

ConvNext as a Basis for Interpretability in Coffee Leaf Rust Classification


Abstract
:1. Introduction
2. Background
2.1. ConvNext
2.2. CAM Methods
2.3. ROAD
3. Materials and Methods
3.1. Dataset
3.2. Pre-Trained Models
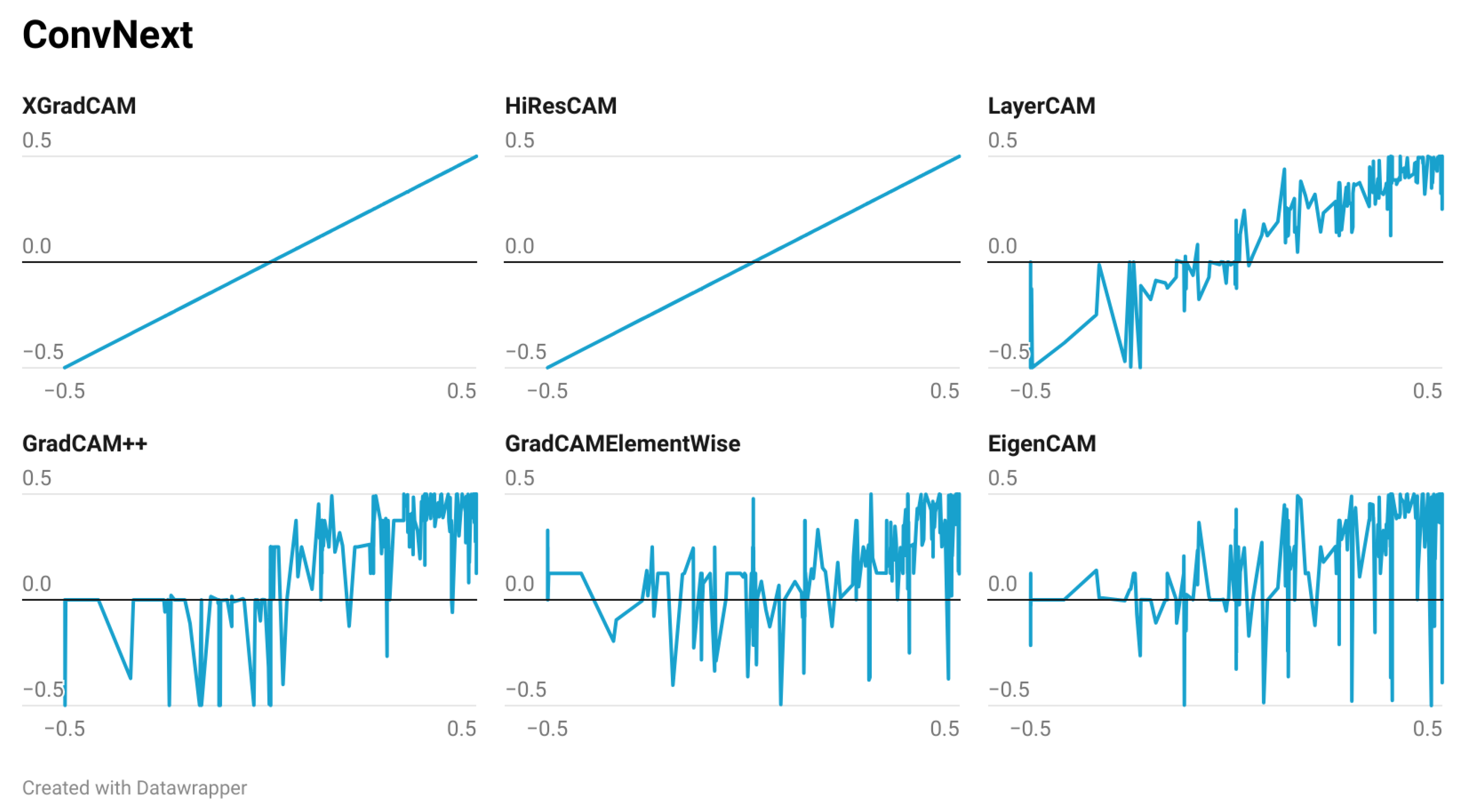
3.3. Selected CAM Methods
- GradCAM;
- XGradCAM;
- HiResCAM;
- LayerCAM;
- GradCAM++;
- GradCAMElementWise;
- EigenCAM.
3.4. Evaluation Using ROAD
4. Results and Discussion
4.1. Preliminary Results (Qualitative)
4.2. Consolidated Results (Quantitative)
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| CAM | Class Activation Mapping |
| GAP | Global Average Pooling |
| GELU | Gaussian Error Linear Unit |
| GradCAM | Gradient-Weighted CAM |
| LeRF | Least Relevant First |
| LIME | Local Interpretable Model-agnostic Explanations |
| MoRF | Most Relevant First |
| ReLU | Rectified Linear Unit |
| ROAD | RemOve And Debias |
| ROAR | RemOve And Retrain |
| SHAP | SHapley Additive exPlanations |
| ViT | Vision Transformers |
| XAI | eXplainable Artificial Intelligence |
References
- Sagar, S.; Javed, M.; Doermann, D.S. Leaf-Based Plant Disease Detection and Explainable AI. arXiv 2023, arXiv:2404.16833. [Google Scholar]
- Yebasse, M.; Shimelis, B.; Warku, H.; Ko, J.; Cheoi, K.J. Coffee disease visualization and classification. Plants 2021, 10, 1257. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part I 13. Springer: Cham, Switzerland; Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Yosinski, J.; Clune, J.; Nguyen, A.; Fuchs, T.; Lipson, H. Understanding neural networks through deep visualization. arXiv 2015, arXiv:1506.06579. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?”. Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13 April 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4768–4777. [Google Scholar]
- Renza, D.; Ballesteros, D. Sp2PS: Pruning Score by Spectral and Spatial Evaluation of CAM Images. Informatics 2023, 10, 72. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 15 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 839–847. [Google Scholar]
- Fu, R.; Hu, Q.; Dong, X.; Guo, Y.; Gao, Y.; Li, B. Axiom-based grad-cam: Towards accurate visualization and explanation of cnns. arXiv 2020, arXiv:2008.02312. [Google Scholar]
- Draelos, R.L.; Carin, L. Use HiResCAM instead of Grad-CAM for faithful explanations of convolutional neural networks. arXiv 2020, arXiv:2011.08891. [Google Scholar]
- Gildenblat, J. PyTorch Library for CAM Methods. 2021. Available online: https://github.com/jacobgil/pytorch-grad-cam (accessed on 10 August 2023).
- Jiang, P.T.; Zhang, C.B.; Hou, Q.; Cheng, M.M.; Wei, Y. Layercam: Exploring hierarchical class activation maps for localization. IEEE Trans. Image Process. 2021, 30, 5875–5888. [Google Scholar] [CrossRef]
- Muhammad, M.B.; Yeasin, M. Eigen-cam: Class activation map using principal components. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- Hooker, S.; Erhan, D.; Kindermans, P.J.; Kim, B. A benchmark for interpretability methods in deep neural networks. Adv. Neural Inf. Process. Syst. 2019, 32, 9737–9748. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 24 June 2022; pp. 11976–11986. [Google Scholar]
- Pachón, C.G.; Ballesteros, D.M.; Renza, D. An efficient deep learning model using network pruning for fake banknote recognition. Expert Syst. Appl. 2023, 233, 120961. [Google Scholar] [CrossRef]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 24 June 2023; pp. 16133–16142. [Google Scholar]
- Samek, W.; Binder, A.; Montavon, G.; Lapuschkin, S.; Müller, K.R. Evaluating the visualization of what a deep neural network has learned. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2660–2673. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R.B. Early Convolutions Help Transformers See Better. arXiv 2021, arXiv:2106.14881. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, A.; Lan, D.; Zhang, X.; Yin, J.; Goh, H.H. ConvNeXt-based anchor-free object detection model for infrared image of power equipment. Energy Rep. 2023, 9, 1121–1132. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 1–74. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016; pp. 2921–2929. [Google Scholar]
- Rong, Y.; Leemann, T.; Borisov, V.; Kasneci, G.; Kasneci, E. A consistent and efficient evaluation strategy for attribution methods. arXiv 2022, arXiv:2202.00449. [Google Scholar]
- Parraga-Alava, J.; Cusme, K.; Loor, A.; Santander, E. RoCoLe: A robusta coffee leaf images dataset for evaluation of machine learning based methods in plant diseases recognition. Data Brief 2019, 25, 104414. [Google Scholar] [CrossRef] [PubMed]
- Krohling, R.A.; Esgario, J.; Ventura, J.A. BRACOL—A Brazilian Arabica Coffee Leaf Images Dataset to Identification and Quantification of Coffee Diseases and Pests. Mendeley Data. 2019. Available online: https://data.mendeley.com/datasets/yy2k5y8mxg/1 (accessed on 10 August 2023).
- Barbedo, J.G.A.; Koenigkan, L.V.; Halfeld-Vieira, B.A.; Costa, R.V.; Nechet, K.L.; Godoy, C.V.; Junior, M.L.; Patricio, F.R.A.; Talamini, V.; Chitarra, L.G.; et al. Annotated plant pathology databases for image-based detection and recognition of diseases. IEEE Lat. Am. Trans. 2018, 16, 1749–1757. [Google Scholar] [CrossRef]
- Brito Silva, L.; Cavalcante Carneiro, A.L.; Silveira Almeida Renaud Faulin, M. Rust (Hemileia vastatrix) and leaf miner (Leucoptera coffeella) in coffee crop (Coffea arabica). Mendeley Data. 2020. Available online: https://data.mendeley.com/datasets/vfxf4trtcg/4/ (accessed on 10 August 2023).
- Montalbo, F.J.P.; Hernandez, A.A. Classifying Barako coffee leaf diseases using deep convolutional models. Int. J. Adv. Intell. Inform. 2020, 6, 197–209. [Google Scholar] [CrossRef]
- Nauta, M.; Trienes, J.; Pathak, S.; Nguyen, E.; Peters, M.; Schmitt, Y.; Schlötterer, J.; Van Keulen, M.; Seifert, C. From anecdotal evidence to quantitative evaluation methods: A systematic review on evaluating explainable ai. ACM Comput. Surv. 2023, 55, 1–42. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017; pp. 1251–1258. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variant ConvNext | Number of Channels in Each Stage | Number of Cycles of Each ConvNext Block |
|---|---|---|
| ConvNext-T | (96, 192, 384, 768) | (3, 3, 9, 3) |
| ConvNext-S | (96, 192, 384, 768) | (3, 3, 27, 3) |
| ConvNext-B | (128, 256, 512, 1024) | (3, 3, 27, 3) |
| ConvNext-L | (192, 384, 768, 1536) | (3, 3, 27, 3) |
| ConvNext-XL | (256, 512, 1024, 2048) | (3, 3, 27, 3) |
| Stage | Output Size | Details |
|---|---|---|
| Stem | , stride 4 | |
| Res2 | ||
| Res3 | ||
| Res4 | ||
| Res5 |
| Model | Val. Loss | Val. Accuracy (%) | Test Accuracy (%) | Epoch | Size (MB) |
|---|---|---|---|---|---|
| VGG16 | 0.1998 | 96.46 | 93.33 | 16 | 512.3 |
| ResNet50 | 0.2089 | 94.38 | 91.25 | 46 | 90 |
| ConvNext-T | 0.2825 | 94.45 | 92.08 | 23 | 106.2 |
| VGG16 | ||||
| Class | Accuracy (%) | Precision | Recall | F1-Score |
| 1 | 96.25 | 0.91 | 0.98 | 0.94 |
| 2 | 95.42 | 0.97 | 0.91 | 0.94 |
| 3 | 95.00 | 0.92 | 0.92 | 0.92 |
| ResNet50 | ||||
| Class | Accuracy (%) | Precision | Recall | F1-Score |
| 1 | 94.38 | 0.86 | 0.98 | 0.91 |
| 2 | 95.42 | 0.97 | 0.91 | 0.94 |
| 3 | 93.00 | 0.91 | 0.85 | 0.88 |
| ConvNext-T | ||||
| Class | Accuracy (%) | Precision | Recall | F1-Score |
| 1 | 94.58 | 0.89 | 0.95 | 0.92 |
| 2 | 96.04 | 0.96 | 0.94 | 0.95 |
| 3 | 93.54 | 0.92 | 0.87 | 0.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chavarro, A.; Renza, D.; Moya-Albor, E. ConvNext as a Basis for Interpretability in Coffee Leaf Rust Classification. Mathematics 2024, 12, 2668. https://doi.org/10.3390/math12172668
Chavarro A, Renza D, Moya-Albor E. ConvNext as a Basis for Interpretability in Coffee Leaf Rust Classification. Mathematics. 2024; 12(17):2668. https://doi.org/10.3390/math12172668
Chicago/Turabian StyleChavarro, Adrian, Diego Renza, and Ernesto Moya-Albor. 2024. "ConvNext as a Basis for Interpretability in Coffee Leaf Rust Classification" Mathematics 12, no. 17: 2668. https://doi.org/10.3390/math12172668
APA StyleChavarro, A., Renza, D., & Moya-Albor, E. (2024). ConvNext as a Basis for Interpretability in Coffee Leaf Rust Classification. Mathematics, 12(17), 2668. https://doi.org/10.3390/math12172668