Design and Analysis of a Non-Iterative Estimator for Target Location in Multistatic Sonar Systems with Sensor Position Uncertainties


Abstract
:1. Introduction
- We establish a statistical model of determining both the position and velocity of a moving target in a multistatic sonar system using differential delays and Doppler shifts. The uncertainties in the sensor positions are carefully taken into account in our model. The performance limit is developed for this problem.
- To tackle the proposed nonlinear hybrid parameter estimation problem, we design an efficient non-iterative solution using parameter transformation, model linearization and two-stage processing.
- We further analyze the bias vector and covariance matrix of our estimator theoretically using the second/first-order perturbation analysis and multivariate statistics.
- We prove that the proposed estimator has approximate statistical efficiency and linear complexity.
2. Notational Conventions
3. Problem Formulation and Statistical Model
- ,
- ,
- ,
- ,
- ,
- .
4. Hybrid Cramér–Rao Bound
5. Estimator Design
5.1. First Stage
5.2. Second Stage
5.3. Summary
| Algorithm 1 First stage of the estimator. |
6. Performance Analysis
6.1. Bias Vector
6.2. Covariance Matrix
6.3. Time and Space Complexity
7. Results and Discussion
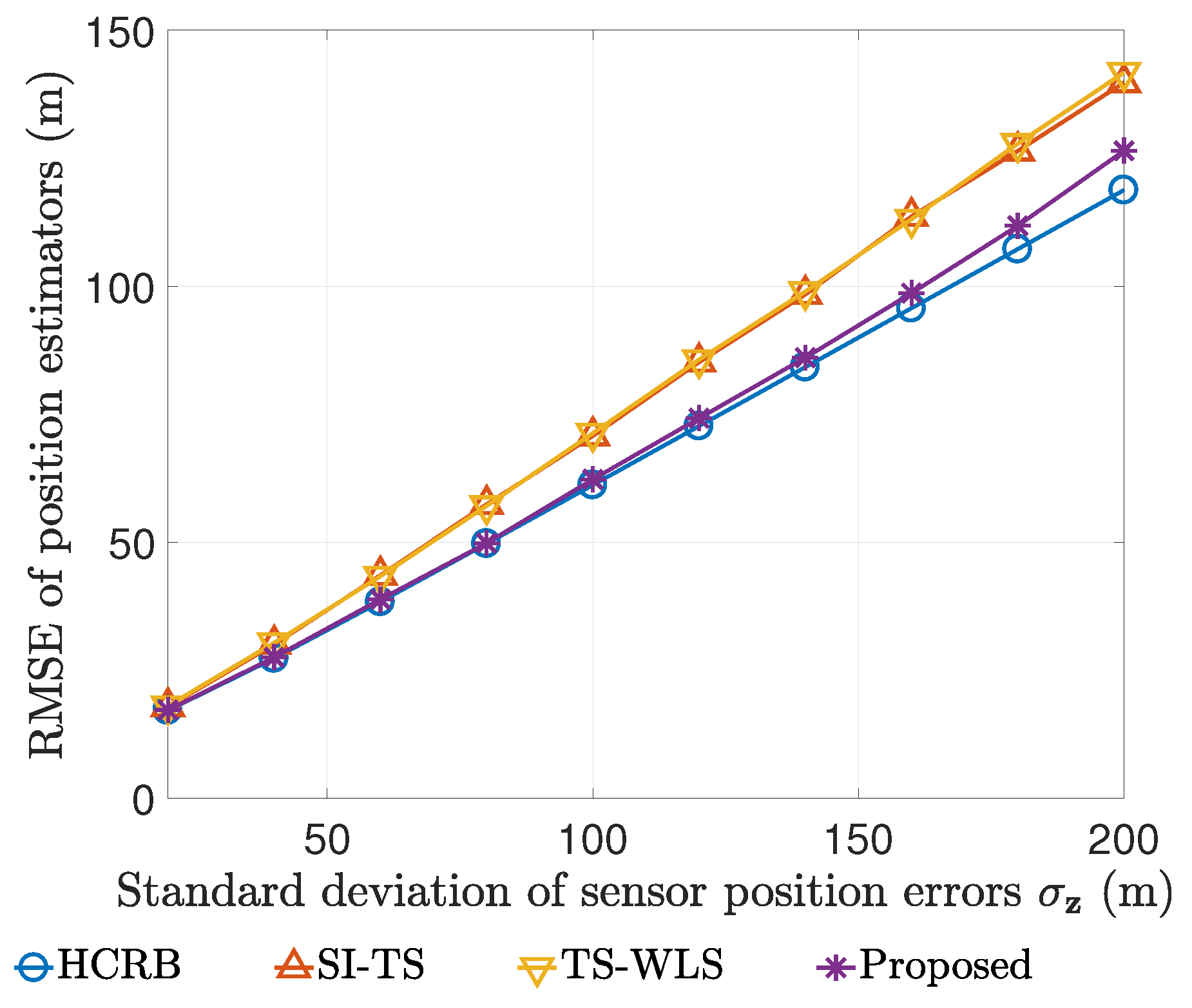
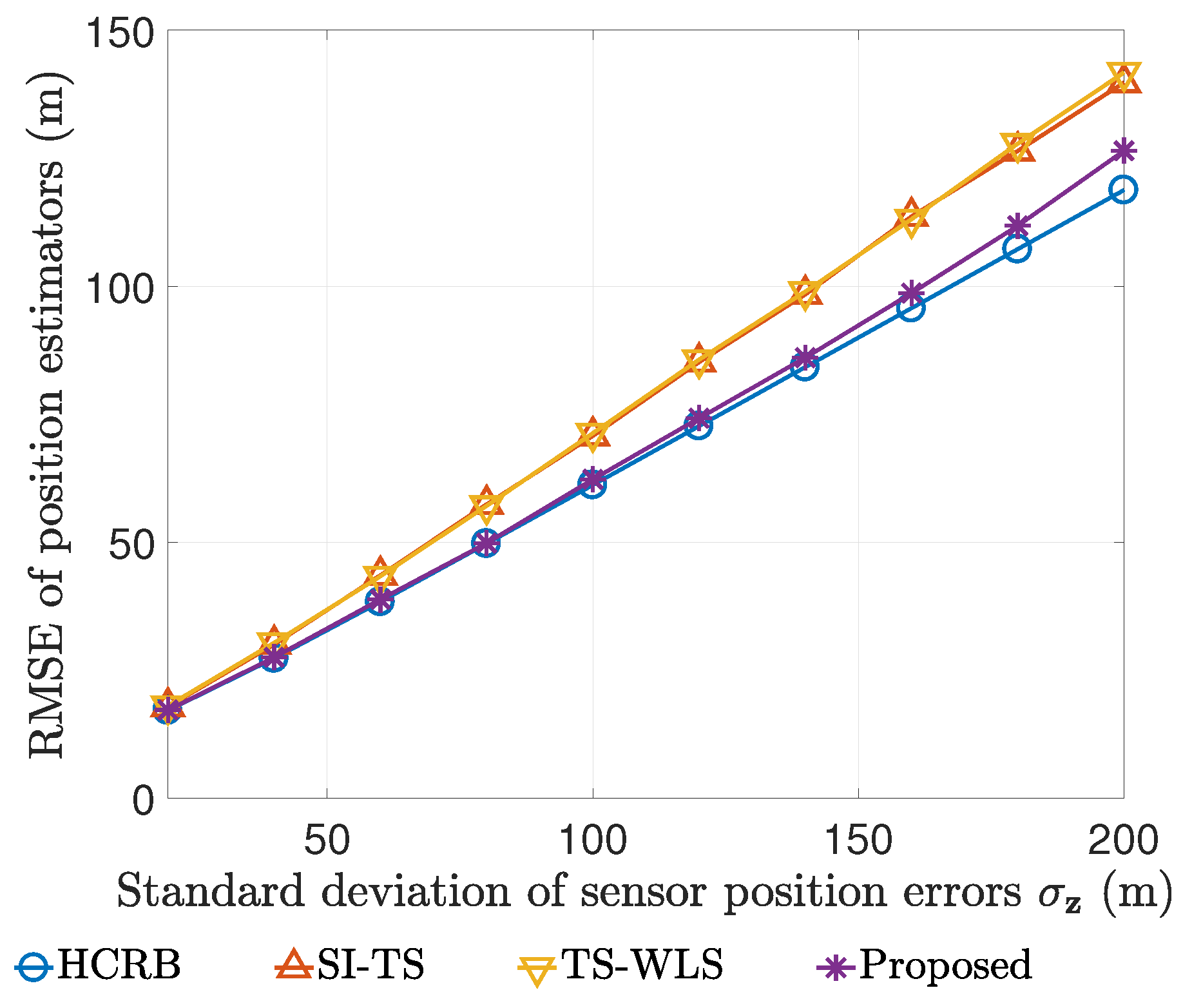
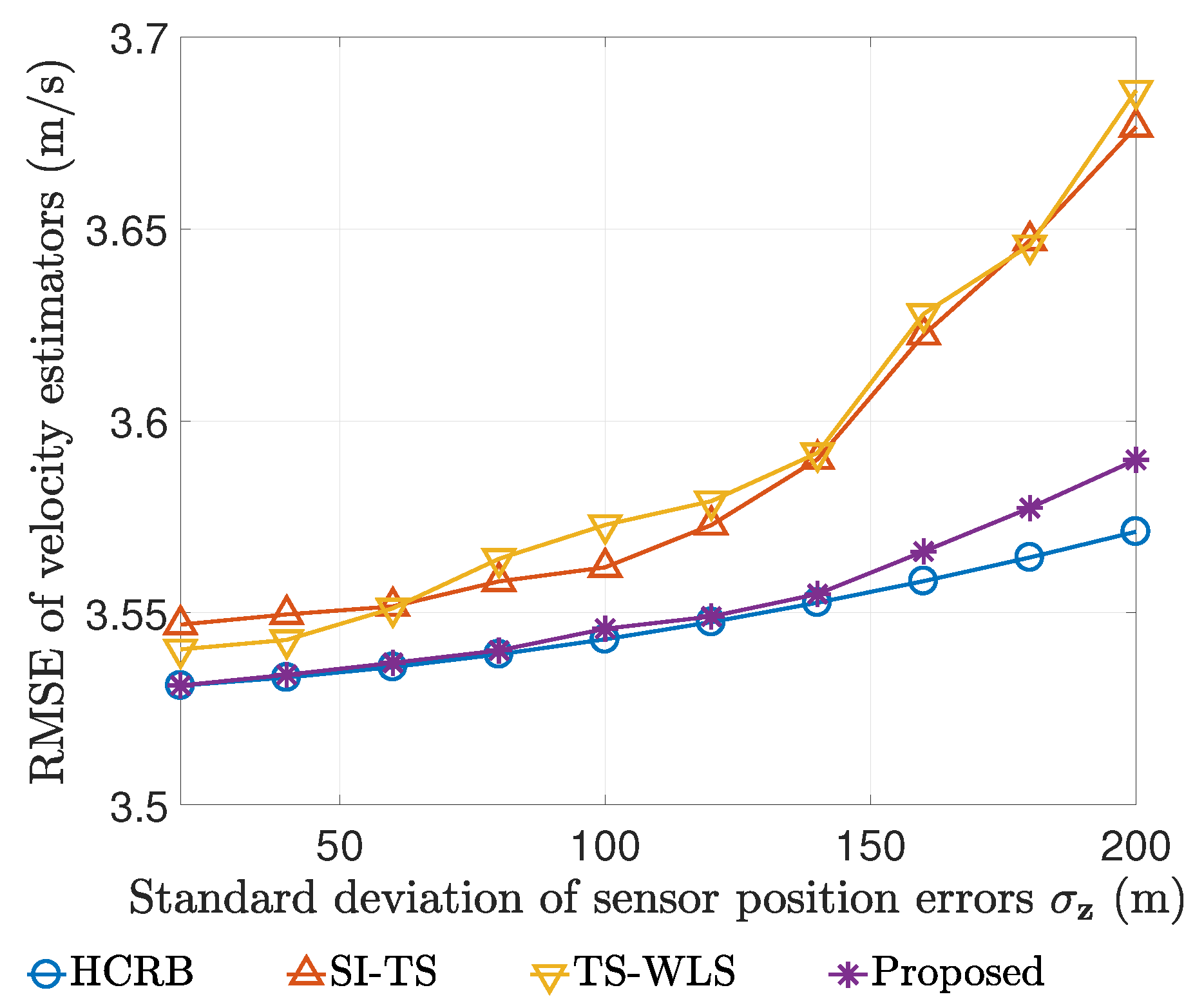
7.1. Performance Comparison
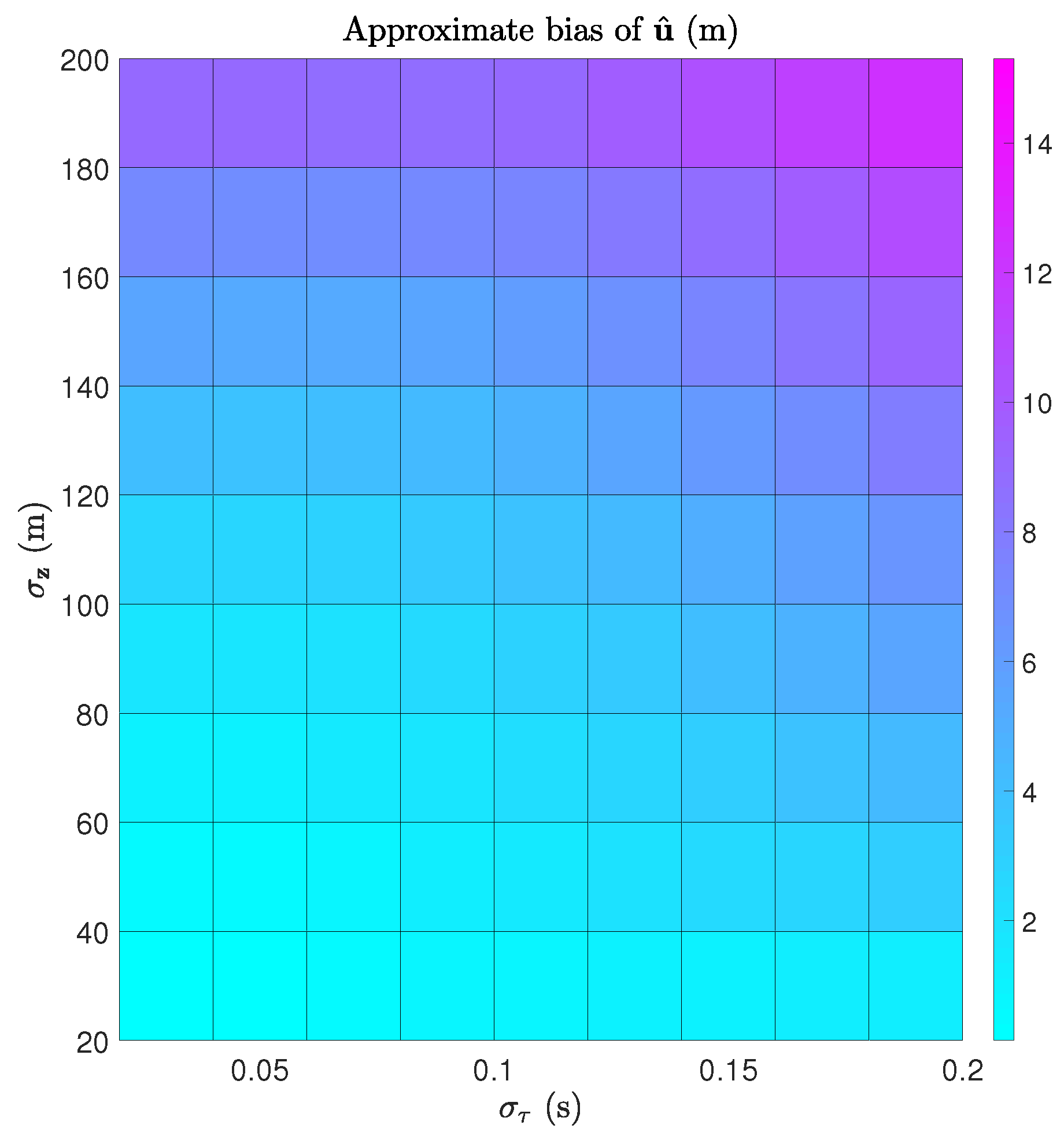
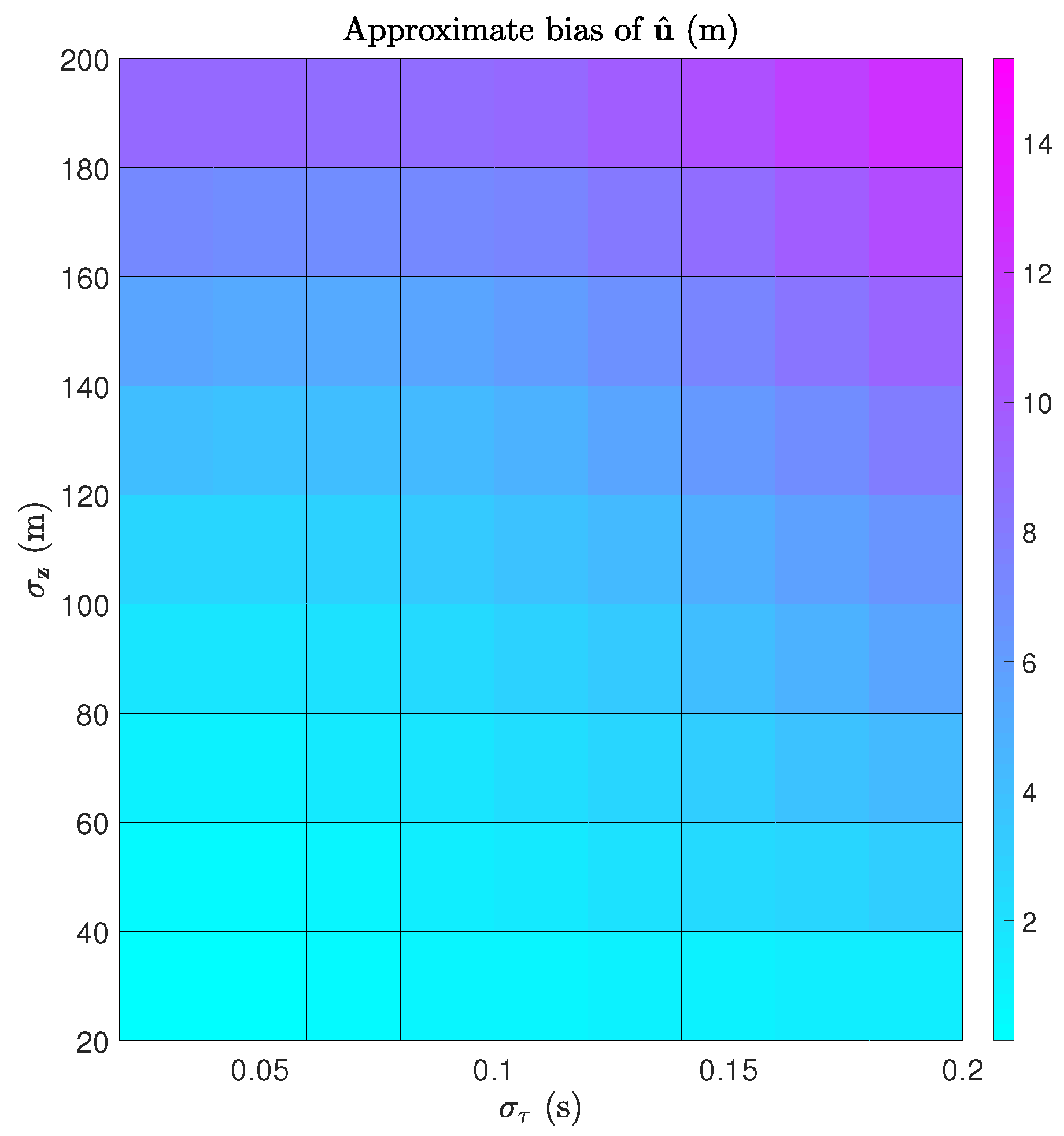
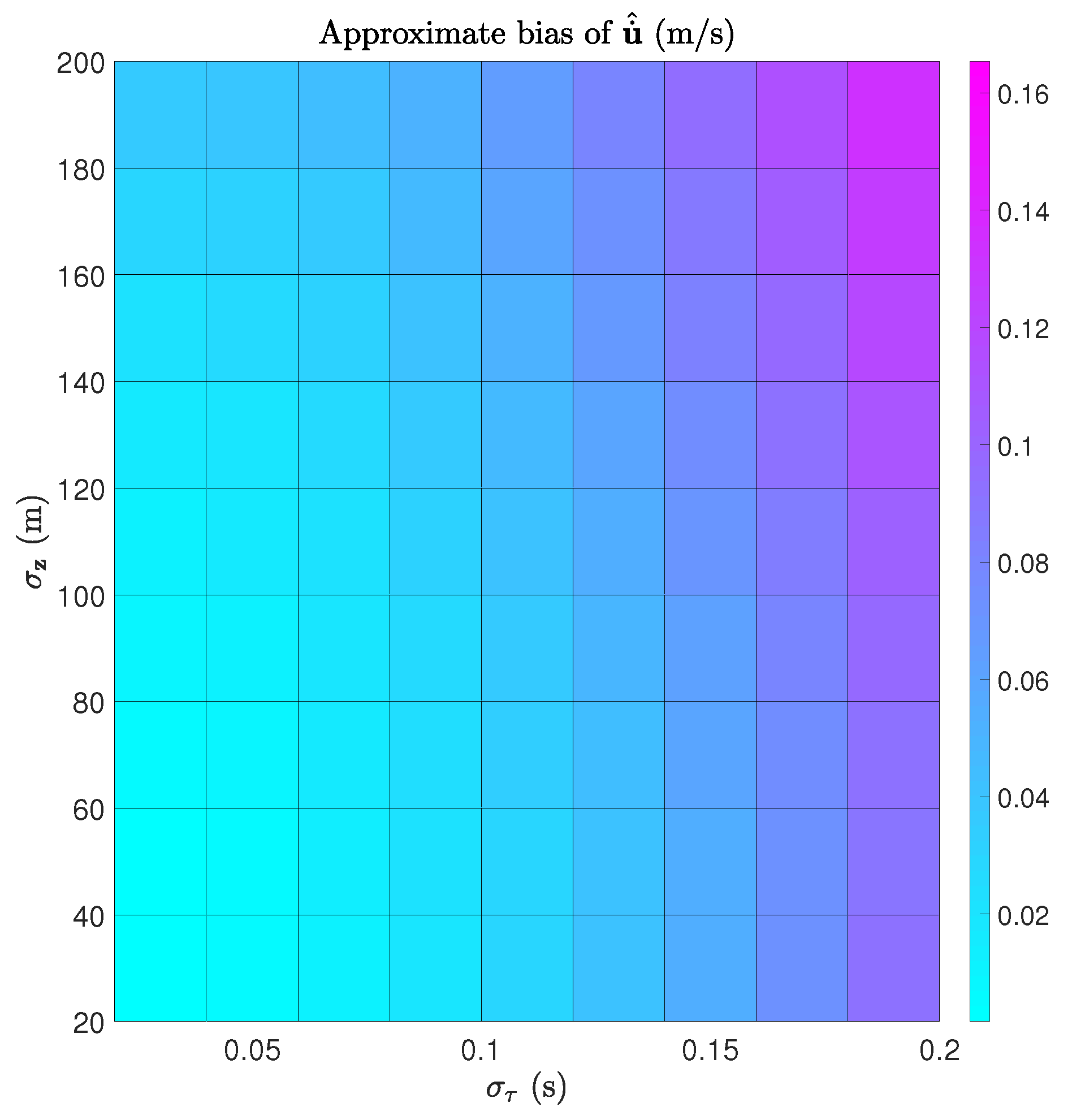
7.2. Bias Calculation
7.3. Localizing Multiple Disjoint Targets
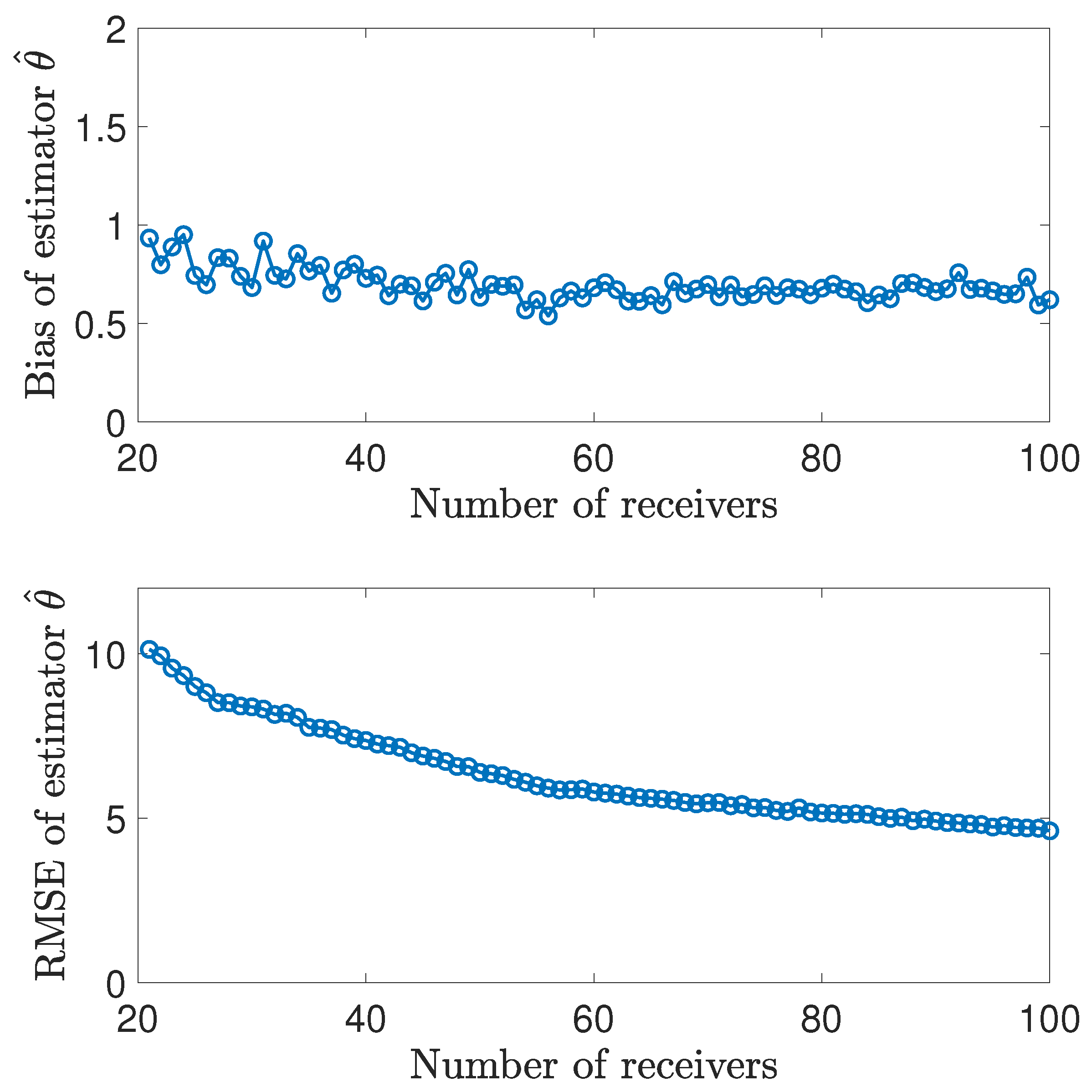
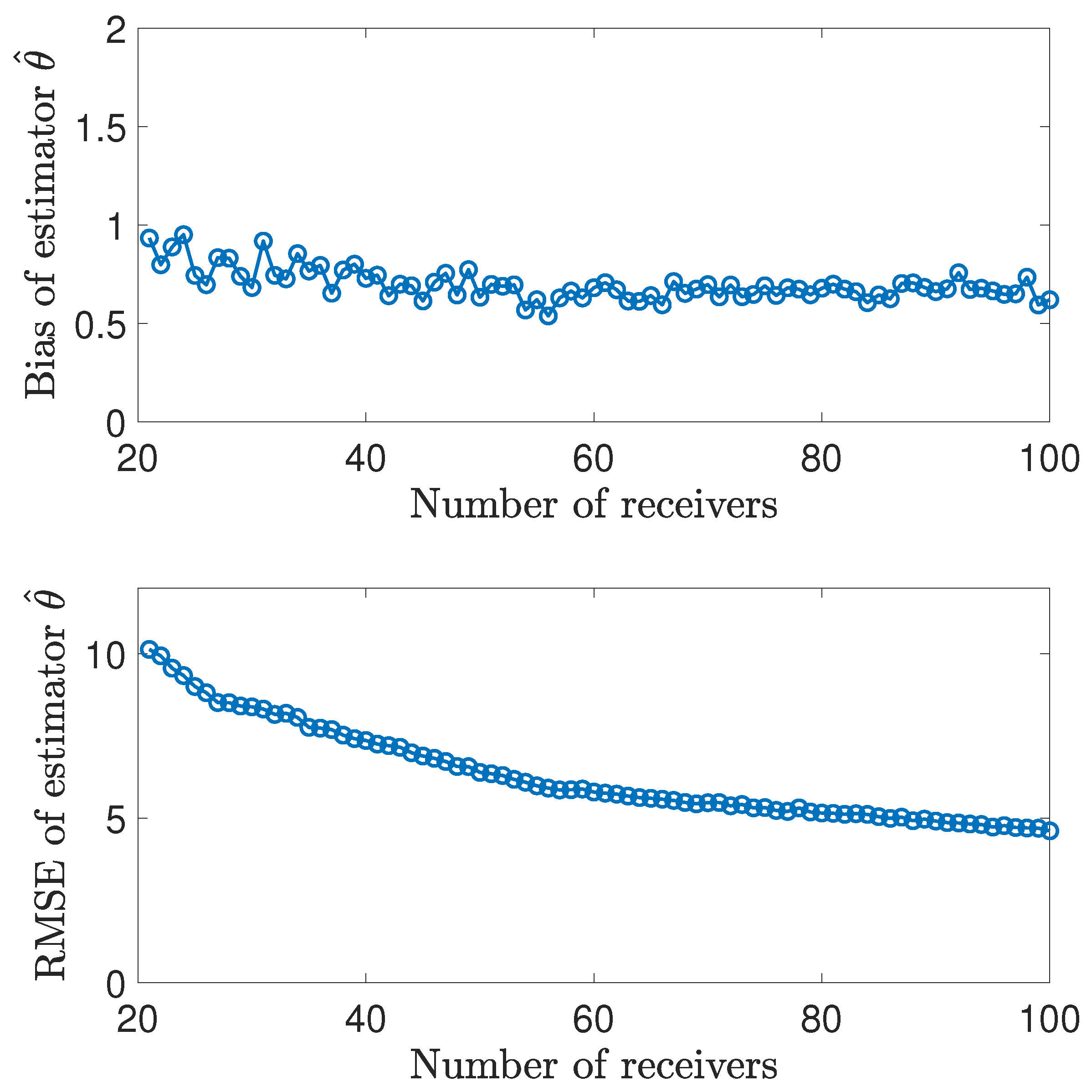
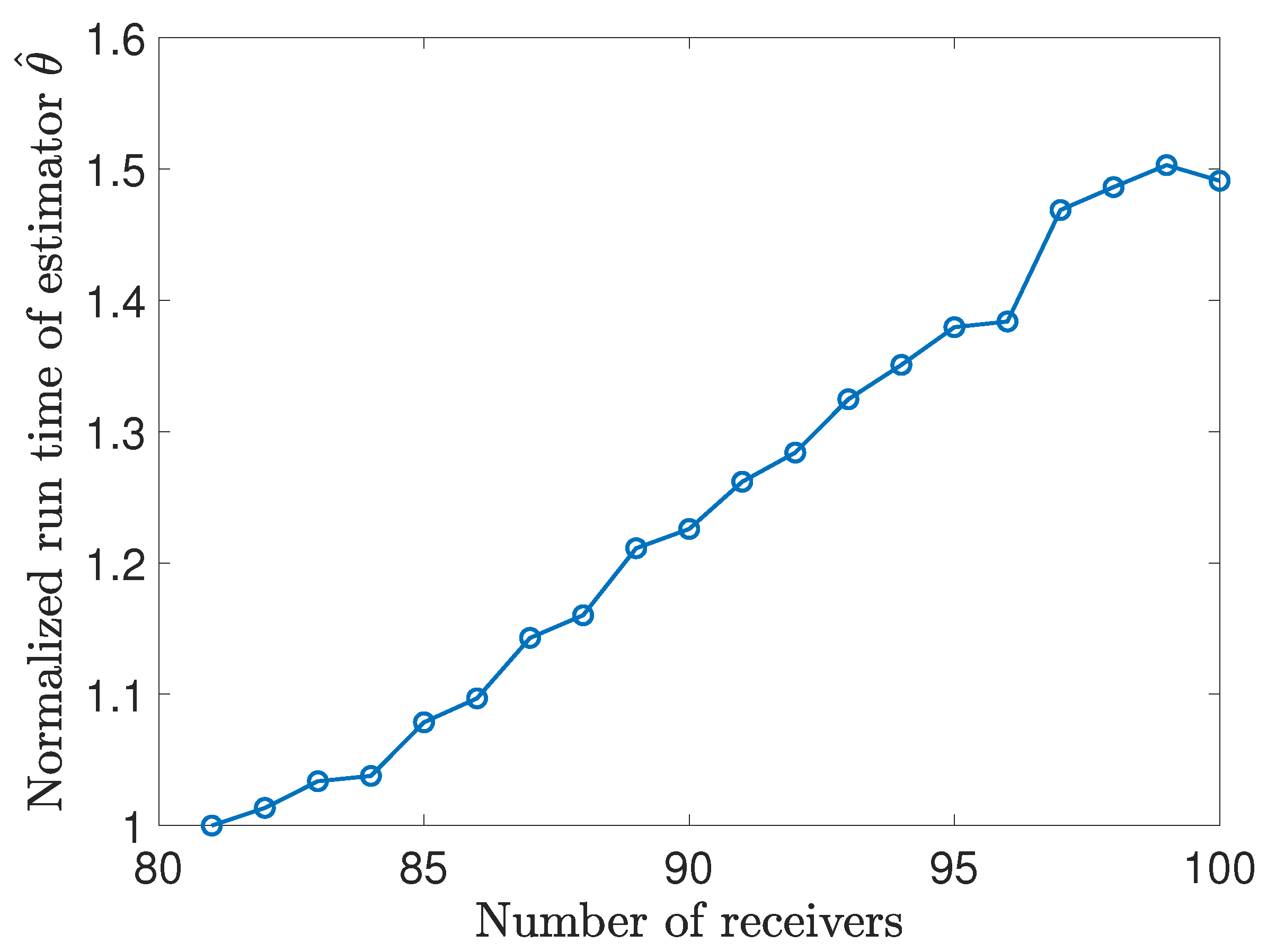
7.4. Large-Scale Simulation Experiments
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| HCRB | Hybrid Cramér–Rao bound |
| WLS | Weighted least-squares |
| SI-TS | Spherical-interpolation initialized Taylor series method |
| SVD | Singular value decomposition |
| TS-WLS | Two-stage weighted least squares method |
| RMSE | Root-mean-square error |
Appendix A. Jacobian Matrices for HCRB
Appendix A.1. Jacobian Matrix of Target Position and Velocity
Appendix A.2. Jacobian Matrix of Sensor Positions
Appendix B. Matrices Related to Weighted Least Squares
Appendix C. Linear Model for the First Stage of Our Algorithm
Appendix D. Linear Model for the Second Stage of Our Algorithm
Appendix E. Formulas for Computing Bias Vector of Our Estimator
Appendix E.1. Formulas for Computing Bias in the First Stage
- Let for . Then
- wherefor .
Appendix E.2. Formulas for Computing Bias in the Second Stage
- where
- wherefor .
- wherefor .
- wherefor .
Appendix F. Some Formula for Proving Proposition 2
References
- Zhang, Y.; Ho, K.C. Multistatic localization in the absence of transmitter position. IEEE Trans. Signal Process. 2019, 67, 4745–4760. [Google Scholar] [CrossRef]
- He, C.; Wang, Y.; Yu, W.; Song, L. Underwater target localization and synchronization for a distributed SIMO sonar with an isogradient SSP and uncertainties in receiver locations. Sensors 2019, 19, 1976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liang, J.; Chen, Y.; So, H.; Jing, Y. Circular/hyperbolic/elliptic localization via Euclidean norm elimination. Signal Process. 2018, 148, 102–113. [Google Scholar] [CrossRef]
- Peters, D.J. A Bayesian method for localization by multistatic active sonar. IEEE J. Ocean. Eng. 2017, 42, 135–142. [Google Scholar] [CrossRef]
- Yang, L.; Yang, L.; Ho, K.C. Moving target localization in multistatic sonar by differential delays and Doppler shifts. IEEE Signal Process. Lett. 2016, 23, 1160–1164. [Google Scholar] [CrossRef]
- Rui, L.; Ho, K.C. Efficient closed-form estimators for multistatic sonar localization. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 600–614. [Google Scholar] [CrossRef]
- Rui, L.; Ho, K.C. Elliptic localization: Performance study and optimum receiver placement. IEEE Trans. Signal Process. 2014, 62, 4673–4688. [Google Scholar] [CrossRef]
- Ehlers, F.; Ricci, G.; Orlando, D. Batch tracking algorithm for multistatic sonars. IET Radar Sonar Navig. 2012, 6, 746–752. [Google Scholar] [CrossRef]
- Daun, M.; Ehlers, F. Tracking algorithms for multistatic sonar systems. EURASIP J. Adv. Signal Process. 2010, 2010, 461538. [Google Scholar] [CrossRef] [Green Version]
- Simakov, S. Localization in airborne multistatic sonars. IEEE J. Ocean. Eng. 2008, 33, 278–288. [Google Scholar] [CrossRef]
- Coraluppi, S. Multistatic sonar localization. IEEE J. Ocean. Eng. 2006, 31, 964–974. [Google Scholar] [CrossRef]
- Coraluppi, S.; Carthel, C. Distributed tracking in multistatic sonar. IEEE Trans. Aerosp. Electron. Syst. 2005, 41, 1138–1147. [Google Scholar] [CrossRef]
- Sandys-Wunsch, M.; Hazen, M.G. Multistatic localization error due to receiver positioning errors. IEEE J. Ocean. Eng. 2002, 27, 328–334. [Google Scholar] [CrossRef]
- Shin, H.; Chung, W. Target localization using double-sided bistatic range measurements in distributed MIMO radar systems. Sensors 2019, 19, 2524. [Google Scholar] [CrossRef] [Green Version]
- Amiri, R.; Behnia, F.; Noroozi, A. Efficient algebraic solution for elliptic target localisation and antenna position refinement in multiple-input–multiple-output radars. IET Radar Sonar Navig. 2019, 13, 2046–2054. [Google Scholar] [CrossRef]
- Amiri, R.; Behnia, F.; Noroozi, A. Efficient joint moving target and antenna localization in distributed MIMO radars. IEEE Trans. Wirel. Commun. 2019, 18, 4425–4435. [Google Scholar] [CrossRef]
- Amiri, R.; Behnia, F.; Zamani, H. Asymptotically efficient target localization from bistatic range measurements in distributed MIMO radars. IEEE Signal Process. Lett. 2017, 24, 299–303. [Google Scholar] [CrossRef]
- Einemo, M.; So, H.C. Weighted least squares algorithm for target localization in distributed MIMO radar. Signal Process. 2015, 115, 144–150. [Google Scholar] [CrossRef]
- Dianat, M.; Taban, M.R.; Dianat, J.; Sedighi, V. Target localization using least squares estimation for MIMO radars with widely separated antennas. IEEE Trans. Aerosp. Electron. Syst. 2013, 49, 2730–2741. [Google Scholar] [CrossRef]
- Godrich, H.; Haimovich, A.M.; Blum, R.S. Target localization accuracy gain in MIMO radar-based systems. IEEE Trans. Inf. Theory 2010, 56, 2783–2803. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Hu, D.; Zhao, Y.; Liu, Z.; Zhao, C. Refining inaccurate transmitter and receiver positions using calibration targets for target localization in multi-static passive radar. Sensors 2019, 19, 3365. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.; Qin, Z.; Wei, S.; Sun, Z.; Xiang, H. Effects of nuisance variables selection on target localisation accuracy in multistatic passive radar. Electron. Lett. 2018, 54, 1139–1141. [Google Scholar] [CrossRef]
- Chalise, B.K.; Zhang, Y.D.; Amin, M.G.; Himed, B. Target localization in a multi-static passive radar system through convex optimization. Signal Process. 2014, 102, 207–215. [Google Scholar] [CrossRef]
- Gorji, A.A.; Tharmarasa, R.; Kirubarajan, T. Widely separated MIMO versus multistatic radars for target localization and tracking. IEEE Trans. Aerosp. Electron. Syst. 2013, 49, 2179–2194. [Google Scholar] [CrossRef]
- Malanowski, M.; Kulpa, K. Two methods for target localization in multistatic passive radar. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 572–580. [Google Scholar] [CrossRef]
- Yin, Z.; Jiang, X.; Yang, Z.; Zhao, N.; Chen, Y. WUB-IP: A high-precision UWB positioning scheme for ndoor multiuser applications. IEEE Syst. J. 2019, 13, 279–288. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Law, C.L.; Guan, Y.L.; Chin, F. Indoor elliptical localization based on asynchronous UWB range measurement. IEEE Trans. Instrum. Meas. 2011, 60, 248–257. [Google Scholar] [CrossRef]
- Smith, J.O.; Abel, J.S. Closed-form least-squares source location estimation from range-difference measurements. IEEE Trans. Acoust. Speech Signal Process. 1987, 35, 1661–1669. [Google Scholar] [CrossRef]
- Schau, H.; Robinson, A. Passive source localization employing intersecting spherical surfaces from time-of-arrival differences. IEEE Trans. Acoust. Speech Signal Process. 1987, 35, 1223–1225. [Google Scholar] [CrossRef]
- Amiri, R.; Behnia, F.; Sadr, M.A.M. Exact solution for elliptic localization in distributed MIMO radar systems. IEEE Trans. Veh. Technol. 2018, 67, 1075–1086. [Google Scholar] [CrossRef]
- Chan, Y.T.; Ho, K.C. A simple and efficient estimator for hyperbolic location. IEEE Trans. Signal Process. 1994, 42, 1905–1915. [Google Scholar] [CrossRef] [Green Version]
- Zheng, B.; Yang, Z. Perturbation analysis for mixed least squares–total least squares problems. Numer. Linear Algebra Appl. 2019, 26, e2239. [Google Scholar] [CrossRef]
- Buranay, S.C.; Iyikal, O.C. A predictor-corrector iterative method for solving linear least squares problems and perturbation error analysis. J. Inequal. Appl. 2019, 2019, 203. [Google Scholar] [CrossRef] [Green Version]
- Xie, P.; Xiang, H.; Wei, Y. A contribution to perturbation analysis for total least squares problems. Numer. Algorithms 2017, 75, 381–395. [Google Scholar] [CrossRef]
- Harville, D.A. Linear Models and the Relevant Distributions and Matrix Algebra; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Bar, S.; Tabrikian, J. The risk-unbiased Cramér–Rao bound for non-Bayesian multivariate parameter estimation. IEEE Trans. Signal Process. 2018, 66, 4920–4934. [Google Scholar] [CrossRef]
- Bergel, I.; Noam, Y. Lower bound on the localization error in infinite networks with random sensor locations. IEEE Trans. Signal Process. 2018, 66, 1228–1241. [Google Scholar] [CrossRef] [Green Version]
- Messer, H. The hybrid Cramér–Rao lower bound—From practice to theory. In Proceedings of the 4th IEEE Sensor Array and Multichannel Signal Processing Workshop, Waltham, MA, USA, 12–14 July 2006; pp. 304–307. [Google Scholar] [CrossRef]
- Noam, Y.; Messer, H. The hybrid Cramér–Rao bound and the generalized Gaussian linear estimation problem. In Proceedings of the 5th IEEE Sensor Array and Multichannel Signal Processing Workshop, Darmstadt, Germany, 21–23 July 2008; pp. 395–399. [Google Scholar] [CrossRef]
- Van Trees, H.L.; Bell, K.L.; Tian, Z. Detection, Estimation, and Modulation Theory Part I: Detection, Estimation, and Filtering Theory; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Rockah, Y.; Schultheiss, P. Array shape calibration using sources in unknown locations—Part I: far-field sources. IEEE Trans. Acoust. Speech Signal Process. 1987, 35, 286–299. [Google Scholar] [CrossRef] [Green Version]
- Magnus, J.R.; Neudecker, H. Matrix Differential Calculus with Applications in Statistics and Econometrics; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Chui, C.K.; Chen, G. Kalman Filtering with Real-Time Applications; Springer International Publishing: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Li, X.; Wang, S.; Cai, Y. Tutorial: Complexity analysis of Singular Value Decomposition and its variants. arXiv 2019, arXiv:1906.12085. [Google Scholar]
- Foy, W.H. Position-location solutions by Taylor-series estimation. IEEE Trans. Aerosp. Electron. Syst. 1976, 12, 187–194. [Google Scholar] [CrossRef]
- Horn, R.A.; Johnson, C.R. Matrix Analysis, 2nd ed.; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
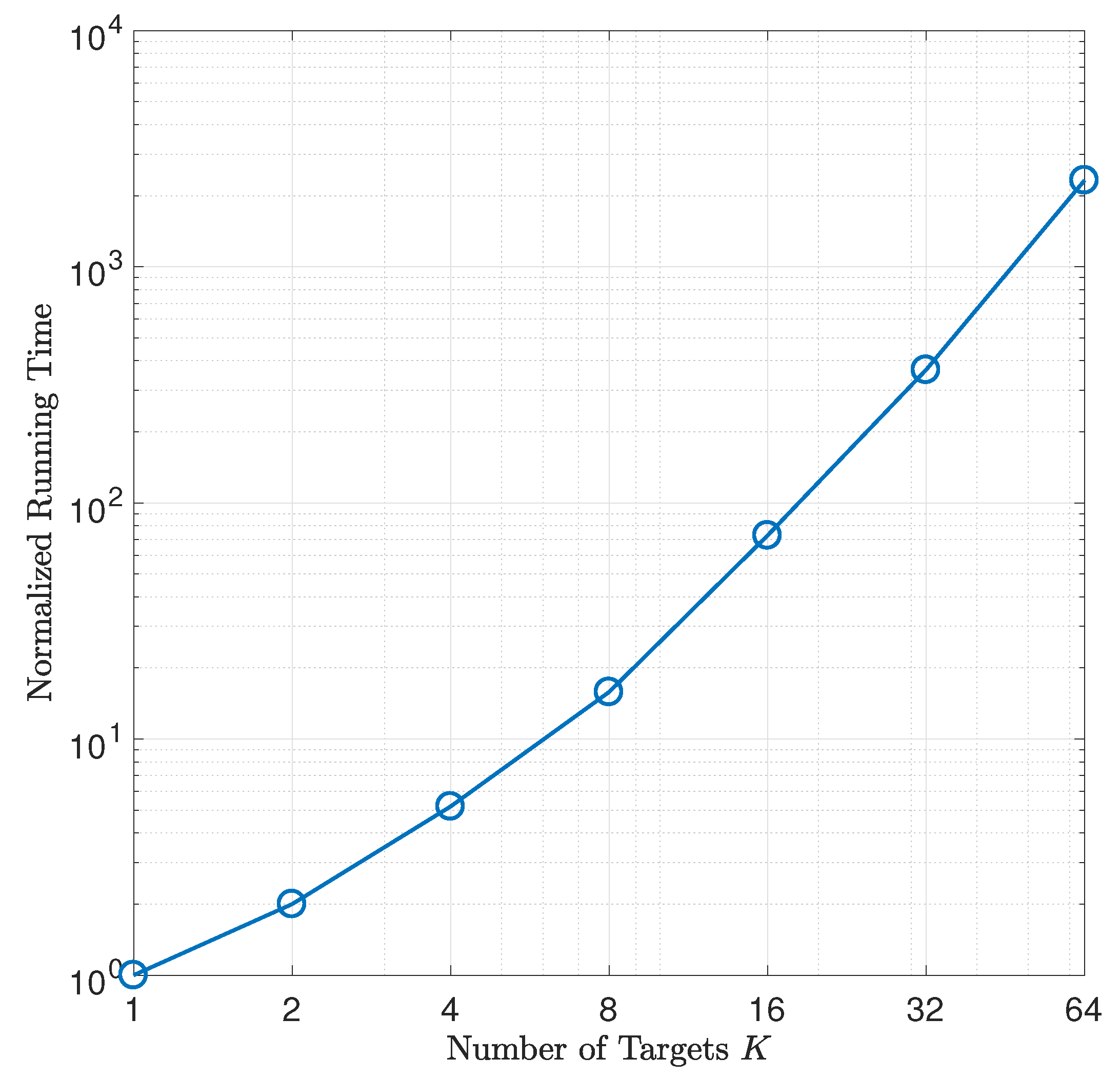{kind=link}
{kind=link}
{kind=link}
| Symbols/Notations | Remarks |
|---|---|
| zero-order approximation of □ | |
| expected or nominal value of □ | |
| estimator of □ | |
| random error or differential of □ | |
| covariance of □ | |
| M | known number of transmitters |
| N | known number of receivers |
| actual unobservable position of the i-th transmitter, | |
| actual unobservable position of the j-th receiver, | |
| known nominal value of | |
| c | known signal speed |
| unknown position of the target | |
| unknown velocity of the target | |
| observed differential delay time between and | |
| observed range rate between and | |
| expected value of | |
| , position uncertainties of transmitters and receivers | |
| , observation errors | |
| , gradient of with respected to | |
| , Hessian of with respected to |
| Matrix Notations | Expressions |
|---|---|
| Matrix Notations | Matrix Sizes |
|---|---|
| Quantities | Values |
|---|---|
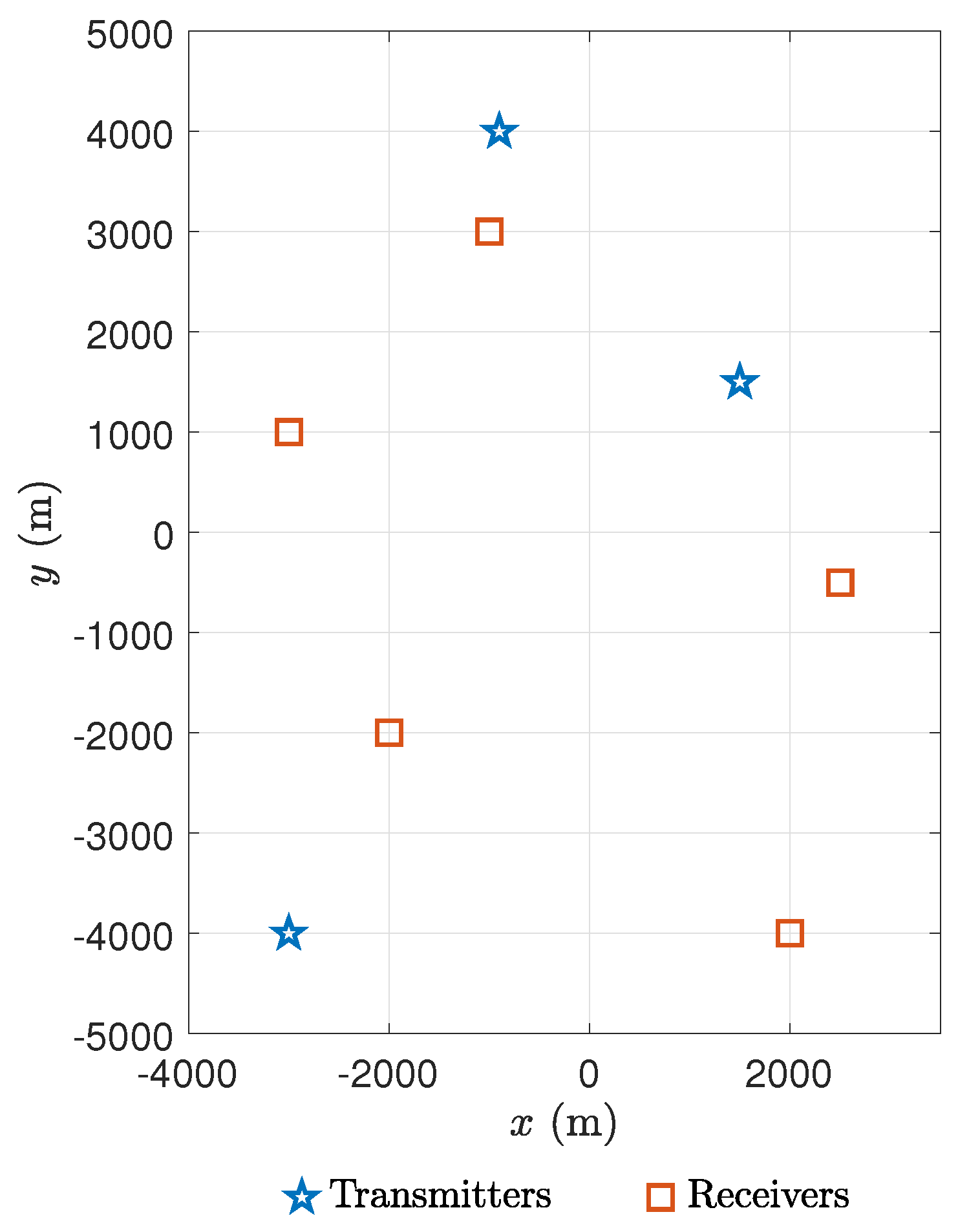
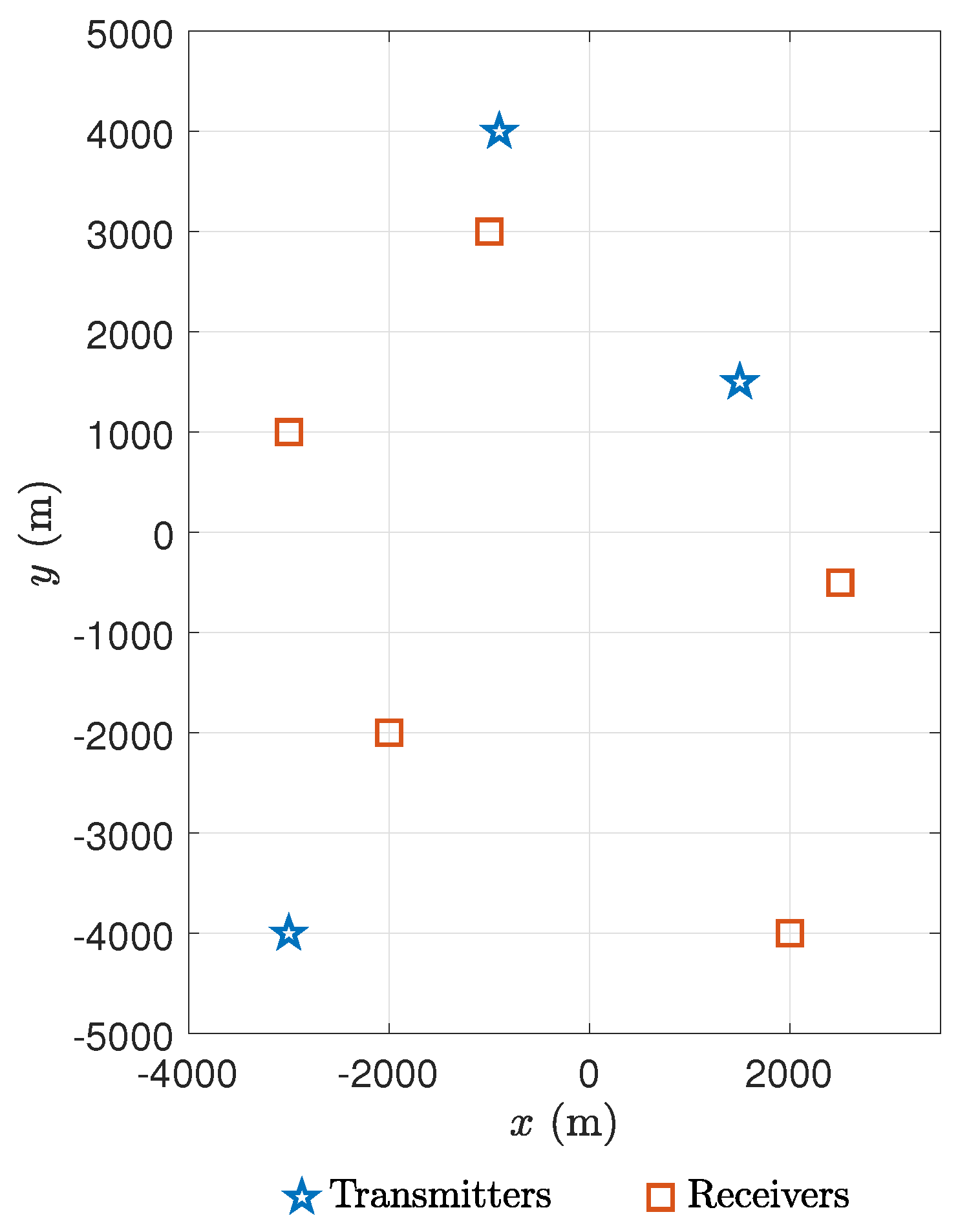
| M | 3 |
| N | 5 |
| c | 1500 m/s |
| m | |
| m | |
| m | |
| m | |
| m | |
| m | |
| m | |
| m | |
| s | |
| m | |
| m | |
| m |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Yu, Z.; Yang, L.; Li, J. Design and Analysis of a Non-Iterative Estimator for Target Location in Multistatic Sonar Systems with Sensor Position Uncertainties. Mathematics 2020, 8, 129. https://doi.org/10.3390/math8010129
Wang X, Yu Z, Yang L, Li J. Design and Analysis of a Non-Iterative Estimator for Target Location in Multistatic Sonar Systems with Sensor Position Uncertainties. Mathematics. 2020; 8(1):129. https://doi.org/10.3390/math8010129
Chicago/Turabian StyleWang, Xin, Zhi Yu, Le Yang, and Ji Li. 2020. "Design and Analysis of a Non-Iterative Estimator for Target Location in Multistatic Sonar Systems with Sensor Position Uncertainties" Mathematics 8, no. 1: 129. https://doi.org/10.3390/math8010129
APA StyleWang, X., Yu, Z., Yang, L., & Li, J. (2020). Design and Analysis of a Non-Iterative Estimator for Target Location in Multistatic Sonar Systems with Sensor Position Uncertainties. Mathematics, 8(1), 129. https://doi.org/10.3390/math8010129