Tuning Multi-Objective Evolutionary Algorithms on Different Sized Problem Sets




Abstract
:1. Introduction
2. Related Work
3. Integration and Testing Order
- MyBatis (http://www.mybatis.org/mybatis-3/) is a first class persistence framework with support for custom SQL, stored procedures and advanced mappings.
- AJHSQLDB (HyperSQL DataBase) (https://sourceforge.net/projects/ajhsqldb/) is the aspect-oriented version of the leading relational database software written in Java.
- BCEL (Byte Code Engineering Library) (https://commons.apache.org/proper/commons-bcel/) is intended to give users a convenient way to analyze, create, and manipulate (binary) Java class files.
- JHotDraw (http://www.jhotdraw.org/) is a Java framework for technical and structured graphics.
- HealthWatcher (http://www.aosd-europe.net/) collects and manages public health related to complaints and notifications.
- JBoss (http://jbossas.jboss.org/downloads) is a Java application server.
- AJHotDraw (http://ajhotdraw.sourceforge.net/) is an aspect-oriented refactoring of JHotDraw.
- TollSystems (http://www.comp.lancs.ac.uk/greenwop/tao) is a concept proof for automatic charging of toll on roads and streets.
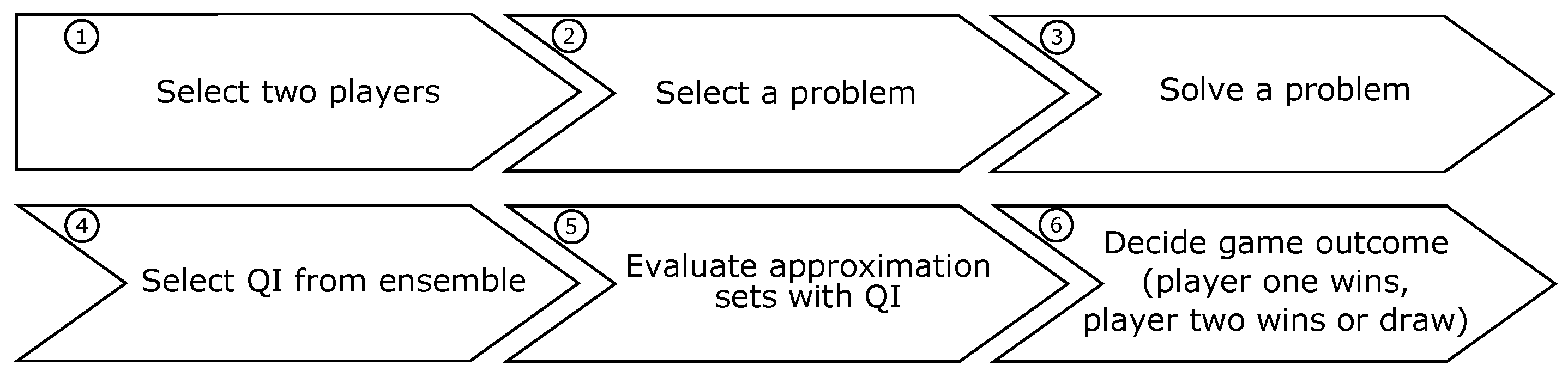
4. Chess Rating System for Evolutionary Algorithms
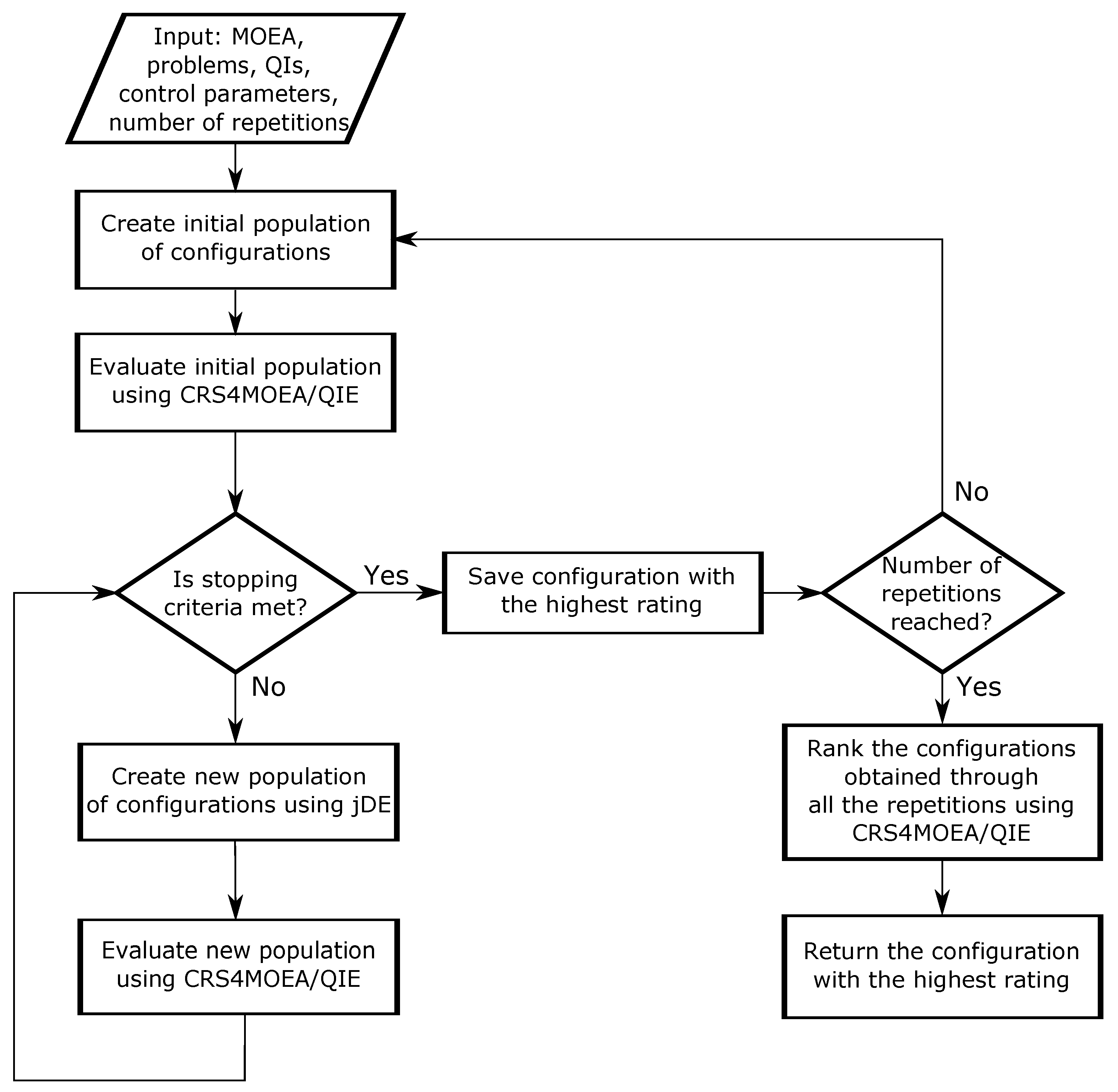
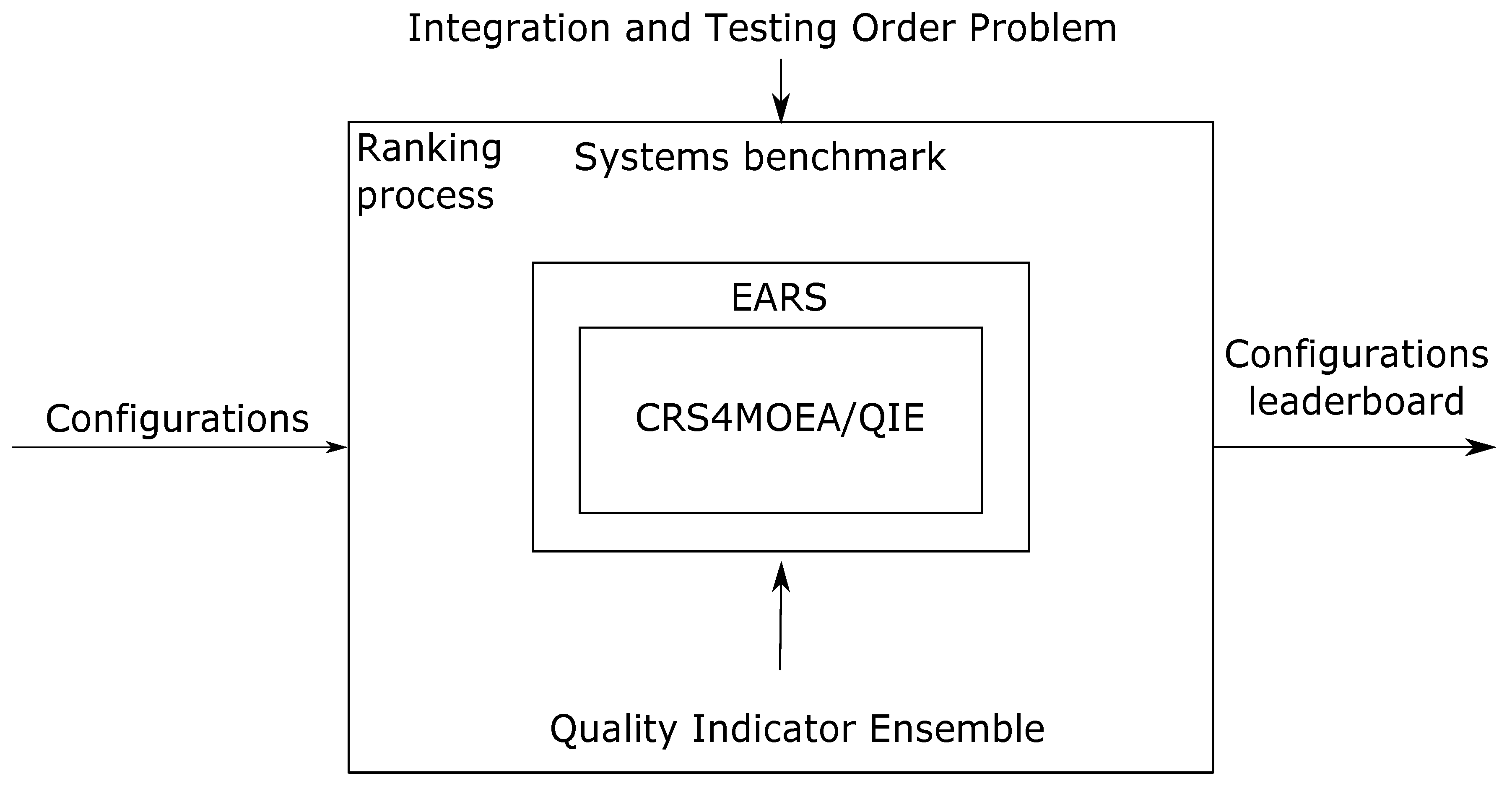
5. MOCRS-Tuning Method
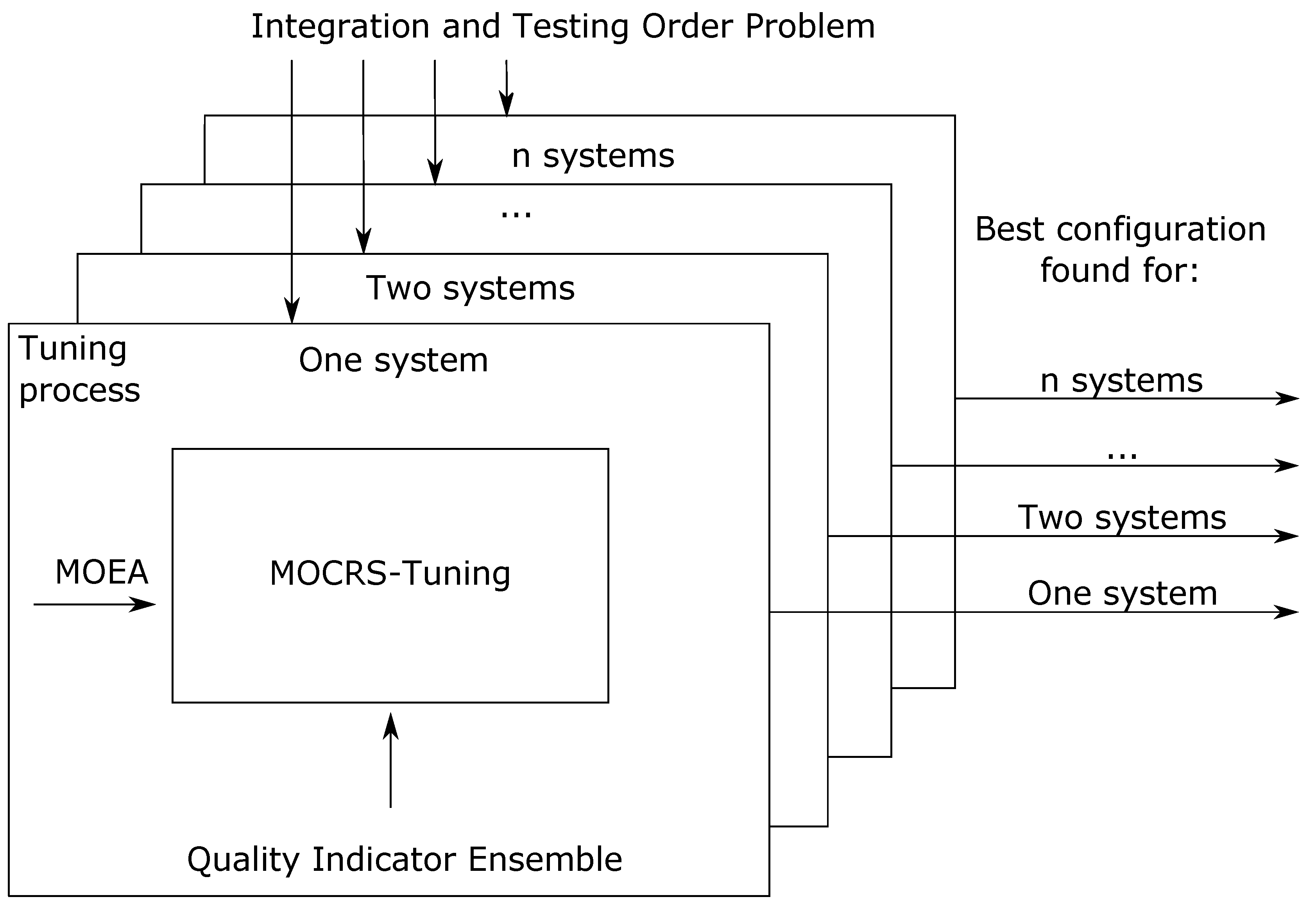
6. Experiment
Experimental Settings
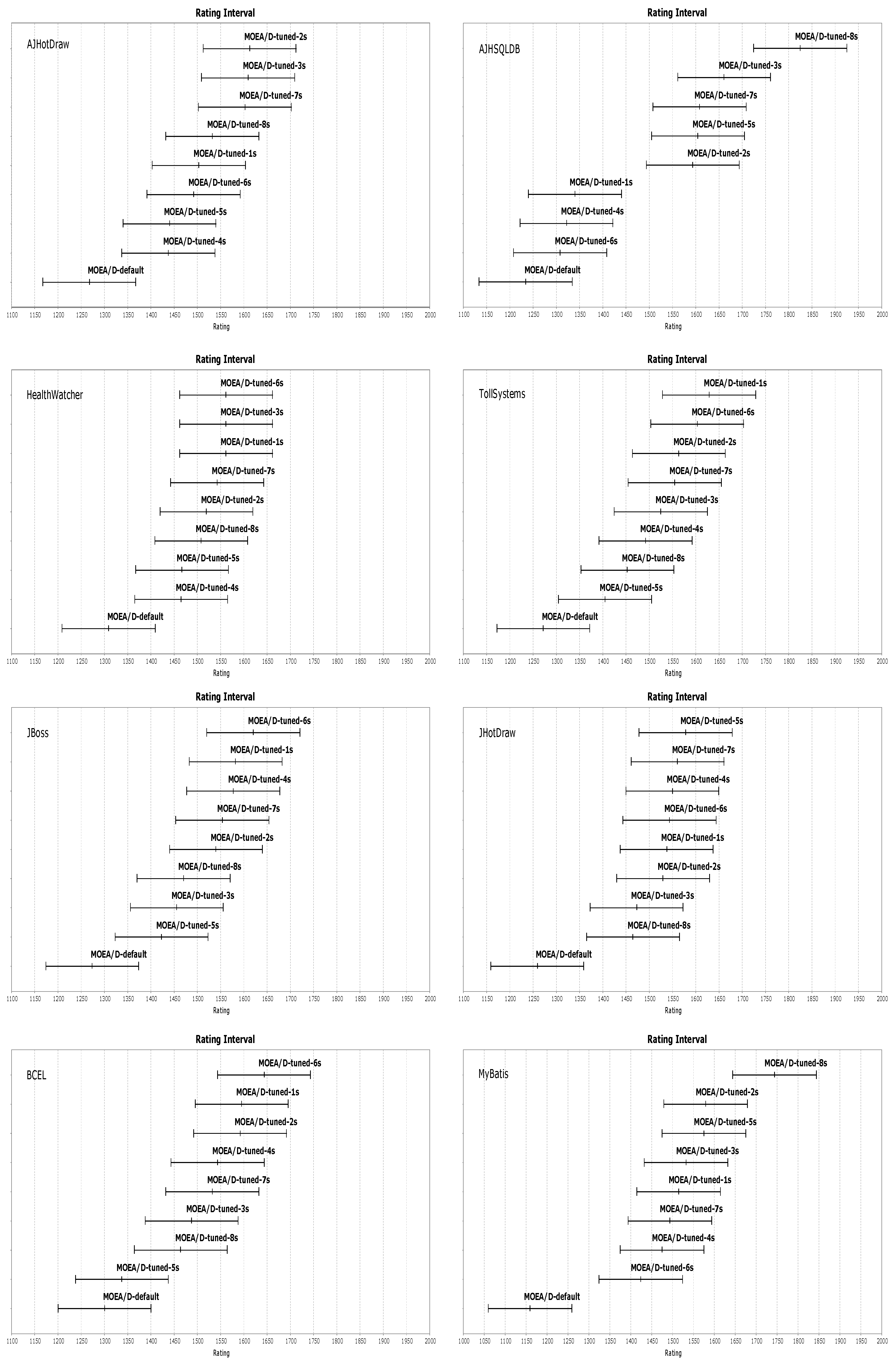
7. Results and Discussion
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Eiben, A.E.; Smit, S.K. Parameter tuning for configuring and analyzing evolutionary algorithms. Swarm Evol. Comput. 2011, 1, 19–31. [Google Scholar] [CrossRef] [Green Version]
- Karafotias, G.; Hoogendoorn, M.; Eiben, Á.E. Parameter control in evolutionary algorithms: Trends and challenges. IEEE Trans. Evol. Comput. 2015, 19, 167–187. [Google Scholar] [CrossRef]
- Veček, N.; Mernik, M.; Filipič, B.; Črepinšek, M. Parameter tuning with Chess Rating System (CRS-Tuning) for meta-heuristic algorithms. Inf. Sci. 2016, 372, 446–469. [Google Scholar] [CrossRef]
- Smit, S.K.; Eiben, A. Parameter tuning of evolutionary algorithms: Generalist vs. specialist. In European Conference on the Applications of Evolutionary Computation; Springer: Berlin/Heidelberg, Germany, 2010; pp. 542–551. [Google Scholar]
- Brest, J.; Žumer, V.; Maučec, M. Self-Adaptive Differential Evolution Algorithm in Constrained Real-Parameter Optimization. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC 2006), Vancouver, BC, Canada, 16–21 July 2006; pp. 215–222. [Google Scholar]
- Ravber, M.; Mernik, M.; Črepinšek, M. Ranking Multi-Objective Evolutionary Algorithms using a Chess Rating System with Quality Indicator ensemble. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC 2017), San Sebastian, Spain, 5–8 June 2017; pp. 1503–1510. [Google Scholar]
- Ravber, M.; Mernik, M.; Črepinšek, M. The Impact of Quality Indicators on the Rating of Multi-objective Evolutionary Algorithms. In Proceedings of the Conference on Bioinspired Optimization Methods and Their Applications (BIOMA 2016), Bled, Slovenia, 18–20 May 2016; pp. 119–130. [Google Scholar]
- EARS—Evolutionary Algorithms Rating System (Github). 2019. Available online: https://github.com/UM-LPM/EARS (accessed on 2 August 2019).
- Assunção, W.K.G.; Colanzi, T.E.; Vergilio, S.R.; Pozo, A. A multi-objective optimization approach for the integration and test order problem. Inf. Sci. 2014, 267, 119–139. [Google Scholar] [CrossRef]
- Assunção, W.K.G.; Colanzi, T.E.; Pozo, A.T.R.; Vergilio, S.R. Establishing integration test orders of classes with several coupling measures. In Proceedings of the Conference on Genetic and Evolutionary Computation (GECCO 2011), Dublin, Ireland, 12–16 July 2011; pp. 1867–1874. [Google Scholar]
- Arcuri, A.; Fraser, G. Parameter tuning or default values? An empirical investigation in search-based software engineering. Empir. Softw. Eng. 2013, 18, 594–623. [Google Scholar] [CrossRef]
- Birattari, M.; Stützle, T.; Paquete, L.; Varrentrapp, K. A racing algorithm for configuring metaheuristics. In Proceedings of the Conference on Genetic and Evolutionary Computation (GECCO 2002), New York, NY, USA, 9–13 July 2002; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2002; pp. 11–18. [Google Scholar]
- Nannen, V.; Eiben, A.E. Relevance Estimation and Value Calibration of Evolutionary Algorithm Parameters. In Proceedings of the 20th International Joint Conference on Artifical Intelligence, Singapore, 25–28 September 2007; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2007; pp. 975–980. [Google Scholar]
- Hutter, F.; Hoos, H.H.; Stützle, T. Automatic Algorithm Configuration Based on Local Search. In Proceedings of the 22Nd National Conference on Artificial Intelligence, Vancouver, BC, Canada, 22–26 July 2007; AAAI Press: New York, NY, USA, 2007; pp. 1152–1157. [Google Scholar]
- Bartz-Beielstein, T.; Lasarczyk, C.W.; Preuß, M. Sequential parameter optimization. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC 2005), Edinburgh, UK, 2–5 September 2005; Volume 1, pp. 773–780. [Google Scholar]
- Smit, S.K.; Eiben, A.E.; Szlávik, Z. An MOEA-based Method to Tune EA Parameters on Multiple Objective Functions. In Proceedings of the IJCCI (ICEC), Valencia, Spain, 24–26 October 2010; pp. 261–268. [Google Scholar]
- Yuan, B.; Gallagher, M. Combining meta-EAs and racing for difficult EA parameter tuning tasks. In Parameter Setting in Evolutionary Algorithms; Springer: Berlin/Heidelberg, Germany, 2007; pp. 121–142. [Google Scholar]
- Montero, E.; Riff, M.C.; Neveu, B. A beginner’s guide to tuning methods. Appl. Soft Comput. 2014, 17, 39–51. [Google Scholar] [CrossRef]
- Smit, S.K.; Eiben, A.E. Comparing parameter tuning methods for evolutionary algorithms. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC 2009), Trondheim, Norway, 18–21 May 2009; pp. 399–406. [Google Scholar]
- Arcuri, A.; Fraser, G. On parameter tuning in search based software engineering. Search Based Softw. Eng. 2011, 33–47. [Google Scholar]
- Zaefferer, M.; Breiderhoff, B.; Naujoks, B.; Friese, M.; Stork, J.; Fischbach, A.; Flasch, O.; Bartz-Beielstein, T. Tuning multi-objective optimization algorithms for cyclone dust separators. In Proceedings of the Conference on Genetic and Evolutionary Computation (GECCO 2014), Vancouver, BC, Canada, 12–16 July 2014; pp. 1223–1230. [Google Scholar]
- Naumchev, A.; Meyer, B.; Mazzara, M.; Galinier, F.; Bruel, J.M.; Ebersold, S. AutoReq: Expressing and verifying requirements for control systems. J. Comput. Lang. 2019, 51, 131–142. [Google Scholar] [CrossRef] [Green Version]
- Choi, W.; Kannan, J.; Babic, D. A scalable, flow-and-context-sensitive taint analysis of android applications. J. Comput. Lang. 2019, 51, 1–14. [Google Scholar] [CrossRef]
- Tsutano, Y.; Bachala, S.; Srisa-An, W.; Rothermel, G.; Dinh, J. Jitana: A modern hybrid program analysis framework for android platforms. J. Comput. Lang. 2019, 52, 55–71. [Google Scholar] [CrossRef] [Green Version]
- Beizer, B. Software Testing Techniques; Dreamtech Press: Delhi, India, 2003. [Google Scholar]
- Zitzler, E.; Thiele, L.; Laumanns, M.; Fonseca, C.M.; Da Fonseca, V.G. Performance assessment of multiobjective optimizers: an analysis and review. IEEE Trans. Evol. Comput. 2003, 7, 117–132. [Google Scholar] [CrossRef] [Green Version]
- Glickman, M.E. Example of the Glicko-2 System; Boston University: Boston, MA, USA, 2012. [Google Scholar]
- Zhang, Q.; Li, H. MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Guizzo, G.; Vergilio, S.R.; Pozo, A.T.; Fritsche, G.M. A multi-objective and evolutionary hyper-heuristic applied to the Integration and Test Order Problem. Appl. Soft Comput. 2017, 56, 331–344. [Google Scholar] [CrossRef] [Green Version]
- Ishibuchi, H.; Masuda, H.; Tanigaki, Y.; Nojima, Y. Difficulties in specifying reference points to calculate the inverted generational distance for many-objective optimization problems. In Proceedings of the IEEE Symposium on Computational Intelligence in Multi-Criteria Decision-Making (MCDM), Orlando, FL, USA, 9–12 December 2014; pp. 170–177. [Google Scholar]
- Zitzler, E.; Thiele, L. Multiobjective evolutionary algorithms: a comparative case study and the strength Pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef] [Green Version]
- Hansen, M.P.; Jaszkiewicz, A. Evaluating the Quality of Approximations to the Non-Dominated Set; IMM, Department of Mathematical Modelling, Technical University of Denmark: Kongens Lyngby, Denmark, 1998. [Google Scholar]
- Yen, G.G.; He, Z. Performance metric ensemble for multiobjective evolutionary algorithms. IEEE Trans. Evol. Comput. 2014, 18, 131–144. [Google Scholar] [CrossRef]
- Pukelsheim, F. The three sigma rule. Am. Stat. 1994, 48, 88–91. [Google Scholar]
- Durillo, J.J.; Nebro, A.J. jMetal: A Java framework for multi-objective optimization. Adv. Eng. Softw. 2011, 42, 760–771. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Num | Name | Dependencies | Classes | Aspects | LOC |
|---|---|---|---|---|---|
| 1 | AJHotDraw | 1592 | 290 | 31 | 18,586 |
| 2 | AJHSQLDB | 1338 | 276 | 15 | 68,550 |
| 3 | MyBatis | 1271 | 331 | - | 23,535 |
| 4 | JHotDraw | 809 | 197 | - | 20,273 |
| 5 | JBoss | 367 | 150 | - | 8434 |
| 6 | HealthWatcher | 289 | 95 | 22 | 5479 |
| 7 | BCEL | 289 | 45 | - | 2999 |
| 8 | TollSystems | 188 | 53 | 24 | 2496 |
| Run | Systems Included | Tuning Time (h) |
|---|---|---|
| 1 | 4 | 14 |
| 2 | 4, 3 | 30 |
| 3 | 4, 3, 7 | 35 |
| 4 | 4, 3, 7, 5 | 37 |
| 5 | 4, 3, 7, 5, 1 | 41 |
| 6 | 4, 3, 7, 5, 1, 8 | 51 |
| 7 | 4, 3, 7, 5, 1, 8, 2 | 56 |
| 8 | 4, 3, 7, 5, 1, 8, 2, 6 | 63 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Črepinšek, M.; Ravber, M.; Mernik, M.; Kosar, T. Tuning Multi-Objective Evolutionary Algorithms on Different Sized Problem Sets. Mathematics 2019, 7, 824. https://doi.org/10.3390/math7090824
Črepinšek M, Ravber M, Mernik M, Kosar T. Tuning Multi-Objective Evolutionary Algorithms on Different Sized Problem Sets. Mathematics. 2019; 7(9):824. https://doi.org/10.3390/math7090824
Chicago/Turabian StyleČrepinšek, Matej, Miha Ravber, Marjan Mernik, and Tomaž Kosar. 2019. "Tuning Multi-Objective Evolutionary Algorithms on Different Sized Problem Sets" Mathematics 7, no. 9: 824. https://doi.org/10.3390/math7090824
APA StyleČrepinšek, M., Ravber, M., Mernik, M., & Kosar, T. (2019). Tuning Multi-Objective Evolutionary Algorithms on Different Sized Problem Sets. Mathematics, 7(9), 824. https://doi.org/10.3390/math7090824