Abstract
Influence maximization in online social networks is used to select a set of influential seed nodes to maximize the influence spread under a given diffusion model. However, most existing proposals have huge computational costs and only consider the dyadic influence relationship between two nodes, ignoring the higher-order influence relationships among multiple nodes. It limits the applicability and accuracy of existing influence diffusion models in real complex online social networks. To this end, in this paper, we present a novel information diffusion model by introducing hypergraph theory to determine the most influential nodes by jointly considering adjacent influence and higher-order influence relationships to improve diffusion efficiency. We mathematically formulate the influence maximization problem under higher-order influence relationships in online social networks. We further propose a hypergraph sampling greedy algorithm (HSGA) to effectively select the most influential seed nodes. In the HSGA, a random walk-based influence diffusion method and a Monte Carlo-based influence approximation method are devised to achieve fast approximation and calculation of node influences. We conduct simulation experiments on six real datasets for performance evaluations. Simulation results demonstrate the effectiveness and efficiency of the HSGA, and the HSGA has a lower computational cost and higher seed selection accuracy than comparison mechanisms.
MSC:
91D30
1. Introduction
With the recent advancements in network technologies, online social networks have become an integral part of our daily lives. Online social networks provide promising and convenient platforms for a variety of social users to promote their products and ideas. Influence maximization in online social networks has attracted substantial attention in recent years due to its widespread applications, such as marketing management and disease prevention [1]. Influence maximization aims to select a set of influential nodes from the online social network to maximize the influence spread based on a given information diffusion model. With the rapid development of emerging network technologies, including 5G and Internet of Things (IoT), the scale of online social networks continues to increase, and the number of social users is growing explosively. The interactions between social users have become more frequent and closer. Unlike traditional binary word-of-mouth communication relationships, the complicated interactions among more than two entities are ubiquitous in real-world online social networks [2]. For example, six researchers from the same scientific institution can collaboratively contribute to a scientific paper, or some social users receive or send emails copied to multiple people. In real network scenarios, an edge with dyadic relationship could hardly characterize the complicated interactions if the interactions involve more than two entities.
Many efforts have been made to solve the influence maximization problem in online social networks. A variety of information diffusion models and influence maximization algorithms have been proposed. These existing algorithms can be primarily classified into four families: greedy algorithms, heuristic algorithms, meta-heuristic algorithms, and community-based algorithms. Greedy algorithms give the worst case bound for influence spread, but suffer from scalability issues. Heuristic algorithms do not give any worst case bound on influence spread, but have more scalability and better running time. Meta-heuristic algorithms are the evolutionary computation techniques-based meta-heuristic optimization algorithms, and do not give any worst case bound on influence spread. Community-based algorithms use community detection of the underlying social network to bring down the problem into community level and improve the scalability, and do not provide any worst case bound on influence spread. Most of the existing algorithms usually require significant computational overheads to select the influential seed nodes. Furthermore, most existing studies mainly focus on detecting the influential nodes based on dyadic connection relationships between social users. However, simple dyadic interactions between social users are inadequate to represent the higher-order influences [3]. In light of higher-order interaction relationships from extensive social connections in online social networks, it is still a mostly unexplored problem with only a few studies focusing on this field.
To more accurately capture and analyze these complex social connections, the concept of hypergraphs has gradually been introduced to extend traditional social network models. Unlike traditional graph models, hypergraph models can characterize more complicated connection relationships among multiple nodes [4]. Hyperedges are used to represent the higher-order connection relationships among different nodes. The complicated social connection relationships could be represented by a hypergraph with hyperedges characterizing the polyadic interactions among more than two nodes. Through the perspective of hypergraphs, they are suitable for representing the diverse and complicated connection relationships between users in online social networks.
To this end, in this paper, we deal with the influence maximization problem by introducing hypergraph theory. By jointly considering adjacent influence relationships and high-order influence relationships, we present a novel influence diffusion model to improve diffusion efficiency. Furthermore, we propose a hypergraph sampling greedy algorithm to effectively select the most influential seed nodes. The main contributions of our work are as follows:
- We take into account adjacent influence and higher-order influence relationships to construct a novel influence diffusion model to improve influence diffusion efficiency, by introducing hypergraph theory.
- We propose a hypergraph sampling greedy algorithm (HSGA) to effectively select the most influential seed nodes, where a random walk-based influence diffusion algorithm and a Monte Carlo-based influence approximation algorithm are devised to achieve fast approximation and calculation of node influences. Influence increments of multiple nodes are calculated and simulation diffusion results are reused.
- We conduct simulations on six real datasets to evaluate the performance of the HSGA. Simulation results demonstrate that compared to benchmark algorithms, the HSGA improves computational efficiency and seed selection accuracy.
The rest of this paper is structured as follows. Section 2 provides a review of related works, and we describe system model and problem formulation in Section 3. Section 4 represents our proposed HSGA solution, and performance evaluations are conducted in Section 5. We finally conclude this paper in Section 6.
Due to the computational hardness of the IM problem, the optimal solution cannot be exactly calculated out within polynomial time.
2. Related Works
To address the influence maximization problem, many efforts have been made to design various influence diffusion models and optimization algorithms in recent years, illustrated in Table 1.
Zhang et al. [5] presented a network motifs-based influence maximization algorithm to determine key motifs by using Bayesian machine learning to maximize the information diffusion spread. Wu et al. [6] designed a parallel greedy influence maximization algorithm for multiple influence maximization to maximize the overall influence spread while guaranteeing seed budget constraints. Ni et al. [7] extended the traditional single information influence maximization problem to a multi-attribute-based influence maximization problem, and used the sandwich algorithm and supermodular algorithm to solve it. Zhang et al. [8] designed a search space reduction strategy to reduce computational overheads of seed selection, and presented a progressive evolutionary influence maximization framework to speed up the optimal solution search process. Li et al. [9] presented an adaptive agent-based evolutionary influence maximization algorithm to capture real-time user and diffusion features to accurately determine seed nodes. Wang et al. [10] designed a multi-transformation evolutionary influence maximization framework to exploit the potential similarities to automatically select suitable transformations, by leveraging overlap degree. Liang et al. [11] considered target nodes and competitive relationships to establish a novel independent cascade model for targeted influence maximization, and presented a reverse reachable set-based greedy algorithm to solve it. He et al. [12] presented a two-stage iterative influence maximization framework to exclude less influential nodes and reduce computational cost for seed selections. In [13], Dong et al. presented a three-stage iterative influence maximization framework to improve computational cost and result accuracy.
Deep Reinforcement Learning (DRL) technologies [14,15] have been applied to deal with the influence maximization problem. Chen et al. [16] designed a DRL-based influence maximization framework to efficiently perform seed selection, by incorporating graph neural networks and double deep Q-network models. Yang et al. [17] designed a DRL-based balanced influence maximization framework to balance the influence maximization of multiple different entities, where a balanced seed selection module is devised to maximize the balanced influence of seed set. He et al. [18] designed a brand-new Q-learning-based multistage competitive opinion maximization framework to support dynamic opinion propagation. Kumar et al. [19] converted the influence maximization problem into a pseudo-regression problem and designed a graph embedding and graph neural network-based algorithm to solve it. Zareie et al. [20] modeled the social network as a fuzzy graph to identify user’s activation level, and designed three fuzzy influence maximization algorithms to identify influential users. Singh et al. [21] presented a link prediction-based influence maximization algorithm to adapt to dynamic changes of social networks.
To capture dynamic changes of social network, Yang et al. [22] designed an activation probability aware influence maximization framework to dynamically update node influence. To improve propagation efficiency, Guo et al. [23] presented a group trust and local topology structure-based influence maximization algorithm, to calculate propagation probability by extracting local topology structure, and select seed nodes by using credibility ranking of groups. To reduce noise in metadata and uncertainties in connectivity inference, Tran et al. [24] designed a topology-aware ranking strategy for influence maximization with unknown topology to select the most influential nodes. Yu et al. [25] presented an adapted greedy algorithm for compatible influence maximization, and devised an efficient heuristic algorithm to approximate the influence spread. To improve the quality of seed nodes, Dai et al. [26] constructed an enhanced independent cascade model by considering the group polarization effect and individual preferences, and designed a group-based effective influence maximization algorithm to determine the optimal seed nodes. Hosni et al. [27] considered network inference factors to design a truth campaign strategy to minimize the influence of rumors. Liu et al. [28] constructed a multi-faceted opinion evolution model by jointly considering individuals’, neighbors’, and communities’ influence factors, and designed a memetic algorithm to maximize community opinion. Umrawal et al. [29] designed a community-aware influence maximization framework to learn the inherent community structure, and select seed nodes by using a progressive budgeting method to reduce runtime. Zhang et al. [30] designed an overlapping community-based particle swarm optimization algorithm to obtain overlapping community structures and determine influential seed nodes.

Table 1.
Related works.
Table 1.
Related works.
| Literature | Optimization Objective | Solution | Method |
|---|---|---|---|
| [5] | maximize information diffusion spread | network motifs-based influence maximization algorithm | Bayesian machine learning |
| [6] | maximize influence spread while guaranteeing seed budget constraints | parallel greedy influence maximization algorithm | multiple influence maximization |
| [7] | maximize multi-attribute-based influence spread | sandwich algorithm and supermodular algorithm | – |
| [8] | minimize computational overheads of seed selection | progressive evolutionary influence maximization framework | search space reduction strategy |
| [9] | accurately determine seed nodes | adaptive agent-based evolutionary influence maximization algorithm | capture real-time user and diffusion features |
| [10] | maximize influence spread | multi-transformation evolutionary influence maximization framework | overlap degree |
| [11] | maximize targeted influence | reverse reachable set-based greedy algorithm | novel independent cascade model |
| [12] | minimize computational cost | two-stage iterative influence maximization framework | exclude less influential nodes |
| [13] | minimize computational cost | three-stage iterative influence maximization framework | — |
| [16] | maximize influence spread | DRL-based influence maximization framework | graph neural networks |
| [17] | maximize balanced influence of seed set | DRL-based balanced influence maximization framework | balance influence of multiple different entities |
| [18] | maximize competitive opinion diffusion spread | multistage competitive opinion maximization framework | dynamic opinion propagation model |
| [19] | maximize influence spread | graph embedding and graph neural network-based algorithm | pseudo-regression model |
| [20] | identify user’s activation level | fuzzy influence maximization algorithm | fuzzy graph |
| [21] | maximize influence spread | link prediction-based influence maximization algorithm | DRL model |
| [22] | maximize influence spread | activation probability aware influence maximization framework | dynamically update node influence |
| [23] | improve propagation efficiency | group trust and local topology structure-based influence maximization algorithm | local topology structure extraction and credibility ranking of groups |
| [24] | reduce noise in metadata and uncertainties in connectivity inference | topology-aware ranking strategy for influence maximization with unknown topology | — |
| [25] | maximize influence spread | adapted greedy-based compatible influence maximization algorithm | — |
| [26] | improve the quality of seed nodes | group-based effective influence maximization algorithm | enhanced independent cascade model |
| [27] | minimize rumors’ influences | truth campaign rumor influence maximization strategy | — |
| [28] | maximize community opinion | memetic-based community opinion maximization algorithm | multi-faceted opinion evolution model |
| [29] | reduce runtime | community-aware influence maximization framework | progressive budgeting method |
| [30] | maximize influence spread | overlapping community-based particle swarm optimization algorithm | obtain overlapping community structures |
| [31] | maximize influence spread | heuristic general weighted social influence maximization algorithm | crowd influence model |
| [32] | maximize information diffusion spread | hypergraph-based sequential interactive framework | dual-channel hypergraph neural networks |
| [33] | reduce influence overlap | adaptive degree-based heuristic influence maximization algorithm | — |
| [34] | maximize influence spread | advanced greedy-based influence maximization algorithm | novel influence evaluation function |
Some works have attempted to apply hypergraph theory in addressing the influence maximization problem. Zhu et al. [31] modeled the crowd influences as a hyperedge and presented a heuristic algorithm to solve the general weighted social influence maximization problem. Jin et al. [32] designed a hypergraph-based sequential interactive framework to model complex interactions, and presenteddual-channel hypergraph neural networks to predict the diffusion for seed node determination. Xie et al. [33] proposed an adaptive degree-based heuristic algorithm for influence maximization in hypergraphs to select nodes with low influence overlap as seed nodes. Wang et al. [34] designed a novel evaluation function, to evaluate spreading influence of nodes in hypergraphs, and further devised an advanced greedy-based influence maximization algorithm to identify seed nodes with maximum spreading influence.
Despite numerous attempts to provide effective influence maximization solutions, higher-order interactions between entities are not considered. Unlike previous studies, in this work, we introduce hyperedge theory to construct an influence diffusion model by considering adjacent influence and hyperedge influence. To speed up seed selection and reduce computational cost, we design an HSGA by leveraging the Monte Carlo and random walk methods.
3. System Model and Problem Formulation
In this section, we present the system model and problem formulation for influence maximization in social networks based on hypergraph. The main notations used in this paper are listed in Table 2.
Table 2.
Main notations.
3.1. System Model
3.1.1. Social Network Model
We model the social network as a hypergraph model, denoted by , where V is the set of nodes and E is the set of hyperedges. Each node represents one individual or entity in the social network. Each hyperedge is a non-empty subset of V, representing a group of entities with certain social connection relationships among them. In the real social networks, the entities that belong to the same hyperedge may participate in the same activity or have some similar or identical social connections. When all hyperedges of a social network hypergraph contain exactly two nodes, the hypergraph degenerates into a regular graph. For each node , we define to represent the set of its neighbor nodes, to represent the set of its in-degree neighbor nodes, to represent the set of its out-degree neighbor nodes, to represent the set of hyperedges that it belongs to, and to represent the set of its hyperedge neighbor node tuples.
3.1.2. Influence Diffusion Model
Unlike traditional influence diffusion modes, during the influence diffusion process in the social network hypergraph, each node can receive information and obtain influence, from its neighbor nodes with certain connection relationships, or from the nodes that belong to the same hyperedge as it. Therefore, unlike most existing works, in our work, the overall influence of one node is the sum of the influence incurred by its ordinary neighbor nodes and the influence incurred by its hyperedge neighbor nodes. The dyadic edges and hyperedges are treated differently.
To distinguish the influences of ordinary neighbor nodes and hyperedge neighbor nodes, we introduce a hyperedge influence factor as the influence proportion of the set of hyperedge neighbor nodes on node u. Thus, we have . And accordingly, the influence proportion of ordinary neighbor nodes on node u is .
For each node u, its each in-degree neighbor node has a certain direct information diffusion influence on it. Thus, we define the influence weight between node u and its in-degree neighbor node v as . We have .
Similarly, its each hyperedge neighbor node also has a certain information diffusion influence on it. We define the influence weight between node u and its hyperedge neighbor node v as . We have .
Thus, the overall influence probability of node u on node v can be expressed as:
As shown in Formula (1), we consider the joint influences of both ordinary neighbor nodes and hyperedge neighbor nodes. The two types of influence probabilities can be adjusted through the weight coefficient , thus more comprehensively reflecting the complex relationships between users in social networks. It is worth noting that quantifies the strength of the influence of hyperedges on node u, which can theoretically be learned from historical data or obtained from initial inputs.
3.2. Problem Formulation
Give a social network and an influence diffusion model, we select k nodes to form a seed node set S, so that the seed node set generates the maximum influence . Thus, the influence maximization problem in the social network hypergraph can be mathematically formulated as follows.
The influence maximization problem has been proved to be an NP-hard problem in [1]. It is difficult to find the optimal solution in polynomial time algorithms. However, traditional methods have huge computation costs. Particularly, the larger the scale of social network, the higher its computational cost. On the other hand, it is difficult to obtain the precise value of node influence. To tackle this challenge, in this paper, we design a hypergraph sampling greedy algorithm, namely HSGA. In HSGA, a random walk-based influence diffusion (RWID) algorithm and a Monte Carlo approximation (MCA) algorithm are devised to achieve fast approximation and calculation of node influences.
4. HSGA Solution
In this section, we describe the details of the proposed HSGA solution, including the RWID algorithm, MCA algorithm, and HSGA.
4.1. RWID Algorithm
Like common diffusion models, in our proposed information diffusion algorithm, each node has only two states, i.e., active state and inactive state. Given a social network hypergraph H and the set S of initial seed nodes, information diffusion rules in our proposed RWID algorithm are described as follows.
- (1)
- At the initial stage, all nodes in the social network are first initialized to be in inactive state. Then, the nodes in the seed set are initialized to be in active state. The diffusion probabilities under two different influence modes are initialized as follows.
- (2)
- At each time step , for each active node u, we find its each hyperedge , and set the influence factor . The probability of randomly selecting one hyperedge is set as .
- (3)
- We select a node that belongs to hyperedge as the next activation object.
- (4)
- We repeat the above steps (2) and (3) until there are no new active nodes added during information propagation process. That is, the information propagation process is completed, and accordingly, the final set of seed nodes can be obtained.
According to the above diffusion rule, the overall influence probability between nodes u and v can be extended as:
Algorithm 1 shows the main workflow of RWID algorithm. Given a social network hypergraph H and the set of initial seed nodes S, we first initialize the set of active nodes and the set of infectious active nodes , illustrated in Line 1. As illustrated in Lines 4–15, during the information propagation process, we traverse the set of active nodes according to the above predefined diffusion rule, and attempt to activate the direct neighbor nodes and hyperedge neighbor nodes with the probabilities and , respectively. After one time activation attempt process is completed, active nodes will lose their infectivity, and newly activated nodes will be added to the infectious active node set . We repeat the above process until no new active nodes appear.
| Algorithm 1 RWID |
| Input: Social network H; Initial seed set S; Output: Set of activated nodes
|
4.2. MCA Algorithm
Influence measurement and calculation are the keys in the seed node set determination process. In realistic social network scenarios, calculating the exact influence value of seed node sets is difficult due to huge computational costs. To quantify the diffusion influence of a node set, we define an influence evaluation function based on random walk theory [35], to approximate the real influence of node set, given by:
where is the probability of the reverse sampling from node u to node set S, i.e., the impact of node set S on node u.
By expanding Formula (10), we can have:
where is a column vector that the u-th element is 1 and all other elements are 0, is the transpose form of e, is the state transition probability matrix from set ) to set S, and Q is the state transition probability matrix of nodes in set .
From Formula (11), we can conclude that in the first information propagation cycle, only the state transition from seed node set S to inactive node set ) will occur. In subsequent propagation cycles, the influence of nodes between node sets ) will be added in sequence. Therefore, let the number of backward walk steps be L, and the approximate influence can be expressed as:
By limiting the number of backward steps t, walking range can be controlled, thereby improving the efficiency of sampling influence estimation. Due to the probability-based walking in the sampling process, there is randomness. Thus, the more reliable influence representation results can be obtained by simulating the walking process multiple times.
To achieve fast approximation and calculation of node influences, in this paper, we introduce the Monte Carlo method [36] to obtain the approximate influence . Starting from node u, reverse walk sampling is performed based on the above diffusion rules. If seed node set S can be finally reached from node u within a certain period, the sampling process ends. Otherwise, the sampling result is empty. Therefore, we define an indicator function to identify whether node u can reach seed node set S within the number of walk steps t at the period m, expressed as:
On the other hand, term in the influence probability can be expressed as the probability of reaching seed node set S at period t starting from node u. Therefore, by Formulas (12) and (13), we have:
where is the expectation of indicator function .
On this basis, we can obtain the approximate value of through multiple Monte Carlo simulations, which can be expressed as:
where M is the times of Monte Carlo simulations.
According to the representation form of , we can further calculate the approximate value of influence probability , expressed as follows.
Algorithm 2 illustrates the specific approximation process of node influence. Given a social network H, the set of initial seed nodes S, node u, the total times of Monte Carlo simulations M, and the total number of walk steps t (i.e., time period), we first initialize the expected influence value. As illustrated in Lines 3–16, in each Monte Carlo simulation process, the hyperedge that node u belongs to is randomly selected to execute backward walking based on probability according to information diffusion rules. If the seed node set S is reached within the period t, the current walk process ends and is updated. Otherwise, the probability p is updated and the next round of simulated walk process is executed. After the total times of Monte Carlo simulations is reached, the final approximation value is obtained.
| Algorithm 2 MCA |
| Input: Social network H; Initial seed set S; Node u; Monte Carlo simulation times M; Walk step number t; Output: Expected influence
|
4.3. HSGA
The core idea of the HSGA is to evaluate the contribution of each node to function through Monte Carlo simulation and random sampling walk, and to use a greedy strategy to select the set S of seed nodes. Through iterative selection and updating, the HSGA aims to find the optimal set of k seed nodes. In the HSGA, we first calculate the influence of all nodes, and select the nodes with the highest influence as the seed nodes. After updating the influence of the remaining nodes, we select the node with maximum influence gain. We continue to repeat the above process until the number of seed nodes reaches k.
The detailed workflow of the HSGA is shown in Algorithm 3. As illustrated in line 1, we first initialize an empty set S to store the selected seed nodes, set the counter , and initialize two arrays and P to record increment and transition probability, respectively. Then, we traverse each node u and execute the following Monte Carlo simulation and reverse walk sampling operations on it, illustrated in Lines 2–16.
- (1)
- We set current node , and set an empty set to store the sampling nodes.
- (2)
- We add current node v to the set , and update node v as its next walk node. We repeat this sampling operation t times iteratively.
- (3)
- After completing t times iterations, we record next node of node v and store it into .
- (4)
- If node v is not in the set , we update the score of node v and to record the real-time visit times of node v, illustrated in Lines 10–13.
After completing the Monte Carlo simulation and sampling process, we select the node with the highest score and add it to the seed set S, illustrated in Line 17. For the remaining nodes in the set S, we perform the following operations. We execute the reverse walk sampling algorithm (i.e., Algorithm 4) to update P and iteratively. Finally, we select the node u with the maximum value of from the set and add u to the set S.
| Algorithm 3 HSGA |
| Input: Social network H; Walk step number t; Size of seed set k; Output: Seed set S
|
| Algorithm 4 RWS |
| Input: Social network H; Random walk record ; Record array r; Increment ; Transition probability P; Output: Updated transition probability ; Updated increment
|
Since the influence function has the nondecreasing submodular property, traditional increment-based optimization algorithms traverse the social network k times, calculate the influence increment of each node in each traversal by Formula (17), and finally add the node v with the maximum influence increment to the seed node set S.
Particularly, the increments of all nodes require being calculated and compared at each time of traversal. To address the problem of high computational cost, we design a process record-based reverse sampling method. It obtains the influence increment of nodes through the reverse sampling method and records influence increment value in each round of calculation for subsequent reuse, thereby reducing the computational cost of the algorithm.
Algorithm 4 illustrates the main workflow of reverse walk sampling algorithm. When a new node u is selected and added to seed node set S, the backward walk sampling information related to that node can be updated, including its increment and transition probability P. We first traverse all random walk records related to node u, and initialize a as the maximum number of walk steps. Then, we check whether the seed set S is hit for each step of the random walk. If the random walk hits the seed set at a certain step, we update a as the index of that step and exit the loop. If the random walk does not hit the seed set, we update the node transition probability P, illustrated in Lines 9–11. If the random walk hits the seed set, of subsequent nodes in the random walk is updated from the next step hit, illustrated in Lines 13–16.
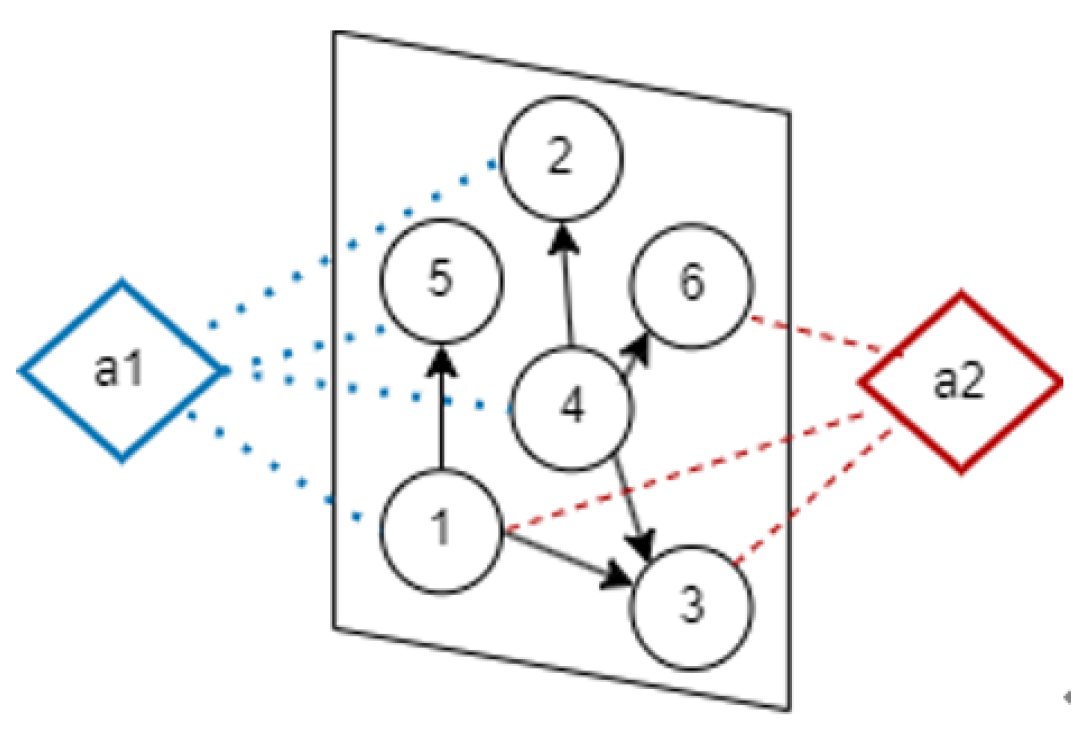
To facilitate the understanding of the proposed HSGA solution, based on the social network hypergraph in Figure 1, we give a simple example as follows. The set of nodes can be represented as and the set of hyperedges can be represented as . For node 1, the set of its neighbor nodes is , the set of its out-degree neighbor nodes is , the set of hyperedges that it belongs to is , and the set of its hyperedge neighbor node tuples is .
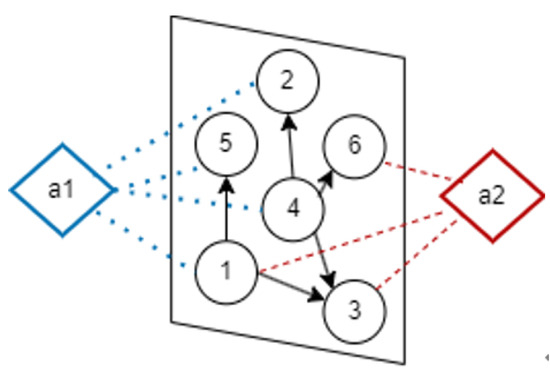
Figure 1.
An illustrative example of social network hypergraph.
Firstly, we set nodes 1, 2, 3, 4, 5, and 6 to be in the inactive state. We assume the initial seed node set . Accordingly, nodes 1 and 5 are in the active state. We traverse all nodes 1, 2, 3, 4, 5, and 6, and start from node 1 to execute the Monte Carlo simulation operation iteratively. For each node u, if the node can reach the seed node set S within period t via reverse random walk, then we update the node’s influence. Otherwise, we will execute the next round of Monte Carlo simulation operation. After M rounds of simulations are completed, the node influence is finally updated. Specifically, for node 1, we randomly select one hyperedge with the probability . Next, we select node as the next step activation objective of random walk with the probability , and update the node influence . Once node 2 is activated, it will select one hyperedge with the probability , and select node 4 as the activation objective of random walk with the probability , and update the node influence . Similarly, we traverse the remaining nodes 3 and 6 to repeat the above operations iteratively. After completing Monte Carlo simulation operations, we update the scores of all nodes. Then, we iteratively select the node with maximum influence gain as the seed node until the number of seed nodes reaches k.
5. Performance Evaluation
In this section, we introduce simulation setups for performance evaluations and analyze simulation results.
5.1. Simulation Setups
All the experiments were conducted on a PC equipped with a 2.8 GHz Intel i7 CPU and 32 GB RAM. Six real social network hypergraph datasets are adopted in simulations, listed in Table 3.
Table 3.
Social network hypergraph datasets.
- Algebra [37]: It contains mathematical websites on the relationships among users who comment on problems. Each node represents a user, and users who comment, ask, or answer the same question (in algebra or geometry) are included in the same hyperedge.
- Restaurant-Rev [38]: It represents restaurant reviews. Each node is a Yelp user, and each hyperedge represents specific category reviews of different types of restaurants in Madison, Wisconsin established by connected users within one month.
- Norwegian Interlocking Directorate (NID) [31]: It is a network of interlocking boards in Norway, which describes the relationships among company directors. Each hyperedge represents the complex impact relationship among the resignations of directors.
- DBLP [39]: It is a collection of co-authors who co-authored DBLP papers. Each node is an author, and each hyperedge is a publication.
- Email Enron [40]: It is a dataset of email addresses for Enron employees. Each node is Enron’s email address, and each hyperedge includes the sender and all recipients of the email.
- Email-W3C [41]: It is a set of email addresses on the W3C mailing list. Each hyperedge consists of a set of email addresses that appear in the same email.
To comprehensively evaluate the performance of our proposed HSGA, the classic influence maximization (IMM) algorithm [42], Heuristic Degree Discount (HDD) algorithm [43], and Hyper Adaptive Degree Pruning (HADP) algorithm [33] are selected as comparison mechanisms for the HSGA. In the HDD algorithm, it iteratively selects the nodes that have small influence and overlap with existing seeds as the candidate seed nodes. In the HADP algorithm, it punishes the nodes that have more neighbors in the seed node set in each iteration. We define the improvement ratio of objective function as . The seed set size k is set to 50 and the number of Monte Carlo simulations M to 20. The parameter is set to 0.1. Each experiment is repeated 20 times during the simulations and the average result is regarded as the final result.
5.2. Simulation Results
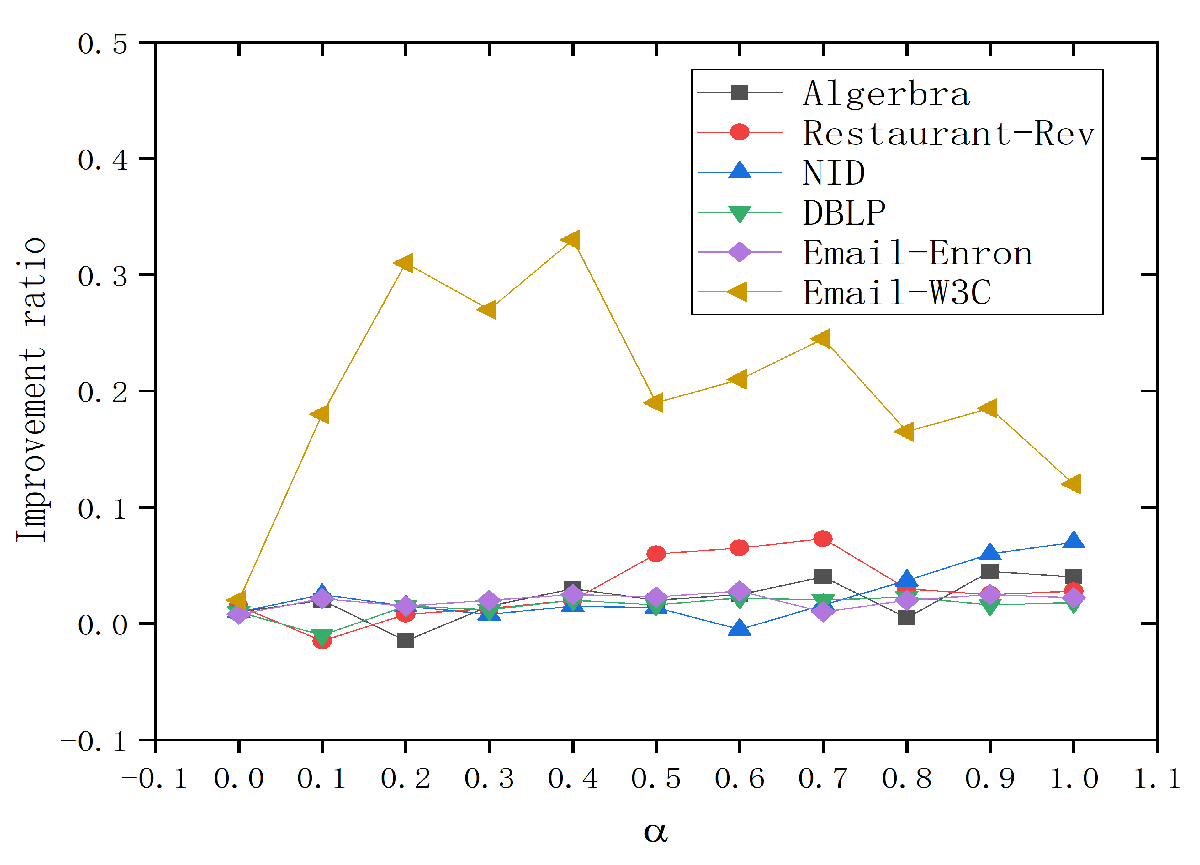
We first verify the impact of the hyperedge influence ratio on the final information propagation results. Figure 2 depicts the impact of hyperedge influence ratio on the improvement ratio. We can observe that the hyperedge influence ratio can improve the propagation effect of seed nodes. In the first five datasets, the improvement ratio shows an overall upward trend with the increase in the hyperedge influence ratio. That is, hyperedge influence has a positive effect on information propagation, and the increase in hyperedge influence ratio is correlated with the overall activity of the network. When the influence of hyperedges on nodes increases, the information flow and interactivity of the entire network may be enhanced, thereby promoting more efficient information propagation. In addition, this trend also reveals the importance of hyperedges in higher-order network structures and their potential role in promoting information propagation.
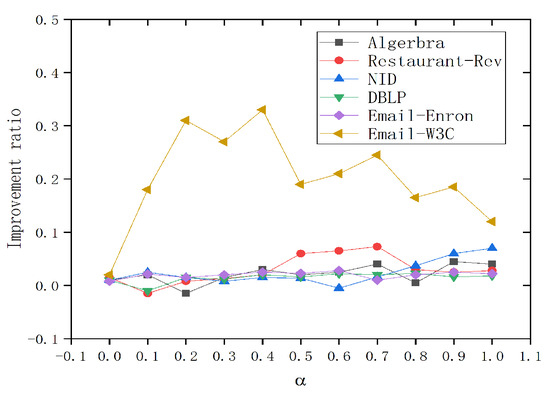
Figure 2.
Influence of hyperedge influence ratio on improvement ratio.
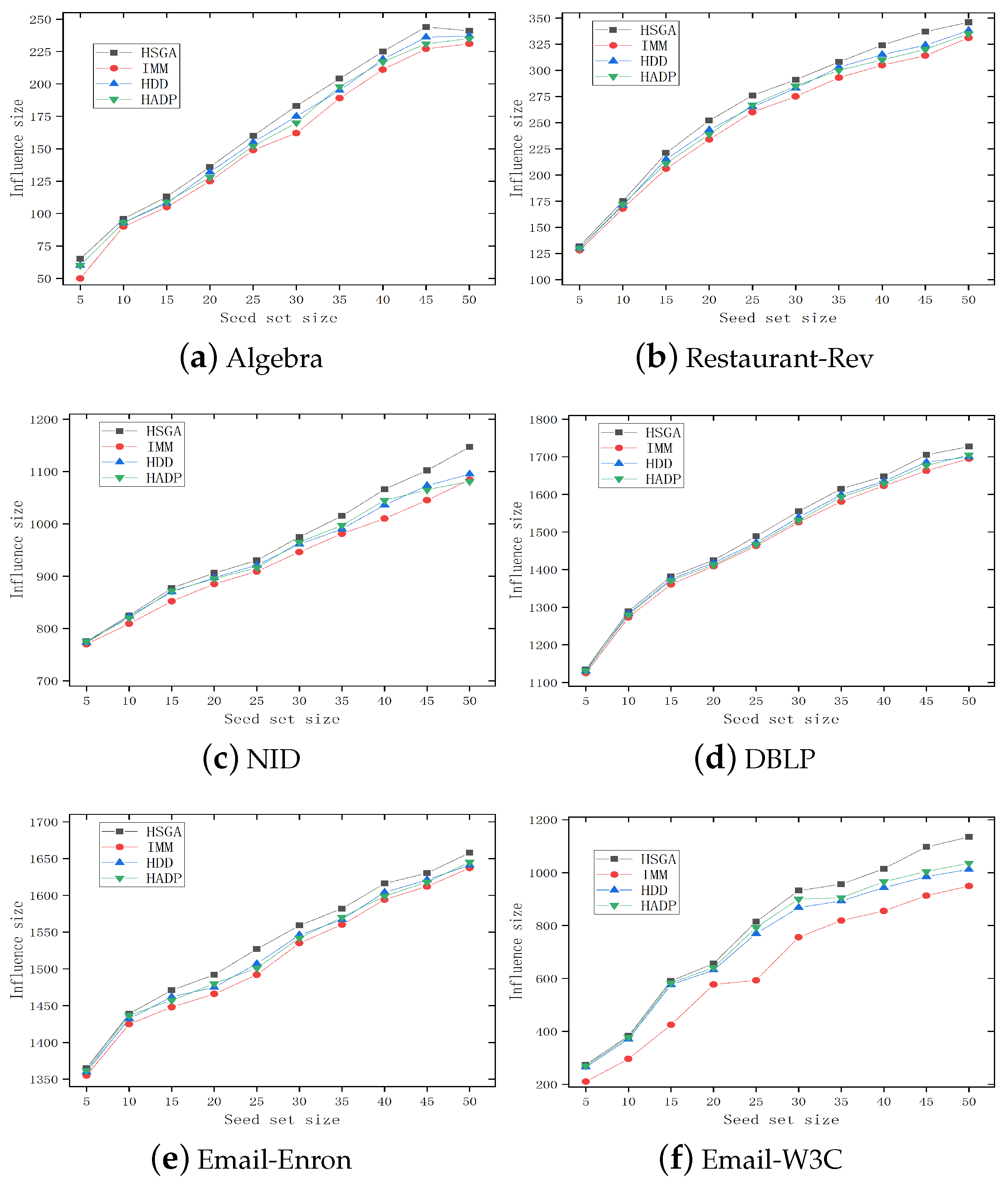
Figure 3 depicts the trend of the influence range of different influence maximization algorithms under different numbers of seed nodes. We can observe that as the number of seed nodes increases, the influence range on each dataset shows an increasing trend, and the increasing trend and influence range differ depending on network data and structure. The HSGA exhibits better performance than the other influence maximization algorithms. As the number of seed nodes increases, the difference between the two algorithms tends to increase. It indicates that when the number of active nodes in the network increases, the information propagation model based on hypergraph can reach a wider range of nodes, thereby having greater propagation potential.
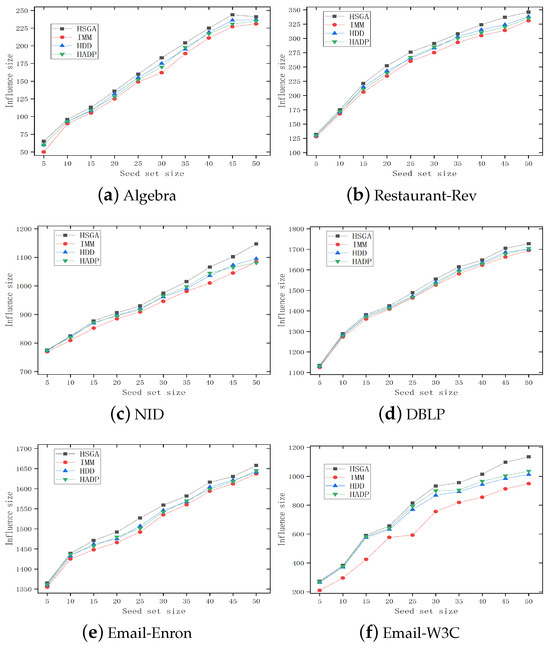
Figure 3.
Comparison results of different algorithms.
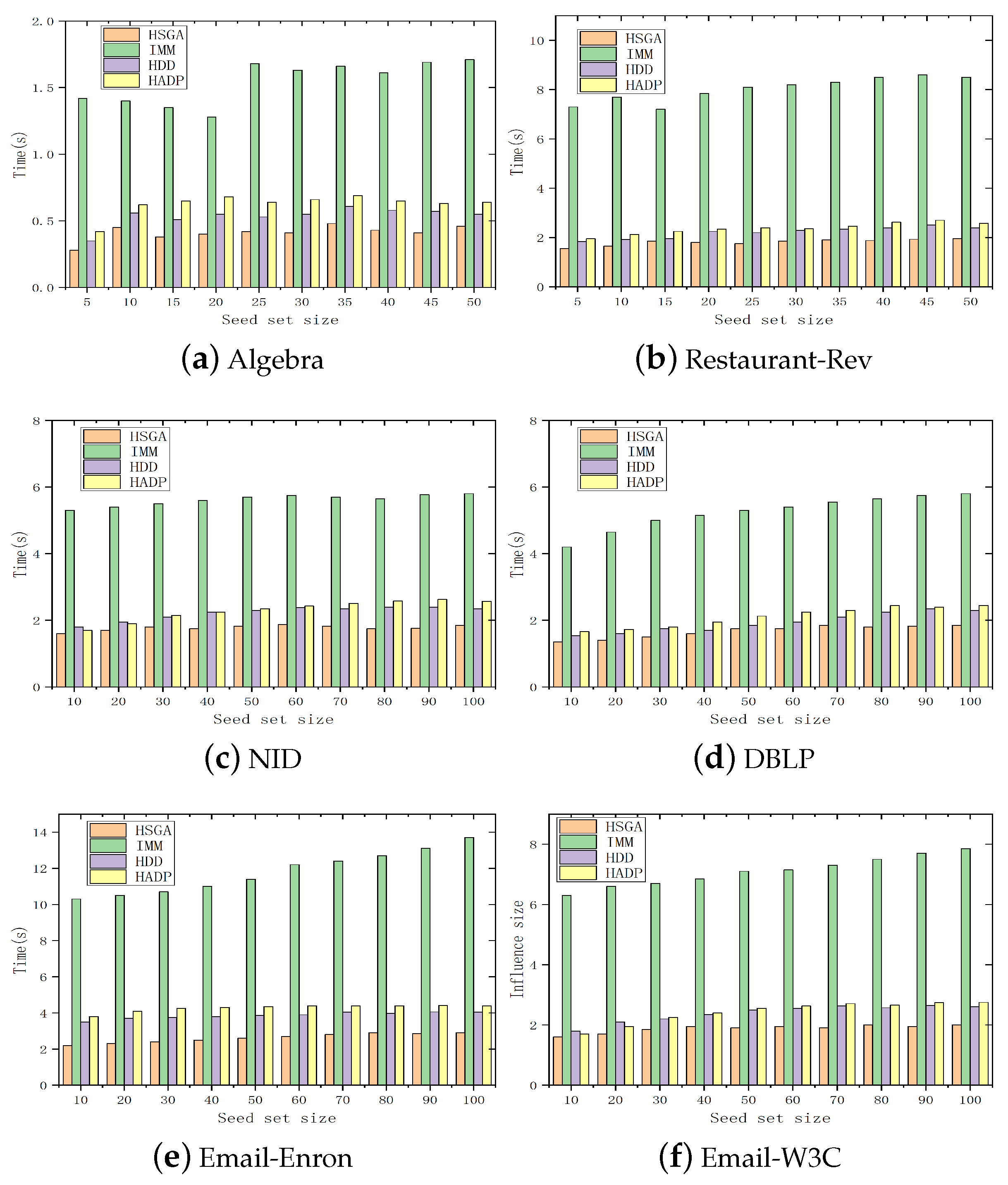
Figure 4 depicts the comparison of the running time spent by different influence maximization algorithms in selecting the same number of seed nodes on six different datasets. It can be observed that the running time of the HSGA is significantly smaller than those of the comparison algorithms on six datasets. This is because the HSGA adopts the Monte Carlo method and random walk sampling method to reuse the results, significantly improving the computational efficiency of selecting seed nodes, thereby shortening the overall running time and achieving relatively stable performance in different social networks. In the case of approximating the influence results, the HSGA has a shorter running time and can effectively improve the efficiency of the influence maximization method.
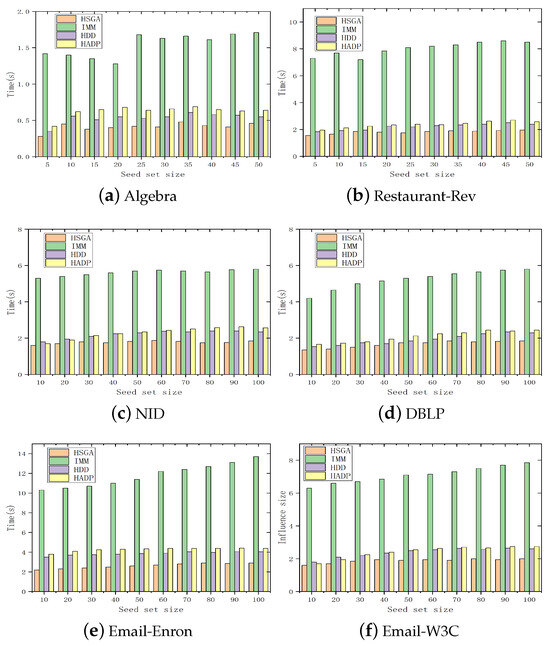
Figure 4.
Comparison of running time.
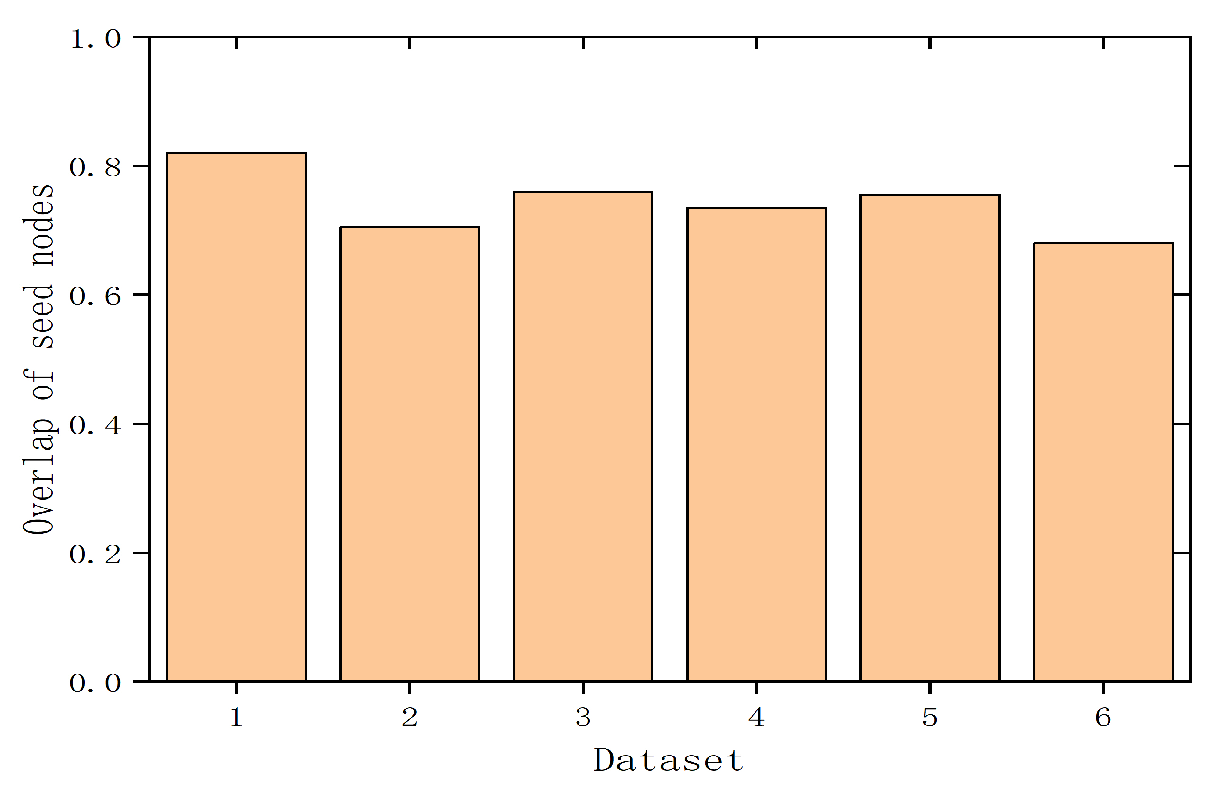
Finally, we compare the overlap of seed nodes selected by different influence maximization algorithms. In the simulations, 100 seed nodes are selected using two influence maximization methods for the overlap rate comparison. Figure 5 depicts the overlap rate of different influence maximization algorithms in seed node selection on six datasets. We can observe that the overall overlap rate range is between 0.68 and 0.82. This indicates that by considering the influence of hyperedges, the selected seed nodes would undergo some changes due to changes in the information propagation mode in the network. This suggests that the setting of information propagation rules plays a crucial role in the process of maximizing influence.
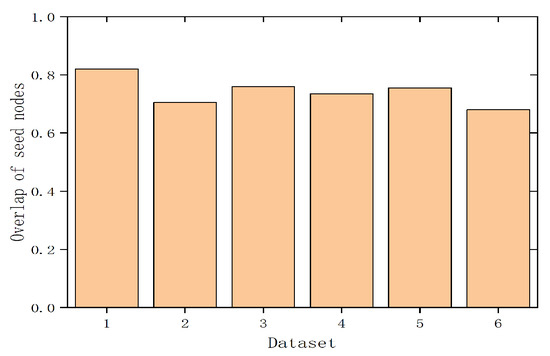
Figure 5.
Overlap of seed nodes.
5.3. Discussion
In the proposed HSGA solution, the overall influence of each node is evaluated through Monte Carlo simulation and random sampling walk, and the set of optimal seed nodes is determined through a greedy strategy. The simulation times in the Monte Carlo simulation method and the number of walk steps in random sampling walk method have significant impacts on efficiency and effectiveness of the proposed HSGA solution. The more simulations are conducted and the longer the random walk step number, the greater the time cost of the proposed HSGA solution. Therefore, in large-scale social networks, the computation overheads of the proposed HSGA solution become bigger.
6. Conclusions
In this work, we introduce hypergraph theory to investigate the problem of influence maximization under higher-order influence relationships among multiple nodes. To improve diffusion efficiency, we design a novel diffusion model by considering adjacent influence relationships and higher-order influence relationships. To further select the most influential seed nodes, we present an HSGA solution, where RWID and MCA algorithms are developed to approximate influence value and reduce computational cost. Simulation experiments demonstrate the effectiveness and efficiency of the HSGA.
However, social networks in real-world scenarios are constantly evolving. Social users can join or leave anytime and anywhere, and relationships among users are dynamically changing. Creation or termination of connection relationships among multiple users has a significant impact on information diffusion. In future work, we plan to design an intelligent influence maximization approach to efficiently identify the most influential seed nodes to adapt to dynamic changes of user behaviors and network status.
Author Contributions
Conceptualization, C.Z and X.W.; methodology, C.Z. and F.L.; formal analysis, C.Z. and W.C.; writing—original draft preparation, C.Z. and W.C.; writing—review and editing, C.Z., F.L., and X.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by Natural Science Foundation of Shandong Province of China under Grants Nos. ZR2021QF086, ZR2020QF047 and ZR2022MF254, National Key Research and Development Program of China under Grants No. 2022YFB4500800, and National Natural Science Foundation of China under Grants Nos. 62032013 and 92267206.
Data Availability Statement
The data used to support the findings of this study are available from the corresponding author upon request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, Y.; Gao, H.; Gao, Y.; Guo, J.; Wu, W. A survey on influence maximization: From an ml-based combinatorial optimization. ACM Trans. Knowl. Discov. Data 2023, 17, 1–50. [Google Scholar] [CrossRef]
- He, Q.; Fang, H.; Zhang, J.; Wang, X. Dynamic opinion maximization in social networks. IEEE Trans. Knowl. Data Eng. 2021, 35, 350–361. [Google Scholar] [CrossRef]
- Wang, R.; Li, Y.; Lin, S.; Xie, H.; Xu, Y.; Lui, J.C.S. On modeling influence maximization in social activity networks under general settings. ACM Trans. Knowl. Discov. Data 2021, 15, 1–28. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, Y.; Zou, J.; Zhu, J.; Liu, D.; Jiao, J. Unifying multimodal interactions for rumor diffusion prediction with global hypergraph modeling. Knowl.-Based Syst. 2024, 301, 112246. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, L.; Xu, Z. Influence maximization based on network motifs in mobile social networks. IEEE Trans. Netw. Sci. Eng. 2022, 9, 2353–2363. [Google Scholar] [CrossRef]
- Wu, G.; Gao, X.; Yan, G.; Chen, G. Parallel greedy algorithm to multiple influence maximization in social network. ACM Trans. Knowl. Discov. Data 2021, 15, 1–21. [Google Scholar] [CrossRef]
- Ni, Q.; Guo, J.; Du, H.W.; Wang, H. Multi-attribute based influence maximization in social networks: Algorithms and analysis. Theor. Comput. Sci. 2022, 921, 50–62. [Google Scholar] [CrossRef]
- Zhang, L.; Ma, K.; Yang, H.; Zhang, C.; Ma, H.; Liu, Q. A search space reduction-based progressive evolutionary algorithm for influence maximization in social networks. IEEE Trans. Comput. Soc. Syst. 2022, 10, 2385–2399. [Google Scholar] [CrossRef]
- Li, W.; Hu, Y.; Jiang, C.; Wu, S.; Bai, Q.; Lai, E. ABEM: An adaptive agent-based evolutionary approach for influence maximization in dynamic social networks. Appl. Soft Comput. 2023, 136, 110062. [Google Scholar] [CrossRef]
- Wang, C.; Zhao, J.; Li, L.; Jiao, L.; Liu, J.; Wu, K. A multi-transformation evolutionary framework for influence maximization in social networks. IEEE Comput. Intell. Mag. 2023, 18, 52–67. [Google Scholar] [CrossRef]
- Liang, Z.; He, Q.; Du, H.; Xu, W. Targeted influence maximization in competitive social networks. Inf. Sci. 2023, 619, 390–405. [Google Scholar] [CrossRef]
- He, Q.; Wang, X.; Lei, Z.; Huang, M.; Cai, Y.; Ma, L. TIFIM: A two-stage iterative framework for influence maximization in social networks. Appl. Math. Comput. 2019, 354, 338–352. [Google Scholar] [CrossRef]
- Dong, C.; Xu, G.; Yang, P.; Meng, L. TSIFIM: A three-stage iterative framework for influence maximization in complex networks. Expert Syst. Appl. 2023, 212, 118702. [Google Scholar] [CrossRef]
- He, Q.; Feng, Z.; Fang, H.; Wang, X.; Zhao, L.; Yao, Y.; Yu, K. A blockchain-based scheme for secure data offloading in healthcare with deep reinforcement learning. IEEE/ACM Trans. Netw. 2023, 32, 65–80. [Google Scholar] [CrossRef]
- He, Q.; Wang, Y.; Wang, X.; Xu, W.; Li, F.; Yang, K.; Ma, L. Routing optimization with deep reinforcement learning in knowledge defined networking. IEEE Trans. Mob. Comput. 2023, 23, 1444–1455. [Google Scholar] [CrossRef]
- Chen, T.; Yan, S.; Guo, J.; Wu, W. ToupleGDD: A fine-designed solution of influence maximization by deep reinforcement learning. IEEE Trans. Comput. Soc. Syst. 2023, 11, 2210–2221. [Google Scholar] [CrossRef]
- Yang, S.; Du, Q.; Zhu, G.; Cao, J.; Chen, L.; Qin, W.; Wang, Y. Balanced influence maximization in social networks based on deep reinforcement learning. Neural Netw. 2024, 169, 334–351. [Google Scholar] [CrossRef] [PubMed]
- He, Q.; Zhang, L.; Fang, H.; Wang, X.; Ma, L.; Yu, K.; Zhang, J. Multistage competitive opinion maximization with Q-learning-based method in social networks. IEEE Trans. Neural Netw. Learn. Syst. 2024. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.; Mallik, A.; Khetarpal, A.; Panda, B. Influence maximization in social networks using graph embedding and graph neural network. Inf. Sci. 2022, 607, 1617–1636. [Google Scholar] [CrossRef]
- Zareie, A.; Sakellariou, R. Fuzzy influence maximization in social networks. ACM Trans. Web 2024, 18, 1–28. [Google Scholar] [CrossRef]
- Singh, A.K.; Kailasam, L. Link prediction-based influence maximization in online social networks. Neurocomputing 2021, 453, 151–163. [Google Scholar] [CrossRef]
- Yang, S.; Song, J.; Tong, S.; Chen, Y.; Zhu, G.; Wu, J.; Liang, W. Extending influence maximization by optimizing the network topology. Expert Syst. Appl. 2023, 215, 119349. [Google Scholar] [CrossRef]
- Guo, C.; Li, W.; Liu, F.; Zhong, K.; Wu, X.; Zhao, Y.; Jin, Q. Influence maximization algorithm based on group trust and local topology structure. Neurocomputing 2024, 564, 126936. [Google Scholar] [CrossRef]
- Tran, C.; Shin, W.Y.; Spitz, A. IM-META: Influence maximization using node metadata in networks with unknown topology. IEEE Trans. Netw. Sci. Eng. 2024, 11, 3148–3160. [Google Scholar] [CrossRef]
- Yu, L.; Li, G.; Yuan, L. Compatible influence maximization in online social networks. IEEE Trans. Comput. Soc. Syst. 2021, 9, 1008–1019. [Google Scholar] [CrossRef]
- Dai, J.; Zhu, J.; Wang, G. Opinion influence maximization problem in online social networks based on group polarization effect. Inf. Sci. 2022, 609, 195–214. [Google Scholar] [CrossRef]
- Hosni, A.I.E.; Li, K.; Ahmad, S. Minimizing rumor influence in multiplex online social networks based on human individual and social behaviors. Inf. Sci. 2020, 512, 1458–1480. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Q.; Wang, Z. Community opinion maximization in social networks. IEEE Trans. Evol. Comput. 2024. [Google Scholar] [CrossRef]
- Umrawal, A.K.; Quinn, C.J.; Aggarwal, V. A community-aware framework for social influence maximization. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 1253–1262. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Y.; Yang, H.; Cheng, F.; Liu, Q.; Zhang, X. Overlapping community-based particle swarm optimization algorithm for influence maximization in social networks. CAAI Trans. Intell. Technol. 2023, 8, 893–913. [Google Scholar] [CrossRef]
- Zhu, J.; Zhu, J.; Ghosh, S.; Wu, W.; Yuan, J. Social influence maximization in hypergraph in social networks. IEEE Trans. Netw. Sci. Eng. 2018, 6, 801–811. [Google Scholar] [CrossRef]
- Jin, H.; Wu, Y.; Huang, H.; Song, Y.; Wei, H.; Shi, X. Modeling information diffusion with sequential interactive hypergraphs. IEEE Trans. Sustain. Comput. 2022, 7, 644–655. [Google Scholar] [CrossRef]
- Xie, M.; Zhan, X.-X.; Liu, C.; Zhang, Z.-K. An efficient adaptive degree-based heuristic algorithm for influence maximization in hypergraphs. Inf. Process. Manag. 2023, 60, 103161. [Google Scholar] [CrossRef]
- Wang, H.; Pan, Q.; Tang, J. HEDV-Greedy: An advanced algorithm for influence maximization in hypergraphs. Mathematics 2024, 12, 1041. [Google Scholar] [CrossRef]
- Zhang, X.; Xie, H.; Yi, P.; Lui, J.C. Enhancing sybil detection via social-activity networks: A random walk approach. IEEE Trans. Dependable Secur. Comput. 2022, 20, 1213–1227. [Google Scholar] [CrossRef]
- Bouyer, A.; Beni, H.A.; Arasteh, B.; Aghaee, Z.; Ghanbarzadeh, R. FIP: A fast overlapping community-based influence maximization algorithm using probability coefficient of global diffusion in social networks. Expert Syst. Appl. 2023, 213, 118869. [Google Scholar] [CrossRef]
- Austin, R. Benson Research Data Sets. Available online: https://www.cs.cornell.edu/~arb/data/ (accessed on 30 June 2021).
- Amburg, I.; Veldt, N.; Benson, A.R. Hypergraph clustering for finding diverse and experienced groups. arXiv 2020, arXiv:2006.05645. [Google Scholar]
- Benson, A.R.; Abebe, R.; Schaub, M.T.; Jadbabaie, A.; Kleinberg, J. Simplicial closure and higher-order link prediction. Proc. Natl. Acad. Sci. USA 2018, 115, E11221–E11230. [Google Scholar] [CrossRef]
- Amburg, I.; Kleinberg, J.; Benson, A.R. Planted hitting set recovery in hypergraphs. J. Phys. Complex. 2021, 2, 035004. [Google Scholar] [CrossRef]
- Craswell, N.; De Vries, A.P.; Soboroff, I. Overview of the TREC 2005 Enterprise Track. Trec 2005, 5, 1–7. [Google Scholar]
- Tang, Y.; Xiao, X.; Shi, Y. Influence maximization: Near-optimal time complexity meets practical efficiency. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 75–86. [Google Scholar]
- Xie, M.; Zhan, X.-X.; Liu, C.; Zhang, Z.-K. Influence maximization in hypergraphs. arXiv 2022, arXiv:2206.01394. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).