Abstract
The paper is devoted to the optimal state filtering of the finite-state Markov jump processes, given indirect continuous-time observations corrupted by Wiener noise. The crucial feature is that the observation noise intensity is a function of the estimated state, which breaks forthright filtering approaches based on the passage to the innovation process and Girsanov’s measure change. We propose an equivalent observation transform, which allows usage of the classical nonlinear filtering framework. We obtain the optimal estimate as a solution to the discrete–continuous stochastic differential system with both continuous and counting processes on the right-hand side. For effective computer realization, we present a new class of numerical algorithms based on the exact solution to the optimal filtering given the time-discretized observation. The proposed estimate approximations are stable, i.e., have non-negative components and satisfy the normalization condition. We prove the assertions characterizing the approximation accuracy depending on the observation system parameters, time discretization step, the maximal number of allowed state transitions, and the applied scheme of numerical integration.
1. Introduction
The Wonham filter [1], as well as the Kalman–Bucy filter [2], is one of the most practically used filtering algorithms for the states of the stochastic differential observation systems. It is applied extensively for signal processing in technics, communications, finance and economy, biology, medicine, etc. [3,4,5,6]. The filter provides the optimal in the Mean Square (MS) sense on-line estimate of the finite-state Markov Jump Process. (MJP) given indirect continuous-time observations, corrupted by the Wiener noise. The elegant algorithm represents the desired estimate as a solution to a Stochastic Differential System (SDS) with continuous random processes on the Right-Hand Side (RHS).
The fundamental condition for the solution to the filtering problem is the independence of the observation noise intensity of the estimated state. It provides the continuity from the right for the natural flow of -algebras induced by the observations, with subsequent utilization of the innovation process framework. The condition violation breaks these advantages. In the case of the state-dependent observation noise, the author of [7] presents the optimal estimate within the class of the linear estimates. Further, the authors of [8,9] use filters of a linear structure for the solution to the -optimal state filtering problem. To find the absolute optimal filtering estimate, one has to make extra efforts. First, for proper utilization of the stochastic analysis framework, one needs to reformulate the optimal filtering problem, “smoothing forward“ the flow of -algebras induced by the observations. Second, in the case of state-dependent noise, the innovation process contains less information than the original observations. One has to supplement the innovation by the observation quadratic characteristic, which represents a continuous-time noiseless function of the estimated MJP state. In general, the optimal filtering given partially noiseless observations is a challenging problem. Its solution can be expressed either as a sequence of some regularized estimates [10] or by the additional differentiation of the smooth observation components or their quadratic characteristics [11,12,13,14]. In both cases, one needs to realize a limit passage, which is difficult in computers.
Even in the traditional settings, the numerical realization of the MJP state filtering is a complicated problem. For example, the explicit numerical methods based on the Itô–Taylor expansion applied to the Wonham filter equation, diverge: the produced approximations do not meet component-wise non-negativity condition. Over time the approximation components reach arbitrary large absolute values. Further, in the presentation, we refer to the approximations, preserving both the component non-negativity and normalization condition as the stable ones.
The Wonham filtering equation is a particular case of the nonlinear Kushner–Stratonovich equation. To solve it, one can use various numerical algorithms
- the procedures based on the weak approximation of the original processes by Markov chains [15,16],
- some variants of the splitting methods [17],
- the robust procedures based on the Clark transform [18,19],
- the schemes, which represent the conditional probability distributions through the logarithm [20], etc.
All the algorithms are developed for the case of additive observation noise and based on the Girsanov’s measure transform. Hence, they are useless for the estimation of the MJP given the observations with state-dependent noise.
The goal of the paper is two-fold. First, it presents a theoretical solution to the MS-optimal filtering problem, given the observations with state-dependent noise. Second, it introduces a new class of stable numerical algorithms for filter realization and investigates its accuracy. We organize the paper as follows. Section 2 contains a description of the studying observation system with state-dependent observation noise along with the MS-optimal filtering problem statement. To solve the problem, one needs to transform the available observations both to preserve the information equivalence and suit for application of the known results of the optimal nonlinear filtering. Section 3 describes both the observation transformation and the SDS defining the optimal filtering estimate. The SDS is discrete–continuous and contains both continuous and counting random processes on the RHS. Previously, the author of the note [21] presents a sketch of the observation transform, but it cannot guarantee the uniqueness of that SDS solution.
Section 4 presents a new class of the stable numerical algorithms of the nonlinear filtering. The main idea is to discretize original continuous-time observations and then find the MS-optimal filtering estimate given the sampled observations. The authors of [22] use this idea to solve a particular case of the estimation problem, namely the classification problem of a finite-state random vector given continuous-time observations with multiplicative noise. Section 4.1 contains a general solution to the problem. The corresponding estimate represents a ratio, which numerator and denominator are the infinite sums of integrals. They are shift-scale mixtures of the Gaussians. The mixing distributions, in turn, describe the occupation time of the system state in each admissible value during the time discretization interval. In Section 4.2, we suggest approximating the estimates by a convergent sequence bounding number s of possible state transitions, which occurred over the discretization interval. We replace the infinite sums in the formula of the optimal estimate by their finite analogs and also investigate the accuracy of the approximations. We refer these approximations as the analytical ones of the s-th order. One cannot calculate the integrals analytically and have to replace them with some integral sums, and this brings an extra error. Section 4.3 analyzes the value of this error and the total distance between the optimal filtering estimate given the discretized observations and its numerical realization. Section 4.4 presents a numerical example that illustrates the conformity of theoretical estimates and their numerical realization. Section 5 contains discussion and concluding remarks.
2. Continuous-Time Filtering Problem Statement
On the probability triplet with filtration we consider the observation system
Here
- is an unobservable state which is a finite-state Markov jump process (MJP) with the state space ( stands for the set of all unit coordinate vectors of the Euclidean space ) with the transition matrix and the initial distribution ; the process is an -adapted martingale,
- is an observation process: is an -adapted standard Wiener process characterizing the observation noise, is an -dimensional observation matrix and the collection of -dimensional matrices defines the conditional observation noise intensities given .
The natural flow of -algebras generated by the observations Y up to the moment t is denoted by , .
The optimal state filtering given the observations Y is to find the Conditional Mathematical Expectation (CME)
3. Observation Transform and Optimal Filtering Equation
Before derivation of the optimal filtering equation we specify the properties of the observation system (1) and (2).
- All trajectories of are continuous from the left and have finite limits from the right, i.e., are cádlág-processes.
- Nonrandom matrix-valued functions , and consist of the cádlág-components.
- The noises in Y are uniformly nondegenerate [10], i.e., for some ; here and after, I is a unit matrix of appropriate dimensionality.
- The processeshave a finite variation; here and after, is an indicator function of the set , and is a zero matrix of appropriate dimensionality.
Conditions 1–3 are standard for the filtering problems [10]. They guarantee the proper description of MJP distribution by the Kolmogorov system . Condition 4 relates to the quadratic characteristic of the observation process as a key information source itself. Below we show that collection of , distinguished for different n, allows to restore the state precisely given the available noisy observations. Condition 4 guarantees the local regularity of the time subsets, where coincide and/or differ each other: one can express them as finite unions of the intervals. The condition is not too restrictive: for instance, they are valid when are piece-wise continuous with bounded derivatives.
Both the system state and observation are special square-integrable semimartingales [6,23] with the predictable characteristics
and
Conditions 1–3 and the properties of guarantee -a.s. fulfilment of the following equalities for the one-sided derivatives of :
where is a jump function of . So, if there exists a nonrandom instant such that , then . The inclusion presumes the flow of -subalgebras is not necessarily continuous from the right for the considered observations [24]. This is a reason to define a filtering estimate as a CME of with respect to the “smoothed” flow for subsequent correct usage of the stochastic analysis framework.
Let us transform the available observations in such a way to derive the optimal filtering estimate by the standard methods [6,23]. Initially, the idea of this transform is suggested in [11]. As the result, the authors introduce the pair
The authors of [11] prove coincidence of the -algebras for the general diffusion observation systems. However, they do not pay attention to the continuity of from the right. The authors of [12,14] suggest to replace the observations by their derivative
Then, one can construct the optimal estimate either to use as a linear constraint or to differentiate (10) for extraction of the dynamic noises. The papers [12,14] contain a rather pessimistic conclusion: the number of differentiations is unbounded in the general case of diffusion observation system. In contrast, we estimate a finite-state MJP and can construct the optimal filtering estimate using Q without additional differentiation.
So, the transformed observations will contain
- diffusion processes with the unit diffusion,
- counting stochastic processes,
- indirect state observations obtained at the nonrandom discrete moments.
The first transformed observation part is the process (8), and in view of (2) and (7) it can be rewritten as
where and is an -adapted standard Wiener [10].
The process could play the role of the second part of the transformed observations since [11], however the natural flow of -algebras generated by the couple is not continuous from the right yet. Moreover, the process is matrix-valued and looks overabundant for the filter derivation. The point is, (10) is a function of the finite-set argument , and it affects the estimate performance through its complete preimage
To go to the preimage we introduce the following transformation of :
is a -adapted vector process with components 0 or 1, but the trajectories are not cádlág processes. Due to the fact -a.s. for the equalities below are valid
where is the -dimensional matrix with the components (4).
The function has the following properties.
- for any .
- The number of jumps occurred in any finite time interval is finite due to condition 4.
- is not a cádlág-function [25].
- for any .
- For any there exists a transformation such that the matrix is trapezoid with orthogonal strings and 0 and 1 as the components.
- for any .
Let us define a -adapted process with the cádlág-trajectories:
From (12) and (13) it follows that -a.s., where .
We denote the set of the process V discontinuity by , stands for the set of X discontinuity and for the analogous set of the process J. The sets and are random, in contrast is nonrandom. The process is purely discontinuous, and due to property 4 it can be rewritten in the form
Due to the definition for . The process characterizes the observable jumps at the nonrandom moments caused by changes, and is an observable part of the state jumps, occurred, at some random instants.
As a second part of the transformed observations, we choose the N-dimensional random process : the components count the jumps of the process into the state , occurred at the random instants over the interval :
The third part of the transformed observations is the N-dimensional process with the jumps at the nonrandom moments.
Lemma 1.
If , then the coincidence is true for any .
Correctness of the Lemma assertion follows immediately from the fact the composite process is constructed to be -adapted, and one-to-one correspondence of the and Y paths:
Below we use the following notations: is a row vector of the appropriate dimensionality formed by units, is the n-th row of the matrix ,
Lemma 2.
The process has the following properties.
- 1.
- n-th component allows the martingale representation
- 2.
- for any ;
- 3.
- The innovation processesare -adapted martingales with the quadratic characteristics
Proof of Lemma 2 is given in Appendix A.
Finally, the transformed observations take the form
Theorem 1.
The optimal filtering estimate is a strong solution to the SDS
where
and is a Moore–Penrose pseudoinverse. The solution is unique within the class of nonnegative piecewise-continuous -adapted processes with discontinuity set lying in .
Proof of Theorem 1 is given in Appendix B.
The transformed observations (22) along with Theorem 1 prompt a condition of the exact identifiability of the state given indirect noisy observations (2).
Corollary 1.
If for any () the inequalities are true almost everywhere on , then -a.s., and is the solution to SDS (23).
The proof of Corollary 1 is given in Appendix C.
4. Numerical Algorithms of Optimal Filtering
4.1. Optimal Filtering Given Discretized Observations
The latter section contains the stochastic system (23) defining the optimal filtering estimate . The problem of its numerical realization seems routine: we should apply the corresponding methods of numerical integration of SDS with jumps on the RHS [26]. However, this simplicity is illusory. The problem is that the “new” countable observation and discrete-time one are results of certain transform of the available observation Y, and this transform includes a limit passage operation. In fact, to obtain we have to estimate/restore the current value of the derivative . First, this leads to some time delay to accumulate observations . Second, any pre-limit variant of either has a.s. continuous trajectories or represents their sampling, which demonstrates oscillating nature. Third, the considered filtering estimate is the CME of the state given the observations Y up to the moment t. The CME has natural properties: its components are a.s. non-negative and satisfy the normalization condition. The estimates and approximations having these properties are referred in the paper as the stable ones. Mostly, the conventional numerical algorithms do not provide these properties for the calculated approximations. They can preserve the normalization condition only, but the components can have the arbitrary signs and absolute values.
In the paper we present another approach to the numerical realization of the filtering algorithm above. We discretize the available observations Y by time with the increment h and then solve the optimal state filtering problem given discretized observations. The estimate can be considered as approximation of the one given the initial continuous-time observations. Properties of the CME guarantee the stability of the proposed approximation.
To simplify derivation of the numerical algorithm and its accuracy analysis we investigate the time-invariant subset of the observation system (1), (2), i.e., , , , . The observations are discretized with the time increment h:
where are equidistant time instants. We denote non-decreasing collection of -algebras generated by the time-discretized observations; .
The optimal state filtering problem given discretized observations is to find .
Let us consider asymptotics of . We fix some and consider a condensed sequence of binary meshes with time increments and corresponding increasing sequence of -subalgebras : . The observation process is separable, hence . Then, by Levy theorem -a.s. Moreover, since , the -convergence is also true: . The convergence also holds, if we replace the sequence of the binary meshes by any condensed sequence with vanishing step. So, we can conclude that the optimal filtering given the discretized observation is a way to design the stable convergent approximations without observation transform introduced in the previous section.
To derive the filtering formula we use the approach of [27] and the mathematical induction.
In the case we have
Let for some the estimate be known. Now we calculate at the next time instant. To do this we have to specify the mutual conditional distribution with respect to . From the observation model and ([10] Lemma 7.5) it follows that the conditional distribution of given -algebra is Gaussian with the parameters
Here, is a random vector composed of the occupation times of the process X in each state during the interval .
Below in the presentation we use the following notations:
- is an -dimensional simplex in the space ; is a distribution support of the vector ;
- is a “probabilistic simplex” formed by the possible values of ;
- is a random number of the state transitions, occurred on the interval ,
- , ;
- is a conditional distribution of the vector given , i.e., for any the following equality is true:
- is an M-dimensional Gaussian probability density function (pdf) with the expectation m and nondegenerate covariance matrix K;
- , .
Markovianity of , formula of the total probability and Fubini theorem provide the equalities below for any set
This means that the integrand in the square brackets defines the conditional distribution given . Further, the conditional distribution is defined component-wisely by the generalized Bayes rule [10]
So, we have proved the following
Lemma 3.
If for the observation system (1), (2) conditions 1–3 are valid, then the filtering estimate given the discretized observations is defined by (26) at , and by recursion (28) at the instant of the discretized observation reception.
4.2. Stable Analytic Approximations
Recursion (23) cannot be realized directly because of infinite summation both in the numerator and denominator. We replace them by the finite sums, and the corresponding vector sequence , calculated by the formula
is called the analytic approximation of the s-th order of . Obviously, that is stable.
Let us introduce the following positive random numbers and matrices:
The estimates (28) and (29) can be rewritten in the recurrent form:
Let us define the global distance [28] between the estimates and as
The pretty natural characteristic shows the maximal expected divergence of the recursions (28) and (29) at the r-th step.
The assertion below defines an upper bound of the characteristic .
Lemma 4.
If the conditions of Lemma 3 are valid, then
where , and is the following parameter:
which is bounded from above: .
The proof of Lemma 4 is given in Appendix D.
Assertion of Lemma brings the practical benefit. The Lemma does not contain any asymptotic requirements neither to the approximation order s nor to the discretization step h: inequality (34) is universal. Mostly, in the digital control systems the data acquisition rate is fixed or bounded from above. There are some extra algorithmic limitations of the rate: the “raw” data should be preprocessed, smoothed, averaged, refined from outliers, etc. For example, utilization of the central limit theorem [29] and diffusion approximation framework [30] for the the renewal processes is legitimate with significant averaging intervals, and their length depends on the process moments.
Now we fix the time instant T and consider an asymptotic . In this case and
4.3. Stable Numerical Approximations
In the recursion (32) we use the integrals , which cannot be calculated analytically. The numerical integration brings some extra approximation error. Let us investigate its affect to the total accuracy of the filter numerical realization.
The integrals are usually approximated by the sums
which are defined by the collection of the pairs . Here, are the points, and () are the weights: .
In complete analogy with we define the approximations . By construction, the elements of are positive random values, hence the approximation
is stable. Below we denote the numerical integration errors and their absolute values as follows
So, the recursion (32) is replaced by the scheme (37), holding the common initial condition .
Both (32) and (37) are constructed in light of the event : the state transition numbers do not exceed the threshold s over any subintervals belonging to . So, the distance between and should be determined taking into account . In view of this fact, we propose the pseudo-metrics
This index reflects maximal divergence of the algorithms (32) and (37) after r steps, being started from the arbitrary but common initial condition.
Theorem 2.
If the inequality
is true for the numerical integration scheme (36), then the distance is bounded from above:
The proof of Theorem 2 is given in Appendix E.
The chance to describe the accuracy of the numerical algorithm for the stochastic filtering using only the condition (41), related to the calculus, looks remarkable. Furthermore, if the total weight separates from the unity, i.e., , then the index is a sublinear function of r, so as the index of the analytic accuracy is. Notably, that in the classic numerical algorithms of the SDS solution the global error grows linearly with respect to the number of steps r [26].
The precision characteristics of both the analytical approximation and its numerical realization should be aggregated into the one. If the conditions of Lemma 4 and Theorem 2 are valid, then the local distance (i.e., the distance after one iteration) between the optimal filtering estimate and its numerical approximation can be bounded from above:
The global distance between and can be bounded in the similar way:
We could choose the parameters of the analytical approximation and of the numerical integration independently each other. However, both the limitation of the computational resources and the accuracy requirements lead to the necessity of the mutual optimization of .
Let us fix some time horizon T along with the order s of analytical approximation, and consider the asymptotic , or, equivalently, . Due to the Bernoulli inequality, and condition we have that
The first summand in the brackets represents the contribution of the analytical approximation error, the second one reflects the error of the specified numerical integration scheme. Obviously, the optimal choice of the parameters provides an equal infinitesimal order for both the summands, and it is possible when .
4.4. Numerical Example
To illustrate the correspondence between the theoretical estimate and its realization along with the performance of the numerical algorithm, we consider the filtering problem for the observation system (1) and (2) with the following parameters: , ,
The specified observation system is the one with state-dependent noise, and the conditions of Corollary 1 hold, so the optimal filter (23) restores the MJP state precisely under available noisy observations. Let us verify this theoretical fact, using the recursive algorithm (37). We choose the analytical approximation of the order with numerical integration by the simple midpoint rectangle scheme and calculate estimate approximations with decreasing time-discretization step: . We expect the descent of the estimation error characterized by the MS-criterion . To calculate the criterion, we use the Monte–Carlo method over the test sample of the size 1000. Figure 1 presents the corresponding plots of the quality index for various values of h.
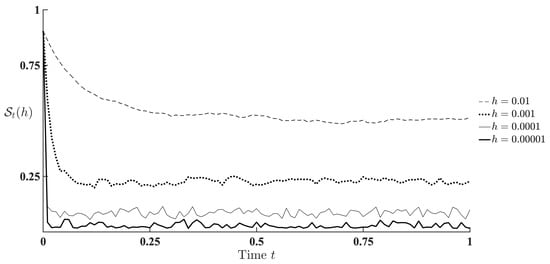
Figure 1.
Estimation quality index depending on the time-discretization step h.
The determination of the precision order provided by the chosen numerical integration method is out of the scope of this investigation. Nevertheless, one can see the expected decrease of the estimation error when the time-discretization step descends. We appraise this result as a practical confirmation of both the theoretical assertions and numerical algorithm.
5. Conclusions
In this paper, we investigated the optimal filtering problem of the MJP states, given the indirect noisy continuous-time observations. The observation noise intensity was a function of the estimated state, so it was impossible to apply the classic Wonham filter to this observation system. To overcome this obstacle, we suggested an observation transform. On the one hand, the transformed observations remained to be equivalent to the original one from the informational point of view. On the other hand, the “new“ observations allowed to apply the effective stochastic analysis framework to process them. We derived the optimal filtering estimate theoretically as a unique strong solution to some discrete–continuous stochastic differential system. The transformed observations included derivative of the quadratic characteristics, i.e., the result of some limit passage in the stochastic settings. Hence, the subsequent numerical realization of the filtering became challenging. We proposed to approximate the initial continuous-time filtering problem by a sequence of the optimal ones given the time-discretized observations. We also involved numerical integration schemes to calculate the integrals included in the estimation formula. We prove assertions, characterizing the accuracy of the numerical approximation of the filtering estimate, i.e., the distance between the calculated approximation and optimal discrete-time filtering estimate. The accuracy depended on the observation system parameters, time discretization step, a threshold of state transition number during the time step, and the chosen scheme of the numerical integration. We suggested the whole class of numerical filtering algorithms. In each case, one could choose any specific algorithm individually, taking into account characteristics of the concrete observation system, accuracy requirements, and available computing resources.
We do not consider the presented investigations as completed. First, the characterization of the distance between the initial optimal continuous-time filtering estimate and its proposed approximation is still an open problem. Second, we can use the theoretical solution to the MJP filtering problem as a base of numerical schemes for the diffusion process filtering, given the observations with state-dependent noise. Third, the obtained optimal filtering estimate looks a springboard for a solution to the optimal stochastic control of the Markov jump processes, given both the counting and diffusion observations with state-dependent noise. All of this research is in progress.
Author Contributions
Conceptualization, A.B., I.S.; methodology, A.B.; formal analysis and investigation, A.B., I.S.; writing—original draft preparation, A.B.; writing—review and editing, I.S.; supervision, I.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CME | Conditional mathematical expectation |
| MJP | Markov jump process |
| Probability density function | |
| RHS | Right-hand side |
| SDS | Stochastic differential system |
Appendix A. Proof of Lemma 2
From (14), (15), the identity , the fact that at most at finite points of any finite interval and property 4 of the function , the following equalities are true
Assertion 1 of Lemma is proved.
The definition of the processes () guarantees their strong orthogonality, i.e., for any and , so .
Let us use (5), (19) and properties of X and to derive the quadratic characteristics of :
Assertion 2 of Lemma is proved.
If s and t are two arbitrary moments, such that , then
i.e., is a -adapted martingale. Note, that is purely discontinuous with unit jumps, hence
where is some -adapted martingale. From the uniqueness of the special martingale representation it follows that . Lemma 2 is proved. □
Appendix B. Proof of Theorem 1
We use the same approach as in ([6], Part III, Sect. 8.7) to derive the MJP filtering equations. The idea exploits the uniqueness of the representation for a special semimartingale along with the integral representation of a martingale [23].
From the Bayes rule it follows that . Let be a random instant of the -th discrete observation . We investigate evolution of over the interval :
Conditioning the left and right parts of the latter equality over , one can show that
where is an adapted martingale. For any the equality holds. The process (24) is a -adapted standard Wiener process [10].
The process is a -adapted semimartingale with -conditionally-independent increments, meanwhile are -adapted point processes. Hence, the martingale admits an integral representation ([23], Chap. 4, §8, Problem 1), i.e.,
where and are -predictable processes of appropriate dimensionality, which should be determined.
Due to the generalized Itô rule
where is an -adapted matringale. Conditioning both sides of the latter equality over , we can show that
where is a -adapted martingale. On the other hand, using the Itô rule, representation (A3) and the fact that is the Wiener process, we can obtain
where is a -adapted martingale. One can see that (A4) and (A5) are two representations of the same special semimartingale , hence due to the representation uniqueness the -predictable process should satisfy the equality
and may be chosen in the form
Due to the generalized Itô rule, Formulae (5), (18) and the properties of X and we can obtain, that
where is an -adapted martingale. Conditioning both sides of this equality over , we get
where is a -adapted martingale. On the other hand, using the Itô rule, representation (A3) and quadratic characteristic (21) we deduce, that
where is a -adapted martingale. Since the representations (A7) and (A8) correspond to the same special semimartingale we conclude that the process should satisfy the equality
Acting as with the coefficient , we choose the predictable processes in the form
So, on the interval the optimal filtering estimate is described by the SDS
Since , Equation (A10) presumes -a.s. fulfilment of the equality
Finally,
so, by the Bayes rule we get that
Equation (23) can be obtained as “gluing“ of local Equation (A10), which describe the evolution of on the intervals , and Formula (A11), which describes the estimate correction given the observations available at the moments .
Uniqueness of the strong solution within the class of nonnegative piecewise-continuous -adapted processes with discontinuity set lying in can be proved in complete analogy with ([31] Chap. 9, Theorem 9.2). Theorem 1 is proved. □
Appendix C. Proof of Corollary 1
The conditions of Corollary guarantee, that the elements of (4) satisfy the equality almost everywhere, hence . This means that in (23) , i.e., . Further, from the properties of transition intensity matrix and the identity it follows that , where , . In this case
and the n-th component counts the jumps of into the state , occurred on the interval . This means is the unique solution to the “purely discontinuous” equation
i.e., the state is measurable with respect to , so -a.s.
Further, we substitute into (23) and verify its validity. To do this we simplify the RHS of the equality using the explicit form of , and , along with the identities and :
The properties of counting processes also provides the following implication: if for some the equality holds, then . Hence, the latter transformation can be continued:
which leads to (A12). So, we have verified that under conditions of Corollary 1 the state is a solution to the filtering Equation (23). Corollary 1 is proved. □
Appendix D. Proof of Lemma 4
Using notations and we can rewrite the estimates and in the explicit form
To simplify inferences we will omit the index r in and . The following relations are valid
Let us consider an auxiliary estimate . From the Bayes rule it follows that and
From (A13) and (A14) we deduce, that for and
The counting process has the quadratic characteristic , hence the probability can be bounded from above as
Formulae (A15) and (A16) lead to the fact, that .
Markovianity of the pair and inequality (A16) also allow to bound the probability from above: , that leads to (34). Lemma 4 is proved. □
Appendix E. Proof of Theorem 2
We have , and . Using the matrix algebra it is easy to verify that . Both the estimates are stable, hence . The following relations are valid:
Using the last inequality, (41) and (A20), it can be shown that
Since the latter inequality is valid for any , we have an upper bound for the local distance characteristic:
Let us define the following products of the random matrices and :
To proceed the proof of Theorem 2 we need the following auxiliary
Lemma A1.
If is a non-negative -measurable random value, and , then
Proof of Lemma A1.
We consider a non-negative integrable function and a -measurable random value
We find :
Let us consider a non-negative integrable function and a -measurable random value
We find :
The correctness of the Lemma assertion in the general case of can be verified similarly. Lemma A1 is proved. □
Let us define an upper estimate for the norm of . From the definitions of , and it follows that
Making the same inferences as for , we can deduce that
To estimate the contribution of each summand in (A22) we use (A18). To simplify derivation we consider the case , function
and the -measurable random value . Let us estimate from above the mathematical expectation
Acting in the same way, we can prove that for arbitrary the inequality
is valid for all r summands in the RHS of (A22). Finally and the correctness of (42) follows from the fact that the latter inequality is valid for arbitrary . Theorem 2 is proved. □
References
- Wonham, W.M. Some Applications of Stochastic Differential Equations to Optimal Nonlinear Filtering. J. Soc. Ind. Appl. Math. Series A Control 1964, 2, 347–369. [Google Scholar] [CrossRef]
- Kalman, R.E.; Bucy, R.S. New results in linear filtering and prediction theory. Trans. ASME Ser. D J. Basic Eng. 1961, 95–108. [Google Scholar] [CrossRef]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Ephraim, Y.; Merhav, N. Hidden Markov processes. IEEE Trans. Inf. Theory 2002, 48, 1518–1569. [Google Scholar] [CrossRef]
- Cappé, O.; Moulines, E.; Ryden, T. Inference in Hidden Markov Models; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Elliott, R.J.; Moore, J.B.; Aggoun, L. Hidden Markov Models: Estimation and Control; Springer: New York, NY, USA, 1995. [Google Scholar]
- McLane, P.J. Optimal linear filtering for linear systems with state-dependent noise. Int. J. Control 1969, 10, 41–51. [Google Scholar] [CrossRef]
- Dragan, V.; Aberkane, S. -optimal filtering for continuous-time periodic linear stochastic systems with state-dependent noise. Syst. Control Lett. 2014, 66, 35–42. [Google Scholar] [CrossRef]
- Dragan, V.; Morozan, T.; Stoica, A. Mathematical Methods in Robust Control of Discrete-Time Linear Stochastic Systems; Springer: New York, NY, USA, 2010. [Google Scholar]
- Liptser, R.; Shiryaev, A. Statistics of Random Processes II: Applications; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Takeuchi, Y.; Akashi, H. Least-squares state estimation of systems with state-dependent observation noise. Automatica 1985, 21, 303–313. [Google Scholar] [CrossRef]
- Joannides, M.; LeGland, F. Nonlinear filtering with continuous time perfect observations and noninformative quadratic variation. In Proceedings of the 36th IEEE Conference on Decision and Control, San Diego, CA, USA, 10–12 December 1997; Volume 2, pp. 1645–1650. [Google Scholar] [CrossRef]
- Borisov, A. Optimal filtering in systems with degenerate noise in the observations. Autom. Remote Control 1998, 59, 1526–1537. [Google Scholar]
- Crisan, D.; Kouritzin, M.; Xiong, J. Nonlinear filtering with signal dependent observation noise. Electron. J. Probab. 2009, 14, 1863–1883. [Google Scholar] [CrossRef]
- Kushner, H. Probability Methods for Approximations in Stochastic Control and for Elliptic Equations; Academic Press: New York, NY, USA, 1977. [Google Scholar]
- Kushner, H.J.; Dupuis, P.G. Numerical Methods for Stochastic Control Problems in Continuous Time; Springer: Berlin/Heidelberg, Germany, 1992. [Google Scholar]
- Ito, K.; Rozovskii, B. Approximation of the Kushner Equation for Nonlinear Filtering. SIAM J. Control Optim. 2000, 38, 893–915. [Google Scholar] [CrossRef]
- Clark, J. The design of robust approximations to the stochastic differential equations of nonlinear filtering. Commun. Syst. Random Proc. Theory 1978, 25, 721–734. [Google Scholar]
- Malcolm, W.P.; Elliott, R.J.; van der Hoek, J. On the numerical stability of time-discretised state estimation via Clark transformations. In 42nd IEEE International Conference on Decision and Control; IEEE: Piscataway, NJ, USA, 2003; Volume 2, pp. 1406–1412. [Google Scholar] [CrossRef]
- Yin, G.; Zhang, Q.; Liu, Y. Discrete-time approximation of Wonham filters. J. Control Theory Appl. 2004, 2, 1–10. [Google Scholar] [CrossRef]
- Borisov, A.V. Wonham Filtering by Observations with Multiplicative Noises. Autom. Remote Control 2018, 79, 39–50. [Google Scholar] [CrossRef]
- Borisov, A.V.; Semenikhin, K.V. State Estimation by Continuous-Time Observations in Multiplicative Noise. IFAC Pap. OnLine 2017, 50, 1601–1606. [Google Scholar] [CrossRef]
- Liptser, R.; Shiryaev, A. Theory of Martingales; Mathematics and its Applications; Springer: Dortrecht, The Netherlands, 1989. [Google Scholar]
- Stoyanov, J. Counterexamples in Probability; Wiley: Hoboken, NJ, USA, 1997. [Google Scholar]
- Kolmogorov, A.; Fomin, S. Elements of the Theory of Functions and Functional Analysis; Dover: Mineola, NY, USA, 1999. [Google Scholar]
- Platen, E.; Bruti-Liberati, N. Numerical Solution of Stochastic Differential Equations with Jumps in Finance; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar] [CrossRef]
- Bertsekas, D.P.; Shreve, S.E. Stochastic Optimal Control: The Discrete-Time Case; Academic Press: New York, NY, USA, 1978. [Google Scholar]
- Zolotarev, V. Metric Distances in Spaces of Random Variables and Their Distributions. Math. USSR-Sbornik 1976, 30, 373–401. [Google Scholar] [CrossRef]
- Zolotarev, V. Limit Theorems as Stability Theorems. Theory Prob. Appl. 1989, 34, 153–163. [Google Scholar] [CrossRef]
- Borovkov, A. Asymptotic Methods in Queuing Theory; John Wiley & Sons: Hoboken, NJ, USA, 1984. [Google Scholar]
- Liptser, R.; Shiryaev, A. Statistics of Random Processes: I. General Theory; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]

© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).