Abstract
This paper employs an integral reinforcement learning (IRL) method to investigate the optimal tracking control problem (OTCP) for nonlinear nonzero-sum (NZS) differential game systems with unknown drift dynamics. Unlike existing methods, which can only bound the tracking error, the proposed approach ensures that the tracking error asymptotically converges to zero. This study begins by constructing an augmented system using the tracking error and reference signal, transforming the original OTCP into solving the coupled Hamilton–Jacobi (HJ) equation of the augmented system. Because the HJ equation contains unknown drift dynamics and cannot be directly solved, the IRL method is utilized to convert the HJ equation into an equivalent equation without unknown drift dynamics. To solve this equation, a critic neural network (NN) is employed to approximate the complex value function based on the tracking error and reference information data. For the unknown NN weights, the least squares (LS) method is used to design an estimation law, and the convergence of the weight estimation error is subsequently proven. The approximate solution of optimal control converges to the Nash equilibrium, and the tracking error asymptotically converges to zero in the closed system. Finally, we validate the effectiveness of the proposed method in this paper based on MATLAB using the ode45 method and least squares method to execute Algorithm 2.
Keywords:
nonzero-sum games; optimal asymptotic tracking control; integral reinforcement learning; neural network MSC:
93C10
1. Introduction
In the processes of manufacturing, military action, economic activities, and other purposeful human activities, it is necessary to apply a certain control to a controlled system and process to make a certain performance index reach the optimal value [1,2]; such a control effect is called optimal control, which is the most basic and core subject of modern control theory. The central issue is determining how to select a control law based on the system’s dynamics to ensure the system operates according to specified technical requirements, thereby optimizing a particular performance index of the system in a defined sense [3]. For example, the use of the minimum amount of fuel or the minimum time to accurately launch space rockets and satellites into the predetermined orbit is a typical optimal control problem (OCP). In the past few decades, optimal control has received much research attention and has been widely used in the fields of aerospace [4], industrial production [5], and power systems [6].
The OCP of linear systems or nonlinear systems can be solved by constructing and solving the Riccati equation or the Hamilton–Jacobi–Bellman (HJB) equation [7]. However, the HJB equation is a nonlinear partial differential equation (NPDE) that is extremely challenging to solve analytically due to the “curse of dimensionality” as the dimensionality increases. Therefore, many scholars have developed an adaptive dynamic programming (ADP) technique that can solve the HJB equation [8,9]. In [10], the convergence and error bound analysis of value iteration (VI) ADP for continuous-time (CT) nonlinear systems were studied. However, most of the previously developed OCP discussed above is for systems affected by a single input parameter or a single agent. In fact, not only are multi-agent systems attracting attention from academics [11,12,13], but many practical systems are controlled by multi-input controllers, such as micro smart grid systems [14] and wireless communication systems [15], where each control input can be thought of as a player, and each player minimizes its own cost functions by influencing the system state. In this case, each player’s optimal problem is coupled to the other players’ optimal problems; therefore, the optimal solution does not exist in the general sense, which promotes the formulation of alternative optimality criteria.
For these multi-input systems, game theory provides an approach to a solution [16,17,18]. Nash equilibrium refers to a combination strategy. The combination strategy consists of the optimal strategy of all players; that is, under the condition of a given strategy of the other players, no individually motivated players choose other strategies, so no one is motivated to break this equilibrium [19]. Therefore, in some game-based control methods, the Nash equilibrium is often used to provide the concept of solutions.
Game theory has been successful in the simulation of strategic behavior in which each player’s outcome depends on their own actions and those of all the other players. Each player influences the state of the system by selecting its own control policy to minimize its own predetermined performance goals independent of the other players. Differential games are an important field of game theory and have been used in different fields [20,21,22]. Differential games can be classified into zero-sum games, cooperative games, and NZS games based on the different tasks and roles of the participants. The objective of NZS games is to find a set of optimal control strategies that minimize the individual performance index function and ensure the stability of the NZS game systems, ultimately producing a Nash equilibrium. The Nash equilibrium can be obtained by solving coupled HJ equations [23]. However, the HJ equation is also an NPDE.
Recently, numerous scholars have investigated approximate dynamic programming (ADP) and reinforcement learning (RL) using an NN to approximate the Nash equilibrium [24,25,26,27]. RL can be classified into model-free RL and model-based RL based on the dynamic model of the system. The difference between the two approaches is whether a system model is required in the solution process. For model-based RL, Werbos [24] was the first to propose the use of ADP to tackle the discrete-time OCP, including two algorithms, VI and policy iteration (PI). However, compared to the PI algorithm, the convergence speed of the VI algorithm is slower, and the control strategy obtained at each iteration cannot ensure system stability. In [25], an online critical NN weight-tuning algorithm combining PI and recursive LS is proposed to solve the optimal control problem for players in nonlinear systems with nonzero-sum games. In [26], Zhang proposed a single-layer critic NN instead of a dual critic–actor NN, which solves the Nash equilibrium of NZS game systems. Vrabie [27] proposed an IRL method to solve the HJB equation with unknown drift dynamics. The IRL method is based on the integration time interval, PI technique, and RL concept to obtain the value function and has become a common method for solving the HJB equation. However, these methods still need to assume some knowledge of the model. This has motivated the development of model-free learning design methods.
Model-free RL can be classified into two categories: identifier-based RL and data-based RL. For identifier-based RL, Liu [28] proposed a critic–identifier structure to tackle the OCP for NZS games with completely unknown dynamics. In this approach, an identifier NN and a critic NN were used for approximating the unknown dynamics system and value function, respectively. However, identifier training is usually time-consuming and inevitably introduces harmful identifier errors. Data-based RL methods are used to solve discrete-time nonlinear NZS game systems [29,30] and CT nonlinear NZS games systems [31,32,33]. Compared to the identifier-based RL method, this method avoids the introduction of identification error.
To our best knowledge, previous studies have focused on the regulation problem, and there have been few studies on the OTCP of NZS game systems. However, for practical systems, it is common to have the state or output of the system trace a given reference (desired) signal. For the OTCP, the traditional approach entails a two-stage process: optimal feedback tracking control and steady-state control [34]. To avoid such a classic two-step control design and reduce the computational cost, we will tackle the OTCP through an augmented system that only needs a one-step design. Currently, the conventional approach to solving the OTCP involves constructing an augmented system. This transforms the original OTCP into a related optimal regulation problem, which is subsequently tackled using the existing methods for such problems. The solution to the OTCP, namely, the Nash equilibrium, can thus be obtained through this process. In [35], an identifier–critic NN based on RL and NZS game theory was proposed to address the OTCP for nonlinear multi-input systems. However, in that paper, they used NN identification, which inevitably introduced identification errors, and the discount factor was not considered in its value function. Wen [36] solved the OTCP for discrete-time linear two-player NZS game systems by using model-free RL, in which the value function takes the discount factor into account. In [37], a new adaptive critic design was proposed to approximate the online Nash equilibrium solution for the robust trajectory tracking control of NZS games for continuous-time uncertain nonlinear systems. Zhao [38] solved the OTCP of NZS games of nonlinear CT systems through RL. However, in that paper, the tracking error is bounded, which is not ideal. In this paper, an offline IRL algorithm based on a single-layer critic NN is proposed to address the OTCP of N-player NZS games with nonlinear CT systems.
Compared to the existing literature, the innovations of this paper are primarily reflected in the following aspects:
- To the best of our knowledge, no offline learning algorithm has been used to tackle the OTCP of nonlinear CT NZS differential game systems.
- In this paper, the discount factor is considered in the cost function, which relaxes the requirement of the reference signal and does not need to require the reference signal to be an asymptotically stable signal.
- In this paper, only the critic NN is considered to avoid the identification errors and to reduce the computational burden.
- The offline IRL algorithm designed in this paper enables the weight error of the NN to converge to zero and the approximate solution to converge to a Nash equilibrium. In addition, the stability of the tracking error in the closed system is asymptotically guaranteed.
The subsequent sections of this paper will proceed as follows. In Section 2, an augmented system is developed to convert the OTCP into an optimal regulation problem, and a model-based PI algorithm is introduced. In Section 3, an IRL technique is proposed to approximate the value function, and the equivalence between the proposed method and this model-based policy iteration is proven. Section 4 presents the offline iterative learning algorithm and proves its convergence. Section 5 provides a simulation example. And Section 6 concludes this paper.
The following notations will be used throughout this paper:
| Symbols | Meaning of Symbols |
| real number set | |
| n-dimensional vector | |
| the set of real matrices | |
| ∇ | gradient operator |
| absolute value | |
| 2-norm of a matrix or vector | |
| sup | supremum |
| a function space on with continuous first derivatives |
2. Preliminaries
2.1. Problem Description
A class of nonlinear CT NZS differential game systems consisting of N-players is given by
where is the control input for player j, denotes the measurable system state, and and are both smooth nonlinear functions. Assume that is known and Lipschitzcontinuous. is the set of control inputs for all players except player i: .
Assumption 1
([39]). For the OTCP, we need the following basic assumptions:
- (a)
- The drift dynamics system is unknown and Lipschitz-continuous on a compact set with .
- (b)
- is bounded by a constant , i.e., .
Remark 1.
Assumption 1 (a) is a standard assumption that guarantees that the solution of system (1) is unique for any finite initial condition. For Assumption 1 (b), although this assumption is somewhat strict, in practice, there are still many systems that meet such a condition, such as robot systems.
The bounded reference signal is generated by a Lipschitz-continuous command generator
where , denotes the reference signal. Note that the reference dynamics only need to be stable in the Lyapunov sense and are not required to be asymptotically stable. Sine and cosine waves are some examples of such signals.
The purpose of tracking control is to achieve following the . Then, the tracking error is given by
Define the cost function of player i as
where , and is the discount factor.
Take the derivative of Equation (3):
The objective of the OTCP is to determine the optimal control inputs that ensure asymptotically converges to zero, and the predetermined cost function (4) for each player i is minimized.
Next, we introduce the augmented state including tracking error and reference signal expressed by , and the corresponding augmented system can be obtained by using Equations (2) and (5):
where
Redefine the cost function of player i as
where .
Definition 1
Remark 2.
As observed from (6), because the augmented system states contain , this state is uncontrollable. However, because the reference signal is assumed to be bounded, the admissible control policy means that is bounded.
For the simplicity of description, we denote admissible control as . Given admissible control , the value functions for player i are given by the following:
The goal of the optimal regulation problem is to find a set of admissible control sequences that minimizes the value functions (8) for each player. also represents the Nash equilibrium of NZS games.
Definition 2
([40]). (Nash equilibrium.) An N-tuple of control policies is called the Nash equilibrium of an N-player game if the following N inequalities are satisfied:
Remark 3.
The value function (8) must use a discount factor because does not go to zero and then the input cost does not go to zero either, and therefore, the performance function is unbounded.
Remark 4.
The cost function (4) for the OTCP of system (1) has been transformed into a cost function (7) for the related problem of partial optimal regulation (i.e., only adjust the tracking error) by building an augmented system (6). Therefore, we can solve the OTCP of system (1) by using the method of dealing with the optimal regulation problem.
Assume that the value function , where is a function space on with continuous first derivatives for . By differentiating along the system trajectories (6), we can write Equation (8) as follows:
Equation (10) can be written as
where , , is the transpose of , and .
Define the Hamiltonian functions:
The optimal value functions can be given:
Using the stationarity conditions [41], the optimal control inputs can be obtained:
Substituting Equation (14) into Equation (11), the N coupled HJ equations are obtained:
It is clear from Equation (14) that must be known if is to be obtained. That is, solving the OTCP for NZS games is ultimately a question of solving the coupled HJ Equation (15). However, because the coupled HJ equation is an NPDE, it is very difficult to solve it directly. Next, we will apply IRL to try to address the coupled HJ equations for augmented systems (6).
2.2. Policy Iteration Solution for NZS Games
It is essential to recognize that solving the coupled HJ Equation (15) requires the information of all the other players’ policies. Thus, Equation (15) is difficult to solve. Next, we try to obtain the solution with the PI technique.
The following Algorithm 1 is actually an infinite iterative process that is only suitable for theoretical analysis in this paper. For practical systems, it is common to set a termination condition on the value function in step 4. According to [28], the convergence of Algorithm 1 is proven, i.e., and as .
It is clear that Equation (16) still requires a full system model because Algorithm 1 does not provide a solution for the HJ equation with unknown drift dynamics. References [35,42] used the identifier technique to solve unknown NZS games. To avoid the identification process, we adopt the IRL method to tackle NZS games with multiple inputs, where is unknown.
| Algorithm 1 Model-based PI for solving the HJ equation |
|
3. IRL Method for NZS Games
In this section, we adopt an IRL method to tackle NZS games and prove the convergence of the IRL method.
3.1. IRL Method
Inspired by [43], we can rewrite system (6) as follows:
where , represents the kth iteration of the jth control input.
According to the IRL technique, taking integrals on both sides of Equation (19) over the time interval ,
From Equation (20), it is evident that dynamics knowledge is not needed. Therefore, by replacing Equation (16) in Algorithm 1 with Equation (20), the NZS games with unknown are solved. Next, we will prove that Equation (16) is equivalent to Equation (20).
Theorem 1.
Proof of Theorem 1.
From the derivation of Equation (20), it is obvious that if is the solution of Equation (16), then satisfies Equation (20). If we can prove that Equation (20) has only one solution, then Equation (20) is equivalent to Equation (16). We use the contradiction method to derive that Equation (20) has only one solution. Before embarking on the proof of contradiction, let us derive the following fact:
From Equation (20), we can obtain
From Theorem 1, it follows that the solution of Equation (16) is equivalent to the solution of Equation (20), so the convergence of the IRL iterative method (20) is guaranteed. That is, the equivalence between Algorithm 1 and the IRL method is proven, which ensures the convergence of the IRL method.
3.2. Single-Layer Critic NN
A single-layer critic NN is utilized for approximating the solution to Equation (20). According to the Weierstrass approximation theorem, the approximate form of the value function and its gradient can be given as follows:
where are linearly independent activation functions, denotes the number of hidden neurons, are the unknown ideal weights, and are the approximation errors. It is shown in [8] that as , the approximation error converges to zero.
Assumption 2
([39]).
- (1)
- The approximation error and its gradient are bounded on Ω, specifically, and , where and , , are positive constants.
- (2)
- The activation functions and their gradients are bounded, i.e., and , with and , , being positive constant.
Remark 5.
For Assumption 2 (1), it is known that as the number of neurons , the error . In addition, for fixed , there exist and . For Assumption 2 (2), this condition is mild in practice because many activation functions, such as the sigmoid function and tanh function, satisfy Assumption 2 (2).
According to Equation (29), Equation (20) can be written as
where is the error from the NN approximation error:
Denote by the estimations of . Thus, can be approximated as
Based on Equation (17), the approximate control policies are
Remark 6.
Because the input dynamics are known, we directly use the critic NN approximation (19) to obtain the approximated optimal control (20). Therefore, the single-layer critic structure is adopted instead of the actor–critic structure, reducing the computational cost and avoiding approximation errors from the action NN.
Due to the estimation error of Equation (29), is replaced by in Equation (20). Therefore, the residual error for player i is given by
Note that
and
For notation simplicity, define
Consider the objective function
In the following section, an algorithm is proposed to update the weights by minimizing and to prove the convergence of the algorithm.
4. Offline Iterative Learning
4.1. Offline Algorithm for Updating the Weights
The LS method will be used for updating . represents a strictly increasing time series, where p represents the number of samples and is a sufficiently large integer. denotes the sample set, where is the state at time and and represent the control input at time with . For simplicity, let and , where
The following persistence of excitation (PE) condition is used for ensuring the convergence of .
Assumption 3.
There exist and such that for all , we have
where denotes the identity matrix.
Based on [8,43], the updating law of is given by
where
An offline algorithm is presented based on the weight updating law (42). In Algorithm 2, we can see that steps 1–2 are a measurement process that is used to collect real data. Steps 3–4 are an offline learning process, which is used to approximate real weights.
| Algorithm 2 NN-based offline learning for updating weights |
Remark 7.
In on-policy learning algorithms [26,38], approximate control policies (not real policies) are usually used for generating data and then learning the value function. This means that during the strategy learning process, “incorrect” data are employed, leading to the accumulation of errors. According to reference [43], Algorithm 2 can be regarded as an off-policy learning algorithm. In this algorithm, control can be arbitrarily selected on , and ensures error-free data generation, thereby preventing cumulative errors.
Remark 8.
As seen from (42), updating the weight requires the inverse of , necessitating the PE condition to ensure the invertibility of this matrix. Thus, in practical applications, it becomes essential to add detection noise, such as random noise or sine waves of different frequencies, to make the given control input meet the PE assumption.
4.2. Convergence Analysis for the Offline Algorithm
To show the effectiveness of the updating law (42), the following theorem is given.
Theorem 2.
Proof of Theorem 2.
A similar proof has already been provided in references [32,44]. To avoid repetition, we omit some similar proof steps.
From Theorem 2, is the solution of iteration Equation (20). Then, with the same procedure used in Theorem 3.1 of reference [44] and Theorem 2 of reference [32], result (43) can be proven.
In other words, there exists , such that if , then
According to Theorem 4 of reference [8], the result of can be proven directly.
Because is linearly independent, using [27] Theorem 2, we know that . We know from Assumption 1 (b) that is bounded, so it is clear that is also bounded. Therefore, the errors will eventually converge to zero. In other words, will converge to , the N-tuple control inputs constitute a Nash equilibrium for the NZS games, and the tracking error dynamics (5) will be asymptotically stable. □
Remark 9.
From Theorem 2, we can easily obtain the following conclusions. The critic weight error converges to zero. The optimal control inputs can enable to track the reference signal , and converges to ; then, the N-tuple control outputs can guarantee that the stability of the tracking error of the closed systems will be asymptotically stable.
5. Simulation Results
We will verify the feasibility of the IRL method through a numerical simulation example. Consider the nonlinear CT differential game with two players as below [35]:
where
are the control inputs and is the system state.
The reference signals are given by the following commands:
Select the initial state , , , , , , and . Set the initial probing control input . We set the interval of integration as 0.05 and the number of samples collected as . The augmented system states are , and select the following activation functions
and the initial NN weights
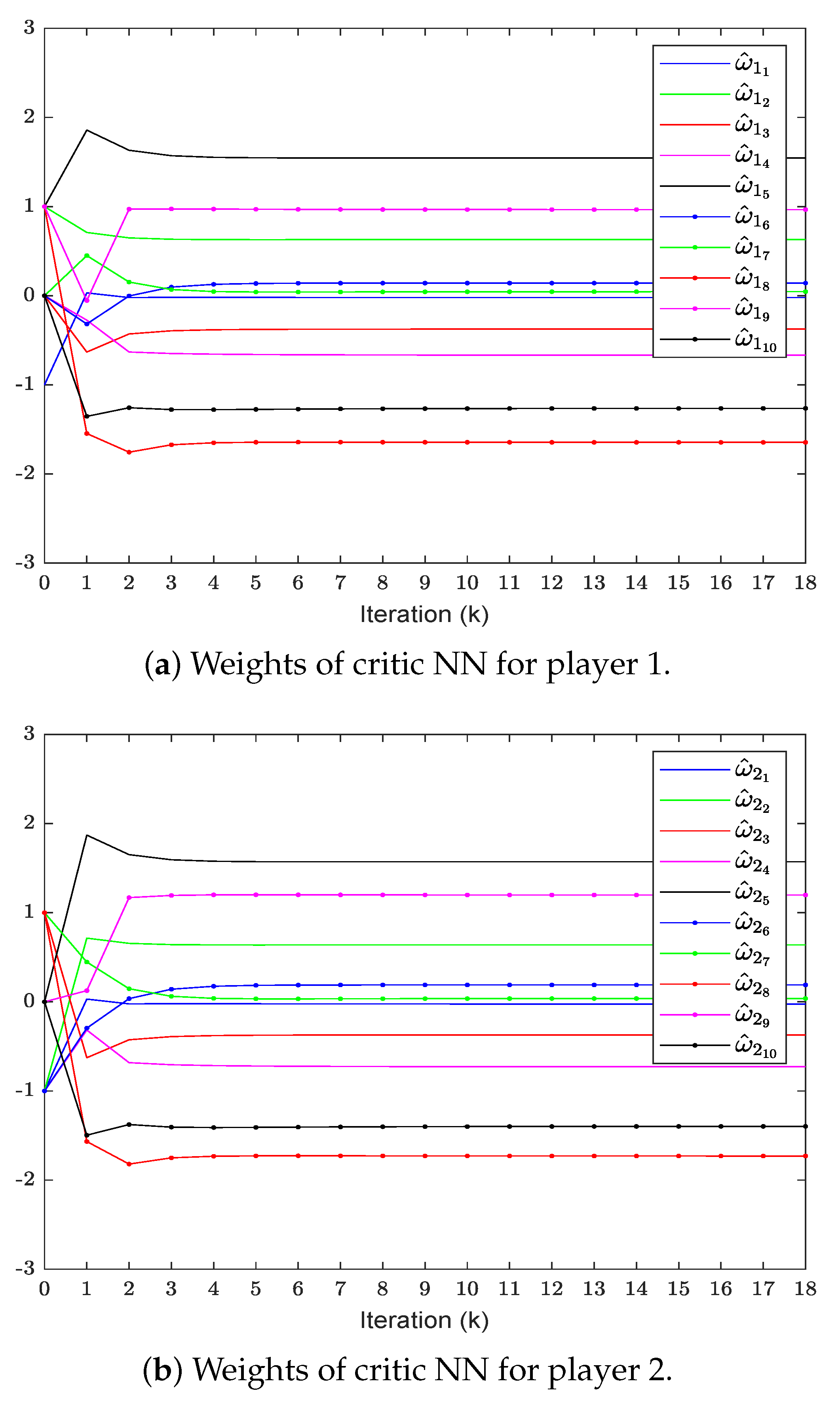
In order to verify the effectiveness of the proposed method, we will compare it with the method in [38] under the same conditions. To save space, this article presents a comparison of only some of the important results. Figure 1 shows the convergence curve of evaluating the weights of the critic NN, which finally converges to
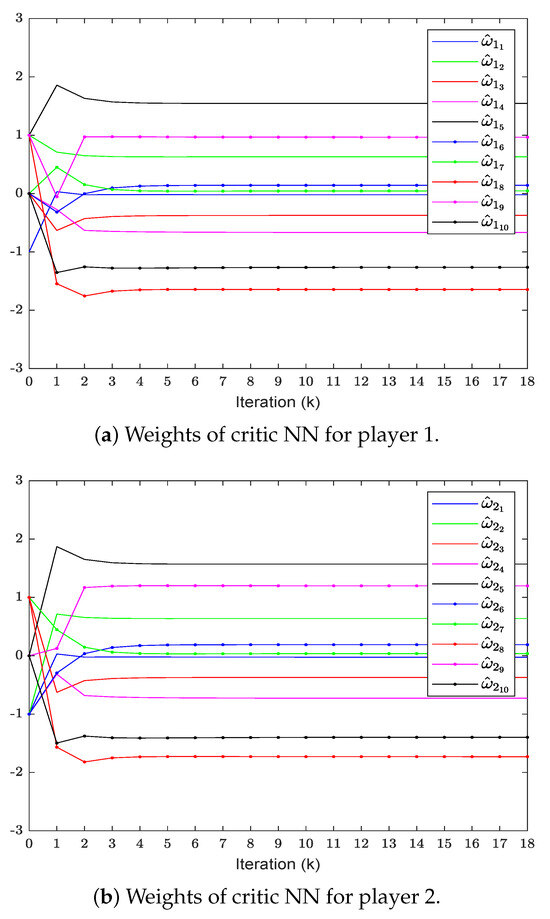
Figure 1.
Critic NN weight convergence curve.
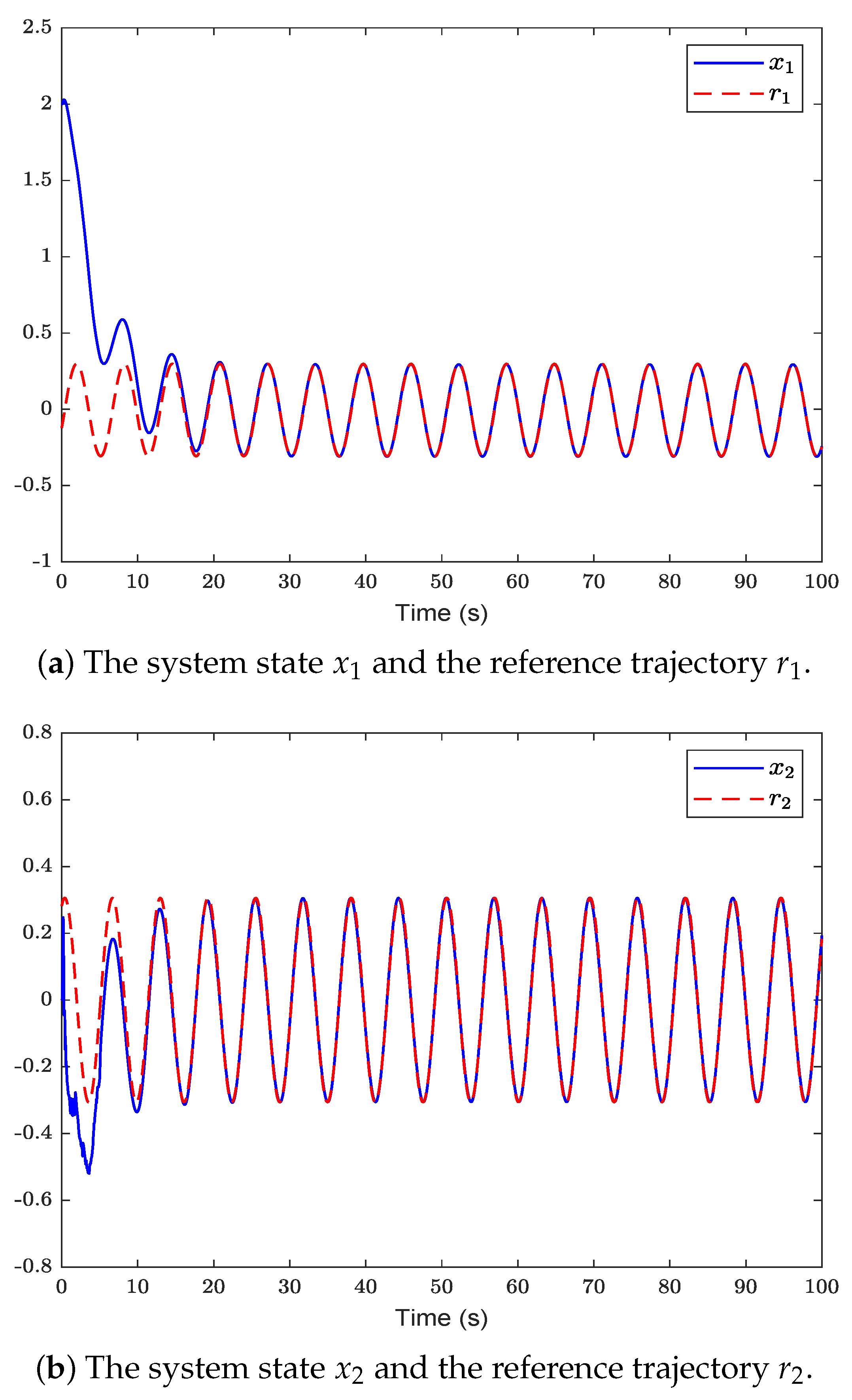
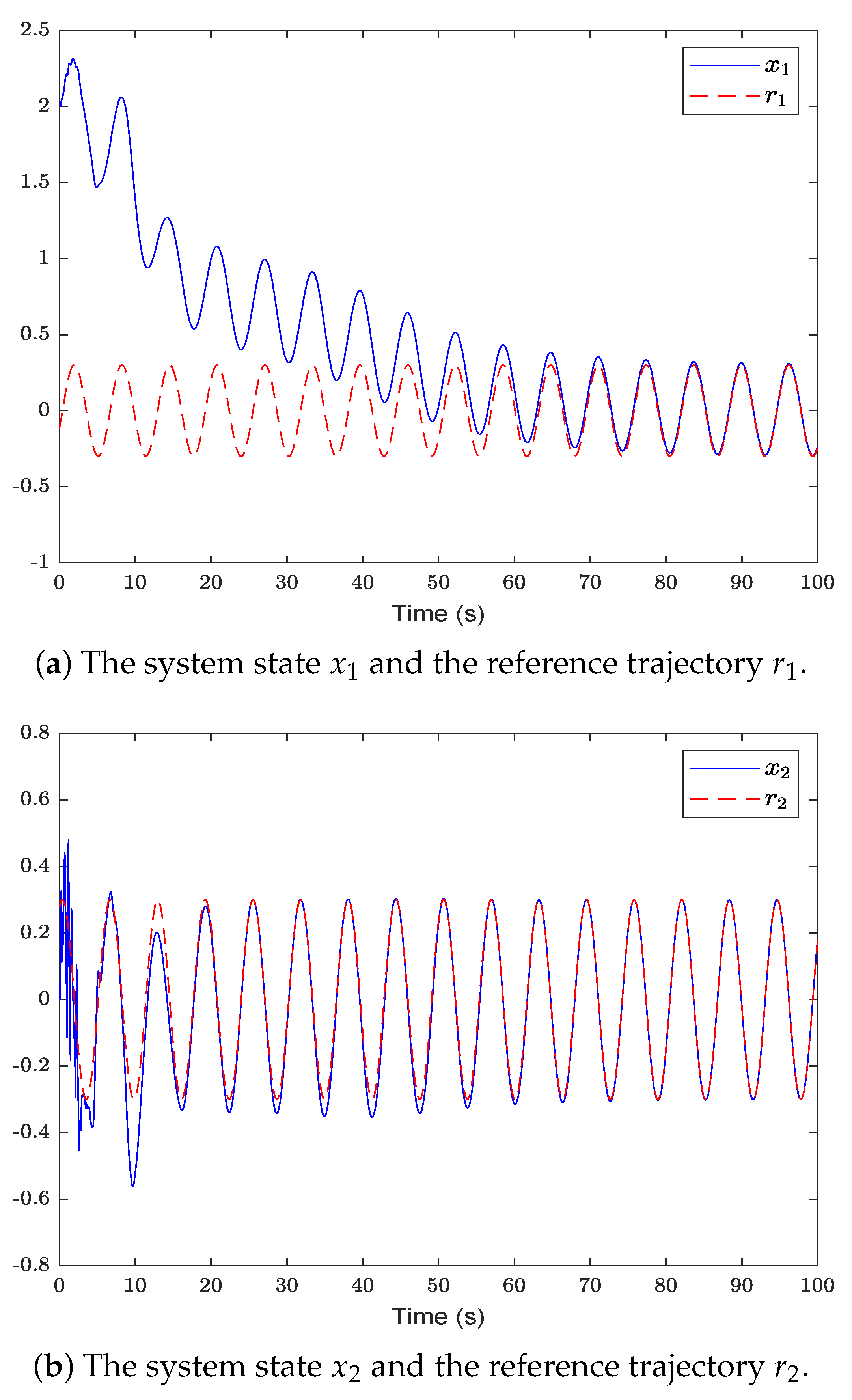
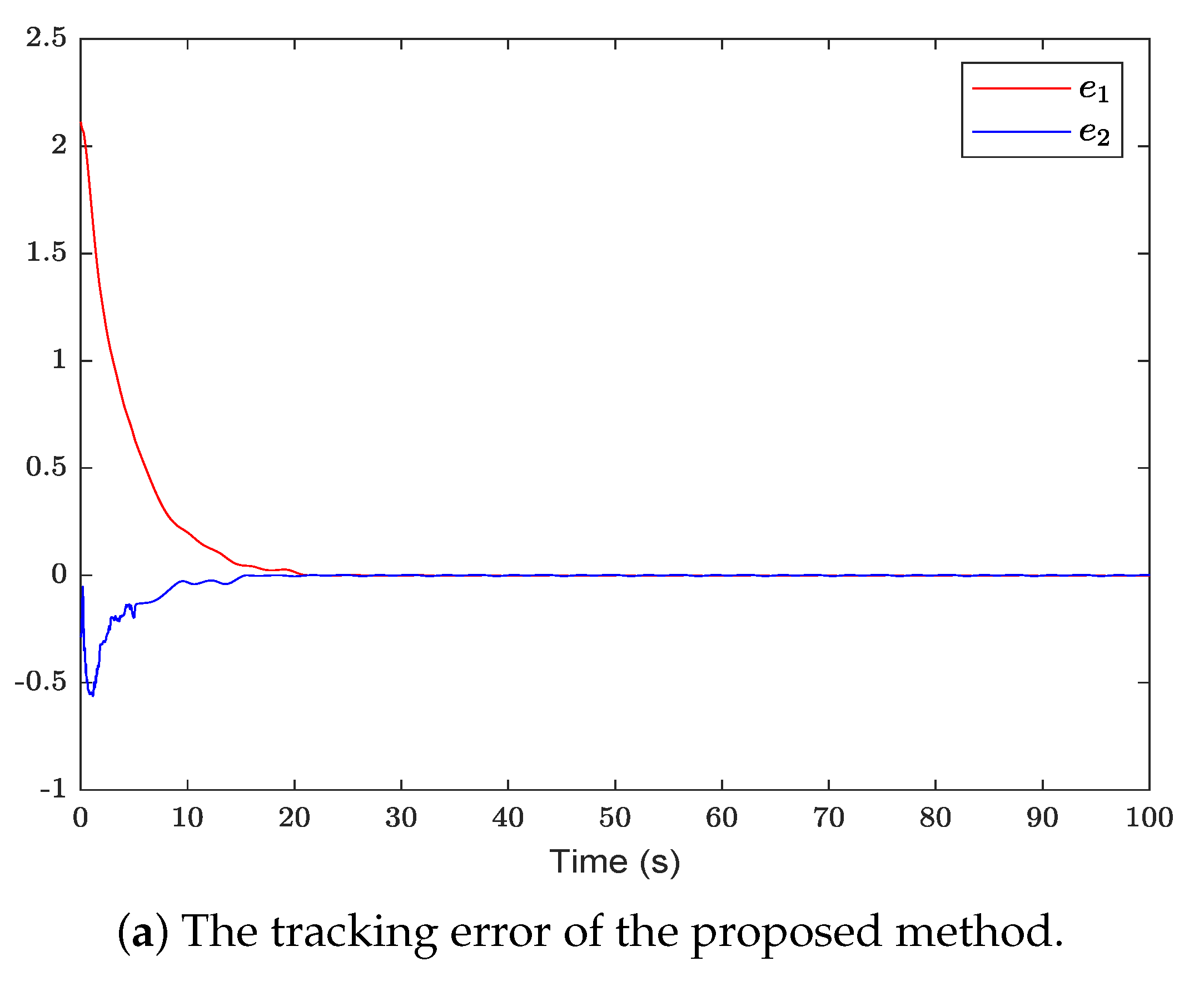
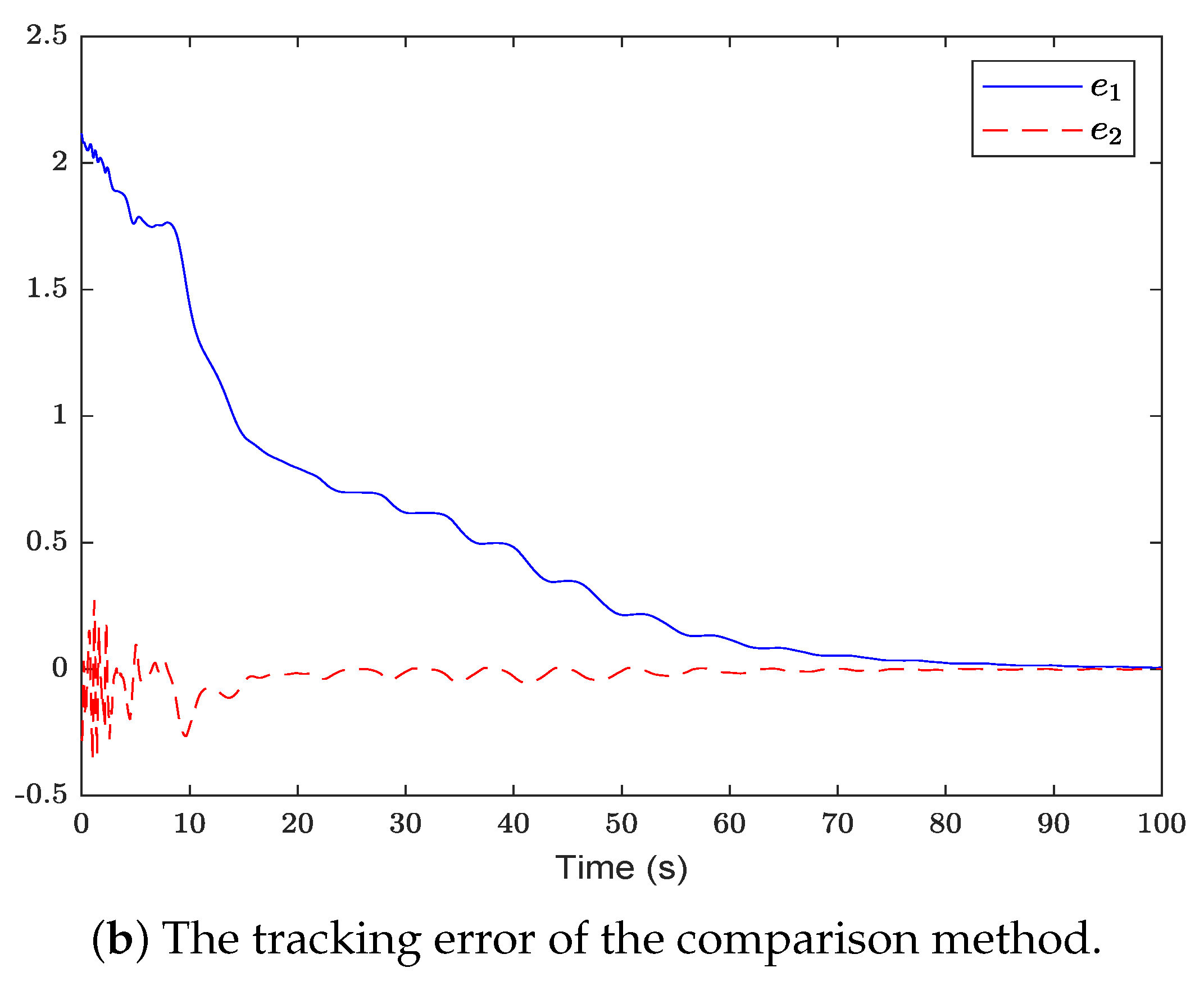
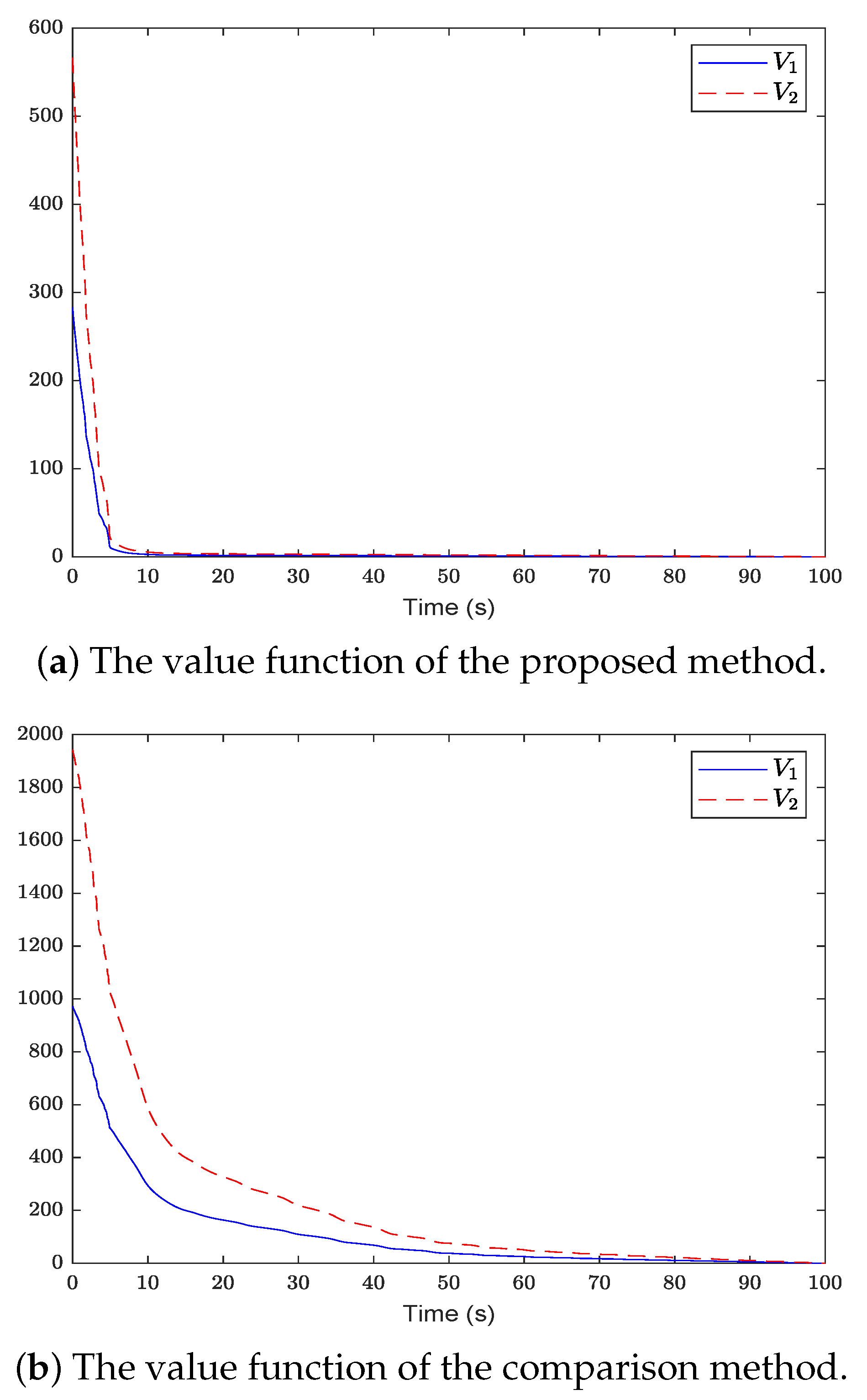
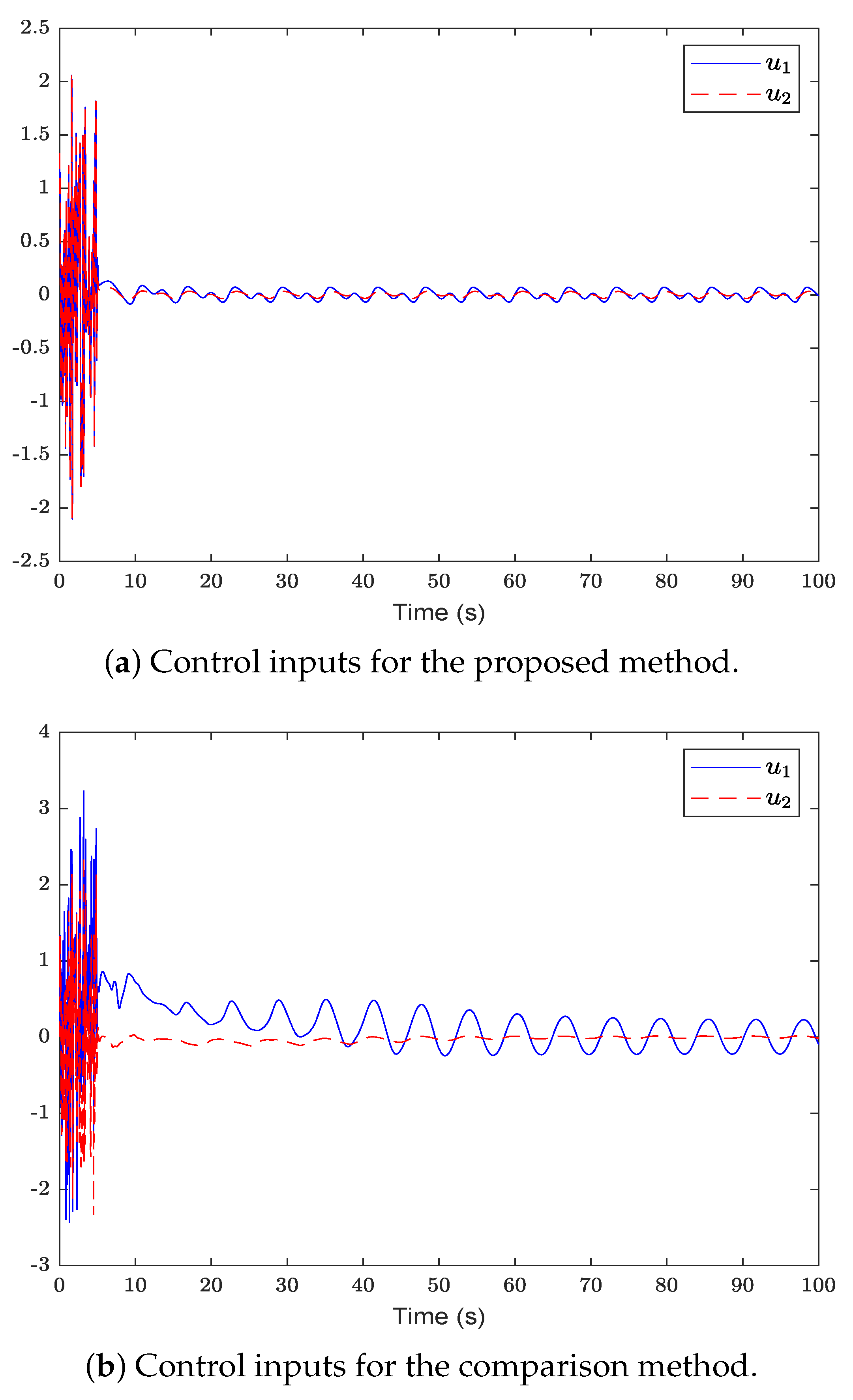
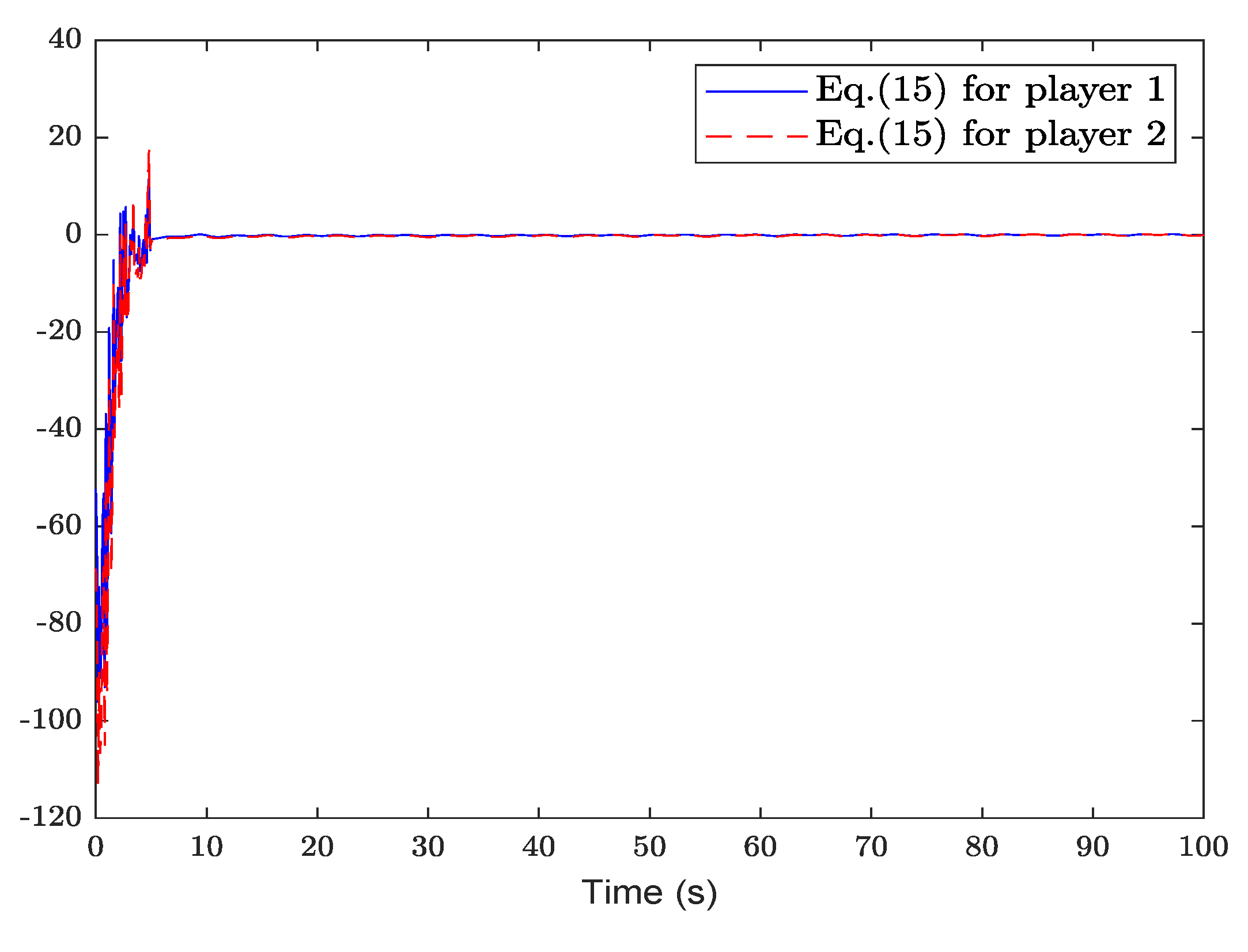
Figure 2 shows the system state and reference trajectory of the proposed method in this paper. It can be seen that the system state can track the reference trajectory after 20 s. Figure 3 shows the system state and reference trajectory of the method given in [38]. It can be seen that the reference trajectory can be tracked in the system state only after 90 s. In Figure 4a,b are the evolution curves of the tracking error of the proposed method in this paper and that of the proposed method in [38], respectively. From Figure 4, it is easy to see that the tracking error convergence speed of the proposed method in this paper is faster than that used in [38]. Figure 5 shows a comparison between the value function obtained by the proposed method and that obtained by the method used in [38]. It is easy to see that the value function of the proposed method in this paper is smaller both at the initial moment and the final moment, that is, the optimal control obtained in this paper is better than that obtained by the comparison method. The control inputs of the proposed method are compared with that of the comparison method in Figure 6. Figure 7 is an evolution curve approximating the HJ equation. For Equation (15), optimal control can make the left end of Equation (15) equal to zero, but for a non-optimal control it is not necessarily possible to make the left end of Equation (15) equal to zero. In this paper, approximate optimal control is used to approximate optimal control, so it is necessary to bring the obtained approximate optimal control back to the right end of Equation (15) to verify whether it is equal to zero. By observing Figure 7, it can be seen that the optimal approximate control obtained by this method makes the left end of Equation (15) equal to zero, i.e., the optimal approximate control converges to the optimal control .
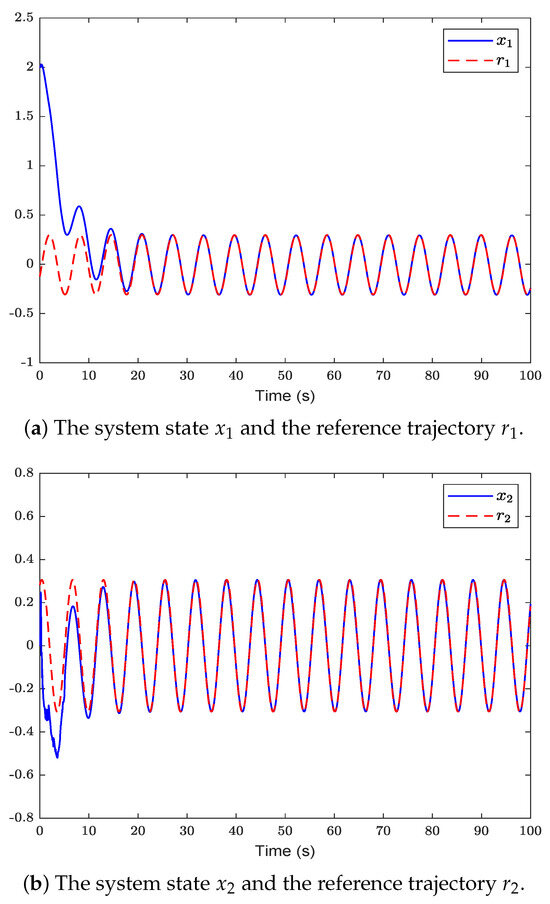
Figure 2.
The system state of the proposed method is compared with the reference trajectory .
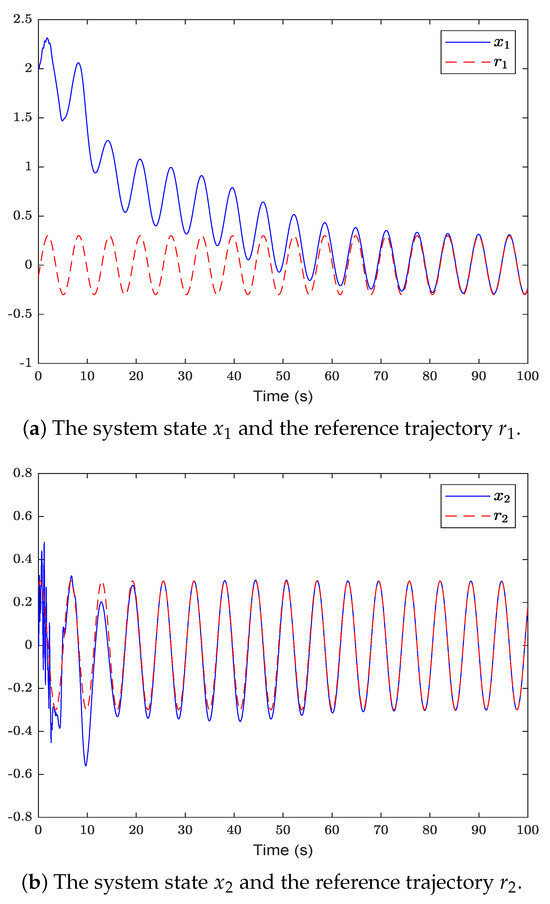
Figure 3.
The system state of the comparison method is compared with the reference trajectory .
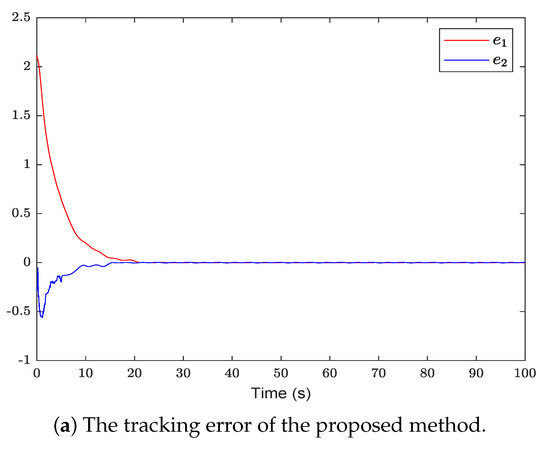
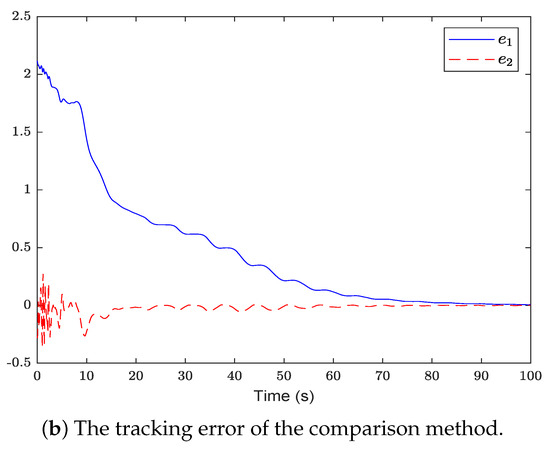
Figure 4.
The evolution curve of the tracking error of the proposed method is compared with that of the comparison method.
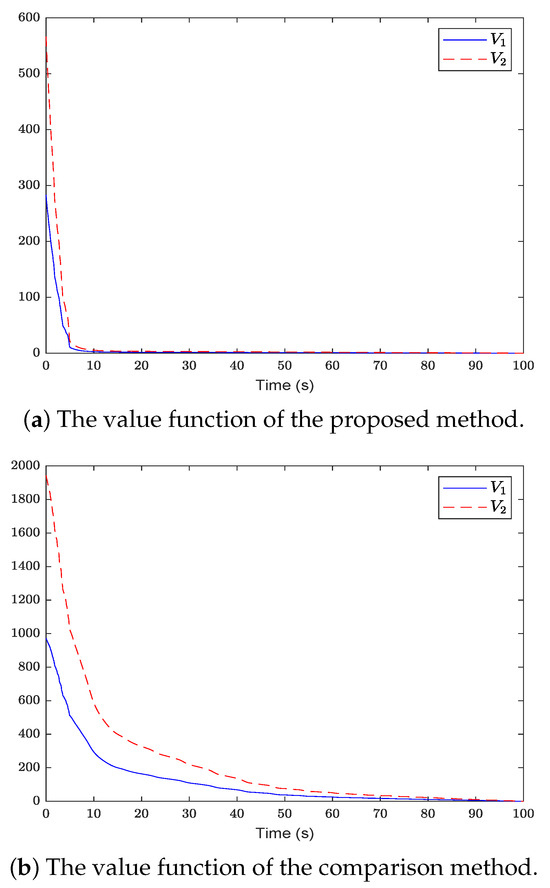
Figure 5.
The comparison between the value function of the proposed method and that of the comparison method.
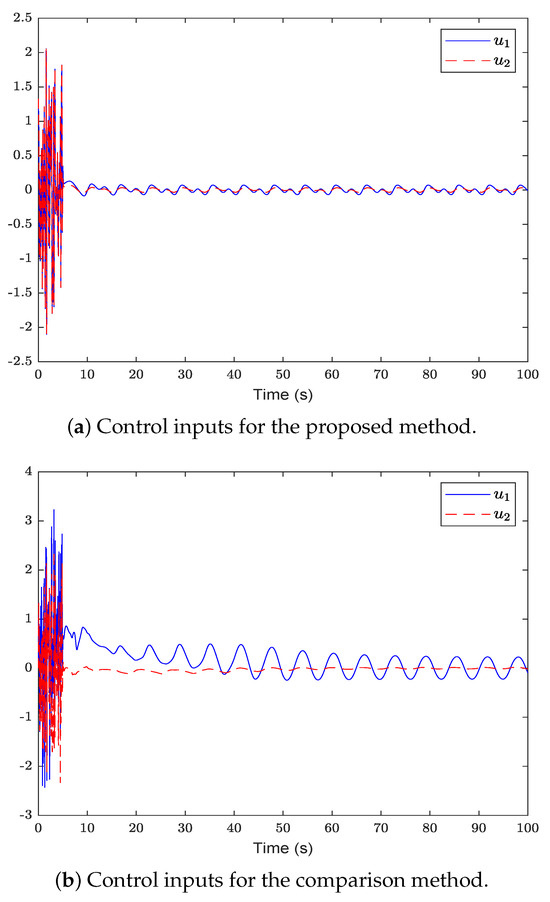
Figure 6.
The control inputs of the proposed method are compared with that of the comparison method.
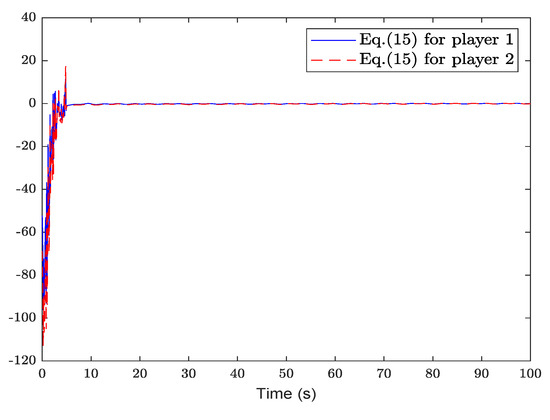
Figure 7.
The evolution of (15).
6. Conclusions
To tackle the OTCP for nonlinear CT NZS differential game systems with unknown drift dynamics, an IRL method based on PI is proposed. Because the HJB equation is an NPDE that cannot be solved directly, the single-layer critic NN is used for approximating the value function of each player, and the LS method is used to update the weight of the NN. Due to the stability of the tracking error dynamics system, the approximate solutions converge to a Nash equilibrium, and the convergence of the weights of the NN is strictly proven. Finally, the validity of Algorithm 2 is verified by MATLAB simulation, and the comparison yields faster convergence and shows the higher convergence accuracy of this method.
Author Contributions
Conceptualization, C.J.; methodology, C.J.; validation, C.J. and Y.S.; writing—original draft preparation, C.J.; writing—review and editing, C.J.; visualization, C.W. and L.H.; supervision, C.W. and H.S.; project administration, C.W.; funding acquisition, C.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the National Natural Science Foundation of China under grants (62173054 and 62173232).
Data Availability Statement
The data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Jiang, Y.; Jiang, Z. Robust Adaptive Dynamic Programming for Large-Scale Systems with an Application to Multimachine Power Systems. IEEE Trans. Circuits Syst. Express Briefs 2012, 59, 693–697. [Google Scholar] [CrossRef]
- Bian, T.; Jiang, Y.; Jiang, Z.P. Decentralized Adaptive Optimal Control of Large-Scale Systems with Application to Power Systems. IEEE Trans. Ind. Electron. 2015, 62, 2439–2447. [Google Scholar] [CrossRef]
- Kirk, D.E. Optimal Control Theory: An Introduction; Dover Publications: New York, NY, USA, 2004. [Google Scholar]
- Rodrigues, L. Affine Quadratic Optimal Control and Aerospace Applications. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 795–805. [Google Scholar] [CrossRef]
- Lu, K.; Yu, H.; Liu, Z.; Han, S.; Yang, J. Inverse Optimal Adaptive Control of Canonical Nonlinear Systems with Dynamic Uncertainties and Its Application to Industrial Robots. IEEE Trans. Ind. Inf. 2024, 20, 5318–5327. [Google Scholar] [CrossRef]
- Alfred, D.; Czarkowski, D.; Teng, J. Reinforcement Learning-Based Control of a Power Electronic Converter. Mathematics 2024, 12, 671. [Google Scholar] [CrossRef]
- Mu, C.; Zhen, N.; Sun, C.; He, H. Data-Driven Tracking Control with Adaptive Dynamic Programming for a Class of Continuous-Time Nonlinear Systems. IEEE Trans. Cybern. 2017, 47, 1460–1470. [Google Scholar] [CrossRef]
- Abu-Khalaf, M.; Lewis, F.L. Nearly optimal control laws for nonlinear systems with saturating actuators using a neural network HJB approach. Automatica 2005, 41, 779–791. [Google Scholar] [CrossRef]
- Lv, Y.; Na, J.; Yang, Q.; Wu, X.; Guo, Y. Online adaptive optimal control for continuous-time nonlinear systems with completely unknown dynamics. Int. J. Control 2015, 89, 99–112. [Google Scholar] [CrossRef]
- Xiao, G.; Zhang, H. Convergence Analysis of Value Iteration Adaptive Dynamic Programming for Continuous-Time Nonlinear Systems. IEEE Trans. Cybern. 2024, 54, 1639–1649. [Google Scholar] [CrossRef] [PubMed]
- Wang, G. Distributed control of higher-order nonlinear multi-agent systems with unknown non-identical control directions under general directed graphs. Automatica 2019, 110, 108559. [Google Scholar] [CrossRef]
- Chen, B.; Hu, J.; Zhao, Y.; Ghosh, B.K. Finite-time observer based tracking control of uncertain heterogeneous underwater vehicles using adaptive sliding mode approach. Neurocomputing 2022, 481, 322–332. [Google Scholar] [CrossRef]
- Wang, G. Consensus Algorithm for Multiagent Systems with Nonuniform Communication Delays and Its Application to Nonholonomic Robot Rendezvous. IEEE Trans. Control Netw. Syst. 2023, 10, 1496–1507. [Google Scholar] [CrossRef]
- Bidram, A.; Davoudi, A.; Lewis, F.L.; Guerrero, J.M. Distributed Cooperative Secondary Control of Microgrids Using Feedback Linearization. IEEE Trans. Power Syst. 2013, 28, 3462–3470. [Google Scholar] [CrossRef]
- Kodagoda, K.R.S.; Wijesoma, W.S.; Teoh, E.K. Fuzzy speed and steering control of an AGV. IEEE Trans. Control Syst. Technol. 2002, 10, 112–120. [Google Scholar] [CrossRef]
- Song, R.; Wei, Q.; Zhang, H.; Lewis, F.L. Discrete-Time Non-Zero-Sum Games with Completely Unknown Dynamics. IEEE Trans. Cybern. 2021, 51, 2929–2943. [Google Scholar] [CrossRef] [PubMed]
- Karg, P.; Kopf, F.; Braun, C.A.; Hohmann, S. Excitation for Adaptive Optimal Control of Nonlinear Systems in Differential Games. IEEE Trans. Autom. Control 2023, 68, 596–603. [Google Scholar] [CrossRef]
- Li, H.; Wei, Q. Initial Excitation-Based Optimal Control for Continuous-Time Linear Nonzero-Sum Games. IEEE Trans. Syst. Man Cybern. Syst. 2024, 1–12. [Google Scholar] [CrossRef]
- Nash, J.F. Non-cooperative Games. In Classics in Game Theory; Princeton University Press: Princeton, NJ, USA, 1951. [Google Scholar]
- Clemhout, S.; Wan, H.Y. Differential games-Economic applications. Handb. Game Theory Econ. Appl. 1994, 2, 801–825. [Google Scholar]
- Zhang, Z.; Xu, J.; Fu, M. Q-Learning for Feedback Nash Strategy of Finite-Horizon Nonzero-Sum Difference Games. IEEE Trans. Cybern. 2022, 52, 9170–9178. [Google Scholar] [CrossRef]
- Savku, E. A Stochastic Control Approach for Constrained Stochastic Differential Games with Jumps and Regimes. Mathematics 2023, 11, 3043. [Google Scholar] [CrossRef]
- Case, J.H. Toward a Theory of Many Player Differential Games. SIAM J. Control 1969, 7, 179–197. [Google Scholar] [CrossRef]
- Werbos, P.J. Approximate dynamic programming for real-time control and neural modeling. In Handbook of Intelligent Control Neural Fuzzy & Adaptive Approaches; Van Nostrand Reinhold: New York, NY, USA, 1992; pp. 493–525. [Google Scholar]
- Song, R.; Yang, G. Online solving Nash equilibrium solution of N-player nonzero-sum differential games via recursive least squares. Soft Comput. 2023, 27, 16659–16673. [Google Scholar] [CrossRef]
- Zhang, H.; Cui, L.; Luo, Y. Near-Optimal Control for Nonzero-Sum Differential Games of Continuous-Time Nonlinear Systems Using Single-Network ADP. IEEE Trans. Cybern. 2013, 43, 206–216. [Google Scholar] [CrossRef] [PubMed]
- Vrabie, D.; Lewis, F. Neural network approach to continuous-time direct adaptive optimal control for partially unknown nonlinear systems. Neural Netw. 2009, 22, 237–246. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Li, H.; Wang, D. Online Synchronous Approximate Optimal Learning Algorithm for Multi-Player Non-Zero-Sum Games with Unknown Dynamics. IEEE Trans. Syst. Man Cybern. Syst. 2014, 44, 1015–1027. [Google Scholar] [CrossRef]
- Zhang, H.; Jiang, H.; Luo, C.; Xiao, G. Discrete-Time Nonzero-Sum Games for Multiplayer Using Policy-Iteration-Based Adaptive Dynamic Programming Algorithms. IEEE Trans. Cybern. 2017, 47, 3331–3340. [Google Scholar] [CrossRef]
- Wei, Q.; Zhu, L.; Song, R.; Zhang, P.; Liu, D.; Xiao, J. Model-Free Adaptive Optimal Control for Unknown Nonlinear Multiplayer Nonzero-Sum Game. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 879–892. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Zhang, H.; Zhang, K.; Cui, X. Data-driven adaptive dynamic programming schemes for non-zero-sum games of unknown discrete-time nonlinear systems. Neurocomputing 2018, 275, 649–658. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhao, D. Data-Based Reinforcement Learning for Nonzero-Sum Games with Unknown Drift Dynamics. IEEE Trans. Cybern. 2019, 49, 2874–2885. [Google Scholar] [CrossRef]
- Qin, C.; Shang, Z.; Zhang, Z.; Zhang, D.; Zhang, J. Robust Tracking Control for Non-Zero-Sum Games of Continuous-Time Uncertain Nonlinear Systems. Mathematics 2022, 10, 1904. [Google Scholar] [CrossRef]
- Kiumarsi, B.; Lewis, F.L. Actor-Critic-Based Optimal Tracking for Partially Unknown Nonlinear Discrete-Time Systems. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 140–151. [Google Scholar] [CrossRef]
- Lv, Y.; Ren, X.; Na, J. Adaptive Optimal Tracking Controls of Unknown Multi-input Systems based on Nonzero-Sum Game Theory. J. Frankl. Inst. 2019, 356, 8255–8277. [Google Scholar] [CrossRef]
- Wen, Y.; Zhang, H.; Su, H.; Ren, H. Optimal tracking control for non-zero-sum games of linear discrete-time systems via off-policy reinforcement learning. Optim. Control Appl. Methods 2020, 41, 1233–1250. [Google Scholar] [CrossRef]
- Qin, C.; Qiao, X.; Wang, J.; Zhang, D.; Hou, Y.; Hu, S. Barrier-Critic Adaptive Robust Control of Nonzero-Sum Differential Games for Uncertain Nonlinear Systems with State Constraints. IEEE Trans. Syst. Man Cybern. Syst. 2024, 54, 50–63. [Google Scholar] [CrossRef]
- Zhao, J. Neural networks-based optimal tracking control for nonzero-sum games of multi-player continuous-time nonlinear systems via reinforcement learning. Neurocomputing 2020, 412, 167–176. [Google Scholar] [CrossRef]
- Modares, H.; Lewis, F.L. Optimal tracking control of nonlinear partially-unknown constrained-input systems using integral reinforcement learning. Automatica 2014, 50, 1780–1792. [Google Scholar] [CrossRef]
- BaÅŸar, T.; Olsder, G.J. Dynamic Noncooperative Game Theory, 2nd ed.; SIAM: Philadelphia, PA, USA, 1999. [Google Scholar]
- Amvoudakis, K.G.V.; Lewis, F.L. Multi-player non-zero-sum games: Online adaptive learning solution of coupled Hamilton-Jacobi equations. Automatica 2011, 47, 1556–1569. [Google Scholar] [CrossRef]
- Kamalapurkar, R.; Klotz, J.R.; Dixon, W.E. Concurrent learning-based approximate feedback-Nash equilibrium solution of N-player nonzero-sum differential games. IEEE/CAA J. Autom. Sin. 2014, 1, 239–247. [Google Scholar] [CrossRef]
- Luo, B.; Wu, H.N.; Huang, T. Off-policy reinforcement learning for H∞ control design. IEEE Trans. Cybern. 2015, 45, 65–76. [Google Scholar] [CrossRef]
- Jiang, Y.; Jiang, Z.P. Robust Adaptive Dynamic Programming and Feedback Stabilization of Nonlinear Systems. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 882–893. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).