Automatic Text Simplification for Lithuanian: Transforming Administrative Texts into Plain Language

 , , , ,
, , , ,  and
and 
Abstract
1. Introduction
2. Related Work
3. Materials and Methods
3.1. Materials
- Paragraph-level simplification.
- (a)
- Sentence splitting: sentences longer than 12 words should be broken down into smaller units, preferably by turning embedded relative clauses into independent clauses.
- (b)
- List creation: where appropriate, homogeneous elements need to be transformed into vertical lists, i.e., if there are more than two coordinated elements (e.g., object or subject noun phrases and clauses) with a homogeneous function in a sentence, they need to be converted into vertical lists.
- Lexical-level simplification.
- (a)
- Preference should be given to the more frequent synonyms determined by the Lithuanian Frequency Dictionary [53], even if the normal formal requirements of the register are not followed.
- (b)
- Avoid metaphors and uncommon acronyms.
- (c)
- Define obscure terms in separate sentences.
- Syntactic-level simplification.
- (a)
- Transform passive voice constructions into active voice.
- (b)
- Replace active participle and gerund constructions with relative clauses.
- (c)
- Minimize the use of nominalizations.
- (d)
- Affirmatives are preferred to negatives.
- (e)
- If necessary, introduce demonstrative pronouns and nouns for clarity.
- Parallel Corpus 1—a dataset where each original (complex) sentence had 1 simplified equivalent. The complex sentences were taken from websites of governmental and non-governmental public institutions.
- Parallel Corpus 2—a dataset in which Parallel Corpus 1 was augmented with additional complex sentences, some of which had more than 1 simplified counterpart (2–3), based on text simplification corpora such as SimPA [54] and Human Simplification with Sentence Fusion Dataset (HSSF) [55]. For complex sentences, we used the same list of sources as for Parallel Corpus 1.
3.2. Methods
- Input:The input X is tokenized into subword units and corrupted by masking spans of tokens.The model predicts the masked spans .
- Span corruption function:The model is trained to maximize the probability of the output spans:where P is the probability distribution modeled by mT5, which predicts the likelihood of the next span ; is the i-th span being predicted; X is the input sequence, which is corrupted by masking spans of tokens; and is all spans predicted prior to , ensuring that predictions are made sequentially and contextually.
- Encoder–Decoder architecture:The encoder processes the input sequence , generating hidden states .The decoder generates the output sequence , conditioned on the encoder’s hidden states and previous decoder outputs.
- Denoising sequence-to-sequence reconstruction:The denoising involves corrupting the input sequence X via token masking and sentence permutation. The model minimizes the negative log-likelihood:where m is the total number of tokens in the output sequence Y, t is the index of the current token being predicted in the output sequence, is the token at position t in the output sequence , is all tokens in the output sequence that precede the current token , H is the encoder’s hidden states, and is the conditional probability of the current token being correct, given the previous tokens in the sequence () and the encoded input H.
- Autoregressive component:The model generates the next token based on the sequence of previous tokens :where is the probability of generating the entire output sequence , m is the total number of tokens in the output sequence Y, t is the index of the current token being predicted in the sequence, is the token at position t in the output sequence, is all tokens that have been generated before the current token in the sequence, and is the conditional probability of the token , given the tokens that precede it in the sequence ().
- Transformer architecture:The self-attention mechanism computes the attention scoreswhere Q, K, and V are the query, key, and value matrices, is the dimensionality of keys, softmax is a normalization function applied to the scaled dot product of Q and , and is the dot product of the query matrix Q and the transpose of the key matrix K, which computes the similarity scores between the query and all keys.
- Optimization:Llama-2 uses adaptive optimization techniques and fine-tunes pre-trained weights for specific tasks.
3.3. Evaluation Methods
- Preliminary evaluation:
- (a)
- Preliminary manual inspection to obtain a general idea of the results of all the models used in this study.
- (b)
- In-depth evaluation of results of the best performing model:
- (a)
- Quantitative and qualitative approaches.We utilized the EASSE [68] and multilingual tseval [69] libraries to facilitate and standardize the automatic evaluation of our best text simplification model. The EASSE library includes reference-based evaluation metrics and methods, such as BLEU [70], SARI [65], and Levenshtein similarity [68]. In contrast, the tseval library provides reference-less simplification assessment metrics and methods, including the proportions of additions and deletions made during the simplification process.To complement these quantitative metrics, we conducted a qualitative evaluation of the text simplification outputs based on three widely recognized criteria: simplicity, meaning retention, and grammaticality (whether the model-simplified sentence is grammatical and understandable) [71,72]. Two experts independently evaluated model-simplified sentences. Additionally, these qualitative assessments were integrated with the tseval library to investigate the correlation between automatic evaluation metrics and the qualitative criteria.
- (b)
- Attention analysis:To gain more insights into the model’s decision-making process, we also applied BertViz [73] to the best and worst examples of the model’s simplified sentences.
4. Results
4.1. Experimental Setup
4.2. Fine-Tuning Process
- Hyperparameters: Based on our previous research, we selected the hyperparameters (batch size and learning rate) that provided the best results.
- Data Augmentation: We evaluated the impact of differently prepared data, using the original data (Parallel Corpus 1) and the updated (augmented) dataset (Parallel Corpus 2), on the results of fine-tuned mT5 and mBART.
4.3. Preliminary Evaluation
4.3.1. Fine-Tuning Results: Parallel Corpus 1 vs. Parallel Corpus 2
4.3.2. Results of Fine-Tuned LT-Llama-2
4.3.3. ChatGPT Results
4.4. In-Depth Evaluation
4.4.1. Qualitative Evaluation
4.4.2. EASSE Report for mBART Results
Comparison with Baselines
Analysis of Sentence-Length Effect
- The mBART model effectively simplified shorter sentences, achieving high BLEU and SARI scores while preserving readability and structural coherence. The metrics indicated a balanced approach to simplification, with minimal length reduction and selective sentence splitting for shorter texts.
- For longer sentences ([242;4830]), mBART’s performance decreased, as showed by lower BLEU and SARI scores, increased FKGL, and greater reliance on deletions and structural modifications. These challenges emphasized the complexity of maintaining both structure and meaning in the simplification of longer sentences.
Analysis of Best and Worst Simplifications
- Sentences that were shortened due to clause deletion, which may sometimes result in incomprehensible sentences when essential information is deleted, as already mentioned in the worst SARI-scoring simplifications.
- Sentences that were shortened due to a replacement of a noun phrase with an anaphoric pronoun, which, again, may or may not be a desirable simplification operation, depending on the complexity of the noun phrase and on the importance of the information it provides. Generally, anaphoric pronouns are discouraged in Plain Language guidelines [3].
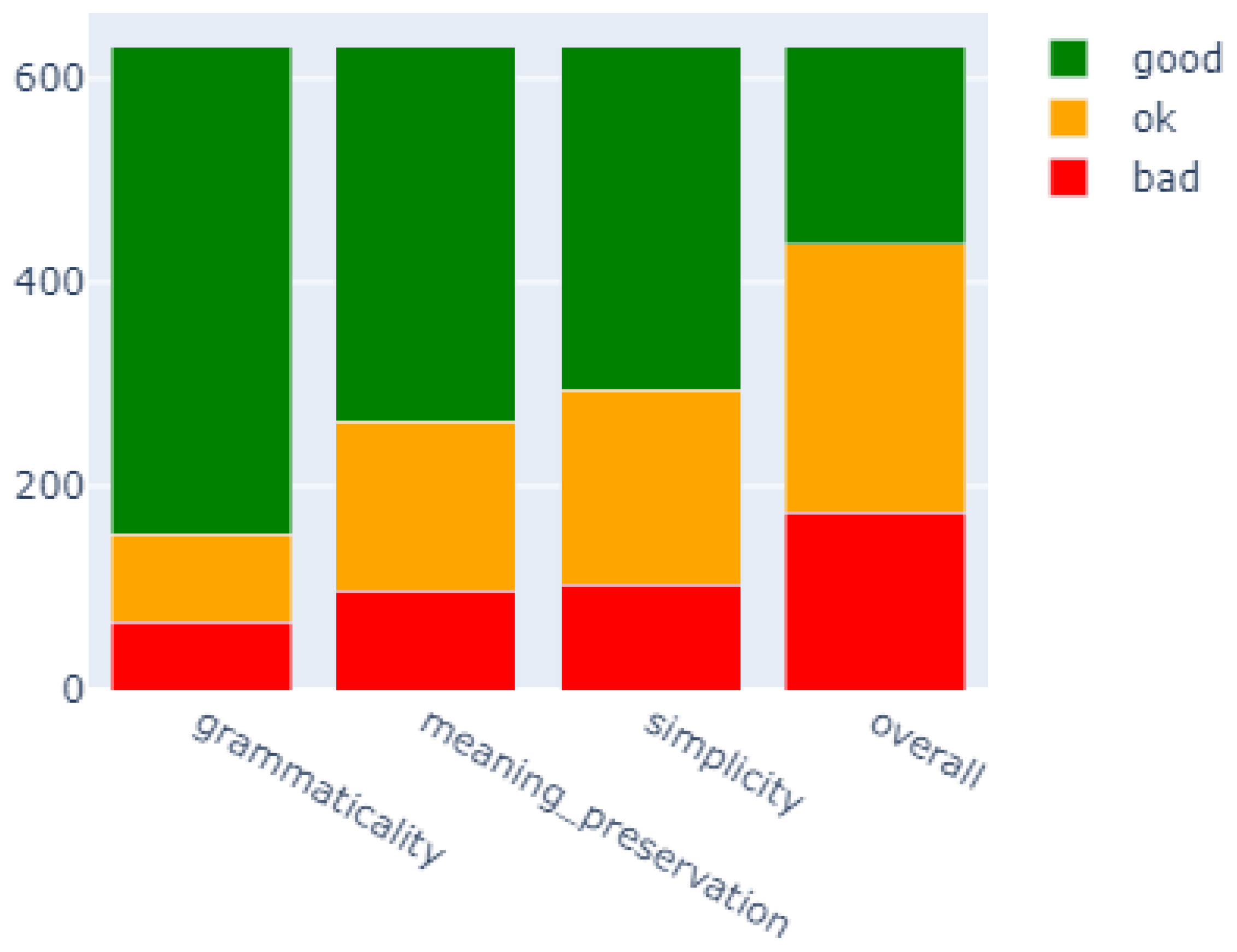
4.4.3. Tseval Results for mBART
- Bad: Scores between 0 and 2.5 indicate a low simplification evaluation level.
- Ok: Scores between 2.5 and 3.5 represent a medium or acceptable simplification evaluation level.
- Good: Scores between 3.5 and 5 indicate a high simplification evaluation level.
Simplicity
Meaning Preservation
Grammaticality
4.4.4. Attention Analysis with BertViz
5. Discussion
5.1. Data Augmentation and Training Data Quality
- Contrary to expectations, data augmentation did not improve the performance of our text simplification models. The original dataset alone was sufficient to achieve satisfactory results, which highlighted the importance of high-quality and representative data in low-resource language contexts [94]. Instead of enhancing the training data, augmented data may have introduced inconsistencies or reduced the overall quality of the dataset, ultimately decreasing the models’ performance.
- When compared to related studies in text simplification and low-resource NLP tasks, these findings reveal a notable contrast. While data augmentation has been effective for other languages, e.g., English [95], its ineffectiveness in this study points to challenges associated with Lithuanian. This could be due to the broader limitations of simplistic augmentation techniques [96] or specific features of the Lithuanian language.
5.2. Limitations of Automated Metrics
5.3. Model Performance
- While mBART performed well in structural simplifications, such as adding pronouns or transforming a passive voice into active voice constructions, it, however, struggled with very long or syntactically complex sentences, which indicated areas where we need further improvements. In comparison, mT5 had difficulties processing longer passages, which likely occurred due to memory limitations or insufficient fine-tuning. This suggested that methods like hierarchical modeling [100] or pre-processing strategies such as sentence splitting could enhance its performance.
- In addition, experiments with LT-Llama-2 revealed limitations, such as the unintended expansion of content, where the model added information not present in the original sentence. These issues likely arose from the model’s design, as it is more suited for conversational or instructional tasks rather than structural rewriting which is more typical for sentence simplification. These findings highlighted the potential need for larger models, alternative architectures, or more targeted fine-tuning techniques to aid in better aligning the model with the requirements of text simplification.
- Finally, ChatGPT, though effective in many general-purpose applications, faced challenges with Lithuanian-specific grammatical rules. This raised a question about the suitability of general-purpose language models for low-resource tasks without extensive customization, such as Reinforcement Learning with Human Feedback (RLHF) [101].
5.4. Sentence-Length Dependency and Structural Changes
- The more in-depth analysis of mBART performance showed a clear dependency on sentence length. The model performed well with short to moderate sentences but struggled with longer, more complex inputs. While techniques like sentence splitting and lexical simplification were effective for shorter sentences, simplifications of longer sentences occasionally resulted in the loss of essential information due to deletions.
- This decline in performance for longer sentences can be attributed to increased syntactic complexity and semantic density. Longer sentences often have complex structures and contain a higher concentration of information [102,103], which makes them more difficult to simplify without losing or altering their meaning. For example, the analysis of input–output pairs revealed that mBART performed well with simple sentence structures but struggled with compound or complex sentences, occasionally producing incomplete simplifications.
5.5. Evaluation Metrics and Correlation Analysis
5.6. Attention Mechanisms and Model Behavior
- An analysis of attention mechanisms revealed that mBART effectively linked input and output content but relied too much on delimiters, which impacted semantic richness. Specifically, the encoder attention frequently focused on delimiters, which indicated that the model relied on these structural cues rather than giving sufficient attention to content (sub)words. This reliance may have resulted in not using important information within the text on some occasions.
- On the other hand, decoder attention prioritized fluency by focusing mainly on identical (sub)words or a few preceding (sub)words. This was particularly evident in the examples with lower SARI scores. While this strategy supported grammatical correctness and coherence, it limited the model’s ability to capture long-range dependencies or fully interpret the broader context of the input [106]. This indicated that mBART primarily focused on local context instead of processing and integrating information from the entire sentence, which could limit its ability to produce semantically meaningful and contextually accurate simplifications.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| BART | Bidirectional and Auto-Regressive Transformers |
| BERT | Bidirectional Encoder Representations from Transformers |
| BLEU | Bilingual Evaluation Understudy |
| EASSE | Easier Automatic Sentence Simplification Evaluation |
| FKGL | Flesch–Kincaid Grade Level |
| GPT | Generative Pre-trained Transformer |
| HSSF | Human Simplification with Sentence Fusion |
| KG | Knowledge Graph |
| LIME | Local Interpretable Model Agnostic Explanation |
| Llama | Large Language Model Meta AI |
| LLMs | Large Language Models |
| LoRA | Low-Rank Adaptation |
| LR | Logistic Regression |
| LSTM | Long Short-Term Memory |
| mBART | Multilingual BART |
| mT5 | Multilingual T5 |
| RLHF | Reinforcement Learning with Human Feedback |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation |
| RST | Rhetorical Structure Theory |
| SARI | System Output Against References and Against the Input Sentence |
| SHAP | SHapley Additive exPlanations |
| T5 | Text-to-Text Transfer Transformer |
| Glosses: | |
| ptcp | participle |
| pst | past tense |
| pr | present tense |
| 1 | first person |
| sg | singular |
| pl | plural |
| nom | nominative case |
| acc | accusative case |
| f | feminine gender |
| m | masculine gender |
| pass | passive voice |
| act | active voice |
References
- Štajner, S. Automatic text simplification for social good: Progress and challenges. ACL-IJCNLP 2021, 2021, 2637–2652. [Google Scholar]
- François, T.; Müller, A.; Rolin, E.; Norré, M. AMesure: A Web platform to assist the clear writing of administrative texts. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations, Suzhou, China, 4–7 December 2020; pp. 1–7. [Google Scholar]
- Adler, M. The Plain Language Movement. In The Oxford Handbook of Language and Law; Tiersma, P.M., Solan, L.M., Eds.; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Maaß, C. Easy Language—Plain Language—Easy Language Plus: Balancing Comprehensibility and Acceptability; Frank & Timme: Berlin, Germany, 2020. [Google Scholar]
- Rennes, E.; Jönsson, A. A tool for automatic simplification of swedish texts. In Proceedings of the 20th Nordic Conference of Computational Linguistics, Vilnius, Lithuania, 11–13 May 2015; Linköping University Electronic Press: Linköping, Sweden, 2015; pp. 317–320. [Google Scholar]
- Suter, J.; Ebling, S.; Volk, M. Rule-based Automatic Text Simplification for German. In Proceedings of the 13th Conference on Natural Language Processing (KONVENS 2016), Bochum, Germany, 19–21 September 2016; pp. 279–287. [Google Scholar] [CrossRef]
- Štajner, S.; Saggion, H. Data-driven text simplification. In Proceedings of the 27th International Conference on Computational Linguistics: Tutorial Abstracts, Santa Fe, NM, USA, 20 August 2018; pp. 19–23. [Google Scholar]
- Srikanth, N.; Li, J.J. Elaborative simplification: Content addition and explanation generation in text simplification. arXiv 2020, arXiv:2010.10035. [Google Scholar]
- Huang, C.Y.; Wei, J.; Huang, T.H. Generating Educational Materials with Different Levels of Readability using LLMs. arXiv 2024, arXiv:2406.12787. [Google Scholar]
- Agrawal, S.; Carpuat, M. Controlling Pre-trained Language Models for Grade-Specific Text Simplification. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 12807–12819. [Google Scholar]
- Qiang, J.; Li, Y.; Zhu, Y.; Yuan, Y.; Wu, X. Lexical simplification with pretrained encoders. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8649–8656. [Google Scholar]
- Alissa, S.; Wald, M. Text simplification using transformer and BERT. Comput. Mater. Contin. 2023, 75, 3479–3495. [Google Scholar] [CrossRef]
- Maddela, M.; Alva-Manchego, F.; Xu, W. Controllable text simplification with explicit paraphrasing. arXiv 2020, arXiv:2010.11004. [Google Scholar]
- Sheang, K.C.; Saggion, H. Controllable sentence simplification with a unified text-to-text transfer transformer. In Proceedings of the 14th International Conference on Natural Language Generation (INLG), Aberdeen, UK, 20–24 September 2021; Association for Computational Linguistics: Aberdeen, UK, 2021. [Google Scholar]
- Seidl, T.; Vandeghinste, V. Controllable Sentence Simplification in Dutch. Comput. Linguist. Neth. J. 2024, 13, 31–61. [Google Scholar]
- Monteiro, J.; Aguiar, M.; Araújo, S. Using a pre-trained SimpleT5 model for text simplification in a limited corpus. In Proceedings of the Working Notes of CLEF, Bologna, Italy, 5–8 September 2022. [Google Scholar]
- Schlippe, T.; Eichinger, K. Multilingual Text Simplification and its Performance on Social Sciences Coursebooks. In Proceedings of the International Conference on Artificial Intelligence in Education Technology, Berlin, Germany, 30 June–2 July 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 119–136. [Google Scholar]
- Ohnesorge, F.; Gutiérrez, M.Á.; Plichta, J. CLEF 2023: Scientific Text Simplification and General Audience. In Proceedings of the Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 18–21 September 2023. [Google Scholar]
- Devaraj, A.; Wallace, B.C.; Marshall, I.J.; Li, J.J. Paragraph-level simplification of medical texts. In Proceedings of the Conference Association for Computational Linguistics, North American Chapter, Meeting, Online Event, 6–11 June 2021; NIH Public Access: Bethesda, MD, USA, 2021; Volume 2021, p. 4972. [Google Scholar]
- Vásquez-Rodríguez, L.; Shardlow, M.; Przybyła, P.; Ananiadou, S. Document-level Text Simplification with Coherence Evaluation. In Proceedings of the Second Workshop on Text Simplification, Accessibility and Readability, Varna, Bulgaria, 7 September 2023; pp. 85–101. [Google Scholar]
- Wen, Z.; Fang, Y. Augmenting low-resource text classification with graph-grounded pre-training and prompting. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, Taipei, Taiwan, 23–27 July 2023; pp. 506–516. [Google Scholar]
- Deilen, S.; Hernandez Garrido, S.; Lapshinova-Koltunski, E.; Maaß, C. Using ChatGPT as a CAT tool in Easy Language translation. In Proceedings of the Second Workshop on Text Simplification, Accessibility and Readability, Varna, Bulgaria, 7 September 2023; Štajner, S., Saggio, H., Shardlow, M., Alva-Manchego, F., Eds.; INCOMA Ltd.: Shoumen, Bulgaria, 2023; pp. 1–10. [Google Scholar]
- Li, Z.; Shardlow, M.; Alva-Manchego, F. Comparing Generic and Expert Models for Genre-Specific Text Simplification. In Proceedings of the Second Workshop on Text Simplification, Accessibility and Readability, Varna, Bulgaria, 7 September 2023; Štajner, S., Saggio, H., Shardlow, M., Alva-Manchego, F., Eds.; INCOMA Ltd.: Shoumen, Bulgaria, 2023; pp. 51–67. [Google Scholar]
- Ayre, J.; Mac, O.; McCaffery, K.; McKay, B.R.; Liu, M.; Shi, Y.; Rezwan, A.; Dunn, A.G. New frontiers in health literacy: Using ChatGPT to simplify health information for people in the community. J. Gen. Intern. Med. 2024, 39, 573–577. [Google Scholar] [CrossRef]
- Sudharshan, R.; Shen, A.; Gupta, S.; Zhang-Nunes, S. Assessing the Utility of ChatGPT in Simplifying Text Complexity of Patient Educational Materials. Cureus 2024, 16, e55304. [Google Scholar] [CrossRef]
- Tariq, R.; Malik, S.; Roy, M.; Islam, M.Z.; Rasheed, U.; Bian, J.; Zheng, K.; Zhang, R. Assessing ChatGPT for Text Summarization, Simplification and Extraction Tasks. In Proceedings of the 2023 IEEE 11th International Conference on Healthcare Informatics (ICHI), Houston, TX, USA, 26–29 June 2023; pp. 746–749. [Google Scholar] [CrossRef]
- Guo, B.; Zhang, X.; Wang, Z.; Jiang, M.; Nie, J.; Ding, Y.; Yue, J.; Wu, Y. How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection. arXiv 2023, arXiv:2301.07597. [Google Scholar] [CrossRef]
- Doshi, R.; Amin, K.S.; Khosla, P.; Bajaj, S.; Chheang, S.; Forman, H.P. Utilizing Large Language Models to Simplify Radiology Reports: A comparative analysis of ChatGPT-3.5, ChatGPT-4.0, Google Bard, and Microsoft Bing. medRxiv 2023. [Google Scholar] [CrossRef]
- Jeblick, K.; Schachtner, B.; Dexl, J.; Mittermeier, A.; Stüber, A.T.; Topalis, J.; Weber, T.; Wesp, P.; Sabel, B.O.; Ricke, J.; et al. ChatGPT makes medicine easy to swallow: An exploratory case study on simplified radiology reports. Eur. Radiol. 2023, 34, 2817–2825. [Google Scholar] [CrossRef] [PubMed]
- Garbacea, C.; Guo, M.; Carton, S.; Mei, Q. Explainable Prediction of Text Complexity: The Missing Preliminaries for Text Simplification. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online Event, 1–6 August 2021. [Google Scholar]
- Ormaechea, L.; Tsourakis, N.; Schwab, D.; Bouillon, P.; Lecouteux, B. Simple, Simpler and Beyond: A Fine-Tuning BERT-Based Approach to Enhance Sentence Complexity Assessment for Text Simplification. In Proceedings of the International Conference on Natural Language and Speech Processing, Online Event, 16–17 December 2023; pp. 120–133. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?" Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Qiao, Y.; Li, X.; Wiechmann, D.; Kerz, E. (Psycho-)Linguistic Features Meet Transformer Models for Improved Explainable and Controllable Text Simplification. arXiv 2022, arXiv:2212.09848. [Google Scholar]
- Xu, W.; Wang, D.; Pan, L.; Song, Z.; Freitag, M.; Wang, W.Y.; Li, L. INSTRUCTSCORE: Towards Explainable Text Generation Evaluation with Automatic Feedback. arXiv 2023, arXiv:2305.14282. [Google Scholar]
- Jiang, D.; Li, Y.; Zhang, G.; Huang, W.; Lin, B.Y.; Chen, W. TIGERScore: Towards Building Explainable Metric for All Text Generation Tasks. Trans. Mach. Learn. Res. 2023, 2024, 1–29. Available online: https://openreview.net/pdf?id=EE1CBKC0SZ (accessed on 26 January 2025).
- Maddela, M.; Dou, Y.; Heineman, D.; Xu, W. LENS: A Learnable Evaluation Metric for Text Simplification. arXiv 2022, arXiv:2212.09739. [Google Scholar]
- Ajlouni, A.B.A.; Li, J.; Ajlouni, M.A. Towards a Comprehensive Metric for Evaluating Text Simplification Systems. In Proceedings of the 2023 14th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 21–23 November 2023; pp. 1–6. [Google Scholar]
- Cripwell, L.; Legrand, J.; Gardent, C. Document-Level Planning for Text Simplification. In Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics, Dubrovnik, Croatia, 2–6 May 2023; pp. 993–1006. [Google Scholar]
- Yamaguchi, D.; Miyata, R.; Shimada, S.; Sato, S. Gauging the Gap Between Human and Machine Text Simplification Through Analytical Evaluation of Simplification Strategies and Errors. In Proceedings of the Findings of the Association for Computational Linguistics: EACL 2023, Dubrovnik, Croatia, 2–6 May 2023; pp. 359–375. [Google Scholar]
- Blinova, S.; Zhou, X.; Jaggi, M.; Eickhoff, C.; Bahrainian, S.A. SIMSUM: Document-level Text Simplification via Simultaneous Summarization. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; pp. 9927–9944. [Google Scholar]
- Alkaldi, W.; Inkpen, D. Text Simplification to Specific Readability Levels. Mathematics 2023, 11, 2063. [Google Scholar] [CrossRef]
- Cardon, R.; Bibal, A. On Operations in Automatic Text Simplification. In Proceedings of the Second Workshop on Text Simplification, Accessibility and Readability (TSAR), Varna, Bulgaria, 7 September 2023; pp. 116–130. [Google Scholar]
- Hewett, F. APA-RST: A Text Simplification Corpus with RST Annotations. In Proceedings of the 4th Workshop on Computational Approaches to Discourse (CODI 2023), Toronto, ON, Canada, 13–14 July 2023. [Google Scholar]
- Colas, A.; Ma, H.; He, X.; Bai, Y.; Wang, D.Z. Can Knowledge Graphs Simplify Text? In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, Birmingham, UK, 21–25 October 2023; pp. 379–389. [Google Scholar]
- Ivchenko, O.; Grabar, N. Impact of the Text Simplification on Understanding. Stud. Health Technol. Inform. 2022, 294, 634–638. [Google Scholar] [CrossRef]
- Wang, J. Research on Text Simplification Method Based on BERT. In Proceedings of the 2022 7th International Conference on Multimedia Communication Technologies (ICMCT), Xiamen, China, 7–9 July 2022; IEEE Computer Society: Washington, DC, USA, 2022; pp. 78–81. [Google Scholar] [CrossRef]
- Corti, L.; Yang, J. ARTIST: ARTificial Intelligence for Simplified Text. arXiv 2023, arXiv:2308.13458. [Google Scholar]
- Harris, L.; Kleimann, S.; Mowat, C. Setting plain language standards. Clarity J. 2010, 64, 16–25. [Google Scholar]
- Martinho, M. International standard for clarity—We bet this works for all languages. Clarity J. 2018, 79, 17–20. [Google Scholar]
- Brunato, D.; Dell’Orletta, F.; Venturi, G.; Montemagni, S. Design and Annotation of the First Italian Corpus for Text Simplification. In Proceedings of the 9th Linguistic Annotation Workshop, Denver, CO, USA, 5 June 2015; pp. 31–41. [Google Scholar] [CrossRef]
- Dębowski, Ł.; Broda, B.; Nitoń, B.; Charzyńska, E. Jasnopis—A program to compute readability of texts in Polish based on psycholinguistic research. In Proceedings of the 12th Workshop on Natural Language Processing and Cognitive Science (NLPCS 2015), Krakow, Poland, 22–23 September 2015; pp. 51–61. [Google Scholar]
- Utka, A. Dažninis Rašytinės Lietuvių Kalbos žodynas; Vytautas Magnus University Press: Kaunas, Lithuania, 2009. [Google Scholar]
- Scarton, C.; Paetzold, G.; Specia, L. Simpa: A sentence-level simplification corpus for the public administration domain. In Proceedings of the LREC 2018, Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Schwarzer, M.; Tanprasert, T.; Kauchak, D. Improving human text simplification with sentence fusion. In Proceedings of the 15th Workshop on Graph-Based Methods for Natural Language Processing (TextGraphs-15), Mexico City, Mexico, 11 June 2021; pp. 106–114. [Google Scholar]
- Zhang, J.; Zhao, H.; Boyd-Graber, J. Contextualized Rewriting for Text Simplification. Proc. Trans. Assoc. Comput. Linguist. 2021, 9, 1525–1540. [Google Scholar] [CrossRef]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online Event, 6–11 June 2021; pp. 483–498. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual Denoising Pre-training for Neural Machine Translation. arXiv 2020, arXiv:2001.08210. [Google Scholar] [CrossRef]
- Nakvosas, A.; Daniušis, P.; Mulevičius, V. Open Llama2 Model for the Lithuanian Language. arXiv 2024, arXiv:2408.12963. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Yenduri, G.; Ramalingam, M.; Chemmalar Selvi, G.; Supriya, Y.; Srivastava, G.; Maddikunta, P.K.R.; Deepti Raj, G.; Jhaveri, R.H.; Prabadevi, B.; Wang, W.; et al. GPT (Generative Pre-trained Transformer) —A Comprehensive Review on Enabling Technologies, Potential Applications, Emerging Challenges, and Future Directions. IEEE Access 2024, 12, 54608–54649. [Google Scholar] [CrossRef]
- Rothman, D. Transformers for Natural Language Processing: Build, Train, and Fine-Tune Deep Neural Network Architectures for NLP with Python, Hugging Face, and OpenAI’s GPT-3, ChatGPT, and GPT-4; Packt Publishing Ltd.: Birmingham, UK, 2022. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:1706.03762. [Google Scholar]
- Xu, W.; Napoles, C.; Chen, Q.; Callison-Burch, C. Optimizing Statistical Machine Translation for Text Simplification. Trans. Assoc. Comput. Linguist. 2016, 4, 401–415. [Google Scholar] [CrossRef]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. In Proceedings of the International Conference on Learning Representations, New Orleans, LO, USA, 6–9 May 2019. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Alva-Manchego, F.; Martin, L.; Scarton, C.; Specia, L. EASSE: Easier Automatic Sentence Simplification Evaluation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP): System Demonstrations, Hong Kong, China, 3–7 November 2019; pp. 49–54. [Google Scholar] [CrossRef]
- Stodden, R.; Kallmeyer, L. A multi-lingual and cross-domain analysis of features for text simplification. In Proceedings of the 1st Workshop on Tools and Resources to Empower People with REAding DIfficulties (READI), Marseille, France, 11 May 2020; pp. 77–84. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the ACL 2002, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Nisioi, S.; Štajner, S.; Ponzetto, S.P.; Dinu, L.P. Exploring neural text simplification models. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 85–91. [Google Scholar]
- Alva-Manchego, F.; Scarton, C.; Specia, L. Data-driven sentence simplification: Survey and benchmark. Comput. Linguist. 2020, 46, 135–187. [Google Scholar] [CrossRef]
- Vig, J. A Multiscale Visualization of Attention in the Transformer Model. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Florence, Italy, 28 July–2 August 2019; pp. 37–42. [Google Scholar] [CrossRef]
- Hu, J.E.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Massaro, A.; Samo, G. Prompting Metalinguistic Awareness in Large Language Models: ChatGPT and Bias Effects on the Grammar of Italian and Italian Varieties. Verbum 2023, 14, 1–11. [Google Scholar] [CrossRef]
- Vladarskienė, R. Lietuvių bendrinės ir administracinės kalbos santykis. Bendrinė Kalba (Iki 2014 Metų–Kalbos KultūRa) 2007, 80, 55–63. [Google Scholar]
- Stodden, R. Reproduction of German Text Simplification Systems. In Proceedings of the Workshop on DeTermIt! Evaluating Text Difficulty in a Multilingual Context@ LREC-COLING 2024, Turin, Italy, 21 May 2024; pp. 1–15. [Google Scholar]
- Magrath, W.J.; Shneyderman, M.; Bauer, T.; Placer, P.N.; Best, S.; Akst, L. Readability Analysis and Accessibility of Online Materials About Transgender Voice Care. Otolaryngol. Neck Surg. 2022, 167, 952–958. [Google Scholar] [CrossRef] [PubMed]
- Vadlamannati, S.; Şahin, G.G. Metric-Based In-context Learning: A Case Study in Text Simplification. arXiv 2023, arXiv:2307.14632. [Google Scholar]
- Chamovitz, E.; Abend, O. Cognitive Simplification Operations Improve Text Simplification. In Proceedings of the 26th Conference on Computational Natural Language Learning (CoNLL) (Hybrid Event), Abu Dhabi, United Arab Emirates, 7–8 December 2022; pp. 241–265. [Google Scholar]
- Iavarone, B.; Brunato, D.; Dell’Orletta, F. Sentence Complexity in Context. In Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics, Online Event, 10 June 2021. [Google Scholar]
- Nau, N.; Spraunienė, B.; Žeimantienė, V. The passive family in Baltic. Balt. Linguist. 2020, 11, 27–128. [Google Scholar] [CrossRef]
- Ramonaitė, J.T. Pronoun Variants in Standard Lithuanian: Diamesic Dimension. Liet. Kalba 2021, 16, 8–24. [Google Scholar] [CrossRef]
- Field, A.P.; Gillett, R. How to do a meta-analysis. Br. J. Math. Stat. Psychol. 2010, 63, 665–694. [Google Scholar] [CrossRef]
- Eddington, D. Statistics for Linguists: A Step-by-Step Guide for Novices; Cambridge Scholars Publishing: Newcastle, UK, 2016. [Google Scholar]
- Aziz Hussin, A. Refining the Flesch Reading Ease formula for intermediate and high-intermediate ESL learners. Int. J.-Learn. High. Educ. (IJELHE) 2015, 3, 123–142. [Google Scholar]
- Po, D.K. Similarity based information retrieval using Levenshtein distance algorithm. Int. J. Adv. Sci. Res. Eng. 2020, 6, 6–10. [Google Scholar] [CrossRef]
- Chen, B.; Cherry, C. A systematic comparison of smoothing techniques for sentence-level BLEU. In Proceedings of the Ninth Workshop on Statistical Machine Translation, Baltimore, MD, USA, 26–27 June 2014; pp. 362–367. [Google Scholar]
- Zhou, K.; Ethayarajh, K.; Card, D.; Jurafsky, D. Problems with Cosine as a Measure of Embedding Similarity for High Frequency Words. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Dublin, Ireland, 22–27 May 2022; pp. 401–423. [Google Scholar]
- Bai, Y.; Yi, J.; Tao, J.; Tian, Z.; Wen, Z.; Zhang, S. Fast end-to-end speech recognition via non-autoregressive models and cross-modal knowledge transferring from BERT. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1897–1911. [Google Scholar] [CrossRef]
- Clark, K.; Khandelwal, U.; Levy, O.; Manning, C.D. What Does BERT Look at? An Analysis of BERT’s Attention. In Proceedings of the BlackboxNLP@ACL, Florence, Italy, 1 August 2019. [Google Scholar]
- Manakul, P.; Gales, M. Sparsity and Sentence Structure in Encoder-Decoder Attention of Summarization Systems. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 9359–9368. [Google Scholar]
- Raganato, A.; Tiedemann, J. An analysis of encoder representations in transformer-based machine translation. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018; pp. 287–297. [Google Scholar]
- Lamar, A.K.; Kaya, Z. Measuring the Impact of Data Augmentation Methods for Extremely Low-Resource NMT. In Proceedings of the Sixth Workshop on Technologies for Machine Translation of Low-Resource Languages (LoResMT 2023), Dubrovnik, Croatia, 6 May 2023. [Google Scholar] [CrossRef]
- Van, H. Mitigating Data Scarcity for Large Language Models. arXiv 2023, arXiv:2302.01806. [Google Scholar]
- Okimura, I.; Reid, M.; Kawano, M.; Matsuo, Y. On the impact of data augmentation on downstream performance in natural language processing. In Proceedings of the Third Workshop on Insights from Negative Results in NLP, Dublin, Ireland, 26 May 2022; pp. 88–93. [Google Scholar]
- Sai, A.B.; Dixit, T.; Sheth, D.Y.; Mohan, S.; Khapra, M.M. Perturbation CheckLists for Evaluating NLG Evaluation Metrics. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 7219–7234. [Google Scholar]
- Zhang, S.; Bansal, M. Finding a Balanced Degree of Automation for Summary Evaluation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 6617–6632. [Google Scholar]
- Liu, Y.; Iter, D.; Xu, Y.; Wang, S.; Xu, R.; Zhu, C. G-Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 2511–2522. [Google Scholar]
- He, Z.; Qin, Z.; Prakriya, N.; Sun, Y.; Cong, J. HMT: Hierarchical Memory Transformer for Long Context Language Processing. arXiv 2024, arXiv:2405.06067. [Google Scholar]
- Wu, Z.; Hu, Y.; Shi, W.; Dziri, N.; Suhr, A.; Ammanabrolu, P.; Smith, N.A.; Ostendorf, M.; Hajishirzi, H. Fine-grained human feedback gives better rewards for language model training. Adv. Neural Inf. Process. Syst. 2023, 36, 59008–59033. [Google Scholar]
- Niklaus, C.; Cetto, M.; Freitas, A.; Handschuh, S. Discourse-Aware Text Simplification: From Complex Sentences to Linked Propositions. arXiv 2023, arXiv:2308.00425. [Google Scholar]
- Salman, M.; Haller, A.; Rodríguez Méndez, S.J. Syntactic Complexity Identification, Measurement, and Reduction Through Controlled Syntactic Simplification. arXiv 2023, arXiv:2304.07774. [Google Scholar]
- Hijazi, R.; Espinasse, B.; Gala, N. GRASS: A Syntactic Text Simplification System based on Semantic Representations. Data Sci. Mach. Learn. 2022, 12, 221–236. [Google Scholar] [CrossRef]
- Lu, J.; Li, J.; Wallace, B.C.; He, Y.; Pergola, G. NapSS: Paragraph-level Medical Text Simplification via Narrative Prompting and Sentence-matching Summarization. In Proceedings of the Findings of the Association for Computational Linguistics: EACL 2023, Dubrovnik, Croatia, 2–6 May 2023; pp. 1079–1091. [Google Scholar]
- Guan, J.; Mao, X.; Fan, C.; Liu, Z.; Ding, W.; Huang, M. Long Text Generation by Modeling Sentence-Level and Discourse-Level Coherence. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online Event, 1–6 August 2021; pp. 6379–6393. [Google Scholar]
- Yu, H.; Wang, C.; Zhang, Y.; Bi, W. TRAMS: Training-free Memory Selection for Long-range Language Modeling. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; pp. 4966–4972. [Google Scholar]
- Fang, J.; Tang, L.; Bi, H.; Qin, Y.; Sun, S.; Li, Z.; Li, H.; Li, Y.; Cong, X.; Lin, Y.; et al. Unimem: Towards a unified view of long-context large language models. arXiv 2024, arXiv:2402.03009. [Google Scholar]
- He, Z.; Karlinsky, L.; Kim, D.; McAuley, J.; Krotov, D.; Feris, R. CAMELoT: Towards Large Language Models with Training-Free Consolidated Associative Memory. arXiv 2024, arXiv:2402.13449. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parallel Corpus 1 | Parallel Corpus 2 | |||
|---|---|---|---|---|
| Original Sentences | Simplified Sentences | Original Sentences | Simplified Sentences | |
| Number of sentences | 2142 | 2521 | 3123 | 2999 |
| Number of words | 36,404 | 34,702 | 64,936 | 52,382 |
| Average sentence length | 14.75 | 12.43 | 16.97 | 13.53 |
| Average word length | 7.10 | 6.79 | 7.03 | 6.68 |
| Metric | ‘New’ mBART * | ‘New’ mT5 * | ‘Old’ mBART * | ‘Old’ mT5 * |
|---|---|---|---|---|
| SARI | 57.2374 | 54.1182 | 72.9781 | 56.0943 |
| BERTScore | 0.8633 | 0.8342 | 0.9155 | 0.8498 |
| ROUGE-1 | 0.6396 | 0.5931 | 0.7797 | 0.6205 |
| ROUGE-2 | 0.4703 | 0.4323 | 0.6753 | 0.4652 |
| ROUGE-L | 0.5993 | 0.5593 | 0.7555 | 0.5875 |
| Simplicity | Meaning Retention | Grammaticality | |
|---|---|---|---|
| mT5 | 2.67 | 3.16 | 3.33 |
| mBART | 2.80 | 3.72 | 3.88 |
| SARI | FKGL | Compression Ratio | Sentence Splits | Levenshtein Similarity | Exact Copies | Additions Proportion | Deletions Proportion | Lexical Complexity Score | |
|---|---|---|---|---|---|---|---|---|---|
| System output | 49.63 | 13.84 | 0.94 | 1.04 | 0.84 | 0.19 | 0.20 | 0.23 | 9.66 |
| Identity baseline | 13.43 | 17.41 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 9.73 |
| Truncate baseline | 23.41 | 15.98 | 0.76 | 0.98 | 0.85 | 0.0 | 0.05 | 0.26 | 9.84 |
| Length | BLEU | SARI | FKGL | Compression Ratio | Sentence Splits | Levenshtein Similarity | Exact Copies | Additions Proportion | Deletions Proportion | Lexical Complexity Score |
|---|---|---|---|---|---|---|---|---|---|---|
| [8;55] | 51.04 | 58.51 | 8.77 | 1.13 | 1.00 | 0.87 | 0.51 | 0.23 | 0.13 | 10.36 |
| [55;102] | 41.26 | 50.77 | 10.35 | 0.97 | 0.98 | 0.86 | 0.19 | 0.21 | 0.20 | 10.14 |
| [102;164] | 40.04 | 48.63 | 13.72 | 0.92 | 1.02 | 0.87 | 0.15 | 0.17 | 0.21 | 9.59 |
| [164;242] | 40.04 | 51.73 | 14.13 | 0.89 | 1.09 | 0.81 | 0.07 | 0.22 | 0.29 | 9.23 |
| [242;4830] | 22.10 | 45.06 | 16.80 | 0.81 | 1.11 | 0.78 | 0.04 | 0.18 | 0.33 | 8.88 |
| Metric | Pearson | p-Value |
|---|---|---|
| BLEUSmoothed | −0.1277 | 0.0071 |
| AverageCosine | −0.1114 | 0.0190 |
| LexicalComplexity | −0.1100 | 0.0206 |
| ProportionDeletedWords | 0.1067 | 0.0247 |
| FleshReadingEase | 0.1061 | 0.0255 |
| AvgPositionWordsFreqTable | −0.1021 | 0.0317 |
| CompressionRatio | 0.1011 | 0.0334 |
| LemmasInCommon | −0.0988 | 0.0377 |
| LevenshteinDistance | 0.0954 | 0.0448 |
| LevenshteinSimilarity | −0.0954 | 0.0448 |
| Metric | Pearson | p-Value |
|---|---|---|
| BLEUSmoothed | 0.1726 | 0.0003 |
| ProportionDeletedWords | −0.1660 | 0.0005 |
| WordsPerSentence | −0.1648 | 0.0005 |
| CharactersPerSentence | −0.1648 | 0.0005 |
| SyllablesPerSentence | −0.1641 | 0.0005 |
| MaxPositionWordsFreqTable | −0.1461 | 0.0021 |
| FKGL | −0.1409 | 0.0030 |
| CharsPerSentenceDifference | −0.1293 | 0.0064 |
| UnchangedWordsProportion | 0.1269 | 0.0075 |
| LexicalComplexityScore | −0.1130 | 0.0174 |
| KeptWordsProportion | 0.1117 | 0.0187 |
| HungarianCosine | 0.0998 | 0.0358 |
| Metric | Pearson | p-Value |
|---|---|---|
| BLEUSmoothed | 0.1651 | 0.0005 |
| Words | −0.1472 | 0.0019 |
| Characters | −0.1472 | 0.0019 |
| SyllablesPerSentence | −0.1463 | 0.0020 |
| LevenshteinDistance | −0.1386 | 0.0035 |
| LevenshteinSimilarity | 0.1386 | 0.0035 |
| UnchangedWordsProportion | 0.1310 | 0.0057 |
| WordsPerSentence | −0.1275 | 0.0072 |
| CharactersPerSentence | −0.1275 | 0.0072 |
| MaxPositionWordsFreqTable | −0.1258 | 0.0080 |
| SyllablesPerSentence | −0.1247 | 0.0086 |
| LemmasInCommon | 0.1243 | 0.0088 |
| ProportionKeptWords | 0.1179 | 0.0131 |
| FKGL | −0.0977 | 0.0399 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mandravickaitė, J.; Rimkienė, E.; Kapkan, D.K.; Kalinauskaitė, D.; Čenys, A.; Krilavičius, T. Automatic Text Simplification for Lithuanian: Transforming Administrative Texts into Plain Language. Mathematics 2025, 13, 465. https://doi.org/10.3390/math13030465
Mandravickaitė J, Rimkienė E, Kapkan DK, Kalinauskaitė D, Čenys A, Krilavičius T. Automatic Text Simplification for Lithuanian: Transforming Administrative Texts into Plain Language. Mathematics. 2025; 13(3):465. https://doi.org/10.3390/math13030465
Chicago/Turabian StyleMandravickaitė, Justina, Eglė Rimkienė, Danguolė Kotryna Kapkan, Danguolė Kalinauskaitė, Antanas Čenys, and Tomas Krilavičius. 2025. "Automatic Text Simplification for Lithuanian: Transforming Administrative Texts into Plain Language" Mathematics 13, no. 3: 465. https://doi.org/10.3390/math13030465
APA StyleMandravickaitė, J., Rimkienė, E., Kapkan, D. K., Kalinauskaitė, D., Čenys, A., & Krilavičius, T. (2025). Automatic Text Simplification for Lithuanian: Transforming Administrative Texts into Plain Language. Mathematics, 13(3), 465. https://doi.org/10.3390/math13030465