
A Self-Training-Based System for Die Defect Classification



Abstract
:1. Introduction
- Development of an SSL that integrates pseudo-labeling, noisy student techniques, curriculum learning, and the Taguchi method.
- Creation of an adaptive system capable of autonomously integrating information from unlabeled data, bypassing the need for extensive feature extraction.
- Application of the Taguchi method for optimizing modeling strategies will diminish the manual annotation burden and save valuable time that would be needed for extensive data labeling prior to modeling.
- This method is notable for its capacity to autonomously update the classifier’s parameters with minimal labeled data while integrating unlabeled data, thus boosting the classifier’s efficacy and adaptability. Empirical validation of the proposed method’s superiority over supervised learning approaches, particularly in scenarios with scarce labeled data.
2. Literature Review
2.1. Literature on Die Defect Inspection
- Golden template matching, also known as the image-to-image reference method, involves comparing a golden template with the inspected image to identify potential defects based on significant differences. Chou et al. employed this method to highlight and classify defects by measuring size, shape, position, and color [3]. Zhang et al. segmented pads and die boundaries to determine defect types based on location, object count, and area [4]. Alignment between the inspected image and the golden template is crucial for accurate subtraction. To address alignment issues, Guan et al. introduced a golden template self-generating method using repetitive wafer patterns [5]. Liu et al. employed discrete wavelet transform (DWT) to extract a standard image from defective IC chip images, highlighting defects through differences and mitigating brightness variations [6]. Li et al. proposed an automatic alignment method for wafer positioning based on the standard samples, effective for measuring multiple targets [7]. Despite avoiding calibration issues, these methods require extended focal lengths for structural pattern capture, making minute defect detection challenging at lower resolutions.
- Machine learning techniques adjust model weights to map die features to defect classes. Su et al. used average grayscale values from segmented die images to train models with backpropagation neural network (BPNN), radial basis function neural network (RBFNN), and learning vector quantization neural network (LVQNN) [8]. Chang et al. used k-means clustering to distinguish areas in LED dies and extracted geometric and texture features for defect identification with LVQNN [9]. Timm and Barth measured the discontinuity around the p-electrode of LED dies using radially encoded features and a one-class support vector machine (OSVM) for high accuracy [10]. Jizat et al. developed die defect classifiers, with logistic regression achieving 86.0% accuracy [11]. Machine learning methods require distinct feature sets for different die images, making the process time-consuming.
- Deep learning adjusts model weights to automatically learn the relationship between die features and defect classes. Cheon et al. used a 4-layer CNN for classifying five types of die defects and employed k-NN in a 3D autoencoder space for unknown defects [12]. Lin et al. designed a 6-layer CNN for LED die defect classification and used CAM for defect localization [13]. Chen et al. created a CNN with convolution, separable convolution, and bottleneck layers for four defect types, utilizing generating adversarial networks (GAN) for data augmentation [14]. Saqlain et al. introduced an ensemble classifier for wafer map defects, improving defect identification efficiency by dividing the wafer into regions and removing noise [15]. Chen et al. combined GAN and YOLOv3 for die defect detection, requiring fewer defective samples and annotations, which is beneficial for diverse die patterns [16].
2.2. Literature on Semi-Supervised Learning
- Deep generative. This approach employs deep neural networks for data generation, applicable to various types of data, including images, audio, and text. Unlike traditional generative models, deep generative models can capture the intricate details of data, such as textures or contours in image data, and progressively learn higher-level features like object shapes and poses, thereby generating more realistic and diverse data. Gordon et al. used a variational autoencoder (VAE) to generate images similar to the original ones by capturing their structural elements [18]. They applied this approach to two datasets: handwritten digit recognition and clothing recognition. Through experiments with different quantities of labeled data, they found that, in the clothing dataset, having only 500 labeled data points outperformed 3000 labeled ones, with an accuracy exceeding 4.36%. In conducting experiments with varying amounts of labeled data, the authors noted that more labeled data does not necessarily correlate with increased accuracy. Zhang et al. employed the VAE method for bearing defect identification across 10 classes [19]. In experiments using varying quantities of labeled data, with the smallest being 0.25% and the largest being 50% of the total data, an accuracy exceeding 7% compared to CNN and Autoencoder was achieved with just 2.5% labeled data, while only a 4% increase was noted with 50% labeled data. The authors highlighted that incorrect labeling could impair the performance of supervised learning, and adopting deep generative models to abstain from labeling uncertain data is an effective solution to this issue.
- Consistency regularization. This approach enhances the model’s generalization ability by ensuring similar outputs under different inputs. This method is particularly beneficial in semi-supervised learning scenarios, where a small portion of the data is labeled and the majority remains unlabeled. The model makes two predictions for the unlabeled data—initially for the original data and secondly for a slightly perturbed version of the same data points. Perturbations can be introduced through random rotations, scaling, or adding noise. Chen et al. introduced a method for the classification of hyperspectral images, utilizing deep representation feature learning (DRFL) and virtual adversarial training (VAT) [20]. DRFL aids in learning representative features from the data that enhance classification accuracy, while VAT regularizes the data to benefit the prediction distribution of the training data. This approach, advantageous in utilizing unlabeled data, not only boosts accuracy but also saves annotation time. With only 0.1% of the data labeled, accuracy rates of 90.45%, 93.31%, and 94.56% were achieved on three public datasets, respectively. Noroozi et al. presented VAT, evaluated across multiple validation tasks, enhancing generalization ability and mitigating overfitting through input perturbations using VAT on unlabeled data [21]. Experiments on three public datasets, with unlabeled data proportions of 0.01%, 0.16%, 37%, and all, consistently outperformed traditional supervised learning methods. However, performance was not proportionally better with fewer labeled data compared to more.
- Graph-based regularization. This method involves smoothing the graphical structural data in images to eliminate noise. It perceives an image as a graph composed of pixels and their interconnections and employs the graph’s smoothing property for regularization. These connections can be spatial relationships between pixels or similarities in attributes like brightness or color. Liao et al. proposed a transformer fault diagnosis method using a graph convolutional network (GCN) that employs a minimal amount of unlabeled data to fully represent the similarity between labeled and unlabeled data [22]. This is a significant improvement over traditional methods that rely on trained models to determine the relationships between data. The experimental results showed that the GCN outperformed CNN, BPNN, XGBoost, and SVM in terms of accuracy.
- Self-training. Self-training involves using a model to make predictions on unlabeled data, adopting the high-confidence predicted labels as true labels to expand the labeled dataset, thereby enhancing the model’s performance. The initial training is performed on labeled data; then, the model is used to make predictions, obtaining some predicted labels. Unlabeled data with predictions exceeding a certain confidence threshold are then added to the training dataset. The model is retrained, and this process is repeated until the model converges or meets the predetermined stopping criteria. Do et al. introduced a pseudo-labeling technique grounded in the challenges of insufficient labeled data and data imbalance [23]. This method leverages both a small amount of labeled data and a large volume of unlabeled data to address the imbalance. When applied to wafer maps, the experimental results demonstrated that this method enhanced classification accuracy to 77.26%, a 6.07% improvement over traditional methods, even with the use of relatively fewer labeled data. Zhuo et al. noted the advancement in technology that has led to the development of nanoscale dies within wafers [24]. These dies are not visible to the naked eye, and computer vision technology is utilized to identify minor defects. In scenarios of scarcely labeled data and class imbalance, the SSL pseudo-labeling method offers a resolution. With less than 10% of labeled data, this approach achieved results comparable to a fully labeled (100%) dataset and outperformed existing advanced methods, reaching an average precision of 93%. Kahng et al. advocated that pseudo-labeling is highly effective for wafer defect detection, yielding impressive results even with limited labeled data [25]. Different volumes of labeled data, namely, 1%, 5%, 10%, 25%, 50%, and 100%, resulted in classification accuracies of 71.8%, 82.3%, 84.5%, 86.4%, 88.6%, and 88.0%, respectively. Interestingly, fully labeled (100%) data did not significantly enhance classification accuracy, underscoring that appropriate data augmentation is pivotal in controlling model performance. Inappropriate data augmentation can inadvertently eliminate valuable information. Liu and Ye introduced the noisy student method for tile surface defect classification, a semi-supervised learning approach [26]. Compared to traditional supervised learning, this method utilizes unlabeled data to reduce annotation costs, and experimental results revealed a defect classification accuracy of 90.13%, even with just 4.4% of the data labeled. Wang et al. developed the curriculum labeling method for semi-supervised human keypoint localization problems [27]. This iterative pseudo-labeling technique assigns labels to unlabeled image data, alternating training between labeled data and pseudo-labeled data. The authors also introduced reinforced learning to automatically learn the optimal curriculum, further enhancing localization accuracy. Kim et al. developed an automatic defect classification system for wafer surfaces using semi-supervised learning with defect localization. Their approach significantly reduces labor by improving classification accuracy by 12.56% compared to supervised models. The system effectively utilizes a combination of a small set of labeled data and a larger pool of unlabeled images, enhancing the robustness and efficiency of defect management processes [28]. Qiao et al. developed DeepSEM-Net, leveraging a dual-branch CNN-transformer architecture for semiconductor defect analysis. Their method uses a self-training, semi-supervised system, reducing manual inspection. It achieved a classification accuracy of 97.25% and a segmentation IoU of 84.40%, demonstrating substantial effectiveness on diverse datasets [29].
3. Research Methods
3.1. Description of Hardware Structure
3.2. Hybrid Self-Training Algorithm

3.2.1. Sub-Function for “Generate Design Matrix”
3.2.2. Sub-Function for “Pre-Processing”
3.2.3. Sub-Function for “Add Noise”
3.2.4. Sub-Function for “Model Training”
3.2.5. Sub-Function for “Model Inference”
3.2.6. Sub-Function for “Pseudo-Label Filtering”
3.2.7. Sub-Function for “Determine Optimal Process”
3.3. Model Evaluation Metrics
4. Experimental Analysis and Results Presentation
4.1. Description of Image Dataset
- Providing image pairs. For each defective image, the manufacturer provides four paired images, as shown in Figure 3a. These include the original image, the corresponding golden template, the residual map, and the binarized defect mask. This study only utilizes the original images and defect masks for analysis.
- Significant background variations. As depicted in Figure 3b, the customization of die patterns for different clients results in a significant variety in the structure and coloration of the dies. Additionally, the AOI system captures only the defect areas, leading to a dramatic increase in the background variation of the images analyzed.
- Defects are not centered. Despite the AOI system’s attempt to center the defects during image capture, there are instances where the defects are not centered, as shown in Figure 3c.
- Large variations in defect sizes. Even within the same defect class, there is a considerable size variation. Small defects may be only 10 pixels in size, while larger ones can span half the width of an image, as illustrated in Figure 3d.
- Mismatch between defect masks and defects. The defect masks do not always align perfectly with the actual defect contours in the original images. Slight deviations in the AOI system’s template matching can lead to additional defect pixels appearing within the defect masks, as shown in Figure 3e.
4.2. Factor Levels and Sensitivity Analysis
- Use of screening: This factor pertains to the activation status of screening. The levels for this factor are defined according to the proposed research methodologies. Selecting “ON” indicates the employment of the curriculum learning technique, which involves selecting unlabeled data with a classification prediction probability above a specified threshold and progressively reducing this threshold to escalate the learning challenge. Selecting “OFF” denotes that the screening process is not implemented.
- Noise addition: This factor considers whether noise is added or not, and the level options are based on the proposed research methods. Selecting “ON” denotes the implementation of the noisy student technique, applying image augmentation, including rotation, horizontal flipping, and brightness adjustment, before the model training process. Choosing “OFF” indicates no use of image augmentation.
- Image pre-processing: This factor is intended to determine whether to enable image pre-processing. The level options are established based on the proposed research methods. Selecting “ON” signifies that a series of pre-processing procedures, including line segment removal from masks, brightness adjustment inside and outside the masks, and image cropping, are performed before feeding images into the model. Choosing “OFF” indicates that the model is fed with raw images without any pre-processing.
- Tr threshold: This is a screening threshold used to select unlabeled data with a classification prediction probability exceeding Tr to generate pseudo-labels. The level choices for this factor, set at 70%, 80%, and 90%, are based on [33]. If the value is set too low, it would easily assign pseudo-labels to any unlabeled data, reducing the reliability of these labels and affecting the quality of model training.
- Dropout rate: This is a regularization technique used to prevent model overfitting. The level choices for this factor, namely 0.5, 0.6, and 0.7, are based on [34]. The dropout mechanism randomly omits a portion of neurons during each training batch, forcing the model not to rely on specific neurons for predictions and thereby enhancing the model’s generalization capability.
- Number of epochs: This refers to the number of times the model sees the entire dataset of images during the training process. The level choices, set at 50, 100, and 300, are based on the default parameters of the balancing coefficient shown in Equation (6). The balancing coefficient allows the model to linearly increase the proportion of unlabeled images considered during the calculation of the loss function as the steps increase.
- Type of encoder: Encoders are used to extract crucial features from images. Different encoders have distinct structures and functions, and their adaptability varies for specific tasks. The level choices for this factor, namely, VGGNet, ResNet, and DenseNet, are based on [25]. Choosing the appropriate encoder helps in determining the best feature extraction network structure for specific tasks to achieve better classification accuracy.
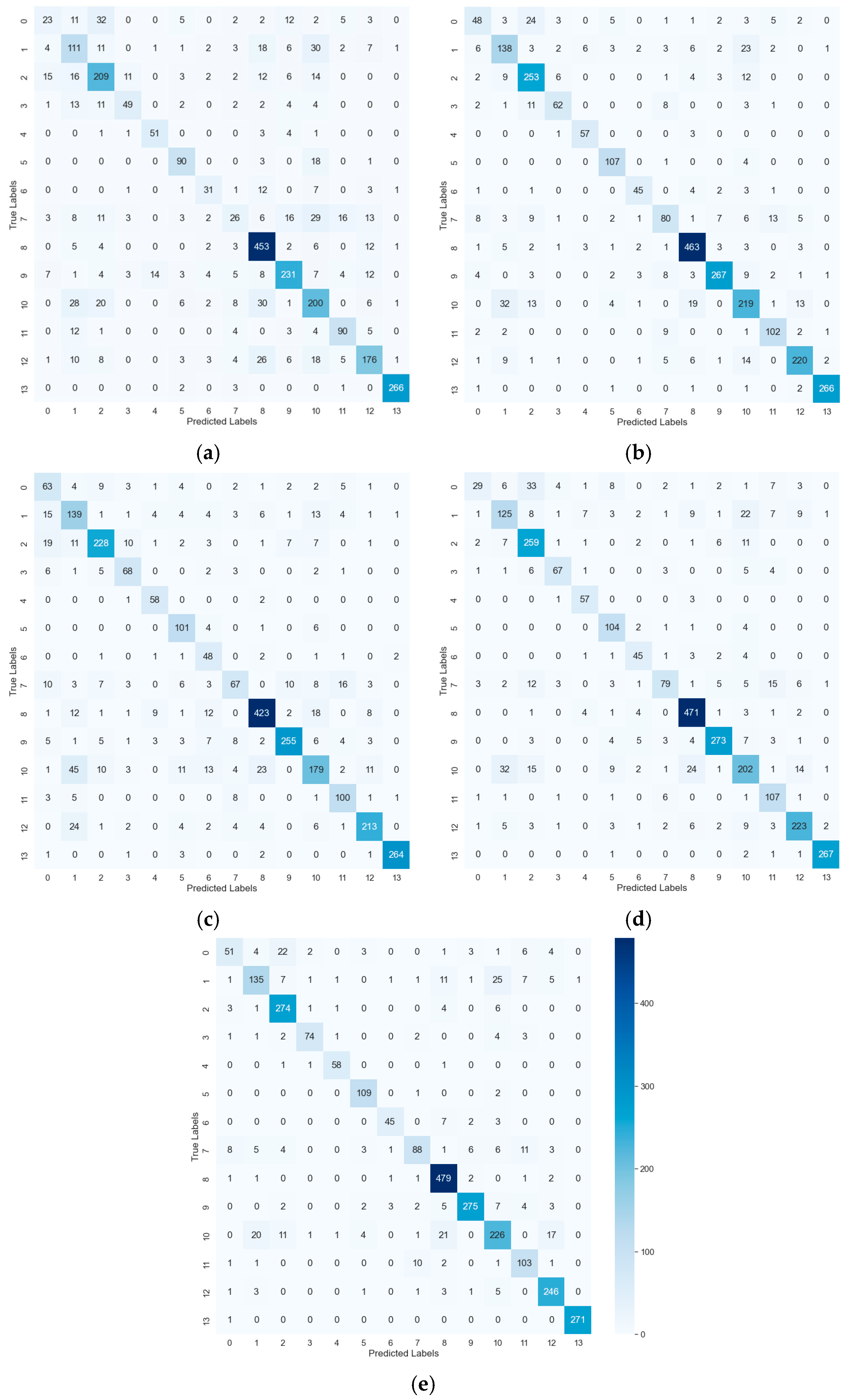
4.3. Comparison of Die Classification Results among Various Algorithms
5. Conclusions and Suggestions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
| # Pseudo Code of Hybrid Self-training algorithm # Given datasets labeled_data unlabeled_data # Set hyper-parameters ST = 0.2 alpha_f = 3 T1 = 50 T2 = 300 # Set factors and levels for Taguchi method factors = [‘use_of_screening’, ‘noise_addition’, ‘image_preprocessing’, ‘Tr_threshold’, ‘dropout_rate’, ‘number_of_epochs’, ‘type_of_encoder’] levels = { ‘use_of_screening’: [True, False], ‘noise_addition’: [True, False], ‘image_preprocessing’: [True, False], ‘Tr_threshold’: [0.7, 0.8, 0.9], ‘dropout_rate’: [0.5, 0.6, 0.7], ‘number_of_epochs’: [50, 100, 300], ‘type_of_encoder’: [‘VGGNet’, ‘ResNet’, ‘DenseNet’] } # Perform Taguchi experiment to determine optimal settings design_matrix = generate_design_matrix(factors, levels) metric_collector = [] for exp in design_matrix: # Train an initial CNN classifier if exp.image_preprocessing: labeled_data = preprocessing(labeled_data) if exp.noise_addition: labeled_data = add_noise(labeled_data) theta, loss, metrics = model_training(exp.type_of_encoder, theta, labeled_data, exp.dropout_rate, exp.number_of_epochs, alpha_f, T1, T2) # Pseudo-labeling unlabeled data if exp.image_preprocessing: unlabeled_data = preprocessing(unlabeled_data) pseudo_labeled_data = model_inference(theta, unlabeled_data) # Iterative training with pseudo-labeled data if exp.use_of_screening: Tr_threshold = exp.Tr_threshold while True: filtered_pseudo_labeled_data = pseudo_labeled_filtering(pseudo_labeled_data, Tr_threshold) if exp.noise_addition: filtered_pseudo_labeled_data = add_noise(filtered_pseudo_labeled_data) theta_new, loss_new, metrics = model_training(exp.type_of_encoder, theta, [labeled_data, filtered_pseudo_labeled_data], exp.dropout_rate, exp.number_of_epochs, alpha_f, T1, T2) Tr_threshold = Tr_threshold - ST # Check if Tr_threshold is less than 0 if Tr_threshold < 0: break # Check if the new loss value is lower if new_loss < loss: theta = theta_new loss = loss_new metric_collector = metrics_collector.append(metrics) else: Tr_threshold = exp.Tr_threshold # Increment time t = t + 1 optimal_setting = determine_optimal_process(design_matrix, metric_collector) |
References
- Mital, D.P.; Teoh, E.K. Computer based wafer inspection system. In Proceedings of the IECON’91: 1991 International Conference on Industrial Electronics, Control and Instrumentation, Kobe, Japan, 28 October 1991—1 November 1991; pp. 2497–2503. [Google Scholar]
- Tobin, K.W., Jr.; Karnowski, T.P.; Lakhani, F. Integrated applications of inspection data in the semiconductor manufacturing environment. In Metrology-Based Control for Micro-Manufacturing; International Society for Optics and Photonics: Bellingham, WA, USA, 2001; Volume 4275, pp. 31–40. [Google Scholar]
- Chou, P.B.; Rao, A.R.; Sturzenbecker, M.C.; Wu, F.Y.; Brecher, V.H. Automatic defect classification for semiconductor manufacturing. Mach. Vis. Appl. 1997, 9, 201–214. [Google Scholar] [CrossRef]
- Zhang, J.M.; Lin, R.M.; Wang, M.J.J. The development of an automatic post-sawing inspection system using computer vision techniques. Comput. Ind. 1999, 40, 51–60. [Google Scholar] [CrossRef]
- Guan, S.U.; Xie, P.; Li, H. A golden-block-based self-refining scheme for repetitive patterned wafer inspections. Mach. Vis. Appl. 2003, 13, 314–321. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, W.; Kuang, Q.; Cao, L.; Gao, B. Defect detection of IC wafer based on two-dimension wavelet transform. Microelectron. J. 2010, 41, 171–177. [Google Scholar] [CrossRef]
- Li, H.; von Kleist-Retzow, F.T.; Haenssler, O.C.; Fatikow, S.; Zhang, X. Multi-target tracking for automated RF on-wafer probing based on template matching. In Proceedings of the 2019 International Conference on Manipulation, Automation and Robotics at Small Scales (MARSS), Helsinki, Finland, 1–5 July 2019; pp. 1–6. [Google Scholar]
- Su, C.T.; Yang, T.; Ke, C.M. A neural-network approach for semiconductor wafer post-sawing inspection. IEEE Trans. Semicond. Manuf. 2002, 15, 260–266. [Google Scholar]
- Chang, C.Y.; Chang, C.H.; Li, C.H.; Jeng, M. Learning vector quantization neural networks for LED wafer defect inspection. In Proceedings of the Second International Conference on Innovative Computing, Information and Control (ICICIC 2007), Kumamoto, Japan, 5–7 September 2007; p. 229. [Google Scholar]
- Timm, F.; Barth, E. Novelty detection for the inspection of light-emitting diodes. Expert Syst. Appl. 2012, 39, 3413–3422. [Google Scholar] [CrossRef]
- Jizat, J.A.M.; Majeed, A.P.A.; Nasir, A.F.A.; Taha, Z.; Yuen, E. Evaluation of the machine learning classifier in wafer defects classification. ICT Express 2021, 7, 535–539. [Google Scholar] [CrossRef]
- Cheon, S.; Lee, H.; Kim, C.O.; Lee, S.H. Convolutional neural network for wafer surface defect classification and the detection of unknown defect class. IEEE Trans. Semicond. Manuf. 2019, 32, 163–170. [Google Scholar] [CrossRef]
- Lin, H.; Li, B.; Wang, X.; Shu, Y.; Niu, S. Automated defect inspection of LED chip using deep convolutional neural network. J. Intell. Manuf. 2019, 30, 2525–2534. [Google Scholar] [CrossRef]
- Chen, X.; Chen, J.; Han, X.; Zhao, C.; Zhang, D.; Zhu, K.; Su, Y. A light-weighted CNN model for wafer structural defect detection. IEEE Access 2020, 8, 24006–24018. [Google Scholar] [CrossRef]
- Saqlain, M.; Jargalsaikhan, B.; Lee, J.Y. A voting ensemble classifier for wafer map defect patterns identification in semiconductor manufacturing. IEEE Trans. Semicond. Manuf. 2019, 32, 171–182. [Google Scholar] [CrossRef]
- Chen, S.H.; Kang, C.H.; Perng, D.B. Detecting and measuring defects in wafer die using GAN and YOLOv3. Appl. Sci. 2020, 10, 8725. [Google Scholar] [CrossRef]
- Yang, X.; Song, Z.; King, I.; Xu, Z. A Survey on Deep Semi-supervised Learning. arXiv 2021, arXiv:2103.00550. [Google Scholar] [CrossRef]
- Gordon, J.; Hernández-Lobato, J.M. Combining deep generative and discriminative models for Bayesian semi-supervised learning. Pattern Recognit. 2020, 100, 107156. [Google Scholar] [CrossRef]
- Zhang, S.; Ye, F.; Wang, B.; Habetler, T.G. Semi-supervised bearing fault diagnosis and classification using variational autoencoder-based deep generative models. IEEE Sens. J. 2020, 21, 6476–6486. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Y.; Zhang, L.; Liu, M.; Plaza, A. DRFL-VAT: Deep representative feature learning with virtual adversarial training for semisupervised classification of hyperspectral image. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5532914. [Google Scholar] [CrossRef]
- Noroozi, V.; Bahaadini, S.; Zheng, L.; Xie, S.; Philip, S.Y. Virtual adversarial training for semi-supervised verification tasks. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Liao, W.; Yang, D.; Wang, Y.; Ren, X. Fault diagnosis of power transformers using graph convolutional network. CSEE J. Power Energy Syst. 2020, 7, 241–249. [Google Scholar]
- Do, J.; Kim, M. Wafer map defect pattern classification with progressive pseudo-labeling balancing. In Proceedings of the Korean Society of Broadcast Engineers Conference, Online, 27–28 November 2020; pp. 248–251. [Google Scholar]
- Zhuo, X.; Rahfeldt, W.; Zhang, X.; Doros, T.; Son, S.W. DAP-SDD: Distribution-aware pseudo labeling for small defect detection. Comput. Sci. Math. Forum 2022, 3, 5. [Google Scholar] [CrossRef]
- Kahng, H.; Kim, S.B. Self-supervised representation learning for wafer bin map defect pattern classification. IEEE Trans. Semicond. Manuf. 2020, 34, 74–86. [Google Scholar] [CrossRef]
- Liu, T.; Ye, W. A semi-supervised learning method for surface defect classification of magnetic tiles. Mach. Vis. Appl. 2022, 33, 35. [Google Scholar] [CrossRef]
- Wang, C.; Jin, S.; Guan, Y.; Liu, W.; Qian, C.; Luo, P.; Ouyang, W. Pseudo-labeled auto-curriculum learning for semi-supervised keypoint localization. arXiv 2022, arXiv:2201.08613. [Google Scholar]
- Kim, Y.; Lee, J.S.; Lee, J.H. Automatic defect classification using semi-supervised learning with defect localization. IEEE Trans. Semicond. Manuf. 2023, 36, 476–485. [Google Scholar] [CrossRef]
- Qiao, Y.; Mei, Z.; Luo, Y.; Chen, Y. DeepSEM-Net: Enhancing SEM defect analysis in semiconductor manufacturing with a dual-branch CNN-Transformer architecture. Comput. Ind. Eng. 2024, 193, 110301. [Google Scholar] [CrossRef]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Workshop on Challenges in Representation Learning (ICML); Springer: Berin, Germany, 2013; Volume 3, p. 896. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10687–10698. [Google Scholar]
- Cascante-Bonilla, P.; Tan, F.; Qi, Y.; Ordonez, V. Curriculum labeling: Revisiting pseudo-labeling for semi-supervised learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 19–21 May 2021; Volume 35, pp. 6912–6920. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C.A. Mixmatch: A holistic approach to semi-supervised learning. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prediction Actual | Class 1 | Class 2 | Class K | |
|---|---|---|---|---|
| Class 1 | C1,1 | C1,2 | C1,K | |
| Class 2 | C2,1 | C2,2 | C2,K | |
| Class K | CK,1 | CK,2 | CK,K |
| Factors | Levels |
|---|---|
| Use of screening | OFF/ON |
| Noise addition | OFF/ON |
| Image pre-processing | OFF/ON |
| Tr threshold | 70%/80%/90% |
| Dropout rate | 0.5/0.6/0.7 |
| Number of epochs | 50/100/300 |
| Type of encoder | VGGNet/ResNet/DenseNet |
| Labeled Data Proportions | Algorithms Metrics | DenseNet | Pseudo-Labeling | Noisy Student | Curriculum Learning | Hybrid Method |
|---|---|---|---|---|---|---|
| 50% | Accuracy (%) | 67.89 | 84.71 | 86.09 | 92.81 | 88.69 |
| Macro precision (%) | 68.33 | 87.50 | 86.33 | 92.83 | 88.83 | |
| Macro recall (%) | 67.52 | 85.50 | 86.17 | 92.67 | 88.83 | |
| Macro F1-score (%) | 67.92 | 86.49 | 86.25 | 92.75 | 88.83 | |
| 25% | Accuracy (%) | 59.63 | 79.36 | 84.10 | 88.83 | 84.10 |
| Macro precision (%) | 61.72 | 77.50 | 84.24 | 88.87 | 83.50 | |
| Macro recall (%) | 58.63 | 79.00 | 84.33 | 88.67 | 84.00 | |
| Macro F1-score (%) | 60.14 | 78.24 | 84.28 | 88.77 | 83.75 | |
| 10% | Accuracy (%) | 59.33 | 77.68 | 77.83 | 81.33 | 81.57 |
| Macro precision (%) | 61.52 | 79.17 | 77.67 | 81.47 | 81.67 | |
| Macro recall (%) | 58.50 | 77.67 | 78.67 | 81.17 | 80.83 | |
| Macro F1-score (%) | 60.00 | 78.41 | 78.17 | 81.32 | 81.25 |
| Labeled Data Proportions | Algorithms Metrics | DenseNet | Pseudo-Labeling | Noisy Student | Curriculum Learning | Hybrid Method |
|---|---|---|---|---|---|---|
| 50% | Accuracy (%) | 87.01 | 86.95 | 86.31 | 87.46 | 88.75 |
| Macro precision (%) | 83.50 | 85.36 | 82.57 | 85.43 | 87.14 | |
| Macro recall (%) | 82.43 | 84.50 | 85.29 | 85.36 | 86.14 | |
| Macro F1-score (%) | 82.96 | 84.93 | 83.91 | 85.40 | 86.46 | |
| 25% | Accuracy (%) | 79.94 | 84.15 | 83.69 | 85.41 | 86.31 |
| Macro precision (%) | 77.14 | 81.79 | 79.57 | 84.14 | 85.41 | |
| Macro recall (%) | 77.07 | 81.14 | 82.07 | 82.29 | 83.29 | |
| Macro F1-score (%) | 77.11 | 81.46 | 80.80 | 83.21 | 84.24 | |
| 10% | Accuracy (%) | 74.91 | 81.24 | 79.27 | 80.21 | 83.61 |
| Macro precision (%) | 68.21 | 79.64 | 74.71 | 80.21 | 81.21 | |
| Macro recall (%) | 68.79 | 77.71 | 78.79 | 79.14 | 80.50 | |
| Macro F1-score (%) | 68.50 | 78.66 | 76.70 | 79.67 | 80.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, P.-H.; Lin, S.-Z.; Chang, Y.-T.; Lai, Y.-W.; Chen, S.-H. A Self-Training-Based System for Die Defect Classification. Mathematics 2024, 12, 2415. https://doi.org/10.3390/math12152415
Wu P-H, Lin S-Z, Chang Y-T, Lai Y-W, Chen S-H. A Self-Training-Based System for Die Defect Classification. Mathematics. 2024; 12(15):2415. https://doi.org/10.3390/math12152415
Chicago/Turabian StyleWu, Ping-Hung, Siou-Zih Lin, Yuan-Teng Chang, Yu-Wei Lai, and Ssu-Han Chen. 2024. "A Self-Training-Based System for Die Defect Classification" Mathematics 12, no. 15: 2415. https://doi.org/10.3390/math12152415