
Joint Optimization-Based Texture and Geometry Enhancement Method for Single-Image-Based 3D Content Creation


Abstract
1. Introduction
- We propose a joint optimization-based approach for texture and geometry enhancement using an LRM model to maintain the overall 3D geometry while achieving a high-quality textured mesh.
- We integrate it with an inverse-rendering-based continuous remeshing technique that enables continuous and complex-shaped mesh estimation without relying on fixed-resolution meshes.
- We propose combining it with inverse texture mapping and applying rendering image enhancement via a diffusion model.
2. Related Work
2.1. 2D Images to 3D Diffusion Model
2.2. Large 3D Reconstruction Model
2.3. Inverse Rendering
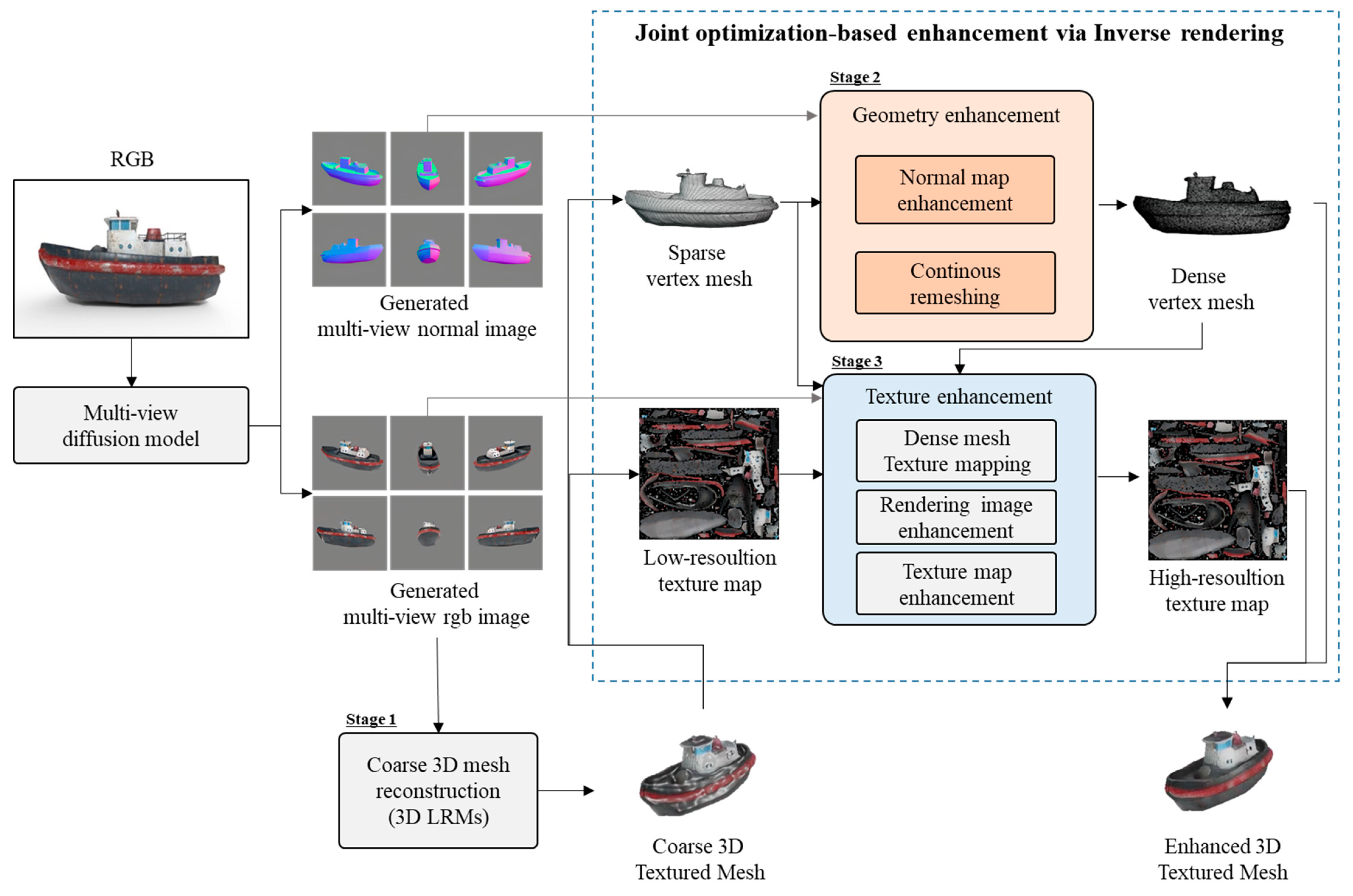
3. Joint-Optimization-Based Texture and Geometry Enhancement Methods
3.1. Overview of the Proposed Joint Optimization Method
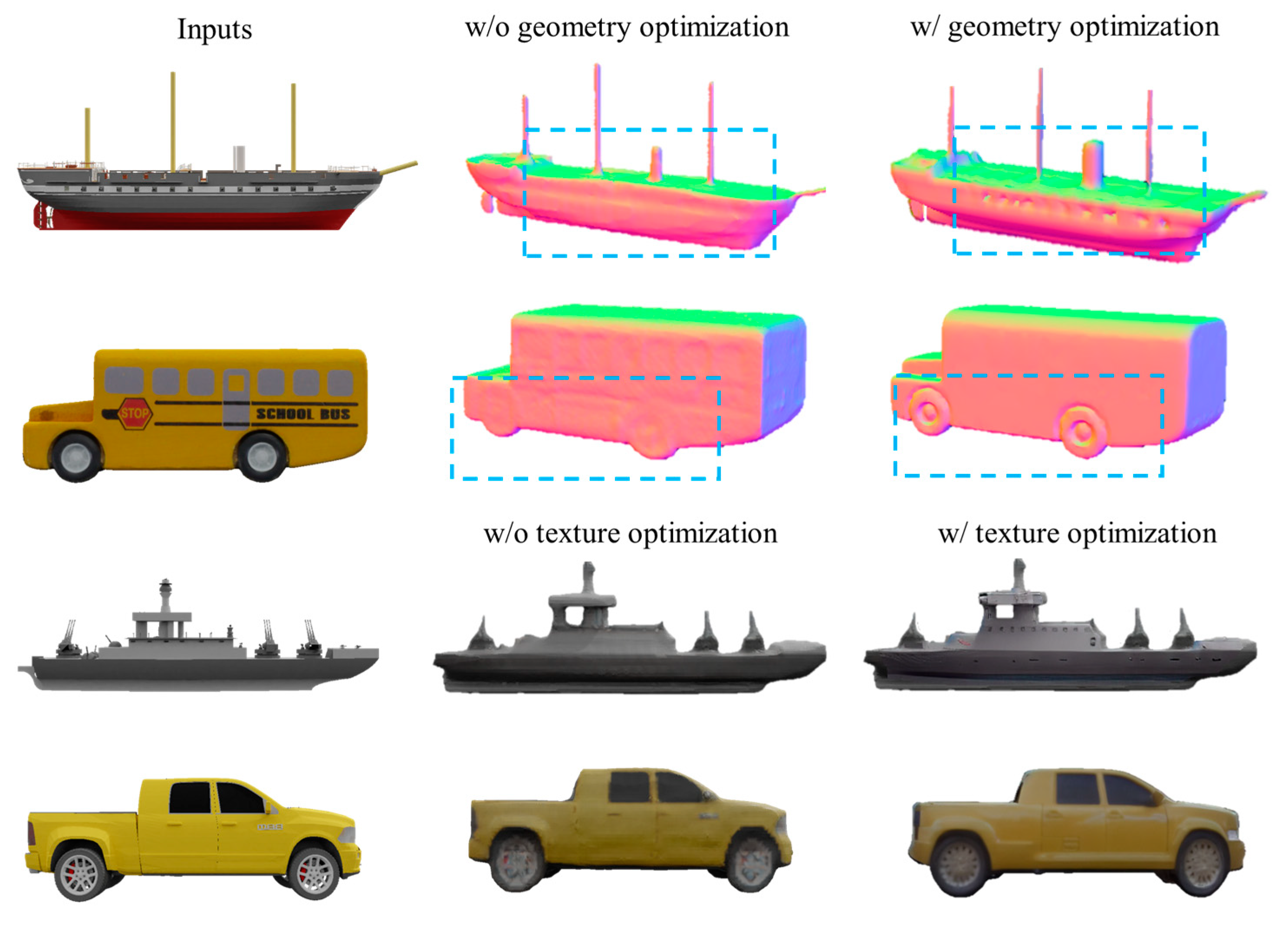
3.2. Geometry Enhancement for Joint Optimization
3.2.1. Normal Map Enhancement
3.2.2. Continuous Remeshing
3.3. Texture Enhancement for Joint Optimization
3.3.1. Dense Mesh Texture Mapping
3.3.2. Rendering Image Enhancement
3.3.3. Texture Enhancement
4. Experiments
4.1. Experimental Settings
4.1.1. Dataset
4.1.2. Evaluation Metrics
4.2. Experimental Results
4.2.1. Results of the Joint Optimization-Based Texture and Geometry Enhancement
4.2.2. Quantitative and Qualitative Results on the ShapeNet [55] Dataset
4.2.3. Quantitative and Qualitative Results on the GSO [54] Dataset
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Furukawa, Y.; Ponce, J. Accurate, dense, and robust multiview stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1362–1376. [Google Scholar] [CrossRef] [PubMed]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Rakotosaona, M.J.; Manhardt, F.; Arroyo, D.M.; Niemeyer, M.; Kundu, A.; Tombari, F. Nerfmeshing: Distilling neural radiance fields into geometricallyaccurate 3d meshes. In Proceedings of the 2024 International Conference on 3D Vision (3DV), Davos, Switzerland, 18–21 March 2024. [Google Scholar]
- Yariv, L.; Hedman, P.; Reiser, C.; Verbin, D.; Srinivasan, P.P.; Szeliski, R.; Barron, J.T.; Mildenhall, B. Bakedsdf: Meshing neural sdfs for real-time view synthesis. arXiv 2023, arXiv:2302.14859. [Google Scholar]
- Tochilkin, D.; Pankratz, D.; Liu, Z.; Huang, Z.; Letts, A.; Li, Y.; Liang, D.; Laforte, C.; Jampani, V.; Cao, Y.-P. TripoSR: Fast 3D Object Reconstruction from a Single Image. arXiv 2024, arXiv:2403.02151. [Google Scholar]
- Wang, Z.; Wang, Y.; Chen, Y.; Xiang, C.; Chen, S.; Yu, D.; Li, C.; Su, H.; Zhu, J. CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model. arXiv 2024, arXiv:2403.05034. [Google Scholar]
- Xu, J.; Cheng, W.; Gao, Y.; Wang, X.; Gao, S.; Shan, Y. InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models. arXiv 2024, arXiv:2404.07191. [Google Scholar]
- Li, J.; Tan, H.; Zhang, K.; Xu, Z.; Luan, F.; Xu, Y.; Hong, Y.; Sunkavalli, K.; Shakhnarovich, G.; Bi, S. Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Hong, Y.; Zhang, K.; Gu, J.; Bi, S.; Zhou, Y.; Liu, D.; Liu, F.; Sunkavalli, K.; Bui, T.; Tan, H. LRM: Large reconstruction model for single image to 3d. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 10674–10685. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; PMLR: New York, NY, USA, 2021; pp. 8821–8831. [Google Scholar]
- Luo, S.; Hu, W. Diffusion probabilistic models for 3d point cloud generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2837–2845. [Google Scholar]
- Nichol, A.; Jun, H.; Dhariwal, P.; Mishkin, P.; Chen, M. Point-e: A system for generating 3d point clouds from complex prompts. arXiv 2022, arXiv:2212.08751. [Google Scholar]
- Zhou, L.; Du, Y.; Wu, J. 3d shape generation and completion through point-voxel diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5826–5835. [Google Scholar]
- Choy, C.B.; Xu, D.; Gwak, J.; Chen, K.; Savarese, S. 3d-r2n2: A unified approach for single and multi-view 3d object reconstruction. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part VIII 14; Springer: Berlin/Heidelberg, Germany, 2016; pp. 628–644. [Google Scholar]
- Tulsiani, S.; Zhou, T.; Efros, A.A.; Malik, J. Multi-view supervision for single-view reconstruction via differentiable ray consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2626–2634. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Ortiz-Cayon, R.; Kalantari, N.K.; Ramamoorthi, R.; Ng, R.; Kar, A.-H. Local light field fusion: Practical view synthesis with prescriptive sampling guidelines. ACM Trans. Graph. (TOG) 2019, 38, 1–14. [Google Scholar] [CrossRef]
- Tucker, R.; Snavely, N. Single-view view synthesis with multiplane images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 551–560. [Google Scholar]
- Liu, Z.; Feng, Y.; Black, M.J.; Nowrouzezahrai, D.; Paull, L.; Liu, W. Meshdiffusion: Score-based generative 3d mesh modeling. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Liu, S.; Li, T.; Chen, W.; Li, H. Soft rasterizer: A differentiable renderer for image based 3d reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7708–7717. [Google Scholar]
- Kerbl, B.; Kopanas, G.; Leimkühler, T.; Drettakis, G. 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph. 2023, 42, 1–14. [Google Scholar] [CrossRef]
- Cheng, Y.-C.; Lee, H.-Y.; Tulyakov, S.; Schwing, A.G.; Gui, L.-Y. Sdfusion: Multimodal 3d shape completion, reconstruction, and generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 4456–4465. [Google Scholar]
- Chou, G.; Bahat, Y.; Heide, F. Diffusion-sdf: Conditional generative modeling of signed distance functions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 2262–2272. [Google Scholar]
- Jun, H.; Nichol, A. Shap-e: Generating conditional 3d implicit functions. arXiv 2023, arXiv:2305.02463. [Google Scholar]
- Müller, N.; Siddiqui, Y.; Porzi, L.; Bulo, S.R.; Kontschieder, P.; Nießner, M. Diffrf: Rendering-guided 3d radiance field diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 4328–4338. [Google Scholar]
- Zhang, B.; Tang, J.; Niessner, M.; Wonka, P. 3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models. ACM Trans. Graph. (TOG) 2023, 42, 1–16. [Google Scholar] [CrossRef]
- Gupta, A.; Xiong, W.; Nie, Y.; Jones, I.; Oguz, B. 3dgen: Triplane latent diffusion for textured mesh generation. arXiv 2023, arXiv:2303.05371. [Google Scholar]
- Karnewar, A.; Mitra, N.J.; Vedaldi, A.; Novotny, D. Holofusion: Towards photo-realistic 3d generative modeling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023. [Google Scholar]
- Kim, S.W.; Brown, B.; Yin, K.; Kreis, K.; Schwarz, K.; Li, D.; Rombach, R.; Torralba, A.; Fidler, S. Neuralfield-ldm: Scene generation with hierarchical latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Poole, B.; Jain, A.; Barron, J.T.; Mildenhall, B. Dreamfusion: Text-to-3d using 2d diffusion. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Lin, C.-H.; Gao, J.; Tang, L.; Takikawa, T.; Zeng, X.; Huang, X.; Kreis, K.; Fidler, S.; Liu, M.-Y.; Lin, T.-Y. Magic3d: High-resolution text-to-3d content creation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 300–309. [Google Scholar]
- Shi, Y.; Wang, P.; Ye, J.; Long, M.; Li, K.; Yang, X. Mvdream: Multi-view diffusion for 3d generation. arXiv 2023, arXiv:2308.16512. [Google Scholar]
- Liu, R.; Wu, R.; Van Hoorick, B.; Tokmakov, P.; Zakharov, S.; Vondrick, C. Zero-1-to-3: Zero-shot One Image to 3D Object. arXiv 2023, arXiv:2303.11328. [Google Scholar]
- Szymanowicz, S.; Rupprecht, C.; Vedaldi, A. Viewset diffusion:(0-) image-conditioned 3d generative models from 2d data. arXiv 2023, arXiv:2306.07881. [Google Scholar]
- Liu, Y.; Lin, C.; Zeng, Z.; Long, X.; Liu, L.; Komura, T.; Wang, W. Syncdreamer: Generating multiview-consistent images from a single-view image. arXiv 2023, arXiv:2309.03453. [Google Scholar]
- Shi, R.; Chen, H.; Zhang, Z.; Liu, M.; Xu, C.; Wei, X.; Chen, L.; Zeng, C.; Su, H. Zero123++: A Single Image to Consistent Multi-view Diffusion Base Model. arXiv 2023, arXiv:2310.15110. [Google Scholar]
- Sohail, S.S.; Himeur, Y.; Kheddar, H.; Amira, A.; Fadli, F.; Atalla, S.; Copiaco, A.; Mansoor, W. Advancing 3D point cloud understanding through deep transfer learning: A comprehensive survey. Inf. Fusion 2024, 113, 102601. [Google Scholar] [CrossRef]
- Wang, P.; Shi, Y. Imagedream: Image-prompt multi-view diffusion for 3d generation. arXiv 2023, arXiv:2312.02201. [Google Scholar]
- Tang, J.; Chen, Z.; Chen, X.; Wang, T.; Zeng, G.; Liu, Z. Lgm: Large multi-view Gaussian model for high-resolution 3d content creation. arXiv 2024, arXiv:2402.05054. [Google Scholar]
- Xu, Y.; Shi, Z.; Yifan, W.; Chen, H.; Yang, C.; Peng, S.; Shen, Y.; Wetzstein, G. Grm: Large gaussian reconstruction model for efficient 3d reconstruction and generation. arXiv 2024, arXiv:2403.14621. [Google Scholar]
- Dong, Y.; Chen, G.; Peers, P.; Zhang, J.; Tong, X. Appearance-from-motion: Recovering spatially varying surface reflectance under unknown lighting. ACM Trans. Graph. (TOG) 2014, 33, 1–12. [Google Scholar] [CrossRef]
- Bi, S.; Xu, Z.; Sunkavalli, K.; Hašan, M.; Hold-Geoffroy, Y.; Kriegman, D.; Ramamoorthi, R. Deep reflectance volumes: Relightable reconstructions from multi-view photometric images. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part III 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 294–311. [Google Scholar]
- Bi, S.; Xu, Z.; Srinivasan, P.; Mildenhall, B.; Sunkavalli, K.; Hašan, M.; Hold-Geoffroy, Y.; Kriegman, D.; Ramamoorthi, R. Neural reflectance fields for appearance acquisition. arXiv 2020, arXiv:2008.03824. [Google Scholar]
- Zhang, K.; Luan, F.; Wang, Q.; Bala, K.; Snavely, N. Physg: Inverse rendering with spherical gaussians for physics-based material editing and relighting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5453–5462. [Google Scholar]
- Srinivasan, P.P.; Deng, B.; Zhang, X.; Tancik, M.; Mildenhall, B.; Barron, J.T. Nerv: Neural reflectance and visibility fields for relighting and view synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7495–7504. [Google Scholar]
- Zhang, Y.; Sun, J.; He, X.; Fu, H.; Jia, R.; Zhou, X. Modeling indirect illumination for inverse rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18643–18652. [Google Scholar]
- Jin, H.; Liu, I.; Xu, P.; Zhang, X.; Han, S.; Bi, S.; Zhou, X.; Xu, Z.; Su, H. Tensoir: Tensorial inverse rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 165–174. [Google Scholar]
- Chen, A.; Xu, Z.; Geiger, A.; Yu, J.; Su, H. Tensorf: Tensorial radiance fields. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 333–350. [Google Scholar]
- Keselman, L.; Hebert, M. Approximate differentiable rendering with algebraic surfaces. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 596–614. [Google Scholar]
- Keselman, L.; Hebert, M. Flexible techniques for differentiable rendering with 3d gaussians. arXiv 2023, arXiv:2308.14737. [Google Scholar]
- Liang, Z.; Zhang, Q.; Feng, Y.; Shan, Y.; Jia, K. Gs-ir: 3d gaussian splatting for inverse rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 3836–3847. [Google Scholar]
- Qiu, L.; Chen, G.; Gu, X.; Zuo, Q.; Xu, M.; Wu, Y.; Yuan, W.; Dong, Z.; Bo, L.; Han, X. Richdreamer: A generalizable normal-depth diffusion model for detail richness in text-to-3d. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Palfinger, W. Continuous remeshing for inverse rendering. Comput. Animat. Virtual Worlds 2022, 33, e2101. [Google Scholar] [CrossRef]
- Downs, L.; Francis, A.; Koenig, N.; Kinman, B.; Hickman, R.; Reymann, K.; McHugh, T.B.; Vanhoucke, V. Google scanned objects: A high quality dataset of 3d scanned household items. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: New York, NY, USA, 2022; pp. 2553–2560. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. Shapenet: An information-rich 3d model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Jiang, H.; Huang, Q.; Pavlakos, G. Real3D: Scaling Up Large Reconstruction Models with Real-World Images. arXiv 2024, arXiv:2406.08479. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Kim, M.; Kim, J.; Kim, W.; Cho, K. Joint Optimization-Based Texture and Geometry Enhancement Method for Single-Image-Based 3D Content Creation. Mathematics 2024, 12, 3369. https://doi.org/10.3390/math12213369
Park J, Kim M, Kim J, Kim W, Cho K. Joint Optimization-Based Texture and Geometry Enhancement Method for Single-Image-Based 3D Content Creation. Mathematics. 2024; 12(21):3369. https://doi.org/10.3390/math12213369
Chicago/Turabian StylePark, Jisun, Moonhyeon Kim, Jaesung Kim, Wongyeom Kim, and Kyungeun Cho. 2024. "Joint Optimization-Based Texture and Geometry Enhancement Method for Single-Image-Based 3D Content Creation" Mathematics 12, no. 21: 3369. https://doi.org/10.3390/math12213369
APA StylePark, J., Kim, M., Kim, J., Kim, W., & Cho, K. (2024). Joint Optimization-Based Texture and Geometry Enhancement Method for Single-Image-Based 3D Content Creation. Mathematics, 12(21), 3369. https://doi.org/10.3390/math12213369