1. Introduction
Event Extraction (EE) aims to identify and extract the event structures from unstructured text, which is a vital sub-task of information extraction [
1]. EE can be generally classified into two subtasks [
2]: (1) Event Detection (ED), with the goal of identifying the trigger word with its event type and (2) Event Argument Extraction (EAE), with the goal of identifying the arguments and classifying the specific roles they play. For example, in
Figure 1a, for event trigger “murder” with its event type “Life: die”, the EAE model can extract arguments “nanny”, “child”, and “Moscow” and argument roles “killer”, “victim”, and “place”. In practice, EAE can benefit a wide range of downstream applications, such as event knowledge graph [
3,
4], recommender system [
5,
6,
7], and question answering [
8,
9].
Moreover, EAE can be typically classified into sentence-level (SEAE) and document-level (DEAE), where most previous methods only extract events in a single sentence [
10,
11,
12,
13,
14]. In addition, DEAE can be generally classified into two categories. (1) The first category is generation-based DEAE, which directly applies specific decoding strategies [
15,
16] or utilizes the pre-trained language models with prompts providing semantic guidance to capture the event arguments [
17,
18,
19,
20]. Other studies convert this problem into question answering (QA) [
13,
21] or machine reading comprehension (MRC) [
22]. However, due to the independent modeling of entity mentions, these methods still exhibit limitations when addressing long-distance dependency. (2) The other one is span-based DEAE, which predicts event argument roles by identifying the start and end positions of candidate text spans [
23,
24,
25,
26,
27]. These methods are capable of capturing cross-sentence arguments and multi-hop structures while suffering from the maximum length limitation. Recently, some studies have constructed an Abstract Meaning Representation (AMR) graph as additional features or training signals [
28,
29,
30,
31]. However, existing approaches typically set up an additional graph structure to better utilize the global information of context. This results in some distracting noise in the AMR graph, which may mislead the extraction. To solve this issue, Xu et al. [
30] proposed a two-stream encoding model to make better use of feasible context. However, these methods mainly focus on leveraging AMR as supplementary features to enhance span representation, ignoring the written pattern of the document. How to figure out useful contextual information in the document still remains under-explored.
To sum up, two critical challenges still remain for DEAE:
(1) Long-range dependency: in practical situations, the event structures are usually scattered in different sentences [
19]. As shown in
Figure 1b, for event trigger word “jail” with event type “Justice: arrestjaildetain” in sentence S3, the arguments “jailer”, “detainee” and “crime” are scattered in S3 and S5, which highly aggravate the complexity of extraction.
(2) Distracting context issue: although a document typically provides more semantic information than a single sentence, distracting noise may also be brought in, which may mislead the extraction of event arguments.
To address the aforementioned challenges, we propose a novel DEAE model with
AMR
Parser and
Sparse
Representation (APSR). Specifically, to alleviate the long-range dependency issue, we construct the AMR parser graph structure, which is capable of providing abundant semantic information from the input sentences [
32]. Inspired by [
33,
34], we consider that differences exist in event argument density between the sentence level and the document level, which means the density of event arguments in a whole document is generally much lower than that of a single sentence with an event trigger word. Based on that, we propose utilizing the sparse argument representation mechanism to capture high-quality argument representation. According to different human writing patterns, we design three types of sparse argument representation masks (i.e., sequential, flashback, and banded, respectively) to skip irrelevant information. In detail, for sequential mask, we consider the events are presented in the order they occur chronologically or logically, so the tokens in the former sentence can observe tokens in the latter. Moreover, the flashback mask refers to the narrative technique of inserting scenes or events that have occurred in the past into the current timeline of a story, so tokens in the latter sentence can observe tokens in the former sentence. In addition, for a banded mask, we argue that the arguments of an event are mostly scattered in the neighbor sentences, so we set that the tokens within a sentence can only observe tokens in the neighbor sentences. By adjusting the reception field of tokens in sparse argument attention mechanism, the model is capable of capturing high-quality argument representation.
In brief, the main contributions of this study are as follows:
We propose a span-based model for DEAE with a sparse argument representation encoder, which consists of an inter- and intra-sentential encoder with well-designed sparse argument attention mechanism to encode the document from different perspectives.
We propose three types of sparse argument attention masks (i.e., sequential, flashback, and banded, respectively), which are capable of introducing useful language bias.
Experimental results on two widely used benchmark datasets, i.e., RAMS and WikiEvents, validate APSR’s superiority over the state-of-the-art baselines.
3. Approach
3.1. Task Formulation
We first formulate the DEAE task by following [
27]. Specifically, we denote a document
that consists of
N sentences as
, where each sentence contains a sequence of words, i.e.,
. Within the dataset, a document
also contains a set of pre-defined event types with a set
, where each event type
is designated by the trigger
. Then, the corresponding role set to each event type
is pre-defined in the dataset as
,
. Our DEAE task aims to detect all
pairs for each event, where
denotes the event argument role related to event type
, and
is a contiguous text span in
.
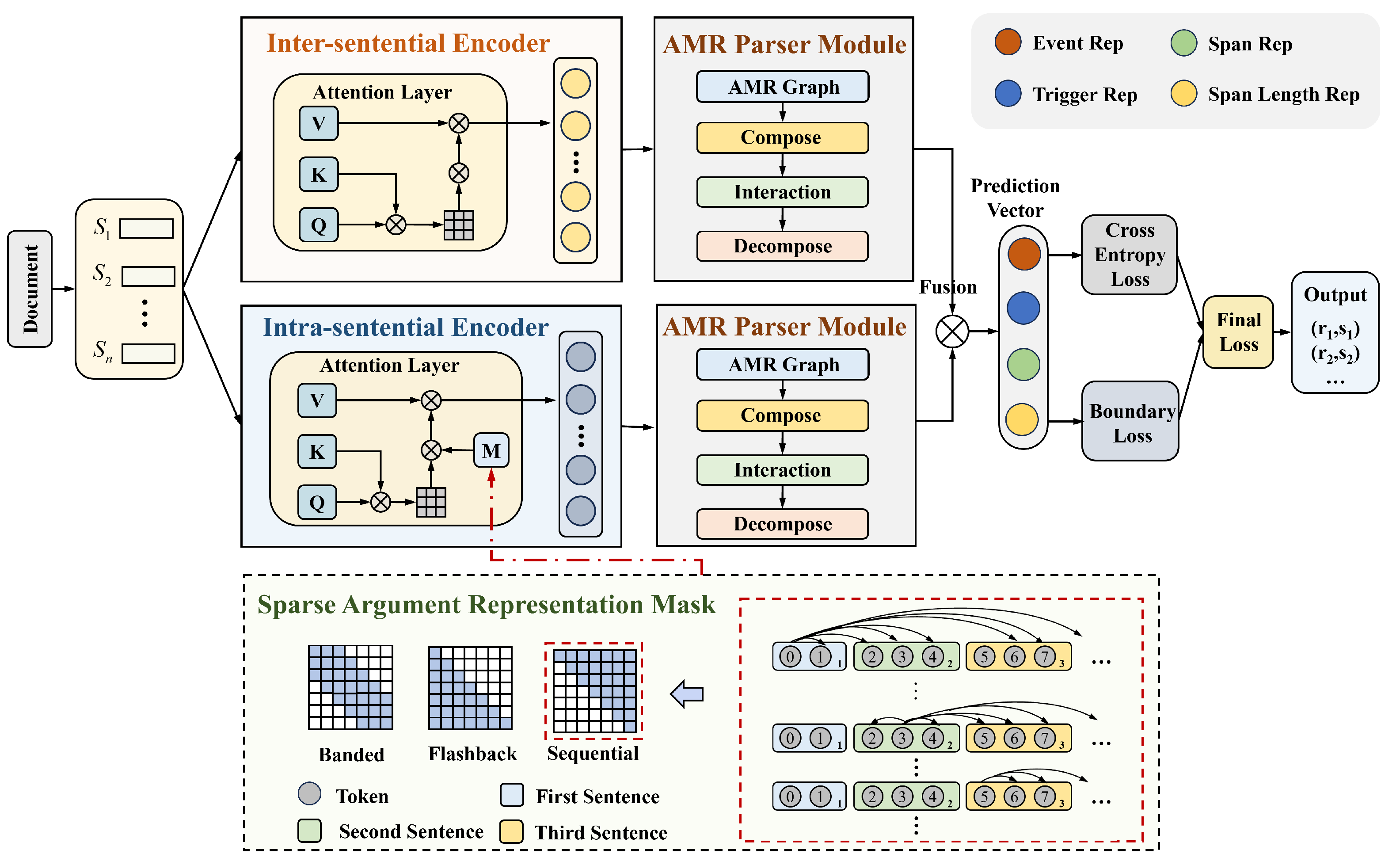
The overall framework of the APSR model is illustrated in
Figure 2, which focuses on high-quality event argument representation. Specifically, as shown in
Figure 2, the framework of APSR consists of three main components: Giving a document as the input, we first encode the document with inter- and intra-sentential encoders using different self-attention mechanisms. Specifically, we design three types of sparse argument representation mask matrices (i.e., sequential, flashback, and banded, respectively) to capture different linguistic bias. The detail of a sparse argument representation mask is illustrated in the dashed box below. Then, we parse each sentence into the AMR graph, and transfer it into DGL graphs. Finally, we fuse the inter- and intra-sentential argument representations and predict what argument role the candidate span plays.
3.2. Sparse Argument Representation Encoder
In order to simultaneously identify the essential contextual information and filter the distracting information, we construct a sparse argument representation encoder, consisting of an inter-sentential encoder that is cognizant of the whole document, and an intra-sentential encoder with a well-designed sparse argument attention mechanism.
We first utilize BERT-
[
46] to encode the document, including an inter-sentential encoder
and an intra-sentential encoder
. Then, we obtain the corresponding representations
and
, as follows:
where
denotes the contextual representation for each word
.
Specifically, on the one hand, the attention technique of the inter-sentential encoder can be formulated as follows [
47]:
where
denote the query, key, and value matrix in the inter-sentential encoder, and
is the model dimension.
Moreover, on the other hand, in the intra-sentential encoder, due to the different information density between the sentence and document, we introduce a mask matrix as
to skip the irrelevant information as follows:
where
denote the query, key, and value matrix in the intra-sentential encoder, and
is the model dimension.
Specifically, we design three types of sparse event argument self-attention mechanisms, including sequential, flashback, and banded. Each represents if the information of the jth sentence can be attended to the token in ith sentence:
Sequential. Sequential means presenting events or information in the order they occur chronologically or logically. We consider the events are described in the sequential order, that is, tokens in the former sentence can see tokens in the latter one:
Flashback. Flashback refers to the narrative technique of inserting scenes or events that have occurred in the past into the current timeline of a story (e.g., in historical documentary and literature), so tokens in latter sentence can observe tokens in the former sentence:
Banded. Considering that the arguments of an event are mostly scattered in neighbor sentences, we set that tokens can only observe tokens in neighbor sentences within the neighbor hop of 3:
3.3. AMR Parser Module
The AMR graph can provide rich logical semantic information to benefit the understanding of intra-sentential and inter-sentential features. Specifically, we first adopt the transition-based AMR parser [
48] to generate AMR graph
. In detail, each node
describes a semantic concept, where
and
denote the span that marks the starting and ending positions in the original sentence, respectively, and each edge
represents the specific relation between node
and
. Following [
31], we then cluster the relation types into 12 clusters.
Due to the ability of the multi-layer Graph Convolutional Network (GCN) [
49] to aggregate information from deeper neighboring nodes and enhance feature representation [
50], we first employed the L-layer stacked GCN to capture interactions among distinct concept nodes connected by edges representing diverse relation types. At the
l-th layer, for node
n, we formulated the graph convolutional operation:
where
is the clusters of 12 relation types that we define above,
represents the set of neighbors of node
n linked by
k-th relation types, where
denotes a normalization constant, and
denotes a trainable parameter.
Then, we concatenate the hidden states across all layers to obtain the ultimate representation of node
n, formulated as follows:
where
denotes the initial representation of node
n.
After that,
is decomposed as the intra-sentential representations of the corresponding words, which are then aggregated token by token as follows:
3.4. Fusion and Classification Module
In the fusion module, we first integrate the intra-sentential representations and the inter-sentential representations to formulate the ultimate representations of the candidate spans.
Then, we adopt a gating mechanism to fuse the two vector representations in the sentence and obtain the gate vector
:
where
and
are trainable parameters.
Subsequently, we calculate the fused representations
:
Moreover, for a candidate span extending from
to
, we calculate integrated representation
where
represents the learnable parameter,
and
.
Finally, following [
30], we introduce token-wise classifiers to predict the likelihood of the word
serves as the first or last word within the golden span:
,
, where
and
are trainable parameters. In order to enhance the boundary information for spans, we adopt boundary loss:
where
and
are the golden labels.
In the classification model, we need to predict what specific role that candidate argument plays. To start with, we need to calculate the final classification vector
(Xu et al. [
30]):
where
denotes trigger representation, and
and
represent the embedding of event type and span length, respectively.
Since DEAE is a multi-class classification task, we then employ cross entropy
:
where
denotes the golden argument role.
Finally, we train the model with final loss function with hyperparameter .
6. Conclusions
In this paper, we propose a novel span-based DEAE model with a sparse argument attention mechanism to address the long-range dependency and distracting context issues simultaneously. Based on different human writing patterns, we design three types of event argument masks, i.e., sequential, flashback, and banded, which encode the document from different perspectives. Experimental results conducted on RAMS and WikiEvents validate that our APSR outperforms competitive baseline approaches by F1 and F1, respectively. Regarding future work, we will study how to combine these sparse attention masks to capture useful event argument representation, and we would like to further explore the sparse argument attention mechanism in zero-shot cross-lingual setting.





{kind=link}
{kind=link}
{kind=link}