1. Introduction
The development in the field of high-performance computing (HPC) have been remarkable, with the computational scale of scientific and engineering calculations continuously increasing. The limited word length of computers leads to unavoidable rounding errors in floating-point operations [
1]. The combination of dynamic scheduling of parallel computing resources, and floating point nonassociativity results in irreproducibility of floating-point calculation results. For instance, the continued summation or product of multiple floating-point numbers depends on the order of calculations.
Reproducibility is the ability to obtain a bit-wise identical and accurate result for multiple executions on the same data in various parallel environments [
2]. We use a floating-point arithmetic that consists in approximating real numbers by a finite, fixed-precision representation number adhering to the IEEE 754 standard, which requires correctly rounded results for the basic arithmetic operations. The correct rounding criterion guarantees a unique, well-defined answer. The main idea is to keep track of both the result and the error during the course of computations.
In the 1960s and 1970s, Knuth, Kahan, and Dekker [
3] proposed the idea of error-free transformations. In 2005, Japanese scholar Ogita, Oishi, and German scholar Rump [
4,
5,
6] systematically summarized compensation algorithms and formally introduced the concept of error-free transformations(EFTs). One approach uses EFTs to compute both the result and the rounding error and stores them in a floating-point expansion (FPE), whose components are ordered in magnitude with minimal overlap to cover the whole range of exponents [
7]. Typically, FPE relies upon the use of the traditional EFT for addition. Another approach projects the finite range of exponents of floating-point numbers into a long (fixed-point) accumulator and stores every bit there. For instance, Kulisch proposed to use a 4288-bit long accumulator for the exact dot product of two vectors composed of binary64 numbers with hardware supports [
8].
Emerging attention to reproducibility strives to draw more careful attention to the problem by the computer arithmetic community. Static data scheduling and deterministic reduction ensure the numerical reproducibility of the Intel Math Kernel Library [
9]. Nevertheless the number of threads has to be set for all runs. Starting from version 11.0, Intel’s MKL library introduced the Conditioned Numerical Reproducibility (CNR) mode [
10]. This mode provides the capability to obtain reproducible floating-point results when calling library functions from the application, under the condition of a limited number of threads. Unfortunately this decreases significantly the performance especially on recent architectures, and requires the number of threads to remain the same from run to run to ensure reproducible results. Reproblas [
11,
12], developed by the University of California, Berkeley, utilizes pre-rounding and 1-Reduction techniques, and is designed for CPU and distributed parallel environments. However, the current version of this library only has the most basic functions and does not support thread-level parallelism. Exblas [
13,
14], developed by the University of Paris-Sud, combines together long accumulator and floating-point expansion into algorithmic solutions as well as efficiently tunes and implements them on various architectures, including conventional CPUs, Nvidia and AMD GPUs, and Intel Xeon Phi co-processors. Ozblas [
15,
16], developed by Tokyo Woman’s University in Japan, achieves reproducibility using the Ozaki scheme. This software supports adjustable precision on both CPUs and GPUs. However, these libraries are mainly developed to demonstrate the methods proposed in their respective research papers and are not yet widely used in practical applications [
17].
The latest research is a general framework for deriving reproducible and accurate variants of a Krylov subspace algorithm, which proposed by Iakymchuk [
18]. The framework is illustrated on the preconditioned BiCGStab method for the solution of non-symmetric linear systems with message-passing. The algorithmic solutions are build around the ExBLAS project.
Modern supercomputer architectures consist of multiple levels of parallelism. As the level of parallelism increases, the uncertainty of computations also increases [
19,
20,
21]. The purpose of this paper is to analyze the blocking implementation approaches of the
function in the BLAS library, We designed and optimized a multi-threaded reproducible algorithm for banded matrix-vector multiplication.
The paper is organized as follows.
Section 2 introduces the relevant knowledge of reproducible techniques.
Section 3 describes how to achieve reproducibility in the banded matrix-vector multiplication algorithm and analyses the error bound. Then, the multi-level parallel optimization design we have performed on this algorithm is explained.
Section 4 presents numerical experiments on the reproducibility, accuracy, and performance of the algorithm. The experimental results demonstrate that the algorithm is reproducible, efficient, and reliable.
2. Background
In scientific computing, the most basic operation is the addition of two floating-point numbers. The use of error-free transformations can greatly control the accumulation of rounding errors.
The algorithm
[
3] is used to add two floating-point numbers
a and
b. The core idea is to transform the floating-point pair
into the floating-point pair
and use compensation to improve the calculation results. The calculation result is corrected by combining a high-order term
x with a low-order term
y.
The algorithm
is mainly used for operations on a vector of floating-point numbers, where it transforms the elements
of the vector
v into the sum of a high-order part
and a trailing part
[
22].
T is the exact sum of
, and
r is a vector composed of
. Our paper uses the reproducible k-fold accurate summation algorithm
in to-nearest rounding mode (Algorithm 7, [
22]). This algorithm requires
FLOPs, where
k is the number of fold,
n is the length of vector
v.
3. Parallel Reproducible Banded Matrix-Vector Multiplication
In this chapter, we will explain how we implemented the reproducible banded matrix-vector multiplication algorithm for double-precision in to-nearest rounding mode.
3.1. Basic Architecture
is a special matrix function in BLAS Level 2. Both the memory access and computational complexity reach . After special memory access processing, converts to or operations. Therefore, the performance heavily relies on the implementation of the level 1 algorithms.
The function is defined as: , where A is an n-row by m-column banded matrix, with being the element at the i-th row and j-th column of A. and are scalars, x is a vector of size m, with being the i-th element in x. y is a vector of size n, with being the i-th element in y. Let and be the number of superdiagonals and subdiagonals, respectively.
Taking
,
as an example,
A can be represented as follows:
Compressed banded matrix exhibits special matrix properties. During storage, compressed banded matrices only store the effective computational elements (referring to the elements on the subdiagonal, main diagonal, and superdiagonal). During computation, dgbmv requires a one-to-one correspondence between matrix elements and vector elements in terms of computation order. The actual memory required for storage is smaller than the size of the uncompressed original matrix.
This paper mainly considers the row-major storage format. In memory, the banded matrix ignores the ineffective computational elements (referring to the subdiagonal and superdiagonal elements that do not participate in the computation) and rearranges them according to certain rules.
Each row has an offset added to the starting address. The offset for the first row is , and for each subsequent row, the offset is reduced by 1 until the offset becomes 0, after which each row is not offset.
Additionally, the effective computational elements of each row need to be recorded to ensure accurate and complete storage. From this, we can conclude that the memory access requires knowledge of the offset and the number of effective elements in each row. Therefore, the storage of matrix
A is as follows:
In actual calculation, the compressed banded matrix takes out each row based on the offset and the number of effective elements, and also takes out the corresponding vector portion that participates in the computation. It then uses
to perform the entire matrix-vector multiplication. The pseudo-code of the specific algorithm implementation is shown in Algorithm 1.
| Algorithm 1 Reproducible Compressed Banded Matrix-Vector Multiplication: |
- Require:
Given that matrix A is a banded matrix of size , with subdiagonals and superdiagonals, stored in the compressed matrix of size . x is a vector of length m, and are coefficients, and y is a vector of length n. - 1:
- 2:
- 3:
for to do - 4:
- 5:
- 6:
- 7:
for to do - 8:
- 9:
end for - 10:
- 11:
- 12:
- 13:
- 14:
end for - Ensure:
.
|
Since the multiplication of two floating-point numbers is reproducible, we calculate the product at each corresponding position and store it in an array . We also store the initial value of y multiplied by in . Then, we use the algorithm to perform the reproducible summation for the array , with the number of folds k set to 2.
3.2. Error Analysis
Let be the machine precision, which is the distance between 1 and the closest floating-point number. , where p is the number of significant digits of a floating-point number. In double precision, .
Theorem 1. In to-nearest rounding mode, for a vector v of length h and using the k-fold reproducible summation algorithm , when , the absolute error bound between the numerical result and the exact result is:where . Proof of Theorem 1. Let
be the
j-th element of
v, and
be the exact sum of all elements in
v. In the
i-th step of the error-free vector transformation, where
, we introduce the following notations:
is the corresponding boundary;
is the high-order part extracted in the
i-th error-free vector transformation for each element;
is the numerical result of the summation of
, which can be computed exactly;
is the low-order part remaining after the
i-th extraction;
is the exact sum of
, which is used for proof purposes. On one hand, for EFTs,
where
. Combining the above two cases, we can get:
By applying Lemma 5 from reference [
22],
we can deduce that
where
will be used in proof of Theorem 2. Therefore,
Furthermore, since
we can get (
1) through simple derivation. □
Based on Theorem 1, we can derive Theorem 2. For convenience, we set is the number of elements in a row. In the banded matrix A, the ith row is denoted as .
Theorem 2. In simplified algorithm to compute , , , . and are the number of superdiagonals and subdiagonals, respectively. The error bound for each element in the numerical solution y is:whereand M is the vector of , , and is the maximum value of Proof of Theorem 2. To perform a dot product operation between each row of
A and
x, it is necessary to first calculate the product result of each
and
, store it in a vector, and then perform a reproducible sum. We call this process as
. By using
in (
2) and the same method in (
3), the detailed calculation process for
and
x is as follows:
where
. From
, We can derive that
By combining equality (
4) and inequality (
5), we can get
Then the error bound is
where
which is easy to deduce the result. □
Note that the error bound of
[
1] is
Therefore if
has a smaller error bound than
. As for
, it’s easy to derive in a similar way.
3.3. Blocking and Parallel Optimization
We separated the compressed banded matrix
A into blocks, and used multi-level parallel reproducible summation algorithms. The number of blocks is determined by the number of threads,
. We used
to allocate tasks to each block. The segmentation process is as follows: first, we calculated the number of rows that each block needs to allocate based on the number of threads and the number of matrix rows. Then, we used
to transfer the calculated control information to each thread. For example, when the number of threads is 4, the blocking is as shown below:
Finally, according to the received control information in different threads, we accessd A, x, and y, and used the algorithm to calculate. The calculated results are assigned to the corresponding positions of y.
We refered to this optimized multi-threaded compressed banded matrix-vector multiplication as .
4. Numerical Experiments
In this chapter, we conducted numerical experiments to verify the reproducibility, accuracy, and performance of the algorithm. In the reproducible summation used, we set the number of folds k to 2.
In experiments to verify reproducibility and accuracy, we generated a set of data using sine function to make the data more ill-conditioned, and store data in a banded matrix A of size . The number of subdiagonals and superdiagonals is set to 500. We also generate floating-point vectors x and y of size 5000 using the sine function.
The experiments were conducted on two different testing platforms: an ARM processor (National University of Defense Technology, Changsha, Hunan) and a x86 processor Intel(R) Xeon(R) Platinum 8180M (Xeon Platinum CPU), with the parameters shown in the
Table 1.
4.1. Reproducibility Verification
We performed the ordinary banded matrix-vector multiplication algorithm and the algorithm on two different platforms with a single thread to verify the reproducibility.
We defined the irreproducibility rate as: the proportion of elements in the numerical results that have the same index but values differ between two results, when using the same program and the same set of input data.
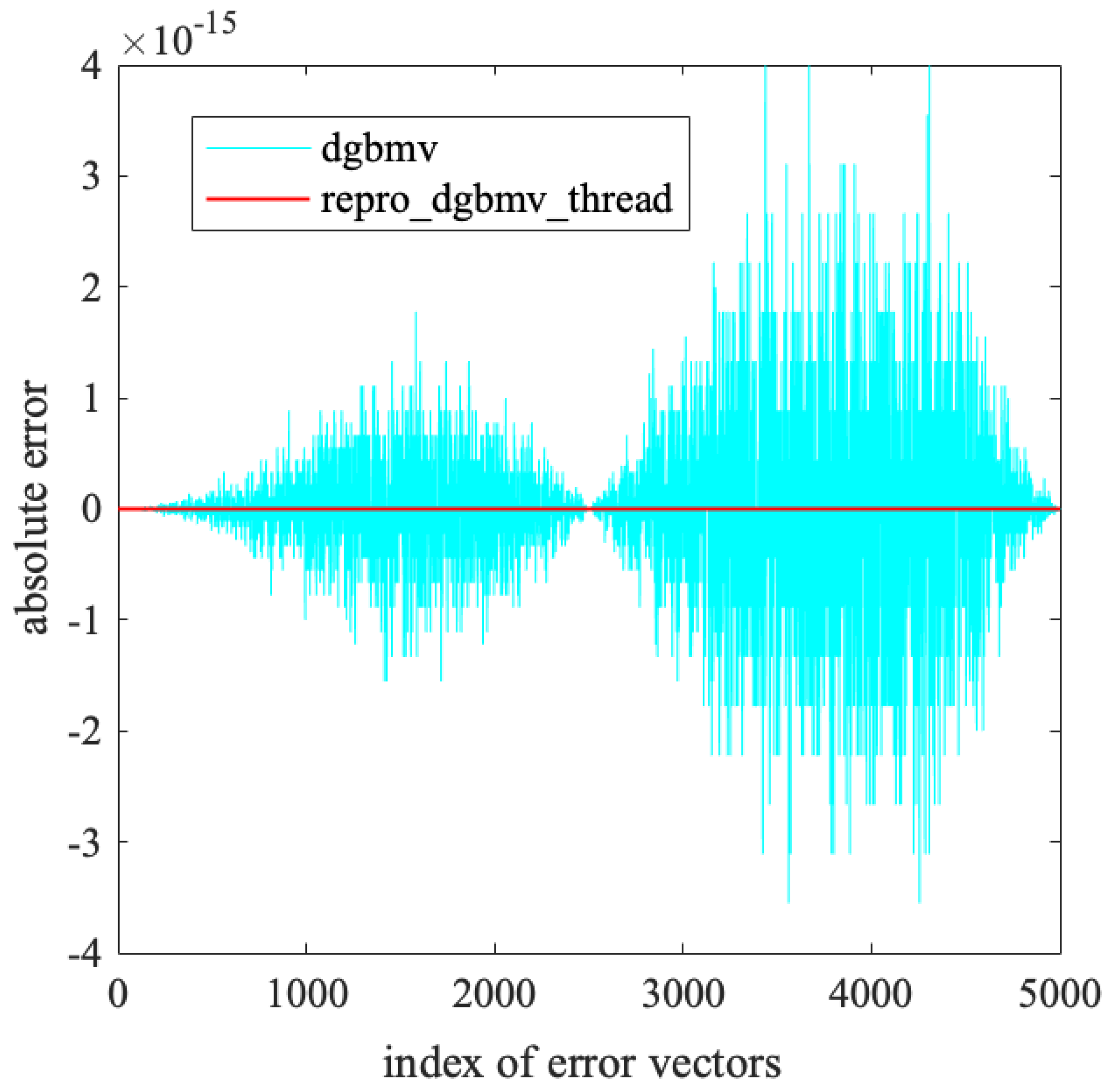
To compare the numerical results, we calculated the absolute errors between different numerical results, as shown in
Figure 1. In the figure, the result calculated on the ARM platform is denoted as
, and the result calculated on the x86 platform is denoted as
. The absolute error is calculated as:
To verify the reproducibility of the algorithm, we also calculated the maximum absolute error between the two results
and
,
as well as the irreproducibility rate, which is the ratio of the number of irreproducible elements to the total number of elements
From
Figure 1 and
Table 2, we can see that the
algorithm produces different results on the two platforms, with a maximum absolute error greater than 0. In the entire result vector, 83.38% of the elements are different. In contrast, the
algorithm produces results with a maximum absolute error of 0 on both platforms, and the irreproducibility rate is 0, which means all corresponding elements of the result vectors are exactly the same. This indicates that
is irreproducible, while
is reproducible.
4.2. Accuracy Verification
On the ARM platform, we denoted these two results of
and
as
y and
, and then calculate the accurate result
using MPFR [
23]. We compare
y and
with
, and the error results are shown in
Figure 2. The maximum absolute error between exact solution and numerical results is computed by
,
.
It can be seen that the has higher accuracy than the .
4.3. Performance Verification
We tested multiple sets of subdiagonals and superdiagonals for the matrix A of size .
First, on the ARM platform, we used
and
to perform different sizes of matrices with single thread and 8 threads. We recorded the running time, as shown in
Figure 3, and calculated speedup, as shown in
Figure 4.
Furthermore, it could be calculated that with single thread, the running time of is 4 to 4.2 times that of the . With 8 threads, the running time of is 1.7 to 2.8 times that of the . Compared to , has higher parallel efficiency.
Second, on the x86 platform, we used single thread, 15 threads, and 30 threads to execute
. The running time are shown in
Figure 5, and the speedup between single thread and 15 threads is shown in
Figure 6.
It could be calculated that the running time of with single thread is 7.7 to 10.6 times that of 15 threads, and the running time with 15 threads is 1.1 to 1.5 times that of 30 threads. However, the running time of with single thread is 4.2 to 6.8 times that of 15 threads, and the running time with 15 threads is 0.8 to 1.2 times that of 30 threads.
Increasing the number of threads further does not improve the parallel efficiency or reduce the running time, because the data size processed by each individual thread is not large enough, leading to increased the proportion of communication time and decreased parallel efficiency.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}