Abstract
Hypertensive disorders in pregnancy, which include preeclampsia, eclampsia, and chronic hypertension, complicate approximately 10% of all pregnancies in the world, constituting one of the most serious causes of mortality and morbidity in gestation. To help predict the occurrence of hypertensive disorders, a study based on algorithms that help model this health problem using mathematical tools is proposed. This study proposes a fuzzy c-means (FCM) model based on the Takagi–Sugeno (T-S) type of fuzzy rule to predict hypertensive disorders in pregnancy. To test different modeling methodologies, cross-validation comparisons were made between random forest, decision tree, support vector machine, and T-S and FCM methods, which achieved 80.00%, 66.25%, 70.00%, and 90.00%, respectively. The evaluation consisted of calculating the true positive rate (TPR) over the true negative rate (TNR), with equal error rate (EER) curves achieving a percentage of 20%. The learning dataset consisted of a total of 371 pregnant women, of which 13.2% were diagnosed with a condition related to gestational hypertension. The dataset for this study was obtained from the Secretaría de Salud del Estado de Hidalgo (SSEH), México. A random sub-sampling technique was used to adjust the class distribution of the data set, and to eliminate the problem of unbalanced classes. The models were trained using a total of 98 samples. The modeling results indicate that the T-S and FCM method has a higher predictive ability than the other three models in this research.
MSC:
68T20
1. Introduction
The processes of pregnancy and childbirth affect the lives of millions of women and families around the world every year. While many pregnancies go smoothly, there are risks to both the mother and baby throughout the stages of pregnancy. Globally, especially in developing and underdeveloped countries, maternal death is a serious public health problem.
The International Society for the Study of Hypertension in Pregnancy defines PE as hypertension of at least 140/90 mmHg on two separate occasions for ≥4 h, accompanied by significant proteinuria of at least 0.3 grams in urine over a 24-hour collection period after the 20th week of gestation in a previously normotensive woman [1,2].
Recently, the use of artificial intelligence techniques and machine-learning algorithms has made it possible to analyze large amounts of information, identifying clear risk factors and patterns from the analysis of large volumes of clinical, genetic, and environmental data that could go unnoticed by doctors using traditional methods. This allows for the monitoring of these indicators, anticipating the development of preeclampsia before evident clinical symptoms appear, enabling early intervention.
With the models obtained from ML, recommendations and treatments can be given based on patient-specific data, enriching medical practice, aiding in clinical decision-making, and reducing workloads. In this way, by automating data analysis and risk detection, human errors and omissions that can occur in clinical practice are reduced.
The advantage of AI algorithms is the emergence of processing platforms in parallel or through cloud systems, which accelerates diagnosis and the start of treatment. Similarly, cloud processing allows these technologies to be implemented in mobile applications and online platforms, facilitating access to monitoring and diagnosis for women in remote areas or with limited access to health services.
Ref. [3] worked on predicting health risks during pregnancy using 11 machine-learning models. Their results show that LightGBM and CatBoost exhibit the highest accuracy of 88%. Similarly, regarding maternal health risk prediction, Ref. [4] focused on the creation of an AI-based system to predict maternal health risks. Their experimental results indicate that SVM with ensemble characteristics achieves an accuracy of 98%.
In [5], the authors proposed an effective approach to reduce the maternal and fetal mortality rate by analyzing pregnancy-related data in a binary CART decision tree. The model yields a good accuracy of 88%. Ref. [6] implemented models with various feature selection techniques. The results indicate that with an accuracy score of 94%, the XGBoost model outperformed other learning models. In [7], a relationship between important variables and the prevalence of cesarean section procedures was demonstrated.
An improved electrocardiogram (ECG) beats classification system based on an FCM clustering algorithm was proposed by [8]. To diagnose the types of arrhythmia present in ECG records, several neural network schemes were applied by [9] to a large database of pregnant women, aiming to generate a predictor to estimate the risk of PE at an early stage. The database was composed of 6838 cases of pregnant women in the UK and was provided by the Harris Birthright Research Center for Fetal Medicine in London.
There are several criteria used to detect PE, among which are blood pressure, proteinuria, thrombocytopenia, renal insufficiency, and impaired liver function [10]. However, in the present paper, relevant characteristics in the development of hypertensive disorders in pregnancy were found using statistical and pattern recognition techniques. The features used to create a learning model were obtained from the clinical history of patients in the state of Hidalgo, México. From a total of 85 features, 8 features were selected to train our fuzzy rule model. A summary of different algorithms and their authors is presented in Table 1.

Table 1.
Summary of algorithms used to predict preeclampsia.
Various solutions have been proposed for predicting preeclampsia, including artificial intelligence; some techniques comprise classification approaches, such as Bayesian networks [11], random forests [12] with a receiver operating characteristic (ROC) curve area of 0.813, or fuzzy logic [13]. Fuzzy logic is a field of artificial intelligence used to analyze real-world information on a scale between false and true [14].
Furthermore, in [15], the authors proposed a successful model of a clinical problem using a temporal Bayesian network model to predict PE. In [13], a tool implemented as a wearable device that applied a fuzzy linguistic approach was proposed. To develop this tool, the authors used a fuzzy linguistic methodology to analyze a set of real data on pregnant women at a high risk of PE from a health center. They presented a wearable application prototype that applied the rules inferred from the fuzzy decision tree to detect PE in women at risk.
A model was constructed by [16] for the classification of women with normal, hypertensive, and preeclamptic pregnancies at different ages, using maternal heart rate variability (HRV) indexes. They applied the artificial neural network for the classification problem.
2. Fuzzy C-Means (FCM) Algorithm
FCM is a clustering technique that assigns membership levels to data points, which makes it suitable for problems with inherent uncertainty. In this paper, we combine it with Takagi–Sugeno fuzzy rules, which are used to model complex systems with imprecise inputs. Table 2 highlights the characteristics and performance of each model in the context of predicting hypertensive disorders in pregnancy.
Table 2.
Models in the context of predicting hypertensive disorders in pregnancy.
2.1. Business and Data Understanding
The Ministry of Health of the State of Hidalgo, in the Pachuca jurisdiction I zone, provided a dataset detailing 371 pregnant women registered at the Jesús del Rosal health institution. The information includes each patient’s background, such as their age, national vaccination record, history of sexually transmitted diseases, and parents’ history of chronic diseases, among other socioeconomic data.
The data obtained by the health center for a pregnant patient are shown in Table 3, and this information remains part of the descriptive characteristics.
Table 3.
Obstetrics data acquired during a visit.
The clinical history has a total of 91 descriptive characteristics, of which Query number was discarded since it is not necessary for the analysis. The date of last menstruation and possible date of delivery are used to generate a field called Childbirth, which represents gestational age.
Table 4 contains all possible diagnoses for a woman in the process of gestation, and that table was reduced to a single characteristic. The diagnoses directly related to gestational hypertension [10] (i.e., chronic arterial hypertension, induced hypertension in pregnancy, PE, eclampsia, and edemas) were grouped to create class 1 or the diseased class; otherwise, patients were classified as belonging to class 0 or the safe class, i.e., it is a supervised learning problem.
Table 4.
Possible diagnoses given to a pregnant woman.
2.2. Data Pre-Processing
This study proposes a sequence of methods for dimensionality reduction, to obtain the smallest number of features, to improve the prediction of the risk of preeclampsia in pregnant women. Table 5 shows the results of an exhaustive analysis in the search to find linear and non-linear relationships.
Table 5.
Proposed order of techniques used to reduce dimensions.
First, the glucose, fetal heart rate, and uterine height fields contained more than 80% missing information. Also, proteinuria, despite being a relevant variable [10], was discarded since only 10% of the women had a record of proteinuria. As a general rule of thumb, only features that are missing in excess of 60% of their values should be considered for complete removal [17]. Furthermore, the height and current weight fields were used to create the body mass index field. Therefore, our analysis started with 85 descriptive variables.
2.2.1. Outliers
Data with erroneous information are transformed using Equation (1), as follows:
where represents the value of the dataset in its ith position. is the threshold given by the first quartile minus 1.5 times the interquartile range. is the threshold given by the third quartile plus 1.5 times the interquartile range [17].
2.2.2. Data Invariants
As mentioned in [18], variables that do represent the phenomenon of interest (preeclampsia) were selected using Equation (2), as follows:
where is the correlation coefficient of the linear relationship between the variables x and y. It is well known that if the coefficient approaches 1, there is a strong linear relationship. The means of the values of the variables x and y are represented by and , respectively.
2.2.3. Multicollinearity
Multicollinearity, in essence, refers to characteristics with redundant information [19]. The magnitude of collinearity is analyzed based on its size. It is usually possible to use a value of and, in combination with the correlation matrix, eliminate variables with redundant information. This is the case for the variables Pulse and Heart Rate, the steps for which are described below.
- First, an ordinary regression of least squares is performed, with as a function of all other explanatory variables, using Equation (4), as follows:where is constant and e represents a deviation from observation (error).
- Subsequently, the VIF for is calculated using Equation (4), as follows:where is the coefficient of determination of the regression equation in the first step.
From the invariant data and following the multicollinearity analysis, 19 features were discarded, of which 15 features were constant and four had multicollinearity problems, mainly due to immunization records, since in México, most of the population must be administered vaccines that are considered indispensable. Following this, the analysis described below is performed for the 66 remaining characteristics.
2.2.4. Factor Analysis and Principal Component Analysis (PCA)
This technique extracts the maximum common variance from all variables and gathers them into a common score.
Each factor provides information useful for effective model prediction. In this work, we found that 36 factors described in Table 6 support 95% of all characteristics. Of the 36 factors, the least significant value of each one was eliminated. Once the least significant characteristic of each factor was removed, the rest was subtracted [20], after which we obtained a total of 39 remaining characteristics to continue processing data.
Table 6.
PCA explained variance ratio (descending order).
2.2.5. Feature Importance and Random Forest
The random forest technique was proposed in [21]; it is a frequently used supervised learning technique known for its versatility and power when making classifications or regressions.
One of the most important features of the RF technique is its variable importance output. Variable importance measures the degree of association between a given variable and the classification result [22,23,24].
Gini impurity is a measure of the class label distribution in a node. When j is the number of children at node t, N is the number of samples. To estimate the variable importance of variable j, the out-of-bag (OOB) samples are passed down the tree, and the prediction accuracy is recorded. Then, the values for variable j are permuted in the OOB samples, and the accuracy is measured again. These calculations are carried out tree by tree as the RF is constructed. The average decrease in accuracy of these permutations is then averaged over all the trees and is used to measure the importance of variable j.
Let be the OOB samples for the tree (Equation (5)).
denotes the number of trees in the forest and is the predicted class for instance i before the permutation in tree t, and is the predicted class for instance i after the permutation. The variable importance for variable j in tree t is given by Equation (6), as follows:
The raw importance value for variable j is then averaged over all trees in the RF using Equation (7):
In the process of finding the features’ importance, we obtained 16 features that represent 95 % of the whole dataset, as shown in Table 7, in which the degree of association between a given variable and the classification result is shown. The measure based on which the optimal condition is chosen is called impurity, typically either Gini impurity or information gain/entropy.
Table 7.
Random forest feature importance, with 16 representative variables obtained.
2.2.6. Clustering Variables
A cluster analysis is used to group variables with similarity. By forming clusters, the number of characteristics for analysis is reduced. The similarity between two conglomerates i and j is calculated as shown in Equation (8):
where is the similarity between the conglomerate i and j. The distance between the i and j conglomerate is given by . Furthermore, is the maximum value of the original distance, with entry for the distance between i and j.
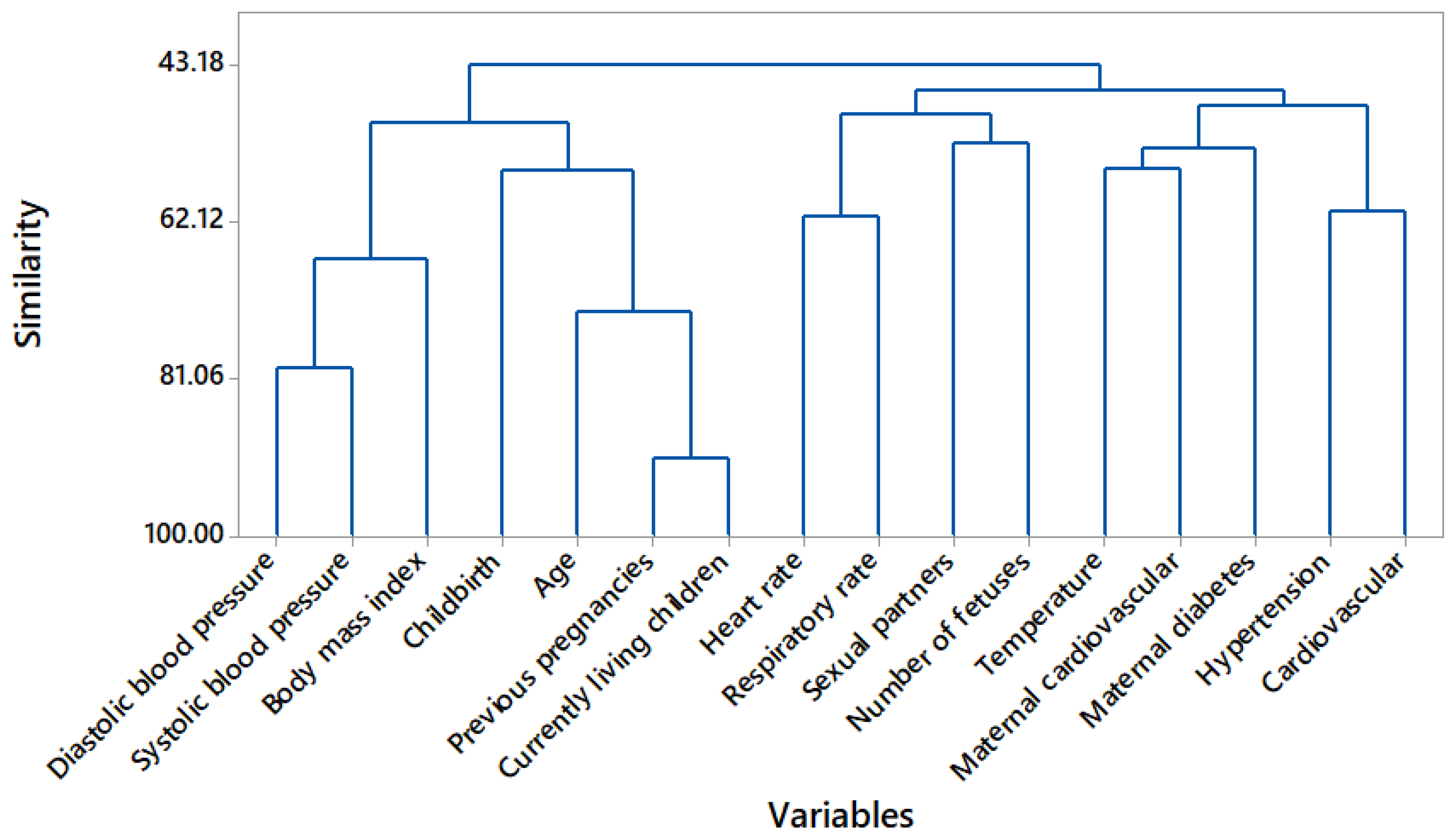
In Figure 1, a dendrogram is used to graphically observe the 16 features and their resemblance. Based on Figure 1, the state of the art and a description of each cluster is provided in Table 8. Previous and current live gestation are considered a single feature [25], as are heart rate and respiratory rate [26] and maternal cardiovascular and maternal diabetes [27]; thus, 13 characteristics are subtracted.
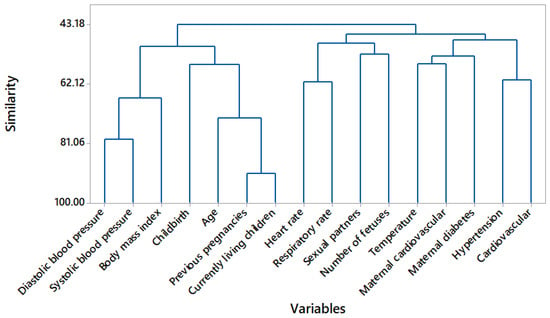
Figure 1.
Dendrogram variable clustering.
Table 8.
Amalgamation steps: description of each cluster.
2.2.7. Recursive Feature Elimination
The recursive feature elimination (RFE) method works by recursively removing attributes and building a model from the remaining attributes. It uses precision metrics to rank the feature according to its importance.
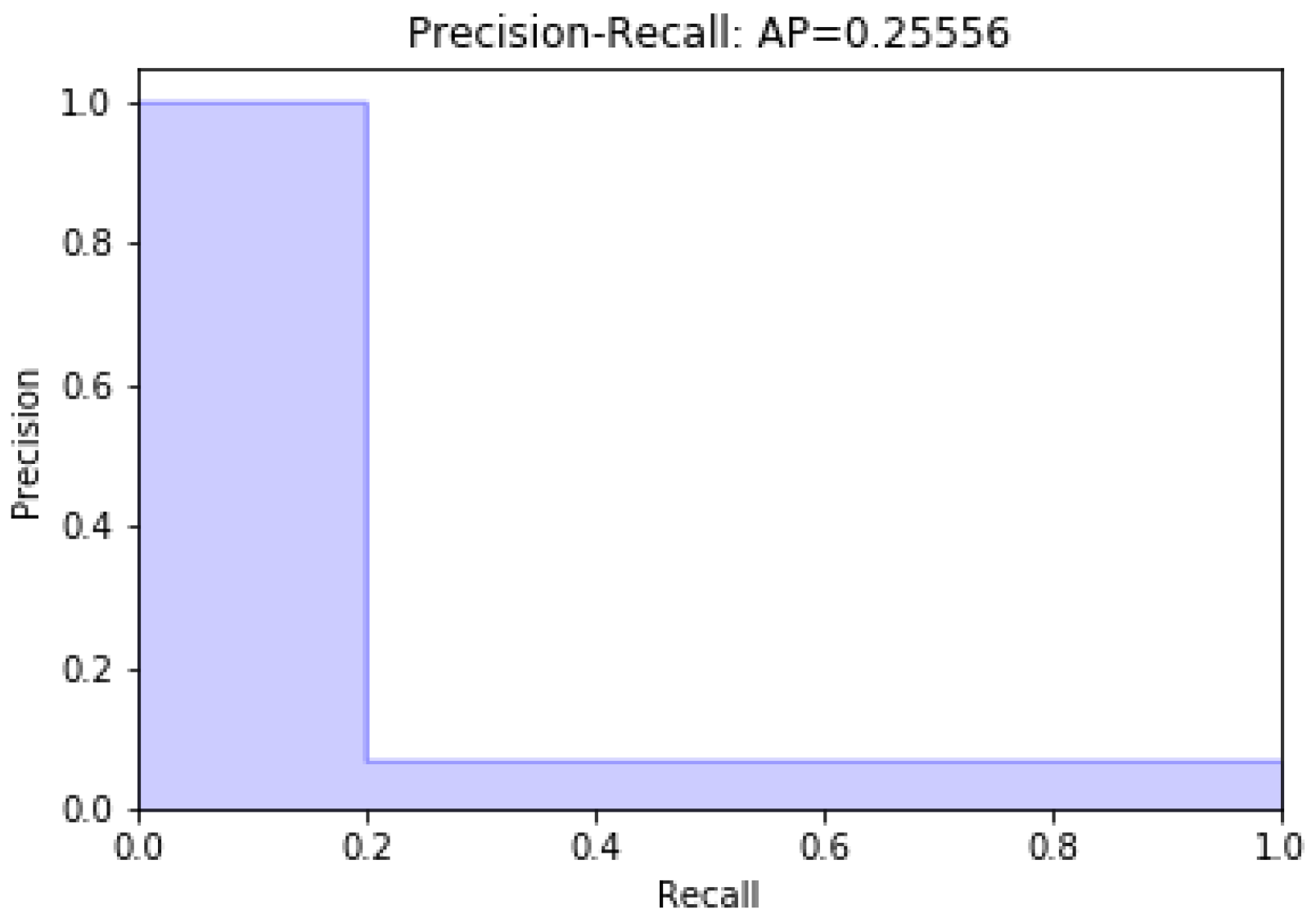
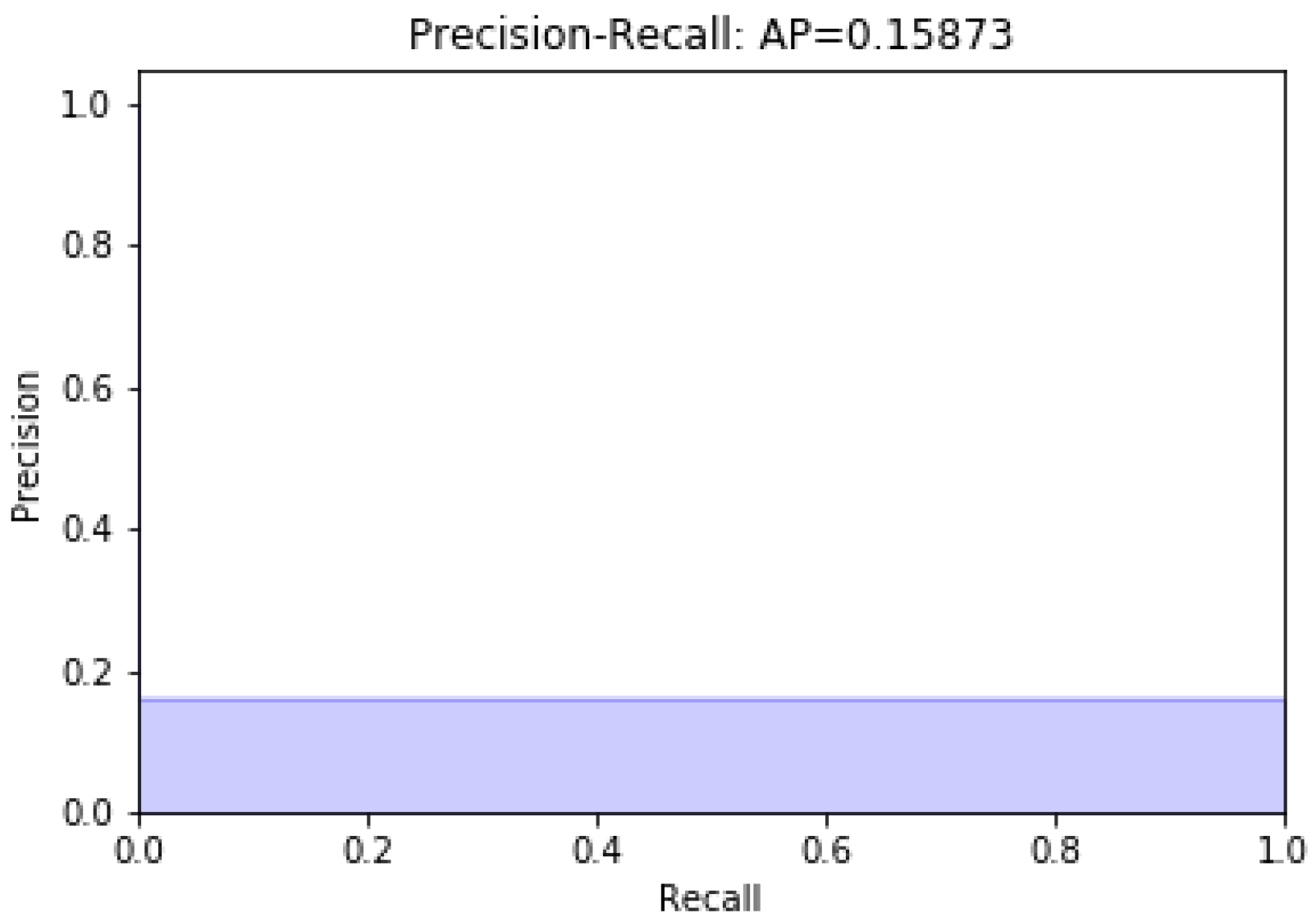
Data modeling with the remaining 13 characteristics was carried out; later, a variable was eliminated. Figure 2 and Figure 3 present unbalanced data modeling with SVM through precision–recall curves and the evaluation of all the features of the dataset, including discrepancy and when a variable is removed, respectively. The model’s performance was evaluated using recovery precision curves (precision–recall curves) through support vector machines for unbalanced classes on the advice of [28,29].
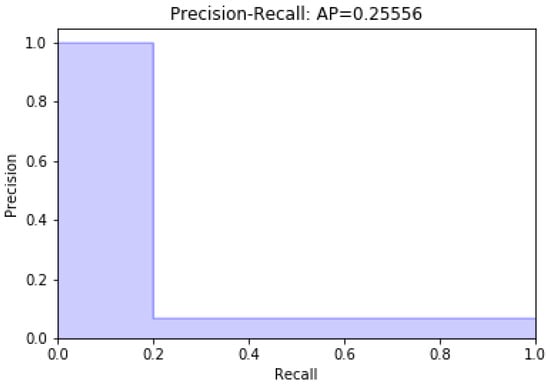
Figure 2.
Modeling with the full dataset.
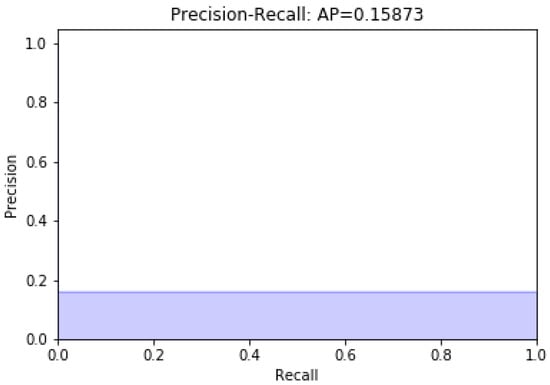
Figure 3.
Modeling without diastolic pressure.
Table 9 summarizes the characteristics considered important following the RFE analysis, which are marked with True, and finally provides a total of eight features to be used when modeling the data.
Table 9.
Recursive feature elimination and significant variables in the RFE analysis.
2.3. Fuzzy Modeling
A rule-based model of the Takagi–Sugeno fuzzy type [30,31] is considered. It consists of a set of fuzzy rules, each describing a local input–output relationship in a linear form, as shown in Equation (9):
where is the ith rule, and i goes from 1 to K, where K denotes the number of rules in the rule base. Two rules are established in this paper: when a pregnant woman is prone to some risk of preeclampsia and when she is not. is the vector of the input variables, is the linear parameter vector [31], are the centroids or prototypes, and is the rule output, where is the diastolic blood pressure, is the heart rate, is the systolic blood pressure, is age, is maternal diabetes, is the number of fetuses, is hypertension, and is the body mass index.
The aggregated output of the model, , , is calculated by taking the weighted average of the rule consequents; see Equations (10) and (11) as follows:
where is the degree of activation of the ith rule, which is shown in Equation (12) as follows:
is the membership function of the fuzzy set in the antecedent of .
Table 10 defines the parameters for Rule 1 and Rule 2, identified using least squares weighted by the values of the degrees of activation of each fuzzy rule.
Table 10.
Consequent parameters for Rules 1 and 2.
A comparative study was carried out, examining the following four techniques: support vector machines, decision trees, random forests, and the T-S and FCM algorithms. There are two main ways to define the premises of fuzzy rules: one uses fuzzy grid partitioning with Gaussian, triangular, and trapezoid membership functions, and the other uses fuzzy clustering techniques, which were used in this work. Because it is an optimal algorithm in the search for multivariable patterns, which are useful for defining the premises of fuzzy rules, the T-S and FCM algorithm is briefly described [32]. The algorithm proposed here to predict preeclampsia in pregnant women considers two patterns: one for women at risk of suffering from preeclampsia and another for those not at risk of suffering from preeclampsia. Therefore, the model learned using the characteristics of women who did and did not suffer from preeclampsia. Only two cluster centers have the fuzzy model, with eight coordinates and eight consequent linear parameters.
FCM is based on the optimization of the target function c-means, as in Equation (13) as follows:
where is the data that must be classified
It is a fuzzy Z-partition matrix,
The vector of centroids or prototypes is determined. It is la norma Euclidiana and is determined by the choice of matrix using Equation (16), as follows:
Once the centers and fuzzy partition matrix have been obtained, defuzzification is carried out [33] to predict the new data, using Equations (18) and (19), as follows:
Equation (19) yields a value for the centroids as the means of the data belonging to a specific class, where weights are the membership functions [31,32].
The fuzzy sets in the antecedent of the rules are obtained from the partition matrix U, whose th element is the membership degree of the data object in cluster i. The ith row of U contains a pointwise definition of a multidimensional fuzzy set. One-dimensional fuzzy sets are obtained from the multidimensional fuzzy sets by projections onto the space of the input variables as in Equation (20) [31]:
where is the pointwise projection operator [34]. The pointwise defined fuzzy sets are then approximated using suitable parametric functions to compute for any value of .
The vector consequents of each T-S fuzzy rule are given using the least squares algorithm weighted by the degree of the firing of the fuzzy rule. The firing degree matrix is defined, with the main diagonal of the elements being .
The solution for the resulting least squares problem, , where is the approximation error, is shown in Equation (21), for every fuzzy rule with . In the learning process, the vector , conditioned with ones for PE cases and zeros for non-PE cases, is contained in the feature matrix .
3. Results
The values established by default were , , , and , where i is the number of rules to , is the maximum number or iterations, is the minimal improvement, and fuzzy m is the exponent. For the learning of the two fuzzy rule patterns, the Matlab® function was used, obtaining the premises of the rules results in the and the fuzzy partition matrix, as shown in Table 11.
Table 11.
Centers obtained in FCM for each variable.
Table 12 shows the statistical measures for each of the features of the resulting dataset. This allows these features to be compared with the centers found in Table 11.
Table 12.
Statistical measures for each feature.
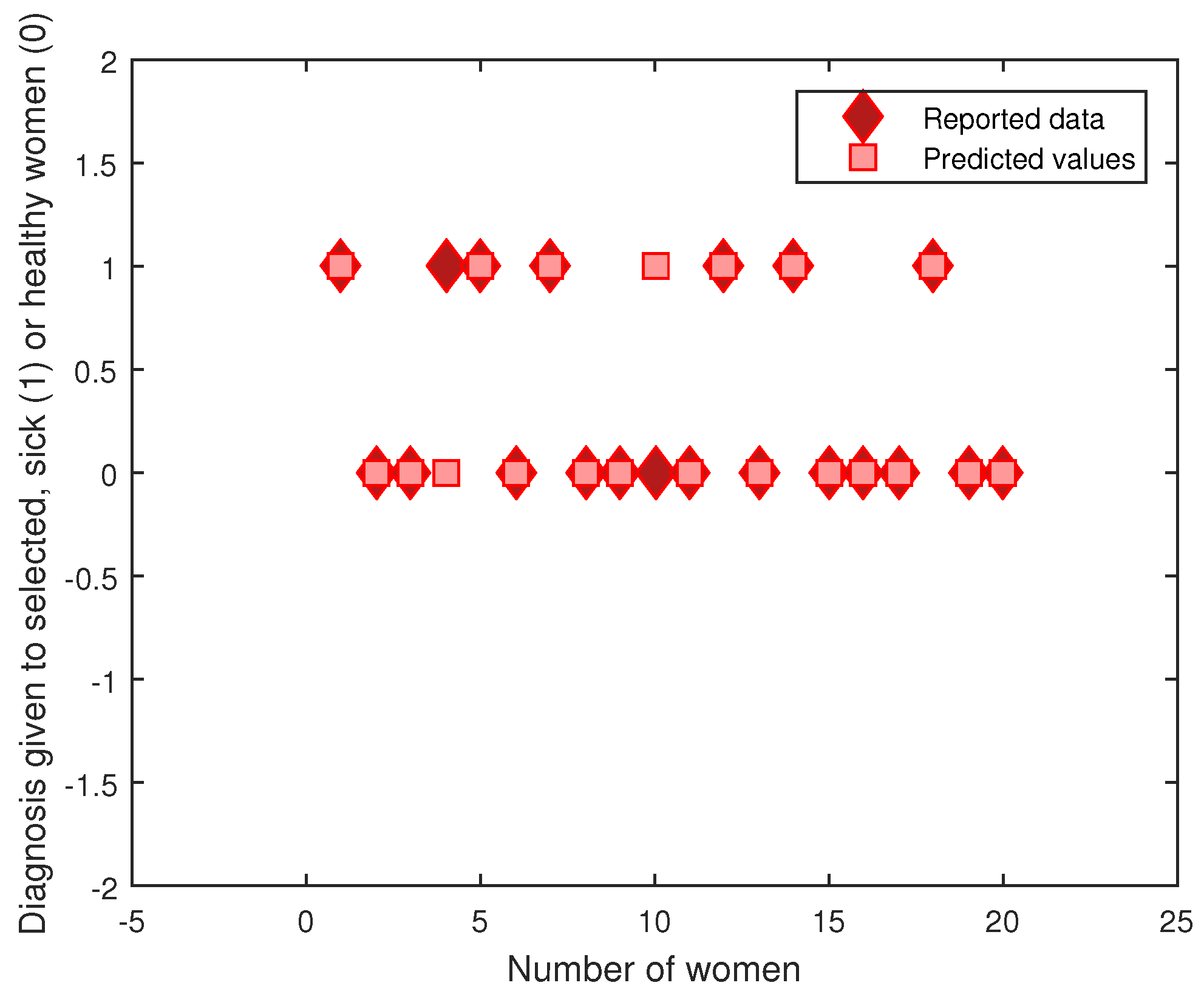
Figure 4 shows the evaluation of the learning performed for the T-S rule base and the premises with the centroids of the FCM algorithm. The 20 sample datasets selected contained 7 cases with hypertension versus 13 healthy cases; for these, there were two prediction errors.
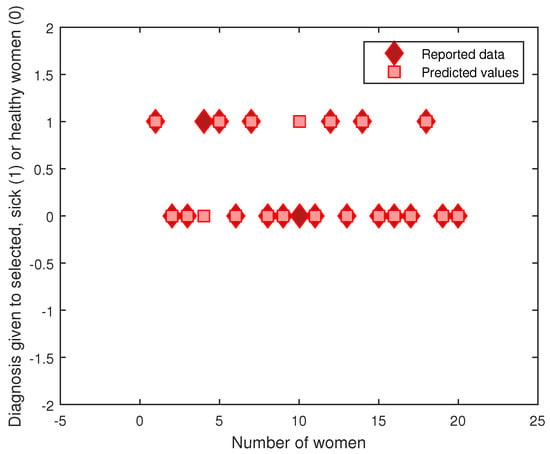
Figure 4.
Predicted values vs. real measurements.
Evaluation
The precision is the ratio , where is the number of true positives and is the number of false positives. The precision is the ability of the classifier not to label as positive a sample that is negative. The recall is the ratio , where is the number of true positives and the number of false negatives, and the F-beta score is a weighted harmonic mean of the precision and recall [35].
Using these measures, a system that performs worse in the objective sense of informedness can appear to perform better under any of these commonly used measures. These standard measures have a significantly higher correlation with human judgments than the other proposed techniques [36]. Table 13 and Table 14 present the information obtained when evaluating the four proposed models without and with reducing dimensions, respectively. The evaluation was developed considering precision, recall, and the f-score to carry out a later evaluation using ROC and EER curves. A considerable increase in evaluation measures for fewer dimensions can be observed. A random undersampling technique [37] was used to adjust the class distribution of the dataset to eliminate the problem of unbalanced classes, therefore training the models with a total of 98 samples.
Table 13.
Evaluation of the four selected models with 85 dimensions.
Table 14.
Evaluation of the four selected models with eight dimensions.
The area under the curve (AUC) is an indicator of the overall quality of a ROC curve. An ROC curve is a graphical representation of the sensitivity to specificity for a binary classification system as the discrimination threshold varies [38,39].
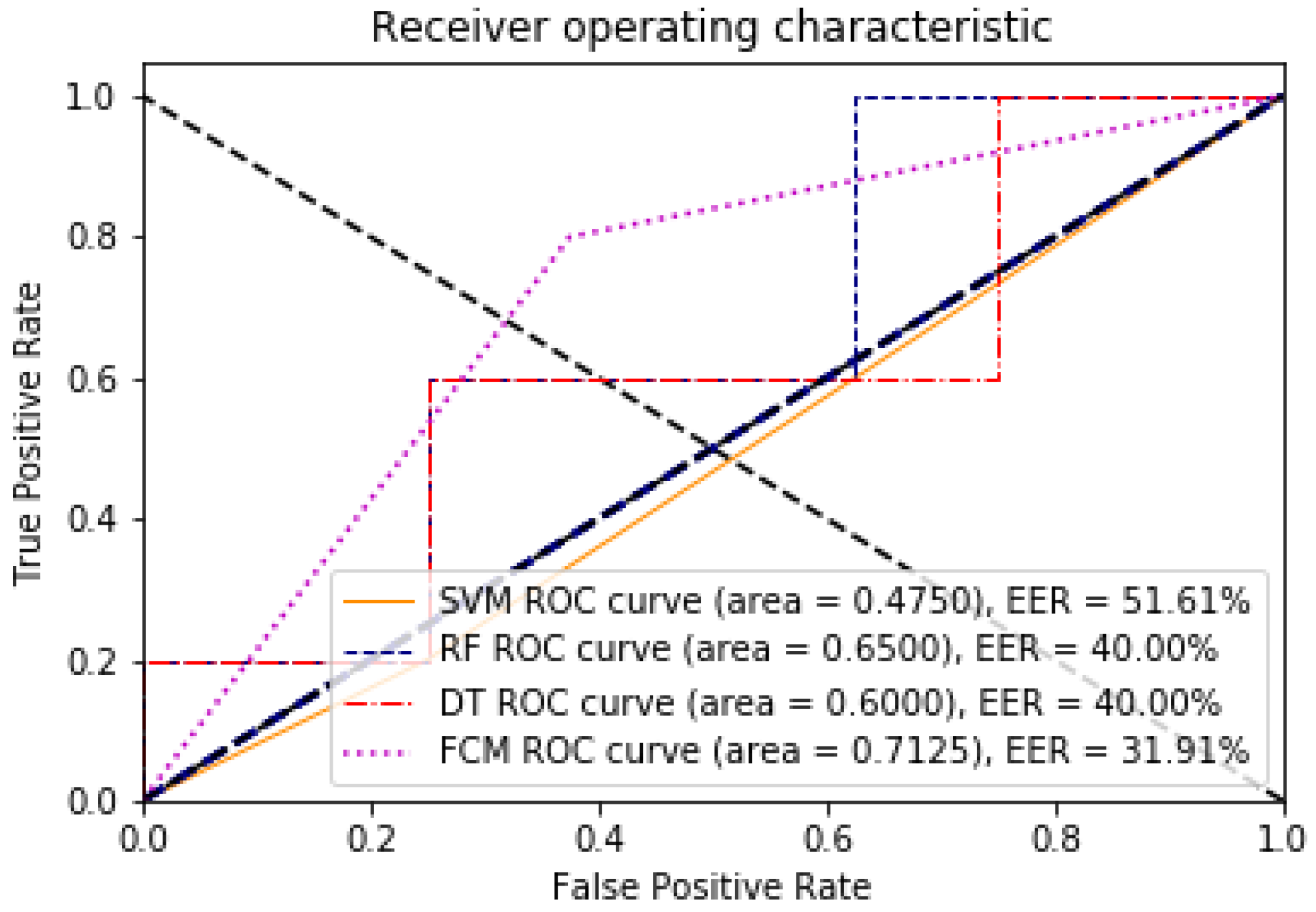
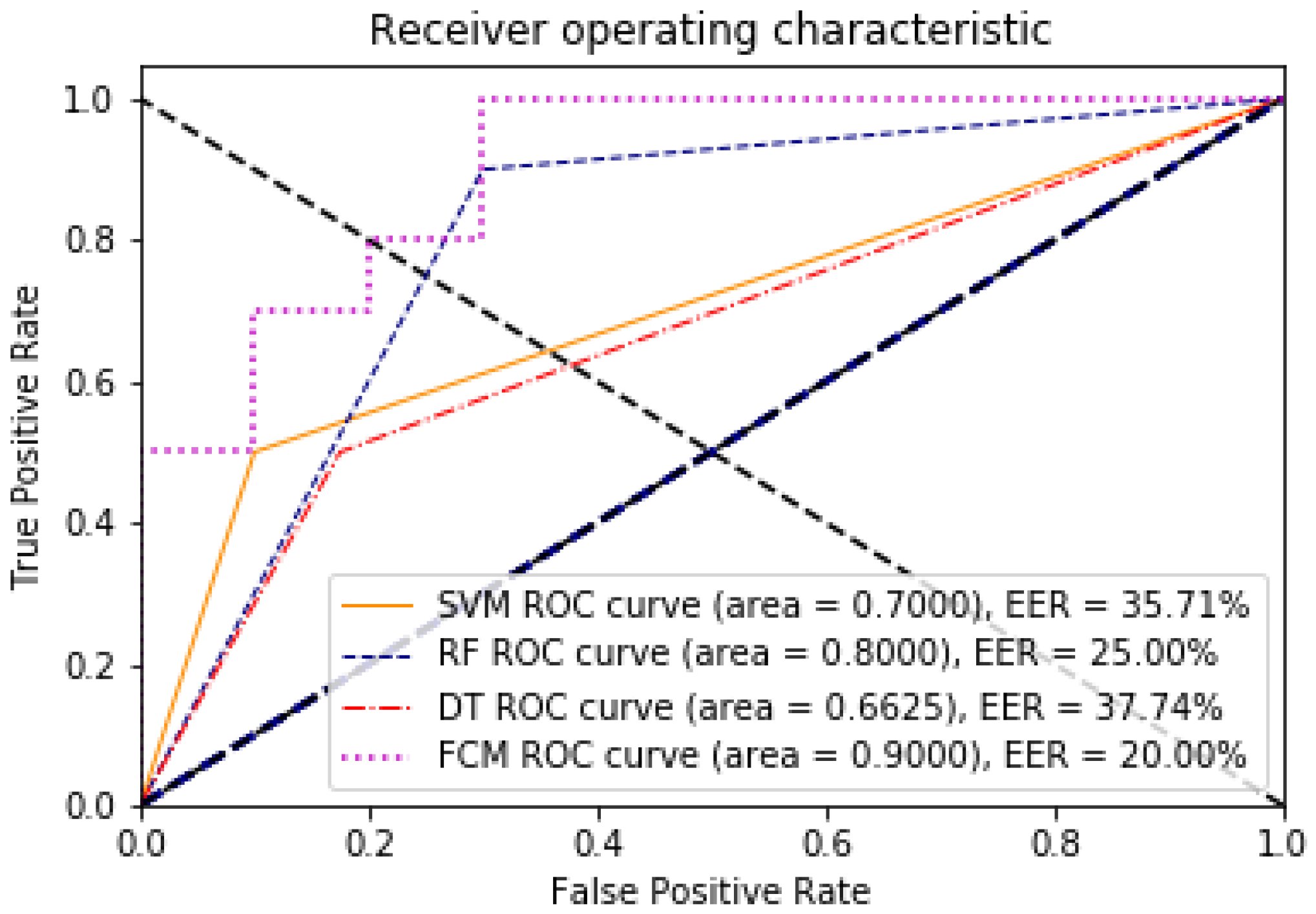
The point on the ROC curve that corresponds to the EER has an equal probability of wrongly classifying a positive or negative sample. This point is obtained by intersecting the ROC curve with a diagonal of the unit square [40]. A comparative analysis of the ROC and EER curves was performed to evaluate the performance of the models with and without dimensionality reduction. The evaluation of the algorithms with respect to these two measures can be seen in Figure 5 and Figure 6, for 85 features against the 8 found through the data discriminant; the improvement of the algorithms in their learning is remarkable.
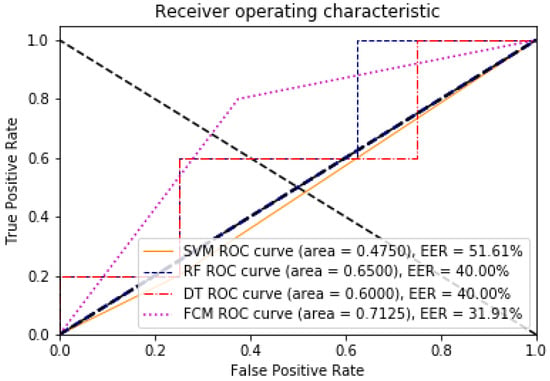
Figure 5.
ROC and EER curves for the model with 85 dimensions, illustrating the trade-off between false positive and true positive rates.
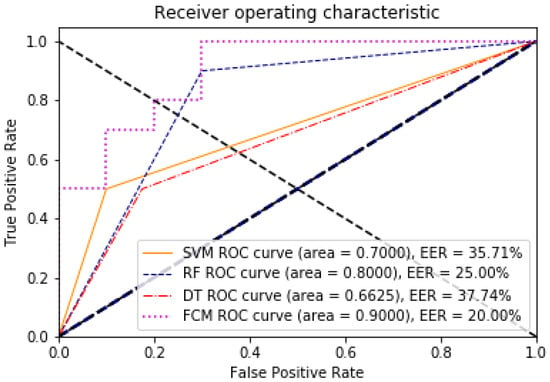
Figure 6.
ROC and EER curves for the model with eight dimensions, demonstrating the impact of dimensionality reduction on model performance.
4. Discussion
According to The American College of Obstetricians and Gynecologists [10], diastolic pressure, systolic pressure, and heart rate are representative variables in the diagnosis of PE [41,42]. There is some evidence of increased mortality among women with a history of hypertension during pregnancy [43]. Similarly, the overall risk of PE is higher for women with multiple pregnancies, nulliparity, and advanced maternal age, as mentioned in [44].
In [45], the authors establish that there is a relationship between pre-pregnancy body mass index and the risk of severe and mild PE, as well as the risk of severe and mild transient pregnancy hypertension. It is well known that there is a relationship between parents with type 2 diabetes and the possible inheritance of diabetes by their descendants [46,47]; it is clear that there is a strong hereditary component to the disease.
In addition, type 1 and 2 diabetes, gestational diabetes, and polycystic ovarian syndrome are all well-established risk factors for pregnancy-induced hypertension [48]. Therefore, based on the statistical and pattern recognition analyses performed, the maternal hypertension variable is accepted as an important characteristic in the prediction of hypertension in pregnancy and its derivatives.
In [13], a fuzzy intelligent system implemented via wearable devices is proposed for patients with preeclampsia. This system works using five descriptive variables, namely systolic pressure, diastolic pressure, proteinuria, age, and weight, to detect preeclampsia and diabetes. However, since the clinical records of women in Hidalgo do not include information on the occurrence of proteinuria, statistics were used to determine representative variables. As a result, eight significant variables (diastolic pressure, body mass index, heart rate, systolic pressure, age, maternal diabetes, number of fetuses, and hypertension) are presented, which agree with the previous literature.
5. Conclusions
The data obtained through the SSEH allowed us to carry out a dimensional reduction analysis to contrast our work with the results established in the literature. Initially, we had 85 dimensions, which were subjected to data pre-processing to find those that were not significant to modeling PE. Based on a study in which the authors reduced the characteristic variables, as reported in the literature, we successfully reduced the dimensionality to only eight critical variables through clamp transformation, correlation coefficients, and a multicollinearity analysis. The correlation coefficient allowed for the elimination of more characteristics by finding 15 constant variables, followed by a multicollinearity analysis through which four variables were reduced by a value of .
The eight variables obtained resulted in a fuzzy T-S model that showed favorable classification results on real data in comparison to other models in the literature. The FCM clearly finds and identifies patterns in biological data. Likewise, some data centers are closely distanced; FCM instead allows for the identification of the type of cluster to which the input vector belongs using features with greater variation.
The present results show an approximate value of for the EER in the FCM analysis with eight dimensions for the evaluation of the precision and recall rate when the worst scenario is shown; this information is consistent with the result obtained in EER (20%). However, by evaluating with respect to the ROC curve, we obtain an approximate value of 90% in the prediction of hypertensive disorders in pregnancy. A lower EER indicates a better balance between these two types of errors, thus reflecting a more accurate model. Having both EER evaluation and ROC curves together is beneficial because EER provides a concise summary of accuracy at the threshold where false positive and false negative rates are equal, simplifying model comparison at a specific point. Another advantage of FCM is that even without reducing dimensions and balancing, it is capable of a higher degree of learning and classification than other algorithms. When all the dimensions were used, the learning rate was 71.25 % without undersampling; therefore, this allows us to say that a fuzzy approach expands the possibilities of using biological data in binary classification.
Author Contributions
Conceptualization, D.R.-C. and I.C.-J.; methodology, J.C.R.-F., D.R.-C. and J.-C.S.-R.; software, I.C.-J. and D.R.-C.; validation, J.C.R.-F., I.C.-J. and D.R.-C.; formal analysis, J.-C.S.-R., D.R.-C., I.C.-J. and J.C.R.-F.; investigation, J.-C.S.-R., D.R.-C., I.C.-J. and J.C.R.-F.; resources, F.M.-G. and J.-C.S.-R.; data curation, O.D.-P. and J.A.R.-V.; writing—original draft preparation, O.D.-P., J.A.R.-V. and J.M.X.-P.; writing—review and editing, O.D.-P., J.A.R.-V., J.C.R.-F., I.C.-J., D.R.-C., F.M.-G. and J.-C.S.-R.; visualization, J.-C.S.-R., D.R.-C., I.C.-J., J.C.R.-F. and J.M.X.-P.; supervision, F.M.-G. and J.-C.S.-R.; project administration, D.R.-C. and I.C.-J.; funding acquisition, J.-C.S.-R., D.R.-C., I.C.-J., J.C.R.-F., F.M.-G. and J.-C.S.-R. All authors have read and agreed to the published version of the manuscript.
Funding
We cordially thank the Pachuca jurisdiction area and the Jesus del Rosal healthcare institution for the supporting information from women in the process of pregnancy. Additionally, we thank the National Laboratory in Autonomous Vehicles and Exoskeletons (LANAVEX) for technical support and the National Council for Humanities, Science and Technology (CONAHCYT) under grant No. 923801.
Data Availability Statement
Data are available on request from the corresponding or first author.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| TPR | True positive rate |
| TNR | True negative rate |
| EER | Equal error rate |
| PE | Preeclampsia |
| FCM | Fuzzy c-means |
| T-S | Takagi–Sugeno |
| AUC | Area under the curve |
| OOB | Out-of-bag |
| RFE | Recursive feature elimination |
| PCA | Principal component analysis |
| ROC | Receiver operating characteristic |
References
- Steegers, E.A.; Von Dadelszen, P.; Duvekot, J.J.; Pijnenborg, R. Pre-eclampsia. Lancet 2010, 376, 631–644. [Google Scholar] [CrossRef]
- Davey, D.A.; MacGillivray, I. The classification and definition of the hypertensive disorders of pregnancy. Am. J. Obstet. Gynecol. 1988, 158, 892–898. [Google Scholar] [CrossRef] [PubMed]
- Özsezer, G.; Mermer, G. Prevention of Maternal Mortality: Prediction of Health Risks of Pregnancy with Machine Learning Models. 2023. Available online: https://www.researchgate.net/publication/368845364_Prevention_of_Maternal_Mortality_Prediction_of_Health_Risks_of_Pregnancy_with_Machine_Learning_Models (accessed on 1 July 2024).
- Raza, A.; Siddiqui, H.U.R.; Munir, K.; Almutairi, M.; Rustam, F.; Ashraf, I. Ensemble learning-based feature engineering to analyze maternal health during pregnancy and health risk prediction. PLoS ONE 2022, 17, e0276525. [Google Scholar] [CrossRef]
- Ramla, M.; Sangeetha, S.; Nickolas, S. Fetal health state monitoring using decision tree classifier from cardiotocography measurements. In Proceedings of the 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 14–15 June 2018; pp. 1799–1803. [Google Scholar]
- Irfan, M.; Basuki, S.; Azhar, Y. Giving more insight for automatic risk prediction during pregnancy with interpretable machine learning. Bull. Electr. Eng. Inform. 2021, 10, 1621–1633. [Google Scholar] [CrossRef]
- Alam, M.S.B.; Patwary, M.J.; Hassan, M. Birth mode prediction using bagging ensemble classifier: A case study of bangladesh. In Proceedings of the 2021 International Conference on Information and Communication Technology for Sustainable Development (ICICT4SD), Dhaka, Bangladesh, 27–28 February 2021; pp. 95–99. [Google Scholar]
- Haldar, N.A.H.; Khan, F.A.; Ali, A.; Abbas, H. Arrhythmia classification using Mahalanobis distance based improved Fuzzy C-Means clustering for mobile health monitoring systems. Neurocomputing 2017, 220, 221–235. [Google Scholar] [CrossRef]
- Neocleous, C.K.; Anastasopoulos, P.; Nikolaides, K.H.; Schizas, C.N.; Neokleous, K.C. Neural networks to estimate the risk for preeclampsia occurrence. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 2221–2225. [Google Scholar]
- American College of Obstetricians and Gynecologists. Hypertension in pregnancy. Report of the American College of Obstetricians and Gynecologists’ task force on hypertension in pregnancy. Obstet. Gynecol. 2013, 122, 1122. [Google Scholar]
- Moreira, M.W.; Rodrigues, J.J.; Oliveira, A.M.; Ramos, R.F.; Saleem, K. A preeclampsia diagnosis approach using Bayesian networks. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–5. [Google Scholar]
- Moreira, M.W.; Rodrigues, J.J.; Oliveira, A.M.; Saleem, K.; Neto, A.J.V. Predicting hypertensive disorders in high-risk pregnancy using the random forest approach. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–5. [Google Scholar]
- Espinilla, M.; Medina, J.; García-Fernández, Á.L.; Campaña, S.; Londoño, J. Fuzzy intelligent system for patients with preeclampsia in wearable devices. Mob. Inf. Syst. 2017, 2017, 7838464. [Google Scholar] [CrossRef]
- Babuška, R. Fuzzy Modeling for Control; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1998; Volume 12. [Google Scholar]
- Velikova, M.; van Scheltinga, J.T.; Lucas, P.J.; Spaanderman, M. Exploiting causal functional relationships in Bayesian network modelling for personalised healthcare. Int. J. Approx. Reason. 2014, 55, 59–73. [Google Scholar] [CrossRef]
- Tejera, E.; Jose areias, M.; Rodrigues, A.; Ramoa, A.; Manuel nieto villar, J.; Rebelo, I. Artificial neural network for normal, hypertensive, and preeclamptic pregnancy classification using maternal heart rate variability indexes. J. -Matern.-Fetal Neonatal Med. 2011, 24, 1147–1151. [Google Scholar] [CrossRef] [PubMed]
- Kelleher, J.D.; Mac Namee, B.; D’arcy, A. Fundamentals of Machine Learning for Predictive Data Analytics: Algorithms, Worked Examples, and Case Studies; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Garcia Asuero, A.; Sayago, A.; González, G. The Correlation Coefficient: An Overview. Crit. Rev. Anal. Chem. 2006, 36, 41–59. [Google Scholar] [CrossRef]
- Mansfield, E.R.; Helms, B.P. Detecting multicollinearity. Am. Stat. 1982, 36, 158–160. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Khalilia, M.; Chakraborty, S.; Popescu, M. Predicting disease risks from highly imbalanced data using random forest. BMC Med. Inform. Decis. Mak. 2011, 11, 51. [Google Scholar] [CrossRef] [PubMed]
- Han, H.; Guo, X.; Yu, H. Variable selection using mean decrease accuracy and mean decrease gini based on random forest. In Proceedings of the 2016 7th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 26–28 August 2016; pp. 219–224. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Altfeld, S.; Handler, A.; Burton, D.; Berman, L. Wantedness of pregnancy and prenatal health behaviors. Women Health 1998, 26, 29–43. [Google Scholar] [CrossRef]
- Mehlsen, J.; Pagh, K.; Nielsen, J.; Sestoft, L.; Nielsen, S. Heart rate response to breathing: Dependency upon breathing pattern. Clin. Physiol. 1987, 7, 115–124. [Google Scholar] [CrossRef] [PubMed]
- Selvin, E.; Marinopoulos, S.; Berkenblit, G.; Rami, T.; Brancati, F.L.; Powe, N.R.; Golden, S.H. Meta-analysis: Glycosylated hemoglobin and cardiovascular disease in diabetes mellitus. Ann. Intern. Med. 2004, 141, 421–431. [Google Scholar] [CrossRef]
- Maldonado, S.; Weber, R.; Famili, F. Feature selection for high-dimensional class-imbalanced data sets using Support Vector Machines. Inf. Sci. 2014, 286, 228–246. [Google Scholar] [CrossRef]
- Maldonado, S.; Weber, R. A wrapper method for feature selection using support vector machines. Inf. Sci. 2009, 179, 2208–2217. [Google Scholar] [CrossRef]
- Takagi, T.; Sugeno, M. Fuzzy identification of systems and its applications to modeling and control. IEEE Trans. Syst. Man Cybern. 1985, SMC-15, 116–132. [Google Scholar] [CrossRef]
- Setnes, M.; Babuska, R.; Verbruggen, H.B. Rule-based modeling: Precision and transparency. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 1998, 28, 165–169. [Google Scholar] [CrossRef]
- Díez, J.L.; Navarro, J.L.; Sala, A. Algoritmos de agrupamiento en la identificación de modelos borrosos. Rev. Iberoam. de Automática e Informática Ind. 2010, 1, 32–41. [Google Scholar]
- Babuška, R. Fuzzy Systems, Modeling and Identification; Delft University of Technology, Department of Electrical Engineering Control Laboratory, Mekelweg: Delft, The Netherlands, 1996; Volume 4. [Google Scholar]
- Kruse, R.; Gebhardt, J.E.; Klowon, F. Foundations of Fuzzy Systems; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1994. [Google Scholar]
- Powers, D. Evaluation: From Precision, Recall and F-Factor to ROC, Informedness, Markedness & Correlation. Mach. Learn. Technol. 2008, 2. [Google Scholar]
- Melamed, I.D.; Green, R.; Turian, J.P. Precision and recall of machine translation. In Proceedings of the HLT-NAACL, Stroudsburg, PA, USA, 31 May 2003; pp. 61–63. [Google Scholar]
- Yap, B.W.; Rani, K.A.; Rahman, H.A.A.; Fong, S.; Khairudin, Z.; Abdullah, N.N. An application of oversampling, undersampling, bagging and boosting in handling imbalanced datasets. In Proceedings of the First International Conference on Advanced Data and Information Engineering (DaEng-2013); Springer: Berlin/Heidelberg, Germany, 2014; pp. 13–22. [Google Scholar]
- Carter, J.V.; Pan, J.; Rai, S.N.; Galandiuk, S. ROC-ing along: Evaluation and interpretation of receiver operating characteristic curves. Surgery 2016, 159, 1638–1645. [Google Scholar] [CrossRef] [PubMed]
- Al-Nima, R.R.O.; Dlay, S.S.; Woo, W.L.; Chambers, J.A. A novel biometric approach to generate ROC curve from the probabilistic neural network. In Proceedings of the 2016 24th Signal Processing and Communication Application Conference (SIU), IEEE, Zonguldak, Turkey, 16–19 May 2016; pp. 141–144. [Google Scholar]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, ACM, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Program, National High Blood Pressure Education. Report of the national high blood pressure education program working group on high blood pressure in pregnancy. Am. J. Obstet. Gynecol. 2000, 183, s1–s22. [Google Scholar] [CrossRef]
- Caritis, S.; Sibai, B.; Hauth, J.; Lindheimer, M.D.; Klebanoff, M.; Thom, E.; VanDorsten, P.; Landon, M.; Paul, R.; Miodovnik, M.; et al. Low-dose aspirin to prevent preeclampsia in women at high risk. N. Engl. J. Med. 1998, 338, 701–705. [Google Scholar] [CrossRef] [PubMed]
- Sjónsdóttir, L.; Arngrimsson, R.; Geirsson, R.T.; Slgvaldason, H.; Slgfússon, N. Death rates from ischemic heart disease in women with a history of hypertension in pregnancy. Acta Obstet. Gynecol. Scand. 1995, 74, 772–776. [Google Scholar] [CrossRef]
- Savitz, D.A.; Zhang, J. Pregnancy-induced hypertension in North Carolina, 1988 and 1989. Am. J. Public Health 1992, 82, 675–679. [Google Scholar] [CrossRef]
- Bodnar, L.M.; Catov, J.M.; Klebanoff, M.A.; Ness, R.B.; Roberts, J.M. Prepregnancy body mass index and the occurrence of severe hypertensive disorders of pregnancy. Epidemiology 2007, 18, 234–239. [Google Scholar] [CrossRef]
- Kaufman, F.R. Type 2 diabetes mellitus in children and youth: A new epidemic. J. Pediatr. Endocrinol. Metab. 2002, 15, 737–744. [Google Scholar] [CrossRef]
- Arslanian, S.A. Type 2 diabetes mellitus in children: Pathophysiology and risk factors. J. Pediatr. Endocrinol. Metab. 2000, 13, 1385–1394. [Google Scholar] [CrossRef] [PubMed]
- Carty, D.M.; Delles, C.; Dominiczak, A.F. Novel biomarkers for predicting preeclampsia. Trends Cardiovasc. Med. 2008, 18, 186–194. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).