Efficient Implementation of ARX-Based Block Ciphers on 8-Bit AVR Microcontrollers


Abstract
1. Introduction
- Fast implementation for CTR mode of operation for LEA and HIGHT on 8-bit AVR MCUsAs nonce is repeatedly used in CTR mode, the result has an identical value when the nonce part is encrypted. Therefore, look-up tables can be generated using the results of encryption data of nonce. In this paper, we present efficient methods that generate look-up tables. Using the optimal implementation, we proposed, in a fixed key scenario, the performance of encryption can be improved by skipping the calculation procedure while loading only the calculation result from the look-up table. For better performance, optimizations of rotation operation and memory access are utilized. Finally, the implementation of LEA-CTR and HIGHT-CTR outperforms previous works by 6.3% and 3.8% than previous works, respectively. Our implementations of LEA and HIGHT are the fastest implementation compared to the previous implementation on 8-bit AVR MCUs. Furthermore, unlike the typical look-up table generation using a separated way, our implementation generates the look-up table, simultaneously, while executing the encryption process. Therefore, in our implementation, the cost of additional function calls that occurred from the generation of look-up table can be reduced. By using this, we obtained performance improvement of 6.7% and 9.1% compared to the previous separated encryption process which generates the look-up table, respectively.
- Optimized CTR_DRBG implementations on 8-bit AVR MCUs for fast random bit generationThe implementation of CTR_DRBG is optimized with the look-up table. In CBC-MAC of the Derivation Function, the look-up table is created for the encryption result of data depending on the initial block bit. The optimization of the Update Function is achieved with the look-up table by taking advantage of the condition that the initial Operational Status is zero. In addition, the look-up table does not require an update, but also requires a low cost of 96 bytes, making it effectively applicable to 8-bit AVR Microcontrollers. Moreover, we presented methods to optimize Korean block cipher in the Extract Function on 8-bit AVR Microcontrollers. The Extract Function is optimized by utilizing the table for the CTR mode that uses fixed keys to reduce the execution timing. Our works of Derivation Function and Update Function outperform previous works by 13.3% and 72.4%, respectively. By applying CTR optimization methods, implementations of Extract Function using LEA and HIGHT outperform the standard implementation of Extract Function by 36.4% and 3.5%, respectively. By combining the proposed Derivation Function, Update Function, and Extract Function, overall, our CTR_DRBG implementation provides 37.2% and 8.7% of performance improvement compared with the native CTR_DRBG implementation using the works from [3,4,5] as an underlying block cipher of Extract Function.
- Proposing optimization methods that can be applied to various platformsIn this paper, we propose general optimization methods for ARX-based block ciphers using the CTR mode. These methods have the advantage to be extended to other Addition-Rotation-XOR (ARX) based ciphers such as CHAM, Simon, and Speck [8,9]. While the significance of DBRG is increasing with the advent of the IoT era, there have been a few academic papers on optimization for CTR_DRBG that are popular to use. In this paper, we present CTR_DRBG optimization methods on 8-bit AVR Microcontrollers, the most limited IoT device. Our work is meaningful as it is the first attempt to optimize CTR_DRBG. Furthermore, our proposed Korean block cipher optimization methods and CTR_DRBG optimization methods are not only applicable to 8-bit AVR Microcontroller, but also to other low-end-processors and high-end-processors such as 16-bit MSP430, 32-bit ARM, and the CPU environment.
2. Background
2.1. 8-Bit AVR Microcontroller
2.2. Target Block Ciphers
2.2.1. LEA Block Cipher
2.2.2. HIGHT Block Cipher
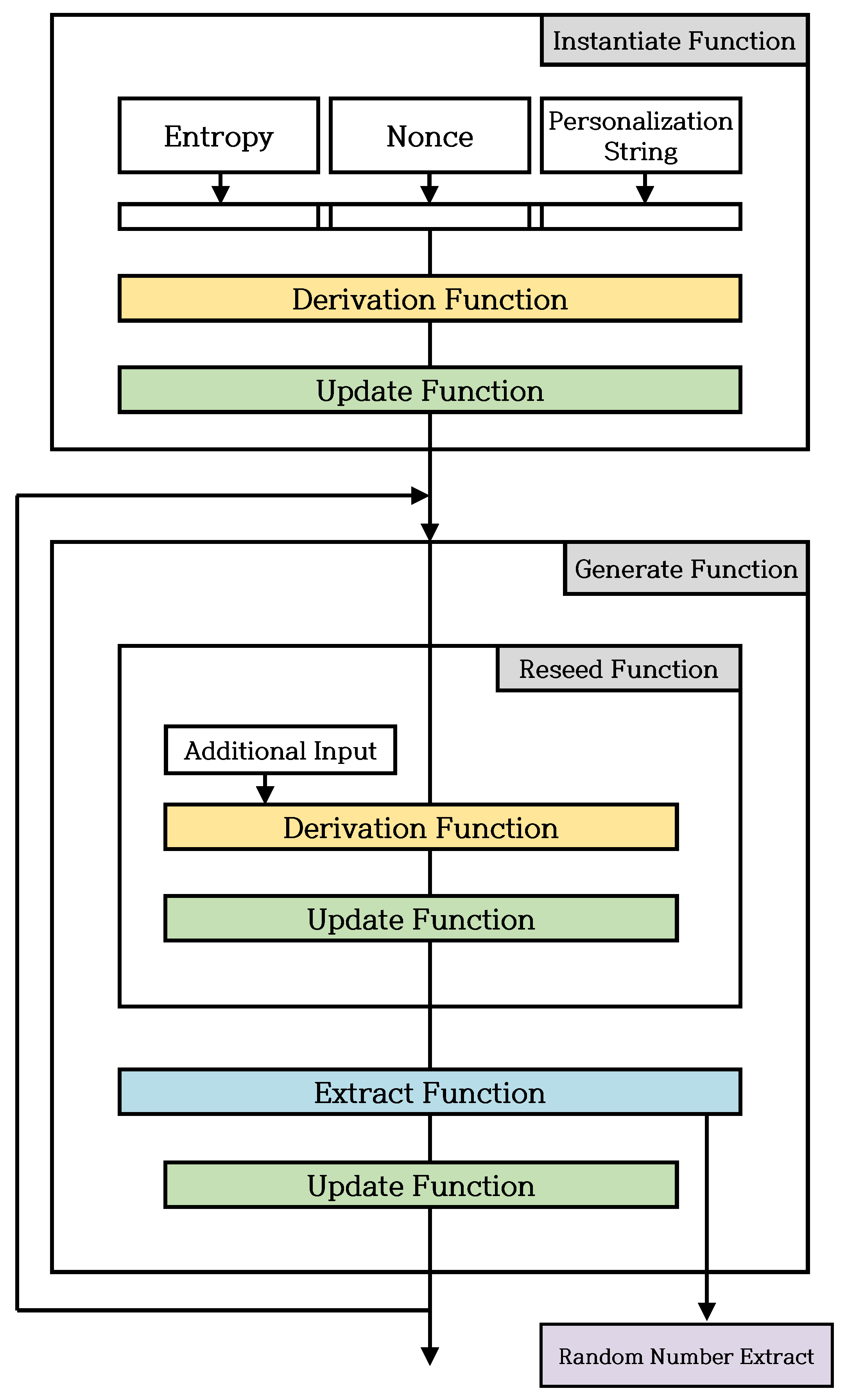
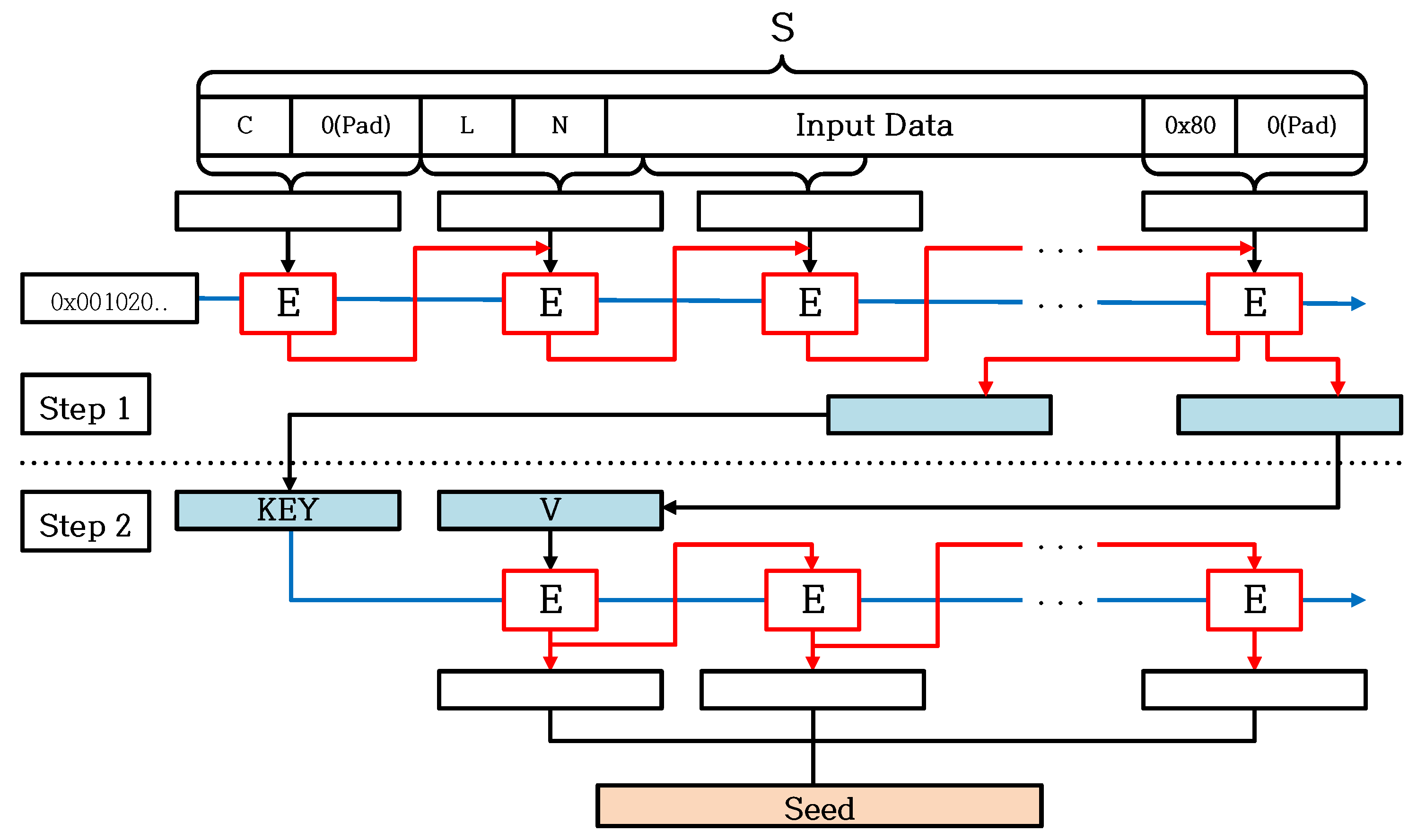
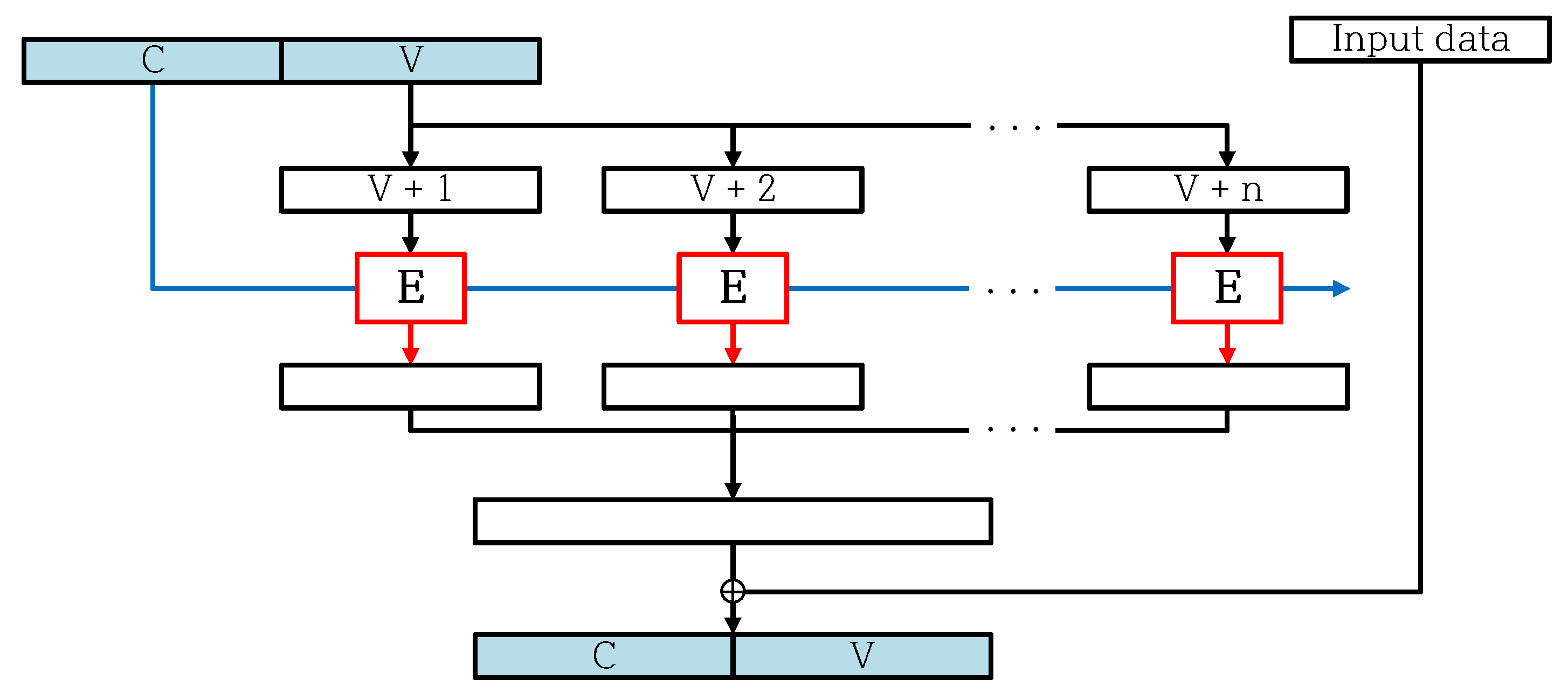
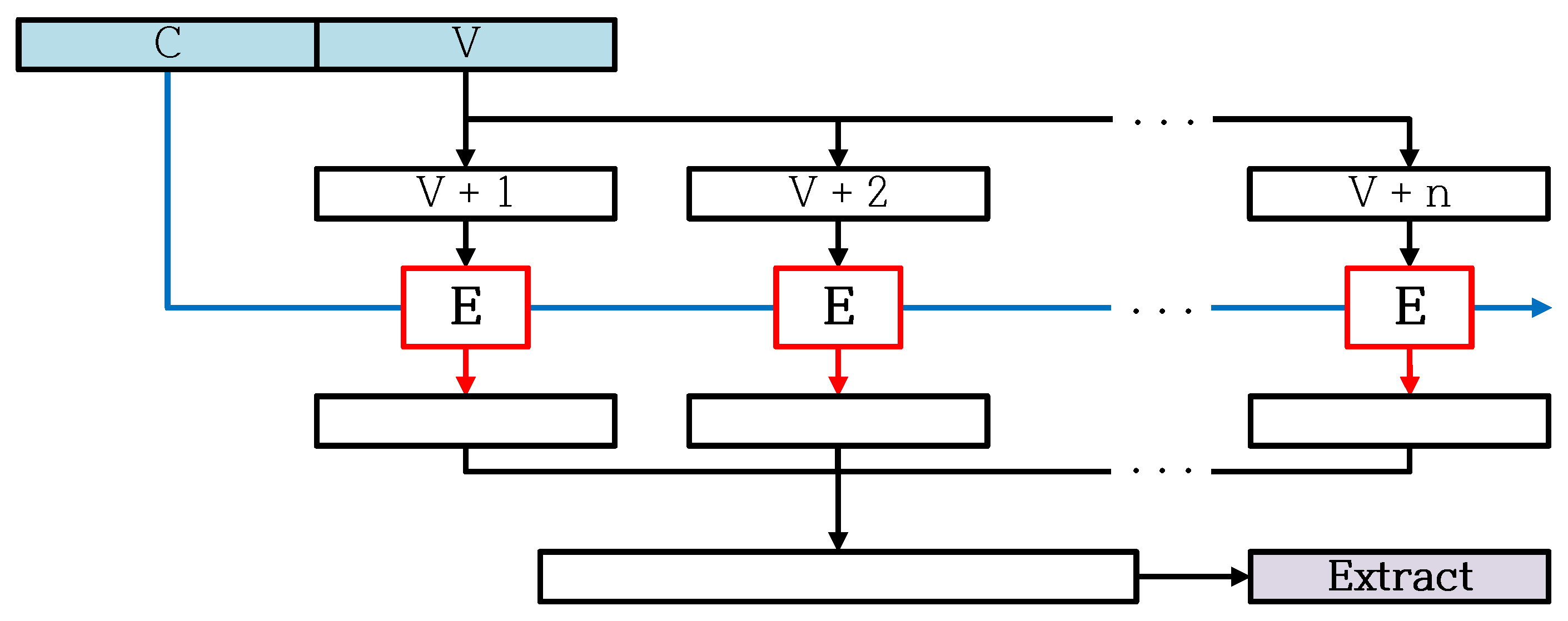
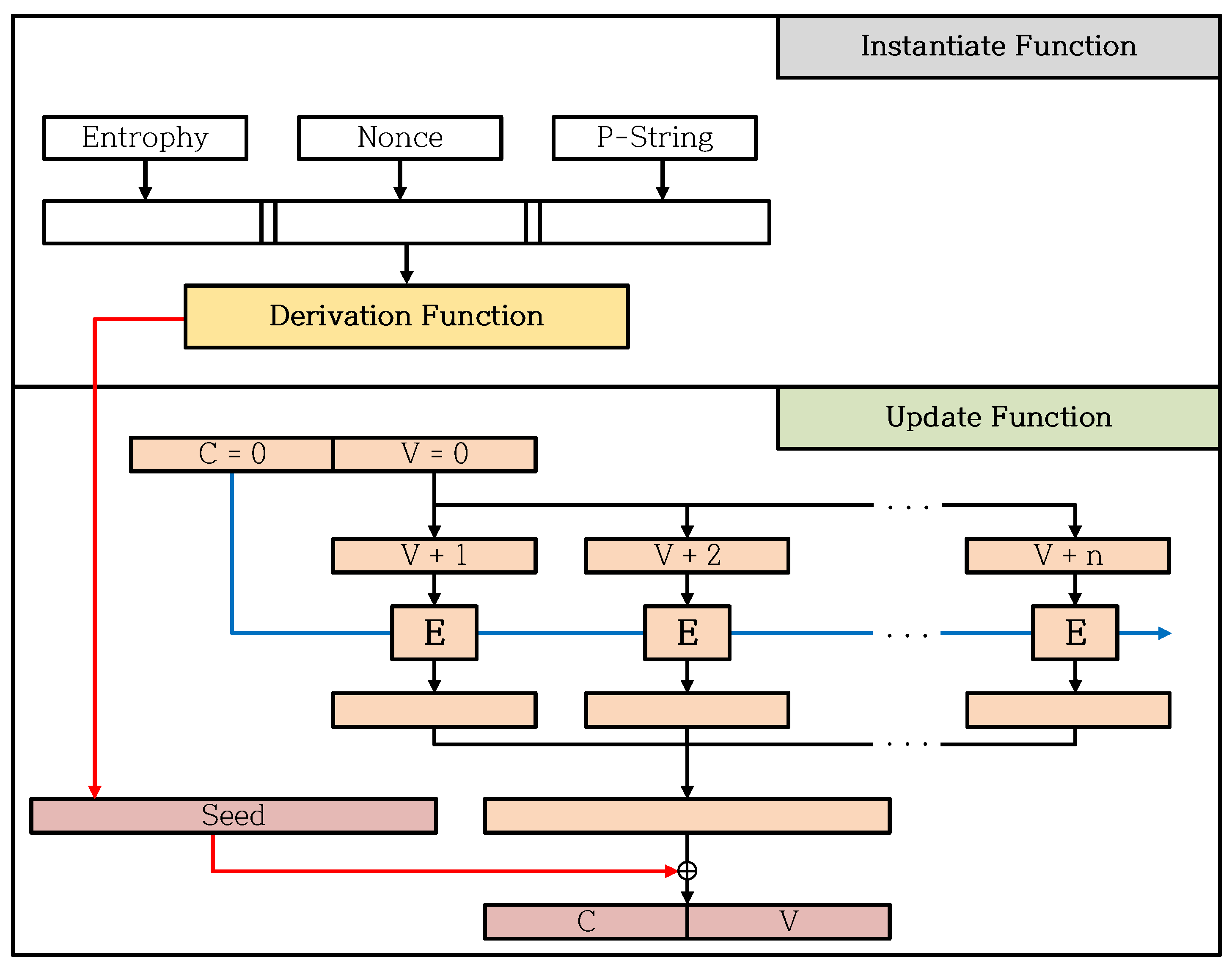
2.3. CTR_DRBG
3. Related Works
3.1. Block Cipher Implementations on AVR
3.2. DRBG Implementations on AVR
4. Optimized Implementations of LEA-CTR and HIGHT-CTR
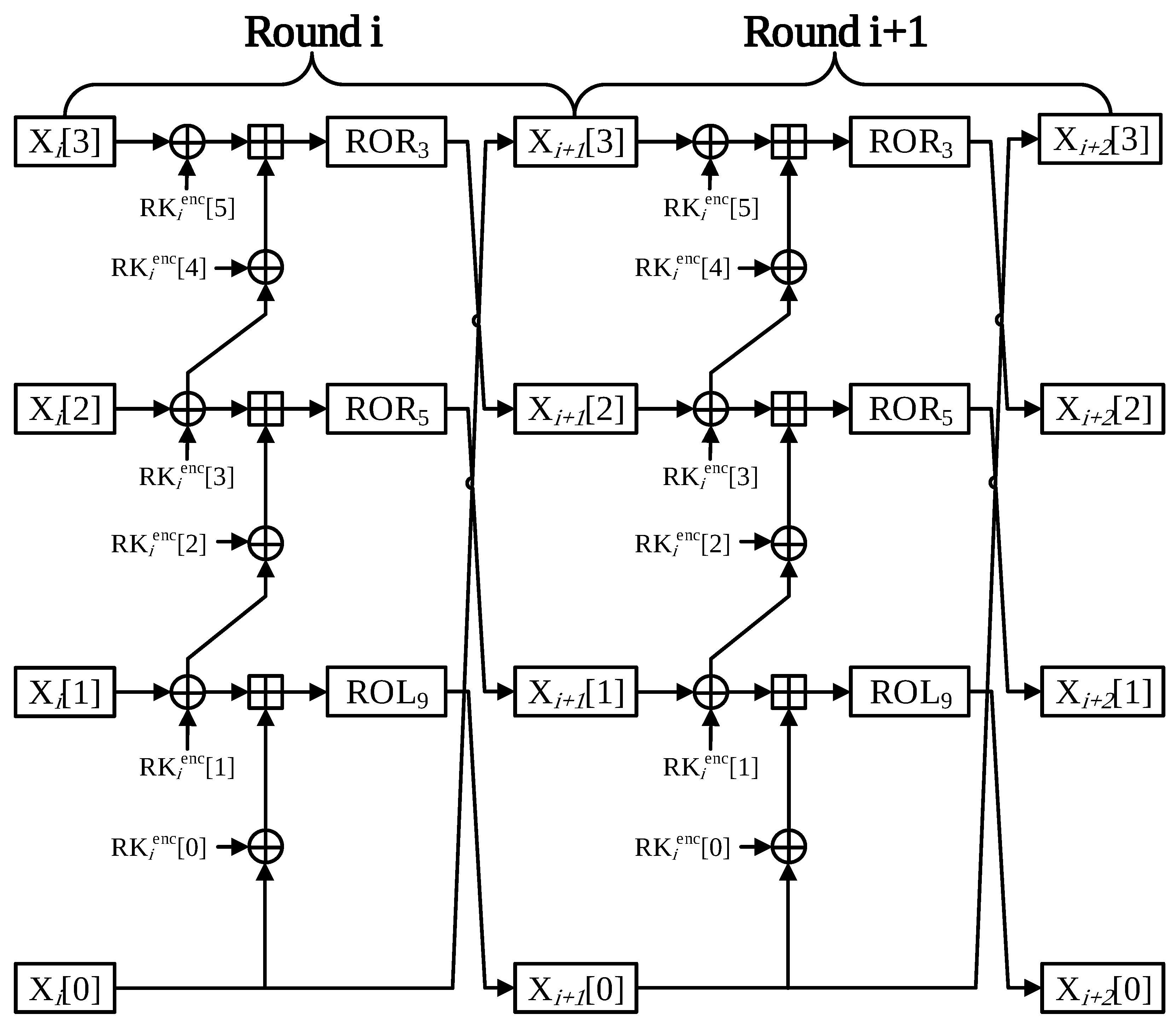
4.1. Optimized Implementation of LEA-CTR
- -
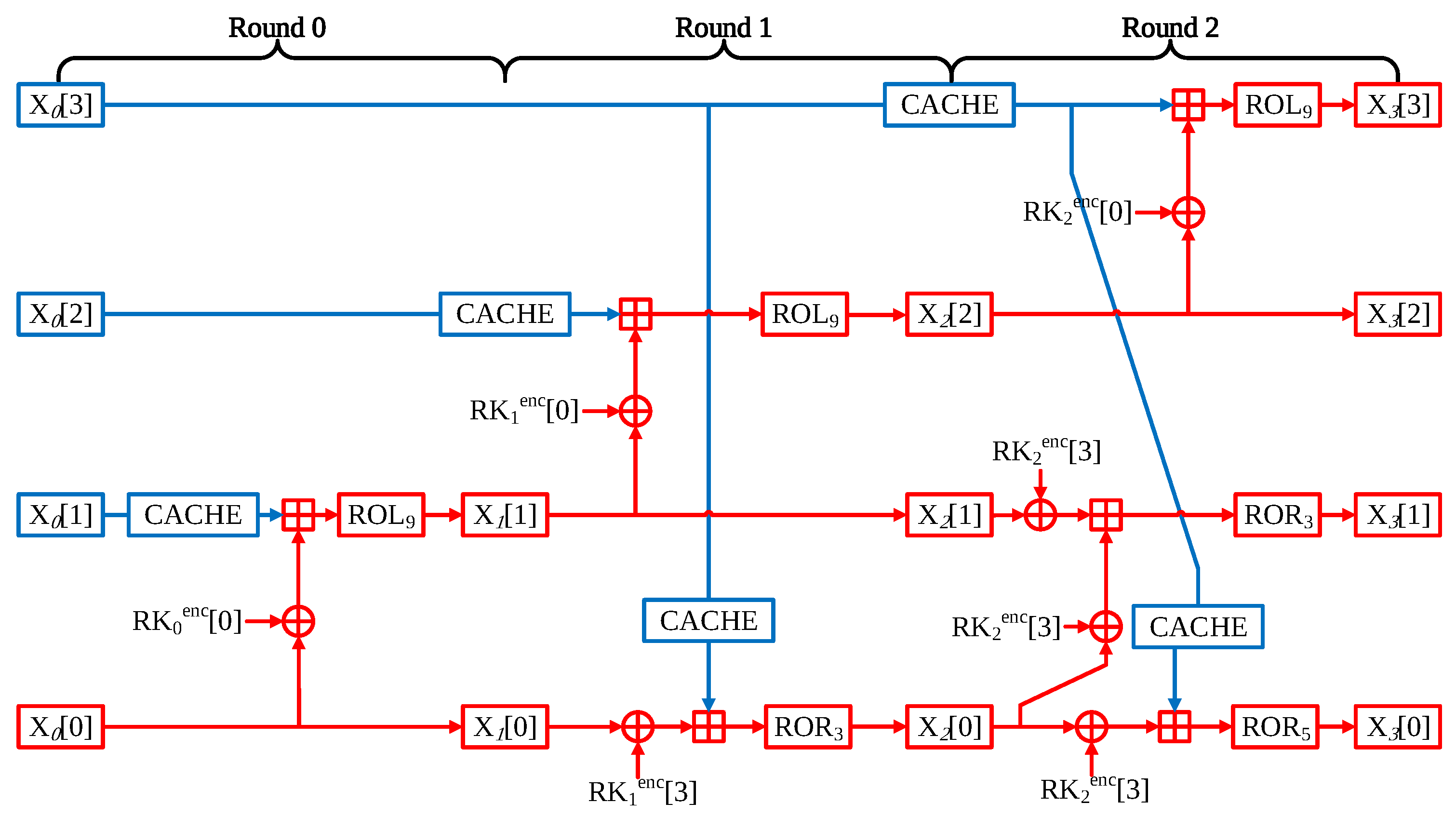
- Round 0 In one round of LEA, the operations are performed in three parts. In Round 0, only X[0] word has a counterpart of IV. Consequently, two words can be implemented through the precomputation method.
- -
- Round 1 However, due to the Round 0, the X[1] word is also beginning to be affected by the counter value. For this reason, it might be thought that the precomputation part is only available at X[2] word. The part where X[3] word is used as the input value of X[0] in Round 1 can be expressed by the following equation:At this equation, it can be seen that the blue parts X[3] word and round key are fixed values. Consequently, XOR instruction between X[3] word and round key part can be skipped.
- -
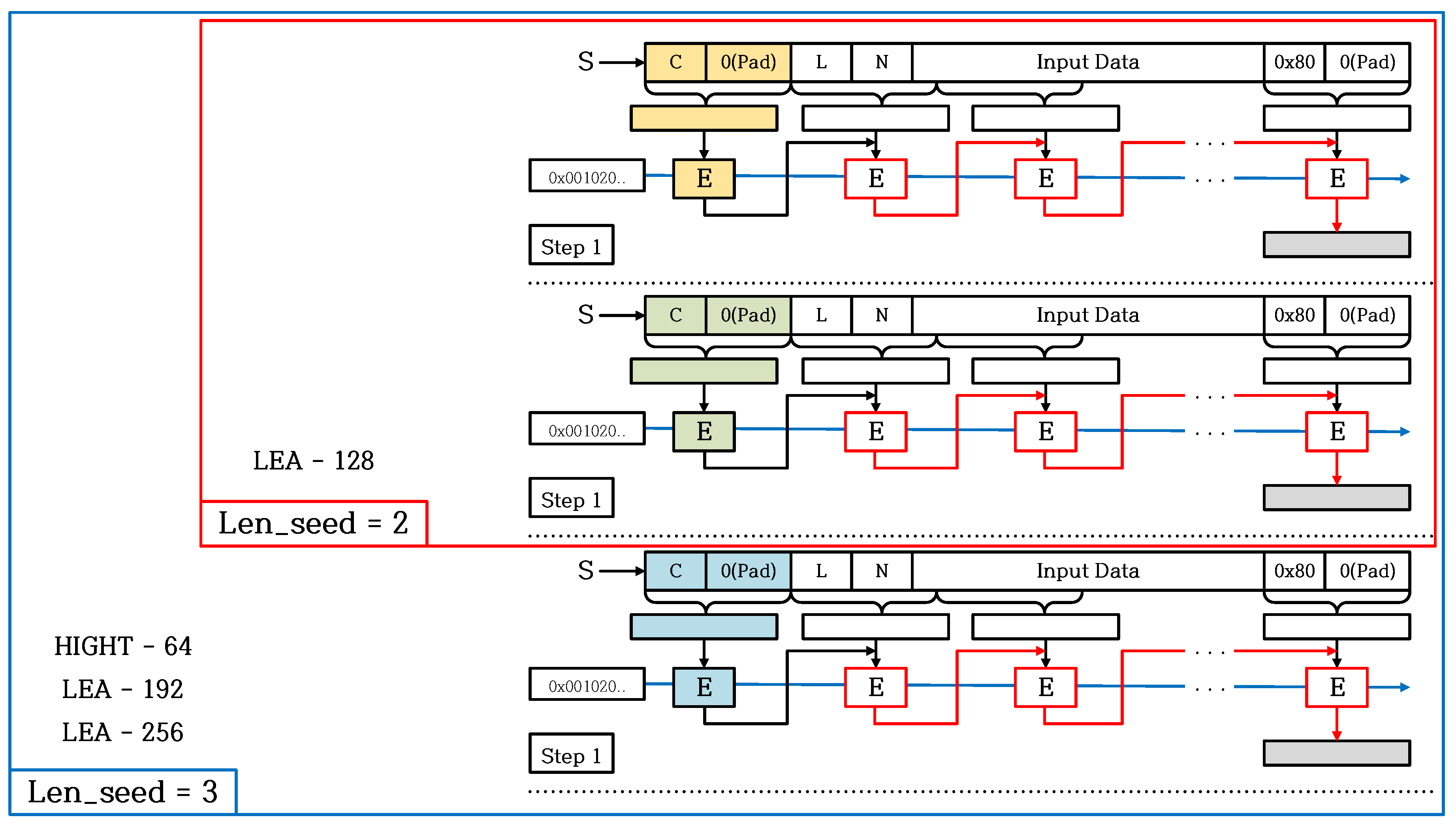
- Round 2 In Round 2, only the X[3] word is not affected by counter value. Therefore, precomputation is not applicable as a whole. However, like the previous round, in order to use X[3] word as an input value for X[0] word, the operation part that performs XOR instruction with a round key can be a precomputation implement. The optimized LEA-128/128 CTR mode of operation is described in Figure 7.
- -
- Generation of look-up table When generating a look-up table, it has the advantage that the table can be generated during the encryption process. CACHE can be saved in the look-up table through the result of the operation in executing each round. When creating the look-up table, only the address translation cost based on ST instruction is incurred.
Optimization for LEA-128/192 and LEA-128/256
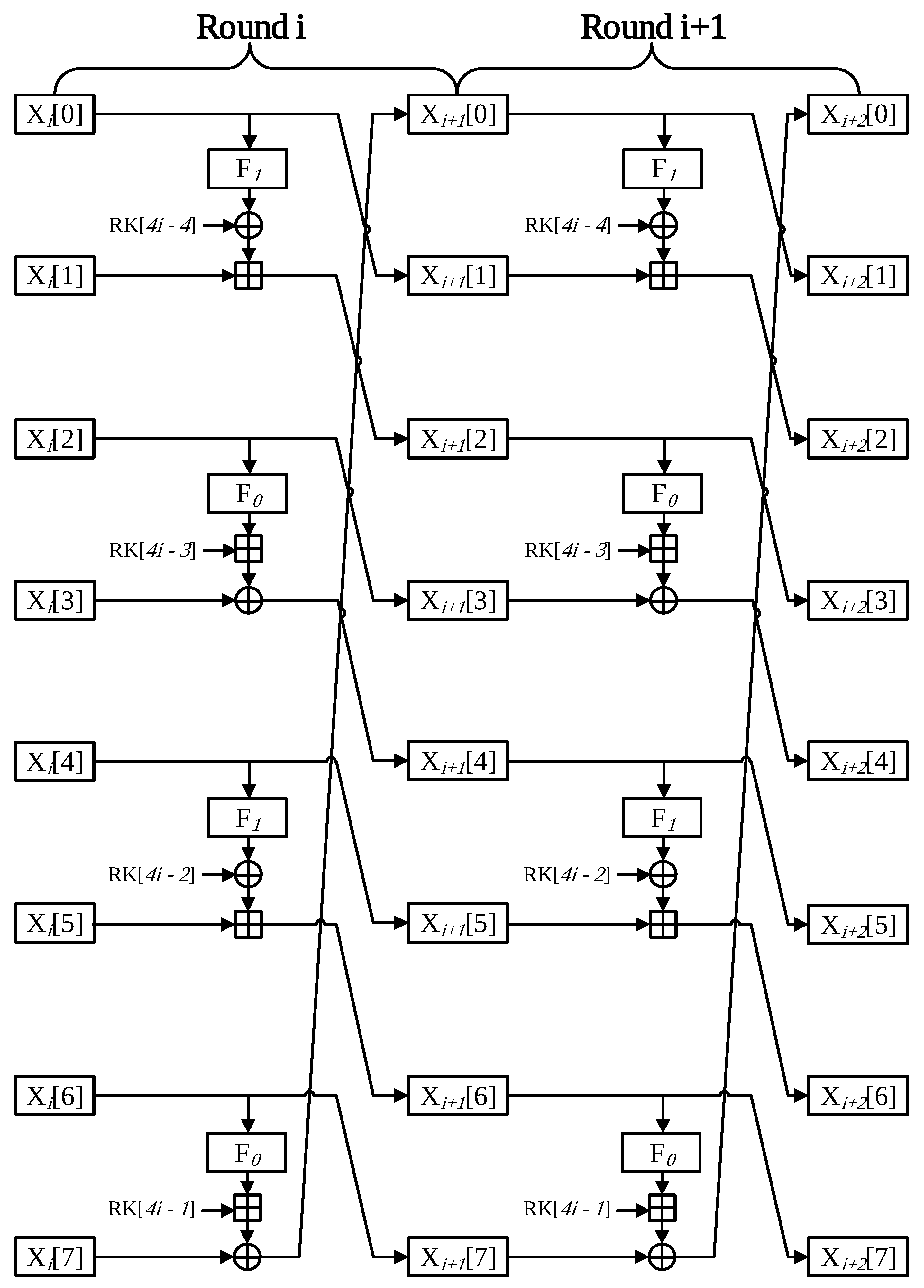
4.2. Optimized Implementation of HIGHT-CTR
- -
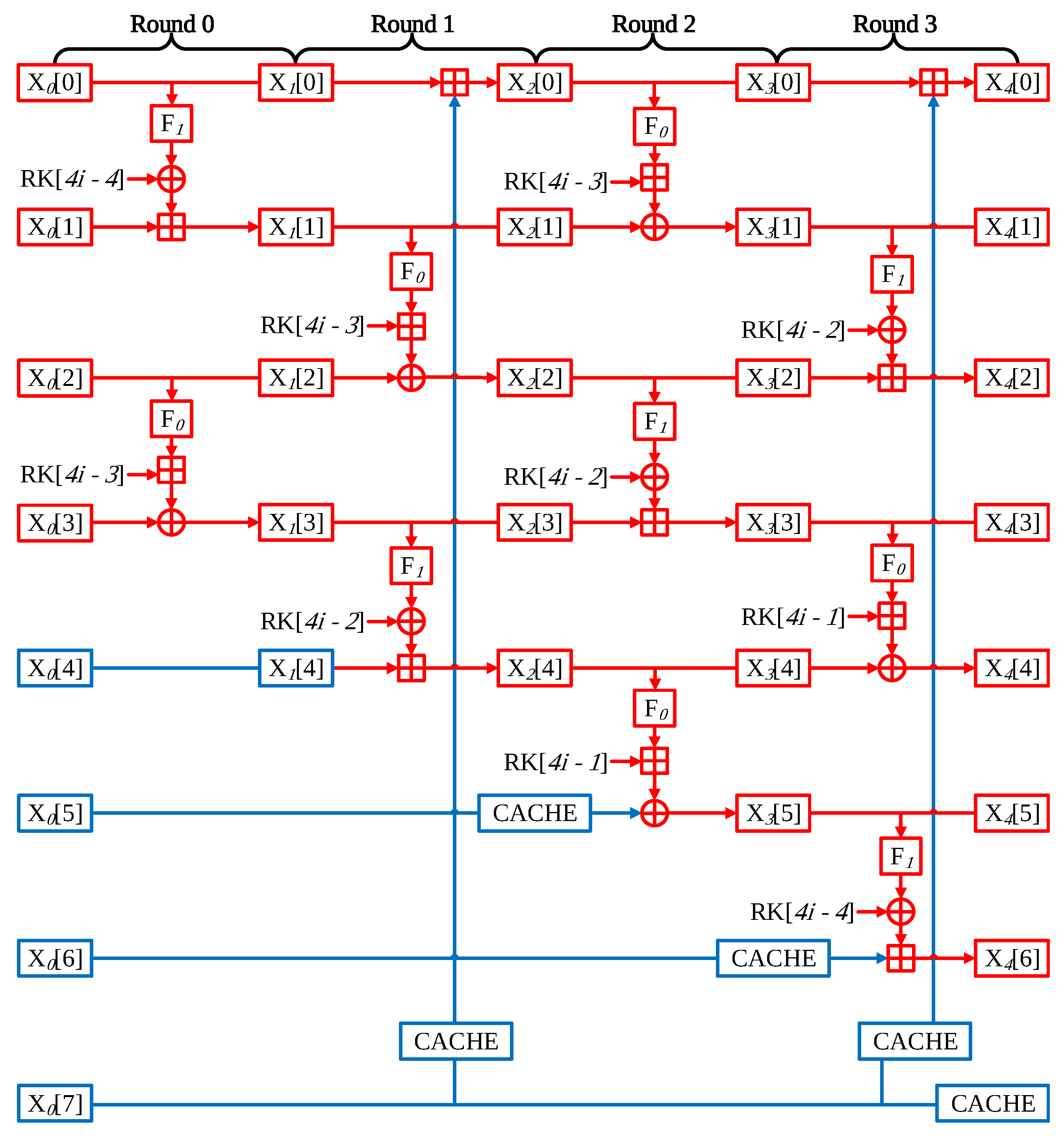
- Round 0 The HIGHT performs four operations in a single round. In Round 0, the operation is performed using the following word pairs; X[0] with X[1], X[2] with X[3], X[4] with X[5], and X[6] with X[7]. First of all, words of X[0], X[1], X[2], X[3] have counter values, which is variable. Thus, two of the four operations must be implemented. However, the other operations part uses only fixed values, which are nonce, and round keys, so precomputation is available for these parts.
- -
- Round 1 Unlike the previous round, the pair of words participating in the operation is slightly different. In this time, the X[4] word is affected by the counter value; then, precomputation is not possible. X[5] and X[6] words still have nonce value, so this part is precomputation implementation available. In addition, lastly, X[0] word operates with a X[7] word that has nonce value. The whole operations cannot be skipped, but the result of X[7] operation through the F1 function is can be omitted because X[7] has nonce value, and the F1 function only conducts left shift operation.
- -
- Round 2 Round 2 has a similar structure to Round 0. However, in this time, X[4] words are affected by counter value, so the precomputation part is reduced by one place and then the Round 0.
- -
- Round 3 Likewise this time, the Round 3 scheme is like Round 1. The difference is that the X[6] word is affected by the counter value. For this reason, precomputation implementation is possible in only one part.
- -
- Generation of look-up table In the same method as the proposed look-up table of LEA, the proposed method for HIGHT implementation has the advantage of generating a look-up table during the encryption process. CACHE data are saved during the CTR mode encryption. When creating the look-up table, only the address translation cost based on ST instruction is incurred.
4.3. Optimized Implementation of Rotation Operation
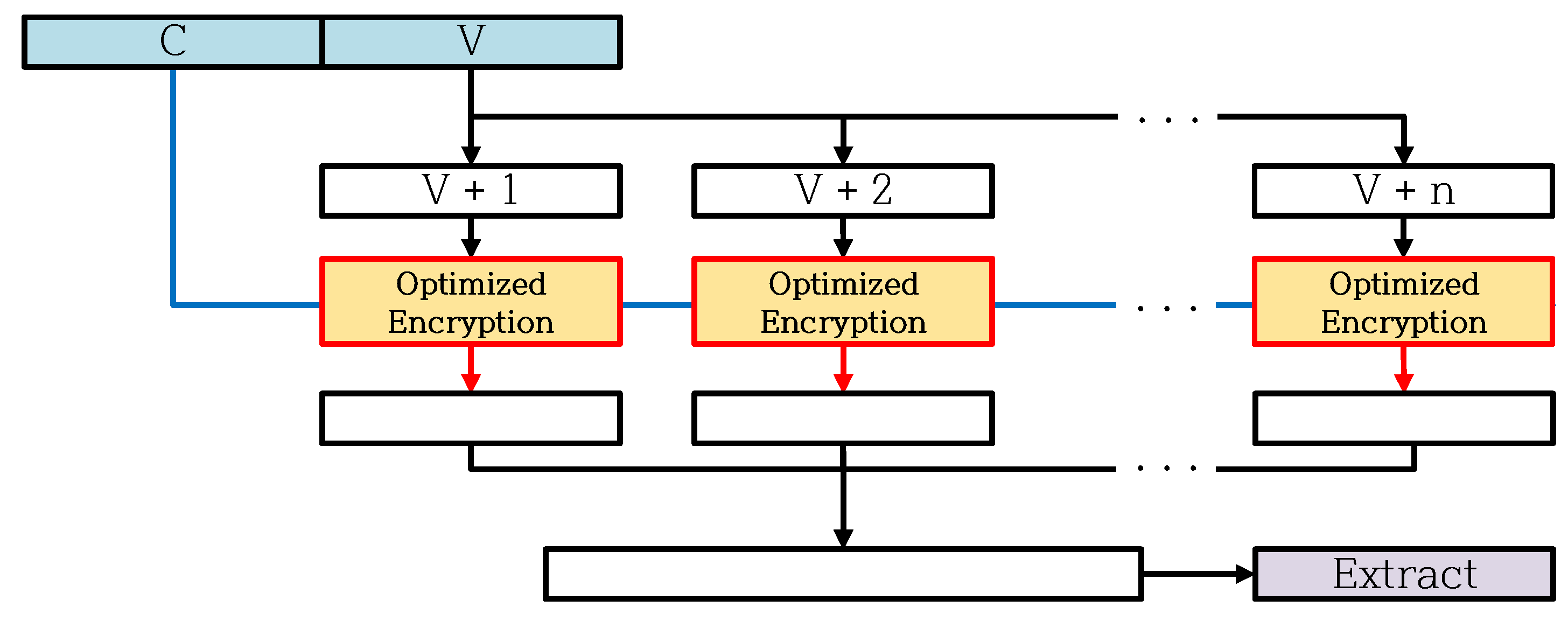
5. Optimization for CTR_DRBG on 8-Bit AVR Microcontroller
6. Implementation Results
6.1. LEA-CTR on 8-bit AVR Microcontrollers
6.2. HIGHT-CTR on 8-Bit AVR Microcontrollers
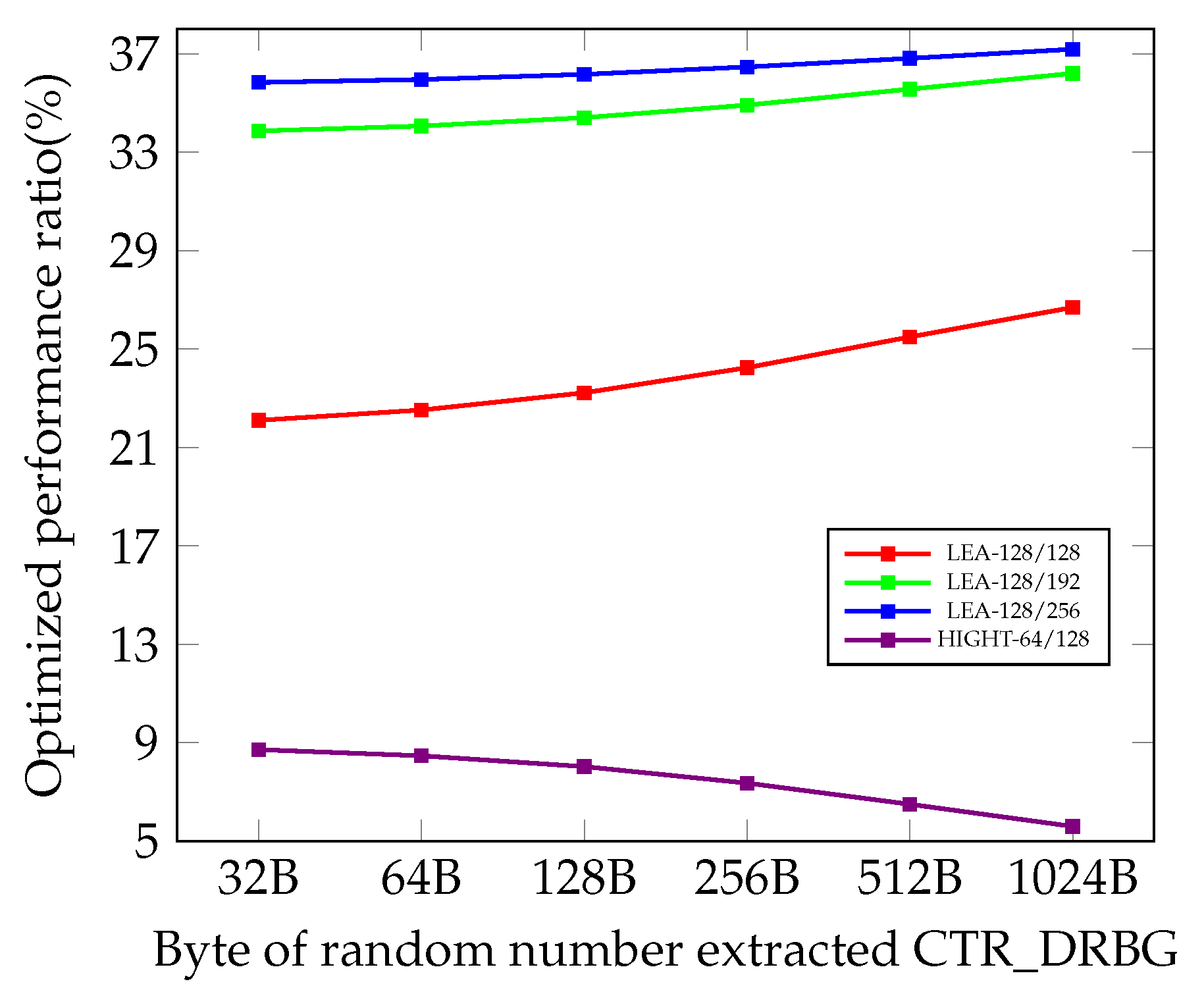
6.3. CTR_DRBG on 8-Bit AVR Microcontrollers
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hong, D.; Sung, J.; Hong, S.; Lim, J.; Lee, S.; Koo, B.S.; Lee, C.; Chang, D.; Lee, J.; Jeong, K.; et al. HIGHT: A new block cipher suitable for low-resource device. In International Workshop on Cryptographic Hardware and Embedded Systems; Springer: Berlin/Heidelberg, Germany, 2006; pp. 46–59. [Google Scholar]
- Hong, D.; Lee, J.K.; Kim, D.C.; Kwon, D.; Ryu, K.H.; Lee, D.G. LEA: A 128-bit block cipher for fast encryption on common processors. In International Workshop on Information Security Applications; Springer: Berlin/Heidelberg, Germany, 2013; pp. 3–27. [Google Scholar]
- Seo, H.; Liu, Z.; Choi, J.; Park, T.; Kim, H. Compact implementations of LEA block cipher for low-end microprocessors. In International Workshop on Information Security Applications; Springer: Berlin/Heidelberg, Germany, 2015; pp. 28–40. [Google Scholar]
- Seo, H.; Jeong, I.; Lee, J.; Kim, W.H. Compact implementations of ARX-based block ciphers on IoT processors. ACM Trans. Embed. Comput. Syst. (TECS) 2018, 17, 1–16. [Google Scholar] [CrossRef]
- Seo, H.; An, K.; Kwon, H. Compact LEA and HIGHT implementations on 8-bit AVR and 16-bit MSP processors. In International Workshop on Information Security Applications; Springer: Berlin/Heidelberg, Germany, 2018; pp. 253–265. [Google Scholar]
- Meltem, S.T.; Elaine, B.; John, K.; Kerry, M.; Mary, B.; Michael, B. Recommendation for the Entropy Sources Used for Random Bit Generation; NIST DRAFT Special Publication 800-90B; NIST: Gaithersburg, MD, USA, 2018; pp. 4–47.
- Kim, Y.; Seo, S. Study on CTR_DRBG Optimization in 8-bit AVR Encironment. In Proceedings of the Conference on Information Security and Cryptography-Summer 2020 (CICS-S’20), Seoul, Korea, 15 July 2020. [Google Scholar]
- Beaulieu, R.; Shors, D.; Smith, J.; Treatman-Clark, S.; Weeks, B.; Wingers, L. The SIMON and SPECK block ciphers on AVR 8-bit microcontrollers. In International Workshop on Lightweight Cryptography for Security and Privacy; Springer: Berlin/Heidelberg, Germany, 2014; pp. 3–20. [Google Scholar]
- Koo, B.; Roh, D.; Kim, H.; Jung, Y.; Lee, D.G.; Kwon, D. CHAM: A Family of Lightweight Block Ciphers for Resource-Constrained Devices. In Proceedings of the International Conference on Information Security and Cryptology (ICISC’17), Seoul, Korea, 29 November–1 December 2017. [Google Scholar]
- Atmel. AVR Instruction Set Manual. 2012. Available online: http://ww1.microch-\ip.com/downloads/en/devicedoc/atmel-0856-avr-instruction-set-manual.pdf (accessed on 10 October 2020).
- Kim, Y.; Seo, S.C. An Efficient Implementation of AES on 8-bit AVR-based Sensor Nodes. In Proceedings of the 21th World Conference on Information Security Applications, Jeju island, Korea, 26–28 August 2020. [Google Scholar]
- Kwon, H.; Kim, H.; Choi, S.J.; Jang, K.; Park, J.; Kim, H.; Seo, H. Compact Implementation of CHAM Block Cipher on Low-End Microcontrollers. In Proceedings of the The 21th World Conference on Information Security Applications, Jeju island, Korea, 26–28 August 2020. [Google Scholar]
- Balasch, J.; Ege, B.; Eisenbarth, T.; Gérard, B.; Gong, Z.; Güneysu, T.; Heyse, S.; Kerckhof, S.; Koeune, F.; Plos, T.; et al. Compact Implementation and Performance Evaluation of Hash Functions in ATtiny Devices. IACR Cryptol. ePrint Arch. 2012, 2012, 507. [Google Scholar]
- Cheng, H.; Dinu, D.; Großschädl, J. Efficient Implementation of the SHA-512 Hash Function for 8-Bit AVR Microcontrollers. In Innovative Security Solutions for Information Technology and Communications; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11359, pp. 273–287. [Google Scholar]
- Seo, H.J. High Speed Implementation of LEA on ARM Cortex-M3 processor. J. Korea Inst. Inf. Commun. Eng. 2018, 22, 1133–1138. [Google Scholar]
- Eisenbarth, T.; Gong, Z.; Güneysu, T.; Heyse, S.; Indesteege, S.; Kerckhof, S.; Koeune, F.; Nad, T.; Plos, T.; Regazzoni, F.; et al. Compact implementation and performance evaluation of block ciphers in ATtiny devices. In International Conference on Cryptology in Africa; Springer: Berlin/Heidelberg, Germany, 2012; pp. 172–187. [Google Scholar]
- Kim, B.; Cho, J.; Choi, B.; Park, J.; Seo, H. Compact Implementations of HIGHT Block Cipher on IoT Platforms. Secur. Commun. Netw. 2019, 2019, 1–10. [Google Scholar] [CrossRef]
- Beaulieu, R.; Treatman-Clark, S.; Shors, D.; Weeks, B.; Smith, J.; Wingers, L. The SIMON and SPECK lightweight block ciphers. In Proceedings of the 52nd Annual Design Automation Conference; IEEE: Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Lee, D.; Kim, D.; Kwon, D.; Kim, H. Efficient Hardware Implementation of the Lightweight Block Encryption Algorithm LEA. Sensors 2014, 14, 975–994. [Google Scholar] [CrossRef] [PubMed]
- Aguilar, J.; Sierra, S.; Jacinto, E. Implementation of ‘HIGHT’ encryption algorithm on microcontroller. In Proceedings of the 2015 CHILEAN Conference on Electrical, Electronics Engineering, Information and Communication Technologies (CHILECON), Santiago, Chile, 28–30 October 2015; pp. 937–942. [Google Scholar]
- Lee, J.H.; Lim, D.G. Parallel Architecture for High-Speed Block Cipher, HIGHT. Int. J. Secur. Its Appl. 2014, 8, 59–66. [Google Scholar] [CrossRef]
- Osvik, D.A.; Bos, J.W.; Stefan, D.; Canright, D. Fast software AES encryption. In International Workshop on Fast Software Encryption; Springer: Berlin/Heidelberg, Germany, 2010; pp. 75–93. [Google Scholar]
- McGrew, D.; Viega, J. The Galois/counter mode of operation (GCM). Submiss. Nist Modes Oper. Process. 2004, 20, 1–13. [Google Scholar]
- Kim, K.; Choi, S.; Kwon, H.; Liu, Z.; Seo, H. FACE–LIGHT: Fast AES–CTR Mode Encryption for Low-End Microcontrollers. In International Conference on Information Security and Cryptology; Springer: Berlin/Heidelberg, Germany, 2019; pp. 102–114. [Google Scholar]
- Park, J.H.; Lee, D.H. FACE: Fast AES CTR mode Encryption Techniques based on the Reuse of Repetitive Data. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2018, 2018, 469–499. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
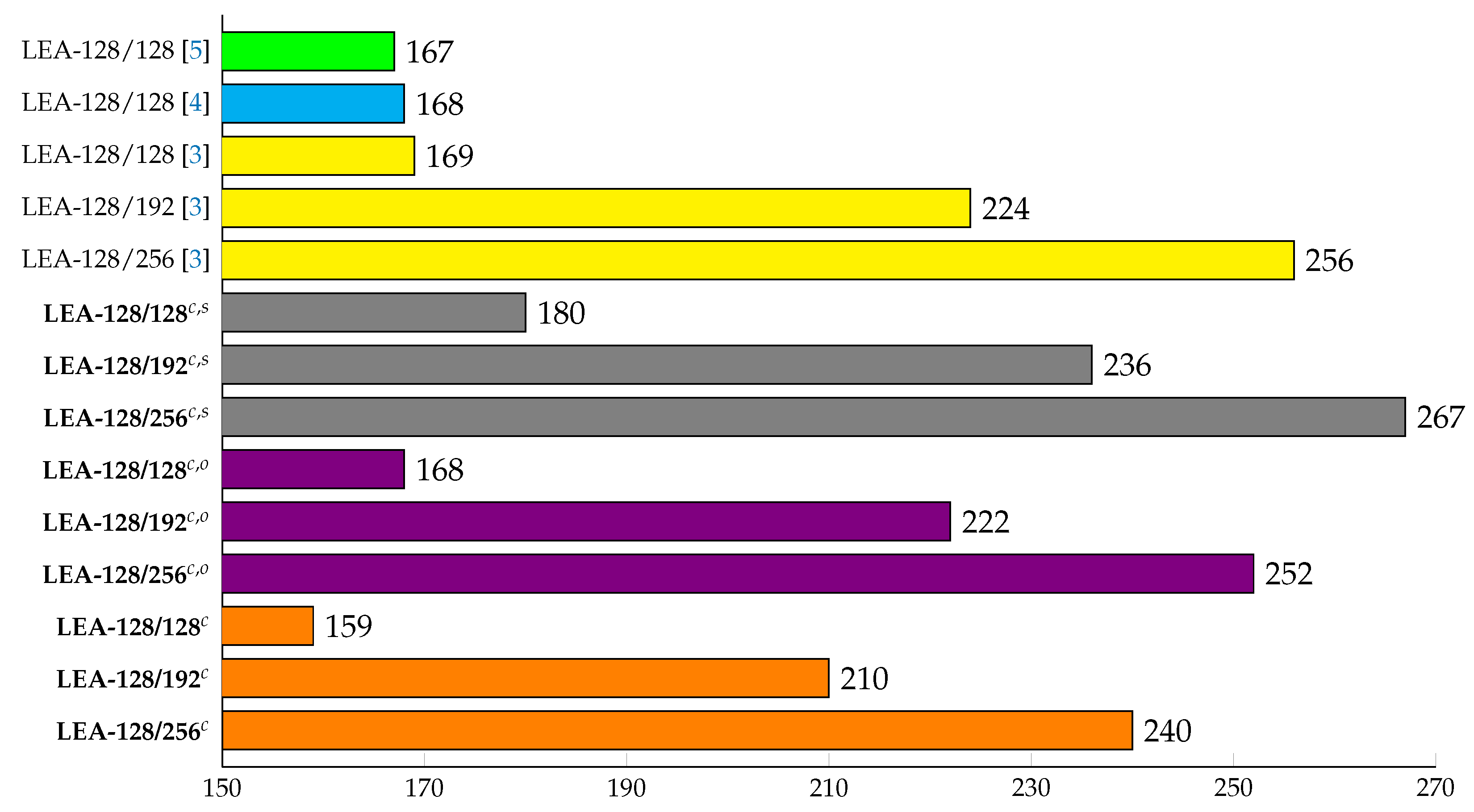{kind=link}
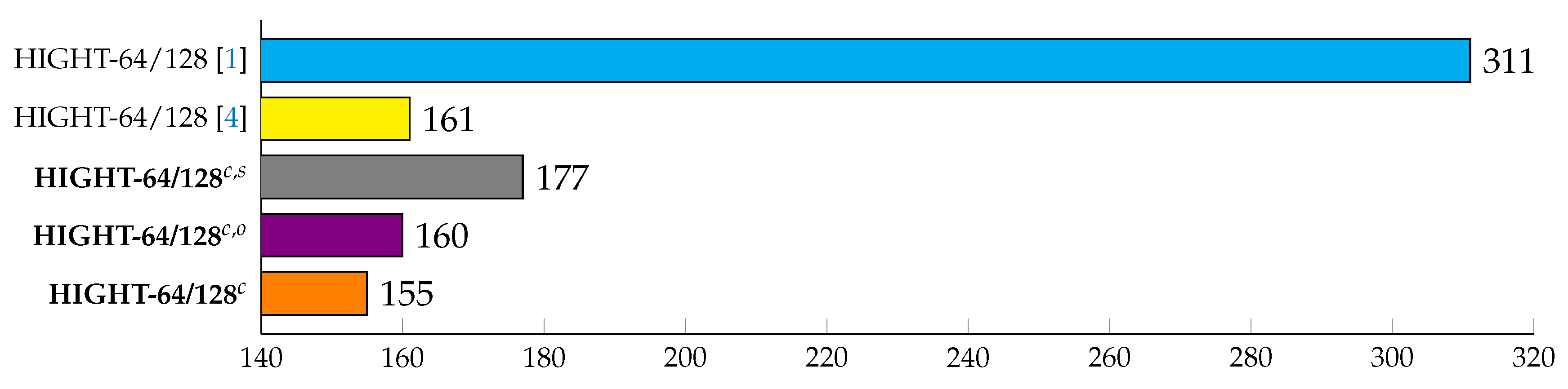{kind=link}
{kind=link}
| Asm | Operands | Description | Operation | cc |
|---|---|---|---|---|
| ADD | Rd, Rr | Add without Carry | Rd ← Rd+Rr | 1 |
| ADC | Rd, Rr | Add with Carry | Rd ← Rd+Rr+C | 1 |
| EOR | Rd, Rr | Exclusive OR | Rd ← Rd⊕Rr | 1 |
| LSL | Rd | Logical Shift Left | C∣Rd ← Rd<<1 | 1 |
| LSR | Rd | Logical Shift Right | Rd∣C ← 1>>Rd | 1 |
| ROL | Rd | Rotate Left Through Carry | C∣Rd ← Rd<<1C | 1 |
| ROR | Rd | Rotate Right Through Carry | Rd∣C ← C1>>Rd | 1 |
| BST | Rd, b | Bit store from Bit in Reg to T Flag | T ← Rd(b) | 1 |
| BLD | Rd, b | Bit load from T Flag to a Bit in Reg | Rd(b) ← T | 1 |
| MOV | Rd, Rr | Copy Register | Rd ← Rr | 1 |
| MOVW | Rd, Rr | Copy Register Word | Rd+1:Rd ← Rr+1:Rr | 1 |
| LDI | Rd, K | Load Immediate | Rd ← K | 1 |
| LD | Rd, X | Load Indirect from | Rd ← (X) | 2 |
| LPM | Rd, Z | Load Program Memory | Rd ← (Z) | 3 |
| ST | Z, Rr | Store Indirect | (Z) ← Rr | 2 |
| Cipher | n | k | rk | r |
|---|---|---|---|---|
| LEA-128/128 | 128 | 128 | 192 | 24 |
| LEA-128/192 | 128 | 192 | 192 | 28 |
| LEA-128/256 | 128 | 256 | 192 | 32 |
| Cipher | n | k | rk | r |
|---|---|---|---|---|
| HIGHT-64/128 | 64 | 128 | 64 | 32 |
| Notation | Descriptions |
|---|---|
| Personalization String | Information for differentiating the instances being created, non-confidential input (optional). |
| Nonce | Input information used to generate a seed during instance Function. |
| Internal State | Information used during CTR_DRBG. It consists of Operational Status and Control Information. |
| Operational Status | Information directly used for random number output. Consisting of C and V, C is the key used for block cipher, and V is the plain text used for block cipher. |
| Control Information | Information consists of security strength, Prediction Resistance flag and Derivation Function flag. |
| Prediction Resistance | Characteristics of the exposure of internal status information of CTR_DRBG without affecting future output. |
| Instantiate Function | Function to create and initialize CTR_DRBG instances as needed. |
| Derivation Function | Function called from an Instantiate Function to generate a seed using entropy input, Nonce and Personalization String. |
| Update Function | Function to update Internal State, using the CTR mode encryption |
| Reseed Function | Function to update Internal State using entropy and additional input. This function is affected by Reseed Counter. |
| Generate Function | Function to generate an output(random number) using Internal State and update Internal State. |
| Extract Function | Function to generate random number sequence, using the CTR mode encryption. |
| Parameters | HIGHT-64/128 | LEA-128/128 | LEA-128/192 | LEA-128/256 |
|---|---|---|---|---|
| Key Bit | 128 | 128 | 192 | 256 |
| Block Bit | 64 | 128 | 128 | 128 |
| Seed Bit | 192 | 256 | 320 | 384 |
| N | 0 × 18 | 0 × 20 | 0 × 30 | 0 × 40 |
| Len_seed | 3 | 2 | 3 | 3 |
| 16-bit ROL1 | 16-bit ROL8 | 32-bit ROL1 | 32-bit ROL8 |
|---|---|---|---|
| LSL LOW ROL HIGH ADC LOW, ZERO | MOV TEMP, LOW MOV LOW, HIGH MOV HIGH, TEMP | LSL R0 ROL R1 ROL R2 ROL R3 ADC R0, ZERO | MOV TEMP, R3 MOV R3, R2 MOV R2, R1 MOV R1, R0 MOV R0, TEMP |
| 3 cycles | 3 cycles | 5 cycles | 5 cycles |
| Block Cipher | LEA-128/128 | LEA-128/192 | LEA-128/256 | HIGHT-64/128 | |
|---|---|---|---|---|---|
| 10.1% | 13.4% | 14.1% | 5.6% | ||
| 51.1% | 69.4% | 72.4% | 40.6% | ||
| 32B | 13.6% | 22.0% | 23.5% | 1.4% | |
| 64B | 16.7% | 25.1% | 26.5% | 1.9% | |
| 128B | 20.2% | 28.7% | 29.9% | 2.4% | |
| 256B | 23.4% | 31.9% | 32.8% | 3.0% | |
| 512B | 25.8% | 34.3% | 35.0% | 3.3% | |
| 1024B | 27.3% | 35.8% | 36.4% | 3.5% | |
| Block Cipher | LEA-128/128 | LEA-128/192 | LEA-128/256 | HIGHT-64/128 | |
|---|---|---|---|---|---|
| Byte | 1024 | 1024 | 1024 | 32 | |
| CTR_DRBG | 26.7% | 36.2% | 37.2% | 8.7% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.; Kwon, H.; An, S.; Seo, H.; Seo, S.C. Efficient Implementation of ARX-Based Block Ciphers on 8-Bit AVR Microcontrollers. Mathematics 2020, 8, 1837. https://doi.org/10.3390/math8101837
Kim Y, Kwon H, An S, Seo H, Seo SC. Efficient Implementation of ARX-Based Block Ciphers on 8-Bit AVR Microcontrollers. Mathematics. 2020; 8(10):1837. https://doi.org/10.3390/math8101837
Chicago/Turabian StyleKim, YoungBeom, Hyeokdong Kwon, SangWoo An, Hwajeong Seo, and Seog Chung Seo. 2020. "Efficient Implementation of ARX-Based Block Ciphers on 8-Bit AVR Microcontrollers" Mathematics 8, no. 10: 1837. https://doi.org/10.3390/math8101837
APA StyleKim, Y., Kwon, H., An, S., Seo, H., & Seo, S. C. (2020). Efficient Implementation of ARX-Based Block Ciphers on 8-Bit AVR Microcontrollers. Mathematics, 8(10), 1837. https://doi.org/10.3390/math8101837