1. Introduction
This paper is the close companion to Reference [
1], in which a novel theory and method are presented for calculating the canonical labelings of digraphs. The center subgraph
[
2] can also be used to determine the first vertex
added into
of undirected graphs.
This article concentrates on the construction of a universal system and a way of calculating the
of undirected graphs [
3,
4,
5], which is also called an
[
6], a
[
7] or a canonical form [
8] and is the single string corresponding one-to-one to a graph such that two graphs are isomorphic if and only if both have the accurate same canonical labelings. Currently, the calculation of the
as the graph isomorphism problem is an unsolved challenge in computational complexity theory such that no polynomial-time algorithm appears for calculating the
of an undirected graph. The study of canonical labeling has contributed to the studies of problems in many fields, including quantum chemistry [
9], biochemistry [
10,
11] and so on.
Many exponential algorithms have emerged to deal with the problem. However, different researchers like to define different canonical labeling. Given a graph of
n vertices, Kuramochi and Karypis build the canonical labeling by concatenating the columns of the upper-triangular part of its adjacency matrix [
12,
13]. Huan et al. concatenate the lower triangular elements (including the diagonal elements) of its adjacency matrix to create its canonical labeling [
14]. Kashani et al. determine the canonical labeling by concatenating the rows of its adjacency matrix to form an
binary number [
15,
16]. Each of these canonical labelings correspondings one-to-one to a lexicographically smallest graph whose adjacency matrix is seen as a linear string, which is lexicographically smallest. Nevertheless, the computation of the lexicographically least graph is
-hard [
8,
17].
Throughout the paper, the of a graph G is the lexicographically largest string constructed by concatenating the rows of the upper triangular portion of the adjacency matrix associated with G (see Definition 5). The computational complexity that determines the of G is also -hard.
Babai and Luks used a general group-theoretic method to calculate canonical labeling [
8]. Nevertheless, combinatorial approaches have operated well in numerous particular situations. For stochastic graphs, Babai et al. generate canonical labeling with high possibility [
8,
18]. Arvind et al. introduce two similar logspace algorithms for partial 2- and 3-Trees [
17,
19].
Currently,
is the most prevalent and pragmatic means for determining the automorphism group and the
of graphs [
3,
20,
21,
22]. It appears to have shifted the industry norm for determining the
also the automorphism group. For calculating the
and automorphism group,
and Yan and Han [
23] use the depth-first search to traverse the latent intermediary vertices in the search tree. The vertices of the search tree produced by
are equitable ordered partitions of vertices in
G.
iteratively refines partitioning vertices until places the vertices that have the exact equivalent features into an automorphism orbit. As the partition refinement becomes finer and finer, it automatically makes the
. Nonetheless,
also needs exponential time to calculate the canonical labeling for a given Miyazaki graph [
24]. Tener and Deo earned advances for processing the problem [
25].
Besides
,
[
4],
[
5,
26] and Conauto [
27] are all state-of-the-art tools for graphs isomorphism testing. Based on the individualization of nodes, backtracking and partition refinement,
[
5,
26] is powerful canonical labeling means for dealing with large and sparse graphs. Katebi et al. combine
with
and show that it is faster for computing the automorphism group of a graph with
and then calculating its canonical labeling with
than for alone calculating its canonical labeling with
[
28]. To fix the vulnerability of
,
uses the policy of breadth-first search to decide the automorphism group and the canonical labeling [
4].
also utilizes the fundamental individualization/refinement method and is quite quick for random graphs and several classes of hard graphs.
For the advancement of performance, current algorithms usually employ backtracking and orbit partitioning way to circumvent frequently visiting the same nodes and contrive to decrease the accessed nodes in the search tree. For the canonical labeling issue, McKay et al. present a full examination of the problem [
22,
23].
governed the area for several decades. Therefore, in-depth research for canonical labeling has been limited to the theoretical skeleton of . This implies that people are only like to support the study trajectory of to extend and build further research.
Since there are several different definitions of canonical labeling, there is no uniform standard such that each researcher works on oneself standard. Besides the lack of a unified standard, the research on the connection between the distinct canonical labeling is also quite lacking. It is a hard task that one wants to confirm the accuracy of canonical labeling achieved by executing an algorithm. Up to now, the criterion by which one can decide which definition is better does not appear.
In this paper, the definition of is completely distinct that of . Unless by chance, the canonical labeling produced by will be not a according to the definition presented by the paper. It is sometimes difficult to confirm the accuracy of the canonical labeling achieved by executing according to the criterion of . Since the insides of many graphs contain a large number of automorphisms, the calculation of canonical labeling becomes extremely arduous in certain situations.
A graph invariant is called complete if the equality of the invariants and implies the isomorphism of the graphs G and H. However, even polynomial-valued invariants such as the chromatic polynomial are not usually complete. A path graph is a graph consisting of exactly its maximal path. For example, the path graph with 4 vertices and the claw graph both have the same chromatic polynomial.
Many algorithms also use the identical definition of as adopted in the paper. However, their main goal is not to consider how to calculate but for other purposes such as mining the frequent subgraphs. Therefore, these algorithms can only run for some limited graph classes. Until now, based on current knowledge and Definition 5 present in this paper, a universal algorithm for calculating the of graphs does not appear.
Jianqiang Hao et al. also provide Propositions 5–6, Lemmas 1–3 and Theorems 10–13 in Reference [
2] by which one can compute the proper vertices added into
. However, they do not give any proof. In this article, we prove Theorems 3–6 that are one-to-one corresponding to Theorems 10–13 in Reference [
2]. We also present the reasons for Lemmas 8–9, which are one-to-one corresponding to Lemmas 2–3 in Reference [
2].
In the rest of this paper,
Section 2 presents some fundamental vocabulary and preparatory knowledge.
Section 3 represents the results followed by some analysis.
Section 4 gives our algorithms for calculating the
.
Section 5 demonstrates the implementation of our algorithms and evaluates our way through many examples. Finally,
Section 6 remarks on our conclusions and future work.
2. Preliminaries
This paper only handles limited undirected graphs with neither loops nor multiple edges. A graph consists of a set of nodes and a collection of edges. For a graph , , assume that and represent the set of vertices of G and the collection of edges of G. Any an edge joins two vertices and . For this article to be self-contained, the relevant concepts and definitions are given below.
Definition 1. Suppose , is an undirected graph of n vertices. A vertex-induced subdigraph on of G is a subgraph with the vertices set together with any side whose endpoints are both in , expressed by .
Definition 2. Given two undirected graphs , and , of n vertices. If there is a bijection such that if and only if . We call f an isomorphic projection of . Furthermore, we state that the graph G and H are isomorphic, signified by . An isomorphic map f of G onto itself is declared to be an automorphism of G.
Let , in and , , ⋯ in be two vectors, the issue emerges as to how to determine which one is larger. When comparing two vectors, the following rules must be satisfied.
Definition 3. Given two vectors , and in N (the collection of natural numbers) satisfying and . Then, the lexicographic order of the two vectors is defined as follows:
- 1.
, if and for all .
- 2.
if and only if either of the following is true.
- (a)
for , .
- (b)
for and .
Definition 4. Given two vectors , and satisfying and , where each , denotes a vector in N (the collection of natural numbers). Then, the lexicographic order of the two vectors is defined as follows:
- 1.
, if and for all .
- 2.
if and only if either of the following is true.
- (a)
for , .
- (b)
for and .
Definition 5. Suppose , is an undirected graph of n vertices with adjacency matrix . To concatenate the rows of the upper triangular part of in the following order , , ⋯, , , , ⋯, , ⋯, , , ⋯, , ⋯, makes a corresponding binary number , which is aof G, signified by (
see (
1)).
The first row of the upper triangular portion of is the 1 of , signified by . Likewise, the second row of the upper triangular portion is the 2 of , signified by . ⋯. The th row of the upper triangular portion is the of , signified by . It is true that .
A permutation of the nodes of G is an order of the n nodes without repeating. The number of shifts of the nodes of G is . Further, each distinct permutation of the n nodes of determines a single adjacency matrix. Therefore, given a permutation , one can get a corresponding to by Definition 5. The collection of all of G is represented by .
For every , , Suppose that , with , or 1. Given and . By Definition 3, if , then we set . Otherwise, if , then we set . Otherwise, if , then we set .
Definitely, , is a well-ordered set, where ≤ signifies the less-than-or-equal-to binary relationship on the collection stated as above. By the well-ordering theorem, it follows that has a minimum and maximum element, signifies by and and called of G and of G respectively. We also call of G.
The two shifts of the n nodes of G associated with and are the , signifies by and . Furthermore, the two adjacency matrices of G associated with and are the , signifies by and .
corresponding to are of canonical labeling , signified by , , ⋯, , respectively. Conversely, , , ⋯, corresponding to are of canonical labeling , signified by , , ⋯, , respectively.
Based on the above definitions, the following equations are established.
Theorem 1. Given two undirected graphs , and , of n vertices with adjacency matrices and respectively. Then if and only if = or =.
Lemma 1. Suppose , is an undirected graph of n vertices whose complement graph is , . Then and hold.
Proof. The adjacency matrices of
G and
meet the following condition.
where
J is an
matrix of zeros and ones whose main diagonal entries are 0 and all other entries are 1. By the complement graph
and
, it can be seen that
. Furthermore, by
, it follows that
for the complement graph
of
G. □
Theorem 2. Suppose , is an undirected graph of n vertices whose complement graph is , . It follows that Proof. By Lemma 1, it holds that . Definitely, the k-bit of is 0 if and only if the k-bit of is 1. Therefore, one can make the of G by executing a complement operation on . Likewise, by Lemma 1, the identity holds. Definitely, the k-bit of is 0 if and only if the k-bit of is 1. Hence, one can make the of by executing a complement operation on .
Since
is a constant binary number, one must maximize
to minimize
. On the opposite, one must minimize
to maximize
. Likewise, one must maximize
to minimize
. Contrariwise, one must minimize
to maximize
. From the above examination, the following results hold.
□
By Theorem 2, it can be seen that if one has computed the , one can simply make . Moreover, the computation means of and are precisely the same.
Theorem 2 shows the mutual relations between and . Because of the existence of the relations, the paper only concentrates on the construction of effective ways to determine . The of G is a graph whose is lexicographically largest.
We signify by the degree of a node u in G, by , the of G, by the degree series of a subset with , and by , the of a subgraph with , and drop the symbol G when no vagueness can occur. We signify by the minimum degree and by the maximum degree of all vertices of a graph G. Throughout this article, suppose . In the following text, when simultaneously involving two graphs, we always assume that their degree sequences are the same except specified.
For each , the quantity of vertices with degree is the of u, signified by . Unless otherwise specified, throughout this article, the degree sequence is decreasing. The distance between any two nodes u and v is the number of edges on the shortest path from u to v.
For every
, an edge connecting two adjacent vertices of
u is a
of
u and an edge connecting
u and its an adjacent vertex is an
of
u. Given a set
S of vertices in
G, let
signify the
of all nodes in
S and
signify the
of all vertices in
S. Such as in the graph
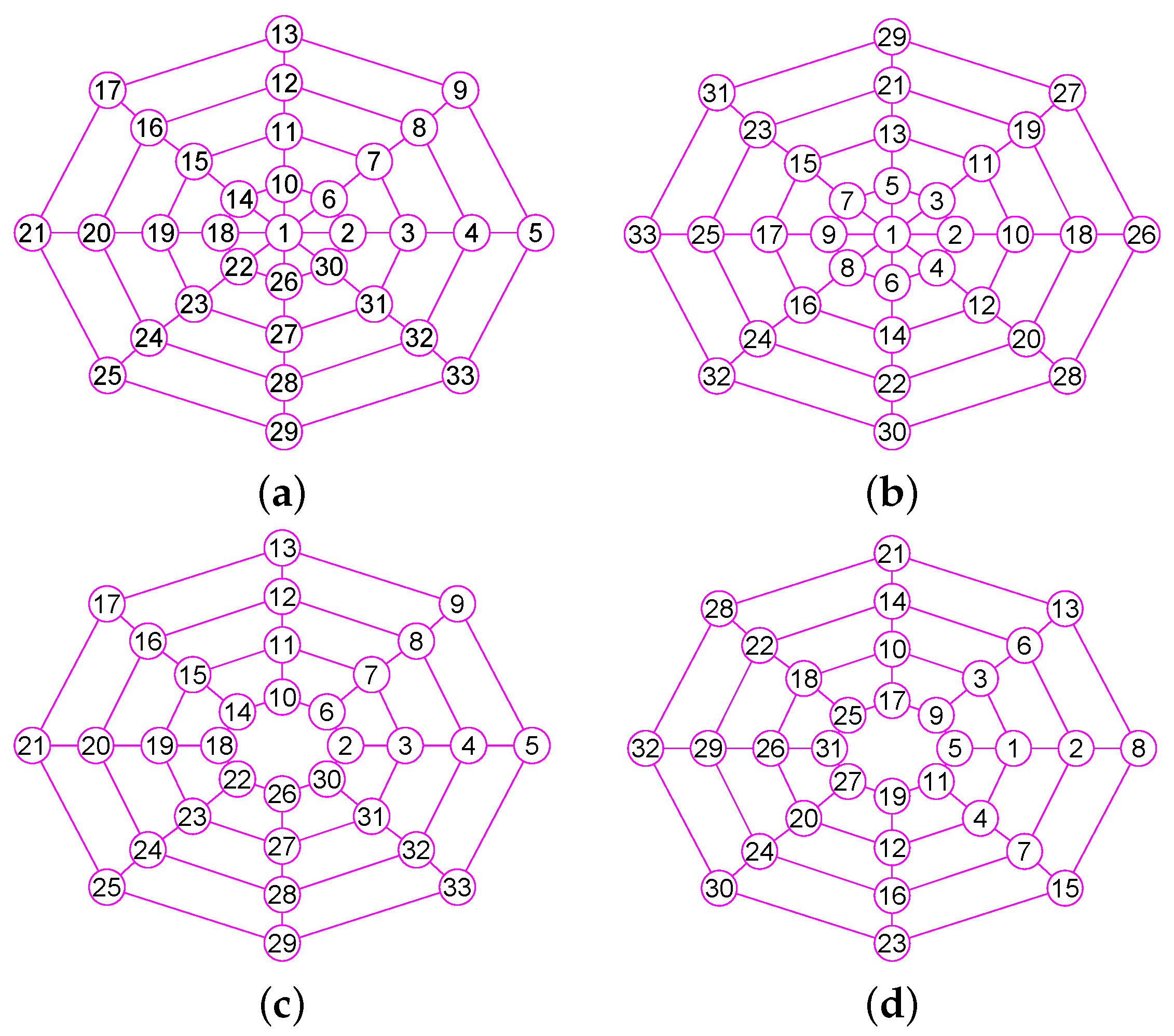
G shown in
Figure 1, the edge
is a
of the vertex 7 and each of the edges
,
and
are its
.
and
.
Definition 6. Suppose , is an undirected graph of n vertices. The open neighborhood subgraph of a node u in G is a subgraph of G, signified by , where is the set of all nodes adjacent to u () and is the collection of all edges, each of which connects two vertices of .
The k- of u with is a subgraph, signified by , with , .
Definition 7. Suppose , is an undirected graph of n vertices. The open neighborhood subgraph of a vertices set is a subgraph of G, signified by where is the set of all nodes each of which is adjacent to at least one node in Q with and is the collection of all edges each of which joins two vertices of .
The k- of Q with is a subgraph, signified by with , .
Remark 1. For some graphs, there may be some edges whose two end vertices lie in but do not belong to by Definition 6. For example, consider the graph G given in Figure 1. Although the vertex 6
and 11
belong to , . In addition, the vertex 14
and 15
belong to . However, . Definition 8. Suppose , is an undirected graph of n vertices. For each , the open kth neighborhood subgraph of u with is a subgraph, signified by with , . For , let and .
Definition 9. Suppose , is an undirected graph of n vertices. Assume that and . We signify by thek-of u in H and bythe of u in H. For , we drop the superscript 1 for clarity and write and , instead.
Definition 10. Suppose , is an undirected connected graph of n vertices. For each , there is a positive integer k meeting conditions and . The value of k is defined as the of u, signified by and we drop the symbol G when no vagueness can occur.
By Definition 10, it is explicit that for each u in G. For notational convenience, we sometimes use as a shorthand for .
Here, we discuss the connection between the
k-
and
with
(see
Figure 2). We present some basic properties of the
k-
by the following Lemma 2.
Lemma 2. Let , , ⋯, , ⋯, be the -neighborhood subgraph of a vertex u in a graph G. If there exists a node , then Likewise, if there exists a node with , then Proof. (
8) and (
9) follow directly from Definition 10 (see
Figure 2). □
By Lemma 2, it is clear that for every
, satisfies
or
. According to whether
v belongs to
or not,
can be partitioned into two disjoint sets
and
. Observe that
and
hold by Definitions 6 and 7 (see
Figure 1). Therefore
.
and
are the
and
of
referred to as the
and
. Correspondingly, a vertex
is a
referred to as a
and a vertex
is a
referred to as an
.
Further note that with . Therefore, . The following Lemma 3 sums up the above discussion.
Lemma 3. Suppose is the- of vertex u in a graph G. Then there exist two disjoint sets, the and the , meeting conditionswith , . Further, it follows that Let and , then and hold for the neighborhood subgraph.
For the -neighborhood subgraph, holds with .
By Lemma 3, it can be seen that the calculation of the - can be simplified by means of the k- for every node v in G.
Definition 11. Assume that , is an undirected graph and u is a vertex in G whose k- is with . A vertex in is a of u. For , a node v in meeting condition is a
k of u.
Each vertex
v in
G is attached a property
whose function is explained in
Section 3.1.2.
Definition 12. Assume that , is an undirected graph and u is a node in G whose k- is with . Suppose H is a connected component of with . Suppose that with , where is in ascending order of attribute with
for every and , contain the of u respectively, meeting conditions and for .
Let , ⋯, , ⋯, be defined as the of H where with are the degree sequences in non-increasing order induced by all nodes in respectively.
Definition 13. Assume that , is an undirected graph and u is a node in G whose k- k is with . Assume that has p connected components , , ⋯, with , , ⋯, respectively, meeting conditions .
We define , , ⋯, to be the of about u in G and drop the symbol G when no vagueness can occur.
We define to be the of about u in G and drop the symbol G when no vagueness can occur.
Remark 2. To define , , ⋯, and , , ⋯, , we pay a great deal of efforts into software testing and theoretical studies. We used more than 20 different kinds of degree sequences in the software experiments and compared the results of distinct degree sequences. Built on the preceding works, it is not difficult to find that performance of the two degree sequences specified by Definitions 12 and 13 is optimal. With the adoption of the two definitions, the accuracy of our algorithm significantly enhances.
Given a graph
G, the
,
, ⋯,
can be used in the literature of finance for the jump-diffusion models [
29,
30].
Definition 14. Suppose , is an undirected graph of n vertices. For each with and, let , , ⋯, be the 1, 2, ⋯, neighborhood subgraph of u with , , ⋯, , respectively. Let , , ⋯, be the 1, 2, ⋯, neighborhood subgraph of v with , , ⋯, , respectively. Let , , ⋯, and , , ⋯, . If , we callconcerning G. Otherwise, if , we callconcerning G. Otherwise, if , we callconcerning G and ignore the sign G when no vagueness can occur. Signify or byand or by.
Observe that ≻, ≺, ≍, ⪰ are all binary relations on the collection of vertices . By Definition 14, for each with , one of the following assertions is true: (1) . (2) . (3) .
It can be noted that , is a well-ordered set, where ⪰ signifies the binary relation on the set . By the well-ordering theorem, it holds that there is a maximum and minimum element in , signified by and respectively with and . The superscript ⪰ can be ignored if no vagueness can occur. The following Lemmas 4–6 immediately hold from Definition 14.
Lemma 4. Suppose , is an undirected graph of n vertices. For each with , if the sign ⪰ signifies the binary relation on the collection , then, all of the vertices in G build a sole linkage L on G: with , , .
Lemma 5. Suppose , is an undirected graph of n vertices. Suppose u ∈ . For each with , if the sign ⪰ signifies the binary relation on the set , then, all of the vertices in build a sole linkage L on G: with .
Lemma 6. Suppose , is an undirected graph of n vertices. For each , Let be the k- of u in G. Suppose v ∈ .
For each with , if the sign ⪰ signifies the binary relation on the collection , then, all of the vertices in build a single linkage L on : with .
By Definitions 3, 4 and 14, the outcomes in the following Propositions 1 and 2 are uncomplicated.
Proposition 1. Suppose , is an undirected graph of n vertices. For each with , let , , ⋯, be the 1, 2, ⋯, neighborhood subgraph of u with , , ⋯, , respectively. Let , , ⋯, be the 1, 2, ⋯, neighborhood subgraph of v with , , ⋯, , respectively. Let , , ⋯, with , , ⋯, and , , ⋯, . Let , , ⋯, with , , ⋯, and , , ⋯, . If , then leads to . Otherwise, leads to . Otherwise, leads to . Accordingly, it follows that if , then leads to . Otherwise, leads to . Otherwise, leads to .
Proposition 2. Suppose , is an undirected graph of n vertices. For each with , let , , ⋯, be the 1, 2, ⋯, neighborhood subgraph of u with , , ⋯, , respectively. Let , , ⋯, be the 1, 2, ⋯, neighborhood subgraph of v with , , ⋯, , respectively. If , , ⋯, , , then concerning G (see Definition 14).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}