Cooperative Co-Evolution Algorithm with an MRF-Based Decomposition Strategy for Stochastic Flexible Job Shop Scheduling


Abstract
:1. Introduction
1.1. Motivation
1.2. Contribution
- A cooperative co-evolution framework is improved and adopted. In the improved framework, CEA works iteratively within each sub solution space until the termination criterion matches. All sub solution spaces are evoluted cooperatively, and the suitable representation selection strategy helps hCEA-MRF find the optimal solution.
- An MRF-based decomposition strategy is proposed for decomposing the decision variables into various decompositions. All decision variables are decomposed according to the network structure with respect to the estimated parameters. The decision variables which are put into the same decomposition are viewed as the strong relevance among each other. Each decomposition is associated with a sub solution space.
- A self-adaptive parameter mechanism is designed. Instead of the general linearity and nonlinearity self-adaptive mechanism, our proposed self-adaptive mechanism is based on the performance, i.e., the number and the percentage of the individuals generated by the current parameters successfully and unsuccessfully go into the next generation.
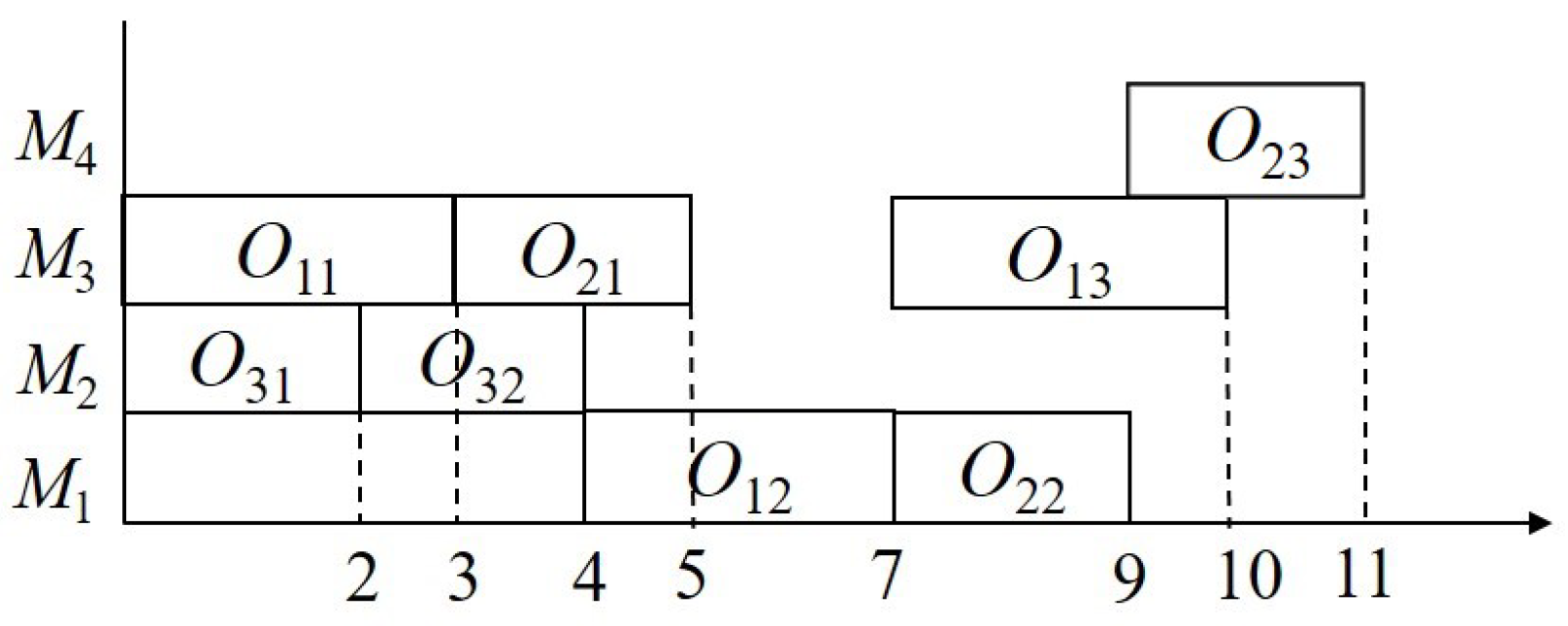
2. Formulation Model of S-FJSP
3. The Implement of hCEA-MRF
3.1. Representation
- The genotype space needs to cover as many as possible candidate solutions in order to search out the optiml solution.
- The necessary decode time needs to be as short as possible.
- Each representation needs to be corresponding to a feasible candidate solution, and the new representation which has completed evolutionary operators needs to be corresponding to a feasible candidate solution as well.
| Algorithm 1 The procedure of hCEA-MRF. |
| Require: problem data, problem model, parameters |
| Ensure:; |
|
3.2. CEA
3.2.1. Evolutionary Strategy
3.2.2. CEA Evaluation
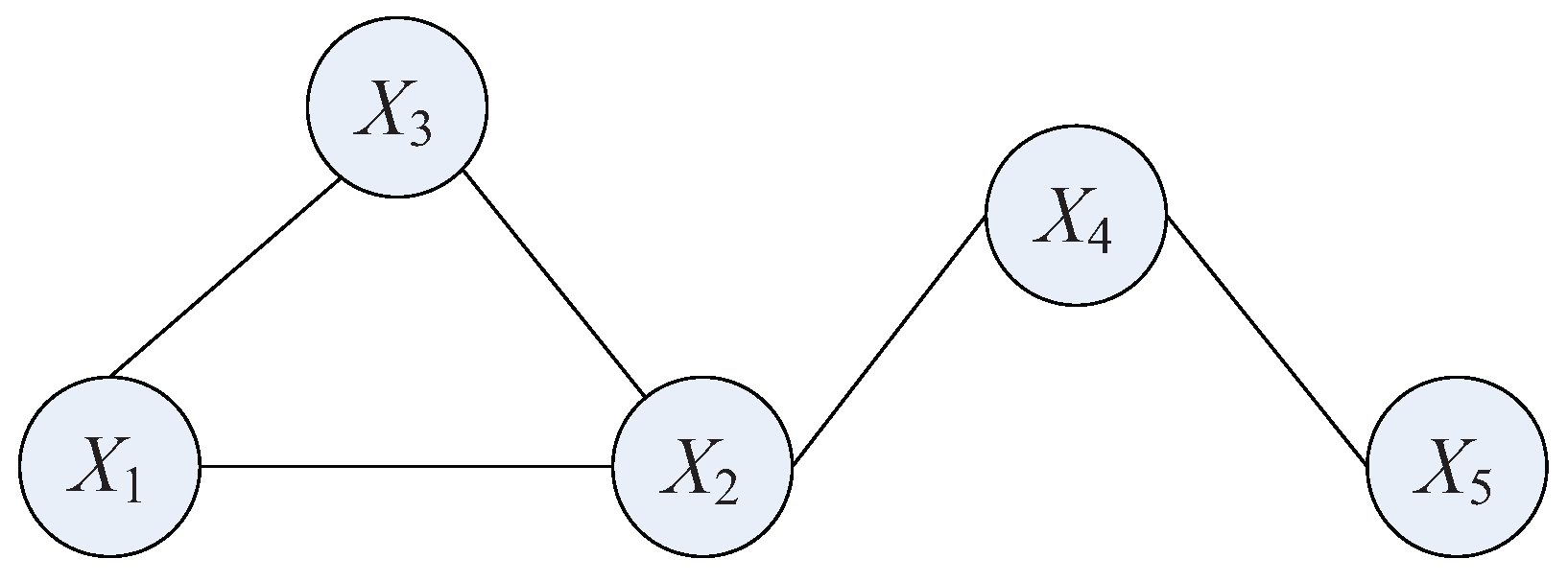
3.3. MRF-Based Decomposition Strategy
3.3.1. MRF Structure Learning
3.3.2. MRF Parameters Learning
3.4. Parameters Self-Adaptive Strategy
4. Simulation Experiments
4.1. Description of the Dataset
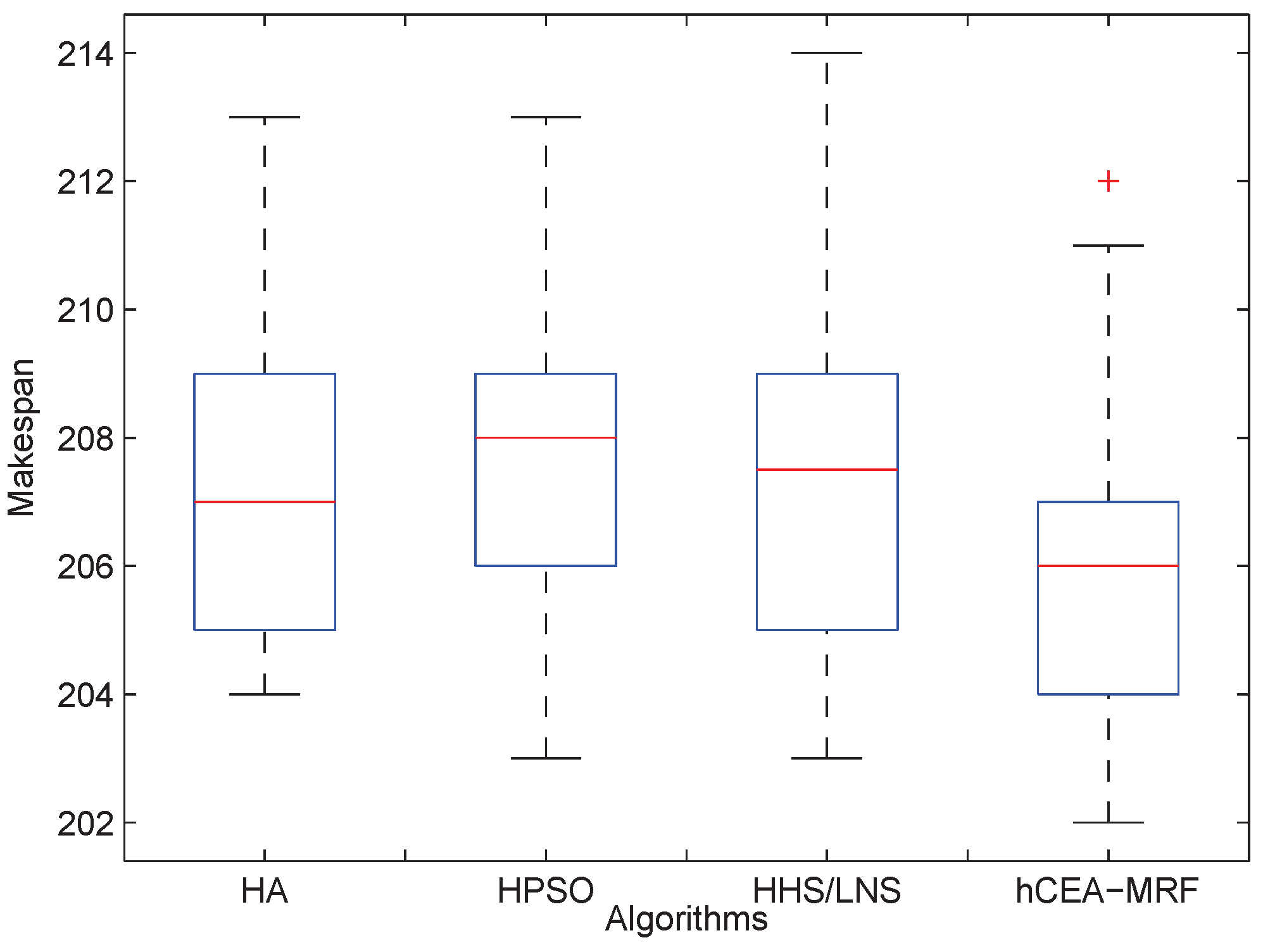
4.2. Superiority of hCEA-MRF
4.2.1. Performance Compared with State-of-the-Art
- The improved cooperative coevolution with the help of the new written update strategy of PSO searches the optimal solution in multiple sub solution spaces.
- The MRF-based decomposition strategy considers the relationship among variables instead of decomposing them only based on the random technique.
- The parameter self-adaptive strategy works in the process of optimization instead of the fixed parameters when facing stochastic factors.
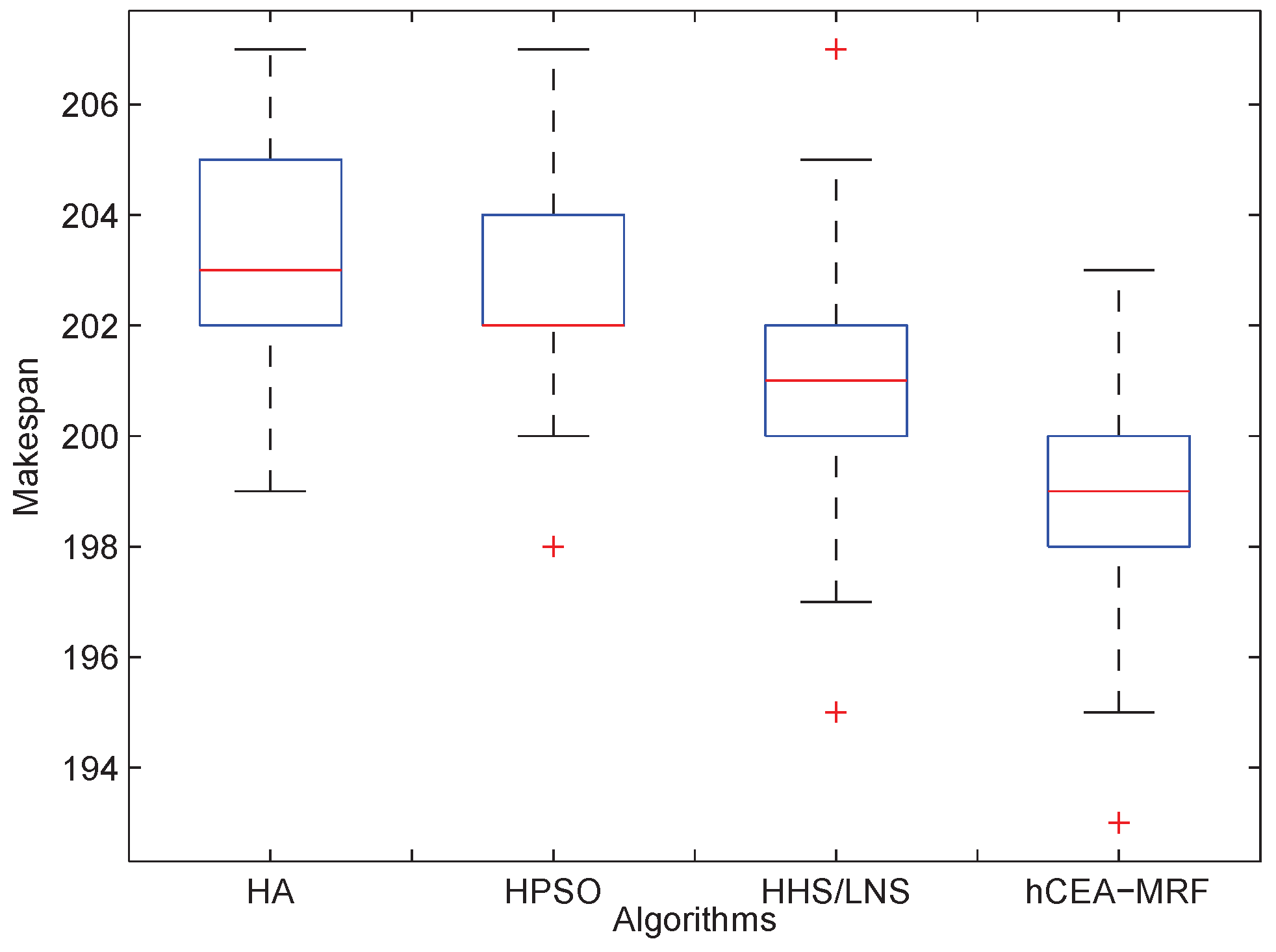
4.2.2. Stability Compared with State-of-the-Art
4.3. Discussion of hCEA-MRF
4.3.1. Effect of the Self-Adaptive Parameter Strategy
4.3.2. Effect of the Decomposition Strategy
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Jiang, T.; Zhang, C.; Zhu, H. Energy-Efficient Scheduling for a Job Shop Using an Improved Whale Optimization Algorithm. Mathematics 2018, 6, 220. [Google Scholar] [CrossRef]
- Gur, S.; Eren, T. Scheduling and Planning in Service Systems with Goal Programming: Literature Review. Mathematics 2018, 6, 265. [Google Scholar] [CrossRef]
- Kim, J.S.; Jeon, E.; Noh, J.; Park, J.H. A Model and an Algorithm for a Large-Scale Sustainable Supplier Selection and Order Allocation Problem. Mathematics 2018, 6, 325. [Google Scholar] [CrossRef]
- Gao, S.; Zheng, Y.; Li, S. Enhancing strong neighbour-based optimization for distributed model predictive control systems. Mathematics 2018, 6, 86. [Google Scholar] [CrossRef]
- Zamani, A.G.; Zakariazadeh, A.; Jadid, S. Day-ahead resource scheduling of a renewable energy based virtual power plant. Appl. Energy 2016, 169, 324–340. [Google Scholar] [CrossRef]
- Wang, C.N.; Le, T.M.; Nguyen, H.K. Application of optimization to select contractors to develop strategies and policies for the development of transport infrastructure. Mathematics 2019, 7, 98. [Google Scholar] [CrossRef]
- Zhan, Z.; Liu, X.; Gong, Y.; Zhang, J.; Chung, H.S.-H.; Li, Y. Cloud computing resource scheduling and a survey of its evolutionary approaches. ACM Comput. Surv. (CSUR) 2015, 47, 63. [Google Scholar] [CrossRef]
- Montoya-Torres, J.R.; Franco, J.L.; Isaza, S.N.; Jimenez, H.F.; Herazo-Padilla, N. A literature review on the vehicle routing problem with multiple depots. Comput. Ind. Eng. 2015, 79, 115–129. [Google Scholar] [CrossRef]
- Ccalics, B.; Bulkan, S. A research survey: Review of AI solution strategies of job shop scheduling problem. J. Intell. Manuf. 2015, 26, 961–973. [Google Scholar] [CrossRef]
- Lin, L.; Gen, M. Hybrid evolutionary optimisation with learning for production scheduling: State-of-the-art survey on algorithms and applications. Int. J. Prod. Res. 2018, 56, 193–223. [Google Scholar] [CrossRef]
- Chaudhry, I.A.; Khan, A.A. A research survey: Review of flexible job shop scheduling techniques. Int. Trans. Oper. Res. 2016, 23, 551–591. [Google Scholar] [CrossRef]
- Ouelhadj, D.; Petrovic, S. A survey of dynamic scheduling in manufacturing systems. J. Sched. 2009, 12, 417. [Google Scholar] [CrossRef]
- Lei, D. Simplified multi-objective genetic algorithms for stochastic job shop scheduling. Appl. Soft Comput. 2011, 11, 4991–4996. [Google Scholar] [CrossRef]
- Hao, X.; Gen, M.; Lin, L.; Suer, G.A. Effective multiobjective EDA for bi-criteria stochastic job-shop scheduling problem. J. Intell. Manuf. 2017, 28, 833–845. [Google Scholar] [CrossRef]
- Kundakci, N.; Kulak, O. Hybrid genetic algorithms for minimizing makespan in dynamic job shop scheduling problem. Comput. Ind. Eng. 2016, 96, 31–51. [Google Scholar] [CrossRef]
- Zhang, R.; Wu, C. An artificial bee colony algorithm for the job shop scheduling problem with random processing times. Entropy 2011, 13, 1708–1729. [Google Scholar] [CrossRef]
- Zhang, R.; Song, S.; Wu, C. A two-stage hybrid particle swarm optimization algorithm for the stochastic job shop scheduling problem. Knowl.-Based Syst. 2012, 27, 393–406. [Google Scholar] [CrossRef]
- Azadeh, A.; Negahban, A.; Moghaddam, M. A hybrid computer simulation-artificial neural network algorithm for optimisation of dispatching rule selection in stochastic job shop scheduling problems. Int. J. Prod. Res. 2012, 50, 551–566. [Google Scholar] [CrossRef]
- Horng, S.; Lin, S.-H.; Yang, F.-Y. Evolutionary algorithm for stochastic job shop scheduling with random processing time. Expert Syst. Appl. 2012, 39, 3603–3610. [Google Scholar] [CrossRef]
- Gu, J.; Gu, X.; Gu, M. A novel parallel quantum genetic algorithm for stochastic job shop scheduling. J. Math. Anal. Appl. 2009, 355, 63–81. [Google Scholar] [CrossRef]
- Nguyen, S.; Zhang, M.; Johnston, M.; Tan, K.C. Automatic design of scheduling policies for dynamic multi-objective job shop scheduling via cooperative coevolution genetic programming. IEEE Trans. Evol. Comput. 2014, 18, 193–208. [Google Scholar] [CrossRef]
- Gu, J.; Gu, M.; Cao, C.; Gu, X. A novel competitive co-evolutionary quantum genetic algorithm for stochastic job shop scheduling problem. Comput. Oper. Res. 2010, 37, 927–937. [Google Scholar] [CrossRef]
- Horng, S.-C.; Lin, S.-S. Two-stage Bio-inspired Optimization Algorithm for Stochastic Job Shop Scheduling Problem. Int. J. Simul. Syst. Sci. Technol. 2015, 16, 4. [Google Scholar] [CrossRef]
- Mei, Y.; Li, X.; Yao, X. Cooperative coevolution with route distance grouping for large-scale capacitated arc routing problems. IEEE Trans. Evol. Comput. 2014, 18, 435–449. [Google Scholar] [CrossRef]
- Ghasemishabankareh, B.; Li, X.; Ozlen, M. Cooperative coevolutionary differential evolution with improved augmented Lagrangian to solve constrained optimisation problems. Inf. Sci. 2016, 369, 441–456. [Google Scholar] [CrossRef]
- Ma, X.; Li, X.; Zhang, Q.; Tang, K.; Liang, Z.; Xie, W.; Zhu, Z. A Survey on Cooperative Co-evolutionary Algorithms. IEEE Trans. Evol. Comput. 2018. [Google Scholar] [CrossRef]
- Qi, Y.; Bao, L.; Ma, X.; Miao, Q.; Li, X. Self-adaptive multi-objective evolutionary algorithm based on decomposition for large-scale problems: A case study on reservoir flood control operation. Inf. Sci. 2016, 367, 529–549. [Google Scholar] [CrossRef]
- Omidvar, M.N.; Li, X.; Mei, Y.; Yao, X. Cooperative co-evolution with differential grouping for large scale optimization. IEEE Trans. Evol. Comput. 2014, 18, 378–393. [Google Scholar] [CrossRef]
- Li, X. Decomposition and cooperative coevolution techniques for large scale global optimization. In Proceedings of the Companion Publication of the 2014 Annual Conference on Genetic and Evolutionary Computation, Vancouver, BC, Canada, 12–16 July 2014; pp. 819–838. [Google Scholar] [CrossRef]
- Sun, Y.; Kirley, M.; Li, X. Cooperative Co-evolution with Online Optimizer Selection for Large-Scale Optimization. In Proceedings of the Genetic and Evolutionary Computation Conference, Kyoto, Japan, 15–19 July 2018. [Google Scholar] [CrossRef]
- Potter, M.A.; De Jong, K.A. A cooperative coevolutionary approach to function optimization. In Proceedings of the International Conference on Parallel Problem Solving from Nature, Jerusalem, Israel, 9–14 October 1994; pp. 249–257. [Google Scholar] [CrossRef]
- Van, D.B.; Frans Engelbrecht, A.P. A cooperative approach to particle swarm optimization. IEEE Trans. Evol. Comput. 2004, 8, 225–239. [Google Scholar] [CrossRef]
- Yang, Z.; Tang, K.; Yao, X. Large scale evolutionary optimization using cooperative coevolution. Inf. Sci. 2008, 178, 2985–2999. [Google Scholar] [CrossRef]
- Mahdavi, S.; Rahnamayan, S.; Shiri, M.E. Multilevel framework for large-scale global optimization. Soft Comput. 2017, 21, 4111–4140. [Google Scholar] [CrossRef]
- Chen, W.; Weise, T.; Yang, Z.; Tang, K. Large-scale global optimization using cooperative coevolution with variable interaction learning. In Proceedings of the International Conference on Parallel Problem Solving from Nature, Krakov, Poland, 11–15 September 2010; pp. 300–309. [Google Scholar] [CrossRef]
- Sun, L.; Yoshida, S.; Cheng, X.; Liang, Y. A cooperative particle swarm optimizer with statistical variable interdependence learning. Inf. Sci. 2012, 186, 20–39. [Google Scholar] [CrossRef]
- Hu, X.-M.; He, F.-L.; Chen, W.-N.; Zhang, J. Cooperation coevolution with fast interdependency identification for large scale optimization. Inf. Sci. 2017, 381, 142–160. [Google Scholar] [CrossRef]
- Omidvar, M.N.; Yang, M.; Mei, Y.; Li, X.; Yao, X. DG2: A faster and more accurate differential grouping for large-scale black-box optimization. IEEE Trans. Evol. Comput. 2017, 21, 929–942. [Google Scholar] [CrossRef]
- Sun, Y.; Kirley, M.; Halgamuge, S.K. A recursive decomposition method for large scale continuous optimization. IEEE Trans. Evol. Comput. 2017. [Google Scholar] [CrossRef]
- Van Haaren, J.; Davis, J. Markov Network Structure Learning: A Randomized Feature Generation Approach. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; pp. 1148–1154. [Google Scholar]
- Shakya, S.; Santana, R.; Lozano, J.A. A markovianity based optimisation algorithm. Genet. Programm. Evol. Mach. 2012, 13, 159–195. [Google Scholar] [CrossRef]
- Sun, L.; Wu, Z.; Liu, J.; Xiao, L.; Wei, Z. Supervised spectral–spatial hyperspectral image classification with weighted markov random fields. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1490–1503. [Google Scholar] [CrossRef]
- Li, C.; Wand, M. Combining markov random fields and convolutional neural networks for image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2479–2486. [Google Scholar]
- Paragios, N.; Ramesh, V. A mrf-based approach for real-time subway monitoring. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001. [Google Scholar] [CrossRef]
- Tombari, F.; Stefano, L. 3D data segmentation by local classification and markov random fields. In Proceedings of the International Conference on 3DIMPVT, Hangzhou, China, 16–19 May 2011; pp. 212–219. [Google Scholar] [CrossRef]
- Li, X.; Gao, L. An effective hybrid genetic algorithm and tabu search for flexible job shop scheduling problem. Int. J. Prod. Econ. 2016, 174, 93–110. [Google Scholar] [CrossRef]
- Nouiri, M.; Bekrar, A.; Jemai, A.; Niar, S.; Ammari, A.C. An effective and distributed particle swarm optimization algorithm for flexible job-shop scheduling problem. J. Intell. Manuf. 2015, 1–13. [Google Scholar] [CrossRef]
- Yuan, Y.; Xu, H. An integrated search heuristic for large-scale flexible job shop scheduling problems. Comput. Oper. Res. 2013, 40, 2864–2877. [Google Scholar] [CrossRef]
- Brandimarte, P. Routing and scheduling in a flexible job shop by tabu search. Ann. Oper. Res. 1993, 41, 157–183. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
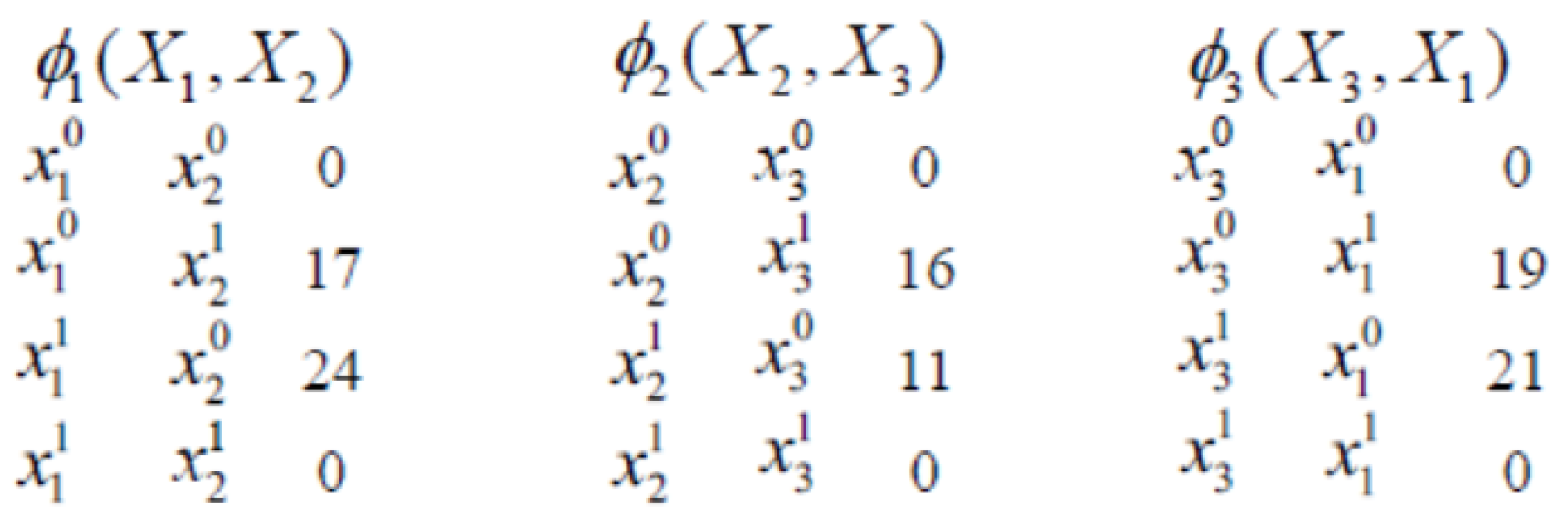{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methodologies | Distribution(s) | Objective(s) (min) |
|---|---|---|
| Simplified multi-objective genetic algorithm [13] | Uniform | Expected makespan |
| Effective multiobjective Estimation of Distribution Algorithm (EDA) [14] | Uniform | Expected makespan & total tardiness |
| Hybrid evolutionary algorithm [15] | Uniform | Expected makespan |
| Artificial bee colony algorithm [16] | Uniform; Normal; Exponent | Maximum lateness |
| Two-stage particle swarm optimization [17] | Uniform; Normal; Exponent | Expected total weighted tardiness |
| Evolutionary strategy in ordinal optimization [19] | Uniform; Normal; Exponent | Expected makespan & total tardiness |
| Algorithm based on artificial neural networks [18] | Uniform; Normal; Exponent | Expected makespan |
| Novel parallel quantum genetic algorithm [20] | Normal | Expected makespan |
| Cooperative coevolution genetic programming (CCGP) [21] | Uniform | Expected makespan |
| Co-evolutionary quantum genetic algorithm [22] | Normal | Expected makespan |
| Two-stage optimization [23] | Uniform; Normal; Exponent | Expected makespan |
| Strategy | Methodologies | Advantage(s) | Disadvantage(s) |
|---|---|---|---|
| One-dimension [31] | Decompose N variables into N groups | Easy to implement with low cost | Lose efficacy on non-separable problems |
| Random [32] | Randomly decompose N variables into k groups | Dependency on random technique | Lose efficacy on non-separable problems |
| Set-based [33] | Random decompose N variables based on set | Effective than one-dimension strategy | Lose efficacy on non-separable problems |
| Delta [28] | Detect relationship based on the averaged difference | More effective than random grouping | Lose efficacy on non-separable problems |
| K-means [34] | Detect relationship based on K-means algorithm | Effective on unbalanced grouping status | High computational cost |
| CCVIL [35] | Detect relationship based on non-monotonicity method | Effective than manual strategies | Exist insurmountable benchmark |
| IL [36] | Detect relationship only once for each variable | Lower computational cost than CCVIL | Worse performance than CCVIL |
| FII [37] | Detect through fast interdependency identification | Lower computational cost than CCVIL | Worse performance for conditional variable |
| DG [38] | Detect relationship by the variance of fitness | Better performance combined with PSO | High computational cost |
| EDG [39] | Detect relationship by the variance of fitness | Better performance compared with PSO | High computational cost |
| Job | Operation | ||||
|---|---|---|---|---|---|
| 2 | 3 | 3 | 3 | ||
| 4 | 1 | 3 | 2 | ||
| 3 | 2 | 3 | 4 | ||
| 3 | 3 | 2 | 1 | ||
| 3 | 2 | 2 | 4 | ||
| 3 | 2 | 3 | 2 | ||
| 3 | 2 | 3 | 2 | ||
| 2 | 2 | 3 | 4 |
| HA | HPSO | HHS/LNS | hCEA-MRF | |||||
|---|---|---|---|---|---|---|---|---|
| Average | Variance | Average | Variance | Average | Variance | Average | Variance | |
| UMk01 | 40.6 | 2.3 | 40.8 | 2.5 | 40.2 | 1.5 | 39.8 | 1.9 |
| UMk02 | 27.1 | 2.4 | 27.3 | 2.1 | 26.5 | 1.7 | 25.9 | 1.4 |
| UMk03 | 206.7 | 43.1 | 206.5 | 42.7 | 206.6 | 42.8 | 205.2 | 41.1 |
| UMk04 | 62.1 | 2.3 | 61.7 | 2.1 | 62.1 | 2.3 | 60.8 | 1.7 |
| UMk05 | 173.4 | 5.7 | 174.1 | 5.3 | 172.3 | 5.5 | 171.1 | 4.6 |
| UMk06 | 60.6 | 4.6 | 61.4 | 4.8 | 60.6 | 4.3 | 58.6 | 3.7 |
| UMk07 | 142.5 | 13.1 | 141.6 | 12.8 | 140.4 | 12.1 | 138.4 | 11.8 |
| UMk08 | 525.3 | 102.7 | 524.6 | 103.2 | 523.4 | 102.1 | 522.3 | 101.7 |
| UMk09 | 304.3 | 161.2 | 303.8 | 161.4 | 304.2 | 160.3 | 302.3 | 156.9 |
| UMk10 | 203.1 | 4.4 | 202.7 | 5.3 | 201.3 | 5.7 | 198.8 | 4.6 |
| HA | HPSO | HHS/LNS | hCEA-MRF | |||||
|---|---|---|---|---|---|---|---|---|
| Average | Variance | Average | Variance | Average | Variance | Average | Variance | |
| GMk01 | 41.6 | 2.6 | 42.1 | 2.9 | 41.3 | 2.0 | 40.7 | 2.3 |
| GMk02 | 27.5 | 2.4 | 26.7 | 2.4 | 26.9 | 2.1 | 26.3 | 1.9 |
| GMk03 | 207.9 | 46.5 | 208.4 | 47.2 | 206.7 | 45.5 | 206.4 | 44.7 |
| GMk04 | 63.2 | 3.6 | 63.6 | 3.1 | 62.9 | 2.6 | 61.6 | 2.3 |
| GMk05 | 175.4 | 6.5 | 176.2 | 5.8 | 174.5 | 6.2 | 173.2 | 5.5 |
| GMk06 | 62.3 | 5.7 | 61.5 | 4.9 | 60.4 | 4.2 | 60.1 | 4.5 |
| GMk07 | 144.5 | 14.2 | 142.7 | 13.8 | 142.9 | 13.1 | 141.4 | 12.9 |
| GMk08 | 532.1 | 106.5 | 527.4 | 105.5 | 525.3 | 103.8 | 524.6 | 104.8 |
| GMk09 | 305.4 | 167.2 | 307.2 | 164.3 | 305.5 | 163.3 | 303.5 | 162.4 |
| GMk10 | 205.6 | 6.1 | 205.6 | 9.5 | 204.6 | 7.9 | 202.8 | 6.8 |
| HA | HPSO | HHS/LNS | hCEA-MRF | |||||
|---|---|---|---|---|---|---|---|---|
| Average | Variance | Average | Variance | Average | Variance | Average | Variance | |
| EMk01 | 44.5 | 4.7 | 43.8 | 4.3 | 42.8 | 2.5 | 42.3 | 3.1 |
| EMk02 | 29.4 | 3.3 | 28.7 | 3.6 | 28.1 | 2.8 | 27.2 | 2.5 |
| EMk03 | 209.4 | 45.3 | 208.4 | 44.6 | 208.1 | 43.8 | 207.2 | 43.2 |
| EMk04 | 64.2 | 3.1 | 63.8 | 3.4 | 63.1 | 2.5 | 62.1 | 2.7 |
| EMk05 | 174.5 | 7.8 | 175.4 | 7.1 | 174.2 | 6.6 | 173.2 | 6.5 |
| EMk06 | 142.3 | 14.6 | 141.8 | 13.8 | 141.2 | 13.5 | 140.2 | 13.2 |
| EMk07 | 526.4 | 104.6 | 527.1 | 105.5 | 525.3 | 101.3 | 524.5 | 103.2 |
| EMk08 | 306.3 | 160.4 | 304.6 | 159.3 | 304.6 | 158.6 | 303.5 | 158.4 |
| EMk09 | 207.4 | 6.4 | 206.5 | 6.7 | 206.1 | 6.1 | 205.8 | 5.9 |
| EMk10 | 207.2 | 5.6 | 207.3 | 6.0 | 207.2 | 7.9 | 205.8 | 5.9 |
| hCEA-MRF(I) | hCEA-MRF(D) | hCEA-MRF | ||||
|---|---|---|---|---|---|---|
| Average | Variance | Average | Variance | Average | Variance | |
| UMk01 | 40.4 | 2.7 | 40.5 | 2.47 | 39.8 | 1.9 |
| UMk02 | 26.8 | 2.1 | 26.9 | 1.7 | 25.9 | 1.4 |
| UMk03 | 208.4 | 48.7 | 209.1 | 47.2 | 205.2 | 41.1 |
| UMk04 | 61.8 | 2.4 | 62.1 | 2.1 | 60.8 | 1.7 |
| UMk05 | 173.5 | 6.5 | 174.1 | 5.8 | 171.1 | 4.6 |
| UMk06 | 61.1 | 2.8 | 60.6 | 3.1 | 58.6 | 3.7 |
| UMk07 | 141.3 | 12.7 | 140.7 | 13.1 | 138.4 | 11.8 |
| UMk08 | 535.7 | 110.4 | 530.9 | 113.2 | 522.3 | 101.7 |
| UMk09 | 310.8 | 170.4 | 308.4 | 167.1 | 302.3 | 156.9 |
| UMk10 | 202.4 | 7.9 | 203.2 | 5.6 | 198.8 | 4.6 |
| hCEA-MRF(I) | hCEA-MRF(D) | hCEA-MRF | ||||
|---|---|---|---|---|---|---|
| Average | Variance | Average | Variance | Average | Variance | |
| GMk01 | 42.1 | 3.4 | 42.6 | 2.9 | 40.7 | 2.3 |
| GMk02 | 27.4 | 2.1 | 26.9 | 1.7 | 26.3 | 1.9 |
| GMk03 | 207.5 | 48.7 | 207.5 | 46.5 | 206.4 | 44.7 |
| GMk04 | 63.1 | 2.5 | 62.6 | 2.9 | 61.6 | 2.3 |
| GMk05 | 175.6 | 6.3 | 174.7 | 5.7 | 173.2 | 5.5 |
| GMk06 | 62.1 | 4.9 | 61.7 | 5.2 | 60.1 | 4.5 |
| GMk07 | 143.2 | 13.8 | 142.5 | 13.1 | 141.4 | 12.9 |
| GMk08 | 527.4 | 106.4 | 526.4 | 105.6 | 524.6 | 104.8 |
| GMk09 | 304.5 | 164.3 | 305.2 | 163.3 | 303.5 | 162.4 |
| GMk10 | 203.4 | 7.6 | 204.3 | 8.4 | 202.8 | 6.8 |
| hCEA-MRF(I) | hCEA-MRF(D) | hCEA-MRF | ||||
|---|---|---|---|---|---|---|
| Average | Variance | Average | Variance | Average | Variance | |
| EMk01 | 44.3 | 3.8 | 43.6 | 3.5 | 42.3 | 3.1 |
| EMk02 | 29.3 | 3.2 | 28.4 | 3.2 | 27.2 | 2.5 |
| EMk03 | 209.4 | 44.7 | 208.4 | 43.5 | 207.2 | 43.2 |
| EMk04 | 64.3 | 3.1 | 63.7 | 2.8 | 62.1 | 2.7 |
| EMk05 | 175.6 | 7.4 | 174.5 | 6.9 | 173.2 | 6.5 |
| EMk06 | 63.6 | 3.4 | 63.9 | 2.8 | 62.1 | 2.3 |
| EMk07 | 142.3 | 14.6 | 141.8 | 13.6 | 140.2 | 13.2 |
| EMk08 | 527.4 | 104.5 | 525.3 | 103.8 | 524.5 | 103.2 |
| EMk09 | 305.4 | 160.2 | 304.8 | 159.4 | 303.5 | 158.4 |
| EMk10 | 206.4 | 6.3 | 207.5 | 6.3 | 205.8 | 5.9 |
| hCEA-MRF(F) | hCEA-MRF(S) | hCEA-MRF | ||||
|---|---|---|---|---|---|---|
| Average | Variance | Average | Variance | Average | Variance | |
| UMk01 | 43.2 | 3.2 | 41.7 | 2.3 | 39.8 | 1.9 |
| UMk02 | 27.3 | 2.5 | 26.4 | 2.1 | 25.9 | 1.4 |
| UMk03 | 208.4 | 43.2 | 206.6 | 42.5 | 205.2 | 41.1 |
| UMk04 | 62.1 | 2.4 | 61.8 | 2.2 | 60.8 | 1.7 |
| UMk05 | 174.2 | 6.8 | 172.8 | 5.4 | 171.1 | 4.6 |
| UMk06 | 63.2 | 4.9 | 61.7 | 4.2 | 58.6 | 3.7 |
| UMk07 | 142.5 | 13.1 | 140.5 | 12.3 | 138.4 | 11.8 |
| UMk08 | 528.8 | 109.3 | 526.4 | 103.5 | 522.3 | 101.7 |
| UMk09 | 308.1 | 164.4 | 305.2 | 160.9 | 302.3 | 156.9 |
| UMk10 | 206.4 | 4.5 | 204.5 | 5.2 | 198.8 | 4.6 |
| hCEA-MRF(F) | hCEA-MRF(S) | hCEA-MRF | ||||
|---|---|---|---|---|---|---|
| Average | Variance | Average | Variance | Average | Variance | |
| GMk01 | 44.3 | 3.5 | 43.6 | 3.1 | 40.7 | 2.3 |
| GMk02 | 28.4 | 2.7 | 27.6 | 2.5 | 26.3 | 1.9 |
| GMk03 | 209.5 | 46.8 | 207.4 | 45.6 | 206.4 | 44.7 |
| GMk04 | 63.2 | 3.5 | 62.8 | 2.8 | 61.6 | 2.3 |
| GMk05 | 175.6 | 6.7 | 174.9 | 6.5 | 173.2 | 5.5 |
| GMk06 | 63.2 | 5.8 | 62.1 | 5.6 | 60.1 | 4.5 |
| GMk07 | 144.2 | 14.6 | 143.1 | 13.7 | 141.4 | 12.9 |
| GMk08 | 527.5 | 106.4 | 529.4 | 105.7 | 524.6 | 104.8 |
| GMk09 | 306.4 | 164.3 | 305.8 | 163.5 | 303.5 | 162.4 |
| GMk10 | 206.3 | 7.8 | 205.6 | 7.2 | 202.8 | 6.8 |
| hCEA-MRF(F) | hCEA-MRF(S) | hCEA-MRF | ||||
|---|---|---|---|---|---|---|
| Average | Variance | Average | Variance | Average | Variance | |
| EMk01 | 44.3 | 3.8 | 43.7 | 2.8 | 42.3 | 3.1 |
| EMk02 | 29.5 | 4.3 | 28.3 | 3.5 | 27.2 | 2.5 |
| EMk03 | 209.6 | 46.3 | 208.3 | 45.3 | 207.2 | 43.2 |
| EMk04 | 64.2 | 3.7 | 63.2 | 3.1 | 62.1 | 2.7 |
| EMk05 | 176.6 | 7.9 | 175.3 | 7.3 | 173.2 | 6.5 |
| EMk06 | 65.3 | 4.5 | 63.8 | 3.6 | 62.1 | 2.3 |
| EMk07 | 143.9 | 15.4 | 142.2 | 14.8 | 140.2 | 13.2 |
| EMk08 | 526.8 | 106.4 | 525.2 | 104.2 | 524.5 | 103.2 |
| EMk09 | 306.6 | 161.5 | 205.8 | 160.9 | 303.5 | 158.4 |
| EMk10 | 207.8 | 7.5 | 206.5 | 6.9 | 205.8 | 5.9 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, L.; Lin, L.; Li, H.; Gen, M. Cooperative Co-Evolution Algorithm with an MRF-Based Decomposition Strategy for Stochastic Flexible Job Shop Scheduling. Mathematics 2019, 7, 318. https://doi.org/10.3390/math7040318
Sun L, Lin L, Li H, Gen M. Cooperative Co-Evolution Algorithm with an MRF-Based Decomposition Strategy for Stochastic Flexible Job Shop Scheduling. Mathematics. 2019; 7(4):318. https://doi.org/10.3390/math7040318
Chicago/Turabian StyleSun, Lu, Lin Lin, Haojie Li, and Mitsuo Gen. 2019. "Cooperative Co-Evolution Algorithm with an MRF-Based Decomposition Strategy for Stochastic Flexible Job Shop Scheduling" Mathematics 7, no. 4: 318. https://doi.org/10.3390/math7040318
APA StyleSun, L., Lin, L., Li, H., & Gen, M. (2019). Cooperative Co-Evolution Algorithm with an MRF-Based Decomposition Strategy for Stochastic Flexible Job Shop Scheduling. Mathematics, 7(4), 318. https://doi.org/10.3390/math7040318