
State Estimators for Plants Implementing ILC Strategies through Delay Links

Abstract
:1. Introduction
1.1. Background
1.2. Related Works
1.3. Motivation and Contribution
- A data pre-processing method is developed to ensure that one piece of data is received despite delays, losses, and data-to-data interference in the links;
- Using the available system information and the developed data pre-processing method, an estimation model is constructed to account for all the disturbances;
- A state estimator is designed to derive accurate outputs necessary for controller learning, thereby improving the input convergence at the controller ends.
2. Problem Formulation
| Algorithm 1 The method to pre-process output data |
| if is received then ; else if is received then ; else ; end if end if |
3. State Estimator Design
3.1. Construction of the Estimation Model
3.2. Design of the State Estimator
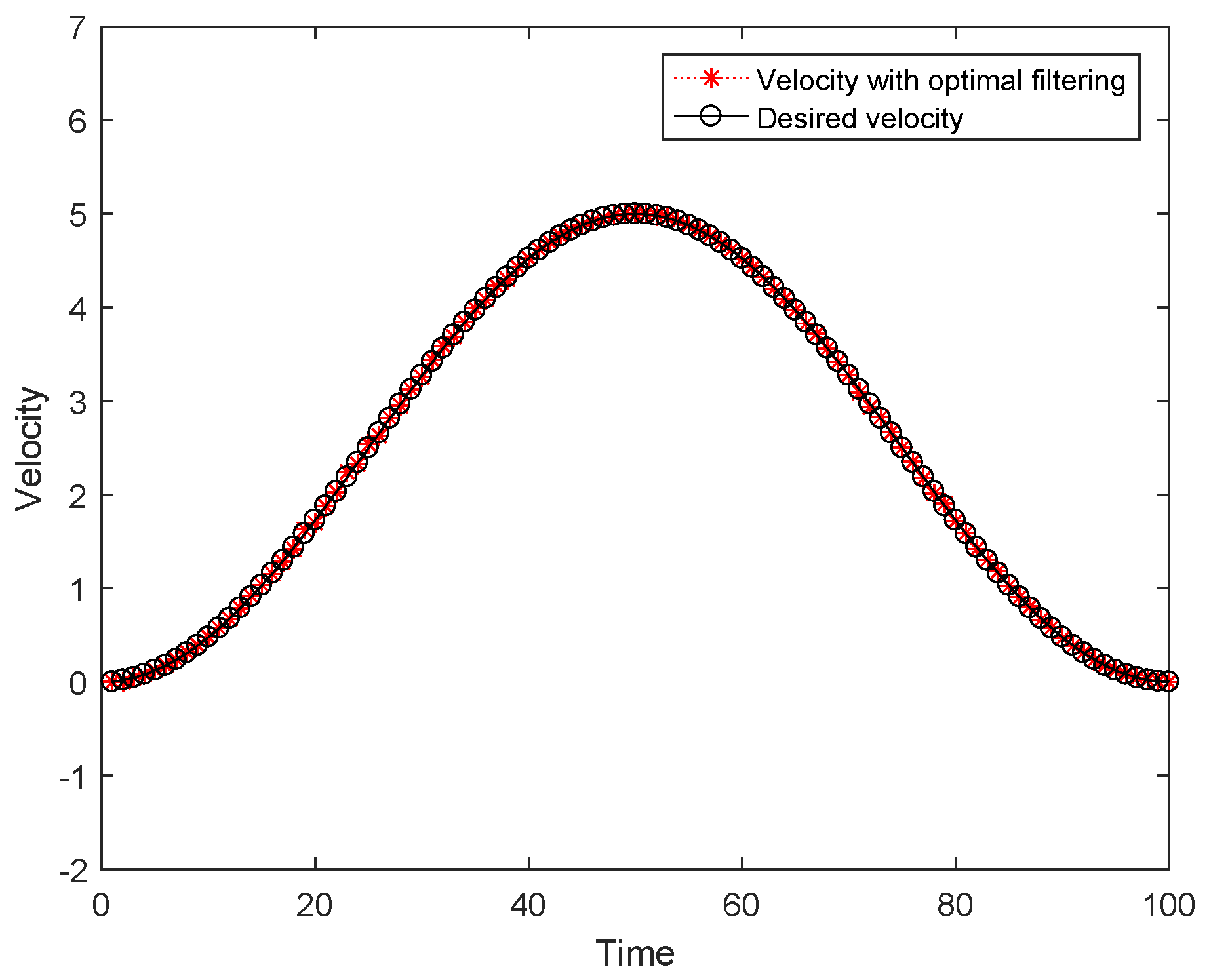
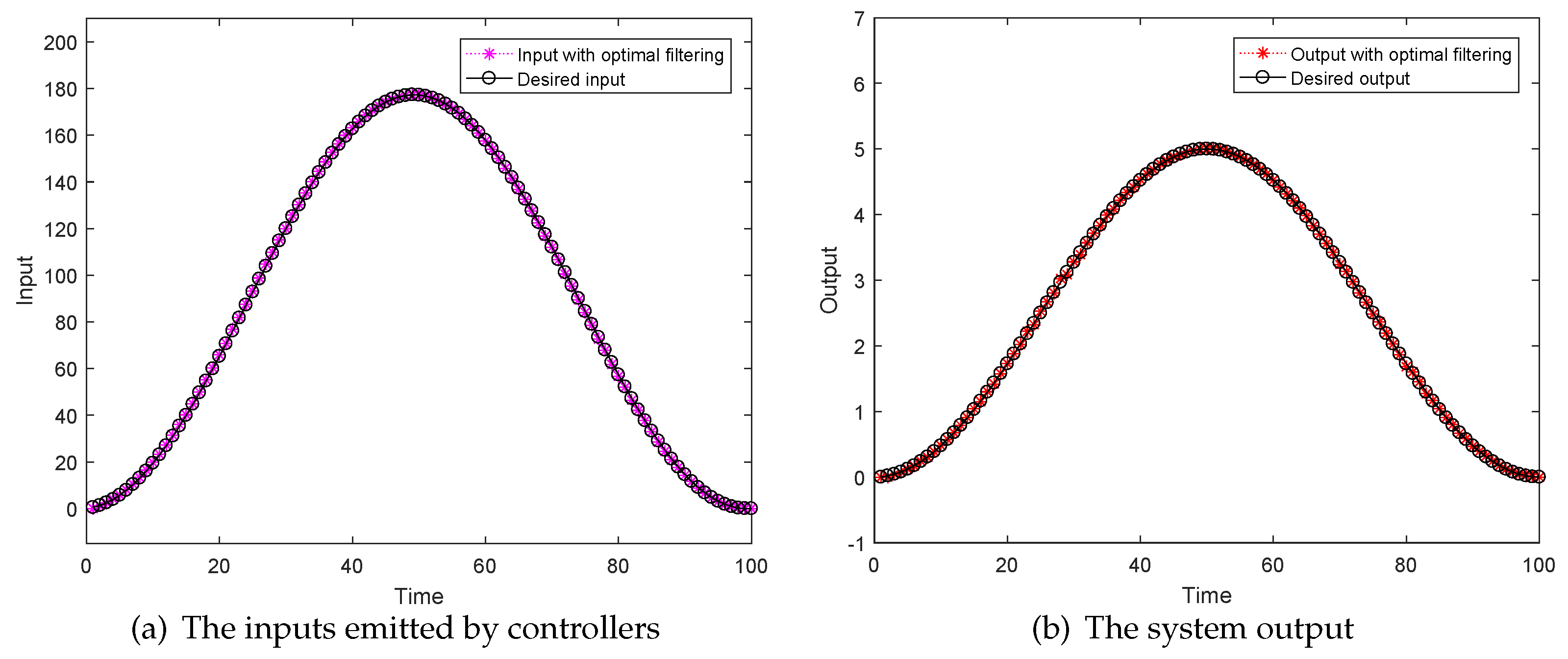
4. Simulation Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.; Han, Q.; Ge, X.; Ding, D.; Ding, L.; Yue, D.; Peng, C. Networked control systems: A survey of trends and techniques. IEEE/CAA J. Autom. Sin. 2019, 7, 1–17. [Google Scholar] [CrossRef]
- Li, M.; Chen, Y. Challenging research for networked control systems: A survey. Trans. Inst. Meas. Control 2019, 41, 2400–2418. [Google Scholar] [CrossRef]
- Mahmoud, M.S.; Hamdan, M.M. Fundamental issues in networked control systems. IEEE/CAA J. Autom. Sin. 2018, 5, 902–922. [Google Scholar] [CrossRef]
- Wang, Y.; Han, Q. Network-based modelling and dynamic output feedback control for unmanned marine vehicles in network environments. Automatica 2018, 91, 43–53. [Google Scholar] [CrossRef]
- Ding, L.; Han, Q.; Wang, L.Y.; Sindi, E. Distributed cooperative optimal control of DC microgrids with communication delays. IEEE Trans. Ind. Inf. 2018, 14, 3924–3935. [Google Scholar] [CrossRef]
- Sandberg, H.; Amin, S.; Johansson, K.H. Cyberphysical security in networked control systems: An introduction to the issue. IEEE Control Syst. Mag. 2015, 35, 20–23. [Google Scholar]
- Hespanha, J.P.; Naghshtabrizi, P.; Xu, Y. A survey of recent results in networked control systems. Proc. IEEE 2007, 95, 138–162. [Google Scholar] [CrossRef]
- Fu, X.; Peng, J. Iterative learning control for UAVs formation based on point-to-point trajectory update tracking. Math. Comput. Simul. 2023, 209, 1–15. [Google Scholar] [CrossRef]
- Sanzida, N.; Nagy, Z.K. Iterative learning control for the systematic design of supersaturation controlled batch cooling crystallisation processes. Comput. Chem. Eng. 2013, 59, 111–121. [Google Scholar] [CrossRef]
- Chen, D.; Xu, Y.; Lu, T.; Li, G. Multi-phase iterative learning control for high-order systems with arbitrary initial shifts. Math. Comput. Simul. 2024, 216, 231–245. [Google Scholar] [CrossRef]
- Feng, X.; Zhang, Y.; Kang, L.; Wang, L.; Duan, C.; Yin, K.; Pang, J.; Wang, K. Integrated energy storage system based on triboelectric nanogenerator in electronic devices. Front. Chem. Sci. Eng. 2021, 15, 238–250. [Google Scholar] [CrossRef]
- Zhou, M.; Wang, J.; Shen, D. Iterative learning based consensus control for distributed parameter type multi-agent differential inclusion systems with time-delay. Comput. Math. Appl. 2022, 127, 25–47. [Google Scholar] [CrossRef]
- Lv, Y.; Chi, R.; Feng, Y. Adaptive estimation-based TILC for the finite-time consensus control of non-linear discrete-time MASs under directed graph. IET Control Theory Appl. 2018, 12, 2516–2525. [Google Scholar] [CrossRef]
- Hui, Y.; Chi, R.; Huang, B.; Hou, Z. Extended state observer-based data-driven iterative learning control for permanent magnet linear motor with initial shifts and disturbances. IEEE Trans. Syst. Man Cybern. Syst. 2019, 51, 1881–1891. [Google Scholar] [CrossRef]
- Wang, Y.; Zhao, Z.; Ge, C.; Wang, L.; Liu, Y. Networked control systems with probabilistic time-varying delay based on event-triggered non-fragile H∞ control. Math. Comput. Simul. 2022, 202, 206–222. [Google Scholar] [CrossRef]
- Pan, Y.; J Marquez, H.; Chen, T.; Sheng, L. Effects of network communications on a class of learning controlled non-linear systems. Int. J. Syst. Sci. 2009, 40, 757–767. [Google Scholar] [CrossRef]
- Huang, L.; Sun, L.; Wang, T.; Liu, W.; Zhang, Z.; Zhang, Q. Optimal input filters for iterative learning control systems with additive noises, random delays, and data dropouts in both channels. Math. Methods Appl. Sci. 2022, 45, 4295–4311. [Google Scholar] [CrossRef]
- Huang, L.; Sun, L.; Chen, T.; Zhang, Q.; Huo, L.; Liu, W. Input predictors for networked iterative learning control systems with data dropouts and time delays. J. Intell. Fuzzy Syst. 2023, 45, 3333–3344. [Google Scholar] [CrossRef]
- Shen, D.; Zhang, C.; Xu, Y. Intermittent and successive ILC for stochastic nonlinear systems with random data dropouts. Asian J. Control 2018, 20, 1102–1114. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, J.; Ruan, X. Iterative learning control for uncertain nonlinear networked control systems with random packet dropout. Int. J. Robust Nonlinear Control 2019, 29, 3529–3546. [Google Scholar] [CrossRef]
- Shen, D.; Wang, Y. Iterative learning control for networked stochastic systems with random packet losses. Int. J. Control 2015, 88, 959–968. [Google Scholar] [CrossRef]
- Shen, D.; Wang, Y. ILC for networked nonlinear systems with unknown control direction through random lossy channel. Syst. Control Lett. 2015, 77, 30–39. [Google Scholar] [CrossRef]
- Shen, D.; Xu, J. A novel markov chain based ILC analysis for linear stochastic systems under general data dropouts environments. IEEE Trans. Autom. Control 2016, 62, 5850–5857. [Google Scholar] [CrossRef]
- Shen, D.; Jin, Y.; Xu, Y. Learning control for linear systems under general data dropouts at both measurement and actuator sides: A markov chain approach. J. Franklin Inst. 2017, 354, 5091–5109. [Google Scholar] [CrossRef]
- Bu, X.; Yu, F.; Hou, Z.; Wang, F. Iterative learning control for a class of nonlinear systems with random packet losses. Nonlinear Anal. Real World Appl. 2013, 14, 567–580. [Google Scholar] [CrossRef]
- Sun, S. Linear optimal state and input estimators for networked control systems with multiple packet dropouts. Int. J. Innov. Comput I 2012, 8, 7289–7305. [Google Scholar]
- Huang, L.; Zhang, Q.; Liu, W.; Li, J.; Sun, L.; Wang, T. Convergence analysis of iterative learning control systems over networks with successive input data compensation in iteration domain. IEEE Access 2019, 7, 160217–160226. [Google Scholar] [CrossRef]
- Liu, J.; Ruan, X. Synchronous-substitution-type iterative learning control for discrete-time networked control systems with bernoulli-type stochastic packet dropouts. IMA J. Math. Control Inf. 2018, 35, 939–962. [Google Scholar] [CrossRef]
- Hao, G.; Sun, S. Distributed fusion filter for nonlinear multi-sensor systems with correlated noises. IEEE Access 2020, 8, 39548–39560. [Google Scholar] [CrossRef]
- Huang, L.; Sun, L.; Wang, T.; Zhang, Q.; Liu, W.; Zhang, Z. An optimal filter for updated input of iterative learning controllers with multiplicative and additive noises. Int. J. Syst. Sci. 2022, 53, 1516–1528. [Google Scholar] [CrossRef]
- Liu, W.; Chi, R. Iterative learning control for nonlinear nonaffine networked systems with stochastic noise in communication channels. Trans. Inst. Meas. Control 2021, 43, 3158–3168. [Google Scholar] [CrossRef]
- Lai, J.; Xiong, J.; Shu, Z. Model-free optimal control of discrete-time systems with additive and multiplicative noises. Automatica 2023, 147, 110685. [Google Scholar] [CrossRef]
- Huang, L.; Sun, L.; Wang, T.; Zhang, Q.; Li, J.; Zhang, Z.; Liu, W. Optimal input filtering for networked iterative learning control systems with packet dropouts and channel noises in both sides. Int. J. Robust Nonlinear Control 2022, 32, 5086–5104. [Google Scholar] [CrossRef]
- Anderson, B.D.; Moore, J.B. Optimal Filtering; Courier Corporation: North Chelmsford, MA, USA, 1979. [Google Scholar]
- Shen, D.; Zhang, C.; Xu, Y. Two updating schemes of iterative learning control for networked control systems with random data dropouts. Inf. Sci. 2017, 381, 352–370. [Google Scholar] [CrossRef]
- Zhou, W.; Yu, M.; Huang, D. A high-order internal model based iterative learning control scheme for discrete linear time-varying systems. Int. J. Autom. Comput. 2015, 12, 330–336. [Google Scholar] [CrossRef]
- Liu, J.; Ruan, X. Networked iterative learning control design for discrete-time systems with stochastic communication delay in input and output channels. Int. J. Syst. Sci. 2017, 48, 1844–1855. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Refs. | FD | RD | TD | ODL | IDL | ALN | MLN |
|---|---|---|---|---|---|---|---|
| [15] | ✓ | ||||||
| [16] | ✓ | ||||||
| [17] | ✓ | ✓ | ✓ | ✓ | |||
| [18] | ✓ | ✓ | |||||
| [19] | ✓ | ||||||
| [20] | ✓ | ✓ | |||||
| [21] | ✓ | ||||||
| [22] | ✓ | ||||||
| [23] | ✓ | ||||||
| [24] | ✓ | ✓ | |||||
| [25] | ✓ | ✓ | |||||
| [26] | ✓ | ✓ | |||||
| [27] | ✓ | ||||||
| [28] | ✓ | ✓ | |||||
| [29] | ✓ | ||||||
| [30] | ✓ | ✓ | |||||
| [31] | ✓ | ||||||
| [32] | ✓ | ✓ | |||||
| [33] | ✓ |
| k | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ⋯ |
|---|---|---|---|---|---|---|---|---|---|---|
| ⋯ | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | ⋯ | |
| ⋯ | 1 | 1 | 0 | 1 | ⋯ | |||||
| ⋯ | ⋯ |
| Parameter | Meaning | Parameter | Meaning |
|---|---|---|---|
| motor position | rotor velocity | ||
| stator current | stator voltage | ||
| flux linkage | L | stator inductance | |
| frictional force | developed force | ||
| load force | ripple force | ||
| disturbances | R | stator resistance | |
| pole pitch | M | rotor mass |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Si, L.; Guo, X.; Huang, L.; Zhang, Q. State Estimators for Plants Implementing ILC Strategies through Delay Links. Mathematics 2024, 12, 2834. https://doi.org/10.3390/math12182834
Si L, Guo X, Huang L, Zhang Q. State Estimators for Plants Implementing ILC Strategies through Delay Links. Mathematics. 2024; 12(18):2834. https://doi.org/10.3390/math12182834
Chicago/Turabian StyleSi, Lina, Xinyang Guo, Lixun Huang, and Qiuwen Zhang. 2024. "State Estimators for Plants Implementing ILC Strategies through Delay Links" Mathematics 12, no. 18: 2834. https://doi.org/10.3390/math12182834