Abstract
This work is devoted to the study of the parameter test for the Generalized Autoregressive Conditional Heteroskedasticity (GARCH) model. Based on the daily GARCH model, using the parameter estimator obtained by intraday high-frequency data, the adjusted Likelihood Ratio test statistic and Wald test statistic are provided. Asymptotic distributions of the two adjusted test statistics are deducted and a way to select the optimal sampling frequency is also discussed. Simulation studies show that the proposed test statistics have better size and power than traditional ones (without using intraday high-frequency data). An empirical study is given to illustrate the potential applications of the proposed tests. The results show the idea of this article is of certain superiority and it can be extended to other GARCH type models.
1. Introduction
Volatility modeling is an important tool for policymaking, asset pricing, investment analysis, and risk management [1]. Since the seminal work by Engle [2] and Bollerslev [3], the Generalized Autoregressive Conditional Heteroskedasticity (GARCH) model has become a popular tool to model volatility in economic and financial time series. During the past decades, the model has been developed into many extensions [4,5,6,7,8,9,10,11,12,13]. From these literature, we can find that most studies on the GARCH model adopt the standard form based on daily close-to-close returns. Let be the log-return of day n, the standard GARCH(1,1) model [3] can be formulated as:
where the sequence of innovations is an i.i.d. with zero mean and unit variance, and the scale factors are the conditional variance of for given information at time , , , and are the model parameters with assumption of , , , and . A common approach to estimate the above model parameters is the Quasi Maximum Likelihood Estimate (QMLE), see [14] for a comprehensive review. Many empirical studies have proven that then GARCH model is particularly suitable for the modeling of financial time series because it can describe well the characteristics of financial time series, namely the time variability of variance and the ability to deal with thick tails, refer to [14] and references therein.
In recent years, high-frequency data of the financial market has become more accessible than before. Intraday high-frequency data, as a kind of financial big data, records the trading data with the sampling frequency of hours, minutes, or seconds within a day and is sampled at equal time intervals. Such data possesses a particular characteristic of high degree irregularity [1]. Research on high-frequency financial data can be dated back to, at least, the 1980s and the mainstream is about the realized volatility or intraday volatility. For example, Wood et al. [15] and Harris [16] found the existence of a distinct U-shaped pattern for the intraday return volatility curve. For other studies, one can refer to [17,18,19,20,21,22,23].
Intraday high-frequency data contain more information and it is straightforward to introduce these data to study GARCH-type models. Unfortunately, Andersen and Bollerslev’s studies show that the GARCH model is inappropriate to directly fit the intraday high-frequency data due to its nonstationarity [24,25]. Namely, although one can estimate the parameters of a GARCH process using a 5 min time unit intraday high-frequency returns while the modeling does not make any sense. Consequently, indirect utilization of intraday high-frequency data could be more practical in studying GARCH model estimation. A case in point is Visser’s work [26], where the information of intraday high-frequency data is firstly transferred to a daily volatility proxy and such a proxy is then adopted to improve daily GARCH model estimation. Further extensions can be referred to [26,27,28,29,30,31,32].
As we all know, in addition to estimation, model test is another important issue in practical modeling. For GARCH model testing, many results have been obtained, see [33,34,35,36,37,38,39]. However, all the available results on the GARCH model test is limited to low-frequency data. To the best of our knowledge, few of them have introduced intraday high frequency data into a daily GARCH model test. Previous studies have shown that high-frequency data can be used to improve daily GARCH mode estimation. A natural question is whether the intraday high-frequency data could also be used to improve the power of daily GARCH model test. Inspired by this, this paper is to study the Wald test and Likelihood Ratio (LR) test of the daily GARCH model by introduction high-frequency data.
The main contribution of this paper is the construction of a new test approach for daily GARCH model with the adoption of intraday high-frequency data. The proposed test statistics are based on the QMLE of daily GARCH model which introduces the intraday high-frequency data, and their distribution are proved to be asymptotic chi-square. It can be found that the proposed test statistics have better size and power performance than traditional ones (without using high-frequency data). Through the theoretical and simulation results, the provided tests are of a certain novelty and superiority.
2. The Test of GARCH Model
2.1. The Daily GARCH Model
Under regularity conditions of the GARCH model, we have:
Define the QMLE as:
Under some regularity conditions, the QMLE is consistent and asymptotically normal, see Theorems 2.1 and 2.2 in [8].
2.2. The Test of the GARCH Model
We consider the following null and alternative hypothesis:
Let be the QMLE of GARCH models (3) and (4) under the alternative and be the hypothesized value. Generally, the Wald test is based upon the difference between and , and the LR test is based upon the difference between and . Although the statistics of the two tests differ in construction, they are all reasonable measures of the distance between and .
2.2.1. The Wald Test
It is well known that the construction of the Wald test statistic depends on the asymptotic distribution of the parameter estimator. Suppose that the conditions (A1) to (A5) and the QML regularity conditions in Appendix A hold, then the QMLE of GARCH models (3) and (4) has a limiting normal distribution:
where with , see [8,40].
From Formula (7), we have:
Sequentially, it is not difficult to obtain the following asymptotic distribution:
Denote . Define:
then can be estimated by the followed :
Let,
By Theorem 2.7 in [40], we have , where . Since (see [8]), we can obtain . Furthermore, we get . Likewise, we have . Thus, we obtain the convergence result .
From the above discussion, we have . That is to say, can be consistently estimated by . Therefore, the Wald test statistic can be constructed as follows:
where with . Under the null hypothesis, the statistic has a limiting distribution, where ”3” is the dimension of parameter .
2.2.2. The LR Test
The LR test statistic is a constructed base on the difference between the maximum of the likelihood under the null and alternative hypotheses. According to the test procedure in [41], under general conditions, the LR test statistic of GARCH models (3) and (4) can be established by:
By Taylor’s expansion as well as stationary and ergodic properties of time series [40], we can prove the below theorem which shows that the Wald test and LR test of the GARCH model are equivalent.
Theorem 1.
With the assumptions of (A1)–(A5), as well as QML regularity conditions in Appendix A, both the statistics , of the GARCH model are distribution, with k being the number of the unknown parameter, under the null, and are asymptotically equivalent.
The detail proofs are relegated to Appendix B.
3. The Test of GARCH Model with High-Frequency Data
Previous studies have shown that high-frequency data can be adopted to improve the estimation accuracy of GARCH-type models, see [21,26]. An intuitive idea is if we replace the in (12) and (13) by a more precise estimator with the expectation that the test statistics would have a better performance. Therefore, in this section, we firstly give a short introduction about GARCH model parameter estimation with high-frequency data based on (3) and (4).
3.1. A Brief Review of GARCH Model Estimation Using High-Frequency Data
To utilize high-frequency data in the daily GARCH models (3) and (4), for each trading day n, Visser introduced a continuous log-return process to describe the intraday price movements [26]. To simplify the notation, we normalize the trading day to the unit time interval and adjust Equation (3) by replacing the variable by a process . This yields the following scale model framework:
where is the scale factor and it is latent. The processes are observable with information set generated by . For different day n, the standard processes are assumed to be i.i.d and its sample paths are right-continuous and have left limits(cadlag). When , we have , and:
where the sequence of random variables is i.i.d implied by the i.i.d assumption of . It is seen that models (14) and (15) takes the intraday information into account and keeps the same parameter to the daily GARCH models (3) and (4). To further estimate the parameters in (14) and (15), we need to use the intraday information to construct a volatility proxy, denoted by . The volatility proxy is a nonnegative function of intraday processes and has the property of positive homogeneity:
One commonly used volatility proxy is the square root of the realized variance:
where denotes the return over the k-th intraday interval of day n. Due to the positive homogeneity of , it follows . Then we can derive the following volatility proxy model:
where . It is seen that the models (18) and (19) retain the structural features of the daily GARCH model. The is computable and has the same frequency to daily return . We further introduce an ancillary random variables as follows:
where the random variables is independent of the models (18) and (19) and it only takes values , with a probability of 0.5 for either value. Then, we get:
Denote to be the quasi log-likelihood function of random variables . We have:
Denote . Define to be the QMLE of the models (18) and (19), which is obtained from the following optimization:
Similar to the daily GARCH models (3) and (4), under some regularity conditions, the QMLE of the models (18) and (19) is consistent and asymptotically normal:
where with , and depends only on the derivatives of with respect to , see Theorem 2.1 in [26]. Consequently, as mentioned by [26], if certain volatility proxy has the small value of , then the corresponding estimator will have small asymptotic variance and hence will be more precise.
Unfortunately, for the QMLE in (22), no detailed procedure is given to choose the optimal volatility proxy . To make the estimator more applicable, in this paper, we provide a way to choose the optimal volatility proxy and it can be applied to choose the sampling frequency of intraday high-frequency data.
Let . Then , . It follows that:
Note that: and is independent of . Hence we obtain:
By dividing two sides of the above two equations, we can get:
where is a constant. Define:
Then it is not difficult to have:
Consequently, in practice, we can choose the optimal proxy according to its value , which can easily be estimated by the related sample means. For a given volatility proxy , its calculation depends on the sampling frequency of intraday data. The above criteria gives a way to choose the optimal sampling frequency according to the smallest value of .
3.2. The Test of GARCH Model Using High-Frequency Data
In this section, we are going to introduce the intraday high-frequency data into the test statistics in (12) and (13) by replacing with . Related theoretical results will be discussed.
3.2.1. The Wald Test
After is replaced by in Formula (12), we denote the new statistic by :
where ,
Since the convergence of is obvious (see [26]), the key point is to prove the asymptotic convergence of . Note that , , so we have . Similar to the proof of asymptotic convergence for , see Formula (10). It is not difficult to get . Thus we can still have follows distribution.
3.2.2. The LR Test
Likewise, the estimator will be replaced by in Formula (13), and the new statistic will be denoted by :
According to the following theorem, the LR test is equivalent to the Wald test , and hence has a limiting distribution.
Theorem 2.
With the assumptions of (A1–A5), as well as QML regularity conditions in Appendix A, both the Wald test and LR test statistics , are asymptotically distributed as with k being the number of unknown parameter, under the null, and they are equivalent.
The detail proofs are also relegated to Appendix B.
4. Simulation Study
In this section, we carry out Monte Carlo experiments to assess the finite-sample performance of the test statistics , , , and . In these experiments, all the size and power results are calculated based on 1000 independent replications.
The calculation of statistics and is straightforward, because it just relies on the daily GARCH models (3) and (4). While the computation of and are based on the estimator using high-frequency data. Note that when the volatility proxy is set to be , namely the absolute daily return, then and are reduced to and . Following [26], throughout the simulation, the parameter involved in the model (3), (4), (18), and (19) is fixed to 1.
In this part, we consider realized volatility as the volatility proxies in models (18) and (19):
which is the square root of realized variance. To generate the realized volatility in each trading day n, we have to simulate a specific intraday process at equidistant points in . For simplicity, we follow Visser’s work and generate the intraday price process with the stationary Ornstein–Uhlenbeck process, see [26,42]. The considered satisfies the below stochastic differential equations:
where , , , the Brownian motions and are uncorrelated, and , can be sampled from its stationary distribution. Furthermore, the intraday log-return processes are generated based on , where , .
To estimate models (18) and (19), we consider the volatility proxies of three frequencies, namely 1 min , 5 min , and 10 min . For 1-min proxy , the formula is given by:
The 5-min and 10-min volatility proxy can be computed similarly.
Given a significance level and taking the sample size , 1000, 1200, 1500, and 2000, we calculate the empirical sizes with null hypothesis parameter . For the power, we first fix parameter and compute the power by changing the value of parameter . Then, we fix parameter and change parameter to observe the change of the power.
The sizes and powers of the Ward test and LR test calculated by and are reported in Table 1, Table 2 and Table 3. Figure 1 charts the trend of the power in Table 2, Figure 2 charts the trend of the power in Table 3.

Table 1.
The size of the adjusted statistics , and the traditional statistics , .
Table 2.
The power of the adjusted statistics , and the traditional statistics , .
Table 3.
The power of the adjusted statistics , and the traditional statistics , .
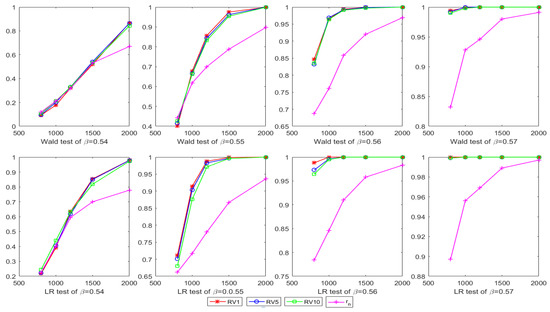
Figure 1.
The power of the Wald test and Likelihood Ratio (LR) test based on changing the value of and fixing .
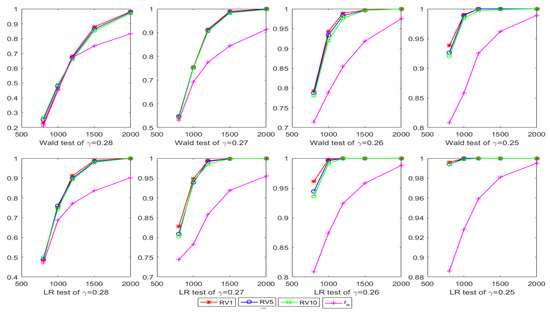
Figure 2.
The power of the Wald test and LR test based on changing the value of and fixing .
It can be seen that the empirical sizes of the Ward test and LR test calculated by are uniformly closer to the nominal size than those calculated by in this experiment. For the power, although the results of the Ward test and LR test calculated by do not show their superiority at a low sample size, but with the increase of the sample size, the superiority is more significant. These results indicate that using high-frequency data can significantly improve the test performance for the GARCH model.
5. Empirical Study
In this section, we apply the proposed tests to analyze the CSI 300 index with a sampling frequency of 1 min. The data set covers from 15 March 2017 to 29 May 2020 (796 days, 241 observations in each day), containing 191,836 pieces of data. For each trading day n, we compute the intraday log-return process as follows:
where , is the n-th intraday price sequence.
In practice, it is of much interest to know whether the GARCH effect exists. Hence in this empirical study, we consider the following test problem:
Similar to the simulation study, the realized volatility is chosen as the volatility proxy. They is a 1-min proxy , 5-min proxy , and 10-min proxy respectively. The parameter is also fixed to 1.
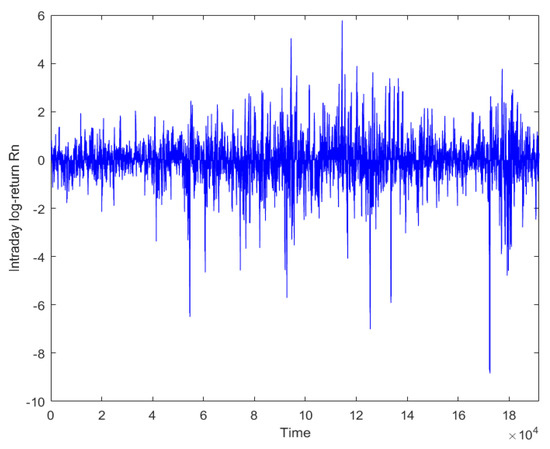
Figure 3.
Time series plot of 1 min intraday return processes .
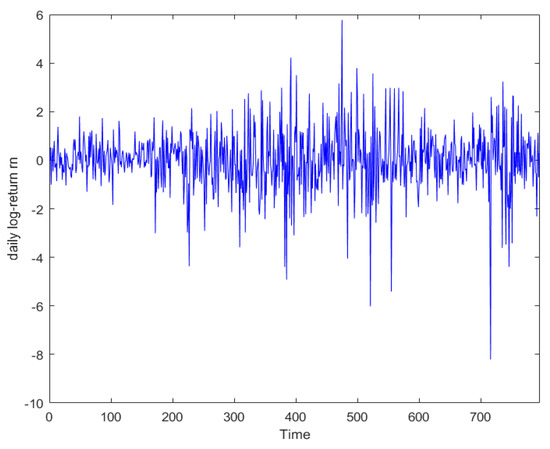
Figure 4.
Time series plot of daily log-return .
The Ward test and LR test statistics calculated by and are reported in Table 4. Given a nominal significance level 5%, the critical value is . We can see from Table 4 that both of the two test statistics of four kinds of estimators are significant. In addition, the Wald test and LR test statistics computed by are more larger than that computed by . This indicates that the GARCH model is suitable for the data studied in this paper.
Table 4.
Results of two tests for four kinds of Generalized Autoregressive Conditional Heteroskedasticity (GARCH) model.
6. Conclusions
In this article, we focused on the test of the daily GARCH model by taking intraday high-frequency data into account. Based on the daily GARCH model estimation using intraday high-frequency data, the adjusted Wald test and LR test for daily GARCH model are provided. Under some regularity conditions, the two considered test statistics were shown to be asymptotically equivalent and the limiting distribution was distribution, with k being the number of unknown parameter. Simulation and empirical studies implied that the proposed test statistics had better size and power performance than traditional ones (without using high-frequency data). Consequently, the considered tests were of a certain novelty and superiority.
For the traditional daily GARCH model test, we could also use the Lagrange multiplier test. But for the adjusted test statistics proposed in this paper, Lagrange multiplier method was not applicable. This is because the Lagrange Multiplier test only uses the parameter estimator of the null hypothesis [41], while our adjusted test required the parameter values of both the null and alternative hypothesis. Hence, the Lagrange Multiplier test was not applicable in our study.
The idea of this paper can easily be extended to study the test of other GARCH type models, such as the GJR-GARCH model, threshold GARCH model, and periodic GARCH model. Moreover, one can also apply the idea to the nonstationary GARCH models and heavy tailed GARCH models.
Author Contributions
Conceptualization, Y.L.; formal analysis, C.D. and X.Z.; methodology, X.Z.; project administration, Y.L. and X.Z.; resources, C.D. and Y.L.; software, C.D.; supervision, X.Z.; validation, Y.L.; visualization, C.D. and X.Z.; writing-original draft, C.D.; writing-review and editing, X.Z. and Q.X. All authors have read and agreed to the published version of the manuscript.
Funding
The work is partially supported by Young Innovative Talents Program for Colleges and Universities in Guangdong Province of China 2018KQNCX241, Natural Science Foundation of Guangdong Province 2018A030310068, National Natural Science Foundation of China 11731015, 11571148, 11701116, and Guangzhou University Research Funding 69-6209254, 220030401.
Acknowledgments
The thorough revision and constructive comments of the editor and anonymous reviewers are gratefully acknowledged.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Let denote the parameter space. The assumptions of Theorems 1 and 2 are:
- (A1)
- is an i.i.d sequence with ;
- (A2)
- is a compact subset of the space given by , , , and int;
- (A3)
- ;
- (A4)
- is a non-degenerate random variable;
- (A5)
- .
The QML regularity conditions B
Before restating the conditions, we introduce the definition of the Uniform Weak Law of Large Numbers(UWLLN) (see [43]) as follows.
A random functions sequence satisfies the UWLLN, if
The QML regularity conditions (refer to [44]) are:
- (B1)
- is compact, has nonempty interior and int;
- (B2)
- The variance functions are measurable functions of the data for all and are twice continuously differentiable with respect to on int;
- (B3)
- satisfies the UWLLN and is the identifiably unique maximizer (see [45]) of
- (B4)
- The Hessian satisfies the UWLLN and the expected Hessian is positive definite;
- (B5)
- The outer product of satisfies the UWLLN, and the expected outer product is positive definite.
Appendix B
Appendix B.1. Proof of Theorem 1
Since the LR test statistic is constructed as
by Taylor’s expansion, we have
Obviously, Formula (A1) can be written as
where .
We know the quasi log-likelihood function of models (3) and (4) equals
where the first and second derivative of likelihood function are computed as follows:
with
From Propositions 3.12, 6.1, 6.2 of [40], one can easily know that and are stationary and ergodic sequence of random elements.
Note that, for a given parameter space , the QMLE of is the maximizer of the above . From Theorem 4.1 of [40], we have , for a sufficient large N. By applying Taylor’s expansion, we can obtain
where . The function takes its maximum value at point . Then Formula (A4) is equivalent to the following Formula (A5):
By Theorem 2.7 of [40], we have
Here . Let , and . Then, , and . Through the computation of derivatives and expectations, we have
Because as , it follows that
Thus,
Denote . It follows that
According to and Formula (A7), we have . Notice that is the consistent estimator of the . Since is the innovation of GARCH model and , we can obtain
Further,
Therefore, Theorem 1 is proved.
Appendix B.2. Proof of Theorem 2
It follows form Formula (A4) that
Here because the likelihood function takes its maximum value at . Applying Taylor’s expansion for the function in Formula (A14), it follows that
where . According to Formulas (A15) and (A16), we can rewrite Formula (A14) as
By and , we further have and . Note that Formula (A8). For any , we have . Hence, Formula (A17) can be transformed into following Formula (A18):
According to and the consistency of , it follows that
Hence, we have
This completes the proof of Theorem 2.
References
- Narsoo, J. High Frequency Exchange Rate Volatility Modelling Using the Multiplicative Component GARCH. Int. J. Stat. Appl. 2016, 6, 8–14. [Google Scholar]
- Engle, R. Autoregressive conditional heteroskedasticity with estimates of the variance of U.K. inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econ. 1986, 31, 307–327. [Google Scholar] [CrossRef]
- Engle, R.F.; Bollerslev, T. Modelling the persistence of conditional variances. Econ. Rev. 1986, 5, 1–50. [Google Scholar] [CrossRef]
- Nelson, D. Conditional heteroscedasticity in stock returns: A new approach. Econometrica 1991, 59, 703–708. [Google Scholar] [CrossRef]
- Glosten, L.R.; Jagannathan, R.; Runkle, D.E. On the relation between the expected value and the volatility of the nominal excess return on stocks. J. Financ. 1993, 48, 1779–1801. [Google Scholar] [CrossRef]
- Bollerslev, T.; Mikkelsen, H.O. Modeling and pricing long memory in stock market volatility. J. Econ. 1996, 73, 151–184. [Google Scholar] [CrossRef]
- Francq, C.; Zakoïan, J.M. Maximum likelihood estimation of pure GARCH and ARMA-GARCH processes. Bernoulli 2004, 10, 605–637. [Google Scholar] [CrossRef]
- Francq, C.; Zakoïan, J.M. The L2-structures of standard and switching-regime GARCH models. Stoch. Process. Appl. 2005, 115, 1557–1582. [Google Scholar] [CrossRef]
- Huang, J.J.; Lee, K.J.; Liang, H.; Lin, W.F. Estimating value at risk of portfolio by conditional copula-GARCH method. Insur. Math. Econ. 2009, 45, 315–324. [Google Scholar] [CrossRef]
- Chan, F.; Theoharakis, B. Estimating m-regimes STAR-GARCH model using QMLE with parameter transformation. Math. Comput. Simul. 2011, 81, 1385–1396. [Google Scholar] [CrossRef]
- Li, D.; Zhang, X.; Zhu, K.; Ling, S. The ZD-GARCH model: A new way to study heteroscedasticity. J. Econ. 2018, 202, 1–17. [Google Scholar] [CrossRef]
- Takaishi, T. Volatility estimation using a rational GARCH model. Quant. Financ. Econ. 2018, 2, 127–136. [Google Scholar] [CrossRef]
- Francq, C.; Zakoïan, J.M. GARCH Models: Structure, Statistical Inference and Financial Applications; John Wiley & Sons, Ltd.: West Sussex, UK, 2010; pp. 141–201. [Google Scholar]
- Wood, R.A.; Mcinish, T.H.; Ord, J.K. An Investigation of Transactions Data for NYSE Stocks. J. Financ. 1985, 25, 723–739. [Google Scholar] [CrossRef]
- Harris, R. Home ownership and class in modern Canada. Int. J. Urban Reg. Res. 1986, 10, 67–86. [Google Scholar] [CrossRef]
- Baillie, R.T.; Bollerslev, T. IntraDay and InterMarket Volatility in Foreign Exchange Rates. Rev. Econ. Stud. 1991, 58, 565–585. [Google Scholar] [CrossRef]
- Goodhart, C.A.; O’Hara, M. High frequency data in financial markets: Issues and applications. J. Empir. Financ. 1997, 4, 73–114. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, O.E.; Shephard, N. Estimating quadratic variation using realized variance. J. Appl. Econ. 2002, 17, 457–477. [Google Scholar] [CrossRef]
- Andersen, T.G.; Bollerslev, T.; Diebold, F.X.; Labys, P. Modeling and Forecasting Realized Volatility. Econometrica 2003, 71, 579–625. [Google Scholar] [CrossRef]
- Hansen, P.R.; Huang, Z.; Shek, H.H. Realized GARCH: A Joint Model for Returns and Realized Measures of Volatility. J. Appl. Econ. 2012, 27, 877–906. [Google Scholar] [CrossRef]
- Hansen, P.R.; Lunde, A.; Voev, V. Realized beta GARCH: A multivariate GARCH model with realized measures of volatility. J. Appl. Econ. 2014, 29, 774–799. [Google Scholar] [CrossRef]
- Hansen, P.R.; Huang, Z. Exponential GARCH Modeling With Realized Measures of Volatility. J. Bus. Econ. Stat. 2016, 34, 269–287. [Google Scholar] [CrossRef]
- Andersen, T.G.; Bollerslev, T. Intraday periodicity and volatility persistence in financial markets. J. Empir. Financ. 1997, 4, 115–158. [Google Scholar] [CrossRef]
- Andersen, T.G.; Bollerslev, T. Answering the Skeptics: Yes, Standard Volatility Models do Provide Accurate Forecasts. Int. Econ. Rev. 1998, 39, 885–905. [Google Scholar] [CrossRef]
- Visser, M.P. Garch Parameter Estimation Using High-Frequency Data. J. Financ. Econ. 2011, 9, 162–197. [Google Scholar] [CrossRef][Green Version]
- Huang, J.; Wu, W.; Chen, Z.; Zhou, J. Robust M-estimate of GJR Model with High Frequency Data. Acta Math. Appl. Sin. 2015, 31, 591–606. [Google Scholar] [CrossRef]
- Wang, M.; Chen, Z.; Wang, C.D. Composite Quantile Regression For GARCH Models Using High-Frequency Data. Econ. Stat. 2017, 7, 115–133. [Google Scholar] [CrossRef]
- Fan, P.; Lan, Y.; Chen, M. The estimating method of VaR based on PGARCH model with high-frequency data. Syst. Eng. Theory Pract. 2017, 37, 2052–2059. [Google Scholar]
- Mariani, M.; Bhuiyan, M.; Tweneboah, O.; Gonzalez-Huizar, H.; Florescu, I. Volatility models applied to geophysics and high frequency fnancial market data. Physica A 2018, 15, 1–32. [Google Scholar]
- Gyamerah, S.A. Modelling the volatility of Bitcoin returns using GARCH models. Quant. Financ. Econ. 2019, 3, 739–753. [Google Scholar] [CrossRef]
- Bhuiyan, M.A.M. Predicting Stochastic Volatility For Extreme Fluctuations In High Frequency Time Series. Open Access Theses Diss. 2020, 2934, 1–77. [Google Scholar]
- Lee, J.H.H. A Lagrange multiplier test for GARCH models. Econ. Lett. 1991, 37, 265–271. [Google Scholar] [CrossRef]
- Berkes, I.; Horváth, L.; Kokoszka, P. Testing for parameter constancy in GARCH(p,q) models. Stat. Probab. Lett. 2004, 70, 263–273. [Google Scholar] [CrossRef]
- Lee, S.; Song, J. Test for parameter change in ARMA models with GARCH innovations. Stat. Probab. Lett. 2008, 78, 1990–1998. [Google Scholar] [CrossRef]
- Carbon, M.; Francq, C. Portmanteau goodness-of-fit test for asymmetric power GARCH models. Austrian J. Stat. 2010, 40, 55–64. [Google Scholar]
- Gel, Y.R.; Chen, B. Robust Lagrange multiplier test for detecting ARCH/GARCH effect using permutation and bootstrap. Can. J. Stat. 2012, 40, 405–426. [Google Scholar] [CrossRef]
- Leucht, A.; Kreiss, J.P.; Neumann, M.H. A Model Specification Test For GARCH(1,1) Processes. Scand. J. Stats 2016, 42, 1167–1193. [Google Scholar] [CrossRef]
- Xiong, Q.; Hu, Z.; Li, Y. Statistic inference for a single-index ARCH-M model. Commun. Stat. Theory Methods 2018, 47, 102–117. [Google Scholar] [CrossRef]
- Straumann, D.; Mikosch, T. Quasi-Maximum-Likelihood Estimation in Conditionally Heteroscedastic Time Series: A Stochastic Recurrence Equations Approach. Ann. Stat. 2006, 34, 2449–2495. [Google Scholar] [CrossRef]
- Engle, R.F. Chapter 13 Wald, likelihood ratio, and Lagrange multiplier tests in econometrics. Handb. Econ. 1984, 2, 775–826. [Google Scholar]
- Scott, L.O. Option Pricing when the Variance Changes Randomly: Theory, Estimation, and an Application. J. Financ. Quant. Anal. 1987, 22, 419–438. [Google Scholar] [CrossRef]
- Wooldridge, J.M. A Unified Approach to Robust, Regression-Based Specification Tests. Econ. Theory 1990, 6, 17–43. [Google Scholar] [CrossRef]
- Bollerslev, T.; Wooldridge, J. Quasi Maximum Likelihood Estimation and Inference in Dynamic Models with Time Varying Covariances. Econ. Rev. 1992, 11, 143–172. [Google Scholar] [CrossRef]
- Bates, C. A Unified Theory of Consistent Estimation for Parametric Models. Econ. Theory 1985, 1, 151–175. [Google Scholar] [CrossRef]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).