The case study is based on a Spanish software factory that develops software and provides services to several financial entities. The company plays an important role in the information technology sector for financial entities in Spain and South America. The company is a subsidiary firm of a banking group. They have started an important process of adaptation and change of their business model a few years ago, with the goal of improving the efficiency and productivity as a way of ensuring its business sustainability. They have adopted a strategic management approach based on a redefined BSC framework, as published in a former work [
27].
Table 1,
Table 2,
Table 3 and
Table 4 summarize the BSC KPIs, which includes the four usual perspectives: Financial, Customer, Internal Business Processes, and Learning and Growth. The KPIs were derived from the strategic goals of the organization.
This framework has been preferred among other existing frameworks in the literature [
28] because it has been designed tailored to the environment of this kind of FSF and is the one established in the studied company. Some of the KPIs are simple (i.e., F2-Reduction of cost), but others are complex (i.e., C1-User Satisfaction, C3-SLA, I4-Software Quality, or L1-Employer Branding) because they group several sub-indicators. The description of the KPIs included in the BSC, the method used to measure every KPI, and their justification are extensively explained in [
27].
3.1. Analytic Hierarchy Process Method
The method was devised by Saaty in the 1970s [
3] and it has been adopted as one of the most used MCDM processes until now. The method is used to prioritize the relative importance of criteria by making pairwise comparisons, instead of sorting, voting, or freely assigning priorities. Saaty establishes an intensity of importance for the comparisons on an absolute scale with nine levels, which is known as Saaty’s scale [
29]. The method starts with defining the goal of the decision and the alternatives and structuring them in a hierarchy. Then, the pairwise comparison of criteria in each category is performed, and the priorities are derived.
If an alternative is preferable to an alternative , then the value of the comparison scale indicates the intensity of relative importance of over . The matrix is the result of all of the comparisons and represents the relative importance of each element.
The method uses the principal eigenvalue method to derive the priorities. The calculation of weights relies on an iterative process in which matrix is successively multiplied by itself, resulting in normalized weights, , which represents the importance of alternative relative to all other alternatives.
The judgment of decision-makers in pairwise comparisons may present inconsistencies when all of the alternatives are taken into consideration simultaneously. So, the consistency index (CI) and the consistency ratio (CR) are calculated to measure the degree to which judgments are not coherent [
30]. It is normally considered that if CR < 0.10, then the degree of consistency is satisfactory [
31]. If the maximum eigenvalue, CI, and CR are satisfactory, then a decision is taken based on the normalized values; else, the procedure is repeated until these values lie in a desired range.
A good description of the usage and different applications of AHP can be found at the work of Ishizaka and Labib [
32]. The evolution of the method can be also followed in the Emrouznejad and Marra publication [
33]. The application related to this work is the utilization of AHP for priority and ranking, where it has been extensively used.
The application of AHP it is not always easy. The number of comparisons grows exponentially according to the number different criterion to be considered. The scale presents some difficulties also, being subjective for the decision-makers discerning between the different levels of intensity of importance when comparing two alternatives. As Buckley and Uppuluri [
34] remark, “It is difficult for people to always assign exact ratios when comparing two alternatives.” In a similar way, Chang [
35] states that, “Due to the complexity and uncertainty involved in real world decision problems, it is sometimes unrealistic or even impossible to require exact judgments.” In addition, the consistency analysis is complicated when a large number of decision-makers are involved, resulting in a complex post-processing process that could entail leaving out several opinions. In addition, despite its wide use, the method is not free of criticism from various perspectives. For example, Costa and Vansnick [
36] state that the priority vector derived can violate the so-called “condition of order preservation” that is fundamental in decision-making.
For a long period, the predominant tendency was to extend the method by hybridizing it with other methods and thus introducing a higher complexity. The original method was combined with Fuzzy Set theory [
37] given the Fuzzy Analytic Hierarchy Process (FAHP) method [
35]. Regardless, the introduced complexity of these new methods (more complex questionnaires, fuzzification and defuzzification models, complexity when calculation, and difficulty of interpretation of the results), there is some controversy about the real benefits. For example, the paper published by K. Zhü openly criticizes the fuzzy approaches to AHP [
38]. The author claims that despite the popularity of the method, this approach has problems, stating that the operational rules of fuzzy numbers oppose the logic of the AHP and analyzing the validity, among other things. K. Zhü holds the opinion that, “It is not necessary to use a complex paradigm to express complex things, sometimes a simple paradigm may be better.” Thomas L. Saaty has also paid close attention to these extensions, writing some papers from a critical perspective [
39,
40]. By contrast, a tendency has recently emerged trying to simplify the application of the method as much as possible. For example, Leal [
41] develops a simplified method that calculates the priorities of each alternative against a set of criteria with only
n − 1 comparisons of
n alternatives for each criterion, instead of
n*(
n − 1)/2 comparisons in the original method.
In any case, our study does not concern the validity or not of the AHP and its extensions, but we want to emphasize the idea that the simplest methods under certain conditions are the most appropriate. Under this context, the Bradley-Terry model could be an easier method, as the Saaty’s scale could be transformed in a win-to-loss scale (the decision-makers only need to specify which criterion is preferred in the comparison, without grading the intensity of importance), and the computing of data might be simpler.
3.2. Bradley-Terry Model and BSC Integration
The Bradley-Terry model [
42] is a method of analysis of paired comparisons based on the logit model. A general introduction can be found in Agresti [
9]. Given a pair of individuals
i and
j / (
i,j ∈{1, …, K}), the model estimates the probability that
i is preferred to
j as:
In the Expression (1),
pi is a positive real-valued score (the underlying worth of each item) assigned to individual
i and
P(i > j) + P(j > i) = 1 for all of the pairs. The Bradley-Terry model uses exponential score functions, so the probability of selection is expressed in terms of exponential functions:
Thus, Expression (1) can be expressed as:
Alternatively, it can be expressed using the logit as:
Then, the parameters {
pi} can be estimated by maximum likelihood using the Zermelo [
43] method. Standard software for generalized linear models can be used for the computing as described by Turner and Firth [
44], who are the authors of one of the most used packages for Bradley-Terry calculation under R software.
The observations required are the outcomes of previous comparisons, which are expressed as pairs (
i,
j), counting the number of times that
i is preferred to
j and summarizing these outcomes as
wij. Thus,
wij accounts the times that an indicator
i was preferred to
j by the decision-makers. The log-likelihood of {
pi} can be obtained as:
It is assumed by convention that
wii = 0. Starting from an arbitrary vector
p, the algorithm iteratively performs the update
for all
i, where
Wi is the number of comparisons ‘won’ by
i. After computing all the parameters, they should be renormalized, so
.
Additional extensions have been proposed. For example Böckenholt [
45] proposed a method for ranking more than two options. The model has also been extended to allow ordinal comparisons. In this case, the subjects can make their preference decisions on more than two preference categories. The works of Tutz [
46], Agresti [
47], Dittrich et al. [
48], and Casalicchio et al. [
49] provide extensions in this sense. However, they are unnecessary here, because our goal is to retrieve the underlying relative worth of each indicator in a simple way. For the calculation, statistical packages have been developed and described in the literature, most of them R extensions: Firth [
50], Turner and Firth [
44], Hankin [
51], or Clark [
52], for example.
In terms of calculation, the process starts surveying the decision-makers through a pairwise questionnaire. The difference with respect to the AHP method is that Saaty’s scale is not used. Instead, they indicate which indicator is the most important (the ‘winner’), without expressing a degree of preference. Then, a table is built summarizing the number of times each indicator ‘wins’. For example, in the case of 4 KPIs, the table will follow the structure shown in
Table 5:
Here, Nij stands for the number of times KPIi was preferred to KPIj. This is a form of coding widely used by most R extensions that allows the calculations of the Bradley-Terry model.
3.3. Method and Empirical Application
A demonstration of the method is explained in this section. It is necessary to bear in mind that in this case, we have started from the data collected in our former study [
53]. The entire process is enumerated, although only those steps specific of the Bradley-Terry modeling are presented in detail. The steps taken to achieve this purpose are:
Analyze the BSC of the studied organization.
Define the hierarchical framework according to each perspective of the BSC.
Survey the decision-makers’ opinions regarding the indicators and perspectives of the BSC using a pairwise questionnaire in a win-to-loss context.
Prepare the answers to be processed with Bradley-Terry software.
Compute the perspectives and indicators’ weights.
Rank the indicators.
Analyze the results and obtain conclusions.
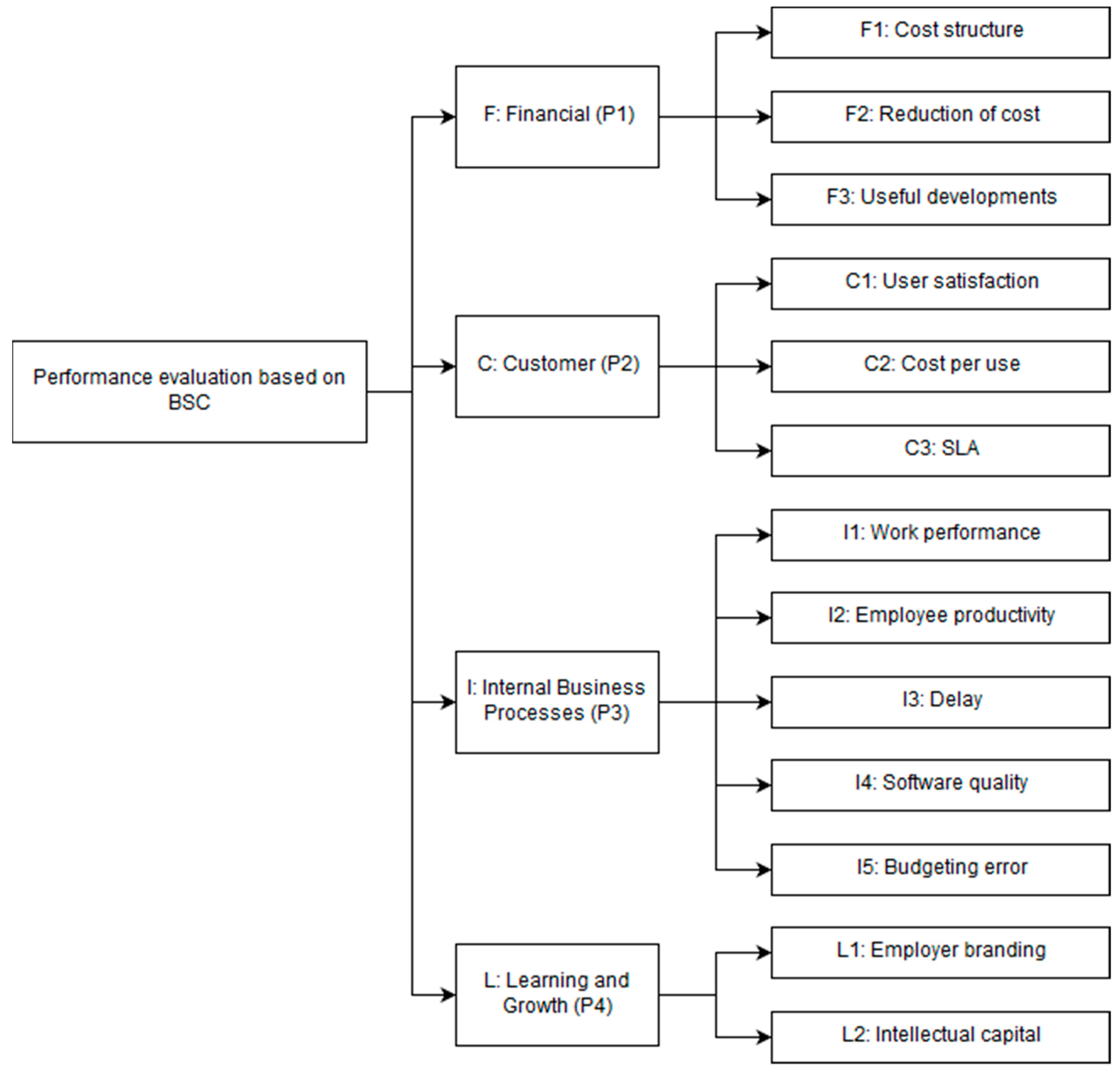
According to the hierarchical structure shown in
Figure 2, a conventional questionnaire in AHP format was distributed. The questionnaires were sent to different internal and external stakeholders of the company and some experts in the field of software factories to ask for their professional point of view on sustainability and performance goals in relation to the company scenario. The number of questionnaires sent was 83, and the number of received questionnaires was 61, which represents 73% of the total of questionnaires sent. A detailed description of the considered roles and additional details about the survey process can be found in the section “Data Collection” from our former paper, where the AHP prioritization was published [
53].
In this particular case, we have started from an AHP conventional questionnaire, following the scale proposed by Saaty [
29], but we have transformed the answers into a win-to-loss context for the application of our method. For each comparison, we have considered only who is the winner (the preferred factor by the expert in the comparison) and the loser, regardless of the intensity of the preference. We have considered the special case of equal importance as a tie. It must be taken into consideration that our proposal starting from scratch consists of carrying out a questionnaire without considering intensities, simply forcing the respondent to indicate the most important factor in the pairwise comparison (or equal).
As a consequence, five different files were built, as shown in
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10.
Table 6 shows decision-makers’ preferences regarding the four different perspectives, which are denoted as P1, …, P4. The column Win1 denotes the number of times that Factor 1 was preferred over Factor 2. For example, the first row in
Table 6 indicates that P1 (Financial Perspective) was preferred by 13 of the respondents over P2 (Customer Perspective), and P2 was preferred by 48 of the respondents over P1. The particular case when the respondent has indicated equal importance is considered as a tie, and then a half point is assigned to each factor, truncating the result to an integer number in order to be computed by the Bradley-Terry model.
The data was processed using the extension “BradleyTerry2” for R, following the process described by Turner and Firth [
44]. RStudio version 1.2.1335 was used for the computation with a standard Core i5 computer. The standard Bradley-Terry model was used alongside fitting by maximum likelihood. The coefficients returned by the model
are the model estimations setting
. In order to turn these coefficients into the BSC weights
, they must be transformed calculating
and normalizing the setting
. The results for the BSC perspectives are presented in
Table 11 as an example.
We have all the local weights of the indicators after computing the Bradley-Terry model for each set (
Table 7,
Table 8,
Table 9 and
Table 10), denoted
(the weight of the indicator
j belonging to the perspective
i). The next step is to calculate the overall weights of the sub-criteria,
. The local weight of each sub-criteria is multiplied by its corresponding relative importance of the criteria
. Mathematically, it can be expressed as given in Equation (7). The overall weight is finally used for ranking the indicators.

 ,
, 




{kind=link}
{kind=link}
{kind=link}