1. Introduction
The drone navigation problem [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11] appeared during the development of systems for autonomous navigation of drones. The question arose about the possibility of determining the coordinates of the drone based on the image of the runway or the airfield control tower, or any characteristic building along the route of the drone.
However, the task of determining the coordinates of the camera with respect to three-dimensional (3D) object images can also be used for other conditions: indoor navigation or inside city navigation. Such navigation programs can be used both in tourist guide devices and in control of autonomous robots.
Usually, GPS (Global Positioning System) [
1] and inertial navigation systems [
2] are used to solve navigation problems. However, each of these navigation methods has its own drawbacks. Inertial systems tend to accumulate errors in the coordinates and angles of a drone during its flight. GPS also has a number of disadvantages, in particular, it has nonautonomous methods depending on correct operation of external satellites, it gives an accuracy of the order of several meters, and sometimes tens of meters, which is unacceptable for accurate navigation, such as, for example, taking off and landing a drone; also, GPS is unstable with respect to external noise or hacking.
Let us discuss the use of computer vision and deep learning for drone navigation. Despite the massive fascination with neural networks and their active implementation in computer applications, their use to determine the coordinates of objects or a camera relative to an object is studied much less often.
Most visual navigation techniques use landmarks to map and locate the camera. We usually use various functions to highlight correspondent features (key points) on video (for example, methods such as SIFT (scale-invariant feature transform) [
3] or the Lucas-Kanade method [
4]). From known points’ motion, we can find egomotion and three-dimensional (3D) environment reconstruction. Unfortunately, such features are not universal, for example, there is a problem of recognizing such point-like features, and to identify correspondent features during large camera egomotion, intrinsic features can be non-point-like, and so on.
We use deep learning and convolutional neural networks to identify such complex features and their correspondence. We can significantly reduce data processing time and improve accuracy, which is especially important for maneuvering a drone [
5,
6,
7,
8,
9,
10].
“PoseNet” [
5] is based on the GoogLeNet architecture. It processes RGB (
Red, Green,
Blue, i.e.,
colour images) images and is modified so that all three softmax and fully connected layers are removed from the original model and replaced by regressors in the training phase. In the testing phase, the other two regressors of the lower layers are removed and the prediction is done solely based on the regressor on the top of the whole network.
For Bayesian PoseNet, Kendall et al. [
6] propose a Bayesian convolutional neural network to estimate uncertainty in the global camera pose, which leads to improving localization accuracy. The Bayesian convolutional neural network is based on PoseNet architecture by adding dropout after the fully connected layers in the pose regressor and after one of the inception layers (layer 9) of the GoogLeNet architecture.
Long short-term memory (LSTM)-Pose [
7] is otherwise similar to PoseNet but applies LSTM (a type of Recurrent Neural Network (RNN)) networks for output features coming from the final fully connected layer. In detail, it is based on utilizing the pre-trained GoogLeNet architecture as a feature extractor followed by four LSTM units applied in the up, down, left, and right directions. The outputs of LSTM units are then concatenated and fed to a regression module consisting of two fully connected layers to predict camera pose.
VidLoc [
8] is a CNN (
Convolution Neural Network)-based system based on short video clips. As in PoseNet and LSTM-Pose, VidLoc incorporates a similarly modified pre-trained GoogLeNet model for feature extraction. The output of this module is passed to bidirectional LSTM units predicting the poses for each frame in the sequence by exploiting contextual information in past and future frames [
9].
In Reference [
9], an encoder-decoder convolutional neural network (CNN) architecture was proposed for estimating camera pose (orientation and location) from a single RGB image. The architecture has an hourglass shape consisting of a chain of convolution and up-convolution layers followed by a regression part.
In Reference [
10], similar to PoseNet, MapNet also learns a DNN (deep learning neural network) that estimates the 6-DoF (
6 Degrees of Freedom) camera pose from an input RGB image on the training set via supervised learning. The main difference, however, is that MapNet minimizes both the loss of the per-image absolute pose and the loss of the relative pose between image pairs.
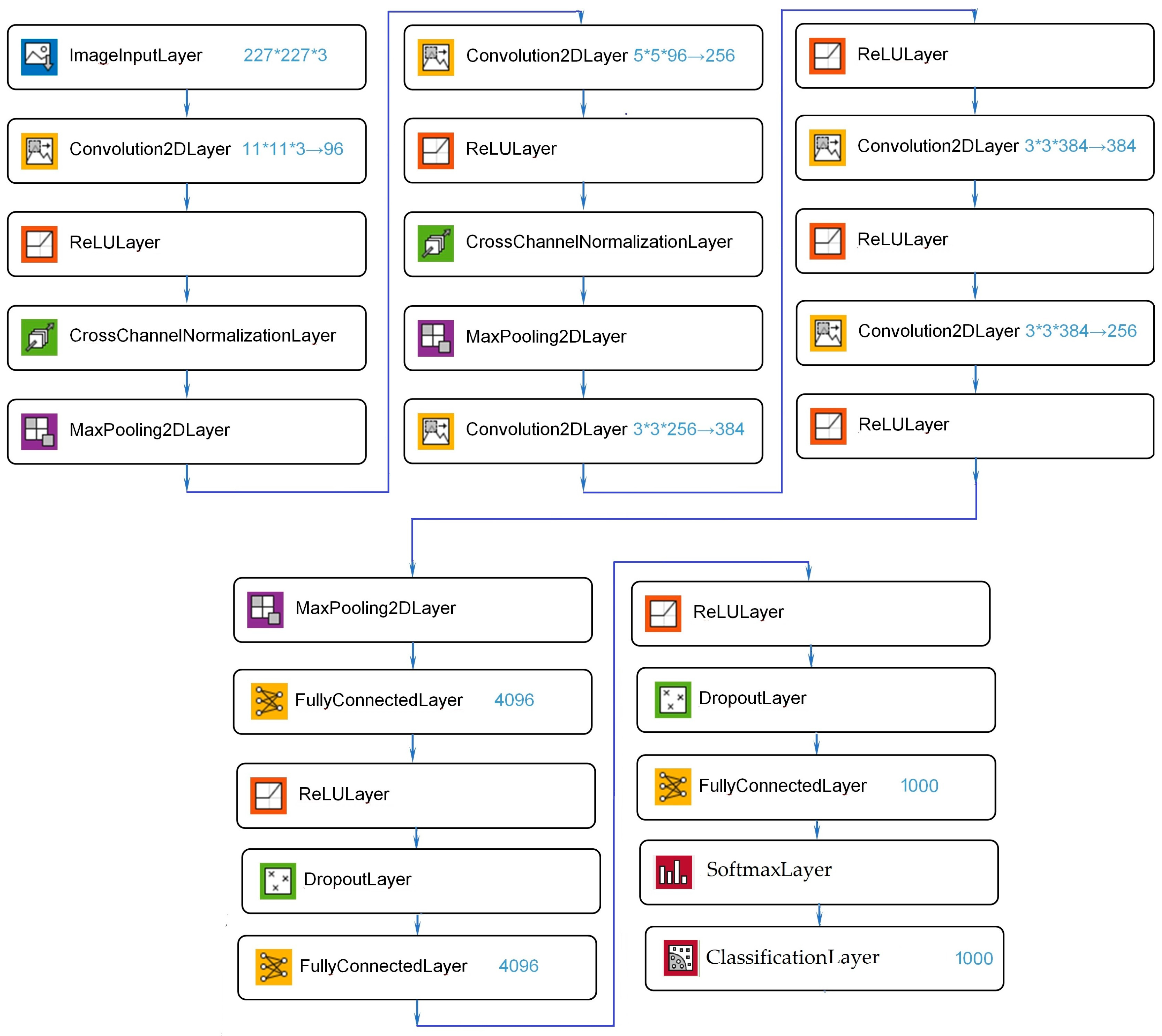
In this study, we used modified AlexNet (see
Figure 1). AlexNet [
12,
13,
14,
15] is the name of a convolutional neural network (CNN), designed by Alex Krizhevsky and published with Ilya Sutskever and Krizhevsky’s doctoral advisor Geoffrey Hinton [
12]. AlexNet competed in the ImageNet Large-Scale Visual Recognition Challenge on 30 September 2012, significantly outperforming other networks. In the original AlexNet, there are only 8 levels (5 convolutional and 3 fully connected). It is possible to load a pretrained version of the network trained on more than a million images from the ImageNet database [
12,
13,
14,
15]. The pretrained network can classify images into 1000 object categories, such as keyboard, mouse, pencil, and many animals. As a result, the network has learned rich feature representations for a wide range of images. The network has an image input size of 227 × 227.
2. Materials and Methods
There is a series of interesting papers [
5,
6] where the authors used deep learning and convolutional neural network to determine camera position and orientation. These papers are pioneer work in the application of deep learning techniques to navigation.
Unfortunately, this technology is used only for ground cameras, that can be placed on ground robots, ground vehicles, or pedestrians. More specifically, in their work [
5,
6], the authors determined the coordinates and angle of the camera using images of the Cambridge Landmarks building, filmed with a smartphone camera by pedestrians.
The flying camera was used in the current paper, unlike in References [
5,
6], where the authors used only the ground camera. So, in the current paper, we are able to analyze the applicability of deep learning technology for many more ranges of angles and coordinates.
In References [
5,
6,
7,
8,
9], Cartesian coordinates and quaternions (logarithm of unit quaternions in Reference [
10]) were used for description of the camera position and orientation. We used a description of the camera position and orientation that is more natural for images. It allows us to get better precision for the camera position and orientation. Indeed, such description provides the data which is easier and more natural for understanding by the artificial neural network.
In more detail, we considered the problem in which the camera can be located at a great distance (up to 1000 m) from the ground object landmark. Therefore, our method involves two stages: determining the position of the object on the image, and then determining the position and orientation of the camera using only a narrow neighborhood of the object.
This position and orientation of the camera is described (i) by two angles describing the camera optical axis rotation with respect to the ray (connecting the object with the camera optical center), (ii) by the distance between the camera optical center and the object, and (iii) by quaternions, describing two angles of the ray and one angle of the camera rotation around the ray.
For the two stages, as described above, we used the two artificial neural networks, which are built on the basis of AlexNet [
12,
13,
14,
15] with small changes in structure and training method.
3. Results
3.1. Deep Learning for Localization: Training and Validation of Dataset Formation
We considered the problem of determining three coordinates and three angles of rotation of the camera using the artificial neural network.
In the game application Unity, the model scene was created, containing an airport control tower in the middle of an endless green field (
Figure 2).
In real life, any object is surrounded by dozens of others—houses, trees, roads, etc.—which give us additional information for orientation. We decided to make the task minimally dependent on additional landmarks, so that the neural network would only use the control tower building for navigation. Obviously, such a solution of a minimalistic task can be easily transformed to an environment where the landmark is surrounded by many other objects.
The basis of the landmark building (named as the object in further parts of the paper) was located at the origin of the ground coordinate system, and the virtual camera was randomly located above ground level at a distance from 200 to 1000 m from the object origin. The camera was always oriented so that the landmark building was completely included in the frame. In total, 6000 images were produced in pixel size of 2000 × 2000: 5000 for training and 1000 for validation (
Figure 3).
All information about the coordinates of the camera in space and the location of the reference object on the image was automatically formed into a table, which was then used for training and validation of the neural network.
3.2. Two Stages and Two Artificial Neural Networks (ANN) for Finding the Drone Camera Position and Orientation
Since the obtained images have pixel size 2000 × 2000, which is too large for processing by a convolutional neural network, we split the task into two stages.
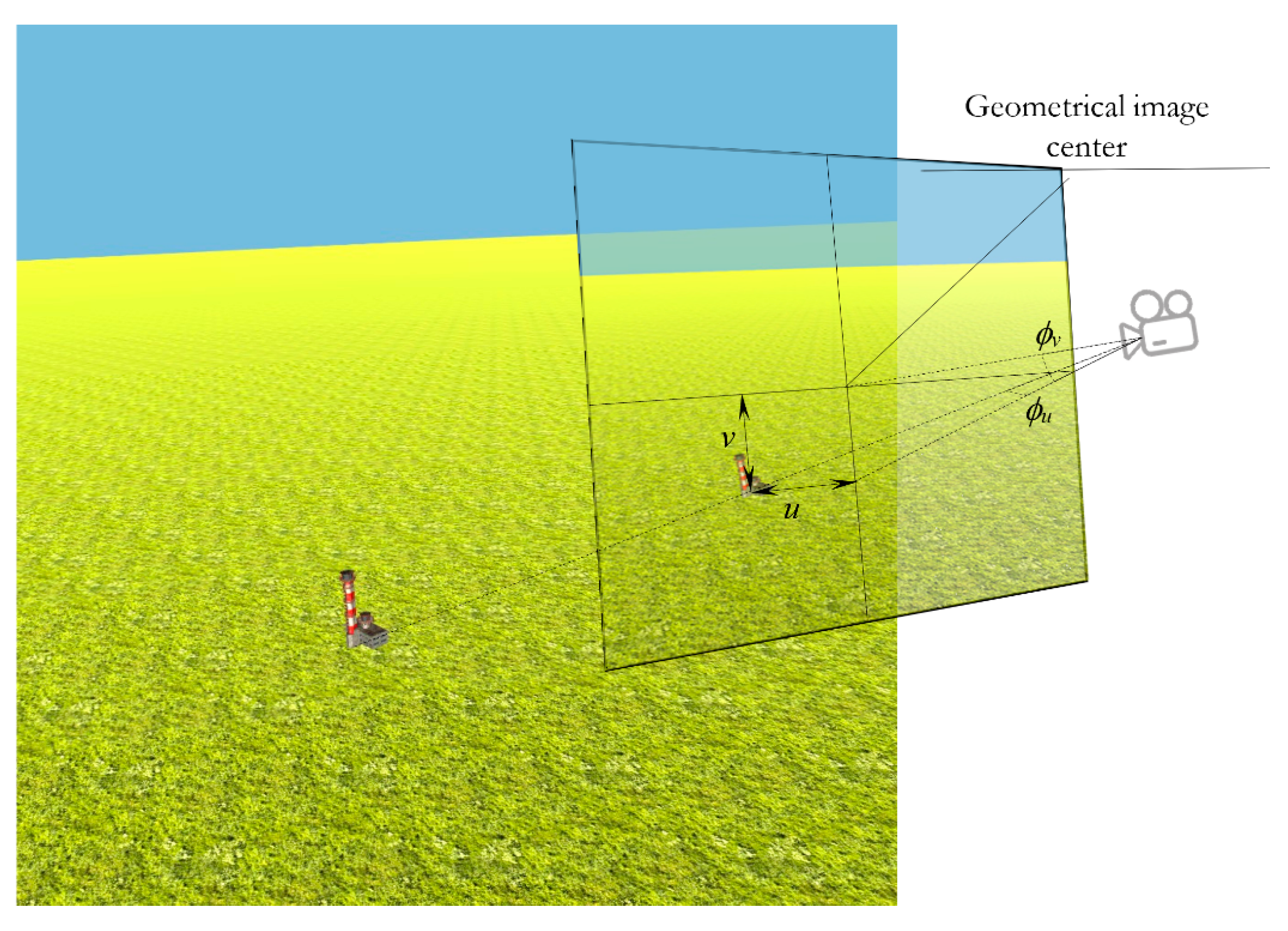
At the first stage, we use the first ANN to find coordinates u and v, describing the position of the object origin projection, on the image with reduced pixel size 227 × 227.
At the second stage, we use the second ANN to find the drone camera position and orientation (—distance between camera optical center and the object origin, —quaternion components, describing the camera orientation, and —the projection point of the object origin on the modified image) using the new modified image with pixel size 227 × 227, where the object origin projection is in the image center.
3.2.1. The first Stage of Drone Camera Localization
Network Architecture and Its Training at the First Stage
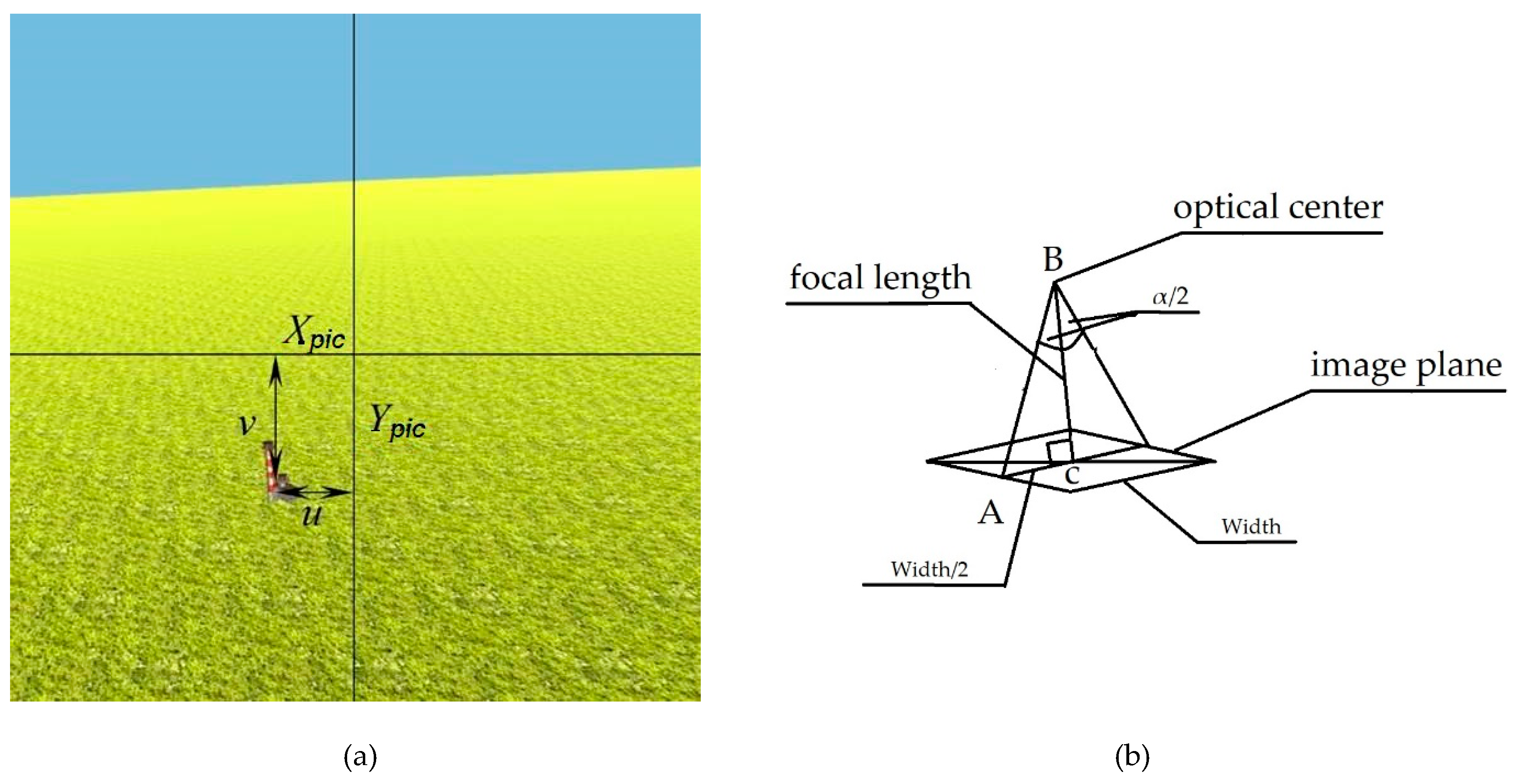
Let us describe the first stage here. We solve here the task to find the horizontal and vertical coordinates
u and
v of the object origin projection in a large image (
Figure 4). These coordinates are equal to the pixel coordinates of the object origin projection according to the center of the image, divided by the focal length of the camera:
where
F is the focal length of the camera in pixels, calculated by the formula (from the right-angled triangle ABC in
Figure 4b)
where
Width is the width size of the image in pixels,
and
α—camera field of view in the x and y direction.
For calculation of
u and
v, we used the artificial neural network, which is built on the basis of AlexNet [
12,
13,
14,
15] with small changes in the structure and training method.
For our tasks, we removed the last two fully connected layers, and replaced them with one fully connected layer with 2 outputs (
u and
v coordinates) and one regression layer. That is, we used the pre-trained AlexNet network to solve the regression problem: determining two coordinates of the camera (
Figure 5).
We reduced all images to pixel size 227 × 227 and used them for neural network training.
For training the solver, we used “adam” with 200 epochs, batch size 60, initial training velocity 0.001, and reduced the training velocity by 2 after every 20 epochs.
We have the training set (used for the artificial neural network (ANN) training) and the validation set for the verification of the pretrained ANN.
Firstly, all errors were found for the training set of images as differences between two angles (
and
), obtained from the pretrained artificial neural network, and the two known angles (
and
), used for creation of images by the Unity program. The root mean square of these errors are shown in the first row of
Table 1.
Secondly, all errors were found for the validation set of images as differences between two angles (
and
), obtained from the pretrained artificial neural network, and the two known angles (
and
), used for creation of images by the Unity program. The root mean square of these errors is shown in the second row of
Table 1.
The error for finding the object origin projection coordinates
u and
v can be found in
Table 1. Errors correspond to errors of two angles (
and
), as demonstrated in
Figure 6.
In this way, we achieved the first-stage program purpose: to find the object origin projection position on the big image.
3.2.2. The Second Stage of Drone Camera Localization
Finding Coordinates of the Object Origin Projection on the New Modified Images
Since and were found by the artificial neural network with some error, we can again find the real coordinates and of the object origin projection on the new modified image (obtained from homology), which will be used for training the artificial neural network in the second stage.
The Artificial Neural Network for the Second Stage
At the second stage, we also used AlexNet with similar modifications, i.e., we removed the last two fully connected layers, and replaced them with one fully connected layer with 7 outputs (—distance between camera optical center and the object origin, —quaternion components, describing the camera orientation, and —the projection point of the object origin on the modified image) and one regression layer.
Since the seven outputs of the fully connected layer have different scales ( changes from 200 to 1000 m, and the rest of the values change between 0 and 1), we multiplied , , and by scale coefficient μ = 1000 for better training.
For the training solver, we used “adam” with 200 epochs, batch size 60, initial training velocity 0.001, and reduced the training velocity by 2 after every 20 epochs.
Training Results
We have the training set (used for the ANN training) and the validation set for the verification of the pretrained ANN.
Firstly, all errors were found for the training set of images as differences between positions and orientations, obtained from the pretrained artificial neural network, and known positions and orientations, used for creation of images by the Unity program. The root mean square of these errors are shown in the first row of
Table 2.
Secondly, all errors were found for the validation set of images as differences between positions and orientations, obtained from the pretrained artificial neural network, and known positions and orientations, used for creation of images by the Unity program. The root mean square of these errors are shown in the second row of
Table 2.
Errors of the second stage are described in
Table 2.
As a result, we get the camera coordinates in the space with precision up to 4 m and the camera orientation with precision up to 1°.
3.3. Automatic Control
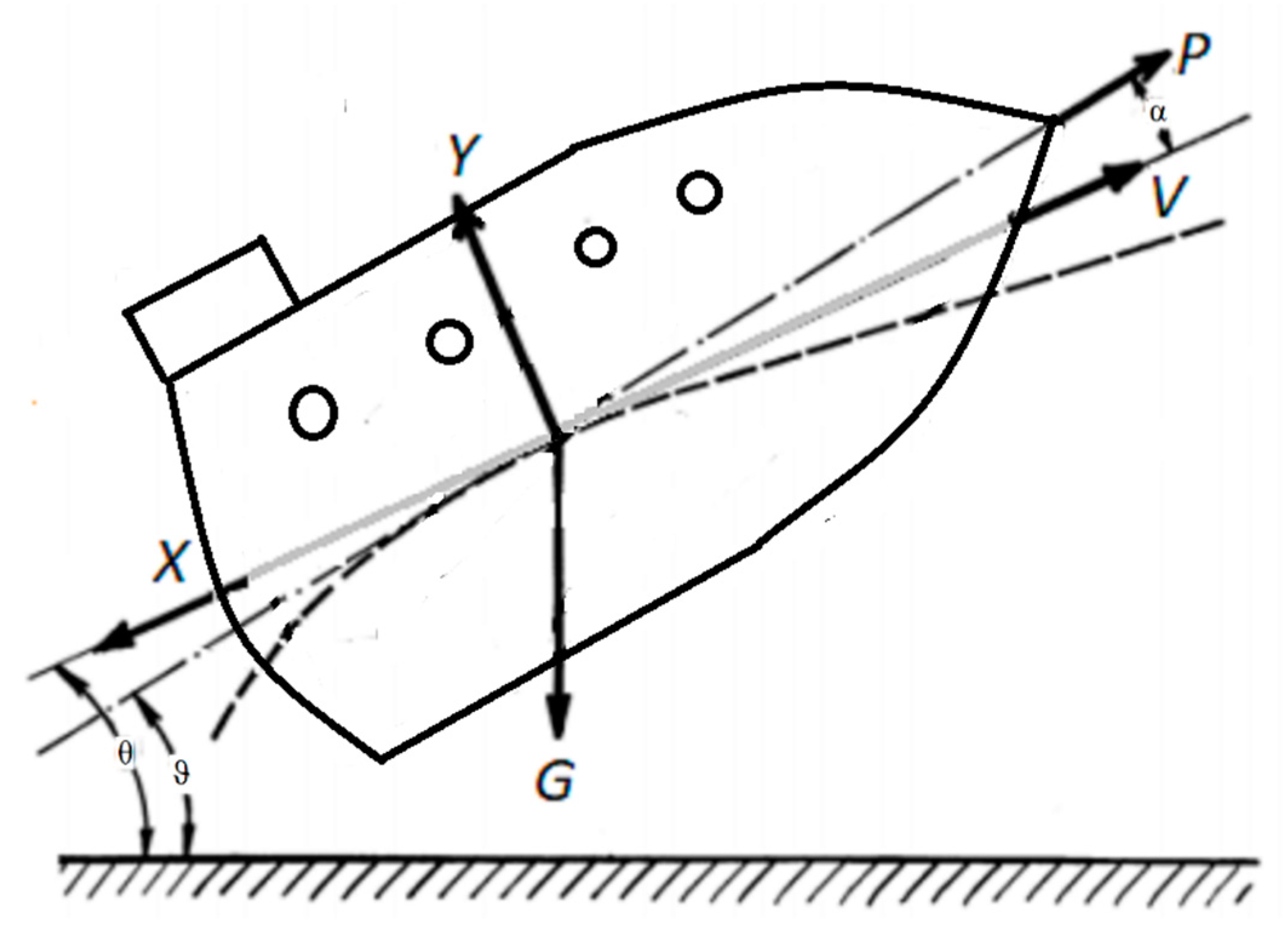
Let us define the following variables and parameters used in equations of motion for the drone (see
Figure 9):
V—Flight velocity tangent to trajectory (with respect to air)
H—Height above mean sea level of a drone flight
ϑ—Pitch angle, i.e., angle between longitudinal drone axis and horizontal plane
α—Angle of attack, i.e., angle between longitudinal axis of a drone and projection of drone velocity on the symmetry plane of the drone. The drone flight is described by the system of nonlinear equations [
16].
We will consider the steady-state solution as drone flight at constant velocity and height.
Let us consider small perturbation with respect to steady state:
Linear equations for perturbations are as follows:
where
is velocity perturbation,
is height perturbation,
is attack angle perturbation,
is pitch angle perturbation,
is normalized by
time
t as defined above,
and
are two autopilot control parameters, and
is time delay, which is necessary for measurement of the perturbations and calculation of the control parameters. All derivatives are made according to normalized time:
All
and
are constant numerical coefficients, for which numerical values are described below.
We would like to consider some example of the flight already described previously with known constant numerical coefficients. Some typical coefficients of the linear equations (for the following flight steady-state conditions: height H
0 = 11 km, time constant
Mach number M = V
0/V
s = 0.9
where V
s—sound velocity and V
0—drone steady-state velocity, see
Table 1 from Reference [
16]):
, , , , , , , , , , , , , , , .
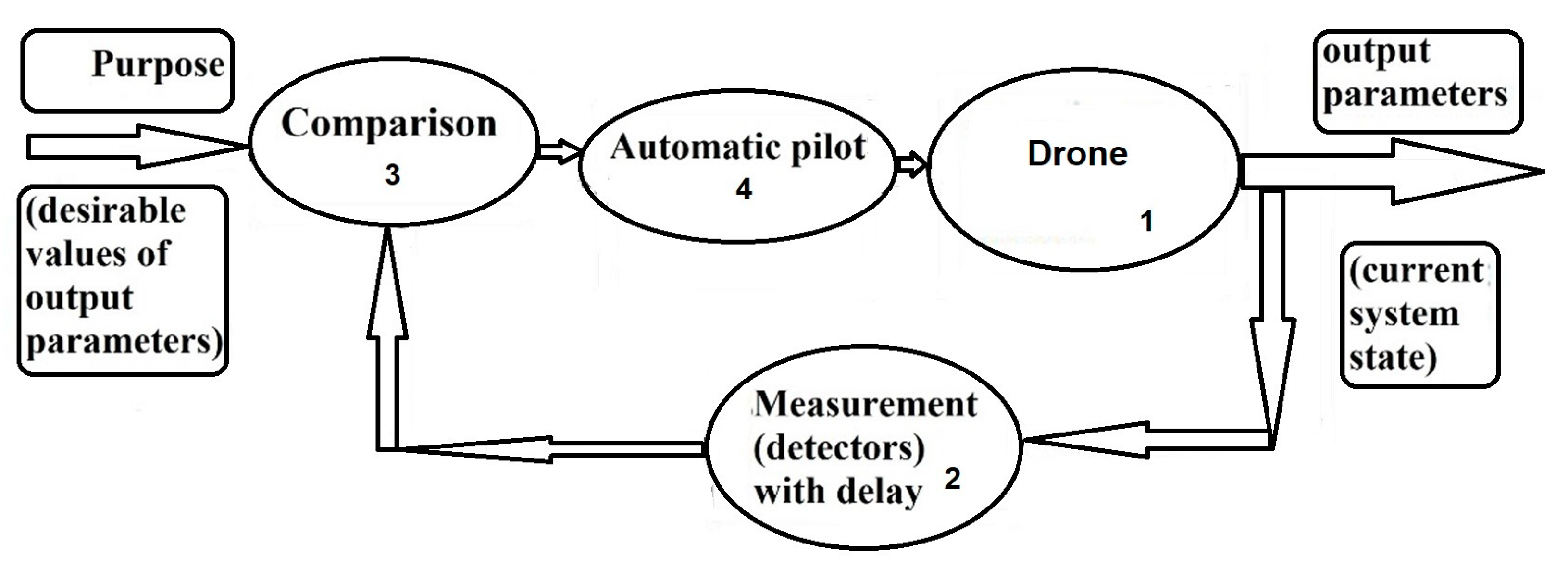
For the case when stationary parameters cannot provide stability of the desirable stationary trajectory themselves, we need to use autopilots (
Figure 10). An autopilot states the control parameters,
to be functions of the output-controlled parameters
:
controlled parameters
are perturbation with respect to the desirable stationary trajectory. The autopilot can get the output parameters from measurements of different navigation devices: from satellite navigation, inertial navigation, vision-based navigation, and so on. Using these measurements of the navigation devices, the autopilot can create controlling signals to decrease undesirable perturbations. However, any navigation measurements have some time delay
in obtaining values of the output parameters which are controlled by autopilot. As a result, the problem exists, because some necessary information which are necessary for control does not exist.
Indeed, image processing for visual navigation demands a lot of time and results in a time delay. We can see from
Figure 10 that the time delay exists in a measurement block because of a large amount of time, which is necessary for image processing of visual navigation. As a result, we know the deviation also with time delay. However, the proposed method allows to get stable control in the presence of this time delay.
In Reference [
16], we demonstrate that it is possible even for such conditions with a time delay to get a controlling signal, providing a stable path.
Final solutions from Reference [
16] are as follows:
We can calculate parameters
:
Then, we can calculate parameters
,
,
,
:
The delay time is as follows:
4. Conclusions
The coordinates found (—distance between camera optical center and the object origin, —quaternion components, describing the camera orientation, and —the projection point of the object origin on the new modified image, and —the projection points of the object origin on the initial image with reduced pixel size) unambiguously define the drone position and orientation (six degrees of freedom).
As a result, we have detailed the program which allows us unambiguously and with high precision to find the drone camera position and orientation with respect to the ground object landmark.
We can improve this result by increasing the number of images in the training set, using ANN with more complex structure, considering a more complex and more natural environment of the ground object landmark.
The errors can also be improved by changing the network configuration (like in References [
7,
8,
9,
10], for example) or by using a set of images instead of a single image [
8,
10].
Errors (completely describing camera position and orientation errors) were given in
Table 1 and
Table 2. We need not object identification error here.
We chose our ground object and background to be strongly different, so recognition quality was almost ideal. This is not because of the high quality of the deep learning network, but because of choosing an object which was very different on the background. Indeed, such a clear object is needed for robust navigation.
Image processing for visual navigation demands a lot of time and results in a time delay. We can see from
Figure 10 that the time delay exists in measurement blocks because of a large amount of time, which is necessary for image processing of visual navigation. As a result, we know the deviation also with time delay. However, the proposed method allowed us to get stable control in the presence of this time delay (smaller than
).
We have not developed real-time realization yet. So, we could not provide a description of hardware in this paper, which is necessary for real-time work. It is a topic for future research.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}