
Effective Methods of Categorical Data Encoding for Artificial Intelligence Algorithms
 , , and
, , and
Abstract
1. Introduction
- Data cleaning from various noises;
- Elimination of various anomalies in the dataset;
- Removing duplicate data;
- Elimination of missing data;
- Change form of categorical data (data encoding);
- Extracting important data from the dataset;
- Data scaling;
- Dividing the dataset into training and test datasets.
- All the research works related to the research of categorical data encoding methods, available in the Google search system and published in journals and various conferences, were analyzed at the same time;
- A methodology for researching the impact of categorical data encoding methods on artificial intelligence algorithms has been developed;
- The process of applying 17 categorical data encoding methods to one artificial intelligence algorithm is described (until this paper, the number of most studied methods in one research work did not exceed 10). Therefore, to solve one problem posed in this process, a set of data that has undergone the same initial processing stage is used;
- An approach to selecting the best method for research from existing categorical data encoding methods has been developed.
2. Literature Review
- The single categorical data encoding method was not always the most effective for all studies. That is, the determination of the best method should be carried out for each study;
- A clear rule or approach to choosing the best method for research has not been developed;
- There is an urgency to conduct research using all categorical data encoding methods in one dataset.
3. Materials and Methods
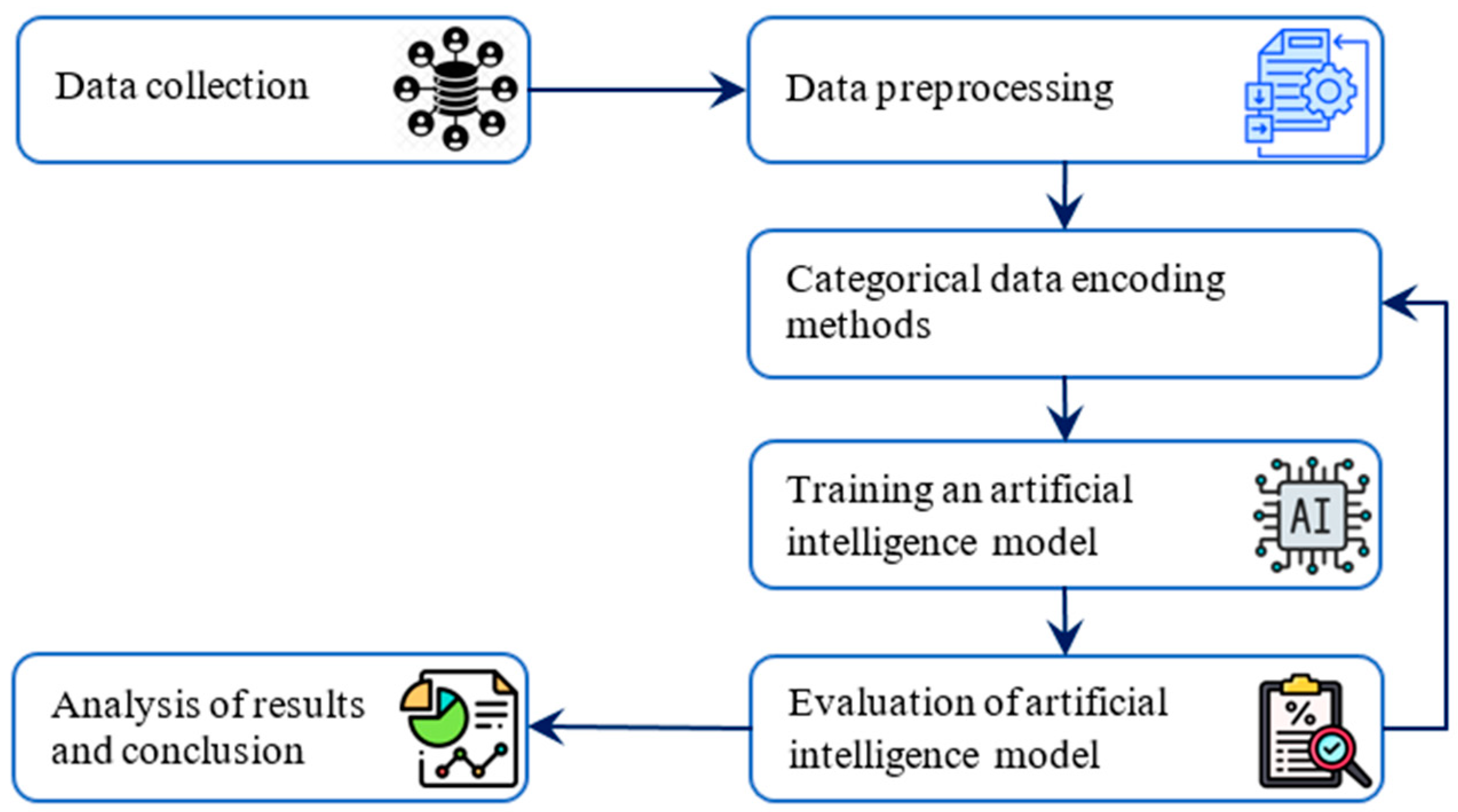
3.1. Steps of Research Implementation
3.2. Research Materials—Identifying the Dataset for the Study
3.2.1. Dataset Description
- Age of the customer (in integer value);
- Annual income of the customer (in integer value);
- Information on the client’s ownership of the house (in text value);
- The customer’s work experience (in real value);
- The purpose of obtaining a credit (in text value);
- Credit level (in text value);
- Loan amount (in integer value);
- Credit rate—loan percentage (in real value);
- Credit status, 0—non-standard status, 1—standard status (integer value);
- Information about the percentage of the annual income received (in real value);
- Customer’s historical credit status (integer value);
- Duration of the customer’s credit history (in integer value).
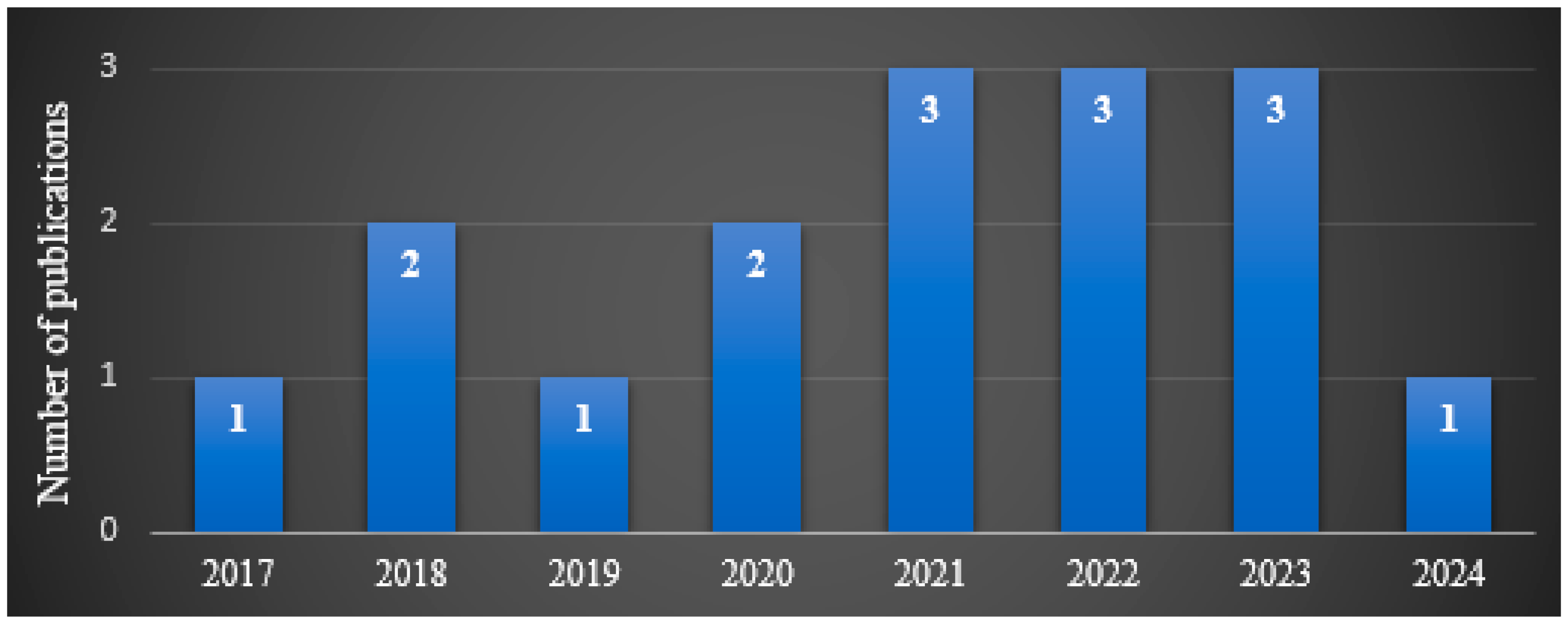
3.2.2. Previous Studies Performed on the Dataset
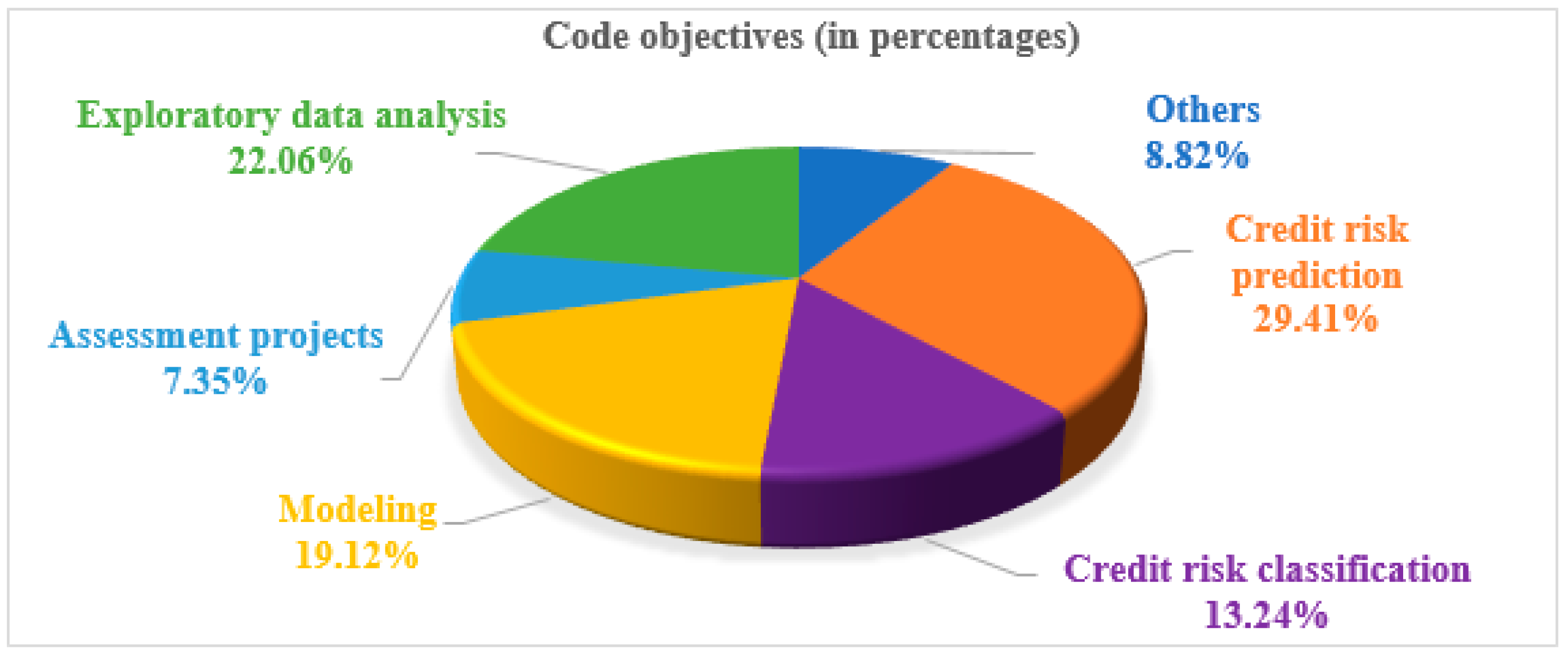
- Exploratory data analysis;
- Credit risk prediction;
- Credit risk classification;
- Modeling;
- Assessment projects.
3.3. Dataset Preprocessing (Except for the Categorical Data Encoding)
- Elimination of missing data;
- Categorical data encoding;
- Data scaling.
3.4. Categorical Data Encoding Methods
3.4.1. Analysis of Categorical Data Encoding Methods
- Ordinal data;
- Nominal data.
- Few, average, many;
- Very unhappy, unhappy, good, happy, very happy;
- Very long, long, medium, short, very short,
- Blue, white, light blue, blue, etc.;
- Samarkand, Tashkent, Jizzakh, Navoi, Bukhara, Khorezm, etc. (cities of Uzbekistan);
- Cows, sheep, horses, dogs, cats, goats, donkeys, chickens, etc.
- Label encoding;
- Ordinal encoding;
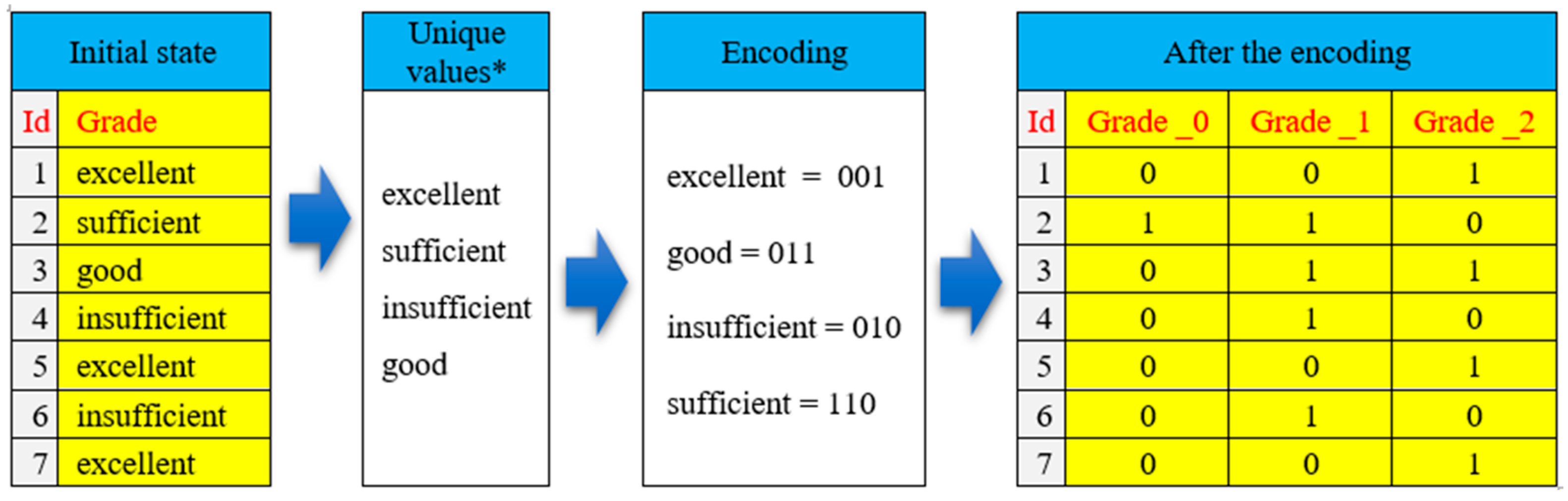
- One-hot encoding;
- Dummy encoding;
- Effect encoding (deviation encoding, sum encoding);
- Binary encoding;
- Base N encoding;
- Gray encoding;
- Target encoding (mean encoding);
- Count encoding;
- Frequency encoding;
- Leave-one-out encoding;
- CatBoost encoding;
- Hash encoding;
- Backward difference encoding;
- Helmert encoding;
- Polynomial encoding.
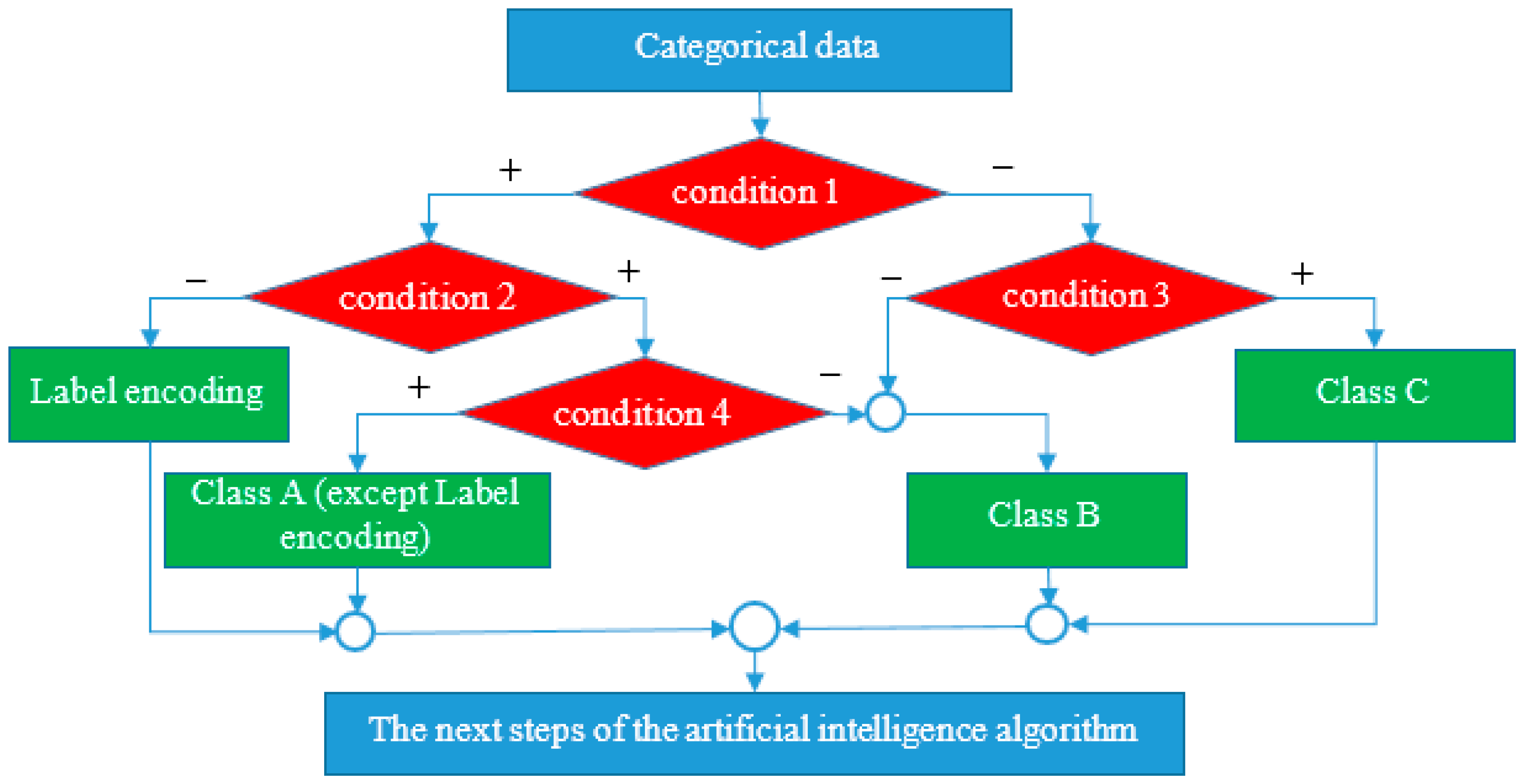
3.4.2. An Approach to Selecting the Best Method for Research
- Class A: label encoding, ordinal encoding, backward difference encoding, Helmert encoding, and polynomial encoding;
- Class B: one-hot encoding, dummy encoding, effect encoding, binary encoding, base N encoding, gray encoding, hash encoding;
- Class C: target encoding, count encoding, frequency encoding, leave-one-out encoding, CatBoost encoding.
- Whether categorical data are nominal or ordinal;
- The number of unique values in the categorical data field;
- Existence of the hypothesis that the number of repetitions of unique values in the categorical data field is significant for the target field;
- Limited computing time and memory space.
3.5. Model of Artificial Intelligence
3.6. Evaluation of Artificial Intelligence Model
- True positive (TP)—the given observation is positive and the predicted value is also positive;
- False positive (FP)—the given observation is negative, but the predicted value is positive;
- True negative (TN)—the given observation is true and the predicted value is negative;
- False negative (FN)—a given observation is actually positive but is predicted to be negative.
3.7. Implementation
- Pandas—to perform actions on data downloaded from Kaggle;
- Scikit-learn:
- sklearn.impute module for missing data imputation (SimpleImputer);
- sklearn.preprocessing module for data scaling (MinMaxScaler) and categorical data encoding;
- sklearn.model_selection module for data collection for splitting training and test datasets (train_test_split);
- sklearn.pipeline module for pipline construction (Pipeline);
- sklearn.linear_model module for artificial intelligence model (LogisticRegression);
- sklearn.metrics module for artificial intelligence model evaluation for (accuracy_score, recall_score, precision_score, f1_score);
- category_encoders—to use categorical data encoding methods that are not available in the sklearn.preprocessing module.
4. Results
5. Discussion
5.1. Research Achievements
5.2. The Superiority of the Research Results over the Results of Previous Studies
5.3. Limitations
- Selection of optional and simplest methods at the stage of initial data processing (elimination of missing data and scaling);
- Voluntary selection of the artificial intelligence model;
- The selected artificial intelligence model is trained and tested based on standard parameters.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ulug‘murodov, S.A. Braille classification algorithms using neural networks. In Artificial intelligence, blockchain, computing and security; CRC Press: Boca Raton, FL, USA, 2024; Volume 2. [Google Scholar]
- Yarmatov, S.; Xamidov, M. Machine Learning Price Prediction on Green Building Prices. In Proceedings of the 2024 International Russian Smart Industry Conference (SmartIndustryCon), Sochi, Russian, 25–29 March 2024; pp. 906–911. [Google Scholar] [CrossRef]
- Rashidov, A.; Akhatov, A.; Nazarov, F. The Same Size Distribution of Data Based on Unsupervised Clustering Algorithms. In Advances in Artificial Systems for Logistics Engineering III. ICAILE 2023. Lecture Notes on Data Engineering and Communications Technologies; Hu, Z., Zhang, Q., He, M., Eds.; Springer: Cham, Switzerland, 2023; Volume 180. [Google Scholar] [CrossRef]
- Zaynidinov, H.; Xuramov, L.; Khodjaeva, D. Intelligent algorithms of digital processing of biomedical images in wavelet methods. In Proceedings of the Artificial Intelligence, Blockchain, Computing and Security—Proceedings of the International Conference on Artificial In-telligence, Blockchain, Computing and Security, ICABCS 2023, Greater Noida, India, 24–25 February 2023; Volume 2, pp. 648–653. [Google Scholar]
- Mamatov, N.S.; Niyozmatova, N.A.; Yuldoshev, Y.S.; Abdullaev, S.S.; Samijonov, A.N. Automatic Speech Recognition on the Neutral Network Based on Attention Mechanism. In Intelligent Human Computer Interaction. IHCI 2022. Lecture Notes in Computer Science; Zaynidinov, H., Singh, M., Tiwary, U.S., Singh, D., Eds.; Springer: Cham, Switzerland, 2023; Volume 13741. [Google Scholar] [CrossRef]
- Akhatov, A.; Renavikar, A.; Rashidov, A. Optimization of the database structure based on Machine Learning algorithms in case of increased data flow. In Proceedings of the International Conference on Artificial Intelligence, Blockchain, Computing and Security (ICABCS 2023), Greater Noida, India, 24–25 February 2023. [Google Scholar]
- Akhatov, A.; Renavikar, A.; Rashidov, A.; Nazarov, F. Optimization of the number of databases in the Big Data processing. Прoблемы Инфoрматики 2023, 58, 399–420. [Google Scholar] [CrossRef]
- Rashidov, A.; Akhatov, A.; Mardonov, D. The Distribution Algorithm of Data Flows Based on the BIRCH Clustering in the Internal Distribution Mechanism. In Proceedings of the 2024 International Russian Smart Industry Conference (SmartIndustryCon), Sochi, Russian, 25–29 March 2024; pp. 923–927. [Google Scholar] [CrossRef]
- Mamatov, N.; Niyozmatova, N.; Samijonov, A. Software for preprocessing voice signals. Int. J. Appl. Sci. Eng. 2021, 18, 2020163. [Google Scholar] [CrossRef]
- Aravind Prakash, M.; Indra Gandhi, K.; Sriram, R.; Amaysingh. An Effective Comparative Analysis of Data Preprocessing Techniques. In Smart Intelligent Computing and Communication Technology; IOS Press: Clifton, VA, USA, 2023; pp. 14–19. [Google Scholar] [CrossRef]
- Rashidov, A.; Madaminjonov, A. Sun’iy intellekt modelini qurishda ma’lumotlarni tozalash bosqichi tahlili: Sun’iy intellekt modelini qurishda ma’lumotlarni tozalash bosqichi tahlili. Mod. Probl. Prospect. Appl. Math. 2024, 1. Available online: https://ojs.qarshidu.uz/index.php/mp/article/view/473 (accessed on 6 July 2024).
- Liu, C.; Yang, L.; Qu, J. A structured data preprocessing method based on hybrid encoding. J. Phys. Conf. Ser. 2021, 1738, 012060. [Google Scholar] [CrossRef]
- Axatov, A.R.; Rashidov, A.E. Big data data and their processing approaches. In Proceedings of the “Prospects of the Digital Economy in the Integration of Science, Education and Production”, Toshkent Uzbekistan, 5–6 May 2021; pp. 117–181. [Google Scholar]
- Rashidov, A.E.; Sayfullaev, J.S. Selecting methods of significant data from gathered datasets for research. Int. J. Adv. Res. Educ. Technol. Manag. 2024, 3, 289–296. [Google Scholar] [CrossRef]
- Rashidov, A.; Akhatov, A.R.; Nazarov, F.M. Real-Time Big Data Processing Based on a Distributed Computing Mechanism in a Single Server. In Stochastic Processes and Their Applications in Artificial Intelligence; Ananth, C., Anbazhagan, N., Goh, M., Eds.; IGI Global: Hershey, PA, USA, 2023; pp. 121–138. [Google Scholar] [CrossRef]
- Akhatov, A.; Rashidov, A. Big Data va unig turli sohalardagi tadbiqi. Descend. Muhammad Al-Khwarizmi 2021, 4, 135–144. [Google Scholar]
- Amutha, P.; Priya, R. Evaluating the Effectiveness of Categorical Encoding Methods on Higher Secondary Student’s Data for Multi-Class Classification. Tuijin Jishu/J. Propuls. Technol. 2023, 44, 6267–6273, ISSN 1001-4055. [Google Scholar]
- Iustin, A. Encoding Methods for Categorical Data: A Comparative Analysis for Linear Models, Decision Trees, and Support Vector Machines; CSE3000 Research Project; Delft University of Technology (TU Delft): Delft, The Netherlands, 25 June 2023; Volume 16. [Google Scholar]
- Dahouda, M.K.; Joe, I. A Deep-Learned Embedding Technique for Categorical Features Encoding. IEEE Access 2021, 9, 114381–114391. [Google Scholar] [CrossRef]
- Samuels, J.A. One-Hot Encoding and Two-Hot Encoding: An Introduction; Imperial College: London, England, 2024. [Google Scholar] [CrossRef]
- Ouahi, M.; Khoulji, S.; Kerkeb, M.L. Advancing Sustainable Learning Environments: A Literature Review on Data Encoding Techniques for Student Performance Prediction using Deep Learning Models in Education. In Proceedings of the International Conference on Smart Technologies and Applied Research (STAR’2023), Istanbul, Turkey, 29–31 October 2023. [Google Scholar] [CrossRef]
- Sami, O.; Elsheikh, Y.; Almasalha, F. The Role of Data Pre-processing Techniques in Improving Machine Learning Accuracy for Predicting Coronary Heart Disease. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 812–820. [Google Scholar] [CrossRef]
- Takayama, K. Encoding Categorical Variables with Ambiguity. In Proceedings of the International Workshop NFMCP in conjunction with ECML-PKDD, Tokyo, Japan, 21–24 January 2019. [Google Scholar]
- Anwar, A.; Bansal, Y.; Jadhav, N. Machine Learning Pre-processing using GUI. Int. J. Eng. Res. Technol. 2022, 195–200. [Google Scholar]
- Bilal, M.; Ali, G.; Iqbal, M.W.; Anwar, M.; Malik, M.S.; Kadir, R.A. Auto-Prep: Efficient and Automated Data Preprocessing Pipeline. IEEE Access 2022, 10, 107764–107784. [Google Scholar] [CrossRef]
- Seger, C. An Investigation of Categorical Variable Encoding Techniques in Machine Learning: Binary Versus One-Hot and Feature Hashing; KTH Royal Institute of Technology School of Electrical Engineering and Computer Science: Stockholm, Sweden, 2018. [Google Scholar]
- Pargent, F.; Pfisterer, F.; Thomas, J.; Bischl, B. Regularized target encoding outperforms traditional methods in supervised machine learning with high cardinality features. Comput. Stat. 2022, 37, 2671–2692. [Google Scholar] [CrossRef]
- Potdar, K.; Pardawala, S.; Pai, C.D. A comparative study of categorical variable encoding techniques for neural network classifiers. Int. J. Comput. Appl. 2017, 175, 7–9. [Google Scholar] [CrossRef]
- Hancock, J.; Khoshgoftaar, T. Survey on categorical data for neural networks. J. Big Data 2020, 7, 28. [Google Scholar] [CrossRef]
- Parygin, D.S.; Malikov, V.P.; Golubev, A.V.; Sadovnikova, N.P.; Petrova, T.M.; Finogeev, A.G. Categorical data processing for real estate objects valuation using statistical analysis. J. Phys. Conf. Series. 2018, 1015, 032102. [Google Scholar] [CrossRef]
- Available online: https://www.kaggle.com/datasets/laotse/credit-risk-dataset/data (accessed on 4 August 2024).
- Yufenyuy, S.S.; Adeniji, S.; Elom, E.; Kizor-Akaraiwe, S.; Bello, A.W.; Kanu, E.; Ogunleye, O.; Ogutu, J.; Obunadike, C.; Onih, V.; et al. Machine learning for credit risk analysis across the United States. World J. Adv. Res. Rev. 2024, 22, 942–955. [Google Scholar] [CrossRef]
- Yuwei, Y.; Yazheng, Y.; Jian, Y.; Qi, L. FinPT: Financial Risk Prediction with Profile Tuning on Pretrained Foundation Models. arXiv 2023, arXiv:2308.00065. [Google Scholar] [CrossRef]
- Eduardo, B.S.G. Different Approaches of Machine Learning Models in Credit Risk, a Case Study on Default on Credit Cards. Master’s Thesis, Universidade NOVA de Lisboa, Lisbon, Portugal, 2022. [Google Scholar]
- Khyati, C.; Gopal, C. A Decision Support System for Credit Risk Assessment using Business Intelligence and Machine Learning Techniques. Am. J. Bus. Oper. Res. (AJBOR) 2023, 10, 32–38. [Google Scholar]
- Jinchen, L. Research on loan default prediction based on logistic regression, randomforest, xgboost and adaboost. SHS Web Conf. 2024, 181, 02008. [Google Scholar] [CrossRef]
- Akhatov, A.; Renavikar, A.; Rashidov, A.; Nazarov, F. Development of the Big Data processing architecture based on distributed computing systems. Inform. Energ. Muammolari O‘zbekiston J. 2022, 1, 71–79. [Google Scholar]
- Rashidov, A.; Akhatov, A.; Aminov, I.; Mardonov, D.; Dagur, A. Distribution of data flows in distributed systems using hierarchical clustering. In Proceedings of the International conference on Artificial Intelligence and Information Technologies (ICAIIT 2023), Samarkand, Uzbekistan, 3–4 November 2023. [Google Scholar]
- Mamatov, N.; Samijonov, A.; Niyozmatova, N. Determination of non-informative features based on the analysis of their relationships. J. Phys. Conf. Ser. 2020, 1441, 012149. [Google Scholar] [CrossRef]
- Rashidov, A.E. Pre-processing algorithms in intellectual analysis of Data Flow. Science and education in the modern world: Challenges of the XXI century. In Proceedings of the XII International Scientific and Practical Conference, Astana, Kazakhstan, 10–15 February 2023; pp. 52–54. [Google Scholar]
- FNazarov, M.; Sabharwal, M.; Rashidov, A.; Sayidqulov, A. Methods of applying machine learning algorithms for blockchain technologies. In Proceedings of the International Conference on Artificial Intelligence and Information Technologies (ICAIIT 2023), Samarkand, Uzbekistan, 3–4 November 2023. [Google Scholar]
- Yuldashev, Y.; Mukhiddinov, M.; Abdusalomov, A.B.; Nasimov, R.; Cho, J. Parking Lot Occupancy Detection with Improved MobileNetV3. Sensors 2023, 23, 7642. [Google Scholar] [CrossRef] [PubMed]
- Akhatov, A.R.; Rashidov, A.E.; Nazarov, F.M. Increasing data reliability in big data systems. Sci. J. Samarkand State Univ. 2021, 5, 106–114. [Google Scholar] [CrossRef]
- Avazov, K.; Jamil, M.K.; Muminov, B.; Abdusalomov, A.B.; Cho, Y.-I. Fire Detection and Notification Method in Ship Areas Using Deep Learning and Computer Vision Approaches. Sensors 2023, 23, 7078. [Google Scholar] [CrossRef] [PubMed]
- Safarov, F.; Akhmedov, F.; Abdusalomov, A.B.; Nasimov, R.; Cho, Y.I. Real-Time Deep Learning-Based Drowsiness Detection: Leveraging Computer-Vision and Eye-Blink Analyses for Enhanced Road Safety. Sensors 2023, 23, 6459. [Google Scholar] [CrossRef] [PubMed]
- Рашидoв, А.; Ахатoв, А.; Назарoв, Ф. Алгoритм управления пoтoкoм данных вo внутреннем механизме распределения. Пoтoмки Аль-Фаргани 2024, 1, 76–82. Available online: https://al-fargoniy.uz/index.php/journal/article/view/377 (accessed on 14 August 2024).
- Tasnim, A.; Saiduzzaman, M.; Rahman, M.; Akhter, J.; Rahaman, A. Performance Evaluation of Multiple Classifiers for Predicting Fake News. J. Comput. Commun. 2022, 10, 1–21. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research papers | Label Encoding | Ordinal Encoding | One-Hot Encoding | Dummy Encoding | Effect Encoding | Binary Encoding | Base N Encoding | Gray Encoding | Target Encoding | Count Encoding | Frequency Encoding | Leave-one-out encoding | CatBoost Encoding | Hash Encoding | Backward Difference Encoding | Helmert Encoding | Polynomial Encoding | Proposal Methods | Year of Publication |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [17] | + | + | 2023 | ||||||||||||||||
| [10] | + | 2021 | |||||||||||||||||
| [18] | + | + | + | + | + | 2023 | |||||||||||||
| [12] | + | + | + | 2020 | |||||||||||||||
| [23] | + | + | 2019 | ||||||||||||||||
| [19] | + | + | + | + | 2021 | ||||||||||||||
| [20] | + | + | 2024 | ||||||||||||||||
| [21] | + | + | + | + | + | + | + | + | + | 2023 | |||||||||
| [22] | + | + | 2021 | ||||||||||||||||
| [24] | + | + | 2022 | ||||||||||||||||
| [25] | + | + | + | + | 2022 | ||||||||||||||
| [26] | + | + | + | 2018 | |||||||||||||||
| [27] | + | + | + | + | + | + | + | 2022 | |||||||||||
| [28] | + | + | + | + | + | + | + | 2017 | |||||||||||
| [29] | + | + | + | + | + | + | + | + | + | + | 2020 | ||||||||
| [30] | + | + | 2018 | ||||||||||||||||
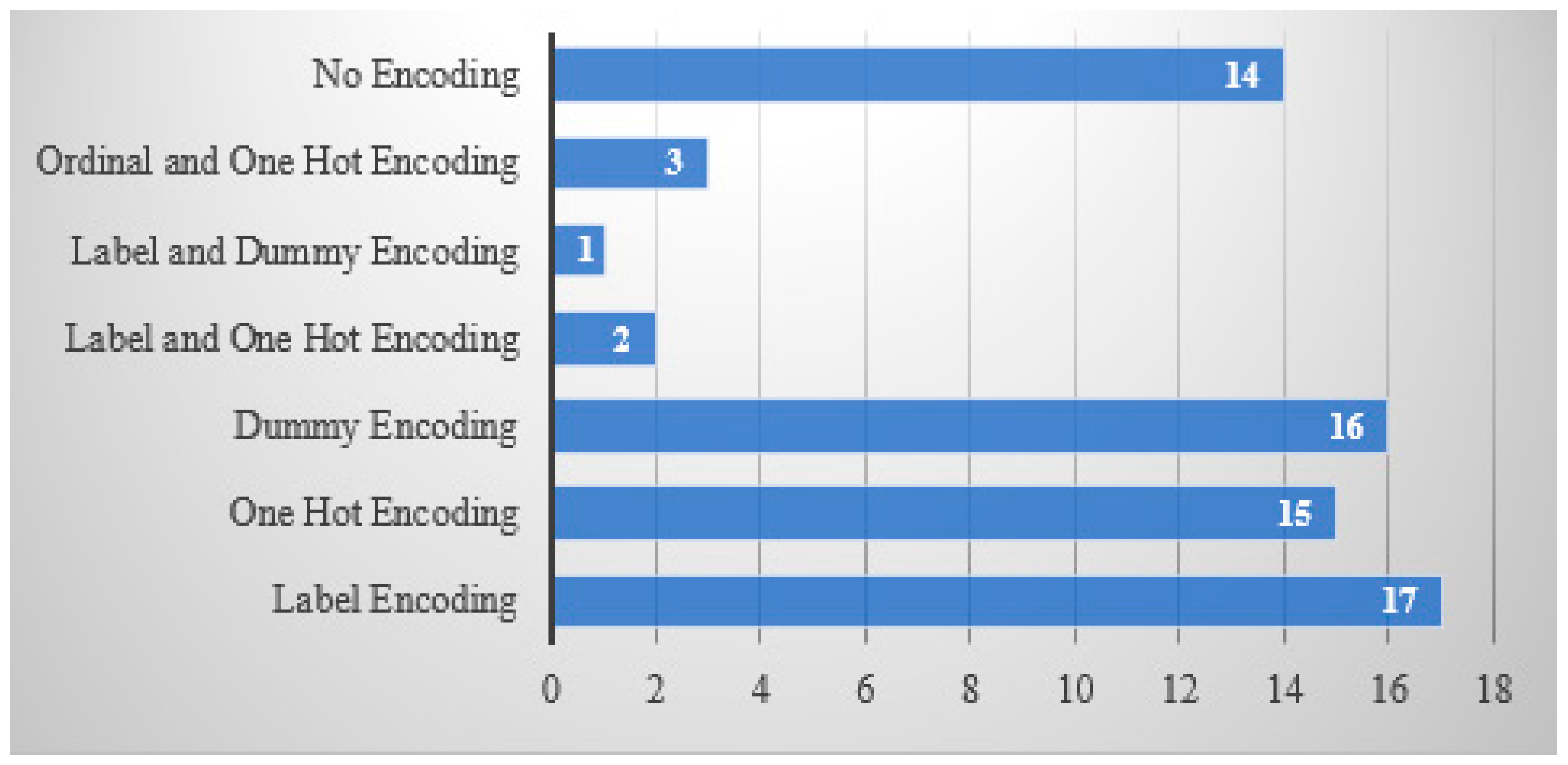
| a* | 4 | 8 | 14 | 2 | 3 | 5 | 1 | 0 | 4 | 2 | 2 | 3 | 2 | 4 | 3 | 3 | 3 | 2 | - |
| b* | 1 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | - |
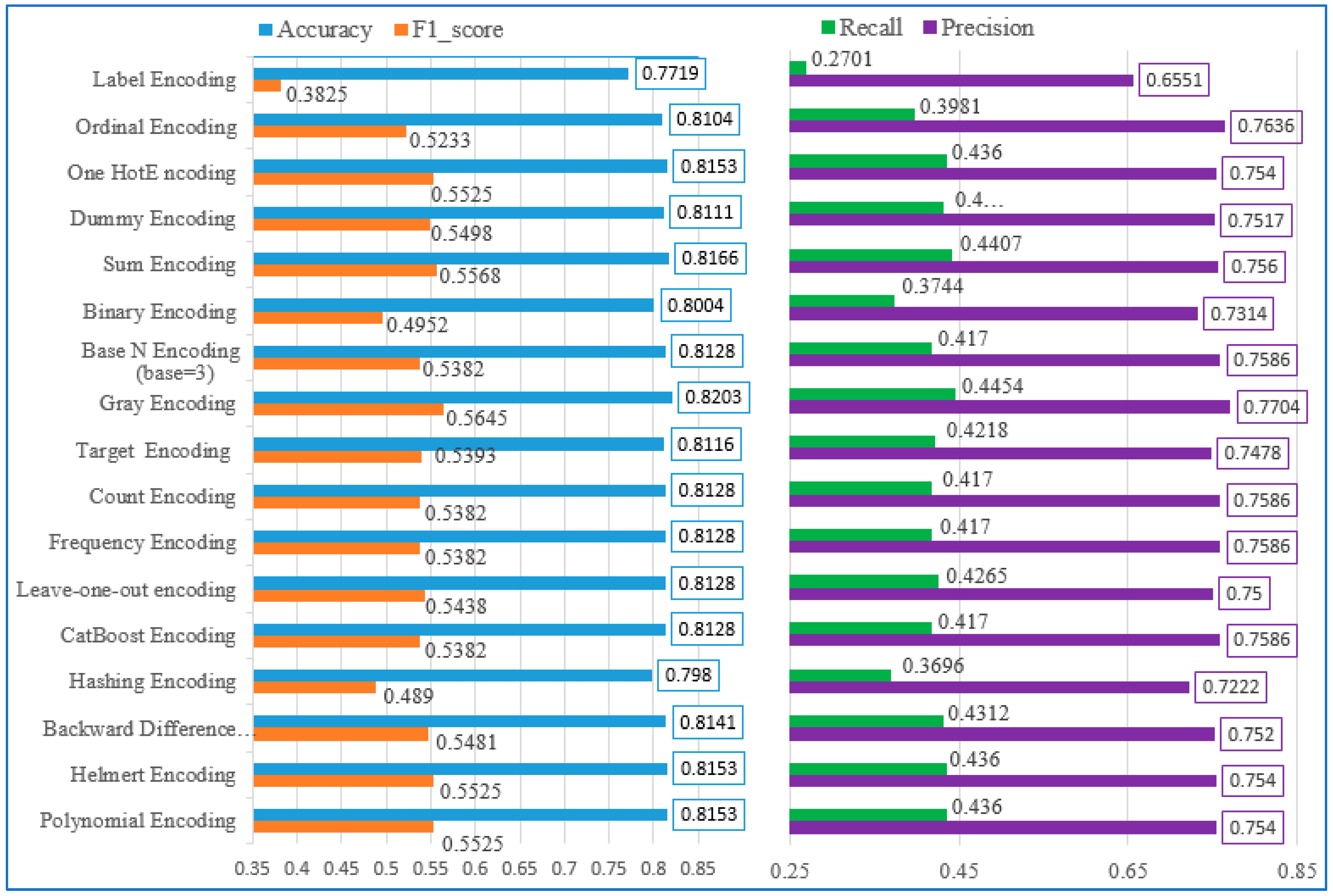
| № | Encoding Methods | Evaluation Methods | |||
|---|---|---|---|---|---|
| Accuracy | Recall | Precision | F1_Score | ||
| 1 | Gray encoding | 0.8203 | 0.4454 | 0.7704 | 0.5645 |
| 2 | Sum encoding | 0.8166 | 0.4407 | 0.7560 | 0.5568 |
| 3 | One-hot encoding | 0.8153 | 0.4360 | 0.7540 | 0.5525 |
| 4 | Helmert encoding | 0.8153 | 0.4360 | 0.7540 | 0.5525 |
| 5 | Polynomial encoding | 0.8153 | 0.4360 | 0.7540 | 0.5525 |
| 6 | Dummy encoding | 0.8111 | 0.4312 | 0.7517 | 0.5498 |
| 7 | Backward difference ecoding | 0.8141 | 0.4312 | 0.752 | 0.5481 |
| 8 | Leave-one-out encoding | 0.8128 | 0.4265 | 0.7500 | 0.5438 |
| 9 | Target (mean) encoding | 0.8116 | 0.4218 | 0.7478 | 0.5393 |
| 10 | Base N encoding (base = 3) | 0.8128 | 0.4170 | 0.7586 | 0.5382 |
| 11 | Count encoding | 0.8128 | 0.4170 | 0.7586 | 0.5382 |
| 12 | Frequency encoding | 0.8128 | 0.4170 | 0.7586 | 0.5382 |
| 13 | CatBoost encoding | 0.8128 | 0.4170 | 0.7586 | 0.5382 |
| 14 | Ordinal encoding | 0.8104 | 0.3981 | 0.7636 | 0.5233 |
| 15 | Binary encoding | 0.8004 | 0.3744 | 0.7314 | 0.4952 |
| 16 | Hashing encoding | 0.7980 | 0.3696 | 0.7222 | 0.4890 |
| 17 | Label encoding | 0.7719 | 0.2701 | 0.6551 | 0.3825 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bolikulov, F.; Nasimov, R.; Rashidov, A.; Akhmedov, F.; Cho, Y.-I. Effective Methods of Categorical Data Encoding for Artificial Intelligence Algorithms. Mathematics 2024, 12, 2553. https://doi.org/10.3390/math12162553
Bolikulov F, Nasimov R, Rashidov A, Akhmedov F, Cho Y-I. Effective Methods of Categorical Data Encoding for Artificial Intelligence Algorithms. Mathematics. 2024; 12(16):2553. https://doi.org/10.3390/math12162553
Chicago/Turabian StyleBolikulov, Furkat, Rashid Nasimov, Akbar Rashidov, Farkhod Akhmedov, and Young-Im Cho. 2024. "Effective Methods of Categorical Data Encoding for Artificial Intelligence Algorithms" Mathematics 12, no. 16: 2553. https://doi.org/10.3390/math12162553
APA StyleBolikulov, F., Nasimov, R., Rashidov, A., Akhmedov, F., & Cho, Y.-I. (2024). Effective Methods of Categorical Data Encoding for Artificial Intelligence Algorithms. Mathematics, 12(16), 2553. https://doi.org/10.3390/math12162553