
Weakly Supervised Specular Highlight Removal Using Only Highlight Images

Abstract
:1. Introduction
2. Related Works
2.1. Model-Based Methods
2.2. Deep-Learning-Based Methods
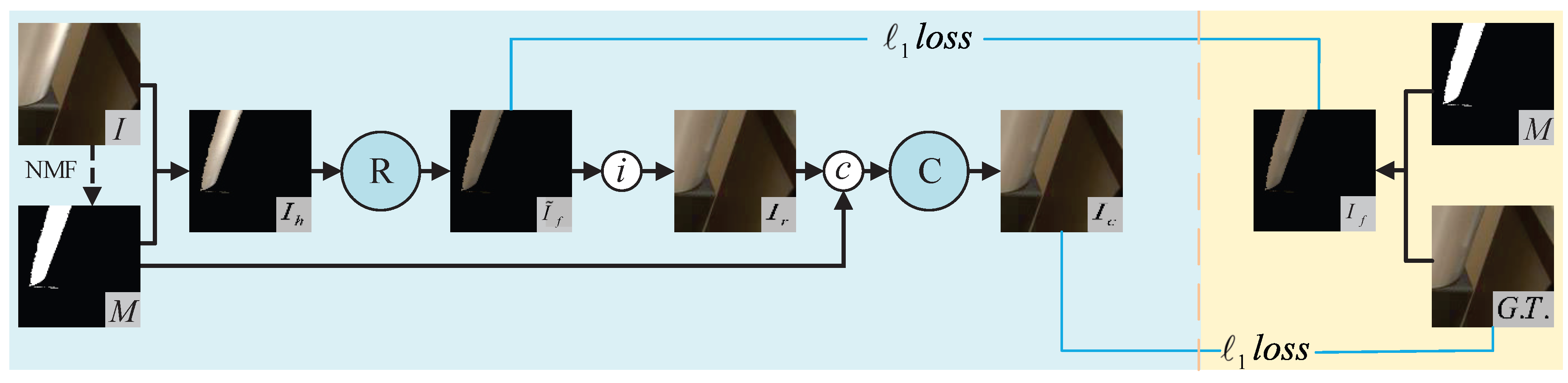
3. Proposed Method
3.1. Mask and Training Data Generation
3.2. Network Architecture
3.3. Module Details
3.4. Loss Function
4. Experiments
4.1. Implementation Details
- (1)
- SHIQ: The SHIQ dataset is specifically designed for the purpose of highlight detection and removal, and provides comprehensive annotations including ground truth, highlight images, and corresponding highlight masks. Each of these components comprises approximately 12,000 images, with a resolution of pixels and 36,000 images in all. Notably, we utilize only the highlight images from this triplet in our experiments, employing the NMF method to generate the corresponding highlight masks. The SHIQ dataset was captured in natural scenes, exhibiting a diverse range of illumination conditions, object materials, and scenarios. For our experiments, we split the datasets into a training set of 24,000 images, a validation set of 6000 images, and a test set of 6000 images. We ensure that the ground truth, highlight images, and corresponding highlight masks are evenly distributed among them. Specifically, each subset contains an equal number of images from these three components, with approximately one-third of the total images allocated to each subset. This balanced distribution allows us to effectively train, validate, and test our proposed approach.
- (2)
- LIME: The LIME dataset comprises images of diverse materials, including specular reflection images representative of these materials, and each comprises approximately 25,000 images. Notably, our experiments solely utilize the highlight images within this dataset. We split the datasets into a training set of 15,000 images, a validation set of 5000 images, and a test set of 5000 images.
4.2. Comparison Results
4.3. Ablation Study
4.4. Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [PubMed]
- Wang, S.; Wang, Y. Weakly supervised semantic segmentation with a multiscale model. IEEE Signal Process. Lett. 2014, 22, 308–312. [Google Scholar]
- Gao, J.; Zhang, T.; Xu, C. Graph convolutional tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4649–4659. [Google Scholar]
- Jachnik, J.; Newcombe, R.A.; Davison, A.J. Real-time surface light-field capture for augmentation of planar specular surfaces. In Proceedings of the 2012 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Atlanta, GA, USA, 5–8 November 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 91–97. [Google Scholar]
- Weyrich, T.; Matusik, W.; Pfister, H.; Bickel, B.; Donner, C.; Tu, C.; McAndless, J.; Lee, J.; Ngan, A.; Jensen, H.W.; et al. Analysis of human faces using a measurement-based skin reflectance model. ACM Trans. Graph. (ToG) 2006, 25, 1013–1024. [Google Scholar]
- Li, C.; Zhou, K.; Lin, S. Intrinsic face image decomposition with human face priors. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 218–233. [Google Scholar]
- Suo, J.; An, D.; Ji, X.; Wang, H.; Dai, Q. Fast and high quality highlight removal from a single image. IEEE Trans. Image Process. 2016, 25, 5441–5454. [Google Scholar]
- Li, C.; Lin, S.; Zhou, K.; Ikeuchi, K. Specular highlight removal in facial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3107–3116. [Google Scholar]
- Tan, P.; Quan, L.; Lin, S. Separation of highlight reflections on textured surfaces. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 2, pp. 1855–1860. [Google Scholar]
- Tan, R.T.; Ikeuchi, K. Separating reflection components of textured surfaces using a single image. In Digitally Archiving Cultural Objects; Springer: Berlin/Heidelberg, Germany, 2008; pp. 353–384. [Google Scholar]
- Yang, Q.; Wang, S.; Ahuja, N. Real-time specular highlight removal using bilateral filtering. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 30 August 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 87–100. [Google Scholar]
- Shen, H.L.; Zheng, Z.H. Real-time highlight removal using intensity ratio. Appl. Opt. 2013, 52, 4483–4493. [Google Scholar] [PubMed]
- Kim, H.; Jin, H.; Hadap, S.; Kweon, I. Specular reflection separation using dark channel prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1460–1467. [Google Scholar]
- Yang, Q.; Tang, J.; Ahuja, N. Efficient and robust specular highlight removal. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1304–1311. [Google Scholar]
- Liu, Y.; Yuan, Z.; Zheng, N.; Wu, Y. Saturation-preserving specular reflection separation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3725–3733. [Google Scholar]
- Ren, W.; Tian, J.; Tang, Y. Specular reflection separation with color-lines constraint. IEEE Trans. Image Process. 2017, 26, 2327–2337. [Google Scholar] [PubMed]
- Souza, A.C.; Macedo, M.C.; Nascimento, V.P.; Oliveira, B.S. Real-time high-quality specular highlight removal using efficient pixel clustering. In Proceedings of the 2018 31st SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Parana, Brazil, 29 October–1 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 56–63. [Google Scholar]
- Guo, J.; Zhou, Z.; Wang, L. Single image highlight removal with a sparse and low-rank reflection model. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 268–283. [Google Scholar]
- Yamamoto, T.; Nakazawa, A. General improvement method of specular component separation using high-emphasis filter and similarity function. ITE Trans. Media Technol. Appl. 2019, 7, 92–102. [Google Scholar]
- Yi, R.; Zhu, C.; Tan, P.; Lin, S. Faces as lighting probes via unsupervised deep highlight extraction. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 317–333. [Google Scholar]
- Le, H.; Samaras, D. From shadow segmentation to shadow removal. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 264–281. [Google Scholar]
- Akashi, Y.; Okatani, T. Separation of reflection components by sparse non-negative matrix factorization. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 611–625. [Google Scholar]
- Zhang, W.; Zhao, X.; Morvan, J.M.; Chen, L. Improving shadow suppression for illumination robust face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 611–624. [Google Scholar] [PubMed]
- Liu, Z.; Yin, H.; Wu, X.; Wu, Z.; Mi, Y.; Wang, S. From Shadow Generation to Shadow Removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4927–4936. [Google Scholar]
- Fu, G.; Zhang, Q.; Zhu, L.; Li, P.; Xiao, C. A Multi-Task Network for Joint Specular Highlight Detection and Removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7752–7761. [Google Scholar]
- Meka, A.; Maximov, M.; Zollhoefer, M.; Chatterjee, A.; Seidel, H.P.; Richardt, C.; Theobalt, C. Lime: Live intrinsic material estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6315–6324. [Google Scholar]
- Lee, S.W.; Bajcsy, R. Detection of specularity using color and multiple views. In Proceedings of the European Conference on Computer Vision, Santa Margherita Ligure, Italy, 19–22 May 1992; Springer: Berlin/Heidelberg, Germany, 1992; pp. 99–114. [Google Scholar]
- Guo, X.; Cao, X.; Ma, Y. Robust separation of reflection from multiple images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2187–2194. [Google Scholar]
- Shen, H.L.; Zhang, H.G.; Shao, S.J.; Xin, J.H. Chromaticity-based separation of reflection components in a single image. Pattern Recognit. 2008, 41, 2461–2469. [Google Scholar]
- Shafer, S.A. Using color to separate reflection components. Color Res. Appl. 1985, 10, 210–218. [Google Scholar]
- Shi, J.; Dong, Y.; Su, H.; Yu, S.X. Learning non-lambertian object intrinsics across shapenet categories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1685–1694. [Google Scholar]
- Lin, J.; Seddik, M.E.A.; Tamaazousti, M.; Tamaazousti, Y.; Bartoli, A. Deep multi-class adversarial specularity removal. In Proceedings of the Scandinavian Conference on Image Analysis, Norrkoping, Sweden, 11–13 June 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 3–15. [Google Scholar]
- Muhammad, S.; Dailey, M.N.; Farooq, M.; Majeed, M.F.; Ekpanyapong, M. Spec-Net and Spec-CGAN: Deep learning models for specularity removal from faces. Image Vis. Comput. 2020, 93, 103823. [Google Scholar]
- Wu, Z.; Zhuang, C.; Shi, J.; Guo, J.; Xiao, J.; Zhang, X.; Yan, D.M. Single-Image Specular Highlight Removal via Real-World Dataset Construction. IEEE Trans. Multimed. 2021, 24, 3782–3793. [Google Scholar]
- Yi, R.; Tan, P.; Lin, S. Leveraging Multi-View Image Sets for Unsupervised Intrinsic Image Decomposition and Highlight Separation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12685–12692. [Google Scholar]
- Fu, G.; Zhang, Q.; Zhu, L.; Xiao, C.; Li, P. Towards High-Quality Specular Highlight Removal by Leveraging Large-Scale Synthetic Data. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 12857–12865. [Google Scholar]
- Xu, J.; Liu, S.; Chen, G.; Liu, Q. Bifurcated convolutional network for specular highlight removal. Optoelectron. Lett. 2023, 19, 756–761. [Google Scholar]
- Phong, B.T. Illumination for computer generated pictures. Commun. ACM 1975, 18, 311–317. [Google Scholar]
- Hoyer, P.O. Non-negative matrix factorization with sparseness constraints. J. Mach. Learn. Res. 2004, 5, 9. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, Montreal, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Taigman, Y.; Polyak, A.; Wolf, L. Unsupervised cross-domain image generation. arXiv 2016, arXiv:1611.02200. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Hu, X.; Jiang, Y.; Fu, C.W.; Heng, P.A. Mask-ShadowGAN: Learning to remove shadows from unpaired data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 27 October–2 November 2019; pp. 2472–2481. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Li, R.; Pan, J.; Si, Y.; Yan, B.; Hu, Y.; Qin, H. Specular reflections removal for endoscopic image sequences with adaptive-RPCA decomposition. IEEE Trans. Med Imaging 2019, 39, 328–340. [Google Scholar] [PubMed]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Training Data | SHIQ | LIME | ||
|---|---|---|---|---|---|
| PSNR (dB) | SSIM | PSNR (dB) | SSIM | ||
| Tan [10] | N/A | ||||
| Yang [11] | N/A | ||||
| Shen [12] | N/A | ||||
| Akashi [22] | N/A | ||||
| Yamamoto [19] | N/A | ||||
| Shi [31] | Hig.Free + Hig.Mask + S (Paired) | ||||
| Yi [35] | Hig.Free (Unpaired) | ||||
| Fu [25] | Hig.Free + Hig.Mask + S (Paired) | ||||
| Ours | N/A | ||||
| Hig.Free (Paired) | |||||
| Dataset Method | SHIQ | LIME | ||
|---|---|---|---|---|
| Accuracy | BER | Accuracy | BER | |
| Tan [10] | 0.62 | 17.8 | 0.70 | 19.9 |
| Akashi [22] | 0.69 | 24.1 | 0.59 | 21.2 |
| Fu [25] | 0.85 | 10.7 | 0.88 | 11.3 |
| Ours | 0.90 | 8.6 | 0.89 | 9.1 |
| Methods | Metrics | |
|---|---|---|
| PSNR (dB) | SSIM | |
| Without discriminator | ||
| Without reconstruction module C | ||
| Full structure | ||
| Methods | Metrics | |
|---|---|---|
| PSNR (dB) | SSIM | |
| Without | ||
| Without | ||
| Without | ||
| Without | ||
| Full loss | ||
| 1 | 5 | 10 | 20 | 30 | |
|---|---|---|---|---|---|
| PSNR (dB) | |||||
| SSIM |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Y.; Hu, G.; Jiang, H.; Wang, H.; Wu, L. Weakly Supervised Specular Highlight Removal Using Only Highlight Images. Mathematics 2024, 12, 2578. https://doi.org/10.3390/math12162578
Zheng Y, Hu G, Jiang H, Wang H, Wu L. Weakly Supervised Specular Highlight Removal Using Only Highlight Images. Mathematics. 2024; 12(16):2578. https://doi.org/10.3390/math12162578
Chicago/Turabian StyleZheng, Yuanfeng, Guangwei Hu, Hao Jiang, Hao Wang, and Lihua Wu. 2024. "Weakly Supervised Specular Highlight Removal Using Only Highlight Images" Mathematics 12, no. 16: 2578. https://doi.org/10.3390/math12162578