1. Introduction
Growth curves with sigmoidal behaviour are widely used for data analysis across several fields of application. Given the variety of approaches employed in the profuse literature dealing with this subject, several mathematical models have been proposed for their study.
In general terms, a sigmoidal function is a function defined in the real line, bounded and differentiable with positive derivative. Its graph has a typical S shape showing a slow growth at the beginning, followed by a fast (exponential) growth that slows down gradually until it reaches an equilibrium value (usually named carrying capacity or level of saturation). Often, the sigmoid function refers to the particular case of the logistic function , although there is a great variety of curves with these characteristics. One of them is the Gompertz function, which is used in the modeling of systems that are saturated for large values of t, and whose most general expression is .
New sigmoidal curves have been introduced over the years, and their application has extended to several new fields. Among them we may mention hyperbolic curves (Eby et al. [
1]), sigmoidal hyperbolic functions of the first and second kind (Menon et al. [
2]), or the beta growth function (Yin et al. [
3]). Regarding their application to new fields, researchers have looked into the diffusion of innovations (Giovanis and Skiadas [
4]); the calculation of oil production peaks (Gallagher [
5]); predicting changes in language (Yokohama and Sanada [
6]); analyzing fatigue and fractures in materials and structures (Paolino and Cavatorta [
7]); etc.
Traditionally, most of the sigmoidal growth models cited above have arisen from the solution of ordinary differential equations. In that sense, they are deterministic and do not include other information than that provided by the variable under study. In order to incorporate these influences, the idea of growth in a random environment emerged (see Ricciardi, [
8] and references therein). Thus, the so-called dynamic growth models appeared, and among them diffusion processes. Some of these diffusion models emerge as solutions to a stochastic differential equation after modifying a deterministic one by introducing in it a term of white noise. Other diffusion processes are constructed in such a way that their mean function is a certain sigmoidal growth curve. Usually, those of the first type retain the name of the corresponding deterministic equation of origin. For instance, Schurz [
9], collect a wide variety of logistic diffusion processes. However, for most of them the stochastic differential equation does not have an explicit solution. For this reason, Román and Torres [
10] constructed a logistic-type stochastic differential equation in the second sense (its mean is a logistic function). The same situation has presented itself in the context of other growth curves and related diffusion processes. Such is the case of the Gompertz process, which was introduced by [
11]. In such process, the upper limit of the curve is independent of the initial value of the population under study, something not always verified in real situations. For this reason, Gutiérrez et al. [
12] introduced a new Gompertz-type process in which the
carrying capacity of the system depends on the initial state. This line of action has also been applied to the Bertalanffy curve (see Quiming et al. [
13] and Román et al. [
14]), the Hubbert curve (Luz-Sant’Ana et al. [
15]), and, more recently, to the hyperbolastic curve of type I (Barrera et al. [
16]).
Dynamic models are used in the fields in which the deterministic case has proved to be useful in fitting sigmoidal behaviour patterns to observed data. Researchers have developed several methods of estimation for these dynamic models. As far as maximum likelihood estimation methods are concerned, we can differentiate between those that take as a starting point the stochastic differential equation related to the model (usually known as continuous sampling methods) from those who build the likelihood function from the transition density functions of the process (discrete sampling methods). Alternatively, some authors have dealt with inference from a Bayesian perspective (Tang and Heron [
17]).
An interesting aspect in this type of processes is the possibility of introducing, into their infinitesimal moments, time functions that allow us to regulate the evolution of the variable under study. Given that the functional form of such functions is not known, several strategies have been devised for their estimation. Some work carried out along this line includes studies by Albano et al. [
18,
19] and Román et al. [
20] which centered on modifications of the Gompertz process.
There are multiple real situations in which the maximum level of growth is reached after successive stages, in each of which there is a deceleration followed by an explosion of the exponential type. For this reason, the use of sigmoidal curves with more than one inflection point is a good approach. A typical example of this behaviour is observed in the growth of various fruit species, such as stone fruits (Álvarez and Boché [
21]). Cairns et al. [
22] used double-sigmoidal models to study fatigue profiles in mouse muscles, while Amorim et al. [
23] detected this type of behaviour in the different phases in which the fungus Ustilago Scitaminea Sydow infects the sugarcane and produces its characteristic smut.
The way that this multi-sigmoidal behaviour is modeled is far from unique. For example, Roper [
24] used hyperbolic functions to study the transition between various temperature states in certain geological zones. Other authors have achieved this goal by including terms that define inflection points and additional parameters (Lipovetsky [
25]). However, these models have not addressed the incorporation of external information to the variable under study, similarly to the dynamic models already mentioned. In this paper we address this problem by introducing a diffusion process whose mean obeys a pattern of multi-sigmoidal behaviour. In particular, we will deal with the case of Gompertz growth with multiple inflection points, following the idea mentioned in [
23] for the case of the generalized monomolecular and Gompertz curves.
The rest of the paper is organized as follows: in
Section 2 the multi-sigmoidal Gompertz curve is introduced by including a polynomial in the usual expression of the curve. In
Section 3, the Gompertz multi-sigmoidal diffusion process is defined. To this end, the lognormal diffusion process with exogenous factors is considered, since it allows us to model behavioral patterns that verify the properties exhibited by the curve. The estimation of the process, which is performed by maximum likelihood using discrete sampling, is the subject of
Section 4. The matter of obtaining initial solutions to solve the resulting system of equations deserves special attention. Other important aspect is to determine the degree of polynomial that should be considered since, in general, this aspect will be unknown in real applications. To this end, some criteria are considered in that section. Finally, in
Section 5, some simulation examples are considered.
2. Multi-Sigmoidal Gompertz Curve
Let
be a
p-degree polynomial, where
(
) denotes a real parametric vector with positive leading coefficient
. We define the multi-sigmoidal Gompertz function as
Denoting
, curve (
1) satisfies the ordinary linear differential equation
where
Taking into account that
, the above equation can be expressed as
However, the resolution of both equations, with initial condition
, leads to two expressions of curve (
1). Indeed, the solution of (
2) is
while the solution of (
4) is
Equation (
4) is a generalization of the classical gompertzian differential equation, giving rise to the curve (
6), used by authors like Ricciardi et al. [
26] in the case
. On the other hand, Equation (
2) is a linear differential equation of the Malthusian type whose solution generalizes the expression of the Gompertz curve used by authors such as Laird [
27] and Gutiérrez et al. [
12].
The main difference between (
5) and (
6) lies in their limit value, which in the first case is
, and
k in the second. This may lead to the choice of either expression depending on the knowledge available about the influence of initial value
on the limit value. This is the case when the phenomenon under study shows Gompertz-type growth and several sample paths are available, each with a common growth pattern but with different initial values and a different limit value (for example, the particular weight of each individual of the same species). In the rest of the paper, we will consider the situation in which the carrying capacity of the system modeled by the curve depends on the initial value of the population under study. So, (
5) can be expressed as
where
, verifying
.
Focusing on the general expression given by (
1), from (
2) it follows that the growth intervals of the curve depend on the roots of the equation
. As for the inflection points, the candidates will be the solutions of
, which results in solving the equation
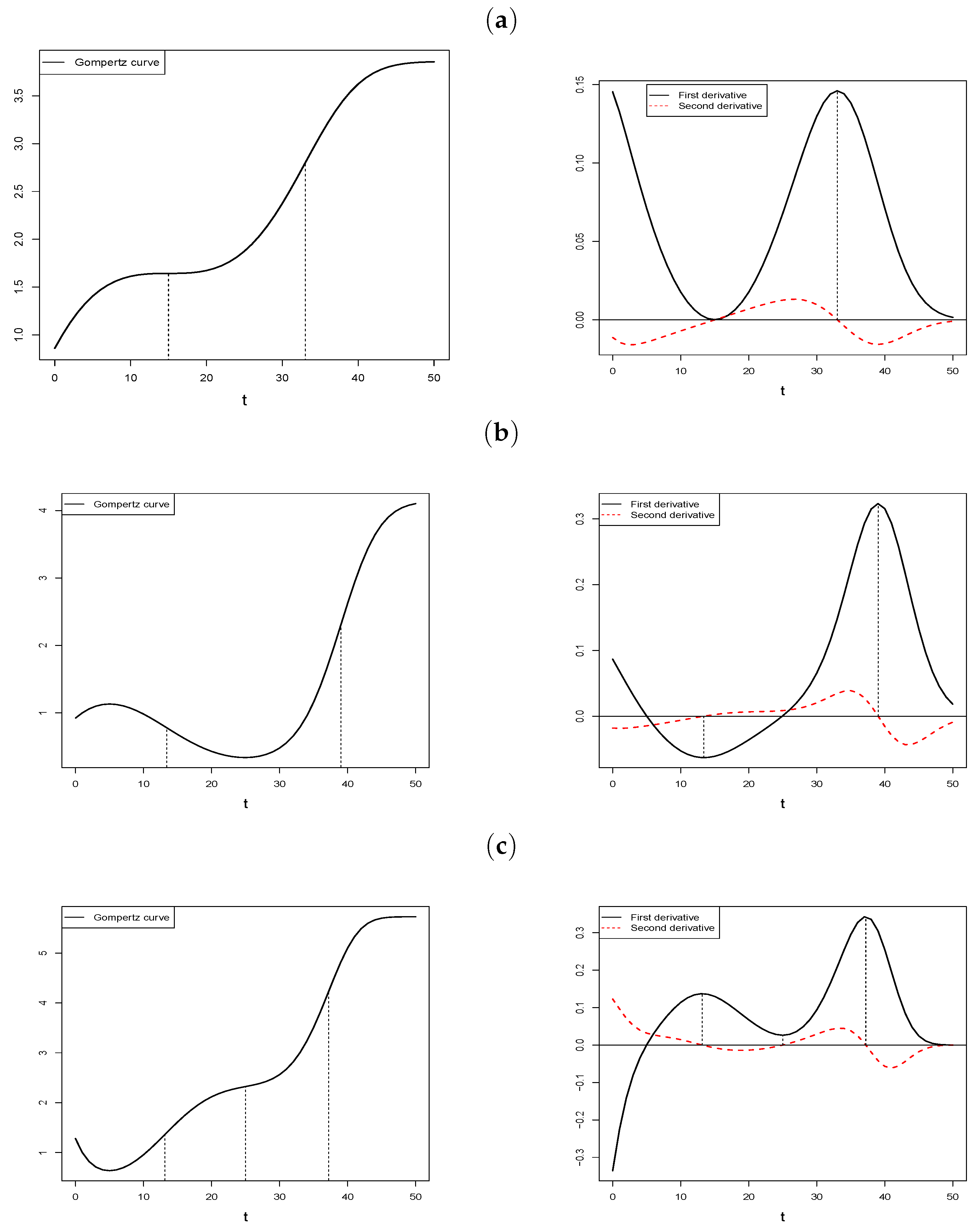
Figure 1 shows some possible situations for various choices of the polynomial
. In each case, the Gompertz curve is represented together with its first and second derivatives. In particular, figure (a) represents the case in which
has no roots and the curve is strictly increasing and presenting two inflection points, as in case (b), although in the latter case the curve presents both decreasing and increasing intervals. Finally, figure (c) shows an example with three inflection points.
3. Multi-Sigmoidal Gompertz Diffusion Process
Assuming that (
7) has at least one solution where
presents an inflection point, this function is found in the conditions listed in Román and Torres [
28], which ensures that the growth phenomenon represented by the curve can be modeled by a non-homogeneous lognormal diffusion process whose mean function is such a function. In Román et al. [
29], a general study of this process is carried out, including the distribution and main characteristics as well as aspects related to inference. Following the notation used in that paper, we define the multi-sigmoidal Gompertz process as a diffusion process
that takes values in
and with infinitesimal moments
where
is a real interval (
) and
is an open set such that
, where
is given by (
3). This process is determined from the stochastic differential equation
where
is a Wiener process (Brownian motion), independent of the initial condition
,
. The solution to this equation can be expressed as
where
Regarding the distribution of the process, if is distributed according to a lognormal distribution , or is a degenerate variable (i.e., ), the finite dimensional distributions of the process are lognormal. Thus, and , vector is distributed according to an n-dimensional lognormal distribution , where the components of the vector are , , being , , those of the matrix .
From the two-dimensional distributions
,
, the transitions of the process can be obtained, which are also lognormal; concretely,
Once the distribution of the process has been established, different characteristics associated with it can be calculated, including the mean and conditioned mean functions, whose expressions are
and
respectively, being able to verify that both functions are of the type introduced in the previous section. The expression that adopts other characteristics can be consulted in Román et al. [
29].
4. Maximum Likelihood Estimation
In this section we will deal with the estimation of the parameters of the process by maximum likelihood. In Román and Torres [
29], a general treatment of this question is carried out for the non-homogeneous lognormal process, of which the process dealt with in this paper is a particular case. Below we summarize the main results obtained in the aforementioned paper, adapting them to the actual case.
The starting point is a discrete sampling of the process based on d sample paths observed at time instants , . Note that the observation time instants do not have to be the same in each trajectory, although we will suppose that , . Denote by , where is the vector that contains the variables of the i-th sample-path, that is , .
Assuming that the distribution of
is lognormal
, and taking into account the transitions of the process, the probability density function of
is given by
where
and
are given by
with
Next, we consider the change of variables
that transforms vector
in
, whit probability density function
where
,
,
, and
is an
n-dimensional vector with components
,
.
For a fixed value
, expression (
9) provides the likelihood function, whose logarithm is
where
is the vector that contains the parameters of the initial distribution, being
Assuming that
and
are functionally independent, the estimate of
leads to
while that of
is obtained (see [
29] for details) from the system of equations
where
Taking into account that
and the previous expressions of
and
, the subsystem of equations (
10) remains in the form
where, for
one has
On the other hand, and since
Equation (
11) transforms into
4.1. System of Equations and Numerical Computations
The system of Equations (
12) and (
13) can not be solved explicitly, and it is therefore necessary to use numerical methods, such as Newton-Raphson, for which an initial solution is required. Next, we present a strategy to achieve this, based on the information provided by the sample data.
As a matter of fact, and taking into account that the mean function of the process is a Gompertz multi-sigmoidal curve, as well as the expression (
1), it follows
Noting
the values of the mean of the sample paths at
, we propose to fit, by linear regression, a polynomial taking as data the pairs of values
. The estimated coefficients will provide the initial values for
and
. Regarding
, its initial estimation is based on the fact that for a lognormal distribution
, the quotient between the arithmetic mean and the geometric one provides an estimation of
; concretely
. Applying this result to the distribution of
we obtain, for each
, an estimate of
; that is,
,
, where
are the values of the geometric sample mean. Finally, the initial value of
is calculated by performing a simple linear regression of the
values against
.
In this procedure there are several questions that must be taken into account:
The value of k, in general, will not be known. Therefore, we suggest taking as an approximation the last value of the mean. However, it is possible that in real cases, and due to the fluctuations of the process, there could be values verifying , so transformation would not be determined. In such cases, usually not many in practical cases, those points must be removed from the regression analysis.
Since, generally, the degree of the polynomial will not be known a priori, it is necessary to have some mechanism that will allow for its selection. To this end we propose a forward procedure, introducing polynomials in a consecutive way in the model. Each time a polynomial is introduced, a measure of the adjustment made is calculated and compared with the previous ones. If the adjustment is improved, the procedure continues; otherwise it stops. However, and even in this case, it is convenient to perform one more iteration due to the parity of the polynomial.
Regarding the measures that can be used to evaluate the adjustment, we propose the following:
- -
The absolute relative errors between the sample mean of the process and the fitted mean for each estimated model
- -
The resistor-average distance (see Johnson and Sinanovic [
30]). This is a distance based on the Kullback–Leibler divergence, which will be used for calculating the distance between the sample distribution (available from the data) and that obtained from each estimated model. The expression for this measure is
where
denotes the Kullback–Leibler divergence between the sample distribution (
) and that for the
i-th estimated model (
). Its expression is given by
In practice, this is the expression of the distance that should be used since the theoretical model will not be known in real applications. However, for simulation studies the distance between theoretical and estimated models could be considered. In this case, the previous expression would be slightly modified.
- -
The Akaike information criterion (AIC) and the Bayes information criterion (BIC).
4.2. About
Another interesting aspect to consider is that of the time instants, especially when they take high values. This can mainly affect the obtention of the initial values for the parameters since a polynomial regression has been proposed. One option is to apply orthogonal polynomials, as it is usual when considering this type of regression.
One alternative is to consider a new diffusion process obtained from by considering a shift of length in time, that is , so that the original data can be considered as observations of the new process with an initial instant equal to zero. Let’s see how this change affects the infinitesimal moments of the processes:
In general, let
be the original process and
verifying
. Denote by
and
their respective
m-th order infinitesimal moments. Taking into account the definition of infinitesimal moment of order
m,
it verifies that
. Obviously, the strategy of considering this translation over time will be useful when the resulting process is of the same type as the original.
In the case of the multi-sigmoidal Gompertz process, let us consider
with infinitesimal moments
where
.
Taking into account that
where
, being
then the corresponding infinitesimal moments for the process
given by
are
with
and
the derivative of polynomial
.
Note that is also a multi-sigmoidal Gompertz diffusion process whose infinitesimal moments differ from those of in the reparametrization occurred in and . The same happens for the finite dimensional distributions, transition distributions and main characteristics of the process. In particular, .
5. Simulations
In this section, some simulation examples will be carried out with the aim of illustrating the developments previously established, focusing on the strategies related to the estimation of the parameters of the model as well as the selection of the model that best fits the data. All the simulations were performed according to the following common pattern: 25 sample paths were simulated, each one obtained from expression (
8), which relates the Gompertz process under consideration and the Wiener process. All of them contain the same number of data (501), being
,
the observation time instants. For simplicity we have chosen a degenerate initial distribution (
). After obtaining each trajectory, we chose 51 values starting from the first one and using a step equal to 1. Hence, a sample of 51 data was obtained for each sample path.
With regard to the processes chosen for the simulation, two have been selected that correspond to situations in which there are two inflection points. The former presents a strictly increasing mean, while in the second an initial decrease is observed.
5.1. The Case of Increasing Mean
As a first example we have selected a multi-sigmoidal Gompertz diffusion process for which the degree of the polynomial included in the infinitesimal mean is
, being
. The value of
is
, while two values of
have been considered (concretely
) to verify the effect of increasing the infinitesimal variance in the estimation process.
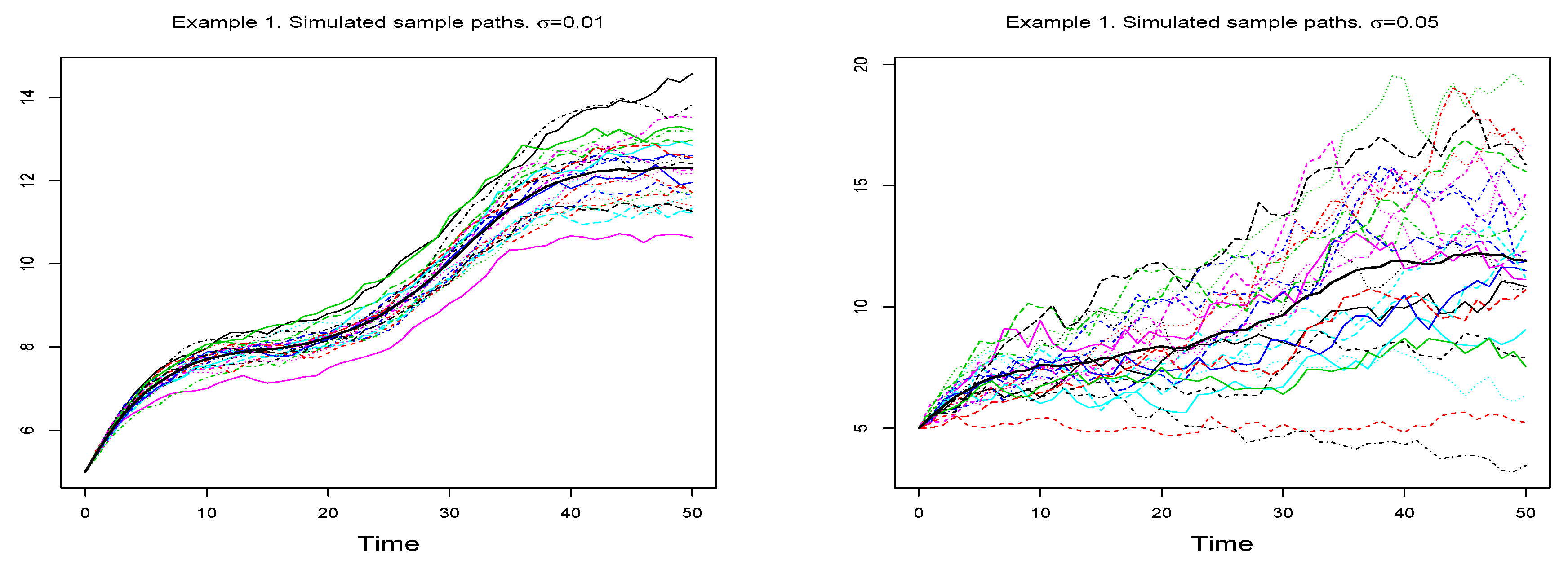
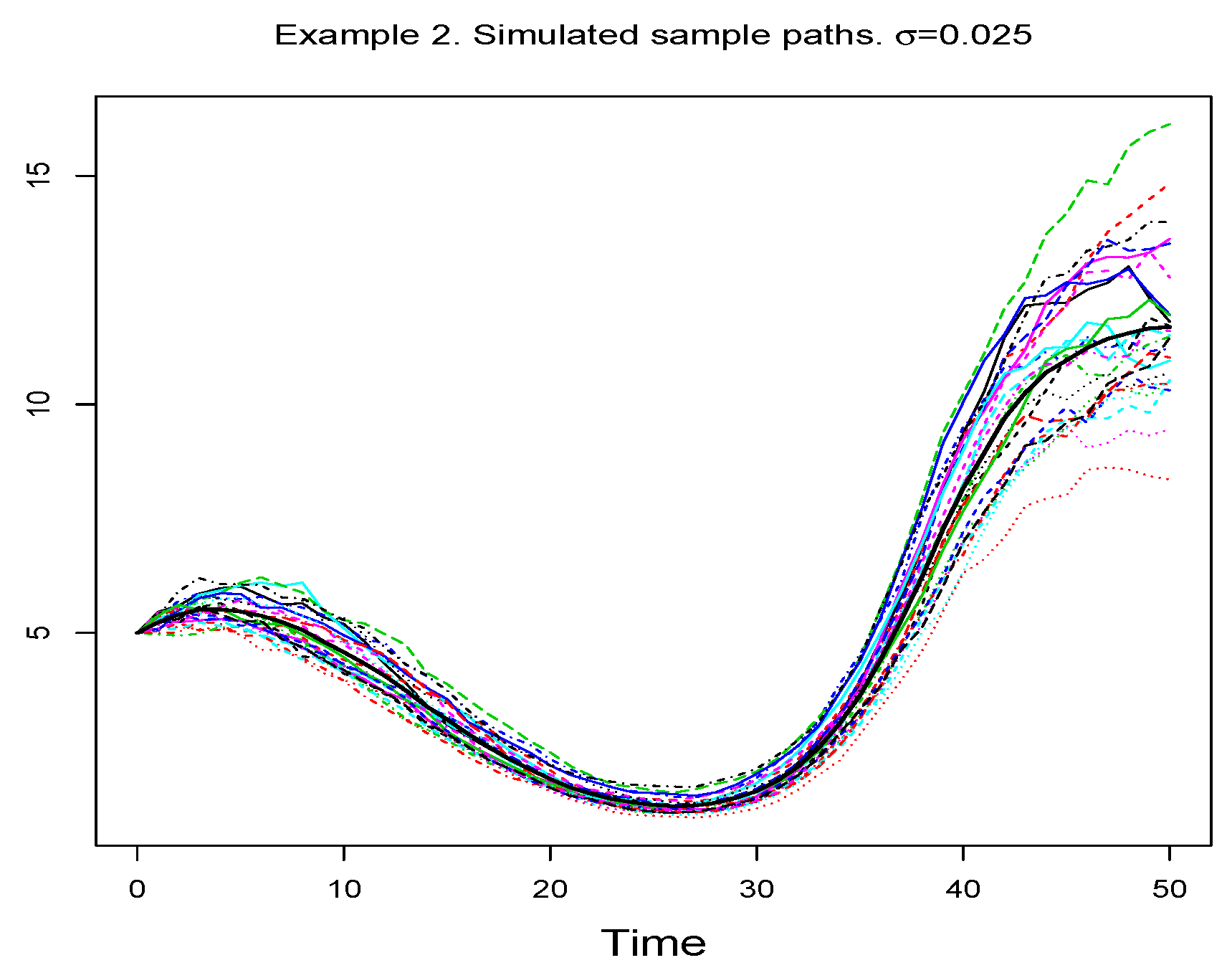
Figure 2 shows the 25 simulated sample paths for each value of
.
In order to find the process that best fits the data, for each sigma value, multi-sigmoidal Gompertz processes including polynomials from grade 2 to 5 have been considered successively.
Table 1 includes, for each model, the initial values of the parameters as well as their definitive estimates. The initial values have been obtained following the procedure described above. Note that the initial
value is common for all cases since it is calculated directly from the sample data.
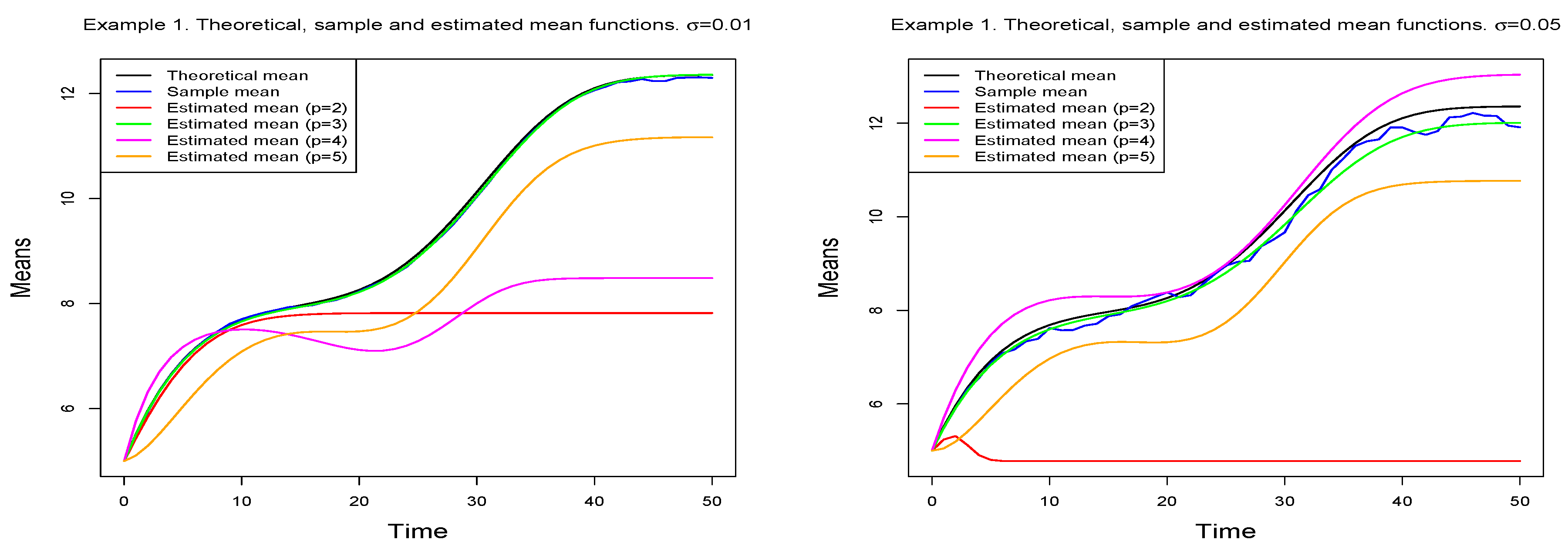
Figure 3 displays the theoretical and the sample mean functions, together with those corresponding to each estimated model. This figure suggests considering the model with
as the optimum, although this must be endorsed by numerical measures of goodness of fit.
Table 2 summarizes the measures that have been used (RAE, AIC and BIC). For all of them, it can be observed how from
the goodness of fit can not be improved. Therefore, the third-degree model has been chosen as the optimal one.
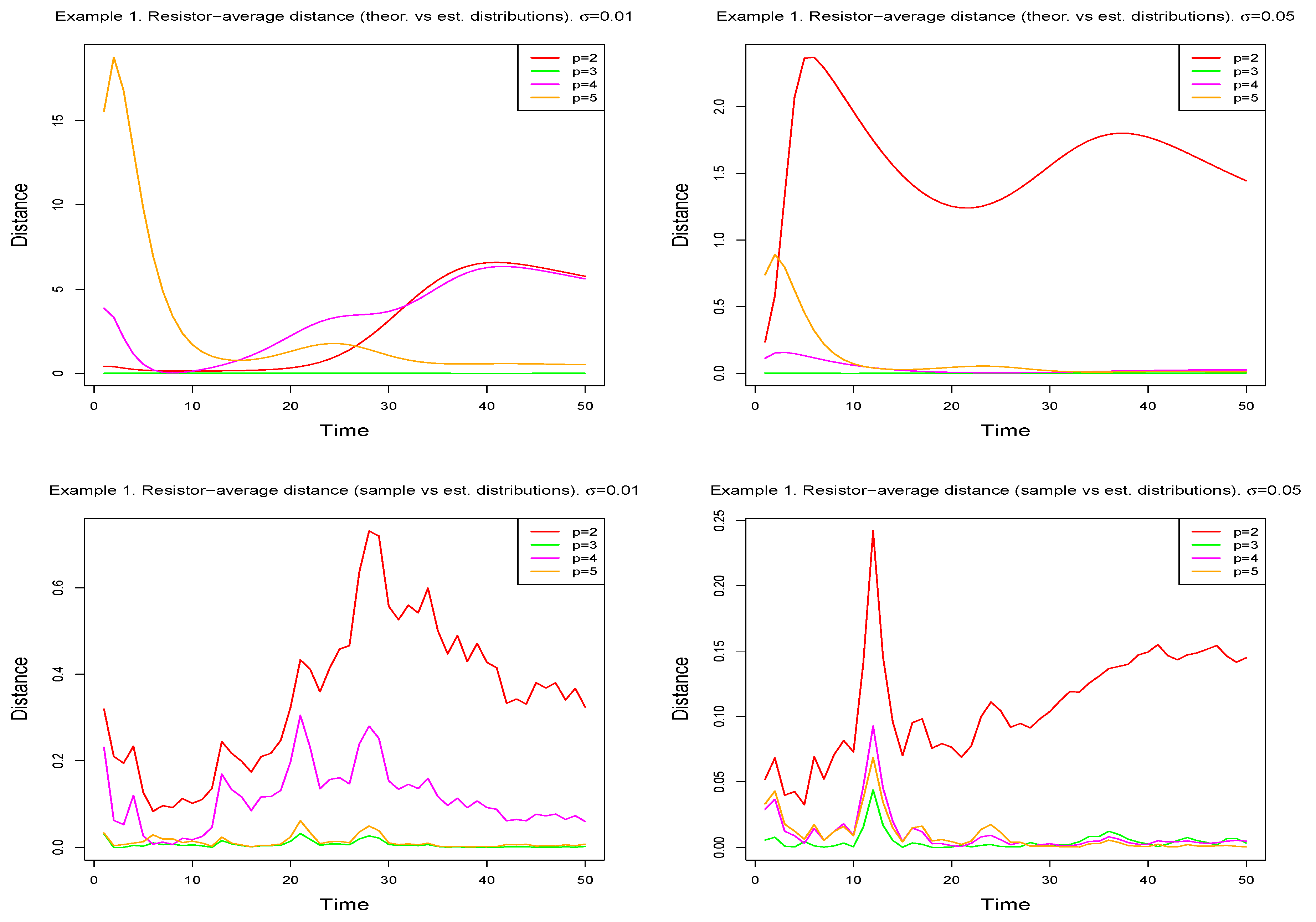
The use of the resistor-average distance also leads us to this conclusion. For each value of
p, and for each value of
t, the distance between the estimated one-dimensional distribution and the corresponding theoretical and sample distributions has been calculated. This provides, for each degree, two functions whose graphs are shown in
Figure 4, showing how odd-grade models seem to be preferable. With the idea of obtaining a globalizing measure that allows selecting the best model,
Table 3 shows, for each of them, the means and medians of the values of the distances. These two measures confirm that the model with
is the one that should be selected as optimal. It should be noted that in practical applications, as the theoretical model is not available, the distance to be considered is that which takes the sample distribution as a reference. However, in this first example we have included the two possibilities.
Finally,
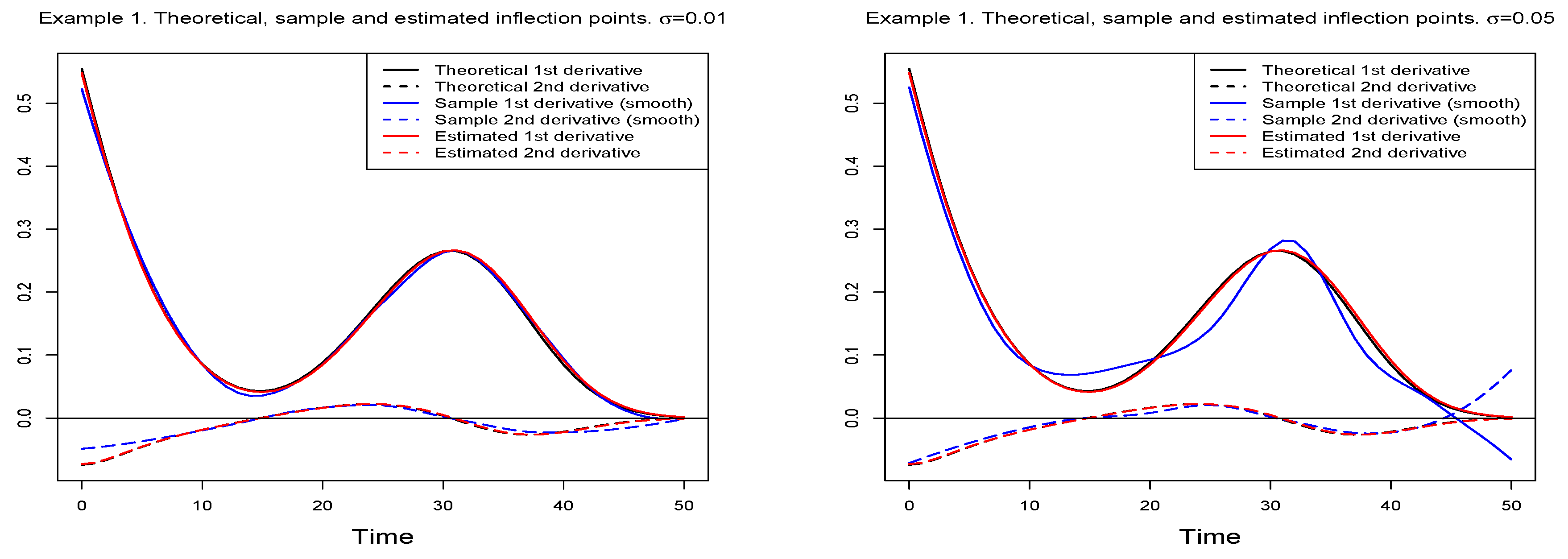
Figure 5 shows, for each
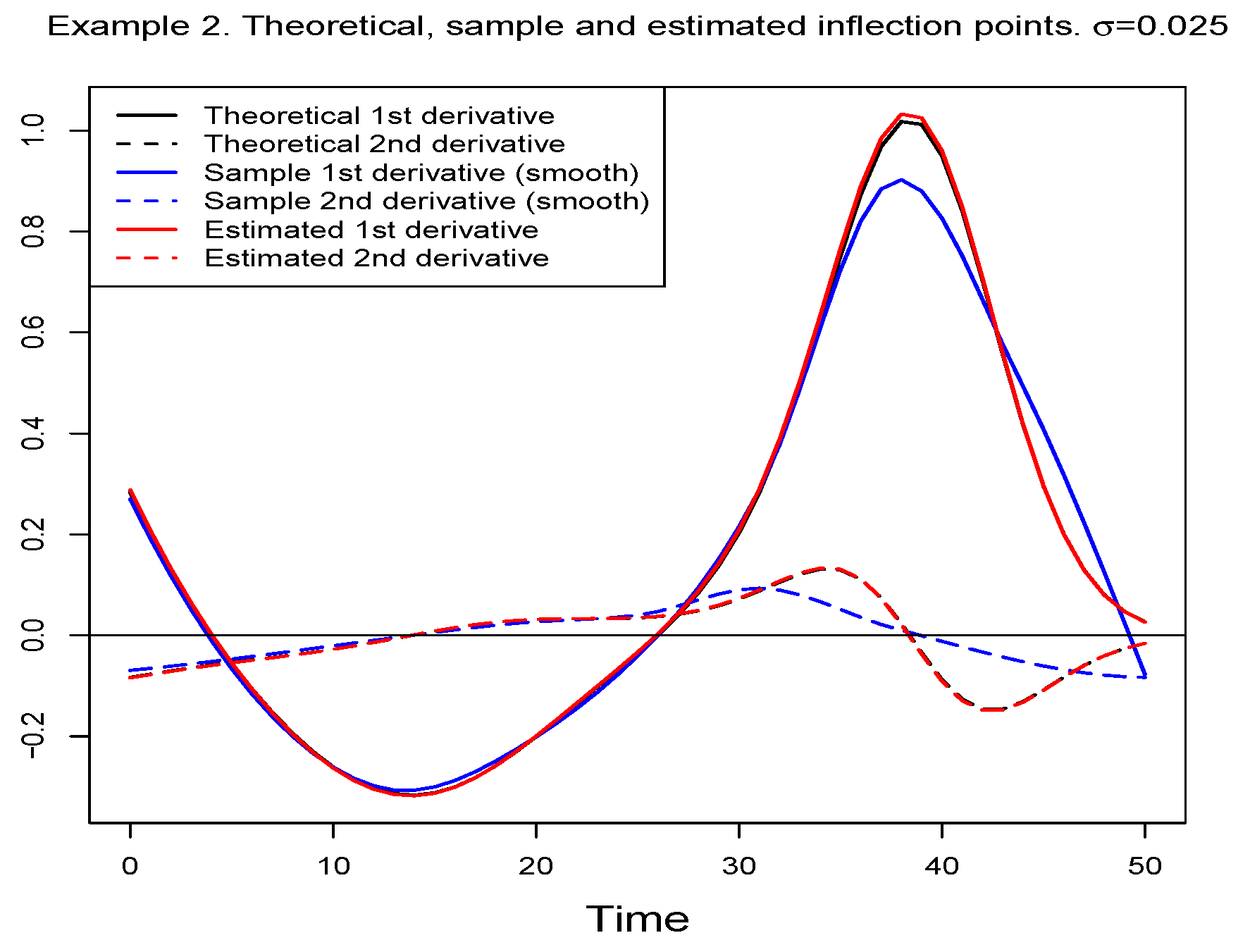
value, the first and second derivatives of the theoretical, sample and estimated mean functions for the selected model. In order to obtain the derivatives of the sample mean function, a smoothing of the function has previously been carried out using polynomial local regression. A good fit between these functions can be observed, which is corroborated by
Table 4, which contains the theoretical, sample, and estimated values of the inflection time instants.
5.2. The Case of Mean Decreasing, Then Increasing
This example illustrates a case in which the data present an initial decrease and then grow up to the value of the upper bound. As in the previous case, we have selected a model with
, being
,
and
.
Figure 6 shows the simulated sample paths.
Following the same methodology developed in the previous example, once again the procedure stops when considering the polynomial of degree 5.
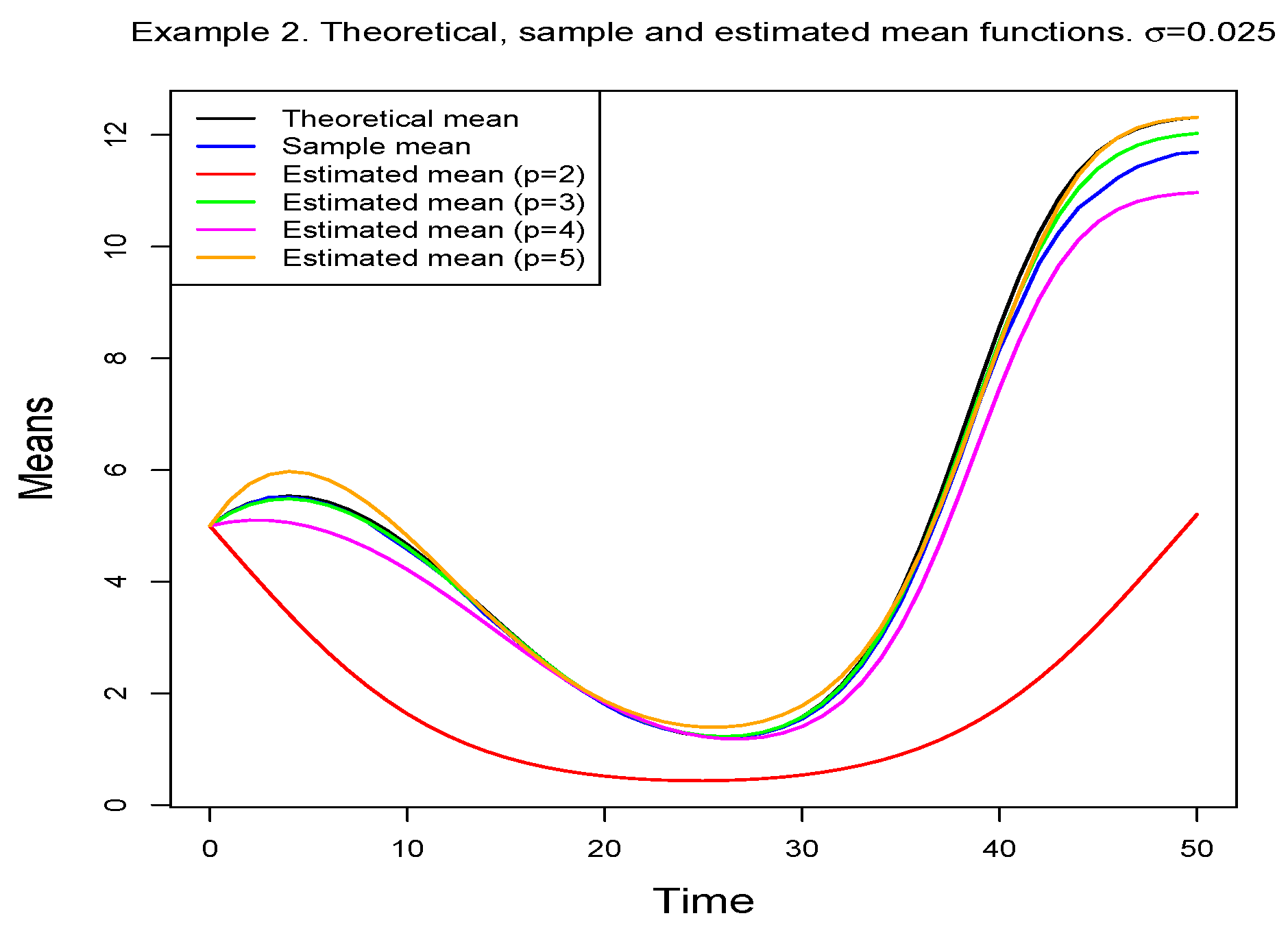
Figure 7 shows the estimated means together with the theoretical and the sample ones.
Table 5 contains the values of goodness-of-fit measurements, from which it follows that the model containing the third-degree polynomial must be chosen.
Regarding resistor-average distances, in this example we have only considered those calculated between the estimated models and the sample distribution.
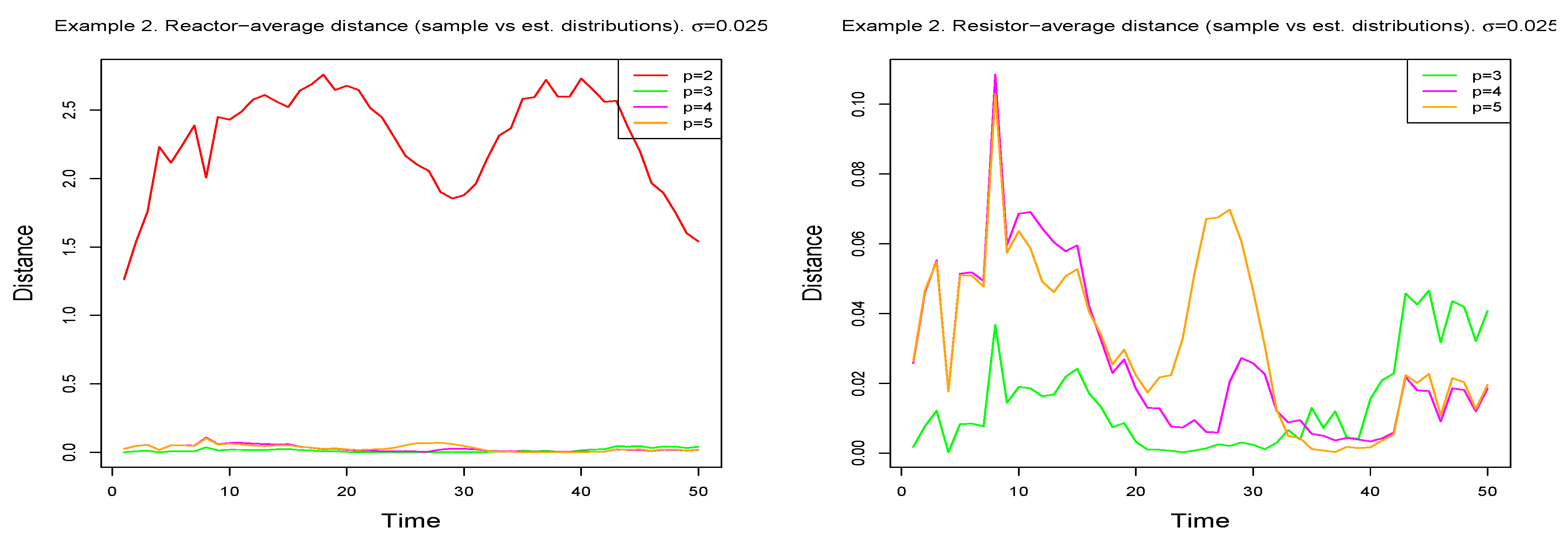
Figure 8 and
Table 6 contain the results obtained, confirming the previous choice of the model.
Table 7 shows the theoretical values of the inflection points (in parentheses) together with the sample and the estimated ones. In each case, the values have been obtained by numerically solving Equation (
7) for the theoretical, estimated, and sample mean functions. In the latter case, a natural cubic spline has been previously adjusted to the sample mean.
Figure 9 shows the situation graphically. It is readily apparent how the estimation is optimal and provides estimated values very close to the theoretical and sample values.
The results of the simulations carried out demonstrate the suitability of the procedures developed to adjust data that follow a Gompertz multi-sigmoidal pattern. The method of obtaining initial solutions for the resolution of the system of likelihood equations provides optimal values for this purpose from the information provided by the data. The procedures introduced for calculating the degree of the polynomial operate according to two types of criteria: one based on the adjustment of the data to the model and another based on the existing proximity between the sample and estimated distributions of the process. It can be seen, in the two simulations carried out, how both types of criteria coincide in the conclusions drawn from their application.
6. Conclusions
A wide variety of curves (logistic, Gompertz, Bertalanffy, Richards, among others) have been used in order to describe sigmoidal growth patterns in many scientific fields. All these curves have a point of inflection that is always at a fixed proportion of its asymptotic value. Nevertheless, there are real situations in which several growth phases appear, each representing a sigmoidal pattern.
Starting from a modification of the classic Gompertz curve (by including a polynomial function in it), this paper introduces a diffusion process whose mean function is a curve of such characteristics, which allows us to model situations showing this type of behaviour. The process introduced, following the methodology given in Román and Torres [
28], is a particular case of the lognormal process with exogenous factors, to which we apply the findings of Román et al. [
29]. In particular, the results relative to the estimation of the process by maximum likelihood are adapted, providing strategies that provide the initial solutions required for solving the system of equations by which the parameters are estimated.
One of the main problems arising from the use of this model in real situations is that of determining the degree of the polynomial. For this purpose, the use of several criteria has been suggested. These criteria are based on the goodness of fit (relative absolute error and Akaike and BIC criteria), as well as on the measurement of the distance between the estimated and sample distributions (resistor-average distance, based on the Kullback–Leibler divergence).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}