1. Introduction
In recent years, parallel machine scheduling problems (PMSPs) have attracted significant attention because they are used in different industrial applications and considered to be important key factors for sustainability at the operational level [
1,
2,
3]. This kind of problems aims at assigning a set of jobs to a number of parallel machines with satisfying the requirements of the customers [
4]. In general, there are three classes of the PMSPs, namely uniform, identical, and unrelated parallel machine scheduling problem (UPMSPs). However, the uniform and identical are considered as special cases of the UPMSPs, where different machines have different capabilities that are used to perform the same function. Also, if the processing times of the jobs are dependent on the machine to which these jobs are assigned, the machines are called unrelated machines.
The UPMSPs have been applied to different applications such as the mass production lines that use banks of machines with different capabilities and age to perform production tasks and those that are used in drilling operations in a printed circuit board factory [
5] and scheduling jobs on a printed wiring board manufacturing line [
6]. In addition, they are used in the textile industry and tested models as in [
7], and the dicing of semiconductor wafer manufacturing [
8]. There are several other applications, including multiprocessor computers and docking systems for ships [
9].
In general, the UPMSPs are considered as a set of
N jobs that must be executed on only one machine
M from a set of unrelated parallel machines (
) minimizing the makespan (
), where the
nth job consists of a single task that demands a given processing time. In addition, the sequence-dependent setup times (
) between the jobs is studied since it is a very common issue in the industry. This means that there exists a difference between the setup time required for two consecutive jobs (
i and
j) on machine
and the reverse two jobs (i.e., the setup time on machine
k between the jobs
j and
i). Also, the setup time between the jobs
i and
j on machine
k is different from the setup time of the same jobs on another machine
(i.e., there exists a unique setup
matrix for each machine) [
10]. According to these definitions, this problem can be represented as
.
The UPMSPs are considered as an NP-hard problem and they are extremely important requirements in practice [
11]. According to this information, the traditional algorithm can be used to find the optimal solution for a small number of instances; however, if the problem has a large number of instances it is very difficult. Therefore, several methods have been proposed to solve the UPMSPs that considered the setup times [
12], and they provide good results. Examples of these methods are simulated annealing (SA) [
13,
14], Tabu Search (TS) algorithm [
15], and firefly algorithm [
16].
In this paper, an alternative method is proposed to solve the UPMSPs, which is a hybrid between the SA algorithm and Sine Cosine Algorithm (SCA). The SCA is used to improve the exploitation ability of SA, where SA is used as a local search method. The proposed algorithm, namely SASCA, starts by generating a random integer solution that represents the solution for the UPMSPs. This solution has dimensions equal to the number of jobs and each value of it refers to the machine index in which the job must be performed on it. The next step of the proposed method is to select a new solution from the neighbors of the current solutions and compare the quality of them and select the best to represent the current solution. However, to ensure the ability of SA to avoid getting stuck in a local point, the operators of SCA is used to improve the current solution in which the sine and cosine functions are used. The previous steps are repeated until the stop conditions are met.
The main contributions of this paper can be summarized as:
A newly proposed method combines the SA and SCA to update the solutions by their properties. Based on these properties the convergence toward the optimal solution increased.
The proposed method aims at minimizing the makespan in solving the unrelated parallel machine scheduling problem (UPMSP) with sequence-dependent and machine-dependent setup times.
A comparison is provided between the proposed method and other meta-heuristics algorithms.
The rest of this paper is organized as the following:
Section 2 gives a review of some related works for the recent UPMSP methods.
Section 3 presents the preliminaries about the Mixed Integer Programming for the UPMSP, Simulated Annealing Algorithm, and Sine Cosine Algorithm. In
Section 4, the proposed method based on the hybrid between the SA and SCA is introduced to solve the UPMSP problem.
Section 5 presents the results and discussion of the proposed method against the other algorithms. The conclusion and future works are presented in
Section 6.
2. Literature Review
Several meta-heuristic algorithms have been used to solve UPMSPs in the literature [
16]. For example, Logendran et al. [
17] proposed a different six algorithms based on the TS to solve the same problem. In contrast, Bozorgirad and Logendran [
18] used the TS algorithm to solve the sequence-dependent group-scheduling problem using unrelated-parallel machines; however, the time of execution for every job differs on different machines. Another Tabu search method based on a hybrid concept was proposed in [
19] which combined the properties of the variable neighborhood descent approach with the TS algorithm. This algorithm was used to solve UPMSP with sequence-dependent setup times and unequal ready times and the objective function was the weighted number of tardy jobs.
In addition, Eva and Rubén [
20] provided a method based on the improvement of the Genetic Algorithm (GA) to solve the same problem but with sequence-dependent setup times. In this modified version of GA, the fast local search and a local search enhanced crossover operator are used. Duygu et al. [
21] proposed hybrid GA with a local search method that aimed at the same problem except the modification was to minimize the relocation operation of random key numbers for genes. Also, the GA was proposed in [
22] to minimize the total completion time and the number of tardy for UPMSPs with sequence-dependent and machine-dependent setup times, due-times, and ready times.
The Ant Colony Optimization (ACO) algorithm was used to solve the unrelated PMSPs as in [
23] which provides results better than TS algorithm and a heuristic algorithm, called Partitioning Heuristic (PH) proposed in [
24]. The author of [
23] proposed an extension to this study in [
25]. They highlighted the difference between the two methods, whereas, in [
23] the performance of ACO was evaluated over only preliminary tests where the parameters of ACO were selected by trial and error. Also, a small number of instances and limited problem structures were used, and the results of ACO was only compared with PH and TS. However, in [
25], the results were compared with Metaheuristic for Randomized Priority Search (MetaRaPS) [
26]. Moreover, another enhancement of ACO was introduced by the same authors to solve the same problem as in [
27] which enhanced the parameters of ACO such as pheromone. The authors concluded that the result of the ACO-II was better than the ACO-I, MetaRaPS, and Simulated Annealing (SA). Lin and Hsieh [
28] used a modified version of ACO algorithm to solve unrelated PMSOs with set-up times and ready times for minimizing the total weighted tardiness. They proposed a heuristic and iterated hybrid metaheuristic methods to solve the problem and according to the evaluation results, the IHM was better than the ACO and TS.
Sheremetov et al. [
29] presented a two-stage GA algorithm to solve UPSMPs of the steam generators for oil cyclic steam stimulation. They considered this petroleum problem as a parallel uniform machine scheduling and they addressed the makespan and the job’s tardiness.
Nguyen and Toggenburger [
2] proposed a mixed-integer linear programming scheme to address the scheduling problem of the identical machines with an additional resource. Ezugwu [
30] presented a solution method to non-pre-emptive UPMS problems to minimize the makespan. Three methods were proposed to solve UPMS problems, namely SA, Hybrid Symbiotic Organisms Search with SA, and Organisms Search algorithm. As the author described, these algorithms outperform existed methods in case of 120 jobs with 12 machines. In addition, a modified differential evolution algorithm was proposed to improve the consumption of energy problem for the UPSMPs [
31]. The developed method characterized each job by determining speed vectors. In [
15], the TS algorithm was applied to large scale UPSMPs according to its multiple-jump strategy. Bektur and Saraç [
12] developed the performance of SA and TS by combining both of them together with a mixed-integer linear programming scheme as an alternative UPSMPs method. This method aims to minimize the total weighted tardiness of the UPSMPs.
In the same context, the SA algorithm was used to solve the unrelated PMSP with machine-independent sequence-dependent setup times for which the total tardiness was the objective function used as in [
32]. However, the SA suffers from some limitations, similar to other single-based meta-heuristic algorithms, such as with increasing the number of jobs, the number of solutions generated from the neighborhood extremely grows. Therefore, determining an efficient solution needs a large computation time, also there is a high probability that the SA can get stuck in a local point. Therefore, all of these points motivated us to provide an alternative method to solve the UPMSP by improving the SA algorithm using the Sine Cosine Algorithm (SCA).
The SCA is a meta-heuristic algorithm proposed in [
33] to solve the global optimization problems. The solutions are updated in SCA through using either the sine or the cosine functions. The SCA has a small number of parameters and also its ability to find the optimal solution is better than other metaheuristic (MH) algorithms; therefore, the SCA has been used in many fields. For examples, Elaziz et al., in [
34] applied SCA to solve features selection problem; whereas, in [
35] SCA was used to select the relevant features to enhance the performance of classification the galaxy images. The authors of [
36] efficiently applied SCA to train the feed-forward neural network. Moreover, the improvement of the data clustering by the SCA was used to determine the cluster centers process [
37]. Ramanaiah and Reddy [
38] solved the Unified Power Quality Conditioner (UPQC) problem using the SCA. Also, the SCA was applied to estimate the parameters of the kernel of Support Vector Regression (SVR) [
39].
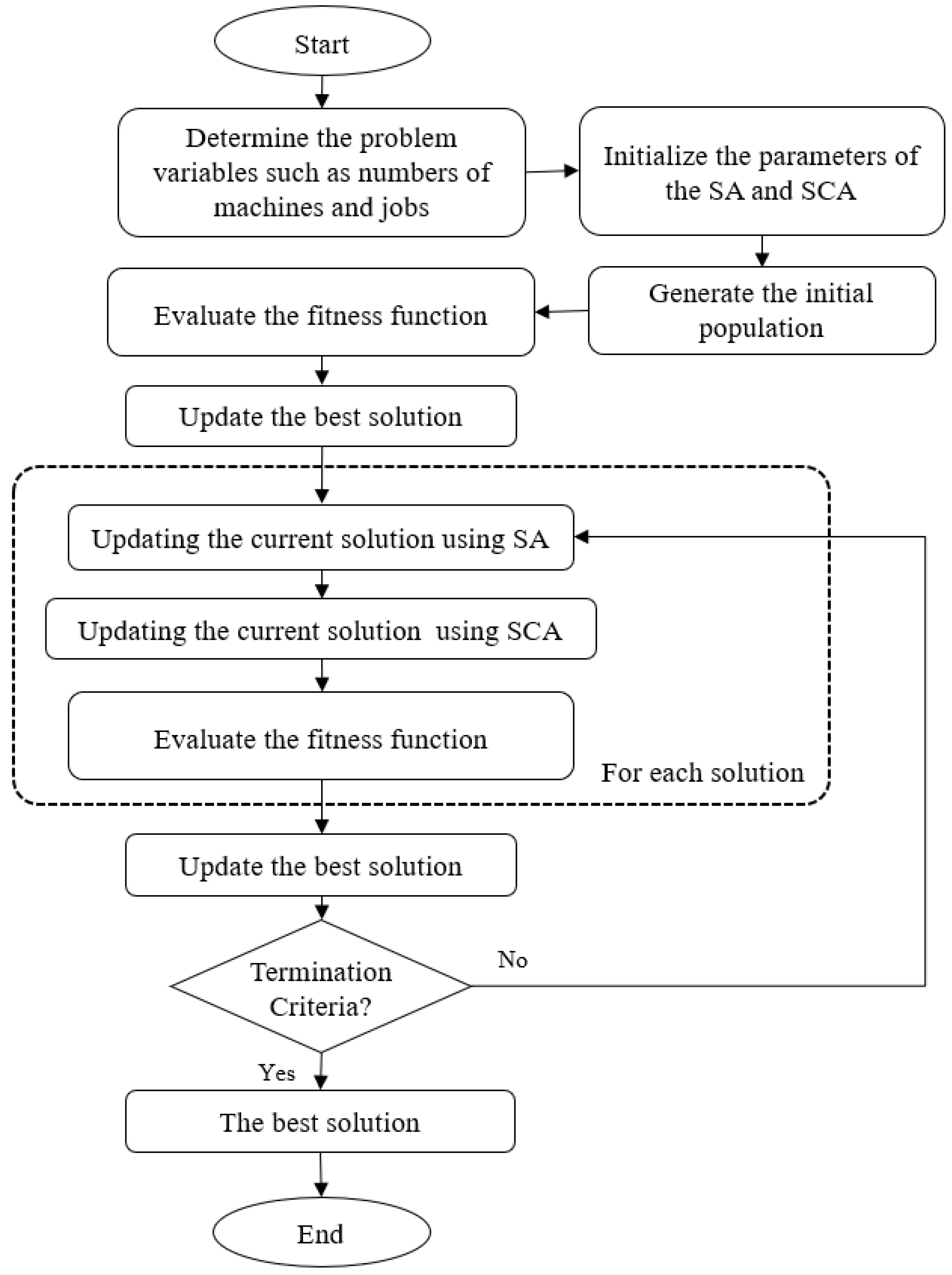
4. Proposed Method
In this section, the proposed method to solve an unrelated parallel machine scheduling problem with setup times is introduced (as in
Figure 1). This proposed method is called SASCA where the SCA is used to enhance the local search ability of the SA.
In general, the proposed SASCA starts by generating a random integer solution that represents the solution to UPMSPs. Then the SA generates a new solution Y from the neighboring () of the current solution X. The objective function (that aimed to minimize the makespan) is computed for both solutions and if the then . Otherwise, the new solution can be replaced X with probability () that is computed based on the difference between the objective function values of both solutions (X and Y). Thereafter, the SCA is used to enhance the X through using its strategy. If the new solution is better than the old one then it will replace it, then the temperature T is decreased after performing . The previous steps are discussed with more details in the following.
4.1. Initial Solution
The proposed SASCA starts by determining the initial value for each parameter such as the current temperature . Then it generates a random integer solution X with dimension (the number of jobs) and it takes value from the interval . For example, consider we have 15 Jobs and 3 machines, then, the representation of the solution X can be given as . This means that the jobs 1, 6, 9, 10, 14 will be performed on machine number one, jobs 2, 4, 11, 12, 15 on machine number two, and jobs 3, 5, 7, 8, 13 on machine number three.
The next step in this stage is to compute the fitness function for the solution
X using Equation (
1) (that represents
) and select the best solutions.
4.2. Updating Solution
The updating of the solution starts by selecting solution
Y from the neighbor
of the solution
X and compute its fitness function
. The difference between the
and
is computed (which represents by
). Then if
then the solution
X will be replaced by
Y. Meanwhile, if this condition not satisfied, then there is another probability the solution
Y can replace
X (this probability is defined in Equation (
10)). If
then
. Thereafter, the next step is to use the operators of SCA algorithm to improve the exploitation ability of SA algorithm as the following: first, the value of the parameter
is updated using Equation (
14) also, the value of parameters
and
are updated. Then based on the value of
the current solution
X will be updated using either the sine or cosine function as in Equation (
13). The next step is to update the best solution
and reduce the temperature as in Equation (
11), after running the inner
from the previous decreasing value of
T. The algorithm is stopped if the terminal criteria are met.
The entire steps of the proposed method are illustrated in Algorithm 1.
| Algorithm 1 The steps of the proposed method |
- 1:
Input: initial temprature, Size of population N, dimension of solution , and total number of generations . - 2:
Output: The best solution . - 3:
Set the initial value of N solutions with dimension . - 4:
Evaluate the quality of each by computing its fitness value , and update number of fitness evaluation. - 5:
Find the best solution . - 6:
Put . - 7:
repeat - 8:
for do - 9:
determine the neighbor solution of . - 10:
Compute the fitness value for . - 11:
if then - 12:
. - 13:
else - 14:
. - 15:
if () then - 16:
. - 17:
end if - 18:
end if - 19:
Update the temprature T using Equation ( 11). - 20:
end for - 21:
for do - 22:
Update the parameters , and . - 23:
Update using Equation ( 13). - 24:
Evaluate the quality of each by computing its fitness value . - 25:
end for - 26:
Find the best solution . - 27:
Set . - 28:
until
|
5. Experiments and Results
In this section, the dataset description, experiment settings, and the discussion of the results are presented. The experiments are divided into two parts, the first one contains the results of the proposed algorithm and the other metaheuristic algorithms such as grey wolf optimization, particle swarm optimization, genetic algorithm in addition to the traditional SA. The second one compare the results of the proposed SASCA with other state-of-the-art methods. Then, the results of the average percent deviations are provided followed by the influence of the () variable on the proposed SASCA.
5.1. Dataset Description
We conducted 30 tests for 4 problems, each problem has its machines and jobs. The first problem has 2 machines with 11 kinds of jobs (i.e., 6, 7, 8, 9, 10, 11, 40, 60, 80, 100, and 120 jobs). The second problem has 4 machines with 10 kinds of jobs (i.e., 6, 7, 8, 9, 10, 11, 60, 80, 100, and 120 jobs). The third problem has 6 machines with 8, 9, 10, 11, 100 and 120 jobs, whereas, the last problem has 8 machines with 10, 11, and 120 jobs. These jobs were selected as in [
24,
25] to evaluate the proposed method on small and large jobs. In this manner, Equation (
15) is applied to select large jobs. For instance, 100/8 = 12.5; so, job 100 is ignored from machine 8 and 120 is selected.
For more information about the dataset used in this paper is available at [
41].
5.2. Experiment Settings
The experiments were performed on “Windows 10” with CPU “Core2Due” and 4GB RAM. Each job, in all problems, was evaluated over 15 different problem instances and the average value of
is calculated. The proposed method used a stop condition equals to 25 for the small problems and 10000 iterations for the large problems to record the best obtained value of fitness function (
). For a fair comparison, the number of iterations is chosen to meet the same setting in the references. The parameters setting of the proposed method are listed in
Table 1. In general, these parameters are selected based on the experiments besides, they showed good performances in our previous works such as [
42,
43,
44,
45].
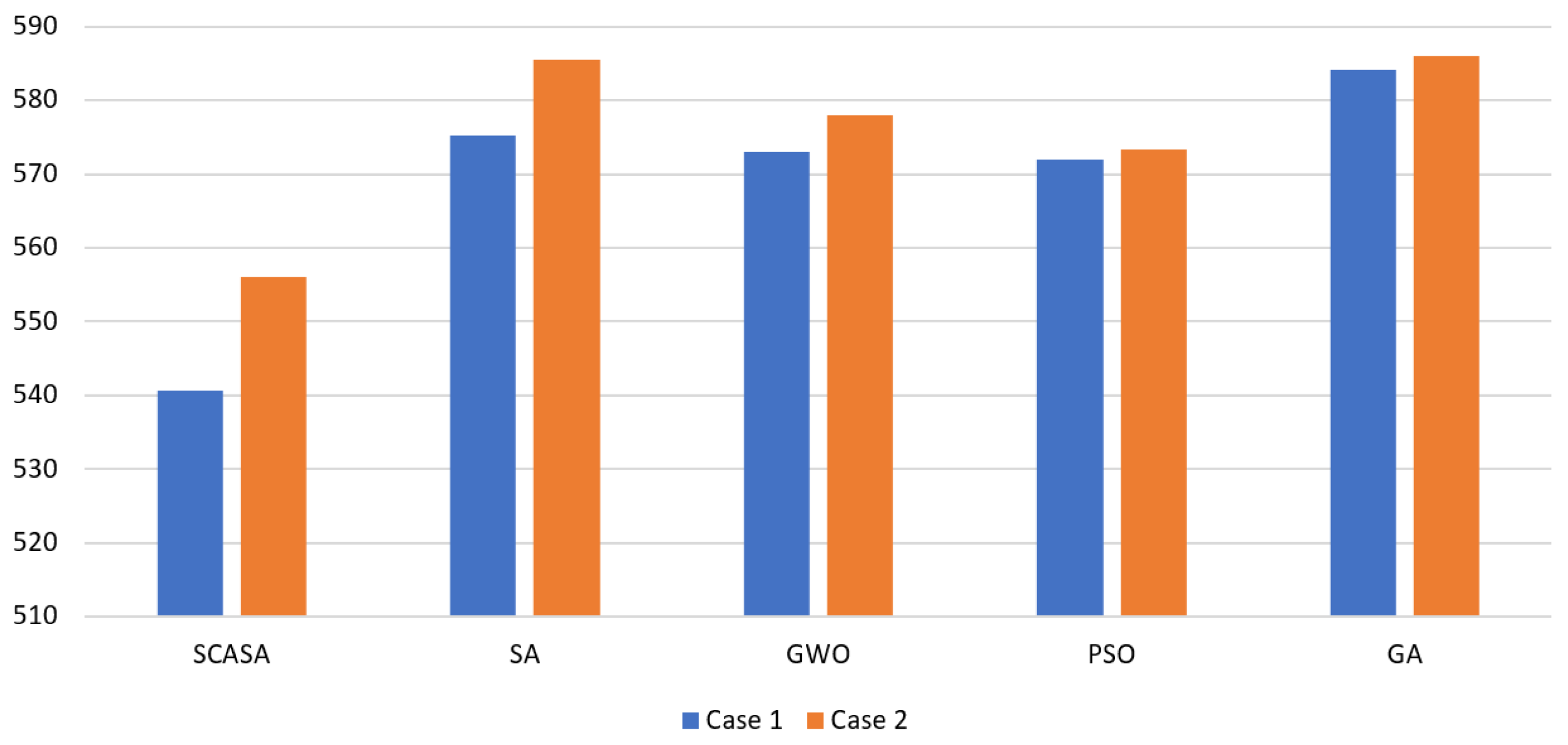
5.3. Comparison with Metaheuristic Methods
In this experiments, the performance of the SASCA is compared with other four MH methods as given in
Table 2 and
Table 3. This comparison are performed using a set of different Jobs (i.e., 6, 7, 8, 9, 10, 11) and number of machines (2, 4, 6, 8). According to the results of the average of
, it can be noticed that the proposed SASCA has high ability to find the smallest
among all the tested number of machines and jobs. Meanwhile, the SA has better
at the small number of jobs especially at jobs 6, 7, and 8. However, when the number of machines become 6 and number of jobs become 8, the GWO gives better results than SA. By comparing, the performance of the four MH methods (i.e., GWO, PSO, SA, and GA) at 8 machines as well as 10 and 11 jobs, it can be seen that the GA and GWO provided smaller results, respectively, than the other two methods (i.e., SA, and PSO).
Moreover, by analysing the results of computational time(s), it can be observed that the SA is the fast algorithm over all the tested problems except for the case when the number of machines is 2 and jobs 6, when the PSO has the smaller CPU time(s). In addition, it can be noticed that the SASCA requires smaller CPU time(s) than the other methods.
5.4. Comparison with the State-of-the-Art Methods
In this section, we compare the performance of the SASCA and the other methods, for example, Tabu (T9) and Tabu (T8) [
24] and Ant Colony Optimization (ACO) [
25], Partitioning Heuristic (PH) [
25], Tabu Search (TS) [
24], and MRPS (Meta-RaPS) [
26]. These experiments are performed through two datasets (i.e, small and large) as given in the following subsections.
5.4.1. Small Problems
Table 4 illustrates the results of the SASCA and other methods. The values of the
and computation time are listed in this table. The SASCA is compared with SA, Tabu(T9), and Tabu(T8). The results of the Tabu (T9) and Tabu (T8) are obtained from [
24] because it used the same problems (i.e., the same numbers of machines and jobs).
From this table, we can see that the proposed method (SASCA) outperforms the other methods in all problems in terms of value followed by Tabu (T9), Tabu (T8), and SA. In terms of computation time, the proposed method ranked second after SA followed by Tabu (T8) and Tabu (T9). The SASCA was close to SA but outperformed SA in computational time, as expected, since the SCA algorithm, in general, consumes more time than SA.
5.4.2. Statistical Test for the Small Problems
The performance of the SASCA is evaluated using Wilcoxon’s rank sum test to check if there is a significant difference between the SASCA and the other methods or not in the small problems [
46,
47,
48]. In addition, the Friedman test is applied to rank these methods. The results are given in
Table 5 and
Table 6, it can be seen from the Wilcoxon test that
p-value is less than 0.05 and this indicates there is a significant difference between the proposed method and other methods except Tabu (T9) in terms of
. In contrast,
Table 6 shows that the SASCA has the smallest average rank in terms of
, and it achieved the second rank in CPU time(s). Therefore, it can be concluded that the proposed method can outperform the other methods in the case of small datasets.
5.4.3. Large Problems
Table 7 displays the results of the proposed method for large problems versus other methods. The calculated values of the
and standard deviation (
) for the SASCA are listed in this table along with the compared results which obtained from the state-of-the-art methods namely Ant Colony Optimization (ACO) [
25], Partitioning Heuristic (PH) [
25], Tabu Search (TS) [
24], and MRPS (Meta-RaPS) [
26]. In addition, the lower bound (LB) is listed in the last column as a reference value.
From this table, we can conclude that, in terms of
, the proposed method outperformed the other methods in 7 out of 12 problems and its results are closer to the reference values. Whereas, in terms of
, the proposed algorithm performed better in 6 out of 12 problems followed by MRPS and ACO, respectively. These results are illustrated in
Figure 2 to show the variation of
among these algorithms; the values in this figure are normalized by the following equation:
5.4.4. Statistical Test for the Large Problems
In this section, the two statistical tests (i.e., Wilcoxon’s rank sum and Friedman test) are used to further analyze the results of the proposed SASCA based on large problems.
Table 8 depicts that there is no significant difference between SASCA and the other methods in terms of
. Meanwhile, there are significant differences between SASCA and TS and PH methods in terms of CPU time(s). The same observation is noticed from
Table 9, where the SASCA and ACO have the same average rank, followed by MRPS, TS, and PH, respectively, in terms of
. Moreover, in terms of the CPU time(s), the MRPS allocates the first rank followed by the SASCA which allocates the second rank, while the ACO in the third rank followed by the TS and PH, respectively.
5.5. Average Percent Deviations
The average percent deviations values (
) for the small and the large problems are provided in
Table 10 and
Table 11 to prove the superiority of the proposed method against the other methods. The
of (
) of each method are recorded where
is calculated as follows:
Table 10 shows that the SASCA outperformed all algorithms in all machines and jobs.
Table 11 illustrates that the SASCA outperformed the PH and TS in all large problems and got over MRPS in 10 out of 12 problems; while the SASCA works better than ACO in 7 out of 12 problems. In general, the SASCA shows good ability to work with both small and large problems.
5.6. Parameters Sensitivity
5.6.1. Influence of () value on the SASCA
In this subsection, the influence of (
) variable on the performance of the SASCA is evaluated. In this test, two machines are used with five types of jobs (i.e., 40, 60, 80, 100, and 120).
Table 12 shows the
and the STD values. It can be observed that the best value for the
is 0.95 which has the smallest
value followed by
. Meanwhile, in the case of
the proposed SASCA becomes more stable than other two values. In addition, the
is more stable than
.
5.6.2. Influence of the Parameters Setting in the Algorithms
In this section, we study the influence of the parameters setting on the performance of the MH. The values of the parameters for each algorithm are given in
Table 13, with the same number of population and the number of iterations used in the previous experiments. Moreover, the number of machines is two and the number of jobs varies from 6 to 11. The comparison results are given in
Table 14 and
Figure 3. From
Table 14 it can be noticed that the SASCA has the smallest
overall the tested problems except at the number of jobs is 10, the PSO is the best algorithm. Whereas,
Figure 3 depicts the comparison between the average of the
of the parameter setting in
Table 1 and the current one (i.e.,
Table 13). It can be noticed that the performance of the MH methods based on the value in
Table 1 is better than their performance based on
Table 13.
From the previous analysis, it can be observed the high performance of the SASCA method, however, there are some limitations. For example, the time computational of the SASCA needs more improvements since it updates the solutions using SA operators followed by the operators of SCA. Besides, the diversity of the solution needs to be enhanced and this can be achieved using the Disruptor operators.
6. Conclusions
Recently, unrelated parallel machine scheduling problems (UPMSPs) have received more attention due to their wide applications in various domains. To solve UPMSPs, Simulated Annealing (SA) algorithm provides suitable results compared to other meta-heuristic methods (MH) methods, but its performance still requires more improvement. Therefore, in this paper, an alternative method was proposed for determining the optimal solution to solve UPMSPs by minimizing the makespan value. The proposed method called SASCA combined the SA algorithm with Sine-Cosine Algorithm (SCA). SASCA worked in sequence order; in the first stage, the optimization process started by using SA to evaluate the problem solution, then the output solution was fed to SCA to continue the optimization process. The final solution was evaluated by the objected function. The performance of the proposed method was compared with several methods including ACO, MRPS, TS, and PH in terms of makespan values and standard deviation. In general, SASCA has the ability to solve small and large problems of unrelated parallel machine scheduling. In the future, the proposed method will be evaluated in different kinds of problems such as image segmentation, task scheduling in cloud computing, and other optimization problems.


 ,
, 



{kind=link}
{kind=link}
{kind=link}