Forming a Hierarchical Choquet Integral with a GA-Based Heuristic Least Square Method

Abstract
:1. Introduction and Presentation of the Problem
2. The Choquet Integral
- (1).
- ;
- (2).
- For all, ifthen(monotonicity).
3. Identification of Fuzzy Measures
3.1. A Maximum Split Approach
3.2. Minimum Variance Approach
3.3. A Less Constrained Approach
- If , begin by ;
- If , begin by .
- Mean value of upper neighbors
- Mean value of lower neighbors
- Minimum distance between and its upper (respectively lower) neighbors, denoted as , (respectively )
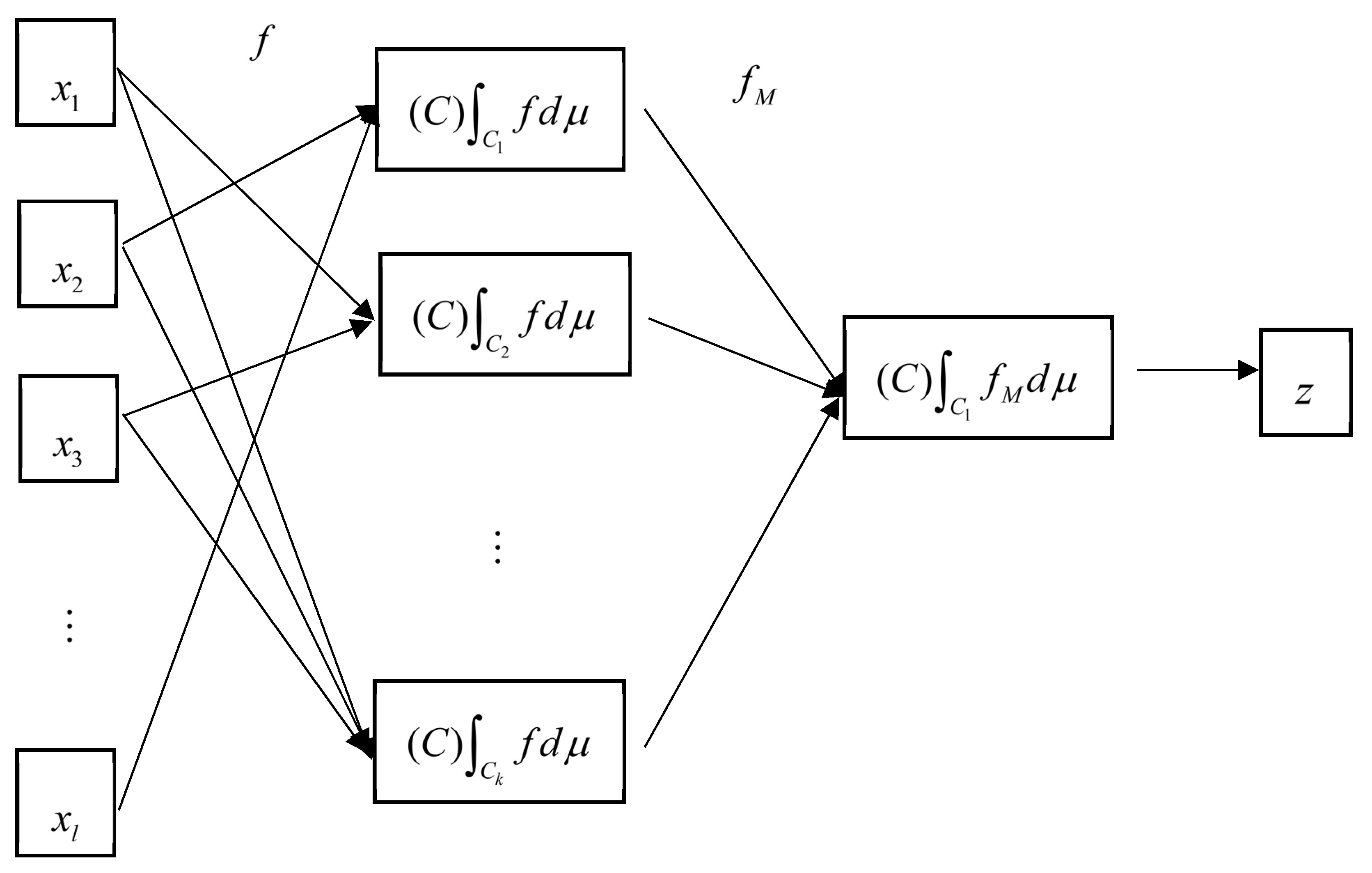
4. Hierarchical Choquet Integral
5. GA-Based HLSM
5.1. GA
5.2. The GA Procedure
String Representation
Population Initialization
Fitness Computation
5.3. Genetic Operators
5.4. Elitist Strategy and Termination Criterion
6. Numerical Experiments
6.1. Parameters of GA
6.2. Dataset Description
6.3. Experiment Results
7. Discussion
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Grabisch, M. Fuzzy integral in multicriteria decision making. Fuzzy Set. Syst. 1995, 69, 279–298. [Google Scholar] [CrossRef]
- Hillier, F. Evaluation and Decision Models: A Critical Perspective; Kluwer Academic Publishers: Boston, MA, USA, 2001. [Google Scholar]
- Sugeno, M. Theory of Fuzzy Integrals and Its Applications. Ph.D. Thesis, Tokyo Institute of Technology, Tokyo, Japan, 1974. [Google Scholar]
- Zhai, J.; Zang, L.; Zhou, Z. Ensemble dropout extreme learning machine via fuzzy integral for data classification. Neurocomputing 2018, 275, 1043–1052. [Google Scholar] [CrossRef]
- Karczmarek, P.; Kiersztyn, A.; Pedrycz, W. On developing Sugeno fuzzy measure densities in problems of face recognition. Int. J. Mach. Intell. Sens. Signal Process. 2017, 2, 80–96. [Google Scholar]
- Couceiro, M.; Dubois, D.; Prade, H.; Rico, A. Enhancing the expressive power of Sugeno integrals for qualitative data analysis. In Advances in Fuzzy Logic and Technology 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 534–547. [Google Scholar]
- Choquet, G. Theory of capacities. Ann. de l’institut Fourier 1954, 5, 131–295. [Google Scholar] [CrossRef]
- Murofushi, T. A technique for reading fuzzy measures (I): The Shapley value with respect to a fuzzy measure. In Proceedings of the 2nd Fuzzy Workshop, Heeze, The Netherland, 4–5 June 2018; pp. 39–48. [Google Scholar]
- Murofushi, T.; Soneda, S. Techniques for reading fuzzy measures (III): Interaction index. In Proceedings of the 9th Fuzzy System Symposium, Sapporo, Japan, 24–26 November 1993; pp. 693–696. [Google Scholar]
- Marichal, J.-L.; Roubens, M. Determination of weights of interacting criteria from a reference set. Eur. J. Oper. Res. 2000, 124, 641–650. [Google Scholar] [CrossRef]
- Kojadinovic, I. Minimum variance capacity identification. Eur. J. Oper. Res. 2007, 177, 498–514. [Google Scholar] [CrossRef]
- Meyer, P.; Roubens, M. Choice, ranking and sorting in fuzzy multiple criteria decision aid. In Multiple Criteria Decision Analysis: State of the Art Surveys; Springer: Berlin/Heidelberg, Germany, 2005; pp. 471–503. [Google Scholar]
- Grabisch, M. The application of fuzzy integrals in multicriteria decision making. Eur. J. Oper. Res. 1996, 89, 445–456. [Google Scholar] [CrossRef]
- Grabisch, M. K-order additive discrete fuzzy measures and their representation. Fuzzy Sets Syst. 1997, 92, 167–189. [Google Scholar] [CrossRef]
- Miranda, P.; Grabisch, M.; Gil, P. p-Symmetric fuzzy measures. Int. J. Unc. Fuzz. Knowl. Based Syst. 2002, 10, 105–123. [Google Scholar] [CrossRef]
- Sugeno, M.; Fujimoto, K.; Murofushi, T. A hierarchical decomposition of Choquet integral model. Int. J. Unc. Fuzz. Knowl. Based Syst. 1995, 3, 1–15. [Google Scholar] [CrossRef]
- Hougaard, J.L.; Keiding, H. Representation of preferences on fuzzy measures by a fuzzy integral. Math. Soc. Sci. 1996, 31, 1–17. [Google Scholar] [CrossRef]
- Mesiar, R. Fuzzy measures and integrals. Fuzzy Set. Syst. 2005, 156, 365–370. [Google Scholar] [CrossRef]
- Ishii, K.; Sugeno, M. A model of human evaluation process using fuzzy measure. Int. J. Man-Mach. Stud. 1985, 22, 19–38. [Google Scholar] [CrossRef]
- Miranda, P.; Grabisch, M. Optimization issues for fuzzy measures. Int. J. Unc. Fuzz. Knowl. Based Syst. 1999, 7, 545–560. [Google Scholar] [CrossRef]
- Murofushi, T.; Sugeno, M.; Fujimoto, K. Separated hierarchical decomposition of the Choquet integral. Int. J. Unc. Fuzz. Knowl. Based Syst. 1997, 5, 563–585. [Google Scholar] [CrossRef]
- Fujimoto, K.; Murofushi, T.; Sugeno, M. Canonical hierarchical decomposition of Choquet integral over finite set with respect to null additive fuzzy measure. Int. J. Unc. Fuzz. Knowl. Based Syst. 1998, 6, 345–363. [Google Scholar] [CrossRef]
- Murofushi, T.; Fujimoto, K.; Sugeno, M. Canonical separated hierarchical decomposition of the Choquet integral over a finite set. Int. J. Unc. Fuzz. Knowl. Based Syst. 1998, 6, 257–272. [Google Scholar] [CrossRef]
- Tzeng, G.-H.; Huang, J.-J. Multiple Attribute Decision Making: Methods and Applications; Chapman and Hall/CRC: Boca Raton, FL, USA, 2011. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems; University of Michigan: Ann Arbor, MI, USA, 1975; Volume 1, p. 975. [Google Scholar]
- Bhandari, D.; Murthy, C.; Pal, S.K. Genetic algorithm with elitist model and its convergence. Int. J. Pattern Recognit. Artif. Intell. 1996, 10, 731–747. [Google Scholar] [CrossRef]
- El Baf, F.; Bouwmans, T.; Vachon, B. Fuzzy integral for moving object detection. In Proceedings of the 2008 IEEE International Conference on Fuzzy Systems (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; pp. 1729–1736. [Google Scholar]
- Yang, R.; Wang, Z.; Heng, P.A.; Leung, K.S. Fuzzified Choquet integral with a fuzzy-valued integrand and its application on temperature prediction. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2008, 38, 367–380. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Gene type | Binary |
| Population size | 50 |
| Number of generations | 30 |
| Elitism | 4 |
| Crossover probability | 0.8 |
| Mutation probability | 0.2 |
| 2-Additive and 2 Sub-Choquet Integral Each Sub-Choquet Integral Contains 5 Features MSE = 2.359 | |||
|---|---|---|---|
| Sub-Choquet 1 | Mobius Capacity | Sub-Choquet 2 | Mobius Capacity |
| {1} | 0.1819 | {2} | 0.2885 |
| {4} | 0.2550 | {3} | 0.1414 |
| {5} | 0.1785 | {4} | 0.1610 |
| {8} | 0.1680 | {6} | 0.1685 |
| {9} | 0.1520 | {7} | 0.1455 |
| {1,4} | 0.1436 | {2,3} | −0.0874 |
| {1,5} | 0.0268 | {2,4} | −0.1140 |
| {1,8} | −0.0039 | {2,6} | 0.0326 |
| {1,9} | −0.0578 | {2,7} | 0.0542 |
| {4,5} | −0.1510 | {3,4} | 0.2016 |
| {4,8} | −0.1012 | {3,6} | −0.0534 |
| {4,9} | 0.0538 | {3,7} | 0.0413 |
| {5,8} | 0.1337 | {4,6} | 0.0148 |
| {5,9} | −0.0275 | {4,7} | −0.0239 |
| {8,9} | 0.0482 | {6,7} | 0.0292 |
| Dataset: Simulated Dataset | |||
| Model | # Sub-Choquet Integral | Condition | MSE |
| 2-additive HCI | 2 | 5 variables for each Sub-Choquet Integral | 2.359 |
| 2-additive HCI | 2 | 6 variables for each Sub-Choquet Integral | 2.221 |
| 2-additive HCI | 2 | Unrestricted | 2.138 |
| Choquet Integral | 0 | Unrestricted | 2.138 |
| Dataset: Add10 Dataset | |||
| Model | # Sub-Choquet Integral | Condition | MSE |
| 2-additive HCI | 2 | 4 variables for each Sub-Choquet Integral | 0.00767 |
| 2-additive HCI | 2 | 5 variables for each Sub-Choquet Integral | 0.00692 |
| 2-additive | 2 | Unrestricted | 0.00663 |
| Choquet Integral | 0 | Unrestricted | 0.00692 |
| Datasets | Logit Model | MLP | 2-Additive HCI |
|---|---|---|---|
| cancer | 0.9640 | 0.9710 | 0.8141 (restrict 4 variables) |
| 0.9531 (unrestricted) | |||
| ILPD | 0.7074 | 0.7149 | 0.7150 (restrict 5 variables) |
| 0.7237 (unrestricted) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.-Y.; Huang, J.-J. Forming a Hierarchical Choquet Integral with a GA-Based Heuristic Least Square Method. Mathematics 2019, 7, 1155. https://doi.org/10.3390/math7121155
Chen C-Y, Huang J-J. Forming a Hierarchical Choquet Integral with a GA-Based Heuristic Least Square Method. Mathematics. 2019; 7(12):1155. https://doi.org/10.3390/math7121155
Chicago/Turabian StyleChen, Chin-Yi, and Jih-Jeng Huang. 2019. "Forming a Hierarchical Choquet Integral with a GA-Based Heuristic Least Square Method" Mathematics 7, no. 12: 1155. https://doi.org/10.3390/math7121155
APA StyleChen, C.-Y., & Huang, J.-J. (2019). Forming a Hierarchical Choquet Integral with a GA-Based Heuristic Least Square Method. Mathematics, 7(12), 1155. https://doi.org/10.3390/math7121155