1. Introduction
A linear program (LP) is an optimization problem consisting of a linear objective function (maximizing or minimizing), linear equality, or inequality constraints. It is ubiquitous in many areas of applied science, such as airline crew scheduling problems [
1,
2,
3], labor scheduling problems [
4], diet problems [
5], and supplier selection and order allocation problems [
6].
There are many popular methods for solving LP models, such as the simplex method and the interior point method. For small-sized to medium-sized LP models, the simplex method using Dantzig’s pivot rule [
7] is an efficient method, while for a large-sized LP model, the interior point method is more effective than the simplex method. The classical interior point method was proposed by Karmarkar [
8] in 1984. Its process starts by moving from an interior feasible point along the improving direction, projected on the feasible region with a step size. However, the transformation of the LP problem into the initial Karmarkar’s form requires excessive computational initialization. Thus, in 1986, Chang [
9] developed the gravitational method for solving LP using the interior point concept, avoiding the complexity of the Karmarkar’s method. The gravitational method starts with the creation of a small ball, covering the initial interior point as the center of the ball. Then, it drops along the gravitational force with the steepest descent direction until it meets the boundary of the feasible region. After that, it moves on the surfaces of the feasible region until it reaches the optimal point.
For the simplex method, it starts at the feasible origin point and moves along the edge of the polytope until it reaches the new optimal one. If the origin point is infeasible, it needs to add artificial variables into the model, and uses the Two-Phase simplex method or the Big-M method to solve the model, which expands the size of the linear program. As a result, many researchers have attempted to improve the simplex method without using artificial variables [
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22]. Moreover, other methods require finding an initial point closer to the optimal point, expecting to reduce the computational time.
In 2002, Luh and Tsaih [
23] proposed a hybrid method based on the interior point method and the simplex method to find an initial basic feasible point of an LP model. The effectiveness of the interior point method is suitable for a large LP model; on the other hand, the effectiveness of the simplex method is more appropriate for a small LP model. Their method applies the idea of the interior point method to choose the direction used to reach the initial basic feasible point that is near an optimal point. Afterwards, the simplex method is used to find the LP optimal point. Their method requires the initial feasible point, so it is not practical for the infeasible LP model.
The improvement of an initial basis from Junior and Lins [
14] in 2005 uses a relation of angles between the gradient vector of the objective function and the gradient vector of each constraint. This method claims that the constraint that includes the smallest angle induces the basic feasible point near the optimal one. For a small-sized linear programming model with a number of constraints and variables of less than 50, Junior et al. assert that their method starts close to the optimal point. However, this method cannot start when the initial matrix is singular.
Arsham’s method [
15,
16] in 2006 provides a better initial basis without using artificial variables, which consist of three phases. Note that the right-hand-side vector of the model must be nonnegative. Phase 1 starts by relaxing the greater-than constraints from the original model, which guarantees the feasibility of the origin point. Subsequently, the simplex method is performed in order to find the optimal point of the relaxation model. Then, phase 2 of Arsham’s method will check the consistency of this point with constraints in the original model. If the point satisfies all constraints in the original model, then phase 2 will stop. Otherwise, the most violated constraint is reinserted and performs the dual simplex method. This process repeats until all constraints are satisfied. After phase 2 terminates, the original objective function is restored (and performs the simplex method if necessary) to find the optimal point of the original model.
Later in 2011, Al-Najjar and Malakooti [
24] proposed a method for finding an initial basic feasible point. Their method consists of two phases. Phase 1 is to find the basic feasible point by moving the initial feasible point through the interior feasible region, which will avoid some extreme points. Phase 2 uses the simplex method in order to find the optimal point by starting from the previous basic feasible point. Nonetheless, the initial feasible point and the user’s parameters must be given before this method can start. In addition, this method only deals with an LP model with a nonempty feasible region.
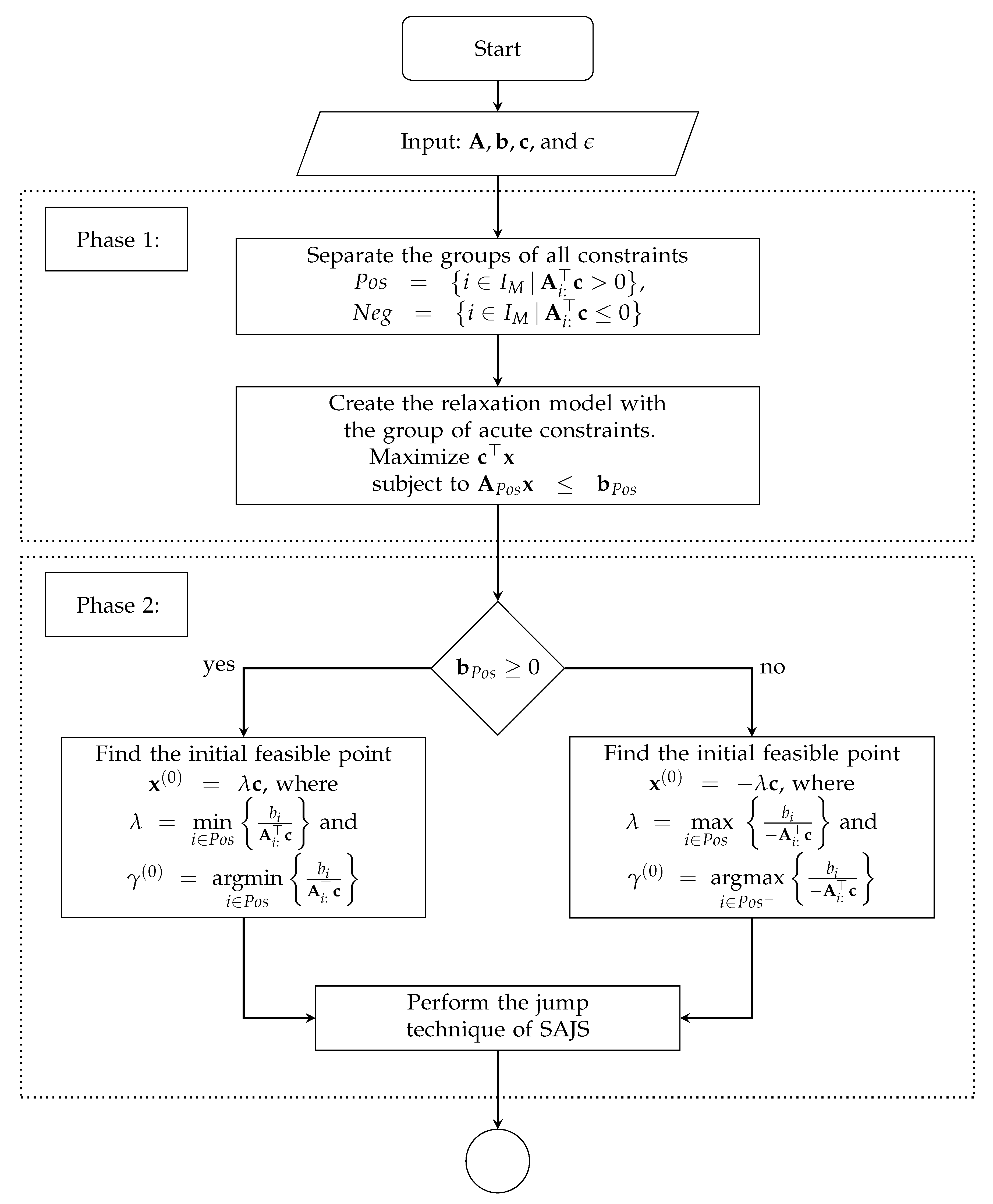
An artificial-free simplex algorithm based on the non-acute constraint relaxation (SNAR) was proposed by Boonperm and Sinapiromsaran [
18] in 2014, starting with a relaxation model consisting of a group of acute constraints formed from the objective gradient vector. With the existence of the initial basic feasible point of the relaxation model, it can be solved by the simplex method. After that, the non-acute constraints are reinserted back into the relaxation model in order to find the point of the original model. From their computational results, if the LP model is unbounded, then each non-acute constraint is reinserted one at a time. In addition, if the original model is unbounded, this method must reinsert all non-acute constraints into the relaxation model until it reports that the problem is unbounded, which requires a high computational time.
When the model has a large number of acute constraints, SNAR performs quite well. This leads to a large number of extreme points, presented in
Figure 1, which may not be suitable for the simplex method. Thus, in this paper, the iterative jump method presented in
Figure 2 is proposed in order to avoid unnecessarily visited extreme points.
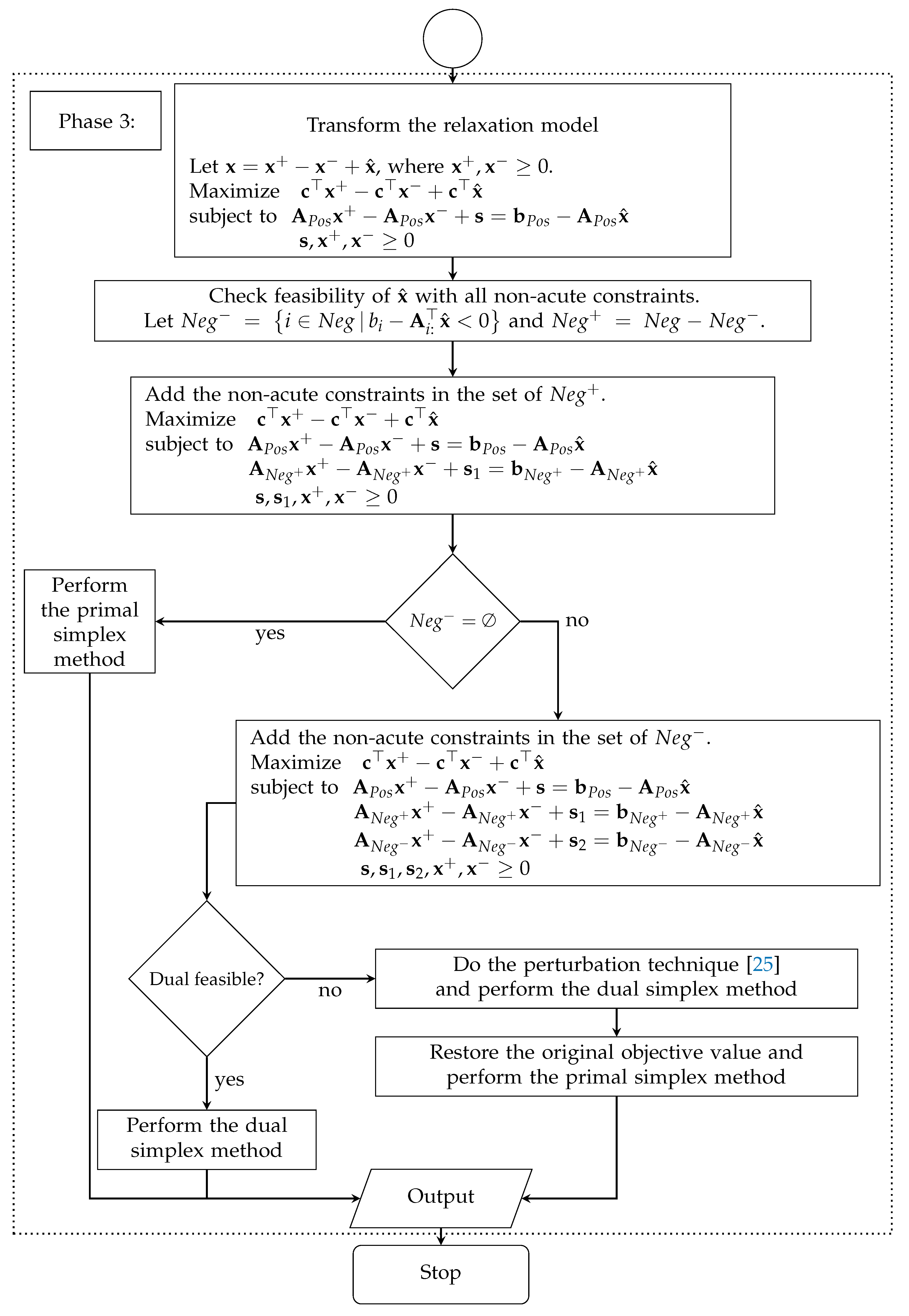
For this reason, a self-regulating artificial-free linear programming solver using jump and simplex method (SAJS) is proposed. It integrates the jump concept on a relaxation model similar to SNAR. SAJS consists of three phases. In phase 1, the relaxation model is created by a group of acute constraints. In phase 2, SAJS applies the technique of iterative jumps along the improving directions of the objective value. The non-acute constraints are restored, and SAJS finds the point using the dual simplex method on the perturbation model before applying the final simplex method in phase 3.
The idea of the iterative jump method uses the improvement direction according to the objective gradient vector, similarly to the gravitational method. However, SAJS combines this direction with the current gradient vector of binding constraints at the current point while the gravitational method drops along the faces at the current point. Moreover, SAJS is applied on the relaxation model before applying the dual simplex method at the last step while the gravitational method works on the original model.
This paper is divided into five parts.
Section 2 details the preliminaries, while SAJS is explained in
Section 3. In
Section 4, experiments and results are shown. Finally, the conclusion is proposed in
Section 5.
4. Experiments and Results
The computational results of the wall-clock time of SAJS, the Two-Phase method, and SNAR on 41 standard problems from netlib and 280 randomly generated problems are presented in this section. The maximizing linear programs are randomly generated with the objective vector , equal to a vector of ones, and the number of constraints is higher than the number of variables, which exhibits the worst-case performance of SNAR. Furthermore, these linear programs check for optimal solutions before they are included in the experiment. The experiments were performed by using an Intel(R) Core(TM) i7-3770 CPU@3.40 GHz processor with 8 GB RAM on Windows 10. Three methods, SAJS, the Two-Phase method, and SNAR, were written by Python libraries numpy.
The rows of matrix are generated in two groups. The first group is generated for row , where . All coefficients in this group of the matrix are uniformly random from , with a high probability of making acute angles with the objective vector. The second group is generated for row , with uniformly random coefficients from and with a high probability of making obtuse angles with the objective vector. To guarantee a nonempty feasible region, the intended feasible solution vector is generated first with , , and then the vector’s right-hand side is calculated from , where , and , where .
The randomly generated problems are simulated by their sizes with varying
m constraints and
n variables according to the following scenarios:
,
. The wall-clock times of each of the sizes of the randomly generated problems are averaged by 10 different problems and are shown in
Figure 5,
Table 1, and
Figure 6.
Figure 5 shows the average wall-clock time varying according to stopping criteria of 0.20, 0.30, 0.40, and 0.50, which are used in phase 2 of SAJS. The stopping criterion is defined as the minimum ratio improvement of two consecutive differences of the objective values of SAJS. However, the average wall-clock times (in seconds) of the computations for each stopping criterion are not significantly different. Thus, in this paper, SAJS uses
= 0.40 to compare with the Two-Phase method and SNAR, which are presented in
Figure 6 and
Figure 7. The reason is that the average total wall-clock time of SAJS with
= 0.40 surpasses those of other stopping criteria.
Table 1 shows the average wall-clock time of SAJS with
= 0.40 to determine the longest time from these three phases: Row represents the number of rows of the LP model and Col represents the number of columns of the LP model. The values under phase 1, phase 2, phase 3, and total time are the actual wall-clock times of each phase. The values in the parentheses present the ratio of the wall-clock time of each phase to the total time. It can be observed that the actual times of phase 1 and phase 2 are very small with respect to the wall-clock time of phase 3. Hence, the largest proportion of the running time of SAJS originates from phase 3.
The comparison of SAJS with
= 0.40, the Two-Phase method (TP), and SNAR using randomly generated problems is presented in
Figure 6. The performance of SAJS outperforms both methods. Since adding artificial variables in Two-Phase method enlarges the LP model, the Two-Phase method requires longer computational time to find the solution. For SNAR, the construction of the relaxation models of the randomly generated problems requires the reinsertion of the non-acute constraints into the model one by one, which takes a long time to find the solution. Moreover,
Figure 6 shows that both the number of variables and the number of constraints affect the wall-clock time of SNAR.
Figure 7 demonstrates the performance computation of SAJS with
, the Two-Phase method (TP), and SNAR using standard test problems from real-world netlib problems.
represents the dimension of the LP model. In this paper, the maximum time limit of computation is set to one day, which is equivalent to 86,400 s. However, the results with wall-clock times that exceed this limit will not appear in the figure; these include SCSD6, SCSD8, 25FV47, SCFXM3, SHIP08S, DEGEN3, SHIP12S, and SHIP08L. The efficacies of the three methods are comparable for small LP models with a number of variables times constraints of less than 30,000, from AFIRO to ADLITTLE. When LP models have of a number of variables times constraints of greater than 30,000, SNAR exhibits poor performance, with the exception of BRANDY, SCTAP1, SCTAP2, and SCTAP3, which have similar performance with SAJS due to the discovery of the optimal point in the relaxation model. For LP models with a number of variables times constraints of greater than 200,000 from SCTAP1 to SHIP08L, SAJS outperforms the Two-Phase method and SNAR, except with SCTAP2. The Two-Phase method has a lower performance when the LP model contains a large number of constraints and variables because the Two-Phase method takes a long time to handle all constraints. On the contrary, SAJS and SNAR start with the relaxation model, dealing with a smaller model. When the solution of the relaxation model is unbounded optimal, SNAR exhibits poor performance compared to other methods due to the reinsertion of the non-acute constraints one by one. The nonparametric Wilcoxon test is used to verify the effectiveness of SAJS against TP and SAJS against SNAR. The
p-value of difference between SAJS and TP from the Wilcoxon signed rank test is equal to 0.003198, while the
p-value of difference between SAJS and SNAR is equal to 3.30828 × 10
. Hence, SAJS statistically significantly outperforms both TP and SNAR.
5. Conclusions
This paper proposes a new self-regulating artificial-free method for solving a linear program, namely SAJS. The three phases of SAJS are the established relaxation model phase (phase 1), the jump phase to find the suitable initial point (phase 2), and the phase of reinsertion of non-acute constraints (phase 3). The relaxation model is created in phase 1 in order to guarantee the existence of a feasible point. The jump technique in phase 2 applies the technique of iterative jumps along the improving directions of the objective value, avoiding extreme points formed by acute constraints. In phase 3, the technique of reinsertion of non-acute constraints restores the group of non-acute constraints to the model.
Improving the solution time of the simplex method is still an active research area, appearing in various publications. The simplex method starts with the initial basic feasible solution before pivoting to the better alternative ones. For a general linear programming problem, the starting initial basic feasible solution is identified by enlarging the dimension of the decision variables, as in the two-phase method. Our method counters this issue by working on the feasible region with a small number of extreme points and avoiding extreme points using the jump technique, which significantly reduces the solution time of the simplex method. Nevertheless, if a linear programming problem has no “greater than or equal to” constraint, this improvement may not be significantly obvious.
Adding the artificial variable into the small-sized model rarely affects solving LP model for the Two-Phase method, whereas adding artificial variables to the large-sized model will have a significant effect on computational time. This does not affect SNAR or SAJS. Moreover, both methods begin with the relaxation model, so the size of the problem will be small. Hence, the performance of the Two-Phase method is inferior to those of both SNAR and SAJS for the large-sized model, though it is comparable with both for the small-sized model.
If the solution of the relaxation model is unbounded, the non-acute constraints will be reinserted into the LP model one by one. This affects the performance of SNAR, while SAJS reinserts two collections of the non-acute constraints at one time and performs the dual simplex method to reach the optimal solution. Therefore, for all randomly generated problems, SAJS outperforms other methods for all problem sizes.
To verify the effectiveness of SAJS, the nonparametric Wilcoxon test is performed on the standard test problems from netlib. SAJS exhibits significantly better overall performance over both the Two-Phase method and SNAR. Nevertheless, after comparing the wall-clock times of all three phases, it is clearly shown that SAJS takes a very short time in phase 1 and phase 2, while it spends almost the entire running time in phase 3 to find the solution by the dual simplex method.
In future work, the appropriate jumping direction of SAJS should be investigated. Moreover, other pivot rules of the dual simplex method in the reinsertion phase may improve the overall performance of SAJS.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}