
Comparative Evaluation of Model Accuracy for Predicting Selected Attributes in Agile Project Management


Abstract
1. Introduction
2. Project Management with AI
- Gathering requirements and planning: AI utilises user data to formulate comprehensive plans, considering schedules, potential risks, and alternative solutions to navigate challenges effectively.
- Analysis and design: AI facilitates optimal resource allocation during the design phase, guiding designers to adopt more accurate and efficient methodologies based on past experiences.
- Implementation: in the implementation stage, AI aids decision-making by assisting project managers in selecting the right individuals for specific tasks within a given environment, ensuring faster and more secure outcomes.
- Testing and delivery: AI continues to play a pivotal role in the testing and delivery phases, supporting the identification of potential risks and contributing to decision-making processes.
2.1. AI Techniques
2.2. Types of Deep Neural Networks
2.2.1. Recurrent Neural Networks (RNNs)
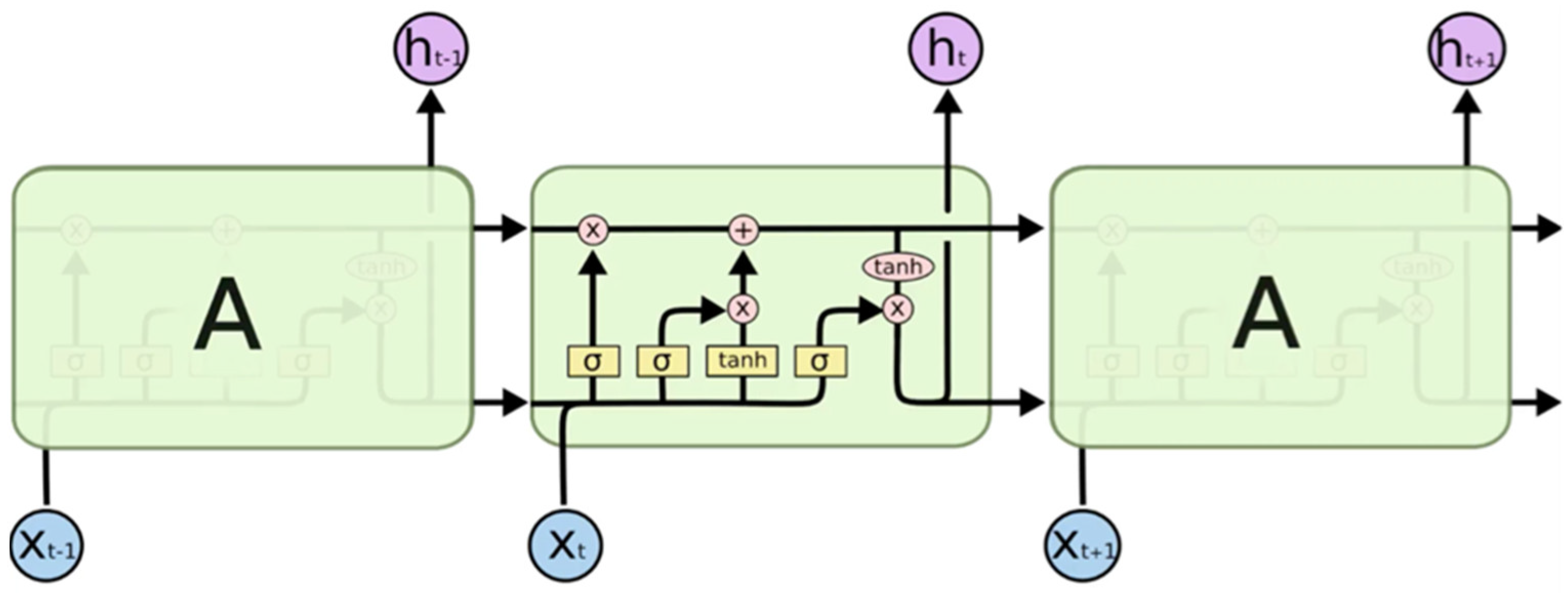
2.2.2. Long Short-Term Memory (LSTM)
2.2.3. Convolutional Neural Networks (CNNs)
2.2.4. CNN-LSTM Hybrid Model
2.2.5. Gated Recurrent Units (GRUs)
2.2.6. Multilayer Perceptron (MLP)
2.3. Comparison between Models
2.4. Evaluation Metrics
- Mean Absolute Error:
- : is the number of observations;
- : is the actual value;
- : is the predicted value.
- Mean Squared Error:
- Mean Absolute Percentage Error:
3. Research Objective
- To precisely assess the performance of LSTM, CNN, CNN-LSTM, GRU, MLP, and RNN models in predicting project completion time, required personnel, and estimated costs. This involves utilising a comprehensive dataset that reflects the complexities of real-world projects to determine how well each model can forecast these crucial project parameters.
- To compare the accuracy of these models using specific evaluation metrics: MAE, MSE, and MAPE. This comparison aims to provide a detailed understanding of each model’s predictive precision, aiding in selecting the most accurate model for project management.
- To determine which machine learning architecture (LSTM, CNN, CNN-LSTM, GRU, MLP, RNN) best predicts project parameters. The goal is to identify the most effective model for different project scenarios and data patterns, thereby supporting more reliable forecasting.
- To elucidate each model’s strengths and limitations, focusing on its ability to handle various project types and complexities. This will help us understand which models are best suited for different project characteristics and provide insights into potential areas for improvement.
- To offer actionable insights for refining predictive models and exploring advanced techniques, such as ensemble methods and hyperparameter optimisation. This objective aims to improve prediction accuracy and robustness in project management.
- To assist students and project managers in ensuring the success of their projects by providing accurate predictions for project completion times and required resources. This includes offering guidance on measuring, estimating, and managing timeframes effectively, enhancing project planning and execution.
- To evaluate the practical implications of the resulting model predictions for real-world project management. This involves understanding how these predictive models can be applied to improve decision-making, resource allocation, and overall project success.
4. Related Work
5. Study Methodology
5.1. Data Collection
5.1.1. Data Collection Process
- We distributed the questionnaire on electronic platforms associated with the academic bodies mentioned above.
- We obtained responses from students, totaling 190 responses.
- We performed data checking and cleaning, including removing incomplete or incomprehensible responses.
- We classified the collected data into two main groups: students following the waterfall methodology and those adopting the agile method.
- Data classification was based on project parameters such as the project type, team size, expected completion time, and project overview.
5.1.2. Respondent Selection
- Affiliation: Only students from the Department of Computers and Informatics at the Technical University of Košice were selected.
- Academic Standing: Respondents needed to be in their final classes, ensuring they had sufficient knowledge and experience in informatics and software development.
- Experience with Project Management: Students who had completed at least one project management course or had practical experience were targeted.
- Project Methodology: Respondents were selected based on their familiarity with the waterfall or agile project management methodologies.
5.2. Consent and Personal Data Protection
- One of the project team members provided the students with a detailed explanation of the study. This session included information about the study’s objectives, the nature of the data being collected, and how the data would be used.
- The study was also distributed on one of the university’s documented platforms, ensuring that all information was accessible to the students.
- Participants were assured that their responses would be kept confidential and that any published results would not include identifiable information.
- All collected data were anonymised to ensure that individual respondents could not be identified from the dataset.
5.3. Machine Learning Models
5.4. Training and Evaluation Process for Each Model
- Data splitting: The dataset was split into training and testing sets to assess the models’ generalisation performance accurately. An 80–20 split was adopted, allocating 80% of the data for training and 20% for testing.
- Model curation: Distinct models were used for each machine learning architecture, incorporating unique layer configurations. For instance, the CNN model featured convolutional layers for spatial feature extraction, while the LSTM model emphasised sequential data understanding.
- Training: Models underwent an iterative training process using the training set. The training involved minimising a predefined loss function, adjusting model weights through back-propagation, and optimising performance over multiple epochs.
- Prediction: After training, each model was evaluated on the testing set to simulate real-world predictive scenarios, and predictions were generated for project completion times based on the patterns learned from the training data.
- Evaluation metrics: Each model’s performance was quantified using standard evaluation metrics such as MAE, MSE, and MAPE. These metrics provided insights into the accuracy and reliability of the models in predicting project completion times.
6. Results and Analysis
6.1. “Predicted Completion Time” Results
6.2. “Persons Needed” Results
6.3. “Estimated Cost” Results
6.4. Comparison of Metrics across Models
6.4.1. Mean Absolute Error
- The RNN stands out as the top-performing model, with the lowest MAE of 0.0056. The MLP and GRU models also demonstrate excellent performance, with MAE values of 0.0175 and 0.0202, respectively.
- The CNN and LSTM models exhibit slightly higher MAE values but remain competitive, showcasing their competence in minimising prediction errors.
- CNN-LSTM hybrid, while still effective, shows a comparatively higher MAE.
6.4.2. Mean Squared Error
- The RNN again leads with the lowest MSE of 0.0001, emphasising its superior ability to minimise squared errors.
- The MLP and GRU models follow closely with impressive MSE values of 0.000580942 and 0.000505865, respectively.
- The CNN model, LSTM model, and CNN-LSTM hybrid model display higher MSE values but maintain effectiveness in reducing squared errors.
6.4.3. Mean Absolute Percentage Error
- The RNN exhibits exceptional accuracy, with the lowest MAPE of 1.39%, indicating its proficiency in providing precise percentage errors.
- MLP and CNN-LSTM hybrid also perform well, demonstrating MAPE values of 4.36% and 9.21%, respectively.
- While slightly higher in MAPE, the CNN, GRU, and LSTM models effectively minimise percentage errors.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, Y.; Xia, X.; Lo, D.; Bi, T.; Grundy, J.; Yang, X. Predictive Models in Software Engineering: Challenges and Opportunities. arXiv 2020, arXiv:2008.03656. Available online: http://arxiv.org/abs/2008.03656 (accessed on 10 August 2024). [CrossRef]
- Wang, Q. How to apply AI technology in Project Management. PM World J. 2019, VIII, 1–12. [Google Scholar]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Auth, G.; Jokisch, O.; Dürk, C. Revisiting automated project management in the digital age—A survey of AI approaches. Online J. Appl. Knowl. Manag. 2019, 7, 27–39. [Google Scholar] [CrossRef]
- Martínez-Fernández, S.; Bogner, J.; Franch, X.; Oriol, M.; Siebert, J.; Trendowicz, A.; Vollmer, A.M.; Wagner, S. Software Engineering for AI-Based Systems: A Survey. ACM Trans. Softw. Eng. Methodol. 2022, 31, 37e. [Google Scholar] [CrossRef]
- McGrath, J.; Kostalova, J. Project Management Trends and New Challenges 2020+. Hradec Econ. Days 2020, 10, 534–542. [Google Scholar] [CrossRef]
- Bodimani, M. AI and Software Engineering: Rapid Process Improvement through Advanced Techniques. J. Sci. Technol. 2021, 2, 95–119. [Google Scholar]
- Hofmann, P.; Jöhnk, J.; Protschky, D.; Urbach, N. Developing Purposeful AI Use Cases—A Structured Method and Its Application in Project Management. In Proceedings of the 15th International Conference on Wirtschaftsinformatik (WI) (WI2020), Postdam, Germany, 9–11 March 2020; pp. 33–49, ISBN 978-3-95545-335-0. [Google Scholar]
- Khan, A. Artificial Intelligence (AI) Techniques. Available online: https://intellipaat.com/blog/artificial-intelligence-techniques/ (accessed on 5 March 2024).
- Anitha, N.N.S.; Reddymalla, N.R.; Karri, V.R. Introduction of Artificial Intelligence techniques and approaches. Asian J. Multidiscip. Stud. 2020, 8, 15–24. [Google Scholar]
- Sarker, I.H. AI-Based Modeling: Techniques, Applications and Research Issues Towards Automation, Intelligent and Smart Systems. SN Comput. Sci. 2022, 3, 158. [Google Scholar] [CrossRef]
- Bouwmans, T.; Javed, S.; Sultana, M.; Jung, S.K. Deep neural network concepts for background subtraction: A systematic review and comparative evaluation. Neural Netw. 2019, 117, 8–66. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, R.M. Recurrent Neural Networks (RNNs): A Gentle Introduction and Overview. arXiv 2019, arXiv:1912.05911. Available online: http://arxiv.org/abs/1912.05911 (accessed on 29 July 2024).
- Bianchi, F.M.; Maiorino, E.; Kampffmeyer, M.C.; Rizzi, A.; Jenssen, R. An Overview and Comparative Analysis of Recurrent Neural Networks for Short Term Load Forecasting. arXiv 2017, arXiv:1705.04378. [Google Scholar]
- Muhammad, A.; Külahcı, F.; Salh, H.; Hama Rashid, P.A. Long Short Term Memory networks (LSTM)-Monte-Carlo simulation of soil ionization using radon. J. Atmos. Sol. Terr. Phys. 2021, 221, 105688. [Google Scholar] [CrossRef]
- Staudemeyer, R.C.; Morris, E.R. Understanding LSTM—A Tutorial into Long Short-Term Memory Recurrent Neural Networks. arXiv 2019, arXiv:1909.09586. Available online: http://arxiv.org/abs/1909.09586 (accessed on 29 July 2024).
- Lynn, H.M.; Pan, S.B.; Kim, P. A Deep Bidirectional GRU Network Model for Biometric Electrocardiogram Classification Based on Recurrent Neural Networks. IEEE Access 2019, 7, 145395–145405. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef]
- Rosebrock, A. Deep Learing for Computer Vision. PYIMAGESEARCH. 2017. Available online: https://pyimagesearch.com/deep-learning-computer-vision-python-book/ (accessed on 9 July 2024).
- Mandal, M. Introduction to Convolutional Neural Networks (CNN), Analytics Vidhya. 2021. Available online: https://www.analyticsvidhya.com/blog/2021/05/convolutional-neural-networks-cnn/ (accessed on 5 March 2024).
- Abdallah, M.; An Le Khac, N.; Jahromi, H.; Delia Jurcut, A. A Hybrid CNN-LSTM Based Approach for Anomaly Detection Systems in SDNs. In Proceedings of the 16th International Conference on Availability, Reliability and Security, Vienna, Austria, 17–20 August 2021; ACM: New York, NY, USA, 2021; pp. 1–7. [Google Scholar]
- Zargar, S.A. Introduction to Sequence Learning Models: RNN, LSTM, GRU. Agric. Philos. 2021. [Google Scholar] [CrossRef]
- Astawa, I.N.G.A.; Pradnyana, I.P.B.A.; Suwintana, I.K. Comparison of RNN, LSTM, and GRU Methods on Forecasting Website Visitors. J. Comput. Sci. Technol. Stud. 2022, 4, 11–18. [Google Scholar] [CrossRef]
- Li, D.; Wang, H.; Li, Z. Accurate and Fast Wavelength Demodulation for Fbg Reflected Spectrum Using Multilayer Perceptron (Mlp) Neural Network. In Proceedings of the 2020 12th International Conference on Measuring Technology and Mechatronics Automation (ICMTMA), Phuket, Thailand, 28–29 February 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 265–268. [Google Scholar]
- Abiodun, O.I.; Kiru, M.U.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Umar, A.M.; Linus, O.U.; Arshad, H.; Kazaure, A.A.; Gana, U. Comprehensive Review of Artificial Neural Network Applications to Pattern Recognition. IEEE Access 2019, 7, 158820–158846. [Google Scholar] [CrossRef]
- Shiri, F.M.; Perumal, T.; Mustapha, N.; Mohamed, R. A Comprehensive Overview and Comparative Analysis on Deep Learning Models: CNN, RNN, LSTM, GRU. arXiv 2023. [Google Scholar] [CrossRef]
- De Myttenaere, A.; Golden, B.; Le Grand, B.; Rossi, F. Mean Absolute Percentage Error for regression models. Neurocomputing 2016, 192, 38–48. [Google Scholar] [CrossRef]
- Prayudani, S.; Hizriadi, A.; Lase, Y.Y.; Fatmi, Y.; Al-Khowarizmi. Analysis Accuracy of Forecasting Measurement Technique on Random K-Nearest Neighbor (RKNN) Using MAPE And MSE. J. Phys. Conf. Ser. 2019, 1361, 012089. [Google Scholar] [CrossRef]
- Filippetto, A.S.; Lima, R.; Barbosa, J.L.V. A risk prediction model for software project management based on similarity analysis of context histories. Inf. Softw. Technol. 2021, 131, 106497. [Google Scholar] [CrossRef]
- Malgonde, O.; Chari, K. An ensemble-based model for predicting agile software development effort. Empir. Softw. Eng. 2019, 24, 1017–1055. [Google Scholar] [CrossRef]
- Pasuksmit, J.; Thongtanunam, P.; Karunasekera, S. Towards Reliable Agile Iterative Planning via Predicting Documentation Changes of Work Items. In Proceedings of the 19th International Conference on Mining Software Repositories, Pittsburgh, PA, USA, 23–24 May 2022; ACM: New York, NY, USA, 2022; pp. 35–47. [Google Scholar]
- Licorish, S.A.; Savarimuthu, B.T.R.; Keertipati, S. Attributes that Predict which Features to Fix: Lessons for App Store Mining. In Proceedings of the Proceedings of the 21st International Conference on Evaluation and Assessment in Software Engineering, Karlskrona, Sweden, 15–16 June 2017; ACM: New York, NY, USA, 2017; pp. 108–117. [Google Scholar]
- Alzeyani, E.M.M.; Szabo, C. A Study on the Methodology of Software Project Management Used by Students whether They are Using an Agile or Waterfall Methodology. In Proceedings of the 2022 20th International Conference on Emerging eLearning Technologies and Applications (ICETA), Stary Smokovec, Slovakia, 20–21 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 22–27. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Application | Strengths | Weaknesses |
|---|---|---|---|
| RNN | Sequential data and time-series analysis | Captures temporal dependencies. Simple architecture. Can handle variable-length sequences. | Vulnerable to vanishing/exploding-gradient problems in long sequences. Struggles with very-long-term dependencies due to its limited memory. Computationally intensive. |
| LSTM | Sequence modelling, time-series prediction, natural language processing | Effectively captures long-term dependencies. Guards against vanishing-gradient problem in RNNs. Suitable for sequential tasks with variable-length inputs/outputs. | More computationally intensive than simpler models. Prone to overfitting with small datasets. |
| CNN | Image application and video analysis; grid-like data processing | Effective at capturing spatial dependencies. Handles local patterns well. Reduces the number of parameters through parameter sharing. | Limited ability to capture long-term dependencies in sequential data. Fixed input size. |
| CNN-LSTM hybrid | Tasks with spatial and temporal aspects | Captures spatial features with its CNN. Captures sequential patterns with its LSTM. Suitable for tasks where both image and time-series information are essential. | Increased complexity compared to standalone models. Requires more training data. |
| GRU | Sequence modelling: similar to LSTM but more computationally efficient | Handles long-term dependencies. More computationally efficient than LSTM. | Struggles with capturing very-long-term dependencies. Less expressive than LSTM. |
| MLP | Various tasks, including classification and regression | Simple architecture. Suitable for tasks with well-defined input–output mappings. Performs well on structured/tabular data. | May struggle with complex, nonlinear relationships in data. Limited ability to handle sequential/temporal patterns. |
| Project Name | Original Dataset | Predicted Results | |||||
|---|---|---|---|---|---|---|---|
| Expected Duration | LSTM | CNN-LSTM | CNN | GRU | MLP | RNN | |
| GPS | 90 | 66 | 64 | 68 | 67 | 64 | 60 |
| Web app | 90 | 68 | 63 | 68 | 67 | 63 | 64 |
| Smart clock | 90 | 60 | 59 | 66 | 66 | 64 | 63 |
| Web game | 90 | 70 | 68 | 66 | 66 | 68 | 64 |
| Desktop blog app | 90 | 72 | 72 | 66 | 67 | 66 | 64 |
| Web-based game | 90 | 77 | 65 | 68 | 66 | 74 | 63 |
| Web application | 90 | 65 | 69 | 66 | 68 | 71 | 59 |
| Custom | 90 | 63 | 68 | 68 | 67 | 62 | 68 |
| Unity game | 90 | 60 | 64 | 67 | 67 | 71 | 72 |
| Lights Out game | 90 | 71 | 58 | 67 | 66 | 60 | 65 |
| Web application for posting blogs | 90 | 73 | 73 | 66 | 68 | 64 | 63 |
| School project | 90 | 67 | 80 | 67 | 67 | 63 | 64 |
| Blog web application with a simple UI | 90 | 68 | 72 | 67 | 68 | 64 | 68 |
| Mobile app to support and automate FP+COCOMO calculations | 90 | 80 | 63 | 68 | 67 | 66 | 71 |
| Shazam application | 90 | 77 | 64 | 67 | 67 | 74 | 62 |
| App for management of save files | 60 | 62 | 68 | 67 | 66 | 71 | 71 |
| Simple service for users, sound recognition | 90 | 58 | 66 | 66 | 68 | 62 | 60 |
| Project Name | Original Dataset | Predicted Results | |||||
|---|---|---|---|---|---|---|---|
| Team Size | LSTM | CNN-LSTM | CNN | GRU | MLP | RNN | |
| GPS | 2 | 4 | 3 | 5 | 5 | 8 | 8 |
| Web app | 5 | 8 | 2 | 5 | 5 | 2 | 3 |
| Smart clock | 3 | 1 | 5 | 5 | 3 | 5 | 1 |
| Web game | 3 | 5 | 1 | 2 | 3 | 4 | 5 |
| Desktop blog app | 2 | 5 | 1 | 2 | 8 | 5 | 2 |
| Web-based game | 3 | 2 | 2 | 2 | 3 | 1 | 2 |
| Web application | 1 | 5 | 8 | 1 | 2 | 2 | 2 |
| Custom | 1 | 8 | 8 | 4 | 2 | 4 | 2 |
| Unity game | 1 | 3 | 2 | 4 | 2 | 4 | 2 |
| Lights Out game | 3 | 4 | 3 | 5 | 3 | 8 | 3 |
| Web application for posting blogs | 2 | 5 | 1 | 8 | 2 | 4 | 5 |
| School project | 4 | 8 | 2 | 1 | 2 | 2 | 1 |
| Blog web application with a simple UI | 5 | 3 | 4 | 2 | 4 | 2 | 3 |
| Mobile app to support and automate FP+COCOMO calculations | 3 | 4 | 4 | 5 | 5 | 8 | 5 |
| Shazam application | 3 | 3 | 5 | 5 | 8 | 4 | 4 |
| App for management of save files | 5 | 3 | 8 | 5 | 5 | 2 | 1 |
| Simple service for users, sound recognition | 1 | 3 | 1 | 5 | 5 | 1 | 1 |
| Project Name | Predicted Results | |||||
|---|---|---|---|---|---|---|
| LSTM | CNN-LSTM | CNN | GRU | MLP | RNN | |
| GPS | 170 | 171 | 170 | 169 | 169 | 170 |
| Web app | 170 | 172 | 170 | 169 | 169 | 170 |
| Smart clock | 165 | 168 | 165 | 166 | 165 | 165 |
| Web game | 164 | 168 | 165 | 166 | 164 | 165 |
| Desktop blog app | 170 | 170 | 165 | 169 | 169 | 170 |
| Web-based game | 165 | 168 | 170 | 166 | 166 | 165 |
| Web application | 170 | 174 | 166 | 170 | 171 | 170 |
| Custom | 169 | 170 | 170 | 169 | 169 | 169 |
| Unity game | 169 | 169 | 169 | 169 | 169 | 169 |
| Lights Out game | 165 | 166 | 169 | 166 | 166 | 165 |
| Web application for posting blogs | 171 | 169 | 165 | 170 | 170 | 171 |
| School project | 167 | 169 | 168 | 168 | 167 | 167 |
| Blog web application with a simple UI | 171 | 173 | 167 | 170 | 170 | 171 |
| Mobile app to support and automate FP+COCOMO calculations | 170 | 170 | 169 | 169 | 169 | 170 |
| Shazam application | 167 | 169 | 170 | 168 | 167 | 167 |
| App for management of save files | 170 | 170 | 167 | 169 | 169 | 170 |
| Simple service for users, sound recognition | 164 | 169 | 169 | 166 | 166 | 165 |
| Model | MAE (avg.) | MSE (avg.) | MAPE (avg.) |
|---|---|---|---|
| CNN | 0.023 | 0.001 | 5.8% |
| CNN-LSTM hybrid | 0.037 | 0.002 | 9.2% |
| GRU | 0.027 | 0.001 | 6.7% |
| LSTM | 0.036 | 0.002 | 9.0% |
| MLP | 0.016 | 0.000 | 4.0% |
| RNN | 0.009 | 0.000 | 2.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alzeyani, E.M.M.; Szabó, C. Comparative Evaluation of Model Accuracy for Predicting Selected Attributes in Agile Project Management. Mathematics 2024, 12, 2529. https://doi.org/10.3390/math12162529
Alzeyani EMM, Szabó C. Comparative Evaluation of Model Accuracy for Predicting Selected Attributes in Agile Project Management. Mathematics. 2024; 12(16):2529. https://doi.org/10.3390/math12162529
Chicago/Turabian StyleAlzeyani, Emira Mustafa Moamer, and Csaba Szabó. 2024. "Comparative Evaluation of Model Accuracy for Predicting Selected Attributes in Agile Project Management" Mathematics 12, no. 16: 2529. https://doi.org/10.3390/math12162529
APA StyleAlzeyani, E. M. M., & Szabó, C. (2024). Comparative Evaluation of Model Accuracy for Predicting Selected Attributes in Agile Project Management. Mathematics, 12(16), 2529. https://doi.org/10.3390/math12162529