
Exploring Consistency in the Three-Option Davidson Model: Bridging Pairwise Comparison Matrices and Stochastic Methods


Abstract
:1. Introduction
2. The Investigated Model: Davidson Model
- (A)
- There is at least one index pair for which .
- (B)
- For any partition S and , , , there is at least one element and , for which , or there are two (not necessarily different) pairs , , , for which and .
- (C)
- With the graph definition given in Definition 2, there exists such a directed cycle , where are nodes, in which the number of the directed ’better’ edges exceeds the number of the bi-directed ‘equal’ edges.
3. Consistency and Its Theoretical Consequences
3.1. Consistency of Data in the Case of PCM-Based Methods
3.2. Consistency in Davidson Model
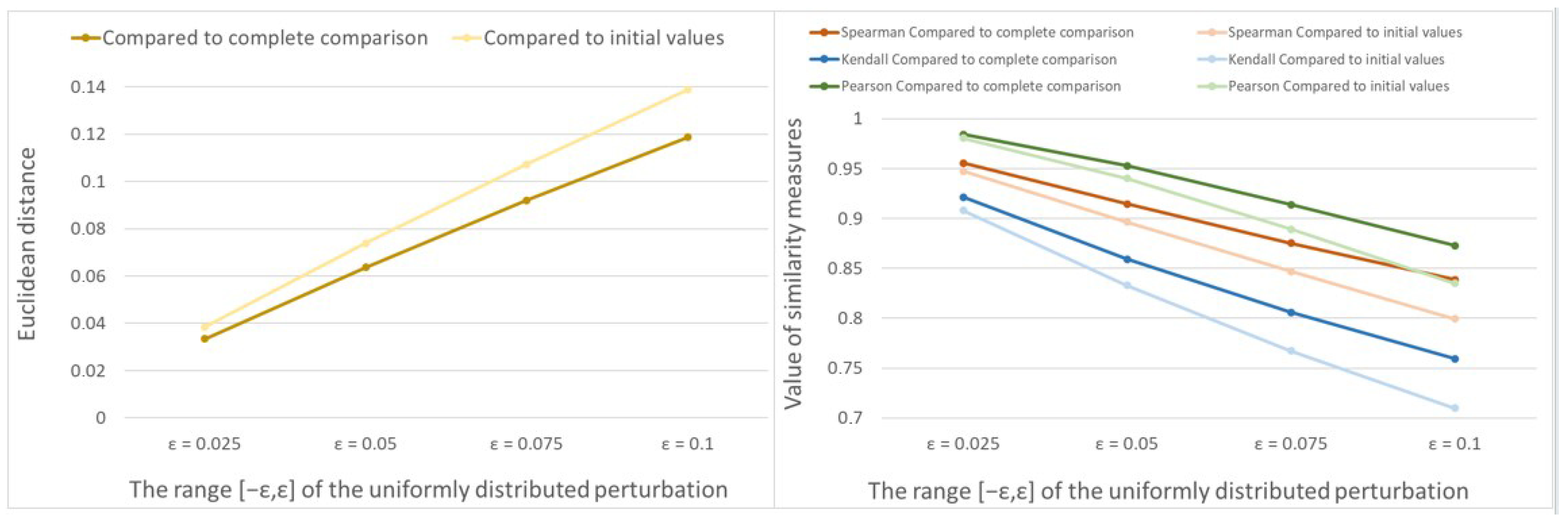
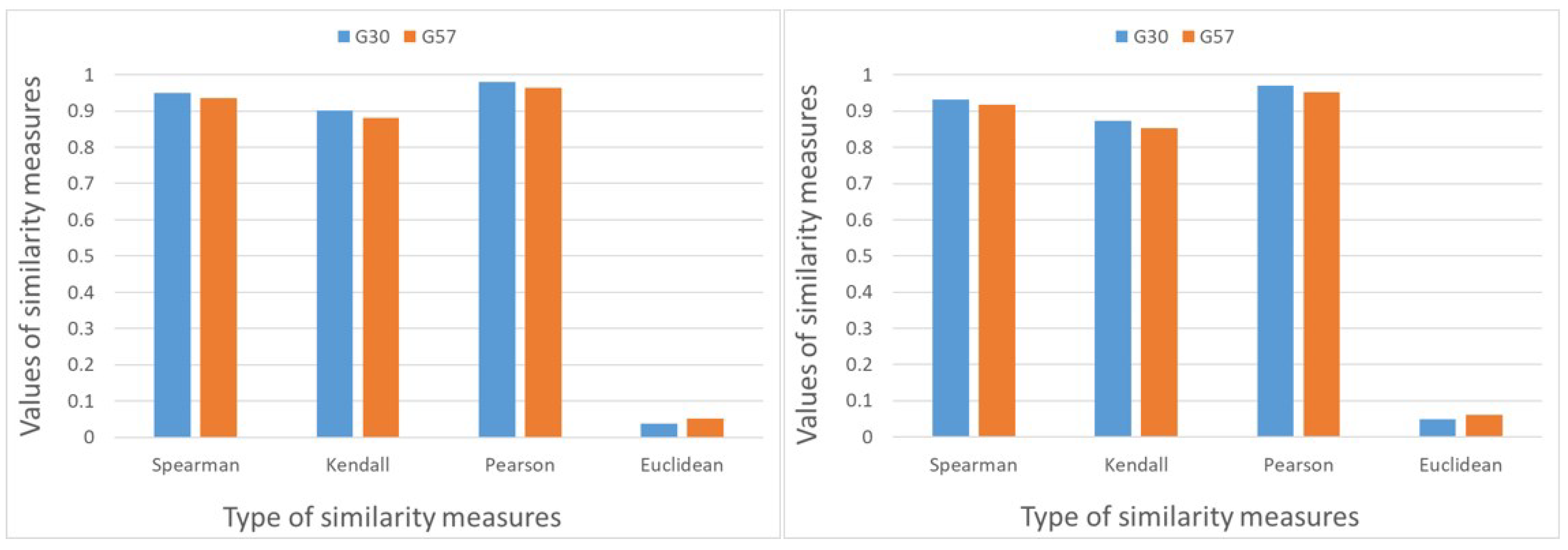
4. Connections in the Case of Inconsistent Data, Based on Simulations
4.1. Method of Simulations
- Generate a normalized random n-length vector, and assign a positive value. The coordinates of and are uniformly distributed random values in the interval . These will be the initial parameter values for the Davidson model. is referred to as the initial priority vector.
- As we know from Theorem 2, in the case of consistent comparison data, MLE recovers the initial values in all (complete or incomplete) cases. For this reason, perturbations are performed on the consistent data set as follows: each probability value is modified by adding independent, uniformly distributed random numbers in the range [, ]. The value can be set between 0 and 1, but we use between 0 and 0.1. We guarantee that the resulting perturbed probability values are also between 0 and 1, then we normalize them by dividing their sum. These data serve as an inconsistent complete data set.
- Using the above perturbed probability values as a data set, the estimated vector and value are calculated using MLE. The vector is referred to as an estimated priority vector based on the complete comparison and is denoted by .
- In the next step, we calculate the estimated priority vectors for different graph structures as follows. We omit data from the complete data set. For each fixed connected graph, we keep only the data that belong to the comparison structure associated with the graph. The remaining data set is incomplete and inconsistent. After performing MLE, the estimated priority vector is called the priority vector belonging to the incomplete data set and is denoted by . We want to determine how much information is retained from the initial priority vector, on the one hand, and from the estimated priority vector based on the complete comparison, on the other hand.
- The differences between the priority vectors computed from the complete and incomplete data sets for the fixed graph structure are determined using various measures.To analyze the similarities of the rankings, we use two rank correlations and two additional distance measures:
- Spearman rank correlationwhere is the difference in rankings of the ith object;
- Kendall rank correlationwhere is the number of concordant pairs, and is the number of discordant pairs.
- Further used distances are the Pearson correlation coefficientwhere is the i-th coordinate of the estimated priority vector from the incomplete comparison and is the i-th coordinate of the estimated priority vector from the complete comparison and the upper line denotes the arithmetic average of the coordinates.Each type of the correlation coefficients is in the interval . The closer the result is to 1, the more information is recovered about the rank or about the coordinates of the priority vector.
- The Euclidean distance of the estimated parameter vectors
The Euclidean distance is always non-negative. It can be larger than 1. Its largest value is , if the Euclidean norms of the vectors equal 1. In this case, the smaller value represents better information retrieval. - It is also interesting to see how much information is retained from the initial priority vector in the case of different comparison structures. In this case, both the perturbation and the omission of part of the data may cause information loss. The same similarity measures as in the previous step are used for the initial parameter set and the estimated parameter vector based on incomplete comparison. More specifically, the same similarity measures as in Step 6 are calculated according to Formulae (53)–(56), but is substituted with .
- Repeat the above-described steps N times, where N is the number of simulations. The similarity measures described in Step 6 are random, due to the random initial parameter vector and the random perturbation value. Therefore, we take their average over the simulations for each fixed comparison structure. These average values characterize the information retrieval measures associated with the fixed comparison structures.
4.2. Results of Simulations in the Case of Uniformly Distributed Random Perturbation Values
4.3. Results of Simulations in the Case of Gaussian-Distributed Random Perturbation Values
5. Summary
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| PCM | Paired Comparison Matrices-based Method |
| THMM | Thurstone motivated method |
| AHP | Analytic Hierarchy Process |
| EM | Eigenvector method |
| LLSM | logarithmic least squares method |
| MLE | maximum likelihood estimation |
| BT2 | Bradley–Terry model that allows two options |
| BT3 | Bradley–Terry model allowing three options in choices |
| MLEP | maximum likelihood estimate of the parameters |
| GRC | graph of comparisons |
| GRDIR | directed graph |
References
- Mangla, S.K.; Kumar, P.; Barua, M.K. Risk analysis in green supply chain using fuzzy AHP approach: A case study. Resour. Conserv. Recycl. 2015, 104, 375–390. [Google Scholar] [CrossRef]
- Shi, W. Construction and evaluation of college students’ psychological quality evaluation model based on Analytic Hierarchy Process. J. Sens. 2022, 2022, 3896304. [Google Scholar] [CrossRef]
- Koczkodaj, W.W.; LeBrasseur, R.; Wassilew, A.; Tadeusziewicz, R. About business decision making by a consistency-driven pairwise comparisons method. J. Appl. Comput. Sci. 2009, 17, 55–70. [Google Scholar]
- Wind, Y.; Saaty, T.L. Marketing applications of the analytic hierarchy process. Manag. Sci. 1980, 26, 641–658. [Google Scholar] [CrossRef]
- Brunelli, M. A study on the anonymity of pairwise comparisons in group decision making. Eur. J. Oper. Res. 2019, 279, 502–510. [Google Scholar] [CrossRef]
- Amorocho, J.A.P.; Hartmann, T. A multi-criteria decision-making framework for residential building renovation using pairwise comparison and TOPSIS methods. J. Build. Eng. 2022, 53, 104596. [Google Scholar] [CrossRef]
- Baker, R.D.; McHale, I.G. A dynamic paired comparisons model: Who is the greatest tennis player? Eur. J. Oper. Res. 2014, 236, 677–684. [Google Scholar] [CrossRef]
- Bozóki, S.; Csató, L.; Temesi, J. An application of incomplete pairwise comparison matrices for ranking top tennis players. Eur. J. Oper. Res. 2016, 248, 211–218. [Google Scholar] [CrossRef]
- Baker, R.D.; McHale, I.G. Estimating age-dependent performance in paired comparisons competitions: Application to snooker. J. Quant. Anal. Sports 2024, 20, 113–125. [Google Scholar] [CrossRef]
- Gisselquist, R.M. Paired comparison and theory development: Considerations for case selection. PS Polit. Sci. Polit. 2014, 47, 477–484. [Google Scholar] [CrossRef]
- Crompvoets, E.A.; Béguin, A.A.; Sijtsma, K. Adaptive pairwise comparison for educational measurement. J. Educ. Behav. Stat. 2020, 45, 316–338. [Google Scholar] [CrossRef]
- Williamson, T.B.; Watson, D.O.T. Assessment of community preference rankings of potential environmental effects of climate change using the method of paired comparisons. Clim. Change 2010, 99, 589–612. [Google Scholar] [CrossRef]
- Verschuren, P.; Arts, B. Quantifying influence in complex decision making by means of paired comparisons. Qual. Quant. 2005, 38, 495–516. [Google Scholar] [CrossRef]
- Tarricone, P.; Newhouse, C.P. A study of the use of pairwise comparison in the context of social online moderation. Aust. Educ. Res. 2016, 43, 273–288. [Google Scholar] [CrossRef]
- Oliveira, I.F.; Ailon, N.; Davidov, O. A new and flexible approach to the analysis of paired comparison data. J. Mach. Learn. Res. 2018, 19, 1–29. [Google Scholar]
- Saaty, T.L.; Vargas, L.G. The Logic of Priorities: Applications of Business, Energy, Health and Transportation; Springer Science & Business Media: Dordrecht, The Netherlands, 2013. [Google Scholar]
- Vaidya, O.S.; Kumar, S. Analytic hierarchy process: An overview of applications. Eur. J. Oper. Res. 2006, 169, 1–29. [Google Scholar] [CrossRef]
- Saaty, T.L. The Analytic Hierarchy Process: Planning, Priority Setting, Resource, Allocation; McGraw-Hill: New York, NY, USA, 1980. [Google Scholar]
- Saaty, T.L. How to make a decision: The analytic hierarchy process. Eur. J. Oper. Res. 1990, 48, 9–26. [Google Scholar] [CrossRef]
- Saaty, T.L. Decision-making with the AHP: Why is the principal eigenvector necessary. Eur. J. Oper. Res. 2003, 145, 85–91. [Google Scholar] [CrossRef]
- Bozóki, S.; Fülöp, J.; Rónyai, L. On optimal completion of incomplete pairwise comparison matrices. Math. Comput. Model. 2010, 52, 318–333. [Google Scholar] [CrossRef]
- Thurstone, L.L. A law of comparative judgment. Psychol. Rev. 1927, 34, 273–286. [Google Scholar] [CrossRef]
- Bradley, R.A.; Terry, M.E. Rank analysis of incomplete block designs: I. The method of paired comparisons. Biometrika 1952, 39, 324–345. [Google Scholar] [CrossRef]
- Glenn, W.A.; David, H.A. Ties in paired-comparison experiments using a modified Thurstone-Mosteller model. Biometrics 1960, 16, 86–109. [Google Scholar] [CrossRef]
- Rao, P.V.; Kupper, L.L. Ties in paired-comparison experiments: A generalization of the Bradley-Terry model. J. Am. Stat. Assoc. 1967, 62, 194–204. [Google Scholar] [CrossRef]
- Agresti, A. Analysis of ordinal paired comparison data. J. R. Stat. Soc. Ser. C Appl. Stat. 1992, 41, 287–297. [Google Scholar] [CrossRef]
- Orbán-Mihálykó, É.; Mihálykó, C.; Koltay, L. Incomplete paired comparisons in case of multiple choice and general log-concave probability density functions. Cent. Eur. J. Oper. Res. 2019, 27, 515–532. [Google Scholar] [CrossRef]
- Orbán-Mihálykó, É.; Koltay, L.; Szabó, F.; Csuti, P.; Kéri, R.; Schanda, J. A new statistical method for ranking of light sources based on subjective points of view. Acta Polytech. Hung. 2015, 12, 195–214. [Google Scholar]
- Gyarmati, L.; Orbán-Mihálykó, É.; Mihálykó, C.; Szádoczki, Z.; Bozóki, S. The incomplete Analytic Hierarchy Process and Bradley–Terry model: (In)consistency and information retrieval. Expert Syst. Appl. 2023, 229, 120522. [Google Scholar] [CrossRef]
- Davidson, R.R. On Extending the Bradley-Terry Model to Accommodate Ties in Paired Comparison Experiments. J. Am. Stat. Assoc. 1970, 65, 317–328. [Google Scholar] [CrossRef]
- Luce, R.D. Individual Choice Behavior; Wiley: New York, NY, USA, 1959; Volume 4. [Google Scholar]
- Luce, R.D. The choice axiom after twenty years. J. Math. Psychol. 1977, 15, 215–233. [Google Scholar] [CrossRef]
- Mihálykó, C.; Gyarmati, L.; Orbán-Mihálykó, É.; Mihálykó, A. Evaluability of paired comparison data in stochastic paired comparison models: Necessary and sufficient condition. arXiv 2025, arXiv:2502.13617. [Google Scholar]
- Bozóki, S.; Tsyganok, V. The (logarithmic) least squares optimality of the arithmetic (geometric) mean of weight vectors calculated from all spanning trees for incomplete additive (multiplicative) pairwise comparison matrices. Int. J. Gen. Syst. 2019, 48, 362–381. [Google Scholar] [CrossRef]
- Kazibudzki, P.T. Redefinition of triad’s inconsistency and its impact on the consistency measurement of pairwise comparison matrix. J. Appl. Math. Comput. Mech. 2016, 15, 71–78. [Google Scholar] [CrossRef]
- Brunelli, M. A survey of inconsistency indices for pairwise comparisons. Int. J. Gen. Syst. 2018, 47, 751–771. [Google Scholar] [CrossRef]
- Ágoston, K.C.; Csató, L. Inconsistency thresholds for incomplete pairwise comparison matrices. Omega 2022, 108, 102576. [Google Scholar] [CrossRef]
- Mihálykó, C.; Orbán-Mihálykó, É.; Gyarmati, L. Consistency and Inconsistency in the Case of a Stochastic Paired Comparison Model. In Proceedings of the 2024 IEEE 3rd Conference on Information Technology and Data Science (CITDS), Debrecen, Hungary, 26–28 August 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Chartier, T.P.; Harris, J.; Hutson, K.R.; Langville, A.N.; Martin, D.; Wessell, C.D. Reducing the effects of unequal number of games on rankings. IMAGE Bull. Int. Linear Algebra Soc. 2014, 52, 15–23. [Google Scholar]
- Bozóki, S.; Szádoczki, Z. Optimal sequences for pairwise comparisons: The graph of graphs approach. arXiv 2022, arXiv:2205.08673. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PCM | BT2 Model | Three-Option Davidson Model | |
|---|---|---|---|
| ∀ | |||
| ∀ | ∀ | and | |
| ⇕ | ⇕ | ⇕ | ⇕ |
| = | |||
| Pairs | |||
|---|---|---|---|
| (1,2) | 1 | 2 | 1 |
| (1,3) | 1 | 4 | 4 |
| (1,4) | 0 | 0 | 0 |
| (1,5) | 0 | 0 | 0 |
| (2,3) | 1 | 4 | 4 |
| (2,4) | 4 | 4 | 1 |
| (2,5) | 0 | 0 | 0 |
| (3,4) | 16 | 8 | 1 |
| (3,5) | 0 | 0 | 0 |
| (4,5) | 1 | 2 | 1 |
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 4 | * | * |
| 2 | 1 | 1 | 4 | 0.25 | * |
| 3 | 0.25 | 0.25 | 1 | * | |
| 4 | * | 4 | 16 | 1 | 1 |
| 5 | * | * | * | 1 | 1 |
| Incomp. Versus Comp. | Incomp. Versus Initial | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ID | |E| | Graph | PE | EU | PE | EU | ||||
| 1 | 3 |  | 0.845 | 0.786 | 0.890 | 0.107 | 0.792 | 0.721 | 0.840 | 0.136 |
| 2 | 3 | 0.835 | 0.774 | 0.880 | 0.114 | 0.784 | 0.711 | 0.832 | 0.140 | |
| 3 | 4 | 0.892 | 0.845 | 0.935 | 0.075 | 0.828 | 0.763 | 0.881 | 0.111 | |
| 4 | 4 |  | 0.912 | 0.869 | 0.959 | 0.060 | 0.845 | 0.783 | 0.904 | 0.097 |
| 5 | 5 |  | 0.946 | 0.918 | 0.979 | 0.037 | 0.863 | 0.805 | 0.920 | 0.086 |
| 6 | 6 |  | 1 | 1 | 1 | 0 | 0.881 | 0.829 | 0.937 | 0.074 |
| Incomp. Versus Comp. | Incomp. Versus Initial | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ID | |E| | Graph | PE | EU | PE | EU | ||||
| 1 | 4 |  | 0.839 | 0.759 | 0.873 | 0.119 | 0.799 | 0.710 | 0.835 | 0.139 |
| 2 | 4 | 0.827 | 0.746 | 0.860 | 0.126 | 0.789 | 0.698 | 0.823 | 0.145 | |
| 3 | 4 | 0.817 | 0.735 | 0.850 | 0.131 | 0.780 | 0.689 | 0.814 | 0.150 | |
| 4 | 5 | 0.868 | 0.797 | 0.904 | 0.097 | 0.824 | 0.739 | 0.864 | 0.121 | |
| 5 | 5 | 0.878 | 0.809 | 0.918 | 0.089 | 0.833 | 0.750 | 0.877 | 0.113 | |
| 6 | 5 | 0.864 | 0.792 | 0.899 | 0.101 | 0.820 | 0.735 | 0.860 | 0.124 | |
| 7 | 5 | 0.855 | 0.782 | 0.891 | 0.105 | 0.812 | 0.727 | 0.852 | 0.127 | |
| 8 | 5 |  | 0.889 | 0.822 | 0.933 | 0.080 | 0.843 | 0.762 | 0.892 | 0.105 |
| 9 | 6 | 0.897 | 0.837 | 0.934 | 0.076 | 0.848 | 0.769 | 0.892 | 0.104 | |
| 10 | 6 |  | 0.916 | 0.860 | 0.958 | 0.061 | 0.865 | 0.789 | 0.914 | 0.091 |
| 11 | 6 | 0.899 | 0.838 | 0.939 | 0.073 | 0.850 | 0.771 | 0.897 | 0.101 | |
| 12 | 6 | 0.911 | 0.853 | 0.952 | 0.065 | 0.860 | 0.784 | 0.909 | 0.094 | |
| 13 | 6 | 0.894 | 0.833 | 0.930 | 0.079 | 0.845 | 0.765 | 0.889 | 0.106 | |
| 14 | 7 | 0.930 | 0.883 | 0.965 | 0.053 | 0.872 | 0.799 | 0.921 | 0.086 | |
| 15 | 7 | 0.928 | 0.880 | 0.966 | 0.053 | 0.872 | 0.800 | 0.921 | 0.086 | |
| 16 | 7 | 0.915 | 0.864 | 0.947 | 0.065 | 0.859 | 0.784 | 0.904 | 0.096 | |
| 17 | 7 |  | 0.934 | 0.887 | 0.972 | 0.049 | 0.877 | 0.806 | 0.927 | 0.082 |
| 18 | 8 | 0.950 | 0.913 | 0.979 | 0.038 | 0.884 | 0.816 | 0.934 | 0.078 | |
| 19 | 8 |  | 0.952 | 0.915 | 0.984 | 0.036 | 0.888 | 0.821 | 0.938 | 0.075 |
| 20 | 9 |  | 0.972 | 0.950 | 0.992 | 0.022 | 0.896 | 0.831 | 0.945 | 0.070 |
| 21 | 10 |  | 1 | 1 | 1 | 0 | 0.904 | 0.842 | 0.952 | 0.064 |
| Incomp. Versus Comp. | Incomp. Versus Initial | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ID | |E| | Graph | PE | EU | PE | EU | ||||
| 1 | 5 |  | 0.837 | 0.743 | 0.860 | 0.123 | 0.805 | 0.703 | 0.828 | 0.139 |
| 19 | 6 | 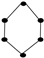 | 0.874 | 0.789 | 0.910 | 0.092 | 0.839 | 0.742 | 0.876 | 0.110 |
| 30 | 7 | 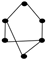 | 0.900 | 0.825 | 0.937 | 0.075 | 0.861 | 0.771 | 0.901 | 0.096 |
| 54 | 8 | 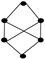 | 0.917 | 0.849 | 0.953 | 0.063 | 0.875 | 0.790 | 0.917 | 0.086 |
| 73 | 9 |  | 0.934 | 0.876 | 0.969 | 0.051 | 0.889 | 0.809 | 0.932 | 0.077 |
| 85 | 10 | 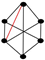 | 0.943 | 0.890 | 0.975 | 0.045 | 0.895 | 0.817 | 0.937 | 0.073 |
| 103 | 11 | 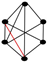 | 0.952 | 0.905 | 0.981 | 0.038 | 0.901 | 0.825 | 0.943 | 0.069 |
| 108 | 12 |  | 0.962 | 0.923 | 0.988 | 0.031 | 0.908 | 0.835 | 0.950 | 0.065 |
| 110 | 13 | 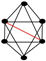 | 0.971 | 0.941 | 0.992 | 0.024 | 0.912 | 0.841 | 0.953 | 0.062 |
| 111 | 14 | 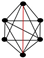 | 0.984 | 0.966 | 0.996 | 0.015 | 0.916 | 0.847 | 0.957 | 0.060 |
| 112 | 15 | 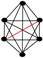 | 1 | 1 | 1 | 0 | 0.920 | 0.853 | 0.961 | 0.057 |
| Incomp. Versus Comp. | Incomp. Versus Initial | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ID | |E| | Graph | PE | EU | PE | EU | ||||
| 1 | 4 |  | 0.932 | 0.885 | 0.968 | 0.052 | 0.922 | 0.869 | 0.961 | 0.058 |
| 2 | 4 | 0.924 | 0.874 | 0.959 | 0.060 | 0.913 | 0.858 | 0.951 | 0.066 | |
| 3 | 4 | 0.917 | 0.865 | 0.951 | 0.066 | 0.906 | 0.849 | 0.942 | 0.073 | |
| 4 | 5 | 0.944 | 0.903 | 0.976 | 0.043 | 0.931 | 0.883 | 0.969 | 0.051 | |
| 5 | 5 | 0.948 | 0.909 | 0.980 | 0.040 | 0.934 | 0.887 | 0.972 | 0.049 | |
| 6 | 5 | 0.941 | 0.899 | 0.974 | 0.046 | 0.928 | 0.879 | 0.966 | 0.054 | |
| 7 | 5 | 0.936 | 0.892 | 0.968 | 0.051 | 0.923 | 0.872 | 0.960 | 0.059 | |
| 8 | 5 | 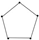 | 0.953 | 0.916 | 0.985 | 0.036 | 0.938 | 0.892 | 0.977 | 0.046 |
| 9 | 6 | 0.957 | 0.923 | 0.985 | 0.034 | 0.941 | 0.898 | 0.977 | 0.043 | |
| 10 | 6 | 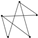 | 0.965 | 0.937 | 0.992 | 0.026 | 0.948 | 0.909 | 0.984 | 0.037 |
| 11 | 6 | 0.956 | 0.923 | 0.986 | 0.033 | 0.941 | 0.898 | 0.978 | 0.043 | |
| 12 | 6 | 0.962 | 0.932 | 0.990 | 0.029 | 0.945 | 0.904 | 0.982 | 0.040 | |
| 13 | 6 | 0.954 | 0.920 | 0.983 | 0.036 | 0.938 | 0.894 | 0.975 | 0.046 | |
| 14 | 7 | 0.971 | 0.947 | 0.993 | 0.022 | 0.952 | 0.914 | 0.986 | 0.035 | |
| 15 | 7 | 0.970 | 0.945 | 0.993 | 0.023 | 0.951 | 0.913 | 0.985 | 0.036 | |
| 16 | 7 | 0.964 | 0.936 | 0.987 | 0.029 | 0.945 | 0.905 | 0.980 | 0.041 | |
| 17 | 7 | 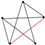 | 0.972 | 0.948 | 0.994 | 0.022 | 0.952 | 0.915 | 0.986 | 0.035 |
| 18 | 8 | 0.979 | 0.960 | 0.996 | 0.016 | 0.956 | 0.921 | 0.988 | 0.032 | |
| 19 | 8 |  | 0.980 | 0.962 | 0.997 | 0.015 | 0.958 | 0.923 | 0.989 | 0.031 |
| 20 | 9 |  | 0.988 | 0.978 | 0.999 | 0.009 | 0.961 | 0.929 | 0.991 | 0.029 |
| 21 | 10 | 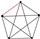 | 1 | 1 | 1 | 0 | 0.964 | 0.933 | 0.992 | 0.027 |
| Incomp. Versus Comp. | Incomp. Versus Initial | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ID | |E| | Graph | PE | EU | PE | EU | ||||
| 1 | 4 | 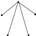 | 0.932 | 0.885 | 0.969 | 0.050 | 0.922 | 0.870 | 0.962 | 0.056 |
| 2 | 4 | 0.925 | 0.875 | 0.961 | 0.057 | 0.914 | 0.859 | 0.953 | 0.064 | |
| 3 | 4 | 0.917 | 0.865 | 0.953 | 0.064 | 0.906 | 0.849 | 0.944 | 0.071 | |
| 4 | 5 | 0.944 | 0.903 | 0.977 | 0.041 | 0.931 | 0.883 | 0.970 | 0.050 | |
| 5 | 5 | 0.948 | 0.910 | 0.981 | 0.038 | 0.935 | 0.888 | 0.973 | 0.047 | |
| 6 | 5 | 0.942 | 0.900 | 0.975 | 0.044 | 0.929 | 0.880 | 0.967 | 0.052 | |
| 7 | 5 | 0.936 | 0.892 | 0.969 | 0.049 | 0.923 | 0.872 | 0.961 | 0.057 | |
| 8 | 5 | 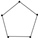 | 0.953 | 0.916 | 0.986 | 0.035 | 0.938 | 0.893 | 0.977 | 0.045 |
| 9 | 6 | 0.957 | 0.924 | 0.985 | 0.032 | 0.942 | 0.899 | 0.978 | 0.042 | |
| 10 | 6 | 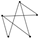 | 0.966 | 0.937 | 0.992 | 0.025 | 0.949 | 0.909 | 0.984 | 0.037 |
| 11 | 6 | 0.956 | 0.923 | 0.986 | 0.032 | 0.941 | 0.899 | 0.978 | 0.042 | |
| 12 | 6 | 0.962 | 0.932 | 0.990 | 0.028 | 0.946 | 0.904 | 0.982 | 0.039 | |
| 13 | 6 | 0.954 | 0.920 | 0.983 | 0.034 | 0.939 | 0.895 | 0.975 | 0.045 | |
| 14 | 7 | 0.971 | 0.947 | 0.993 | 0.022 | 0.952 | 0.915 | 0.986 | 0.034 | |
| 15 | 7 | 0.970 | 0.945 | 0.993 | 0.022 | 0.951 | 0.913 | 0.985 | 0.035 | |
| 16 | 7 | 0.964 | 0.936 | 0.988 | 0.028 | 0.946 | 0.906 | 0.980 | 0.040 | |
| 17 | 7 | 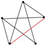 | 0.972 | 0.949 | 0.994 | 0.021 | 0.953 | 0.915 | 0.986 | 0.035 |
| 18 | 8 | 0.979 | 0.960 | 0.996 | 0.016 | 0.957 | 0.922 | 0.988 | 0.031 | |
| 19 | 8 |  | 0.980 | 0.962 | 0.997 | 0.015 | 0.958 | 0.924 | 0.989 | 0.031 |
| 20 | 9 |  | 0.988 | 0.978 | 0.999 | 0.009 | 0.961 | 0.929 | 0.991 | 0.028 |
| 21 | 10 |  | 1 | 1 | 1 | 0 | 0.964 | 0.934 | 0.992 | 0.027 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tóth-Merényi, A.; Mihálykó, C.; Orbán-Mihálykó, É.; Gyarmati, L. Exploring Consistency in the Three-Option Davidson Model: Bridging Pairwise Comparison Matrices and Stochastic Methods. Mathematics 2025, 13, 1374. https://doi.org/10.3390/math13091374
Tóth-Merényi A, Mihálykó C, Orbán-Mihálykó É, Gyarmati L. Exploring Consistency in the Three-Option Davidson Model: Bridging Pairwise Comparison Matrices and Stochastic Methods. Mathematics. 2025; 13(9):1374. https://doi.org/10.3390/math13091374
Chicago/Turabian StyleTóth-Merényi, Anna, Csaba Mihálykó, Éva Orbán-Mihálykó, and László Gyarmati. 2025. "Exploring Consistency in the Three-Option Davidson Model: Bridging Pairwise Comparison Matrices and Stochastic Methods" Mathematics 13, no. 9: 1374. https://doi.org/10.3390/math13091374
APA StyleTóth-Merényi, A., Mihálykó, C., Orbán-Mihálykó, É., & Gyarmati, L. (2025). Exploring Consistency in the Three-Option Davidson Model: Bridging Pairwise Comparison Matrices and Stochastic Methods. Mathematics, 13(9), 1374. https://doi.org/10.3390/math13091374