

Structural Equation Modeling Approaches to Estimating Score Dependability Within Generalizability Theory-Based Univariate, Multivariate, and Bifactor Designs


Abstract
:1. Introduction
2. Background
2.1. GT Designs
2.2. Representing Univariate, Multivariate, and Bifactor GT Designs Within SEMs
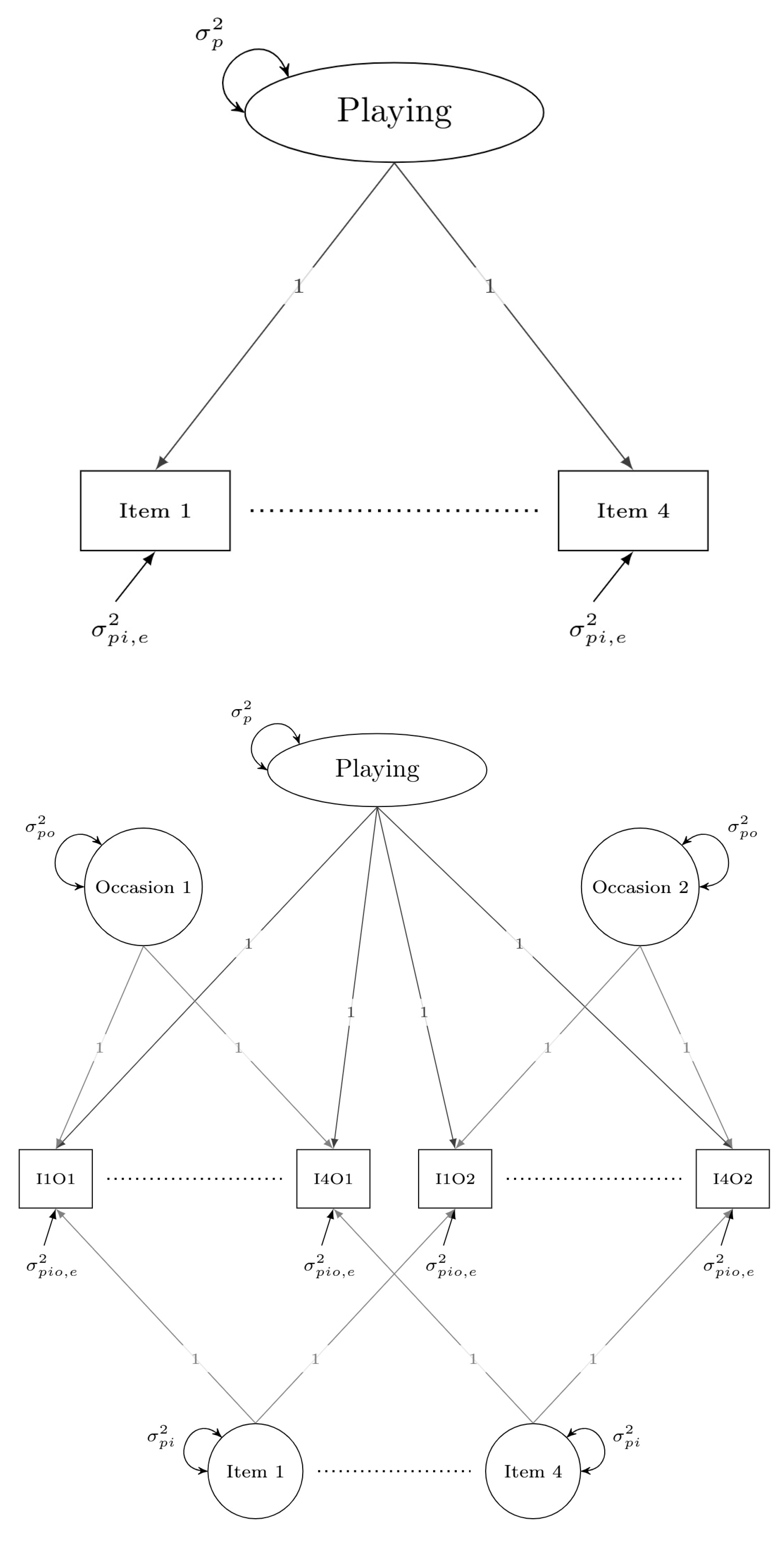
2.2.1. Univariate GT Designs
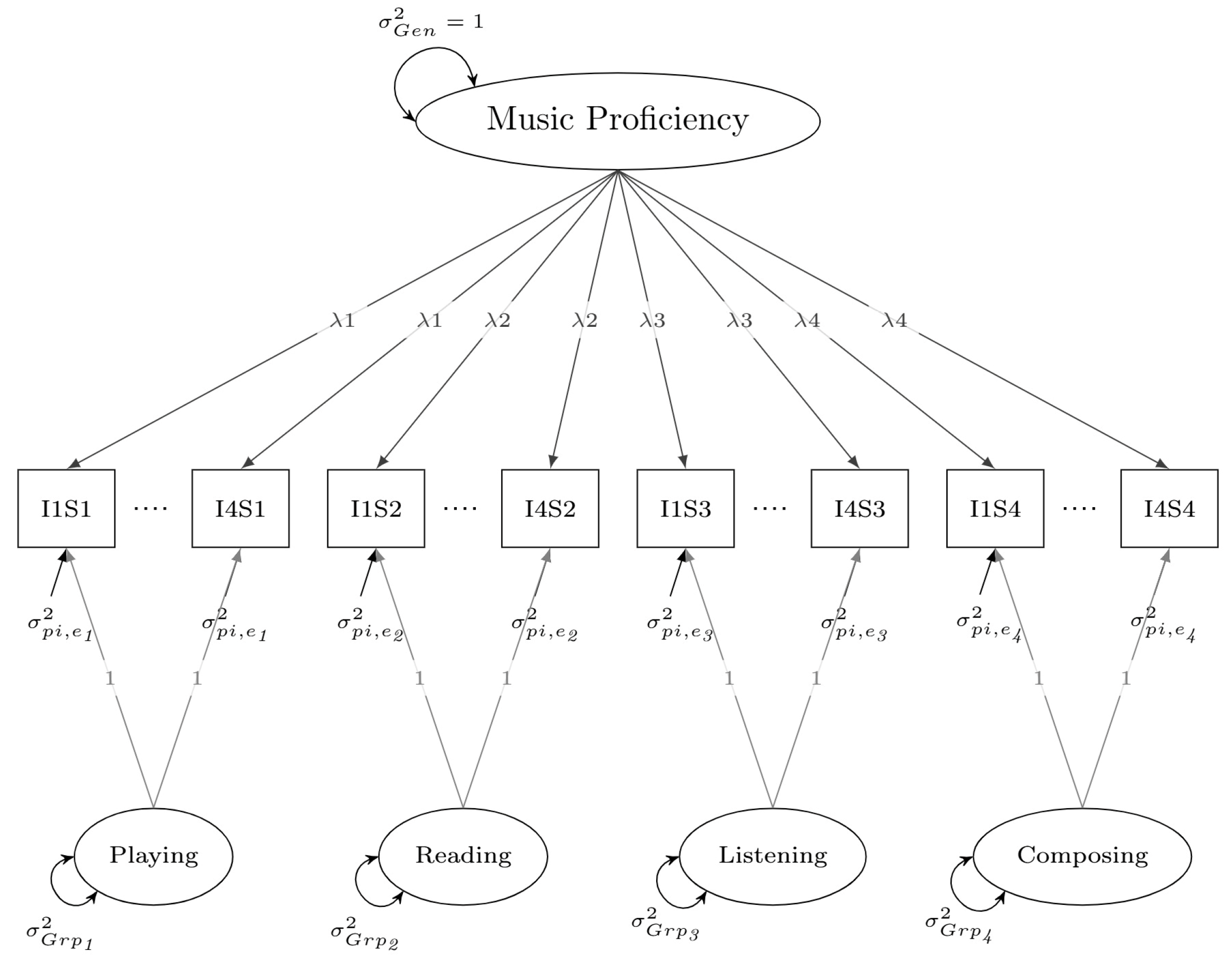
2.2.2. Multivariate GT Designs
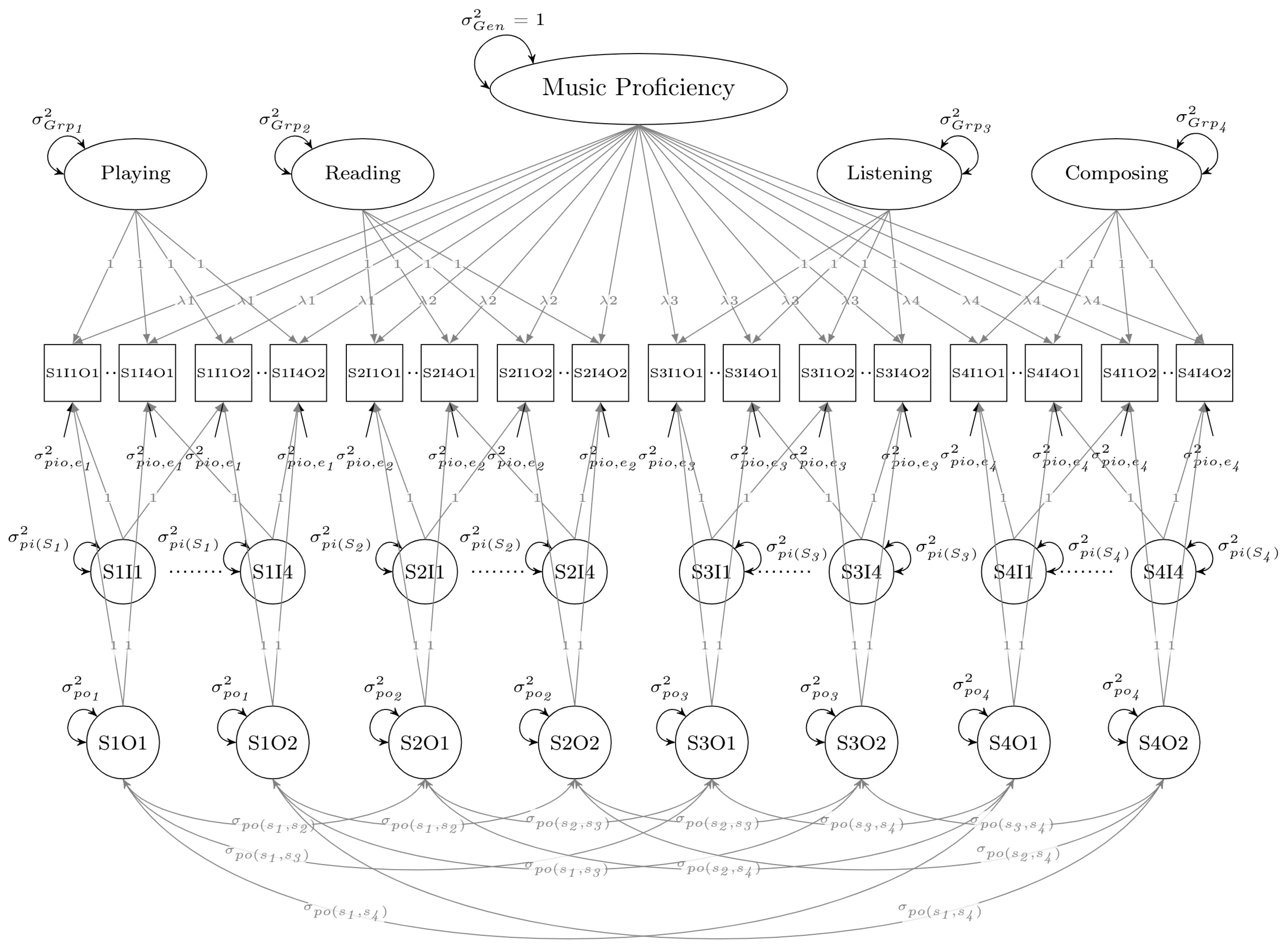
2.2.3. Bifactor GT Designs
2.3. Evaluating Subscale Viability Within GT Multivariate and Bifactor Designs
2.4. Comparing GT Univariate, Multivariate, and Bifactor Designs
2.5. Further Advantages of Using SEMs to Perform GT Analyses
3. Investigation
- G coefficients, D coefficients, and variance components obtained from the GT-based univariate and multivariate SEMs will be highly congruent with those obtained from mGENOVA.
- Multivariate and bifactor GT SEMs will yield comparable G and D coefficients for subscale and composite scores.
- G and D coefficients for the pi designs will exceed those for the pio designs due to control of fewer sources of measurement error.
- Across all multivariate designs, correlation coefficients between scale scores will be higher after correcting for measurement error, but the differences between corrected and uncorrected coefficients will be greater in pio than in pi designs.
- General factor effects will exceed group factor effects at both subscale and composite levels within the bifactor designs.
- Similar patterns of VARs for subscales will be found across multivariate and bifactor designs.
- Composite and subscale scores will be affected by specific-factor (method), transient (state), and response-random (within-occasion noise) measurement error within the pio designs, but those effects will be greater overall at the subscale than composite level due to inclusion of fewer item scores.
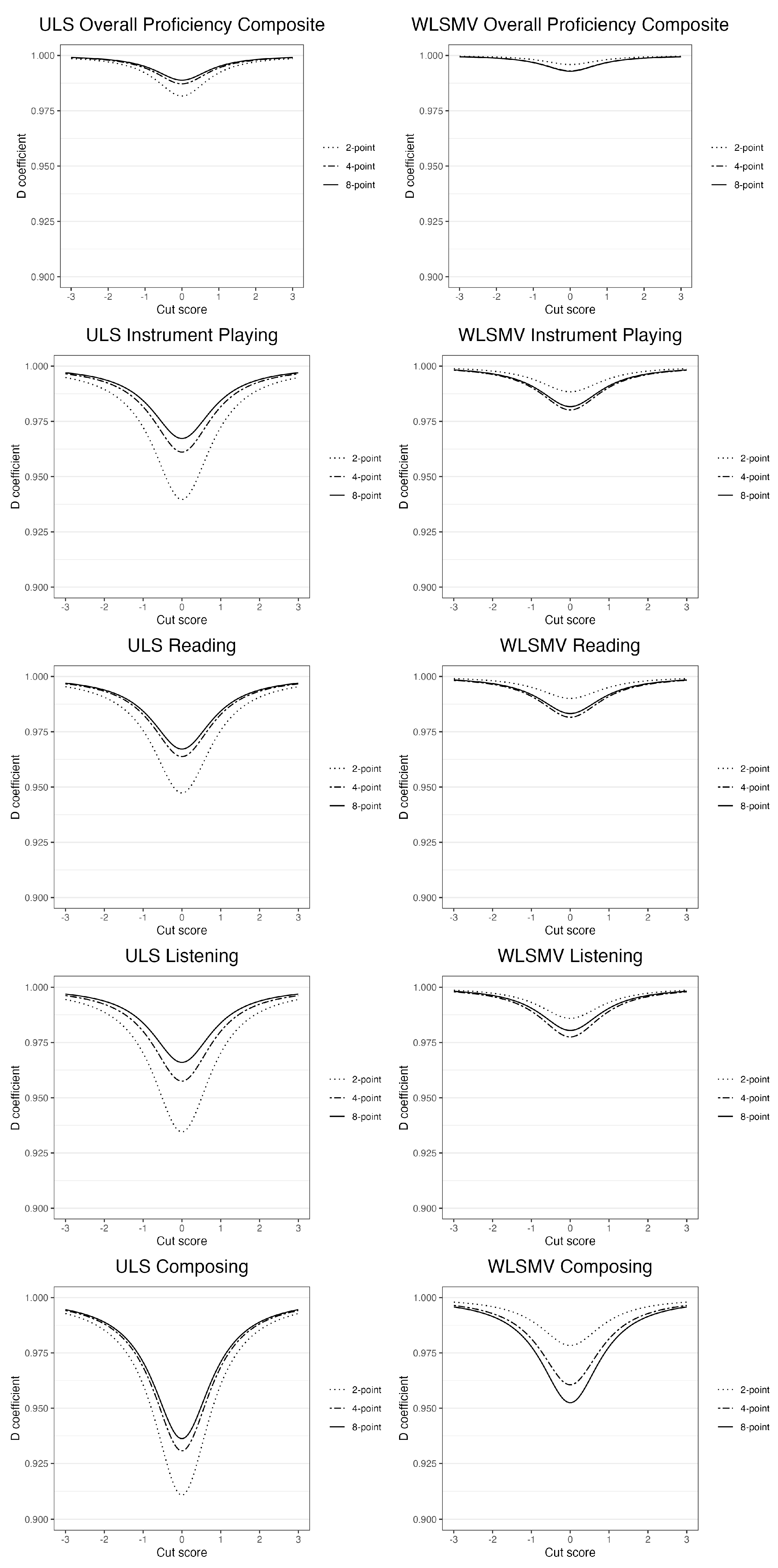
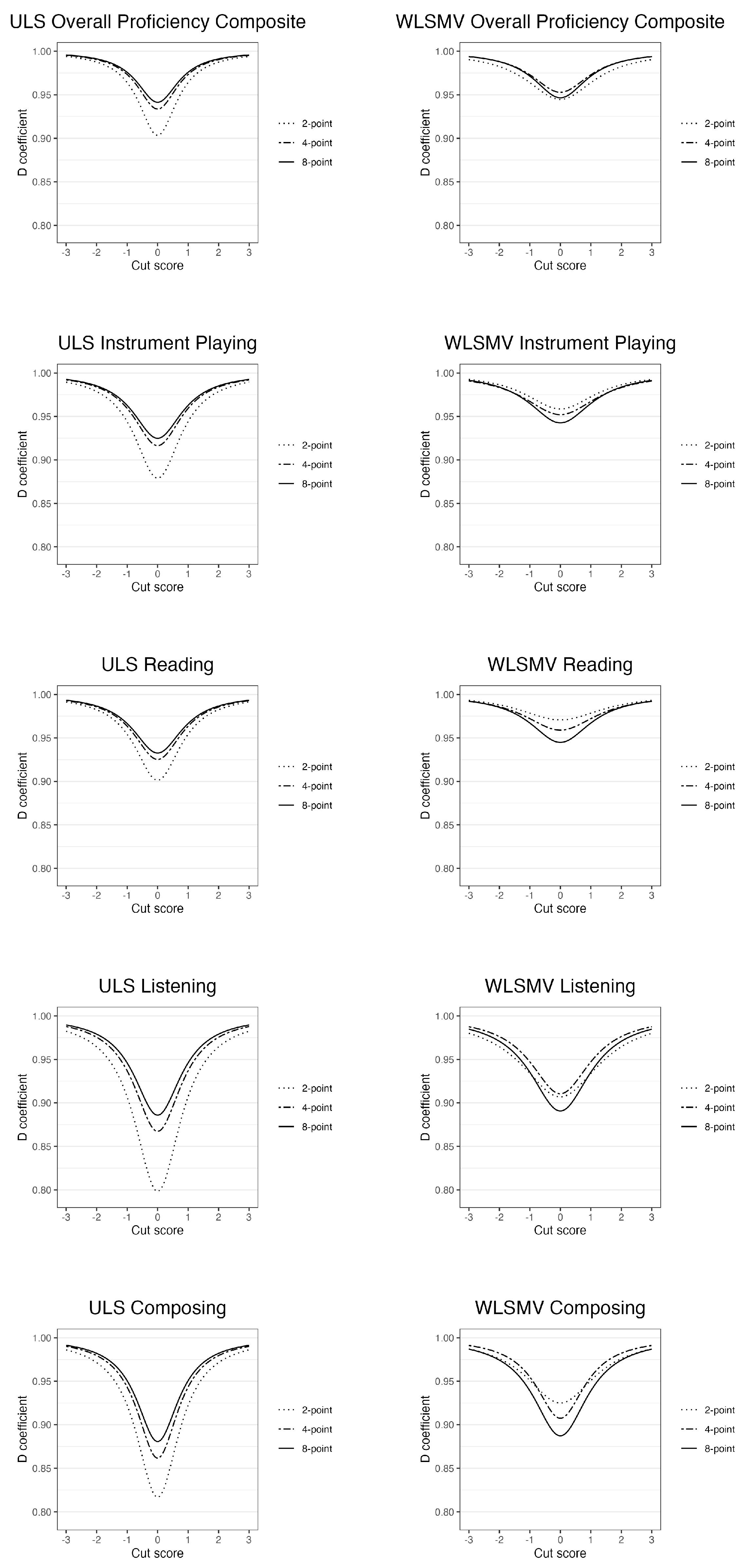
- Differences in G and D coefficients for 2-, 4-, and 8-item scale points will be greater on observed score than on continuous latent response variable metrics.
- G and D coefficients will be greater on continuous latent response variable than on observed score metrics, but to diminishing degrees with increases in numbers of item scale points.
4. Methods
4.1. Participants, Measures, and Procedure
4.2. Analyses
5. Results
5.1. Means, Standard Deviations, and Conventional Reliability Estimates for MUSPI-S Scores
5.2. GT pi Analyses
5.2.1. Univariate and Multivariate Designs
5.2.2. Bifactor Designs
5.2.3. Subscale Viability
5.3. GT pio Analyses
5.3.1. Univariate and Multivariate Designs
5.3.2. Bifactor Designs
5.3.3. Subscale Viability
6. Discussion
6.1. Overview
6.2. Effectiveness of the Indicator-Mean Method
6.3. Univariate GT Analyses for Shortened Versus Full-Length Forms of the MUSPI-S
6.4. Multivariate and Embedded Univariate GT Analyses of MUSPI-S Scores
6.5. Bifactor GT Analyses of MUSPI-S Scores
6.6. Other Noteworthy Aspects of the GT SEM Designs
7. Limitations and Future Research
8. Final Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cronbach, L.J.; Rajaratnam, N.; Gleser, G.C. Theory of generalizability: A liberalization of reliability theory. Br. J. Stat. Psychol. 1963, 16, 137–163. [Google Scholar] [CrossRef]
- Rajaratnam, N.; Cronbach, L.J.; Gleser, G.C. Generalizability of stratified-parallel tests. Psychometrika 1965, 30, 39–56. [Google Scholar] [CrossRef] [PubMed]
- Gleser, G.C.; Cronbach, L.J.; Rajaratnam, N. Generalizability of scores influenced by multiple sources of variance. Psychometrika 1965, 30, 395–418. [Google Scholar] [CrossRef]
- Cronbach, L.J.; Gleser, G.C.; Nanda, H.; Rajaratnam, N. The Dependability of Behavioral Measurements: Theory of Generalizability for Scores and Profiles; Wiley: New York, NY, USA, 1972. [Google Scholar]
- Brennan, R.L. Elements of Generalizability Theory (Revised Edition); American College Testing: Iowa City, IA, USA, 1992. [Google Scholar]
- Fyans, L.J. Generalizability Theory: Inferences and Practical Applications; Jossey-Bass: San Francisco, CA, USA, 1983. [Google Scholar]
- Shavelson, R.J.; Webb, N.M. Generalizability Theory: A Primer; Sage: Thousand Oaks, CA, USA, 1991. [Google Scholar]
- Brennan, R.L. Generalizability Theory; Springer: New York, NY, USA, 2001. [Google Scholar]
- Cardinet, J.; Johnson, S.; Pini, G. Applying Generalizability Theory Using EduG; Routledge: New York, NY, USA, 2010. [Google Scholar]
- Crocker, L.; Algina, J. Introduction to Classical and Modern Test Theory; Harcourt Brace: New York, NY, USA, 1986. [Google Scholar]
- McDonald, R.P. Test Theory: A Unified Approach; Erlbaum: Mahwah, NJ, USA, 1999. [Google Scholar]
- Raykov, T.; Marcoulides, G.A. Introduction to Psychometric Theory; Routledge: New York, NY, USA, 2011. [Google Scholar]
- Marcoulides, G.A. Generalizability theory. In Handbook of Applied Multivariate Statistics and Mathematical Modeling; Tinsley, H., Brown, S., Eds.; Academic Press: San Diego, CA, USA, 2000; pp. 527–551. [Google Scholar]
- Wiley, E.W.; Webb, N.M.; Shavelson, R.J. The generalizability of test scores. In APA Handbook of Testing and Assessment in Psychology: Vol. 1. Test Theory and Testing and Assessment in Industrial and Organizational Psychology; Geisinger, K.F., Bracken, B.A., Carlson, J.F., Hansen, J.C., Kuncel, N.R., Reise, S.P., Rodriguez, M.C., Eds.; American Psychological Association: Washington, DC, USA, 2013; pp. 43–60. [Google Scholar]
- Webb, N.M.; Shavelson, R.J.; Steedle, J.T. Generalizability theory in assessment contexts. In Handbook on Measurement, Assessment, and Evaluation in Higher Education; Secolsky, C., Denison, D.B., Eds.; Routledge: New York, NY, USA, 2012; pp. 152–169. [Google Scholar]
- Gao, X.; Harris, D.J. Generalizability theory. In APA Handbook of Research Methods in Psychology, Vol. 1. Foundations, Planning, Measures, and Psychometrics; Cooper, H., Camic, P.M., Long, D.L., Panter, A.T., Rindskopf, D., Sher, K.J., Eds.; American Psychological Association: Washington, DC, USA, 2012; pp. 661–681. [Google Scholar]
- Allal, L. Generalizability theory. In The International Encyclopedia of Educational Evaluation; Walberg, H.J., Haertel, G.D., Eds.; Pergamon: Oxford, UK, 1990; pp. 274–279. [Google Scholar]
- Shavelson, R.J.; Webb, N.M. Generalizability theory. In Encyclopedia of Educational Research; Alkin, M.C., Ed.; Macmillan: New York, NY, USA, 1992; Volume 2, pp. 538–543. [Google Scholar]
- Brennan, R.L. Generalizability theory. In The SAGE Encyclopedia of Social Science Research Methods; Lewis-Beck, M.S., Bryman, A.E., Liao, T.F., Eds.; SAGE: Thousand Oaks, CA, USA, 2004; Volume 2, pp. 418–420. [Google Scholar]
- Shavelson, R.J.; Webb, N.M. Generalizability theory. In Encyclopedia of Statistics in Behavioral Science; Everitt, B.S., Howell, D.C., Eds.; Wiley: New York, NY, USA, 2005; pp. 717–719. [Google Scholar]
- Brennan, R.L. Generalizability theory. In International Encyclopedia of Education, 3rd ed.; Peterson, P., Baker, E., McGaw, B., Eds.; Elsevier: New York, NY, USA, 2010; Volume 4, pp. 61–68. [Google Scholar]
- Matt, G.E.; Sklar, M. Generalizability theory. In International Encyclopedia of the Social & Behavioral Sciences; Wright, J.D., Ed.; Elsevier: New York, NY, USA, 2015; Volume 9, pp. 834–838. [Google Scholar]
- Franzen, M. Generalizability theory. In Encyclopedia of Clinical Neuropsychology; Kreutzer, J.S., DeLuca, J., Caplan, B., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 1554–1555. [Google Scholar]
- Brennan, R.L.; Kane, M.T. Generalizability theory: A review. In New Directions for Testing and Measurement: Methodological Developments (No.4); Traub, R.E., Ed.; Jossey-Bass: San Francisco, CA, USA, 1979; pp. 33–51. [Google Scholar]
- Brennan, R.L. Applications of generalizability theory. In Criterion-Referenced Measurement: The State of the Art; Berk, R.A., Ed.; The Johns Hopkins University Press: Baltimore, MD, USA, 1980; pp. 186–232. [Google Scholar]
- Jarjoura, D.; Brennan, R.L. Multivariate generalizability models for tests developed according to a table of specifications. In New Directions for Testing and Measurement: Generalizability Theory: Inferences and Practical Applications (No. 18); Fyans, L.J., Ed.; Jossey-Bass: San Francisco, CA, USA, 1983; pp. 83–101. [Google Scholar]
- Webb, N.M.; Shavelson, R.J.; Maddahian, E. Multivariate generalizability theory. In New Directions in Testing and Measurement: Generalizability Theory (No. 18); Fyans, L.J., Ed.; Jossey-Bass: San Francisco, CA, USA, 1983; pp. 67–82. [Google Scholar]
- Brennan, R.L. Estimating the dependability of the scores. In A Guide to Criterion-Referenced Test Construction; Berk, R.A., Ed.; The Johns Hopkins University Press: Baltimore, MD, USA, 1984; pp. 292–334. [Google Scholar]
- Allal, L. Generalizability theory. In Educational Research, Methodology, and Measurement; Keeves, J.P., Ed.; Pergamon: New York, NY, USA, 1988; pp. 272–277. [Google Scholar]
- Feldt, L.S.; Brennan, R.L. Reliability. In Educational Measurement, 3rd ed.; Linn, R.L., Ed.; American Council on Education and Macmillan: New York, NY, USA, 1989; pp. 105–146. [Google Scholar]
- Brennan, R.L. Generalizability of performance assessments. In Technical Issues in Performance Assessments; Phillips, G.W., Ed.; National Center for Education Statistics: Washington, DC, USA, 1996; pp. 19–58. [Google Scholar]
- Marcoulides, G.A. Applied generalizability theory models. In Modern Methods for Business Research; Marcoulides, G.A., Ed.; Erlbaum: Mahwah, NJ, USA, 1998; pp. 1–21. [Google Scholar]
- Strube, M.J. Reliability and generalizability theory. In Reading and Understanding More Multivariate Statistics; Grimm, L.G., Yarnold, P.R., Eds.; American Psychological Association: Washington, DC, USA, 2000; pp. 23–66. [Google Scholar]
- Haertel, E.H. Reliability. In Educational Measurement, 4th ed.; Brennan, R.L., Ed.; American Council on Education/Praeger: Westport, CT, USA, 2006; pp. 65–110. [Google Scholar]
- Kreiter, C.D. Generalizability theory. In Assessment in Health Professions Education; Downing, S.M., Yudkowsky, R., Eds.; Routledge: New York, NY, USA, 2009; pp. 75–92. [Google Scholar]
- Streiner, D.L.; Norman, G.R.; Cairney, J. Generalizability theory. In Health Measurement Scales: A Practical Guide to Their Development and Use; Oxford University Press: Oxford, UK, 2014; pp. 200–226. [Google Scholar]
- Shavelson, R.J.; Webb, N. Generalizability theory and its contribution to the discussion of the generalizability of research findings. In Generalizing from Educational Research: Beyond Qualitative and Quantitative Polarization; Ercikan, K., Roth, W., Eds.; Routledge: New York, NY, USA, 2019; pp. 13–32. [Google Scholar]
- Kreiter, C.D.; Zaidi, N.L.; Park, Y.S. Generalizability theory. In Assessment in Health Professions Education; Yudkowsky, R., Park, Y.S., Downing, S.M., Eds.; Routledge: New York, NY, USA, 2020; pp. 51–69. [Google Scholar]
- Brennan, R.L. Generalizability theory. In The History of Educational Measurement: Key Advancements in Theory, Policy, and Practice; Clauser, B.E., Bunch, M.B., Eds.; Routledge: New York, NY, USA, 2022; pp. 206–231. [Google Scholar]
- Cardinet, J.; Tourneur, Y.; Allal, L. The symmetry of generalizability theory: Applications to educational measurement. J. Educ. Meas. 1976, 13, 119–135. [Google Scholar]
- Shavelson, R.J.; Dempsey Atwood, N. Generalizability of measures of teaching behavior. Rev. Educ. Res. 1976, 46, 553–611. [Google Scholar] [CrossRef]
- Cardinet, J.; Tourneur, Y.; Allal, L. Extension of generalizability theory and its applications in educational measurement. J. Educ. Meas. 1981, 18, 183–204. [Google Scholar]
- Shavelson, R.J.; Webb, N.M. Generalizability theory: 1973–1980. Br. J. Math. Stat. Psychol. 1981, 34, 133–166. [Google Scholar] [CrossRef]
- Webb, N.M.; Shavelson, R.J. Multivariate generalizability of General Educational Development ratings. J. Educ. Meas. 1981, 18, 13–22. [Google Scholar] [CrossRef]
- Nußbaum, A. Multivariate generalizability theory in educational measurement: An empirical study. Appl. Psychol. Meas. 1984, 8, 219–230. [Google Scholar]
- Shavelson, R.J.; Webb, N.M.; Rowley, G.L. Generalizability theory. Am. Psychol. 1989, 44, 922–932. [Google Scholar] [CrossRef]
- Brennan, R.L. Generalizability theory. Educ. Meas. Issues Pract. 1992, 11, 27–34. [Google Scholar] [CrossRef]
- Demorest, M.E.; Bernstein, L.E. Applications of generalizability theory to measurement of individual differences in speech perception. J. Acad. Reh. 1993, 26, 39–50. [Google Scholar]
- Brennan, R.L.; Johnson, E.G. Generalizability of performance assessments. Educ. Meas. Issues Pract. 1995, 14, 9–12. [Google Scholar] [CrossRef]
- Cronbach, L.J.; Linn, R.L.; Brennan, R.L.; Haertel, E. Generalizability analysis for performance assessments of student achievement for school effectiveness. Educ. Psychol. Meas. 1997, 57, 373–399. [Google Scholar] [CrossRef]
- Lynch, B.K.; McNamara, T.F. Using G-theory and many-facet Rasch measurement in the development of performance assessments of the ESL speaking skills of immigrants. Lang. Test. 1998, 15, 158–180. [Google Scholar] [CrossRef]
- Hoyt, W.T.; Melby, J.N. Dependability of measurement in counseling psychology: An introduction to generalizability theory. Couns. Psychol. 1999, 27, 325–352. [Google Scholar] [CrossRef]
- Brennan, R.L. (Mis)conceptions about generalizability theory. Educ. Meas. Issues Pract. 2000, 19, 5–10. [Google Scholar] [CrossRef]
- Brennan, R.L. Performance assessments from the perspective of generalizability theory. Appl. Psychol. Meas. 2000, 24, 339–353. [Google Scholar] [CrossRef]
- Brennan, R.L. Generalizability theory and classical test theory. Appl. Meas. Educ. 2010, 24, 1–21. [Google Scholar] [CrossRef]
- Cronbach, L.J.; Shavelson, R.J. My current thoughts on coefficient alpha and successor procedures. Educ. Psychol. Meas. 2004, 64, 391–418. [Google Scholar] [CrossRef]
- Tavakol, M.; Brennan, R.L. Medical education assessment: A brief overview of concepts in generalizability theory. Int. J. Med. Educ. 2013, 4, 221–222. [Google Scholar] [CrossRef]
- Trejo-Meja, J.A.; Sanchez-Mendiola, M.; Mendez-Ramrez, I.; Martnez-Gonzlez, A. Reliability analysis of the objective structured clinical examination using generalizability theory. Med. Educ. Online 2016, 21, 31650. [Google Scholar]
- Vispoel, W.P.; Morris, C.A.; Kilinc, M. Applications of generalizability theory and their relations to classical test theory and structural equation modeling. Psychol. Methods 2018, 23, 1–26. [Google Scholar] [PubMed]
- Vispoel, W.P.; Morris, C.A.; Kilinc, M. Practical applications of generalizability theory for designing, evaluating, and improving psychological assessments. J. Personal. Assess. 2018, 100, 53–67. [Google Scholar]
- Vispoel, W.P.; Morris, C.A.; Kilinc, M. Using generalizability theory to disattenuate correlation coefficients for multiple sources of measurement error. Multivar. Behav. Res. 2018, 53, 481–501. [Google Scholar]
- Vispoel, W.P.; Morris, C.A.; Kilinc, M. Using generalizability theory with continuous latent response variables. Psychol. Methods 2019, 24, 153–178. [Google Scholar]
- Vispoel, W.P.; Xu, G.; Schneider, W.S. Using parallel splits with self-report and other measures to enhance precision in generalizability theory analyses. J. Personal. Assess. 2022, 104, 303–319. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Lee, H.; Hong, H.; Chen, T. Applying multivariate generalizability theory to psychological assessments. Psychol. Methods 2023. advance online publication. [Google Scholar] [CrossRef]
- Andersen, S.A.W.; Nayahangan, L.J.; Park, Y.S.; Konge, L. Use of generalizability theory for exploring reliability of and sources of variance in assessment of technical skills: A systematic review and meta-analysis. Acad. Med. 2021, 96, 1609–1619. [Google Scholar]
- Andersen, S.A.W.; Park, Y.S.; Sørensen, M.S.; Konge, L. Reliable assessment of surgical technical skills is dependent on context: An exploration of different variables using Generalizability Theory. Acad. Med. 2020, 95, 1929–1936. [Google Scholar] [CrossRef]
- Kreiter, C.; Zaidi, N.B. Generalizability theory’s role in validity research: Innovative applications in health science education. Health Prof. Educ. 2020, 6, 282–290. [Google Scholar]
- Suneja, M.; Hanrahan, K.D.; Kreiter, C.; Rowat, J. Psychometric properties of entrustable professional activity-based objective structured clinical examinations during transition from undergraduate to graduate medical education: A generalizability study. Acad. Med. 2025, 100, 179–183. [Google Scholar] [PubMed]
- Anderson, T.N.; Lau, J.N.; Shi, R.; Sapp, R.W.; Aalami, L.R.; Lee, E.W.; Tekian, A.; Park, Y.S. The utility of peers and trained raters in technical skill-based assessments a generalizability theory study. J. Surg. Educ. 2022, 79, 206–215. [Google Scholar] [PubMed]
- Jogerst, K.M.; Eurboonyanun, C.; Park, Y.S.; Cassidy, D.; McKinley, S.K.; Hamdi, I.; Phitayakorn, R.; Petrusa, E.; Gee, D.W. Implementation of the ACS/APDS Resident Skills Curriculum reveals a need for rater training: An analysis using generalizability theory. Am. J. Surg. 2021, 222, 541–548. [Google Scholar]
- Winkler-Schwartz, A.; Marwa, I.; Bajunaid, K.; Mullah, M.; Alotaibi, F.E.; Bugdadi, A.; Sawaya, R.; Sabbagh, A.J.; Del Maestro, R. A comparison of visual rating scales and simulated virtual reality metrics in neurosurgical training: A generalizability theory study. World Neurosurg. 2019, 127, e230–e235. [Google Scholar]
- Kuru, C.A.; Sezer, R.; Çetin, C.; Haberal, B.; Yakut, Y.; Kuru, İ. Use of generalizability theory evaluating comparative reliability of the scapholunate interval measurement with X-ray, CT and US. Acad. Radiol. 2023, 30, 2290–2298. [Google Scholar]
- Gatti, A.A.; Stratford, P.W.; Brisson, N.M.; Maly, M.R. How to optimize measurement protocols: An example of assessing measurement reliability using generalizability theory. Physiother Can. 2020, 72, 112–121. [Google Scholar]
- O’Brien, J.; Thompson, M.S.; Hagler, D. Using generalizability theory to inform optimal design for a nursing performance assessment. Eval. Health Prof. 2019, 42, 297–327. [Google Scholar]
- Peeters, M.J. Moving beyond Cronbach’s alpha and inter-rater reliability: A primer on generalizability theory for pharmacy education. Innov. Pharm. 2021, 12, 14. [Google Scholar]
- Atilgan, H. Reliability of essay ratings: A study on Generalizability Theory. Eurasian J. Educ. Res. 2019, 19, 133–150. [Google Scholar]
- Chen, D.; Hebert, M.; Wison, J. Examining human and automated ratings of elementary students’ writing quality: A multivariate generalizability theory application. Am. Educ. Res. J. 2022, 59, 1122–1156. [Google Scholar] [CrossRef]
- Deniz, K.Z.; Ilican, E. Comparison of G and Phi coefficients estimated in generalizability theory with real cases. Int. J. Assess. Tools Educ. 2021, 8, 583–595. [Google Scholar]
- Wilson, J.; Chen, D.; Sandbank, M.P.; Hebert, M.; Graham, S. Generalizability of automated scores of writing quality in Grades 3–5. J. Educ. Psychol. 2019, 111, 619–640. [Google Scholar]
- Eskin, D. Generalizability of Writing Scores and Language Program Placement Decisions: Score Dependability, Task Variability, and Score Profiles on an ESL Placement Test. Stud. Appl. Linguist. TESOL 2022, 21, 21–42. [Google Scholar] [CrossRef]
- Liao, R.J.T. The use of generalizability theory in investigating the score dependability of classroom-based L2 reading assessment. Lang. Test. 2023, 40, 86–106. [Google Scholar]
- Shin, J. Investigating and optimizing score dependability of a local ITA speaking test across language groups: A generalizability theory approach. Lang. Test. 2022, 39, 313–337. [Google Scholar]
- Vispoel, W.P.; Hong, H.; Lee, H.; Jorgensen, T.R. Analyzing complete generalizability theory designs using structural equation models. Appl. Meas. Educ. 2023, 36, 372–393. [Google Scholar]
- Ford, A.L.B.; Johnson, L.D. The use of generalizability theory to inform sampling of educator language used with preschoolers with autism spectrum disorder. J. Speech Lang. Hear. Res. 2021, 64, 1748–1757. [Google Scholar] [CrossRef]
- Hollo, A.; Staubitz, J.L.; Chow, J.C. Applying generalizability theory to optimize analysis of spontaneous teacher talk in elementary classrooms. J. Speech Lang. Hear. Res. 2020, 63, 1947–1957. [Google Scholar] [CrossRef]
- Van Hooijdonk, M.; Mainhard, T.; Kroesbergen, E.H.; Van Tartwijk, J. Examining the assessment of creativity with generalizability theory: An analysis of creative problem solving assessment tasks. Think. Ski. Creat. 2022, 43, 100994. [Google Scholar]
- Li, G.; Xie, J.; An, L.; Hou, G.; Jian, H.; Wang, W. A generalizability analysis of the mobile phone addiction tendency scale for Chinese college students. Front. Psychiatry 2019, 10, 241. [Google Scholar]
- Kumar, S.S.; Merkin, A.G.; Numbers, K.; Sachdev, P.S.; Brodaty, H.; Kochan, N.A.; Trollor, J.N.; Mahon, S.; Medvedev, O. A novel approach to investigate depression symptoms in the aging population using generalizability theory. Psychol. Assess. 2022, 34, 684–696. [Google Scholar] [CrossRef] [PubMed]
- Truong, Q.C.; Krageloh, C.U.; Siegert, R.J.; Landon, J.; Medvedev, O.N. Applying generalizability theory to differentiate between trait and state in the Five Facet Mindfulness Questionnaire (FFMQ). Mindfulness 2020, 11, 953–963. [Google Scholar]
- Anthony, C.J.; Styck, K.M.; Volpe, R.J.; Robert, C.R.; Codding, R.S. Using many-facet Rasch measurement and Generalizability Theory to explore rater effects for Direct Behavior Rating–Multi-Item Scales. Sch. Psychol. 2023, 38, 119–128. [Google Scholar]
- Lyndon, M.P.; Medvedev, O.N.; Chen, Y.; Henning, M.A. Investigating stable and dynamic aspects of student motivation using generalizability theory. Aust. J. Psychol. 2020, 72, 199–210. [Google Scholar]
- Sanz-Fernández, C.; Morales-Sánchez, V.; Castellano, J.; Mendo, A.H. Generalizability theory in the evaluation of psychological profile in track and field. Sports 2024, 12, 127. [Google Scholar] [CrossRef]
- Mushquash, C.; O’Connor, B.P. SPSS and SAS programs for generalizability theory analyses. Behav. Res. Methods 2006, 38, 542–547. [Google Scholar] [CrossRef]
- Crick, J.E.; Brennan, R.L. Manual for GENOVA: A Generalized Analysis of Variance System; American College Testing Technical Bulletin No. 43; ACT, Inc.: Iowa City, IA, USA, 1983. [Google Scholar]
- Brennan, R.L. Manual for urGENOVA, version 2.1; University of Iowa, Iowa Testing Programs: Iowa City, IA, USA, 2001. [Google Scholar]
- Brennan, R.L. Manual for mGENOVA, version 2.1; University of Iowa, Iowa Testing Programs: Iowa City, IA, USA, 2001. [Google Scholar]
- Moore, C.T. gtheory: Apply Generalizability Theory with R, R package version 0.1.2; 2016. Available online: https://cran.r-project.org/web/packages/gtheory/index.html (accessed on 7 January 2025).
- Huebner, A.; Lucht, M. Generalizability theory in R. Pract. Assess. Res. Eval. 2019, 24, n5. [Google Scholar]
- Jorgensen, T.D. How to estimate absolute-error components in structural equation models of generalizability theory. Psych 2021, 3, 113–133. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Xu, G.; Kilinc, M. Expanding G-theory models to incorporate congeneric relationships: Illustrations using the Big Five Inventory. J. Personal. Assess. 2021, 104, 429–442. [Google Scholar]
- Vispoel, W.P.; Xu, G.; Schneider, W.S. Interrelationships between latent state-trait theory and generalizability theory in a structural equation modeling framework. Psychol. Methods 2022, 27, 773–803. [Google Scholar] [CrossRef] [PubMed]
- Vispoel, W.P.; Lee, H.; Xu, G.; Hong, H. Expanding bifactor models of psychological traits to account for multiple sources of measurement error. Psychol. Assess. 2022, 32, 1093–1111. [Google Scholar]
- Vispoel, W.P.; Lee, H.; Xu, G.; Hong, H. Integrating bifactor models into a generalizability theory structural equation modeling framework. J. Exp. Educ. 2023, 91, 718–738. [Google Scholar]
- Vispoel, W.P.; Lee, H.; Chen, T.; Hong, H. Extending applications of generalizability theory-based bifactor model designs. Psych 2023, 5, 545–575. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Lee, H. Merging generalizability theory and bifactor modeling to improve psychological assessments. Psychol. Psychother. Rev. Study 2023, 7, 1–4. [Google Scholar]
- Vispoel, W.P.; Lee, H.; Chen, T.; Hong, H. Using structural equation modeling to reproduce and extend ANOVA-based generalizability theory analyses for psychological assessments. Psych 2023, 5, 249–272. [Google Scholar] [CrossRef]
- Lee, H.; Vispoel, W.P. A robust indicator mean-based method for estimating generalizability theory absolute error and related dependability indices within structural equation modeling frameworks. Psych 2024, 6, 401–425. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Hong, H.; Lee, H. Benefits of doing generalizability theory analyses within structural equation modeling frameworks: Illustrations using the Rosenberg Self-Esteem Scale [Teacher’s corner]. Struct. Equ. Model. 2024, 31, 165–181. [Google Scholar]
- Vispoel, W.P.; Lee, H.; Hong, H. Analyzing multivariate generalizability theory designs within structural equation modeling frameworks [Teacher’s corner]. Struct. Equ. Model. 2024, 31, 552–570. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Lee, H.; Chen, T. Multivariate structural equation modeling techniques for estimating reliability, measurement error, and subscale viability when using both composite and subscale scores in practice. Mathematics 2024, 12, 1164. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Lee, H.; Chen, T.; Hong, H. Analyzing and comparing univariate, multivariate, and bifactor generalizability theory designs for hierarchically structured personality traits. J. Personal. Assess. 2024, 106, 285–300. [Google Scholar]
- Marcoulides, G.A. Estimating variance components in generalizability theory: The covariance structure analysis approach. Struct. Equ. Model. 1996, 3, 290–299. [Google Scholar]
- Raykov, T.; Marcoulides, G.A. Estimation of generalizability coefficients via a structural equation modeling approach to scale reliability evaluation. Int. J. Test. 2006, 6, 81–95. [Google Scholar]
- Brennan, R.L.; Kane, M.T. An index of dependability for mastery tests. J. Educ. Meas. 1977, 14, 277–289. [Google Scholar] [CrossRef]
- Kane, M.T.; Brennan, R.L. Agreement coefficients as indices of dependability for domain-referenced tests. Appl. Psychol. Meas. 1980, 4, 105–126. [Google Scholar]
- Morin, A.J.S.; Scalas, L.F.; Vispoel, W.; Marsh, H.W.; Wen, Z. The Music Self-Perception Inventory: Development of a short form. Psychol. Music 2016, 44, 915–934. [Google Scholar]
- Scalas, L.F.; Marsh, H.W.; Vispoel, W.; Morin, A.J.S.; Wen, Z. Music self-concept and self-esteem formation in adolescence: A comparison between individual and normative models of importance within a latent framework. Psychol. Music. 2017, 45, 763–780. [Google Scholar]
- Fiedler, D.; Hasselhorn, J.; Katrin Arens, A.; Frenzel, A.C.; Vispoel, W.P. Validating scores from the short form of the Music Self-Perception Inventory (MUSPI-S) with seventh- to ninth-grade school students in Germany. Psychol. Music 2024. advance online publication. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Lee, H. Music self-concept: Structure, correlates, and differences across grade-level, gender, and musical activity groups. Psychol. Psychol. Res. Int. J. 2024, 9, 00413. [Google Scholar]
- Schmidt, F.L.; Hunter, J.E. Measurement error in psychological research: Lessons from 26 research scenarios. Psychol. Methods 1996, 1, 199–223. [Google Scholar]
- Schmidt, F.L.; Le, H.; Ilies, R. Beyond alpha: An empirical examination of the effects of different sources of measurement error on reliability estimates for measures of individual differences constructs. Psychol. Methods 2003, 8, 206–224. [Google Scholar] [PubMed]
- Le, H.; Schmidt, F.L.; Putka, D.J. The multifaceted nature of measurement artifacts and its implications for estimating construct-level relationships. Organ. Res. Methods 2009, 12, 165–200. [Google Scholar]
- Thorndike, R.L. Reliability. In Educational Measurement; Lindquist, E.F., Ed.; American Council on Education: Washington, DC, USA, 1951; pp. 560–620. [Google Scholar]
- Spearman, C. The proof and measurement of association between two things. Am. J. Psychol. 1904, 15, 72–101. [Google Scholar]
- Spearman, C. Correlation calculated from faulty data. Br. J. Psychol. 1910, 3, 271–295. [Google Scholar]
- Reise, S.P. The rediscovery of bifactor measurement models. Multivar. Behav. Res. 2012, 47, 667–696. [Google Scholar]
- Reise, S.P.; Bonifay, W.E.; Haviland, M.G. Scoring psychological measures in the presence of multidimensionality. J. Personal. Assess. 2013, 95, 129–140. [Google Scholar]
- Rodriguez, A.; Reise, S.P.; Haviland, M.G. Applying bifactor statistical indices in the evaluation of psychological measures. J. Personal. Assess. 2016, 98, 223–237. [Google Scholar]
- Rodriguez, A.; Reise, S.P.; Haviland, M.G. Evaluating bifactor models: Calculating and interpreting statistical indices. Psychol. Methods 2016, 21, 137–150. [Google Scholar] [CrossRef]
- Zinbarg, R.E.; Revelle, W.; Yovel, I.; Li, W. Cronbach’s α, Revelle’s β, and McDonald’s ωH: Their relations with each other and two alternative conceptualizations of reliability. Psychometrika 2005, 70, 123–133. [Google Scholar]
- Haberman, S.J. When can subscores have value? J. Educ. Behav. Stat. 2008, 33, 204–229. [Google Scholar]
- Haberman, S.J.; Sinharay, S. Reporting of subscores using multidimensional item response theory. Psychometrika 2010, 75, 209–227. [Google Scholar] [CrossRef]
- Feinberg, R.A.; Jurich, D.P. Guidelines for interpreting and reporting subscores. Educ. Meas. Issues Pract. 2017, 36, 5–13. [Google Scholar] [CrossRef]
- Sinharay, S. Added value of subscores and hypothesis testing. J. Educ. Behav. Stat. 2019, 44, 25–44. [Google Scholar] [CrossRef]
- Hjarne, M.S.; Lyrén, P.E. Group differences in the value of subscores: A fairness issue. Front. Educ. 2020, 5, 55. [Google Scholar] [CrossRef]
- Feinberg, R.A.; Wainer, H. A simple equation to predict a subscore’s value. Educ. Meas. Issues Pract. 2014, 33, 55–56. [Google Scholar] [CrossRef]
- Rosseel, Y. lavaan: An R package for structural equation modeling. J. Stat. Softw. 2012, 48, 1–36. [Google Scholar] [CrossRef]
- Rosseel, Y.; Jorgensen, T.D.; De Wilde, L. Package ‘lavaan’. R Package Version (0.6-17). 2023. Available online: https://cran.r-project.org/web/packages/lavaan/lavaan.pdf (accessed on 8 December 2024).
- Preacher, K.J.; Selig, J.P. Advantages of Monte Carlo confidence intervals for indirect effects. Commun. Methods Meas. 2012, 6, 77–98. [Google Scholar] [CrossRef]
- Jorgensen, T.D.; Pornprasertmanit, S.; Schoemann, A.M.; Rosseel, Y. semTools: Useful Tools for Structural Equation Modeling. R Package Version 0.5-6. 2022. Available online: https://CRAN.R-project.org/package=semTools (accessed on 8 December 2024).
- Ark, T.K. Ordinal Generalizability Theory Using an Underlying Latent Variable Framework. Ph.D. Thesis, University of British Columbia, Vancouver, BC, Canada, 2015. Available online: https://open.library.ubc.ca/soa/cIRcle/collections/ubctheses/24/items/1.0166304 (accessed on 8 December 2024).
- Vispoel, W.P.; Hong, H.; Chen, T.; Lee, H. Estimating item wording effects in self-report measures within G-theory-based SEMs: Illustrations using the Self-Description Questionnaire-III. Manuscript submitted for publication.
- Honaker, J.; King, G.; Blackwell, M. Amelia II: A program for missing data. J. Stat. Softw. 2011, 45, 1–47. [Google Scholar] [CrossRef]
- Honaker, J.; King, G.; Blackwell, M. Amelia: A Program for Missing Data (R Package Version 1.8.3). 2024. Available online: https://cran.rproject.org/web/packages/Amelia/index.html (accessed on 7 January 2025).
- Harrell, F.E., Jr.; Dupont, C. Hmisc: Harrell Miscellaneous (R package version 4.7-2). 2022. Available online: https://cran.r-project.org/web/packages/Hmisc/index.html (accessed on 7 January 2025).
- Su, Y.S.; Yajima, M.; Goodrich, B.; Si, Y.; Kropko, J. mi: Missingdata Imputation and Model Checking (R Package Version 1.1). 2022. Available online: https://cran.r-project.org/web/packages/mi/index.html (accessed on 7 January 2025).
- van Buuren, S.; Groothuis-Oudshoorn, K. mice: Multivariate Imputation by Chained Equations (R Package Version 3.15.0). 2022. Available online: https://cran.r-project.org/web/packages/mice/index.html (accessed on 31 January 2025).
- Lumley, T. Package ‘mitools’ (R Package Version 2.4). 2022. Available online: https://cran.r-project.org/web/packages/mitools/mitools.pdf (accessed on 7 January 2025).
- Stekhoven, D.J. missForest: Nonparametric Missing Value Imputation Using Random Forest (R Package Version 1.5). 2022. Available online: https://cran.rproject.org/web/packages/missForest/index.html (accessed on 7 January 2025).
- Grund, S.; Robitzsch, A.; Luedtke, O. mitml: Tools for Multiple Imputation in Multilevel Modeling (R Package Version 0.4-4). 2023. Available online: https://cran.r-project.org/web/packages/mitml/mitml.pdf (accessed on 7 January 2025).
- Vispoel, W.P. Music self-concept: Instrumentation, structure, and theoretical linkages. In Self-Concept, Theory, Research and Practice: Advances for the New Millennium; Craven, R.G., Marsh, H.W., Eds.; Self-Concept Enhancement and Learning Facilitation Research Centre: Sydney, Australia, 2000; pp. 100–107. [Google Scholar]
- Vispoel, W.P. Integrating self-perceptions of music skill into contemporary models of self-concept. Vis. Res. Music Educ. 2021, 16, 33. [Google Scholar]
- Vispoel, W.P. Measuring and understanding self-perceptions of musical ability. In International Advances in Self Research; Marsh, H.W., Craven, R.G., McInerney, D.M., Eds.; Information Age Publishing: Charlotte, NC, USA, 2003; pp. 151–180. [Google Scholar]
- Schmid, J.; Leiman, J.M. The development of hierarchical factor solutions. Psychometrika 1957, 22, 53–61. [Google Scholar] [CrossRef]
- Schmid, J. The comparability of the bi-factor and second-order factor patterns. J. Exp. Educ. 1957, 25, 249–253. [Google Scholar]
- American Psychological Association (APA). Technical recommendations for psychological tests and diagnostic techniques. Psychol. Bull. 1954, 51, 1–38. [Google Scholar] [CrossRef] [PubMed]
- Cronbach, L.J.; Schönemann, P.; McKie, D. Alpha coefficients for stratified-parallel tests. Educ. Psychol. Meas. 1965, 25, 291–312. [Google Scholar]
- Holzinger, K.J.; Harman, H.H. Comparison of two factorial analyses. Psychometrika 1938, 3, 45–60. [Google Scholar]
- Holzinger, K.J.; Swineford, F. The bi-factor method. Psychometrika 1937, 2, 41–54. [Google Scholar]
- Rhemtulla, M.; Brosseau-Liard, P.É.; Savalei, V. When can categorical variables be treated as continuous? A comparison of robust continuous and categorical SEM estimation methods under suboptimal conditions. Psychol. Methods 2012, 17, 354–373. [Google Scholar]
- Vispoel, W.P.; Tao, S. A generalizability analysis of score consistency for the Balanced Inventory of Desirable Responding. Psychol. Assess. 2013, 25, 94–104. [Google Scholar]
- Vispoel, W.P.; Morris, C.A.; Kilinc, M. Using G-theory to enhance evidence of reliability and validity for common uses of the Paulhus Deception Scales. Assessment 2018, 25, 69–83. [Google Scholar]
- Wickham, H. ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016. [Google Scholar]
- Morin, A.J.S.; Scalas, L.F.; Vispoel, W.P. The Music Self-Perception Inventory: Development of parallel forms A and B. Psychol. Music 2017, 45, 530–549. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Design/VC | Formula |
|---|---|
| pi design | |
| p | |
| pi,e | |
| i | . |
| pio design | |
| p | |
| pi | |
| po | |
| pio,e | |
| i | . |
| o | |
| io |
| Design/Index | Formula |
|---|---|
| pi design | |
| G | |
| Global D | |
| Cut-score-specific D | |
| Total relative error | |
| pio design | |
| G | |
| Global D | |
| Cut-score-specific D | |
| Specific-factor error | |
| Transient error | |
| Random-response error | |
| Total relative error |
| Design/VC | Formula | |
|---|---|---|
| Composite | Subscale | |
| pi design | ||
| p | , = the total number of subscales. | |
| pi,e | ||
| i | = the total number of items in subscale s, . | |
| pio design | ||
| p | ||
| pi | ||
| po | ||
| pio,e | ||
| i | . | |
| o | = the number of occasions for subscales, | |
| io | ||
| Design/VC | Formula | |
|---|---|---|
| Composite | Subscale | |
| pi design | ||
| General | , where = the total number of subscales. | |
| Group | ||
| p | ||
| pi,e | ||
| i | where = the total number of items in subscale s, = subscale s‘s intercept for its item, and . | |
| pio design | ||
| General | ||
| Group | ||
| p | ||
| pi | ||
| po | ||
| pio,e | ||
| i | where . | |
| o | where = the total number of occasions for subscales, and | |
| io | ||
| Metric/Scale | Occasion/Index | ||||||
|---|---|---|---|---|---|---|---|
| Time 1 | Time 2 | ||||||
| Mean Scale (Item) | SD Scale (Item) | Mean Scale (Item) | SD Scale (Item) | Test–Retest | |||
| 2-Point | |||||||
| Composite | 22.90 (1.43) | 6.06 (0.38) | 0.954 | 23.12 (1.45) | 6.15 (0.38) | 0.957 | 0.906 |
| Instrument playing | 5.78 (1.44) | 1.83 (0.46) | 0.940 | 5.81 (1.45) | 1.85 (0.46) | 0.946 | 0.885 |
| Reading music | 5.77 (1.44) | 1.85 (0.46) | 0.948 | 5.83 (1.46) | 1.84 (0.46) | 0.942 | 0.908 |
| Listening | 5.78 (1.44) | 1.83 (0.46) | 0.935 | 6.12 (1.53) | 1.84 (0.46) | 0.940 | 0.799 |
| Composing | 5.32 (1.33) | 1.67 (0.42) | 0.911 | 5.37 (1.34) | 1.73 (0.43) | 0.934 | 0.826 |
| 4-Point | |||||||
| Composite | 35.83 (2.24) | 14.98 (0.94) | 0.967 | 36.48 (2.28) | 14.85 (0.93) | 0.971 | 0.936 |
| Instrument playing | 9.08 (2.27) | 4.46 (1.11) | 0.961 | 9.20 (2.30) | 4.41 (1.10) | 0.966 | 0.921 |
| Reading music | 9.03 (2.26) | 4.52 (1.13) | 0.964 | 9.14 (2.29) | 4.38 (1.09) | 0.971 | 0.930 |
| Listening | 9.08 (2.27) | 4.46 (1.11) | 0.958 | 9.88 (2.47) | 4.26 (1.07) | 0.959 | 0.871 |
| Composing | 8.06 (2.02) | 3.79 (0.95) | 0.932 | 8.26 (2.06) | 3.80 (0.95) | 0.950 | 0.870 |
| 8-Point | |||||||
| Composite | 63.06 (3.94) | 31.64 (1.98) | 0.971 | 64.54 (4.03) | 31.32 (1.96) | 0.975 | 0.944 |
| Instrument playing | 15.97 (3.99) | 9.42 (2.36) | 0.967 | 16.29 (4.07) | 9.24 (2.31) | 0.973 | 0.929 |
| Reading music | 15.91 (3.98) | 9.49 (2.37) | 0.968 | 16.12 (4.03) | 9.17 (2.29) | 0.978 | 0.937 |
| Listening | 15.97 (3.99) | 9.42 (2.36) | 0.966 | 17.72 (4.43) | 8.79 (2.20) | 0.967 | 0.890 |
| Composing | 14.01 (3.50) | 7.89 (1.97) | 0.937 | 14.41 (3.60) | 7.91 (1.98) | 0.958 | 0.891 |
| Metric/Procedure | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 2-Point | 4-Point | 8-Point | |||||||
| Scale/ Index | mGENOVA | ULS | WLSMV | mGENOVA | ULS | WLSMV | mGENOVA | ULS | WLSMV |
| Composite | |||||||||
| G | 0.977 | 0.977 (0.964, 0.989) | 0.996 (0.995, 0.997) | 0.985 | 0.985 (0.983, 0.987) | 0.993 (0.992, 0.994) | 0.988 | 0.988 (0.987, 0.988) | 0.993 (0.992, 0.994) |
| Total RE | 0.023 | 0.023 | 0.004 | 0.015 | 0.015 | 0.007 | 0.012 | 0.012 | 0.007 |
| Global D | 0.977 | 0.977 (0.964, 0.988) | 0.996 (0.995, 0.997) | 0.985 | 0.985 (0.983, 0.987) | 0.993 (0.992, 0.994) | 0.987 | 0.987 (0.987, 0.988) | 0.993 (0.991, 0.994) |
| 0.140 | 0.140 | 1.262 | 0.864 | 0.864 | 1.093 | 3.861 | 3.861 | 1.233 | |
| 0.013 | 0.013 | 0.020 | 0.052 | 0.052 | 0.031 | 0.194 | 0.194 | 0.036 | |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.002 | 0.003 | 0.001 | |
| Instrument playing | |||||||||
| G | 0.940 | 0.940 (0.866, 1.000) | 0.989 (0.984, 0.993) | 0.961 | 0.961 (0.950, 0.973) | 0.980 (0.976, 0.984) | 0.967 | 0.967 (0.965, 0.970) | 0.982 (0.979, 0.985) |
| Total RE | 0.060 | 0.060 | 0.011 | 0.039 | 0.039 | 0.020 | 0.033 | 0.033 | 0.018 |
| Global D | 0.940 | 0.940 (0.863, 1.000) | 0.988 (0.984, 0.993) | 0.961 | 0.961 (0.949, 0.972) | 0.980 (0.976, 0.984) | 0.967 | 0.967 (0.965, 0.970) | 0.982 (0.978, 0.985) |
| 0.197 | 0.197 | 1.995 | 1.195 | 1.195 | 1.869 | 5.367 | 5.367 | 1.771 | |
| 0.050 | 0.050 | 0.092 | 0.192 | 0.192 | 0.150 | 0.722 | 0.722 | 0.131 | |
| 0.000 | 0.000 | 0.001 | 0.000 | 0.001 | 0.001 | 0.002 | 0.004 | 0.001 | |
| Reading music | |||||||||
| G | 0.948 | 0.948 (0.876, 1.000) | 0.991 (0.987, 0.994) | 0.964 | 0.964 (0.953, 0.976) | 0.982 (0.979, 0.986) | 0.968 | 0.968 (0.966, 0.971) | 0.984 (0.982, 0.987) |
| Total RE | 0.052 | 0.052 | 0.009 | 0.036 | 0.036 | 0.018 | 0.032 | 0.032 | 0.016 |
| Global D | 0.948 | 0.947 (0.873, 1.000) | 0.990 (0.986, 0.994) | 0.964 | 0.964 (0.952, 0.975) | 0.982 (0.978, 0.985) | 0.967 | 0.967 (0.965, 0.970) | 0.983 (0.980, 0.986) |
| 0.202 | 0.202 | 1.556 | 1.230 | 1.230 | 1.364 | 5.445 | 5.445 | 1.768 | |
| 0.045 | 0.045 | 0.059 | 0.181 | 0.181 | 0.098 | 0.715 | 0.715 | 0.112 | |
| 0.000 | 0.000 | 0.003 | 0.003 | 0.003 | 0.004 | 0.021 | 0.022 | 0.008 | |
| Listening | |||||||||
| G | 0.935 | 0.935 (0.860, 1.000) | 0.986 (0.981, 0.991) | 0.958 | 0.958 (0.946, 0.969) | 0.978 (0.973, 0.982) | 0.966 | 0.966 (0.963, 0.969) | 0.981 (0.977, 0.983) |
| Total RE | 0.065 | 0.065 | 0.014 | 0.042 | 0.042 | 0.022 | 0.034 | 0.034 | 0.019 |
| Global D | 0.935 | 0.935 (0.857, 0.998) | 0.986 (0.981, 0.991) | 0.958 | 0.958 (0.945, 0.969) | 0.978 (0.973, 0.982) | 0.966 | 0.966 (0.963, 0.969) | 0.980 (0.977, 0.983) |
| 0.196 | 0.196 | 1.546 | 1.158 | 1.158 | 1.626 | 4.927 | 4.927 | 1.413 | |
| 0.055 | 0.055 | 0.088 | 0.205 | 0.205 | 0.149 | 0.692 | 0.692 | 0.112 | |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Composing | |||||||||
| G | 0.911 | 0.911 (0.818, 0.993) | 0.979 (0.972, 0.986) | 0.932 | 0.932 (0.915, 0.948) | 0.962 (0.954, 0.968) | 0.937 | 0.937 (0.934, 0.941) | 0.954 (0.946, 0.960) |
| Total RE | 0.089 | 0.089 | 0.021 | 0.068 | 0.068 | 0.038 | 0.063 | 0.063 | 0.046 |
| Global D | 0.911 | 0.911 (0.815, 0.990) | 0.978 (0.971, 0.986) | 0.931 | 0.931 (0.914, 0.947) | 0.961 (0.953, 0.967) | 0.937 | 0.936 (0.932, 0.940) | 0.953 (0.944, 0.959) |
| 0.159 | 0.159 | 1.026 | 0.837 | 0.837 | 0.595 | 3.649 | 3.649 | 1.123 | |
| 0.062 | 0.062 | 0.088 | 0.246 | 0.246 | 0.095 | 0.974 | 0.974 | 0.218 | |
| 0.000 | 0.000 | 0.003 | 0.003 | 0.003 | 0.002 | 0.016 | 0.018 | 0.006 | |
| Metric/ Estimator/Subscale | Correlation Coefficient | |||
|---|---|---|---|---|
| 2-Point/ULS | Instrument playing | Reading music | Listening | Composing |
| Instrument playing | 0.844 | 0.609 | 0.626 | |
| Reading music | 0.797 | 0.657 | 0.558 | |
| Listening | 0.571 | 0.618 | 0.646 | |
| Composing | 0.579 | 0.518 | 0.596 | |
| 2-Point/WLSMV | Instrument playing | Reading music | Listening | Composing |
| Instrument playing | 0.920 | 0.731 | 0.749 | |
| Reading music | 0.910 | 0.778 | 0.685 | |
| Listening | 0.721 | 0.769 | 0.784 | |
| Composing | 0.737 | 0.675 | 0.770 | |
| 4-Point/ULS | Instrument playing | Reading music | Listening | Composing |
| Instrument playing | 0.878 | 0.678 | 0.681 | |
| Reading music | 0.845 | 0.716 | 0.617 | |
| Listening | 0.650 | 0.689 | 0.689 | |
| Composing | 0.645 | 0.585 | 0.651 | |
| 4-Point/WLSMV | Instrument playing | Reading music | Listening | Composing |
| Instrument playing | 0.915 | 0.736 | 0.736 | |
| Reading music | 0.898 | 0.776 | 0.679 | |
| Listening | 0.721 | 0.760 | 0.745 | |
| Composing | 0.715 | 0.660 | 0.722 | |
| 8-Point/ULS | Instrument playing | Reading music | Listening | Composing |
| Instrument playing | 0.884 | 0.696 | 0.704 | |
| Reading | 0.855 | 0.727 | 0.652 | |
| Listening | 0.673 | 0.703 | 0.719 | |
| Composing | 0.671 | 0.621 | 0.684 | |
| 8-Point/WLSMV | Instrument playing | Reading music | Listening | Composing |
| Instrument playing | 0.885 | 0.725 | 0.732 | |
| Reading music | 0.871 | 0.744 | 0.685 | |
| Listening | 0.711 | 0.731 | 0.748 | |
| Composing | 0.708 | 0.664 | 0.724 | |
| Metric/Procedure | ||||||
|---|---|---|---|---|---|---|
| 2-Point | 4-Point | 8-Point | ||||
| Scale/Index | ULS | WLSMV | ULS | WLSMV | ULS | WLSMV |
| Composite | ||||||
| G | 0.977 (0.964, 0.989) | 0.996 (0.995, 0.997) | 0.985 (0.983, 0.987) | 0.993 (0.991, 0.994) | 0.988 (0.987, 0.988) | 0.992 (0.991, 0.993) |
| 0.869 (0.837, 0.899) | 0.938 (0.925, 0.950) | 0.900 (0.895, 0.905) | 0.930 (0.918, 0.940) | 0.909 (0.908, 0.910) | 0.924 (0.913, 0.934) | |
| 0.108 (0.073, 0.143) | 0.058 (0.046, 0.071) | 0.085 (0.080, 0.091) | 0.063 (0.053, 0.073) | 0.078 (0.077, 0.079) | 0.068 (0.060, 0.079) | |
| Total RE | 0.023 | 0.004 | 0.015 | 0.007 | 0.012 | 0.008 |
| Global D | 0.977 (0.963, 0.988) | 0.996 (0.995, 0.997) | 0.985 (0.983, 0.987) | 0.992 (0.991, 0.993) | 0.987 (0.987, 0.988) | 0.992 (0.991, 0.993) |
| 0.140 | 4.299 | 0.863 | 2.573 | 3.859 | 1.982 | |
| 0.125 | 4.050 | 0.789 | 2.411 | 3.553 | 1.846 | |
| 0.015 | 0.249 | 0.075 | 0.162 | 0.305 | 0.137 | |
| 0.013 | 0.071 | 0.052 | 0.078 | 0.194 | 0.060 | |
| 0.000 | 0.002 | 0.000 | 0.001 | 0.003 | 0.002 | |
| Instrument playing | ||||||
| G | 0.940 (0.865, 1.000) | 0.989 (0.984, 0.993) | 0.961 (0.950, 0.973) | 0.980 (0.976, 0.984) | 0.967 (0.965, 0.970) | 0.982 (0.979, 0.985) |
| 0.744 (0.568, 0.953) | 0.888 (0.830, 0.948) | 0.806 (0.774, 0.840) | 0.882 (0.843, 0.920) | 0.819 (0.811, 0.826) | 0.860 (0.826, 0.890) | |
| 0.196 (0.000, 0.394) | 0.101 (0.042, 0.158) | 0.155 (0.118, 0.191) | 0.098 (0.062, 0.135) | 0.149 (0.140, 0.157) | 0.122 (0.094, 0.153) | |
| Total RE | 0.060 | 0.011 | 0.039 | 0.020 | 0.033 | 0.018 |
| Global D | 0.940 (0.863, 1.000) | 0.988 (0.984, 0.993) | 0.961 (0.949, 0.972) | 0.980 (0.976, 0.984) | 0.967 (0.965, 0.970) | 0.982 (0.978, 0.984) |
| 0.197 | 5.114 | 1.195 | 4.327 | 5.367 | 2.621 | |
| 0.156 | 4.593 | 1.002 | 3.895 | 4.541 | 2.294 | |
| 0.041 | 0.521 | 0.193 | 0.432 | 0.825 | 0.326 | |
| 0.050 | 0.237 | 0.192 | 0.348 | 0.722 | 0.194 | |
| 0.000 | 0.004 | 0.001 | 0.002 | 0.004 | 0.002 | |
| Reading music | ||||||
| G | 0.948 (0.876, 1.000) | 0.991 (0.987, 0.994) | 0.964 (0.953, 0.976) | 0.982 (0.979, 0.986) | 0.968 (0.966, 0.971) | 0.984 (0.982, 0.987) |
| 0.741 (0.568, 0.941) | 0.889 (0.830, 0.947) | 0.800 (0.768, 0.833) | 0.881 (0.842, 0.920) | 0.810 (0.803, 0.818) | 0.844 (0.809, 0.876) | |
| 0.206 (0.000, 0.401) | 0.102 (0.044, 0.159) | 0.165 (0.128, 0.200) | 0.101 (0.064, 0.139) | 0.158 (0.150, 0.166) | 0.140 (0.110, 0.174) | |
| Total RE | 0.052 | 0.009 | 0.036 | 0.018 | 0.032 | 0.016 |
| Global D | 0.947 (0.873, 1.000) | 0.990 (0.986, 0.994) | 0.964 (0.952, 0.975) | 0.982 (0.978, 0.985) | 0.967 (0.965, 0.970) | 0.983 (0.980, 0.986) |
| 0.202 | 6.891 | 1.230 | 2.628 | 5.445 | 2.529 | |
| 0.158 | 6.182 | 1.020 | 2.358 | 4.557 | 2.169 | |
| 0.044 | 0.710 | 0.210 | 0.270 | 0.888 | 0.360 | |
| 0.045 | 0.263 | 0.181 | 0.189 | 0.715 | 0.161 | |
| 0.000 | 0.013 | 0.003 | 0.008 | 0.022 | 0.011 | |
| Listening | ||||||
| G | 0.935 (0.861, 1.000) | 0.986 (0.981, 0.991) | 0.958 (0.945, 0.969) | 0.978 (0.973, 0.982) | 0.966 (0.963, 0.969) | 0.981 (0.977, 0.983) |
| 0.529 (0.399, 0.684) | 0.695 (0.613, 0.776) | 0.602 (0.576, 0.628) | 0.674 (0.614, 0.730) | 0.626 (0.619, 0.632) | 0.663 (0.612, 0.709) | |
| 0.405 (0.217, 0.559) | 0.291 (0.212, 0.373) | 0.356 (0.325, 0.386) | 0.304 (0.249, 0.362) | 0.341 (0.333, 0.348) | 0.318 (0.272, 0.367) | |
| Total RE | 0.065 | 0.014 | 0.042 | 0.022 | 0.034 | 0.019 |
| Global D | 0.935 (0.859, 0.999) | 0.986 (0.981, 0.991) | 0.958 (0.945, 0.969) | 0.978 (0.973, 0.981) | 0.966 (0.963, 0.969) | 0.980 (0.977, 0.983) |
| 0.196 | 3.577 | 1.158 | 2.671 | 4.927 | 2.305 | |
| 0.111 | 2.522 | 0.727 | 1.842 | 3.190 | 1.558 | |
| 0.085 | 1.055 | 0.430 | 0.830 | 1.737 | 0.747 | |
| 0.055 | 0.204 | 0.205 | 0.245 | 0.692 | 0.183 | |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Composing | ||||||
| G | 0.911 (0.819, 0.992) | 0.979 (0.971, 0.986) | 0.932 (0.915, 0.948) | 0.962 (0.954, 0.968) | 0.937 (0.934, 0.941) | 0.954 (0.946, 0.960) |
| 0.468 (0.342, 0.626) | 0.651 (0.562, 0.735) | 0.527 (0.501, 0.556) | 0.606 (0.541, 0.667) | 0.569 (0.563, 0.576) | 0.626 (0.574, 0.675) | |
| 0.443 (0.237, 0.606) | 0.328 (0.245, 0.415) | 0.404 (0.368, 0.438) | 0.356 (0.297, 0.417) | 0.368 (0.360, 0.377) | 0.327 (0.282, 0.375) | |
| Total RE | 0.089 | 0.021 | 0.068 | 0.038 | 0.063 | 0.046 |
| Global D | 0.911 (0.816, 0.989) | 0.978 (0.970, 0.985) | 0.931 (0.914, 0.947) | 0.961 (0.953, 0.967) | 0.936 (0.932, 0.940) | 0.953 (0.944, 0.959) |
| 0.159 | 5.052 | 0.837 | 2.869 | 3.649 | 2.187 | |
| 0.082 | 3.358 | 0.474 | 1.808 | 2.216 | 1.436 | |
| 0.077 | 1.694 | 0.363 | 1.062 | 1.433 | 0.751 | |
| 0.062 | 0.434 | 0.246 | 0.459 | 0.974 | 0.424 | |
| 0.000 | 0.013 | 0.003 | 0.011 | 0.018 | 0.011 | |
| Design/Subscale | Metric/Estimator | |||||
|---|---|---|---|---|---|---|
| 2-Point | 4-Point | 8-Point | ||||
| ULS | WLSMV | ULS | WLSMV | ULS | WLSMV | |
| Multivariate design | ||||||
| Instrument playing | 1.196 | 1.122 | 1.154 | 1.111 | 1.145 | 1.136 |
| Reading | 1.216 | 1.134 | 1.168 | 1.120 | 1.155 | 1.154 |
| Listening | 1.338 | 1.225 | 1.278 | 1.217 | 1.268 | 1.259 |
| Composing | 1.421 | 1.305 | 1.373 | 1.367 | 1.322 | 1.289 |
| Bifactor design | ||||||
| Instrument playing | 1.185 | 1.105 | 1.146 | 1.093 | 1.137 | 1.123 |
| Reading | 1.199 | 1.098 | 1.153 | 1.113 | 1.143 | 1.137 |
| Listening | 1.363 | 1.272 | 1.299 | 1.264 | 1.287 | 1.274 |
| Composing | 1.438 | 1.263 | 1.386 | 1.292 | 1.335 | 1.263 |
| Scale/ Index | Metric/Procedure | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 2-Point | 4-Point | 8-Point | |||||||
| mGENOVA | ULS | WLSMV | mGENOVA | ULS | WLSMV | mGENOVA | ULS | WLSMV | |
| Composite | |||||||||
| G | 0.904 | 0.904 (0.853, 0.956) | 0.946 (0.925, 0.967) | 0.935 | 0.935 (0.926, 0.943) | 0.954 (0.944, 0.964) | 0.943 | 0.943 (0.941, 0.945) | 0.948 (0.939, 0.955) |
| SFE | 0.002 | 0.002 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| TE | 0.075 | 0.075 | 0.05 | 0.052 | 0.052 | 0.039 | 0.046 | 0.046 | 0.046 |
| RRE | 0.021 | 0.021 | 0.003 | 0.012 | 0.012 | 0.006 | 0.010 | 0.010 | 0.005 |
| Total RE | 0.097 | 0.097 | 0.054 | 0.065 | 0.065 | 0.046 | 0.057 | 0.057 | 0.052 |
| Global D | 0.904 | 0.904 (0.851, 0.954) | 0.945 (0.923, 0.966) | 0.934 | 0.934 (0.925, 0.942) | 0.953 (0.942, 0.963) | 0.942 | 0.942 (0.939, 0.944) | 0.947 (0.937, 0.954) |
| 0.132 | 0.132 | 10.766 | 0.812 | 0.812 | 10.282 | 3.649 | 3.649 | 1.088 | |
| 0.001 | 0.001 | 0.004 | 0.004 | 0.004 | 0.003 | 0.017 | 0.017 | 0.003 | |
| 0.011 | 0.011 | 0.094 | 0.045 | 0.045 | 0.053 | 0.179 | 0.179 | 0.053 | |
| 0.012 | 0.012 | 0.024 | 0.043 | 0.043 | 0.032 | 0.153 | 0.153 | 0.023 | |
| 0.000 | 0.000 | 0.001 | 0.000 | 0.000 | 0.000 | 0.001 | 0.002 | 0.001 | |
| 0.000 | 0.000 | 0.002 | 0.001 | 0.001 | 0.001 | 0.004 | 0.004 | 0.001 | |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Instrument playing | |||||||||
| G | 0.880 | 0.879 (0.740, 1.000) | 0.959 (0.943, 0.976) | 0.917 | 0.917 (0.892, 0.943) | 0.953 (0.943, 0.962) | 0.926 | 0.926 (0.920, 0.931) | 0.944 (0.934, 0.952) |
| SFE | 0.006 | 0.006 | 0.002 | 0.003 | 0.003 | 0.002 | 0.003 | 0.003 | 0.000 |
| TE | 0.063 | 0.063 | 0.030 | 0.046 | 0.046 | 0.029 | 0.045 | 0.045 | 0.039 |
| RRE | 0.051 | 0.051 | 0.009 | 0.033 | 0.033 | 0.017 | 0.027 | 0.027 | 0.017 |
| Total RE | 0.120 | 0.121 | 0.041 | 0.083 | 0.083 | 0.047 | 0.074 | 0.074 | 0.057 |
| Global D | 0.879 | 0.879 (0.737, 1.000) | 0.959 (0.942, 0.975) | 0.917 | 0.917 (0.891, 0.942) | 0.952 (0.942, 0.962) | 0.925 | 0.925 (0.919, 0.931) | 0.943 (0.933, 0.951) |
| 0.186 | 0.186 | 10.878 | 1.128 | 1.128 | 2.057 | 5.038 | 5.038 | 1.490 | |
| 0.005 | 0.005 | 0.017 | 0.016 | 0.016 | 0.013 | 0.064 | 0.064 | 0.003 | |
| 0.013 | 0.013 | 0.059 | 0.057 | 0.057 | 0.062 | 0.243 | 0.243 | 0.062 | |
| 0.043 | 0.043 | 0.067 | 0.164 | 0.164 | 0.147 | 0.580 | 0.580 | 0.106 | |
| 0.000 | 0.000 | 0.002 | 0.001 | 0.001 | 0.001 | 0.003 | 0.004 | 0.001 | |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 | 0.003 | 0.003 | 0.001 | |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Reading music | |||||||||
| G | 0.902 | 0.902 (0.761, 1.000) | 0.972 (0.959, 0.985) | 0.926 | 0.926 (0.901, 0.952) | 0.960 (0.951, 0.968) | 0.934 | 0.934 (0.928, 0.939) | 0.946 (0.937, 0.953) |
| SFE | 0.006 | 0.006 | 0.002 | 0.003 | 0.003 | 0.002 | 0.003 | 0.003 | 0.004 |
| TE | 0.042 | 0.042 | 0.018 | 0.041 | 0.041 | 0.024 | 0.039 | 0.039 | 0.041 |
| RRE | 0.049 | 0.049 | 0.008 | 0.029 | 0.029 | 0.014 | 0.024 | 0.024 | 0.009 |
| Total RE | 0.098 | 0.098 | 0.028 | 0.074 | 0.074 | 0.040 | 0.066 | 0.066 | 0.054 |
| Global D | 0.902 | 0.902 (0.757, 1.000) | 0.971 (0.957, 0.984) | 0.926 | 0.925 (0.899, 0.951) | 0.959 (0.950, 0.967) | 0.933 | 0.933 (0.927, 0.938) | 0.945 (0.936, 0.953) |
| 0.192 | 0.192 | 2.661 | 1.145 | 1.145 | 2.028 | 5.077 | 5.077 | 1.397 | |
| 0.005 | 0.005 | 0.025 | 0.015 | 0.015 | 0.015 | 0.059 | 0.059 | 0.024 | |
| 0.009 | 0.009 | 0.049 | 0.051 | 0.051 | 0.051 | 0.214 | 0.214 | 0.060 | |
| 0.042 | 0.042 | 0.089 | 0.145 | 0.145 | 0.121 | 0.530 | 0.530 | 0.054 | |
| 0.000 | 0.000 | 0.003 | 0.001 | 0.002 | 0.003 | 0.009 | 0.011 | 0.003 | |
| 0.000 | 0.000 | 0.001 | 0.000 | 0.000 | 0.001 | 0.000 | 0.001 | 0.000 | |
| 0.000 | 0.000 | 0.001 | 0.000 | 0.000 | 0.001 | 0.003 | 0.002 | 0.001 | |
| Listening | |||||||||
| G | 0.799 | 0.800 (0.664, 0.949) | 0.909 (0.879, 0.940) | 0.869 | 0.869 (0.843, 0.895) | 0.912 (0.895, 0.928) | 0.888 | 0.888 (0.882, 0.894) | 0.893 (0.876, 0.907) |
| SFE | 0.000 | 0.000 | 0.000 | 0.002 | 0.002 | 0.001 | 0.001 | 0.001 | 0.001 |
| TE | 0.138 | 0.138 | 0.078 | 0.089 | 0.089 | 0.064 | 0.078 | 0.078 | 0.090 |
| RRE | 0.063 | 0.063 | 0.013 | 0.040 | 0.040 | 0.022 | 0.032 | 0.032 | 0.016 |
| Total RE | 0.201 | 0.201 | 0.092 | 0.131 | 0.131 | 0.088 | 0.112 | 0.112 | 0.107 |
| Global D | 0.799 | 0.799 (0.661, 0.944) | 0.907 (0.876, 0.938) | 0.868 | 0.868 (0.841, 0.893) | 0.911 (0.893, 0.927) | 0.886 | 0.886 (0.880, 0.893) | 0.891 (0.873, 0.905) |
| 0.168 | 0.168 | 2.240 | 1.019 | 1.019 | 1.316 | 4.407 | 4.407 | 1.299 | |
| 0.000 | 0.000 | 0.000 | 0.008 | 0.008 | 0.006 | 0.029 | 0.029 | 0.007 | |
| 0.029 | 0.029 | 0.193 | 0.105 | 0.105 | 0.093 | 0.389 | 0.389 | 0.131 | |
| 0.053 | 0.053 | 0.133 | 0.189 | 0.189 | 0.128 | 0.638 | 0.638 | 0.091 | |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| 0.000 | 0.000 | 0.004 | 0.001 | 0.002 | 0.002 | 0.009 | 0.010 | 0.003 | |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 | 0.000 | |
| Composing | |||||||||
| G | 0.818 | 0.818 (0.661, 0.998) | 0.927 (0.902, 0.952) | 0.864 | 0.864 (0.830, 0.898) | 0.910 (0.893, 0.924) | 0.883 | 0.883 (0.875, 0.891) | 0.889 (0.871, 0.904) |
| SFE | 0.007 | 0.007 | 0.003 | 0.007 | 0.007 | 0.003 | 0.008 | 0.008 | 0.003 |
| TE | 0.105 | 0.105 | 0.058 | 0.077 | 0.077 | 0.058 | 0.065 | 0.065 | 0.081 |
| RRE | 0.070 | 0.070 | 0.013 | 0.053 | 0.053 | 0.029 | 0.044 | 0.044 | 0.026 |
| Total RE | 0.182 | 0.182 | 0.074 | 0.136 | 0.136 | 0.090 | 0.117 | 0.117 | 0.110 |
| Global D | 0.817 | 0.817 (0.657, 0.991) | 0.925 (0.900, 0.951) | 0.862 | 0.862 (0.827, 0.896) | 0.908 (0.890, 0.923) | 0.881 | 0.881 (0.873, 0.889) | 0.888 (0.869, 0.902) |
| 0.148 | 0.148 | 1.753 | 0.777 | 0.777 | 0.865 | 3.445 | 3.445 | 1.051 | |
| 0.005 | 0.005 | 0.025 | 0.024 | 0.024 | 0.012 | 0.122 | 0.122 | 0.015 | |
| 0.019 | 0.019 | 0.109 | 0.069 | 0.069 | 0.055 | 0.253 | 0.253 | 0.096 | |
| 0.051 | 0.051 | 0.096 | 0.189 | 0.189 | 0.110 | 0.693 | 0.693 | 0.123 | |
| 0.000 | 0.000 | 0.006 | 0.002 | 0.002 | 0.003 | 0.011 | 0.012 | 0.004 | |
| 0.000 | 0.000 | 0.001 | 0.001 | 0.001 | 0.001 | 0.004 | 0.005 | 0.001 | |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 | 0.000 | |
| Metric/ Estimator/Subscale | Correlation Coefficient | ||||
|---|---|---|---|---|---|
| 2-Point/ULS | Instrument playing | Reading music | Listening | Composing | |
| Instrument playing | 0.848 | 0.660 | 0.629 | ||
| Reading music | 0.756 | 0.689 | 0.571 | ||
| Listening | 0.553 | 0.585 | 0.666 | ||
| Composing | 0.534 | 0.491 | 0.539 | ||
| 2-Point/WLSMV | Instrument playing | Reading music | Listening | Composing | |
| Instrument playing | 0.915 | 0.756 | 0.735 | ||
| Reading music | 0.883 | 0.785 | 0.682 | ||
| Listening | 0.706 | 0.738 | 0.779 | ||
| Composing | 0.693 | 0.647 | 0.715 | ||
| 4-Point/ULS | Instrument playing | Reading music | Listening | Composing | |
| Instrument playing | 0.880 | 0.701 | 0.700 | ||
| Reading music | 0.811 | 0.741 | 0.650 | ||
| Listening | 0.626 | 0.665 | 0.723 | ||
| Composing | 0.623 | 0.581 | 0.627 | ||
| 4-Point/WLSMV | Instrument playing | Reading music | Listening | Composing | |
| Instrument playing | 0.911 | 0.749 | 0.744 | ||
| Reading music | 0.871 | 0.789 | 0.701 | ||
| Listening | 0.698 | 0.738 | 0.767 | ||
| Composing | 0.692 | 0.655 | 0.699 | ||
| 8-Point/ULS | Instrument playing | Reading music | Listening | Composing | |
| Instrument playing | 0.889 | 0.715 | 0.723 | ||
| Reading music | 0.826 | 0.754 | 0.680 | ||
| Listening | 0.649 | 0.687 | 0.749 | ||
| Composing | 0.654 | 0.617 | 0.663 | ||
| 8-Point/WLSMV | Instrument playing | Reading music | Listening | Composing | |
| Instrument playing | 0.899 | 0.747 | 0.750 | ||
| Reading music | 0.849 | 0.777 | 0.707 | ||
| Listening | 0.686 | 0.714 | 0.775 | ||
| Composing | 0.687 | 0.649 | 0.691 | ||
| Scale/Index | Metric/Procedure | |||||
|---|---|---|---|---|---|---|
| 2-Point | 4-Point | 8-Point | ||||
| ULS | WLSMV | ULS | WLSMV | ULS | WLSMV | |
| Composite | ||||||
| G | 0.904 (0.854, 0.955) | 0.949 (0.927, 0.969) | 0.934 (0.926, 0.943) | 0.962 (0.952, 0.971) | 0.942 (0.940, 0.944) | 0.952 (0.943, 0.959) |
| 0.813 (0.761, 0.864) | 0.882 (0.852, 0.910) | 0.861 (0.852, 0.870) | 0.909 (0.893, 0.924) | 0.875 (0.873, 0.877) | 0.890 (0.873, 0.904) | |
| 0.091 (0.070, 0.119) | 0.066 (0.054, 0.082) | 0.073 (0.069, 0.077) | 0.052 (0.045, 0.062) | 0.067 (0.067, 0.068) | 0.062 (0.054, 0.072) | |
| SFE | 0.002 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| TE | 0.075 | 0.047 | 0.052 | 0.032 | 0.047 | 0.043 |
| RRE | 0.021 | 0.003 | 0.012 | 0.006 | 0.010 | 0.005 |
| Total RE | 0.097 | 0.051 | 0.065 | 0.038 | 0.058 | 0.048 |
| Global D | 0.903 (0.852, 0.953) | 0.948 (0.925, 0.969) | 0.933 (0.924, 0.942) | 0.961 (0.950, 0.970) | 0.941 (0.939, 0.943) | 0.951 (0.942, 0.958) |
| 0.132 | 5.998 | 0.812 | 2.878 | 3.647 | 1.477 | |
| 0.118 | 5.578 | 0.748 | 2.721 | 0.017 | 1.380 | |
| 0.013 | 0.420 | 0.064 | 0.157 | 0.181 | 0.097 | |
| 0.001 | 0.015 | 0.004 | 0.007 | 0.153 | 0.004 | |
| 0.011 | 0.300 | 0.045 | 0.095 | 0.002 | 0.066 | |
| 0.012 | 0.086 | 0.043 | 0.072 | 0.004 | 0.033 | |
| 0.000 | 0.003 | 0.000 | 0.001 | 0.000 | 0.001 | |
| 0.000 | 0.005 | 0.001 | 0.003 | 3.647 | 0.002 | |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.017 | 0.000 | |
| Instrument playing | ||||||
| G | 0.879 (0.747, 1.000) | 0.959 (0.943, 0.976) | 0.917 (0.892, 0.942) | 0.953 (0.943, 0.962) | 0.926 (0.920, 0.932) | 0.944 (0.934, 0.952) |
| 0.712 (0.574, 0.837) | 0.862 (0.799, 0.915) | 0.767 (0.744, 0.790) | 0.848 (0.807, 0.884) | 0.782 (0.777, 0.787) | 0.832 (0.797, 0.862) | |
| 0.167 (0.041, 0.360) | 0.097 (0.050, 0.156) | 0.150 (0.123, 0.179) | 0.104 (0.074, 0.141) | 0.144 (0.137, 0.150) | 0.112 (0.087, 0.141) | |
| SFE | 0.006 | 0.002 | 0.003 | 0.002 | 0.003 | 0.000 |
| TE | 0.063 | 0.030 | 0.046 | 0.029 | 0.045 | 0.039 |
| RRE | 0.051 | 0.009 | 0.033 | 0.017 | 0.027 | 0.017 |
| Total RE | 0.121 | 0.041 | 0.083 | 0.047 | 0.074 | 0.056 |
| Global D | 0.879 (0.744, 1.000) | 0.959 (0.942, 0.975) | 0.917 (0.890, 0.941) | 0.952 (0.942, 0.962) | 0.925 (0.919, 0.931) | 0.943 (0.933, 0.951) |
| 0.186 | 4.799 | 1.128 | 4.898 | 1.636 | 1.636 | |
| 0.151 | 4.315 | 0.944 | 4.361 | 4.256 | 1.441 | |
| 0.035 | 0.484 | 0.184 | 0.537 | 0.783 | 0.194 | |
| 0.005 | 0.043 | 0.016 | 0.031 | 0.064 | 0.003 | |
| 0.013 | 0.150 | 0.057 | 0.147 | 0.243 | 0.068 | |
| 0.043 | 0.172 | 0.164 | 0.351 | 0.580 | 0.116 | |
| 0.000 | 0.004 | 0.001 | 0.003 | 0.004 | 0.001 | |
| 0.000 | 0.001 | 0.000 | 0.002 | 0.003 | 0.001 | |
| 0.000 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Reading music | ||||||
| G | 0.902 (0.766, 1.000) | 0.972 (0.959, 0.985) | 0.926 (0.901, 0.952) | 0.960 (0.951, 0.968) | 0.934 (0.928, 0.939) | 0.946 (0.937, 0.954) |
| 0.710 (0.573, 0.836) | 0.861 (0.793, 0.917) | 0.778 (0.755, 0.802) | 0.859 (0.817, 0.895) | 0.795 (0.790, 0.800) | 0.829 (0.794, 0.858) | |
| 0.192 (0.061, 0.382) | 0.111 (0.059, 0.176) | 0.148 (0.120, 0.177) | 0.101 (0.069, 0.139) | 0.139 (0.132, 0.145) | 0.117 (0.092, 0.147) | |
| SFE | 0.006 | 0.002 | 0.003 | 0.002 | 0.003 | 0.004 |
| TE | 0.042 | 0.018 | 0.041 | 0.024 | 0.039 | 0.041 |
| RRE | 0.049 | 0.008 | 0.029 | 0.014 | 0.024 | 0.009 |
| Total RE | 0.098 | 0.028 | 0.074 | 0.040 | 0.066 | 0.054 |
| Global D | 0.902 (0.763, 1.000) | 0.971 (0.957, 0.984) | 0.925 (0.900, 0.950) | 0.959 (0.950, 0.967) | 0.933 (0.927, 0.939) | 0.945 (0.936, 0.953) |
| 0.192 | 7.984 | 1.145 | 4.202 | 5.077 | 1.647 | |
| 0.151 | 7.076 | 0.962 | 3.761 | 4.324 | 1.443 | |
| 0.041 | 0.908 | 0.183 | 0.441 | 0.753 | 0.204 | |
| 0.005 | 0.074 | 0.015 | 0.031 | 0.059 | 0.029 | |
| 0.009 | 0.147 | 0.051 | 0.105 | 0.214 | 0.071 | |
| 0.042 | 0.268 | 0.145 | 0.250 | 0.530 | 0.064 | |
| 0.000 | 0.008 | 0.002 | 0.007 | 0.011 | 0.004 | |
| 0.000 | 0.004 | 0.000 | 0.001 | 0.001 | 0.000 | |
| 0.000 | 0.002 | 0.000 | 0.001 | 0.002 | 0.001 | |
| Listening | ||||||
| G | 0.800 (0.667, 0.951) | 0.909 (0.878, 0.939) | 0.869 (0.843, 0.895) | 0.912 (0.895, 0.928) | 0.888 (0.882, 0.894) | 0.893 (0.876, 0.907) |
| 0.499 (0.404, 0.600) | 0.660 (0.578, 0.738) | 0.579 (0.560, 0.597) | 0.654 (0.595, 0.708) | 0.606 (0.602, 0.611) | 0.640 (0.589, 0.685) | |
| 0.300 (0.165, 0.462) | 0.248 (0.181, 0.324) | 0.290 (0.264, 0.318) | 0.258 (0.210, 0.311) | 0.282 (0.275, 0.288) | 0.253 (0.215, 0.295) | |
| SFE | 0.000 | 0.000 | 0.002 | 0.001 | 0.001 | 0.001 |
| TE | 0.138 | 0.078 | 0.089 | 0.065 | 0.078 | 0.090 |
| RRE | 0.063 | 0.013 | 0.040 | 0.022 | 0.032 | 0.016 |
| Total RE | 0.201 | 0.092 | 0.131 | 0.088 | 0.112 | 0.107 |
| Global D | 0.799 (0.663, 0.946) | 0.907 (0.875, 0.938) | 0.868 (0.841, 0.894) | 0.911 (0.893, 0.927) | 0.886 (0.880, 0.892) | 0.891 (0.874, 0.905) |
| 0.168 | 6.950 | 1.019 | 2.338 | 4.407 | 2.119 | |
| 0.105 | 5.051 | 0.679 | 1.677 | 3.010 | 1.519 | |
| 0.063 | 1.899 | 0.340 | 0.661 | 1.397 | 0.600 | |
| 0.000 | −0.011 | 0.008 | 0.011 | 0.029 | 0.012 | |
| 0.029 | 0.598 | 0.105 | 0.165 | 0.389 | 0.214 | |
| 0.053 | 0.413 | 0.189 | 0.227 | 0.638 | 0.149 | |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| 0.000 | 0.012 | 0.002 | 0.004 | 0.010 | 0.005 | |
| 0.000 | 0.001 | 0.000 | 0.001 | 0.001 | 0.000 | |
| Composing | ||||||
| G | 0.818 (0.666, 0.995) | 0.927 (0.902, 0.951) | 0.864 (0.831, 0.899) | 0.910 (0.893, 0.924) | 0.883 (0.875, 0.891) | 0.889 (0.873, 0.904) |
| 0.419 (0.332, 0.515) | 0.592 (0.502, 0.677) | 0.520 (0.501, 0.539) | 0.592 (0.530, 0.650) | 0.564 (0.559, 0.568) | 0.600 (0.548, 0.648) | |
| 0.399 (0.246, 0.575) | 0.335 (0.260, 0.416) | 0.344 (0.311, 0.377) | 0.317 (0.266, 0.373) | 0.319 (0.312, 0.327) | 0.290 (0.250, 0.333) | |
| SFE | 0.007 | 0.003 | 0.007 | 0.003 | 0.008 | 0.003 |
| TE | 0.105 | 0.057 | 0.077 | 0.058 | 0.065 | 0.082 |
| RRE | 0.070 | 0.013 | 0.053 | 0.029 | 0.044 | 0.026 |
| Total RE | 0.182 | 0.073 | 0.136 | 0.090 | 0.117 | 0.111 |
| Global D | 0.817 (0.661, 0.988) | 0.925 (0.899, 0.950) | 0.862 (0.828, 0.896) | 0.908 (0.890, 0.923) | 0.881 (0.873, 0.889) | 0.888 (0.870, 0.902) |
| 0.148 | 9.489 | 0.777 | 2.499 | 3.445 | 1.680 | |
| 0.076 | 6.063 | 0.468 | 1.627 | 2.200 | 1.133 | |
| 0.072 | 3.427 | 0.309 | 0.872 | 1.245 | 0.547 | |
| 0.005 | 0.134 | 0.024 | 0.036 | 0.122 | 0.023 | |
| 0.019 | 0.588 | 0.069 | 0.160 | 0.253 | 0.154 | |
| 0.051 | 0.519 | 0.189 | 0.319 | 0.693 | 0.197 | |
| 0.000 | 0.033 | 0.002 | 0.007 | 0.012 | 0.006 | |
| 0.000 | 0.007 | 0.001 | 0.004 | 0.005 | 0.002 | |
| 0.000 | 0.002 | 0.000 | 0.000 | 0.001 | 0.000 | |
| Design/Subscale | Metric/Estimator | |||||
|---|---|---|---|---|---|---|
| 2-Point | 4-Point | 8-Point | ||||
| ULS | WLSMV | ULS | WLSMV | ULS | WLSMV | |
| Multivariate design | ||||||
| Instrument playing | 1.184 | 1.162 | 1.151 | 1.117 | 1.140 | 1.137 |
| Reading music | 1.232 | 1.178 | 1.164 | 1.123 | 1.149 | 1.148 |
| Listening | 1.187 | 1.157 | 1.191 | 1.191 | 1.191 | 1.157 |
| Composing | 1.369 | 1.303 | 1.291 | 1.303 | 1.262 | 1.219 |
| Bifactor design | ||||||
| Instrument playing | 1.176 | 1.153 | 1.145 | 1.091 | 1.135 | 1.126 |
| Reading music | 1.218 | 1.159 | 1.154 | 1.103 | 1.140 | 1.132 |
| Listening | 1.210 | 1.195 | 1.210 | 1.206 | 1.209 | 1.151 |
| Composing | 1.386 | 1.250 | 1.304 | 1.263 | 1.275 | 1.206 |
| Index or Design/Metric | MUSPI-S Reliability/GT Index from This Study | MUSPI-S Reliability/GT Index from Lee and Vispoel (2024) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| α (occ 1) | α (occ 2) | Test–Retest | G | Global D | α (occ 1) | α (occ 2) | Test–Retest | G | Global D | |
| Means across subscales | ||||||||||
| 2-Point | 0.933 | 0.940 | 0.858 | 0.957 | 0.960 | 0.912 | ||||
| 4-Point | 0.953 | 0.963 | 0.898 | 0.972 | 0.976 | 0.932 | ||||
| 8-Point | 0.963 | 0.970 | 0.913 | 0.976 | 0.980 | 0.936 | ||||
| persons × items (Composing subscale) | ||||||||||
| 2-Point | 0.911 | 0.934 | 0.826 | 0.911 | 0.911 | 0.942 | 0.954 | 0.894 | 0.943 | 0.940 |
| 4-Point | 0.932 | 0.950 | 0.870 | 0.932 | 0.931 | 0.959 | 0.971 | 0.911 | 0.959 | 0.957 |
| 8-Point | 0.937 | 0.958 | 0.891 | 0.937 | 0.936 | 0.965 | 0.975 | 0.919 | 0.965 | 0.962 |
| persons × items × occasions (Composing subscale) | ||||||||||
| 2-Point | 0.818 | 0.817 | 0.884 | 0.882 | ||||||
| 4-Point | 0.864 | 0.862 | 0.905 | 0.902 | ||||||
| 8-Point | 0.883 | 0.881 | 0.913 | 0.911 | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vispoel, W.P.; Lee, H.; Chen, T. Structural Equation Modeling Approaches to Estimating Score Dependability Within Generalizability Theory-Based Univariate, Multivariate, and Bifactor Designs. Mathematics 2025, 13, 1001. https://doi.org/10.3390/math13061001
Vispoel WP, Lee H, Chen T. Structural Equation Modeling Approaches to Estimating Score Dependability Within Generalizability Theory-Based Univariate, Multivariate, and Bifactor Designs. Mathematics. 2025; 13(6):1001. https://doi.org/10.3390/math13061001
Chicago/Turabian StyleVispoel, Walter P., Hyeryung Lee, and Tingting Chen. 2025. "Structural Equation Modeling Approaches to Estimating Score Dependability Within Generalizability Theory-Based Univariate, Multivariate, and Bifactor Designs" Mathematics 13, no. 6: 1001. https://doi.org/10.3390/math13061001
APA StyleVispoel, W. P., Lee, H., & Chen, T. (2025). Structural Equation Modeling Approaches to Estimating Score Dependability Within Generalizability Theory-Based Univariate, Multivariate, and Bifactor Designs. Mathematics, 13(6), 1001. https://doi.org/10.3390/math13061001