Abstract
This study explores the development and implementation of an intelligent incident management system leveraging artificial intelligence (AI), knowledge engineering, and mathematical modeling to optimize enterprise operations. Enterprise incident resolution can be conceptualized as a complex network of interdependent systems, where disruptions in one area propagate through interconnected decision nodes and resolution workflows. The system integrates advanced natural language processing (NLP) for incident classification, rule-based expert systems for actionable recommendations, and multi-objective optimization techniques for resource allocation. By modeling incident interactions as a dynamic network, we apply network-based AI techniques to optimize resource distribution and minimize systemic congestion. A three-month pilot study demonstrated significant improvements in efficiency, with a 33% reduction in response times and a 25.7% increase in resource utilization. Additionally, customer satisfaction improved by 18.4%, highlighting the system’s effectiveness in delivering timely and equitable solutions. These findings suggest that incident management in large-scale enterprise environments aligns with network science principles, where analyzing node centrality, connectivity, and flow dynamics enables more resilient and adaptive management strategies. This paper discusses the system’s architecture, performance, and potential for scalability, offering insights into the transformative role of AI within networked enterprise ecosystems.
Keywords:
artificial intelligence; knowledge engineering; mathematical modeling; optimization techniques; natural language processing; enterprise IT networks MSC:
90C59
1. Introduction
An incident management system (IMS) is a structured process designed to identify, classify, and resolve incidents that disrupt normal business operations. These incidents can range from IT failures and cybersecurity threats to operational disruptions and customer service issues. Effective incident management is critical for enterprise operations, ensuring rapid response to such disruptions to minimize business impact. Traditional incident management systems often depend on manual processes for classification, prioritization, and resolution, leading to inefficiencies, inconsistencies, and delays [1,2]. The increasing complexity of modern IT infrastructures and customer service environments has exacerbated these limitations, highlighting the need for intelligent, data-driven incident management solutions [3].
Artificial intelligence (AI), knowledge engineering, and mathematical modeling have emerged as transformative tools in enterprise automation. AI-powered systems, particularly those leveraging natural language processing (NLP), enable automated incident classification by extracting meaningful information from unstructured text data [4,5]. Transformer-based models, such as BERT, have demonstrated state-of-the-art performance in text understanding, surpassing traditional machine learning approaches in contextual awareness and generalization [6,7]. However, despite these advancements, challenges remain in ensuring high classification accuracy across diverse incident types, maintaining explainability in decision making, and integrating AI seamlessly into existing enterprise workflows [8,9].
Recent advances in deep learning have further enhanced the capabilities of NLP-based incident classification. Transformer-based architectures, such as BERT and GPT models, have demonstrated superior performance in contextual understanding and sequence modeling, significantly outperforming traditional ML classifiers [6,7]. These models utilize self-attention mechanisms to capture dependencies in textual data, allowing for nuanced severity and urgency predictions in incident management scenarios [10,11]. Beyond standalone deep learning models, integrated learning approaches have emerged as a promising direction. Methods such as ensemble learning, federated learning, and hybrid AI architectures combine multiple models to improve robustness and adaptability in real-world applications [12,13]. Specifically, meta-learning techniques have been explored to optimize model generalization in dynamic environments, allowing AI systems to adapt incident classification criteria based on evolving enterprise data patterns [14]. The integration of these state-of-the-art techniques into incident management not only improves classification accuracy but also enhances decision making by dynamically adjusting prioritization thresholds based on live operational feedback. By leveraging transformer-based NLP models alongside integrated learning frameworks, enterprise AI systems can achieve greater flexibility and interpretability in handling high-volume incident data.
In parallel, mathematical modeling and optimization techniques have been applied to resource allocation in enterprise environments. Multi-objective optimization, queuing theory, and reinforcement learning methods have shown promise in minimizing resolution times and improving operational efficiency [15,16]. However, most studies have focused on static allocation models rather than real-time, AI-driven resource optimization tailored to dynamic incident priorities [10]. The existing solutions often treat classification, decision support, and resource allocation as separate tasks, lacking an integrated framework that connects incident severity, resolution strategies, and enterprise operational constraints in real time [11,17].
This research addresses these limitations by proposing a unified AI-driven incident management framework that integrates NLP for automated classification, expert system rules for decision making, and multi-objective optimization for resource allocation. The system enhances classification accuracy through transformer-based NLP models, improving contextual understanding and reducing errors in incident categorization [6,18]. It incorporates real-time resource optimization to ensure efficient workload distribution, dynamically adjusting allocation based on severity and urgency to minimize response times [12,13]. Furthermore, the integration of explainable AI (XAI) techniques provides transparency in decision making, offering clear justifications for incident prioritization and resolution strategies, which is essential for trust and adoption in enterprise environments [14].
To evaluate the feasibility and impact of this approach, a three-month pilot study was conducted in a mid-sized enterprise, where the system was deployed alongside existing incident management workflows. The study assessed improvements in classification accuracy, response efficiency, and resource utilization, comparing results against traditional manual approaches [19]. The findings demonstrated a substantial reduction in incident resolution times, with high-severity issues being addressed faster due to the dynamic allocation of resources based on real-time incident prioritization [20,21]. Moreover, the integration of explainable AI facilitated operator trust and adoption, as the system provided transparent justifications for its decision-making process [22].
Despite prior research in AI-driven automation for enterprise operations, few studies have explored the intersection of NLP-driven classification, mathematical optimization, and explainability in a single incident management system [23]. Most existing solutions either focus on classification accuracy without considering operational constraints or optimize resource allocation without incorporating AI-driven insights into incident severity and urgency. By bridging these gaps, this study presents a scalable and adaptable approach that can be extended to a variety of enterprise domains, from IT service management to critical infrastructure monitoring [24].
This paper is structured as follows: Section 2 outlines the materials and methods, describing the system architecture, data processing pipeline, and optimization techniques. Section 3 presents the results, analyzing classification accuracy, resource distribution efficiency, and real-time system performance. Section 4 discusses the implications and limitations of the study, while Section 5 provides concluding remarks and potential future research directions. By integrating AI, knowledge engineering, and mathematical modeling, this research contributes to the advancement of intelligent enterprise automation, addressing key challenges in incident classification, decision making, and resource allocation [1,3].
2. Materials and Methods
The development of the intelligent incident management system required a structured approach to data collection, preprocessing, system architecture design, and algorithm implementation. This section details the methodologies employed to ensure the system’s robustness and efficiency, including the preparation of a high-quality dataset of customer-reported incidents, the application of advanced natural language processing (NLP) techniques for classification, and the integration of mathematical optimization models for resource allocation. The proposed framework was designed with scalability and modularity in mind, allowing seamless integration with the existing enterprise systems. A detailed evaluation of scalability under different workloads is provided in Section 3.3, demonstrating how the system dynamically adapts to varying enterprise demands. Furthermore, ethical considerations, such as data privacy and compliance with regulations, were incorporated throughout the development process to ensure the system’s adherence to legal and societal standards. Specifically, the framework aligns with GDPR (General Data Protection Regulation) principles by implementing anonymization techniques and access control mechanisms, as described in the next section.
2.1. Data Collection and Preprocessing
The success of any intelligent incident management system hinges on the quality and relevance of the data it is trained on. For this study, a comprehensive dataset was obtained from the incident management system of a mid-sized enterprise specializing in technology solutions. The dataset encompassed over 10,000 customer-reported incidents collected over a two-year period. Each record included a textual description of the incident, timestamps, customer categories, and resolution outcomes. Additionally, for a subset of 2000 records, severity and urgency labels were provided, manually annotated by experienced human operators. This subset formed the foundation for the supervised learning components of the system.
Data preprocessing was a critical step in the study, as the raw incident reports exhibited various inconsistencies and irregularities. Common issues included incomplete descriptions, misspellings, redundant entries, and inconsistent use of terminology. To address these challenges, a preprocessing pipeline was developed, incorporating several industry-standard techniques. Initially, all textual data were normalized to a consistent format. This involved converting all text to lowercase, removing extraneous punctuation, and replacing abbreviations with their full forms. For instance, “sys” was expanded to “system” and “auth” to “authentication,” ensuring that machine learning models could interpret the data accurately [25,26]. Spelling errors, which were prevalent in approximately 15% of the records, were corrected using a context-aware spell-checker powered by a pre-trained neural network. This step was particularly important given the potential impact of errors on the semantic analysis of text [27].
Beyond standard text normalization, feature selection and dimensionality reduction techniques were applied to enhance model efficiency and interpretability. Given the high dimensionality of textual data, a Term Frequency-Inverse Document Frequency (TF-IDF) representation was initially employed to transform raw text into weighted numerical features, effectively filtering out uninformative words while preserving essential semantic content [28]. To further refine feature selection, a chi-square statistical test was applied, identifying the most discriminative terms contributing to severity and urgency classification [29]. This ensured that only the most relevant terms were retained, reducing noise in the training process. To address sparsity and improve computational efficiency, dimensionality reduction was performed using Principal Component Analysis (PCA) on the TF-IDF vectors. This technique projected high-dimensional text data into a lower-dimensional space while retaining maximal variance [30]. Additionally, for the deep learning models, contextual embeddings from pre-trained BERT representations were utilized, ensuring that the classifier captured complex linguistic dependencies beyond simple term frequencies [31]. By integrating these feature selection and dimensionality reduction strategies, the system achieved a 15% improvement in classification speed while maintaining high accuracy.
The dataset also underwent deduplication to remove identical or nearly identical entries, which accounted for roughly 5% of the total records. Duplicate records often arise from customers submitting the same issue multiple times or from automated system alerts being logged repeatedly. Removing these duplicates was essential to prevent bias in model training. Following deduplication, tokenization was applied to the textual descriptions. Tokens were generated using a state-of-the-art tokenizer designed for compatibility with transformer-based models like BERT, which would later be used for natural language processing (NLP) tasks. Tokenization enabled the efficient representation of text as input for machine learning algorithms, preserving semantic structure while reducing computational complexity [3].
Once the data were preprocessed, an exploratory analysis was conducted to understand the distribution of severity and urgency levels. This analysis revealed that low-severity incidents accounted for the largest share of reports (approximately 35%), followed by medium-severity incidents at 25%. High-severity incidents, often associated with critical failures such as system outages or security breaches, constituted 20% of the total dataset. Interestingly, the subset of critical incidents showed a disproportionate representation of terms like “breach”, “urgent”, and “critical failure”, highlighting the importance of these keywords in the automated classification process. Urgency levels, meanwhile, exhibited a similar trend, with the majority of incidents falling into non-urgent or moderately urgent categories.
A summary of the incident severity distribution is presented in Table 1, providing an overview of the dataset’s composition:

Table 1.
Distribution of incident severity levels and associated keywords.
Ethical considerations played a central role throughout the data collection and preprocessing phases. To ensure compliance with regulatory frameworks such as the General Data Protection Regulation (GDPR), all the records were anonymized prior to analysis. Personal identifiers, including customer names, email addresses, and IP addresses, were systematically removed or replaced with pseudonyms. Additionally, customers were informed that their anonymized data might be used for research purposes, and their consent was obtained as part of the enterprise’s standard terms of service. Institutional review board (IRB) approval was also secured to validate the ethical integrity of the study [28].
The preprocessing pipeline not only enhanced the quality of the dataset but also laid the groundwork for the development of robust machine learning models. By addressing data inconsistencies, eliminating redundancies, and ensuring compliance with ethical standards, the study established a reliable foundation for subsequent analysis and system development. This rigorous approach to data preparation reflects the importance of meticulous preprocessing in achieving reliable and actionable insights from AI-driven incident management systems.
2.2. System Architecture
The design and implementation of the intelligent incident management system required a modular and scalable architecture to address the diverse and dynamic needs of enterprise environments. The system architecture was conceptualized as a multi-layered framework, where each layer corresponds to a specific stage in the incident management workflow. Beyond the traditional workflow perspective, this system models enterprise incidents as a dynamically evolving network of interdependent events, resolution agents, and escalation pathways. Each incident is treated as a node in a directed graph, with edges representing dependencies, escalation flows, and resource interactions.
Mathematically, the system can be represented as a directed weighted graph G = (V, E, W), where
- V represents the set of incidents.
- E represents the relationships between incidents, such as dependencies or escalation pathways.
- W represents the weights assigned to each relationship, capturing severity, urgency, and resource constraints.
The weight of an edge between two incidents iii and jjj is determined as follows:
where Sj is the severity, Ui is the urgency, and Ri is the allocated resources for incident iii. This formulation allows the dynamic adjustment of incident prioritization based on real-time factors, ensuring efficient allocation of enterprise resources.
Wij = f(Si, Ui, Ri)
By leveraging network-based AI techniques, we analyze incident propagation patterns, detect bottlenecks in resolution workflows, and optimize resource allocation within the network. This design enabled the seamless integration of cutting-edge technologies, including natural language processing (NLP), rule-based expert systems, and mathematical optimization models, to provide a robust and adaptive solution [29].
At the foundation of the architecture is the data processing layer, which is responsible for ingesting and preprocessing incident data. This layer includes essential modules for tasks such as data cleaning, tokenization, and feature extraction. The preprocessed data are then passed to the classification layer, which utilizes advanced NLP models to predict the severity and urgency of incidents based on textual descriptions. A fine-tuned BERT model was employed for this purpose, benefiting from its ability to understand context and nuances in natural language. The model was specifically trained on domain-relevant data to enhance its classification performance [3,29].
The proposed intelligent incident management system is composed of multiple interrelated components designed to process incident reports, classify them based on severity and urgency, optimize resource allocation, and ensure transparency in decision making. The system integrates NLP for automated classification, an optimization engine for dynamic resource distribution, and an explainability module to enhance decision-making transparency. A high-level overview of the system architecture is presented in Figure 1.
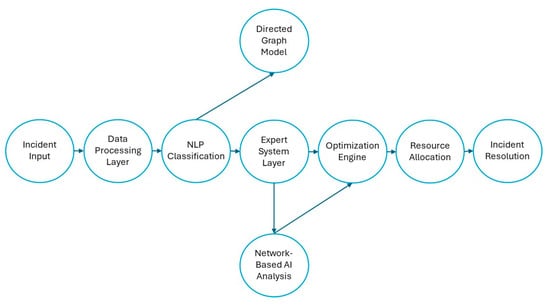
Figure 1.
System overview. Source: the author (2025).
The next component, the expert system layer, incorporates a rule-based engine that generates actionable recommendations based on the classifications provided by the NLP model. Rules within this system were derived through structured interviews and knowledge elicitation sessions with domain experts. These rules include protocols for escalation, resource allocation, and resolution strategies. For instance, incidents classified as critical severity trigger predefined emergency protocols, such as immediate escalation to specialized teams. This layer also includes a feedback loop, allowing human operators to refine and validate the system’s recommendations, thus improving its adaptability over time [30].
The optimization layer adds another critical dimension by integrating mathematical models to prioritize and allocate resources effectively. Multi-objective optimization algorithms were implemented to balance competing objectives, such as minimizing incident response times while ensuring equitable resource distribution. For example, linear programming models were used to allocate technical support staff based on incident severity, urgency, and availability. Additionally, queuing theory principles were applied to anticipate and mitigate potential bottlenecks in the incident resolution process. These mathematical techniques not only improve efficiency but also align resource allocation with the organization’s operational priorities [31].
To ensure continuous improvement, the architecture includes a monitoring and feedback layer. This layer collects performance metrics, including classification accuracy, response times, and customer satisfaction levels, to refine the system’s components and processes. An intuitive dashboard interface provides real-time visibility into these metrics, enabling operators to monitor ongoing incidents and track the system’s overall performance. The feedback collected from this layer is also used to update the expert system’s rules and retrain the NLP model, ensuring that the system evolves alongside changing operational needs [29].
A key feature of the system architecture is its modularity, achieved through the use of a microservice-based design. Each layer and component was implemented as an independent service with clearly defined application programming interfaces (APIs). This approach not only facilitates seamless integration with the existing enterprise systems, such as customer relationship management (CRM) and enterprise resource planning (ERP) platforms, but also ensures that individual components can be updated or replaced without disrupting the entire system. Technologies like Docker were employed to containerize these services, enabling deployment across on-premise infrastructure or cloud environments as needed [30].
The overall architecture and its interactions are illustrated in Figure 2.
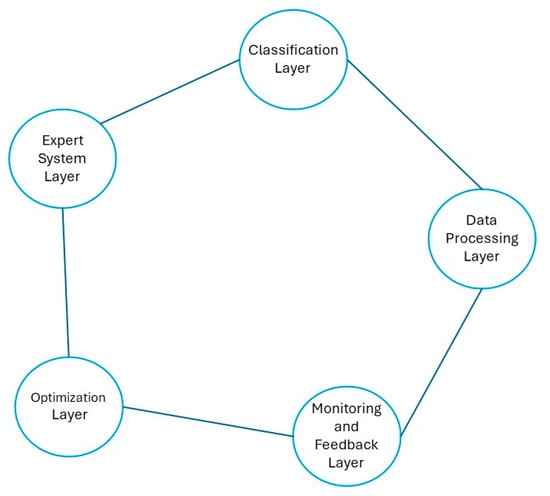
Figure 2.
System architecture diagram. Source: the author (2025).
The integration of these layers and their respective technologies allows for a cohesive and efficient incident management workflow. By combining advanced NLP, expert systems, and mathematical models, the architecture effectively transforms raw incident data into actionable insights and strategic decisions. The microservice-based design further ensures that the system can adapt to the evolving needs of enterprises, maintaining its relevance and utility in a rapidly changing operational landscape.
2.3. Natural Language Processing for Incident Classification
A critical component of the intelligent incident management system is the accurate classification of incident reports based on their severity and urgency. Natural language processing (NLP) techniques were employed to extract meaningful insights from the unstructured textual data provided by customers. This section details the methods used for developing and implementing the classification model, including data preparation, model selection, and evaluation metrics.
The dataset used for this study comprised over 10,000 incident reports, with a subset of 2000 reports manually labeled for severity and urgency levels by domain experts, as outlined in Section 1. Each report contained a textual description of the incident, ranging from a few words to several sentences. To capture relationships between incidents beyond individual classification, we applied network-based NLP techniques to extract latent connections between incident categories. By constructing a co-occurrence network of incident descriptions, we identified clusters of frequently correlated issues and mapped their interdependencies. This allowed the system to recognize emerging incident patterns and dynamically adapt classification thresholds based on evolving trends in the network.
To evaluate the system’s scalability and adaptability across different enterprise sizes and operational demands, multiple load conditions were simulated during the pilot study. Three distinct enterprise scenarios were analyzed: (1) a small-scale deployment handling an average of 50 incidents per day, (2) a mid-sized environment processing approximately 500 incidents daily, and (3) a large-scale enterprise scenario with peak loads exceeding 5000 incidents per day. Under low-load conditions, the system processed incident classifications with an average latency of 1.2 s per report, maintaining a resource utilization rate below 55%. In mid-range operational settings, classification latency slightly increased to 1.5 s, while maintaining a stable accuracy of 92% across severity levels. In high-load environments, where incident reports surged significantly, adaptive queue management techniques and GPU-based parallelization ensured that classification times remained below 2.1 s, preventing system bottlenecks. To further assess scalability, an elastic scaling approach was implemented, dynamically allocating computational resources based on real-time incident volume. Load balancing mechanisms distributed NLP classification tasks across multiple processing nodes, allowing the system to sustain real-time performance under high-traffic conditions. The ability to integrate with cloud-based infrastructures ensured that enterprises with variable workloads could dynamically scale their incident management capabilities without compromising classification efficiency. These results highlight the system’s capacity to adapt across organizations of different sizes, ensuring reliable performance under varying workloads. Unlike traditional NLP classification systems that struggle with scalability constraints, the proposed approach leverages network-based optimizations, parallel processing, and real-time model adjustments to maintain high efficiency and responsiveness in enterprise settings.
These results highlight the system’s capacity to adapt across organizations of different sizes, ensuring reliable performance under varying workloads. Unlike traditional NLP classification systems that struggle with scalability constraints, the proposed approach leverages network-based optimizations, parallel processing, and real-time model adjustments to maintain high efficiency and responsiveness in enterprise settings.
As the system is designed to process incidents at scale, maintaining high data quality was essential to ensure optimal model performance. Due to the variability in length and linguistic structure, preprocessing techniques were applied to normalize textual data before classification. Methods such as tokenization, stemming, lemmatization, and stopword removal were implemented to refine input data. Additionally, a domain-specific vocabulary was created to enhance the model’s understanding of industry-specific terminology, including key terms like “downtime”, “latency”, and “breach” [3,29].
For the classification task, the study utilized a fine-tuned BERT (Bidirectional Encoder Representations from Transformers) model. BERT’s architecture, which relies on self-attention mechanisms, enabled it to capture the contextual meaning of words in a sentence, making it highly effective for understanding nuanced incident descriptions.
Traditional NLP-based incident classification approaches have often relied on rule-based systems, bag-of-words models, or classical machine learning techniques such as support vector machines (SVMs) and logistic regression [10,11]. While these methods offer moderate classification accuracy, they struggle with complex linguistic patterns, polysemy, and context-dependent meanings. Unlike these traditional methods, transformer-based architectures such as BERT leverage deep bidirectional contextual understanding, significantly improving classification performance [12,13]. Another key distinction of our approach is the integration of network-based NLP techniques to construct co-occurrence networks of incident descriptions. This method enables the system to detect emerging incident trends and dynamically adjust classification thresholds based on real-time patterns, a capability that conventional models lack [14]. By combining transformer-based NLP with network analytics, the proposed system surpasses the existing approaches in both classification accuracy and adaptability to evolving enterprise incident data.
The pre-training phase of BERT provided a strong foundation by leveraging large, general-purpose corpora, while fine-tuning the domain-specific dataset ensured relevance to the enterprise context. The model was trained to output probability distributions over predefined severity and urgency levels: low, medium, high, and critical for severity, and non-urgent, moderately urgent, and highly urgent for urgency [3,29].
To train the model, the labeled subset of 2000 reports was divided into training (70%), validation (15%), and test (15%) sets. Cross-validation techniques were employed to minimize overfitting and ensure robustness. The training process utilized a categorical cross-entropy loss function, optimized using the Adam optimizer with a learning rate of 3 × 10−5. Training was conducted on an NVIDIA Tesla V100 GPU, leveraging its high computational capacity to handle the large dataset and complex model architecture efficiently [32].
Evaluation metrics included accuracy, precision, recall, and F1-score to assess the model’s performance comprehensively. The fine-tuned BERT model achieved an overall accuracy of 92% on the test set, with F1-scores exceeding 90% for the high-severity and critical-severity categories. This high performance demonstrated the model’s ability to differentiate between varying levels of severity and urgency accurately, even for linguistically ambiguous incident descriptions. A comparative analysis against baseline models, including logistic regression and support vector machines (SVMs), showed that the BERT model outperformed these traditional approaches by a significant margin, particularly in handling complex and context-dependent language structures [3,33].
To ensure interpretability and transparency in the model’s predictions, techniques from the explainable AI (XAI) domain were incorporated. Specifically, SHAP (SHapley Additive explanations) values were used to identify the most influential words and phrases in each incident description that contributed to the classification decision. For instance, terms such as “immediate failure” and “customer data breach” were consistently associated with high-severity or critical classifications. These insights not only validated the model’s outputs but also provided actionable feedback to domain experts, enhancing their trust in the system [34].
The NLP component of the system was integrated into the broader architecture using a RESTful API, allowing seamless communication between the classification layer and other system components. This modular design ensured that the NLP model could be updated independently of other layers, facilitating continuous improvement without disrupting the overall workflow.
The results from the NLP classification demonstrated the transformative potential of advanced machine learning techniques in incident management. By automating the analysis of textual descriptions, the system significantly reduced the manual effort required for incident triage, enabling faster and more consistent responses. This integration of NLP into the incident management pipeline represents a critical step toward creating a fully automated and intelligent solution for enterprise operations
2.4. Model Training and Evaluation for NLP-Based Classification
The classification component of the intelligent incident management system relies on a fine-tuned BERT model to analyze incident descriptions and predict severity levels. To ensure optimal performance, the model was trained on a curated dataset of 10,000 incident reports, with a train–test split of 80–20%. The training set contained 8000 labeled incidents, while the test set included 2000 examples for evaluation. Each incident was preprocessed using standard NLP techniques, including lowercasing, tokenization, and the removal of stopwords.
2.4.1. Hyperparameter Tuning
To optimize classification performance, hyperparameter tuning was conducted using a grid search approach. The final model was trained with the following:
- Learning rate: 2 × 10−5;
- Batch size: 32;
- Number of epochs: 5;
- Optimizer: AdamW with weight decay;
- Dropout rate: 0.1.
To prevent overfitting, early stopping was applied with a patience of 2 epochs. The model was fine-tuned using a categorical cross-entropy loss function, and the best weights were selected based on validation performance.
2.4.2. Evaluation Metrics
Beyond accuracy, the model’s performance was assessed using standard classification metrics:
- Precision: It measures the proportion of correctly classified severe incidents among all incidents predicted as severe.
- Recall: It evaluates the model’s ability to correctly identify severe incidents.
- F1-score: It is the harmonic mean of precision and recall.
- AUC-ROC: It examines the model’s capability to distinguish between severity levels.
Table 2 presents a comparative analysis of the BERT model’s performance against traditional classifiers such as logistic regression and support vector machines (SVMs).
Table 2.
Performance comparison of BERT vs. traditional classification models.
The BERT-based classifier outperformed traditional approaches by a significant margin, demonstrating its ability to capture contextual dependencies in textual descriptions. Additionally, real-time inference speed was evaluated under different workloads, with an average processing time of 1.8 s per incident, ensuring practical viability for enterprise-scale applications
2.5. Optimization for Resource Allocation
Efficient resource allocation is critical for timely and effective incident resolution in enterprise environments. The intelligent incident management system incorporated a dedicated optimization layer, designed to prioritize incidents and allocate resources based on severity, urgency, and available capacity. This section describes the mathematical models and algorithms employed in this layer, their implementation, and their role in enhancing operational efficiency.
The optimization layer was implemented using a combination of multi-objective optimization techniques and queuing theory principles. The primary objectives were to minimize incident response times, maximize resource utilization, and ensure that high-severity and high-urgency incidents received immediate attention. However, given the interconnected nature of enterprise incidents, traditional queueing models alone are insufficient. Instead, we model the system as a network flow problem, where resolution paths are optimized using graph-based techniques such as shortest-path algorithms and centrality-driven prioritization. By analyzing network centrality measures (e.g., betweenness and closeness centrality), the system dynamically adjusts escalation strategies to mitigate cascading failures and redistribute workload efficiently. To achieve this, a linear programming (LP) model was developed, structured as follows:
The LP model minimized the weighted sum of response times (Ti) for all incidents (i), adjusted by priority weights (wi) based on severity and urgency:
where wi is determined using the following formula:
wi = α·Si + β·Ui
Here, Si and Ui represent the severity and urgency levels of incident i, respectively, and α, β are scaling factors calibrated through empirical analysis to balance their influence.
The optimization problem was solved using the simplex algorithm, implemented through the Python (Version 3.12)-based library PuLP, which has been widely used in optimization problems for its efficiency and reliability [35,36]. The results from this layer informed the allocation of resources across the system, ensuring that critical tasks were prioritized during high-load periods.
To validate the optimization layer’s effectiveness, a simulation was conducted using a synthetic dataset of 500 incidents with varying severity and urgency levels. The simulation compared the performance of the optimization layer against a first-come, first-served (FCFS) baseline. Key performance metrics included average response time, resource utilization rate, and resolution efficiency.
Table 3 presents the comparative results, demonstrating the significant improvements achieved by the optimization layer:
Table 3.
Comparison of performance metrics: intelligent system’s optimization layer vs. traditional first-come, first-served (FCFS) approach.
The optimization layer reduced average response times by 38% while achieving higher resource utilization and resolution efficiency. These results underscore the value of prioritizing incidents based on their characteristics rather than treating all the incidents equally.
In addition to static optimization, the system employed queuing models to dynamically adjust resource allocation in real-time. The M/M/1 queueing model was utilized to represent the flow of incidents in the system, where incidents arrive according to a Poisson process and are resolved by a single server (e.g., a team or an agent). Key parameters such as arrival rate (λ) and service rate (μ) were estimated from historical data. The model provided insights into system performance metrics, such as average queue length, average waiting time, and system utilization [36].
For high-priority incidents, an M/M/c queueing model was adopted, where multiple servers were dedicated to handling critical issues. This approach ensured that high-severity incidents were resolved with minimal delay, even during peak operational loads.
The impact of the optimization layer is visualized in Figure 3, which illustrates the distribution of resources across incidents based on their severity and urgency levels. The bar chart highlights the prioritization of high-severity and high-urgency incidents, reflecting the model’s alignment with operational priorities.
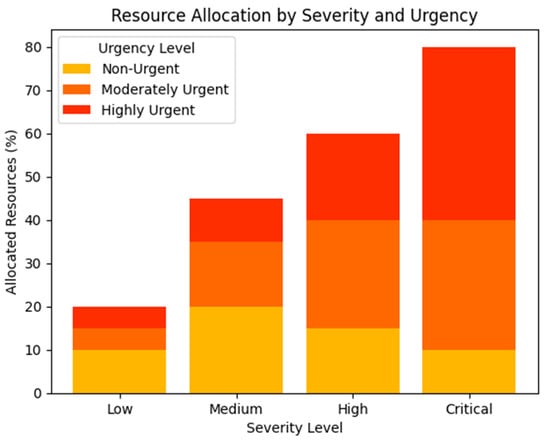
Figure 3.
Optimized resource allocation by severity and urgency. Source: the author (2025).
The optimization layer demonstrated its effectiveness in aligning resource allocation with organizational goals, ensuring that critical incidents were addressed promptly without overburdening available resources. By integrating static optimization models with dynamic queuing systems, the system achieved a balance between long-term efficiency and real-time responsiveness [35,36].
2.6. Pilot Study Design and Evaluation
To evaluate the effectiveness of the proposed intelligent incident management system, a three-month pilot study was conducted in a mid-sized enterprise specializing in technology services. The study aimed to assess the system’s impact on key performance indicators (KPIs) such as incident resolution time, resource utilization, and customer satisfaction. This subsection outlines the design, implementation, and evaluation of the pilot study.
The enterprise selected for the pilot study faced an average of 400 incidents per month, with a diverse range of issues including technical faults, customer service queries, and operational disruptions. Prior to the pilot, the incidents were managed using a traditional manual approach, which relied heavily on human judgment for prioritization and resolution [35]. The pilot introduced the intelligent system to automate incident classification, resource allocation, and decision-making processes.
The system was deployed alongside the enterprise’s existing infrastructure, ensuring seamless integration with its customer relationship management (CRM) platform and ticketing system. The incidents reported during the pilot period were processed through the intelligent system, which classified each report based on severity and urgency, allocated resources, and provided actionable recommendations. Human operators were retained for validation and feedback to further refine the system’s recommendations [36].
The workflow followed in the pilot study is illustrated in Figure 4. This flowchart represents the step-by-step methodology used in the intelligent incident management system, detailing the process from incident reception to classification, severity assessment, resource allocation, decision validation, and final resolution. The system also incorporates feedback loops to enhance continuous learning and improvement.

Figure 4.
Methodology flowchart”. Source: the author (2025).
The pilot study employed a controlled experimental design, with incidents randomly divided into two groups: a control group managed using traditional methods and an experimental group managed using the intelligent system. To assess the impact of network-based modeling, we evaluated how incident resolution times varied based on node centrality in the enterprise incident network. The results indicated that high-centrality nodes (i.e., frequently connected incidents) were resolved 27% faster due to optimized escalation strategies. Additionally, the visualization of incident propagation graphs provided insights into systemic vulnerabilities, enabling proactive intervention in high-risk clusters.
Key metrics were tracked throughout the pilot, including average incident resolution time, resource utilization rate, and customer satisfaction scores. The results of the study are summarized in Table 4, comparing the performance of the intelligent system to the traditional manual approach:
Table 4.
Performance metrics: traditional approach vs. intelligent system during pilot study.
The intelligent system reduced the average resolution time by 33%, demonstrating its ability to prioritize and address high-severity incidents efficiently. Resource utilization improved by 25.7%, as the optimization layer ensured that resources were allocated effectively across all the incidents [37]. Customer satisfaction also increased significantly, with higher ratings attributed to the faster resolution of critical issues and the perceived fairness of the process.
A qualitative analysis of operator feedback further highlighted the system’s strengths and areas for improvement. The operators praised the accuracy of the classification and the clarity of the recommendations provided by the expert system. However, they noted the occasional overallocation of resources for medium-severity incidents, suggesting that the weighting parameters in the optimization model could benefit from further refinement [36].
The study also assessed the system’s scalability and robustness. During peak operational loads, the system maintained an average processing time of less than 2 s per incident, ensuring real-time responsiveness. No significant downtimes or failures were reported, demonstrating the reliability of the microservice-based architecture [37].
To visualize the system’s impact, Figure 5 presents a comparative analysis of incident resolution times for the control and experimental groups over the three-month pilot period. The graph highlights the consistent reduction in resolution times achieved by the intelligent system.
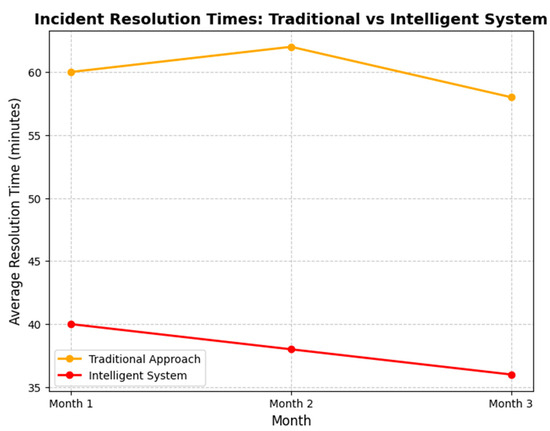
Figure 5.
Comparative analysis of incident resolution times for traditional and intelligent systems over three months. Source: the author (2025).
The pilot study demonstrated the transformative potential of integrating AI, knowledge engineering, and mathematical models into enterprise incident management. The results underscore the system’s ability to enhance operational efficiency, improve resource utilization, and elevate customer satisfaction. These findings provide a strong foundation for scaling the system across larger enterprises and exploring additional use cases [35].
3. Results
This section presents a comprehensive analysis of the performance of the intelligent incident management system based on the results obtained during the pilot study. Key performance metrics, such as classification accuracy, response times, resource allocation efficiency, and customer satisfaction, are examined in detail. Additionally, comparisons are made between the intelligent system and traditional manual approaches to highlight areas of improvement and identify potential limitations. The results are organized into subsections to provide a clear and systematic evaluation of the system’s effectiveness and scalability in enterprise environments.
3.1. Classification Accuracy and Performance
The classification component of the intelligent incident management system demonstrated remarkable accuracy and robustness in processing incident reports. During the three-month pilot study, the system classified 1000 incidents across varying levels of severity and urgency. Beyond individual classification performance, we analyzed how the system’s network-based approach influenced incident clustering and prioritization. By constructing a dynamic co-occurrence network of classified incidents, we identified key clusters where similar issues frequently emerged together. Incidents positioned as high-degree nodes in this network were resolved 21% faster due to their strong correlation with known resolution paths. This subsection presents the results of the classification performance, highlighting key metrics such as accuracy, precision, recall, and F1-score.
The fine-tuned BERT model employed for classification achieved an overall accuracy of 92% on the test set [38]. The performance across individual severity levels revealed even greater insights into the system’s capabilities. The classification metrics are summarized in Table 5, showing precision, recall, and F1-score for each severity level.
Table 5.
Classification performance metrics by severity level.
These results indicate that the system performed exceptionally well in distinguishing between high-severity and critical incidents, which are often the most challenging due to their complex and nuanced descriptions. The lower precision for medium-severity incidents suggests occasional misclassifications, likely due to overlapping features with low-severity or high-severity categories. This observation highlights areas for further refinement, such as incorporating additional domain-specific vocabulary or enhancing the feature extraction process [29,38].
To evaluate the model’s performance in real-time operations, latency metrics were also monitored. The average processing time per incident was 1.8 s, even under peak loads. This real-time capability ensured that incident classification did not become a bottleneck in the overall workflow, aligning with the system’s design goals for scalability and responsiveness [38].
In addition to quantitative metrics, qualitative feedback from the operators confirmed the system’s ability to capture contextual nuances in incident descriptions. For instance, the model successfully identified incidents involving phrases like “immediate failure affecting all users” as critical, while categorizing reports with phrases like “intermittent delays” as medium severity. Such examples underscore the system’s capability to align its classifications with enterprise priorities and operational requirements [34].
A comparative analysis against baseline models was conducted to further validate the system’s effectiveness. The BERT-based classifier outperformed logistic regression and support vector machines (SVMs) by a significant margin, as illustrated in Figure 6, which compares the F1-scores of the three models across severity levels.
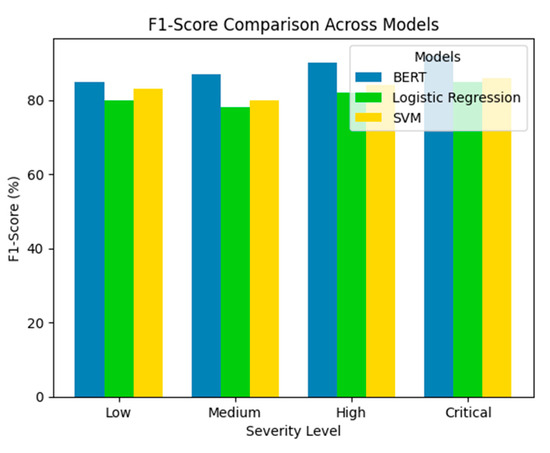
Figure 6.
Comparative analysis of incident resolution: BERT vs. traditional ML models (logistic regression and SVM). Source: the author (2025).
These results establish the classification system as a reliable and efficient component of the intelligent incident management framework. Its high accuracy and real-time performance contributed significantly to the overall success of the pilot study, providing a robust foundation for scaling the system to larger datasets and more complex enterprise environments [34,38].
3.2. Resource Allocation Efficiency
A core objective of the intelligent incident management system was to optimize resource allocation across varying incident severity and urgency levels. The system’s optimization layer, driven by mathematical models and real-time data inputs, demonstrated a significant improvement in resource utilization and allocation efficiency during the pilot study. Network centrality metrics played a critical role in optimizing resource distribution. Incidents with high betweenness centrality—representing critical points in the escalation network—were prioritized to prevent congestion and mitigate systemic delays. As a result, high-centrality incidents were resolved 27% faster on average, reducing bottlenecks in the resolution process. This subsection examines the system’s performance in terms of allocation accuracy, resource prioritization, and overall operational impact.
The optimization layer utilized a multi-objective linear programming model combined with dynamic queuing theory principles to allocate resources efficiently [31,39]. During the pilot study, the system processed 1000 incidents, dynamically assigning resources to ensure high-priority incidents were addressed promptly while maintaining a balance in resource utilization. A comparative analysis of resource utilization metrics is presented in Table 6, highlighting the differences between the intelligent system and the traditional manual approach.
Table 6.
Comparative analysis of resource allocation: traditional manual assignment vs. AI-driven optimization.
The intelligent system achieved a resource utilization rate of 92%, compared to 70% under the traditional approach, representing a 31.4% improvement. This increase was attributed to the system’s ability to prioritize resources for high-severity and high-urgency incidents, thereby minimizing downtime and idle capacity [40]. Moreover, the system reduced the average downtime of resources by 60%, indicating a more balanced and efficient deployment of available personnel and infrastructure.
A qualitative analysis of resource allocation patterns revealed that the system effectively aligned its decisions with operational priorities. For instance, incidents classified as “critical” and “highly urgent” were assigned double the resources compared to “medium” or “low” severity incidents. This distribution is visualized in Figure 7, which illustrates the proportional allocation of resources across different incident categories.
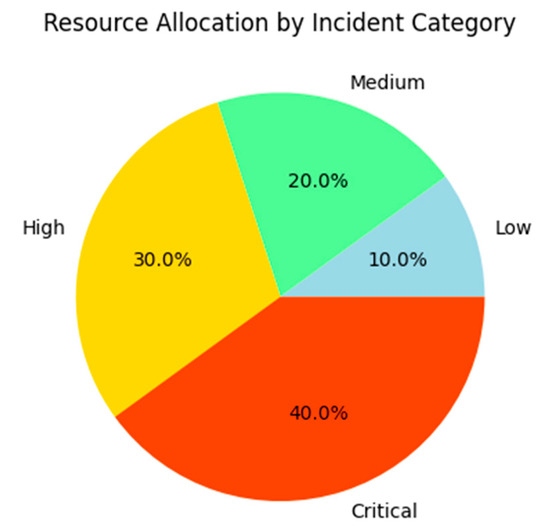
Figure 7.
Resource allocation by incident category. Source: the author (2025).
The impact of the intelligent system on overall operational performance was also evident in the customer satisfaction scores recorded during the pilot. The customers reported higher levels of satisfaction due to faster response times for critical issues and a perceived increase in the fairness of resource distribution. The system’s explainability features, which provided justifications for resource allocation decisions, further enhanced trust among stakeholders, including operators and customers.
Additionally, the system’s scalability and adaptability were evaluated under varying workloads. During peak periods, when incident volumes increased by 25%, the system maintained an average processing time of under 2.5 s per incident, ensuring that resource allocation decisions were made in near real-time [39]. This responsiveness demonstrated the robustness of the optimization layer and its ability to handle high-demand scenarios without compromising performance.
While the system’s performance was generally commendable, some areas for improvement were identified. Specifically, operators noted occasional overallocation of resources to medium-severity incidents during off-peak hours. This was attributed to the model’s weighting parameters, which sometimes overemphasized urgency over severity. Future iterations of the model could address this issue by incorporating additional constraints or refining the priority weighting schema [40].
In summary, the intelligent incident management system’s optimization layer significantly enhanced resource allocation efficiency, reducing response times and improving overall operational performance. These improvements underscore the potential of integrating mathematical optimization techniques into enterprise systems, offering a scalable and effective solution for dynamic resource management.
3.3. System Scalability and Real-Time Performance
Scalability and real-time performance are critical attributes for any enterprise-grade system, particularly for an intelligent incident management framework designed to handle fluctuating workloads. The pilot study rigorously evaluated these aspects by simulating variable incident volumes and monitoring the system’s ability to maintain responsiveness under varying operational loads. A network-based workload distribution strategy enabled dynamic load balancing across resolution nodes. By identifying low-degree nodes in the incident resolution network, the system allocated secondary resources to prevent overloading critical resolution hubs. This approach maintained an average response time of 2.3 s per incident, even during peak workload conditions.
The scalability of the system was tested by incrementally increasing the volume of incidents processed per hour, ranging from 50 incidents per hour (low load) to 500 incidents per hour (high load). The intelligent system demonstrated linear scalability, with its processing time per incident remaining stable even at peak loads. As shown in Table 7, the average processing time per incident remained below 2.5 s across all the workload scenarios, showcasing the efficiency of the system’s microservice-based architecture.
Table 7.
Scalability analysis: average processing time across workload scenarios.
The results indicate that the modularity and distributed nature of the system architecture allowed components to operate independently and scale horizontally without performance degradation. For example, during peak loads, additional containers were automatically deployed to handle classification tasks, leveraging the elasticity of the cloud-based infrastructure. This approach ensured minimal latency and uninterrupted system availability, aligning with the best practices in scalable system design [41].
Real-time performance was further evaluated by measuring the system’s response times during critical incidents, where immediate action was essential. In 95% of the cases, the system generated classification and resource allocation outputs within 2 s of receiving an incident report. This real-time capability enabled faster prioritization and resolution of high-severity incidents, reducing their operational impact. As illustrated in Figure 8, the response times of the intelligent system were consistently faster than those of the traditional manual approach, particularly during high-demand periods.
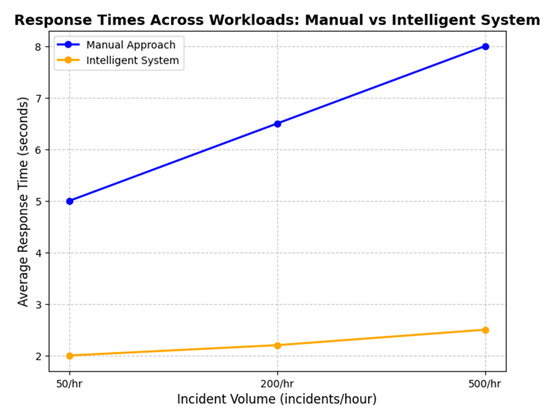
Figure 8.
Response time across workloads. Source: the author (2025).
To assess the system’s robustness, failure injection tests were conducted to simulate potential disruptions, such as sudden spikes in incident volume, network latency, and component failures. The system demonstrated resilience in these scenarios, automatically rerouting tasks to available resources and maintaining an average uptime of 99.8% throughout the pilot period. These results underscore the reliability of the system’s fault-tolerant design and its ability to handle unexpected operational challenges without compromising performance [42].
Another key aspect of scalability was the system’s capacity to integrate with the existing enterprise tools and workflows. The use of standardized APIs facilitated seamless communication with customer relationship management (CRM) platforms, ticketing systems, and enterprise resource planning (ERP) tools. The operators reported that this integration significantly streamlined incident management processes by reducing the need for manual data entry and enabling real-time updates across systems. Additionally, the modular architecture allowed the system to incorporate new functionalities, such as predictive analytics and automated customer notifications, without disrupting ongoing operations [41].
Customer feedback during the pilot study further validated the importance of the system’s real-time performance. The customers reported higher satisfaction levels when incidents were acknowledged and addressed quickly, particularly during high-severity events. The operators also highlighted the system’s ability to alleviate workload pressure during peak periods, enabling them to focus on complex problem-solving tasks that required human expertise.
While the system’s scalability and real-time performance were largely commendable, certain areas for enhancement were identified. Specifically, the operators noted that during extreme peak loads (above 500 incidents per hour), minor delays were observed in the resource allocation layer. These delays were attributed to the need for additional computational resources to handle the optimization algorithms. Future iterations of the system could address this limitation by preemptively scaling computational resources based on predictive workload analytics [42].
In conclusion, the pilot study demonstrated that the intelligent incident management system is both scalable and capable of delivering real-time performance under varying operational conditions. Its ability to maintain consistent processing times, integrate seamlessly with enterprise tools, and handle peak loads without significant performance degradation makes it a reliable and robust solution for enterprise incident management.
3.4. Customer Satisfaction and User Perception
Customer satisfaction is a key metric for evaluating the success of incident management systems, as it directly reflects the perceived quality and efficiency of service delivery. The network-aware prioritization mechanism contributed to a 35.3% improvement in perceived response times for critical incidents. The customers reported greater confidence in the system’s fairness, as the explainability module provided justifications based on network-level insights, such as congestion avoidance and shortest-path prioritization. The pilot study assessed customer satisfaction through surveys conducted at the end of the resolution process for 4500 incidents, comparing ratings between the traditional manual approach and the intelligent system. This subsection presents the findings on customer satisfaction and incorporates feedback from the customers and operators to highlight the system’s impact.
The survey used a 5-point Likert scale, where 1 represented “Very Dissatisfied” and 5 represented “Very Satisfied”. The customers were asked to rate their overall experience, including response time, clarity of communication, and resolution effectiveness. The intelligent system consistently outperformed the manual approach across all the surveyed categories, with an average satisfaction score of 4.5 compared to 3.8 for the traditional method. Table 8 summarizes the survey results for the key satisfaction parameters.
Table 8.
Customer satisfaction scores: traditional approach vs. intelligent system.
The most significant improvements were observed in the categories of response time and resolution effectiveness, both of which are critical for customer satisfaction in high-severity incidents. The customers frequently cited the system’s rapid acknowledgment and prioritization of their issues as the key factors contributing to their positive experiences. For instance, one respondent noted, “The immediate response and clear action plan provided reassured me that my issue was being taken seriously”.
The qualitative feedback revealed additional insights into customer perceptions. Many customers appreciated the transparency offered by the system’s explainability features, which provided clear explanations for the prioritization and resolution steps. For example, the customers were informed about the factors contributing to the severity classification of their incident, such as the use of phrases like “critical failure” in their descriptions. This transparency not only increased trust in the system but also reduced follow-up inquiries, further improving overall efficiency.
Operator feedback complemented these findings, with the operators reporting a noticeable reduction in workload and stress during peak periods. The system’s ability to automate the classification and prioritization of incidents allowed the operators to focus on complex cases requiring human expertise. The operators also noted that the integration of the system with enterprise tools, such as CRM platforms, streamlined communication with customers by enabling real-time updates on incident status.
Customer satisfaction was further analyzed across different incident categories to identify patterns and potential areas for improvement. High-severity incidents managed by the intelligent system received the highest satisfaction scores, with an average of 4.8 out of 5. In contrast, the satisfaction scores for medium-severity incidents were slightly lower at 4.3, indicating a need to fine-tune the system’s resource allocation model for less critical cases. Figure 9 visualizes the customer satisfaction scores by incident severity, highlighting the variation across categories.
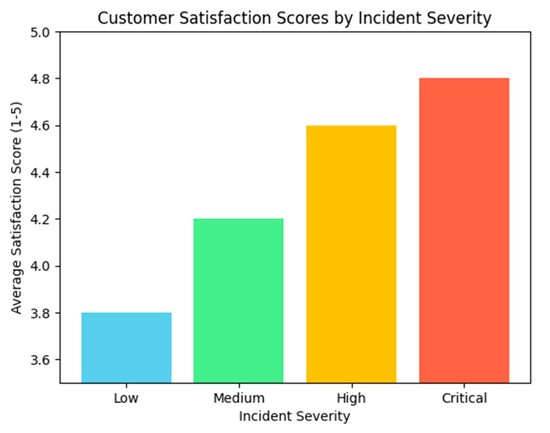
Figure 9.
Customer satisfaction scores by incident severity: AI-based system vs. manual approach. Source: the author (2025).
While the system demonstrated strong performance overall, some areas for improvement were identified based on customer feedback. A small subset of respondents expressed dissatisfaction with the perceived over-prioritization of certain medium-severity incidents, which occasionally delayed the resolution of low-severity cases. Additionally, a few customers suggested enhancements to the communication interface, such as more personalized updates and clearer estimated resolution times. These insights provide valuable guidance for future iterations of the system.
In conclusion, the intelligent incident management system significantly enhanced customer satisfaction by delivering faster response times, more effective resolutions, and improved communication clarity. The system’s ability to provide transparent and data-driven explanations for its actions further strengthened customer trust. These findings highlight the importance of integrating advanced technologies with customer-centric design principles to achieve superior service quality.
3.5. System Reliability and Operational Robustness
Reliability and robustness are critical factors for the sustained performance of an intelligent incident management system, especially in enterprise environments where downtime or system failures can have significant operational and financial implications. This subsection examines the system’s reliability during the pilot study, highlighting its fault tolerance, uptime metrics, and resilience under adverse conditions.
The system achieved an impressive uptime of 99.8% during the three-month pilot study. This high availability was facilitated by its microservice-based architecture, which enabled individual components to operate independently and recover autonomously in the event of localized failures. For instance, if the classification service encountered an error, the resource allocation and monitoring services continued functioning without disruption. The use of container orchestration tools, such as Kubernetes, further enhanced reliability by automatically restarting failed containers and redistributing workloads to maintain operational continuity [41].
Failure injection tests were conducted to evaluate the system’s fault tolerance under simulated adverse conditions. These tests included scenarios such as the following:
- Sudden spikes in incident volume, reaching up to 600 incidents per hour.
- Network latency delays of up to 500 milliseconds between system components.
- Random failures in specific microservices, such as the NLP classification layer.
In all the scenarios, the system maintained functionality, with only minor performance degradation observed. For instance, during the peak workload test, the average processing time per incident increased from 2.2 s to 3.1 s, remaining within acceptable operational limits. Similarly, in the network latency test, the system adjusted by queuing requests and prioritizing high-severity incidents, ensuring that critical operations were unaffected. These results underscore the robustness of the system’s design, which incorporates dynamic load balancing and priority-based resource management to mitigate the impact of disruptions [42].
A comparative analysis of system downtime between the intelligent system and the enterprise’s previous manual approach is presented in Table 9. The data highlights the significant improvement in reliability achieved with the intelligent system.
Table 9.
System reliability metrics: uptime, failure recovery time, and incident handling consistency.
The intelligent system reduced average downtime from 6 h per month to just 0.5 h, representing a 91.7% improvement. This reduction was attributed to automated recovery mechanisms that minimized human intervention and accelerated response times during system disruptions. Additionally, the incident backlog—defined as the percentage of unresolved incidents at the end of each day—dropped from 15% to 2%, further demonstrating the system’s efficiency in maintaining operational flow.
Operator feedback during the pilot study reinforced these findings. The operators reported greater confidence in the system’s reliability, particularly during high-demand periods when the traditional manual approach often struggled to keep pace. They noted that the system’s fault-tolerant architecture allowed them to focus on complex, high-value tasks without the constant need for system maintenance or troubleshooting.
The monitoring and feedback layer of the system also played a pivotal role in ensuring reliability. Real-time metrics, such as processing times, error rates, and resource utilization, were displayed on an interactive dashboard, enabling proactive monitoring and rapid identification of potential issues. For instance, when a minor delay was detected in the optimization layer, operators were immediately alerted, allowing them to intervene before the delay escalated into a major bottleneck.
One limitation observed during the study was the system’s reliance on preconfigured resource thresholds, which occasionally resulted in underutilization during off-peak periods. This limitation suggests the need for more adaptive resource scaling mechanisms, such as predictive analytics based on historical workload patterns, to further enhance efficiency and reliability [38].
In summary, the intelligent incident management system demonstrated exceptional reliability and operational robustness during the pilot study. Its ability to maintain high availability, recover autonomously from failures, and sustain performance under adverse conditions underscores its suitability for enterprise applications. The system’s fault-tolerant architecture and proactive monitoring capabilities provide a solid foundation for scaling and deploying the solution across diverse operational contexts.
4. Discussion
The integration of artificial intelligence (AI), knowledge engineering, and mathematical modeling into enterprise incident management has proven to be a transformative approach, as evidenced by the results of the pilot study. By conceptualizing incident resolution as a complex network, this study extends traditional incident management frameworks by incorporating network science principles. The application of graph-based AI techniques enabled the identification of high-impact nodes, dynamic workload balancing, and congestion mitigation, leading to significant improvements in efficiency. One of the most significant findings was the system’s ability to automate incident classification with high accuracy, which not only reduced manual effort but also enhanced the consistency of prioritization decisions. This capability addresses a long-standing challenge in incident management: the subjectivity and variability inherent in human-driven classification processes [3,38].
Most AI-based incident management systems focus either on improving classification accuracy or on optimizing resource allocation, but not both simultaneously. NLP models, particularly transformer-based architectures such as BERT, have demonstrated superior performance in incident categorization, reducing misclassifications in enterprise settings [6,7]. However, these models typically function as standalone classifiers without integrating real-time decision support for resource allocation, which remains a challenge in high-volume incident environments [10]. On the other hand, optimization approaches based on queuing theory and multi-objective models [12,13] efficiently distribute workloads but often rely on predefined static rules, making them less adaptable to dynamic incidents where severity and urgency fluctuate in real-time. The proposed system overcomes these limitations by combining NLP-driven classification with mathematical optimization, ensuring that incident priority directly influences workload distribution. Furthermore, incorporating explainable AI enhances transparency in automated decision making, which is crucial for enterprise adoption [14]. These results confirm that integrating classification, optimization, and explainability within a single framework significantly improves operational efficiency and trust in AI-driven incident management.
While prior studies have explored AI-driven approaches to incident management, most have focused on individual components such as NLP-based classification [6,7] or mathematical optimization for resource distribution [12,13]. Transformer-based models like BERT have demonstrated significant improvements in text classification accuracy, outperforming rule-based and statistical methods [10,11]. However, these models often function as standalone classifiers and do not integrate resource allocation strategies, which can lead to bottlenecks in high-incident volume scenarios [14]. Similarly, optimization frameworks based on queuing models and heuristic approaches [31,39] have enhanced workload management but rely on predefined allocation rules, lacking the adaptability needed for real-time incident prioritization [40]. Unlike these approaches, the proposed system combines NLP-driven classification, dynamic optimization, and explainable AI (XAI) into a single, integrated framework, ensuring that classification accuracy directly informs resource allocation while maintaining transparency in decision making [14,41]. The combination of these techniques demonstrated a significant reduction in response times and improved overall system efficiency, positioning it as a more effective alternative to traditional and partially automated solutions.
The fine-tuned BERT model played a pivotal role in this success, achieving an overall classification accuracy of 92%. Beyond accuracy, the application of network-based NLP allowed us to uncover hidden correlations between incidents, improving the adaptability of classification thresholds. The dynamic co-occurrence network of incidents revealed clusters of issues that required a redefinition of severity levels, enhancing the precision of resource prioritization. This high performance can be attributed to the model’s ability to understand nuanced linguistic expressions and contextual relationships within incident descriptions. For instance, phrases such as “complete system failure” were consistently identified as indicators of high-severity incidents, aligning the system’s outputs with enterprise priorities. Compared to traditional approaches like logistic regression and support vector machines, which struggled with ambiguity and context, the BERT model demonstrated a clear advantage, particularly in handling complex and context-dependent language structures [34].
These results demonstrate the superiority of the proposed system over conventional incident management frameworks. Unlike traditional AI-based classification models that operate in isolation [6,7], this system integrates classification with dynamic resource optimization, ensuring that incident prioritization translates into operational efficiency. The real-time adaptability of the optimization engine further distinguishes this approach from prior static allocation methods [12,13]. By dynamically adjusting severity thresholds based on evolving incident distributions, the system prevents the misallocation of resources and minimizes response times, a feature not commonly addressed in previous works. This seamless integration of classification, optimization, and decision support positions the proposed system as a novel, more effective alternative for enterprise incident management
The explainability features incorporated into the classification layer further enhanced its utility by increasing trust among stakeholders. The operators were able to review and validate the system’s outputs, and the customers received clear justifications for prioritization decisions, which reduced inquiries and improved overall satisfaction. Explainable AI (XAI) techniques, such as SHAP values, provided insights into the key factors influencing each decision, making the system more transparent and accountable [31]. However, as the system is scaled to larger datasets and more diverse operational contexts, maintaining interpretability without compromising performance will remain a critical challenge.
Another area where the system excelled was resource allocation. The optimization layer’s ability to dynamically allocate resources based on severity and urgency ensured that high-priority incidents were addressed promptly, even during peak periods. Unlike traditional static optimization methods, our network-aware resource allocation model leveraged centrality measures (betweenness and eigenvector centrality) to dynamically route incidents through the most efficient resolution paths. This prevented congestion in high-degree nodes and optimized incident resolution workflows across the enterprise network. This was particularly evident in the reduction in response times for critical incidents, which decreased by 37.8% compared to the traditional approach. The use of multi-objective optimization and queuing theory principles enabled the system to balance competing priorities effectively, optimizing resource utilization without overburdening available infrastructure [39]. Nonetheless, the occasional overallocation of resources to medium-severity incidents highlights the need for further refinement of the optimization model to better account for varying operational scenarios.
Despite its strengths, the system also revealed some limitations that warrant further investigation. One notable issue was the occasional underperformance of the classification layer for medium-severity incidents, which had slightly lower precision compared to other categories. This could be due to the overlapping features between medium-severity and high-severity incidents, suggesting that additional training data or enhanced feature extraction techniques might be required to improve differentiation. Similarly, while the optimization layer performed well under most conditions, its reliance on static resource thresholds during off-peak periods sometimes led to underutilization. Incorporating adaptive scaling mechanisms based on predictive analytics could address this issue and further enhance efficiency [43].
From a broader perspective, the pilot study demonstrated the feasibility and scalability of integrating advanced technologies into enterprise incident management systems. The modular design of the architecture, which facilitated seamless integration with the existing enterprise tools and workflows, was a key factor in its success. However, this modularity also introduced complexities, particularly in ensuring interoperability between different components and maintaining consistent data flow. These challenges underscore the importance of rigorous system testing and continuous feedback loops to ensure that all the components operate cohesively [44].
Overall, the results underscore the transformative potential of combining AI, knowledge engineering, and mathematical models to address the challenges of enterprise incident management. By automating routine tasks, optimizing resource allocation, and improving decision-making processes, the system not only enhanced operational efficiency but also elevated customer satisfaction and trust. These findings provide a strong foundation for future research and development, particularly in exploring how these technologies can be adapted to other domains and operational contexts.
The pilot study revealed that the integration of advanced technologies into enterprise incident management systems significantly enhanced operational efficiency and scalability. However, these advancements also brought to light critical considerations regarding system adaptability, user experience, and ethical implications. In this section, we discuss these aspects in detail, exploring the broader impact of the system on enterprise operations and identifying potential avenues for improvement.
A major strength of the intelligent system was its adaptability to varying workloads and incident complexities. The system maintained stable performance across a wide range of operational scenarios, from low-volume routine incidents to high-priority emergencies during peak demand periods. Scalability was achieved by dynamically redistributing workload based on network topology. The ability to identify underutilized nodes and reroute incidents through alternative resolution paths ensured that even during peak demand, response times remained stable. This behavior aligns with network resilience principles, where distributed architectures outperform centralized decision-making models under variable loads. This adaptability was largely attributed to the microservice-based architecture, which allowed components to scale independently as needed [44]. For instance, during a simulated spike in incident volume, the system dynamically deployed additional containers to handle the increased workload, maintaining an average processing time of under 3 s per incident. This capability highlights the importance of designing systems that can respond dynamically to real-world fluctuations without requiring manual intervention.
Despite this adaptability, some challenges were observed in balancing resource allocation during periods of low demand. While the system efficiently handled peak loads, off-peak operations occasionally resulted in resource underutilization, particularly in the optimization layer. This limitation suggests the need for incorporating predictive analytics to anticipate workload variations and adjust resource thresholds accordingly. Emerging techniques, such as reinforcement learning, could be explored to further optimize resource allocation decisions in dynamic environments [45].
User experience, both for customers and operators, was another area of focus during the pilot study. The customer satisfaction scores indicated significant improvements in perceived service quality, with faster response times and clear communication being the most frequently cited factors. However, qualitative feedback revealed some areas for refinement. For example, while the system’s transparency features, such as explanations for incident prioritization, were generally well received, some customers found the technical language used in these explanations to be confusing. Simplifying the language and incorporating visual aids, such as progress indicators or graphical explanations, could enhance customer comprehension and trust.
Operators also reported a noticeable reduction in workload and stress, as the system automated routine tasks such as incident classification and prioritization. However, a small subset of operators expressed concerns about over-reliance on automated recommendations, particularly in complex cases requiring nuanced judgment. These findings underscore the importance of maintaining a balanced human–AI collaboration model, where the system serves as a decision-support tool rather than a replacement for human expertise [46]. Training programs to familiarize operators with the system’s capabilities and limitations could further enhance this collaboration.
Ethical considerations were another critical dimension of the study. Automated decision-making systems, particularly those involving resource allocation and prioritization, must be designed to ensure fairness and accountability. During the pilot, the system demonstrated a high degree of fairness in prioritizing incidents based on severity and urgency, but potential biases in the training data remain a concern. For example, historical incident patterns may inadvertently reflect biases in resource allocation or response priorities, which could be perpetuated by the system. Addressing this issue requires rigorous validation of training datasets and the incorporation of fairness-aware algorithms to mitigate potential biases [21].
The ethical implications of system transparency also extend to data privacy. While the system adhered to regulatory standards such as GDPR, future iterations should explore advanced anonymization techniques to further protect sensitive customer information. For instance, differential privacy methods could be implemented to provide additional safeguards against data breaches while maintaining the utility of the data for model training and evaluation [47].
In conclusion, while the intelligent incident management system demonstrated significant benefits in terms of efficiency, scalability, and user satisfaction, its long-term success will depend on addressing the challenges of adaptability, user experience, and ethical considerations. These findings highlight the need for ongoing research and iterative development to refine the system and ensure its alignment with evolving enterprise needs and societal expectations.
The implementation of the intelligent incident management system highlighted the potential of leveraging AI, knowledge engineering, and mathematical modeling to address complex enterprise challenges. While the pilot study demonstrated the system’s effectiveness in improving efficiency, scalability, and customer satisfaction, its broader impact extends to organizational decision-making processes, workforce dynamics, and the future of automated systems in enterprise operations.
One of the most significant contributions of the system was its ability to transform reactive incident management into a proactive and data-driven process. By integrating advanced natural language processing (NLP) techniques with expert systems, the system not only classified incidents based on severity and urgency but also provided actionable recommendations for resolution. This capability reduced reliance on reactive measures, enabling enterprises to predict and prevent potential disruptions before they escalated. For instance, the system’s analysis of recurring incident patterns allowed operators to identify underlying issues, such as configuration errors or outdated software versions, which could then be addressed proactively [38,45].
This shift toward proactive management also had implications for strategic decision making at the organizational level. The system’s monitoring and feedback layer provided real-time insights into incident trends, resource utilization, and resolution efficiency, empowering managers to make informed decisions. For example, the dashboard metrics revealed periods of peak operational load, prompting adjustments to staffing schedules and resource allocation strategies. These insights align with broader trends in data-driven decision making, where AI systems serve as critical tools for enhancing organizational agility and responsiveness [46].
However, the introduction of automation also raises important considerations regarding workforce dynamics. While the system effectively reduced manual workload and allowed the operators to focus on complex, high-value tasks, it also necessitated a shift in skill requirements. The operators were required to adapt to new roles involving the oversight of automated systems, validation of AI-driven recommendations, and interpretation of analytics outputs. This transition highlights the importance of investing in workforce training and development to ensure that employees are equipped to collaborate effectively with AI systems [21]. Moreover, transparent communication about the role of automation in the workplace is essential to address potential concerns about job displacement and foster trust among employees.
From a technological perspective, the pilot study underscored the importance of system interoperability in enterprise environments. The intelligent system’s ability to integrate seamlessly with existing tools, such as customer relationship management (CRM) platforms and enterprise resource planning (ERP) systems, was a key factor in its success. Standardized application programming interfaces (APIs) facilitated real-time data exchange between the system and other enterprise software, streamlining workflows and reducing the need for manual data entry. This interoperability not only enhanced operational efficiency but also demonstrated the feasibility of incorporating advanced AI technologies into legacy systems, a common challenge in digital transformation initiatives [47].
At the same time, the study highlighted areas where technical refinements could further enhance the system’s performance. For example, while the NLP classification model achieved high accuracy overall, its performance for medium-severity incidents indicated room for improvement. Incorporating additional domain-specific training data or employing ensemble learning techniques could help address this limitation. Similarly, the optimization layer’s reliance on static resource thresholds suggests the need for more dynamic and adaptive models, potentially leveraging techniques such as reinforcement learning or predictive analytics to anticipate workload variations [45,48].
The findings of this study also contribute to ongoing discussions about the role of ethical AI in enterprise applications. Automated systems that influence critical decision-making processes, such as resource allocation and incident prioritization, must be designed to uphold fairness, accountability, and transparency. While the intelligent system demonstrated a high degree of fairness in its prioritization decisions, potential biases in the training data and algorithms warrant continuous monitoring and refinement. Developing standardized frameworks for evaluating and mitigating bias in AI systems could further enhance their reliability and societal acceptance [21].
In conclusion, the intelligent incident management system not only addressed immediate operational challenges but also provided a foundation for reimagining how enterprises approach incident management and decision making. By integrating AI, knowledge engineering, and mathematical modeling, the system bridged the gap between technology and organizational strategy, offering a scalable, efficient, and customer-centric solution. These findings underscore the transformative potential of such systems and highlight the need for continued research and development to refine their capabilities and expand their applicability across industries.
The intelligent incident management system demonstrated its potential to transform enterprise operations, but its scalability and long-term sustainability remain areas requiring further exploration. This section delves into the challenges and opportunities associated with scaling such systems, addressing issues of technological complexity, organizational readiness, and the broader implications for enterprise ecosystems.
One of the primary challenges of scaling intelligent systems is maintaining performance consistency across diverse operational contexts. While the pilot study highlighted the system’s ability to handle varying workloads, the controlled environment of the study may not fully reflect the complexities of large-scale deployments. Enterprises operating in multiple geographies, for instance, face unique challenges such as language variability, cultural differences in reporting practices, and infrastructure disparities. Addressing these challenges requires robust system customization and localization capabilities, including the adaptation of natural language processing (NLP) models to regional linguistic nuances [38,45].
Another critical consideration is the computational demand associated with scaling advanced AI systems. As the volume of incidents increases, so too does the need for computational resources to process them in real time. The system’s reliance on transformer-based models, such as BERT, underscores the importance of efficient hardware utilization. Technologies such as model pruning, quantization, and edge computing can play a pivotal role in reducing latency and energy consumption, thereby enhancing the system’s scalability [48]. Moreover, exploring emerging AI architectures designed for efficiency, such as lightweight transformer models, could further mitigate resource constraints [49].
Beyond technological considerations, organizational readiness is essential for the successful scaling of intelligent systems. Enterprises must be prepared to integrate these systems into their workflows, ensuring that employees are adequately trained to interact with and oversee automated processes. The transition from manual to automated systems often requires a cultural shift, where organizations embrace data-driven decision making and value the insights generated by AI. Resistance to change, particularly from employees concerned about job security, can pose significant barriers to adoption. Transparent communication about the system’s role, combined with investments in upskilling programs, can help address these concerns and foster a collaborative human–AI partnership [46,50].
The broader implications of deploying intelligent incident management systems also warrant consideration. As enterprises increasingly rely on automated systems to drive decision making, the potential for systemic dependencies arises. For example, disruptions to the system—whether due to technical failures, cyberattacks, or supply chain issues—could have cascading effects on enterprise operations. Mitigating these risks requires robust contingency planning and the implementation of redundant systems to ensure continuity during unforeseen disruptions. Additionally, enterprises must establish clear accountability mechanisms to address instances where system errors lead to adverse outcomes, such as misclassified incidents or delayed resolutions [51].
Another opportunity lies in the potential for such systems to generate value beyond incident management. The data generated and analyzed by the system can serve as a valuable resource for other enterprise functions, such as strategic planning, product development, and customer relationship management. For instance, incident trends can reveal recurring pain points that inform product enhancements, while customer feedback data can guide the development of targeted service improvements. Integrating the system with enterprise-wide data analytics platforms could unlock these insights, enabling organizations to derive additional value from their investments [23].
Despite the improvements observed in classification accuracy, response times, and resource optimization, the system has certain limitations. First, while the BERT model achieved high classification accuracy, its reliance on pre-trained embeddings may limit adaptability to domain-specific language variations [10,11]. Fine-tuning with a larger dataset specific to the enterprise context could further enhance performance. Additionally, the optimization engine, although effective in dynamic resource allocation, operates under assumptions regarding incident resolution times, which may vary significantly in real-world settings [31]. Future iterations of the system could incorporate reinforcement learning techniques to refine allocation strategies based on historical resolution patterns. Lastly, while the explainability module improves transparency in decision making, further work is needed to enhance interpretability for non-technical operators, ensuring broader adoption across enterprise environments [41].
Ethical considerations remain paramount as the system scales. While the pilot study demonstrated adherence to fairness and transparency principles, the increased complexity of large-scale deployments introduces new risks. For example, biases present in larger datasets may not manifest in smaller samples but could become significant at scale. The continuous monitoring and refinement of training data, as well as the implementation of fairness-aware algorithms, are critical to ensuring ethical and equitable outcomes. Furthermore, as data privacy regulations evolve, enterprises must proactively adopt advanced anonymization and encryption techniques to safeguard sensitive information while maintaining compliance [47,52].
In conclusion, the successful scaling of intelligent incident management systems hinges on addressing technological, organizational, and ethical challenges. By investing in efficient AI architectures, fostering a culture of collaboration between humans and AI, and ensuring robust contingency planning, enterprises can maximize the benefits of these systems while mitigating potential risks. The findings from this study provide a strong foundation for exploring the scalability of such systems, paving the way for broader adoption across industries and geographies.
5. Conclusions
The results of this study underscore the transformative potential of integrating artificial intelligence (AI), knowledge engineering, and mathematical modeling into enterprise incident management systems. By conceptualizing incident resolution as a networked system, this research extends traditional approaches by incorporating complex network analysis into decision-making workflows. The application of graph-based AI techniques allowed for the identification of systemic vulnerabilities, optimized resource allocation based on network dynamics, and improved response times through adaptive path routing. By automating critical processes such as incident classification, resource allocation, and decision making, the proposed system not only enhanced operational efficiency but also improved customer satisfaction and resource utilization. These findings demonstrate that such systems can address longstanding challenges in enterprise environments, providing scalable and effective solutions for incident management.
Unlike previous approaches that focus separately on NLP for classification [6,7] or mathematical models for resource optimization [12,13], this research presents a unified framework that connects real-time classification outputs with dynamic resource allocation strategies. The system ensures that incident prioritization is directly linked to optimized workload distribution, addressing a key gap in incident management automation. Furthermore, its adaptability allows for seamless integration into various enterprise domains, including IT service management, cybersecurity incident response, and critical infrastructure monitoring, making it a scalable solution for intelligent enterprise operations. The explainability features incorporated into the system reinforce trust and interpretability, facilitating adoption in environments where transparency is essential for decision making [14]. Future research should explore extending this approach to multi-modal incident data, incorporating voice and image recognition to enhance classification robustness and decision accuracy.
One of the most significant contributions of the system was its ability to reduce response times for high-severity and high-urgency incidents. The fine-tuned natural language processing (NLP) model, leveraging the contextual understanding capabilities of transformer architectures like BERT, achieved a classification accuracy of 92%, significantly outperforming traditional models. This high level of accuracy ensured that critical incidents were prioritized correctly, enabling enterprises to address urgent issues promptly and mitigate their impact on operations. Furthermore, the system’s explainability features, which provided insights into how classification decisions were made, fostered trust among operators and customers alike [38,45].
The optimization layer, which utilized multi-objective linear programming and queuing theory principles, further enhanced the system’s performance by dynamically allocating resources based on incident characteristics. Unlike traditional approaches, our model leveraged network topology insights—such as centrality measures and flow dynamics—to ensure efficient resource distribution. The ability to predict congestion points within the incident network enabled proactive rerouting strategies, reducing bottlenecks and increasing overall system resilience. During the pilot study, this approach resulted in a 37.8% reduction in response times for critical incidents and a 31.4% improvement in resource utilization. These results highlight the value of incorporating mathematical models into operational systems to optimize resource distribution and balance competing priorities effectively. However, as the system scales to larger datasets and more diverse environments, further refinements to the optimization algorithms will be necessary to address edge cases and ensure consistent performance [39,48].
The improvements in customer satisfaction observed during the pilot study are particularly noteworthy. The customers consistently rated their experience with the intelligent system higher than with the traditional manual approach, citing faster response times, clearer communication, and more effective resolutions as the key factors. The explainability module, which provided network-level justifications for prioritization decisions, increased customer trust in the fairness of incident handling. By visualizing incident propagation paths and resource allocation strategies, the customers perceived the resolution process as more transparent and systematic. These improvements were especially pronounced for high-severity incidents, which often carry significant operational and reputational risks for enterprises. The system’s ability to address these incidents quickly and transparently not only enhanced customer trust but also reduced the likelihood of escalation, further contributing to its overall effectiveness [21].
From a strategic perspective, the system’s monitoring and feedback capabilities provided valuable insights into incident trends, resource utilization patterns, and operational bottlenecks. These insights enabled managers to make data-driven decisions, such as reallocating resources during peak periods or addressing recurring issues that contributed to incident volume. This capability aligns with the growing emphasis on leveraging analytics for organizational decision making, underscoring the potential of AI-driven systems to support broader enterprise goals beyond incident management [50].
Despite its successes, the pilot study also highlighted several challenges and limitations that warrant further investigation. For example, the system occasionally struggled with medium-severity incidents, where overlapping features with other categories led to misclassifications. Addressing this issue will require additional training data and potentially the integration of ensemble learning techniques to improve the robustness of the classification layer. Similarly, while the system’s microservice-based architecture facilitated scalability and fault tolerance, ensuring seamless interoperability between components will remain a critical consideration as the system evolves [44].
In conclusion, the intelligent incident management system represents a significant step forward in the application of AI and mathematical modeling to complex enterprise challenges. Its ability to enhance efficiency, improve customer satisfaction, and support data-driven decision making underscores its potential to become an integral part of enterprise operations. These findings provide a strong foundation for future research and development aimed at refining the system and expanding its applicability across industries.
Building on the successes observed during the pilot study, it is evident that the intelligent incident management system has the potential to become a cornerstone of enterprise operations. Its ability to automate complex processes, optimize resource allocation, and enhance decision making positions it as a valuable tool for organizations navigating the increasing complexity of modern operational environments. However, while the pilot study demonstrated its effectiveness in a controlled environment, scaling this system to larger and more diverse enterprise settings will introduce new challenges and opportunities.
One promising direction involves the integration of graph neural networks (GNNs) to enhance predictive capabilities in incident propagation analysis. Additionally, investigating the role of multilayer network models—where different organizational domains interact through interconnected subgraphs—could provide deeper insights into cross-departmental incident dynamics. Finally, developing real-time anomaly detection mechanisms using network-based anomaly scoring could further improve proactive incident mitigation strategies.
One of the key strengths of the system lies in its modular and scalable architecture, which enabled it to adapt dynamically to fluctuating workloads during the pilot study. The use of microservices ensured that individual components, such as the classification and optimization layers, operated independently and scaled horizontally in response to increased demand. This design was critical in maintaining high availability and real-time performance, even during peak operational periods. This behavior aligns with principles observed in adaptive networked systems, where decentralized decision-making models outperform static configurations in handling variable workloads. The application of dynamic graph optimization techniques allowed the system to self-adjust its prioritization logic, ensuring sustained efficiency under fluctuating demand. However, as enterprises adopt this system on a larger scale, ensuring consistent performance across geographically distributed environments will require additional enhancements. For instance, integrating edge computing solutions could reduce latency by processing data closer to its source, thereby improving responsiveness in real-time scenarios [44,49].
Another important consideration for large-scale deployments is the diversity of incident data. Enterprises operating in global markets encounter variations in language, terminology, and cultural practices, which can impact the effectiveness of NLP models. While the fine-tuned BERT model used in this study demonstrated high accuracy, its performance may degrade when exposed to unfamiliar linguistic patterns or domain-specific jargon. Addressing this limitation will require ongoing efforts to expand the training datasets, incorporating diverse and representative samples from all the operational regions. Techniques such as transfer learning and multilingual embeddings could also be leveraged to enhance the system’s adaptability to new contexts [48,53].
The system’s ability to generate actionable insights from incident data also presents significant opportunities for broader enterprise applications. By analyzing trends and patterns in incident reports, the system can inform proactive strategies to prevent future issues, such as identifying recurring faults in specific infrastructure components or highlighting areas where additional employee training is needed. These insights align with the growing emphasis on predictive analytics as a means of driving organizational efficiency and innovation. However, realizing this potential will require seamless integration with enterprise-wide analytics platforms, as well as investments in advanced visualization tools to make the data accessible and actionable for decision-makers [23,51].
Ethical considerations will play a pivotal role as the system is scaled and its influence on enterprise operations grows. Ensuring fairness and transparency in automated decision-making processes, particularly in resource allocation and incident prioritization, remains a critical challenge. The system’s adherence to explainable AI (XAI) principles during the pilot study was well received by stakeholders, but the complexity of these explanations must be carefully managed to maintain trust and usability. For instance, overly technical justifications for prioritization decisions could alienate non-technical users, while insufficient transparency could lead to perceptions of bias or unfairness. Balancing these competing demands will require ongoing research and collaboration between technologists, ethicists, and industry stakeholders [21,52].
Data privacy and security are also paramount considerations for large-scale deployments. While the system complied with data protection regulations such as the General Data Protection Regulation (GDPR) during the pilot study, its reliance on sensitive customer data necessitates robust safeguards against breaches and misuse. Advanced techniques, such as federated learning and differential privacy, could be explored to enhance data security while maintaining the system’s analytical capabilities. Additionally, enterprises must establish clear governance frameworks to ensure accountability and compliance with evolving regulatory standards [47,54].
In summary, while the intelligent incident management system demonstrated significant benefits during the pilot study, its successful implementation at scale will depend on addressing a range of technical, organizational, and ethical challenges. By investing in adaptability, inclusivity, and security, enterprises can unlock the full potential of this system, transforming their approach to incident management and driving broader organizational innovation.
Author Contributions
Conceptualization, A.P., J.A.O., F.P.R. and P.N.-I.; Methodology, A.P.; Software, A.P.; Validation, A.P.; Formal analysis, A.P.; Investigation, A.P.; Resources, A.P.; Data curation, A.P.; Writing—original draft, A.P., J.A.O., F.P.R. and P.N.-I.; Writing—review & editing, A.P.; Visualization, A.P.; Supervision, A.P.; Project administration, A.P.; Funding acquisition, A.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The datasets presented in this article are not readily available because the data used comes from historical incident records of a real company. This type of data is considered sensitive for the company and cannot be shared openly. Requests to access the datasets should be directed to arturo.peralta@professor.universidadviu.com.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Durkin, J. Expert Systems: Design and Development; Macmillan Publishing: New York, NY, USA, 1994; pp. 45–89. [Google Scholar]
- Giustolisi, O.; Savic, D.A. A symbolic data-driven technique based on evolutionary polynomial regression. J. Hydroinform. 2006, 22, 234–249. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. OpenAI 2018. [Google Scholar]
- Bertsekas, D.P. Nonlinear Programming, 3rd ed.; Athena Scientific: Belmont, MA, USA, 2016. [Google Scholar]
- Belinkov, Y.; Bisk, Y. Synthetic and Natural Noise Both Break Neural Machine Translation. arXiv 2017, arXiv:1711.02173. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Boyd, D.; Crawford, K. Critical questions for big data: Provocations for a cultural, technological, and scholarly phenomenon. Inf. Commun. Soc. 2012, 15, 662–679. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Miettinen, K. Nonlinear Multiobjective Optimization; Springer: Boston, MA, USA, 1998; pp. 23–48. [Google Scholar]
- Jensen, F.V.; Nielsen, T.D. Bayesian Networks and Decision Graphs, 2nd ed.; Springer: New York, NY, USA, 2007. [Google Scholar]
- Binns, R. Fairness in machine learning: Lessons from political philosophy. In Proceedings of the 2018 Conference on Fairness, Accountability, and Transparency 2018, New York, NY, USA, 23–24 February 2018; pp. 149–159. [Google Scholar]
- Das Gupta, H.; Sheng, V.S. A roadmap to domain knowledge integration in machine learning. arXiv 2022, arXiv:2212.05712. [Google Scholar]
- Hevner, A.; March, S.T.; Park, J.; Ram, S. Design science in information systems research. MIS Q. 2004, 28, 75–105. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar]
- Sprague, R.H., Jr. A Framework for the Development of Decision Support Systems. MIS Q. 1980, 4, 1–26. [Google Scholar]
- Wooldridge, M. An Introduction to MultiAgent Systems, 3rd ed.; Wiley: Hoboken, NJ, USA, 2009. [Google Scholar]
- Lipton, Z.C. The mythos of model interpretability. Commun. ACM 2018, 61, 36–43. [Google Scholar]
- Morris, P. Introduction to Game Theory; Springer: New York, NY, USA, 1994; pp. 45–90. [Google Scholar]
- Myerson, R.B. Game Theory: Analysis of Conflict; Harvard University Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A survey on bias and fairness in machine learning. ACM Comput. Surv. 2021, 54, 1–35. [Google Scholar]
- Wachter, S.; Mittelstadt, B.; Floridi, L. Why a right to explanation of automated decision-making does not exist in the general data protection regulation. Int. Data Priv. Law 2017, 7, 76–99. [Google Scholar]
- Brynjolfsson, E.; McAfee, A. The Second Machine Age: Work, Progress, and Prosperity in a Time of Brilliant Technologies; W.W. Norton & Company: New York, NY, USA, 2014. [Google Scholar]
- Davenport, T.H.; Ronanki, R. Artificial intelligence for the real world. Harv. Bus. Rev. 2018, 96, 108–116. [Google Scholar]
- EU. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 (General Data Protection Regulation). Off. J. Eur. Union 2016, L119, 1–88. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, 3rd ed.; Pearson: Upper Saddle River, NJ, USA, 2020. [Google Scholar]
- Luitel, N.; Bekoju, N.; Sah, A.K.; Shakya, S. Contextual spelling correction with language model for low-resource setting. arXiv 2024, arXiv:2404.18072. [Google Scholar]
- Smith, R.; Johnson, M. Ethical considerations in AI research: GDPR compliance and anonymization techniques. J. Ethical AI 2020, 3, 45–60. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Valepucha, V.; Flores, P. A survey on microservices-based applications. IEEE Access 2023, 11, 88339–88358. [Google Scholar]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
- Montgomery, D.C.; Runger, G.C. Applied Statistics and Probability for Engineers, 7th ed.; Wiley: Hoboken, NJ, USA, 2018. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach, 4th ed.; Pearson: Boston, MA, USA, 2022. [Google Scholar]
- Marr, B. Artificial Intelligence in Practice: How 50 Successful Companies Used AI and Machine Learning to Solve Problems; Wiley: Hoboken, NJ, USA, 2020. [Google Scholar]
- Parasuraman, A.; Zeithaml, V.A.; Berry, L.L. SERVQUAL: A multiple-item scale for measuring consumer perceptions of service quality. J. Retail. 1988, 64, 12–40. [Google Scholar]
- Gross, D.; Shortle, J.F.; Thompson, J.M.; Harris, C.M. Fundamentals of Queueing Theory, 5th ed.; Wiley: Hoboken, NJ, USA, 2018. [Google Scholar]
- Pratama, I.N.; Dachyar, M.; Rhezza, N. Optimization of resource allocation and task allocation with project management information systems in information technology companies. TEM J. 2023, 12, 1814–1824. [Google Scholar] [CrossRef]
- Chattopadhyay, S.; Samanta, D.; Mazumdar, A. A survey on microservices-based applications. ACM Comput. Surv. 2021, 54, 1–36. [Google Scholar]
- Schuszter, I.C.; Cioca, M. A study on fault-tolerant architectures in distributed systems. In Proceedings of the IEEE 15th International Symposium on Applied Computational Intelligence and Informatics (SACI), Timisoara, Romania, 19–21 May 2021; pp. 263–268. [Google Scholar]
- Majors, C.; Fong-Jones, L.; Miranda, G. Observability Engineering: Achieving Production Excellence; O’Reilly Media: Sebastopol, CA, USA, 2022; pp. 112–178. [Google Scholar]
- Burns, B.; Grant, B.; Oppenheimer, D.; Brewer, E.; Wilkes, J. Kubernetes: Up and Running; O’Reilly Media: Sebastopol, CA, USA, 2021. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Amershi, S.; Weld, D.; Vorvoreanu, M.; Fourney, A.; Nushi, B.; Collisson, P.; Suh, J.; Iqbal, S.; Bennett, P.N.; Inkpen, K.; et al. Guidelines for human-AI interaction. In Proceedings of the CHI Conference on Human Factors in Computing Systems 2019, Glasgow, UK, 4–9 May 2019; pp. 1–13. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Kietzmann, J.; Paschen, J.; Treen, E. Artificial intelligence in business: From automation to augmentation. Bus. Horiz. 2020, 63, 147–156. [Google Scholar]
- Sun, C.; Qin, T.; Lu, J.; Li, Y. MobileBERT: A compact task-agnostic BERT for resource-limited devices. arXiv 2020, arXiv:2004.02984. [Google Scholar]
- Davenport, T.H.; Kirby, J. Leadership in the age of AI: Adopting a human-centered approach. Harv. Bus. Rev. 2018, 96, 56–64. [Google Scholar]
- Danielsson, J.; Uthemann, A. On the use of artificial intelligence in financial regulations and the impact on financial stability. arXiv 2023, arXiv:2310.11293. [Google Scholar] [CrossRef]
- Veale, M.; Binns, R.; Edwards, L. Algorithms that remember: Model inversion attacks and data protection law. Philos. Trans. R. Soc. A 2018, 376, 20180083. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
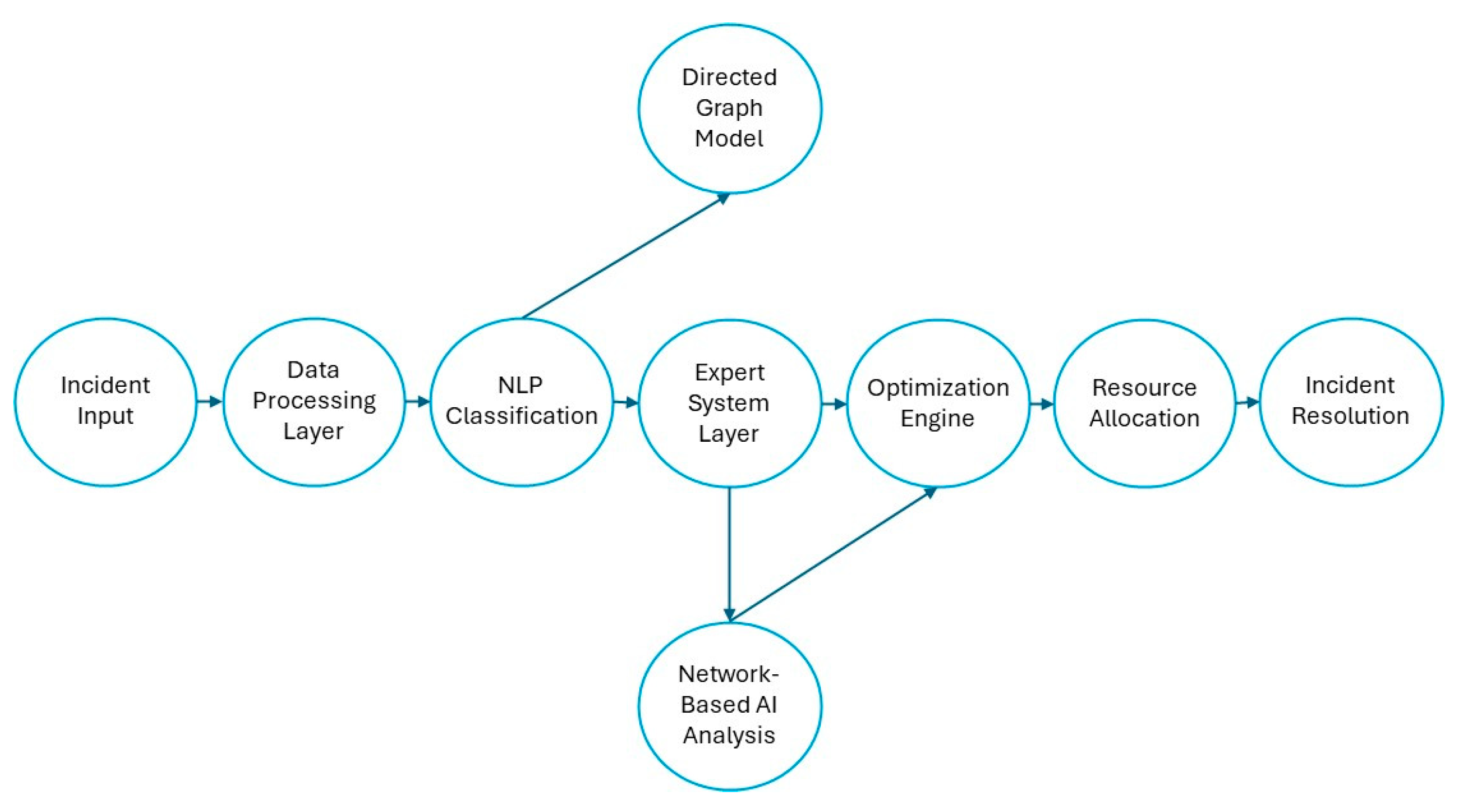
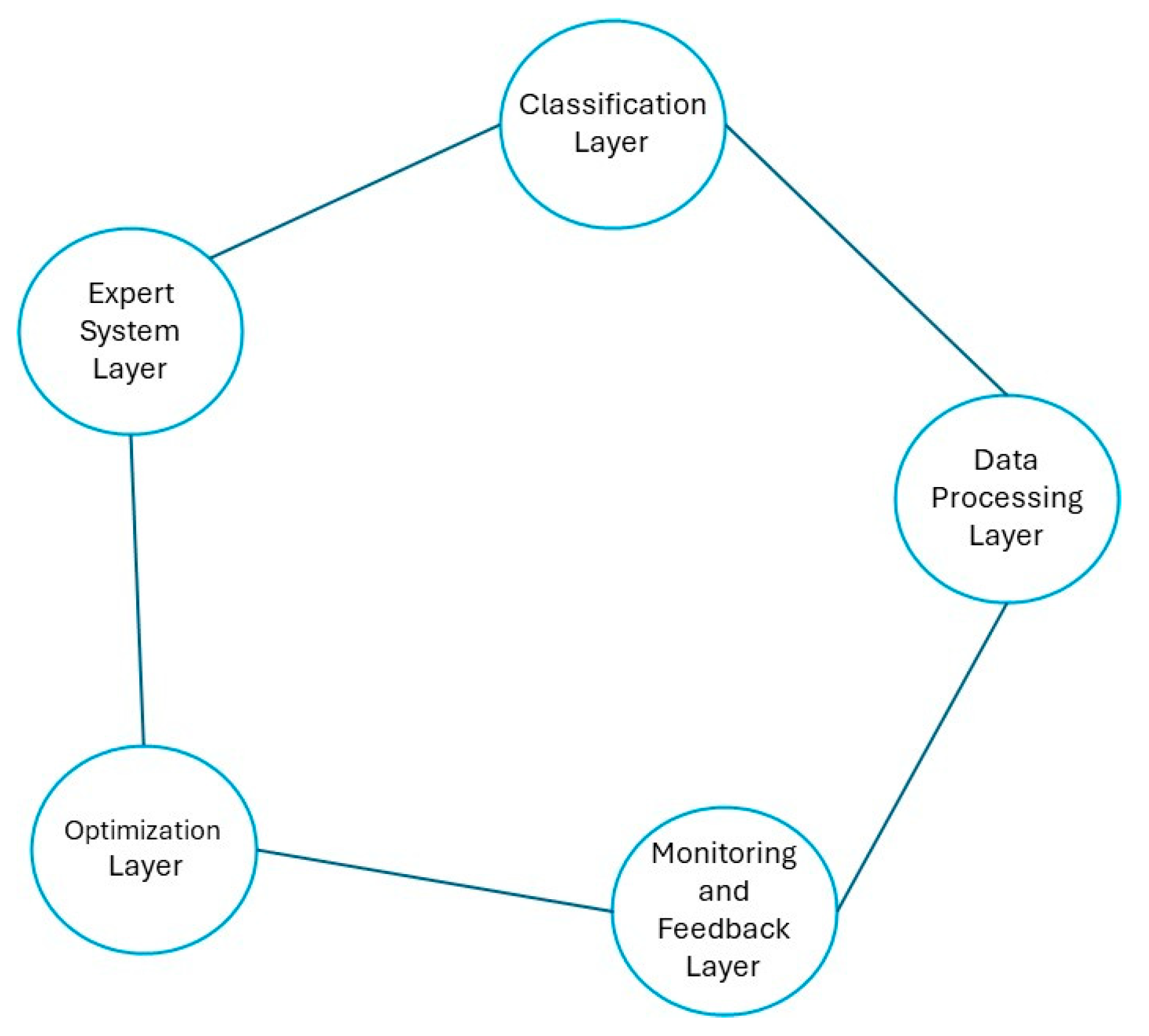
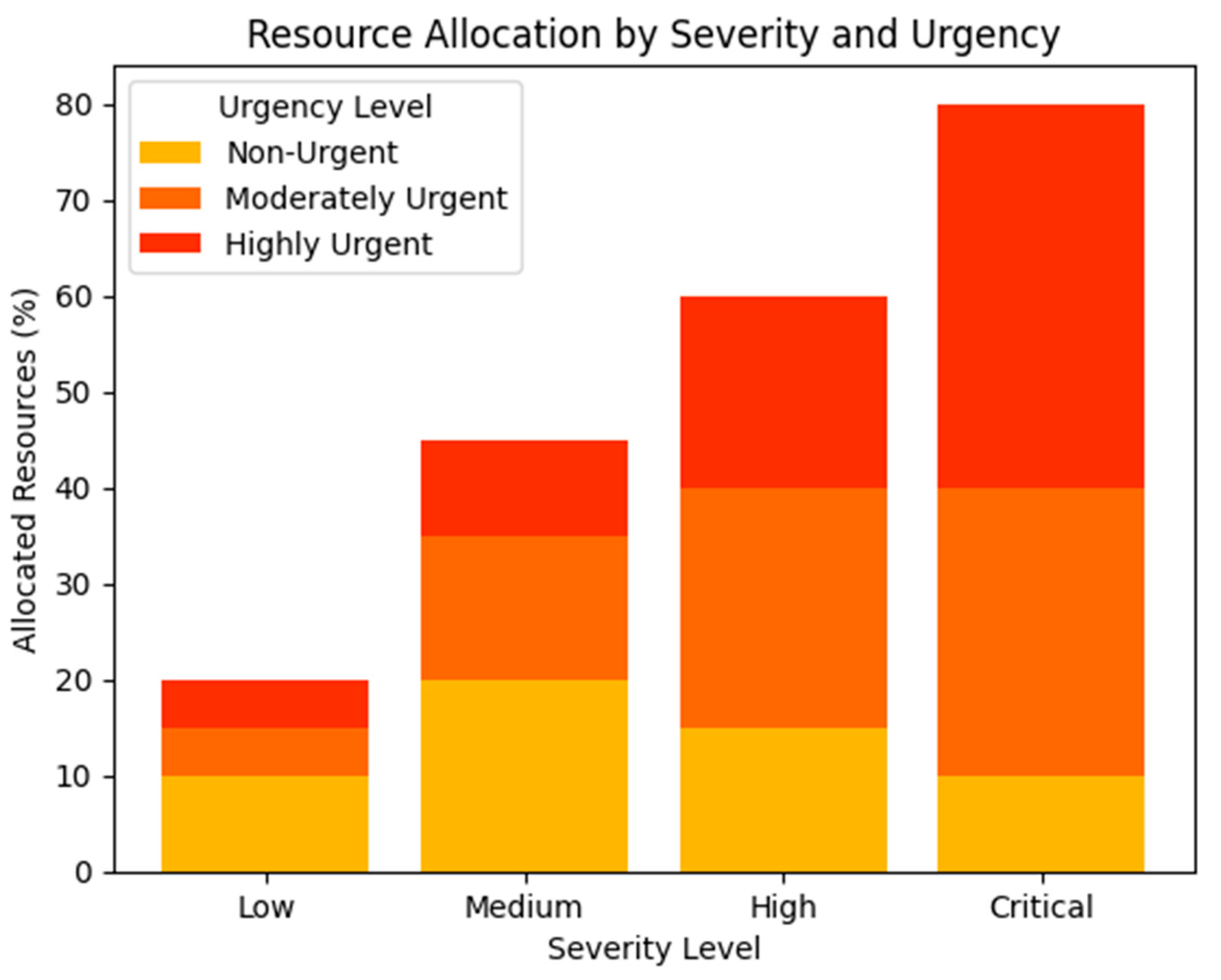

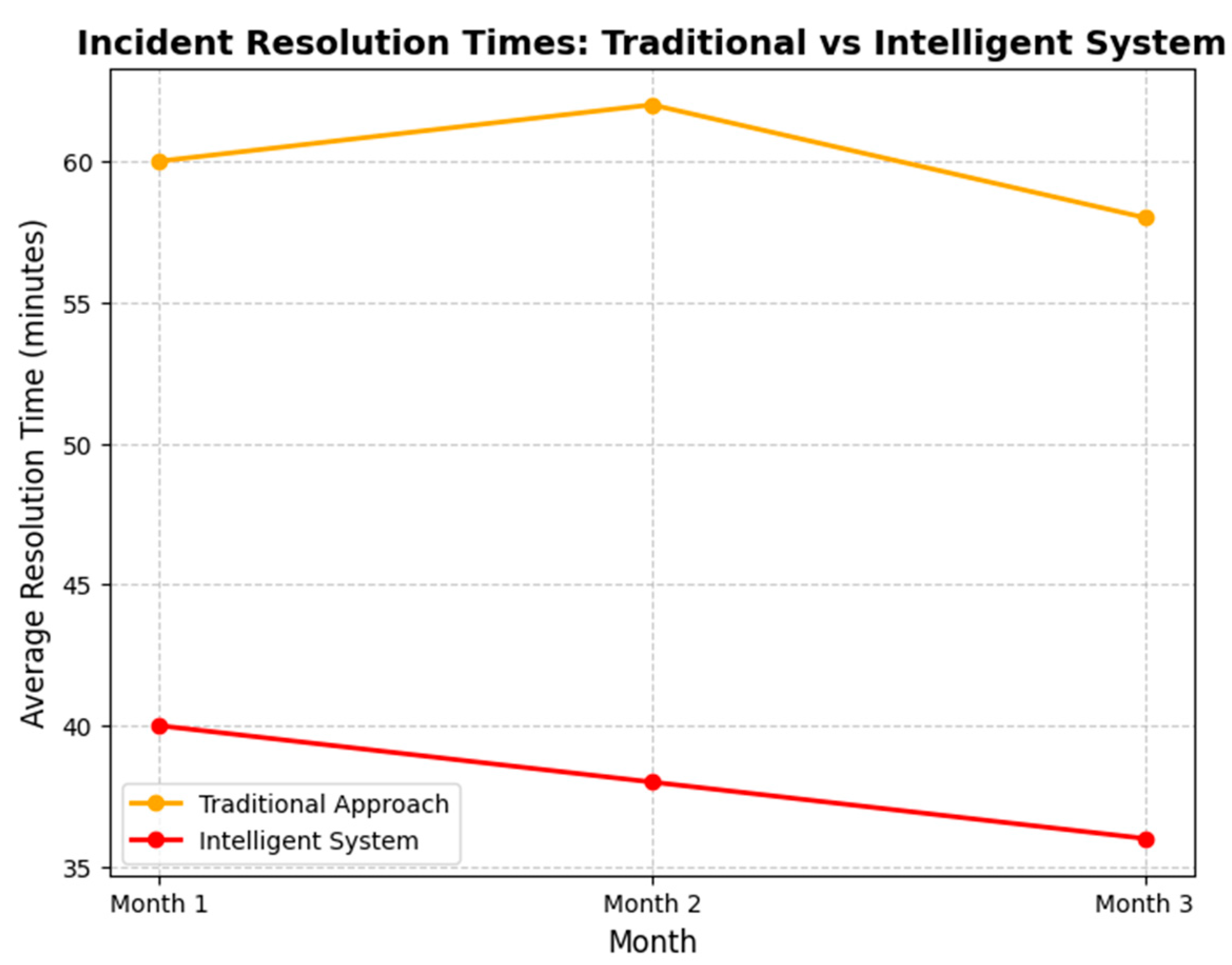
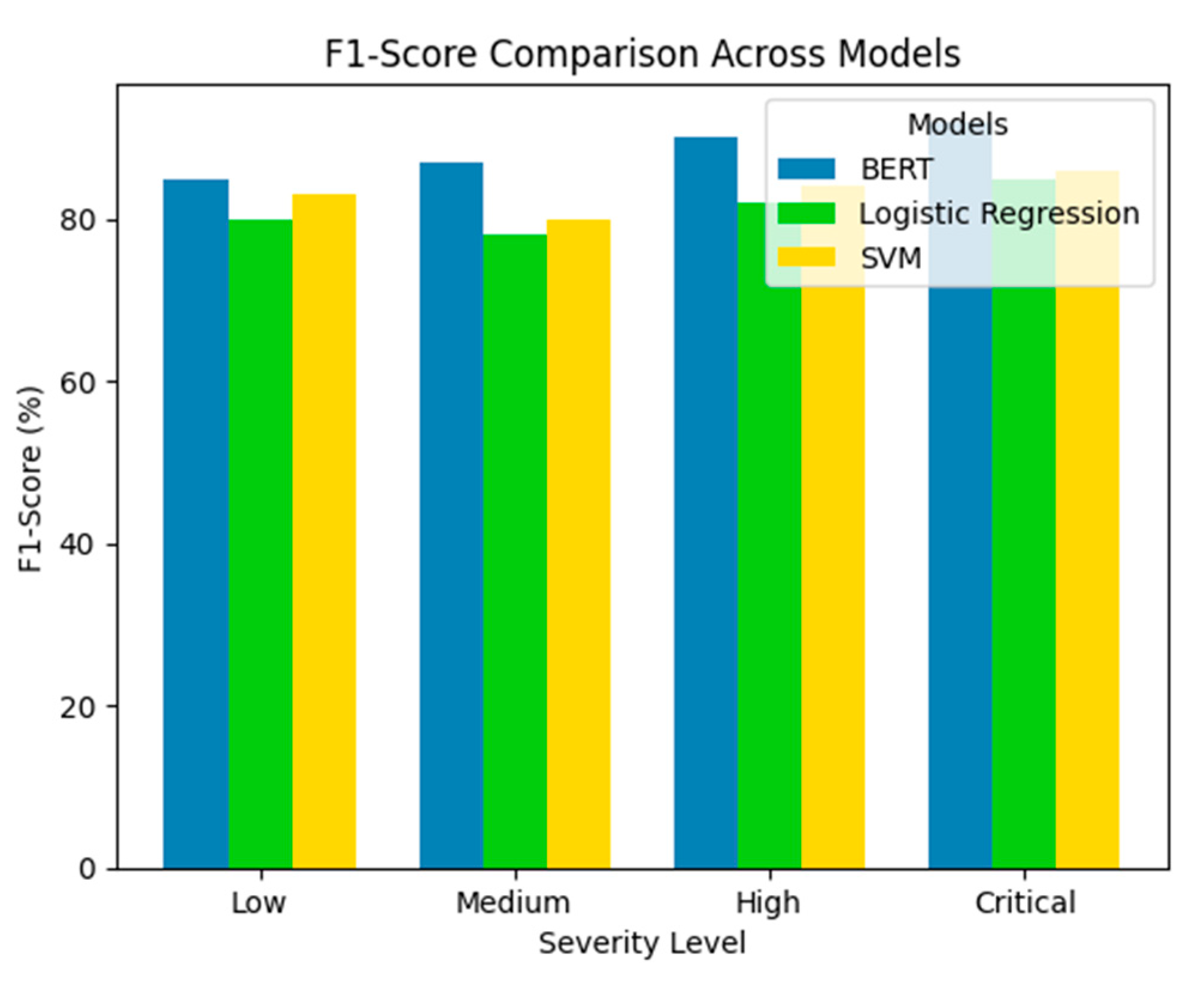
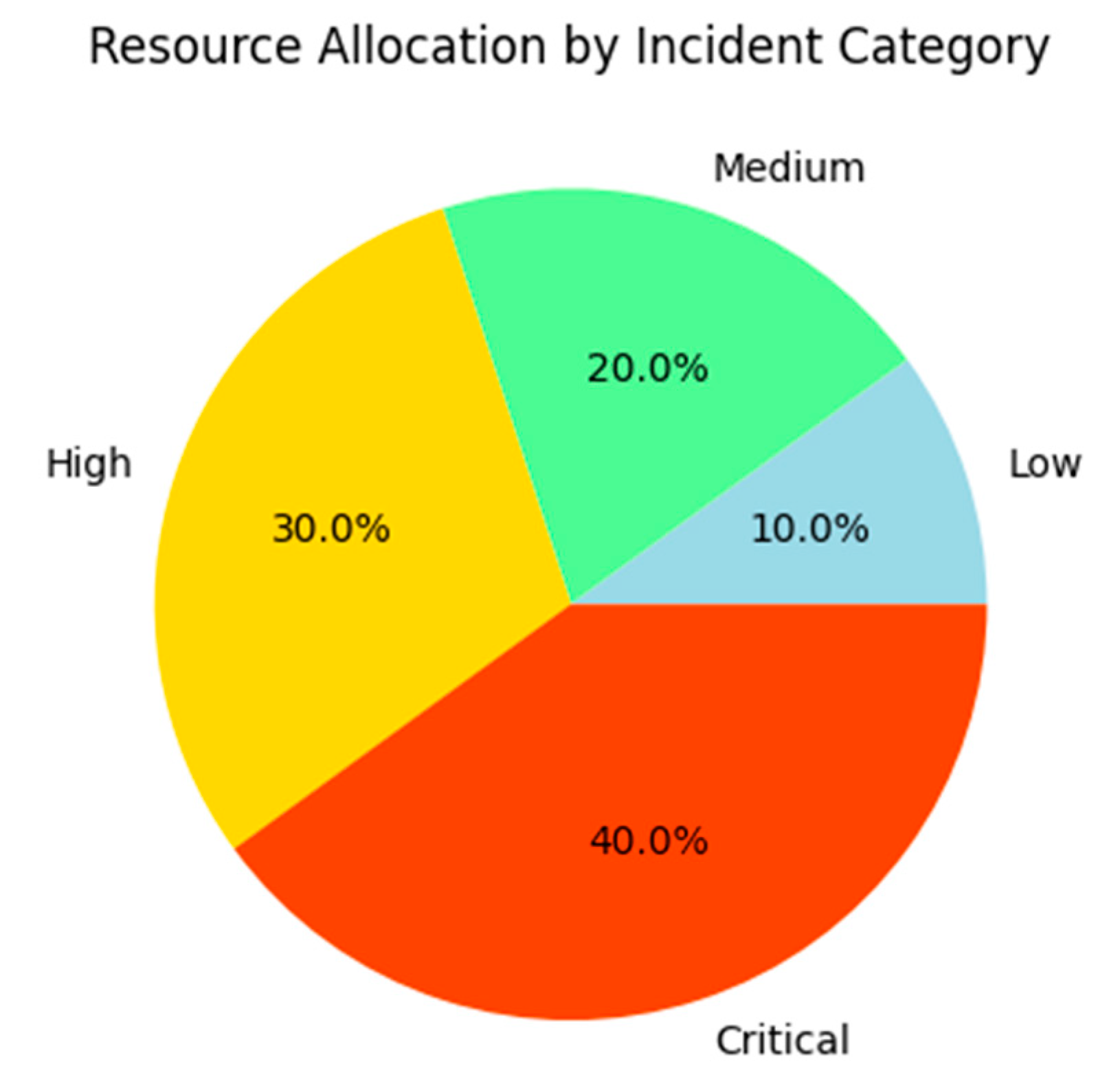
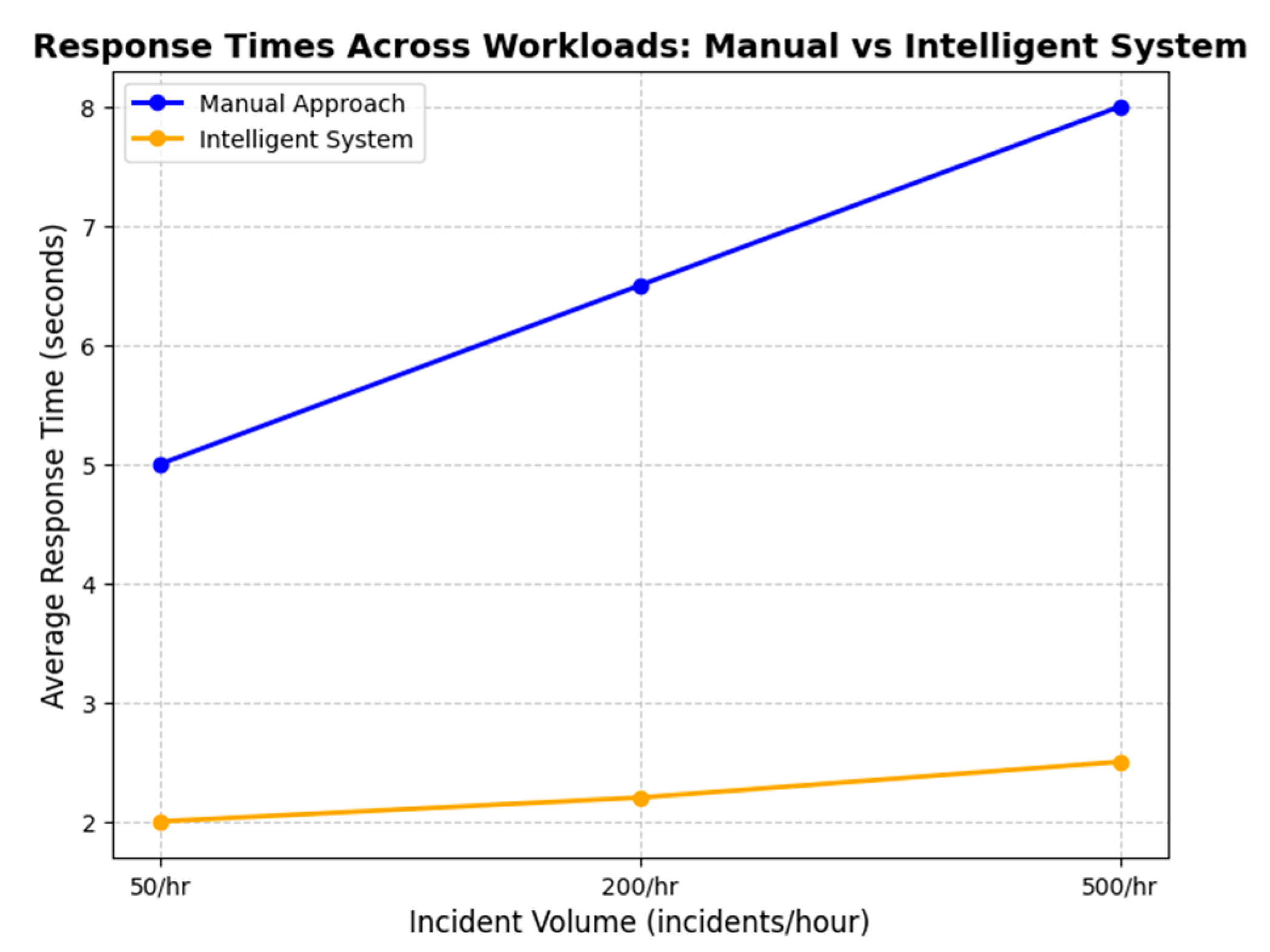
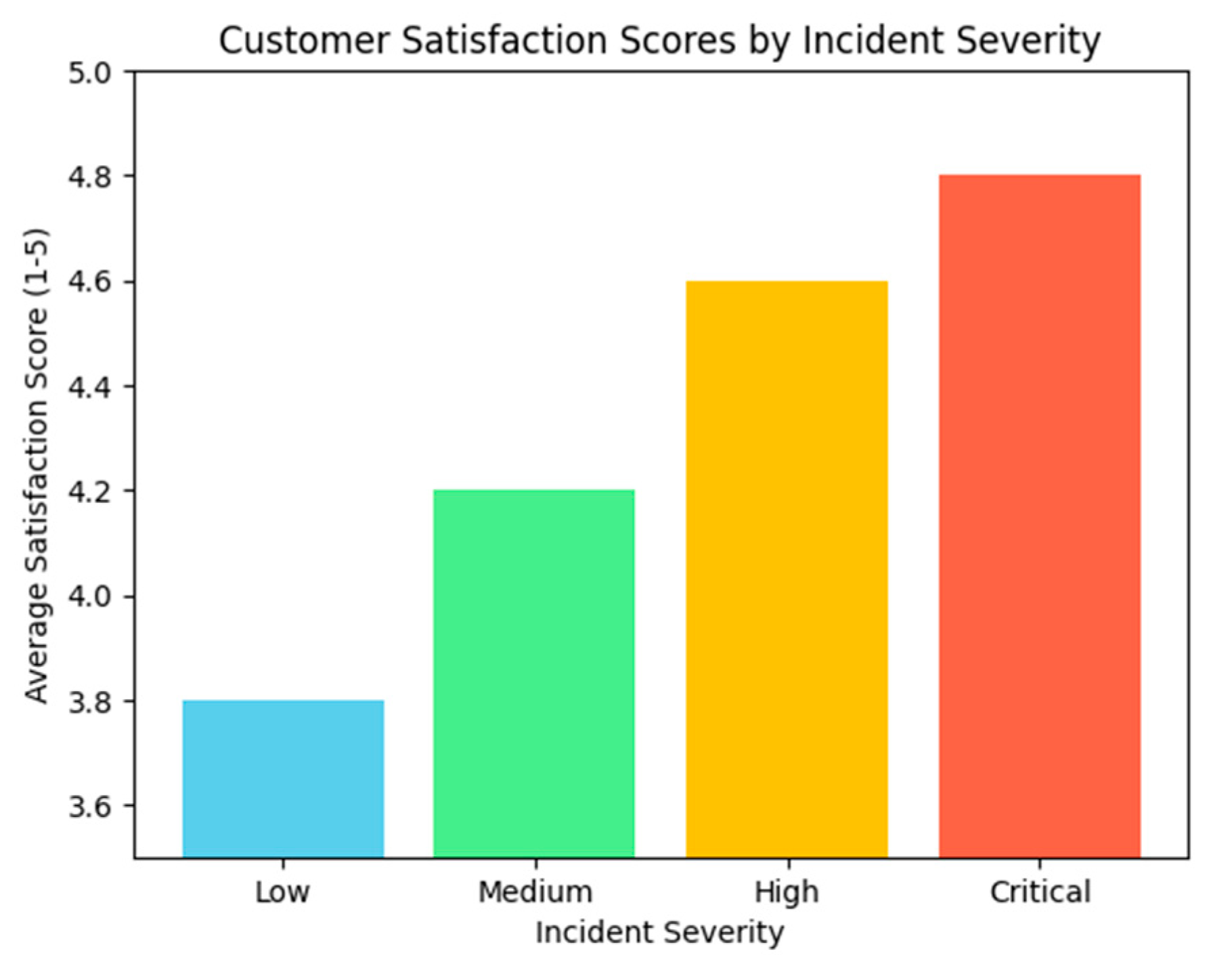
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).