
Shift-Invariance Robustness of Convolutional Neural Networks in Side-Channel Analysis


Abstract
:1. Introduction
- We show that commonly used CNNs in DLSCA have a limited shift-invariance and should be carefully used when attacking desynchronized datasets. Additionally, our experiments show that the pooling layer has a negligible effect on the shift-invariance of CNNs. Still, this might need a separate, more thorough investigation.
- We show how data augmentation can successfully improve the shift-invariance of CNNs in DLSCA.
- We show how to use ensembles of data augmentation settings to provide superior attack performance using CNNs when dealing with highly desynchronized datasets.
2. Deep Learning-Based Side-Channel Analysis
3. Related Works
4. CNNs and Invariance
5. The Shift-Invariance Robustness of Deep Learning Models in SCA
- Neural networks are trained with a synchronized profiling set.
- Neural networks are trained with a desynchronized profiling set.
- Neural networks are trained with a synchronized profiling set and data augmentation.
- Neural networks are trained with a desynchronized profiling set and data augmentation.
- Datasets
- ASCADf: This dataset contains side-channel measurements consisting of 700 features representing side-channel leakages from processing the third S-Box output byte in the first AES encryption round. We split this dataset into profiling, validation, and attack sets with 45,000, 5000, and 5000 traces, respectively. All sets have the same fixed key.
- ASCADr: This dataset contains side-channel measurements where each trace consists of 1400 features. Similar to ASCADf, this measurement interval also represents side-channel leakages from processing the third S-Box output byte in the first AES encryption round. We split this dataset into profiling, validation, and attack sets with 200,000, 5000, and 5000 traces, respectively. The profiling set has random keys, while the validation and attack sets have the fixed key.
- ASCADf_desync100: Desynchronized version of ASCADf, and each trace is randomly shifted inside the interval . Shifts are drawn from a uniform distribution.
- ASCADr_desync100: Desynchronized version of ASCADr. Each trace is randomly shifted (also from a uniform distribution) inside the interval .
- Deep Neural Network Architectures
- zaid_ascad_desync_0 for architecture from [40] for ASCADf.
- noConv1_ascad_desync_0 for architecture from [8]. The network is a reduced version of zaid_ascad_desync_0, where the convolution and batch normalization layers are removed, and the input layer is the pooling layer.
- zaid_ascad_desync_100 for architecture from [40] for ASCADf_desync100.
- noConv1_ascad_desync_100 for design from [8]. This architecture is a reduced version of zaid_ascad_desync_100 in the same manner as noConv1_ascad_desync_0.
- Reading the Graphs
5.1. Shift-Invariance Robustness of CNNs Trained with Synchronized Datasets
5.2. Shift-Invariance Robustness of CNNs Trained with Desynchronized Datasets
5.3. DA Effect on Shift-Invariance Robustness of CNNs Trained with Synchronized Datasets
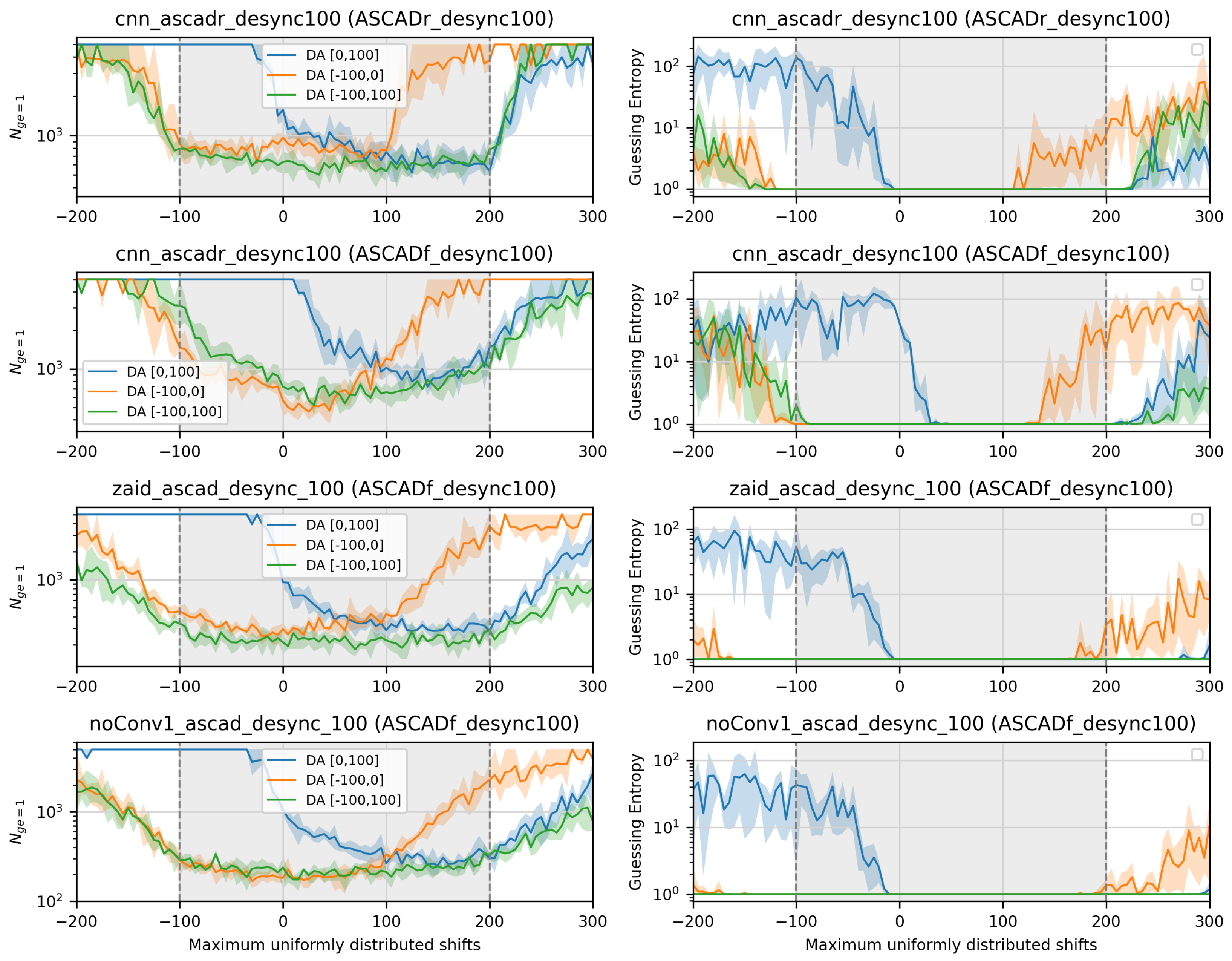
5.4. DA Effect on Shift-Invariance Robustness of CNNs Trained with Desynchronized Datasets
6. Ensembles to Defeat Larger Desynchronization Levels
- Datasets
- Deep Neural Networks
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Kim, T.; Lee, J.; Nam, J. Comparison and Analysis of SampleCNN Architectures for Audio Classification. IEEE J. Sel. Top. Signal Process. 2019, 13, 285–297. [Google Scholar] [CrossRef]
- Picek, S.; Perin, G.; Mariot, L.; Wu, L.; Batina, L. SoK: Deep Learning-Based Physical Side-Channel Analysis. ACM Comput. Surv. 2022, 55, 227. [Google Scholar] [CrossRef]
- Perin, G.; Wu, L.; Picek, S. Exploring Feature Selection Scenarios for Deep Learning-based Side-channel Analysis. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2022, 2022, 828–861. [Google Scholar] [CrossRef]
- Lu, X.; Zhang, C.; Cao, P.; Gu, D.; Lu, H. Pay Attention to Raw Traces: A Deep Learning Architecture for End-to-End Profiling Attacks. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2021, 2021, 235–274. [Google Scholar] [CrossRef]
- Bronstein, M.M.; Bruna, J.; Cohen, T.; Velickovic, P. Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges. arXiv 2021, arXiv:2104.13478. [Google Scholar]
- Standaert, F.X.; Malkin, T.G.; Yung, M. A Unified Framework for the Analysis of Side-Channel Key Recovery Attacks. In Proceedings of the Advances in Cryptology—EUROCRYPT 2009, Santa Barbara, CA, USA, 16–20 August 2009; Joux, A., Ed.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 443–461. [Google Scholar]
- Wouters, L.; Arribas, V.; Gierlichs, B.; Preneel, B. Revisiting a Methodology for Efficient CNN Architectures in Profiling Attacks. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 2020, 147–168. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 113–123. [Google Scholar]
- Cagli, E.; Dumas, C.; Prouff, E. Convolutional Neural Networks with Data Augmentation Against Jitter-Based Countermeasures. In Proceedings of the Cryptographic Hardware and Embedded Systems—CHES 2017, Taipei, Taiwan, 25–28 September 2017; Fischer, W., Homma, N., Eds.; Springer: Cham, Switzerland, 2017; pp. 45–68. [Google Scholar]
- Timon, B. Non-Profiled Deep Learning-Based Side-Channel Attacks. Cryptology ePrint Archive, Paper 2018/196. 2018. Available online: https://eprint.iacr.org/2018/196 (accessed on 1 October 2024).
- Perin, G.; Chmielewski, L.; Batina, L.; Picek, S. Keep it Unsupervised: Horizontal Attacks Meet Deep Learning. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 2021, 343–372. [Google Scholar] [CrossRef]
- Benadjila, R.; Prouff, E.; Strullu, R.; Cagli, E.; Dumas, C. Deep learning for side-channel analysis and introduction to ASCAD database. J. Cryptogr. Eng. 2020, 10, 163–188. [Google Scholar] [CrossRef]
- Zotkin, Y.; Olivier, F.; Bourbao, E. Deep Learning vs Template Attacks in front of fundamental targets: Experimental study. IACR Cryptol. ePrint Arch. 2018. [Google Scholar]
- Hajra, S.; Saha, S.; Alam, M.; Mukhopadhyay, D. TransNet: Shift Invariant Transformer Network for Side Channel Analysis. In Progress in Cryptology—AFRICACRYPT 2022: 13th International Conference on Cryptology in Africa, AFRICACRYPT 2022, Fes, Morocco, July 18–20, 2022, Proceedings; Springer: Berlin/Heidelberg, Germany, 2022; pp. 371–396. [Google Scholar] [CrossRef]
- Hajra, S.; Chowdhury, S.; Mukhopadhyay, D. EstraNet: An Efficient Shift-Invariant Transformer Network for Side-Channel Analysis. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2024, 2024, 336–374. [Google Scholar] [CrossRef]
- Perin, G.; Chmielewski, L.; Picek, S. Strength in Numbers: Improving Generalization with Ensembles in Machine Learning-based Profiled Side-channel Analysis. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 2020, 337–364. [Google Scholar] [CrossRef]
- Zaid, G.; Bossuet, L.; Habrard, A.; Venelli, A. Efficiency through Diversity in Ensemble Models applied to Side-Channel Attacks: A Case Study on Public-Key Algorithms. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2021, 2021, 60–96. [Google Scholar] [CrossRef]
- LeCun, Y. Generalization and Network Design Strategies. In Connectionism in Perspective; Pfeifer, R., Schreter, Z., Fogelman, F., Steels, L., Eds.; Elsevier: Zurich, Switzerland, 1989; An extended version was published as a technical report of the University of Toronto. [Google Scholar]
- Gens, R.; Domingos, P.M. Deep Symmetry Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Kayhan, O.S.; van Gemert, J.C. On Translation Invariance in CNNs: Convolutional Layers Can Exploit Absolute Spatial Location. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 13–19 June 2020; pp. 14262–14273. [Google Scholar] [CrossRef]
- Azulay, A.; Weiss, Y. Why do deep convolutional networks generalize so poorly to small image transformations? arXiv 2018, arXiv:1801.01450. [Google Scholar]
- Goodfellow, I.J.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 1 October 2024).
- Marcos, D.; Volpi, M.; Tuia, D. Learning rotation invariant convolutional filters for texture classification. arXiv 2016, arXiv:1604.06720. [Google Scholar]
- Lenc, K.; Vedaldi, A. Understanding Image Representations by Measuring Their Equivariance and Equivalence. Int. J. Comput. Vis. 2018, 127, 456–476. [Google Scholar] [CrossRef]
- Chaman, A.; Dokmanic, I. Truly shift-invariant convolutional neural networks. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 20–25 June 2021; pp. 3772–3782. [Google Scholar] [CrossRef]
- Zhang, R. Making Convolutional Networks Shift-Invariant Again. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR, Proceedings of Machine Learning Research. Chaudhuri, K., Salakhutdinov, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 97, pp. 7324–7334. [Google Scholar]
- Kauderer-Abrams, E. Quantifying Translation-Invariance in Convolutional Neural Networks. arXiv 2018, arXiv:1801.01450. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Ho, D.; Liang, E.; Chen, X.; Stoica, I.; Abbeel, P. Population based augmentation: Efficient learning of augmentation policy schedules. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR. Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 2731–2741. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple copy-paste is a strong data augmentation method for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 2918–2928. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Feng, S.Y.; Gangal, V.; Wei, J.; Chandar, S.; Vosoughi, S.; Mitamura, T.; Hovy, E. A survey of data augmentation approaches for NLP. arXiv 2021, arXiv:2105.03075. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Meng, L.; Xu, J.; Tan, X.; Wang, J.; Qin, T.; Xu, B. Mixspeech: Data augmentation for low-resource automatic speech recognition. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7008–7012. [Google Scholar]
- Min, J.; McCoy, R.T.; Das, D.; Pitler, E.; Linzen, T. Syntactic data augmentation increases robustness to inference heuristics. arXiv 2020, arXiv:2004.11999. [Google Scholar]
- Sun, S.; Yeh, C.F.; Ostendorf, M.; Hwang, M.Y.; Xie, L. Training augmentation with adversarial examples for robust speech recognition. arXiv 2018, arXiv:1806.02782. [Google Scholar]
- Zheng, S.; Song, Y.; Leung, T.; Goodfellow, I. Improving the robustness of deep neural networks via stability training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4480–4488. [Google Scholar]
- Hernandez-Garcia, A. Data augmentation and image understanding. arXiv preprint 2020, arXiv:2012.14185. [Google Scholar]
- Zaid, G.; Bossuet, L.; Habrard, A.; Venelli, A. Methodology for Efficient CNN Architectures in Profiling Attacks. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 2020, 1–36. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | cnn_pooling_2 | cnn_pooling_4 | cnn_pooling_6 | cnn_ascadr_desync100 |
|---|---|---|---|---|
| Conv. blocks | 2 | 5 | ||
| Filters (ordered) | 8, 16 | 12, 24, 36, 48, 60 | ||
| Kernel size | 30 | 40 | ||
| Strides | 2 | 15 | ||
| Pool size | 2 | 4 | 6 | 6 |
| Pool strides | 2 | 4 | 6 | 6 |
| FC layers | 1 | 2 | ||
| FC Nb. neurons | 40 | 50 | ||
| Weight initializer | glorot_normal | glorot_uniform | ||
| Activation function | elu | elu | ||
| Learning rate | 0.001 | 0.00025 | ||
| Optimizer | RMSprop | Adam | ||
| Epochs | 100 | |||
| Hyperparameters | cnn_large_desync_ascadr400 | cnn_large_desync_dpa_v42 |
|---|---|---|
| Conv. blocks | 3 | 4 |
| Filters (ordered) | 8, 16, 24 | 16, 32, 48, 64 |
| Kernel size | 40 | 30 |
| Strides | 2 | 1 |
| Pool size | 2 | 4 |
| Pool strides | 2 | 4 |
| FC layers | 1 | 1 |
| FC Nb. neurons | 300 | 50 |
| Weight initializer | random_normal | |
| Activation function | selu | |
| Learning rate | 0.00025 | 0.001 |
| Optimizer | Adam | |
| Batch size | 400 | |
| Epochs | 100 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krček, M.; Wu, L.; Perin, G.; Picek, S. Shift-Invariance Robustness of Convolutional Neural Networks in Side-Channel Analysis. Mathematics 2024, 12, 3279. https://doi.org/10.3390/math12203279
Krček M, Wu L, Perin G, Picek S. Shift-Invariance Robustness of Convolutional Neural Networks in Side-Channel Analysis. Mathematics. 2024; 12(20):3279. https://doi.org/10.3390/math12203279
Chicago/Turabian StyleKrček, Marina, Lichao Wu, Guilherme Perin, and Stjepan Picek. 2024. "Shift-Invariance Robustness of Convolutional Neural Networks in Side-Channel Analysis" Mathematics 12, no. 20: 3279. https://doi.org/10.3390/math12203279
APA StyleKrček, M., Wu, L., Perin, G., & Picek, S. (2024). Shift-Invariance Robustness of Convolutional Neural Networks in Side-Channel Analysis. Mathematics, 12(20), 3279. https://doi.org/10.3390/math12203279