Abstract
Penalized regression estimators have become widely adopted alternatives to ordinary least squares while analyzing collinear data, despite introducing some bias. However, existing penalized methods lack universal superiority across diverse data conditions. To address this limitation, we propose a novel adaptive ridge estimator that automatically adjusts its penalty structure based on key data characteristics: (1) the degree of predictor collinearity, (2) error variance, and (3) model dimensionality. Through comprehensive Monte Carlo simulations and real-world applications, we evaluate the estimator’s performance using mean squared error (MSE) as our primary criterion. Our results demonstrate that the proposed method consistently outperforms existing approaches across all considered scenarios, with particularly strong performance in challenging high-collinearity settings. The real-data applications further confirm the estimator’s practical utility and robustness.
Keywords:
mean squared error; Monte Carlo simulation; multicollinearity; ordinary least squared; ridge regression MSC:
62J05; 62J07; 62H20; 65C05
1. Introduction
The multiple linear regression model (MLRM) remains a cornerstone of statistical analysis due to its mathematical elegance, interpretability, and predictive performance [1,2]. While ordinary least squares (OLS) estimation provides optimal results under ideal conditions, also known as Gauss–Markov assumptions, practical applications often violate these requirements [2]. A particularly common challenge is multicollinearity among predictors. To address these limitations, researchers have developed several alternative estimation approaches, including ridge regression (RR) [3,4], principal component regression [5], elastic net regression [6], raised regression [7], and residualization [8]. Among these alternatives, ridge regression has emerged as particularly popular due to its computational efficiency, mathematical tractability, straightforward interpretation, and, more importantly, its ability to retain all predictors while stabilizing estimates through coefficient shrinkage [9]. Although RR introduces some bias, it often substantially reduces variance, providing overall improved estimation in the presence of multicollinearity [10]. This bias–variance tradeoff makes RR particularly valuable for practical applications where predictor correlations are non-negligible. Considering the following classical MLRM,
where is a vector of responses, is a design matrix of predictors, is a vector of unknown regression coefficients, i.e., , where is assumed as zero, and is a vector of error terms. The error terms follow a multivariate normal distribution with a mean vector of 0 and a variance–covariance matrix ; n is the number of observations; p is the number of predictors in the model; and is an identity matrix of order n. The OLS estimator and covariance matrix of ϒ are defined as follows:
As evident from Equation (2), the OLS estimates and the covariance matrix of heavily depends on the characteristics of matrix. The collinearity amongst predictors makes the matrix ill-conditioned, resulting in reducing the few eigen values of matrix to zero and significantly inflating the variances of OLS estimates, compromising their efficiency and stability. To address the problem of multicollinearity, refs. [3,4] proposed the ridge regression (RR) estimator as
where is an identity matrix and k is any positive scalar value, known as “ridge parameter” or “ridge penalty”. The spirit of the RR is to obtain stable estimates at the cost of some bias, i.e., “k”. The existing literature provides ample evidence to state that no ridge estimator performs uniformly superior; rather, its performance is dynamic based on important features of the data, i.e., level of multicollinearity, error variance, and number of predictors. Consequently, ref. [11] mentioned that the selection of the optimum value of the ridge penalty is both art and science. To find such a superior value of ridge penalty, several experts proposed different methods; for instance, we have a generalized ridge estimator proposed by Hocking et al. [12]. They mentioned that their estimator is superior in terms of minimum MSE. Similarly, Hoerl et al. [13] proposed their version of the ridge estimator and compared it with existing ridge estimators, including OLS, through a simulation study. Quantile-based ridge estimators are proposed by Suhail et al. [14]. Lipovetsky et al. [1] noticed that there is a limited liberty in the selection of the ridge penalty owing to the inverse relation of the ridge penalty and the goodness of fit of RR. Hence, to improve the goodness of fit of RR, they proposed a two-parameter ridge (TPR) estimator as follows:
where
They mentioned that their TPR estimator has not only improved the goodness of fit but also provided better orthogonality property between the predicted values of the response variable and residuals. Subsequently, numerous researchers contributed to bringing improvements in the two-parameter ridge regression model, see for example [15,16,17,18,19]. Though the existing ridge estimators often excel in specific scenarios, they lack robustness and adaptability when applied to diverse data sets. To narrow this gap, this study proposes an auto-adjusted two-parameter ridge estimator (AATPR) that is based on a dynamic ridge penalty and provides an automatic adjustment option to practitioners for diverse data types. The performance of the proposed estimators is evaluated in a range of scenarios through an extensive Monte Carlo simulation by using the minimum mean squared error (MSE) criterion. The applications of the proposed estimator are also evaluated using two real-life data sets.
The remainder of this article unfolds as follows: Section 2 includes statistical methodology, along with a brief review of some popular and widely used existing ridge estimators, followed by our proposed estimator. Simulation design is discussed in Section 3, while Section 4 provides a comprehensive discussion on simulation results. Section 5 assesses the application of proposed estimators on real-life data sets. Finally, some concluding remarks are given in Section 6.
2. Statistical Methodology
The model (1) may be rewritten in canonical form as
where . Matrix D is an orthogonal matrix that contains eigen vectors of the matrix and is an identity matrix. Moreover, such that and are the ordered eigen values (in descending order) of the matrix .
Equations (2)–(4) may be written in canonical form, respectively, as follows:
2.1. Existing Estimators
This section provides a brief discussion on some popular ridge estimators, while our proposed estimators are discussed in the subsequent section. The pioneering work on ridge regression was conducted by [3]. They proposed the following generalized ridge estimator as an alternative to the OLS estimator for circumventing the multicollinearity issue in regression modeling.
where and are the unbiased estimators of the population variance and regression coefficients, respectively. The following ridge estimators are considered in this study.
- Hoerl and Kennard Estimator
Hoerl and Kennard introduced RR using a single optimum value of the ridge estimator. In their subsequent work [4], they proposed the following single value for their ridge estimator.
where is the maximum OLS regression coefficient.
- 2.
- Hoerl, Kennard, and Baldwin Estimator
The first improvement in the foremost ridge estimator was suggested in [13], where they proposed their ridge estimator as follows:
- 3.
- Kibria Estimators
In recent times, ref. [20] suggested three ridge estimators by taking the arithmetic mean, geometric mean, and median of the generalized estimator of Hoerl and Kennard, as defined in Equation (10). However, ref. [20] concluded that amongst the ridge estimators considered in the research, the arithmetic mean estimator performed superiorly. Thus, in this study, we considered the best estimator, which is expressed as follows:
- 4.
- Suhail, Chand, and Kibria Estimator
The idea of Kibria [20] was further improved by [21], who suggested six quantile-based estimators of the generalized estimator of Hoerl and Kennard. According to their simulative results, the 95th quantile performed superiorly on the majority of occasions; hence, in this study, we considered the superior estimator as follows:
- 5.
- Lipovetsky and Conklin Two-Parameter Ridge Estimator
The pioneering work on the two-parameter ridge estimator of Lipovetsky and Conklin [1] is included in this paper. They used Equation (11) as their first ridge parameter, i.e., ridge penalty (k), while for their second ridge parameter (q), Equation (5) was utilized.
- 6.
- Toker and Kaciranlar Two-Parameter Ridge Estimator
To improve the work of [1], Toker and Kaciranlar [16] proposed optimum values of “q” and “k”. The optimum value of is calculated as follows:
Subsequently, , is utilized in Equation (16) to compute as
- 7.
- Akhtar and Alharti Estimators
More recently, Akhtar and Alharti [18] proposed some modifications in the two-parameter ridge estimation by suggesting three condition-adjusted ridge estimators (CARE) as follows:
where is the index number of matrix.
2.2. Proposed Estimators
As established, existing ridge estimators demonstrate variable performance across different data conditions. This limitation stems from their dependence on three critical factors: (1) the severity of multicollinearity, (2) model dimensionality, (3) error variance, and (4) sample size. To address this challenge, we propose an adaptive ridge estimator that dynamically adjusts its penalty parameter based on the degree of multicollinearity in the data and model dimensionality. It is important to note that the MSE of the RR estimator generally exhibits a U-shaped curve with respect to k. Initially, as k increases, the MSE decreases as overfitting is reduced. However, beyond a certain point, increasing k too much leads to underfitting, causing the MSE to rise again. It is well-established that the MSE of a ridge estimator is strongly influenced by multicollinearity and model dimensionality. The degree of multicollinearity is precisely diagnosed using eigen values. Metrics like the Condition Number and Condition Index offer a robust framework for its detection. In the absence of multicollinearity, eigen values are balanced and moderate. However, under multicollinearity, this balance is disrupted, inflating the largest eigen value while others shrink toward zero. Moreover, multicollinearity may adversely impact the regression coefficients () by significantly inflating their values with incorrect signs. Our proposed estimator synthesizes these insights by formulating the ridge penalty k as a function of model dimensionality, regression coefficients, and the condition indices of the data to achieve a unique balance that mitigates both overfitting and underfitting, ensuring robust performance. The numerator addresses overfitting using a function of the eigen values, regression coefficients, and data dimensionality. Simultaneously, the denominator safeguards against underfitting induced by an overly aggressive ridge penalty parameter. The generalized form of our auto-adjusted two-parameter ridge (AATPR) estimator is expressed in mathematical form as follows:
The existing literature strongly emphasizes the critical role of single optimal ridge penalty parameter selection. For our proposed estimators, we adopt the penalty selection framework introduced by [20] to obtain our proposed estimator from the genderized estimator (20) as follows:
where is the maximum eigen value and is the minimum eigen value of matrix.
Although deriving the exact probability distribution of our proposed estimator is theoretically complex, previous work [22] has shown that the asymptotic distribution of the ridge estimator exhibits the properties of a sampling distribution, which in our case follows a normal distribution.
2.3. Performance Evaluation Criteria
Generally, the ridge estimators contain some amount of bias, contrary to OLS estimators that are unbiased. As mentioned by [23], the mean squared error criterion is an appropriate tool for comparing one or more biased estimators. Moreover, the available literature also unanimously advocates for using the minimum MSE criterion in choosing the best estimator, such as in refs. [4,20,24,25] among others.
The MSE is defined as follows:
Since the theoretical comparison of the estimators mentioned in Section 2.1 and Section 2.2 is intractable, Monte Carlo simulations are performed to empirically evaluate the estimators using the minimum MSE criterion.
3. Simulation Study
In this section, the data generation process for empirical evaluations of the considered estimators is explained. Data is generated based on different values of important varying factors, i.e., pair-wise correlations amongst predictors (ρ), error variance (σ), sample size (n), and number of predictors in the model, to examine the performance of all the considered estimators in the range of situations. For instance, four levels of and = 0.5, 1, 5, and 10, three levels of sample size, and two levels of number of predictors are considered to generate the data. The predictors are generated following [10,18,26,27] as follows:
where wji is a pseudo-random number generated from the standard normal distribution.
The response variable is generated as follows:
where are computed, following [26,28,29], based on the most favorable (MF) direction. Moreover, without loss of generality, , the intercept term, is considered as zero in this study. The is a random error term, computed from a normal distribution with a mean of 0 and a variance of . The simulations are replicated 5000 times; hence, the estimated MSE (EMSE) is computed as follows:
All the necessary calculations are performed using the R programming language. The EMSEs of all the estimators are summed up in Table 1, Table 2 and Table 3, while their graphical display is provided in Figure 1, Figure 2 and Figure 3, respectively.

Table 1.
Estimated MSE values.
Table 2.
Estimated MSE values.
Table 3.
Estimated MSE values.

Figure 1.
Graphical display of Table 1.
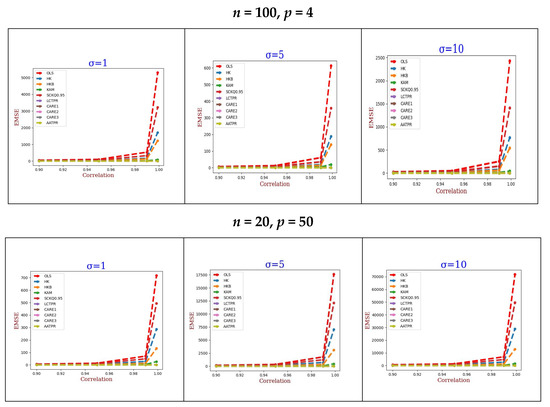
Figure 2.
Graphical display of Table 2.

Figure 3.
Graphical display of Table 3.
4. Simulation Result Discussion
Our comprehensive simulation studies yield the following significant findings:
- Superior Performance of AATPR:
The proposed AATPR estimator consistently outperforms all competing ridge estimators in terms of minimum mean squared error (MSE) across all simulated scenarios. This superior performance persists regardless of sample size, error variance, or number of predictors. As expected, the OLS estimator demonstrates the least robustness to multicollinearity, consistent with previous findings [2,18,20].
- 2.
- Robustness Against Multicollinearity:
Figure 1, Figure 2 and Figure 3 (derived from Table 1, Table 2 and Table 3) clearly demonstrate that while MSE values for OLS and existing ridge estimators increase with rising multicollinearity [14,18,19,30], our AATPR estimator shows an inverse relationship. This remarkable performance stems from the estimator’s dynamic ability to automatically adapt its penalty structure in response to varying levels of predictor correlation.
- 3.
- Stability Across Error Variance Levels:
Simulation results confirm a strong positive association between error variance and MSE for most estimators. However, AATPR maintains exceptional stability, showing only marginal MSE increases even under high error variance conditions combined with multicollinearity.
- 4.
- Dimensionality Effects:
As model complexity increases (particularly in the presence of multicollinearity), all estimators exhibit rising MSE values. However, OLS shows particularly rapid deterioration compared to ridge-type estimators, aligning with established literature [30,31].
- 5.
- Sample Size Considerations:
In compliance with general property, increasing the sample size improves estimation accuracy for all methods. However, ridge estimators (including AATPR) demonstrate consistently better performance than OLS across all sample sizes, corroborating previous findings [20].
5. Applications
To demonstrate the real-world applications of our proposed estimators and methodology, we considered two published data sets manufacturing sector data set adopted by [32] and the Pakistan GDP Growth data set [24]. These data sets possess similar features that were considered earlier in our simulation work.
5.1. Analysis of Manufacturing Sector Data
The data set contains 31 observations using three predictor variables, in the period from 1960 to 1990, considering the following regression model:
In model (26), the response variable (y) shows the product value in the manufacturing sector, m1 represents the values of the imported intermediate commodities, m2 is the imported capital commodities, and m3 is the value of imported raw materials. The eigen values of the matrix are 2.9851, 0.00989, and 0.0050, respectively. The condition number is computed as 600.2598. Similarly, the variance inflation factor (VIF) for all the predictors is significantly greater than 10, i.e., for m1, m2, and m3, the VIFs computed are 128.2639, 103.4284, and 70.8708. The pair-wise correlation amongst the predictors is provided in Figure 4. All these indicate a severe multicollinearity problem in the data.
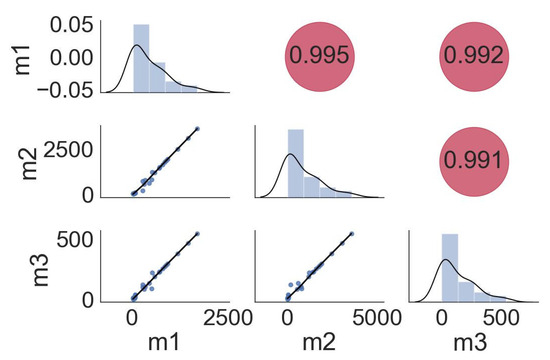
Figure 4.
Pair-wise correlation for manufacturing sector data.
The EMSE and regression coefficients of all the considered estimators are given in Table 4. The results revealed that all the ridge estimators performed much better compared to OLS, as reported by [14,20]. The proposed estimator AATPR recorded the minimum MSE amongst all the considered estimators. Moreover, as mentioned by [33], multicollinearity may cause the regression coefficients of OLS to alter their signs; in our case, this happens with and .
Table 4.
EMSE and regression coefficients of manufacturing sector data.
5.2. Analysis of Pakistan GDP Growth Data
This data set contains data for the financial years 2008 to 2021, considering the linear regression model as follows:
In model (27), “y” is the GDP rate, m1 is milk production, m2 is meat production, m3 is the number of Buffalo, m4 is the number of Cattle, m5 is the number of Poultry, m6 is Consumer Price Index, m7 is tax to GDP ratio, and m8 is investment to GDP ratio. The eigen values, of the matrix are 6.04, 1.13, 0.74, 0.08, 0.0018, 0.00003, 0.000004, and 0.000001, respectively. The condition number is computed as 5,210,223. Similarly, the variance inflation factor (VIF) for most of the predictors is significantly greater than 10, i.e., for m1, m2, m3, m4, m5, m6, m7, and m8, the VIFs computed are 132,350, 633,144, 21,894, 194,158, 144,521, 6, 32, and 8. The pair-wise correlation amongst the predictors is provided in Figure 5. All these indicate a severe multicollinearity problem in the data. The EMSE and regression coefficients for Pakistan DGP Growth Data are given in Table 5.
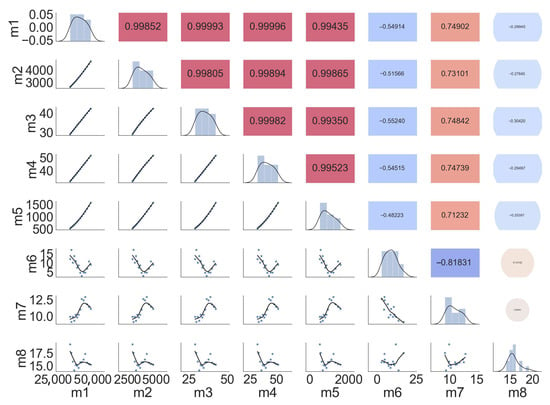
Figure 5.
Pair-wise correlation for Pakistan DGP Growth Data.
Table 5.
EMSE and regression coefficients of Pakistan GDP Growth Data.
6. Conclusions
In this paper, we propose an auto-tuning two-parameter ridge (AATPR) estimator that dynamically adjusts shrinkage parameters in response to the condition number of the design matrix (multicollinearity), model dimensionality, and error variance. The estimator’s adaptive mechanism optimizes the bias–variance tradeoff, yielding superior performance compared to existing ridge methods as demonstrated through Monte Carlo simulations and empirical applications. Potential extensions to models with concurrent multicollinearity and heteroscedasticity are identified as valuable future research directions.
Author Contributions
Conceptualization, M.S.K. and A.S.A.; Methodology, M.S.K.; Software, M.S.K.; Validation, A.S.A.; Formal analysis, M.S.K.; Investigation, M.S.K.; Resources, A.S.A.; Writing—original draft, M.S.K.; Writing—review & editing, A.S.A.; Visualization, M.S.K.; Supervision, A.S.A.; Project administration, A.S.A.; Funding acquisition, A.S.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Taif University, Saudi Arabia, Project No. (TU-DSPP-2025-39).
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
The authors extend their appreciation to Taif University, Saudi Arabia, for supporting this work through project number (TU-DSPP-2025-39).
Conflicts of Interest
The authors declare that they have no conflicts of interest.
References
- Lipovetsky, S.; Conklin, W.M. Ridge regression in two-parameter solution. Appl. Stoch. Models Bus. Ind. 2005, 21, 525–540. [Google Scholar] [CrossRef]
- Khan, M.S.; Ali, A.; Suhail, M.; Alotaibi, E.S.; Alsubaie, N.E. On the estimation of ridge penalty in linear regression: Simulation and application. Kuwait J. Sci. 2024, 51, 100273. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression: Biased Estimation for Nonorthogonal Problems. Technometrics 1970, 42, 80. [Google Scholar]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression: Applications to Nonorthogonal Problems. Technometrics 1970, 12, 69. [Google Scholar] [CrossRef]
- Massy, W.F. Principal Components Regression in Exploratory Statistical Research. J. Am. Stat. Assoc. 1965, 60, 234–256. [Google Scholar] [CrossRef]
- Zou, H.; Trevor, H. Regularization and Variable Selection Via the Elastic Net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Garcia, C.G.; Pérez, J.G.; Liria, J.S. The raise method. An alternative procedure to estimate the parameters in presence of collinearity. Qual. Quant. 2011, 45, 403–423. [Google Scholar] [CrossRef]
- Garcia, C.B.; Salmeron, R.; Claudia, G.; Jose, G. Residualization: Justification, Properties and Application. J. Appl. Stat. 2020, 47, 1990–2010. [Google Scholar] [CrossRef]
- Belsley, D. A Guide to Using the Collinearity Diagnostics. Comput. Sci. Econ. Manag. 1991, 4, 33–50. [Google Scholar] [CrossRef]
- Dar, I.S.; Chand, S. Bootstrap-quantile ridge estimator for linear regression with applications. PLoS ONE 2024, 19, e0302221. [Google Scholar] [CrossRef]
- McDonald, G.C. Ridge Regression. Wiley Interdiscip. Rev. Comput. Stat. 2009, 1, 93–100. [Google Scholar] [CrossRef]
- Hocking, R.R.; Speed, F.M.; Lynn, M.J. American Society for Quality A Class of Biased Estimators in Linear Regression. Technometrics 1976, 18, 425–437. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kannard, R.W.; Baldwin, K.F. Ridge regression: Some simulations. Commun. Stat. 1975, 4, 105–123. [Google Scholar] [CrossRef]
- Suhail, M.; Chand, S.; Kibria, B.M.G. Quantile based estimation of biasing parameters in ridge regression model. Commun. Stat. Simul. Comput. 2020, 49, 2732–2744. [Google Scholar] [CrossRef]
- Lipovetsky, S. Two-parameter ridge regression and its convergence to the eventual pairwise model. Math. Comput. Model. 2006, 44, 304–318. [Google Scholar] [CrossRef]
- Toker, S.; Kaçiranlar, S. On the performance of two parameter ridge estimator under the mean square error criterion. Appl. Math. Comput. 2013, 219, 4718–4728. [Google Scholar] [CrossRef]
- Kuran, Ö.; Özbay, N. Improving prediction by means of a two parameter approach in linear mixed models. J. Stat. Comput. Simul. 2021, 91, 3721–3743. [Google Scholar] [CrossRef]
- Akhtar, N.; Alharthi, M.F. Enhancing accuracy in modelling highly multicollinear data using alternative shrinkage parameters for ridge regression methods. Sci. Rep. 2025, 15, 10774. [Google Scholar] [CrossRef]
- Alharthi, M.F.; Akhtar, N. Newly Improved Two-Parameter Ridge Estimators: A Better Approach for Mitigating Multicollinearity in Regression Analysis. Axioms 2025, 14, 186. [Google Scholar] [CrossRef]
- Kibria, B.M.G. Performance of some New Ridge regression estimators. Commun. Stat. Part B Simul. Comput. 2003, 32, 419–435. [Google Scholar] [CrossRef]
- Khalaf, G.; Mansson, K.; Shukur, G. Modified ridge regression estimators. Commun. Stat. Theory Methods 2013, 42, 1476–1487. [Google Scholar] [CrossRef]
- Sengupta, N.; Sowell, F. On the Asymptotic Distribution of Ridge Regression Estimators Using Training and Test Samples. Econometrics 2020, 8, 39. [Google Scholar] [CrossRef]
- Cochran, W.G. Sampling Techniques; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Khan, M.S.; Ali, A.; Suhail, M.; Awwad, F.A.; Ismail, E.A.A.; Ahmad, H. On the performance of two-parameter ridge estimators for handling multicollinearity problem in linear regression: Simulation and application. AIP Adv. 2023, 13, 115208. Available online: https://pubs.aip.org/adv/article/13/11/115208/2920711/On-the-performance-of-two-parameter-ridge (accessed on 2 September 2025). [CrossRef]
- Haq, M.S.; Kibira, B.M.G. A Shrinkage Estimator for the Restricted Linear Regression Model: Ridge Regression Approach. J. Appl. Stat. Sci. 1996, 3, 301–316. [Google Scholar]
- Mcdonald, G.C.; Galarneau, D.I.; Galarneau, D.I. A Monte Carlo Evaluation of Some Ridge-Type Estimators. J. Am. Stat. Assoc. 1975, 70, 407–416. [Google Scholar] [CrossRef]
- Suhail, M.; Chand, S.; Aslam, M. New quantile based ridge M-estimator for linear regression models with multicollinearity and outliers. Commun. Stat. Simul. Comput. 2021, 52, 1417–1434. [Google Scholar] [CrossRef]
- Halawa, A.M.; El Bassiouni, M.Y. Tests of regression coefficients under ridge regression models. J. Stat. Comput. Simul. 2000, 65, 341–356. [Google Scholar] [CrossRef]
- Newhouse, J.P.; Oman, S.D. An Evaluation of Ridge Estimators; Rand Corporation: Santa Monica, CA, USA, 1971; 716p. [Google Scholar]
- Yasin, S.; Kamal, S.; Suhail, M. Performance of Some New Ridge Parameters in Two-Parameter Ridge Regression Model. Iran. J. Sci. Technol. Trans. A Sci. 2021, 45, 327–341. [Google Scholar] [CrossRef]
- Majid, A.; Ahmad, S.; Aslam, M.; Kashif, M. A robust Kibria–Lukman estimator for linear regression model to combat multicollinearity and outliers. Concurr. Comput. 2022, 35, e7533. [Google Scholar] [CrossRef]
- Eledum, H.; Zahri, M. RELAXATION METHOD FOR TWO STAGES RIDGE REGRESSION ESTIMATOR. Int. J. Pure Appl. Math. 2013, 85, 653–667. [Google Scholar] [CrossRef]
- Gujarati, D.N.; Porter, D.C. Basic Econometrics, 5th ed.; McGraw Hill: Columbus, OH, USA, 2009. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).