
Urban Origin–Destination Travel Time Estimation Using K-Nearest-Neighbor-Based Methods


Abstract
1. Introduction
- We propose the haversine metric as a new distance metric for KNN. This metric enables the elimination of bias inherent in the commonly used Euclidean distance. Additionally, we include a correction factor for the KNN’s estimated times, adjusting predictions based on the distances traveled by the KNNs.
- An adaptive algorithm is proposed to efficiently partition the neighbor search based on the trip’s starting time. Employing a binary search approach, the algorithm generates time partitions to define the training observation neighbors. This method facilitates the inclusion of a new predictor variable in the model without necessitating adjustments to the distance metric. This extension to the KNN framework enables the incorporation of additional input variables into the model.
- Finally, a comprehensive computational study was conducted using a taxi company database to examine methods and algorithms commonly utilized in machine learning. The results and analysis offer meaningful insights into the times (hours) of the day exhibiting the most similar travel times. These insights are deemed potentially valuable to decision-makers.
2. Literature Review
2.1. Travel Time Prediction Using Trajectory Data
2.2. Travel Time Prediction Using Partial Data
3. Problem Definition
4. Methodology
4.1. K-Nearest Neighbor (KNN)
4.2. Time Partitioning Predicting Methods
| Algorithm 1: Binary search algorithm. |
|
Input: Tolerance , time points Output: Value of time ℓ
|
| Algorithm 2: Time partitioning algorithm. |
| Input: Tolerance , list of time points L Output: List of new time points L
|
5. Computational Experiments
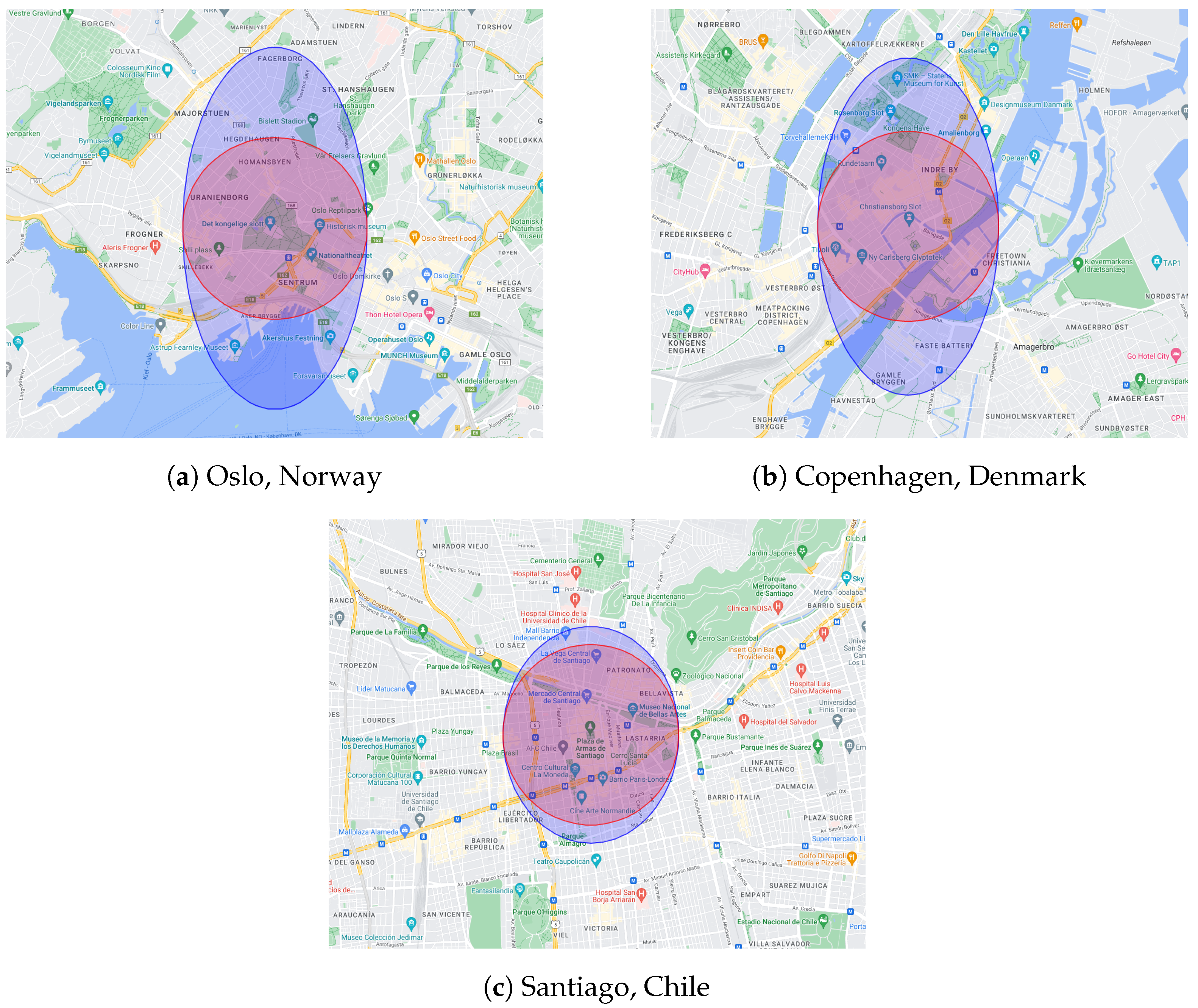
5.1. Dataset Description and Preprocessing
5.2. Initial Model Comparison
- KNN-U: KNN with Euclidean distance using uniform prediction.
- KNN-W: KNN with Euclidean distance using weighted prediction.
- KNN-WH: KNN with haversine distance using the weighted prediction.
- KNN-H: KNN-WH with the bias correction in (7).
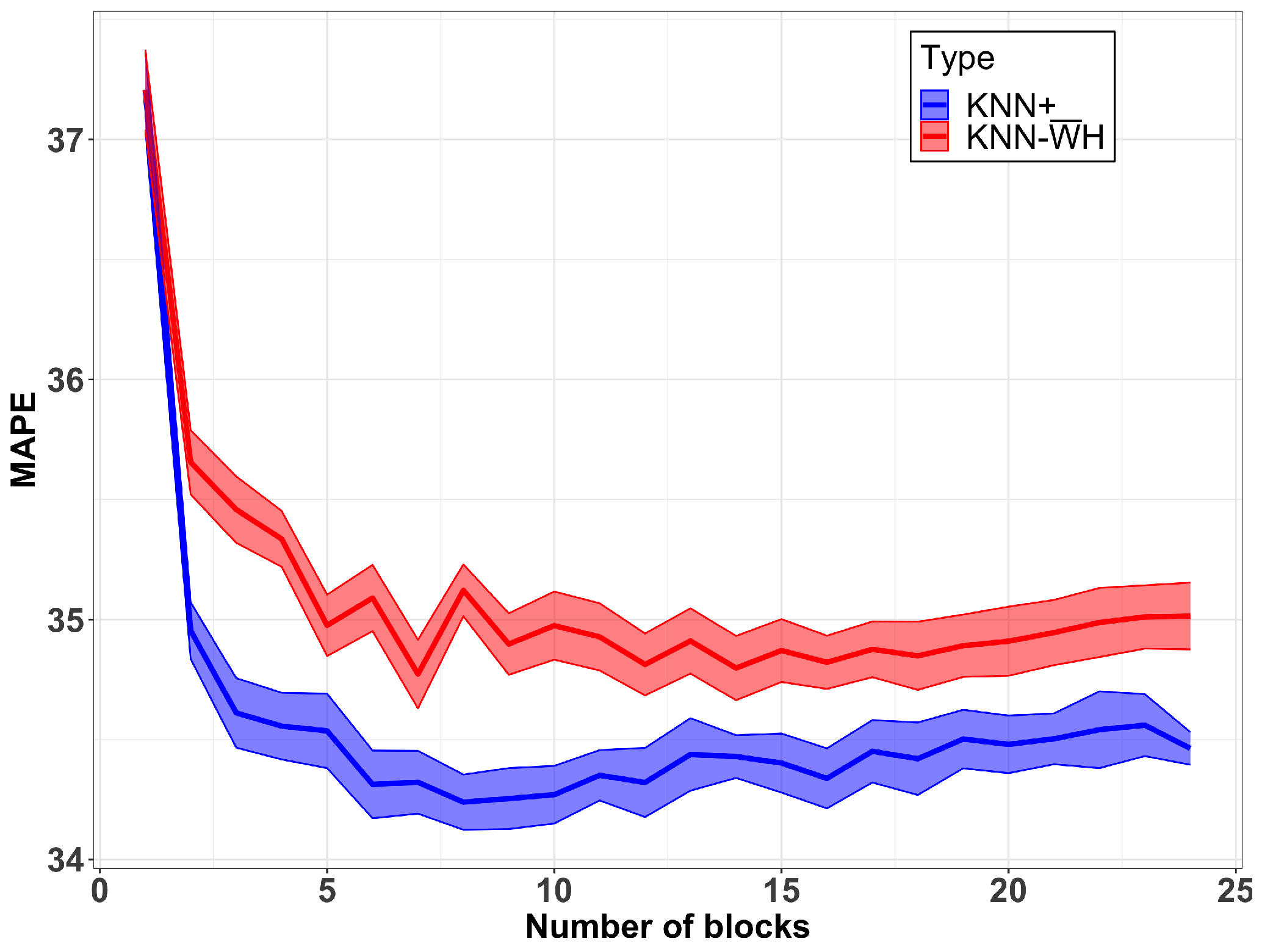
- KNN+: KNN-H that applies the TPA for a given number of blocks (used in experiments 5.3 and 5.4).
5.3. Fixed Time Partition
- 7:01 to 9:00, high fare.
- 9:01 to 18:00, medium fare.
- 18:01 to 20:00, high fare.
- 20:01 to 20:45, medium fare.
- 20:46 to 23:00, low fare.
- 23:00 to 6:00, closed.
- 6:01 to 7:00, low fare.
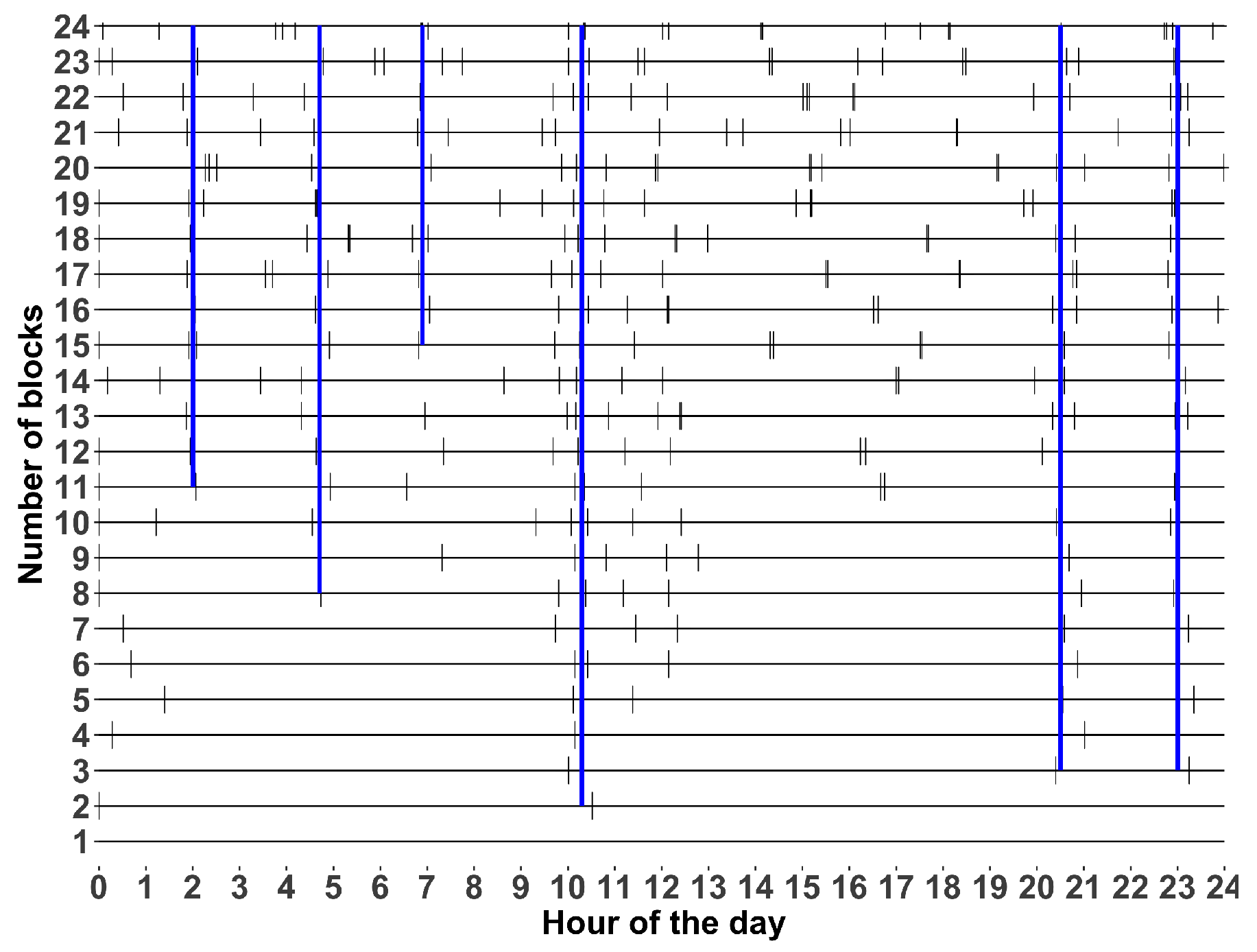
5.4. Variable Time Partition
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bertsimas, D.; Delarue, A.; Jaillet, P.; Martin, S. Travel time estimation in the age of big data. Oper. Res. 2019, 67, 498–515. [Google Scholar] [CrossRef]
- Wu, X.; Kumar, V.; Ross Quinlan, J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Vlahogianni, E.I.; Karlaftis, M.G.; Golias, J.C. Short-term traffic forecasting: Where we are and where we’re going. Transp. Res. Part C Emerg. Technol. 2014, 43, 3–19. [Google Scholar] [CrossRef]
- Woodard, D.; Nogin, G.; Koch, P.; Racz, D.; Goldszmidt, M.; Horvitz, E. Predicting travel time reliability using mobile phone GPS data. Transp. Res. Part C Emerg. Technol. 2017, 75, 30–44. [Google Scholar] [CrossRef]
- Prokhorchuk, A.; Dauwels, J.; Jaillet, P. Estimating Travel Time Distributions by Bayesian Network Inference. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1867–1876. [Google Scholar] [CrossRef]
- Putatunda, S.; Laha, A. Travel Time Prediction in Real time for GPS Taxi Data Streams and its Applications to Travel Safety. Hum. Cent. Intell. Syst. 2023, 3, 381–401. [Google Scholar] [CrossRef]
- Satrinia, D.; Saptawati, G.P. Traffic speed prediction from GPS data of taxi trip using support vector regression. In Proceedings of the International Conference on Data and Software Engineering (ICoDSE), Palembang, Indonesia, 1–2 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Gmira, M.; Gendreau, M.; Lodi, A.; Potvin, J.Y. Travel speed prediction based on learning methods for home delivery. EURO J. Transp. Logist. 2020, 9, 100006. [Google Scholar] [CrossRef]
- Sun, S.; Chen, J.; Sun, J. Traffic congestion prediction based on GPS trajectory data. Int. J. Distrib. Sens. Netw. 2019, 15, 1550147719847440. [Google Scholar] [CrossRef]
- Stipancic, J.; Miranda-Moreno, L.; Labbe, A.; Saunier, N. Measuring and visualizing space–time congestion patterns in an urban road network using large-scale smartphone-collected GPS data. Transp. Lett. 2019, 11, 391–401. [Google Scholar] [CrossRef]
- Zheng, L.; Xia, D.; Zhao, X.; Tan, L.; Li, H.; Chen, L.; Liu, W. Spatial–temporal travel pattern mining using massive taxi trajectory data. Phys. A Stat. Mech. Its Appl. 2018, 501, 24–41. [Google Scholar] [CrossRef]
- Krause, C.M.; Zhang, L. Short-term travel behavior prediction with GPS, land use, and point of interest data. Transp. Res. Part B Methodol. 2019, 123, 349–361. [Google Scholar] [CrossRef]
- Chughtai, J.U.R.; Haq, I.U.; Shafiq, O.; Muneeb, M. Travel Time Prediction Using Hybridized Deep Feature Space and Machine Learning Based Heterogeneous Ensemble. IEEE Access 2022, 10, 98127–98139. [Google Scholar] [CrossRef]
- Vankdoth, S.R.; Arock, M. Deep intelligent transportation system for travel time estimation on spatio-temporal data. Neural Comput. Appl. 2023, 35, 19117–19129. [Google Scholar] [CrossRef]
- Sheng, Z.; Lv, Z.; Li, J.; Xu, Z. Deep spatial-temporal travel time prediction model based on trajectory feature. Comput. Electr. Eng. 2023, 110, 108868. [Google Scholar] [CrossRef]
- Zhuang, L.; Wu, X.; Chow, A.H.; Ma, W.; Lam, W.H.; Wong, S.C. Reliability-based journey time prediction via two-stream deep learning with multi-source data. J. Intell. Transp. Syst. 2024, 1–19. [Google Scholar] [CrossRef]
- Zhang, H.; Zhao, F.; Wang, C.; Luo, H.; Xiong, H.; Fang, Y. Knowledge Distillation for Travel Time Estimation. IEEE Trans. Intell. Transp. Syst. 2024, in press. [CrossRef]
- Zhou, X.; Yang, Z.; Zhang, W.; Tian, X.; Bing, Q. Urban Link Travel Time Estimation Based on Low Frequency Probe Vehicle Data. Discret. Dyn. Nat. Soc. 2016, 2016, 7348705. [Google Scholar] [CrossRef]
- Vu, L.H.; Passow, B.N.; Paluszczyszyn, D.; Deka, L.; Goodyer, E. Estimation of Travel Times for Minor Roads in Urban Areas Using Sparse Travel Time Data. IEEE Intell. Transp. Syst. Mag. 2021, 13, 220–233. [Google Scholar] [CrossRef]
- Sanaullah, I.; Quddus, M.; Enoch, M. Developing travel time estimation methods using sparse GPS data. J. Intell. Transp. Syst. Technol. Plan. Oper. 2016, 20, 532–544. [Google Scholar] [CrossRef]
- Ghandeharioun, Z.; Kouvelas, A. Link Travel Time Estimation for Arterial Networks Based on Sparse GPS Data and Considering Progressive Correlations. IEEE Open J. Intell. Transp. Syst. 2022, 3, 679–694. [Google Scholar] [CrossRef]
- Zhan, X.; Hasan, S.; Ukkusuri, S.V.; Kamga, C. Urban link travel time estimation using large-scale taxi data with partial information. Transp. Res. Part C Emerg. Technol. 2013, 33, 37–49. [Google Scholar] [CrossRef]
- NYCTLC. Trip Record Data. 2016. Available online: https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page (accessed on 25 March 2024).
- Zhan, X.; Ukkusuri, S.V.; Yang, C. A Bayesian mixture model for short-term average link travel time estimation using large-scale limited information trip-based data. Autom. Constr. 2016, 72, 237–246. [Google Scholar] [CrossRef]
- Wang, H.; Tang, X.; Kuo, Y.H.; Kifer, D.; Li, Z. A Simple Baseline for Travel Time Estimation using Large-scale Trip Data. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–22. [Google Scholar] [CrossRef]
- Araujo, A.C.D.; Etemad, A. Deep Neural Networks for Predicting Vehicle Travel Times. In Proceedings of the IEEE Sensors, Montreal, QC, Canada, 27–30 October 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: Cham, Switzerland, 2006; Volume 4. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Cham, Switzerland, 2009; Volume 2. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Wang, H. Nearest neighbors by neighborhood counting. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 942–953. [Google Scholar] [CrossRef] [PubMed]
- Ooi, H.L.; Ng, S.C.; Lim, E. Ano detection with k-nearest neighbor using minkowski distance. Int. J. Signal Process. Syst. 2013, 1, 208–211. [Google Scholar] [CrossRef]
- Bailey, T.; Jain, A. A Note on Distance-Weighted k-Nearest Neighbor Rules. IEEE Trans. Syst. Man Cybern. 1978, 8, 311–313. [Google Scholar] [CrossRef]
- Yao, Z.; Ruzzo, W.L. A regression-based K nearest neighbor algorithm for gene function prediction from heterogeneous data. BMC Bioinform. 2006, 7, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Navot, A.; Shpigelman, L.; Tishby, N.; Vaadia, E. Nearest neighbor based feature selection for regression and its application to neural activity. Adv. Neural Inf. Process. Syst. 2005, 18. [Google Scholar]
- Liu, T.; Moore, A.W.; Gray, A. New Algorithms for Efficient High-Dimensional Nonparametric Classification. J. Mach. Learn. Res. 2006, 7, 1135–1158. [Google Scholar]
- Qin, W.; Zhang, M.; Li, W.; Liang, Y. Spatiotemporal K-Nearest Neighbors Algorithm and Bayesian Approach for Estimating Urban Link Travel Time Distribution From Sparse GPS Trajectories. IEEE Intell. Transp. Syst. Mag. 2023, 15, 152–176. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Notation |
|---|---|
| Transportation network graph | |
| Trip observation | |
| Total number of observations | D |
| Total number of observations for training | |
| Input vector for time estimation | |
| K-nearest neighbor parameter | k |
| Neighborhood of input observation | |
| Distance from a point to a point y |
| Model | Hyperparameters | Training Error | Testing Error |
|---|---|---|---|
| G-Boosting | depth , trees | 44.52 (0.36) | 48.10 (1.12) |
| KNN-U | 39.78 (0.01) | 41.87 (0.71) | |
| KNN-W | 0.00 | 39.44 (0.66) | |
| KNN-WH | 0.00 | 39.37 (0.70) | |
| KNN-H | 0.00 | 37.93 (0.42) | |
| Regression Tree | depth | 59.95 (0.30) | 60.70 (1.57) |
| RT-Time | depth | 46.22 (0.29) | 51.12 (1.64) |
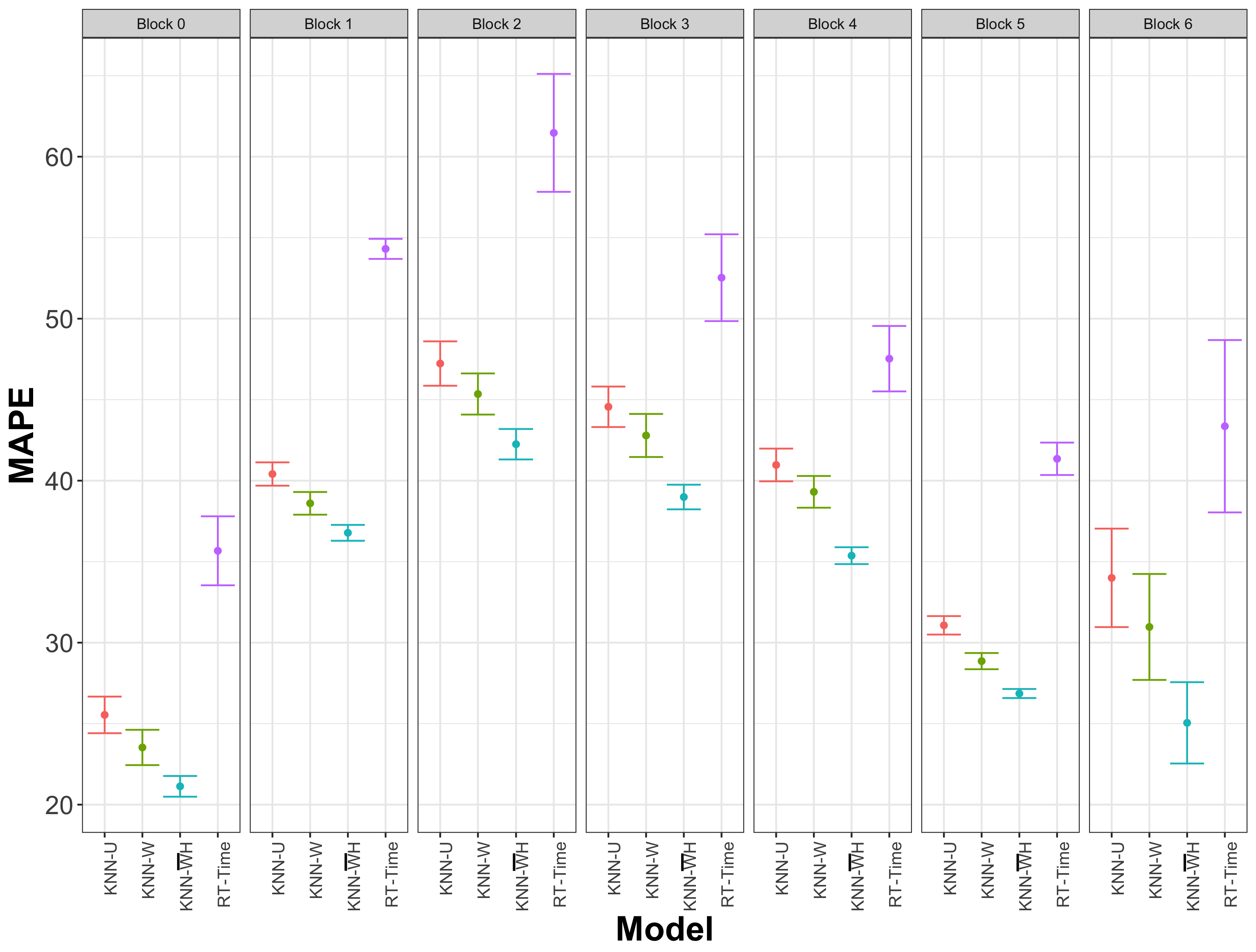
| G-Boosting | KNN-U | KNN-W | KNN-WH | KNN-H | Regression Tree | RT-Time | |
|---|---|---|---|---|---|---|---|
| Block 0 | 36.36 (2.21) | 25.54 (1.13) | 23.53 (1.09) | 23.20 (1.05) | 21.13 (0.64) | 37.55 (2.05) | 35.67 (2.13) |
| Block 1 | 60.29 (2.66) | 40.41 (0.72) | 38.60 (0.70) | 38.37 (0.72) | 36.78 (0.49) | 61.55 (1.40) | 54.31 (0.62) |
| Block 2 | 65.01 (2.68) | 47.23 (1.37) | 45.35 (1.27) | 45.07 (1.30) | 42.25 (0.94) | 67.06 (3.24) | 61.47 (3.64) |
| Block 3 | 61.52 (3.02) | 44.56 (1.25) | 42.79 (1.33) | 42.73 (1.27) | 38.99 (0.76) | 60.39 (2.47) | 52.53 (2.68) |
| Block 4 | 57.96 (3.79) | 40.97 (1.01) | 39.31 (0.98) | 39.34 (1.03) | 35.37 (0.52) | 55.96 (2.08) | 47.53 (2.02) |
| Block 5 | 43.49 (2.62) | 31.07 (0.57) | 28.86 (0.50) | 28.85 (0.51) | 26.86 (0.28) | 44.54 (1.29) | 41.35 (1.00) |
| Block 6 | 41.12 (3.55) | 34.00 (3.04) | 30.97 (3.27) | 31.37 (4.48) | 25.05 (2.51) | 45.49 (3.49) | 43.36 (5.32) |
| Average | 54.52 | 37.87 | 35.95 | 35.80 | 33.58 | 55.40 | 49.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lagos, F.; Moreno, S.; Yushimito, W.F.; Brstilo, T. Urban Origin–Destination Travel Time Estimation Using K-Nearest-Neighbor-Based Methods. Mathematics 2024, 12, 1255. https://doi.org/10.3390/math12081255
Lagos F, Moreno S, Yushimito WF, Brstilo T. Urban Origin–Destination Travel Time Estimation Using K-Nearest-Neighbor-Based Methods. Mathematics. 2024; 12(8):1255. https://doi.org/10.3390/math12081255
Chicago/Turabian StyleLagos, Felipe, Sebastián Moreno, Wilfredo F. Yushimito, and Tomás Brstilo. 2024. "Urban Origin–Destination Travel Time Estimation Using K-Nearest-Neighbor-Based Methods" Mathematics 12, no. 8: 1255. https://doi.org/10.3390/math12081255
APA StyleLagos, F., Moreno, S., Yushimito, W. F., & Brstilo, T. (2024). Urban Origin–Destination Travel Time Estimation Using K-Nearest-Neighbor-Based Methods. Mathematics, 12(8), 1255. https://doi.org/10.3390/math12081255