
Integrating Sensor Embeddings with Variant Transformer Graph Networks for Enhanced Anomaly Detection in Multi-Source Data

Abstract
:1. Introduction
2. Preliminary
3. Methodology
3.1. Temporal Encoding with Multi-Layer Variant Transformer
3.2. Spatial Embedding for Spatial Embedding
3.3. Graph Structure Learning
3.4. Joint Optimization
3.5. Anomaly Score and Inference
| Algorithm 1: The algorithm of proposed model | |
| Training Stage | |
| Input: Processed time window sequence . | |
| For in epoch: | |
| Calculate multi-source sensor embedding vectors and time representation ; | |
| Calculate the node feature representation and then put it into the graph network to acquire model feature representation ; | |
| Calculate the reconstruction loss and prediction loss; | |
| Minimize the joint loss function. | |
| end for | |
| Test Stage | |
| Input: Test time window sequence . | |
| Return: Predicted label list of | |
4. Experimental Results and Discussion
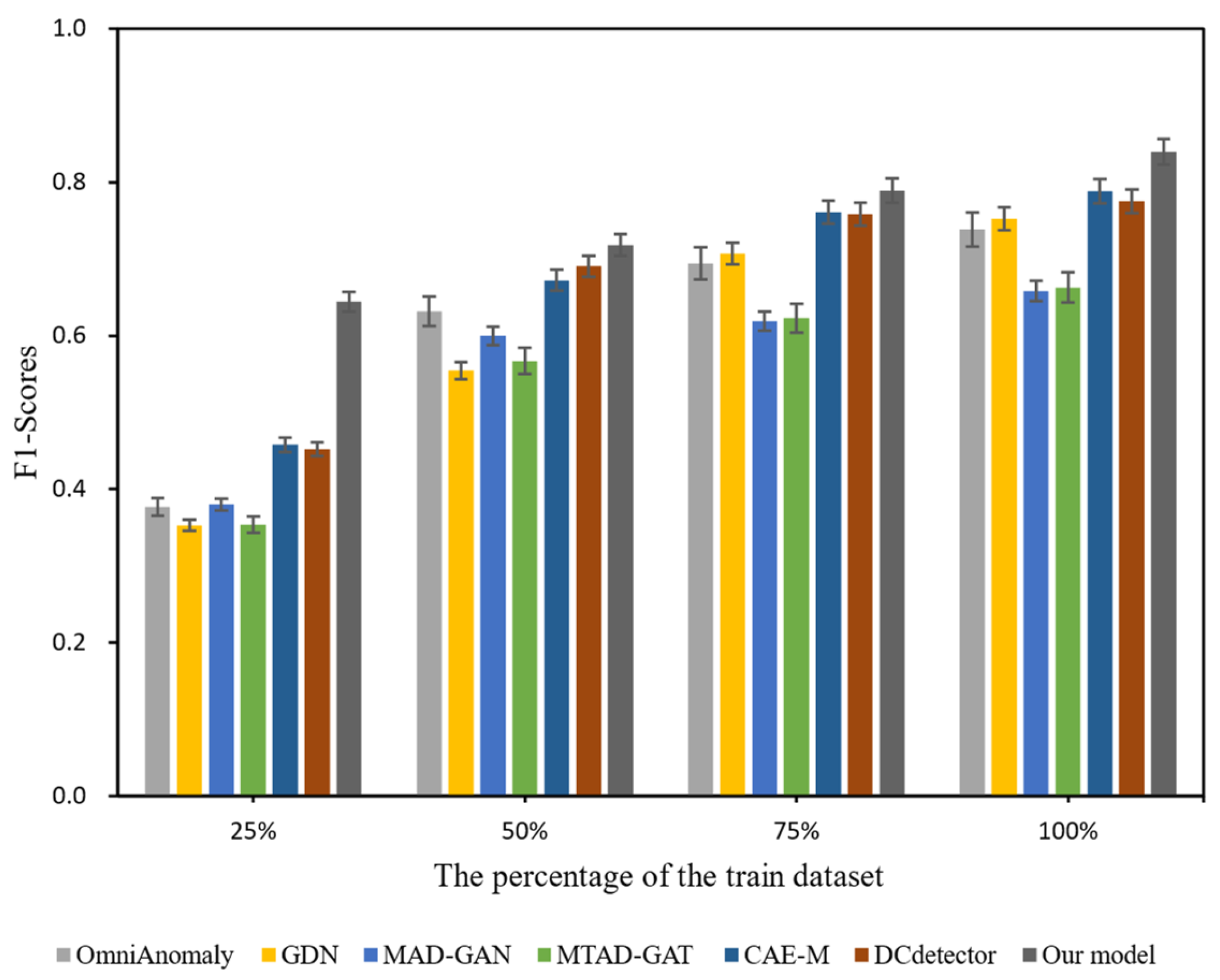
4.1. Model Performance
4.2. Interpretability of Model
4.3. Ablation Experiment
4.4. Sensitivity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ren, H.; Xu, B.; Wang, Y.; Yi, C.; Huang, C.; Kou, X.; Xing, T.; Yang, M.; Tong, J.; Zhang, Q. Time-Series Anomaly Detection Service at Microsoft. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 3009–3017. [Google Scholar]
- Lin, Y.; Wang, Y. Multivariate Time Series Imputation with Bidirectional Temporal Attention-Based Convolutional Network. In Neural Computing for Advanced Applications; Zhang, H., Chen, Y., Chu, X., Zhang, Z., Hao, T., Wu, Z., Yang, Y., Eds.; Communications in Computer and Information Science; Springer Nature: Singapore, 2022; Volume 1638, pp. 494–508. ISBN 978-981-19613-4-2. [Google Scholar]
- Schmidl, S.; Wenig, P.; Papenbrock, T. Anomaly Detection in Time Series: A Comprehensive Evaluation. Proc. VLDB Endow. 2022, 15, 1779–1797. [Google Scholar] [CrossRef]
- Wang, P.; Li, M.; Zhi, X.; Liu, X.; He, Z.; Di, Z.; Zhu, X.; Zhu, Y.; Cui, W.; Deng, W.; et al. Deep Smooth Random Sampling and Association Attention for Air Quality Anomaly Detection. Mathematics 2024, 12, 2048. [Google Scholar] [CrossRef]
- Králik, Ľ.; Kontšek, M.; Škvarek, O.; Klimo, M. GAN-Based Anomaly Detection Tailored for Classifiers. Mathematics 2024, 12, 1439. [Google Scholar] [CrossRef]
- Ma, M.; Zhang, Z.; Zhai, Z.; Zhong, Z. Sparsity-Constrained Vector Autoregressive Moving Average Models for Anomaly Detection of Complex Systems with Multisensory Signals. Mathematics 2024, 12, 1304. [Google Scholar] [CrossRef]
- Gao, J.; Song, X.; Wen, Q.; Wang, P.; Sun, L.; Xu, H. RobustTAD: Robust Time Series Anomaly Detection via Decomposition and Convolutional Neural Networks. arXiv 2020, arXiv:2002.09545. [Google Scholar]
- Ge, D.; Dong, Z.; Cheng, Y.; Wu, Y. An Enhanced Spatio-Temporal Constraints Network for Anomaly Detection in Multivariate Time Series. Knowl.-Based Syst. 2024, 283, 111169. [Google Scholar] [CrossRef]
- Kim, D.; Park, S.; Choo, J. When Model Meets New Normals: Test-Time Adaptation for Unsupervised Time-Series Anomaly Detection. arXiv 2024, arXiv:2312.11976. [Google Scholar] [CrossRef]
- Mandrikova, O.; Mandrikova, B. Hybrid Model of Natural Time Series with Neural Network Component and Adaptive Nonlinear Scheme: Application for Anomaly Detection. Mathematics 2024, 12, 1079. [Google Scholar] [CrossRef]
- Zhang, G.P. Time Series Forecasting Using a Hybrid ARIMA and Neural Network Model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Keogh, E.; Lin, J.; Fu, A. HOT SAX: Efficiently Finding the Most Unusual Time Series Subsequence. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005; pp. 226–233. [Google Scholar]
- Ting, K.M.; Xu, B.-C.; Washio, T.; Zhou, Z.-H. Isolation Distributional Kernel A New Tool for Point & Group Anomaly Detection. IEEE Trans. Knowl. Data Eng. 2021, 35, 2697–2710. [Google Scholar] [CrossRef]
- Shyu, M.-L.; Chen, S.-C.; Sarinnapakorn, K.; Chang, L. A Novel Anomaly Detection Scheme Based on Principal Component Classifier. In Proceedings of the IEEE Foundations and New Directions of Data Mining Workshop, Melbourne, FL, USA, 19–22 November 2003. [Google Scholar]
- Chauhan, S.; Vig, L. Anomaly Detection in ECG Time Signals via Deep Long Short-Term Memory Networks. In Proceedings of the 2015 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Paris, France, 19–21 October 2015; pp. 1–7. [Google Scholar]
- Zhao, H.; Wang, Y.; Duan, J.; Huang, C.; Cao, D.; Tong, Y.; Xu, B.; Bai, J.; Tong, J.; Zhang, Q. Multivariate Time-Series Anomaly Detection via Graph Attention Network. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 841–850. [Google Scholar]
- Ding, C.; Sun, S.; Zhao, J. MST-GAT: A Multimodal Spatial–Temporal Graph Attention Network for Time Series Anomaly Detection. Inf. Fusion 2023, 89, 527–536. [Google Scholar] [CrossRef]
- Belay, M.A.; Blakseth, S.S.; Rasheed, A.; Salvo Rossi, P. Unsupervised Anomaly Detection for IoT-Based Multivariate Time Series: Existing Solutions, Performance Analysis and Future Directions. Sensors 2023, 23, 2844. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Kou, G.; Peng, Y.; Yu, P.S. An Integrated Cluster Detection, Optimization, and Interpretation Approach for Financial Data. IEEE Trans. Cybern. 2022, 52, 13848–13861. [Google Scholar] [CrossRef] [PubMed]
- Hundman, K.; Constantinou, V.; Laporte, C.; Colwell, I.; Soderstrom, T. Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 387–395. [Google Scholar]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; Cho, D.; Chen, H. Deep autoencoding gaussian mixture model for unsupervised anomaly detection. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Su, Y.; Zhao, Y.; Niu, C.; Liu, R.; Sun, W.; Pei, D. Robust Anomaly Detection for Multivariate Time Series through Stochastic Recurrent Neural Network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2828–2837. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Deng, A.; Hooi, B. Graph Neural Network-Based Anomaly Detection in Multivariate Time Series. AAAI 2021, 35, 4027–4035. [Google Scholar] [CrossRef]
- Xu, J.; Li, Z.; Du, B.; Zhang, M.; Liu, J. Reluplex Made More Practical: Leaky ReLU. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; pp. 1–7. [Google Scholar]
- Siffer, A.; Fouque, P.-A.; Termier, A.; Largouet, C. Anomaly Detection in Streams with Extreme Value Theory. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13 August 2017; pp. 1067–1075. [Google Scholar]
- Li, D.; Chen, D.; Jin, B.; Shi, L.; Goh, J.; Ng, S.-K. MAD-GAN: Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks. In Artificial Neural Networks and Machine Learning—ICANN 2019: Text and Time Series; Tetko, I.V., Kůrková, V., Karpov, P., Theis, F., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; Volume 11730, pp. 703–716. ISBN 978-3-030-30489-8. [Google Scholar]
- Belay, M.A.; Rasheed, A.; Rossi, P.S. MTAD: Multiobjective Transformer Network for Unsupervised Multisensor Anomaly Detection. IEEE Sens. J. 2024, 24, 20254–20265. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Y.; Wang, J.; Pan, Z. Unsupervised Deep Anomaly Detection for Multi-Sensor Time-Series Signals. IEEE Trans. Knowl. Data Eng. 2021, 35, 2118–2132. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, C.; Zhou, T.; Wen, Q.; Sun, L. DCdetector: Dual Attention Contrastive Representation Learning for Time Series Anomaly Detection. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 6–10 August 2023; pp. 3033–3045. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Mathur, A.P.; Tippenhauer, N.O. SWaT: A Water Treatment Testbed for Research and Training on ICS Security. In Proceedings of the 2016 International Workshop on Cyber-physical Systems for Smart Water Networks (CySWater), Vienna, Austria, 11 April 2016; pp. 31–36. [Google Scholar]
- Ahmed, C.M.; Palleti, V.R.; Mathur, A.P. WADI: A Water Distribution Testbed for Research in the Design of Secure Cyber Physical Systems. In Proceedings of the 3rd International Workshop on Cyber-Physical Systems for Smart Water Networks, Pittsburgh, PA, USA, 21 April 2017; pp. 25–28. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Test | Dimensions | Anomalies (%) |
|---|---|---|---|---|
| MSL [20] | 58,317 | 73,729 | 27 | 10.72 |
| SWAT [32] | 496,800 | 449,919 | 51 | 11.98 |
| WADI [33] | 1,048,571 | 172,801 | 123 | 5.99 |
| SMD [22] | 708,405 | 708,420 | 38 | 4.16 |
| Methods | MSL | SWAT | ||||
| P | R | F1 | P | R | F1 | |
| OmniAnomaly | 0.7485 | 0.7289 | 0.7386 | 0.5637 | 0.5351 | 0.5490 |
| MTAD-GAT | 0.7832 | 0.7236 | 0.7522 | 0.7013 | 0.6694 | 0.6850 |
| MAD-GAN | 0.6211 | 0.7005 | 0.6584 | 0.7082 | 0.4587 | 0.5568 |
| GDN | 0.6485 | 0.6779 | 0.6629 | 0.7632 | 0.7388 | 0.7508 |
| CAE-M | 0.8164 | 0.6915 | 0.7882 | 0.8861 | 0.6121 | 0.7240 |
| DCdetector | 0.8032 | 0.7491 | 0.7752 | 0.8532 | 0.7139 | 0.7773 |
| Proposed model | 0.8277 | 0.8518 | 0.8396 | 0.8674 | 0.7475 | 0.8030 |
| Methods | SMD | WADI | ||||
| P | R | F1 | P | R | F1 | |
| OmniAnomaly | 0.8189 | 0.8490 | 0.8337 | 0.3022 | 0.5705 | 0.3951 |
| MTAD-GAT | 0.7898 | 0.7300 | 0.7587 | 0.4076 | 0.7095 | 0.5178 |
| MAD-GAN | 0.8289 | 0.7983 | 0.8133 | 0.3497 | 0.8007 | 0.4868 |
| GDN | 0.8274 | 0.7768 | 0.8013 | 0.3982 | 0.7176 | 0.5122 |
| CAE-M | 0.7921 | 0.8014 | 0.7967 | 0.4746 | 0.7882 | 0.5925 |
| DCdetector | 0.8240 | 0.7964 | 0.8100 | 0.4978 | 0.8056 | 0.6154 |
| Proposed model | 0.8381 | 0.8539 | 0.8459 | 0.5015 | 0.8175 | 0.6216 |
| MSL | SWAT | |
|---|---|---|
| OmniAnomaly | 46.2 | 77.3 |
| MTAD-GAT | 43.7 | 73.9 |
| MAD-GAN | 45.9 | 75.1 |
| GDN | 43.4 | 74.2 |
| CAE-M | 42.2 | 76.4 |
| DCdetector | 41.5 | 72.8 |
| Proposed model | 40.8 | 72.3 |
| Method | Prec | Rec | F1 |
|---|---|---|---|
| Proposed model | 0.8277 | 0.8518 | 0.8396 |
| w/o topk | 0.8021 | 0.8256 | 0.8137 |
| w/o time encoding | 0.8115 | 0.8409 | 0.8259 |
| w/o spatial embedding | 0.7765 | 0.7994 | 0.7878 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, F.; Ma, L.; Chen, Y.; He, W.; Wang, Z.; Wang, Y. Integrating Sensor Embeddings with Variant Transformer Graph Networks for Enhanced Anomaly Detection in Multi-Source Data. Mathematics 2024, 12, 2612. https://doi.org/10.3390/math12172612
Meng F, Ma L, Chen Y, He W, Wang Z, Wang Y. Integrating Sensor Embeddings with Variant Transformer Graph Networks for Enhanced Anomaly Detection in Multi-Source Data. Mathematics. 2024; 12(17):2612. https://doi.org/10.3390/math12172612
Chicago/Turabian StyleMeng, Fanjie, Liwei Ma, Yixin Chen, Wangpeng He, Zhaoqiang Wang, and Yu Wang. 2024. "Integrating Sensor Embeddings with Variant Transformer Graph Networks for Enhanced Anomaly Detection in Multi-Source Data" Mathematics 12, no. 17: 2612. https://doi.org/10.3390/math12172612