3 | 2 | No | No |
| Uses memristors | No | No | Yes | Yes |
| Is manufacturable | Yes 1 | Yes 1 | No 2 | Yes 3 |
| Is Volatile? | Yes | Yes | No | No |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Juarez-Lora, A.; Ponce-Ponce, V.H.; Sossa-Azuela, H.; Espinosa-Sosa, O.; Rubio-Espino, E. Building an Analog Circuit Synapse for Deep Learning Neuromorphic Processing. Mathematics 2024, 12, 2267. https://doi.org/10.3390/math12142267
Juarez-Lora A, Ponce-Ponce VH, Sossa-Azuela H, Espinosa-Sosa O, Rubio-Espino E. Building an Analog Circuit Synapse for Deep Learning Neuromorphic Processing. Mathematics. 2024; 12(14):2267. https://doi.org/10.3390/math12142267
Chicago/Turabian StyleJuarez-Lora, Alejandro, Victor H. Ponce-Ponce, Humberto Sossa-Azuela, Osvaldo Espinosa-Sosa, and Elsa Rubio-Espino. 2024. "Building an Analog Circuit Synapse for Deep Learning Neuromorphic Processing" Mathematics 12, no. 14: 2267. https://doi.org/10.3390/math12142267
APA StyleJuarez-Lora, A., Ponce-Ponce, V. H., Sossa-Azuela, H., Espinosa-Sosa, O., & Rubio-Espino, E. (2024). Building an Analog Circuit Synapse for Deep Learning Neuromorphic Processing. Mathematics, 12(14), 2267. https://doi.org/10.3390/math12142267