1. Introduction
Many complex networks, which arise from extremely diverse areas of study, surprisingly share a number of common properties. They are sparse, in the sense that the number of edges scales only linearly with the number of nodes, they have small radius, connected nodes tend to have many of their neighbors in common (beyond what would be expected from, for example, random graphs drawn from a distribution with a fixed degree sequence), and their degree sequence has a power law tail, generally with an exponent less than 3 [
1,
2,
3,
4]. One of the major efforts of network science is to devise models which are able to simultaneously capture these common properties.
Many models of complex networks have been proposed which are able to capture some of the common properties above. Perhaps the most well known is the Barabási–Albert model of preferential attachment [
5]. This model is described in terms of a growing network, in which nodes of high degree are more likely to attract connections from newly born nodes. It is effective in capturing the power law degree sequence, but fails to generate graphs in which connected nodes tend to have a large fraction of their neighbors in common (often called ‘strong clustering’). There are growing indications that the strong clustering, the tendency for affiliation of neighbors of connected nodes, is a manifestation of the network having a geometric structure [
6], based upon the notion of a geometric random graph. However, geometric random graphs based upon a flat, Euclidean geometry do not give rise to power law degree distributions. Curved space, on the other hand, in particular the negatively curved space of hyperbolic geometry, does give rise to such heterogeneous distribution of degrees, as shown by Krioukov et al. [
7]. Random geometric graphs in hyperbolic geometry therefore provide extremely promising models for the structure of complex networks. Besides curvature, an arguably even more fundamental aspect of a geometric space is its dimension. After all, a lot more possibilities open when one is attempting to navigate a space of higher dimension. Can random geometric graph models based on higher dimensional geometry account for structures in graphs which so far have eluded description within lower dimensional models?
Recent developments in machine learning for natural language processing suggest that this is likely the case, as higher dimensional hyperbolic geometries prove more effective at link prediction in author collaboration networks than do embeddings into lower dimensional hyperbolic space [
8]. High dimensional hyperbolic embeddings are also proving fruitful in representing taxonomic information within machine generated knowledge bases [
9,
10]. It may be worth noting that, in these machine learning contexts, the hyperbolic geometry generally plays a slightly different role. There one often seeks an isometric embedding of some structured data, such as word proximity graphs in natural language texts, into hyperbolic space of some dimension. In our approach based upon random geometric graphs, we are taking the geometric description more fundamentally, as we seek an embedding which covers the entire space uniformly, rather than covering merely an isometric subset of the space. The idea, ultimately, is to associate data with a dynamical description of geometry, for example, as is done in gravitational physics [
11].
We consider statistical mechanical models of complex networks as introduced in [
12], and, in particular, their application to random geometric graphs in hyperbolic space [
7]. Fountoulakis has computed the asymptotic distribution of the degree of an arbitrary vertex in the hyperbolic model, and shown that it gives rise to a degree sequence which follows a power law [
13]. More generally, it is known that the hyperbolic models are effective in capturing all of the above properties, including the strong clustering behavior which typically evades non-geometric models. Fountoulakis also proves that the degrees of any finite collection of vertices are asymptotically independent, so that in this sense the correlations that one might expect from spatial proximity vanish in the
and
limit. Furthermore, it is possible to assign an effective meaning to the dimensions of the hyperbolic embedding space: the radial dimension can be regarded as a measure of popularity of a network node, while the angular dimension acts as a space in which the similarity of nodes can be represented, such that nearby nodes are similar to each other, while distant nodes are not [
14].
As far as we are aware, to date, all attention on this model has been focused on two -dimensional hyperbolic space. Generalization to higher dimension does appear in an as yet unpublished manuscript [
15], which extends the hyperbolic geometric models to arbitrary dimension, however, explicit proofs regarding the degree distribution are not provided. High dimensional hyperbolic embeddings have also been explored from the machine learning perspective, but not as an explicit model of random geometric graphs as considered here [
8]. It is reasonable to expect that, in order to capture the behavior of real world complex networks, it will be necessary to allow for similarity spaces of larger than one dimension. We therefore construct a model of random geometric graphs in a ball of
, in direct analogy to the
construction of [
7]. In this model, the radial coordinate retains its effective meaning as a measure of the popularity of a node, while the similarity space becomes a full
d-sphere, allowing for a much richer characterization of the interests of a person in a social network, or the role of an entity in some complex organizational structure. We perform a careful asymptotic analysis, yielding precise results which help clarify various aspects of the model.
In particular, we compute the asymptotic degree distribution in five regions of the parameter space, for arbitrary dimension, only one region of which (
and
) was considered in Fountoulakis’ treatment of
[
13]. For
, the angular probability distribution is simply a constant
, while when
it is a dimension-dependent power of the sine of the angular separation between two nodes, so that we cannot expect to straightforwardly generalize the prior results for
to higher dimension. In fact, the angular integrals are tedious and not easy to compute. We use the series expansion to decompose the integrated function, to get a fine infinitesimal estimation of the angular integral, which is the key step to performing the high dimensional analysis.
For
Fountoulakis also computes the correlation of node degrees in the model, and shows that it goes to zero in the asymptotic limit [
13]. We generalize this result to arbitrary dimension, finding that the asymptotic independence of degree requires a steeper fall off for the degree distribution (governed by the parameter
) at larger dimension
d. This dimensional dependence is reasonable, in the sense that, in higher dimensions, there are more directions in which nodes can interact. When computing clustering for the high dimensional model, the non-trivial angular dependence will pose an even greater challenge, since for three nodes there is much less angular symmetry. Hence our present analysis paves the way for future research in high dimensional hyperbolic space.
Our model employs a random mapping of graph nodes to points in a hyperbolic ball, giving these nodes hyperbolic coordinates, and connecting pairs of nodes if they are nearby in the hyperbolic geometry. Based upon their close relationship with hyperbolic geometry, we might assume that they are therefore intrinsically hyperbolic, in the sense of Gromov’s notion of
-hyperbolicity. This may be an important question, in that it would connect to a number of important results on hyperbolicity of graphs [
16], and may cast an important light on the relevance of these hyperbolic geometric models to real world networks [
17]. We do not expect our model to generate
-hyperbolic networks for the entire range of the parameter space of our model because, for example, one can effectively send the curvature to zero by choosing
(with
). However, we would expect it to be the case when the effect of curvature is large, such as when
R grows rapidly with respect to
N. We do not know for certain whether the particular ranges of parameters that we explore in this paper generate
-hyperbolic graphs for
, almost surely, but imagine it likely to be the case.
1.1. Model Introduction
We consider a class of exponential random graph models, which are Gibbs (or Boltzmann) distributions on random labeled graphs. [
12,
18] These models define a probability distribution on graphs which is defined in terms of a Hamiltonian ‘energy functional’, for which the probability of a graph
G is
.
T is a ‘temperature’, which controls the relevance of the Hamiltonian
, and
is a normalizing factor, often called the ‘partition function’. Note that the probability distribution becomes uniform in the limit
. The Hamiltonian, which encodes the ‘energy’ of the graph, consists of a sum of ‘observables’, each multiplied by a corresponding Lagrange multiplier, which controls the relevance of that observables’ value in the probability of a given graph. We begin with the most general model for which the probability of each edge is independent, wherein each probability is governed by its own Lagrange multiplier
. Thus, our Hamiltonian is
, where
if
u and
v are connected by an edge in
G, and 0 otherwise. The partition function
, and the therefore the probability of occurrence of an edge between vertices
u and
v is
Following [
7], we embed each of
N nodes into a hyperbolic ball of finite radius
R in
, and set the ‘link energies’
to be based on the distances
between the embedded locations of the vertices
u and
v, through here we allow all integer values of
. In particular, we set
where
is a connectivity distance threshold. Note that each pair of vertices for which
contribute negatively to the ‘total energy’ whenever a link between them is present, so that the ‘ground state’ (minimum energy, highest probability) graph will have links between every pair of vertices
for which
, and no links with
. Note that in the limit as
, the probability of the ground state graph goes to 1, and that of every other graph vanishes. Thus
In a real world network, we may expect the largest node degree to be comparable with
N itself, and the lowest degree nodes to have degree of order 1. To maintain this behavior, following [
7], we restrict attention to the submanifold of models for which
(If
then
, the expected degree of the origin node, satisfies
if
then
from (
10); if
then
.) Thus
Additionally, for ease of comparison with numerous results in the literature, and to keep track of ‘distance units’, we follow [
7] in retaining the parameter
which governs the curvature
of the hyperbolic geometry, even though modifying it adds nothing to the space of models which cannot be achieved through a tuning of
R. (Changing
has the sole effect of scaling all radial coordinates, which can equivalently be achieved by scaling
R.)
We will use spherical coordinates on
, so that each point
x has coordinates
, with the usual coordinates
on
, with
,
for
, and
. In these coordinates the distance
between two points
and
is given by the hyperbolic law of cosines
where
is the angular distance between
and
on
. In these coordinates the uniform probability density function, from the volume element in
, factorizes into a product of functions of the separate radial and spherical coordinates
With the usual spherical coordinates on
, the uniform distribution arises from
, with
for
and
. In place of a uniform distribution of points, we use a spherically symmetric distribution whose radial coordinates are sampled from the probability density
where
is a real parameter which controls the radial density profile, and the normalizing factor
. Note that
corresponds to a uniform density with respect to the hyperbolic geometry. Thus, when
, the nodes are more likely to lie at large radius than they would with a uniform embedding in hyperbolic space, and when
they are more likely to lie nearer the origin than in hyperbolic geometry. We will see later that the degree of a node diminishes exponentially with its distance from the origin, and that with larger values of
the model tends to produce networks with a degree distribution which falls off more rapidly at large degree, while with smaller
it produces networks whose degree distribution possesses a ‘fatter tail’ at large degree.
We would like to compute the expected degree sequence of the model, in a limit with and as . The model is label independent, meaning that, before embedding the vertices into , each vertex is equivalent. To determine the expected degree sequence, it is therefore sufficient to compute the degree distribution of a single vertex, as a function of its embedding coordinates, and then integrate over the hyperbolic ball.
Given that each of the other
vertices are randomly distributed in
according to the probability density (
3), the expected degree of
u will be equal to the connection probability
, integrated over
, for each of the other
vertices. Thus,
Since the geometry is independent of angular position, without loss of generality, we can assume our vertex
u is embedded at the ‘north pole’
, so the relative angle
between
u and any other embedding vertex
v is just the angle
of
v. (The full hyperbolic geometry is of course completely homogeneous, and thus independent of the radial coordinate as well; however, the presence of the boundary at
breaks the radial homogeneity.) Thus,
where
are the radial coordinates of the vertices
;
is the angle between them in the
direction, and
, with
To simplify the notation below, we use
in place of
.
In the case of
, we have
and
1.2. Main Results
Let be the vertex set of a random graph G with N vertices, whose elements are randomly distributed with a radially dependent density into a ball of radius R in , . Let denote the degree of the vertex u. Throughout as , unless otherwise indicated.
The main results of this paper are as follows:
Theorem 1. Let and , and k be a non-negative integer, thenwhere , the parameter (introduced in Section 2), is defined by (A3), and is defined by (5). Here, as . Theorem 2. Let and , and k be a non-negative integer, thenwhere , , and are defined by (A5). Here, as . Theorem 3. Let , and , for dimension d, for any integer and for any collection of m pairwise distinct vertices , , their degrees are asymptotically independent in the sense that, for any non-negative integers , The paper is organized as follows. In
Section 1.1 above, we introduce the model. Specifically, we explain the exponential random graph model in hyperbolic space, explain the roles of the parameters, and provide some basic formulas for mean degree. In
Section 1.2 above, we state three main theorems. Theorems 1 and 2 state that the probability of degree taking value
k for any node, in the limit of large
N, takes the form of a power law. Theorem 4 states that the probability of several nodes taking respective
k values is asymptotically independent as the number of nodes is growing. In
Section 2, we provide some useful preliminary results; in particular, we give an explicit approximation of the hyperbolic distance formula for two points on some conditions, which is superior to previous such expressions. In
Section 3, we compute the angular integral, which is the key obstacle that we need to overcome to extend the model to high dimensional hyperbolic space. We use analytic expansion to perform a fine infinitesimal estimation for the angular integral, which could not be done on a computer. We put these computations in
Appendix A. Our main proof processes lie in
Section 4,
Section 5,
Section 6 and
Section 7. We compute the expected degree of a given vertex as a function of radial coordinate, the mean degree of the network, and the asymptotic distribution of degree for the cases
,
, and
, respectively, in
Section 4,
Section 5 and
Section 6. The proof of Theorem 1 lies in
Section 4.1 and the proof of Theorem 2 lies in
Section 6.1. In
Section 7, we analyze the asymptotic correlations of degree for
and finally prove Theorem 4.
1.3. Simulations
The
Cactus High Performance Computing Framework [
19] defines a new paradigm in scientific computing, by defining software in terms of abstract APIs, which allows scientists to construct interoperable modules without having to know the details of function argument specifications from these modules at the outset. One can write
toolkits within the framework, which are collections of modules which perform computations in some scientific domain. For the simulation results shown in this paper, we have used a
ComplexNetworks toolkit within Cactus, which we hope to be available soon under a freely available open source license.
The
ComplexNetworks toolkit is an extension of the
CausalSets toolkit [
20] which allows many computations involving complex networks to be easily run on distributed memory supercomputers, though the simulations we perform here are small enough to fit on a single 12 core Xeon workstation. The model is implemented by a module which allows direct control of a number of parameters, including
,
, and
T,
of (
1), and
N.
3. Angular Integral
The conditional probability
that a node
u at fixed radial coordinate
connects to a node
v at fixed radius
is the connection probability (
2) integrated over their possible relative angular separations
:
We call this the angular integral, and, to simplify the notation, we will rescale variables as follows:
and set
so from Lemma 2, if
and
, then
with
so
Claim 1. If , then .
Proof. For , so we get □
Now, we set
which means
as
, where
Thus, for
, we divide the integral (
16) as follows:
We begin from the first part of the integral
The second part of the integral
Notice the estimation
in
Appendix A, for the integral
Setting
, and taking account of (
18), we have
for
,
since
,
Finally, we get the angular integral estimation:
Lemma 3. assuming . 7. Asymptotic Correlations of Degree
We extend Theorem 4.1 of [
13], governing the independence of degrees of vertices at separate angular positions in a hyperbolic ball in
, to arbitrary dimension
.
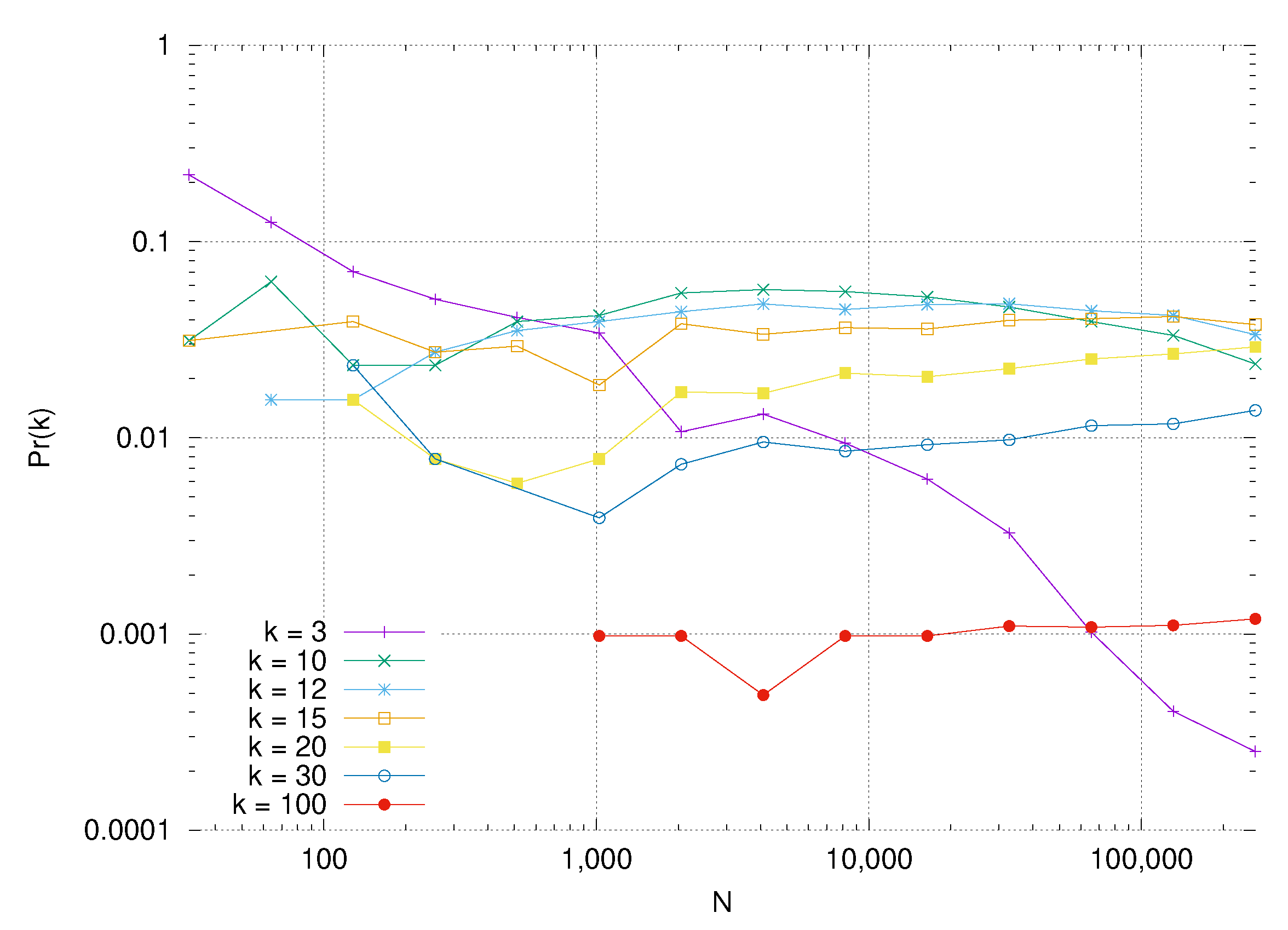
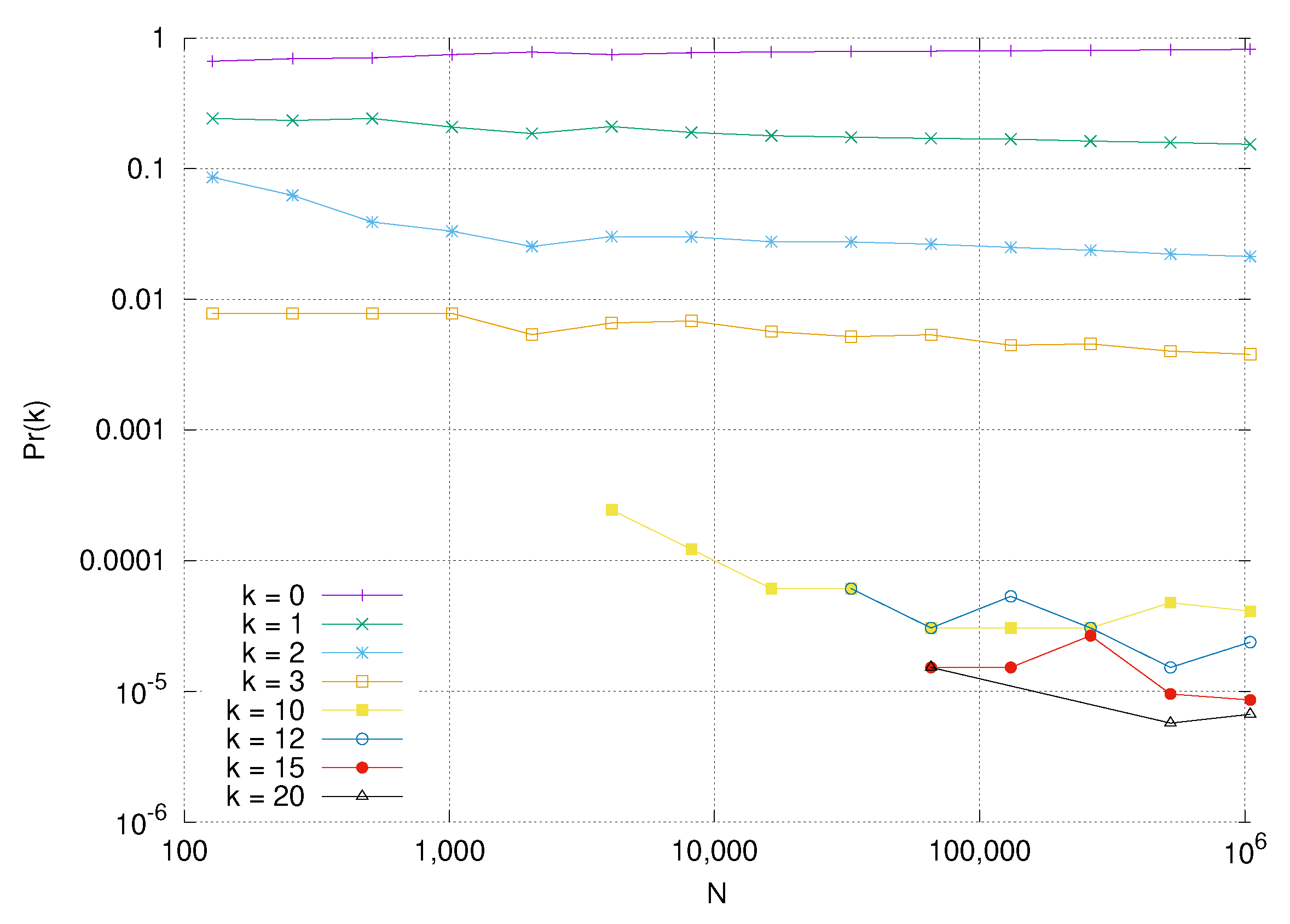
Theorem 4. If , and for dimension d, and any fixed integer , and for any collection of m pairwise distinct vertices , , their degrees are asymptotically independent in the sense that, for any non-negative integers , , It is important to note that m is constant while , so the collection of m vertices of Theorem 4 forms a vanishingly small fraction of all vertices. Furthermore, since each of these m vertices has a finite degree, each of their neighbors will almost surely not be found among the other m vertices.
For the purposes of this section, we choose and .
Definition 1. For a vertex , define to be the set of points where is the angle between the points v and w in , and . is called the vital region in [13] (Note that might not be a topological neighborhood for the vertex v because v might lie outside of its vital region). ( is defined at the end of Section 2.1, and at the beginning of Section 3.) Similarly, we write to indicate that the embedded location of vertex u lies in the vital region . We will prove that the vital regions , are mutually disjoint with high probability. Let be this event, i.e., that
Claim 5. Let be fixed. Then, .
Proof. Assume
. For any point
the parameter
is maximized when
, so let
be this maximum, that is
Thus, for
and
, we have
if
The probability for this to occur is bounded as the following equation, for sufficiently large
N. Making use of the angular symmetry, we have
Additionally, for a vertex
v, we have from (
7) and (
8)
Since
, and we may choose
small enough to satisfy
then
so
. □
Definition 2. Define by the event that , . For a given vertex , define by the event that w is connected to and . Define by the event that the vertex w is outside of but is connected to . Furthermore, define as the event that vertices satisfy the event , i.e., are vertices connected to vertex and lying within its vital region, for , whereas all other vertices do not. In addition, lastly, let . Thus, is the event that at least one of the vertices has a neighbor outside of its vital region.
Note that, from Corollary 1, . Assuming , if is not realized, then the event that vertex has degree , for all , is realized if and only if is realized.
Lemma 4. For any and we have
We first calculate the probability of event that the vertex is located in and is linked to . Notice that does not depend directly on , but only the angle between and w, and furthermore the volume element in is rotationally invariant, so, when averaging over the position of w, is independent of . Thus, by the angular symmetry, we have the below lemma.
Lemma 5. For and ,uniformly for . Proof. Set
. We have
Firstly, we estimate the second part. Assuming
, and making use of (
21), we have
For the first part,
where
for
from (
17). The above estimation is because
and
where
Thus, similar to the calculation process for the degree of a vertex with
and
we have
assuming
Finally we get
uniformly for
when
and
. □
Comment: For and , we found . This is important because we can see that, for the vertex w,
so we can expect that the vertex w has a very small relative angle with , and lies only in , and not in any other vital regions , , . Thus, we expect that the events are asymptotically independent. For and , we cannot get the above analysis, so the same result may not hold in that case.
Lemma 6. Let and . For fixed , are vertices in , and are integers; then,
Proof. The proof is lengthy so we put it in
Appendix C. □
Finally, together with (
46), we get Theorem 4, i.e., for
and
, then
8. Summary and Conclusions
Models of complex networks based upon hyperbolic geometry are proving to be effective in their ability to capture many important characteristics of real world complex networks, including a power law degree distribution and strong clustering. As explicated in Ref. [
14], the radial dimension can be regarded as a measure of popularity of a network node, while the angular dimension provides a space to summarize internal characteristics of a network node. Prior to this work, all hyperbolic models that have been considered to date have been two-dimensional, thus allowing only a one-dimensional representation of these internal characteristics. However, it is reasonable to expect that, in order to capture the behavior of real world complex networks, one must allow for similarity spaces of larger than one dimension. One place to see this need is in networks embedded in space, such as transportation at intracity and intercity scales, or galaxies arranged in clusters and superclusters, each of which naturally live in two or three dimensions, respectively. However, the greater need may in fact be in information-based networks, such as those which represent how data are organized, for example in the realm of natural language processing. See, for example, the following references: [
8,
10,
22,
23,
24,
25]. We thus have generalized the hyperbolic model to allow for arbitrarily large dimensional similarity spaces.
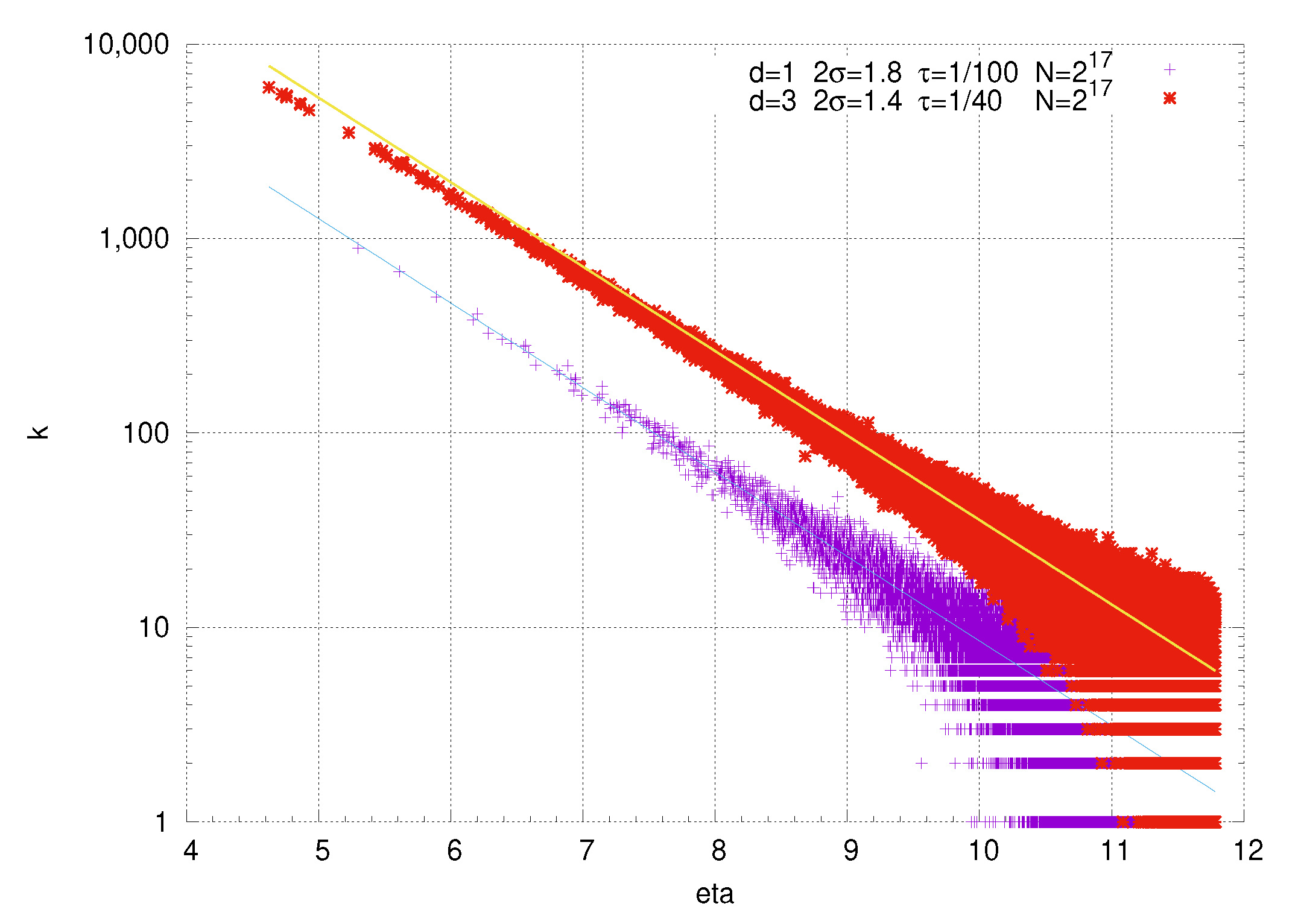
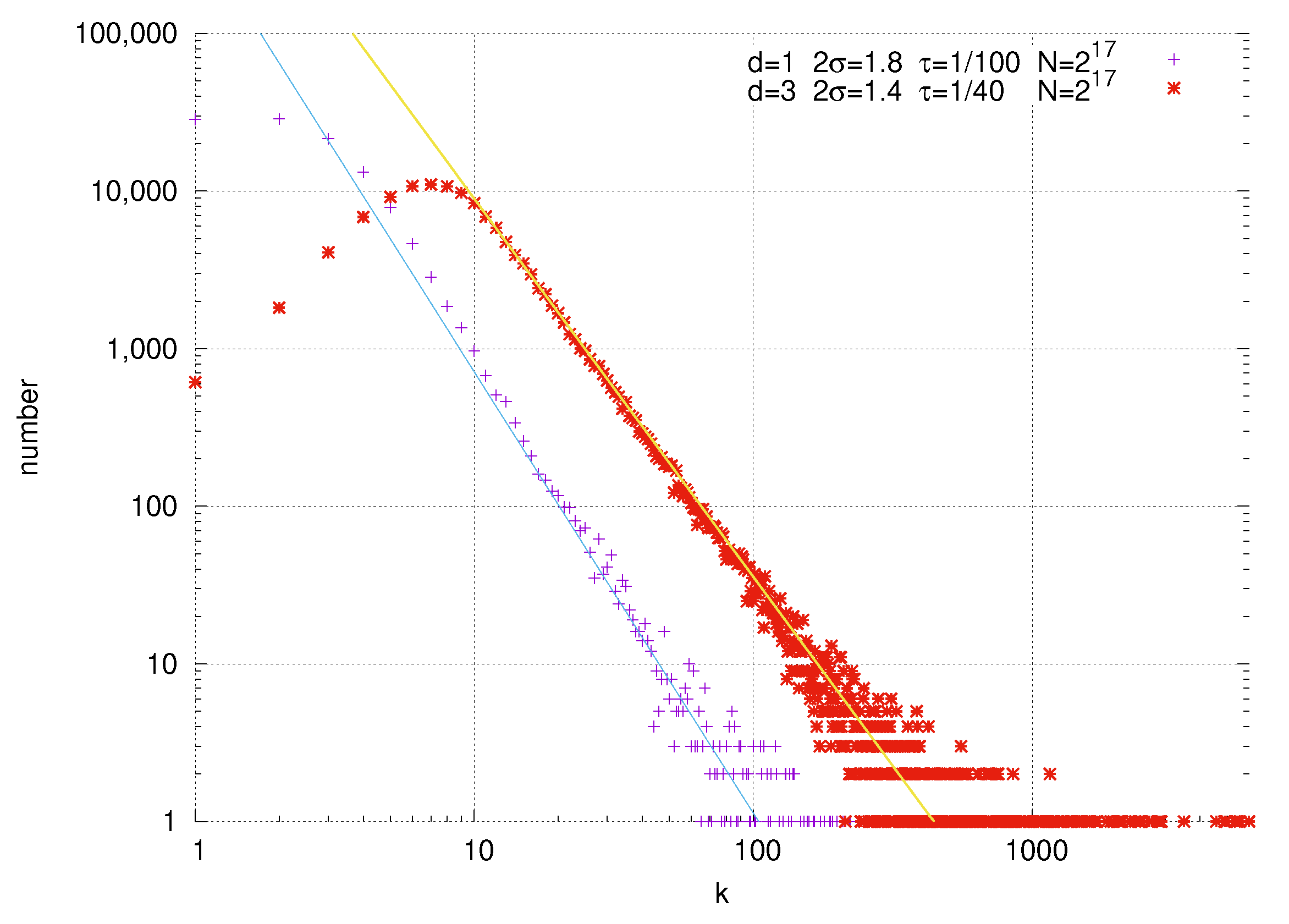
Specifically, we have computed the exact asymptotic degree distribution for a generalization of hyperbolic geometric random graphs in arbitrary dimensional hyperbolic space. We considered five regions of the parameter space, as depicted in
Figure 5: one for temperature
and
, another at
and
, a third at a critical temperature
and
, and last two at high temperature regimes with
: one with
, and a second with
. For two of the regions, we found a power law expected degree distribution whose exponent is governed by the parameter
, which controls the radial concentration of nodes in the geometric embedding. When
, we find that the degree distribution degenerates, such that only zero degree nodes have non-vanishing probability, i.e., almost every node is disconnected from the rest of the network. For the remaining two regions, with
or
, we find that the degree distribution ‘runs off to infinity’, such that the probability of any node having finite degree goes to zero in the asymptotic limit.
We have also proved a generalization of Fountoulakis’s theorem governing correlations in degree to arbitrary dimension, and discovered a non-trivial dependence on the dimension and the exponent of the power law in these correlations.
It is important to be able to model somewhat denser complex networks with ‘fat tailed’ degree distributions, for example those whose degree sequence is still a power law , but with . We have made an important first step in this direction, by exploring three parameter regimes with . One of them manifests a power law degree distribution, at , while, for the two others, the degree distribution ‘runs off to infinity’, which is not necessarily unexpected in the context of a fat tailed distribution. It would be instructive to understand this denser regime of complex networks in more detail, and provide models which can help predict the behavior of these networks.
Another significant step is to explore the clustering behavior of these higher dimensional models. Krioukov has shown that clustering can be an important herald of geometric structure of networks, and is common in real-world complex networks. [
6] Does the clustering behavior of the two-dimensional hyperbolic models generalize to arbitrary dimension?
One can also study more carefully the effect of the constraints we impose on the growth of
R with
N, such as the choice
. Might some other characterization of the ball radius as a function of network size be more effective, in a wider region of the parameter space? We have already seen hints to this effect in
Section 5 and
Section 6.
Another important step is to extend the model to allow for bipartite networks, by assigning to each node one of two possible ‘types’, and allowing only nodes of different types to connect. This would generalize the approach of [
26] to arbitrary dimensional hyperbolic space.
Of course, it is arguably of greatest interest to apply the model to real world networks, by embedding such networks into higher dimensional hyperbolic space. To do so, one would need to estimate the model parameters which are most closely associated with a given network. The ideal process for doing so is Bayesian parameter estimation; however, there are a number of techniques, such as measuring the network’s degree sequence, which can serve as efficient proxies in place a full Bayesian statistical analysis. Some steps in this direction for a somewhat similar (
) model, along with some initial results for link prediction and soft community detection, are given in [
27]. It will be of great interest to see if these higher dimensional models provide more effective predictions for many real world networks, such as the information-based networks mentioned above, or social or biological networks, where we may expect that a one-dimensional similarity space lacks the depth and sophistication necessary to effectively represent the behavior of these complicated entities.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




