Abstract
The dynamic range of an image represents the difference between its darkest and brightest areas, a crucial concept in digital image processing and computer vision. Despite display technology advancements, replicating the broad dynamic range of the human visual system remains challenging, necessitating high dynamic range (HDR) synthesis, combining multiple low dynamic range images captured at contrasting exposure levels to generate a single HDR image that integrates the optimal exposure regions. Recent deep learning advancements have introduced innovative approaches to HDR generation, with the cycle-consistent generative adversarial network (CycleGAN) gaining attention due to its robustness against domain shifts and ability to preserve content style while enhancing image quality. However, traditional CycleGAN methods often rely on unpaired datasets, limiting their capacity for detail preservation. This study proposes an improved model by incorporating a switching map (SMap) as an additional channel in the CycleGAN generator using paired datasets. The SMap focuses on essential regions, guiding weighted learning to minimize the loss of detail during synthesis. Using translated images to estimate the middle exposure integrates these images into HDR synthesis, reducing unnatural transitions and halo artifacts that could occur at boundaries between various exposures. The multilayered application of the retinex algorithm captures exposure variations, achieving natural and detailed tone mapping. The proposed mutual image translation module extends CycleGAN, demonstrating superior performance in multiexposure fusion and image translation, significantly enhancing HDR image quality. The image quality evaluation indices used are CPBDM, JNBM, LPC-SI, S3, JPEG_2000, and SSEQ, and the proposed model exhibits superior performance compared to existing methods, recording average scores of 0.6196, 15.4142, 0.9642, 0.2838, 80.239, and 25.054, respectively. Therefore, based on qualitative and quantitative results, this study demonstrates the superiority of the proposed model.
MSC:
68T45
1. Introduction
The dynamic range of an image is crucial in digital imaging and computer vision, representing the difference between the lowest and highest luminance in an image. A more extensive dynamic range allows for the simultaneous representation of dark shadows and bright highlights, enhancing the detail and realism of the image. However, the current display technology has a limited dynamic range compared to the broad range perceived by the human visual system, restricting the ability to reproduce real-world scenes accurately. One approach to overcoming this limitation is high dynamic range (HDR) synthesis, combining multiple low dynamic range (LDR) images captured at various exposure levels and integrating optimal exposure regions from each image to create a single HDR image that expands the overall dynamic range [1,2].
The deep learning techniques for HDR image generation have recently spurred the development of novel approaches. Liu et al. [3] utilized a transformer-based HDR fusion model based on a CNN architecture to simultaneously handle noise removal and image fusion. The TransU-Fusion network focuses on reducing ghost artifacts using transformers and using residual dense blocks based on the U-net architecture [4]. In addition, MSANLnet generates HDR images using a multi-scale attention mechanism and non-local networks [5]. These methods highlight the various approaches of deep learning for HDR image synthesis. However, these often require multiple sequences of LDR images or reference images. In contrast, the proposed method generates HDR images using only two exposure levels, low exposure (LE) and high exposure (HE), and can be applied in environments where it is difficult to capture multiple exposure levels.
In line with these approaches, the cycle-consistent generative adversarial network (CycleGAN) is robust to domain variations and suitable for image translations with significant changes in style or lighting conditions, such as converting LE images to resemble HE images, and it is widely employed to enhance image quality [6]. The model maintains content style during translation, making it ideal for tasks that require changing appearance while preserving critical content. Although CycleGAN was initially designed for unaligned datasets, this study employs paired datasets to preserve critical image details better.
This study augments the generator in CycleGAN with an additional channel, incorporating a switching map (SMap) to enable weighted learning of regions of interest [7]. As a surround SMap, the SMap is designed to select desired local regions in the image and serves as a guide in CycleGAN, learning the optimal regions for each exposure and reducing the loss of details during image synthesis. IID-MEF separates reflectance, shading, and color components and fuses them separately [8]. However, it has been challenging to simultaneously address side effects such as color distortion, halo effect, and poor tone compression problems during the image synthesis process. To overcome these limitations, the proposed module estimates the ME image, preserves boundary information, and thereby minimizes side effects such as color distortion and the halo effect, which commonly occur when merging images with large exposure differences. In addition, the Retinex algorithm is applied to effectively handle tone compression. Retinex applies a convolutional mask to each pixel and measures the change rate relative to neighboring pixels, achieving natural and realistic tone compressing [9]. We extended this approach by applying retinex in a multilayer manner, allowing each layer to capture variations between exposures with distinct characteristics. This multilayer approach allows the precise adjustment of details across exposures, facilitating exposure fusion that results in tone compressing with enhanced naturalness and preserved details. This improved CycleGAN module facilitates generating multiexposure images and their subsequent multi-image fusion, leading to HDR image quality that surpasses conventional methods. In Section 2, we explain traditional multi-image fusion techniques, as well as CycleGAN, which serves as the foundation for the proposed model. In Section 3, we structurally divide the proposed method into the proposed module, high-mid and mid-low fusion, and SSR multilayer fusion. Finally, we present the visual and quantitative results of applying the proposed method to various images, comparing them with existing approaches. The contributions of our study are summarized as follows:
- To address halo effects that occur between bright and dark areas when using a limited number of multi-exposure images without reference images, we estimate the ME image to preserve boundary information and generate high-mid and mid-low images to reduce the exposure gap.
- To improve consistency in exposure levels during CycleGAN-based bidirectional learning using a paired dataset, we incorporate the SMap as an additional channel in the generator, assigning weighted importance to specific features during learning to achieve improved consistency and quality.
- To simultaneously address side effects such as halo artifacts and color distortion, along with tone compression, we combine CycleGAN with the Retinex algorithm, allowing HDR images to be synthesized in a single process.
- To tailor the Retinex algorithm for tone compression according to varying image characteristics, we apply it in a multiscale manner and use the trans-SMap, adjusting it to each scale’s specific features for optimized fusion.
2. Related Work
2.1. Conventional Multi-Image Fusion
Multi-image-fusion techniques combine information from multiple images of the same scene to create a single composite image, integrating the most critical features from each input [10]. This process is helpful when images are captured under varying conditions, such as diverse lighting, focus settings, or exposure levels. By merging these diverse inputs, the fused image enhances the overall quality and retains essential details that could be lost if relying solely on a single exposure or setting.
A common application of multi-image fusion is multiexposure fusion, where images captured at various exposure levels are combined to extend the dynamic scene range, capturing details across the brightest and darkest areas [11]. In this process, LDR images used as multiexposure inputs display different optical characteristics depending on the exposure times, affecting the characteristics of the generated HDR image. For instance, as depicted in Figure 1a, longer exposure times can reveal more detailed information in dark areas but may cause overexposure in bright regions. Conversely, as presented in Figure 1b, shorter exposure times preserve details in bright areas, resulting in a loss of information and reduced saturation in dark regions. This approach addresses the limitations of individual images, compensating for the loss of shadow detail due to underexposure or highlight details due to overexposure, resulting in a final image that is more visually appealing.

Figure 1.
Multi-exposed images: (a) high-exposure image and (b) low-exposure image.
Traditional techniques of multi-image fusion include the wavelet transform, weighted averaging, gradient-based, and pyramid-based methods. Wavelet transform-based fusion decomposes images into high- and low-frequency components, with fusion rules focusing on retaining high-frequency information from detailed regions while preserving the low-frequency components for overall image smoothness [12]. This approach preserves edge details and local contrasts; however, it can introduce artifacts, such as ringing or blurring, at sharp transitions, primarily occurring around edges or regions with abrupt intensity changes. These artifacts can degrade the visual quality of the fused image, particularly in areas with high-frequency textures.
Weighted averaging and gradient-based methods employ weighted averaging, where the weights are frequently based on image gradients, contrast, or edge information [13]. These methods preserve details by emphasizing regions with high gradient values, ensuring that significant changes are maintained across fused images. However, despite their effective detail preservation, these techniques suffer from a loss of fine details, especially in extremely bright or dark areas. These methods also require careful and often manual tuning of the weights, which may not generalize well across different sets of images.
Pyramid-based methods decompose images into Laplacian and Gaussian pyramids to capture and merge multiscale details [14]. Gaussian pyramids are created by smoothing and downsampling the images, whereas Laplacian pyramids emphasize high-frequency details by computing differences between consecutive Gaussian levels. In the fusion process, the corresponding levels of the Laplacian pyramids are combined using adaptive weights, and the final fused image is reconstructed by expanding and combining these levels to merge the multiscale details accurately. However, these methods may struggle to adapt to diverse image conditions and may not perform optimally in complex scenes with significant exposure differences. Further, slight errors in pyramid construction and reconstruction can lead to artifacts. While traditional multi-image-fusion methods are effective for many applications, their adaptability, potential for artifacts, and manual parameter tuning requirements limit their general applicability.
2.2. Cycle-Consistent Generative Adversarial Networks
The CycleGAN unsupervised learning model is primarily used for image style transfer and domain adaptation tasks [6]. Recently, this model has also been applied to image fusion, which is a technique that combines valuable information from multiple input images to generate a high-quality composite image. This approach is essential to integrating images captured under various exposure levels, focus settings, or lighting conditions. Due to the ability of CycleGAN to translate images between different domains, it is quite suitable for integrating images with varying conditions into a single fused image [15].
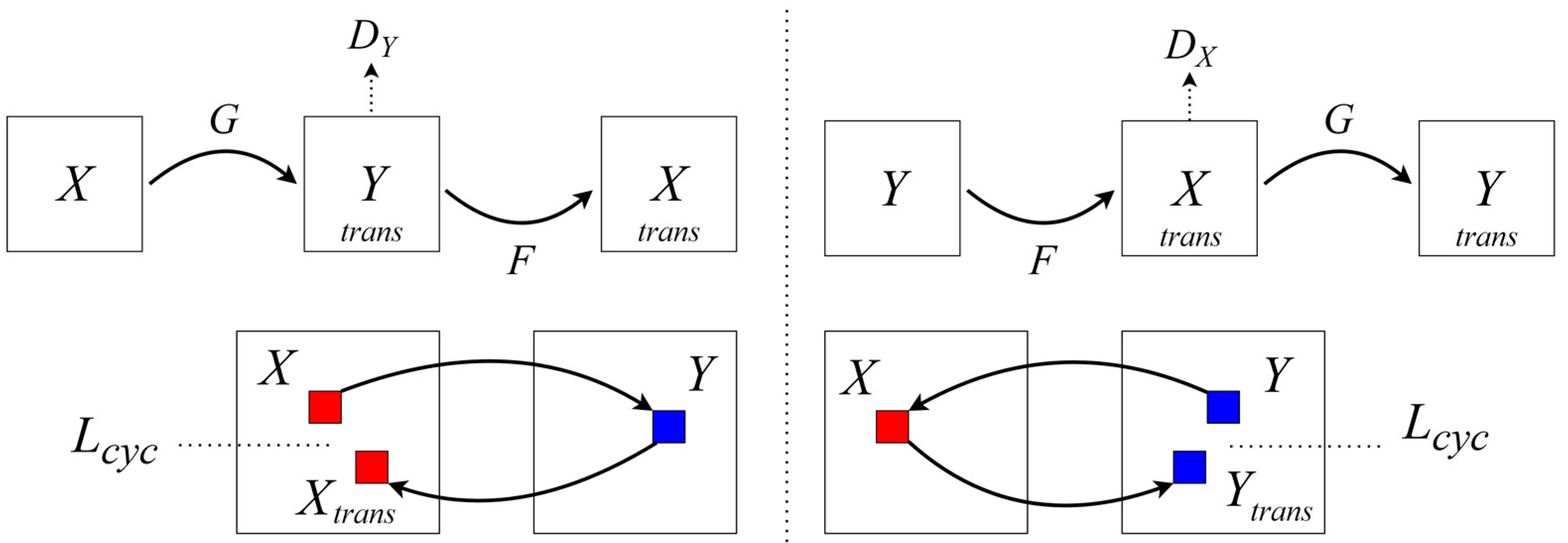
As illustrated in Figure 2, the main components of CycleGAN are two generators and two discriminators. The core concept of CycleGAN is employing cycle-consistency loss to minimize information loss when an image is translated from one domain to another and then back to its original domain [16]. The adversarial loss helps the generator learn to deceive the discriminator into recognizing the generated images as authentic, whereas the cycle-consistency loss ensures that the translations between domains are consistent in both directions [17].
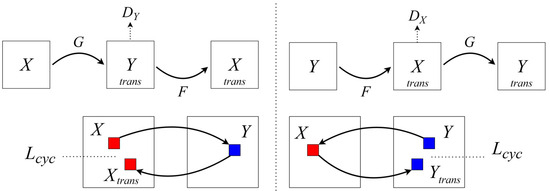
Figure 2.
Components of the cycle-consistent generative adversarial network (CycleGAN).
The CycleGAN loss functions are adversarial and cycle-consistency loss. Adversarial loss aims for the generated images to be indistinguishable from the actual images by the discriminator, mathematically expressed as follows:
where represents the adversarial loss, which measures the ability of generator to deceive discriminator . The generator aims to produce images that the discriminator cannot distinguish from the actual image . In addition, denotes the expectation that the discriminator correctly identifies authentic image sampled from the actual data distribution, . Further, indicates the expectation that the discriminator correctly identifies generated images , produced by the generator from input image sampled from , as fake.
Cycle-consistency loss minimizes the difference when generators and cross-translate the domains and revert to the original domain:
where represents the cycle-consistency loss, which measures the difference between the original images and and their reconstructions after being translated through generators , respectively. Moreover, refers to the expectation that the reconstructed image, , closely resembles the original image , with the difference measured using the L1 norm. Similarly, represents the expectation that the reconstructed image closely matches the original image, .
The total loss function of CycleGAN is given by the following:
where represents the combined loss function, incorporating the adversarial and cycle-consistency loss. This combined loss is applied to train the CycleGAN model. In addition, and are the adversarial losses for each direction of the domain translation, ensuring that the generated images, and , are indistinguishable from the actual images in domains and , respectively. Moreover, represents the cycle-consistency loss weighted by the hyperparameter , determining the relative importance of maintaining consistency in the image translations between domains.
Although CycleGAN is highly effective for image translation between unpaired datasets, it has some limitations. In complex scenes or images with high-frequency details, CycleGAN may fail to preserve details adequately due to its reliance on cycle consistency, which can lead to information loss or distortion, particularly in images with complex textures or sharp boundaries. Additionally, the training process for CycleGAN is highly sensitive and unstable, making achieving optimal hyperparameter tuning and training stability challenging.
Modifications have been proposed to overcome the limitations of CycleGAN. For example, AttentionGAN [18] introduces an attention mechanism that assigns weights to essential regions during the translation process, enhancing the preservation of image details. However, if the attention map is not correctly learned, unnecessary emphasis or information loss can occur, and computational costs may increase. Additionally, DualGAN [19] replaces cycle consistency with symmetric domain translations to improve training stability. Although these variants aim to address the limitations of CycleGAN, they still struggle to resolve the detail preservation problems under complex exposure conditions. Detail loss and artifact generation under significant exposure differences remain prevalent across most variants.
3. Proposed Method
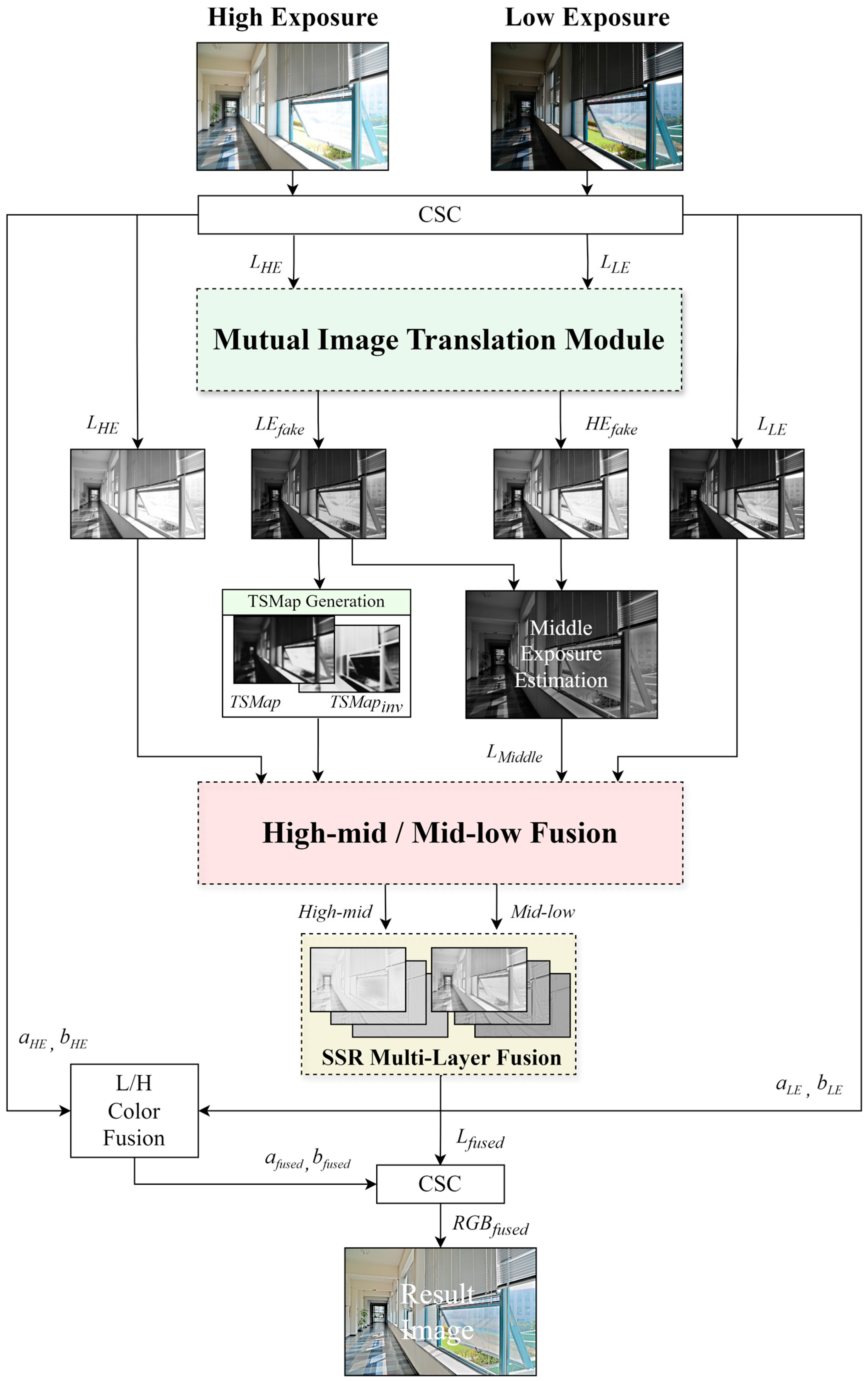
Figure 3 illustrates the overall flowchart of the proposed method, detailing the step-by-step multiexposure image fusion process. First, HE and LE images are input. These images are converted to their respective luminance (L) channels (, ) through color space conversion (CSC) [20]. The translated L channel images are input into the mutual image translation module (MITM), an extended module of the CycleGAN framework, enhanced by adding the SMap as an extended channel. It performs bidirectional translations from LE to HE and from HE to LE, focusing on essential image regions to improve translation quality.
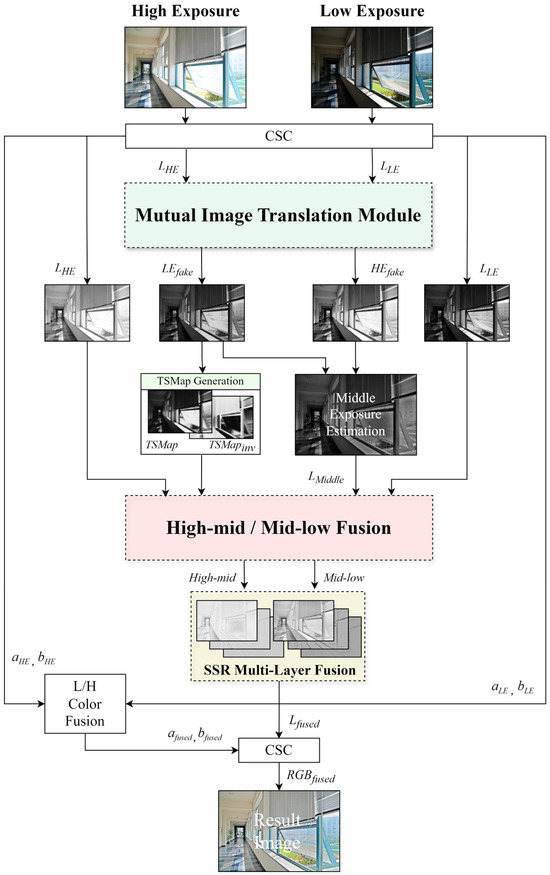
Figure 3.
Overall flowchart of the proposed method.
The MITM outputs are represented as fake LE () and fake HE () images. Due to the ambiguity in the exposure levels of these translated images, an ME image must be estimated. This estimation involves mapping the surround components of the difference map between the fake HE and LE images to the fake HE image and using the inverse surrounding components of the fake LE image for the fake LE mapping. These results are combined in the ME image via a simple sigma fusion.
The estimated ME image generates high-mid and mid-low images using the trans-SMap (TSMap) by fusing the image with the actual HE and LE images, respectively. The TSMap is generated from the fake LE image translated by the MITM and displays superior region selection ability compared with the existing SMap. In this process, the ME image maintains detail at the boundaries between various exposure levels, enhancing the overall image fusion quality. The generated high-mid and mid-low images are applied in the LDR image fusion pipeline. The single-scale retinex (SSR) tone compression algorithm is applied in a multilayer manner to fuse the high-mid and mid-low images using the TSMap to ensure consistent tonal quality across images with varying exposure levels.
Finally, the fused L channel undergoes L/H color fusion and CSC to produce the final HDR image result. This process addresses common problems in multiexposure image fusion, such as halo effects and information loss.
The proposed method ensures detail preservation and high translation quality across varying exposures by employing the MITM approach. Thus, the proposed approach generates HDR images with enhanced dynamic range and fine details, demonstrating significant improvements over traditional fusion techniques. The MITM approach achieves detailed preservation and translation quality across varying exposures. In summary, the progression of the proposed method is classified into the following key stages:
- The CycleGAN framework is modified by adding the SMap channel to perform effective bidirectional translations between LE and HE images.
- The images transformed through MITM are processed with separate maps tailored to their specific characteristics, allowing the estimation of the ME image and the preservation of fine detail information at the boundaries of different exposure levels.
- The ME image is fused with the actual LE and HE images using the TSMap. Through this process, the generated high-mid and mid-low images help reduce the large exposure gaps present in the input images.
- The SSR tone compression algorithm is applied in a multilayer manner to ensure consistent tonal quality.
3.1. CycleGAN-Based Mutual Image Translation Module
This section details the generation of the SMap and the CycleGAN-based MITM. The proposed module introduces a novel approach to enhancing HDR image synthesis using the SMap as an additional channel in the generator network. By incorporating SMap, the module translates images and estimates an ME image, improving the overall HDR synthesis performance.
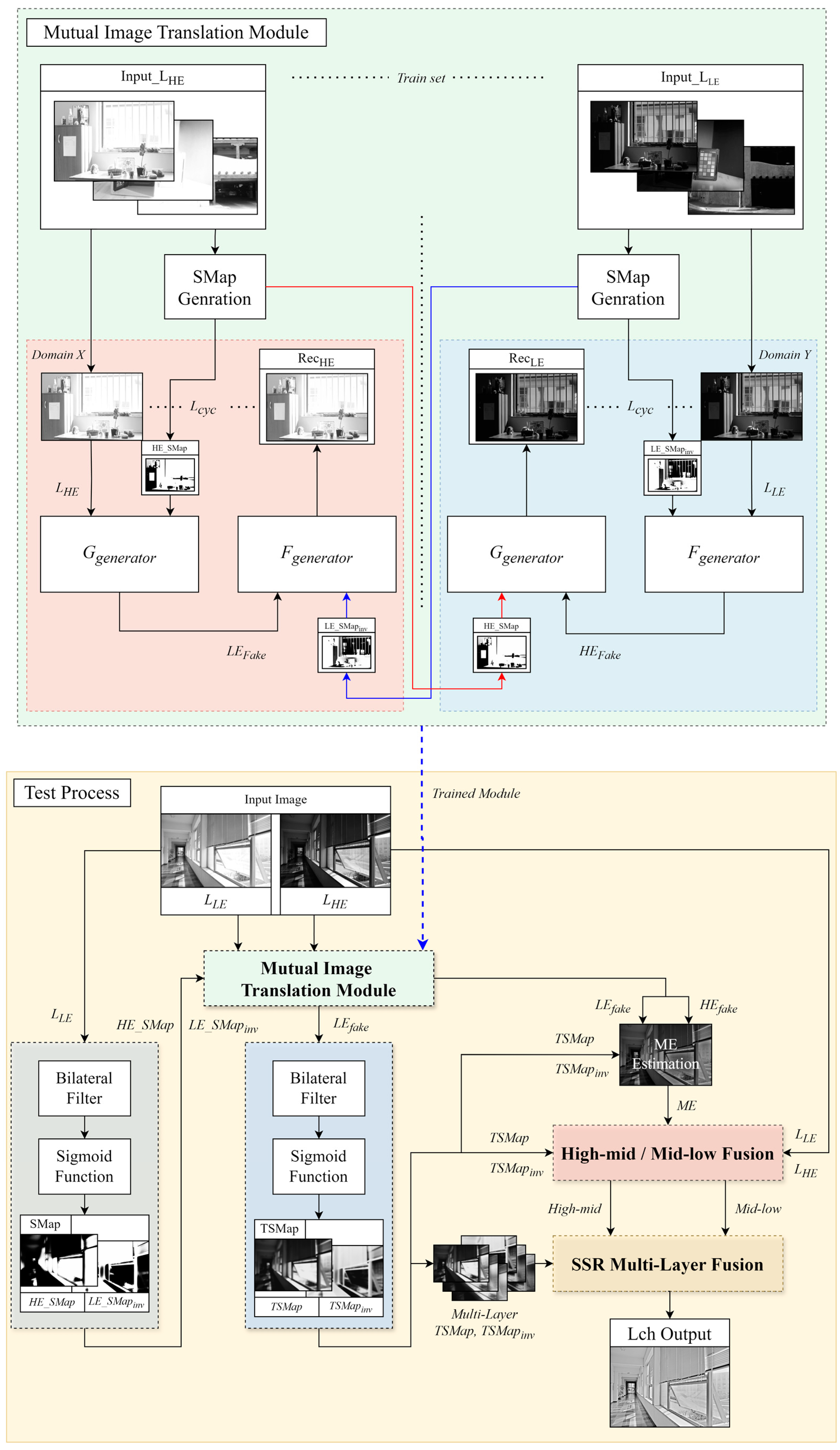
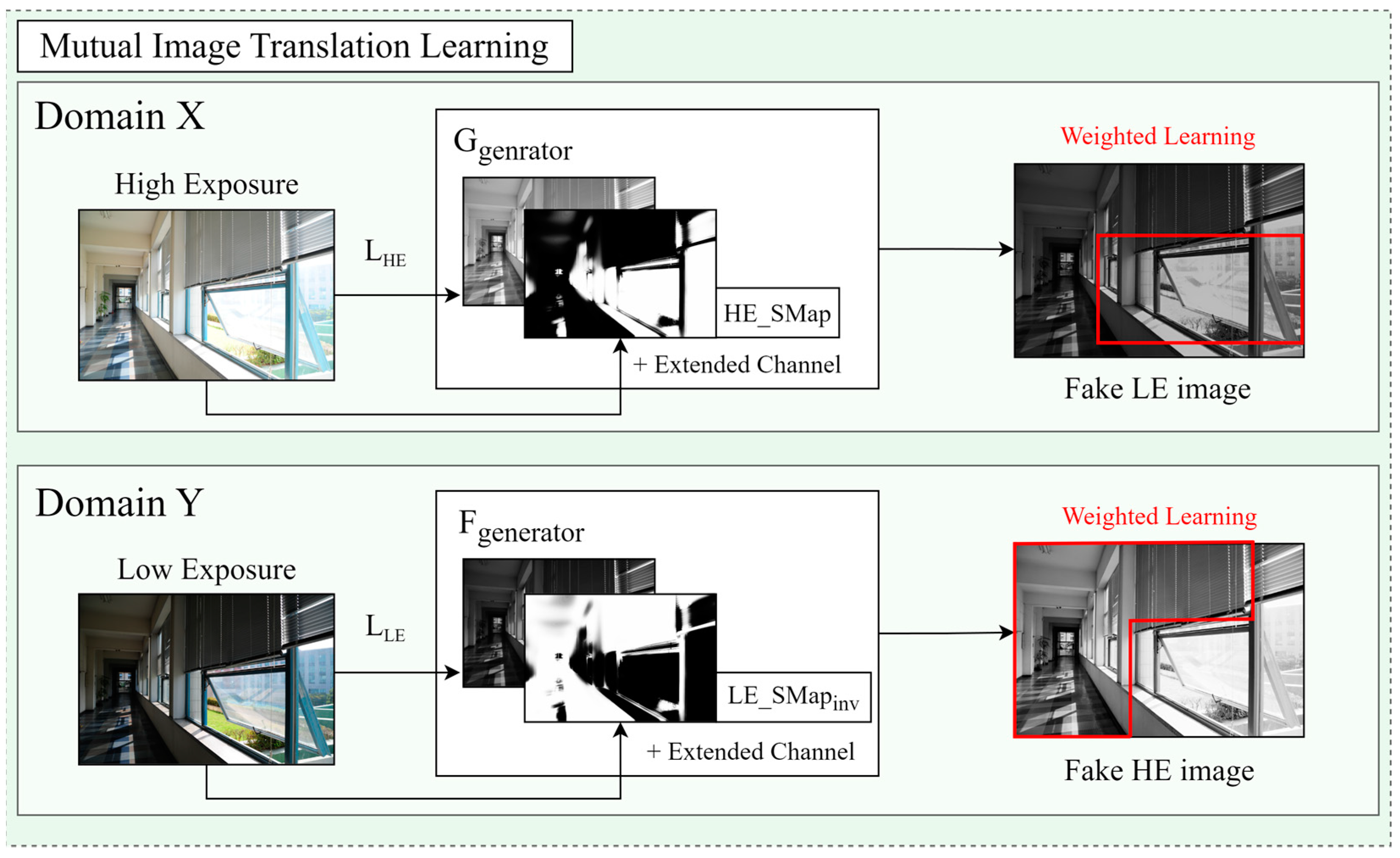
The SMap was initially developed as a switching mechanism to select optimal regions from images with varying exposure levels. By applying the unique advantages of each exposure setting, the SMap identifies and selects high-quality regions, enhancing the overall image quality during synthesis. The SMap is integrated as an additional input channel in the CycleGAN generator in the proposed module. Figure 4 illustrates the improved MITM in CycleGAN and the test process. The blue dotted line illustrates the structure in which the trained module is applied during the test process. In Domain X, HE_SMap is added as an additional channel to generator G, while LE_SMapinv is added to generator F, enhancing the mutual learning in CycleGAN. In the module, represents the cycle-consistency loss. The test process demonstrates how SMap and TSMap are utilized within the module and fusion process.
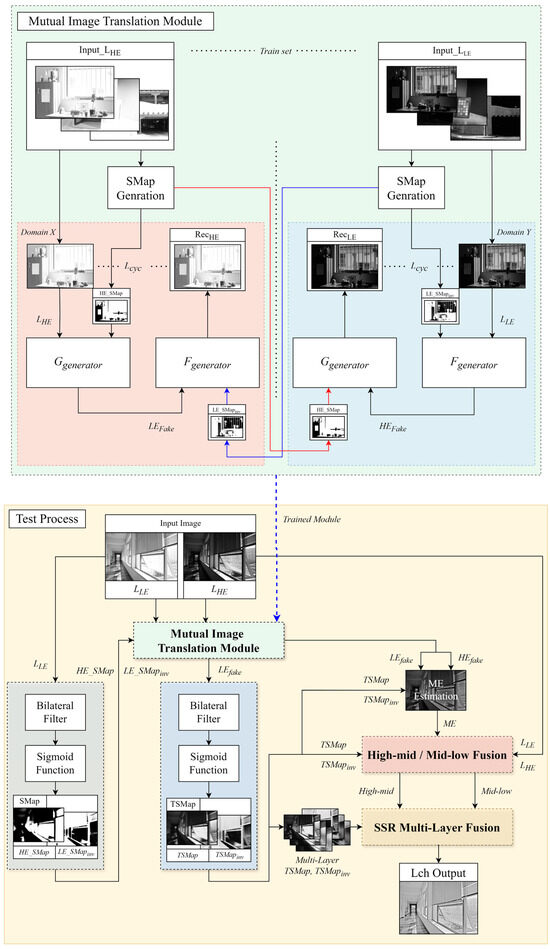
Figure 4.
Detailed flowchart illustrating the utilization of the switching map (SMap), the Trans-SMap, the mutual image translation module, and the test process.
3.1.1. SMap Generation and Application
The SMap is designed to select regions of interest from LE and HE images, enhancing the fusion process for HDR image synthesis. The SMap generation begins by applying a bilateral filter to the luminance components of LE and HE images, creating blurred surround maps for each exposure. These surround maps are processed with a sigmoid function to enhance the robust edge detection and selection abilities, resulting in the final SMap. The generated SMap is based on the exposure distribution of each image and is introduced as an additional channel in the CycleGAN generator, guiding the weighted learning process. Adjusting the spatial range parameter of the bilateral filter generates multiscale maps with various characteristics [21]. The spatial range defines the extent of Gaussian blur in the filter coordinate space, more significantly affecting neighboring pixels in regions with similar pixel intensities and weak edges. This process preserves crucial information in vital edge areas:
In Equation (4), denotes the value of pixel in the filtered image, indicates the normalization factor, and represents the set of neighboring pixels. The function represents the spatial Gaussian, weighting pixels based on the distance between pixel and its neighbor , controlled by the spatial range parameter .
The function is the range Gaussian, weighting pixels based on the intensity difference between and , with controlling the sensitivity to these differences:
In Equation (5), and adjust the spatial and range filters, respectively, balancing edge preservation with smooth filtering. Moreover, controls the spatial range, creates maps at various scales, and applies a broader influence in regions with similar pixel intensities, smoothing the image while maintaining the edge details [22].
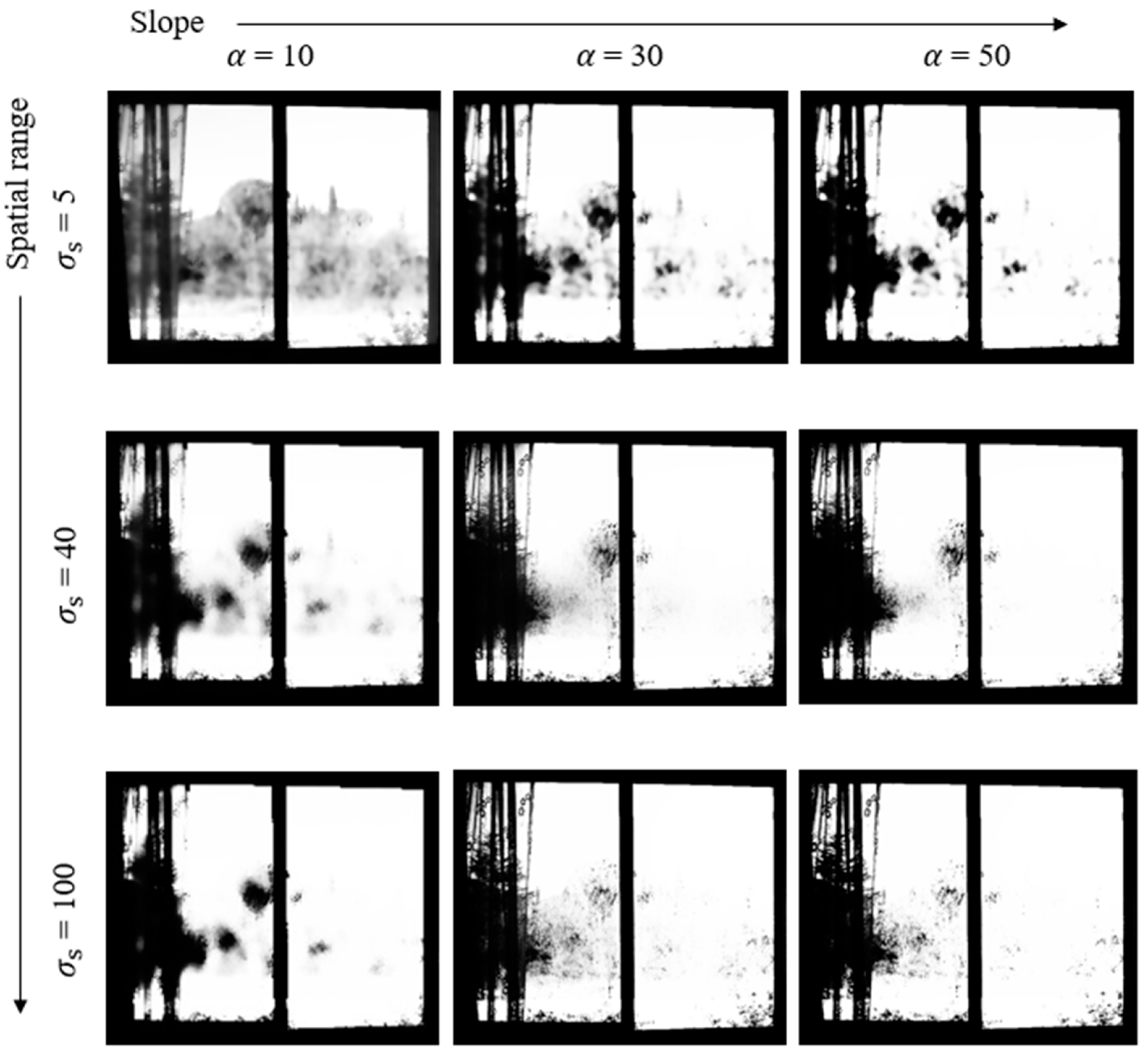
Increasing the slope of the sigmoid function applied to the surround map improves the switching performance in strong edge regions. Figure 5 illustrates the changes in the distribution of saturated areas in the SMap according to and .
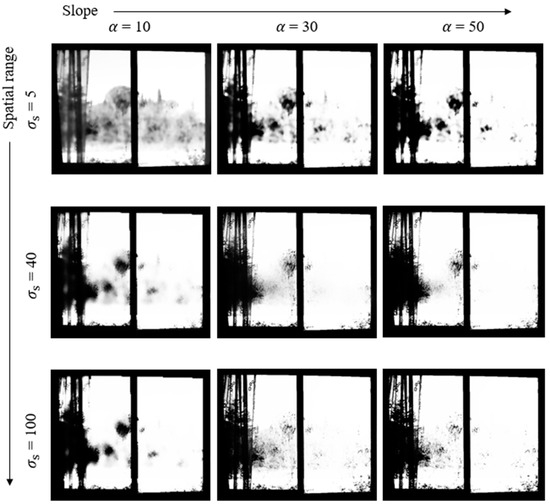
Figure 5.
Effects of the spatial range and sigmoid function slope on the switching map saturation area and edge detection.
Strong edge regions are more distinctly detected as the sigmoid function slope increases [23]. At = 10, the distinction between edges and saturated areas is less clear, but as increases to 50, edge detection performance improves, generating sharper boundaries. When is low, such as 5, edge details are well preserved. However, as increases to 40 and then to 100, the blurring effect intensifies, making the edges less distinct and causing the saturated areas to spread. These results demonstrate that the sigmoid slope and spatial range combination significantly influences the edge detection and distribution of saturated areas in the SMap.
The SMap selects and maps local regions based on the valid information in each exposure image. For example, in Figure 6a, the SMap selects outdoor regions in the window frames containing abundant valid information in the LE image. Conversely, in Figure 6b, the inverse of the SMap (SMapinv) selects unsaturated indoor areas in the HE image.

Figure 6.
Introduction of the switching map (SMap) and exposure features: (a) low-exposure (LE)-based SMap, (b) LE-based SMapinv, (c) saturation crosstalk region in LE-based SMap, and (d) saturation crosstalk region in the high-exposure-based SMap.
Figure 6c reveals that, with the LE-based SMap, the blurred LE image distinguishes dark background regions in strong edge areas, displaying superior performance in selecting detailed regions across varying exposures. In contrast, Figure 6d illustrates that the HE-based SMap applied to the HE image provides less distinct boundary regions due to flare and light scattering in bright, saturated areas.
Boundary region blurring may cause interference depending on the intended use. However, if detailed information exists in boundary regions, it can preserve those details.
Consequently, during fusion, blurring captures boundary details between exposures, improving the quality of the final composite image. This approach focuses on mapping the unsaturated regions of each exposure to optimize HE and LE image fusion. By strategically applying blurring, the proposed method preserves critical details in boundary regions, enhancing visual fidelity and details in HDR image synthesis.
3.1.2. Mutual Image Translation Module
This section describes the MITM, which employs CycleGAN to enhance the quality of translated images by incorporating the SMap as an additional channel. CycleGAN is a machine learning model designed for bidirectional transformation, primarily used for data conversion between two different domains. The key objective is to ensure that the transformed images maintain structural consistency while learning the features of each domain through bidirectional learning. The proposed module leverages this bidirectional learning capability of CycleGAN. In Figure 7, this module extends the input structure of the generator network by adding the SMap and its inverse, guiding the image translation process.
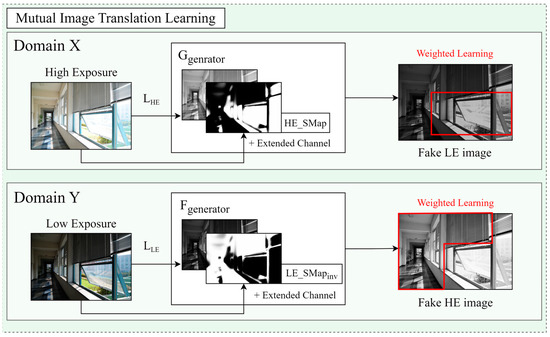
Figure 7.
The modified generator network of CycleGAN.
The CycleGAN deep learning models typically input unpaired datasets of LE and HE images with varying exposure levels. However, accurate matching of exposure regions is crucial for the translation of LE and HE images; thus, the proposed module uses paired datasets [24]. The input images undergo CSC to separate the luminance component in the CIELAB color space, splitting the images into color channels (a, b) and a luminance channel (L). The separated luminance channel is input for CycleGAN, and the SMap is integrated as an additional channel into the generator during training. A CycleGAN generator accepts images in the following form:
where represents the input image, and are the height and width of the image, and denotes the number of channels (e.g., for grayscale images).
In the proposed module, the input is extended to include additional information as follows:
where represents the number of additional channels. For example, when the SMap is included as an additional channel, the extended input can be expressed as follows:
The modified generator operates on this expanded input as follows:
where denotes the output of the generator, and represents the modified generator that processes the extended input . This approach encourages the generator to learn to assign weights to critical regions of the image through the SMap.
During bidirectional training, domain X processes HE images using the HE-based SMap (HESMap), whereas domain Y processes LE images using the inverse of the LE-based SMap (LESMapinv). This method teaches the model to assign complementary weights to various regions, allowing it to retain and emphasize valid information from each exposure level.
Integrating these additional input channels allows the generator to assign higher weights to selected regions during training, providing superior image generation outcomes compared with paired datasets alone, as depicted in Figure 8.

Figure 8.
Performance comparison of fake low- (LE) and high-exposure (HE) images generated by standard CycleGAN (SCP) and the proposed module, mutual image translation module (MITM): (a) real HE image, (b) fake LE image by SCP, (c) fake LE image by MITM, (d) real LE image, (e) fake HE image by SCP, and (f) fake HE image by MITM.
In Figure 8b, the first- and second-row images illustrate that, although fake LE images were generated, they failed to become sufficiently dark, and boundary details between exposures were not preserved. In Figure 8e, the second- and third-row images demonstrate that, while fake HE images were generated from authentic LE images, the tone was not adequately adjusted, making it difficult to capture detailed information.
Thus, the translation results vary based on the input images and lack consistency in mutual learning when employing a simple paired dataset with a standard CycleGAN. In contrast, the proposed module demonstrates effective tone adjustment suitable for translation objectives across images with various exposure levels and preserves fine details at the exposure boundaries, presenting superior translation performance.
Figure 9b presents an example of applying the proposed module, where the SMap-guided learning from LE images makes parts of the original HE image, previously obscured by saturation, appear clearer. The proposed module preserves details that could be lost due to saturation when merging images with various exposures. Figure 9d also depicts a fake HE image translated from an original LE image, indicating that this module enhances the visibility of details in dark areas via tone manipulation. In conclusion, the MITM plays a crucial role in more effectively merging images with varying exposures and improving the image generation quality.

Figure 9.
Results of the proposed mutual image translation module: (a) real high-exposure (HE) image, (b) fake low-exposure (LE) image, (c) real LE image, and (d) fake HE image.
By integrating the SMap as an additional channel in the generator, the proposed method enhances edge detection and region selection capabilities, improving visual fidelity and detail in HDR synthesis.
3.2. High-Mid and Mid-Low Fusion
This stage generates the ME image for multiexposure fusion using fake images translated through the MITM to estimate the ME [25]. However, these fake images have ambiguous exposure levels after translation, making direct ME estimation challenging.
We applied distinct mapping strategies to fake LE and HE images to address this problem. This process refines the exposure levels of each image, enabling practical ME estimation. The generated ME image is fused with the real HE and LE images.
We employ the TSMap derived from the fake LE results in the fusion process. The TSMap outperforms the SMap by more accurately selecting the superior regions of each image, allowing for the optimal fusion of details across exposure levels. This approach employs real and synthetic exposure information, achieving superior HDR image quality.
3.2.1. Middle-Exposure Estimation
Estimating the ME image is crucial in the multiexposure fusion process [2k2]. Images translated through the input module exhibit various exposure levels in the dynamic range. However, the exact exposure levels of these translated images are unknown, making it challenging to estimate the ME from these ambiguous images directly. To address this problem, we employed a strategy combining distinct mapping techniques for fake LE and HE images to estimate the ME level.
Fake HE images often display a tonal offset toward brighter values due to the translation process, making them unsuitable for directly estimating the ME level by mapping the entire image. Therefore, these images primarily extract critical information at exposure boundaries. A difference map is employed to capture these crucial features systematically [26].
The difference map quantifies the absolute difference between the fake HE image and fake HE image at each pixel location :
This equation emphasizes regions with significant luminance differences between the fake HE and LE images, highlighting critical boundary information. Gaussian blurring is applied to the difference map to extract the surrounding components to refine these details :
where represents a Gaussian kernel with standard deviation , and denotes the convolutional operation. This process smooths the difference map, enhancing the local context and aiding in integrating boundary-specific information. The processed surrounding components are mapped onto the fake HE image. The mapped output incorporates the critical boundary information highlighted by the difference map into the ME image.
Consequently, using the boundary-specific information from the fake HE image allows a more precise and reliable estimation of the ME level.
Conversely, fake LE images exhibit an overall darker tone, which is advantageous for recovering the visibility of lost details due to saturation interference in the boundary regions of real HE images.
The information from the fake LE image is mapped using the surrounding components obtained from the inverted fake LE image via Gaussian blurring. The resulting image preserves details from the exposure boundaries of the fake LE image. The blurring process in mapping more comprehensively captures these details. The mapped components from fake HE and LE images are combined using a simple summation to estimate the ME level at the exposure boundaries, generating the ME image.
This approach is employed because the real HE and LE images contain the most accurate information in their respective exposure ranges. However, if only these areas are selected and switched, information loss could occur at the exposure boundaries due to the saturation effects during fusion. We can capture and retain information that might otherwise be lost by estimating the ME image at these critical boundary areas, as depicted in Figure 10.

Figure 10.
Results of the middle-exposure (ME) image: (a) real high-exposure image, (b) fake low-exposure image, and (c) estimated ME image.
The ME images generated with this method retain more information at the exposure boundaries than the original images, contributing to the overall quality of the HDR composite. This approach augments the representation of transition areas between exposures, reduces data loss, and significantly improves the final HDR image quality.
3.2.2. Trans-Switching Map for High-Mid and Mid-Low Fusion
To fuse the estimated ME image with the real HE and LE images, we employed the TSMap, which is generated via a process similar to the SMap process, applying a bilateral filter and sigmoid function. The critical difference from the SMap is that the TSMap is derived explicitly from the fake LE image, and the slope value of the sigmoid function is reduced from 30 to 5.
Even when a bilateral filter and sigmoid function are applied for authentic LE images, certain regions inevitably remain influenced by mutual exposure images, as illustrated in Figure 11.

Figure 11.
Comparisons of the (a) switching map and (b) trans-switching map.
These crosstalk regions prevent the optimal selection of superior areas from each exposure, leading to information loss in boundary regions between exposures. As the ME image is estimated with a focus on the boundary areas between exposures, using the conventional SMap results in capturing information from poorly preserved areas of the ME image.
The fake LE image undergoes a tone-down translation that reduces the influence of the saturated regions from the real HE image.
Thus, the TSMap derived from fake LE images provides another SMap that reduces unnecessary interference from mutual exposure images. This characteristic demonstrates the superior switching performance of the TSMap across images.
The real HE and LE images are fused using the TSMap and estimated ME image. Specifically, the TSMap fuses the real HE image with the ME image to generate the high-mid image and fuses the real LE image with the ME image to produce the mid-low image.
The TSMap minimizes mutual exposure interference and delineates critical boundaries, supporting a more precise and efficient fusion process. ME images help preserve the boundary information between exposure levels. However, it is still important to capture as much detail as possible from the original LE and HE images. For this reason, TSMap, which provides a better transition function, is used instead of SMap to fuse the high-mid and mid-low images. As a result, as shown in Figure 12, the high-mid and mid-low images help to reduce the difference between the extreme exposure levels of the input images. The reduced difference in exposure levels enables the natural expression of colors, and balanced images can be generated under various exposure conditions. In addition, these images better preserve the details at the exposure boundary, greatly improving the quality of the HDR composite image. The TSMap refines the fusion process and applies the unique strengths of the ME image, facilitating HDR synthesis with superior detail preservation and dynamic range.

Figure 12.
Distribution of exposure levels in high-mid and mid-low images.
3.3. SSR Multilayer Fusion
Effective tone mapping and tone compression techniques are critical in HDR image synthesis to preserve details and enhance image quality across exposure levels [27].
The SSR algorithm is a fundamental approach to dynamic range compression by approximating the response of the human visual system to illumination changes. Typically, SSR separates the reflectance and illumination components of an image via a logarithmic translation followed by Gaussian blurring [28]. The following equation mathematically describes the SSR process:
where represents the reflectance component that preserves scene details, indicates the input image, denotes a Gaussian function with spatial variance range , and signifies the convolution operation. In conventional implementations, larger values result in broader blurring of background elements, whereas smaller values preserve the finer details.
However, in fast Fourier transform-based implementations, the role of is reversed. Smaller values cause wide blurring of background components, and larger values narrow the blurring effect, preserving the details.
A multiscale SSR approach is employed to enhance dynamic range compression, generating a multiscale image representation by applying SSR with varying spatial variances . Each scale is adjusted according to the selected , addressing broad and fine features. This approach processes spatial frequencies based on their range, removing unnecessary background elements and enhancing the visibility of critical details. The multilayer SSR fusion process is implemented using the fast Fourier transform, reducing computational complexity and enabling efficient blurring [29].
Figure 13 illustrates these scale-specific characteristics. Figure 13a represents the large-scale image, where noise reduction is observed.

Figure 13.
Multiscale high-exposure single-scale retinex images with different variance values: (a) large-scale image and (b) small-scale image.
However, this reduction also leads to the smoothing of fine details and less compression of the global tone. Conversely, Figure 13b represents the small-scale image, displaying better preservation of the fine details, but some areas exhibit more pronounced noise than others. These multiscale characteristics adapt to spatial frequencies, enhancing the overall detail preservation.
The TSMap adjusts the spatial range of the bilateral filter according to the characteristics of each SSR scale, aiming to capture the strengths of each scale more precisely. We used the SMap, which contains substantial cross-image interference information, to illustrate the differences between spatial ranges. In Figure 14a, the blurring in highlighted areas is insufficient with the small spatial range of the SMap, leading to severe interference in saturated regions and potential loss of detail. However, the advantage of this approach is the reduction of the halo effects.

Figure 14.
Switching map (SMap) images by spatial range: (a) large scale, (b) middle scale, and (c) small scale.
In contrast, Figure 14c demonstrates an extensive spatial range, resulting in strong blurring that uniformly affects the sharp boundaries, leading to pronounced halo effects. However, this extensive blurring also allows for better mapping of fine image details.
The TSMap exhibits similar characteristics across spatial ranges; therefore, the TSMap is matched appropriately to the characteristics of each SSR scale, performing fusion on a per-layer basis. In Figure 15a, a TSMap with reduced halo effects but potential loss of detail is matched with the large-scale SSR to maintain natural image rendering. Moreover, in Figure 15c, a TSMap with pronounced halo effects but can capture extensive boundary information is matched with the small-scale SSR, where fine details are prevalent. This approach enhances detail preservation across scales and minimizes halo artifacts commonly observed in single-scale approaches.

Figure 15.
Single-scale retinex images by the spatial range of the applied trans-switching map: (a) large scale, (b) middle scale, and (c) small scale.
The L/H color fusion techniques are also applied in the color space. By employing the TSMap, the fusion process blends color information while respecting the content of cross-exposure images.
This approach reduces color artifacts and maintains color consistency throughout the fused image, improving the overall quality and visual coherence of the HDR output.
The SSR multilayer fusion strategy, fused with TSMaps tailored to each SSR scale, offers a robust HDR image synthesis framework that balances detail preservation and noise suppression across multiple scales. This method achieves superior tone compression and image fidelity, even in scenes with complex lighting variations.
4. Simulation Results
In this study, MITM was trained using a paired dataset comprising 1165 pairs from the LDR dataset by Jang et al. [30], the Brightening Train [31] dataset, and publicly available data from the internet. The evaluation was conducted with images that were not part of the training set, specifically MEFB [32] and self-images [33], to objectively assess the performance of the proposed method using quantitative metrics. Images with various exposure levels were employed for performance comparison, and the effectiveness of the proposed multiexposure fusion method was analyzed compared to several existing fusion techniques.
The experiments were conducted on a system equipped with an RTX 3090 GPU (Nvidia, Santa Clara, CA, USA) and an i7-10700K CPU (Intel, Santa Clara, CA, USA). The training module was configured with a batch size of 1, 500 epochs and a learning rate of .
4.1. Comparative Experiments
Comparative experiments to evaluate the performance of the proposed multiexposure fusion method were conducted against several existing fusion methods, including DCT [34], EF [35], FMMR [36], and GRW [37]. These existing techniques are widely used in image-fusion domains, each with strengths and weaknesses. The superior performance of the proposed method was confirmed by comparing these methods. Figure 16, Figure 17, Figure 18, Figure 19, Figure 20, Figure 21, Figure 22 and Figure 23 present the results generated using various exposure-level inputs for each method.

Figure 16.
Input and result images: (a) left: low-exposure image, right: high-exposure image, (b) DCT, (c) EF, (d) FMMR, (e) GRW, and (f) proposed.

Figure 17.
Input and result images: (a) left: low-exposure image, right: high-exposure image, (b) DCT, (c) EF, (d) FMMR, (e) GRW, and (f) proposed.

Figure 18.
Input and result images: (a) left: low-exposure image, right: high-exposure image, (b) DCT, (c) EF, (d) FMMR, (e) GRW, and (f) proposed.

Figure 19.
Input and result images: (a) left: low-exposure image, right: high-exposure image, (b) DCT, (c) EF, (d) FMMR, (e) GRW, and (f) proposed.


Figure 20.
Input and result images: (a) left: low-exposure image, right: high-exposure image, (b) DCT, (c) EF, (d) FMMR, (e) GRW, and (f) proposed.

Figure 21.
Input and result images: (a) left: low-exposure image, right: high-exposure image, (b) DCT, (c) EF, (d) FMMR, (e) GRW, and (f) proposed.


Figure 22.
Input and result images: (a) left: low-exposure image, right: high-exposure image, (b) DCT, (c) EF, (d) FMMR, (e) GRW, and (f) proposed.

Figure 23.
Input and result images: (a) left: low-exposure image, right: high-exposure image, (b) DCT, (c) EF, (d) FMMR, (e) GRW, and (f) proposed.
Overall, the proposed multiexposure image-fusion method performs better than traditional techniques, such as DCT, EF, FMMR, and GRW. The DCT method generates natural-looking images but lacks detail in shadow regions. In Figure 16c, the EF method performs well in color saturation in bright areas but suffers from a loss of detail in dark regions, adversely affecting the boundaries between exposures. In Figure 16e, the GRW method displays reduced saturation in bright regions and severe halo effects, making it challenging to achieve a balanced fusion. In Figure 22d, the FMMR method estimates weights based on contrast, brightness, and color features; however, it is significantly affected by halo artifacts and noise, reducing the overall image quality.
These comparative results reveal that the proposed method consistently delivers higher image quality, excelling at preserving fine details, minimizing halo effects, and reducing noise. These findings imply that the proposed approach can reliably generate high-quality images across exposure conditions, ensuring stability and visual fidelity.
4.2. Quantitative Evaluation
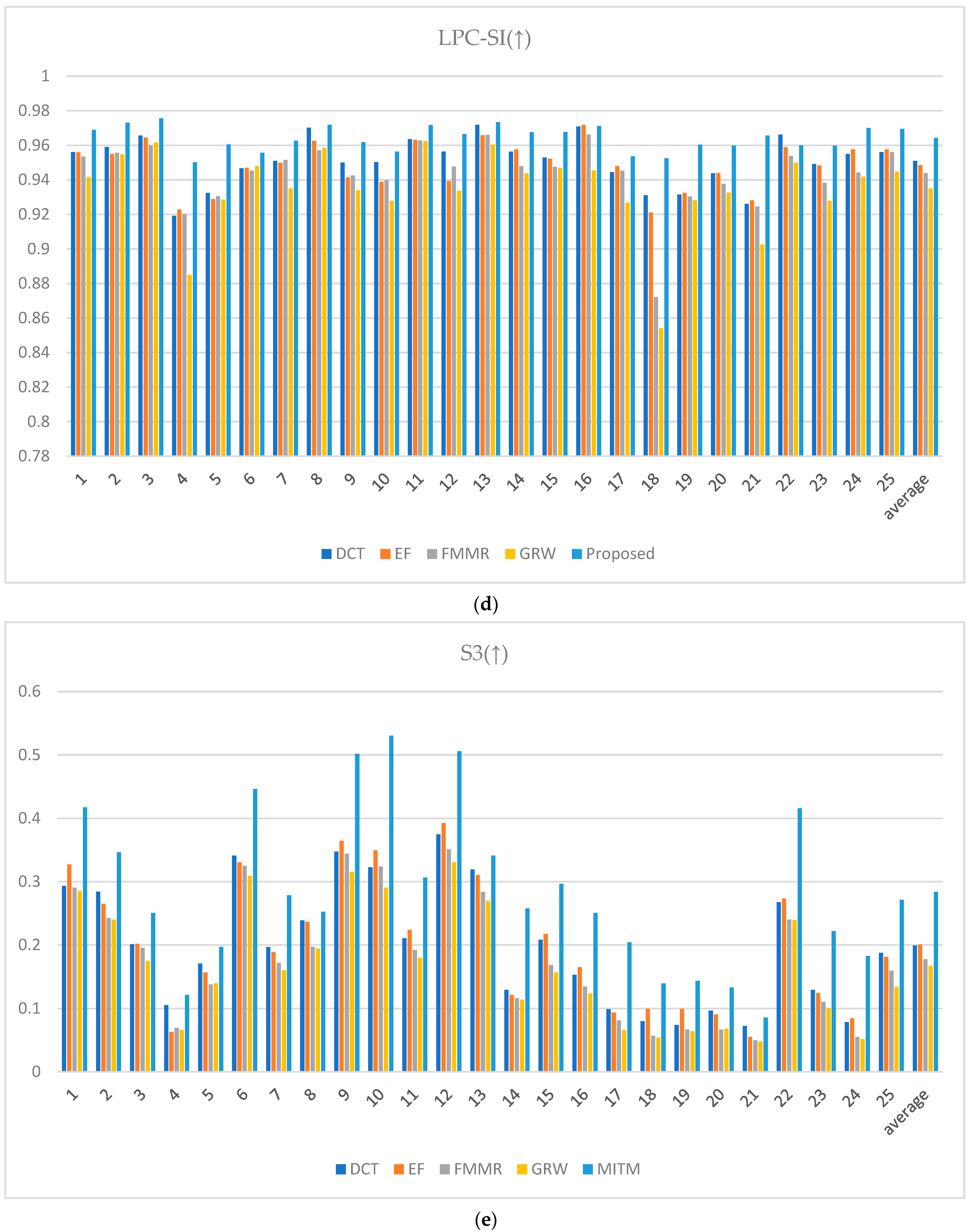
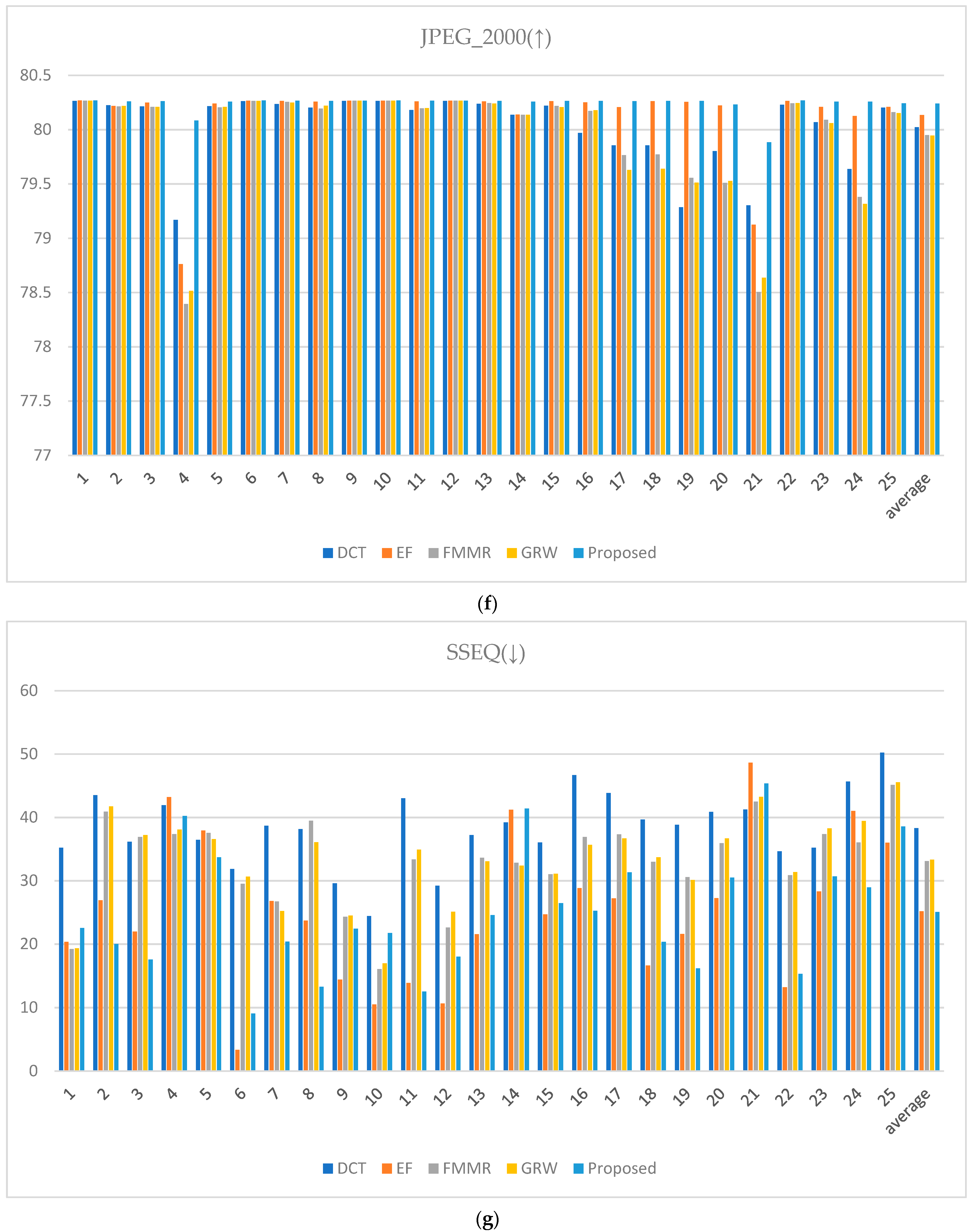
The performance of the proposed method was quantitatively evaluated via image quality metrics. The cumulative probability blur detection metric (CPBDM) assesses the image sharpness, indicating how clear the image appears [38]. The just noticeable blur metric (JNBM) measures the level of blur perceptible to human observers, evaluating the image clarity [39]. The no-reference perceptual quality assessment (NRPQA) method evaluates the perceptual quality of JPEG-compressed images without a reference image. It analyzes horizontal and vertical features to generate a score, effectively quantifying visual quality and detecting compression artifacts [40]. The localized perceptual contrast-sharpness index (LPC-SI) assesses how well contrast and structural information are preserved, demonstrating effectiveness in maintaining fine image details [41]. The spatial-spectral sharpness measure (S3) evaluates image sharpness by combining spatial and spectral characteristics, using local spectral slope and total variation to produce the final sharpness index [42]. The JPEG_2000 metric assesses image quality for the JPEG 2000 format by analyzing spatial features and artifacts to quantify visual degradation from compression [43].
The CPBDM, JNBM, LPC-SI, S3, and JPEG_2000 metrics indicate higher image quality with higher values, reflecting the superiority of the image characteristics assessed by each metric. The CPBDM and JNBM metrics measure image sharpness and clarity, indicating the sharpness and clarity of the image. Higher values suggest that the image has less blur with well-preserved fine details. NRPQA provides a method to assess JPEG-compressed images, with higher scores reflecting fewer compression artifacts. The LPC-SI assesses the ability to maintain contrast and structural information, indicating how well-defined the image is and how details are retained. The S3 metric evaluates image quality based on spatial and spectral entropy, awarding higher scores when the image retains fine details and complex textures. The JPEG_2000 evaluates image quality based on the JPEG 2000 format, where higher scores indicate minimal quality loss after compression and reveal how well the original features of the image are preserved post-compression.
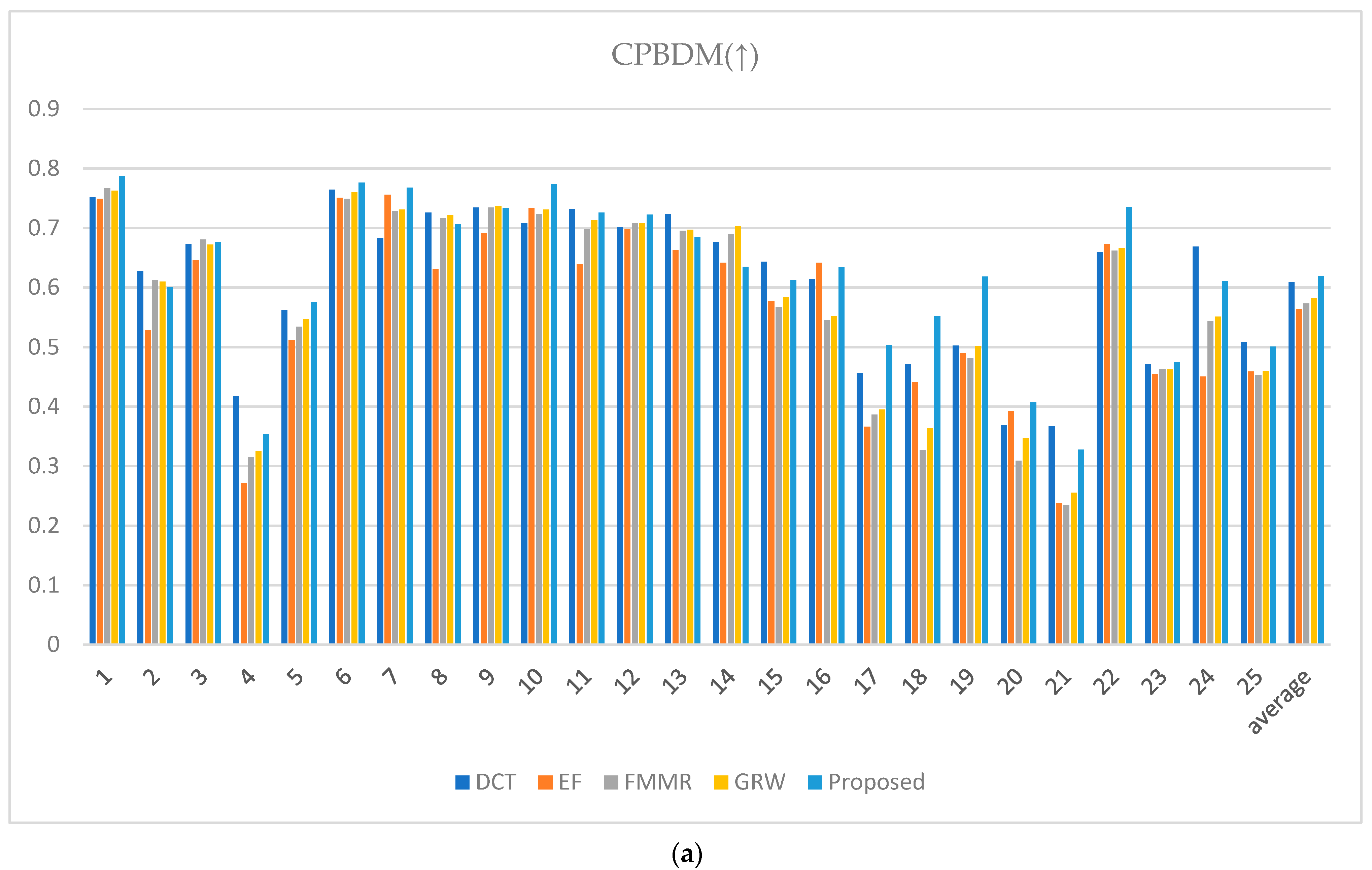
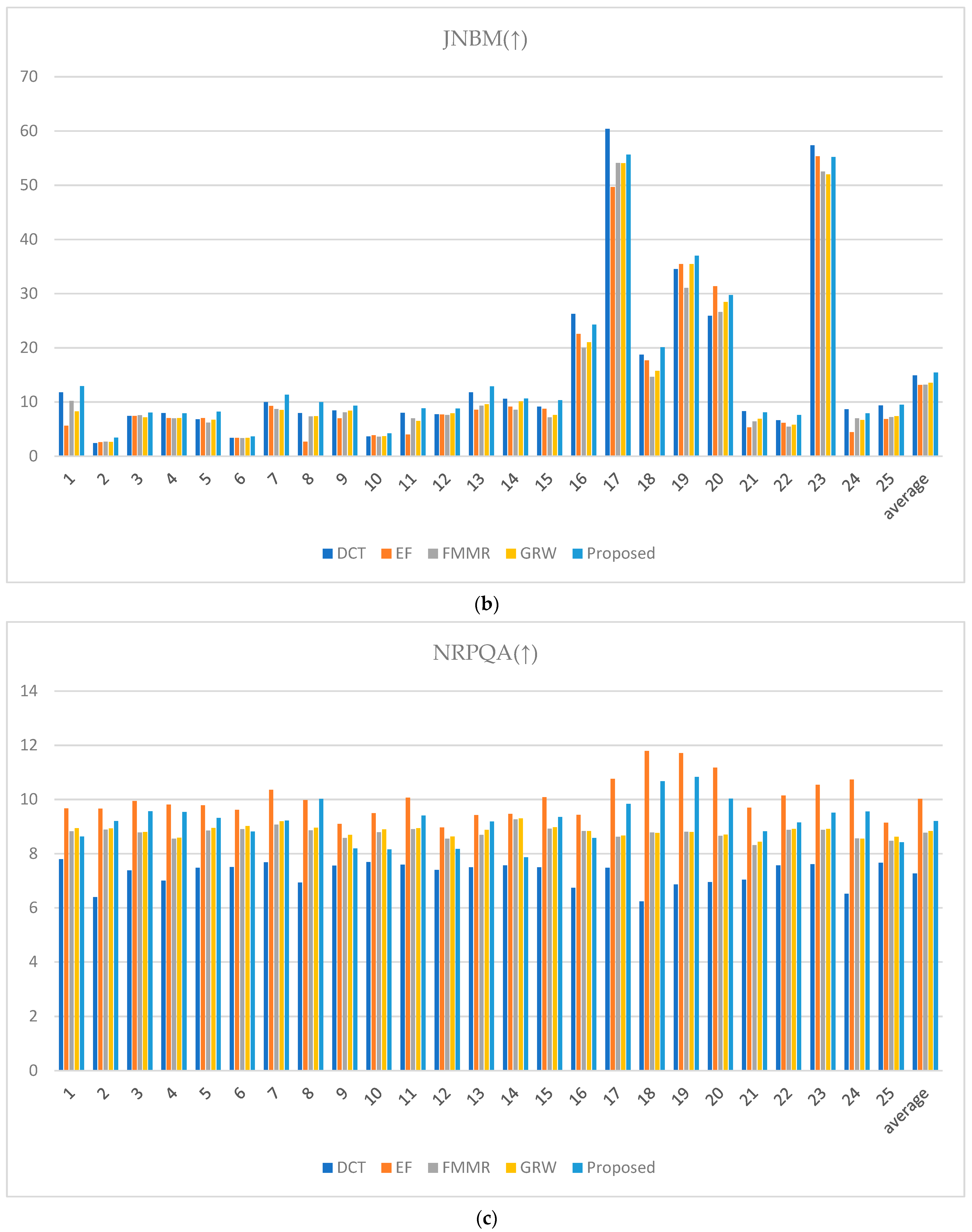
Conversely, spatial-spectral entropy-based quality (SSEQ) for perceptual image quality assessment is a metric where lower values indicate better image quality. Lower SSEQ values suggest high visual fidelity with minimal perceptual distortion or artifacts, reflecting a high-quality image from a perceptual standpoint [44]. When evaluating the metrics in Figure 24, the rankings vary slightly depending on the image. However, the proposed method demonstrates its ability to achieve effective HDR image synthesis overall with only two input images at different exposure levels, even in challenging environments characterized by large exposure differences.
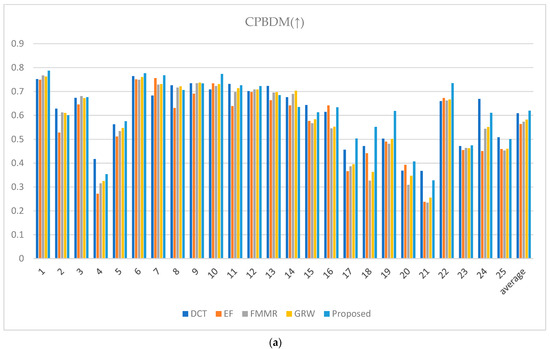
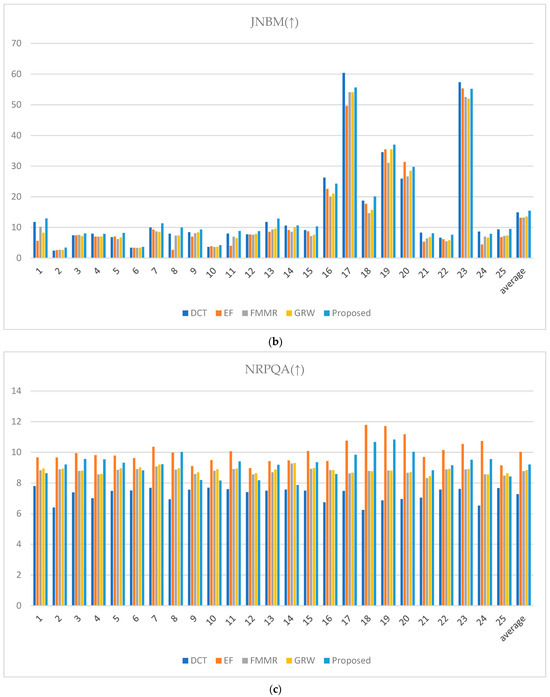
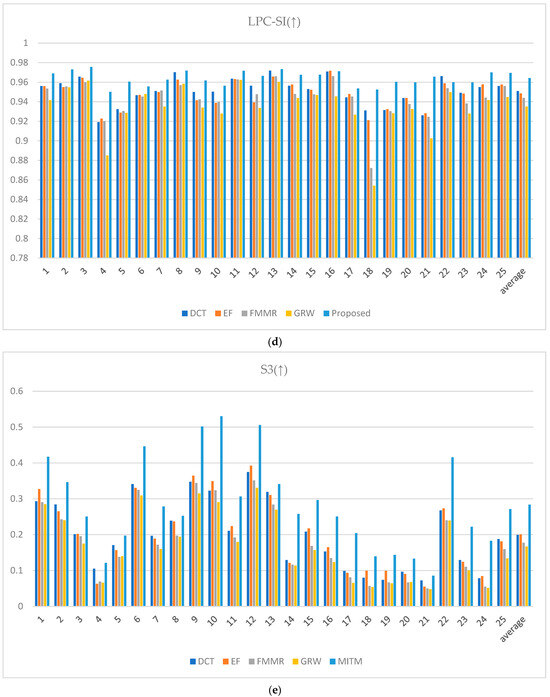
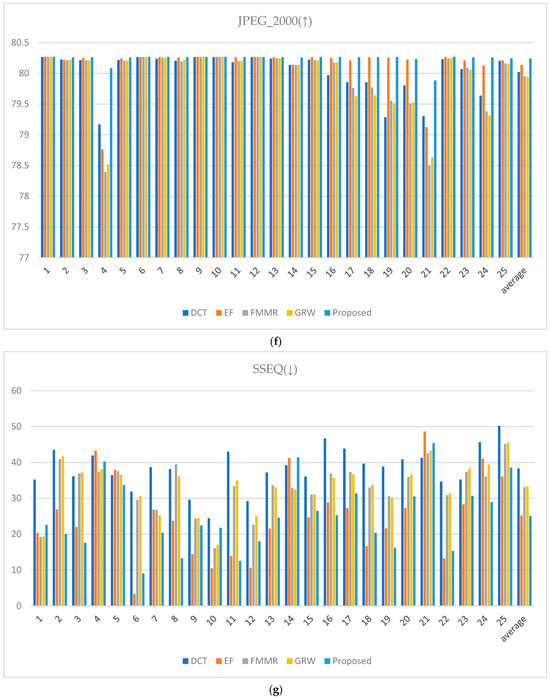
Figure 24.
Metric scores: (a) cumulative probability blur detection metric (CPBDM) score, (b) just noticeable blur metric (JNBM), (c) no-reference perceptual quality assessment (NRPQA) score, (d) localized perceptual contrast-sharpness index (LPC-SI) score, (e) spatial-spectral sharpness measure (S3) score, (f) JPEG_2000 score, and (g) spatial-spectral entropy-based quality (SSEQ) score.
5. Discussion
In this study, we propose a method to synthesize high-quality HDR images even when the exposure difference between input images is large. When the number of input images is limited and the exposure level difference is extreme, the halo effect or color distortion is likely to occur during the image synthesis process. The proposed method improves translation performance by using SMap as an additional channel in the generator of the CycleGAN module. By estimating the ME image from the converted image and synthesizing it with the real HE and LE images, the generated high-mid and mid-low images are then used to effectively reduce the exposure gap. The simulation results show that the proposed method is more effective overall than existing methods by simultaneously handling image blending and tone compression to enhance low-level details and reduce the halo effect. In addition, by separating the color channels and blending the best areas of the LE and HE images using TSMap, color distortion is successfully prevented.
When saturation causes intersection areas in the HE image, the halo effect tends to occur partially. The proposed method’s improved TSMap performance and ME image estimation preserve edge information while minimizing the side effects that occur during synthesis. As shown in Table 1, the proposed method not only shows visually uniform and superior results but also outperforms existing fusion methods in various evaluation metrics. Indices such as CPBDM and JNBM confirm that the proposed method improves the sharpness and clarity of the image. Furthermore, even without employing techniques such as upsampling during the fusion process, the LPC-SI and S3 indices indicate that the proposed module effectively preserves contrast and structural information to minimize boundary information between exposure levels, thereby preserving details through ME image estimation.

Table 1.
Comparisons with metric scores.
However, the main goal of the proposed method is to obtain as much local information as possible to improve the image blending quality. Therefore, it may not guarantee optimal performance in cases where the exposure difference is minimal, such as in medical imaging, remote sensing, or scenes that are uniformly bright or dark.
The proposed method achieves effective synthesis using minimal captured images by leveraging multiple deep learning modules and method-based synthesis techniques. However, it faces limitations in processing images in near real-time due to high computational complexity. The goal of future research is to enable real-time image synthesis using embedded ASIC boards, facilitating the implementation of a suitable system. Future research should also focus on real-time operation when integrated into video surveillance systems, with attention to improving vulnerable object detection performance.
6. Conclusions
This study introduced an advanced multiexposure HDR image synthesis approach, applying a modified MITM in the CycleGAN framework. The process initiates with converting RGB color channels to the lab space via CSC, focusing on processing the L channel to maintain color integrity. The proposed method addresses the challenges of multi-image HDR synthesis by integrating translated images to generate a TSMap and estimating an ME.
The proposed method incorporates an SMap as an additional input channel in the CycleGAN generator, directing the MITM to prioritize critical regions. This integration enhances the consistency and fidelity of image translations, preserving details while minimizing artifacts throughout synthesis. The bidirectional translation capability of the MITM is instrumental in estimating the ME image, which is essential for maintaining detail continuity at exposure boundaries—an area where conventional multiexposure fusion methods often falter. The proposed approach significantly mitigates interference and noise artifacts prevalent in the traditional SMap during the fusion process using the TSMap derived from MITM-translated images.
Furthermore, the application and multilayered fusion of the SSR algorithm facilitate natural tone mapping and uniform dynamic range compression, substantially enhancing HDR image quality. This approach preserves intricate details across varying exposure levels, ensuring seamless transitions between regions of differing luminance and elevating the overall visual fidelity of the synthesized HDR images. Quantitative evaluations and a comparative analysis of the resulting images substantiate these advancements. Notwithstanding these improvements, this method adjusts the generator structure by incorporating additional channels into the CycleGAN framework, indicating the potential for further exploration in optimizing loss functions, discriminators, or additional network modules.
The study contributions have significant implications for high-fidelity HDR synthesis in applications where precise information retention is critical, such as autonomous driving, surveillance, and advanced digital imaging. By overcoming the limitations of the existing HDR synthesis techniques, the proposed approach sets the stage for developing more robust and efficient image-fusion technology capable of operating under diverse and complex lighting conditions. Future research could include extending this framework for real-time implementation and exploring its adaptability across network components to fundamentally enhance the generation and application of HDR content in practical scenarios.
Author Contributions
Conceptualization, S.-H.L. (Sung-Hak Lee); methodology, Y.-H.G. and S.-H.L. (Sung-Hak Lee); software, Y.-H.G.; validation, Y.-H.G., S.-H.L. (Seung-Hwan Lee) and S.-H.L. (Sung-Hak Lee); formal analysis, Y.-H.G. and S.-H.L. (Sung-Hak Lee); investigation, Y.-H.G. and S.-H.L. (Sung-Hak Lee); resources, Y.-H.G. and S.-H.L. (Sung-Hak Lee); data curation, Y.-H.G., S.-H.L. (Seung-Hwan Lee) and S.-H.L. (Sung-Hak Lee); writing—original draft preparation, Y.-H.G.; writing—review and editing, S.-H.L. (Sung-Hak Lee); visualization, Y.-H.G.; supervision, S.-H.L. (Sung-Hak Lee); project administration, S.-H.L. (Sung-Hak Lee); funding acquisition, S.-H.L. (Sung-Hak Lee). All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by Korea Creative Content Agency(KOCCA) grant funded by the Ministry of Culture, Sports and Tourism (MCST) in 2024 (Project Name: Development of optical technology and sharing platform technology to acquire digital cultural heritage for high quality restoration of composite materials cultural heritage, Project Number: RS-2024-00442410, Contribution Rate: 50%) and the Innovative Human Resource Development for Local Intellectualization program through the Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korean government (MSIT) (IITP-2024-RS-2022-00156389, 50%).
Data Availability Statement
The data presented in this study are openly available in Jang et al. in reference [30], the Brightening Train in reference [31], MEFB in reference [32], and our self-images on GitHub in reference [33].
Conflicts of Interest
The authors declare no conflict of interest.
References
- Debevec, P.E.; Malik, J. Recovering high dynamic range radiance maps from photographs. In Proceedings of the 24th Annual Conference on Computer Graphics and Interactive Techniques—SIGGRAPH 1997, Los Angeles, CA, USA, 3–8 August 1997; ACM Press: New York, NY, USA, 1997; pp. 369–378. [Google Scholar] [CrossRef]
- Nayar, S.K.; Mitsunaga, T. High dynamic range imaging: Spatially varying pixel exposures. In Proceedings of the Proceedings IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No.PR00662), Hilton Head, SC, USA, 15 June 2000; pp. 472–479. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, X.; Sun, L.; Liang, Z.; Zeng, H.; Zhang, L. Joint HDR Denoising and Fusion: A Real-World Mobile HDR Image Dataset. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 13966–13975. [Google Scholar] [CrossRef]
- Song, B.; Gao, R.; Wang, Y.; Yu, Q. Enhanced LDR Detail Rendering for HDR Fusion by TransU-Fusion Network. Symmetry 2023, 15, 1463. [Google Scholar] [CrossRef]
- Yoon, H.; Uddin, S.M.N.; Jung, Y.J. Multi-Scale Attention-Guided Non-Local Network for HDR Image Reconstruction. Sensors 2022, 22, 7044. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef]
- Lee, S.-H.; Lee, S.-H. U-Net-Based Learning Using Enhanced Lane Detection with Directional Lane Attention Maps for Various Driving Environments. Mathematics 2024, 12, 1206. [Google Scholar] [CrossRef]
- Zhang, H.; Ma, J. IID-MEF: A multi-exposure fusion network based on intrinsic image decomposition. Inf. Fusion 2023, 95, 326–340. [Google Scholar] [CrossRef]
- Land, E.H. The Retinex Theory of Color Vision. Sci. Am. 1977, 237, 108–128. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Xu, F.; Liu, J.; Song, Y.; Sun, H.; Wang, X. Multi-Exposure Image Fusion Techniques: A Comprehensive Review. Remote Sens. 2022, 14, 771. [Google Scholar] [CrossRef]
- Pajares, G.; de la Cruz, J.M. A wavelet-based image fusion tutorial. Pattern Recognit. 2004, 37, 1855–1872. [Google Scholar] [CrossRef]
- Petrovic, V.S.; Xydeas, C.S. Gradient-Based Multiresolution Image Fusion. IEEE Trans. Image Process. 2004, 13, 228–237. [Google Scholar] [CrossRef]
- Burt, P.J.; Adelson, E.H. The Laplacian Pyramid as a Compact Image Code. In Readings in Computer Vision; Elsevier: Amsterdam, The Netherlands, 1987; pp. 671–679. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.J.; Ward, R.K.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Tang, H.; Liu, H.; Xu, D.; Torr, P.H.S.; Sebe, N. AttentionGAN: Unpaired Image-to-Image Translation Using Attention-Guided Generative Adversarial Networks. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 1972–1987. [Google Scholar] [CrossRef]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2868–2876. [Google Scholar] [CrossRef]
- Connolly, C.; Fleiss, T. A study of efficiency and accuracy in the transformation from RGB to CIELAB color space. IEEE Trans. Image Process. 1997, 6, 1046–1048. [Google Scholar] [CrossRef] [PubMed]
- Paris, S.; Kornprobst, P.; Tumblin, J.; Durand, F. Bilateral Filtering: Theory and Applications; Now Foundations and Trends: Boston, MA, USA, 2009; Volume 4, pp. 1–75. [Google Scholar] [CrossRef]
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No.98CH36271), Bombay, India, 7 January 1998; pp. 839–846. [Google Scholar] [CrossRef]
- Braun, G.J. Image lightness rescaling using sigmoidal contrast enhancement functions. J. Electron. Imaging 1999, 8, 380. [Google Scholar] [CrossRef]
- Sun, L.; Shen, D.; Feng, H. Theoretical Insights into CycleGAN: Analyzing Approximation and Estimation Errors in Unpaired Data Generation. arXiv 2024, arXiv:2407.11678v1. [Google Scholar] [CrossRef]
- Robertson, M.A.; Borman, S.; Stevenson, R.L. Dynamic range improvement through multiple exposures. In Proceedings of the Proceedings 1999 International Conference on Image Processing (Cat. 99CH36348), Kobe, Japan, 24–28 October 1999; pp. 159–163. [Google Scholar] [CrossRef]
- Radke, R.J.; Andra, S.; Al-Kofahi, O.; Roysam, B. Image change detection algorithms: A systematic survey. IEEE Trans. Image Process. 2005, 14, 294–307. [Google Scholar] [CrossRef]
- Reinhard, E.; Stark, M.; Shirley, P.; Ferwerda, J. Photographic tone reproduction for digital images. ACM Trans. Graph. 2002, 21, 267–276. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.; Woodell, G.A. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef]
- Ibrahim, M.; Shuaibu, Z.; Nura, M. Enhancement of Retinex Algorithm using Fast Fourier Transform. Int. J. Comput. Appl. 2019, 177, 26–31. [Google Scholar] [CrossRef]
- Jang, H.; Bang, K.; Jang, J.; Hwang, D. Dynamic Range Expansion Using Cumulative Histogram Learning for High Dynamic Range Image Generation. IEEE Access 2020, 8, 38554–38567. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep Retinex Decomposition for Low-Light Enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar] [CrossRef]
- Zhang, X. Benchmarking and comparing multi-exposure image fusion algorithms. Inf. Fusion 2021, 74, 111–131. [Google Scholar] [CrossRef]
- GYHrlt, GYHrlt/Dataimg_MEF/Self_Image. 2024. Available online: https://github.com/GYHrlt/dataimg_MEF/tree/main/self_image (accessed on 19 September 2024).
- Lee, G.-Y.; Lee, S.-H.; Kwon, H.-J. DCT-Based HDR Exposure Fusion Using Multiexposed Image Sensors. J. Sens. 2017, 2017, 1–14. [Google Scholar] [CrossRef]
- Mertens, T.; Kautz, J.; Van Reeth, F. Exposure Fusion: A Simple and Practical Alternative to High Dynamic Range Photography. Comput. Graph. Forum 2009, 28, 161–171. [Google Scholar] [CrossRef]
- Li, S.; Kang, X. Fast multi-exposure image fusion with median filter and recursive filter. IEEE Trans. Consum. Electron. 2012, 58, 626–632. [Google Scholar] [CrossRef]
- Shen, R.; Cheng, I.; Shi, J.; Basu, A. Generalized Random Walks for Fusion of Multi-Exposure Images. IEEE Trans. Image Process. 2011, 20, 3634–3646. [Google Scholar] [CrossRef]
- Narvekar, N.D.; Karam, L.J. A No-Reference Image Blur Metric Based on the Cumulative Probability of Blur Detection (CPBD). IEEE Trans. Image Process. 2011, 20, 2678–2683. [Google Scholar] [CrossRef] [PubMed]
- Ferzli, R.; Karam, L.J. A No-Reference Objective Image Sharpness Metric Based on the Notion of Just Noticeable Blur (JNB). IEEE Trans. Image Process. 2009, 18, 717–728. [Google Scholar] [CrossRef]
- Wang, Z.; Sheikh, H.R.; Bovik, A.C. No-reference perceptual quality assessment of JPEG compressed images. In Proceedings of the Proceedings International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; pp. 477–480. [Google Scholar] [CrossRef]
- Hassen, R.; Wang, Z.; Salama, M.M.A. Image sharpness assessment based on local phase coherence. IEEE Trans. Image Process. 2013, 22, 2798–2810. [Google Scholar] [CrossRef]
- Vu, C.T.; Chandler, D.M. S3: A Spectral and Spatial Sharpness Measure. In Proceedings of the 2009 First International Conference on Advances in Multimedia, Colmar, France, 20–25 July 2009; pp. 37–43. [Google Scholar] [CrossRef]
- Sazzad, Z.M.P.; Kawayoke, Y.; Horita, Y. No reference image quality assessment for JPEG2000 based on spatial features. Signal Process. Image Commun. 2008, 23, 257–268. [Google Scholar] [CrossRef]
- Liu, L.; Liu, B.; Huang, H.; Bovik, A.C. No-reference image quality assessment based on spatial and spectral entropies. Signal Process. Image Commun. 2014, 29, 856–863. [Google Scholar] [CrossRef]




















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).