

Lp-Norm for Compositional Data: Exploring the CoDa L1-Norm in Penalised Regression


Abstract
:1. Introduction
2. Some Basic Concepts
2.1. Elements of the Aitchison Geometry
2.2. Norms and Measures of Central Tendency
- For , the average absolute deviation is a convex function of λ; however, it is not strictly convex. Thus, the median may be a non-unique value.
- For , the total p-deviation function is strictly convex; thus, if exists, this is unique.
3. -Norms on the Compositional Space
- Scale invariance: , .
- Permutation invariance: .
- Subcompositional dominance: , where denotes any subset formed by d parts of .
- The CoDa -norm on iswhere and are the median of the sets and , respectively. As the logarithm function is strictly increasing, as per Definition 1, the set of points that serve as solutions to the variational problem when applied to log-transformed values precisely corresponds to the log-transformed set of points that are solutions to the variational problem when applied to the raw data, that is, .Wu et al. [17] proposed the median of a D-part composition as an alternative denominator to the geometric mean in an attempt to extend the definition of -scores. In general, the performance of the median as a robust estimator of the midpoint of a dataset is better when the data have high asymmetry. The CoDa -norm captures the distance between two points when movement is restricted to paths that run parallel to the -axes (), as is the case in a grid or city street network (Manhattan distance, Figure 1). The CoDa -norm has an equivalent expression that captures the information about the ratio between the components of a composition; indeed, the median is the central point that divides a set into two equal parts, with half of the values falling below this central position and half above it. Therefore, half of the log-ratios are positive and the other half are negative. If we rearrange the parts of a composition in increasing order (small to large), i.e., , then the CoDa -norm can be written in the following manner:
- ∗
- if ;
- ∗
- if .
Thus, the CoDa -norm is a balance between the large parts and small parts. - The CoDa -norm on iswhere is the geometric mean of the set . Because -subspace, the CoDa -norm is the restricted Euclidean -norm on the -subspace. This norm is commonly referred to as Aitchison’s norm [18].
- The CoDa -norm on iswhere and are respectively the mid-range and geometric mid-range of the sets and . Note that ; thus, . The CoDa -norm can be interpreted as a form of log-pairwise, as the CoDa -norm represents half of the log-pairwise between the largest part against the smallest part. This log-pairwise is the greatest among all log-pairwise in the composition:
4. Penalised Regression with a Compositional Covariate
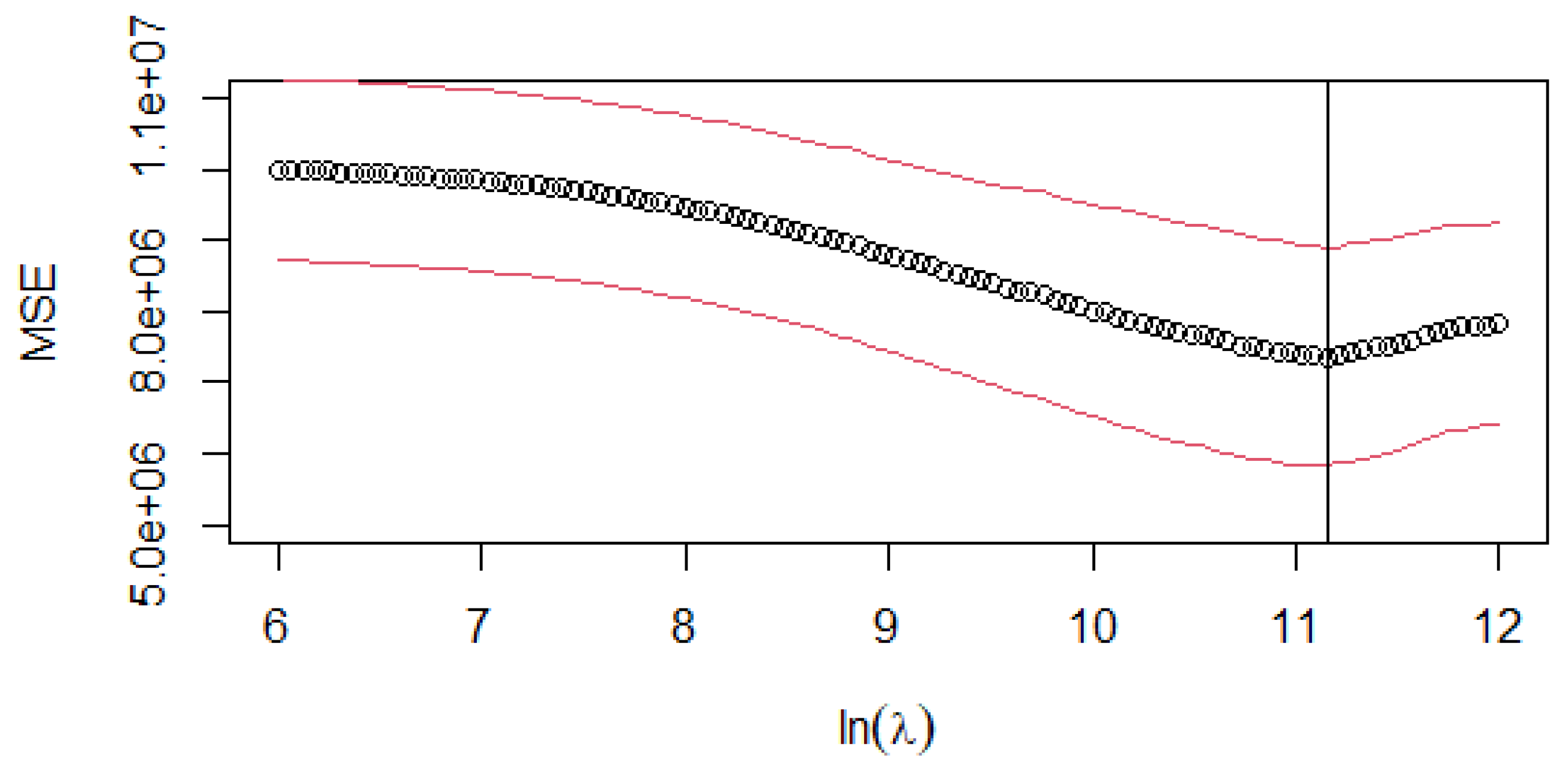
5. Study Case
| Algorithm 1 Generalised LASSO for CoDa |
|
6. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LASSO | Least Absolute Shrinkage and Selection Operator |
| CoDa | Compositional Data |
| clr | Centered Log-Ratio |
| -plr | Pairwise Log-Ration norm |
| - | Centered Log-Ration norm |
| TD | Total p-Deviation Function |
| MSE | Mean Squarred Error |
| OSQP | Operator-Splitting Quadratic Program |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Taxon | L1-clr | L1-CoDa | L1-plr |
|---|---|---|---|
| Intercept | 6563.19 | 7023.88 | 7244.88 |
| g_Subdoligranulum | 455.51 | 409.93 | 249.27 |
| f_Lachnospiraceae_g_Incertae_Sedis | 245.69 | 77.35 | |
| g_Dialister | 229.23 | 182.53 | |
| g_Bacteroides | 193.46 | 186.23 | |
| g_Dorea | 159.97 | 104.06 | |
| g_Desulfovibrio | 88.32 | 53.57 | |
| f_Peptostreptococcaceae_g_Incertae_Sedis | 70.37 | 37.38 | 26.54 |
| g_Faecalibacterium | 63.74 | 33.07 | |
| g_Paraprevotella | 45.15 | 38.71 | |
| f_Defluviitaleaceae_g_Incertae_Sedis | 39.35 | 34.48 | 54.86 |
| g_Alistipes | 27.18 | 14.05 | |
| g_Clostridium_sensu_stricto_1 | 20.52 | ||
| g_Brachyspira | 4.33 | ||
| g_Elusimicrobium | 2.25 | ||
| g_Butyricimonas | 0.16 | ||
| k_Bacteria_g_unclassified | −7.48 | −33.79 | −41.56 |
| g_Streptococcus | −11.71 | ||
| g_Catenibacterium | −21.83 | −12.10 | −19.66 |
| g_Succinivibrio | −34.64 | −31.51 | −10.83 |
| g_Lachnospira | −40.80 | −4.21 | −29.65 |
| g_Parabacteroides | −52.41 | −0.28 | |
| o_Clostridiales_g_unclassified | −111.82 | −107.08 | −85.66 |
| g_Mitsuokella | −219.27 | −192.13 | −144.62 |
| g_Collinsella | −233.08 | −235.68 | −228.94 |
| g_Bifidobacterium | −263.23 | −225.95 | −154.34 |
| f_Lachnospiraceae_g_unclassified | −626.20 | −563.00 | −365.84 |
| g_subcomp | 231.83 | ||
| g_subcomp_1 | 212.52 | ||
| g_subcomp_2 | 248.34 | ||
| g_subcomp_3 | 41.25 | ||
| g_subcomp_4 | 255.78 | ||
| g_subcomp_5 | −27.66 |
| Taxon | |
|---|---|
| g_Subdoligranulum | 249.27 |
| g_subcomp_1: | 212.52 |
| g_Bacteroides, g_Dialister | |
| f_Defluviitaleaceae_g_Incertae_Sedis | 54.86 |
| g_subcomp_2: | 248.34 |
| f_Lachnospiraceae_g_Incertae_Sedis, g_Dorea, g_Faecalibacterium, | |
| g_Alistipes, g_Desulfovibrio, g_Paraprevotella | |
| f_Peptostreptococcaceae_g_Incertae_Sedis | 26.54 |
| g_Clostridium_sensu_stricto_1 | 20.52 |
| g_subcomp_3: | 41.25 |
| g_Escherichia-Shigella, f_Ruminococcaceae_g_unclassified, g_Butyricimonas | |
| g_subcomp_4: | 255.78 |
| g_Brachyspira, g_Barnesiella, g_Blautia, f_Rikenellaceae_g_unclassified, | |
| g_Odoribacter, f_Erysipelotrichaceae_g_unclassified, g_Streptococcus, | |
| g_Anaerostipes, g_Phascolarctobacterium, g_Acidaminococcus, | |
| g_Anaerovibrio, g_Roseburia, g_Alloprevotella, | |
| f_Erysipelotrichaceae_g_Incertae_Sedis, g_Megasphaera, g_Coprococcus, | |
| g_Intestinimonas, g_Solobacterium, g_Oribacterium, g_Anaeroplasma, | |
| g_Victivallis, f_Ruminococcaceae_g_Incertae_Sedis, o_NB1-n_g_unclassified, | |
| g_Sutterella, o_Bacteroidales_g_unclassified, g_Prevotella, g_RC9_gut_group, | |
| f_Christensenellaceae_g_unclassified, g_Anaerotruncus | |
| g_Parabacteroides | −0.28 |
| g_subcomp_5: | −27.66 |
| g_Ruminococcus, g_Elusimicrobium, f_vadinBB60_g_unclassified | |
| g_Succinivibrio | −10.83 |
| g_Catenibacterium | −19.66 |
| g_Lachnospira | −29.65 |
| k_Bacteria_g_unclassified | −41.56 |
| o_Clostridiales_g_unclassified | −85.66 |
| g_Mitsuokella | −144.62 |
| g_Bifidobacterium | −154.34 |
| g_Collinsella | −228.94 |
| f_Lachnospiraceae_g_unclassified | −365.84 |
References
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Aitchison, J. The Statistical Analysis of Compositional Data; Chapman & Hall: London, UK, 1986. [Google Scholar]
- Lin, W.; Shi, R.; Feng, R.; Li, H. Variable selection in regression with compositional covariates. Biometrika 2014, 101, 785–797. [Google Scholar] [CrossRef]
- Shi, P.; Zhang, A.; Li, H. Regression analysis for microbiome compositional data. Ann. Appl. Stat. 2016, 10, 1019–1040. [Google Scholar] [CrossRef]
- Lu, J.; Shi, P.; Li, H. Generalized linear models with linear constraints for microbiome compositional data. Biometrics 2019, 75, 235–244. [Google Scholar] [CrossRef] [PubMed]
- Susin, A.; Wang, Y.; Lê Cao, K.A.; Calle, M.L. Variable selection in microbiome compositional data analysis. NAR Genom. Bioinform. 2020, 2, lqaa029. [Google Scholar] [CrossRef] [PubMed]
- Saperas-Riera, J.; Martín-Fernández, J.; Mateu-Figueras, G. Lasso regression method for a compositional covariate regularised by the norm L1 pairwise logratio. J. Geochem. Explor. 2023, 255, 107327. [Google Scholar] [CrossRef]
- Egozcue, J.J.; Pawlowsky-Glahn, V. Groups of parts and their balances in compositional data analysis. Math. Geol. 2005, 37, 795–828. [Google Scholar] [CrossRef]
- Pawlowsky-Glahn, V.; Egozcue, J.J. Geometric approach to statistical analysis on the simplex. Stoch. Environ. Res. Risk Assess. 2001, 15, 384–398. [Google Scholar] [CrossRef]
- Billheimer, D.; Guttorp, P.; Fagan, W.F. Statistical Interpretation of Species Composition. J. Am. Stat. Assoc. 2001, 96, 1205–1214. [Google Scholar] [CrossRef]
- Aitchison, J.; Bacon-Shone, J. Log contrast models for experiments with mixtures. Biometrika 1984, 71, 323–330. [Google Scholar] [CrossRef]
- Van der Boogaart, K.G.; Tolosana, R. Analyzing Compositional Data with R; Use R! Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Dave, A. Measurement of Central Tendency. In Applied Statistics for Economics; Horizon Press: Toronto, ON, Canada, 2014; Chapter 3. [Google Scholar]
- Barceló-Vidal, C.; Martín-Fernández, J.A. The Mathematics of Compositional Analysis. Austrian J. Stat. 2016, 45, 57–71. [Google Scholar] [CrossRef]
- Brezis, H. Functional Analysis, Sobolev Spaces and Partial Differential Equations; Universitext; Springer: New York, NY, USA, 2011. [Google Scholar]
- Pawlowsky-Glahn, V.; Egozcue, J.J.; Tolosana-Delgado, R. Modeling and Analysis of Compositional Data; John Wiley & Sons: Chichester, UK, 2015. [Google Scholar]
- Wu, J.R.; Macklaim, J.M.; Genge, B.L.; Gloor, G.B. Finding the Centre: Compositional Asymmetry in High-Throughput Sequencing Datasets. In Advances in Compositional Data Analisys; Springer: Berlin/Heidelberg, Germany, 2021; Chapter 17; pp. 329–342. [Google Scholar] [CrossRef]
- Martín-Fernández, J. Measures of Difference and Non-Parametric Classification of Compositional Data. Ph.D. Thesis, Department of Applied Mathematics, Universitat Politècnica de Catalunya, Barcelona, Spain, 2001. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. Introduction to Statistical Learning, 2nd ed.; Springer: New York, NY, USA, 2021. [Google Scholar]
- Bates, S.; Tibshirani, R. Log-ratio lasso: Scalable, sparse estimation for log-ratio models. Biometrics 2019, 75, 613–624. [Google Scholar] [CrossRef]
- Monti, G.; Filzmoser, P. Sparse least trimmed squares regression with compositional covariates for high-dimensional data. Bioinformatics 2021, 37, 3805–3814. [Google Scholar] [CrossRef] [PubMed]
- Monti, G.; Filzmoser, P. Robust logistic zero-sum regression for microbiome compositional data. Adv. Data Anal. Classif. 2022, 16, 301–324. [Google Scholar] [CrossRef]
- Tibshirani, R.; Taylor, J. The solution path of the generalized lasso. Ann. Statist. 2011, 39, 1335–1371. [Google Scholar] [CrossRef]
- Noguera-Julian, M.; Rocafort, M.; Guillén, Y.; Rivera, J.; Casadellà, M.; Nowak, P.; Hildebrand, F.; Zeller, G.; Parera, M.; Bellido, R.; et al. Gut Microbiota Linked to Sexual Preference and HIV Infection. eBioMedicine 2016, 5, 135–146. [Google Scholar] [CrossRef] [PubMed]
- Rivera-Pinto, J.; Egozcue, J.J.; Pawlowsky-Glahn, V.; Paredes, R.; Noguera-Julian, M.; Calle, M.L. Balances: A new perspective for microbiome analysis. mSystems 2018, 3, e00053-18. [Google Scholar] [CrossRef] [PubMed]
- Calle, M.; Susin, T.; Pujolassos, M. coda4microbiome: Compositional Data Analysis for Microbiome Studies; R Package Version 0.2.1. BMC Bioinf. 2023; 24, 82. [Google Scholar]
- Palarea-Albaladejo, J.; Martín-Fernández, J.A. zCompositions—R package for multivariate imputation of left-censored data under a compositional approach. Chemom. Intell. Lab. Syst. 2015, 143, 85–96. [Google Scholar] [CrossRef]
- Palarea-Albaladejo, J.; Martin-Fernandez, J. zCompositions: Treatment of Zeros, Left-Censored and Missing Values in Compositional Data Sets; R Package Version 1.5. 2023. Available online: https://cran.r-project.org/web/packages/zCompositions/zCompositions.pdf (accessed on 13 March 2024).
- Martín-Fernández, J.; Hron, K.; Templ, M.; Filzmoser, P.; Palarea-Albaladejo, J. Bayesian-multiplicative treatment of count zeros in compositional data sets. Stat. Model. 2015, 15, 134–158. [Google Scholar] [CrossRef]
- Fu, A.; Narasimhan, B.; Boyd, S. CVXR: An R Package for Disciplined Convex Optimization. J. Stat. Softw. 2020, 94, 1–34. [Google Scholar] [CrossRef]
- Stellato, B.; Banjac, G.; Goulart, P.; Bemporad, A.; Boyd, S. OSQP: An Operator Splitting Solver for Quadratic Programs. Math. Program. Comput. 2020, 12, 637–672. [Google Scholar] [CrossRef]
- Boogaart, K.; Filzmoser, P.; Hron, K.; Templ, M.; Tolosana-Delgado, R. Classical and robust regression analysis with compositional data. Math. Geosci. 2021, 53, 823–858. [Google Scholar] [CrossRef]
- Hyun, S.; G’Sell, M.; Tibshirani, R.J. Exact post-selection inference for the generalized lasso path. Electron. J. Stat. 2018, 12, 1053–1097. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saperas-Riera, J.; Mateu-Figueras, G.; Martín-Fernández, J.A. Lp-Norm for Compositional Data: Exploring the CoDa L1-Norm in Penalised Regression. Mathematics 2024, 12, 1388. https://doi.org/10.3390/math12091388
Saperas-Riera J, Mateu-Figueras G, Martín-Fernández JA. Lp-Norm for Compositional Data: Exploring the CoDa L1-Norm in Penalised Regression. Mathematics. 2024; 12(9):1388. https://doi.org/10.3390/math12091388
Chicago/Turabian StyleSaperas-Riera, Jordi, Glòria Mateu-Figueras, and Josep Antoni Martín-Fernández. 2024. "Lp-Norm for Compositional Data: Exploring the CoDa L1-Norm in Penalised Regression" Mathematics 12, no. 9: 1388. https://doi.org/10.3390/math12091388
APA StyleSaperas-Riera, J., Mateu-Figueras, G., & Martín-Fernández, J. A. (2024). Lp-Norm for Compositional Data: Exploring the CoDa L1-Norm in Penalised Regression. Mathematics, 12(9), 1388. https://doi.org/10.3390/math12091388