Abstract
To overcome the shortcoming of the Fuzzy C-means algorithm (FCM)—that it is easy to fall into local optima due to the dependence of sub-spatial clustering on initialization—a Multi-Strategy Tuna Swarm Optimization-Fuzzy C-means (MSTSO-FCM) algorithm is proposed. Firstly, a chaotic local search strategy and an offset distribution estimation strategy algorithm are proposed to improve the performance, enhance the population diversity of the Tuna Swarm Optimization (TSO) algorithm, and avoid falling into local optima. Secondly, the search and development characteristics of the MSTSO algorithm are introduced into the fuzzy matrix of Fuzzy C-means (FCM), which overcomes the defects of poor global searchability and sensitive initialization. Not only has the searchability of the Multi-Strategy Tuna Swarm Optimization algorithm been employed, but the fuzzy mathematical ideas of FCM have been retained, to improve the clustering accuracy, stability, and accuracy of the FCM algorithm. Finally, two sets of artificial datasets and multiple sets of the University of California Irvine (UCI) datasets are used to do the testing, and four indicators are introduced for evaluation. The results show that the MSTSO-FCM algorithm has better convergence speed than the Tuna Swarm Optimization Fuzzy C-means (TSO-FCM) algorithm, and its accuracies in the heart, liver, and iris datasets are 89.46%, 63.58%, 98.67%, respectively, which is an outstanding improvement.
MSC:
68T07
1. Introduction
As technology improves by leaps and bounds, the emergence of data expansion has had a definite impact on all walks of life. Countries around the world have gradually paid attention to the analysis of data and internal knowledge. A commonly used data analysis method, data mining, is used to transform the original data into useful data or information through specific identification methods [1]. The existing supervised learning has a very strong dependence on data labels. If the data labels are accurate, the supervised algorithm can learn well, but when the labels are wrong, the supervised algorithm is difficult to analyze, and the internal knowledge mined will produce deviations. The ways of labeling massive data and mining internal connections are the unique function of clustering algorithms [2].
The current clustering algorithms are divided into five categories: density-based methods, grid-based methods, hierarchical-based methods, model-based methods, and division-based methods [3]. The Fuzzy C-means clustering method is a division-based clustering method, which is widely used in the segmentation and classification of brain tumors [4], the evaluation of power grid reliability performance [5], and the recognition of the whitewashing behavior of college accounting statements [6]. However, because the FCM algorithm is a hard subspace clustering algorithm, its computational complexity is high. In addition, it is not sensitive to noise, and the processing effect of high data is poor. It also does not overcome the dependence of the sub-spatial clustering method on initialization, so it easily falls into local optima. To overcome the above shortcomings, an improved particle swarm optimization algorithm was proposed by using the foraging behavior of birds, which is applied to the clustering algorithm and has achieved certain improvements [7]. The hybrid Fuzzy C-means clustering and gray wolf optimization (GWO) for image segmentation were proposed to overcome the shortcomings of Fuzzy C-means clustering [8]. A new collaborative multi-population differential evolution method with elite strategies was proposed to identify approximate optimal initial clustering prototypes, determine the optimal number of clusters in the data, and optimize the initial structure of FCM [9]. A hybrid optimization algorithm for simulated annealing and ant colony optimization was put forward to improve the clustering method and enhance the accuracy of data clustering [10]. The particle swarm algorithm was improved by using the Levy flight strategy and applied to the clustering algorithm, which improved its initialization process, greatly reduced the computational complexity, and improved the clustering accuracy [11]. The particle swarm optimization was combined with FCM, and the FCM fitness was optimized for each iteration [12]. Three improved particle swarm optimization algorithms were proposed and used differently according to data characteristics, which improved the clustering performance and weakened data sensitivity [13]. An improved artificial bee colony optimization algorithm was proposed to optimize the clustering problem and significantly improved the efficiency of data processing [14].
From the above research, the heuristic optimization algorithm plays a positive role in the clustering problem and overcomes a considerable part of the defects of the clustering algorithm itself, according to the different improvement methods. Tuna Swarm Optimization (TSO) is a novel algorithm with excellent searchability and excellent performance in various problems. An improved TSO was used to segment images of forest canopies [15]. An improved nonlinear tuna swarm optimization algorithm based on a Circle Chaos map and Levy flight operator (CLTSO) was proposed to optimize a BP neural network [16]. A hybrid model based on the long short-term memory (LSTM) and the TSO algorithm was established to predict wind speed [17]. TSO was blended with improved adaptive differential evolution with an optional external archive to form a new heuristic algorithm, which has been well demonstrated in the problem of photovoltaic parameter identification [18]. An enhanced tuna swarm optimization was proposed for performance optimization of FACTS devices [19]. A chaotic tuna swarm optimizer was proposed to find the optimal parameters of the Three-Diode Model, and it was hybridized with the Newton–Raphson method to improve the ability of convergence [20]. An improved particle swarm optimization algorithm can adaptively adjust the relevant parameters of the fuzzy decision tree, effectively improving the recognition accuracy in lithology recognition [21]. A multi-objective algorithm using a grid-based method was proposed to do privacy-preserving data mining and achieved excellent performance [22]. A multi-objective neural evolutionary algorithm based on decomposition and dominance (MONEADD) was proposed to evolve neural networks [23]. Ref. [24] proposed novel hybrid optimized clustering schemes with a genetic algorithm and PSO for segmentation and classification. An Improved Fruit Fly Optimization (IFFO) algorithm was proposed to minimize the makespan and costs of scheduling multiple workflows in the cloud computing environment [25]. An advanced encryption standard (AES) algorithm was used to deal with workflow scheduling [26]. Ref. [27] proposed an enhanced hybrid glowworm swarm optimization algorithm for traffic-aware vehicular networks, and technical delays were significantly reduced.
FCM dependence on initialization was not overcome in the above research. It is very easy to fall into local optima. In summary, to overcome the defects, an FCM based on multi-strategy tuna swarm optimization (MSTSO-FCM) is proposed. A chaotic local search strategy is introduced to improve the development ability of the algorithm, and the dominant population is fully utilized by an offset distribution estimation strategy to enhance the performance of the algorithm. Another contribution is that the search and development characteristics of the MSTSO algorithm are introduced into the fuzzy matrix of FCM, which overcomes the defects of poor global search ability and sensitive initialization. It not only uses the searchability of MSTSO but also retains the fuzzy mathematical ideas of FCM, to improve the clustering, stability, and accuracy of the FCM algorithm.
The rest of this paper is organized as follows. Section 2 introduces the existing related algorithms, which are the tuna swarm optimization algorithm and the Fuzzy C-means clustering algorithm. Section 3 proposes the Multi-Strategy Tuna Swarm Optimization algorithm, and MSTSO-FCM is proposed based on it. Section 4 carries out the simulation experiment and does the comparative analysis. Finally, the conclusion is described in Section 5.
2. Existing Related Algorithms
2.1. Tuna Swarm Optimization
As a top marine predator, the tuna is a social animal. They choose the corresponding predation strategy according to the object they forage. The first strategy is spiral foraging, that is, when tuna feed, they swim in a spiral to take their prey into shallow water, attack, and catch it. The second strategy is parabolic foraging, in which each tuna follows the previous individual to form a parabolic shape to surround its prey. Tuna successfully forage through the above two methods. TSO is modeled based on these natural foraging behaviors, and the algorithm follows the basic rules as follows.
(1) Population initialization: TSO starts the optimization process by randomly generating the initial swarm evenly to update the position.
where is the initial population, and and are the upper and lower boundaries of the problem space.
(2-1) Spiral foraging. Schools of tuna chase their prey by forming a tight spiral, and in addition to chasing their prey, they also exchange information with each other. Each tuna follows the previous one, so information can be shared between neighboring tuna. Based on the above principles, the mathematical formulas of the spiral foraging strategy are as follows:
where is the position of the th individual in the t + 1 generation, is the current optimal individual, and are the coefficients that control the degree of follow-up of the individual towards the optimal individual and the previous individual in the chain, is a constant which is 0.6, and represent the current number of iterations and the maximum number of iterations, respectively, and is a random number evenly distributed from 0 to 1. When the optimal individual cannot find food, blindly following the optimal individual to forage is not conducive to group foraging. Therefore, a random coordinate in the search space is generated to serve as a reference point for the spiral search. It enables each individual to explore in a wider space and enables TSO to explore globally. The specific mathematical model is described as follows:
In particular, meta-heuristics typically perform extensive global exploration in the early stage, followed by a gradual transition to precise local development. Therefore, as the number of iterations increases, TSO changes the reference point for spiral foraging from random individuals to optimal individuals. In summary, the final mathematical model of the spiral foraging strategy is as follows:
(2-2) Parabolic foraging. In addition to feeding through a spiral formation, tuna can also form a parabolic cooperative feeding formation. One method is that tuna feed in a parabolic shape using food as a reference point. Another is that tuna can forage for food by looking around. We assume that the selection probability of both is 50%, and both methods are executed at the same time. Tuna hunt synergistically through these two foraging strategies and then find their prey.
In the formula, TF is a random number with a value of 1 or −1.
(3) Termination condition. The algorithm continuously updates and calculates all individual tuna until the final condition is met, and then returns the optimal individual and the corresponding fitness value.
2.2. Fuzzy C-Means Clustering Algorithm
The FCM algorithm [28] is a clustering algorithm based on division, which measures the clustering effect by dividing the similarity between objects. The similarity within the same cluster is high, but that between different clusters is low. So, the fuzzy mean is used for flexible division, which is mainly divided into the following steps:
Step 1: Initialize the membership matrix. The FCM algorithm blurs the concept of 0, 1 binary values to between 0~1, or the degree of membership which measures the relationship between each data point and the cluster center.
where represents the cluster category, represents the number of objects in the dataset, and represents the membership degree of different categories of each set of data, and its sum is 1. The larger the relative membership degree, the greater the probability of the category.
Step 2: Iterative termination judgment. The maximum number of iterations, , is set to determine whether the current number of iterations has reached the upper limit of iterations. Output the clustering result if the current number of iterations exceeds , or update the cluster center;
Step 3: Calculate the cluster center. After the FCM cluster center is established, the membership degree sum of all points to the cluster center is calculated first, and then the cluster center is updated by multiplying the proportion of the membership degree of each category by the original data. The calculation formula is below:
where represents the jth cluster center, and is the current data point.
Step 4: Update the membership matrix. Based on the cluster center and data points, the membership degree is updated through the membership calculation formula:
As can be seen from the above equation, represents the Euclidean distance from the data point to the cluster center , and represents the distance from the data point to all cluster centers. The closer the data point is to , the greater the membership value.
Step 5: Judgment of iteration termination conditions. When the current number of iterations is less than the maximum number of iterations, the iteration termination conditions are as follows:
where indicates the degree of membership under the current number of iterations , and indicates the degree of membership before the update. When the difference between the two is less than the set threshold , it means that a better solution has been found; hence, the ending of iteration and the return of the fuzzy clustering result. If the termination condition is not met, return to step 3.
3. MSTSO-FCM
In this section, two improvement strategies, which are the Chaotic local search strategy and the Offset distribution estimation strategy, are introduced in detail, and the design scheme of MSTSO is described. On this basis, the MSTSO-FCM algorithm is proposed.
3.1. Chaotic Local Search Strategy
The chaotic local search strategy finds a better solution by searching the vicinity of each solution. Therefore, this strategy can effectively improve the exploitation ability of algorithms. Besides, chaos mapping has the characteristics of randomness and ergodicity, so the use of chaos mapping could further improve the effectiveness of the local search strategy. In MSTSO, the chaotic local search strategy is applied only to the dominant group of the population. The top half of individuals from the population with less fitness are selected to form the dominant group. The formula of the chaotic local search strategy is as follows:
where is a new solution generated using the chaotic local search strategy, and are two different individuals randomly selected from the dominant population, and is the chaos value generated by the chaos mapping. In MSTSO, a tent chaos mapping is used to generate . Tent chaos mapping is a classical one, and, compared with logistic mapping, it has better traversal uniformity, which can improve the optimization speed of the algorithm, and, at the same time, produce a more evenly distributed initial value between [0, 1]. The tent mapping expression is as follows:
3.2. Offset Distribution Estimation Strategy
The distribution estimation strategy represents relationships between individuals through probabilistic models. This strategy uses the current dominant population to calculate the probability distribution model, generates new offspring populations based on the sampling of the probability distribution model, and finally obtains the optimal solution through continuous iteration. In this paper, the top half of the individuals with better performance are sampled and the strategy is used for the poor individuals. The mathematical model of the strategy is described below:
where represents the weighted mean of the dominant population, is the population size, and represents the weight coefficient in the descending order of fitness value in the dominant population. Each weight coefficient ranges from 0 to 1, and the sum of the weight coefficient is 1. is the weighted covariance matrix of the dominant population.
3.3. MSTSO Design
MSTSO adds the proposed Chaotic local search strategy and Offset distribution estimation strategy to the original TSO. The specific algorithm design is shown in Algorithm 1.
| Algorithm 1: The procedure of MSTSO | |
| Input: | Fitness function f, Range [xmin, xmax], Fitness evaluation maximum times FEsmax. |
| Output: | xbest. |
| //Initialization. | |
| 1. | Initialize population X by using Equation (1). |
| 2. | Assign a = 0.6 and z = 0.03 |
| 3. | Evaluate X to determine their fitness value by using f(X). |
| 4. | Initialize Fes using Fes = Fes+NP |
| //Main loop. | |
| 5. | While FEs < FEsmax do |
| 6. | Update a1, a2, p through Equations (3), (4) and (10); |
| 7. | If rand < z |
| 8. | Update X through Equation (1); |
| 9. | else |
| 10. | If rand < 0.5 |
| 11. | Update X through Equation (17); |
| 12. | else |
| 13. | If t/tmax < rand |
| 14. | Update X through Equation (7); |
| 15. | else |
| 16. | Update X through Equation (2); |
| 17. | end |
| 18. | end |
| 19. | end |
| 20. | Update X through Equation (15); |
| 21. | Evaluate X to determine their fitness value by using f(X); |
| 22. | Updata xbest; |
| 23. | end |
3.4. FCM Clustering Based on MSTSO Optimization
Due to the fuzzy theory, FCM has more flexible clustering results than traditional hard subspace clustering (mean clustering) [29]. The iterative process of FCM clustering can be understood as a central continuous moving process, which leads to a large improvement in global search ability. FCM does not overcome the dependence of the sub-spatial clustering method on initialization, so it is very easy to fall into local optima. It is difficult to effectively cluster when dealing with high-dimensional spatial data. Considering the above problems using the MSTSO algorithm to improve FCM, the search and development characteristics of the MSTSO algorithm are introduced into the fuzzy matrix of FCM to overcome the shortcomings of poor global searchability and sensitive initialization. It not only uses the searchability of MSTSO but also retains the fuzzy mathematical ideas of FCM, and improves the clustering, stability, and accuracy of the FCM algorithm.
To obtain a better clustering center for FCM, the MSTSO algorithm is used to optimize the membership matrix and replace the original random initialization and update method. It is necessary to know the number of categories of clustered data.
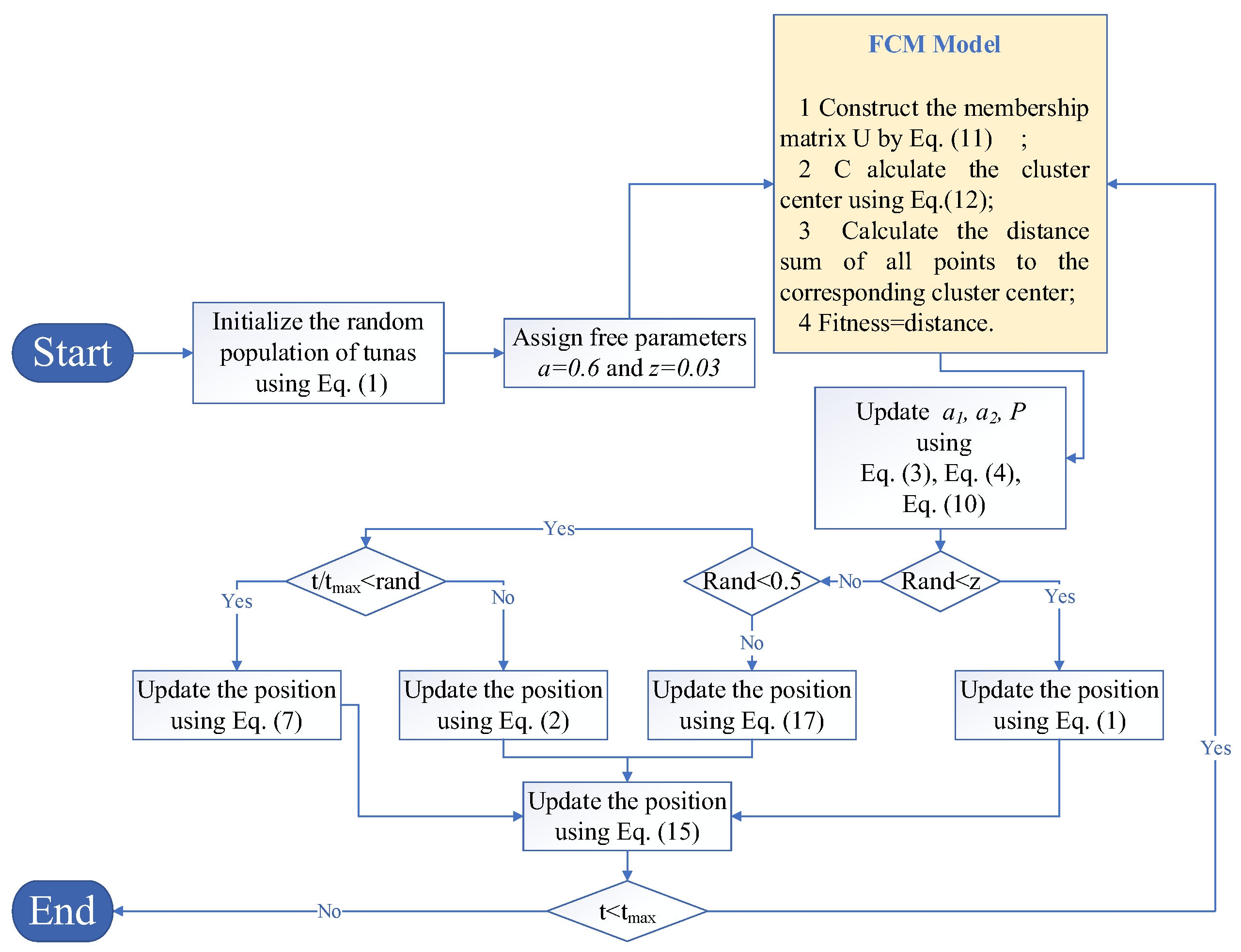
The process of MSTSO optimizing the FCM cluster is as follows: the flowchart is shown in Figure 1; the pseudo-code is shown in Algorithm 2.
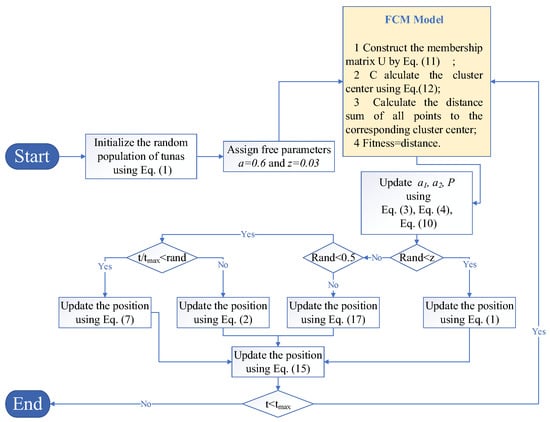
Figure 1.
MSTSO optimizes the FCM cluster.
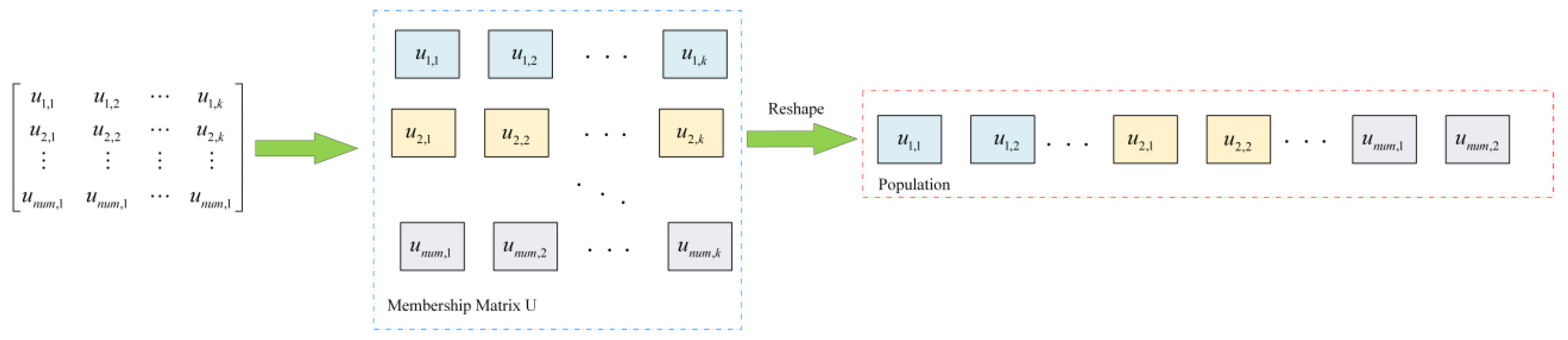
Step 1: Use Equation (1) to randomly initialize the population and assign the parameters a and z, where means the population dimension, with each dimension including all the elements in the membership matrix , as shown in Figure 2:
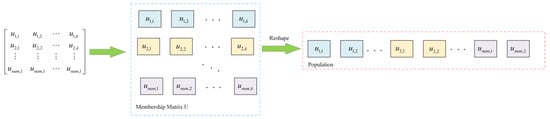
Figure 2.
Membership matrix U reshaped to the population in MSTSO.
Step 2: Introduce the FCM module to calculate the fitness value. Equation (11) is used to reconstruct the membership matrix into the data, in which the dimension of each population and the number of parameters of the membership matrix in the MSTSO algorithm are the same and Equation (12) is used to calculate the cluster center point, and finally the sum of the distances from all arrays to the cluster center is calculated, as shown in the following:
Step 3: Update the population position and calculate the fitness value. Update . When random number , use Equation (1) to initially update the population position. When , make a finer division. Use Equation (13) to initially update the position, and vice versa. When , use Equation (7) to conduct a preliminary update. When , use Equation (2) to perform a preliminary update and finally use Equation (11) to again update the position information that enters the FCM model before calculating the fitness value.
Step 4: Determine whether the iteration is terminated. When the iteration is terminated, output the membership matrix U corresponding to the optimal fitness value at this time. As the optimal FCM model is constructed, if the iteration termination condition is not met, return to Step 2.
| Algorithm 2: The procedure of MSTSO-FCM | |
| Input: | fFCM, [Xmin, Xmax], FEsmax. |
| Output: | membership matrix U |
| 1. | Reshape the membership matrix U to population X using Equation (11); |
| 2. | Initialize population X by using Equation (1); |
| 3. | Assign a = 0.6 and z = 0.03 |
| 5. | Evaluate X to determine their fitness value by using fFCM(X) (Equation (22)). |
| 6. | Update Fes using Fes = Fes + NPFes = Fes + NP |
| 7. | Execute MSTSO’s Main Loop; |
| 8. | Reshape the xbest. to U, and output. |
4. Simulation Experiment and Comparative Analysis
4.1. MSTSO Algorithm Performance Verification
To illustrate the performance of the MSTSO algorithm proposed in this paper, the CEC2017 test set is selected for verification, including 1 unimodal function, 7 multimodal functions, 10 mixed functions, and 10 combined functions. All simulations in this paper are run on MATLAB R2016b software, and the experimental environment is an Intel(R) Core(TM) i7-8700 CPU, 16 GB memory computer. In this paper, the butterfly optimization algorithm (BOA), reptile search algorithm (RSA), arithmetic optimization algorithm (AOA), tunicate swarm algorithm (TSA), and sparrow search algorithm (SSA) are selected as comparison algorithms to illustrate the performance of the improved algorithm MSTSO. To ensure the fairness of the experiment, the population of all algorithms is 500, the maximum number of iterations is 600, and the parameter settings of the rest of the algorithms are based on the parameter values of the original paper. Each algorithm runs independently 51 times, and the statistical average results are shown in Appendix A.
From Appendix A, we can see that MSTSO performs well on most test functions. Specifically, for the unimodal test function F1, although MSTSO fails to stably obtain the optimal solution, the MSTSO optimization accuracy is significantly better than that of other algorithms, reaching nine orders of magnitude, illustrating that MSTSO has excellent local search ability. The multimodal functions F2–F8 are often used to test the global search ability of algorithms, which usually have multiple local minimums, so excellent algorithms can jump out of local minima to obtain global optimal values. MSTSO performs best on all seven of these functions, ranking behind RSA only on F8. For TSO, MSTSO performs better on all multimodal functions, indicating that MSTSO’s improvement strategy significantly improves TSO’s global search ability. F9–F18 and F19–F28 are mixed and combination functions, respectively. These two types of functions have complex structures better able to test the ability of algorithms to solve complex optimization problems. As can be seen from Appendix A, MSTSO ranked second only on F19. In the remaining mixed functions and combination functions, MSTSO is the best performer, achieving significantly better results than TSO, which shows that the improvement strategy proposed in this paper has well enhanced the ability of algorithms to solve complex structural problems. It has the potential to better solve complex optimization problems in the real world.
Appendix B illustrates the p-values calculated by the Wilcoxon signed rank test for each function of each algorithm. If the value is less than 0.05, it means that there is a significant difference between MSTSO and the other competitors; otherwise, there is no significant difference. It can be seen that MSTSO is significantly different from the other algorithms for most functions except for F20. In summary, MSTSO can strike a balance between the development and exploration capabilities of the algorithm and has a good local optimal avoidance ability, which can effectively avoid the premature convergence of the algorithm.
4.2. Cluster Dataset and Comparison Algorithm
To verify the clustering ability of MSTSO-FCM, two sets of artificial large datasets and four sets of UCI datasets are selected [30] and are available from https://archive.ics.uci.edu/datasets (accessed on 3 January 2024), of which two sets of artificial datasets contain three categories, with each category containing 5000 sets of data, respectively, two-dimensional characteristic data and three-dimensional characteristic data, which conformed to Gaussian distribution, and the basic information of the data is shown in Table 1.

Table 1.
Information about the dataset.
To evaluate the clustering performance of each algorithm, three clustering indicators, Accuracy (Ac), Silhouette (Sil), Davies-Bouldin (DB), and Area Under Curve (AUC) are introduced, and the specific information of each index is shown in Table 2.
Table 2.
Cluster indicators.
Four comparison algorithms are selected, namely the TSO-FCM algorithm, PSO-FCM algorithm [13], FCM algorithm, Gaussian mixed clustering (GMM) [31], and K-means clustering algorithm [32]. Table 3 shows the clustering algorithm parameters.
Table 3.
Comparison algorithm settings.
4.3. Evaluation of Clustering Results
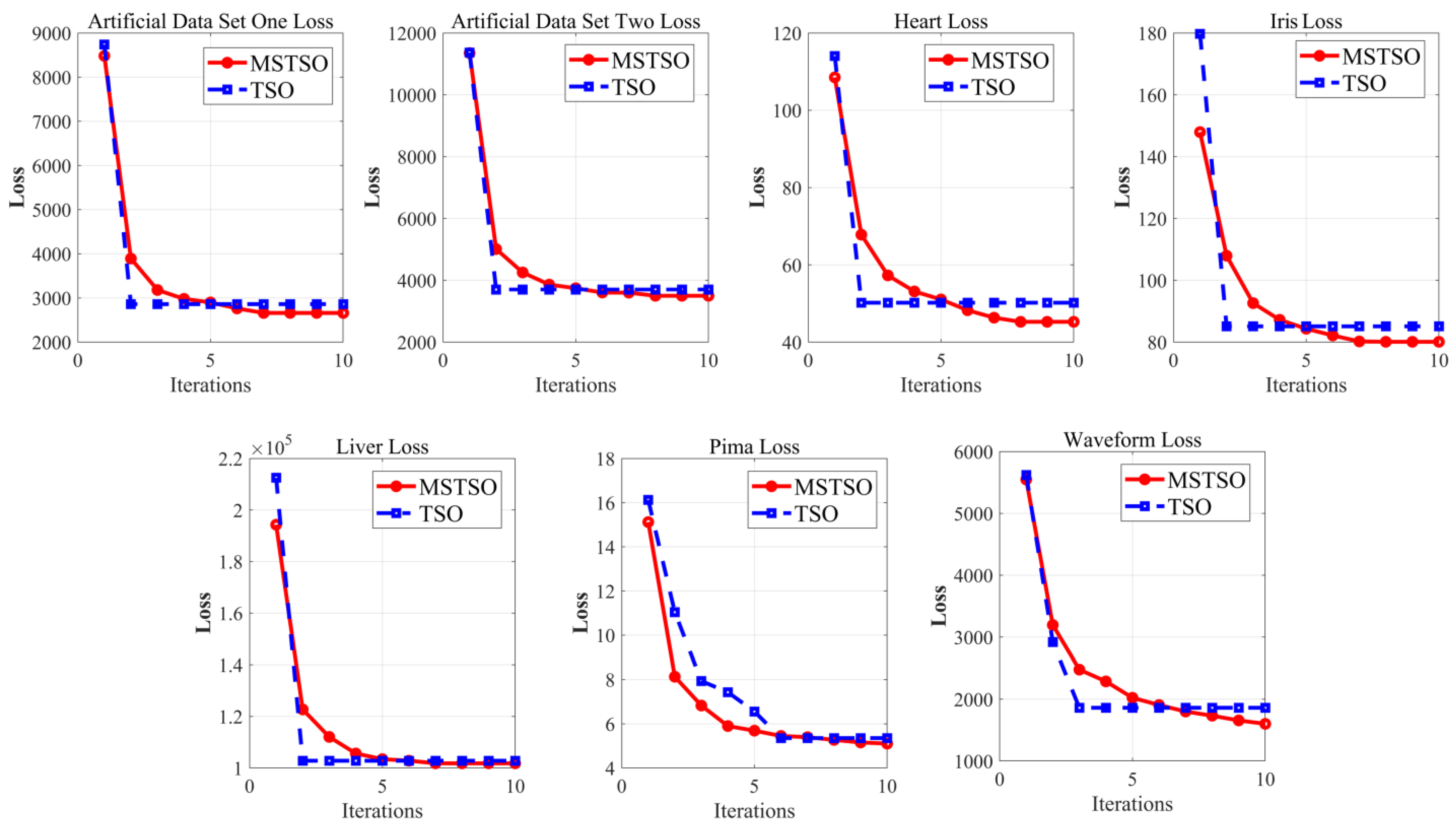
To verify that MSTSO can achieve a better improvement effect on FCM clustering, in the above five datasets, the loss reduction curve of the traditional TSO algorithm is compared. The loss reduction curve is a curve in which the value of the loss function changes as the number of times it is learned increases. The comparison results are shown in Figure 3, in which the convergence ability of MSTSO in the early stage is not as good as that of TSO, but its development performance is better. After TSO stagnates, MSTSO can still search for a better development posture. Generally, after iterating to 8 times, MSTSO will stagnate. From the decline curve of the UCI public data set in the figure, it can be intuitively seen that the late convergence ability of MSTSO is stronger than that of traditional TSO, and it can better explore the global situation and obtain smaller loss values.
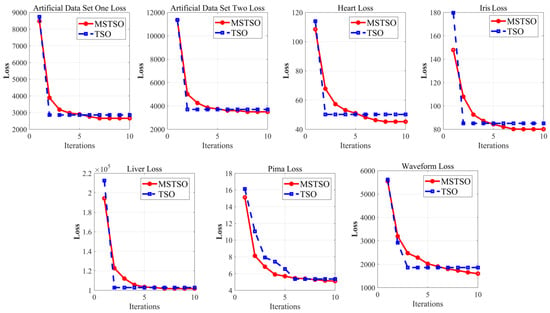
Figure 3.
MSTSO optimization and TSO optimization loss reduction curve comparison.
To further verify the clustering effect, AC, Sil, DB, and AUC are used for evaluation, in which AC indicates the clustering accuracy, Sil and DB represent the internal indicators of the cluster, and AUC is to evaluate the classification ability of positive and negative cases of the cluster. It can be seen from Table 4 that MSTSO-FCM has achieved the best score in the AC indicators of the six datasets. In addition, there is significant progress compared with TSO-FCM, PSO-FCM, and FCM. It has good clustering ability. MSTSO-FCM also has progressed in the Sil index. For artificial dataset 1, the Sil index of FCM is only 0.60, the Sil index of TSO-FCM is 0.74 compared with FCM, and the Sil value of PSO-FCM is 0.73. However, the Sil index of MSTSO-FCM reaches 0.84, showing that the discrimination between clusters is significantly improved on dataset 1. On dataset 2, the DB index of FCM is 1.39, while the DB index of TSO-FCM on dataset 2 is 0.87, the DB index of PSO-FCM is 0.85, and the DB index of MSTSO-FCM on dataset 2 is 0.4735. Compared with TSO-FCM and PSO-FCM, the intra-cluster compactness and inter-cluster separation have been improved, and the clustering effect is better. Regarding the AUC index, MSTSO-FCM achieved first in the four groups of UCI data sets, and had significant advantages compared with TSO-FCM and PSO-FCM, indicating that MSTSO-FCM has excellent classification ability.
Table 4.
Comparison of clustering performance results.
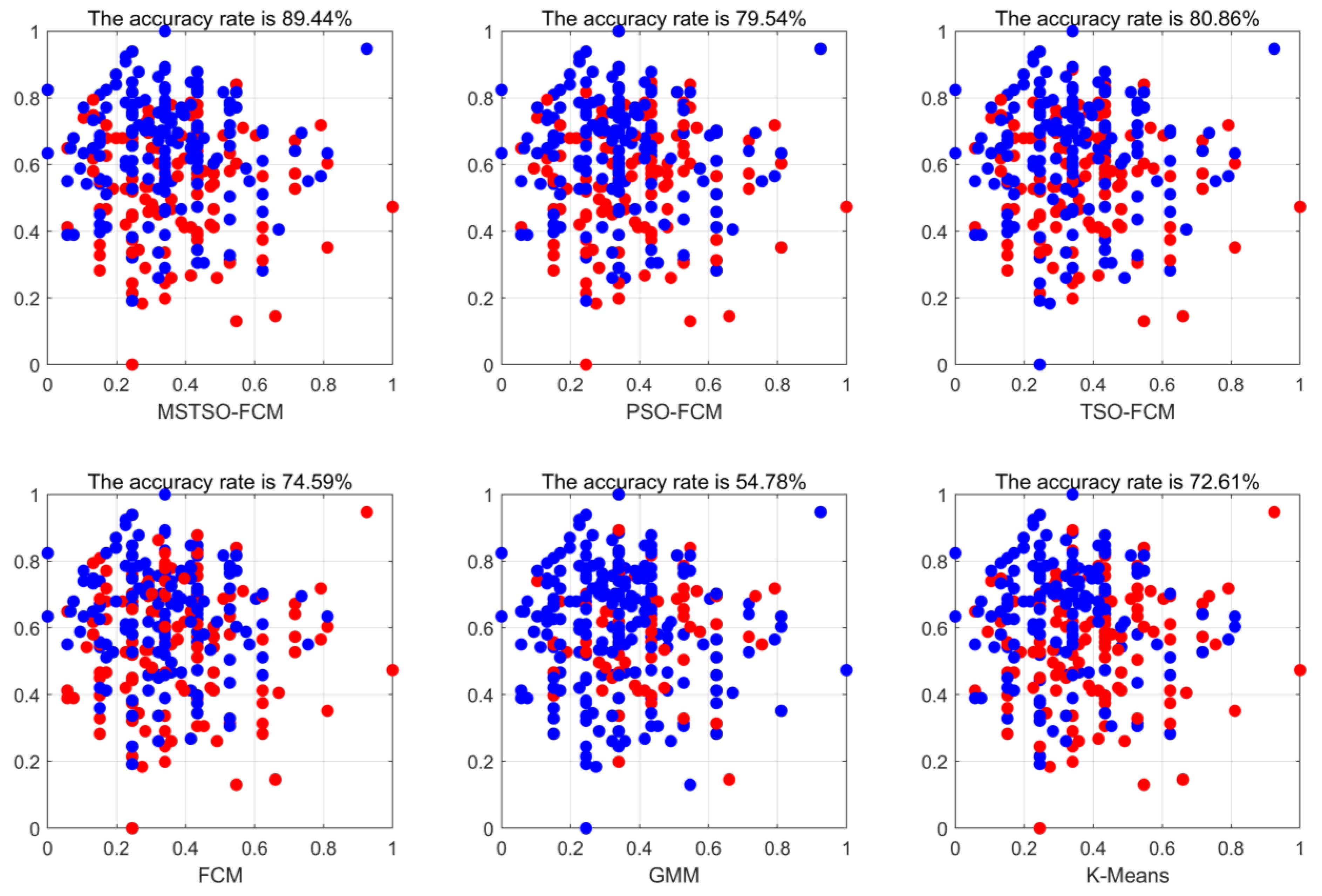
To visualize the clustering effect, the two-dimensional features of the dataset Heart are selected for display. Each color in Figure 4 corresponds to a cluster, and the same color representation of different algorithms may not be the same, but it does not affect the results. It can be seen from the figure that MSTSO-FCM has achieved better clustering results than FCM, TSO-FCM, and PSO-FCM.
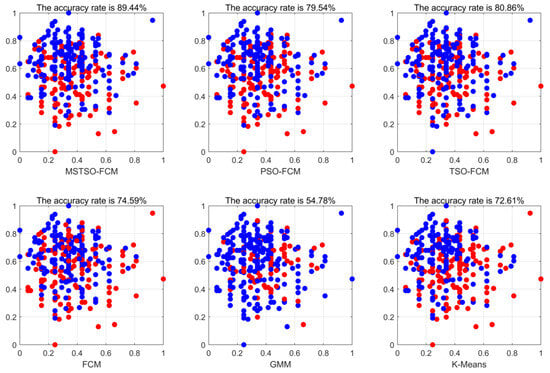
Figure 4.
Heart dataset two-dimensional feature clustering effect visualization.
It can be seen from Table 4 that MTSO-FCM can achieve better classification results in a variety of different sample situations. Compared with FCM, MTSO-FCM overcomes the data sensitivity better and shows excellent classification performance. It can be seen from the AUC index that this algorithm has a better classification ability of positive and negative cases. In Figure 3, the MSTSO algorithm has a better global search ability. However, its computational complexity has not been significantly improved, and it is an improvement on the traditional hard clustering algorithm.
5. Conclusions
In this paper, a clustering algorithm of MSTSO-FCM is proposed, which first integrates the chaotic local search strategy and the shift distribution estimation strategy into the TSO algorithm, which improves the performance of basic TSO by enhancing the development ability and maintaining population diversity. Secondly, the search and development characteristics of the MSTSO algorithm are introduced into the fuzzy matrix of FCM, which overcomes the defects of poor global search ability and sensitive initialization. It not only uses the searchability of MSTSO but also retains the fuzzy mathematical ideas of FCM, to improve the clustering accuracy, stability, and accuracy of the FCM algorithm. In two groups of artificial datasets and four groups of UCI datasets, MSTSO-FCM achieves the first good results in the AC index and AUC index, indicating that it has excellent clustering and classification ability, and has significant improvement compared with TSO-FCM and PSO-FCM in Sil and DB two internal indicators; this shows that the intra-cluster compactness and inter-cluster separation have been improved. The simulation results show that the improved clustering algorithm has better convergence ability and clustering effect.
In the future research direction, the density clustering method will be studied, FCM will be combined with density clustering, and it is necessary to focus more on solving real-world engineering application problems.
Author Contributions
Conceptualization, C.S. and J.Z.; Data curation, C.S.; Formal analysis, Q.S.; Investigation, Z.Z.; Methodology, C.S.; Project administration, J.Z.; Resources, J.Z.; Software, C.S.; Supervision, J.Z.; Validation, C.S., Q.S. and Z.Z.; Visualization, Q.S.; Writing—original draft, C.S.; Writing—review & editing, C.S. and Q.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (Grant No. 42001336).
Data Availability Statement
Data are contained within the article.
Acknowledgments
The authors express their gratitude to the reviewers and editors for their valuable feedback and contributions to refining this manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Table A1.
Test results of seven algorithms at CEC2017.
Table A1.
Test results of seven algorithms at CEC2017.
| Algorithm | Indicator | BOA | RSA | AOA | TSA | SSA | TSO | MSTSO |
|---|---|---|---|---|---|---|---|---|
| F1 | Mean | 3.82 × 104 | 6.76 × 103 | 6.91 × 104 | 3.83 × 104 | 8.40 × 104 | 7.52 × 104 | 2.67 × 10−6 |
| Std | 6.97 × 103 | 2.46 × 103 | 1.15 × 104 | 1.19 × 104 | 6.59 × 103 | 8.60 × 103 | 9.20 × 10−7 | |
| Rank | 3 | 2 | 5 | 4 | 7 | 6 | 1 | |
| F2 | Mean | 9.33 × 103 | 8.48 × 101 | 7.61 × 103 | 1.62 × 103 | 1.44 × 103 | 8.10 × 103 | 5.90 × 101 |
| Std | 1.29 × 103 | 3.03 × 101 | 2.45 × 103 | 1.40 × 103 | 1.09 × 103 | 2.45 × 103 | 1.51 × 100 | |
| Rank | 7 | 2 | 5 | 4 | 3 | 6 | 1 | |
| F3 | Mean | 3.49 × 102 | 1.23 × 102 | 2.95 × 102 | 2.76 × 102 | 3.50 × 102 | 4.04 × 102 | 3.42 × 101 |
| Std | 2.16 × 101 | 2.19 × 101 | 3.20 × 101 | 4.09 × 101 | 4.40 × 101 | 2.46 × 101 | 1.25 × 101 | |
| Rank | 5 | 2 | 4 | 3 | 6 | 7 | 1 | |
| F4 | Mean | 6.63 × 101 | 2.49 × 101 | 6.21 × 101 | 6.15 × 101 | 8.06 × 101 | 8.29 × 101 | 6.44 × 10−3 |
| Std | 5.76 × 100 | 7.04 × 100 | 6.71 × 100 | 1.43 × 101 | 8.84 × 100 | 8.30 × 100 | 8.25 × 10−3 | |
| Rank | 5 | 2 | 4 | 3 | 6 | 7 | 1 | |
| F5 | Mean | 5.57 × 102 | 2.12 × 102 | 6.00 × 102 | 4.83 × 102 | 7.12 × 102 | 6.59 × 102 | 6.07 × 101 |
| Std | 3.17 × 101 | 5.10 × 101 | 5.66 × 101 | 7.78 × 101 | 6.85 × 101 | 5.57 × 101 | 1.48 × 101 | |
| Rank | 4 | 2 | 5 | 3 | 7 | 6 | 1 | |
| F6 | Mean | 2.93 × 102 | 9.91 × 101 | 2.25 × 102 | 2.34 × 102 | 2.72 × 102 | 3.28 × 102 | 3.64 × 101 |
| Std | 1.54 × 101 | 2.68 × 101 | 2.67 × 101 | 3.99 × 101 | 4.31 × 101 | 1.94 × 101 | 1.30 × 101 | |
| Rank | 6 | 2 | 3 | 4 | 5 | 7 | 1 | |
| F7 | Mean | 6.82 × 103 | 1.53 × 103 | 4.50 × 103 | 8.57 × 103 | 9.35 × 103 | 8.55 × 103 | 1.56 × 10−1 |
| Std | 8.69 × 102 | 6.00 × 102 | 7.24 × 102 | 3.01 × 103 | 1.85 × 103 | 9.42 × 102 | 2.74 × 10−1 | |
| Rank | 4 | 2 | 3 | 6 | 7 | 5 | 1 | |
| F8 | Mean | 7.33 × 103 | 3.76 × 103 | 5.51 × 103 | 5.55 × 103 | 7.05 × 103 | 7.22 × 103 | 4.84 × 103 |
| Std | 2.85 × 102 | 6.30 × 102 | 5.83 × 102 | 6.07 × 102 | 7.45 × 102 | 3.98 × 102 | 7.52 × 102 | |
| Rank | 7 | 1 | 3 | 4 | 5 | 6 | 2 | |
| F9 | Mean | 2.19 × 103 | 1.00 × 102 | 1.72 × 103 | 2.23 × 103 | 3.91 × 103 | 7.28 × 103 | 2.42 × 101 |
| Std | 6.72 × 102 | 4.16 × 101 | 9.74 × 102 | 1.69 × 103 | 1.64 × 103 | 1.81 × 103 | 2.31 × 101 | |
| Rank | 4 | 2 | 3 | 5 | 6 | 7 | 1 | |
| F10 | Mean | 2.08 × 109 | 8.30 × 104 | 6.27 × 109 | 8.88 × 108 | 4.69 × 108 | 1.32E+10 | 3.09 × 102 |
| Std | 7.43 × 108 | 7.32 × 104 | 2.56 × 109 | 1.07 × 109 | 3.76 × 108 | 2.71 × 109 | 2.15 × 102 | |
| Rank | 5 | 2 | 6 | 4 | 3 | 7 | 1 | |
| F11 | Mean | 3.15 × 108 | 1.01 × 104 | 3.80 × 104 | 1.75 × 108 | 8.55 × 107 | 8.92 × 109 | 4.96 × 101 |
| Std | 2.10 × 108 | 1.20 × 104 | 1.71 × 104 | 4.14 × 108 | 4.66 × 108 | 3.93 × 109 | 1.67 × 101 | |
| Rank | 6 | 2 | 3 | 5 | 4 | 7 | 1 | |
| F12 | Mean | 1.19 × 105 | 2.45 × 103 | 5.72 × 104 | 3.73 × 105 | 1.50 × 106 | 5.68 × 106 | 3.23 × 101 |
| Std | 7.62 × 104 | 2.63 × 103 | 4.92 × 104 | 6.73 × 105 | 1.21 × 106 | 4.39 × 106 | 8.21 × 100 | |
| Rank | 4 | 2 | 3 | 5 | 6 | 7 | 1 | |
| F13 | Mean | 1.82 × 106 | 7.17 × 103 | 2.35 × 104 | 2.48 × 107 | 1.83 × 107 | 5.67 × 108 | 2.41 × 101 |
| Std | 1.46 × 106 | 7.41 × 103 | 1.22 × 104 | 7.80 × 107 | 2.37 × 107 | 3.47 × 108 | 4.53 × 100 | |
| Rank | 4 | 2 | 3 | 6 | 5 | 7 | 1 | |
| F14 | Mean | 3.18 × 103 | 9.68 × 102 | 1.98 × 103 | 1.43 × 103 | 2.74 × 103 | 3.90 × 103 | 4.12 × 102 |
| Std | 4.12 × 102 | 3.29 × 102 | 5.09 × 102 | 2.92 × 102 | 5.38 × 102 | 6.13 × 102 | 2.62 × 102 | |
| Rank | 6 | 2 | 4 | 3 | 5 | 7 | 1 | |
| F15 | Mean | 1.22 × 103 | 4.21 × 102 | 9.12 × 102 | 6.06 × 102 | 1.20 × 103 | 2.69 × 103 | 1.04 × 102 |
| Std | 2.49 × 102 | 1.77 × 102 | 2.67 × 102 | 2.30 × 102 | 3.85 × 102 | 1.14 × 103 | 4.28 × 101 | |
| Rank | 6 | 2 | 4 | 3 | 5 | 7 | 1 | |
| F16 | Mean | 9.60 × 105 | 1.21 × 105 | 1.29 × 106 | 2.08 × 106 | 1.51 × 107 | 3.51 × 107 | 3.02 × 101 |
| Std | 6.22 × 105 | 1.09 × 105 | 1.60 × 106 | 4.09 × 106 | 1.51 × 107 | 2.38 × 107 | 2.15 × 100 | |
| Rank | 3 | 2 | 4 | 5 | 6 | 7 | 1 | |
| F17 | Mean | 4.61 × 106 | 8.43 × 103 | 1.08 × 106 | 1.11 × 107 | 4.23 × 107 | 6.66 × 108 | 2.17 × 101 |
| Std | 4.06 × 106 | 9.45 × 103 | 1.39 × 105 | 3.45 × 107 | 1.23 × 108 | 3.75 × 108 | 3.32 × 100 | |
| Rank | 4 | 2 | 3 | 5 | 6 | 7 | 1 | |
| F18 | Mean | 7.29 × 102 | 3.97 × 102 | 6.94 × 102 | 7.24 × 102 | 8.59 × 102 | 9.81 × 102 | 1.76 × 102 |
| Std | 9.88 × 101 | 1.32 × 102 | 1.54 × 102 | 2.09 × 102 | 2.42 × 102 | 1.38 × 102 | 6.63 × 101 | |
| Rank | 5 | 2 | 3 | 4 | 6 | 7 | 1 | |
| F19 | Mean | 1.97 × 102 | 3.03 × 102 | 4.87 × 102 | 4.68 × 102 | 5.06 × 102 | 6.05 × 102 | 2.35 × 102 |
| Std | 3.01 × 101 | 2.44 × 101 | 5.23 × 101 | 4.96 × 101 | 5.36 × 101 | 4.53 × 101 | 1.51 × 101 | |
| Rank | 1 | 3 | 5 | 4 | 6 | 7 | 2 | |
| F20 | Mean | 4.71 × 102 | 1.01 × 102 | 5.13 × 103 | 4.47 × 103 | 4.18 × 103 | 6.15 × 103 | 1.00 × 102 |
| Std | 7.76 × 101 | 2.02 × 100 | 1.21 × 103 | 2.09 × 103 | 1.88 × 103 | 1.31 × 103 | 5.68 × 10−1 | |
| Rank | 3 | 2 | 6 | 5 | 4 | 7 | 1 | |
| F21 | Mean | 6.97 × 102 | 4.97 × 102 | 9.68 × 102 | 7.86 × 102 | 8.60 × 102 | 1.13 × 103 | 3.86 × 102 |
| Std | 5.59 × 101 | 4.04 × 101 | 9.10 × 101 | 8.15 × 101 | 1.00 × 102 | 1.10 × 102 | 1.59 × 101 | |
| Rank | 3 | 2 | 6 | 4 | 5 | 7 | 1 | |
| F22 | Mean | 1.10 × 103 | 5.59 × 102 | 1.14 × 103 | 8.47 × 102 | 8.99 × 102 | 1.20 × 103 | 4.57 × 102 |
| Std | 1.68 × 102 | 5.59 × 101 | 1.09 × 102 | 8.08 × 101 | 1.37 × 102 | 1.92 × 102 | 1.41 × 101 | |
| Rank | 5 | 2 | 6 | 3 | 4 | 7 | 1 | |
| F23 | Mean | 1.75 × 103 | 3.93 × 102 | 1.67 × 103 | 7.61 × 102 | 7.84 × 102 | 2.54 × 103 | 3.87 × 102 |
| Std | 2.01 × 102 | 1.44 × 101 | 4.55 × 102 | 3.02 × 102 | 1.30 × 102 | 5.87 × 102 | 6.52 × 10−2 | |
| Rank | 6 | 2 | 5 | 3 | 4 | 7 | 1 | |
| F24 | Mean | 5.21 × 103 | 2.34 × 103 | 6.40 × 103 | 5.01 × 103 | 6.30 × 103 | 8.12 × 103 | 1.32 × 103 |
| Std | 1.49 × 103 | 9.05 × 102 | 7.22 × 102 | 8.76 × 102 | 1.11 × 103 | 6.89 × 102 | 1.46 × 102 | |
| Rank | 4 | 2 | 6 | 3 | 5 | 7 | 1 | |
| F25 | Mean | 8.14 × 102 | 5.59 × 102 | 1.34 × 103 | 7.30 × 102 | 9.56 × 102 | 1.49 × 103 | 5.00 × 102 |
| Std | 9.81 × 101 | 4.78 × 101 | 2.14 × 102 | 9.92 × 101 | 1.65 × 102 | 3.99 × 102 | 8.10 × 100 | |
| Rank | 4 | 2 | 6 | 3 | 5 | 7 | 1 | |
| F26 | Mean | 3.28 × 103 | 3.71 × 102 | 2.95 × 103 | 1.27 × 103 | 1.06 × 103 | 3.57 × 103 | 3.53 × 102 |
| Std | 3.99 × 102 | 5.38 × 101 | 6.15 × 102 | 4.52 × 102 | 3.22 × 102 | 7.74 × 102 | 6.03 × 101 | |
| Rank | 6 | 2 | 5 | 4 | 3 | 7 | 1 | |
| F27 | Mean | 3.04 × 103 | 1.01 × 103 | 2.43 × 103 | 1.58 × 103 | 2.64 × 103 | 4.07 × 103 | 5.42 × 102 |
| Std | 4.72 × 102 | 2.69 × 102 | 5.22 × 102 | 4.08 × 102 | 6.35 × 102 | 1.11 × 103 | 7.38 × 101 | |
| Rank | 6 | 2 | 4 | 3 | 5 | 7 | 1 | |
| F28 | Mean | 3.98 × 107 | 6.41 × 103 | 1.47 × 107 | 1.33 × 107 | 4.85 × 107 | 1.58 × 109 | 2.00 × 103 |
| Std | 2.31 × 107 | 3.26 × 103 | 1.01 × 107 | 1.07 × 107 | 3.75 × 107 | 5.48 × 108 | 8.39 × 101 | |
| Rank | 5 | 2 | 4 | 3 | 6 | 7 | 1 |
Appendix B
Table A2.
Wilcoxon signed rank results on CEC2017.
Table A2.
Wilcoxon signed rank results on CEC2017.
| Function | BOA | RSA | AOA | TSA | SSA | TSO |
|---|---|---|---|---|---|---|
| F1 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F2 | 5.15 × 10−10 | 2.31 × 10−6 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F3 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F4 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F5 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F6 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F7 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F8 | 5.15 × 10−10 | 6.03 × 10−8 | 1.62 × 10−5 | 5.23 × 10−6 | 5.15 × 10−10 | 5.15 × 10−10 |
| F9 | 5.15 × 10−10 | 8.27 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F11 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F12 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F13 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F14 | 5.15 × 10−10 | 1.02 × 10−8 | 5.46 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F15 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F16 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F17 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F18 | 5.15 × 10−10 | 9.87 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F19 | 4.40 × 10−8 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F20 | 5.15 × 10−10 | 3.68 × 10−1 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F21 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F22 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F23 | 5.15 × 10−10 | 2.76 × 10−2 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F24 | 5.15 × 10−10 | 3.96 × 10−7 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F25 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F26 | 5.15 × 10−10 | 3.92 × 10−2 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F27 | 5.15 × 10−10 | 5.80 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
| F28 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 | 5.15 × 10−10 |
References
- Atluri, G.; Karpatne, A.; Kumar, V. Spatio-temporal data mining: A survey of problems and methods. Acm Comput. Surv. 2018, 51, 1–41. [Google Scholar] [CrossRef]
- Jia, H.M.; Jiang, Z.C.; Li, Y. Simultaneous feature selection optimization based on improved bald eagle search algorithm. Control Decis. 2022, 37, 445–454. [Google Scholar]
- Banerjee, D. Recent progress on cluster and meron algorithms for strongly correlated systems. Indian J. Phys. 2021, 95, 1669–1680. [Google Scholar] [CrossRef]
- Mohapatra, S.K.; Sahu, P.; Almotiri, J.; Alroobaea, R.; Rubaiee, S.; Bin Mahfouz, A.; Senthilkumar, A.P. Segmentation and classification of encephalon tumor by applying improved fast and robust FCM Algorithm with PSO-based ELM Technique. Comput. Intell. Neurosci. 2022, 2002, 1–9. [Google Scholar] [CrossRef]
- Mehran, M.; Ali, K.; Hamed, H. Clustering-based reliability assessment of smart grids by fuzzy c-means algorithm considering direct cyber–physical interdependencies and system uncertainties. Sustain. Energy Grids Netw. 2002, 31, 100757. [Google Scholar]
- Yang, Q. An FCM clustering algorithm based on the identification of accounting statement whitewashing behavior in universities. J. Intell. Syst. 2022, 31, 345–355. [Google Scholar] [CrossRef]
- Poli, R.; Kennedy, J.; Blackwell, T. Particle swarm optimization. Swarm Intell. 2007, 1, 33–57. [Google Scholar] [CrossRef]
- Maryam, M.; Reza, S.A.; Arash, D. Optimization of fuzzy c-means (FCM) clustering in cytology image segmentation using the gray wolf algorithm. BMC Mol. Cell Biol. 2022, 23, 9. [Google Scholar]
- Amit, B.; Issam, A. A novel adaptive FCM with cooperative multi-population differential evolution optimization. Algorithms 2022, 15, 380. [Google Scholar]
- Niknam, T.; Olamaei, J.; Amiri, B. A Hybrid Evolutionary Algorithm Based on ACO and SA for Cluster Analysis. J. Appl. Sci. 2008, 8, 2695–2702. [Google Scholar] [CrossRef]
- Gao, H.; Li, Y.; Kabalyants, P.; Xu, H.; Martinez-Bejar, R. A Novel Hybrid PSO-K-Means Clustering Algorithm Using Gaussian Estimation of Distribution Method and Lévy Flight. IEEE Access 2020, 8, 122848–122863. [Google Scholar] [CrossRef]
- Izakian, H.; Abraham, A. Fuzzy C-means and fuzzy swarm for fuzzy clustering problem. Expert Syst. Appl. 2011, 38, 1835–1838. [Google Scholar] [CrossRef]
- Qian, Z.; Cao, Y.; Sun, X.; Ni, L.; Wang, Z.; Chen, X. Clustering optimization for triple-frequency combined obser-vations of BDS-3 based on improved PSO-FCM algorithm. Remote Sens. 2022, 14, 3713. [Google Scholar] [CrossRef]
- Celal, O.; Emrah, H.; Dervis, K. Dynamic clustering with improved binary artificial bee colony algorithm. Appl. Soft Comput. 2015, 28, 69–80. [Google Scholar]
- Wang, J.; Zhu, L.; Wu, B.; Ryspayev, A. Forestry Canopy Image Segmentation Based on Improved Tuna Swarm Optimization. Forests 2022, 13, 1746. [Google Scholar] [CrossRef]
- Wang, W.; Tian, J. An Improved Nonlinear Tuna Swarm Optimization Algorithm Based on Circle Chaos Map and Levy Flight Operator. Electronics 2022, 11, 3678. [Google Scholar] [CrossRef]
- Tuerxun, W.; Xu, C.; Guo, H.; Guo, L.; Zeng, N.; Cheng, Z. An ultra-short-term wind speed prediction model using LSTM based on modified tuna swarm optimization and successive variational mode decomposition. Energy Sci. Eng. 2022, 10, 3001–3022. [Google Scholar] [CrossRef]
- Tan, M.; Li, Y.; Ding, D.; Zhou, R.; Huang, C. An Improved JADE Hybridizing with Tuna Swarm Optimization for Numerical Optimization Problems. Math. Probl. Eng. 2022, 2022, 1–17. [Google Scholar] [CrossRef]
- Awad, A.; Kamel, S.; Hassan, M.H.; Elnaggar, M.F. An Enhanced Tuna Swarm Algorithm for Optimizing FACTS and Wind Turbine Allocation in Power Systems. Electr. Power Compon. Syst. 2023. [Google Scholar] [CrossRef]
- Kumar, C.; Mary, D.M. A novel chaotic-driven Tuna Swarm Optimizer with Newton-Raphson method for parameter identification of three-diode equivalent circuit model of solar photovoltaic cells/modules. Optik 2022, 264, 169379. [Google Scholar] [CrossRef]
- Ren, Q.; Zhang, H.; Zhang, D.; Zhao, X. Lithology identification using principal component analysis and particle swarm optimization fuzzy decision tree. J. Pet. Sci. Eng. 2023, 220, 111233. [Google Scholar] [CrossRef]
- Wu, T.-Y.; Lin, J.C.-W.; Zhang, Y.; Chen, C.-H. A Grid-Based Swarm Intelligence Algorithm for Privacy-Preserving Data Mining. Appl. Sci. 2019, 9, 774. [Google Scholar] [CrossRef]
- Shao, Y.; Lin, J.C.-W.; Srivastava, G.; Guo, D.; Zhang, H.; Yi, H.; Jolfaei, A. Multi-Objective Neural Evolutionary Algorithm for Combinatorial Optimization Problems. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 2133–2143. [Google Scholar] [CrossRef]
- Kubicek, J.; Varysova, A.; Cerny, M.; Skandera, J.; Oczka, D.; Augustynek, M.; Penhaker, M. Novel Hybrid Optimized Clustering Schemes with Genetic Algorithm and PSO for Segmentation and Classification of Articular Cartilage Loss from MR Images. Mathematics 2023, 11, 1027. [Google Scholar] [CrossRef]
- Aggarwal, A.; Dimri, P.; Agarwal, A.; Verma, M.; Alhumyani, H.A.; Masud, M. IFFO: An Improved Fruit Fly Optimization Algorithm for Multiple Workflow Scheduling Minimizing Cost and Makespan in Cloud Computing Environments. Math. Probl. Eng. 2021, 2021, 1–9. [Google Scholar] [CrossRef]
- Aggarwal, A.; Kumar, S.; Bhatt, A.; Shah, M.A. Solving User Priority in Cloud Computing Using Enhanced Optimization Algorithm in Workflow Scheduling. Comput. Intell. Neurosci. 2022, 2022, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Upadhyay, P.; Marriboina, V.; Kumar, S.; Kumar, S.; Shah, M.A. An Enhanced Hybrid Glowworm Swarm Optimization Algorithm for Traffic-Aware Vehicular Networks. IEEE Access 2022, 10, 110136–110148. [Google Scholar] [CrossRef]
- Balaji, P.; Muniasamy, V.; Bilfaqih, S.M. Chimp Optimization Algorithm Influenced Type-2 Intuitionistic Fuzzy C-Means Clustering-Based Breast Cancer Detection System. Cancers 2023, 15, 1131. [Google Scholar] [CrossRef] [PubMed]
- Usman, Q. A dissimilarity measure based fuzzy c-means (FCM) clustering algorithm. J. Intell. Fuzzy 2014, 26, 229–238. [Google Scholar]
- Tanveer, M.; Gautam, C.; Suganthan, P. Comprehensive evaluation of twin SVM based classifiers on UCI datasets. Appl. Soft Comput. 2019, 83, 105617. [Google Scholar] [CrossRef]
- Ma, Y.; Hao, Y. Antenna Classification Using Gaussian Mixture Models (GMM) and Machine Learning. IEEE Open J. Antennas Propag. 2020, 1, 320–328. [Google Scholar] [CrossRef]
- Mao, B.; Li, B. Building façade semantic segmentation based on K-means classification and graph analysis. Arab. J. Geosci. 2019, 12, 1–9. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).