
Visualizing Convergence Dynamics across Regions and States: h-Convergence


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Convergence Dynamics for Regions and States: Challenges
2.1. Data
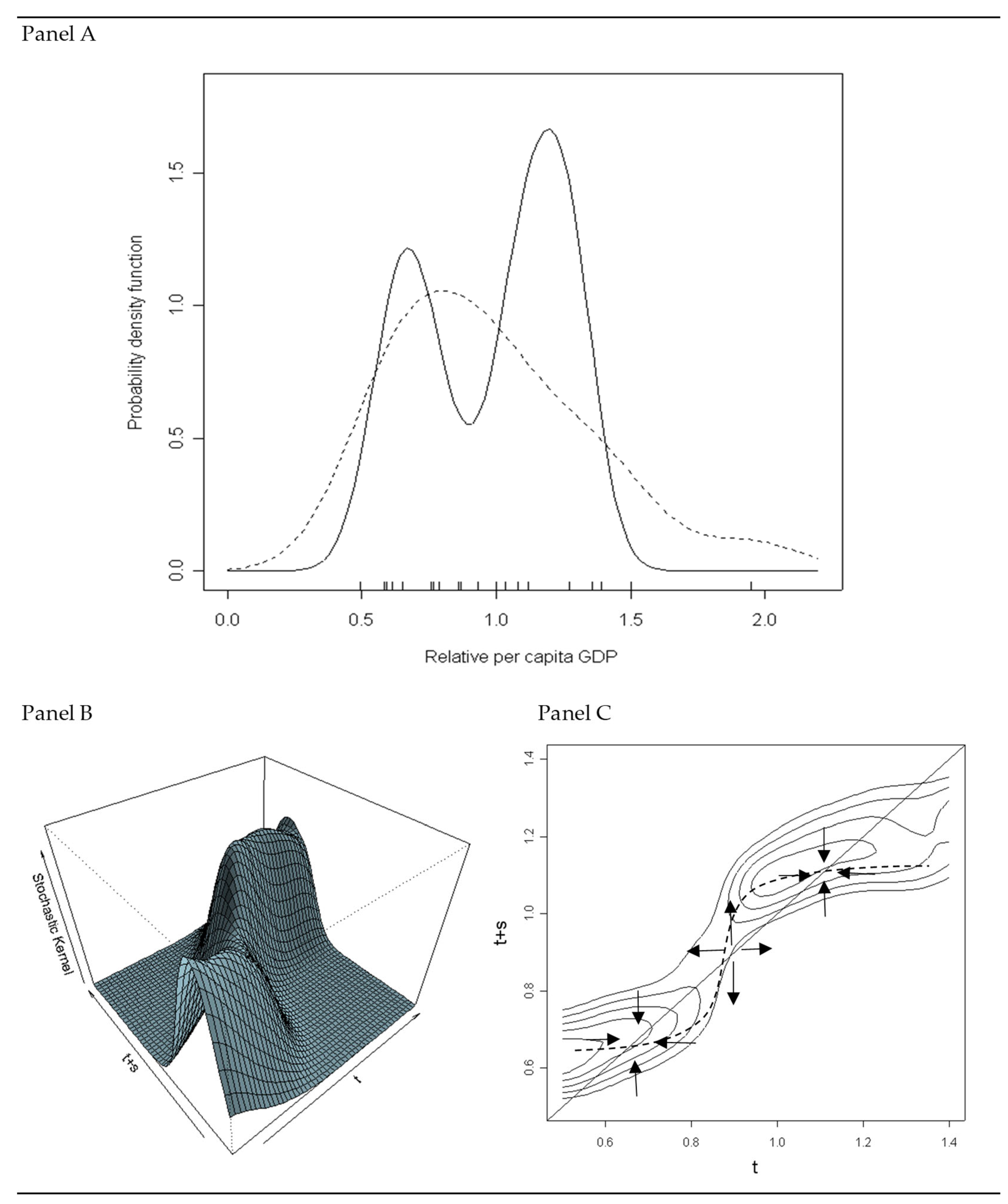
2.2. Can Absolute and Club Convergence Co-Exist? The Case of Italian Regions
3. Research Design
3.1. De-Nesting ACH and CCH
3.2. A Bandwidth-Based Test for Convergence
3.3. The De-Nested ACH and CCH in the Non-Parametric Setup
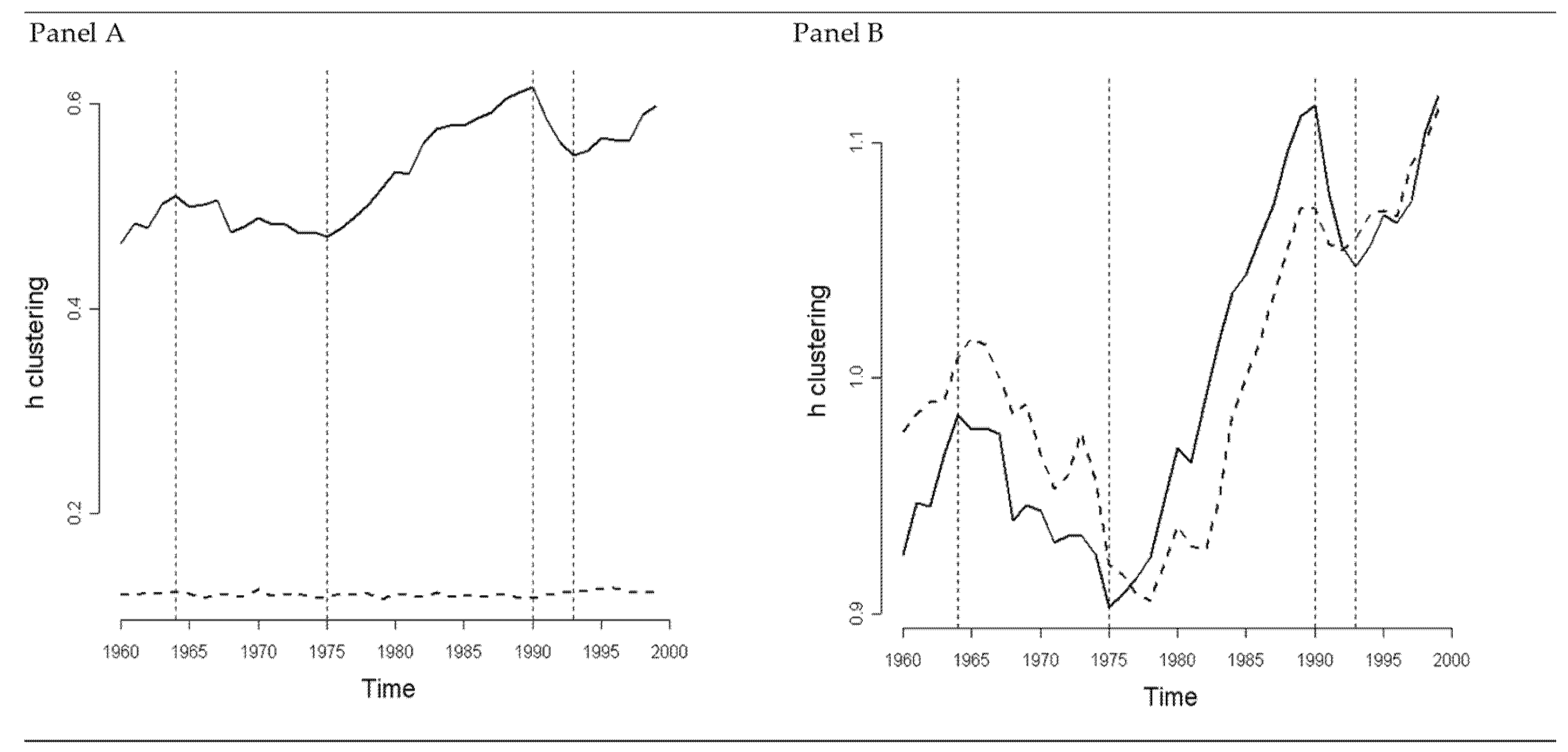
3.4. h-Convergence
- 1.
- 2.
- Extract the following metrics from each distribution of incomes per capita:
- i.
- A metric of the optimal bandwidth, under one chosen criterion, :
- ii.
- A metric of the critical bandwidth, , taken as a metric of clustering, :
- iii.
- A metric of the sample variance, :
- iv.
- The average of the metrics defined in ii and iii, :
- 3.
- Analyze the series , and and their time evolution. The comparison between the index and informs about whether the critical amount of smoothing lies above or below the optimal bandwidth, and it also therefore provides information about the shape of the distribution. This defines the number of groups and modes that the sample displays.
- 3.1.
- Statement 1: if then the distribution has two clusters of observations.
- 3.2.
- Statement 2: if then the clusters are diverging. The series informs about club convergence dynamics—h-clustering. In the case of a positive trend, we can conclude in favor of divergence between groups; that is, in favor of the CCH hypothesis.
- 3.3.
- Statement 3: if then the economies are diverging. The series informs about whether clustering is offset by reduction in the variance and therefore informs about whether the absolute convergence process is in place—h-convergence.
4. Empirical Results
4.1. Convergence and Divergence across Italian Regions
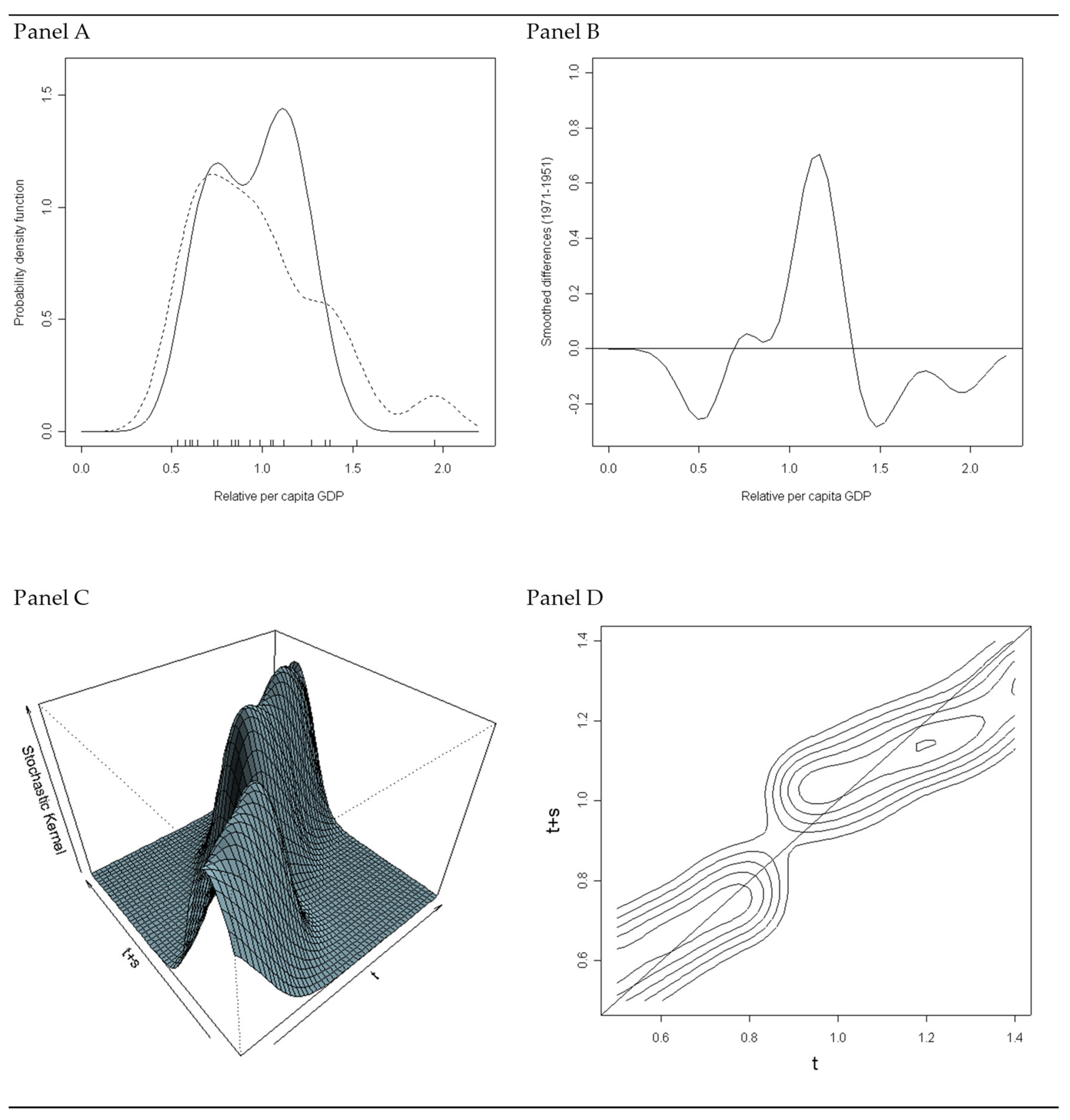
4.2. Divergence across Italian Provinces
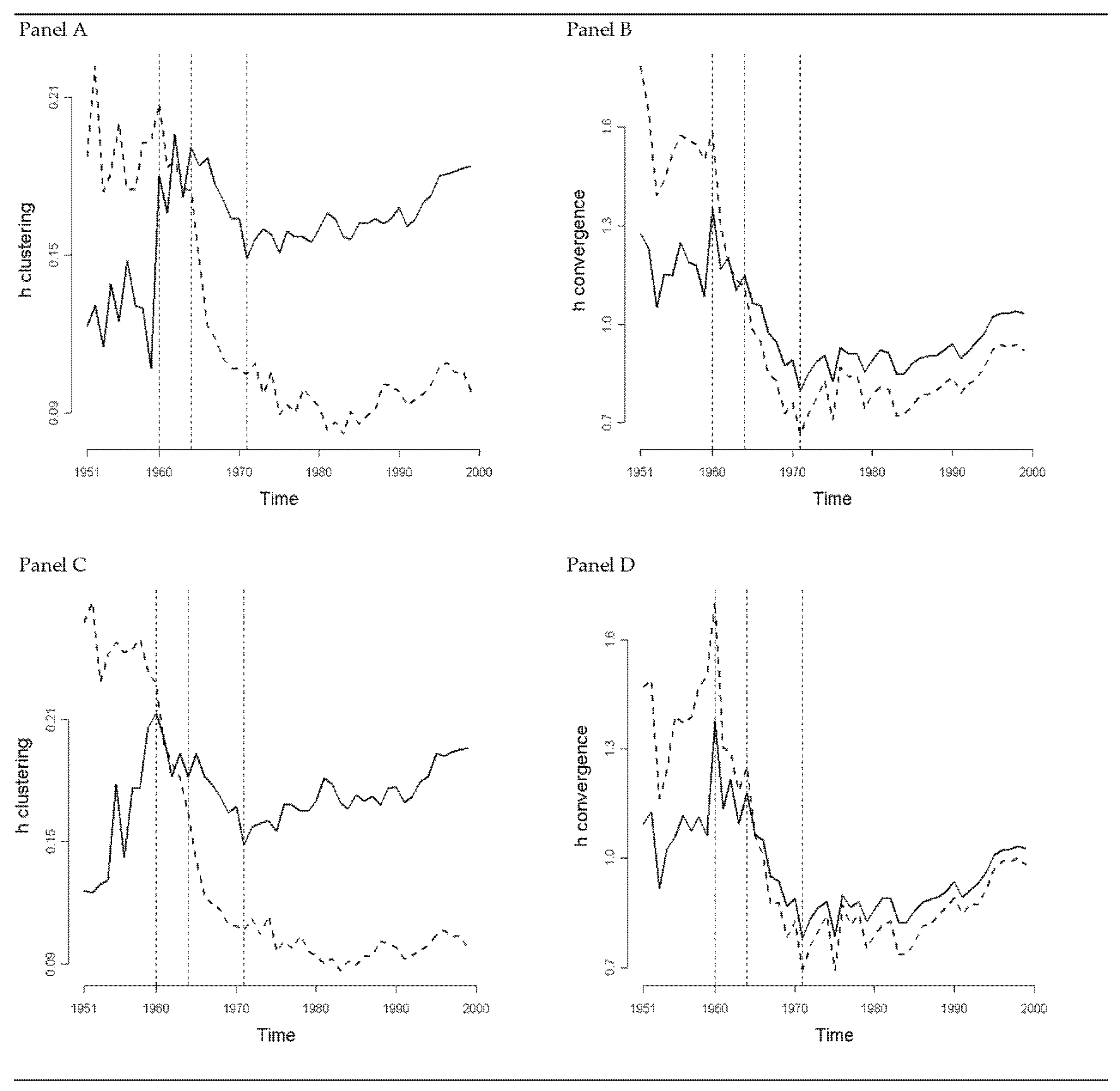
4.3. Are European Regions Converging?
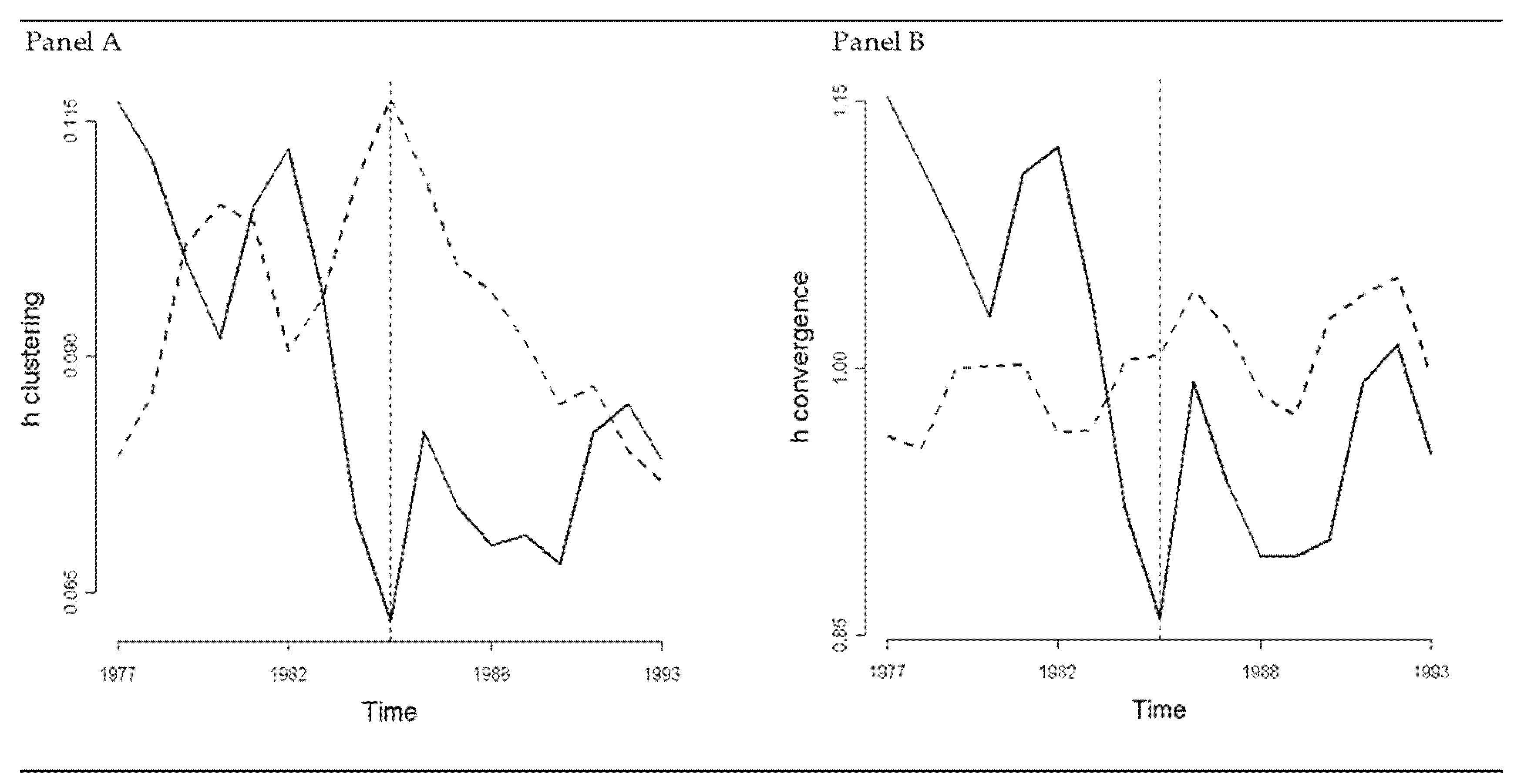
4.4. Divergence and Convergence across World Economies
5. Concluding Remarks
Funding
Data Availability Statement
Conflicts of Interest
References
- Gonzalez-Paramo, J.M.; Martinez-Lopez, D. Convergence Across Spanish Regions: New Evidence on the Effect of Public Investment. R. Reg. Stud. 2003, 33, 184–205. [Google Scholar] [CrossRef]
- Lima, L.R.; Hostalacio, H.; Reis Gomes, F.A. Empirical Evidence on Convergence Across Brazilian States. Rev. Braz. Econ. 2010, 64, 135–160. [Google Scholar]
- Kholodilin, K.A.; Oshchepkov, A.; Siliverstovs, B. The Russian Regional Convergence. East. Eur. Econ. 2012, 50, 5–26. [Google Scholar] [CrossRef]
- Goeche, H.; Huter, M. Regional Convergence in Europe. Intereconomics 2016, 11, 165–171. [Google Scholar] [CrossRef]
- Puente, S. Regional Convergence in Spain: 1980-2015. Econ. Bull. 2017, 21, 1–7. [Google Scholar]
- Eichergreen, B. Convergence and Divergence in the EU: Lessons from Italy. Intereconomics 2019, 54, 31–34. [Google Scholar] [CrossRef]
- Lehmann, H.; Oshchepkov, A.Y.; Silvagni, M.G. Regional Convergence in Russia: Estimating a Neoclassical Growth Model; Higher School of Economics Research Paper No. WP BRP 232/EC/2020; SSRN: Rochester, NY, USA, 2020; pp. 1–48. [Google Scholar]
- Savoia, F. Income Inequality Convergence Across EU Regions; LIS Working Paper Series No. 760; Luxembourg Income Study (LIS): Luxembourg, 2020; pp. 1–40. [Google Scholar]
- Ram, R. Income convergence across the U.S. states: Further evidence from new recent data. J. Econ. Finan. 2021, 45, 372–380. [Google Scholar] [CrossRef]
- Acemoglu, D. Introduction to Modern Economic Growth; Princeton University Press: Princeton, NY, USA, 2009. [Google Scholar]
- Quah, D. Empirics for Growth and Distribution: Stratification, Polarization and Convergence Clubs. J. Econ. Gr. 1997, 2, 27–59. [Google Scholar] [CrossRef]
- Bianchi, M. Testing for convergence: Evidence from nonparametric multimodality test. J. Appl. Economet. 1997, 12, 393–409. [Google Scholar] [CrossRef]
- Fanti, L.; Pereira, M.C.; Virgillito, M.E. The North-South divide: Sources of divergence, policies for convergence. J. Pol. Mod. 2023, 45, 405–429. [Google Scholar] [CrossRef]
- Silverman, B.W. Using Kernel Density to Investigate Multimodality. J. Roy. Stat. Soc. 1981, 43, 97–99. [Google Scholar] [CrossRef]
- Terrasi, M. Convergence and Divergence Across Italian Regions. An. Reg. Sc. 1999, 33, 491–510. [Google Scholar] [CrossRef]
- Calcagnini, G.; Perugini, F. Income distribution dynamics among Italian provinces. The role of Bank Foundations. Appl. Econ. 2019, 29, 3198–3211. [Google Scholar] [CrossRef]
- Quah, D. Empirical Cross-Section Dynamics in Economic Growth. Eur. Econ. R. 1993, 37, 426–434. [Google Scholar] [CrossRef]
- Barro, R.J.; Sala-i-Martin, X. Convergence across States and Regions. Brook. Pap. Econ. Act. 1991, 1, 1107–1182. [Google Scholar] [CrossRef]
- Canova, F.; Marcet, A. The Poor Stay Poor: Non-Convergence across Countries and Regions; Discussion Paper No. 1265; Centre for Economic Policy Research (CEPR): London, UK, 1995. [Google Scholar]
- Bernard, A.; Durlauf, S.N. Convergence in International Output. J. Appl. Economet. 1995, 10, 97–108. [Google Scholar] [CrossRef]
- Quah, D. Twin Peaks: Growth and Convergence in Models of Distribution Dynamics. Econ. J. 1996, 106, 1045–1055. [Google Scholar] [CrossRef]
- Kremer, M.; Willis, J.; Yu, Y. Converging to Convergence. BFI WP 2021, 1–50. [Google Scholar]
- Patel, D.; Sandefur, J. Subramanian, A. The new era of unconditional convergence. J. Dev. Econ. 2021, 152, 1–18. [Google Scholar] [CrossRef]
- Rosenblatt, M. Remarks on Some Nonparametric Estimates of a Density Function. An. Math. Stat. 1956, 27, 832–837. [Google Scholar] [CrossRef]
- Caggiano, G.; Leonida, L. International output convergence: Evidence from an autocorrelation function approach. J. Appl. Economet. 2009, 24, 139–162. [Google Scholar] [CrossRef]
- Caggiano, G.; Leonida, L. Multimodality in the distribution of GDP and the absolute convergence hypothesis. Emp. Econ. 2013, 44, 1204–1215. [Google Scholar] [CrossRef]
- Leonida, L. What Have We Not Learned from the Convergence Debate? Mathematics 2023, 11, 2119. [Google Scholar] [CrossRef]
- Marron, J.S.; Schmitz, H.P. Simultaneous density estimation of several income distributions. Econ. Theory 1992, 8, 476–488. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Chapman and Hall: London, UK, 1986. [Google Scholar]
- Sheather, S.J.; Jones, M.C. A reliable data-based bandwidth selection method for kernel density estimation. J. Roy. Statist. Sot. Ser. E 1991, 53, 683–690. [Google Scholar] [CrossRef]
- Mauro, L.; Podrecca, E. The Case of Italian Regions: Convergence or Dualism. Econ. Not. 1994, 447–472. [Google Scholar]
- Paci, R.; Saba, A. The Empirics of Regional Economic Growth in Italy, 1951–1993. Riv. Inter. Sci. Econ. Comm. 1998, 5, 513–542. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leonida, L. Visualizing Convergence Dynamics across Regions and States: h-Convergence. Mathematics 2024, 12, 256. https://doi.org/10.3390/math12020256
Leonida L. Visualizing Convergence Dynamics across Regions and States: h-Convergence. Mathematics. 2024; 12(2):256. https://doi.org/10.3390/math12020256
Chicago/Turabian StyleLeonida, Leone. 2024. "Visualizing Convergence Dynamics across Regions and States: h-Convergence" Mathematics 12, no. 2: 256. https://doi.org/10.3390/math12020256
APA StyleLeonida, L. (2024). Visualizing Convergence Dynamics across Regions and States: h-Convergence. Mathematics, 12(2), 256. https://doi.org/10.3390/math12020256