Abstract
In paired-organ studies such as ophthalmology, otolaryngology, and rheumatology, etc., various approaches take highly correlated bilateral data into account for homogeneity tests but are less likely to focus on combined bilateral and unilateral data structures. Also, it is necessary and important to adjust the effect of confounders on stratified combined bilateral and unilateral data since, in these data structures, ignoring intra-class correlation and confounding effects can cause biased statistical inference. This article derived three homogeneity tests (the likelihood ratio test, the Wald test, and the score test) concerning these cooperative structure data to detect if ratios of proportions retain consistency across strata. Simulation shows that the score test provides a robust Type I error rate and satisfactory power performance. Finally, a real example is applied to demonstrate the application of these three proposed tests.
Keywords:
Donner’s model; correlated bilateral outcomes; relative risk test; score test; Wald test; stratified data MSC:
62F03
1. Introduction
Paired bilateral data occur naturally in clinical trial studies, especially in ophthalmology, otolaryngology, and rheumatology, etc. Numerous clinical trials in ophthalmology widely utilize data collection involving one or both eyes [1]. In these scenarios, each subject may contribute either bilaterally or unilaterally, resulting in the data structure being bilateral and unilateral data existing simultaneously. Also, in practice, to determine the effect of exposure, some clinical trial procedures desire to stratify the data to avoid confounding by stratifying two or more categories in subgroups, aiming to obtain unbiased treatment effects. Estimating the effect of exposure can be biased if the investigator fails to adjust for stratified factors when analyzing the homogeneity test during trials.
Data were stratified by some control variables such as location, age, gender, etc., to detect whether the inference we were interested in involved treatment-by-stratum interaction. In the stratified sample design with two groups, the homogeneity test concerning proportions ratios is often referred to as inspecting if relative risk maintains the same across strata. When the ratio of proportions in the two groups is significantly different, we can include a confounding effect. If homogeneity is claimed, stratified data can be combined in a pooled dataset to investigate statistical inference. Therefore, it was necessary and important that we applied a homogeneity test to the stratified clinical data.
We investigated three homogeneity test methods of ratios of proportions on stratified unilateral and bilateral data structures in two groups. For unilateral cases, the homogeneity test can be treated as independent and applied by a usual method that has been studied in detail and thoroughly in the literature [2]. Naturally, two eyes in the same patient tend to be highly correlated in bilateral cases [3]. Without considering such a situation, standard inference and test methods may produce misleading statistical significance and inadequate power. Previous studies have explored models specially designed to address intraclass correlated data. Rosner introduced an approach referred to as the “constant R model” with the assumption that dependence between two paired organs of the same subject is measured as a constant R. Tang et al. [4], Ma et al. [5], Shan and Ma [6], and Liu et al. [7] then developed related asymptotic and exact test methods based this model. Afterward, Dallal [8] pointed out that the “Constant R model” could have poor performance on compound multinomial sampling and then provided a new approach with the assumption that the conditional probability of one eye given the other eye in the same person is not connected to the probabilities of the individual in the general population. Donner [9] introduced a widely used model under the assumption that the intraclass correlation coefficient, denoted as “”, is generally considered uniform across groups. The model, along with an adjusted chi-square test, has been further validated in subsequent studies ([10,11,12]). Additionally, asymptotic and exact testing methods ([7,13,14,15]) have been explored in later research. In this paper, we incorporate Donner’s model since the model can also be applied to an arbitrary number of units provided by an individual.
Statistical data analysis focusing on stratified data also has been extensively studied in clinical trials. Lui and Kelly [16] focused on the homogeneity test of risk difference in unilateral cases and then discussed sparse data with a bootstrap method to improve the power of previous test designs. Li and Tang [17] applied the model to fit stratified matched-pair studies to develop computationally effective score test statistics. Tang and Qiu [18] conducted the homogeneity test for risk difference under Rosner’s R model. Then, Pei et al. [19], based on Donner’s model, explored homogeneity tests on stratified bilateral data. However, several issues have been raised here, considering the combined data structure. The aforementioned stratified data test methods only consider bilateral cases. Therefore, to evaluate treatment effectiveness in these scenarios, unilateral and bilateral cases occurred simultaneously. We further analyze and develop bilateral test methods appropriate to the combined data structure. In this paper, our goal is to develop new statistical test methods aiming to evaluate the homogeneity of the ratio of proportions across strata under a combined data structure without the assumption of a common ratio.
The remainder of this article is structured as follows. Section 2 derives both constrained and unconstrained maximum likelihood estimates for the parameters and examines three different testing procedures: the likelihood ratio test, the Wald test, and the score test. Section 3 presents Monte Carlo simulation studies designed to assess the performance of these tests in terms of empirical Type I error rates and statistical power. Section 4 provides an application of the methodologies to a real data example. Finally, Section 5 provides conclusions and remarks.
2. Methods
Suppose there are J strata, and for each stratum, there are patients, which provide bilateral records and patients, which provide unilateral records in g groups, . represents the number of patients having l responses () in the ith group () of the jth stratum (). is the total number of patients having l responses among all groups, and is the total number of patients in the ith group. The same notations are also applied to the unilateral case. The data structure of the jth stratum is summarized in Table 1.

Table 1.
Data structure for the jth stratum in the stratified unilateral and bilateral cases.
For the bilateral case, we denote as an event that the kth eye () of the hth patient in the ith treatment group from the jth stratum has an expected response, cured or effected, otherwise. Since we applied Donner’s model here, it assumes that the correlations of response between two eyes are the same across all individuals in the two groups from a single stratum but can be different in different strata. Hence, for a given j stratum, we can express Donner’s model as , ; , where is the ith group proportion in the jth stratum that has an expected event, and is the common correlation of the jth stratum. Then, the probabilities of an expected response for none, one, or both eyes are as follows:
Similarly, let be the same event in the unilateral case that there is an expected response from hth patient in the ith treatment group of the jth stratum. Since is the group probability of which patient has an exposure treatment, will be straightforward.
2.1. Maximum Likelihood Estimation
As previously mentioned, our lies in whether the risk ratio exhibits consistency across strata. Consequently, we can formulate the following hypotheses:
vs.
where is the ratio of proportions between two groups in the jth stratum. Under this assumption, with and the corresponding log-likelihood can be expressed as
where
and is the parameter that we focus on while , are nuisance parameters.
2.1.1. Unconstrained Maximum Likelihood Estimate
Under the unconstrained condition, the maximum likelihood estimation (MLE) of and , denoted as and , can be determined as the solution to the following equations:
For a given in the jth stratum, we can simplify the above equation for as a fourth-order polynomial, and let the data for the ith group be . We have
where
The th update for can be computed directly from the formula above, whereas is updated using the Fisher scoring algorithm.
Continue iterating these steps until convergence is achieved. The form of the second derivative is detailed in Appendix A regarding the information matrix. Then, the risk ratio can be obtained by by each stratum. After the above iteration procedure, we obtain unconstrained MLEs denoted by ,
2.1.2. Constrained Maximum Likelihood Estimates
Under the null hypothesis, , are same across strata. Then, we know , which means that the response rates are known once we obtain so that the log-likelihood function can be simplified as follows:
where
In the jth stratum, we begin by determining constrained MLEs by setting the score statistics for and to zero,
However, there is no closed-form for these solutions, so we applied the iterative methods proposed by Ma and Liu [15]
(1) For the jth stratum, start with the initial value , then the initial estimates of and can be obtained by treating data as a whole without a strata effect, which are also the same as the estimates under null hypotheses using Donner’s approach [20], which is as follows:
(2) Since is constant across strata, we update this by
(3) The th updates for and can be obtained by the Fisher Scoring algorithm as follows:
where is the Fisher information matrix with respect to , , . For more details on the derivation of the Fisher information matrix, please see Appendix A.
(4) Repeat steps (2) and (3) until convergence.
After the above iteration procedure, we obtain constrained MLEs denoted by ,
2.2. Hypothesis Testing Methods
2.2.1. Likelihood Ratio Test ()
The likelihood ratio test is usually defined by
which, under null hypothesis, asymptotically follows a chi-square distribution with degrees of freedom.
2.2.2. Wald-Type Test ()
The null hypotheses is equivalent to for all strata , which can be rewritten as follows:
where and
The Wald-type test statistic () for testing can be defined as follows:
where is the Fisher information matrix for (see Appendix A) and still, is asymptotically distributed as a chi-square distribution with J-1 degrees of freedom. Then, should be rejected at the significant level if .
Then, the Wald test statistic is provided as the objective to test vs. given by
where with in the th element to th element, th element to th element, and 0 otherwise. is asymptotically distributed as a chi-square distribution with 1 degree of freedom.
2.2.3. Score Tests ()
The score test statistic utilizes constrained MLEs, and under the null hypothesis, each stratum has the same ratio . is given by
where the score is
since is nuisance parameter. See Appendix A for the formula of .
is also asymptotically distributed as a chi-square distribution with 1 degree of freedom. Then, should be rejected at the significance level if .
3. Simulations
In this section, we evaluate the performance of these three methods, , , and , as investigated in the previous section, specifically assessing their effectiveness in controlling the Type I error rate and statistical power. Empirical Type I errors are summarized under various parameter settings: 25, 50, 100, with strata , , and for a balanced design. Additionally, different parameter settings consider as the imbalanced data structure. Here, we choose for the null hypothesis. For each parameter setting, we generate 50,000 random samples under the null hypothesis, and the empirical Type I error is calculated as the ratio of the number of rejections to 50,000. The results for all configurations with are shown in Table 2, Table 3 and Table 4.
Table 2.
The empirical Type I error rates for testing corresponding to nominal based on 50,000 replications under .
Table 3.
The empirical Type I error rates for testing corresponding to nominal based on 50,000 replications under .
Table 4.
The empirical Type I error rates for testing corresponding to nominal based on 50,000 replications under .
In addition to the specific parameter configurations mentioned earlier, we also construct the empirical Type I error rates for random parameter settings across each of , and various sample sizes m = n = 20, 40, 80. The parameters and are drawn from a uniform distribution. For each of the 1000 configurations, we processed 50,000 replications and calculated the empirical Type I error rate. The 1000 empirical Type I error rates are summarized in the box plot shown in Figure 1. This plot reveals that the score test performs satisfactorily, as its Type I error remains close to the assumed nominal level of 0.05 across various configurations. The likelihood ratio test performs a wider range of empirical Type I error rates, while the Wald test tends to be more liberal compared to the other two tests across different configurations. Additionally, as the number of strata increases, the performance of the test becomes less stable, particularly for extra strata. However, the score test continues to demonstrate robustness within an acceptable range. As the group and sample size become larger, the discrepancy between the score test and the other two tests about the Type I error rate range becomes smaller, with the median of the Type I error rate among the three tests being closer than the small sample size of .
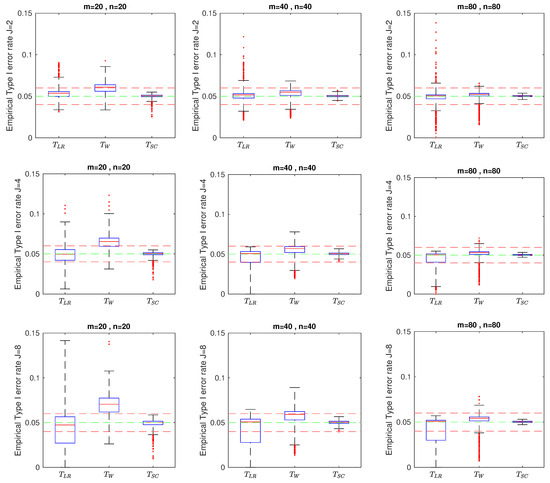
Figure 1.
Box plots of empirical sizes when J = 2, 4, 8 and m = n = 20, 40, 80.
As defined by Tang et al. [4], hypothesis testing is classified as liberal if the ratio of the empirical Type I error rate to the nominal Type I error rate is greater than 1.2 (i.e., exceeding 6% for = 5%, emphasized as bolded numbers in the results). It is considered conservative if this ratio is below 0.8 (i.e., less than 4%, also highlighted in the results) and robust if the ratio falls between 0.8 and 1.2. The results presented in Table 2, Table 3 and Table 4 indicate that the score test consistently produces stable Type I error rates across all scenarios. In contrast, the likelihood ratio test is liberal, especially in cases with small sample sizes, while the Wald test exhibits a conservative behavior. Notably, the likelihood ratio test and Wald test tend to be either liberal or conservative with moderate or small sample size (e.g., m = 25 or fewer) and also show similar trends as the correlation coefficient increases. However, when the sample size is sufficiently large (e.g., or more, as indicated by the simulation results), both the likelihood ratio test and the Wald test perform comparably to the score test, providing similar results for Type I error rate and power. Consequently, the score test and adjusted chi-square test are preferred for stable control of the Type I error rate.
Next, we assess the power performance of the proposed statistics under similar Type I error parameter settings. The empirical power for , , and across these settings is shown in Table 5, Table 6 and Table 7. Each table includes footnotes specifying the different settings for each stratum. The simulation results indicate that the score test consistently provides satisfactory power compared to the others. The likelihood ratio test tends to overestimate power due to its empirical level exceeding the nominal level, whereas the Wald test often shows reduced power due to overfitting. As previously mentioned, increasing the sample size results in the power of the three statistics becoming more comparable. The score test is recommended for practical use among the methods evaluated as our conclusion from simulation results.
Table 5.
Power performance for J = 2.
Table 6.
Power performance for J = 4.
Table 7.
Power performance for J = 8.
4. Application
To address the unilateral and bilateral combined data structure, a double-blinded clinical trial reported by Mandel et al. [21] and Le [20] provides us with the ability to implement our methodology for real-world data. This trial aimed to compare the efficacy of two antibiotics, Cefaclor and Amoxicillin, in treating acute otitis media with effusion (AOM) in children. The study sought to evaluate the safety and effectiveness of Cefaclor compared to Amoxicillin, the standard first-line treatment, in order to identify potentially more effective medications [22]. The trial involved 214 children (293 ears) who received either unilateral or bilateral tympanocentesis before being randomly assigned to one of the treatment groups. After a 14-day treatment course, outcomes were recorded. The unilateral group had binary outcomes (cured or not cured), while the bilateral group was categorized into three outcomes: cured (both ears AOM-free), partially cured (one ear AOM-free), and not cured. Table 8 summarizes the frequency of patients in each outcome category by intervention group at the end of the trial.
Table 8.
Number of ears in different age strata of children cured by antibiotics (Treatment arm—Cefaclor vs. Control arm—Amoxicillin).
The parameter estimates shown in Table 9 and Table 10 provide the statistics and corresponding p-values for the three methods. Notably, all p-values are greater than 0.05. Table 9 indicates no evidence to reject the null hypothesis with , suggesting that there is no significant difference in the proportions between Cefaclor and Amoxicillin across the strata.
Table 9.
MLEs of risk ratios, correlation coefficient, and risk incidence for each strata.
Table 10.
Statistic and p-value for comparing two groups treatment effect.
5. Conclusions
In this article, we developed three test procedures to assess homogeneity in combined unilateral and bilateral samples within stratified two-group clinical trial data. For the estimation of unrestricted and restricted MLEs, we proposed relatively efficient iteration solutions by treating relative risks as common to decrease the estimator dimension.
Simulation results demonstrate that the score test performs robustly, maintaining a satisfactory Type I error rate and power across various parameter settings, including different group sizes and numbers of strata. In contrast, the likelihood ratio test tends to produce inflated results when sample sizes are small, while the Wald test is conservative and prone to overfitting with small sample sizes. However, as the number of strata increases and the relative risk becomes larger, the Wald test’s performance also becomes inflated. When the sample size is large, especially when it exceeds 100, the results of the three tests converge closely to the true values. Therefore, the score test is generally preferred for assessing homogeneity in combined sample designs. Simulation results furthermore indicated that a combined data structure incorporating unilateral and bilateral data at once could gain more power than bilateral data only [19].
This study utilizes a statistical approach grounded in Donner’s parametric model, which calculates the rate by aggregating outcomes across groups, treating paired organs and bilateral results as indistinguishable. Given the inflated or conservative Type I error rates observed in the likelihood ratio and Wald tests, future research may explore the development of an exact test tailored to small sample size settings. It is important to note that Donner’s model assumes a common intra-class correlation for bilateral outcomes, which may present challenges if significant differences in correlation exist between the paired organs of different individuals or across different groups in clinical trials. In other words, we should initially validate the correlation in conjunction with our model-based method presentation. In addition, there is necessity to adjust for confounding effect when we involves in strata. Furthermore, some research examines the difference between the paired organs such eyes can be dominant and non-dominant [23] while researchers usually do not collect (or it is hard to collect) the handedness of the individuals [1]. We could consider if those data are available in a real-world example. Considering the assumptions discussed above, we plan to explore these topics in future work to support our methods using a more stable foundation.
In addition to risk ratio exploration, Zhang and Ma [24] investigated homogeneity testing on the risk difference between stratified bilateral and unilateral combined data. She proposed that the score test is a worthwhile hypothesis testing with well-performed power and a robust Type I error rate, which can be evidence supporting that our model-based method on risk ratio holds more comprehensive conclusions.
Author Contributions
Conceptualization, H.W. and C.-X.M.; Methodology, H.W. and C.-X.M.; Writing—original Draft Preparation, H.W.; Writing—Review and Editing, H.W. and C.-X.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in this study are openly available in reference.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Appendix A.1. Fisher Information Matrix for Given δ
Under the null hypothesis, and can be obtained by the Fisher scoring algorithm. The Fisher information matrix for jth stratum is written as follows:
where
Appendix A.2. Fisher Information Matrix for the Wald Test and Score Test
The Fisher information matrix is a block diagonal matrix.
with the diagonal elements
where
References
- Fan, Q.; Teo, Y.Y.; Saw, S.M. Application of Advanced Statistics in Ophthalmology. Investig. Ophthalmol. Vis. Sci. 2011, 52, 6059–6065. [Google Scholar] [CrossRef]
- Burton, P.; Gurrin, L.; Sly, P. Extending the simple linear regression model to account for correlated responses: An introduction to generalized estimating equations and multi-level mixed modelling. Stat. Med. 1998, 17, 1261–1291. [Google Scholar] [CrossRef]
- Murdoch, I.E.; Morris, S.S.; Cousens, S.N. People and eyes: Statistical approaches in ophthalmology. Br. J. Ophthalmol. 1998, 82, 971–973. [Google Scholar] [CrossRef]
- Tang, N.S.; Tang, M.L.; Qiu, S.F. Testing the equality of proportions for correlated otolaryngologic data. Comput. Stat. Data Anal. 2008, 52, 2719–3729. [Google Scholar] [CrossRef]
- Ma, C.X.; Shan, G.; Liu, S. Homogeneity test for binary correlated data. PLoS ONE 2015, 10, e0124337. [Google Scholar] [CrossRef]
- Shan, G.; Ma, C. Exact methods for testing the equality of proportions for binary clustered data from otolaryngologic studies. Stat. Biopharm. Res. 2014, 6, 115–122. [Google Scholar] [CrossRef]
- Liu, X.; Shan, G.; Tian, L.; Ma, C.X. Exact methods for testing homogeneity of proportions for multiple groups of paired binary data. Commun. Stat.—Simulat. Comput. 2017, 46, 6074–6082. [Google Scholar] [CrossRef]
- Dallal, G.E. Paired Bernoulli Trials. Biometrics 1988, 44, 253–257. [Google Scholar] [CrossRef]
- Donner, A. Statistical methods in ophthalmology: An adjusted chi-square approach. Biometrics 1989, 45, 605–611. [Google Scholar] [CrossRef]
- Thompson, J.R. The chi-square test for data collected on eyes. Br. J. Ophthalmol. 1993, 77, 115–117. [Google Scholar] [CrossRef]
- Donner, A.; Klar, N. Methods for comparing event rates in intervention studies when the unit of allocation is a cluster. Am. J. Epidemiol. 1994, 140, 279–289. [Google Scholar] [CrossRef] [PubMed]
- Jung, S.H.; Ahn, C.D.A. A study of an adjusted χ2 statistic as applied to observational studies involving clustered binary data. Stat. Med. 2001, 20, 2149–2161. [Google Scholar] [CrossRef] [PubMed]
- Tang, N.S.; Qiu, S.F.; Tang, M.L.; Pei, Y.B. Asymptotic confidence interval construction for proportion difference in medical studies with bilateral data. Stat. Methods Med. Res. 2011, 20, 233–259. [Google Scholar] [CrossRef]
- Pei, Y.B.; Tang, M.L.; Guo, J.H. Testing the equality of two proportions for combined unilateral and bilateral data. Commun. Stat.-Comput. 2008, 37, 1515–1529. [Google Scholar] [CrossRef]
- Ma, C.X.; Liu, S. Testing equality of proportions for correlated binary data in ophthalmologic studies. J. Biopharm. Stat. 2017, 27, 611–619. [Google Scholar] [CrossRef]
- Lui, K.J.; Kelly, C. Tests for homogeneity of the risk ratio in a series of 2 × 2 tables. Stat. Med. 2000, 19, 2919–2932. [Google Scholar] [CrossRef]
- Li, H.Q.; Tang, N.S. Homogeneity test of rate ratios in stratified matched-pair studies. Biom. J. 2011, 53, 614–627. [Google Scholar] [CrossRef]
- Tang, N.S.; Qiu, S.F. Homogeneity test, sample size determination and interval construction of difference of two proportions in stratified bilateral-sample designs. J. Stat. Plan. Inference 2012, 142, 1243–1251. [Google Scholar] [CrossRef]
- Pei, Y.; Tian, G.L.; Tang, M.L. Testing homogeneity of proportion ratios for stratified correlated bilateral data in two-arm randomized clinical trials. Stat. Med. 2014, 33, 4370–4386. [Google Scholar] [CrossRef]
- Le, C.T. Testing for Linear Trends in Proportions Using Correlated Otolaryngology or ophthalmology Data. Biometrics 1988, 44, 299–303. [Google Scholar] [CrossRef]
- Mandel, E.M.; Bluestone, C.D.; Rockette, H.E.; Blatter, M.M.; Reisinger, K.S.; Wucher, F.P.; Harper, J. Duration of effusion after antibiotic treatment for acute otitis media: Comparison of cefaclor and amoxicillin. Pediatr. Infect. Dis. 1982, 1, 310–316. [Google Scholar] [CrossRef]
- McLinn, S.E. Cefaclor in treatment of otitis media and pharyngitis in children. Am. J. Dis. Child. 1980, 134, 560–563. [Google Scholar] [CrossRef] [PubMed]
- Linke, S.J.; Druchkiv, V.; Steinberg, J.; Richard, G.; Katz, T. Eye laterality: A comprehensive analysis in refractive surgery candidates. Acta Ophthalmol. 2013, 91, e363–e368. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Ma, C. Testing the Homogeneity of Differences between Two Proportions for Stratified Bilateral and Unilateral Data across Strata. Mathematics 2023, 11, 4156. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).