
Design of an Automatic Classification System for Educational Reform Documents Based on Naive Bayes Algorithm

 , ,
, ,
Abstract
1. Introduction
- The classification standards are not uniform, and it is impossible to form a widely accepted and recognized classification.
- The training sample data retrieval is difficult, the lack of standardized retrieval methods.
- It is difficult to train pre-trained language models with domain background knowledge.
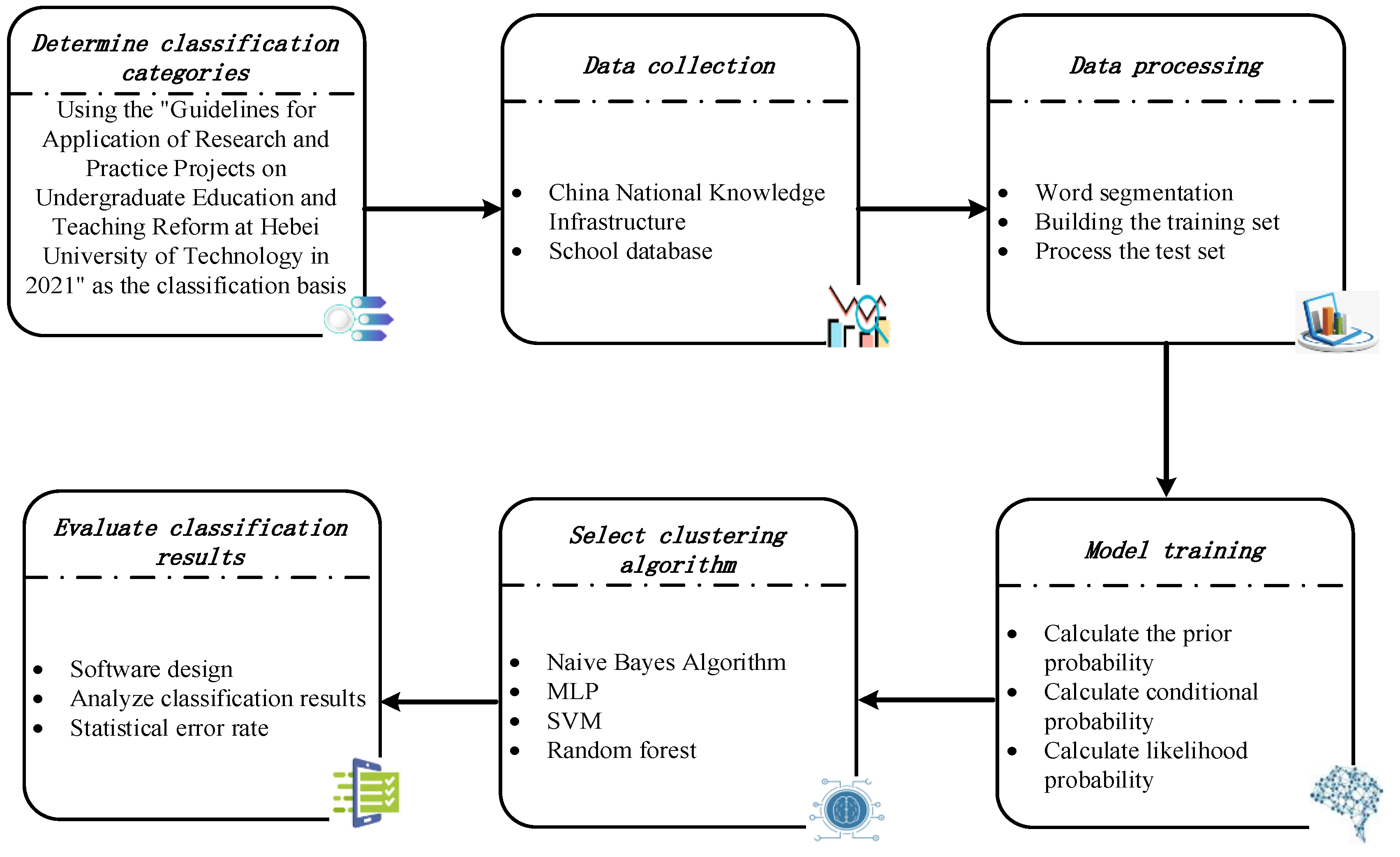
2. Methods
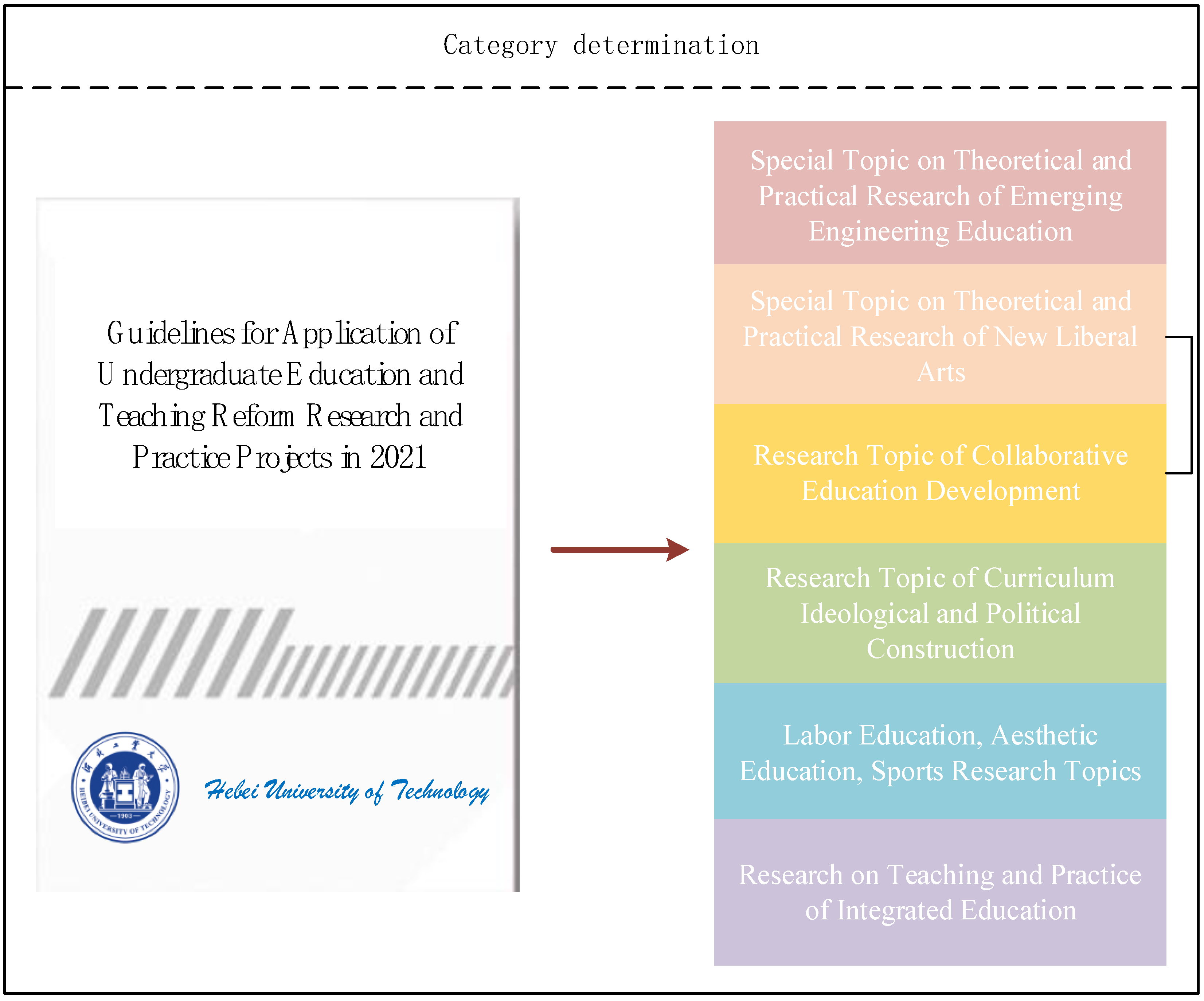
- Determine the categories for classification based on the “Guidelines for Application of Research and Practice Projects on Undergraduate Education and Teaching Reform at Hebei University of Technology in 2021”.
- Collect data from sources such as CNKI (China National Knowledge Infrastructure) and the school database for training and testing data.
- Preprocess the data by segmenting the obtained Chinese text, and construct training and testing sets.
- Train the model by using various algorithms to train the training set and calculate the probability analysis of each feature under each category.
- Analyze the training results and error rates, select the optimal algorithm for further design.
- Design corresponding software to achieve automatic classification.

2.1. Categories of Documents Related to Educational Reform
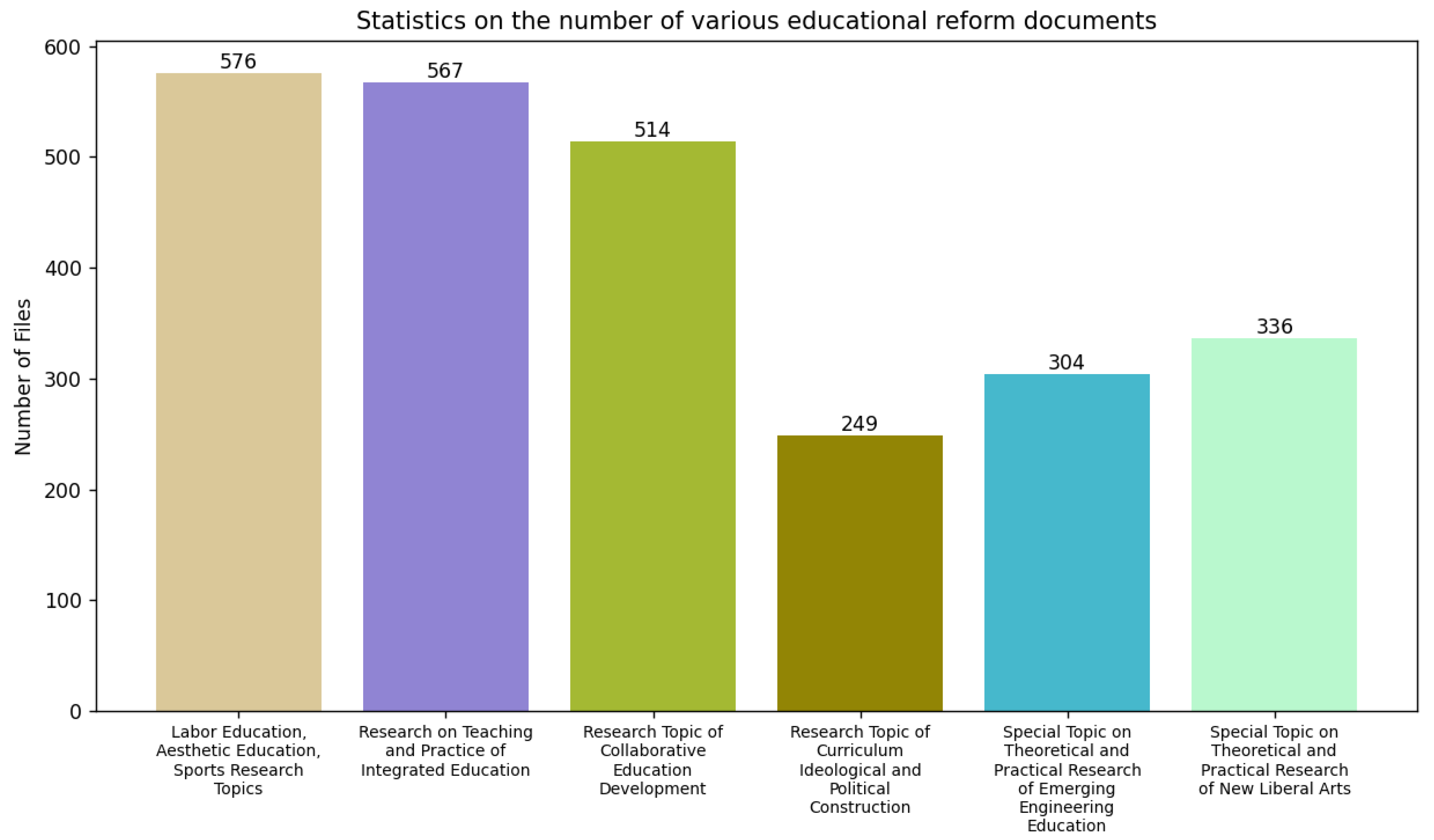
2.2. Data Set Extraction
2.3. Algorithm Selection and Application
2.3.1. Data Preprocessing
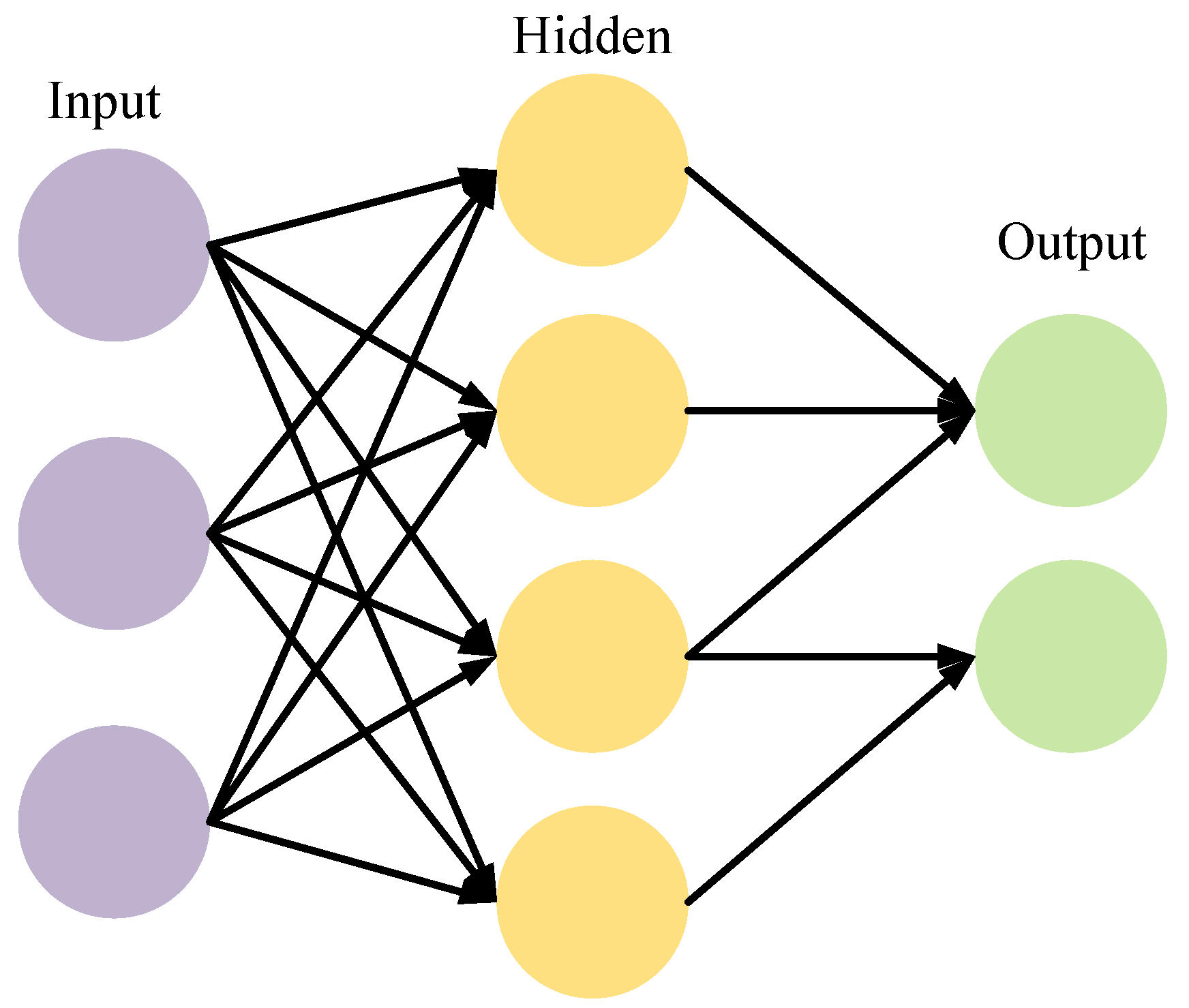
2.3.2. Algorithm Selection
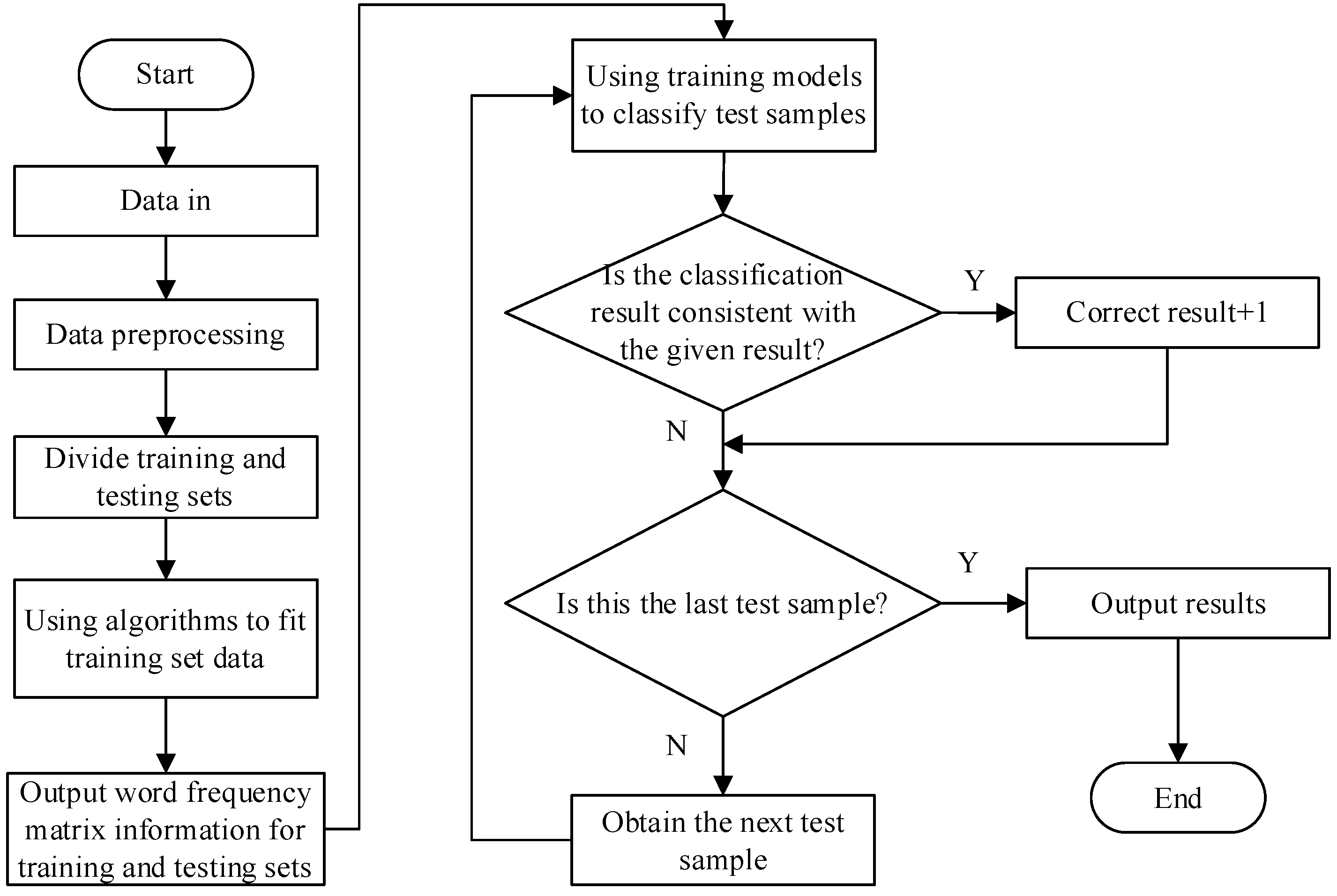
- Data preprocessing: Pre-process the data, including steps such as data cleaning, denoising, and standardization.
- Divide the training and testing sets: Divide the pre-processed data into training and testing sets, and divide the dataset into training and testing sets in an 8:2 ratio.
- Use algorithms to fit the training set data: Select the above four algorithms to train the data and establish a model.
- Output word frequency matrix information: Perform word frequency statistics on the training and testing sets to generate word frequency matrix information.
- Use training models to classify test samples: Use the established model to classify test samples.
- Determine whether the classification result is correct: Evaluate the classification result to determine whether it is consistent with the given result. If the classification is consistent, the correct result is+1; if not correct, proceed to the next step.
- Determine if it is the last test sample: Determine if there are still unclassified test samples, and if so, continue to classify the next test sample; if not, output the result and the classification ends.
- Obtain the next test sample: Obtain the next test sample for classification testing, and then repeat steps 5–7.
2.4. Software Design
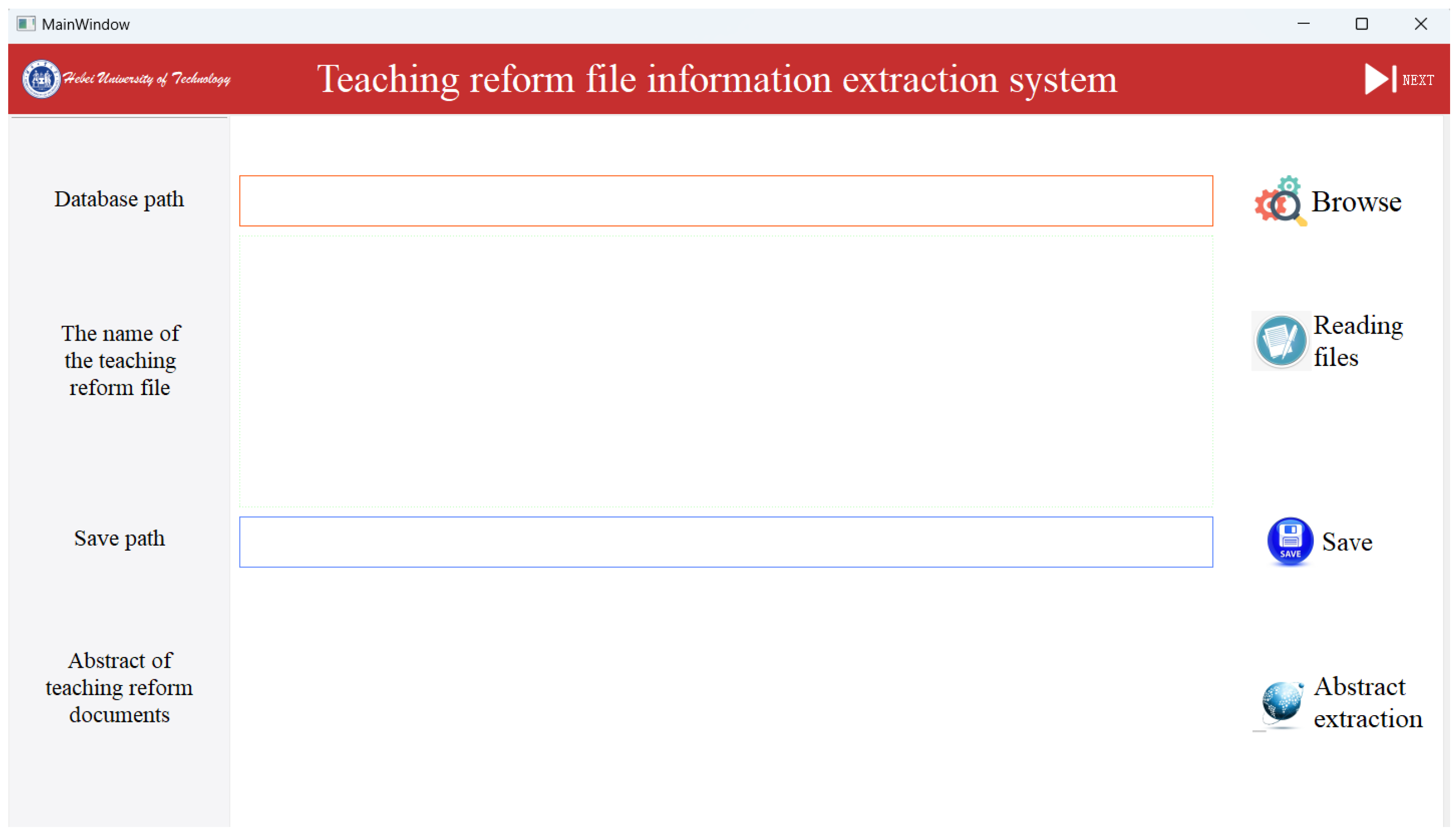
2.4.1. Teaching Reform File Information Extraction System
- Obtain relevant education reform documents based on the classification category from patent retrieval systems such as CNKI (China National Knowledge Infrastructure).
- When the user clicks the “Browse” button, the system will open a file dialog box allowing the user to select the path where the files to be classified are located. The program will then display the selected directory path in the text box corresponding to that button.
- When the user clicks the “Reading files” button, the program will read all file names in the previously selected directory and display these file names in a text box.
- When the user clicks the “Save” button, the program will open a file dialog box allowing the user to choose a directory. The program will then iterate through all PDF files in the previously selected directory, extract the abstracts and keywords from these files, and save the abstracts and keywords to a TXT file named after the PDF file. These TXT files will be saved in the user-selected directory.
- Implement the functionality to navigate to the next interface, which is bound to the “NEXT” button. When the user clicks this button, the program will close the current interface and call the run_next_script method to execute the next script. In the run_next_script method, the program will start the next script using the subprocess Popen method.

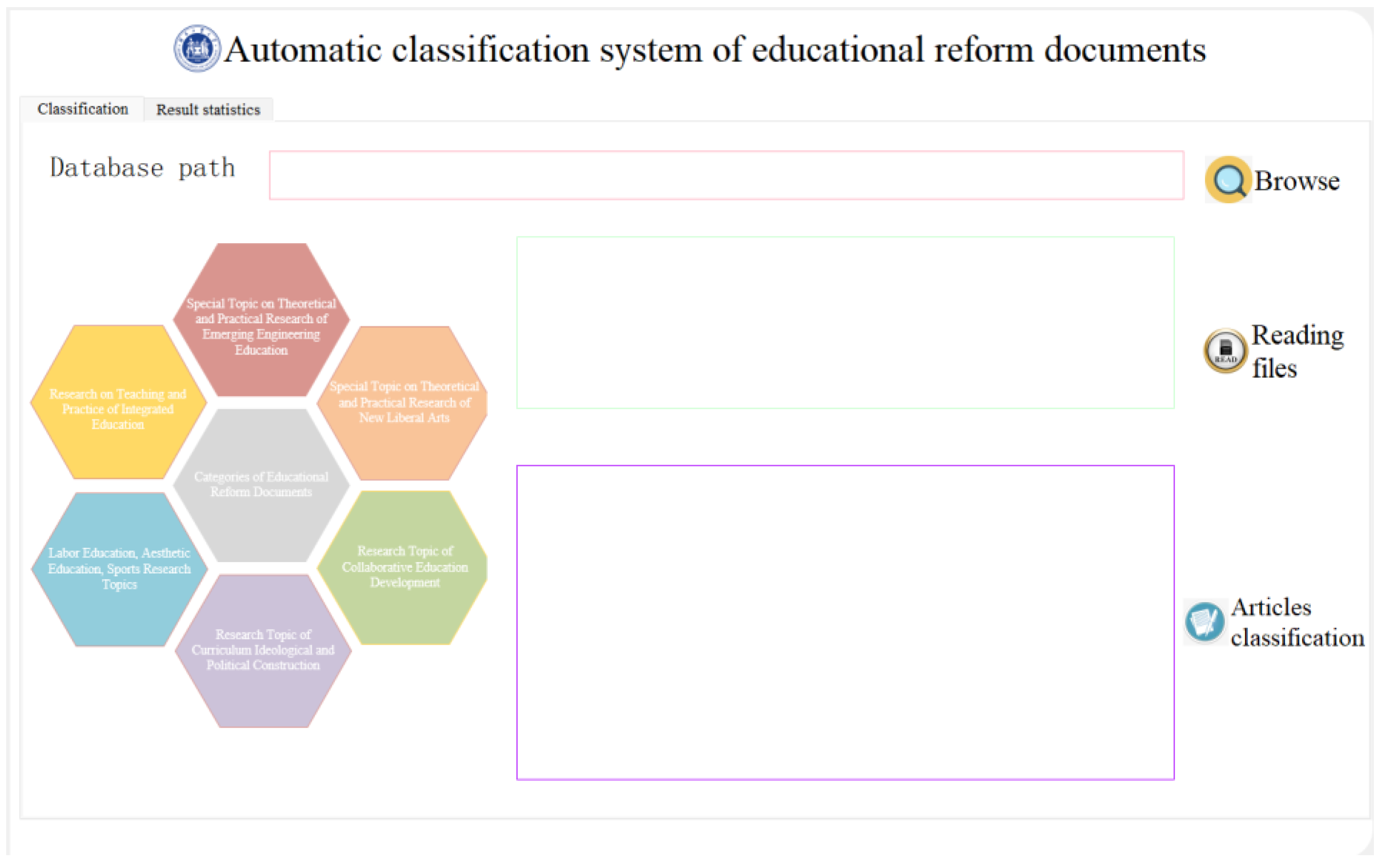
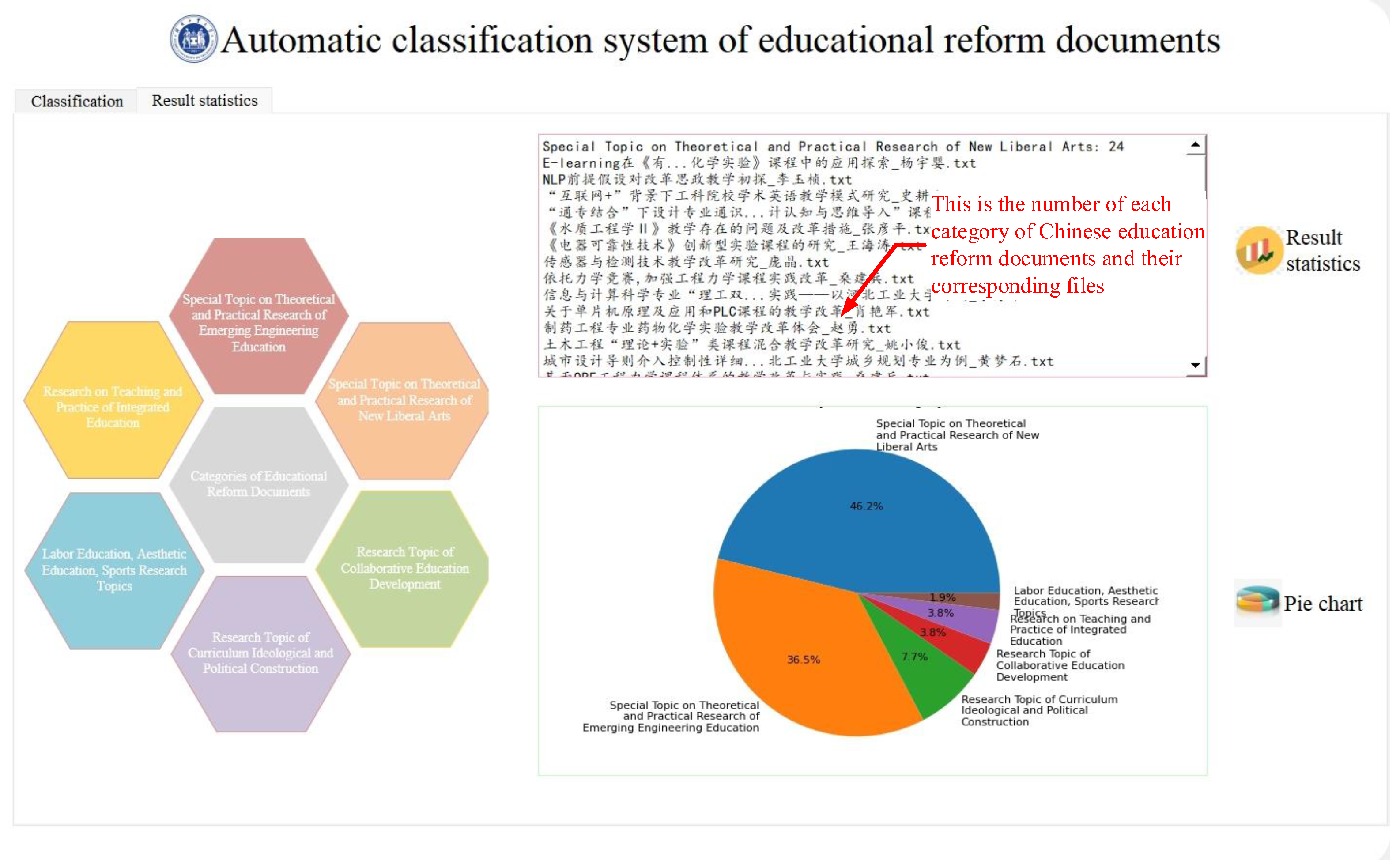
2.4.2. Automatic Classification System of Educational Reform Documents
- Initialize the interface, load the UI file, and connect the click events of the buttons.
- After clicking the “Browse” button, a folder selection dialog will pop up, allowing the user to choose the folder containing the files to be classified, and display the selected path in the corresponding text box.
- After clicking the “Reading files” button, read all the files in the selected folder and display the file names in the connected text box.
- After clicking the “Articles classification” button, the system will start classifying the files in the selected folder. First, it will iterate through all the TXT files in the folder; next, it will open and read the content of each file, tokenize the content, and remove stop words. Then, it will construct the TF-IDF term frequency vector space, convert the tokenized text into a TF-IDF frequency matrix, and save it as a binary file. Finally, it will utilize the model built using the Naive Bayes algorithm to calculate the conditional probabilities of different categories based on the TF-IDF vectors, thus achieving the classification of the test files. The classification results will be output and written into an Excel file. The classification results will be displayed in the text box associated with the “Articles classification” button.

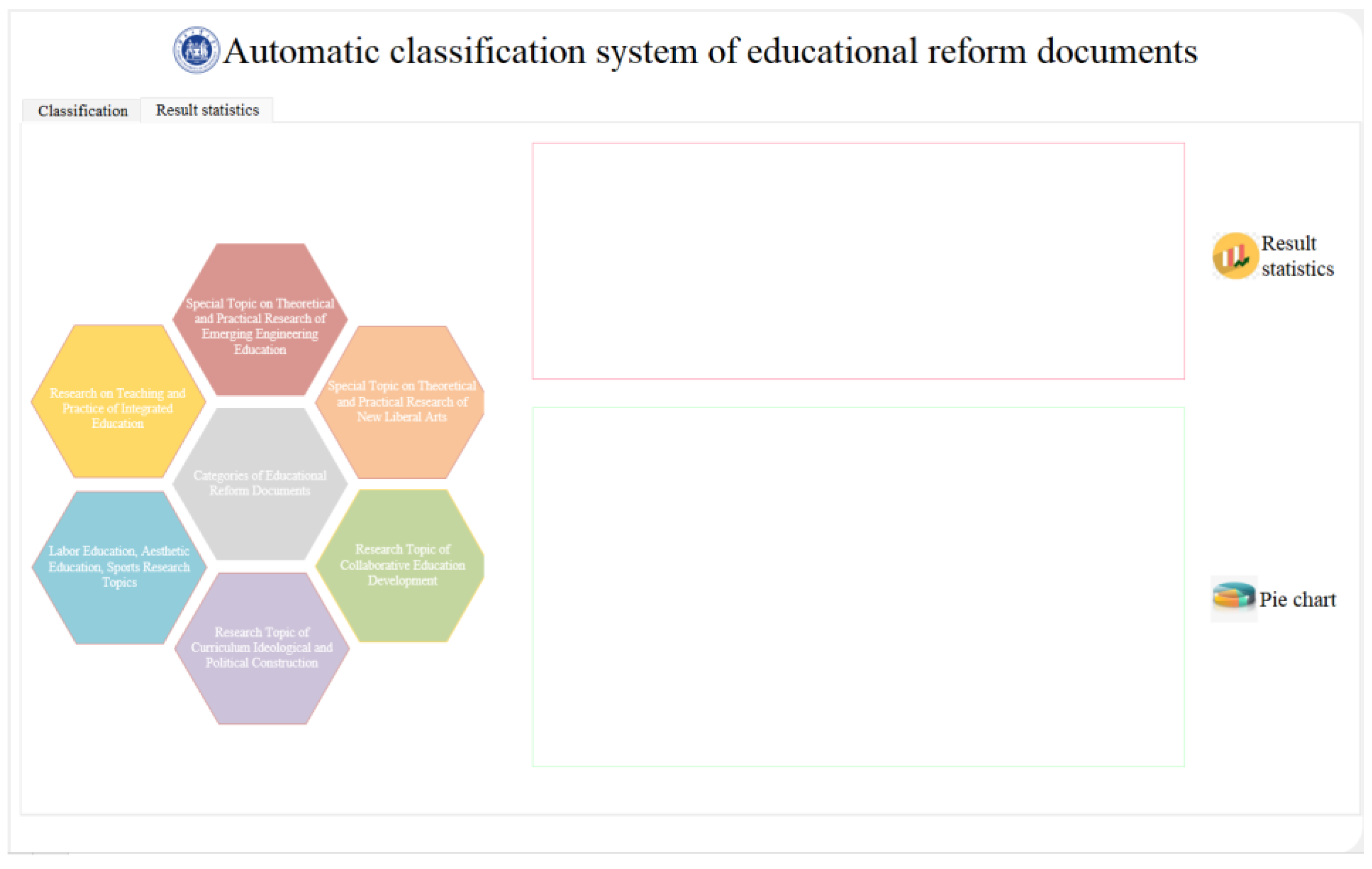
- After clicking the “Result statistics” button, read the classification results saved in the Excel file from the above interface, count the number of each category, and display the number of each category and the corresponding file names in their respective text boxes.
- After clicking the “Pie chart” button, generate a pie chart based on the classification results to visualize the proportion of each file category within the processed folder. The corresponding results will be displayed in the output box associated with the “Pie chart” button.

3. Experimental Verification, Taking the Educational Reform Documents of Hebei University of Technology as an Example
3.1. Background
3.2. Extracting Information from Educational Reform Documents of Hebei University of Technology
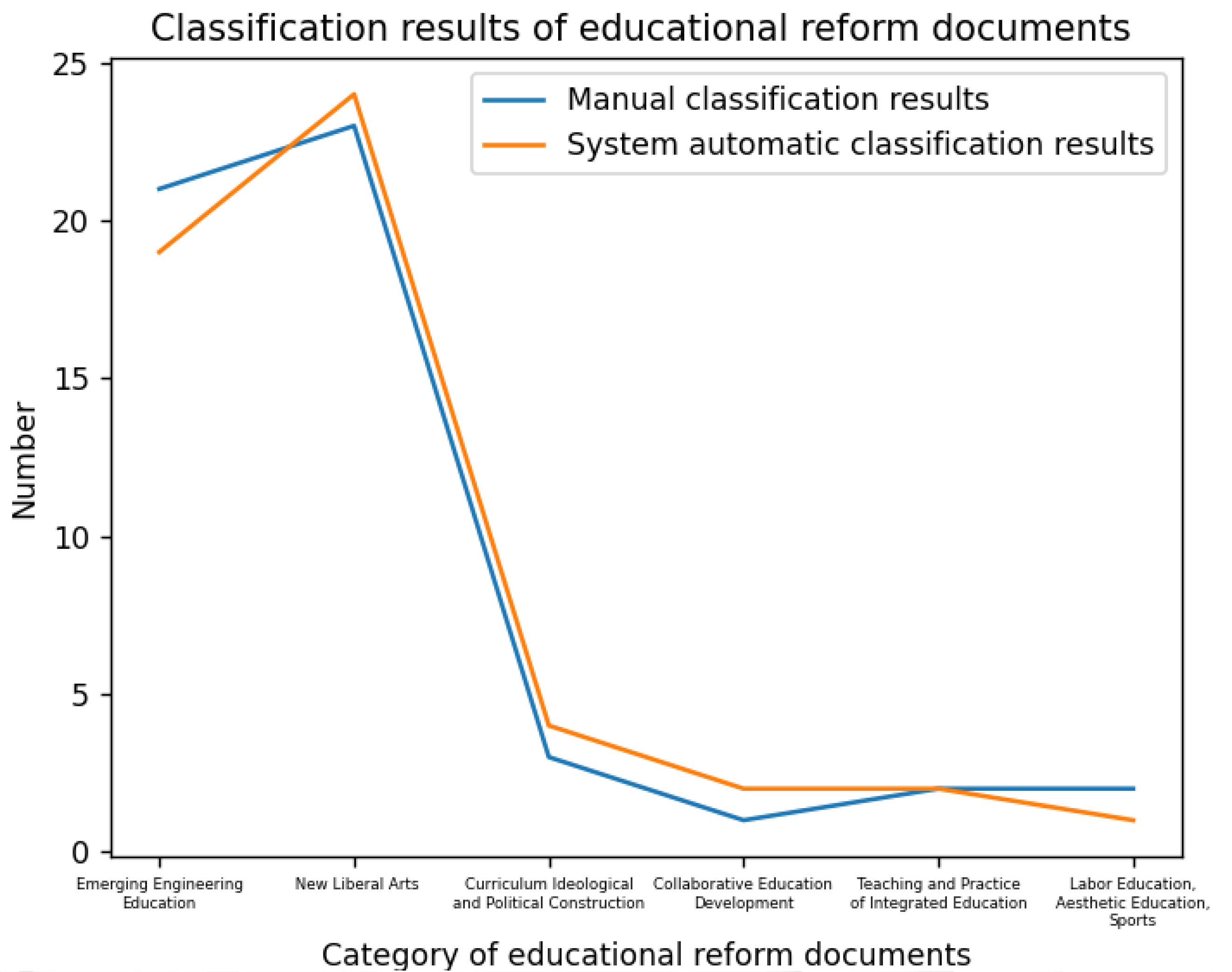
3.3. Automatic Classification of Educational Reform Documents at Hebei University of Technology
- Click “Browse” and select the file path saved in the previous step.
- Click “Reading files”, and the names and file types of the files to be processed in this folder will be automatically displayed in the text box corresponding to this button.
- Utilize the model trained using the Naive Bayes algorithm to classify the documents to be processed. The classification results of the educational reform documents at Hebei University of Technology will be displayed in the text box corresponding to the “Articles classification” button.

4. Verification and Discussion
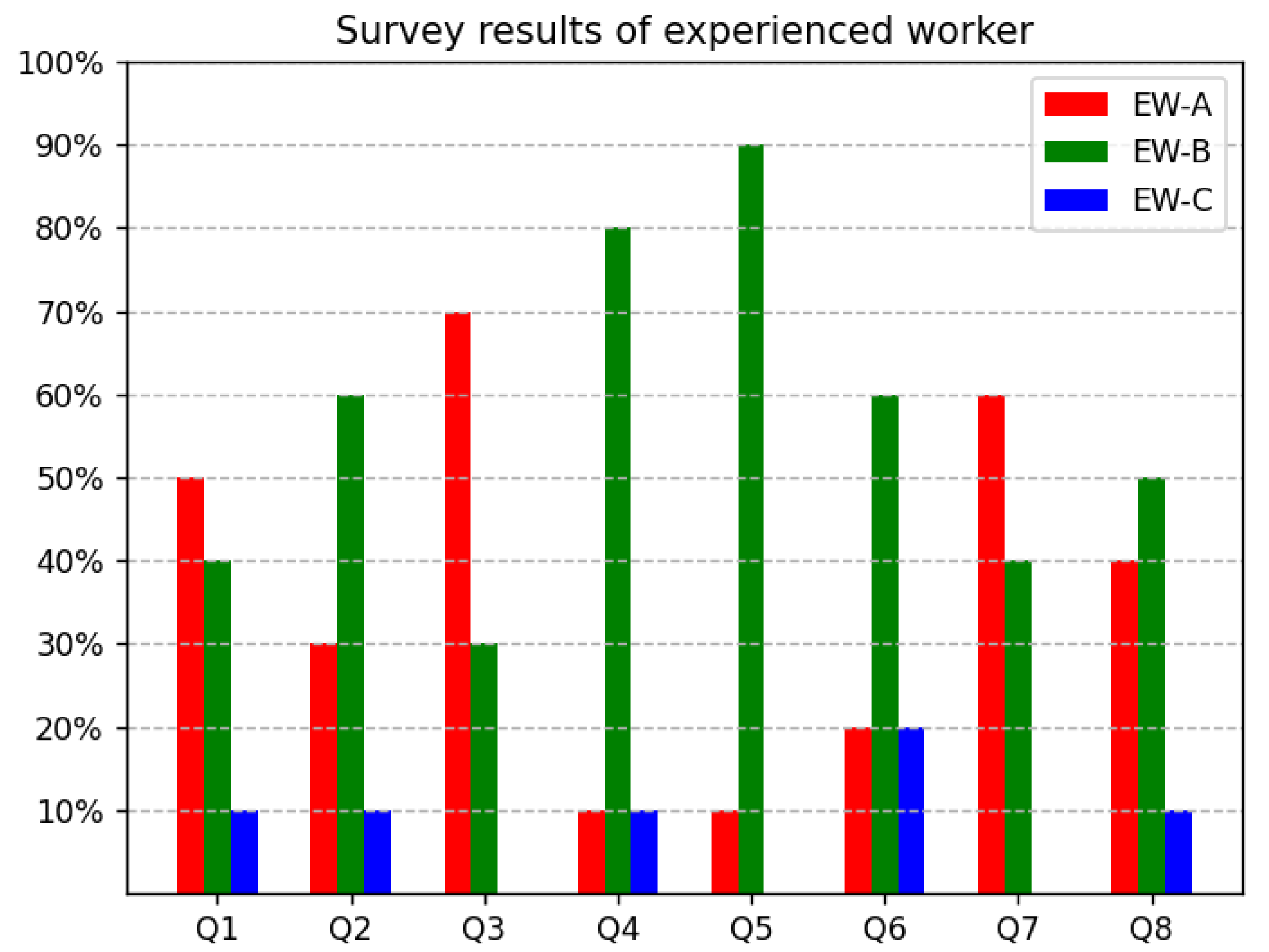
4.1. Analysis of Survey Results from Experienced Worker
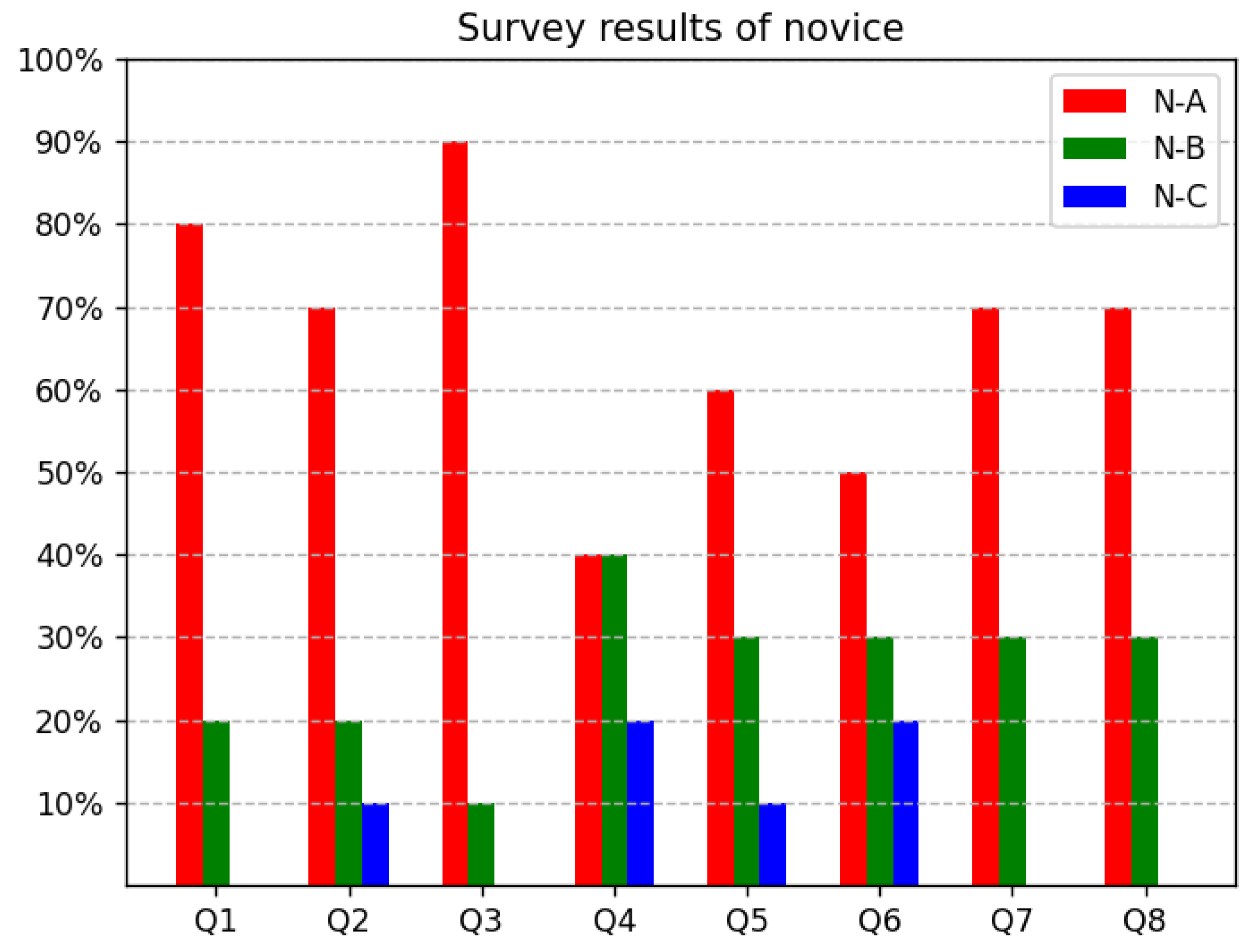
4.2. Analysis of Survey Results from Novice
4.3. Discussion
5. Conclusions
- Determined the classification direction for educational reform documents based on the “Guidelines for the Declaration of Undergraduate Education Reform Research and Practice Projects in 2021”.
- Constructed retrieval strategies for educational reform documents using “AND”, “OR”, and “NOT” combinations based on the keywords obtained from the guidelines.
- Conducted data cleaning, algorithm construction, training, and selection for educational reform documents, identifying the most suitable classification algorithm for this type of document.
- Developed an automatic classification software for educational reform documents based on the naive Bayes algorithm, which significantly reduces classification time while lowering the requirement for professional knowledge storage of classifiers, all while ensuring accuracy.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Maron, M.E. Automatie indexing: An experimental in-quiry. J. ACM 1961, 8, 404–417. [Google Scholar] [CrossRef]
- Zhang, Z.J.; Wang, Z.Q. Summary of text classification and algorithm. Comput. Knowl. Technol. 2012, 8, 825–828. [Google Scholar]
- Alina, P.; Ioana, D.; Yoon, H.J.; Mohd, Y.J.; Tanmoy, B. Deep learning uncertainty quantification for clinical text classification. J. Biomed. Inform. 2024, 149, 104576. [Google Scholar]
- Liu, H.; Hao, Y.; Zhang, W.H.; Zhang, H.Y.; Gao, F. Online urban-waterlogging monitoring based on a recurrent neural network for classification of microblogging text. Nat. Hazards Earth Syst. Sci. 2021, 21, 1179–1194. [Google Scholar] [CrossRef]
- Yang, X.Z.; Wang, Q.Q.; Jiang, J.L. Analysis of classroom teacher-student dialogue based on artificial intelligence:automatic classification and sub-level construction of lRE. E-Educ. Res. 2023, 44, 79–86. [Google Scholar]
- Vishaal, U.; Abhishek, A.; Anubha, G.; Tanmoy, C. InPHYNet: Leveraging attention-based multitask recurrent networks for multi-label physics text classification. Knowl.-Based Syst. 2021, 211, 106487. [Google Scholar]
- Chen, Y.W.; Wang, J.L.; Cai, Y.Q.; DU, J.X. A method for Chinese text classification based on apparent semantics and latent aspects. J. Ambient Intell. Humaniz. Comput. 2015, 6, 473–480. [Google Scholar] [CrossRef]
- Li, H.M.; Huang, H.N.; Cao, X.; Qian, J.G. Falcon: A novel Chinese short text classification method. J. Comput. Commun. 2018, 6, 216–226. [Google Scholar] [CrossRef][Green Version]
- Wang, G.S.; Huang, X.J. Convolutional neural network text classification model based on Word2vec and improved TF-IDF. J. Chin. Comput. Syst. 2019, 40, 1120–1126. [Google Scholar]
- Du, J.C.; Gui, L.; He, Y.L.; Xu, R.F.; Wang, X. Convolution-Based Neural Attention with Applications to Sentiment Classification. IEEE Access 2019, 7, 27983–27992. [Google Scholar] [CrossRef]
- Peng, Y.Q.; Song, C.B.; Yan, Q.; Zhao, X.S.; Wei, M. Research on Chinese text classification based on Hybrid Model of VDCNN and LSTM. Comput. Eng. 2018, 44, 190–196. [Google Scholar]
- Yun, X.P. Research progress and prospect of emergency management based on CNKI and CiteSpace. China Saf. Sci. J. 2022, 32, 185. [Google Scholar]
- Nan, M.Y.; Chen, J. Research Progress, Hotspots and Trends of Land Use under the Background of Ecological Civilization in China: Visual Analysis Based on the CNKI Database. Sustainability 2022, 15, 249. [Google Scholar] [CrossRef]
- Li, X.P.; Zhou, Y. Research on information text extraction and analysis technology based on natural language processing. Wirel. Internet Technol. 2023, 20, 157–159. [Google Scholar]
- Zhu, Y.H. Medical text mining and knowledge extraction based on natural language processing and knowledge graph. China Comput. Commun. 2023, 35, 1–3. [Google Scholar]
- Aizawa, A. An information-theoretic perspective of tf–idf measures. Inf. Process. Manag. 2003, 39, 45–65. [Google Scholar] [CrossRef]
- Paulsen, D.; Yash, G.; AnHai, D. Sparkly: A Simple yet Surprisingly Strong TF/IDF Blocker for Entity Matching. Proc. VLDB Endow. 2023, 16, 1507–1519. [Google Scholar] [CrossRef]
- Wan, Q.; Xu, X.H.; Han, J. A dimensionality reduction method for large-scale group decision-making using TF-IDF feature similarity and information loss entropy. Appl. Soft Comput. 2024, 150, 111039. [Google Scholar] [CrossRef]
- González, F.; Torres-Ruiz, M.; Rivera-Torruco, G.; Chonona-Hernández, L.; Quintero, R. A Natural-Language-Processing-Based Method for the Clustering and Analysis of Movie Reviews and Classification by Genre. Mathematics 2023, 11, 4735. [Google Scholar] [CrossRef]
- Jitchaijaroen, W.; Keawsawasvong, S.; Wipulanusat, W.; Kumar, D.R.; Jamsawang, P. Machine learning approaches for stability prediction of rectangular tunnels in natural clays based on MLP and RBF neural networks. Intell. Syst. Appl. 2024, 21, 200329. [Google Scholar] [CrossRef]
- Xiang, M.; Zhou, B.T.; Cheng, S.Q.; Liu, S. MCMP-Net: MLP combining max pooling network for sEMG gesture recognition. Biomed. Signal Process. Control 2024, 90, 105846. [Google Scholar]
- Sun, H.L.; Lu, Y.F. A novel approach for solving linear Fredholm integro-differential equations via LS-SVM algorithm. Appl. Math. Comput. 2024, 470, 128557. [Google Scholar] [CrossRef]
- Chen, C.F.; He, Q.X.; Li, Y.Y. Downscaling and merging multiple satellite precipitation products and gauge observations using random forest with the incorporation of spatial autocorrelation. J. Hydrol. 2024, 632, 130919. [Google Scholar] [CrossRef]
- Lauzon, D.; Gloaguen, E. Quantifying uncertainty and improving prospectivity mapping in mineral belts using transfer learning and Random Forest: A case study of copper mineralization in the Superior Craton Province, Quebec, Canada. Ore Geol. Rev. 2024, 166, 105918. [Google Scholar] [CrossRef]
- Li, C.; Managi, S. Mental health and natural land cover: A global analysis based on random forest with geographical consideration. Sci. Rep. 2024, 14, 2894. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Li, Z.W.; Zhu, C.D.; Li, Y.J. Research on spam filtering based on NB algorithm. Transducer Microsyst. Technol. 2020, 39, 46–48. [Google Scholar]
- Yuan, L.H.; Li, X.W.; Xu, J. An improved anti-spam filtering method based on bayesian. Comput. Digit. Eng. 2020, 48, 513–516. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | Recall | F1-Score | Support | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MLP | SVM | R-F | N-B | MLP | SVM | R-F | N-B | MLP | SVM | R-F | N-B | ||
| Topic 1 | 0.93 | 0.90 | 0.75 | 0.96 | 0.89 | 0.90 | 0.74 | 0.90 | 0.91 | 0.90 | 0.75 | 0.93 | 58 |
| Topic 2 | 0.93 | 0.96 | 0.82 | 0.97 | 0.91 | 0.88 | 0.79 | 0.98 | 0.92 | 0.92 | 0.80 | 0.97 | 57 |
| Topic 3 | 0.92 | 0.92 | 0.86 | 0.96 | 0.86 | 0.90 | 0.73 | 0.96 | 0.89 | 0.91 | 0.79 | 0.96 | 51 |
| Topic 4 | 0.70 | 0.83 | 0.63 | 0.88 | 0.84 | 0.96 | 0.60 | 0.88 | 0.76 | 0.89 | 0.61 | 0.88 | 25 |
| Topic 5 | 0.84 | 0.90 | 0.61 | 0.85 | 0.90 | 0.90 | 0.83 | 0.97 | 0.87 | 0.90 | 0.70 | 0.91 | 30 |
| Topic 6 | 0.91 | 0.86 | 0.71 | 0.93 | 0.88 | 0.91 | 0.73 | 0.91 | 0.89 | 0.88 | 0.72 | 0.92 | 33 |
| Accuracy | 0.89 | 0.90 | 0.75 | 0.94 | 255 | ||||||||
| Macro avg | 0.87 | 0.90 | 0.73 | 0.93 | 0.88 | 0.91 | 0.74 | 0.93 | 0.87 | 0.90 | 0.73 | 0.93 | 255 |
| Weighted avg | 0.89 | 0.90 | 0.75 | 0.94 | 0.88 | 0.90 | 0.74 | 0.94 | 0.89 | 0.90 | 0.75 | 0.94 | 255 |
| Chinese Version | English Version |
|---|---|
| 您的身份: | Identity: |
| Q1:使用该系统是否对相应文件分类有帮助? | Q1: Does the system help in classifying the corresponding files? |
| ☐很有帮助☐有一定帮助☐没有帮助 | A Very helpful. B Some help. C No help. |
| Q2:使用该系统是否能解决由于专业知识不足而导致分类错误? | Q2: Can the use of the system solve the classification errors caused by lack of professional knowledge ? |
| ☐能☐一定程度上可以☐不能 | A Yes. B To some extent. C No. |
| Q3:使用该系统是否能提高文件分类速度? | Q3: Can the system improve the speed of file classification ? |
| ☐能☐一定程度上可以☐不能 | A Yes. B To some extent. C No. |
| Q4:使用该系统是否能提高文件分类准确性? | Q4: Can the use of the system improve the accuracy of file classification ? |
| ☐能☐一定程度上可以☐不能 | A Yes. B To some extent. C No. |
| Q5:该系统是否有实用价值? | Q5: Does the system have practical value ? |
| ☐有☐有一定价值☐没有 | A Yes. B To some extent. C No. |
| Q6:使用该系统是否能得到期望的分类效果? | Q6: Can the system be used to get the desired classification results ? |
| ☐能☐一定程度上可以☐不能 | A Yes. B To some extent. C No. |
| Q7:使用该系统时是否遇到困难,使用效果如何? | Q7: Do you encounter difficulties when using the system, and what is the effectiveness of its usage? |
| ☐使用简单,没有任何困难 | A User-friendly, no difficulty. |
| ☐有一些困难,使用效果一般 | B Some difficulties, average performance. |
| ☐完全不会使用,非常困难 | C Not used at all, very difficult. |
| Q8:是否推荐其他人员使用? | Q8: Do you recommend other personnel to use it |
| ☐是的!我推荐☐可以尝试☐不推荐 | A Yes. B Probably. C No. |
| 其他: | Other: |
| _________________________________________ | _________________________________________ |
| Q is question |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, P.; Ma, Z.; Ren, Z.; Wang, H.; Zhang, C.; Wan, Q.; Sun, D. Design of an Automatic Classification System for Educational Reform Documents Based on Naive Bayes Algorithm. Mathematics 2024, 12, 1127. https://doi.org/10.3390/math12081127
Zhang P, Ma Z, Ren Z, Wang H, Zhang C, Wan Q, Sun D. Design of an Automatic Classification System for Educational Reform Documents Based on Naive Bayes Algorithm. Mathematics. 2024; 12(8):1127. https://doi.org/10.3390/math12081127
Chicago/Turabian StyleZhang, Peng, Zifan Ma, Zeyuan Ren, Hongxiang Wang, Chuankai Zhang, Qing Wan, and Dongxue Sun. 2024. "Design of an Automatic Classification System for Educational Reform Documents Based on Naive Bayes Algorithm" Mathematics 12, no. 8: 1127. https://doi.org/10.3390/math12081127
APA StyleZhang, P., Ma, Z., Ren, Z., Wang, H., Zhang, C., Wan, Q., & Sun, D. (2024). Design of an Automatic Classification System for Educational Reform Documents Based on Naive Bayes Algorithm. Mathematics, 12(8), 1127. https://doi.org/10.3390/math12081127