
Consequential Advancements of Self-Supervised Learning (SSL) in Deep Learning Contexts
 , , , ,
, , , ,  , and
, and 
Abstract
:1. Introduction
- Section 2 is prepared to outline the principal research method adopted to identify the dominant advantages of SSL algorithms in accomplishing efficient classification tasks without the identification of essential datasets crucial for training and testing procedures to maximize the model’s classification effectiveness.
- Section 3 is structured to explain the extensive review’s prominent findings and influential characteristics that allow SSL paradigms to accomplish different classification tasks, offering elevated scales of robustness and efficacy.
- Section 4 illustrates further breakthroughs and state of the art that have been lately implemented through several research investigations and numerical simulations to foster the SSL algorithms’ categorization productivity and feasibility.
- Section 5 provides noteworthy illustrations and discussion pertaining to the evaluation of SSL serviceable applications and other crucial aspects for classifying and recognizing unlabeled data.
- Section 6 expresses the main research conclusions.
- Section 7 points out the imperative areas of future work that can be considered by other investigators to provide further modifications and enhancements to the current SSL models.
- Section 8 expresses the critical research limitations encountered in the review implementation until it is completed.
- Cutting much time, effort, and cost connected with essential data annotation for conventional DL and ML models adopted to support medical therapists in diagnosing the type of problem in visual databases,
- Achieving the same relevance for industrial engineers, who wish to make machine prognostics as necessary periodic maintenance actions robustly,
- Performing precise predictions of different problems in medicine, industry, or other important disciplines, where new behaviors of data do not follow previously noted trends, helps predict new data patterns flexibly and reliably in real-life situations.
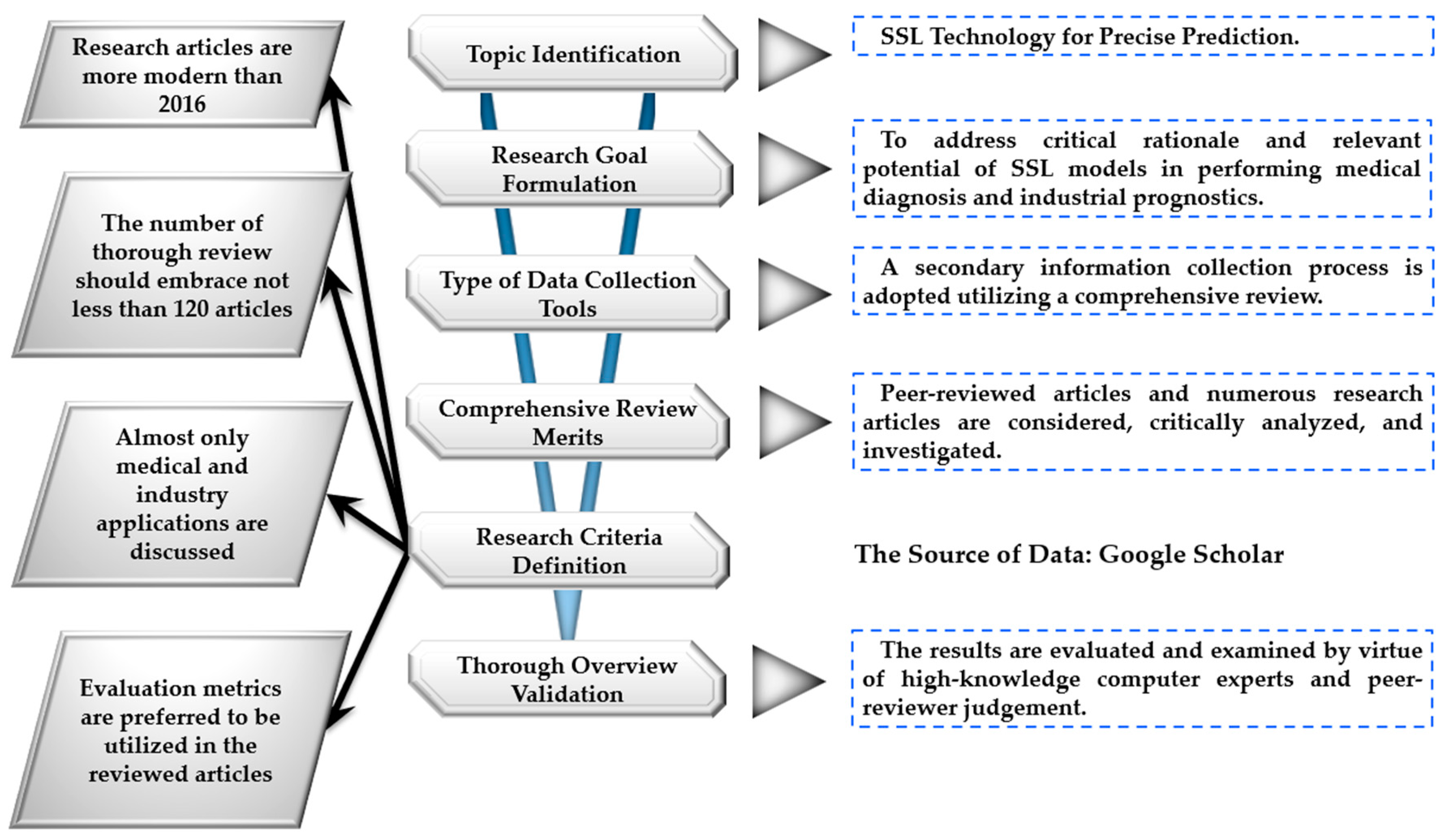
2. Materials and Methods
2.1. Data Collection Approach
2.2. The Database Selection Criteria
- The multiple research publications analyzed and surveyed are more modern than in 2016. Thus, the latest results and state-of-the-art advantages can be extracted.
- The core focus of the inspected articles in this thorough overview is linked to SSL’s significance in industry and medicine when involved in periodic machinery prognostics and clinical diagnosis, respectively.
- After completing the analysis of SSL’s relevant merits from the available literature, critical appraisal is applied, referring to some expert estimations and peer reviewer opinions to validate and verify the reliability and robustness of the paper’s overall findings.
3. Related Work
3.1. Major Characteristics and Essential Workabilities of SSL
3.2. Main SSL Categories
3.2.1. Generative SSL Models
- —A group of random noise vectors with an overall amount of N
- —A dataset comprising a set of real images having a total number of .
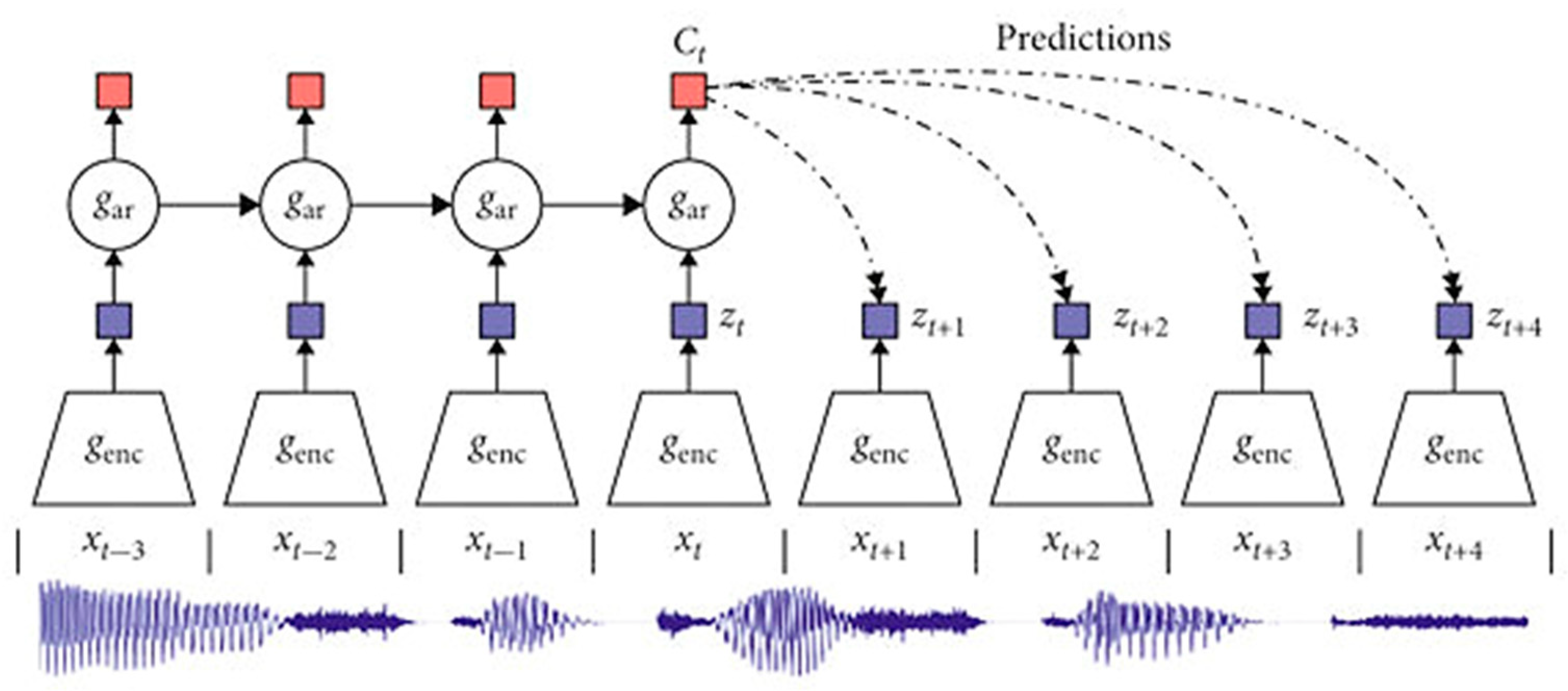
3.2.2. Predictive SSL Paradigms
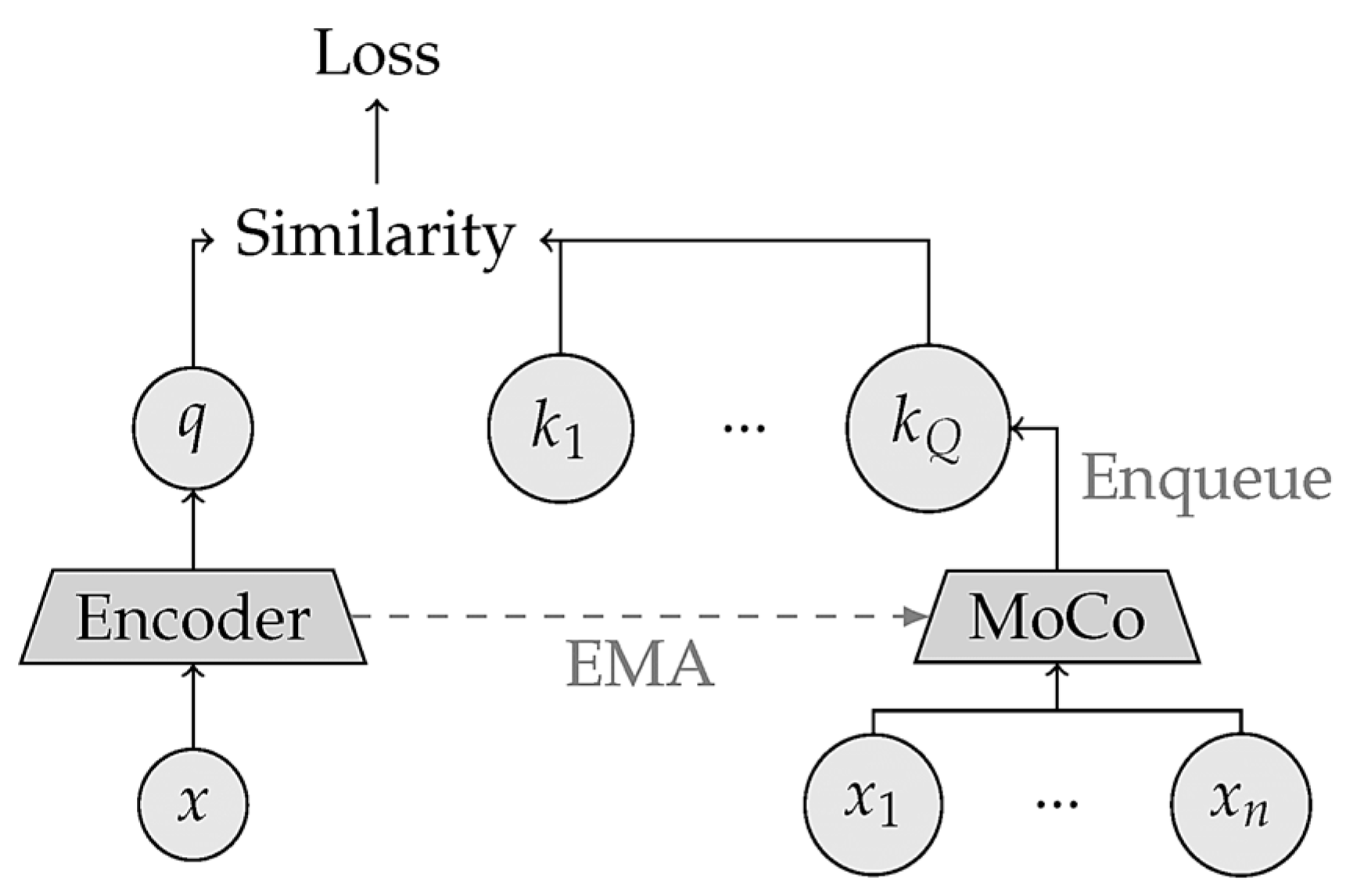
3.2.3. Contrastive SSL Paradigms
- —The positive vector value of the anchor x
- —The negative vector value of the anchor x
- —The embedding function
- —The value of the margin parameter.
- the dot product between and .
- the temperature variable to scale the levels of similarity, distribution, and sharpness.
- the embedding function.
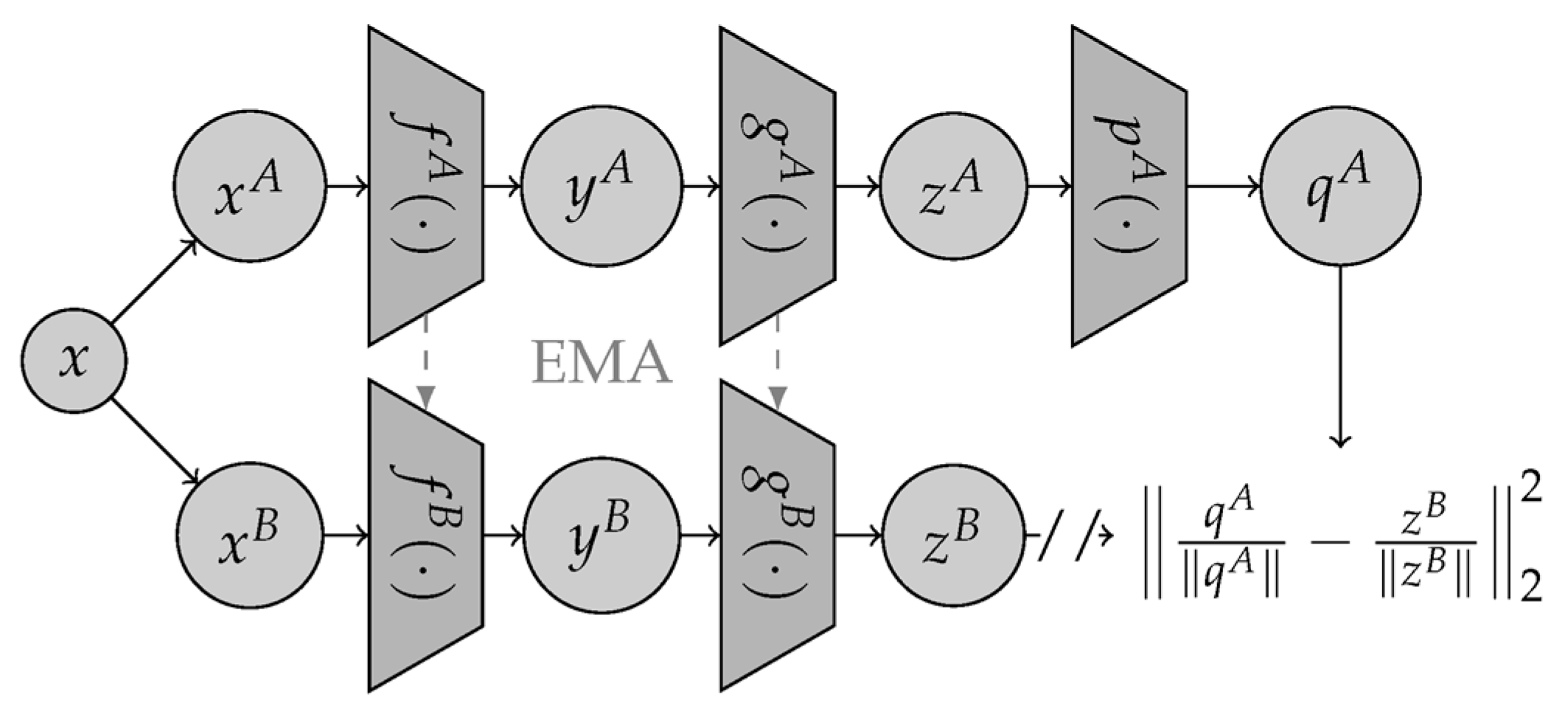
3.2.4. Non-Contrastive SSL Models
3.3. Practical Applications of SSL Models
- Minimizing the massive cost connected with data labeling phases is essential to facilitating a high-quality classification/prediction process.
- Alleviating the corresponding time needed to classify/recognize vital information in a dataset,
- Optimizing the data preparation lifecycle is typically a lengthy procedure in various ML models. It relies on filtering, cleaning, reviewing, annotating, and reconstructing processes through training phases.
- Enhancing the effectiveness of AI models. SSL paradigms can be recognized as functional tools that allow flexible involvement in innovative human thinking and machine cognition.
3.3.1. SSL Models for Medical Predictions
3.3.2. SSL Models for Engineering Contexts
3.3.3. Patch Localization
3.3.4. Context-Aware Pixel Prediction
3.3.5. Natural Language Processing
3.3.6. Auto-Regressive Language Modeling
3.4. Commonly-Utilized Feature Indicators of SSL Models’ Performance

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Indicator Type | Major Formula | Eq# |
|---|---|---|
| Mean Value | (7) | |
| Standard Deviation | (8) | |
| Square Root Amplitude | (9) | |
| Absolute Mean Value | (10) | |
| Skewness | (11) | |
| Kurtosis | (12) | |
| Variance | (13) | |
| Kurtosis Index | (14) | |
| Peak Index | (15) | |
| Waveform Index | (16) | |
| Pulse Index | (17) | |
| Skewness Index | (18) | |
| Frequency Mean Value | (19) | |
| Frequency Variance | (20) | |
| Frequency Skewness | (21) | |
| Frequency Steepness | (22) | |
| Gravity Frequency | (23) | |
| Frequency Standard Deviation | (24) | |
| Frequency Root Mean Square | (25) | |
| Average Frequency | (26) | |
| Regularity Degree | (27) | |
| Variation Parameter | (28) | |
| Eigth-Order Moment | (29) | |
| Sixteenth-Order Moment | (30) |
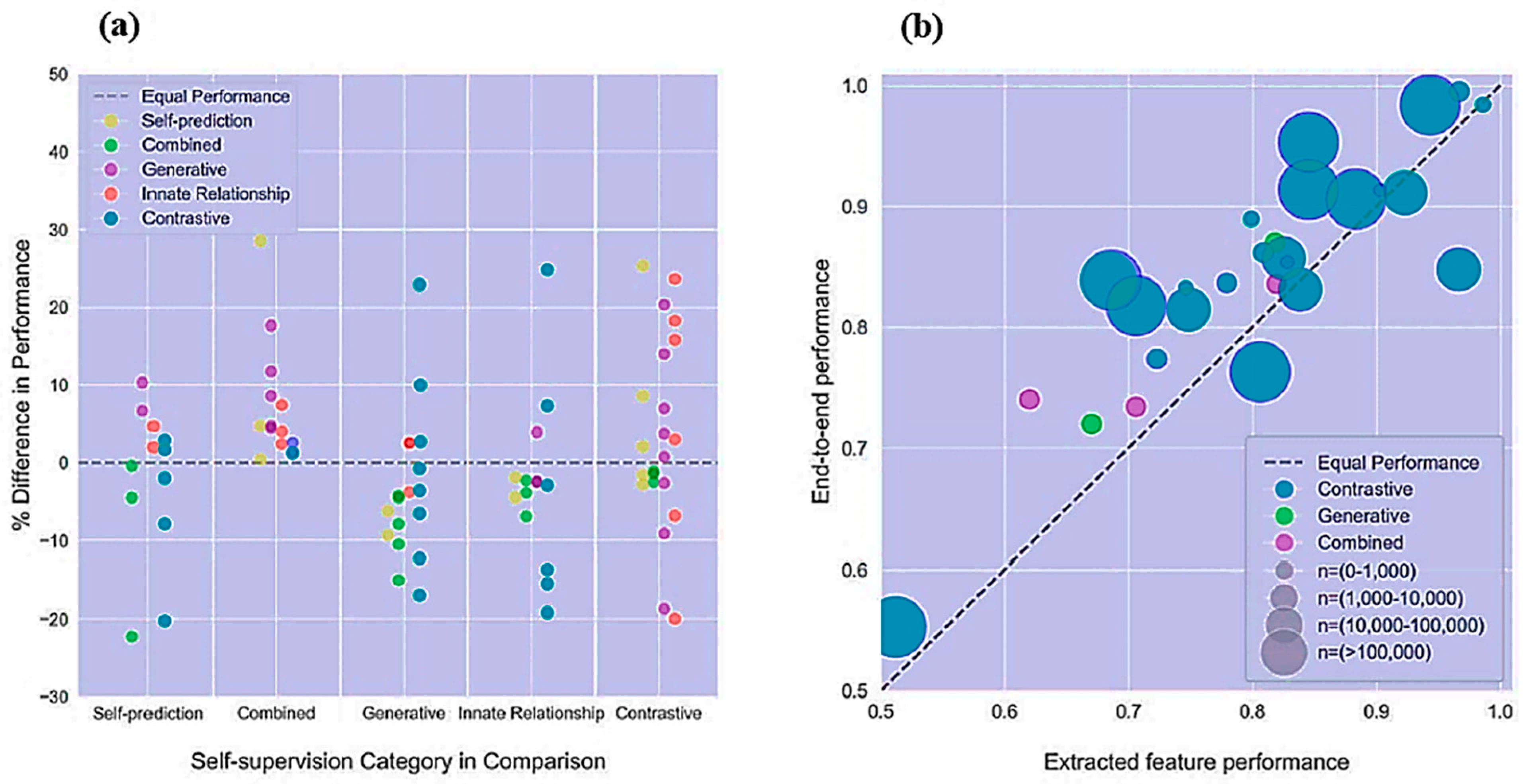
4. Statistical Figures on Critical SSL Rationale
5. Discussion
- Generative Adversarial Networks (GAN);
- Deep InfoMax (DIM);
- Pre-trained Language Models (PTM);
- Contrastive Predictive Coding (CPC);
- Autoencoder and its associated extensions.
5.1. Generative Adversarial Networks (GAN)
5.2. Deep InfoMax (DIM)
5.3. Pre-Trained Language Models (PTM)
5.4. Contrastive Predictive Coding (CPC)
5.5. Autoencoder and Its Associated Extensions
6. Conclusions
- Involving SSL algorithms in industrial engineering and clinical contexts could support manufacturing engineers and therapists in carrying out efficient classification procedures and predictions of the current machine fault and patient problems with remarkable levels of performance, accuracy, and feasibility.
- Profitable savings in the computational budget, time, storage, and effort needed in the annotation and training of unlabeled data can be eliminated when SSL is utilized, maintaining approximately optimum prediction efficacy.
- Functional human thinking, learning approaches, and cognition are utilized in SSL models, contributing to upgraded machine classification and computer prediction outcomes correlated with different fields.
7. Future Work
- To review the importance of SSL in carrying out accurate predictions pertaining to other scientific domains.
- To overcome some problems not addressed carefully in the literature encountering most SSL models, reflected in SSL trials, analyze and take into consideration solely semantic characteristics linked to the investigated dataset. They do not benefit from critical features existing in visual medical databases.
- To classify other crucial applications of SSL, including either recognition or categorization, not correlated with the relevance of the predictions addressed in this paper.
- To identify other remarkable profitabilities and workable practicalities of SSL other than their contributions to cutting much computational time, budget, and effort for necessary data annotation in the same prediction context.
- To expand this overview with a few case studies in which contributory SSL predictions are carefully explained.
8. Research Limitations
- Some newly published academic papers (more than 2022) have no direct access to download the overall document. Additionally, some web journals do not have full access to researchers, even for oldly published papers. For this reason, the only extracted data from those articles were the abstract.
- There is a lack of abundant databases correlated with the direct applications involved in SSL in machinery prognostics and medical diagnosis.
- There were no direct explanations or abundant classifications of major SSL limitations that needed to be addressed and handled.
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| AI | Artificial Intelligence |
| AE | Autoencoder |
| AP | Average Precision |
| APC | Autoregressive Predictive Coding |
| AUCs | Area under the Curve |
| AUROC | Area Under the Receiver Operating Characteristic |
| BERT | Bidirectional Encoder Representations from Transformers |
| BoW | Bag-of-Visual-Words |
| BYOL | Bootstrap Your Own Latent |
| CaiD | Context-Aware instance Discrimination |
| CERT | Contrastive self-supervised Encoder Representations through Transformers |
| CNNs | Convolutional Neural Networks |
| CPC | Contrastive Predictive Coding |
| CT | Computed Tomography |
| DCL | Dense Contrastive Learning |
| DIM | Deep InfoMax |
| DL | Deep Learning |
| DNN | Deep Neural Network |
| DSC | Dice Similarity Coefficient |
| EHRs | Electronic Health Records |
| EMA | Exponentially Moving Average |
| EVs | Electric Vehicles |
| GAN | Generative Adversarial Network |
| GPT | Generative Pre-trained Transformer |
| HVAC | Heating, Ventilation, And Air-Conditioning |
| IoU | Intersection over Union |
| Li-ion | Lithium-ion |
| LMLM | Label-Masked Language Model |
| LMs | Language Models |
| LR | Logistic Regression |
| LSTM | Long Short-Term Memory |
| MAE | Mean-Absolute-Error |
| ML | Machine Learning |
| MLC | Multi-Layer Classifiers |
| MLM | Masked Language Model |
| MoCo | Momentum Contrast |
| MPC | Model Predictive Control |
| MPQA | Multi-Perspective Question Answering |
| MRs | Movie Reviews |
| MSAs | Multiple Sequence Alignments |
| NAIP | National Agricul-ture Imagery Pro-gram |
| NLP | Natural Language Processing |
| NSA | Natural Synthetic Anomalies |
| PdL | Predictive Learning |
| pLMs | protein LMs |
| PPG | Phoneme Posteriororgram |
| PTM | Pre-trained Language Models |
| PxL | Pretext Learning |
| RF | Random Forest |
| RMSE | Root-Mean-Square-Error |
| RNN | Recurrent Neural Network |
| ROC | Receiver Operating Characteristic |
| RUL | Remaining Useful Life |
| SL | Supervised Learning |
| SOC | State of Charge |
| SSEDD | Self-Supervised Efficient Defect Detector |
| SSL | Self-Supervised Learning |
| SST2 | Stanford Sentiment Treebank-2 |
| SwAV | Swapping Assignments across Views |
| TREC | Text Retrieval Conference |
| USL | Unsupervised Learning |
| VAE | Variational Auto-Encoders |
| VC | Voice Conversion |
| VICReg | Variance, Invariance, and Covariance Regularization |
References
- Lai, Y. A Comparison of Traditional Machine Learning and Deep Learning in Image Recognition. J. Phys. Conf. Ser. 2019, 1314, 012148. [Google Scholar] [CrossRef]
- Rezaeianjouybari, B.; Shang, Y. Deep learning for prognostics and health management: State of the art, challenges, and opportunities. Measurement 2020, 163, 107929. [Google Scholar] [CrossRef]
- Thoppil, N.M.; Vasu, V.; Rao, C.S.P. Deep Learning Algorithms for Machinery Health Prognostics Using Time-Series Data: A Review. J. Vib. Eng. Technol. 2021, 9, 1123–1145. [Google Scholar] [CrossRef]
- Zhang, L.; Lin, J.; Liu, B.; Zhang, Z.; Yan, X.; Wei, M. A Review on Deep Learning Applications in Prognostics and Health Management. IEEE Access 2019, 7, 162415–162438. [Google Scholar] [CrossRef]
- Deng, W.; Nguyen, K.T.P.; Medjaher, K.; Gogu, C.; Morio, J. Bearings RUL prediction based on contrastive self-supervised learning. IFAC-PapersOnLine 2023, 56, 11906–11911. [Google Scholar] [CrossRef]
- Akrim, A.; Gogu, C.; Vingerhoeds, R.; Salaün, M. Self-Supervised Learning for data scarcity in a fatigue damage prognostic problem. Eng. Appl. Artif. Intell. 2023, 120, 105837. [Google Scholar] [CrossRef]
- Zhuang, J.; Jia, M.; Ding, Y.; Zhao, X. Health Assessment of Rotating Equipment with Unseen Conditions Using Adversarial Domain Generalization Toward Self-Supervised Regularization Learning. IEEE/ASME Trans. Mechatron. 2022, 27, 4675–4685. [Google Scholar] [CrossRef]
- Melendez, I.; Doelling, R.; Bringmann, O. Self-supervised Multi-stage Estimation of Remaining Useful Life for Electric Drive Units. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; IEEE: Amsterdam, The Netherlands, 2019; pp. 4402–4411. [Google Scholar] [CrossRef]
- Von Hahn, T.; Mechefske, C.K. Self-supervised learning for tool wear monitoring with a disentangled-variational-autoencoder. Int. J. Hydromechatronics 2021, 4, 69. [Google Scholar] [CrossRef]
- Wang, R.; Chen, H.; Guan, C. A self-supervised contrastive learning framework with the nearest neighbors matching for the fault diagnosis of marine machinery. Ocean. Eng. 2023, 270, 113437. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-Supervised Visual Feature Learning with Deep Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4037–4058. [Google Scholar] [CrossRef]
- Kong, D.; Zhao, L.; Huang, X.; Huang, W.; Ding, J.; Yao, Y.; Xu, L.; Yang, P.; Yang, G. Self-supervised knowledge mining from unlabeled data for bearing fault diagnosis under limited annotations. Measurement 2023, 220, 113387. [Google Scholar] [CrossRef]
- Chowdhury, A.; Rosenthal, J.; Waring, J.; Umeton, R. Applying Self-Supervised Learning to Medicine: Review of the State of the Art and Medical Implementations. Informatics 2021, 8, 59. [Google Scholar] [CrossRef]
- Nadif, M.; Role, F. Unsupervised and self-supervised deep learning approaches for biomedical text mining. Brief. Bioinform. 2021, 22, 1592–1603. [Google Scholar] [CrossRef] [PubMed]
- Fang, H.; Wang, S.; Zhou, M.; Ding, J.; Xie, P. Cert: Contrastive self-supervised learning for language understanding. arXiv 2020, arXiv:2005.12766. [Google Scholar]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A Survey on Contrastive Self-Supervised Learning. Technologies 2020, 9, 2. [Google Scholar] [CrossRef]
- Shurrab, S.; Duwairi, R. Self-supervised learning methods and applications in medical imaging analysis: A survey. PeerJ Comput. Sci. 2022, 8, e1045. [Google Scholar] [CrossRef] [PubMed]
- Ohri, K.; Kumar, M. Review on self-supervised image recognition using deep neural networks. Knowl. Based Syst. 2021, 224, 107090. [Google Scholar] [CrossRef]
- He, Y.; Carass, A.; Zuo, L.; Dewey, B.E.; Prince, J.L. Autoencoder based self-supervised test-time adaptation for medical image analysis. Med. Image Anal. 2021, 72, 102136. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.-C.; Pareek, A.; Jensen, M.; Lungren, M.P.; Yeung, S.; Chaudhari, A.S. Self-supervised learning for medical image classification: A systematic review and implementation guidelines. NPJ Digit. Med. 2023, 6, 74. [Google Scholar] [CrossRef]
- Baek, S.; Yoon, G.; Song, J.; Yoon, S.M. Self-supervised deep geometric subspace clustering network. Inf. Sci. 2022, 610, r235–r245. [Google Scholar] [CrossRef]
- Zhang, X.; Mu, J.; Zhang, X.; Liu, H.; Zong, L.; Li, Y. Deep anomaly detection with self-supervised learning and adversarial training. Pattern Recognit. 2022, 121, 108234. [Google Scholar] [CrossRef]
- Ciga, O.; Xu, T.; Martel, A.L. Self supervised contrastive learning for digital histopathology. Mach. Learn. Appl. 2022, 7, 100198. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, S.; Wu, H.; Han, W.; Li, C.; Chen, H. Joint optimization of autoencoder and Self-Supervised Classifier: Anomaly detection of strawberries using hyperspectral imaging. Comput. Electron. Agric. 2022, 198, 107007. [Google Scholar] [CrossRef]
- Hou, Z.; Liu, X.; Cen, Y.; Dong, Y.; Yang, H.; Wang, C.; Tang, J. GraphMAE: Self-Supervised Masked Graph Autoencoders. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 14–18 August 2022; ACM: New York, NY, USA, 2022; pp. 594–604. [Google Scholar] [CrossRef]
- Li, Y.; Lao, Q.; Kang, Q.; Jiang, Z.; Du, S.; Zhang, S.; Li, K. Self-supervised anomaly detection, staging and segmentation for retinal images. Med. Image Anal. 2023, 87, 102805. [Google Scholar] [CrossRef]
- Wang, T.; Wu, J.; Zhang, Z.; Zhou, W.; Chen, G.; Liu, S. Multi-scale graph attention subspace clustering network. Neurocomputing 2021, 459, 302–314. [Google Scholar] [CrossRef]
- Li, J.; Ren, W.; Han, M. Variational auto-encoders based on the shift correction for imputation of specific missing in multivariate time series. Measurement 2021, 186, 110055. [Google Scholar] [CrossRef]
- Sun, C. HAT-GAE: Self-Supervised Graph Auto-encoders with Hierarchical Adaptive Masking and Trainable Corruption. arXiv 2023, arXiv:2301.12063. [Google Scholar] [CrossRef]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked Autoencoders Are Scalable Vision Learners. In IEEE/CVF Conference on Computer Vision and Pattern Recognition; Ernest N. Morial Convention Center: New Orleans, LA, USA; IEEE: Amsterdam, The Netherlands, 2022; pp. 16000–16009. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Fekri, M.N.; Ghosh, A.M.; Grolinger, K. Generating Energy Data for Machine Learning with Recurrent Generative Adversarial Networks. Energies 2019, 13, 130. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Berg, P.; Pham, M.-T.; Courty, N. Self-Supervised Learning for Scene Classification in Remote Sensing: Current State of the Art and Perspectives. Remote Sens. 2022, 14, 3995. [Google Scholar] [CrossRef]
- Doersch, C.; Gupta, A.; Efros, A.A. Unsupervised Visual Representation Learning by Context Prediction. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; IEEE: Amsterdam, The Netherlands, 2015; pp. 1422–1430. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful Image Colorization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 649–666. [Google Scholar] [CrossRef]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised Representation Learning by Predicting Image Rotations. In Proceedings of the Sixth International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; ICLR 2018. Cornel University: Ithaca, NY, USA, 2018. [Google Scholar]
- Noroozi, M.; Favaro, P. Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2016; pp. 69–84. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Springenberg, J.T.; Riedmiller, M.; Brox, T. Discriminative unsupervised feature learning with convolutional neural networks. Adv. Neural Inf. Process Syst. 2014, 27, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.P.; Lim, K.M.; Song, Y.X.; Alqahtani, A. Plant-CNN-ViT: Plant Classification with Ensemble of Convolutional Neural Networks and Vision Transformer. Plants 2023, 12, 2642. [Google Scholar] [CrossRef]
- Dong, X.; Shen, J. Triplet Loss in Siamese Network for Object Tracking. In European Conference on Computer Vision (ECCV); Springer: Munich, Germany, 2018; pp. 459–474. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In 37th International Conference on Machine Learning, PMLR 119; PLMR: Vienna, Austria, 2020; pp. 1597–1607. [Google Scholar]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition; IEEE: Seattle, WA, USA, 2020; pp. 9729–9738. [Google Scholar]
- Li, X.; Zhou, Y.; Zhang, Y.; Zhang, A.; Wang, W.; Jiang, N.; Wu, H.; Wang, W. Dense Semantic Contrast for Self-Supervised Visual Representation Learning. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; ACM: New York, NY, USA, 2021; pp. 1368–1376. [Google Scholar] [CrossRef]
- Fini, E.; Astolfi, P.; Alahari, K.; Alameda-Pineda, X.; Mairal, J.; Nabi, M.; Ricci, E. Semi-Supervised Learning Made Simple with Self-Supervised Clustering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; IEEE: New York, NY, USA, 2023; pp. 3187–3197. [Google Scholar]
- Khan, A.; AlBarri, S.; Manzoor, M.A. Contrastive Self-Supervised Learning: A Survey on Different Architectures. In Proceedings of the 2022 2nd International Conference on Artificial Intelligence (ICAI), Islamabad, Pakistan, 30–31 March 2022; IEEE: New York, NY, USA, 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, Y.; Zhu, L.; Yamada, M.; Yang, Y. Semantic Correspondence as an Optimal Transport Problem. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); IEEE: New York, NY, USA, 2020; pp. 4462–4471. [Google Scholar] [CrossRef]
- Shvetsova, N.; Petersen, F.; Kukleva, A.; Schiele, B.; Kuehne, H. Learning by Sorting: Self-supervised Learning with Group Ordering Constraints. arXiv 2023, arXiv:2301.02009. [Google Scholar]
- Li, H.; Liu, J.; Cui, L.; Huang, H.; Tai, X.-C. Volume preserving image segmentation with entropy regularized optimal transport and its applications in deep learning. J. Vis. Commun. Image Represent. 2020, 71, 102845. [Google Scholar] [CrossRef]
- Li, R.; Lin, G.; Xie, L. Self-Point-Flow: Self-Supervised Scene Flow Estimation from Point Clouds with Optimal Transport and Random Walk. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 19–25 June 2021; IEEE: New York, NY, USA, 2021; pp. 15577–15586. [Google Scholar]
- Scetbon, M.; Cuturi, M. Low-rank optimal transport: Approximation, statistics and debiasing. Adv. Neural Inf. Process Syst. 2022, 35, 6802–6814. [Google Scholar]
- Zhang, C.; Zhang, C.; Zhang, K.; Zhang, C.; Niu, A.; Feng, J.; Yoo, C.D.; Kweon, I.S. Decoupled Adversarial Contrastive Learning for Self-supervised Adversarial Robustness. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 725–742. [Google Scholar] [CrossRef]
- Liu, W.; Li, Z.; Zhang, H.; Chang, S.; Wang, H.; He, J.; Huang, Q. Dense lead contrast for self-supervised representation learning of multilead electrocardiograms. Inf. Sci. 2023, 634, 189–205. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, R.; Shen, C.; Kong, T. DenseCL: A simple framework for self-supervised dense visual pre-training. Vis. Inform. 2023, 7, 30–40. [Google Scholar] [CrossRef]
- Liu, X.; Sinha, A.; Unberath, M.; Ishii, M.; Hager, G.D.; Taylor, R.H.; Reiter, A. Self-Supervised Learning for Dense Depth Estimation in Monocular Endoscopy. In OR 2.0 Context-Aware. Operating Theaters, Computer Assisted Robotic Endoscopy, Clinical Image-Based Procedures, and Skin. Image Analysis: First International Workshop, OR 2.0 2018, 5th International Workshop, CARE 2018, 7th International Workshop, CLIP 2018, Third International Workshop, ISIC 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, September 16 and 20, 2018, Proceedings 5; Springer International Publishing: Cham, Switzerland, 2018; pp. 128–138. [Google Scholar] [CrossRef]
- Kar, S.; Nagasubramanian, K.; Elango, D.; Nair, A.; Mueller, D.S.; O’Neal, M.E.; Singh, A.K.; Sarkar, S.; Ganapathysubramanian, B.; Singh, A. Self-Supervised Learning Improves Agricultural Pest Classification. In Proceedings of the AI for Agriculture and Food Systems, Vancouver, BC, Canada, 28 February 2021. [Google Scholar]
- Niizumi, D.; Takeuchi, D.; Ohishi, Y.; Harada, N.; Kashino, K. BYOL for Audio: Self-Supervised Learning for General-Purpose Audio Representation. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; IEEE: New York, NY, USA, 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Wang, J.; Zhu, T.; Gan, J.; Chen, L.L.; Ning, H.; Wan, Y. Sensor Data Augmentation by Resampling in Contrastive Learning for Human Activity Recognition. IEEE Sens. J. 2022, 22, 22994–23008. [Google Scholar] [CrossRef]
- Wu, J.; Gong, X.; Zhang, Z. Self-Supervised Implicit Attention: Guided Attention by The Model Itself. arXiv 2022, arXiv:2206.07434. [Google Scholar]
- Haresamudram, H.; Essa, I.; Plötz, T. Investigating Enhancements to Contrastive Predictive Coding for Human Activity Recognition. In Proceedings of the 2023 IEEE International Conference on Pervasive Computing and Communications (PerCom), Atlanta, GA, USA, 13–17 March 2023; IEEE: New York, NY, USA, 2023; pp. 232–241. [Google Scholar] [CrossRef]
- Caron, M.; Touvron, H.; Misra, I.; Jegou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging Properties in Self-Supervised Vision Transformers. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV); IEEE: New York, NY, USA, 2021; pp. 9630–9640. [Google Scholar] [CrossRef]
- Balestriero, R.; Ibrahim, M.; Sobal, V.; Morcos, A.; Shekhar, S.; Goldstein, T.; Bordes, F.; Bardes, A.; Mialon, G.; Tian, Y.; et al. A cookbook of self-supervised learning. arXiv 2023, arXiv:2304.12210. [Google Scholar]
- Chen, Y.; Liu, Y.; Jiang, D.; Zhang, X.; Dai, W.; Xiong, H.; Tian, Q. SdAE: Self-distillated Masked Autoencoder. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 108–124. [Google Scholar] [CrossRef]
- Alfaro-Contreras, M.; Ríos-Vila, A.; Valero-Mas, J.J.; Calvo-Zaragoza, J. Few-shot symbol classification via self-supervised learning and nearest neighbor. Pattern Recognit. Lett. 2023, 167, 1–8. [Google Scholar] [CrossRef]
- Lee, D.; Aune, E. VIbCReg: Variance-invariance-better-covariance regularization for self-supervised learning on time series. arXiv 2021, arXiv:2109.00783. [Google Scholar]
- Mialon, G.; Balestriero, R.; LeCun, Y. Variance covariance regularization enforces pairwise independence in self-supervised representations. arXiv 2022, arXiv:2209.14905. [Google Scholar]
- Bardes, A.; Ponce, J.; LeCun, Y. Vicreg: Variance-invariance-covariance regularization for self-supervised learning. arXiv 2021, arXiv:2105.04906. [Google Scholar]
- Chen, S.; Guo, W. Auto-Encoders in Deep Learning—A Review with New Perspectives. Mathematics 2023, 11, 1777. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Liu, Z.; Miao, Z.; Zhan, X.; Wang, J.; Gong, B.; Yu, S.X. Open Long-Tailed Recognition in A Dynamic World. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 46, 1836–1851. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Jin, M.; Pan, S.; Zhou, C.; Zheng, Y.; Xia, F.; Yu, P. Graph Self-Supervised Learning: A Survey. IEEE Trans. Knowl. Data Eng. 2022, 35, 5879–5900. [Google Scholar] [CrossRef]
- Krishnan, R.; Rajpurkar, P.; Topol, E.J. Self-supervised learning in medicine and healthcare. Nat. Biomed. Eng. 2022, 6, 1346–1352. [Google Scholar] [CrossRef] [PubMed]
- Azizi, S.; Mustafa, B.; Ryan, F.; Beaver, Z.; Freyberg, J.; Deaton, J.; Loh, A.; Karthikesalingam, A.; Kornblith, S.; Chen, T.; et al. Big Self-Supervised Models Advance Medical Image Classification. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV); IEEE: New York, NY, USA, 2021; pp. 3458–3468. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, H.; Miura, Y.; Manning, C.D.; Langlotz, C.P. Contrastive learning of medical visual representations from paired images and text. In Machine Learning for Healthcare Conference; PMLR: Vienna, Austria, 2022; pp. 2–25. [Google Scholar]
- Bozorgtabar, B.; Mahapatra, D.; Vray, G.; Thiran, J.-P. SALAD: Self-supervised Aggregation Learning for Anomaly Detection on X-rays. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020, Proceedings, Part I 23; Springer International Publishing: Cham, Switzerland, 2020; pp. 468–478. [Google Scholar] [CrossRef]
- Tian, Y.; Pang, G.; Liu, F.; Chen, Y.; Shin, S.H.; Verjans, J.W.; Singh, R.; Carneiro, G. Constrained Contrastive Distribution Learning for Unsupervised Anomaly Detection and Localisation in Medical Images. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021, Proceedings, Part V 24; Springer International Publishing: Cham, Switzerland, 2021; pp. 128–140. [Google Scholar] [CrossRef]
- Ouyang, J.; Zhao, Q.; Adeli, E.; Sullivan, E.V.; Pfefferbaum, A.; Zaharchuk, G.; Pohl, K.M. Self-supervised Longitudinal Neighbourhood Embedding. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021, Proceedings, Part II 24; Springer International Publishing: Cham, Switzerland, 2021; pp. 80–89. [Google Scholar] [CrossRef]
- Liu, F.; Tian, Y.; Cordeiro, F.R.; Belagiannis, V.; Reid, I.; Carneiro, G. Self-supervised Mean Teacher for Semi-supervised Chest X-ray Classification. In International Workshop on Machine Learning in Medical Imaging; Springer International Publishing: Cham, Switzerland, 2021; pp. 426–436. [Google Scholar] [CrossRef]
- Li, H.; Xue, F.F.; Chaitanya, K.; Luo, S.; Ezhov, I.; Wiestler, B.; Zhang, J.; Menze, B. Imbalance-Aware Self-supervised Learning for 3D Radiomic Representations. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021, Proceedings, Part II 24; Springer International Publishing: Cham, Switzerland, 2021; pp. 36–46. [Google Scholar] [CrossRef]
- Manna, S.; Bhattacharya, S.; Pal, U. Interpretive Self-Supervised pre-Training. In Twelfth Indian Conference on Computer Vision, Graphics and Image Processing; ACM: New York, NY, USA, 2021; pp. 1–9. [Google Scholar] [CrossRef]
- Zhao, Z.; Yang, G. Unsupervised Contrastive Learning of Radiomics and Deep Features for Label-Efficient Tumor Classification. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021, Proceedings, Part II 24; Springer International Publishing: Cham, Switzerland, 2021; pp. 252–261. [Google Scholar] [CrossRef]
- Esrafilian-Najafabadi, M.; Haghighat, F. Towards self-learning control of HVAC systems with the consideration of dynamic occupancy patterns: Application of model-free deep reinforcement learning. Build. Environ. 2022, 226, 109747. [Google Scholar] [CrossRef]
- Long, J.; Chen, Y.; Yang, Z.; Huang, Y.; Li, C. A novel self-training semi-supervised deep learning approach for machinery fault diagnosis. Int. J. Prod. Res. 2023, 61, 8238–8251. [Google Scholar] [CrossRef]
- Yang, Z.; Huang, Y.; Nazeer, F.; Zi, Y.; Valentino, G.; Li, C.; Long, J.; Huang, H. A novel fault detection method for rotating machinery based on self-supervised contrastive representations. Comput. Ind. 2023, 147, 103878. [Google Scholar] [CrossRef]
- Wei, M.; Liu, Y.; Zhang, T.; Wang, Z.; Zhu, J. Fault Diagnosis of Rotating Machinery Based on Improved Self-Supervised Learning Method and Very Few Labeled Samples. Sensors 2021, 22, 192. [Google Scholar] [CrossRef]
- Lei, Y.; Karimi, H.R.; Chen, X. A novel self-supervised deep LSTM network for industrial temperature prediction in aluminum processes application. Neurocomputing 2022, 502, 177–185. [Google Scholar] [CrossRef]
- Xu, R.; Hao, R.; Huang, B. Efficient surface defect detection using self-supervised learning strategy and segmentation network. Adv. Eng. Inform. 2022, 52, 101566. [Google Scholar] [CrossRef]
- Bharti, V.; Kumar, A.; Purohit, V.; Singh, R.; Singh, A.K.; Singh, S.K. A Label Efficient Semi Self-Supervised Learning Framework for IoT Devices in Industrial Process. IEEE Trans. Ind. Inform. 2023, 20, 2253–2262. [Google Scholar] [CrossRef]
- Hannan, M.A.; How, D.N.T.; Lipu, M.S.H.; Mansor, M.; Ker, P.J.; Dong, Z.Y.; Sahari, K.S.M.; Tiong, S.K.; Muttaqi, K.M.; Mahlia, T.M.I.; et al. Deep learning approach towards accurate state of charge estimation for lithium-ion batteries using self-supervised transformer model. Sci. Rep. 2021, 11, 19541. [Google Scholar] [CrossRef] [PubMed]
- Li, C.L.; Sohn, K.; Yoon, J.; Pfister, T. CutPaste: Self-Supervised Learning for Anomaly Detection and Localization. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, North America; IEEE: Washington, DC, USA, 2021; pp. 9664–9674. [Google Scholar]
- Yang, C.; Wu, Z.; Zhou, B.; Lin, S. Instance Localization for Self-Supervised Detection Pretraining. In CVF Conference on Computer Vision and Pattern Recognition, North America; IEEE: Washington, DC, USA, 2021; pp. 3987–3996. [Google Scholar]
- Schlüter, H.M.; Tan, J.; Hou, B.; Kainz, B. Natural Synthetic Anomalies for Self-supervised Anomaly Detection and Localization. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 474–489. [Google Scholar] [CrossRef]
- Taher, M.R.H.; Haghighi, F.; Gotway, M.B.; Liang, J. CAiD: Context-Aware Instance Discrimination for Self-Supervised Learning in Medical Imaging. In International Conference on Medical Imaging with Deep Learning; MIDL Foundation: Zürich, Switzerland, 2022; pp. 535–551. [Google Scholar]
- Gidaris, S.; Bursuc, A.; Puy, G.; Komodakis, N.; Cord, M.; Pérez, P. Obow: Online Bag-of-Visual-Words Generation for Self-Supervised Learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, North America; IEEE: Washington, DC, USA, 2021; pp. 6830–6840. [Google Scholar]
- Baevski, A.; Babu, A.; Hsu, W.N.; Auli, M. Efficient Self-Supervised Learning with Contextualized Target Representations for Vision, Speech and Language. In Proceedings of the 40th International Conference on Machine Learning, PMLR 2023, Honolulu, HI, USA, 23–29 July 2023; PMLR: Vienna, Austria, 2023; pp. 1416–1429. [Google Scholar]
- Park, D.; Ahn, C.W. Self-Supervised Contextual Data Augmentation for Natural Language Processing. Symmetry 2019, 11, 1393. [Google Scholar] [CrossRef]
- Elnaggar, A.; Heinzinger, M.; Dallago, C.; Rehawi, G.; Wang, Y.; Jones, L.; Gibbs, T.; Feher, T.; Angerer, C.; Steinegger, M.; et al. ProtTrans: Toward Understanding the Language of Life Through Self-Supervised Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 7112–7127. [Google Scholar] [CrossRef]
- Lin, J.H.; Lin, Y.Y.; Chien, C.M.; Lee, H.Y. S2VC: A Framework for Any-to-Any Voice Conversion with Self-Supervised Pretrained Representations. arXiv 2021, arXiv:2104.02901. [Google Scholar]
- Chung, Y.-A.; Hsu, W.-N.; Tang, H.; Glass, J. An Unsupervised Autoregressive Model for Speech Representation Learning. In Interspeech 2019; ISCA: Singapore, 2019; pp. 146–150. [Google Scholar] [CrossRef]
- Pan, T.; Chen, J.; Zhou, Z.; Wang, C.; He, S. A Novel Deep Learning Network via Multiscale Inner Product with Locally Connected Feature Extraction for Intelligent Fault Detection. IEEE Trans. Ind. Inform. 2019, 15, 5119–5128. [Google Scholar] [CrossRef]
- Chen, J.; Wang, C.; Wang, B.; Zhou, Z. A visualized classification method via t-distributed stochastic neighbor embedding and various diagnostic parameters for planetary gearbox fault identification from raw mechanical data. Sens. Actuators A Phys. 2018, 284, 52–65. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, J.; He, S.; Zhou, Z. Prior Knowledge-Augmented Self-Supervised Feature Learning for Few-Shot Intelligent Fault Diagnosis of Machines. IEEE Trans. Ind. Electron. 2022, 69, 10573–10584. [Google Scholar] [CrossRef]
- Yuan, Y.; Lin, L. Self-Supervised Pretraining of Transformers for Satellite Image Time Series Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 474–487. [Google Scholar] [CrossRef]
- Zhao, Z.; Luo, Z.; Li, J.; Chen, C.; Piao, Y. When Self-Supervised Learning Meets Scene Classification: Remote Sensing Scene Classification Based on a Multitask Learning Framework. Remote Sens. 2020, 12, 3276. [Google Scholar] [CrossRef]
- Tao, C.; Qi, J.; Zhang, G.; Zhu, Q.; Lu, W.; Li, H. TOV: The Original Vision Model for Optical Remote Sensing Image Understanding via Self-Supervised Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4916–4930. [Google Scholar] [CrossRef]
- Stojnic, V.; Risojevic, V. Evaluation of Split-Brain Autoencoders for High-Resolution Remote Sensing Scene Classification. In Proceedings of the 2018 International Symposium ELMAR, Zadar, Croatia, 16–19 September 2018; IEEE: New York, NY, USA, 2018; pp. 67–70. [Google Scholar] [CrossRef]
- Jung, H.; Jeon, T. Self-supervised learning with randomised layers for remote sensing. Electron. Lett. 2021, 57, 249–251. [Google Scholar] [CrossRef]
- Jiang, L.; Song, Z.; Ge, Z.; Chen, J. Robust Self-Supervised Model and Its Application for Fault Detection. Ind. Eng. Chem. Res. 2017, 56, 7503–7515. [Google Scholar] [CrossRef]
- Yu, Z.; Lei, N.; Mo, Y.; Xu, X.; Li, X.; Huang, B. Feature extraction based on self-supervised learning for RUL prediction. J. Comput. Inf. Sci. Eng. 2023, 24, 021004. [Google Scholar] [CrossRef]
- Hu, C.; Wu, J.; Sun, C.; Yan, R.; Chen, X. Interinstance and Intratemporal Self-Supervised Learning With Few Labeled Data for Fault Diagnosis. IEEE Trans. Ind. Inform. 2023, 19, 6502–6512. [Google Scholar] [CrossRef]
- Huang, C.; Wang, X.; He, X.; Yin, D. Self-Supervised Learning for Recommender System. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; ACM: New York, NY, USA, 2022; pp. 3440–3443. [Google Scholar] [CrossRef]
- Wang, T.; Qiao, M.; Zhang, M.; Yang, Y.; Snoussi, H. Data-driven prognostic method based on self-supervised learning approaches for fault detection. J. Intell. Manuf. 2020, 31, 1611–1619. [Google Scholar] [CrossRef]
- Nair, A.; Chen, D.; Agrawal, P.; Isola, P.; Abbeel, P.; Malik, J.; Levine, S. Combining Self-Supervised Learning and Imitation for Vision-Based Rope Manipulation. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; IEEE: New York, NY, USA, 2017; pp. 2146–2153. [Google Scholar] [CrossRef]
- Ren, L.; Wang, T.; Laili, Y.; Zhang, L. A Data-Driven Self-Supervised LSTM-DeepFM Model for Industrial Soft Sensor. IEEE Trans. Ind. Inform. 2022, 18, 5859–5869. [Google Scholar] [CrossRef]
- Senanayaka, J.S.L.; Van Khang, H.; Robbersmyr, K.G. Toward Self-Supervised Feature Learning for Online Diagnosis of Multiple Faults in Electric Powertrains. IEEE Trans. Ind. Inform. 2021, 17, 3772–3781. [Google Scholar] [CrossRef]
- Berscheid, L.; Meisner, P.; Kroger, T. Self-Supervised Learning for Precise Pick-and-Place Without Object Model. IEEE Robot. Autom. Lett. 2020, 5, 4828–4835. [Google Scholar] [CrossRef]
- Geng, H.; Yang, F.; Zeng, X.; Yu, B. When Wafer Failure Pattern Classification Meets Few-shot Learning and Self-Supervised Learning. In Proceedings of the 2021 IEEE/ACM International Conference on Computer Aided Design (ICCAD), Munich, Germany, 1–4 November 2021; IEEE: New York, NY, USA, 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Yoa, S.; Lee, S.; Kim, C.; Kim, H.J. Self-Supervised Learning for Anomaly Detection with Dynamic Local Augmentation. IEEE Access 2021, 9, 147201–147211. [Google Scholar] [CrossRef]
- Li, J.; Huang, R.; Chen, J.; Xia, J.; Chen, Z.; Li, W. Deep Self-Supervised Domain Adaptation Network for Fault Diagnosis of Rotating Machine with Unlabeled Data. IEEE Trans. Instrum. Meas. 2022, 71, 3510509. [Google Scholar] [CrossRef]
- Lu, N.; Xiao, H.; Ma, Z.; Yan, T.; Han, M. Domain Adaptation with Self-Supervised Learning and Feature Clustering for Intelligent Fault Diagnosis. IEEE Trans. Neural Netw. Learn Syst. 2022, 1–14. [Google Scholar] [CrossRef]
- Ding, Y.; Zhuang, J.; Ding, P.; Jia, M. Self-supervised pretraining via contrast learning for intelligent incipient fault detection of bearings. Reliab. Eng. Syst. Saf. 2022, 218, 108126. [Google Scholar] [CrossRef]
- Yan, Z.; Liu, H. SMoCo: A Powerful and Efficient Method Based on Self-Supervised Learning for Fault Diagnosis of Aero-Engine Bearing under Limited Data. Mathematics 2022, 10, 2796. [Google Scholar] [CrossRef]
- Chen, L.; Bentley, P.; Mori, K.; Misawa, K.; Fujiwara, M.; Rueckert, D. Self-supervised learning for medical image analysis using image context restoration. Med. Image Anal. 2019, 58, 101539. [Google Scholar] [CrossRef]
- Nguyen, X.-B.; Lee, G.S.; Kim, S.H.; Yang, H.J. Self-Supervised Learning Based on Spatial Awareness for Medical Image Analysis. IEEE Access 2020, 8, 162973–162981. [Google Scholar] [CrossRef]
- Jamaludin, A.; Kadir, T.; Zisserman, A. Self-supervised Learning for Spinal MRIs. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: Third International Workshop, DLMIA 2017, and 7th International Workshop, ML-CDS 2017, Held in Conjunction with MICCAI 2017, Québec City, QC, Canada, September 14, Proceedings 3; Springer International Publishing: Cham, Switzerland, 2017; pp. 294–302. [Google Scholar] [CrossRef]
- Zhu, J.; Li, Y.; Hu, Y.; Zhou, S.K. Embedding task knowledge into 3D neural networks via self-supervised learning. arXiv 2020, arXiv:2006.05798. [Google Scholar]
- Xie, Y.; Zhang, J.; Liao, Z.; Xia, Y.; Shen, C. PGL: Prior-guided local self-supervised learning for 3D medical image segmentation. arXiv 2020, arXiv:2011.12640. [Google Scholar]
- Li, X.; Jia, M.; Islam, M.T.; Yu, L.; Xing, L. Self-Supervised Feature Learning via Exploiting Multi-Modal Data for Retinal Disease Diagnosis. IEEE Trans. Med. Imaging 2020, 39, 4023–4033. [Google Scholar] [CrossRef] [PubMed]
- Sowrirajan, H.; Yang, J.; Ng, A.Y.; Rajpurkar, P. MoCo Pretraining Improves Representation and Transferability of Chest X-ray Models. In Machine Learning Research 143; Stanford University: Stanford, CA, USA, 2021; pp. 728–744. [Google Scholar]
- Vu, Y.N.T.; Wang, R.; Balachandar, N.; Liu, C.; Ng, A.Y.; Rajpurkar, P. Medaug: Contrastive Learning Leveraging Patient Metadata Improves Representations for Chest X-ray Interpretation. In Proceedings of the 6th Machine Learning for Healthcare Conference, Virtual, 6–7 August 2021; Doshi-Velez, F., Ed.; PMLR: Vienna, Austria, 2021; pp. 755–769. [Google Scholar]
- Sriram, A.; Muckley, M.; Sinha, K.; Shamout, F.; Pineau, J.; Geras, K.J.; Azour, L.; Aphinyanaphongs, Y.; Yakubova, N.; Moore, W. COVID-19 prognosis via self-supervised representation learning and multi-image prediction. arXiv 2021, arXiv:2101.04909. [Google Scholar]
- Chen, X.; Yao, L.; Zhou, T.; Dong, J.; Zhang, Y. Momentum contrastive learning for few-shot COVID-19 diagnosis from chest CT images. Pattern Recognit. 2021, 113, 107826. [Google Scholar] [CrossRef]
- Chaitanya, K.; Erdil, E.; Karani, N.; Konukoglu, E. Contrastive learning of global and local features for medical image segmentation with limited annotations. Adv. Neural Inf. Process. Syst. 2020, 33, 12546–12558. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Adv. Neural Inf. Process Syst. 2014, 27, 1–9. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Bachman, P.; Trischler, A.; Bengio, Y. Learning Deep Representations by Mutual Information Estimation and Maximization. In Proceedings of the Seventh International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. ICLR Committe 2019. [Google Scholar]
- Oord, A.V.D.; Li, Y.; Vinyals, O. Representation Learning with Contrastive Predictive Coding. arXiv 2019, arXiv:1807.03748. [Google Scholar]
- Bachman, P.; Hjelm, R.D.; Buchwalter, W. Learning representations by maximizing mutual information across views. Adv. Neural Inf. Process Syst. 2019, 32. [Google Scholar]
- Veličković, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. In Proceedings of the Seventh International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. ICLR Committe 2019. [Google Scholar]
- Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Yao, Y.; Zhang, A.; Zhang, L.; et al. Pre-trained models: Past, present and future. AI Open 2021, 2, 225–250. [Google Scholar] [CrossRef]
- Deldari, S.; Smith, D.V.; Xue, H.; Salim, F.D. Time Series Change Point Detection with Self-Supervised Contrastive Predictive Coding. In Web Conference 2021; ACM: New York, NY, USA, 2021; pp. 3124–3135. [Google Scholar] [CrossRef]
- Henaff, O. Data-Efficient Image Recognition with Contrastive Predictive Coding. In Proceedings of the 37th International Conference on Machine Learning, PMLR, Vienna, Austria, 13–18 July 2020; PMLR: Vienna, Austria, 2020; pp. 4182–4192. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Multiview Coding. arXiv 2019, arXiv:1906.05849. [Google Scholar]
- Ye, F.; Zhao, W. A Semi-Self-Supervised Intrusion Detection System for Multilevel Industrial Cyber Protection. Comput. Intell. Neurosci. 2022, 2022, 4043309. [Google Scholar] [CrossRef]
- Wang, Y.C.; Venkataramani, S.; Smaragdis, P. Self-supervised learning for speech enhancement. arXiv 2020, arXiv:2006.10388. [Google Scholar]















| No. | Variable Category | Magnitude |
|---|---|---|
| 1 | Input Data | A Length of 1024 Data Points |
| 2 | Temperature | 10 |
| 3 | Feature Encoder | Sixteen Convolutional Layers |
| 4 | Output Size | 128 |
| 5 | Training Epoch | 200 |
| # | Author(s) (Year) | Industrial SSL Application Sort | Dataset Category | Encountered Research Limitations | Critical Contributions and Positive SSL Impacts |
|---|---|---|---|---|---|
| 1 | Yuan and Lin (2020) [107] | Generative SSL Recognition | SITS-BERT | Not available (N/A) | The classification accuracy of a transformer, 1D CNN, and bidirectional long short-term memory (LSTM) network is significantly improved by the proposed pre-training approach in experimental data. |
| 2 | Zhao et al. (2020) [108] | Scene SSL Classification | NWPU, AID, UC Merced, and WHU-RS19 | The loss function forced the primary classifier to be invariant with respect to the transformations. Therefore, the utilization of additional labeling in the SSL did not guarantee performance improvement in fully supervised classification conditions. | Their results related to the NWPU, AID, UC Merced, and WHU-RS19 dataset classifications revealed state-of-the-art average accuracy levels, recording 94.21%, 96.89%, 99.11%, and 98.98%, respectively. Their suggested strategy enhanced the accuracy of remote sensing scene categorization, as evidenced by experimental findings and visual representations, by learning additional discriminative features while simultaneously encoding orientation information. |
| 3 | Tao et al. (2023) [109] | Remote Sensing Image Understanding | DLRSD and AID | N/A | Based on their numerical simulations, it was found that utilizing their TOV model to help facilitate the classification process of information related to RSIU using SSL principles contributed to enhanced levels of classification accuracy. |
| 4 | Stojnic and Risojevic (2018) [110] | SSL Classification of Visual Dataset Considering LAB and RGB Color Spaces | AID | N/A | Their simulation outcomes confirmed that near-state-of-the-art performance was attained, registering a classification accuracy of 89.27% on the AID dataset, needing a minimal amount of unlabeled training images. |
| 5 | Jung and Jeon (2021) [111] | SSL Classification of Visual Database | National Agriculture Imagery Program (NAIP) and CDL | The original Tile2Vec classification model faced a degradation issue when the epoch reached the maximum number of epochs, which was 50. On the other hand, the Tile2Vec classification model, which had one randomized layer, contributed to a slight degradation in the classification process. | The scholars found that obtaining more robust representations was facilitated by not updating the completely connected layers. Their proposed Tile2Vec algorithm provided more significant performance in terms of classification accuracy compared with random forest (RF), logistic regression (LR), and multi-layer classifiers (MLC). |
| 6 | Hahn and Mechefske (2021) [9] | SSL Forecasting in the Context of Machinery Health Monitoring | Milling and CNC Dataset | Vibrations from the table and spindle would cause sources of error in carrying out the necessary detection process, influencing the final outcomes of the anomaly model. Also, the trained models, which correlated with the CNC data, did not generalize well across all the unique parts in the dataset. Furthermore, the investigated models did not generalize well across multiple metal-cutting variables. | The approach got the best PR-AUC score of 0.80 for shallow-depth cuts and a score of 0.45 for all cutting parameters on a milling dataset. The best PR-AUC score of this SSL method attained an ultimate PR-AUC score of roughly 0.41 based on a real-world industrial CNC dataset. |
| 7 | Jiang et al. (2017) [112] | SSL Process Monitoring of Chemical Processes | Finite Discrete Dataset consisting of 100 Samples | When more variations of faults occur, RSS models may not perform robust identification of segments free from noise. Comparatively, conventional models reduce reconstruction errors, contributing to lower sensitivity to fault variations. When Gaussian noise is considered, the sensitivity correlated with the RSS model could be increased in processing drifts. | Their theoretical analysis revealed that their SSL models offered more sensitive aspects of fault occurrence in the analytical process. The efficiencies of both robust autoencoders and robust principal component analysis (PCA) monitoring provided enhanced performance and optimum and active monitoring levels of chemical processes. |
| 8 | Yu et al. (2023) [113] | SSL Estimation of the RUL | C-MAPSS | The complicated operating conditions and variant fault behaviors in industrial environments may result in multiple difficulties and further challenges to achieving maximum accuracy in fault diagnosis and identification. | Their approach could successfully enhance the model’s feature extraction capacity. Hidden characteristics were preferable to raw data when the clustering process was applied. |
| 9 | Hu et al. (2023) [114] | SSL Fault Diagnosis and Defect Prediction | Open-Source and Self-Designed Datasets | The single-task dominance problem did exist in the multitask algorithm that conducted necessary fault diagnosis and failure identification in the industrial context. (To solve this issue, an uncertainty-correlated dynamic weighting tactic was utilized to automatically distribute weight for every task referring to its uncertainty level, helping ensure better stability in multi-task optimization.) | Their proposed SSL model provided more superiority in performing crucial machine fault prognostics, which could help handle efficient fault maintenance more flexibly with upgraded levels of accuracy and performance compared with other semi-supervised and supervised models. |
| 10 | Huang et al. (2022) [115] | SSL Distilling Process for Recommender Systems from Ubiquitous, Sparse, And Noisy Data | N/A | N/A | SSL models in recommender systems could support engineers in minimizing the rates of noisy data and ineffective information that lower the performance and reliability of recommender systems. |
| 11 | Wang et al. (2020) [116] | SSL Fault Detection in Prognostics and Health Management (PHM) | The LAM 9600 Metal Etcher | Their suggested method, which formulated an SS algorithm and relied on the Kernel PCA (KPCA), was only trained utilizing normal samples. At the same time, fault detection was merely accomplished by KPCA rather than a combination of various ML models. | SSL offered relevant fault detection findings, outperforming existing fault detection methods with enhanced efficacy. |
| 12 | Nair et al. (2017) [117] | SSL Manipulation of Deformable Objects | (Self-Collected Datasetby Robotic System) Raw Images of a Rope | When the changes in rope orientation are not very sharp, the robot might perform better. Furthermore, because the researchers did not have a comparable number of additional randomly collected databases, they were not capable of identifying the levels of improvement. This issue is correlated with the higher quality and quantity of the collected databases. | Robots could successfully manipulate a rope into a broad range of goal shapes with only a sequence of photographs offered by a person by merging the high- and low-level plans. |
| 13 | Ren et al. (2022) [118] | SSL Monitoring and Prediction of Production Status | Real-World Froth Flotation Dataset | Due to their recursive nature or deep network structure, SSFAN and LSTM have relatively higher computational costs. In addition, since GSTAE adopts ‘tanh’ and ‘sigmoid’ activation functions to control the information flow, it has the most considerable computational cost. | Considering the real-world mining dataset, their proposed LSTM-DeepFM technique achieved state-of-the-art performance contributions compared with other stacked autoencoder-based models, semisupervised parallel DeepFM, and variational autoencoder-based models. |
| 14 | Senanayaka et al. (2020) [119] | SSL Defect Categorization and Fault Diagnosis | Balanced and Training Dataset | Statistical tests have not been adopted for the comparison since there is no established guideline to select a proper test in this powertrain application. Further, constructing a proper statistical test requires a performance analysis on multiple datasets. Also, the effect of unbalanced datasets is out of scope in their study. | Their SSL principles, applied to the proposed CNN algorithm, allowed an improved online diagnosis scheme to learn features according to the latest data. The effectiveness of their paradigm was validated via comparative analysis, explaining the significant practicality of the trained CNN model in detecting defects. |
| 15 | Berscheid et al. (2020) [120] | Better Decision-Making Process for Robots Regarding Flexible Pick-and-Place | Self-Defined Visual Dataset: (A) RGBD-Images Handling Screws on Around 3500 Pick-and-Place Actions) and (B) Depth-Images of 25,000 Pick-and-Place Actions. | Due to reliability problems with the RealSense camera, their model utilized only depth images from the Ensenso N-10. It was trained on wooden primitive shapes having side lengths of 4 cm. Additionally, the prediction process for the displacement of the cross shape during clamping was difficult to accomplish. | Based on the SSL enhancements on the CNN model, it was determined that their robot could infer several pick-and-place operations from a single objective state, learn to select the correct thing when presented with multiple object kinds, accurately insert objects within a peg game, and pick screws out of dense clutter. |
| 16 | Akrim et al. (2023) [6] | SSL Detection of Fatigue Damage Prognostic Problems | Synthetic Datasets of Strain Data | More neurons or layers in DNNs might encounter lengthy training processes connected with significant convergence scales. Unfortunately, pre-training might not offer remarkable practicalities since the evaluation of the ramining useful life (RUL) could vary. If more unlabeled data is offered, classification findings would be enhanced when limited annotated data is available. | SSL pre-trained models were capable of significantly outperforming the non-pre-trained models in the downstream RUL prediction challenge with lower computational expenses. |
| 17 | Zhang et al. (2022) [106] | Active and Intelligent SSL Diagnosis to Mine the Health Information of Machines | Self-Collected Faulty Monitoring Dataset | N/A | Their proposed SSL framework has successfully extracted more detailed monitoring information. Two experiments that simulated mechanical faults confirmed the remarkable efficacy of their suggested model. Their new approach gave workable inspections necessary for indsutrial fault issues by cognitive diagnosis of machines. Their model proved its practicality, especially for imbalanced data, where imbalance and instability would exist between normal data and faulty data in realistic industrial scenarios. |
| 18 | Geng et al. (2021) [121] | Wafer Failure Pattern Detection to Prevent Yield Loss Excursion Events Linked to Semiconductor Manufacturing | N/A | N/A | Their SSL model, which considered few-shot learning principles with the help of intrinsic relationships in unlabeled wafer maps, achieved significant enhancements. Their suggested approach outperformed various state-of-the-art tactics for wafer defect classification. SSL could alleviate the imbalance problem of data distribution in real industrial failure patterns since it utilizes the comprehensive advantage of the massive unlabeled wafer failure data. |
| 19 | Yoa et al. (2021) [122] | SSL Anomaly Detection of Visual Databases with the Help of Dynamic Local Augmentation | MVTec Anomaly Detection Dataset | Dynamic local augmentation was helpful, but conventional local augmentation interferes with the performance. | Competitive performance was achieved for pixel-wise anomaly segmentation. A variety of combinations of four losses affected the performance. |
| 20 | Li, et al. (2022) [123] | SSL Domain Adaptation-Based Fault Diagnosis | A Gearbox Dataset | N/A | SSL could help achieve significant rates of effectiveness, accuracy, and reliability in detecting faults related to industrial engineering activities. |
| 21 | Lu et al. (2022) [124] | Intelligent SSL Fault Diagnosis via Feature Clustering | Industrial Training and Testing Datasets | N/A | SSL offered elevated performance and efficacy to detect faults related to industrial applications. |
| 22 | Ding et al. (2022) [125] | Practical Fault Prediction of Incipient Failure in Bearings | FEMTO-ST Datasets | Hyperparameter manual modifications of the SSPCL model are needed. Integrating SSL could improve its practicality for further machine-prognostic tasks. A minimal data annotation rate could alleviate the model’s machine prognostic performance. | Superior effectiveness was realized in SSL contrast learning (SSLCL). SSL pre-training was helpful for achieving better identification. Momentum contrast learning (MCL) was addressed to distinguish beneficial data from unlabeled datasets, overcoming time-consuming and expensive labeling processes. |
| 23 | Yan, and Liu (2022) [126] | Practical Fault Diagnosis of Bearnings Related to Aerspace Industry under Limited Databases | Two Independent Bearing Datasets from Paderborn University and the Polytechnic University of Turin for Experimental Verification | MixMatch could offer lower prediction performance compared with FFT + SVM. More noise levels do exist because of the gap between the unannotated dataset and its corresponding data distribution. This gap might broaden in a gradual manner if the noise escalates, contributing to the worse capability of MixMatch to benefit from the unlabeled data necessary for diagnostic precision enhancement. | SMoCo performed feature extraction of vibration signals, considering frequency and time scales. SMoCo could learn potent and efficient feature extraction by pre-training using artificially injected fault-bearing data, improving data diagnosis accuracy regardless of the types of equipment, failure modes, noise magnitude, or working circumstances, and achieving prediction in a considerably shorter interval. |
| # | Author(s) (Year) | Medical SSL Application | Dataset Category | Encountered Research Limitations | Critical Contributions and Preferable SSL Impacts |
|---|---|---|---|---|---|
| 1 | Chen et al. (2019) [127] | SSL Medical Image Categorization via Image Context Restoration | Fetal 2D Ultrasound Images Linked to Abdominal Organs in CT Images and Brain Tumors in Multi-Modal MR Images | Not available (N/A) | The created SSL context restoration model strategy learned semantic image features, which are beneficial for various categories of corresponding visual dataset analysis. Their SSL algorithm was flexible to implement. Its applicability in three situations of data recognition—(1) segmentation, (2) localization, and (3) classification was competitive. |
| 2 | Nguyen et al. (2020) [128] | SSL Medical Image Recognition Utilizing Spatial Awareness | Struct- Seg-2019 Dataset | The overall SSL models achieved escalated performance outcomes because of abundant information for the pretext task. Nonetheless, the margin of enhancement is not considerably satisfying. (They showed that if more unannotated data is utilized, then the performance would enhance.) | Organ segmentation and cerebral bleeding detection via SSL models tested in their work demonstrated remarkable efficacy compared with other ML methods. |
| 3 | Jamaludin et al. (2017) [129] | Longitudinal Spinal MRI | A Dataset of 1016 subjects, 423 Possessing Follow-Up Scans. | The SSL model needed a few more labeled training samples to attain an equivalent efficiency to that linked to the network trained from scratch. | Relying on the SSL involvement in longitudinal spinal MRI categorization, it was found that the effectiveness of the pre-trained SSL CNN model outperformed the performance of other models that were trained from scratch. |
| 4 | Zhu et al. (2020) [130] | 3D Medical Image Classification; Task-Related Contrastive Prediction Coding (TCPC) | Brain Hemorrhage Dataset: 1,486 Brain CT Volumes | N/A | Their experimental analysis confirmed remarkable effectiveness correlated with lesion-related embedding before knowledge into NNs for 3D medical image classification. |
| 5 | Xie et al. (2020) [131] | Extensive Evaluation on Four Public Computerized Tomography (CT) Datasets of 11 Kinds of Major Human Organs and Two Tumors. | Pretext Task Dataset, including 1808 CT Scans from 5 Public Datasets | N/A | The results indicated that utilizing a pre-trained SSL PGL model could help initialize the downstream network, contributing to a preferable effectiveness compared with random initialization and the initialization by global consistency-based models. |
| 6 | Li et al. (2020) [132] | Diagnosis of Retinal Diseases from Fundus Images | Two Public Benchmark Datasets for Retinal Disease Diagnosis | N/A | The experimental results revealed that the SSL model had clearly outperformed other SSL feature learning mechanisms and was comparable to the supervised level. |
| 7 | Sowrirajan et al. (2021) [133] | Utilizing a proposed SSL Model (MoCo-CXR) to Classify Problems in Patients’ Chest | Visual Chest X-ray Datasets | There were fewer unlabeled chest X-ray images than natural images. This aspect could limit the applicability of contrastive SSL to the necessary classification of chest X-rays. | The SSL models operated by MoCo-CXR-pre-training outperformed other non-MoCo-CXR-pre-training models. The MoCo-CXR pre-training provided the most benefit with a few labeled training datasets. Simultaneously, similar high-performance outputs were attained on the target Tuberculosis dataset, confirming that MoCo-CXR-pre-training endowed other superior models for chest X-ray classification. |
| 8 | Vu et al. (2021) [134] | Selecting positive pairs coming from views of possibly different images by the patient metadata | Visual Chest X-ray Datasets | Their approach was not practical for datasets that lack patient meta-data altogether. In addition, their strategies for negative pair selection did not enhance pre-trained representations. Their SSL models leveraged data on image laterality. However, future work is needed to determine whether negative pair selection strategies utilize other meta-data, notably image view (anteroposterior or posteroanterior), patient age, or patient gender. | Their contrastive SSL model achieved a performance upgrade of 14.4% in mean AUC from the ImageNet pre-trained baseline. Also, their controlled experiments showed that the ways to improve downstream performance on patient disease classification include (a) utilizing patient meta-data to properly create positive pairs from variant images with the same underlying pathologies and (b) maximizing the number of various images utilized in query pairing. |
| 9 | Sriram et al. (2021) [135] | Classification of Clinical Diseases Correlated with Large Mortality Rate Due to COVID-19 and Chest X-ray | Dataset of Chest X-ray Linked to COVID-19 and non-COVID-19 Risks | It was found that the inversion of the trend for oxygen requirement prediction (ORP) could not be illustrated by label scarcity. It could be that there were image features that became readily apparent for the ORP task closer to the actual moment of raised oxygen needs. | Their SSL model utilization showed that an improved AUC of 0.786 could be attained for predicting an adverse event at 96 h and an AUC of 0.848 for predicting mortalities at 96 h. |
| 10 | Chen et al. (2021) [136] | Classification of Chest CT Images Linked to the COVID-19 | Dataset of Chest CT images Correlated with COVID-19 Problems | The resizing operation done in their classification process slightly affected the overall identification performance. | Their SSL model classification results affirmed superior performance of accuracy in classifying COVID-19 problems related to chest CT images. |
| 11 | Chaitanya et al. (2020) [137] | To leverage structural similarity across volumetric medical images (domain-specific cue) and to learn distinctive representations of local regions that are practical for per-pixel segmentation (problem-specific cue). | Three Magnetic Resonance Imaging (MRI) datasets | N/A | The created SSL model yielded substantial improvement compared with other SSL and semi-supervised learning (SiSL) techniques. When combined with simple data augmentation, the created model reached within 8% of benchmark performance utilizing solely two annotated MRI data for training. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdulrazzaq, M.M.; Ramaha, N.T.A.; Hameed, A.A.; Salman, M.; Yon, D.K.; Fitriyani, N.L.; Syafrudin, M.; Lee, S.W. Consequential Advancements of Self-Supervised Learning (SSL) in Deep Learning Contexts. Mathematics 2024, 12, 758. https://doi.org/10.3390/math12050758
Abdulrazzaq MM, Ramaha NTA, Hameed AA, Salman M, Yon DK, Fitriyani NL, Syafrudin M, Lee SW. Consequential Advancements of Self-Supervised Learning (SSL) in Deep Learning Contexts. Mathematics. 2024; 12(5):758. https://doi.org/10.3390/math12050758
Chicago/Turabian StyleAbdulrazzaq, Mohammed Majid, Nehad T. A. Ramaha, Alaa Ali Hameed, Mohammad Salman, Dong Keon Yon, Norma Latif Fitriyani, Muhammad Syafrudin, and Seung Won Lee. 2024. "Consequential Advancements of Self-Supervised Learning (SSL) in Deep Learning Contexts" Mathematics 12, no. 5: 758. https://doi.org/10.3390/math12050758
APA StyleAbdulrazzaq, M. M., Ramaha, N. T. A., Hameed, A. A., Salman, M., Yon, D. K., Fitriyani, N. L., Syafrudin, M., & Lee, S. W. (2024). Consequential Advancements of Self-Supervised Learning (SSL) in Deep Learning Contexts. Mathematics, 12(5), 758. https://doi.org/10.3390/math12050758