
Asymmetric-Convolution-Guided Multipath Fusion for Real-Time Semantic Segmentation Networks

Abstract
:1. Introduction
2. Textual Algorithm
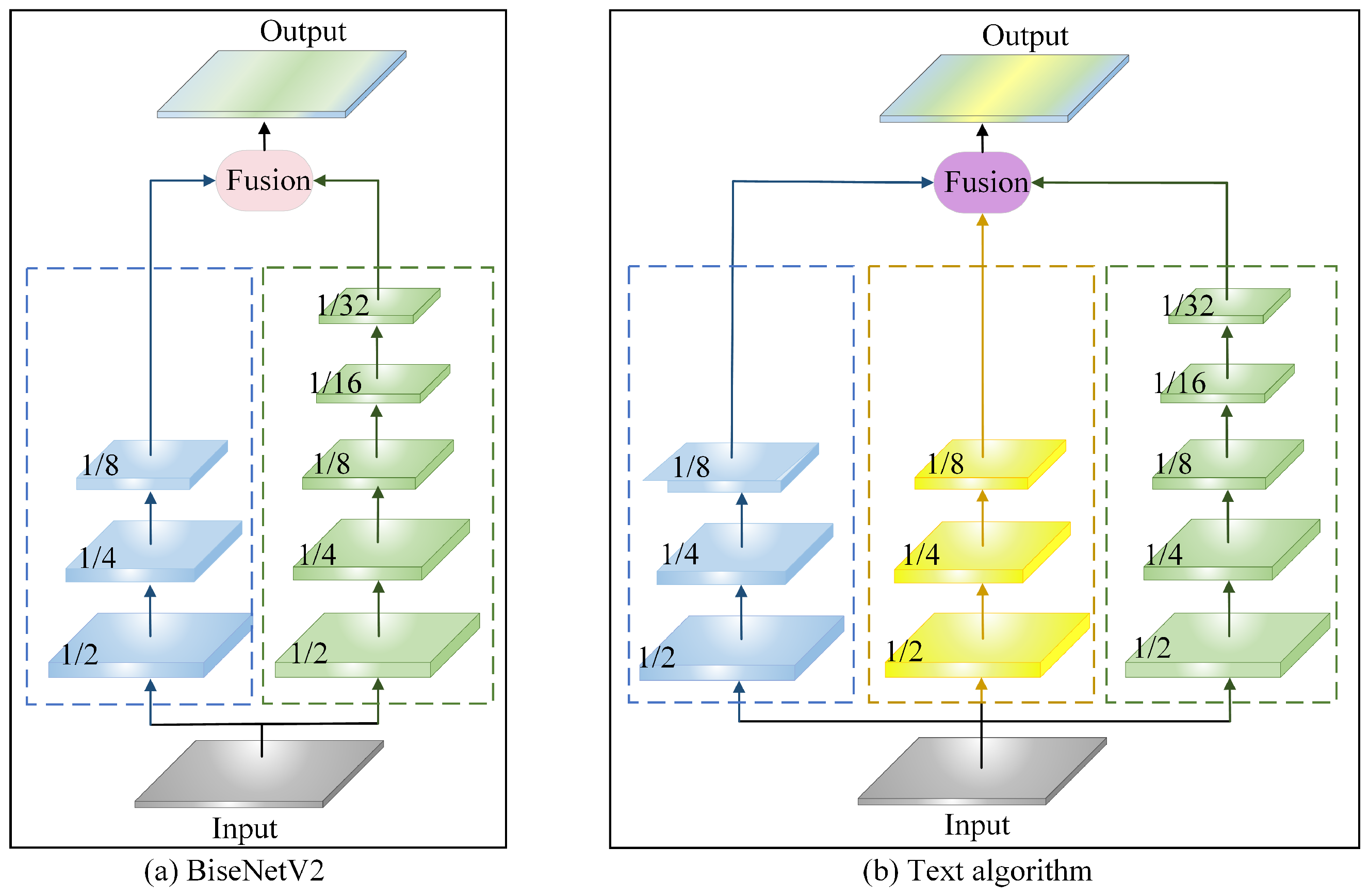
2.1. Overall Structure
2.2. Auxiliary Branch
2.3. Alignment-and-Fusion Module
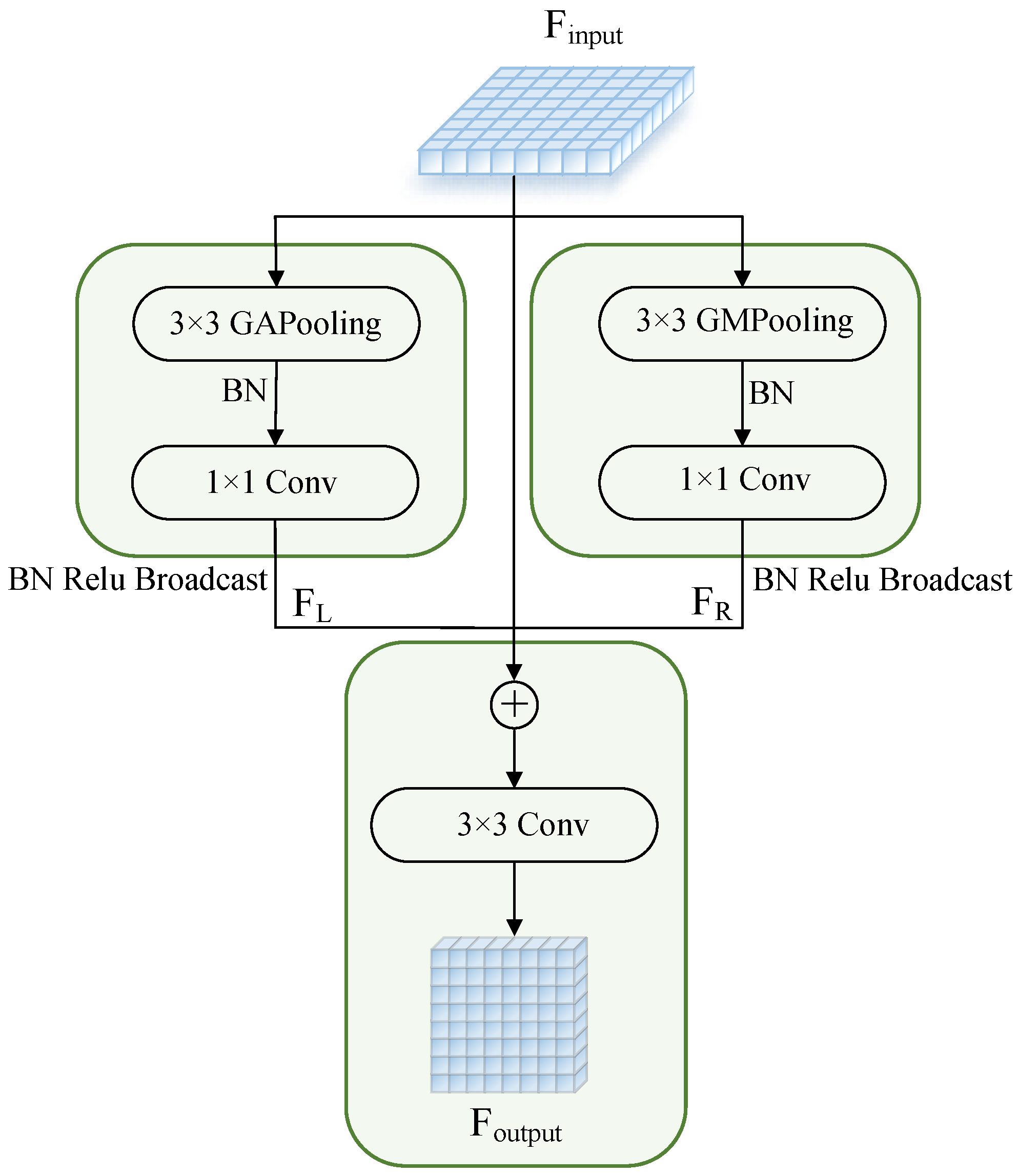
2.4. Global Context Module
3. Experiment and Result Analysis
3.1. Dataset Introduction
3.1.1. Cityscapes Dataset
3.1.2. CamVid Dataset
3.2. Evaluation Index
3.3. Training Strategy
3.3.1. Experimental Parameter
3.3.2. Data Enhancement
3.3.3. Training Optimization Strategy
3.4. Ablation Experiment
3.5. Contrast Experiment
3.6. Visual Result
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Ren, F.; Zhou, H.; Yang, L.; Liu, F.; He, X. ADPNet: Attention based dual path network for lane detection. J. Vis. Commun. Image Represent. 2022, 87, 103574. [Google Scholar] [CrossRef]
- Huang, X.; Wang, P.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The apolloscape open dataset for autonomous driving and its application. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2702–2719. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Pfister, T. Learning fast sample re-weighting without reward data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 725–734. [Google Scholar]
- Tian, S.; Yao, G.; Chen, S. Faster SCDNet: Real-Time Semantic Segmentation Network with Split Connection and Flexible Dilated Convolution. Sensors 2023, 23, 3112. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Zhang, S.; Liu, J.; Li, B. Towards a Deep Learning Approach for Detecting Malicious Domains. In Proceedings of the 2018 IEEE International Conference on Smart Cloud (SmartCloud), New York, NY, USA, 21–23 September 2018; pp. 190–195. [Google Scholar]
- Hu, X.; Jiang, Y.; Tang, K.; Chen, J.; Miao, C.; Zhang, H. Learning to segment the tail. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14045–14054. [Google Scholar]
- Gao, G.; Xu, G.; Li, J.; Yu, Y.; Lu, H.; Yang, J. FBSNet: A fast bilateral symmetrical network for real-time semantic segmentation. IEEE Trans. Multimed. 2022, 50, 1609–1620. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M.; Arroyo, R. ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2017, 19, 263–272. [Google Scholar] [CrossRef]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for Real-Time Semantic Segmentation on High-Resolution Images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hu, P.; Perazzi, F.; Heilbron, F.C.; Wang, O.; Lin, Z.; Saenko, K.; Sclaroff, S. Real-Time Semantic Segmentation with Fast Attention. In Proceedings of the International Conference on Robotics and Automation, Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Wang, H.; Jiang, X.; Ren, H.; Hu, Y.; Bai, S. SwiftNet: Real-time Video Object Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Yang, Q.; Chen, T.; Fan, J.; Lu, Y.; Chi, Q. EADNet: Efficient Asymmetric Dilated Network for Semantic Segmentation. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-Time Semantic Segmentation; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- He, J.; Deng, Z.; Zhou, L.; Wang, Y.; Qiao, Y. Adaptive pyramid context network for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7519–7528. [Google Scholar]
- Li, X.; You, A.; Zhu, Z.; Zhao, H.; Yang, M.; Yang, K.; Tan, S.; Tong, Y. Semantic flow for fast and accurate scene parsing. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16. Springer: Cham, Switzerland, 2020; pp. 775–793. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Brostow, G.J.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and recognition using structure from motion point clouds. In Proceedings of the Computer Vision–ECCV 2008: 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Proceedings, Part I 10. Springer: Berlin/Heidelberg, Germany, 2008; pp. 44–57. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Poudel, R.P.; Liwicki, S.; Cipolla, R. Fast-scnn: Fast semantic segmentation network. arXiv 2019, arXiv:1902.04502. [Google Scholar]
- Li, G.; Yun, I.; Kim, J.; Kim, J. DABNet: Depth-Wise Asymmetric Bottleneck for Real-Time Semantic Segmentation. 2021. Available online: http://arxiv.org/pdf/1907.11357.pdf (accessed on 12 January 2024).
- Li, H.; Xiong, P.; Fan, H.; Sun, J. Dfanet: Deep feature aggregation for real-time semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9522–9531. [Google Scholar]
- Fan, M.; Lai, S.; Huang, J.; Wei, X.; Chai, Z.; Luo, J.; Wei, X. Rethinking bisenet for real-time semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9716–9725. [Google Scholar]
- Hao, S.; Zhou, Y.; Guo, Y.; Hong, R.; Cheng, J.; Wang, M. Real-time semantic segmentation via spatial-detail guided context propagation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 24, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Jiang, J.; Huang, Z.; Tian, Y. FPANet: Feature pyramid aggregation network for real-time semantic segmentation. Appl. Intell. 2022, 52, 3319–3336. [Google Scholar] [CrossRef]
- Yang, Z.; Yu, H.; Fu, Q.; Sun, W.; Jia, W.; Sun, M.; Mao, Z.H. NDNet: Narrow while deep network for real-time semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2020, 22, 5508–5519. [Google Scholar] [CrossRef]
- Chen, Y.; Zhan, W.; Jiang, Y.; Zhu, D.; Guo, R.; Xu, X. LASNet: A light-weight asymmetric spatial feature network for real-time semantic segmentation. Electronics 2022, 11, 3238. [Google Scholar] [CrossRef]
- Kim, M.; Park, B.; Chi, S. Accelerator-aware fast spatial feature network for real-time semantic segmentation. IEEE Access 2020, 8, 226524–226537. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, Q.; Liu, J.; Xiong, J.; Gao, G.; Wu, X.; Latecki, L.J. Lednet: A lightweight encoder-decoder network for real-time semantic segmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1860–1864. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Detail Branch | Auxiliary Branch | Semantic Branch | |
|---|---|---|---|---|
| Operation | Operation | Operation | Output Size | |
| S1 | Conv2d, k = 3, c = 64, s = 2, r = 1 Conv2d, k = 3, c = 64, s = 1, r = 1 | asymmetric conv2d, k = 1 × 3, c = 64, s = 2, r = 1 asymmetric conv2d, k = 3 × 1, c = 64, s = 2, r = 1 | stem, k = 3, c = 16, e = _, s = 4, r = 1 | 256 × 512 256 × 512 |
| S2 | Conv2d, k = 3, c = 64, s = 2, r = 1 Conv2d, k = 3, c = 64, s = 1, r = 2 Conv2d, k = 3, c = 64, s = 1, r = 2 | asymmetric conv2d, k = 1 × 3, c = 64, s = 1, r = 1 asymmetric conv2d, k = 3 × 1, c = 64, s = 1, r = 1 | 128 × 256 128 × 256 | |
| S3 | Conv2d, k = 3, c = 128, s = 2, r = 1 Conv2d, k = 3, c = 128, s = 1, r = 2 Conv2d, k = 3, c = 128, s = 1, r = 2 | asymmetric conv2d, k = 1 × 3, c = 128, s = 2, r = 1 asymmetric conv2d, k = 3 × 1, c = 128, s = 2, r = 1 | GE, k = 3, c = 32, e = 6, s = 2, r = 1 GE, k = 3, c = 32, e = 6, s = 1, r = 1 | 64 × 128 64 × 128 |
| S4 | GE, k = 3, c = 64, e = 6, s = 2, r = 1 GE, k = 3, c = 64, e = 6, s = 1, r = 1 | 32 × 64 32 × 64 | ||
| S5 | GE, k = 3, c = 128, e = 6, s = 2, r = 1 GE, k = 3, c = 128, e = 6, s = 1, r = 3 GCM, k = 3, c = 128, e = _, s = 1, r = 1 | 16 × 32 16 × 32 16 × 32 |
| Model | mIoU% | Running Speed (Frames·s−1) | Parameters (M) |
|---|---|---|---|
| Baseline | 72.60 | 156.00 | - |
| +Auxiliary Branch | 74.30 | 139.00 | 3.74 |
| +AAFM | 74.40 | 137.00 | 4.25 |
| +CGM | 73.30 | 150.00 | 3.37 |
| +Auxiliary Branch + AAFM + CGM | 77.10 | 127.00 | 4.65 |
| Network Type | Network Name | Pre-Training | mIoU% | Running Speed (Frames·s−1) | Resolution | Parameters (M) |
|---|---|---|---|---|---|---|
| Large scale | SegNet [17] | Y | 57.0 | 17 | 640 × 360 | 29.5 |
| PSPNet [6] | Y | 81.2 | <1 | 713 × 713 | 65.7 | |
| DeepLabV2 [8] | Y | 70.4 | <1 | 512 × 1024 | 44 | |
| Light weight | Fast-SCNN [33] | N | 68 | 123.5 | 1024 × 2048 | 0.4 |
| ESPNet [22] | Y | 60.3 | 112.9 | 512 × 1024 | 0.4 | |
| DABNet [34] | Y | 70.1 | 27.7 | 1024 × 2048 | - | |
| DFANet A [35] | Y | 71.3 | 100 | 1024 × 2048 | - | |
| STDC-Seg50 [36] | Y | 73.4 | 156.6 | 512 × 1024 | 12.3 | |
| SGCPNet [37] | Y | 70.9 | 103.7 | 1024 × 2048 | 0.61 | |
| FPANet [38] | Y | 75.9 | 31 | 1024 × 2048 | 2.59 | |
| SwiftNet [23] | Y | 75.4 | 39.9 | 1024 × 2048 | 11.8 | |
| Faster:SCDNet [13] | Y | 77.6 | 66.1 | 1024 × 2048 | 17.8 | |
| BiseNetV1 [25] | Y | 68.4 | 105.8 | 786 × 1536 | 5.8 | |
| BiseNetV2 [26] | N | 72.6 | 156.0 | 512 × 1024 | - | |
| Ours | Y | 77.1 | 127.0 | 512 × 1024 | 4.65 |
| Network Name | mIoU% | Running Speed (Frames·s−1) | Resolution |
|---|---|---|---|
| DFANet A [35] | 64.7 | 120 | 960 × 720 |
| STDC-Seg50 [36] | 73.9 | 152.2 | 720 × 960 |
| FPANet [38] | 72.9 | 88 | 720 × 960 |
| Faster:SCDNet [13] | 74.2 | 154.2 | 720 × 960 |
| BiseNetV1 [25] | 65.6 | 175 | 960 × 720 |
| BiseNetV2 [26] | 72.4 | 124.5 | 960 × 720 |
| Ours | 77.4 | 112.0 | 960 × 720 |
| Network Name | Lane | Footpath | Unit | Wall | Fence | Support Bar | Traffic Light | Mark | Plant | Topography |
| SegNet [17] | 96.4 | 73.2 | 84.0 | 28.4 | 29.0 | 35.7 | 39.8 | 45.1 | 87.0 | 63.8 |
| ENet [18] | 96.3 | 74.3 | 75.0 | 32.2 | 33.2 | 43.4 | 34.1 | 44.0 | 88.6 | 61.4 |
| ESPNet [22] | 95.7 | 73.3 | 86.6 | 32.8 | 36.4 | 47.0 | 46.9 | 55.4 | 89.8 | 66.0 |
| NDNet [39] | 96.6 | 75.2 | 87.2 | 44.2 | 46.1 | 29.6 | 40.4 | 53.3 | 87.4 | 57.9 |
| LASNet [40] | 97.1 | 80.3 | 89.1 | 64.5 | 58.8 | 48.6 | 48.5 | 62.6 | 89.9 | 62.0 |
| FSFNet [41] | 97.7 | 81.1 | 90.2 | 41.7 | 47.0 | 47.0 | 61.1 | 65.3 | 91.8 | 69.3 |
| ERFNet [19] | 97.9 | 82.1 | 90.7 | 45.2 | 50.4 | 59.0 | 62.6 | 68.4 | 91.9 | 69.4 |
| LEDNet [42] | 98.1 | 79.5 | 91.6 | 47.7 | 49.9 | 62.8 | 61.3 | 72.8 | 92.6 | 61.2 |
| BisNetV2 [26] | 98.2 | 82.9 | 91.7 | 44.5 | 51.1 | 63.5 | 71.3 | 75.0 | 92.9 | 71.1 |
| Ours | 97.9 | 83.8 | 92.3 | 63.7 | 63.8 | 64.9 | 63.1 | 77.5 | 92.4 | 63.0 |
| Network Name | Sky | Pede Strian | Rider | Car | Truck | Bus | Train | Bike | Motor Cycle | mIoU |
| SegNet [17] | 91.8 | 62.8 | 42.8 | 89.3 | 38.1 | 43.1 | 44.1 | 35.8 | 51.9 | 55.6 |
| ENet [18] | 90.6 | 65.5 | 38.4 | 90.6 | 36.9 | 50.5 | 48. 1 | 38.8 | 55.4 | 58.3 |
| ESPNet [22] | 92.5 | 68.5 | 45.9 | 89.9 | 40.0 | 47.7 | 40.7 | 36.4 | 54.9 | 60.3 |
| NDNet [39] | 90.2 | 62.6 | 41.6 | 88.5 | 57.8 | 63.7 | 35.1 | 31.9 | 59.4 | 60.6 |
| LASNet [40] | 91.8 | 70.8 | 51.3 | 91.1 | 77.3 | 81.7 | 69.2 | 48.0 | 65.8 | 70.9 |
| FSFNet [41] | 94.2 | 77.8 | 57.8 | 92.8 | 47.3 | 64.4 | 59.4 | 53.1 | 66.2 | 65.3 |
| ERFNet [19] | 94.2 | 78.5 | 59.8 | 93.4 | 52.3 | 60.8 | 53.7 | 49.9 | 64.2 | 69.7 |
| LEDNet [42] | 94.9 | 76.2 | 53.7 | 90.9 | 64.4 | 64.0 | 52.7 | 44.4 | 71.6 | 70.6 |
| BisNetV2 [26] | 94.9 | 83.6 | 65.4 | 94.9 | 60.5 | 68.7 | 56.8 | 61.5 | 51.9 | 72.6 |
| Ours | 94.8 | 81.0 | 58.5 | 94.3 | 80.6 | 83.8 | 78.0 | 57.2 | 76.5 | 77.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Zhao, B.; Tian, M. Asymmetric-Convolution-Guided Multipath Fusion for Real-Time Semantic Segmentation Networks. Mathematics 2024, 12, 2759. https://doi.org/10.3390/math12172759
Liu J, Zhao B, Tian M. Asymmetric-Convolution-Guided Multipath Fusion for Real-Time Semantic Segmentation Networks. Mathematics. 2024; 12(17):2759. https://doi.org/10.3390/math12172759
Chicago/Turabian StyleLiu, Jie, Bing Zhao, and Ming Tian. 2024. "Asymmetric-Convolution-Guided Multipath Fusion for Real-Time Semantic Segmentation Networks" Mathematics 12, no. 17: 2759. https://doi.org/10.3390/math12172759