
YOLO11-Driven Deep Learning Approach for Enhanced Detection and Visualization of Wrist Fractures in X-Ray Images


Abstract
1. Introduction
Contribution
- This study confirms that, compared to the YOLO11 baseline model, the performance of the YOLO11_GAM and ResNet_GAM models shows significant improvement in the GRAZPEDWRI-DX dataset.
- The integration of ResNet_GAM outperforms YOLO11_GAM, demonstrating that ResNet enhances feature extraction capabilities, leading to superior model accuracy.
- Additionally, we explore the use of Squeeze-and-Excitation (SE_BLOCK) in the Backbone part of the architecture, providing a further comparative analysis of attention-based enhancement in convolutional neural networks (CNN) feature learning.
- Section 2 presents an existing study on fracture detection using deep learning and explores the role of attention mechanisms in CNN architectures. Section 3 details the proposed YOLO11_GAM and ResNet_GAM model, along with the SE_Block enhanced architecture used in comparative studies. Section 4 provides a performance analysis of different models, comparing YOLO11_GAM, ResNet_GAM, and the SE_BLOCK-based approach against the baseline YOLO11 model. Section 5 discusses the impact of GAM on fracture detection accuracy, highlights the benefits of combining ResNet with GAM and analyzes the capability of ResNet with the SE_BLOCK in the ablation study. Section 6 concludes this research and overviews future directions.
2. Related Work
2.1. Transforming Medical Imaging with Deep Learning
2.2. Fracture Detection
2.3. YOLO-Based Deep Learning Models
2.4. Two-Stage Detection
2.5. Attention Module
2.6. Identified Gaps and Study Motivation
3. Material and Methods
3.1. Model Architecture
3.2. Backbone
3.2.1. Convolutional Layers (Conv)
3.2.2. C3K2 Blocks (CSP Bottleneck with Kernel Size 2)
3.2.3. Residual Connections (Shortcut = False, n = 3 d)
3.2.4. Residual Connections (Shortcut = True, n = 6 × d)
3.3. Neck
3.3.1. SPFF (Spatial Pyramid Feature Fusion)
3.3.2. C2PSA (Channel and Spatial Attention)
3.3.3. Up-Sampling Operation
3.3.4. Concatenation of Feature Maps
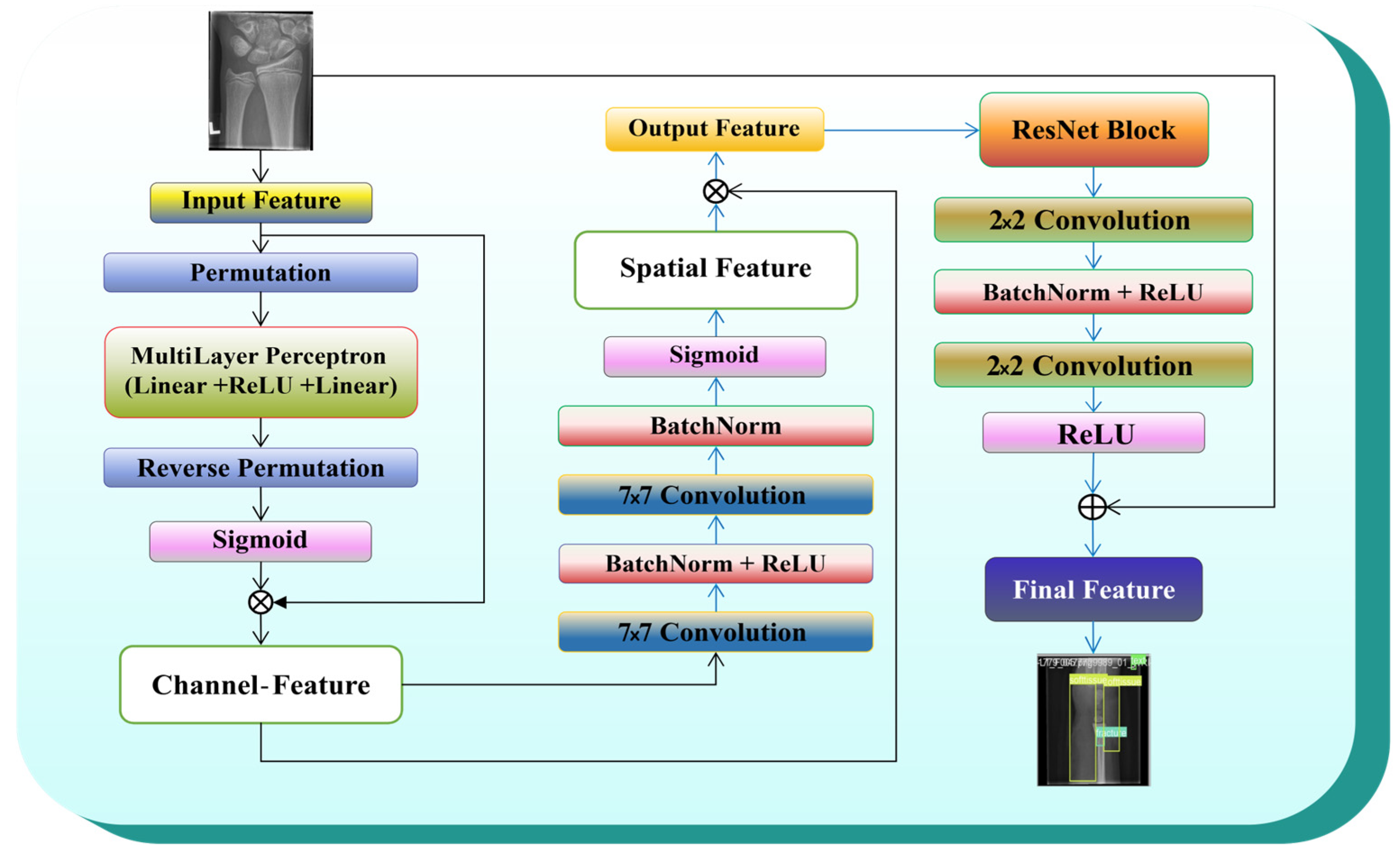
3.3.5. ResNet_GAM
3.4. Head
3.4.1. Feature Maps from the Neck to the Head
3.4.2. Detection (DETECT)
3.5. ResNet with GAM
3.5.1. Global Attention Mechanism (GAM)
3.5.2. Channel Attention Mechanism (CAM)
3.5.3. Spatial Attention Mechanism (SAM)
3.5.4. Residual Block (ResNet_Block)
3.6. Squeeze-and-Excitation (SE_BLOCK)
3.6.1. Squeeze (Global Information Embedding)
3.6.2. Excitation (Channel-Wise Attention)
3.6.3. Rescale (Feature Recalibration)
3.7. Evaluation Matrices
3.7.1. FLOPs (Floating-Point Operations)
3.7.2. Intersection over Union (IoU)
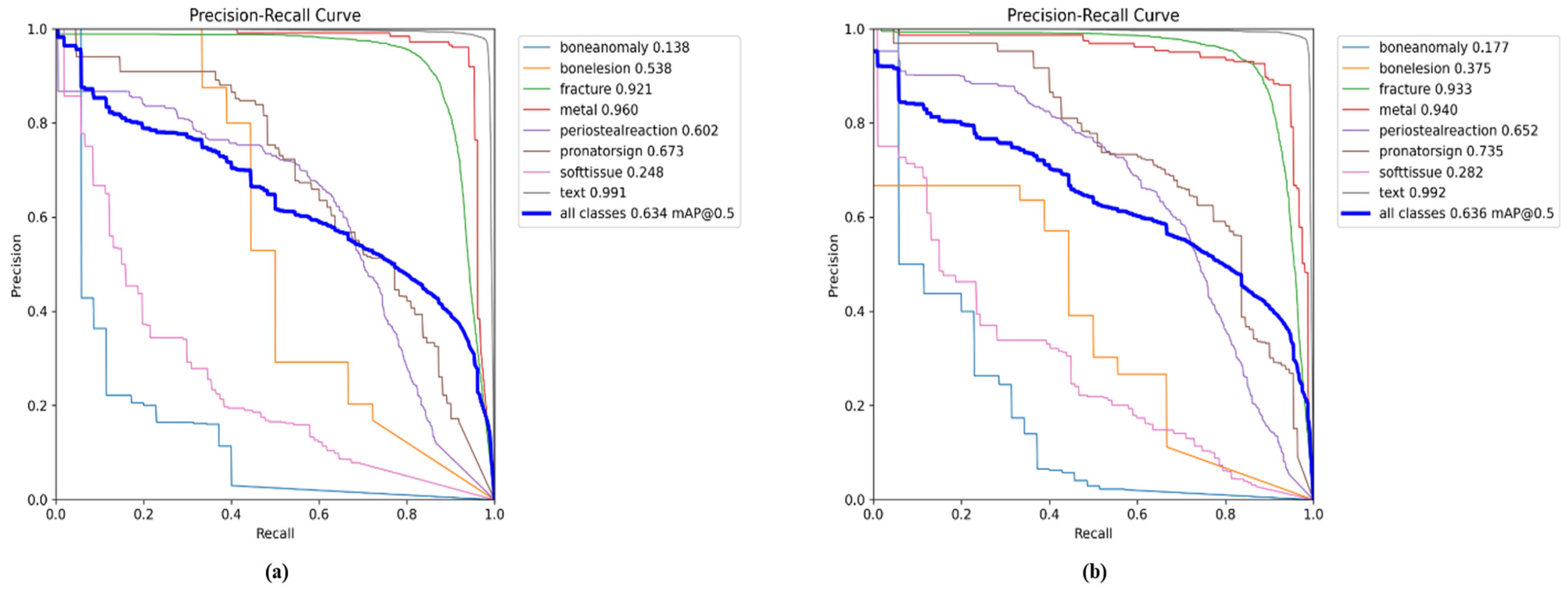
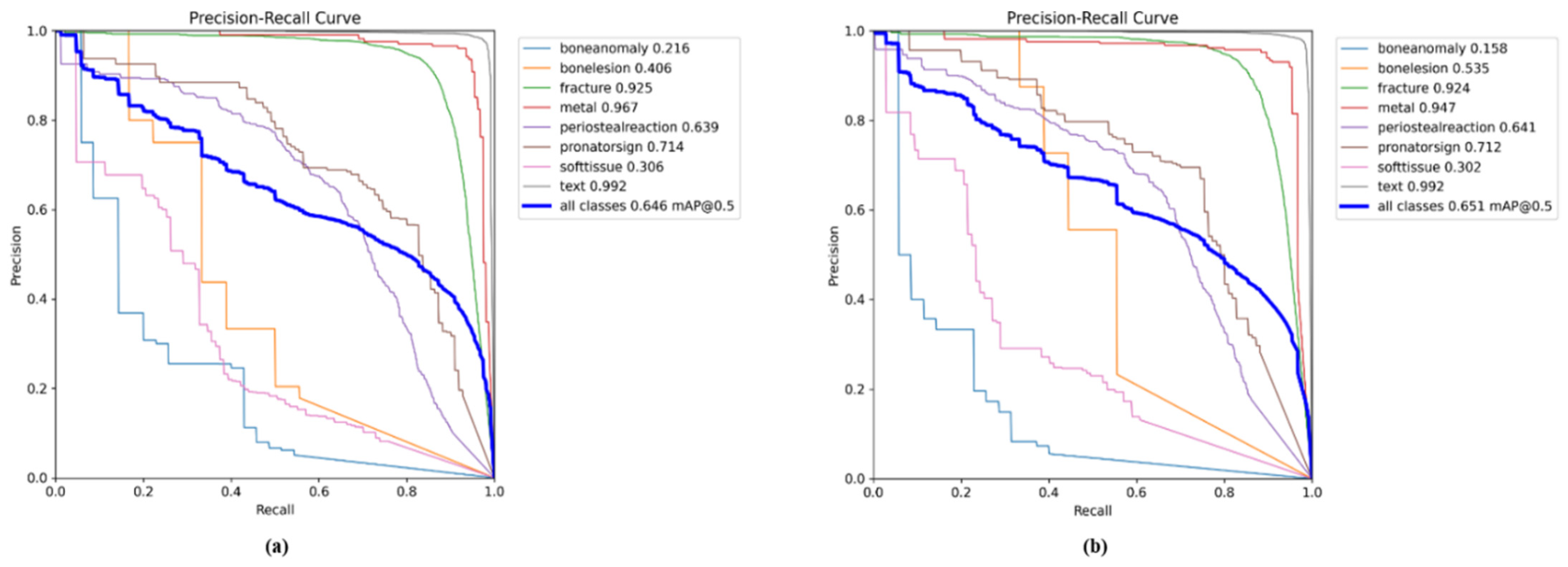
3.7.3. Precision–Recall Curve
3.7.4. Mean Average Precision (mAP)
3.7.5. F1-Score
4. Experimental Settings
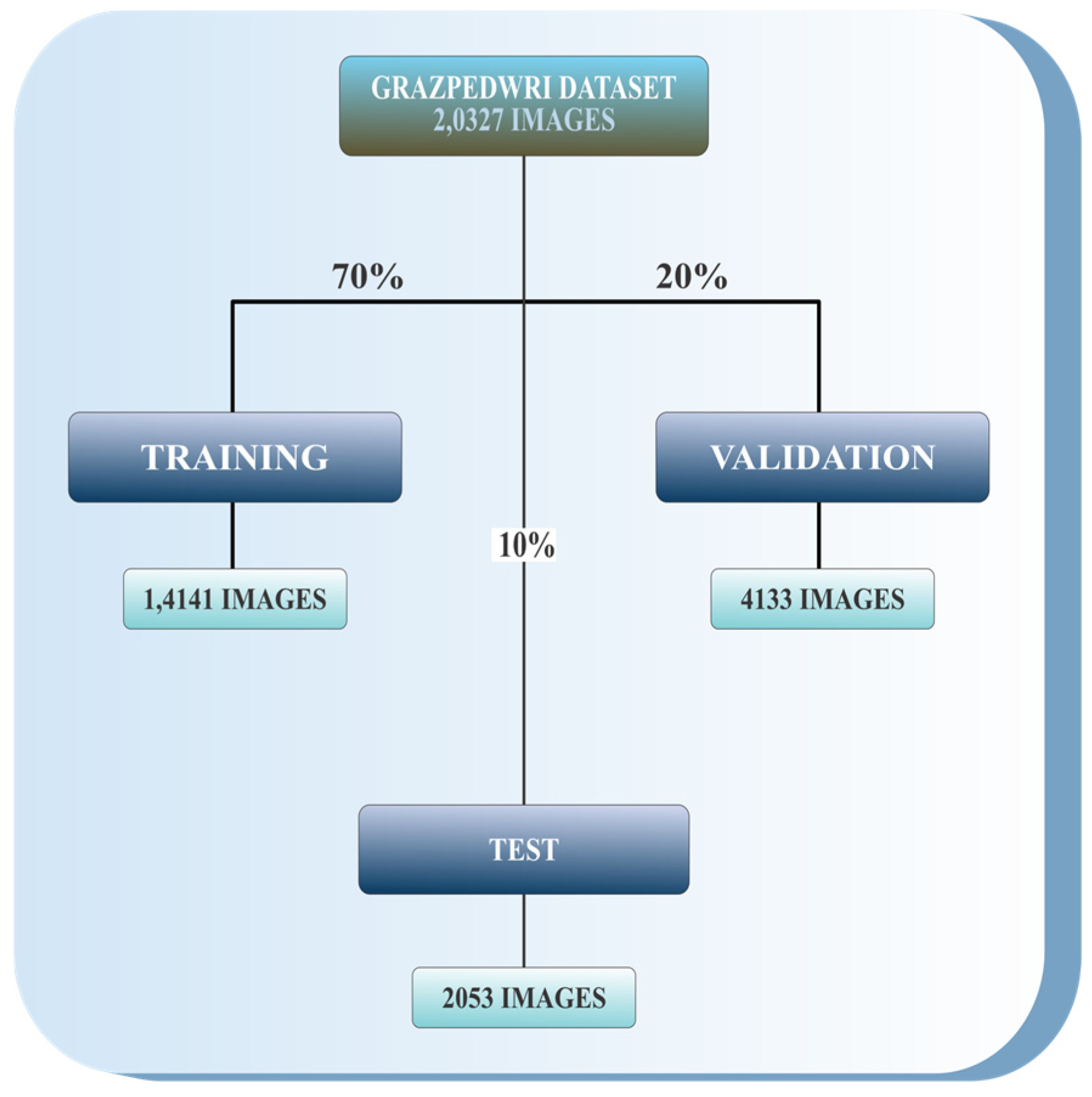
4.1. Dataset
- This dataset is general, containing 20,327 labelled and categorized images, and is ideal for developing and testing computer vision models.
- The dataset includes a wide variety of images capturing early bone development in children.
- Reviewing wrist development at this stage provides important insights for identifying, managing, and preventing abnormalities that might not be noticeable in adult wrists.
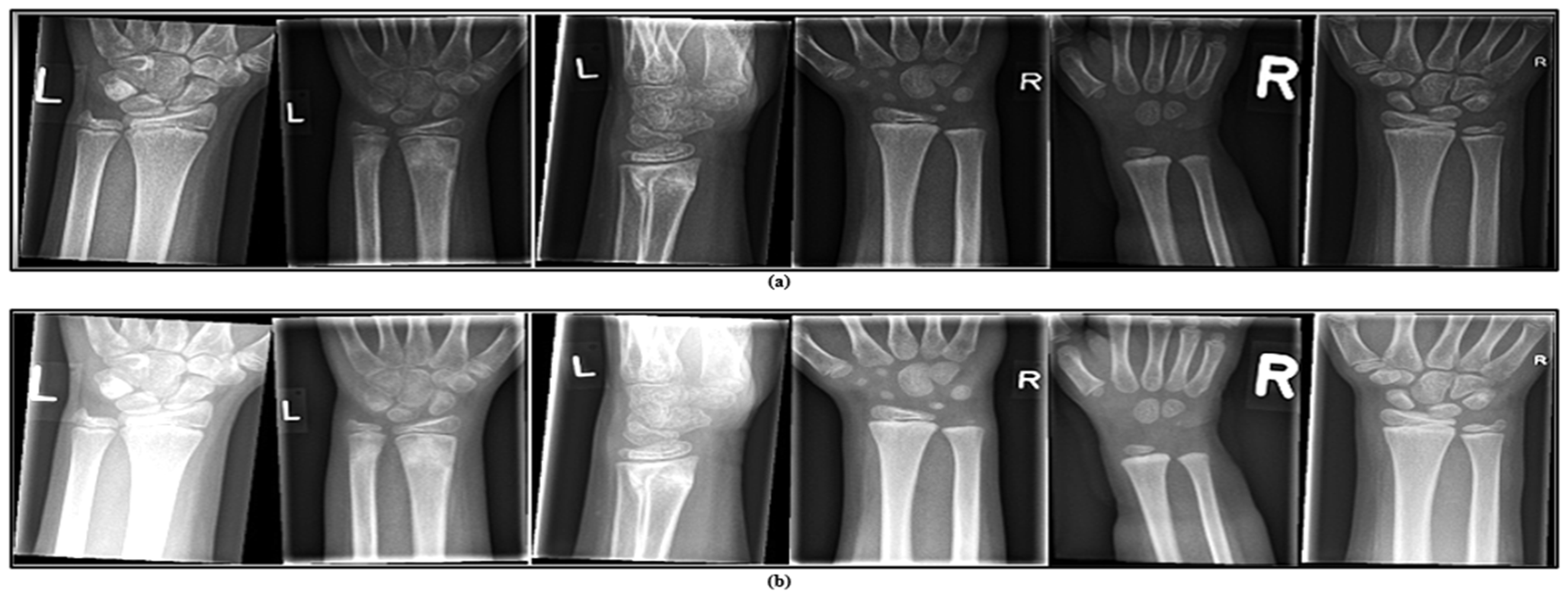
4.2. Data Preprocessing
4.3. Data Augmentation
4.4. Experimental Setup
4.5. Model Training
5. Results and Discussion
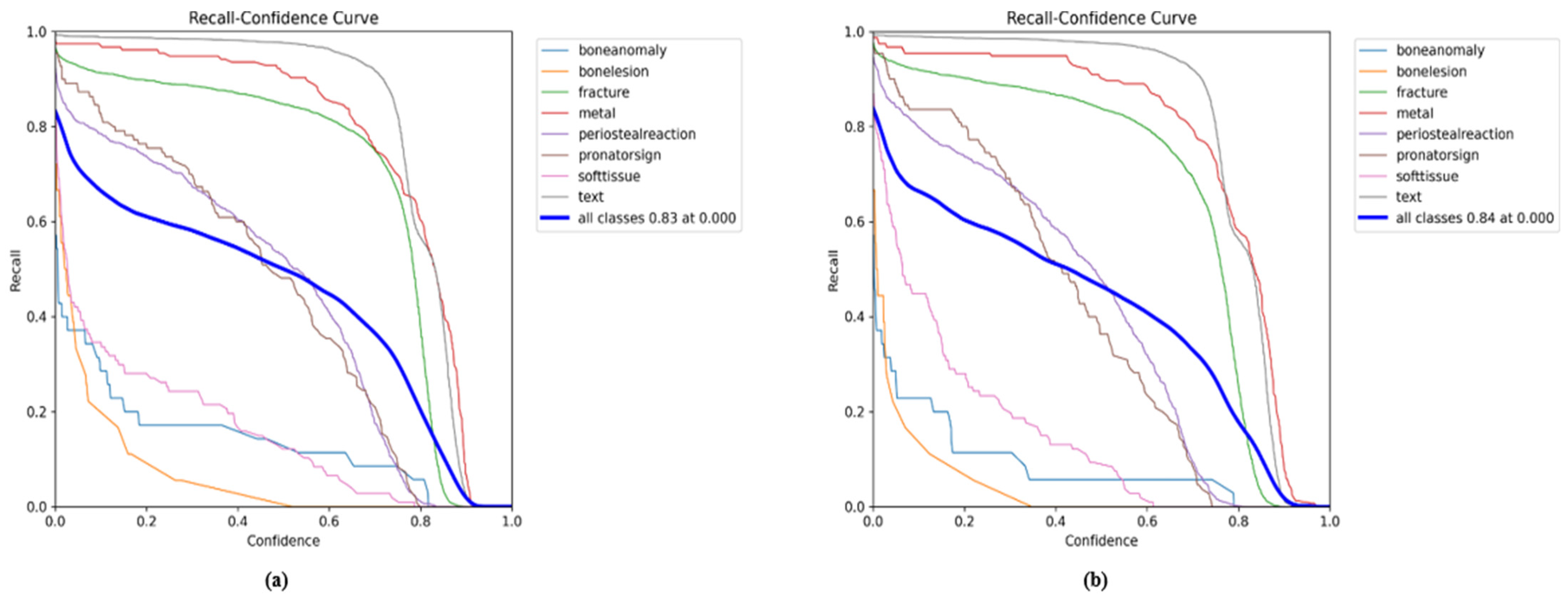
5.1. YOLO11 Results for All Classes
5.2. Comparison Results of YOLO11n with GAM and ResNet_GAM
5.3. Comparison Results of YOLO11s with GAM and ResNet_GAM
5.4. Comparison Results of YOLO11m with GAM and ResNet_GAM
5.5. Fracture Detection of All Model
5.6. GAM and ResNet_GAM Model Performance on Different Image Size
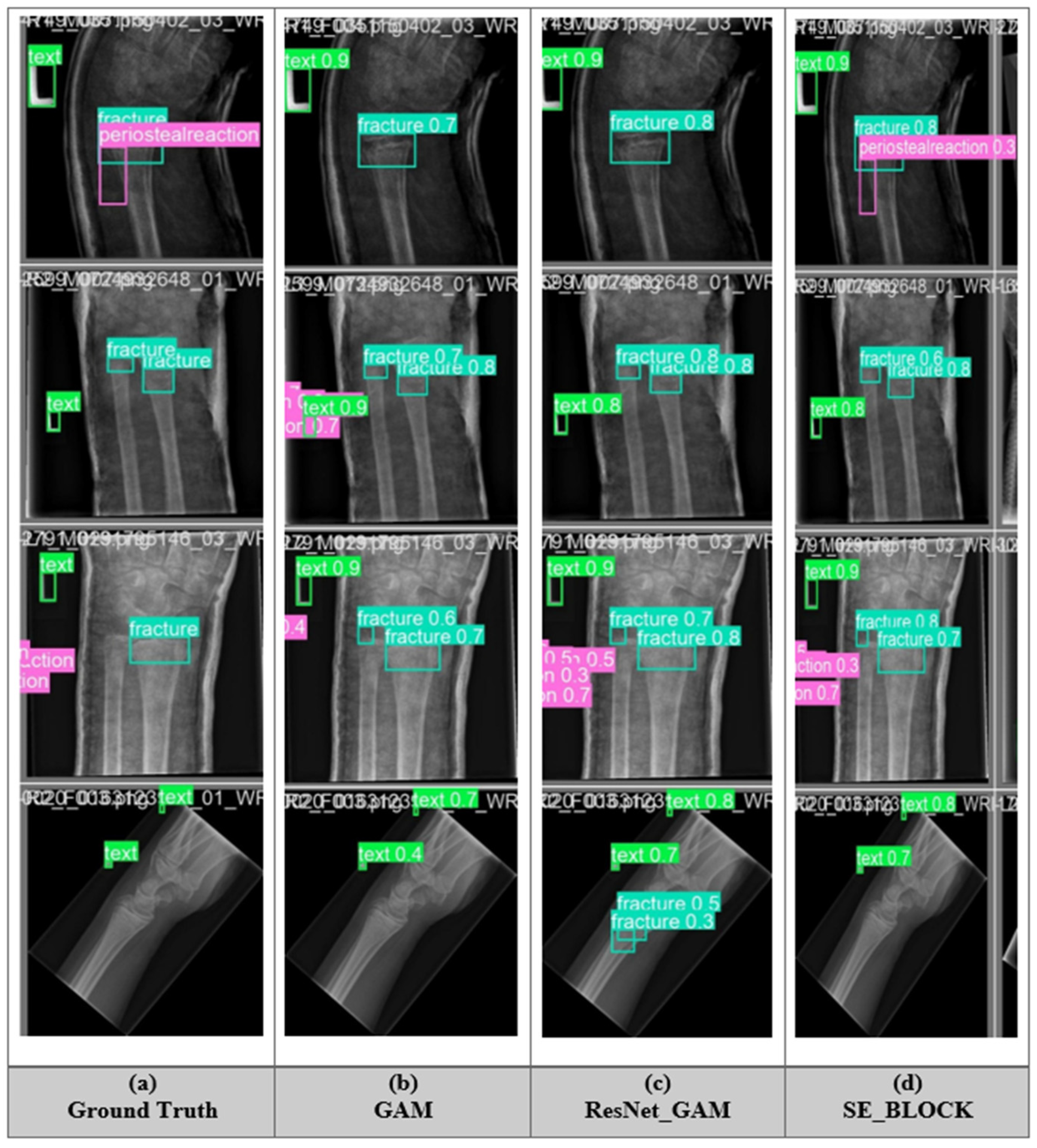
5.7. Ablation Study
5.8. Evaluate the Model Training and Confusion Matrix
5.9. Application
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Abbas, W.; Adnan, S.M.; Javid, M.A.; Majeed, F.; Ahsan, T.; Hassan, S.S. Lower leg bone fracture detection and classification using faster RCNN for X-ray images. In Proceedings of the 2020 IEEE 23rd International Multitopic Conference (INMIC), Bahawalpur, Pakistan, 5–7 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- International Osteoporosis Foundation. Broken Bones, Broken Lives: A Roadmap to Solve the Fragility Fracture Crisis in Europe; International Osteoporosis Foundation: Nyon, Switzerland, 2018. [Google Scholar]
- Hedström, E.M.; Svensson, O.; Bergström, U.; Michno, P. Epidemiology of fractures in children and adolescents: Increased incidence over the past decade: A population-based study from northern Sweden. Acta Orthop. 2010, 81, 148–153. [Google Scholar] [CrossRef] [PubMed]
- Randsborg, P.H.; Gulbrandsen, P.; Benth, J.Š.; Sivertsen, E.A.; Hammer, O.L.; Fuglesang, H.F.; Årøen, A. Fractures in children: Epidemiology and activity-specific fracture rates. JBJS 2013, 95, e42. [Google Scholar] [CrossRef]
- Landin, L.A. Epidemiology of children’s fractures. J. Pediatr. Orthop. B 1997, 6, 79–83. [Google Scholar] [CrossRef]
- Cheng, J.C.; Shen, W.Y. Limb fracture pattern in different pediatric age groups: A study of 3350 children. J. Orthop. Trauma 1993, 7, 15–22. [Google Scholar] [CrossRef]
- McCollough, C.H.; Bushberg, J.T.; Fletcher, J.G.; Eckel, L.J. Answers to common questions about the use and safety of CT scans. Mayo Clin. Proc. 2015, 90, 1380–1392. [Google Scholar] [CrossRef]
- Burr David, B. Introduction–Bone turnover and fracture risk. J. Musculoskelet. Neuronal. Interact. 2003, 3, 408–409. [Google Scholar]
- Yadav, D.P.; Rathor, S. Bone fracture detection and classification using deep learning approach. In Proceedings of the 2020 International Conference on Power Electronics & IoT Applications in Renewable Energy and its Control (PARC), Mathura, India, 28–29 February 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 282–285. [Google Scholar]
- Anu, T.C.; Raman, R. Detection of bone fracture using image processing methods. Int. J. Comput. Appl. 2015, 975, 8887. [Google Scholar]
- Hallas, P.; Ellingsen, T. Errors in fracture diagnoses in the emergency department–characteristics of patients and diurnal variation. BMC Emerg. Med. 2006, 6, 4. [Google Scholar] [CrossRef]
- Guly, H.R. Diagnostic errors in an accident and emergency department. Emerg. Med. J. 2001, 18, 263–269. [Google Scholar] [CrossRef]
- Mounts, J.; Clingenpeel, J.; McGuire, E.; Byers, E.; Kireeva, Y. Most frequently missed fractures in the emergency department. Clin. Pediatr. 2011, 50, 183–186. [Google Scholar] [CrossRef]
- Erhan, E.R.; Kara, P.H.; Oyar, O.; Unluer, E.E. Overlooked extremity fractures in the emergency department. Ulus Travma Acil Cerrahi Derg 2013, 19, 25–28. [Google Scholar]
- Juhl, M.; Moller-Madsen, B.; Jensen, J. Missed injuries in an orthopedic department. Injury 1990, 21, 110–112. [Google Scholar] [CrossRef] [PubMed]
- Burki, T.K. The shortfall of consultant clinical radiologists in the UK. Lancet Oncol. 2018, 19, 518. [Google Scholar] [CrossRef] [PubMed]
- Rimmer, A. Radiologist shortage leaves patient care at risk, warns royal college. BMJ Br. Med. J. 2017, 359, 4683. [Google Scholar] [CrossRef]
- Body, J.J.; Acklin, Y.P.; Gunther, O.; Hechmati, G.; Pereira, J.; Maniadakis, N.; Terpos, E.; Finek, J.; von Moos, R.; Talbot, S.; et al. Pathologic fracture and healthcare resource utilisation: A retrospective study in eight European countries. J. Bone Oncol. 2016, 5, 185–193. [Google Scholar] [CrossRef]
- Rosman, D.A.; Nshizirungu, J.J.; Rudakemwa, E.; Moshi, C.; de Dieu Tuyisenge, J.; Uwimana, E.; Kalisa, L. Imaging in the land of 1000 hills: Rwanda radiology country report. J. Glob. Radiol. 2015, 1, 5. [Google Scholar] [CrossRef]
- Smith-Bindman, R.; Kwan, M.L.; Marlow, E.C.; Theis, M.K.; Bolch, W.; Cheng, S.Y.; Bowles, E.J.; Duncan, J.R.; Greenlee, R.T.; Kushi, L.H.; et al. Trends in use of medicasl imaging in US health care systems and Ontario, Canada, 2000–2016. JAMA 2019, 322, 843–856. [Google Scholar] [CrossRef]
- Chhem, R.K. Radiation protection in medical imaging: A never-ending story? Eur. J. Radiol. 2010, 76, 1–2. [Google Scholar] [CrossRef]
- Neubauer, J.; Benndorf, M.; Reidelbach, C.; Krauß, T.; Lampert, F.; Zajonc, H.; Kotter, E.; Langer, M.; Fiebich, M.; Goerke, S.M. Comparison of diagnostic accuracy of radiation dose-equivalent radiography, multidetector computed tomography, and cone beam computed tomography for fractures of adult cadaveric wrists. PLoS ONE 2016, 11, e0164859. [Google Scholar] [CrossRef]
- Tanzi, L.; Vezzetti, E.; Moreno, R.; Aprato, A.; Audisio, A.; Massè, A. Hierarchical fracture classification of proximal femur X-ray images using a multistage Deep Learning approach. Eur. J. Radiol. 2020, 133, 109373. [Google Scholar] [CrossRef]
- Choi, J.W.; Cho, Y.J.; Lee, S.; Lee, J.; Lee, S.; Choi, Y.H.; Cheon, J.E.; Ha, J.Y. Using a dual-input convolutional neural network for automated detection of pediatric supracondylar fracture on conventional radiography. Investig. Radiol. 2020, 55, 101–110. [Google Scholar] [CrossRef] [PubMed]
- Chung, S.W.; Han, S.S.; Lee, J.W.; Oh, K.S.; Kim, N.R.; Yoon, J.P.; Kim, J.Y.; Moon, S.H.; Kwon, J.; Lee, H.J.; et al. Automated detection and classification of the proximal humerus fracture by using a deep learning algorithm. Acta Orthop. 2018, 89, 468–473. [Google Scholar] [CrossRef] [PubMed]
- Gan, K.; Xu, D.; Lin, Y.; Shen, Y.; Zhang, T.; Hu, K.; Zhou, K.; Bi, M.; Pan, L.; Wu, W.; et al. Artificial intelligence detection of distal radius fractures: A comparison between the convolutional neural network and professional assessments. Acta Orthop. 2019, 90, 394–400. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.H.; MacKinnon, T. Artificial intelligence in fracture detection: Transfer learning from deep convolutional neural networks. Clin. Radiol. 2018, 73, 439–445. [Google Scholar] [CrossRef]
- Lindsey, R.; Daluiski, A.; Chopra, S.; Lachapelle, A.; Mozer, M.; Sicular, S.; Hanel, D.; Gardner, M.; Gupta, A.; Hotchkiss, R.; et al. Deep neural network improves fracture detection by clinicians. Proc. Natl. Acad. Sci. USA 2018, 115, 11591–11596. [Google Scholar] [CrossRef]
- Urakawa, T.; Tanaka, Y.; Goto, S.; Matsuzawa, H.; Watanabe, K.; Endo, N. Detecting intertrochanteric hip fractures with orthopedist-level accuracy using a deep convolutional neural network. Skelet. Radiol. 2019, 48, 239–244. [Google Scholar] [CrossRef]
- Yahalomi, E.; Chernofsky, M.; Werman, M. Detection of distal radius fractures trained by a small set of X-ray images and Faster R-CNN. In Intelligent Computing: Proceedings of the 2019 Computing Conference; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; Volume 1, pp. 971–981. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ju, R.Y.; Chen, C.C.; Chiang, J.S.; Lin, Y.S.; Chen, W.H. Resolution enhancement processing on low-quality images using a swim transformer based on interval interval-dense connection strategy. Multimed. Tools Appl. 2024, 83, 14839–14855. [Google Scholar] [CrossRef]
- Hržić, F.; Tschauner, S.; Sorantin, E.; Štajduhar, I. Fracture recognition in pediatric wrist radiographs: An object detection approach. Mathematics 2022, 10, 2939. [Google Scholar] [CrossRef]
- Samothai, P.; Sanguansat, P.; Kheaksong, A.; Srisomboon, K.; Lee, W. The evaluation of bone fracture detection of yolo series. In Proceedings of the 2022 37th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), Phuket, Thailand, 5–8 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1054–1057. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Wu, S.; Wang, J.; Liu, L.; Chen, D.; Lu, H.; Xu, C.; Hao, R.; Li, Z.; Wang, Q. Enhanced YOLOv5 Object Detection Algorithm for Accurate Detection of Adult Rhynchophorus ferruginous. Insects 2023, 14, 698. [Google Scholar] [CrossRef]
- Das, S.; Bhattachya, D.; Biswas, T. Detection of Bone Fractures Along with Other Abnormalities in Wrist X-Ray Images Using Enhanced-Yolo11. Available online: https://ouci.dntb.gov.ua/en/works/4gVVAd17/ (accessed on 1 April 2025).
- Nagy, E.; Janisch, M.; Hržić, F.; Sorantin, E.; Tschauner, S. A pediatric wrist trauma X-ray dataset (GRAZPEDWRI-DX) for machine learning. Sci. Data 2022, 9, 222. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hardalaç, F.; Uysal, F.; Peker, O.; Çiçeklidağ, M.; Tolunay, T.; Tokgöz, N.; Kutbay, U.; Demirciler, B.; Mert, F. Fracture detection in wrist X-ray images using deep learning-based object detection models. Sensors 2022, 22, 1285. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Faes, L.; Kale, A.U.; Wagner, S.K.; Fu, D.J.; Bruynseels, A.; Mahendiran, T.; Moraes, G.; Shamdas, M.; Kern, C.; et al. A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging: A systematic review and meta-analysis. Lancet Digit. Health 2019, 1, e271–e297. [Google Scholar] [CrossRef]
- Xu, Y.; Hosny, A.; Zeleznik, R.; Parmar, C.; Coroller, T.; Franco, I.; Mak, R.H.; Aerts, H.J. Deep learning predicts lung cancer treatment response from serial medical imaging. Clin. Cancer Res. 2019, 25, 3266–3275. [Google Scholar] [CrossRef]
- Zhou, S.K.; Greenspan, H.; Davatzikos, C.; Duncan, J.S.; Van Ginneken, B.; Madabhushi, A.; Prince, J.L.; Rueckert, D.; Summers, R.M. A review of deep learning in medical imaging: Imaging traits, technology trends, case studies with progress highlights, and future promises. Proc. IEEE 2021, 109, 820–838. [Google Scholar] [CrossRef]
- Rahimzadeh, M.; Attar, A.; Sakhaei, S.M. A fully automated deep learning-based network for detecting COVID-19 from a new and large lung CT scan dataset. Biomed. Signal Process. Control. 2021, 68, 102588. [Google Scholar] [CrossRef] [PubMed]
- Kalmet, P.H.; Sanduleanu, S.; Primakov, S.; Wu, G.; Jochems, A.; Refaee, T.; Ibrahim, A.; Hulst, L.V.; Lambin, P.; Poeze, M. Deep learning in fracture detection: A narrative review. Acta Orthop. 2020, 91, 215–220. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, C.I.; Zheng, K.; Lin, C.; Mei, L.; Lu, L.; Li, W.; Chen, F.P.; Wang, Y.; Zhou, X.; Wang, F.; et al. Automated bone mineral density prediction and fracture risk assessment using plain radiographs via deep learning. Nat. Commun. 2021, 12, 472. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Detecting apples in orchards using YOLOv3 and YOLOv5 in general and close-up images. In Advances in Neural Networks–ISNN 2020: 17th International Symposium on Neural Networks, ISNN 2020, Cairo, Egypt, 4–6 December 2020; Proceedings 17; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 233–243. [Google Scholar]
- Burkow, J.; Holste, G.; Otjen, J.; Perez, F.; Junewick, J.; Alessio, A. Avalanche decision schemes to improve pediatric rib fracture detection. In Medical Imaging 2022: Computer-Aided Diagnosis; SPIE: Washington, WA, USA, 2022; Volume 12033, pp. 611–618. [Google Scholar]
- Tsai, H.C.; Qu, Y.Y.; Lin, C.H.; Lu, N.H.; Liu, K.Y.; Wang, J.F. Automatic rib fracture detection and localization from frontal and oblique chest X-rays. In Proceedings of the 2022 10th International Conference on Orange Technology (ICOT), Shanghai, China, 10–11 November 2022; pp. 1–4. [Google Scholar]
- Warin, K.; Limprasert, W.; Suebnukarn, S.; Paipongna, T.; Jantana, P.; Vicharueang, S. Maxillofacial fracture detection and classification in computed tomography images using convolutional neural network-based models. Sci. Rep. 2023, 13, 3434. [Google Scholar] [CrossRef]
- Yuan, G.; Liu, G.; Wu, X.; Jiang, R. An improved yolov5 for skull fracture detection. In International Symposium on Intelligence Computation and Applications; Springer Nature: Singapore, 2021; pp. 175–188. [Google Scholar]
- Mushtaq, M.; Akram, M.U.; Alghamdi, N.S.; Fatima, J.; Masood, R.F. Localization and edge-based segmentation of lumbar spine vertebrae to identify the deformities using deep learning models. Sensors 2022, 22, 1547. [Google Scholar] [CrossRef]
- Meza, G.; Ganta, D.; Gonzalez Torres, S. Deep Learning Approach for Arm Fracture Detection Based on an Improved YOLOv8 Algorithm. Algorithms 2024, 17, 471. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.; Luo, Y. Bone fracture detection through the two-stage system of Crack-Sensitive Convolutional Neural Network. Inf. Med. Unlocked 2020, 22, 100452. [Google Scholar] [CrossRef]
- Su, Z.; Adam, A.; Nasrudin, M.F.; Ayob, M.; Punganan, G. Skeletal fracture detection with deep learning: A comprehensive review. Diagnostics 2023, 13, 3245. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Tran, T.B.; Tran, T.T. Fracture Detection in Bone: An Approach with Versions of YOLOv4. SN Comput. Sci. 2024, 5, 765. [Google Scholar] [CrossRef]
- Sha, G.; Wu, J.; Yu, B. Detection of spinal fracture lesions based on improved Yolov2. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 27–29 June 2020; pp. 235–238. [Google Scholar]
- Fan, Q.; Brown, L.; Smith, J. A closer look at Faster R-CNN for vehicle detection. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 124–129. [Google Scholar]
- Thian, Y.L.; Li, Y.; Jagmohan, P.; Sia, D.; Chan, V.E.Y.; Tan, R.T. Convolutional neural networks for automated fracture detection and localization on wrist radiographs. Radiol. Artif. Intell. 2019, 1, e180001. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Chen, Y.; Kalantidis, Y.; Li, J.; Yan, S.; Feng, J. A^ 2-nets: Double attention networks. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spacial Interaction. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Zhang, Q.L.; Yang, Y.B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2235–2239. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Jegham, N.; Koh, C.Y.; Abdelatti, M.; Hendawi, A. YOLO Evolution: A Comprehensive Benchmark and Architectural Review of YOLOv12, YOLO11, and Their Previous Versions. Yolo11, and Their Previous Versions. arXiv 2025, arXiv:2411.00201. [Google Scholar]
- Ke, H.; Li, H.; Wang, B.; Tang, Q.; Lee, Y.H.; Yang, C.F. Integrations of LabelImg, You Only Look Once (YOLO), and Open-Source Computer Vision Library (OpenCV) for Chicken Open Mouth Detection. Sens. Mater. 2024, 36, 4903. [Google Scholar] [CrossRef]
- Ahmed, A.; Imran, A.S.; Manaf, A.; Kastrati, Z.; Daudpota, S.M. Enhancing wrist abnormality detection with yolo: Analysis of state-of-the-art single-stage detection models. Biomed. Signal Process. Control. 2024, 93, 106144. [Google Scholar] [CrossRef]
- Ju, R.Y.; Cai, W. Fracture detection in pediatric wrist trauma X-ray images using YOLOv8 algorithm. Sci. Rep. 2023, 13, 20077. [Google Scholar] [CrossRef] [PubMed]
- Till, T.; Tschauner, S.; Singer, G.; Lichtenegger, K.; Till, H. Development and optimization of AI algorithms for wrist fracture detection in children using a freely available dataset. Front. Pediatr. 2023, 11, 1291804. [Google Scholar] [CrossRef] [PubMed]
- Erzen, E.M.; BÜtÜn, E.; Al-Antari, M.A.; Saleh, R.A.; Addo, D. Artificial Intelligence Computer-Aided Diagnosis to automatically predict the Pediatric Wrist Trauma using Medical X-ray Images. In Proceedings of the 2023 7th International Symposium on Innovative Approaches in Smart Technologies (ISAS), Istanbul, Turkey, 23–25 November 2023; pp. 1–7. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classes (640) | Images | Instances | Precision | Recall | mAPval 50 | mAPval 50-95 |
|---|---|---|---|---|---|---|
| Bone anomaly | 30 | 35 | 0.59 | 0.171 | 0.241 | 0.111 |
| Bone lesion | 15 | 18 | 1.0 | 0.148 | 0.547 | 0.262 |
| Fracture | 2821 | 3789 | 0.81 | 0.902 | 0.93 | 0.55 |
| Metal | 133 | 155 | 0.88 | 0.955 | 0.967 | 0.799 |
| Periosteal reaction | 451 | 696 | 0.51 | 0.711 | 0.639 | 0.307 |
| Pronator sign | 110 | 110 | 0.62 | 0.745 | 0.714 | 0.389 |
| Soft tissue | 99 | 107 | 0.43 | 0.327 | 0.306 | 0.149 |
| Text | 4123 | 4790 | 0.96 | 0.984 | 0.992 | 0.752 |
| Classes (1024) | Images | Instances | Precision | Recall | mAPval 50 | mAPval 50-95 |
|---|---|---|---|---|---|---|
| Bone anomaly | 30 | 35 | 1.0 | 0.113 | 0.205 | 0.084 |
| Bone lesion | 15 | 18 | 1.0 | 0.257 | 0.535 | 0.274 |
| Fracture | 2821 | 3789 | 0.87 | 0.894 | 0.938 | 0.559 |
| Metal | 133 | 155 | 0.85 | 0.942 | 0.966 | 0.763 |
| Periosteal reaction | 451 | 696 | 0.44 | 0.76 | 0.652 | 0.327 |
| Pronator sign | 110 | 110 | 0.70 | 0.726 | 0.737 | 0.413 |
| Soft tissue | 99 | 107 | 0.61 | 0.175 | 0.304 | 0.143 |
| Text | 4123 | 4790 | 0.95 | 0.987 | 0.992 | 0.758 |
| Model-11n | Input Size | Prams (M) | Inference (ms) | GFLOP’s | Precision | Recall | mAPval 50 | mAPval 50-95 |
|---|---|---|---|---|---|---|---|---|
| YOLO11 | 640 | 2.583 | 1.1 | 6.3 | 0.680 | 0.553 | 0.585 | 0.380 |
| GAM | 640 | 3.548 | 0.8 | 14.4 | 0.706 | 0.549 | 0.603 | 0.382 |
| RES_GAM | 640 | 5.393 | 0.9 | 15.2 | 0.723 | 0.554 | 0.611 | 0.376 |
| YOLO11 | 1024 | 2.583 | 1.3 | 6.3 | 0.703 | 0.565 | 0.588 | 0.381 |
| GAM | 1024 | 3.547 | 2.2 | 11.4 | 0.799 | 0.554 | 0.617 | 0.378 |
| RES_GAM | 1024 | 5.399 | 2.2 | 15.2 | 0.717 | 0.602 | 0.624 | 0.380 |
| Model-11m | Input Size | Prams (M) | Inference (ms) | GFLOP’s | Precision | Recall | mAPval 50 | mAPval 50-95 |
|---|---|---|---|---|---|---|---|---|
| YOLO11 | 640 | 20.93 | 2.3 | 67.7 | 0.639 | 0.599 | 0.626 | 0.415 |
| GAM | 640 | 35.288 | 4.0 | 163.5 | 0.731 | 0.601 | 0.618 | 0.383 |
| RES_GAM | 640 | 50.631 | 5.7 | 212.6 | 0.623 | 0.639 | 0.637 | 0.394 |
| YOLO11 | 1024 | 20.036 | 5.4 | 67.7 | 0.639 | 0.610 | 0.638 | 0.417 |
| GAM | 1024 | 35.288 | 12.5 | 163.5 | 0.573 | 0.632 | 0.636 | 0.396 |
| RES_GAM | 1024 | 50.631 | 9.8 | 212.6 | 0.633 | 0.590 | 0.641 | 0.397 |
| Model-11s | Input Size | Prams (M) | Inference (ms) | GFLOP’s | Precision | Recall | mAPval 50 | mAPval 50-95 |
|---|---|---|---|---|---|---|---|---|
| YOLO11 | 640 | 9.416 | 2.2 | 21.3 | 0.665 | 0.551 | 0.606 | 0.392 |
| GAM | 640 | 14.101 | 1.8 | 45.1 | 0.649 | 0.633 | 0.617 | 0.385 |
| RES_GAM | 640 | 21.479 | 2.1 | 60.2 | 0.692 | 0.603 | 0.627 | 0.394 |
| YOLO11 | 1024 | 9.416 | 2.8 | 21.2 | 0.546 | 0.574 | 0.608 | 0.398 |
| GAM | 1024 | 14.101 | 4.4 | 45.1 | 0.666 | 0.598 | 0.626 | 0.392 |
| RES_GAM | 1024 | 21.479 | 5.7 | 60.2 | 0.653 | 0.615 | 0.643 | 0.408 |
| SE_BLOCK | Input Size | Prams (M) | Inference (ms) | GFLOP’s | Precision | Recall | mAPval 50 | mAPval 50-95 |
|---|---|---|---|---|---|---|---|---|
| YOLO11 | 640 | 25.286 | 3.4 | 60.0 | 0.637 | 0.606 | 0.635 | 0.423 |
| SE_BLOCK | 640 | 49.318 | 4.7 | 172.3 | 0.700 | 0.614 | 0.646 | 0.408 |
| YOLO11 | 1024 | 25.286 | 8.2 | 86.6 | 0.680 | 0.613 | 0.646 | 0.425 |
| SE_BLOCK | 1024 | 49.319 | 11.5 | 172.3 | 0.705 | 0.605 | 0.651 | 0.410 |
| Model | Precision | mAPval 50 |
|---|---|---|
| YOLOv5n [71] | 0.77 | 0.590 |
| YOLOv6n [71] | 0.50 | 0.510 |
| YOLOv7n [71] | 0.59 | 0.500 |
| YOLOv8n [71] | 0.73 | 0.590 |
| YOLOv6s [71] | 0.51 | 0.620 |
| YOLOv6m [71] | 0.59 | 0.64 |
| YOLOv8m [71] | 0.60 | 0.60 |
| YOLOv6L [71] | 0.60 | 0.640 |
| Ours YOLO-11n | 0.79 | 0.610 |
| Ours YOLO-11s | 0.69 | 0.627 |
| Ours YOLO-11m | 0.63 | 0.641 |
| Ours YOLO-11L | 0.70 | 0.651 |
| Model | mAPval 50 | mAPval 50-95 |
|---|---|---|
| Image Size-640 | ||
| YOLOv6n [72] | 0.605 | 0.379 |
| YOLOv7n [72] | 0.612 | 0.392 |
| YOLOv8n [72] | 0.629 | 0.404 |
| YOLOv6s [72] | 0.637 | 0.406 |
| Image Size-1024 | ||
| YOLOv8m [72] | 0.608 | 0.391 |
| YOLOv6L [72] | 0.631 | 0.402 |
| YOLOv8m [72] | 0.635 | 0.411 |
| YOLOv6L [72] | 0.638 | 0.415 |
| Ours Image Size-640 | ||
| YOLO-11n | 0.611 | 0.376 |
| YOLO-11s | 0.627 | 0.394 |
| YOLO-11m | 0.637 | 0.394 |
| YOLO-11L | 0.646 | 0.408 |
| Ours Image Size-1024 | ||
| YOLO-11n | 0.624 | 0.380 |
| YOLO-11s | 0.643 | 0.408 |
| YOLO-11m | 0.641 | 0.397 |
| YOLO-11L | 0.651 | 0.410 |
| Model | Precision | Recall | mAPval 50 | mAPval 50-95 |
|---|---|---|---|---|
| YOLOv7 [73] | 0.774 | 0.536 | 0.544 | 0.326 |
| YOLOv8 [74] | 0.778 | 0.546 | 0.591 | 0.372 |
| Ours YOLO-11 | 0.799 | 0.554 | 0.617 | 0.378 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tariq, M.; Choi, K. YOLO11-Driven Deep Learning Approach for Enhanced Detection and Visualization of Wrist Fractures in X-Ray Images. Mathematics 2025, 13, 1419. https://doi.org/10.3390/math13091419
Tariq M, Choi K. YOLO11-Driven Deep Learning Approach for Enhanced Detection and Visualization of Wrist Fractures in X-Ray Images. Mathematics. 2025; 13(9):1419. https://doi.org/10.3390/math13091419
Chicago/Turabian StyleTariq, Mubashar, and Kiho Choi. 2025. "YOLO11-Driven Deep Learning Approach for Enhanced Detection and Visualization of Wrist Fractures in X-Ray Images" Mathematics 13, no. 9: 1419. https://doi.org/10.3390/math13091419
APA StyleTariq, M., & Choi, K. (2025). YOLO11-Driven Deep Learning Approach for Enhanced Detection and Visualization of Wrist Fractures in X-Ray Images. Mathematics, 13(9), 1419. https://doi.org/10.3390/math13091419