1. Introduction
Neural networks, popular nonlinear models, have demonstrated success in wind speed forecasting. These models often leverage activation functions and the Adam optimization algorithm. Multilayer Perceptron and Radial Basis Function networks are examples of such applications [
1]. Additionally, studies have explored Bayesian regularization, Levenberg–Marquardt, and recurrent neural networks [
2,
3]. Beyond neural networks, various nonlinear models can be used for long-term time series prediction, including reinforcement learning [
4], fuzzy logic [
5], and Support Vector Machines [
6]. In recent years, Long Short-Term Memory (LSTM) networks have emerged as a popular alternative due to their ability to capture long-term dependencies and nonlinear relationships in time series data [
7]. However, their complex architecture can hinder interpretability, and existing variants have not shown significant advantages over the standard architecture according to Greff [
8].
An alternative approach is Echo State Network (ESN), a recurrent network similar to LSTM. ESNs require only one training phase, making them faster to train [
9]. They excel at handling large, complex datasets and are robust to noise in the input data. These characteristics make ESNs a suitable choice for long-term forecasting and dealing with missing values. Additionally, research has explored deep and multilayer neural networks for time series forecasting [
10], with Bai et al. [
11] proposing a double-layer staged training ESN.
The ARIMA (Autoregressive Integrated Moving Average) model is a widely used and effective tool for time series forecasting, demonstrating its value in wind power generation forecasting, as shown by Yati et al. [
12]. The model’s structure can be determined using the autocorrelation function, as described in Elsara et al. [
13]. Eldali et al. [
14] further improved ARIMA’s accuracy by incorporating aerodynamic atmospheric models. However, Yumeng [
15] found its limitations in long-term prediction when applied to multivariate time series. Complex mathematical equations relying on fundamental physical law are used to forecast future weather conditions. Numerical weather prediction (NWP) models are fed with a massive amount of current weather data and are solved on supercomputers. Running high-resolution NWP models can be computationally expensive [
16]. NWP models can predict large-scale weather patterns over longer timeframes (days in advance). NWP model computations are resource-intensive; the end user (e.g., wind power company) typically accesses forecasts through weather service providers who handle the heavy lifting. However, our focus is on the limitations inherent in NWP data themselves, particularly for short-term wind speed prediction. NWP accuracy can decrease significantly at shorter horizons crucial for wind speed operations. This is where our proposed method with transfer learning comes in. By using historical data and incorporating missing data handling techniques [
17], our approach aims to improve the accuracy of short-term wind speed forecasts, even with potentially incomplete NWP data from traditional sources.
Time series forecasting involves predicting future values over extended periods. Accuracy depends on data quality, method selection, and incorporating relevant external factors. The presence of missing data in the time series adds another layer of challenge, impacting both data quality and model selection, as noted by Weina et al. [
18]. One limitation of the ARIMA model is its linear nature, potentially contributing to lower accuracy in predictions. To address this, various methods, categorized as physical and statistical, have been developed [
19]. Statistical methods are generally suited for short-term forecasting, while physical methods are typically used for long-term forecasting, as indicated by [
20].
Missing values in time series data significantly impact prediction accuracy, making careful handling essential for reliable results [
21,
22,
23]. To address this, consider techniques like Domain Adaptation Extreme Learning Machines (DA-ELM) and Transfer Learning combined with Ensemble Learning (TL-EL). DA-ELM provides robust classification from limited labeled data in E-nose systems, maintaining ELM’s efficiency [
24]. TL-EL tackles data variability in time series prediction, leveraging older data to enhance the network’s memory for current predictions [
25]. DA-ELM focuses specifically on drift in gas recognition, while TL-EL offers a broader approach for enhancing time series prediction models.
A primary challenge in time series forecasting lies in the presence of complex patterns like seasonality and trends. Frequency decomposition is a powerful technique to identify and isolate these patterns within the data. Decomposing a time series into its frequency components allows for focused analysis of each component, providing insights into their behavior and enabling more accurate forecasting. Often, data preprocessing techniques play a crucial role in improving data quality. Methods like high-frequency low-frequency decomposition [
26], variational mode decomposition [
27], and wavelet transform [
20] are widely used. The ARIMA model, specifically, leverages this separation of high and low frequencies to extract temporal correlations and probability distributions within the time series [
26].
Several studies have explored hybrid approaches to improve forecasting accuracy [
28]. In [
29], the authors propose combining Empirical Mode Decomposition (EMD) and Local Mean Decomposition (LMD) to reduce decomposition error and enhance the efficiency and accuracy of a Stochastic Configuration Network for large datasets. Liu et al. [
30] present four hybrid methods for multi-step wind speed prediction using Adaboost and Multilayer Perceptron (MLP) neural networks with different training algorithms. While both approaches aim to improve accuracy, they face tradeoffs: the EMD-LMD method heavily relies on data availability, while the Adaboost-MLP method requires significant execution time.
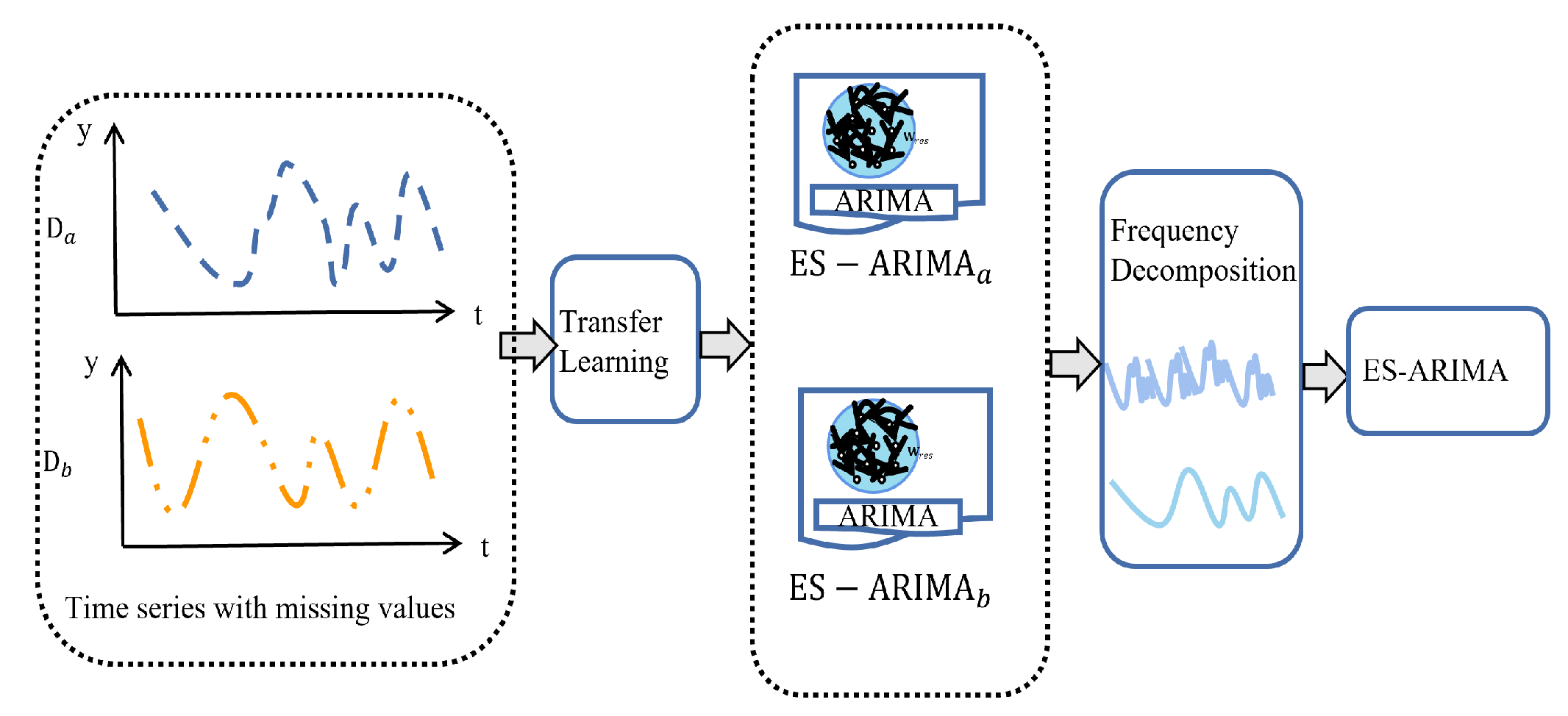
The aim of the paper is to design an effective method to predict time series with missing values. We propose an effective model named Echo State ARIMA (ES-ARIMA). This model integrates the ARIMA model as the recurrent layer in an Echo State Network (ESN), introducing an error feedback mechanism that enhances performance. Unlike traditional fusion methods [
31] that use ESN solely to compensate for the ARIMA model, our approach leverages the strengths of both models.
To further improve prediction accuracy, we employ frequency decomposition to separate high-frequency signals from low-frequency ones, allowing for a focused “fine-tuning” phase in the short-term data. Additionally, we incorporate online transfer learning, guided by a specialized performance index, to effectively leverage information from other time series during training. This work offers the following key contributions:
Addressing forecasting with missing data: We propose a novel method to address the challenge of low accuracy in forecasting with missing data. By integrating an ESN into the ARIMA model, we significantly improve prediction accuracy. To our knowledge, this is the first time an ARIMA model has been enhanced by an ESN.
Leveraging frequency decomposition and transfer learning: We utilize frequency decomposition to account for the specific characteristics of forecasts. Furthermore, we incorporate online transfer learning to tackle the accuracy issues caused by missing data.
Successful application in wind speed prediction: The proposed ES-ARIMA model demonstrates its effectiveness through successful application in wind speed prediction.
2. Echo State ARIMA Model
The ARIMA model is an extended version of the ARMA (Auto Regressive Moving Average) model that incorporates an integration component. This model consists of three stages [
26]. Echo State Networks (ESNs) are a type of recurrent neural network. They differ from traditional ones by utilizing a fixed random connection pattern between neurons. Only a small fraction of neurons are connected, creating a sparse network. The network input is added to the activity of each neuron, and the output is a linear combination of their activities. These activities update with each time step, forming a dynamic system suitable for tasks like time-series forecasting and signal processing.
Neither ARIMA nor Echo State Networks (ESNs) on their own are sufficient for effectively modeling time series data with missing values. To address this challenge, we introduce Echo State ARIMA (ES-ARIMA), a novel method that combines the strengths of both techniques. ARIMA is powerful at capturing linear trends in data, while ESNs excel at modeling nonlinear relationships and the dynamic behavior of systems. By incorporating ARIMA’s predictions into the ESN framework, we provide the network with additional information, ultimately enhancing the overall accuracy of the forecasts.
2.1. ARIMA Model
(1) Auto Regressive (AR). It expresses the past values of time series
as
where
are the coefficients of the linear AR model,
is white noise. It has zero mean and independent and identically distributed (i.i.d.).
(2) Moving Average (MA). It expresses the past values of noise
as
here,
indicates the coefficients of MA model.
(3) Integration (I). Stationarity is a critical factor in time series forecasting and a key parameter for designing the ARIMA model. We calculate the difference as
It introduces differentiation to smoothen the time series and make it closer to being stationary.
The zero mean
-order ARMA model is
Let
z be the lag operator
d-order integration can be defined as
-order ARIMA model is
The parameters of the ARIMA model are defined by the vector
as
We can use least square method to estimate the parameter
For the
i-th data,
where
n is the data size, the ARIMA model (
5) in vector form is
The objective of the parameter identification is
Because (
8) is a linear-in-parameter process, the optimal solution of
is
2.2. Echo State Network
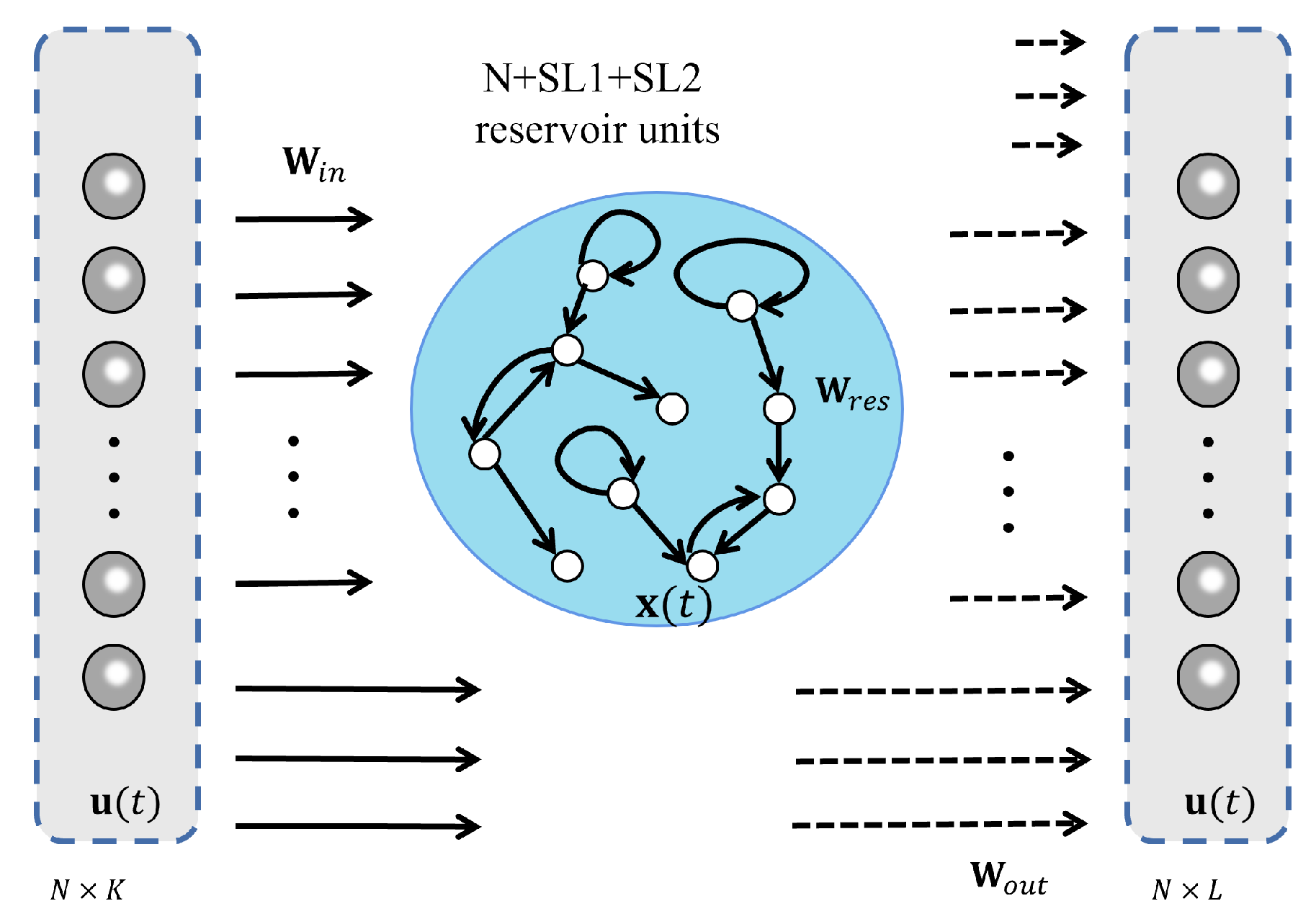
Figure 1 illustrates an ESN structure. An ESN architecture consists of three layers: (1) Input Layer: Receives external data and feeds them into the reservoir layer. (2) Reservoir Layer: This large layer contains interconnected neurons with fixed weights (a key ESN feature). These neurons process the input data through a complex nonlinear transformation and forward the result to the output layer. (3) Output Layer: A linear layer that maps the transformed data to the desired output.
The mathematical expression of ESN is
where the input to the ESN at time step
t is denoted by
, where
n is the dimensionality of the input. The output of the network at time step
t is denoted by
, where
m is the dimensionality of the output. The state of the reservoir layer at time step
t is provided by
. The ESN has a reservoir layer consisting of
N neurons,
is the input weight matrix,
is the recurrent weight matrix,
is the output weight matrix, and
is an element-wise activation function.
The recurrent layer is
where
is the leaking rate.
The weights
and
are randomly initialized with fixed weights. The weights of the output layer
are adjusted using the least squre algorithm
where
X is the matrix of reservoir states
for all time steps
t,
Y is the matrix of desired outputs
for all time steps
t,
is a regularization parameter, and
I is the identity matrix.
For time series modeling, Y is the target vector, and X is historical data. This approach greatly simplifies the training process and reduces the risk of overfitting since the complexity of the model is largely determined by the size and connectivity of the reservoir layer.
2.3. Echo State ARIMA Model (ES-ARIMA)
To address forecast lag, where predictions lag behind actual values, the AR and “I” models are commonly used, which are described in the above Equation (
5). AR models can also correct other errors, like over- or under-prediction, by capturing trends, seasonality, and other patterns in the data through linear relationships between observations. Additionally, the error feature layer, inspired by the MA model in the above Equation (
2), tackles the issue of random errors or noise in the time series data.
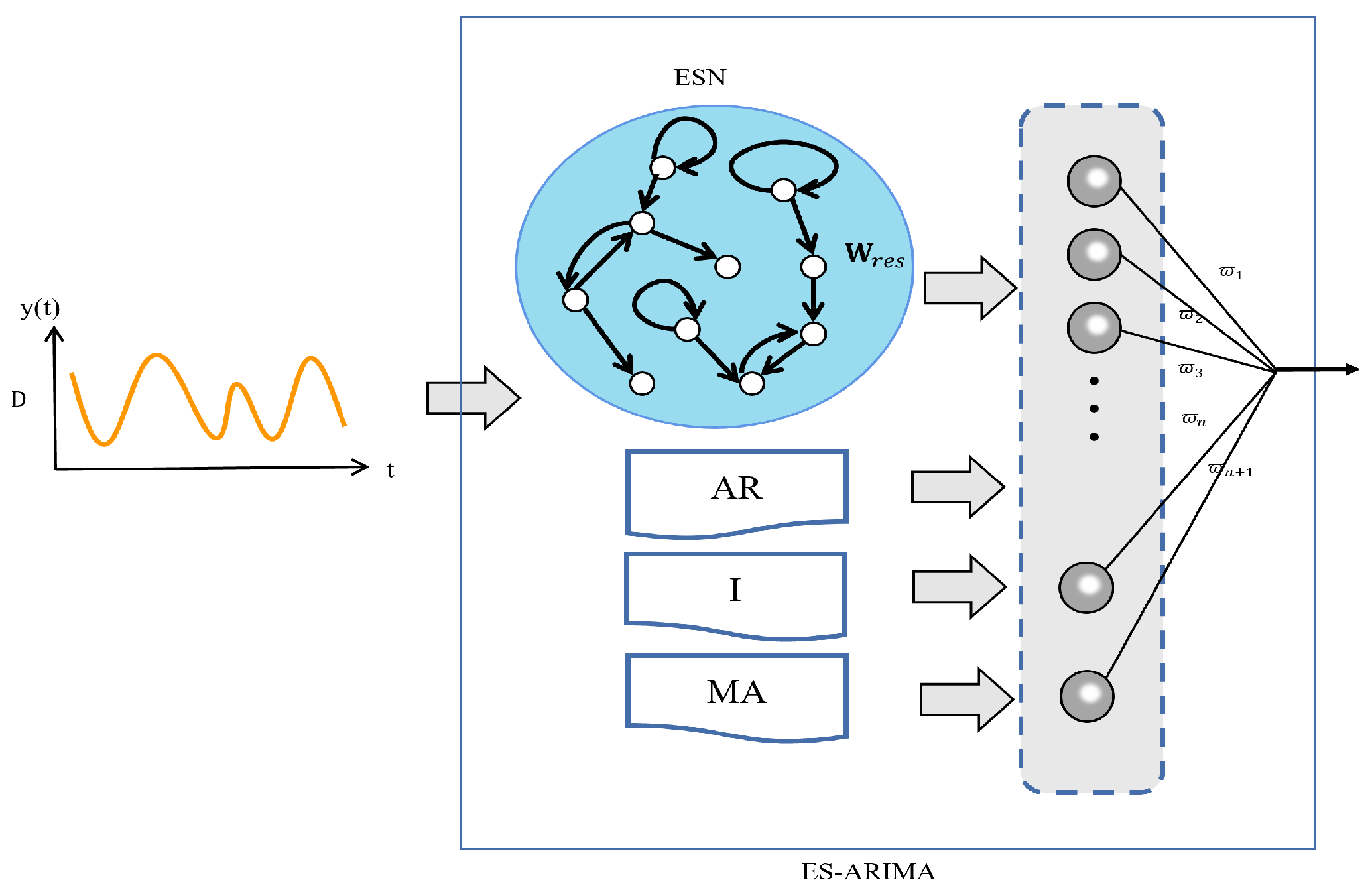
In this paper, we integrate the ARIMA model into the recurrent part of the ESN, resulting in the ES-ARIMA model.
Figure 2 illustrates its structure. ES-ARIMA combines an ESN with an ARIMA model. ES-ARIMA has two main blocks:
ESN section: This section includes elements similar to the ESN diagram, such as reservoir neurons, input layer, and output layer. It also shows connections between these elements.
ARIMA section: This section depicts elements representing the ARIMA model’s components, such as Autoregressive (AR) and Moving Average (MA) components, with arrows indicating the flow of information.
The ES-ARIMA model includes three parts: linear features error features , and nonlinear features They are
The linear features
at time step
t are composed of observations from the input vector
in
Figure 1, the input is previous time series
in dataset
D. At the current time
t and previous time
,
where
is a
l-dimensional vector,
has
matrix, and
s is the number of skipped steps between consecutive observations.
is used in the ARIMA model in
Figure 2.
The error features
is
where
and
q are defined in (
2). It is the MA model in
Figure 1. In time series forecasting, random errors can have a significant impact on the accuracy of predictions, causing them to deviate from the actual values. By modeling the noises as in (
15), the accuracy of predictions can be improved. Additionally, MA models can help the ES-ARIMA model to identify the short-term fluctuations in the data.
The nonlinear feature
is obtained from the echo state network,
where
is defined in (
12). Obviously,
is the state vector of classical ESN.
The state of ES-ARIMA model
is
where
c is a constant.
The output signal of ES-ARIMA
can be expressed as
The training of the ES-ARIMA is the same as ARIMA (
10) and ESN (
13), and the parameter vector
is the combination of
defined in (
6) and
defined in (
11), i.e.,
ES-ARIMA models, like many other statistical models, are susceptible to overfitting. We use the following method to prevent overfitting:
Information Criteria: When choosing the ARIMA order , rely on information criteria like AIC or BIC instead of simply picking the model with the lowest in-sample error on the training data. These criteria penalize models for complexity, favoring simpler models that perform well on unseen data.
Limit Model Complexity: Avoid excessively high orders for the ES-ARIMA model. Start with a simpler model and increase complexity only if the information criteria or diagnostics on the residuals suggest a need for more parameters.
3. Training of ES-ARIMA Model
3.1. Frequency Decomposition
Time series forecasting involves predicting the future values of a series over time, essentially anticipating its behavior several steps ahead. Frequency decomposition is a valuable technique that separates a time series into its constituent frequencies. This decomposition reveals hidden patterns within the data, which are particularly beneficial for prediction tasks.
High-frequency components capture short-term fluctuations, while low-frequency components reflect long-term trends. By decomposing the signal, the neural network can effectively distinguish between these timescales. It can then focus on the relevant component, whether it is the underlying trend (low frequency) or the short-term volatility (high frequency). For long-term forecasts, the model prioritizes the information contained in the low-frequency components.
Predicting the original time series
directly with models like ESN and ARIMA can be challenging. However, decomposing the signal into its constituent frequencies makes each component more suitable for specific prediction methods
where
, it corresponds to the cutoff frequencies, which can be obtained by applying the more general lowpass-to-highpass transformation. or short-term predictions. If long-term forecasting is required, the weight of low frequency will be higher than high frequency.
Low-frequency components are well-suited for linear prediction using ARIMA, while high-frequency components benefit from nonlinear prediction methods like ESN:
Here,
represents the forget weight, allowing the network to combine high- and low-frequency signals at different times.
Low-frequency signals facilitate long-term memory in ESN. By incorporating the ARIMA model’s weights as the forgetting rate, the network can selectively choose relevant information from the ESN, improving its ability to adapt to changes over time. This essentially allows the model to “forget” outdated information and focus on the most relevant data for prediction.
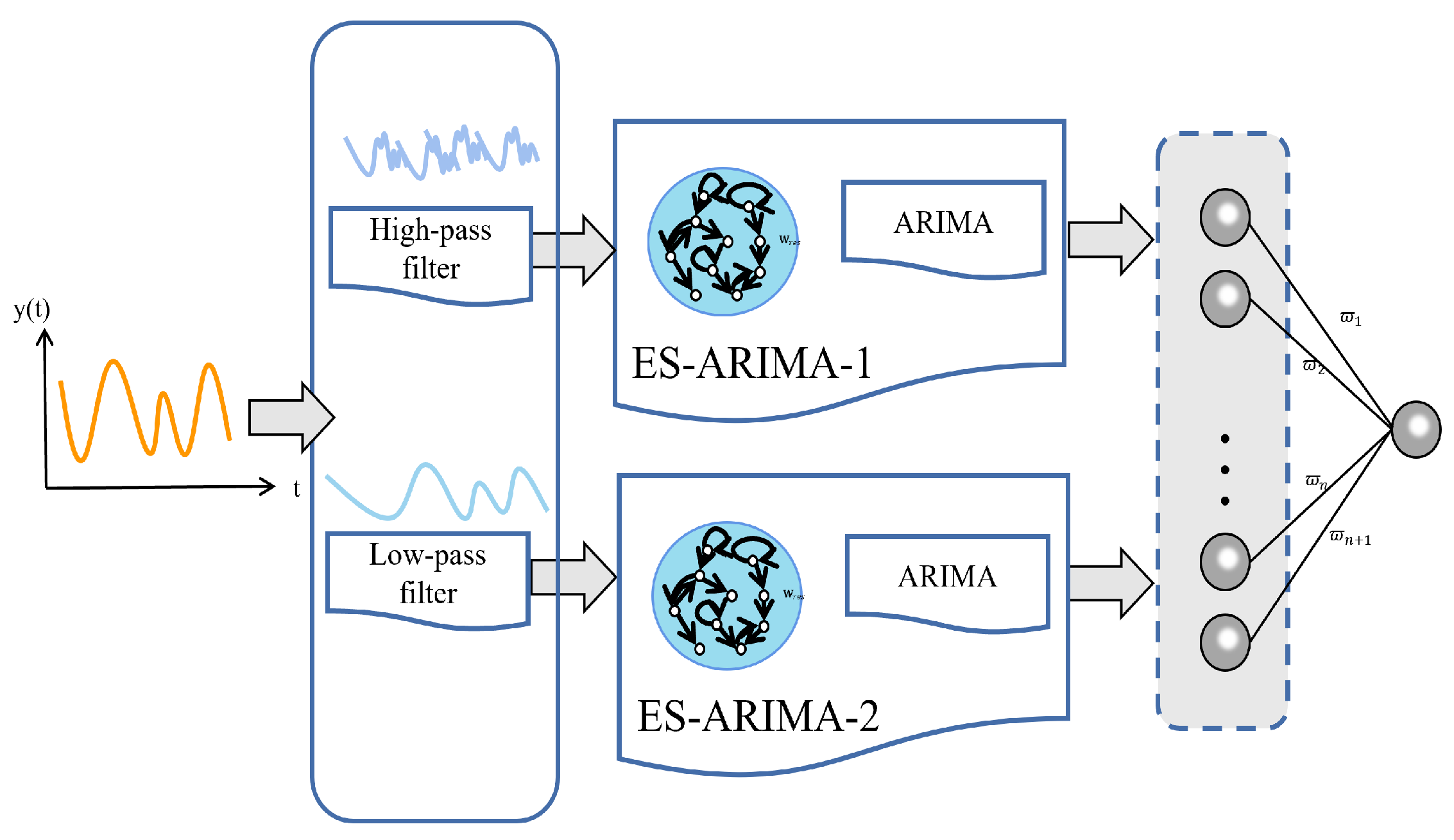
As shown in
Figure 3, high-frequency signals capture fine details, while low-frequency signals provide the overall form and structure. We utilize another neural network to fuse the high-frequency and low-frequency components obtained after decomposition:
where
is high-frequency signal,
is low-frequency signal, where
and
are the outputs of the low- and high-frequency ES-ARIMA models, respectively.
Finally, a two-layer Multilayer Perceptron (MLP) combines
and
:
where
, and
are the weights,
is the final prediction, and
is a nonlinear activation function.
3.2. Transfer Learning
Missing values in time series data can be handled in two ways: dropping them or imputing them (replacing them with estimated values). While methods like linear interpolation, spline interpolation, and k-nearest neighbors exist for imputation, they may not work well for non-randomly distributed missing values. Recent research suggests that deep learning methods like Long Short-Term Memory (LSTM) networks can handle such scenarios more effectively.
Many existing prediction methods require sufficient and evenly distributed data. Transfer learning can be used to address this challenge by transferring knowledge from one time series (e.g., with complete data) to another (e.g., with missing values). This can improve the accuracy of machine learning algorithms for time series data with missing values.
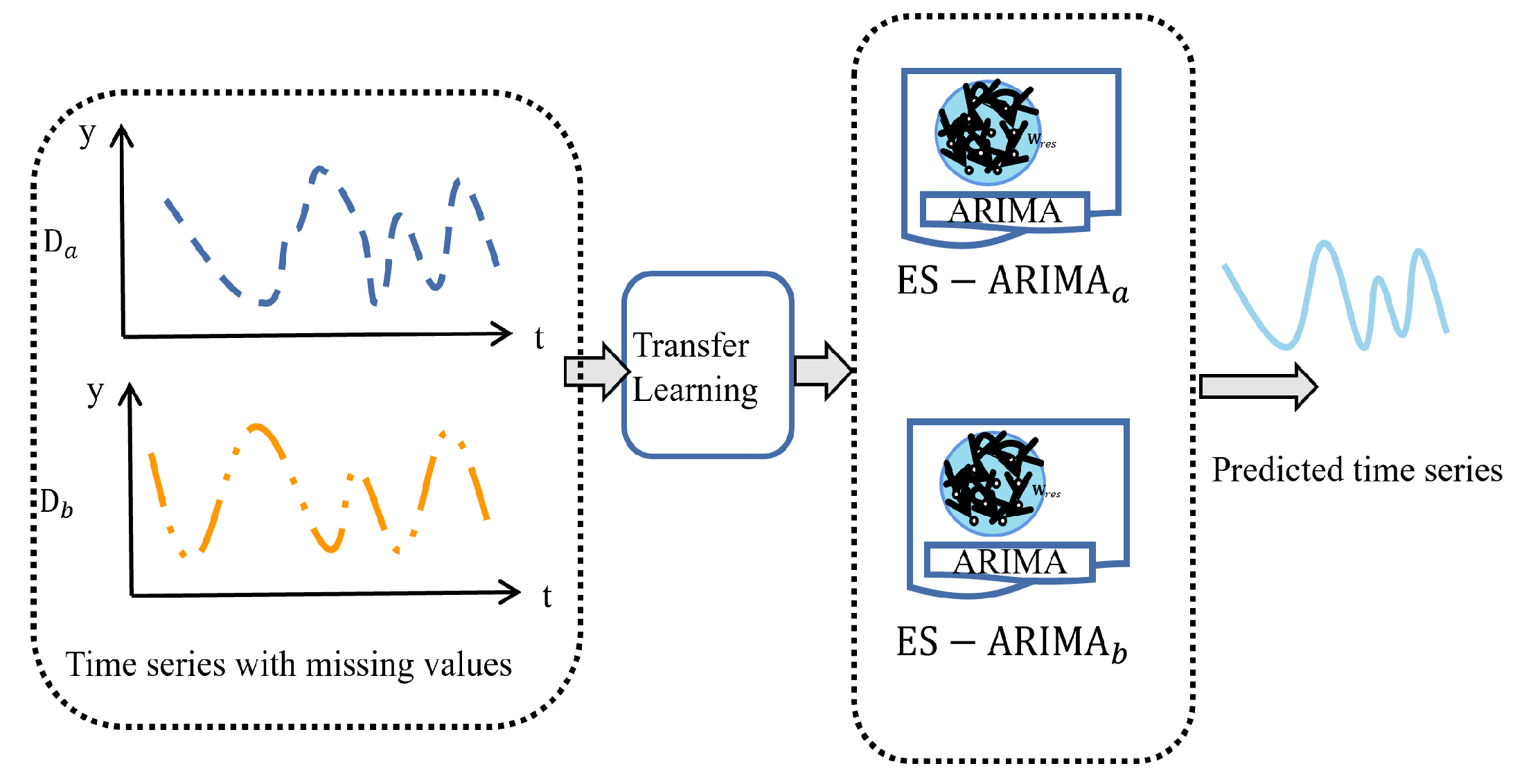
Traditional ARIMA models struggle when dealing with uncertainties in training data, such as missing values. Let us assume the training data has missing values, while datasets and share similar distributions with . Our goal is to recover using data from and . If a relationship exists between and , we can express as a function of them . This section proposes a transfer learning approach where the ESN-ARIMA_a model can utilize the combined dataset .
For an ESN-ARIMA_a model, the training objective is to minimize both the training error and the number of parameters, as shown in the following equation:
where
and
are the weight and the state of the ESN-ARIMA model,
is the desired value.
For an ESN-ARIMAa model, the training objective is to minimize both training error and parameters, as follows: where it is the regularization parameter,
When there are missing values in we use to help us to improve the model ES-ARIMAa.
This source task
uses a pre-trained Echo State Network (ESN) on a different but related time series forecasting problem of
. The pre-trained ESN captures some general knowledge in
that can be beneficial for the target task
. The knowledge transfering from the source task
to the target task
involves using the weights or activations learned by the pre-trained ESN as a starting point for training the ESN component within the ES-ARIMA model. This transfer learning is shown in
Figure 4.
The training index is defined as
where
,
and
are positive constants: they are the penalty coefficients on the prediction error from source and target domain, and
and
are the lengths of datasets
and
.
denotes the output weight vector of the domain
;
is the target dataset
From (
24), we obtain the local solution
. From (
25), we will learn
using all data from the source domain
by leveraging a limited number.
For ES-ARIMA model,
,
,
denote the states of reservoir, the prediction error, and the target value in the domain
.
,
,
denote the states of reservoir, the prediction error, and the target value in the domain
. The corresponding Lagrangian problem of (
25) is
where
and
are Lagrangian multiplier vectors. The problem (
26) can be solved by
where
and
are the output matrix of reservoir layer with respect to the data from target domain
and source domain
, respectively.
Calculating the matrix inverse, as shown in Equation (
28), can be computationally expensive and resource-intensive, especially for real-time applications and large matrices. This high demand for computational power and memory limits its practical use. To address this challenge, this paper proposes a novel recursive method for finding the inverse. This method offers several benefits, including
Fast convergence: It reaches the solution quickly, making it suitable for real-time applications.
Low computational complexity: It requires fewer calculations compared to traditional methods, reducing computational burden.
Improved numerical stability: It produces more accurate results, especially when dealing with ill-conditioned matrices.
To implement the recursive method, we require the use of the following matrix inverse lemma:
where
,
,
,
. We define
,
,
. Then,
Then, we can define
,
,
,
using (
29), (
30) is
If
, then
We define
as gain vectors, and then
So, the output weight updates can be performed using
where the error
and
can be easily computed. The scheme of the long-term prediction of time series with missing values using echo state ARIMA model is shown in
Figure 5.
For implementation, the ES-ARIMA algorithm is summarized in Algorithm 1.
| Algorithm 1 ARMA-ESN |
- 1:
The inputs are the time series in datasets . is the target domain. is the source domain. - 2:
Initialize two ESN networks, with N hidden neurons, random input weights , and reservoir W for both target and source domains. - 3:
Use algorithm RLS to obtain AR model weights as ESN forgetting rate. - 4:
Calculate the hidden matrix and according to ( 21). - 5:
Compute the output weights using ( 33). - 6:
Return the output weights and predicted output . - 7:
The outputs are predicted output and .
|
Here, several remarks on the proposed method are presented:
While the proposed method offers significant advantages in handling missing data and improving forecasting accuracy, it is important to acknowledge the potential increase in computational complexity compared to simpler approaches. This is particularly relevant for large-scale datasets.
The potential increase in computational cost needs to be weighed against the significant benefits gained in terms of accuracy and robustness, especially for applications where high-fidelity wind speed prediction is crucial. Further research can explore optimization techniques to further enhance the scalability of the proposed method for even larger datasets.
The effectiveness of the method can be influenced by the quality of the data, particularly the extent and pattern of missing data. High percentage of missing values, especially if randomly distributed, could hinder the model’s ability to learn the underlying patterns in the data. One ideal approach might involve a combination of the method with data preprocessing techniques specifically tailored to the characteristics of the missing data.
While the proposed model offers significant improvements in accuracy by combining multiple techniques (ESN, ARIMA, frequency decomposition, and transfer learning), this complexity might come at the cost of interpretability. Understanding the exact contributions of each component to the final prediction can be challenging. Further research can explore additional methods for enhancing interpretability, such as visualization techniques or model-agnostic interpretable machine learning approaches. This will enable deeper understanding of the internal workings of the model and potentially lead to further improvements in its performance.
We acknowledge that the proposed method’s success is tied to the availability of sufficient historical data. However, the framework incorporates techniques that can use even smaller datasets effectively. Additionally, the transfer learning component allows the model to potentially benefit from knowledge learned from related domains, even if the target domain has limited data. While the ideal scenario involves abundant high-quality data, our approach offers advantages over existing methods by achieving a good baseline level of accuracy and capturing essential trends even with limited data availability.
4. Applications
To demonstrate the effectiveness of our Echo State ARIMA (ES-ARIMA) model for handling such data, we apply the proposed approach to real-world wind speed systems.
In recent decades, wind speed has emerged as a key solution to address the challenges of climate change and the growing demand for electricity. Its cleaner and more sustainable nature has propelled it to become one of the most important clean energy sources globally [
32,
33,
34]. However, the efficiency of wind power generation is hampered by the inherent variability and uncertainty of wind speed and direction [
35].
Wind speed forecasting, a crucial application of time series prediction, plays a vital role in mitigating these challenges. The existing prediction models can be broadly categorized into four types: physics-based, statistical, neural network, and fusion models. Each type is suitable for different time scales, with statistical models commonly employed for short-term forecasting and physical models favored for long-term predictions [
20]. These time scales range from very short-term (seconds to 30 min) to very long-term (beyond 72 h).
This study utilizes three datasets from diverse geographical regions: Kaggle [
36], Germany [
37], and California [
38]. We employ
of each dataset for training multiple ARIMA models and the remaining
for testing. These datasets contain 18,000 records. We used the first 15,000 records for training the model and the remaining 3000 records for testing.
The dataset details are (1) Time Period: the date range covered by the data is one year. (2) Features: the datasets include wind speed, wind direction, temperature, pressure, and humidity. (3) Target variable: wind speed. (4) Time Step: hourly. We aggregate these hourly values to create a daily time series. (5) Missing Values: approximately
Kaggle Dataset: It contains hourly values from 7 wind farms spanning from July 2009 to June 2012. We use data from the first wind farm between 1 July 2009 and 31 December 2010.
California Dataset: It records hourly energy production from 5 wind farms, including geothermal, biomass, biogas, mini-hydraulic, total wind, solar photovoltaic, and solar thermal. We use data from 1 September 2011 to 31 August 2012.
Germany Dataset: This dataset encompasses data from four wind farms: Tennet, 50 Hertz, TransnetBW, and Amprion. The data are from 1 January 2011 to 31 December 2011.
We use the following min–max normalization to scale the data to a similar range, leading to faster training and convergence of neural networks,
where
is each datum of the time series,
is the minimum of the data
y, and
is the maximum of the data
y.
For long-term prediction of time series,
where
in this paper, we select
i.e., for daily records of wind speed. We consider 48 h forecasts in the simulations because
While short-term forecasts are most valuable for real-time operations, including 48 h forecasts, this showcases the proposed method’s ability to handle a wider range of prediction horizons.
Research suggests that incorporating information from longer time frames can sometimes improve the accuracy of shorter-term forecasts. By including 48 h data in the training process, we might be capturing underlying patterns that benefit the overall performance, even for the crucial short-term predictions.
The model is
Time series forecasting is
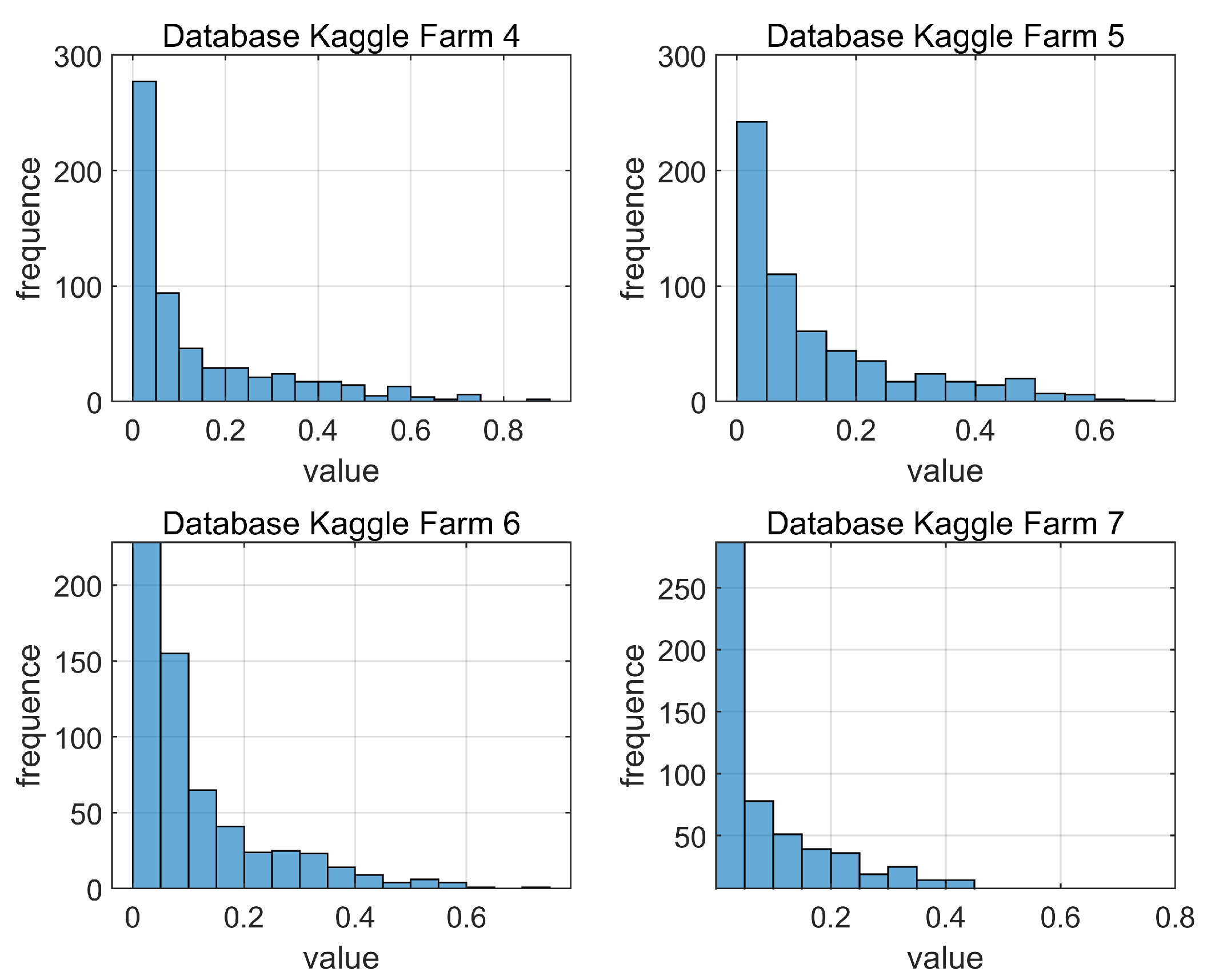
Wind speed plays a critical role in determining electricity generation by wind turbines. However, wind speed datasets often exhibit limitations. High wind speeds, crucial for accurate forecasting, occur only for a small fraction of the year (around ). This imbalance can negatively impact prediction accuracy for high wind speeds compared to regular wind speeds.
To demonstrate the effectiveness of our transfer learning approach, we utilize the Kaggle dataset. It contains hourly wind speed data from 7 wind farms between July 2009 and June 2012. Despite the missing data, the wind speed data across the different farms exhibit substantial similarity due to their geographic proximity. This similarity is ideal for applying transfer learning techniques. These techniques can leverage knowledge gained from one dataset (source domain) to improve predictions for another (target domain). The histogram of wind speed data from different farms is illustrated in
Figure 6.
The equation for the ES-ARIMA model is shown in (
17). To determine the appropriate ARIMA model structure, we need to analyze the stationarity of the data and obtain the value of d. We use the Augmented Dickey–Fuller (ADF) test [
39] for stationarity analysis. The results are presented in
Table 1.
Critical values of , , and are used for the ADF hypothesis test. If the hypothesis is accepted, the ARIMA model contains a unit root, indicating non-stationarity. For the Kaggle dataset, the initial test with zero differentiation produces a value of . This value is less than all critical values, indicating the time series needs differencing. After one differentiation, the hypothesis is accepted, making the Kaggle set stationary with .
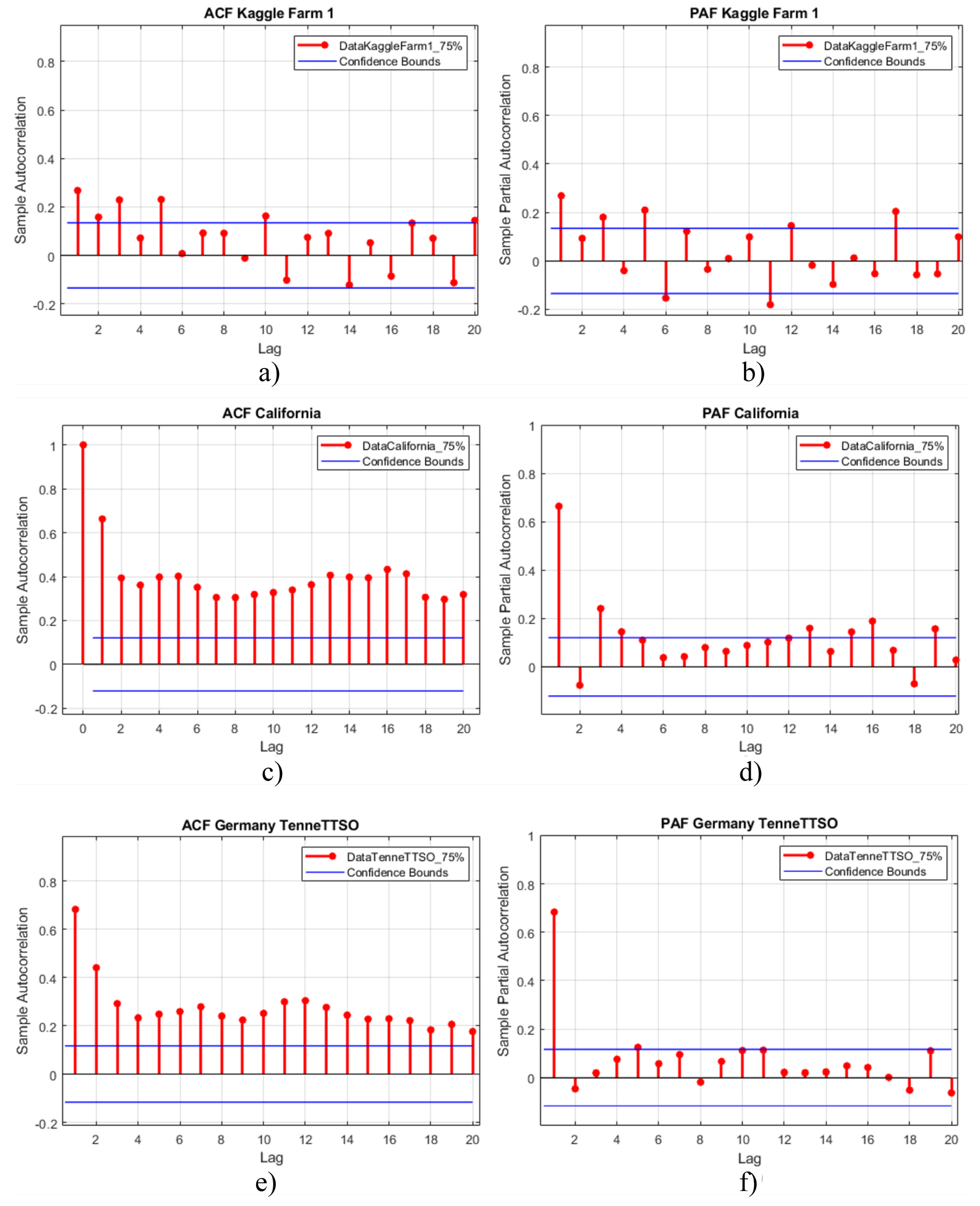
ACF (Autocorrelation Function) and PAF (Partial Autocorrelation Function) are crucial tools for selecting the appropriate ARIMA model order (p, d, q). By analyzing their patterns, we can identify and address autocorrelations in our time series data, leading to a more accurate model.
Figure 7 shows the ACF/PAF plots for the three datasets.
Table 2 displays the ARIMA parameters obtained from ACF/PAF analysis and the ADF test. So, the optimal ARIMA models for the datasets are Kaggle—ARIMA(1,1,2), Germany—ARIMA(1,0,4), and California—ARIMA(0,1,2).
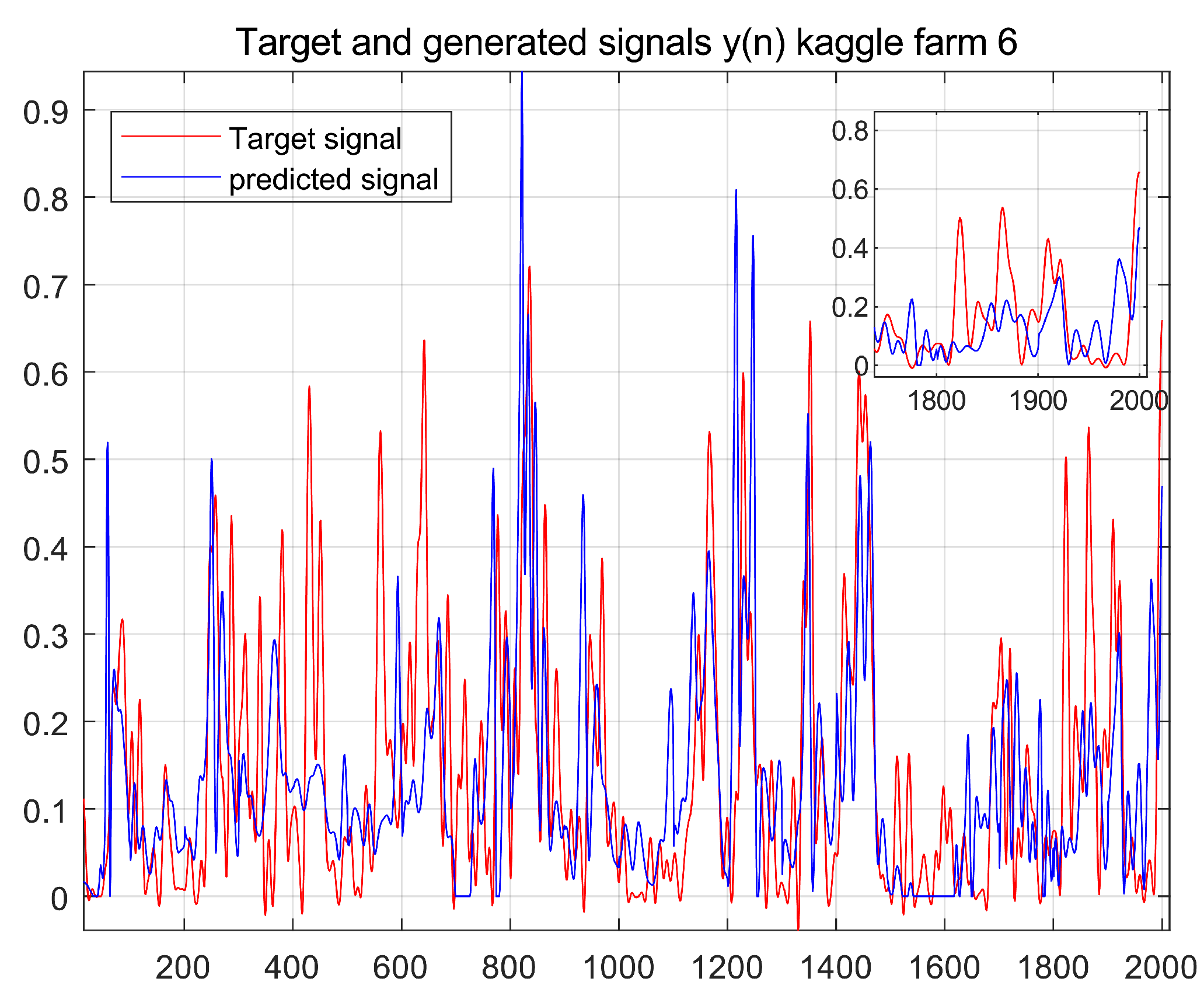
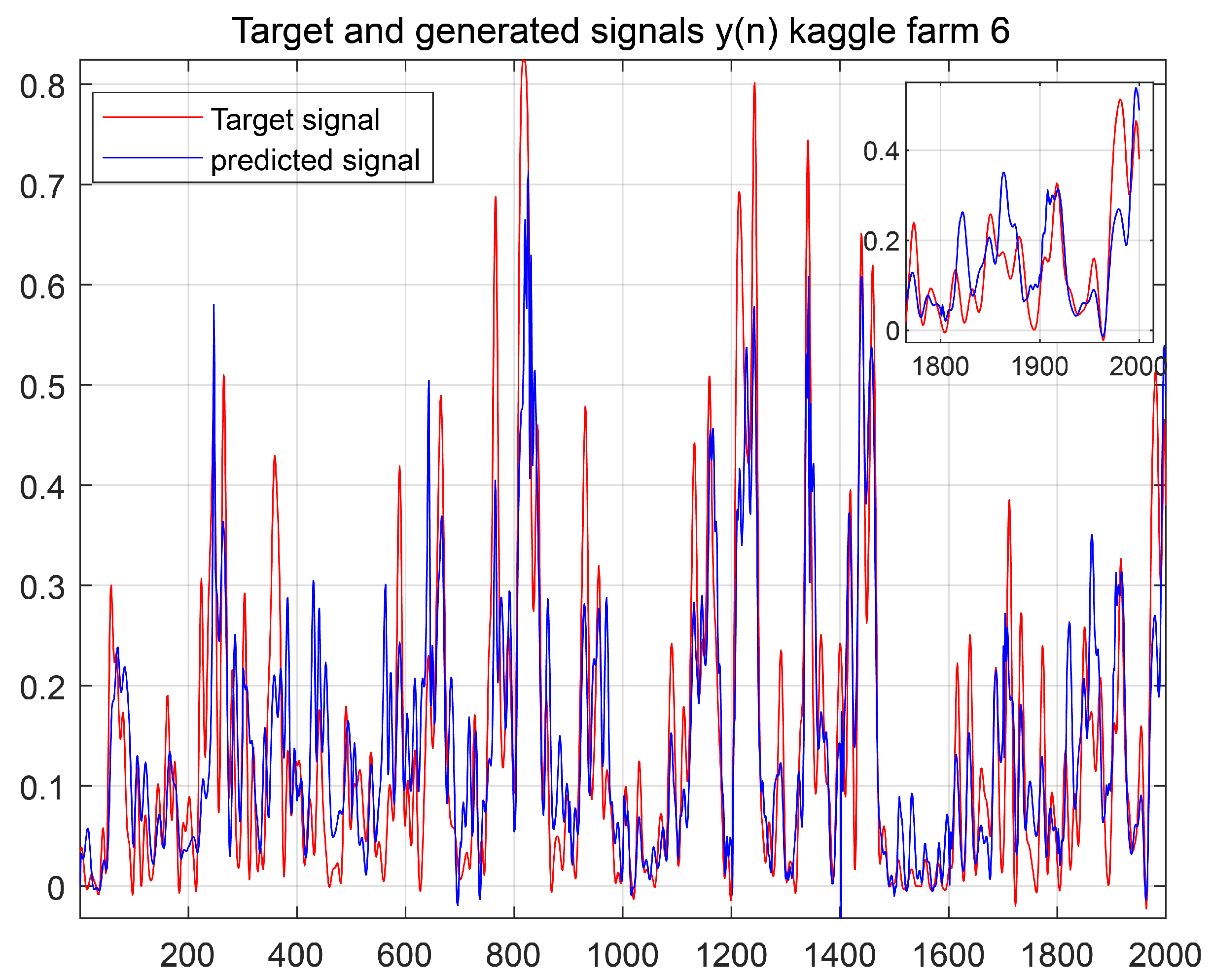
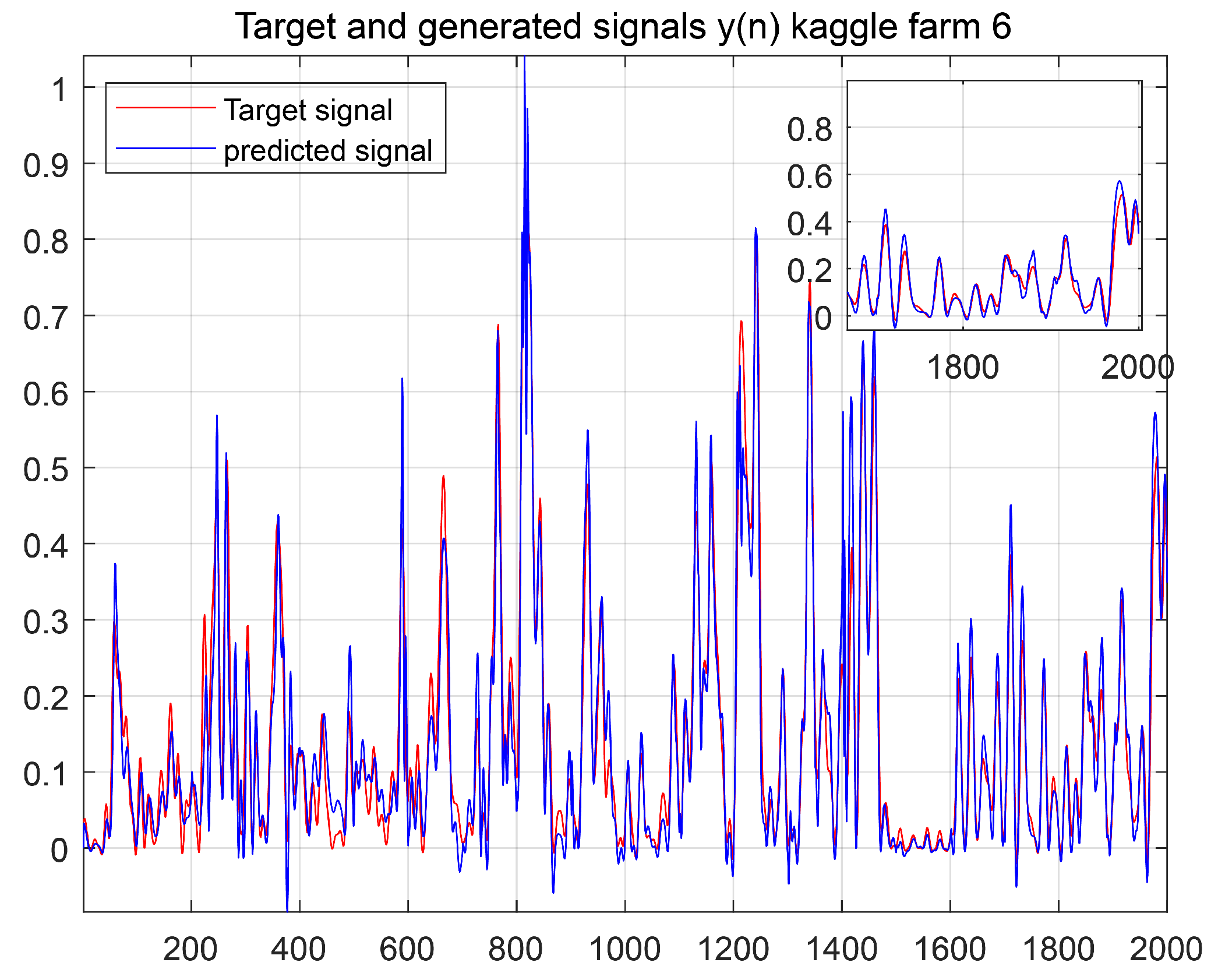
The prediction results using the ES-ARIMA model are shown in
Figure 8.
In frequency decomposition, the transfer function of the filters is
where
corresponds to the cutoff frequencies.
Figure 9 depicts the prediction results with frequency decomposition and ES-ARIMA. While these results are better than using only ES-ARIMA, missing data still affect the accuracy.
We aim to enhance prediction accuracy by leveraging transfer learning. This technique allows the model to identify patterns and relationships common across different datasets, leading to more accurate and robust predictions. Our objective is to forecast data in Farm 6 by utilizing information from other farms (source domain).
As shown in
Figure 10, transfer learning generally delivers favorable results when source and target domains exhibit high similarity. However, low similarity can lead to lower performance, as illustrated in
Figure 9.
Despite the limitations in this case, transfer learning still outperforms directly supplementing Farm 6 data with data from Farm 5. This highlights the potential of transfer learning to improve predictions even with low similarity between source and target domains. By utilizing knowledge from related datasets, transfer learning can help to mitigate the impact of missing data in the target domain.
Comparisons
ARIMA Models vs. Neural Networks:
ARIMA Models: These models are widely used for time series forecasting and excel at identifying patterns and trends in historical data. However, they may struggle with complex relationships or nonlinear data.
Neural Networks: These powerful machine learning techniques can learn complex patterns and relationships, even in nonlinear data. They often outperform ARIMA models in terms of accuracy but require more computational power and data for training.
Comparison with Other Forecasting Methods:
We compared our ES-ARIMA model with several classical methods:
Multilayer Perceptron (MLP): A type of artificial neural network.
Classical Echo State Network (ESN): A type of recurrent neural network.
ARIMA: The standard ARIMA model.
T-ARIMA: ARIMA with classical transfer learning.
ARIMA: classical ARIMA model
Evaluation Metrics:
The following metrics were used to compare forecasting errors:
where Mean Absolute Error (MAE): Average absolute difference between predicted and actual values. Symmetric Mean Absolute Percentage Error (SMAPE): Error metric less sensitive to outliers than other measures. Root Mean Squared Error (RMSE): Square root of the average squared difference between predicted and actual values. R-squared (
): Proportion of variance in the predicted values that can be explained by the independent variable (closer to 1 indicates better fit). However, high
could be overfitting the training data.
Results and Discussion:
Table 3,
Table 4 and
Table 5 present the comparison results for the three datasets (California, Germany, and Kaggle).
California: The multiple ARIMA model significantly outperforms the single ARIMA model, with improvements exceeding in all metrics (e.g., improvement in MAE).
Germany: The multiple ARIMA model exhibits an average improvement of compared to the single ARIMA model.
Kaggle: The ES-ARIMA model achieves an average improvement of in SMAPE, RMSE, and compared to the other models.
The proposed ES-ARIMA models with frequency decomposition and transfer learning outperform the other classical models for long-term prediction with missing data. The ES-ARIMA model achieves significant improvements over ESN and classical ARIMA models, particularly for the Germany dataset (nearly improvement).
The comparative tables show that the proposed ES-ARIMA models significantly reduce prediction errors compared to the other methods. These models achieve lower MAE, SMAPE, and RMSE values, while exhibiting values closer to 1, indicating a superior fit to the data.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}